
Keywords:GPT-4.5, 大模型, GPT-4.5训练细节, 华为盘古Ultra性能, RLHF对推理能力影响, 人类学习上限4GB研究, 开源数学数据集MegaMath, GPT-4.5, النماذج الكبيرة (大模型), تفاصيل تدريب GPT-4.5, أداء Huawei盘古Ultra, تأثير RLHF على القدرة الاستدلالية, دراسة الحد الأقصى للتعلم البشري 4GB, مجموعة البيانات الرياضية مفتوحة المصدر MegaMath
🔥 الأضواء
OpenAI تكشف عن تفاصيل تدريب GPT-4.5 وتحدياته: في حوار مع الرئيس التنفيذي لـ OpenAI سام ألتمان والفريق التقني الأساسي لـ GPT-4.5، تم الكشف عن تفاصيل تطوير النموذج. بدأ المشروع قبل عامين، وشارك فيه كل الموظفين تقريبًا، واستغرق وقتًا أطول من المتوقع. واجه التدريب “مشاكل كارثية” مثل أعطال في مجموعة تضم 100 ألف وحدة معالجة رسوميات (GPU) وأخطاء برمجية (bugs) خفية، مما كشف عن اختناقات في البنية التحتية، ولكنه أدى أيضًا إلى تحديث حزمة التكنولوجيا (tech stack). والآن، يحتاج الأمر إلى 5-10 أشخاص فقط لإعادة إنتاج نموذج بمستوى GPT-4. يعتقد الفريق أن مفتاح تحسين الأداء المستقبلي يكمن في كفاءة البيانات وليس القدرة الحاسوبية، مما يتطلب تطوير خوارزميات جديدة لتعلّم المزيد من نفس كمية البيانات. تتجه بنية النظام نحو مجموعات متعددة (multi-cluster)، وقد يشمل المستقبل تعاون عشرات الملايين من وحدات معالجة الرسوميات (GPU)، مما يفرض متطلبات أعلى لتحمل الأخطاء (fault tolerance). كما تطرق الحوار إلى Scaling Law، والتعلم الآلي وتصميم الأنظمة المشترك (system co-design)، وجوهر التعلم غير الخاضع للإشراف (unsupervised learning)، وغيرها، مما يعكس رؤى وممارسات OpenAI في دفع تطوير النماذج الكبيرة المتطورة (المصدر: 36氪)

هواوي تطلق نموذج Pangu Ultra الكبير الكثيف بمعاملات 135B أصلي لـ Ascend: أطلق فريق Pangu في هواوي نموذج اللغة العام الكثيف Pangu Ultra بمعاملات 135B، والذي تم تدريبه باستخدام معالجات NPU الصينية Ascend. يعتمد النموذج على بنية Transformer مكونة من 94 طبقة، ويقدم تقنيات Depth-scaled sandwich-norm (DSSN) و TinyInit لحل مشاكل استقرار تدريب النماذج العميقة جدًا، محققًا تدريبًا مستقرًا بدون طفرات في الخسارة (loss spikes) على 13.2 تريليون من البيانات عالية الجودة. على مستوى النظام، من خلال التحسينات مثل التوازي المختلط، ودمج العمليات، وتقسيم التسلسلات الفرعية، تم رفع كفاءة استخدام القدرة الحاسوبية (MFU) إلى أكثر من 50% على مجموعة Ascend المكونة من 8192 وحدة. تظهر التقييمات أن Pangu Ultra يتفوق على النماذج الكثيفة مثل Llama 405B و Mistral Large 2 في العديد من المعايير، ويمكنه التنافس مع نماذج MoE الأكبر حجمًا مثل DeepSeek-R1، مما يثبت جدوى تطوير نماذج كبيرة متطورة بالاعتماد على القدرة الحاسوبية المحلية (المصدر: 机器之心)

دراسة تشكك في أهمية التعلم المعزز (RL) لتحسين قدرات الاستدلال لدى نماذج اللغة الكبيرة (LLM): شكك باحثون من جامعتي توبنغن وكامبريدج في الادعاءات الأخيرة بأن التعلم المعزز (RL) يمكن أن يحسن بشكل كبير قدرات الاستدلال لدى نماذج اللغة. من خلال تحقيق دقيق في معايير الاستدلال الشائعة (مثل AIME24)، وجد الباحثون أن النتائج غير مستقرة للغاية، وأن مجرد تغيير البذور العشوائية (random seeds) يمكن أن يؤدي إلى تقلبات كبيرة في الدرجات. في ظل التقييم الموحد، كان التحسن في الأداء الناتج عن RL أقل بكثير مما ورد في التقارير الأصلية، وغالبًا ما يفتقر إلى الدلالة الإحصائية، بل إنه أضعف من تأثير الضبط الدقيق الخاضع للإشراف (SFT)، كما أن قدرته على التعميم ضعيفة نسبيًا. تشير الدراسة إلى أن اختلافات العينات، وتكوينات فك التشفير، وأطر التقييم، وعدم تجانس الأجهزة هي الأسباب الرئيسية لعدم الاستقرار، وتدعو إلى اعتماد معايير تقييم أكثر صرامة وقابلية للتكرار للنظر بهدوء وقياس التقدم الحقيقي في قدرات استدلال النماذج (المصدر: 机器之心)

خطاب ألتمان في TED: سيتم إطلاق نموذج قوي مفتوح المصدر، ويعتقد أن ChatGPT ليس ذكاءً اصطناعيًا عامًا (AGI): صرح الرئيس التنفيذي لـ OpenAI سام ألتمان في مؤتمر TED بأن الشركة تعمل على تطوير نموذج قوي مفتوح المصدر، سيتجاوز أداؤه جميع النماذج مفتوحة المصدر الحالية، في رد مباشر على المنافسين مثل DeepSeek. وأكد أن قاعدة مستخدمي ChatGPT تستمر في النمو بجنون، وأن ميزة الذاكرة الجديدة ستعزز التجربة الشخصية. يعتقد أن الذكاء الاصطناعي سيشهد اختراقات في مجالات الاكتشاف العلمي وتطوير البرمجيات (مع تحسن هائل في الكفاءة)، لكن النماذج الحالية مثل ChatGPT لا تزال تفتقر إلى القدرة على التعلم الذاتي المستمر والتعميم عبر المجالات، وبالتالي فهي ليست ذكاءً اصطناعيًا عامًا (AGI). كما ناقش قضايا حقوق النشر و “حقوق الأسلوب” التي أثارتها القدرات الإبداعية لـ GPT-4o، وأعاد التأكيد على ثقة OpenAI في أمان نماذجها وآليات التحكم في المخاطر (المصدر: 新智元)

دراسة تقدر أن الحد الأقصى لتعلم الإنسان مدى الحياة يبلغ حوالي 4GB، مما يثير نقاشًا حول واجهات الدماغ والحاسوب وتطور الذكاء الاصطناعي: نشرت دراسة من معهد كاليفورنيا للتكنولوجيا في مجلة Neuron التابعة لـ Cell، قدرت أن سرعة معالجة المعلومات في الدماغ البشري تبلغ حوالي 10 بت في الثانية، وهو أقل بكثير من معدل جمع البيانات في الأنظمة الحسية البالغ 10 مليارات بت في الثانية. بناءً على ذلك، استنتجت الدراسة أن الحد الأقصى لتراكم المعرفة لدى الإنسان مدى الحياة (بافتراض 100 عام من التعلم المستمر دون نسيان) يبلغ حوالي 4GB، وهو أقل بكثير من قدرة تخزين معاملات النماذج الكبيرة (على سبيل المثال، يمكن لنموذج 7B تخزين 14 مليار بت). تعتقد الدراسة أن هذا القيد ينبع من آلية المعالجة التسلسلية للجهاز العصبي المركزي، وتتوقع أن تجاوز الذكاء الآلي للبشر هو مجرد مسألة وقت. كما شككت الدراسة في مشروع Neuralink لإيلون ماسك، معتبرة أنه لا يمكنه تجاوز القيود الهيكلية الأساسية للدماغ، وأنه من الأفضل تحسين طرق الاتصال الحالية. أثارت هذه الدراسة نقاشًا واسعًا حول حدود الإدراك البشري، وإمكانات تطوير الذكاء الاصطناعي، واتجاه واجهات الدماغ والحاسوب (المصدر: 量子位)

🎯 اتجاهات
GPT-4 على وشك الإيقاف، وقد يظهر GPT-4.1 ونماذج جديدة غامضة: أعلنت OpenAI أنها ستبدأ في 30 أبريل باستبدال GPT-4 الذي تم إصداره قبل عامين بالكامل بـ GPT-4o في ChatGPT، وسيظل GPT-4 متاحًا عبر API. في الوقت نفسه، تشير تسريبات المجتمع والشيفرات البرمجية إلى أن OpenAI قد تصدر قريبًا سلسلة من النماذج الجديدة، بما في ذلك GPT-4.1 (وإصداراته mini/nano)، ونموذج الاستدلال o3 بكامل طاقته، وسلسلة o4 الجديدة (مثل o4-mini). تم إطلاق نموذج غامض يسمى Optimus Alpha على OpenRouter، ويظهر أداءً ممتازًا (خاصة في البرمجة)، ويدعم سياقًا يصل إلى مليون توكن، ويُعتقد على نطاق واسع أنه أحد النماذج الجديدة التي ستصدرها OpenAI قريبًا (ربما GPT-4.1 أو o4-mini)، ويشترك في العديد من أوجه التشابه مع نماذج OpenAI (مثل أخطاء برمجية محددة). يشير هذا إلى تسارع وتيرة تحديث نماذج OpenAI، وأنها تعمل بنشاط على تعزيز ريادتها التكنولوجية (المصدر: source، source)

نموذج Qwen3 الكبير من علي بابا يستعد للإطلاق: تشير الأنباء إلى أن علي بابا تتوقع إطلاق نموذج Qwen3 الكبير في المستقبل القريب، وقد أكد فريق البحث والتطوير أن النموذج دخل مرحلة الإعداد النهائية، لكن لم يتم تحديد موعد الإطلاق الدقيق. يُذكر أن Qwen3 هو منتج نموذجي مهم لعلي بابا في النصف الأول من عام 2025، وقد بدأ تطويره بعد Qwen2.5. متأثرًا بالنماذج المنافسة مثل DeepSeek-R1، قام فريق النماذج الأساسية في سحابة علي بابا بتحويل تركيزه الاستراتيجي بشكل أكبر نحو تعزيز قدرات الاستدلال للنموذج، مما يدل على التركيز الاستراتيجي على قدرات محددة في ظل مشهد المنافسة بين النماذج الكبيرة (المصدر: InfoQ)

منصة Kimi المفتوحة تخفض الأسعار وتفتح مصدر نموذج رؤية خفيف الوزن: أعلنت منصة Kimi المفتوحة التابعة لشركة Moonshot AI عن خفض أسعار خدمة استدلال النماذج والتخزين المؤقت للسياق، بهدف تقليل تكاليف المستخدمين من خلال التحسينات التقنية. في الوقت نفسه، فتحت Kimi مصدر نموذجين للغة والرؤية خفيفي الوزن يعتمدان على بنية MoE وهما Kimi-VL و Kimi-VL-Thinking، يدعمان سياق 128K، مع حوالي 3 مليارات معامل نشط فقط، ويُقال إنهما يتفوقان بشكل كبير في قدرات الاستدلال متعدد الوسائط على النماذج الكبيرة التي تحتوي على 10 أضعاف عدد المعاملات، بهدف تعزيز تطوير وتطبيق نماذج متعددة الوسائط صغيرة وفعالة (المصدر: InfoQ)
جوجل تطلق بروتوكول التشغيل البيني للوكلاء A2A والعديد من منتجات الذكاء الاصطناعي الجديدة: في مؤتمر Google Cloud Next ’25، أطلقت جوجل بالتعاون مع أكثر من 50 شريكًا بروتوكولًا مفتوحًا Agent2Agent (A2A)، يهدف إلى تحقيق التشغيل البيني والتعاون بين الوكلاء الأذكياء (AI agents) الذين تم تطويرهم بواسطة شركات ومنصات مختلفة. في الوقت نفسه، أطلقت العديد من نماذج وتطبيقات الذكاء الاصطناعي، بما في ذلك Gemini 2.5 Flash (إصدار فعال من النموذج الرائد)، و Lyria (توليد الموسيقى من النص)، و Veo 2 (إنشاء الفيديو)، و Imagen 3 (توليد الصور)، و Chirp 3 (أصوات مخصصة)، وأطلقت الجيل السابع من رقائق TPU باسم Ironwood، المصممة خصيصًا لتحسين الاستدلال. تعكس هذه السلسلة من الإصدارات تخطيط جوجل الشامل واستراتيجيتها المفتوحة في مجالات البنية التحتية للذكاء الاصطناعي، والنماذج، والمنصات، والوكلاء الأذكياء (المصدر: InfoQ)
ByteDance تطلق نموذج الاستدلال Seed-Thinking-v1.5 بمعاملات 200B: أصدر فريق Doubao في ByteDance تقريرًا تقنيًا يقدم نموذج الاستدلال MoE الخاص به Seed-Thinking-v1.5، الذي يمتلك إجمالي 200 مليار معامل. يقوم النموذج بتنشيط 20 مليار معامل في كل مرة، ويظهر أداءً ممتازًا في العديد من اختبارات المعايير، ويُقال إنه يتفوق على DeepSeek-R1 الذي يمتلك إجمالي 671 مليار معامل. يتكهن المجتمع بأن هذا قد يكون النموذج المستخدم حاليًا في وضع “التفكير العميق” في تطبيق Doubao من ByteDance، مما يدل على تقدم ByteDance في تطوير نماذج استدلال فعالة (المصدر: InfoQ)
Midjourney تطلق نموذج V7، لتحسين جودة الصور وكفاءة التوليد: أطلقت أداة توليد الصور بالذكاء الاصطناعي Midjourney نموذجها الجديد V7 (إصدار ألفا). يعمل الإصدار الجديد على تحسين ترابط واتساق توليد الصور، خاصة في تفاصيل اليدين وأجزاء الجسم والأشياء، ويمكنه توليد مواد (textures) أكثر واقعية وثراءً. يقدم V7 وضع Draft Mode، الذي يحقق سرعة عرض أسرع بعشر مرات بنصف التكلفة، وهو مناسب للتكرار السريع والاستكشاف. في الوقت نفسه، يوفر وضعي توليد هما turbo (أسرع ولكن أغلى) و relax (أبطأ ولكن أرخص)، لتلبية احتياجات المستخدمين المختلفة (المصدر: InfoQ)
أمازون تطلق نموذج الصوت بالذكاء الاصطناعي Nova Sonic: أطلقت أمازون الجيل الجديد من نماذج الذكاء الاصطناعي التوليدية التي تعالج الصوت أصلاً، Nova Sonic. يُقال إن النموذج يمكن مقارنته بأفضل نماذج الصوت من OpenAI وجوجل في المؤشرات الرئيسية مثل السرعة والتعرف على الصوت وجودة المحادثة. يتم توفير Nova Sonic من خلال منصة مطوري Amazon Bedrock، باستخدام واجهة برمجة تطبيقات (API) تدفق ثنائية الاتجاه جديدة، وبسعر أرخص بنحو 80% من GPT-4o، بهدف توفير قدرات تفاعل صوتي طبيعي عالية الفعالية من حيث التكلفة لتطبيقات الذكاء الاصطناعي على مستوى المؤسسات (المصدر: InfoQ)
ميزات الذكاء الاصطناعي في إصدار iPhone الصيني قد تتوفر منتصف العام، مع دمج تقنيات Baidu و Alibaba: تفيد التقارير بأن Apple تخطط لتقديم خدمة Apple Intelligence لأجهزة iPhone في السوق الصينية (ربما في iOS 18.5) قبل منتصف عام 2025. ستستخدم الميزة نموذج Baidu Wenxin الكبير لتوفير القدرات الذكية، وستدمج محرك المراجعة الخاص بـ Alibaba للامتثال لمتطلبات تنظيم المحتوى. لم توقع Apple اتفاقيات حصرية مع Baidu أو Alibaba، مما يدل على استراتيجيتها للتعاون المحلي في الأسواق الرئيسية لنشر ميزات الذكاء الاصطناعي بسرعة (المصدر: InfoQ)
🧰 أدوات
Volcano Engine تطلق وكيل البيانات الذكي للمؤسسات Data Agent: أطلقت Volcano Engine وكيل البيانات الذكي للمؤسسات Data Agent. تستخدم هذه الأداة قدرات النماذج الكبيرة في الاستدلال والتحليل واستدعاء الأدوات، بهدف فهم احتياجات العمل المؤسسي بعمق، وأتمتة تنفيذ مهام تحليل وتطبيق البيانات المعقدة مثل كتابة تقارير بحثية متعمقة وتصميم حملات تسويقية، مما يعزز كفاءة استخدام بيانات المؤسسة ومستوى اتخاذ القرار (المصدر: InfoQ)
أسلوب جديد لتوليد الصور باستخدام GPT-4o يحظى بالاهتمام: يعرض مستخدمو وسائل التواصل الاجتماعي أساليب جديدة تم إنشاؤها باستخدام ميزة توليد الصور في GPT-4o، على سبيل المثال، دمج عناصر واجهة Windows 2000 القديمة مع صور الشخصيات لإنشاء تأثيرات كولاج فريدة. شارك المستخدمون تقنيات كتابة المطالبات (prompts)، مثل استخدام الصور المرجعية (垫图) لتوجيه العملية، والجمع بين وصف الأسلوب والمحتوى، مما أثار اهتمام المجتمع باستكشاف الإمكانات الإبداعية لـ GPT-4o (المصدر: source، source)

📚 تعلم
إطلاق MegaMath: أكبر مجموعة بيانات مفتوحة المصدر للتدريب المسبق في الرياضيات: أطلقت LLM360 مجموعة بيانات MegaMath، وهي مجموعة بيانات مفتوحة المصدر للتدريب المسبق على الاستدلال الرياضي تحتوي على 371 مليار توكن، متجاوزة حجم DeepSeek-Math Corpus. تغطي مجموعة البيانات صفحات الويب كثيفة المحتوى الرياضي (279B)، والشيفرات البرمجية المتعلقة بالرياضيات (28B)، والبيانات الاصطناعية عالية الجودة (64B). من خلال عملية معالجة بيانات دقيقة، بما في ذلك تحسين بنية HTML، والاستخراج على مرحلتين، والفرز والتنقيح بمساعدة LLM، ضمن الفريق حجم البيانات وجودتها وتنوعها. أظهر التحقق من التدريب المسبق على نموذج Llama-3.2 أن استخدام MegaMath يمكن أن يحقق تحسنًا مطلقًا بنسبة 15-20% في معايير مثل GSM8K و MATH، مما يوفر للمجتمع مفتوح المصدر أساسًا قويًا لتدريب قدرات الاستدلال الرياضي (المصدر: 机器之心)

Nabla-GFlowNet: موازنة التنوع والكفاءة في الضبط الدقيق لنماذج الانتشار: اقترح باحثون من الجامعة الصينية في هونغ كونغ (شينزن) ومؤسسات أخرى Nabla-GFlowNet، وهي طريقة جديدة لضبط نماذج الانتشار باستخدام المكافآت تعتمد على شبكات التدفق التوليدية (GFlowNet). تهدف هذه الطريقة إلى حل مشكلة التقارب البطيء في الضبط الدقيق التقليدي باستخدام التعلم المعزز ومشكلة التجهيز المفرط (overfitting) وفقدان التنوع في تحسين المكافأة المباشر. من خلال اشتقاق شرط توازن تدفق جديد (Nabla-DB) وتصميم دالة خسارة محددة وتمثيل حدودي لتدرج التدفق اللوغاريتمي، يمكن لـ Nabla-GFlowNet مواءمة النموذج بكفاءة مع دالة المكافأة (مثل درجة الجمالية، اتباع التعليمات) مع الحفاظ على تنوع العينات المولدة. أثبتت التجارب على Stable Diffusion تفوقها مقارنة بطرق مثل DDPO و ReFL و DRaFT (المصدر: 机器之心)
Llama.cpp يصلح المشكلات المتعلقة بـ Llama 4: قام مشروع llama.cpp بدمج إصلاحين يستهدفان نماذج Llama 4، يتعلقان بـ RoPE (تضمينات الموضع الدورانية) وحسابات المعايير (norms) الخاطئة. تهدف هذه الإصلاحات إلى تحسين جودة مخرجات النموذج، ولكن قد يحتاج المستخدمون إلى إعادة تنزيل ملفات نموذج GGUF التي تم إنشاؤها باستخدام أداة التحويل بعد الإصلاح حتى تصبح سارية المفعول (المصدر: source)
💼 أعمال
Nvidia تكمل استحواذها على Lepton AI: وفقًا للتقارير، استحوذت Nvidia على شركة Lepton AI الناشئة في مجال البنية التحتية للذكاء الاصطناعي، والتي أسسها نائب الرئيس السابق لشركة علي بابا Jia Yangqing، بقيمة صفقة قد تصل إلى مئات الملايين من الدولارات. يتمثل العمل الرئيسي لشركة Lepton AI في تأجير خوادم Nvidia GPU وتوفير البرامج لمساعدة الشركات على بناء وإدارة تطبيقات الذكاء الاصطناعي. انضم Jia Yangqing والمؤسس المشارك له Bai Junjie وحوالي 20 موظفًا آخر إلى Nvidia. تعتبر هذه الخطوة بمثابة توسع استراتيجي لـ Nvidia في سوق الخدمات السحابية وبرامج المؤسسات، لمواجهة المنافسة من رقائق مطورة ذاتيًا من شركات مثل AWS و Google Cloud (المصدر: InfoQ)
القلق يسود قطاع التكنولوجيا الأمريكي، والذكاء الاصطناعي يؤثر على سوق العمل: تشير التقارير إلى أن قطاع التكنولوجيا في الولايات المتحدة يمر بصعوبات تتمثل في انخفاض عدد الوظائف، وتقلص الرواتب، وإطالة فترات البحث عن عمل. أدت عمليات التسريح الجماعي، واستخدام الشركات (مثل Salesforce، Meta، Google) للذكاء الاصطناعي كبديل للقوى العاملة أو تعليق التوظيف (خاصة في المناصب الهندسية والمبتدئة) إلى تفاقم القلق المهني لدى العاملين في هذا المجال. تظهر البيانات ارتفاع نسبة الأشخاص الذين أبلغوا عن انخفاض رواتبهم والتحول من المناصب الإدارية إلى مناصب المساهمين الفرديين. يعيد الذكاء الاصطناعي تشكيل سوق العمل، مما يجبر الباحثين عن عمل على توسيع آفاقهم إلى قطاعات غير تكنولوجية أو التحول إلى ريادة الأعمال. يوصي الخبراء بالتركيز على فرص العمل خارج “السبع الكبار” وإتقان أدوات الذكاء الاصطناعي لتعزيز القدرة التنافسية (المصدر: InfoQ)

أنباء عن نية OpenAI الاستحواذ على شركة أجهزة الذكاء الاصطناعي التي يتعاون فيها Altman و Jony Ive: تشير الأنباء إلى أن OpenAI تناقش الاستحواذ على شركة الذكاء الاصطناعي io Products، التي أسسها رئيسها التنفيذي Altman بالتعاون مع مدير التصميم السابق في Apple جوني إيف، مقابل مبلغ لا يقل عن 500 مليون دولار. تهدف الشركة إلى تطوير أجهزة شخصية مدفوعة بالذكاء الاصطناعي، قد تتخذ شكل “هاتف” بدون شاشة أو جهاز منزلي. يقوم فريق من المهندسين في io Products ببناء الأجهزة، وتوفر OpenAI التكنولوجيا، ويتولى استوديو Ive التصميم، ويشارك Altman بعمق. إذا تمت عملية الاستحواذ، فسيتم دمج فريق الأجهزة هذا في OpenAI، مما يسرع من تخطيطها في مجال أجهزة الذكاء الاصطناعي (المصدر: InfoQ)
شركة ناشئة لمديرة التكنولوجيا السابقة في OpenAI تستقطب موظفين قدامى من الشركة الأم: استقطبت شركة الذكاء الاصطناعي “Mind Machines Lab” التي أسستها مديرة التكنولوجيا السابقة في OpenAI ميرا موراتي، شخصيتين رئيسيتين سابقتين من OpenAI للانضمام إلى فريقها الاستشاري: كبير مسؤولي الأبحاث السابق Bob McGrew والباحث السابق Alec Radford. كان Radford هو المؤلف الرئيسي للأوراق البحثية الأساسية لسلسلة GPT. يعزز هذا التوظيف القوة التقنية للشركة الناشئة، ويعكس أيضًا المنافسة الشديدة على المواهب في مجال الذكاء الاصطناعي (المصدر: InfoQ)
Baichuan Intelligence تعدل تركيز أعمالها، وتركز على المجال الطبي: أصدر مؤسس Baichuan Intelligence وانغ شياو تشوان رسالة إلى جميع الموظفين بمناسبة الذكرى السنوية الثانية لتأسيس الشركة، مؤكدًا مجددًا أن الشركة ستركز على المجال الطبي، وتطور خدمات تطبيقات مثل Baixiaoying، وطب الأطفال بالذكاء الاصطناعي، والطب العام بالذكاء الاصطناعي، والطب الدقيق. وأكد على الحاجة إلى تقليل الإجراءات غير الضرورية، وأن الهيكل التنظيمي سيصبح أكثر تسطحًا. في وقت سابق، تم الكشف عن تسريح فريق عملاء قطاع الأعمال (B2B) في القطاع المالي بالشركة، واستقالة الشريك التجاري Deng Jiang، بالإضافة إلى استقالة أو قرب استقالة العديد من المؤسسين المشاركين الآخرين، مما يشير إلى أن الشركة تمر بمرحلة تركيز استراتيجي وتعديل تنظيمي (المصدر: InfoQ)
سحابة علي بابا تطلق خطة “繁花” (Fanhua) لشركاء النظام البيئي للذكاء الاصطناعي: أطلقت سحابة علي بابا خطة “繁花” (Fanhua)، التي تهدف إلى دعم شركاء النظام البيئي للذكاء الاصطناعي. ستوفر الخطة، بناءً على نضج منتجات الشركاء، موارد سحابية، ودعمًا للقدرة الحاسوبية، وتجميع المنتجات، وتخطيطًا تجاريًا، وخدمات دورة حياة كاملة. في الوقت نفسه، أطلقت سحابة علي بابا سوقًا لتطبيقات وخدمات الذكاء الاصطناعي، بهدف بناء نظام بيئي مزدهر للذكاء الاصطناعي، وتسريع تطبيق تقنيات وتطبيقات الذكاء الاصطناعي (المصدر: InfoQ)
Kugou Music و DeepSeek تتوصلان إلى تعاون عميق: أعلنت Kugou Music عن تعاونها مع شركة الذكاء الاصطناعي DeepSeek، لإطلاق سلسلة من الميزات المبتكرة القائمة على الذكاء الاصطناعي. تشمل هذه الميزات استخدام التحليل متعدد الوسائط لإنشاء تقارير استماع مخصصة، وتوصيات يومية بالذكاء الاصطناعي، وبحث ذكي، وإدارة قوائم التشغيل بالذكاء الاصطناعي، وإنشاء أغلفة ديناميكية بالذكاء الاصطناعي، بالإضافة إلى “معلق ذكاء اصطناعي” يتمتع بسمات شخصية محددة، بهدف تعزيز تجربة المستخدم الموسيقية والتفاعل المجتمعي من خلال تقنية الذكاء الاصطناعي (المصدر: InfoQ)
أنباء عن استخدام جوجل لاتفاقيات عدم منافسة “متشددة” للاحتفاظ بمواهب الذكاء الاصطناعي: تفيد التقارير بأن DeepMind التابعة لجوجل تفرض اتفاقيات عدم منافسة لمدة عام واحد على بعض الموظفين في المملكة المتحدة لمنع انتقال المواهب إلى المنافسين. خلال هذه الفترة، لا يُطلب من الموظفين العمل ولكنهم يظلون يتقاضون رواتبهم (إجازة مدفوعة الأجر)، لكن هذا يجعل بعض الباحثين يشعرون بالتهميش وعدم القدرة على المشاركة في تطورات الصناعة السريعة. قد يكون هذا الإجراء محظورًا في الولايات المتحدة بموجب قوانين لجنة التجارة الفيدرالية (FTC)، ولكنه مطبق في المقر الرئيسي بلندن، مما أثار نقاشات حول المنافسة على المواهب وتقييد الابتكار (المصدر: InfoQ)
موظفون سابقون في OpenAI يقدمون وثائق قانونية لدعم دعوى ماسك القضائية: قدم 12 موظفًا سابقًا في OpenAI وثائق قانونية لدعم الدعوى القضائية التي رفعها إيلون ماسك ضد OpenAI. يعتقدون أن خطة إعادة هيكلة OpenAI (التحول إلى هيكل ربحي) قد تنتهك بشكل أساسي مهمة الشركة الأصلية غير الربحية، والتي كانت عاملاً رئيسيًا في جذبهم للانضمام. ردت OpenAI بأن مهمتها لن تتغير، حتى مع تغير الهيكل (المصدر: InfoQ)
🌟 مجتمع
دراسة Anthropic تكشف عن أنماط وتحديات استخدام الذكاء الاصطناعي في التعليم العالي: قامت Anthropic بتحليل ملايين المحادثات المجهولة للطلاب على منصة Claude.ai، ووجدت أن طلاب العلوم والهندسة (خاصة تخصص علوم الكمبيوتر) هم المستخدمون الأوائل للذكاء الاصطناعي. تشمل أنماط تفاعل الطلاب مع الذكاء الاصطناعي أربعة أنواع بنسب متساوية: حل المشكلات مباشرة، وتوليد المحتوى مباشرة، وحل المشكلات التعاوني، وتوليد المحتوى التعاوني. يُستخدم الذكاء الاصطناعي بشكل أساسي في المهام المعرفية العليا مثل الإبداع (مثل البرمجة، كتابة التمارين) والتحليل (مثل شرح المفاهيم). كشفت الدراسة أيضًا عن سلوكيات أكاديمية غير نزيهة محتملة (مثل الحصول على الإجابات، وتجنب كشف الانتحال)، مما أثار مخاوف بشأن النزاهة الأكاديمية، وتنمية التفكير النقدي، وطرق التقييم (المصدر: 新智元)

توليد الصور بـ GPT-4o يقود اتجاهات جديدة: من أسلوب Ghibli إلى بطاقات مشاهير الذكاء الاصطناعي: تستمر قدرات توليد الصور القوية لـ GPT-4o في إثارة موجة إبداعية على وسائل التواصل الاجتماعي. بعد الانتشار الواسع لـ “صور عائلية بأسلوب Ghibli” (التي كان وراءها المهندس السابق في أمازون Grant Slatton)، بدأ المستخدمون في إنشاء بطاقات بأسلوب “Magic: The Gathering” لمشاهير مجال الذكاء الاصطناعي (مثل تصوير Altman على أنه “سيد AGI”)، بالإضافة إلى بطاقات تاروت مخصصة. تعرض هذه الأمثلة إمكانات الذكاء الاصطناعي في تقليد الأساليب الفنية والتوليد الإبداعي، لكنها تثير أيضًا نقاشات حول الأصالة وحقوق النشر والقيمة الجمالية وتأثير الذكاء الاصطناعي على مهنة المصممين (المصدر: 新智元)

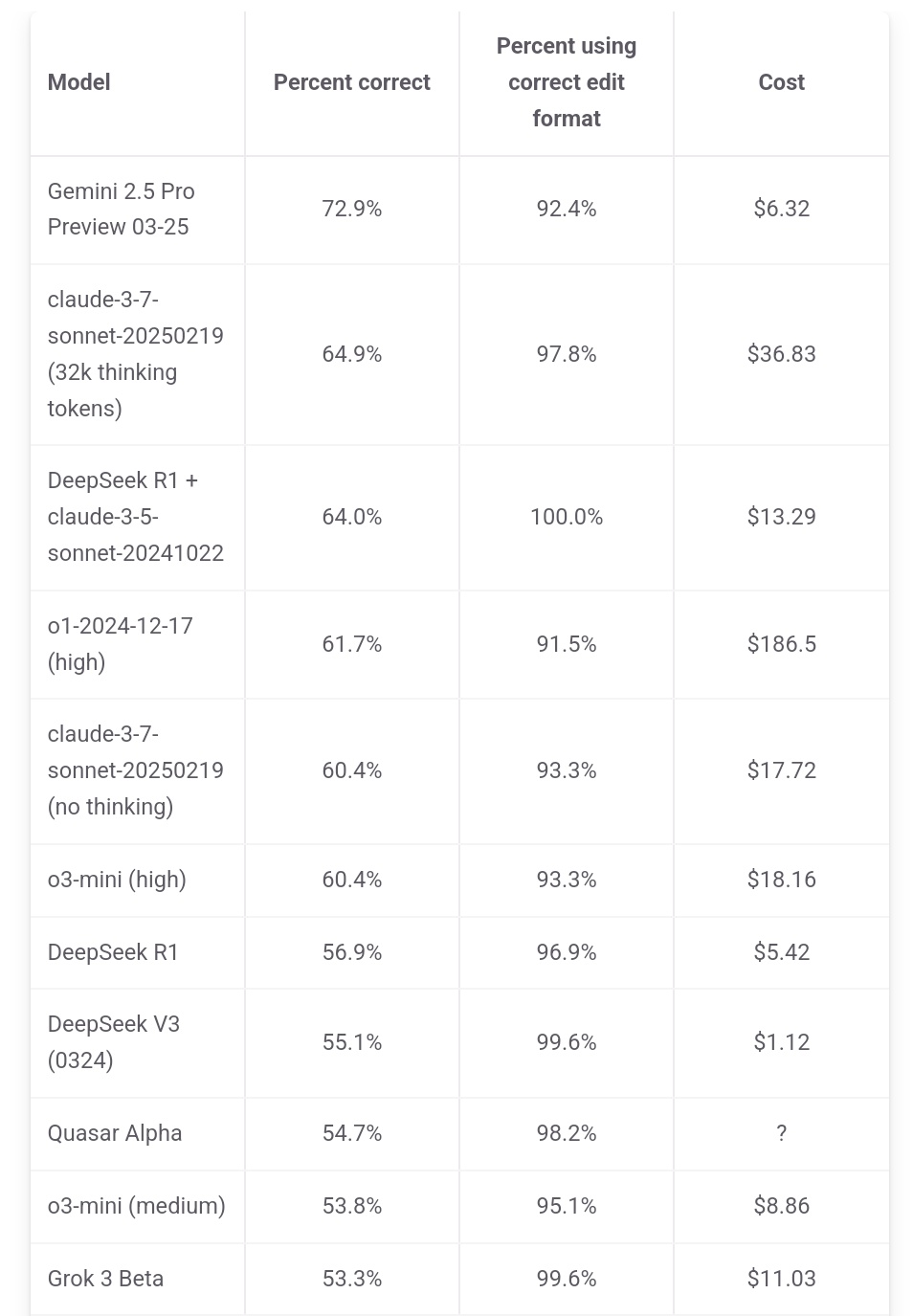
Jeff Dean يؤكد على ميزة التكلفة لـ Gemini 2.5 Pro: أعاد Jeff Dean، رئيس قسم الذكاء الاصطناعي في جوجل، نشر بيانات تصنيف من aider.chat، وأشار إلى أن Gemini 2.5 Pro لا يتصدر فقط في اختبار البرمجة Polyglot من حيث الأداء، ولكن تكلفته (6 دولارات) أقل بكثير أيضًا من النماذج العشرة الأوائل الأخرى باستثناء DeepSeek، مؤكدًا على ميزة القيمة مقابل السعر. تصل تكلفة بعض النماذج المنافسة إلى ضعفين أو 3 أضعاف أو حتى 30 ضعف تكلفة Gemini 2.5 Pro (المصدر: JeffDean)
نقاش حاد على Reddit حول تأثير الذكاء الاصطناعي على سوق العمل، خاصة الوظائف المبتدئة: أثار منشور على منتدى Reddit نقاشًا حادًا، حيث أعرب صاحب المنشور (طالب ماجستير في نظم المعلومات الحاسوبية CIS) عن قلقه العميق بشأن استبدال الذكاء الاصطناعي للوظائف المبتدئة غير اليدوية (خاصة هندسة البرمجيات، وتحليل البيانات، ودعم تكنولوجيا المعلومات IT)، معتبرًا أن مقولة “الذكاء الاصطناعي لن يسرق الوظائف” تتجاهل محنة الخريجين الجدد. وأشار إلى أن الشركات الكبرى بدأت بالفعل في تقليص التوظيف من الجامعات، وأن سوق العمل المستقبلي قد يكون صعبًا. انقسمت الآراء في قسم التعليقات، حيث اتفق البعض مع الأزمة، بينما اعتبر آخرون أن هذا هو الوضع الطبيعي للتغيير التكنولوجي، ويتطلب التكيف مع أدوار جديدة (مثل إدارة فرق الذكاء الاصطناعي)، وشكك البعض في مقولة “اختفاء 90% من الوظائف”، معتبرين أن الدورة الاقتصادية واختلاف الأوضاع بين الدول كبير جدًا، وأن قدرات الذكاء الاصطناعي الحالية لا تزال محدودة (المصدر: source)
مستخدمو Claude يشتكون من تدهور الأداء وتشديد القيود: ظهر نقاش مركّز في قسم ClaudeAI على Reddit، حيث أفاد العديد من المستخدمين (بمن فيهم مستخدمو Pro) بأنهم واجهوا مؤخرًا قيود استخدام (quota) أكثر صرامة، حتى مع العمليات العادية، ووصلوا إلى الحد الأقصى بشكل متكرر. يعتقد بعض المستخدمين أن Anthropic تقوم بتشديد الحصص سرًا، وأعربوا عن استيائهم، معتبرين أن هذا سيجبر المستخدمين على التحول إلى المنافسين. بالإضافة إلى ذلك، أفاد بعض المستخدمين بأن “شخصية” Claude تبدو وكأنها تغيرت، وأصبحت أكثر “برودًا” و “آلية”، وفقدت الإحساس الفلسفي والشاعري الذي كان يميز الإصدارات السابقة، مما دفع بعض المستخدمين إلى إلغاء اشتراكاتهم (المصدر: source، source، source، source)
توليد الصور باستخدام ChatGPT يثير المرح والنقاش: يشارك مستخدمو Reddit تجارب ونتائج متنوعة لاستخدام ChatGPT في توليد الصور. طلب أحدهم “تحويل” كلب إلى إنسان، وكانت النتيجة صورة تشبه “الوحش البشري/الفروي (furry)”، مما أثار نقاشًا حول فهم المطالبات والتحيزات المحتملة. طلب مستخدم آخر رسم نفسه كنافذة زجاجية ملونة من أكوان متعددة، وكانت النتيجة مذهلة. طلب مستخدم آخر توليد صور استعارية حول الذكاء الاصطناعي، أو سأل عن “كوابيس” الذكاء الاصطناعي، مما أظهر قدرات وقيود توليد الصور بالذكاء الاصطناعي في التعبير الإبداعي وتصور المفاهيم المجردة (المصدر: source، source، source، source، source)

المجتمع يناقش اختيار نماذج LLM واستراتيجيات استخدامها: اقترح مستخدم في قسم LocalLLaMA على Reddit إجراء مناقشة شهرية حول استخدام النماذج، لمشاركة أفضل النماذج (مفتوحة المصدر ومغلقة المصدر) التي يستخدمها كل منهم في سيناريوهات مختلفة (البرمجة، الكتابة، البحث، إلخ) وأسباب ذلك. شارك المستخدمون في قسم التعليقات مجموعات النماذج التي يستخدمونها حاليًا، مثل Deepseek V3.1/Gemini 2.5 Pro/4o/R1/Qwen 2.5 Max/Sonnet 3.7/Gemma 3/Claude 3.7/Mistral Nemo وغيرها، وذكروا استخدامات محددة (مثل استدعاء الأدوات، التصنيف، لعب الأدوار)، مما يعكس اتجاه المستخدمين نحو اختيار ودمج نماذج مختلفة بناءً على متطلبات المهمة (المصدر: source)
💡 أخرى
قمة صناعة AIGC الصينية ستعقد قريباً: ستعقد الدورة الثالثة لقمة صناعة AIGC الصينية في 16 أبريل في بكين. ستجمع القمة أكثر من 20 من قادة الصناعة من شركات مثل Baidu، Huawei، Microsoft Research Asia، Amazon Web Services، Mianbi Intelligence، Shengshu Technology، لمناقشة اختراقات تكنولوجيا الذكاء الاصطناعي (القدرة الحاسوبية، النماذج الكبيرة)، والتطبيقات الصناعية (التعليم، الترفيه، البحث العلمي، خدمات المؤسسات)، وبناء النظام البيئي (الأمان والتحكم، تحديات التنفيذ) وغيرها من القضايا. ستصدر القمة أيضًا قوائم شركات/منتجات AIGC وخريطة بانورامية لتطبيقات AIGC في الصين (المصدر: 量子位)

تقرير ستانفورد: فجوة الأداء بين أفضل نماذج الذكاء الاصطناعي في الصين والولايات المتحدة تتقلص إلى 0.3%: أظهر تقرير مؤشر الذكاء الاصطناعي لعام 2025 الصادر عن جامعة ستانفورد أن الفجوة في الأداء بين أفضل نماذج الذكاء الاصطناعي في الصين والولايات المتحدة قد تقلصت بشكل كبير من 20% في عام 2023 إلى 0.3%. على الرغم من أن الولايات المتحدة لا تزال متقدمة من حيث عدد النماذج المعروفة (40 مقابل 15) والشركات الرائدة في الصناعة، إلا أن سرعة لحاق النماذج الصينية تتسارع. أشار التقرير أيضًا إلى أن فجوة الأداء بين أفضل النماذج نفسها تتقلص أيضًا، من 12% في عام 2024 إلى 5%، مما يشير إلى ظاهرة تقارب واضحة (المصدر: InfoQ)