
كلمات مفتاحية:أوبن إيه آي, أمازون AWS, قوة الحوسبة للذكاء الاصطناعي, ستانفورد AgentFlow, ميتوان LongCat-Flash-Omni, علي بابا Qwen3-Max-Thinking, سامسونج TRM, يونيتي AI Graph, تعاون أوبن إيه آي وأمازون في قوة الحوسبة, إطار AgentFlow للتعلم التعزيزي, نموذج LongCat-Flash-Omni متعدد الوسائط, قدرات الاستدلال في Qwen3-Max-Thinking, هندسة TRM للاستدلال التكراري
🔥 تركيز
OpenAI تبرم شراكة حوسبة بقيمة 38 مليار دولار مع Amazon: وقعت OpenAI اتفاقية قدرة حاسوبية بقيمة 38 مليار دولار مع Amazon AWS، بهدف الحصول على موارد وحدات معالجة الرسوميات (GPU) من NVIDIA لدعم بناء بنيتها التحتية لنماذج AI وأهدافها الطموحة في مجال AI. تمثل هذه الخطوة تقدمًا مهمًا لـ OpenAI في تنويع مزودي الخدمات السحابية، مما يقلل من اعتمادها الحصري على Microsoft، ويمهد الطريق لطرحها العام الأولي (IPO) المستقبلي. من جانبها، تعزز Amazon من خلال هذا التعاون مكانتها الريادية في مجال البنية التحتية لـ AI، مع الحفاظ على شراكتها مع Anthropic، المنافس لـ OpenAI. ستوفر هذه الاتفاقية لـ OpenAI قدرة حاسوبية قابلة للتوسع لاستدلال AI وتدريب نماذج الجيل التالي، وستعزز تطبيق نماذجها الأساسية على منصة AWS. (المصدر: Ronald_vanLoon, scaling01, TheRundownAI)

إطار عمل AgentFlow من ستانفورد: النماذج الصغيرة تتفوق على GPT-4o: أطلق فريق بحثي من جامعة ستانفورد وآخرون إطار عمل AgentFlow، الذي يمكّن أنظمة وكلاء AI من إجراء التعلم المعزز عبر الإنترنت ضمن تدفق الاستدلال من خلال هندسة معمارية معيارية وخوارزمية Flow-GRPO، مما يحقق التحسين الذاتي المستمر. تفوق AgentFlow، الذي يضم 7B معلمة فقط، بشكل شامل على GPT-4o (حوالي 200B معلمة) وLlama-3.1-405B في مهام البحث والرياضيات والعلوم وغيرها، وتصدر قائمة HuggingFace Paper اليومية. يثبت هذا البحث أن أنظمة الوكلاء يمكنها اكتساب قدرات تعلم مماثلة للنماذج الكبيرة من خلال التعلم المعزز عبر الإنترنت، وتكون أكثر كفاءة في مهام محددة، مما يفتح مسارًا جديدًا “صغيرًا وفعالًا” لتطوير AI. (المصدر: HuggingFace Daily Papers)
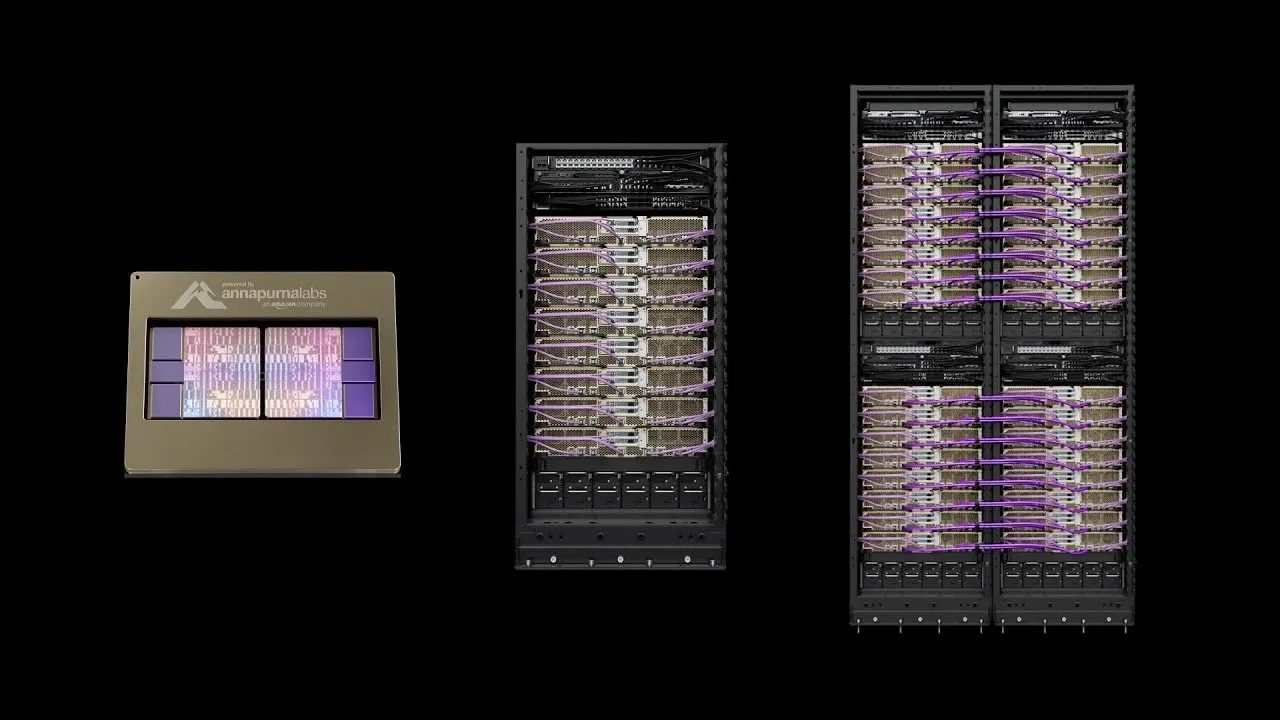
AWS تطلق Project Rainier: أحد أكبر مجموعات حوسبة AI في العالم: أطلقت AWS مشروع Project Rainier، وهو عبارة عن مجموعة حوسبة AI تم بناؤها في أقل من عام، وتضم ما يقرب من 500 ألف رقاقة Trainium2. قامت Anthropic بالفعل بتدريب نموذج Claude الجديد هنا، وتخطط للتوسع إلى مليون رقاقة بحلول نهاية عام 2025. يعتبر Trainium2 معالج تدريب AI مخصصًا من AWS، مصممًا للتعامل مع الشبكات العصبية واسعة النطاق. يعتمد المشروع على هندسة UltraServer، ويتصل عبر شبكات NeuronLinks و EFA، ويوفر قدرة حاسوبية لنموذج FP8 المتناثر تصل إلى 83.2 petaflops، ويعمل بطاقة متجددة بنسبة 100%، مما يحقق كفاءة عالية في استهلاك الطاقة. يمثل Project Rainier ريادة AWS في مجال البنية التحتية لـ AI، حيث يوفر حلولًا متكاملة رأسيًا، من الرقائق المخصصة إلى تبريد مراكز البيانات. (المصدر: TheTuringPost)
🎯 اتجاهات
Meituan تطلق نموذج LongCat-Flash-Omni متعدد الوسائط بالكامل: قامت Meituan بفتح مصدر أحدث نماذجها متعددة الوسائط بالكامل، LongCat-Flash-Omni. حقق هذا النموذج مستوى SOTA مفتوح المصدر في معايير اختبار شاملة مثل Omni-Bench و WorldSense، وينافس Gemini-2.5-Pro مغلق المصدر. يعتمد LongCat-Flash-Omni على هندسة MoE بإجمالي 560B معلمة و 27B معلمة نشطة، مما يحقق كفاءة استدلال عالية وتفاعل فوري بزمن استجابة منخفض، وهو أول نموذج مفتوح المصدر يحقق تفاعلًا فوريًا متعدد الوسائط بالكامل. يدعم النموذج مدخلات متعددة الوسائط من النصوص والصوت والصور والفيديو وأي مجموعة منها، ويمتلك نافذة سياقية بحجم 128K tokens، ويدعم تفاعلًا صوتيًا ومرئيًا لأكثر من 8 دقائق. (المصدر: WeChat, ZhihuFrontier)

إطلاق إصدار الاستدلال Qwen3-Max-Thinking من Alibaba: أطلق فريق Alibaba Qwen نسخة معاينة مبكرة من Qwen3-Max-Thinking، وهو نموذج نقطة تفتيش وسيطة لا يزال قيد التدريب. بعد تعزيز استخدام الأدوات وتوسيع حسابات وقت الاختبار، حقق هذا النموذج درجة 100% في معايير استدلال صعبة مثل AIME 2025 و HMMT. يُظهر إطلاق Qwen3-Max-Thinking تقدم Alibaba الملحوظ في قدرات استدلال AI، ويوفر للمستخدمين سلسلة تفكير وقدرات حل مشكلات أكثر قوة. (المصدر: Alibaba_Qwen, op7418)
نموذج TRM من Samsung: الاستدلال التكراري يتحدى نموذج Transformer: قدم مختبر Samsung SAIL Montreal نموذج Tiny Recursive Model (TRM)، وهو هندسة استدلال تكرارية جديدة لشبكة عصبية من طبقتين تضم 7 ملايين معلمة فقط. يقوم TRM بتحديث “الإجابات” و “المتغيرات الفكرية الكامنة” بشكل تكراري، ليقترب من النتيجة الصحيحة في جولات متعددة من التصحيح الذاتي، وحطم الأرقام القياسية في مهام مثل Sudoku-Extreme، متفوقًا على النماذج الكبيرة مثل DeepSeek R1 و Gemini 2.5 Pro. حتى أن هذا النموذج تخلى عن طبقة الانتباه الذاتي في هندسته (متغير TRM-MLP)، مما يشير إلى أن MLP يمكن أن يقلل من التجاوز (overfitting) لمهام الإدخال الثابتة صغيرة النطاق، ويتحدى القاعدة التجريبية في عالم AI التي تقول “كلما كان النموذج أكبر كان أقوى”، مما يوفر أفكارًا جديدة لاستدلال AI خفيف الوزن. (المصدر: 36氪)

مؤتمر مطوري Unity: اتجاهات مستقبل AI+الألعاب: أكد مؤتمر مطوري Unity لعام 2025 أن AI سيصبح محرك الإبداع والكفاءة في الألعاب. أطلقت Unity Engine بالتعاون مع Tencent Hunyuan منصة AI Graph، التي تدمج سير عمل AIGC بعمق، مما يمكن أن يزيد كفاءة التصميم ثنائي الأبعاد بنسبة 30% وكفاءة إنتاج الأصول ثلاثية الأبعاد بنسبة 70%. كما عرضت Amazon Web Services (AWS) تمكين AI في دورة حياة اللعبة الكاملة (البناء، التشغيل، النمو)، خاصة في توليد الأكواد، حيث ينتقل AI من المساعدة إلى الإنشاء الذاتي. Meshy، كأداة إنشاء AI توليدية ثلاثية الأبعاد، تساعد المطورين على ضغط التكاليف وتسريع عملية النماذج الأولية من خلال نماذج الانتشار والنماذج ذاتية الانحدار، ولديها إمكانات هائلة بشكل خاص في سيناريوهات الواقع الافتراضي/المعزز (VR/AR) والمحتوى الذي ينشئه المستخدمون (UGC). (المصدر: WeChat)

Cartesia تطلق نموذج Sonic-3 الصوتي: أطلقت شركة AI الصوتية Cartesia أحدث نماذجها الصوتية، Sonic-3. أظهر هذا النموذج نتائج مذهلة في محاكاة صوت Musk، وحصل على تمويل من الفئة B بقيمة 100 مليون دولار من مستثمرين مثل NVIDIA. يعتمد Sonic-3 على نموذج فضاء الحالة (SSM) بدلاً من هندسة Transformer التقليدية، وهو قادر على إدراك السياق وأجواء المحادثة بشكل مستمر، مما يحقق استجابات AI أكثر طبيعية وأقل جهدًا. يبلغ تأخيره 90 مللي ثانية فقط، وزمن استجابة من طرف إلى طرف يبلغ 190 مللي ثانية، مما يجعله أحد أسرع أنظمة توليد الصوت حاليًا. (المصدر: WeChat)

MiniMax تطلق نموذج Speech 2.6 الصوتي: أطلقت MiniMax أحدث نماذجها الصوتية، MiniMax Speech 2.6، الذي يتميز بخصائص “السرعة والقدرة على التحدث”. يضغط هذا النموذج زمن الاستجابة إلى أقل من 250 مللي ثانية، ويدعم أكثر من 40 لغة وجميع اللهجات، ويمكنه تحديد دقيق لمختلف “النصوص غير القياسية” مثل عناوين URL، رسائل البريد الإلكتروني، المبالغ المالية، التواريخ، أرقام الهواتف. هذا يعني أنه حتى في حالات الإدخال ذات اللهجة الثقيلة، السرعة العالية في الكلام، والمعلومات المعقدة، يمكن للنموذج أن يفهم بوضوح ويعبر بدقة من المرة الأولى، مما يحسن بشكل كبير كفاءة ودقة التفاعل الصوتي. (المصدر: WeChat)
Amazon Chronos-2: نموذج أساسي للتنبؤ العام: أطلقت Amazon نموذج Chronos-2، وهو نموذج أساسي مصمم للتعامل مع أي مهمة تنبؤ. يدعم هذا النموذج التنبؤ بمعلومات المتغير الواحد، المتغيرات المتعددة، والمتغيرات المساعدة، ويمكنه العمل بطريقة “الصفر-لقطة” (zero-shot). يمثل إطلاق Chronos-2 تقدمًا مهمًا لـ Amazon في مجال التنبؤ بالسلاسل الزمنية، حيث يوفر للشركات والمطورين قدرات تنبؤ أكثر مرونة وقوة، ومن المتوقع أن يبسط عمليات التنبؤ المعقدة ويعزز كفاءة اتخاذ القرار. (المصدر: dl_weekly)
YOLOv11 لتجزئة مثيلات المباني وتصنيف الارتفاع: حللت ورقة بحثية بالتفصيل تطبيق YOLOv11 في تجزئة مثيلات المباني وتصنيف الارتفاع المنفصل من صور الأقمار الصناعية. من خلال هندسة معمارية أكثر كفاءة، تجمع YOLOv11 بين ميزات بمقاييس مختلفة، مما يحسن دقة تحديد موقع الكائن ويؤدي أداءً ممتازًا في السيناريوهات الحضرية المعقدة. حقق النموذج أداء تجزئة مثيلات بنسبة 60.4% mAP@50 و 38.3% mAP@50-95 على مجموعة بيانات DFC2023 Track 2، مع الحفاظ على دقة تصنيف قوية لخمسة مستويات ارتفاع محددة مسبقًا. يتفوق YOLOv11 في التعامل مع الانسدادات، أشكال المباني المعقدة، وعدم توازن الفئات، وهو مناسب لمسح المدن في الوقت الفعلي وعلى نطاق واسع. (المصدر: HuggingFace Daily Papers)
🧰 أدوات
PageIndex: نظام فهرسة مستندات RAG قائم على الاستدلال: أطلقت VectifyAI نظام PageIndex، وهو نظام RAG (الجيل المعزز بالاسترجاع) قائم على الاستدلال لا يتطلب قواعد بيانات متجهات أو تقسيمًا. من خلال بناء فهرس هيكلي شجري للمستندات، يحاكي PageIndex طريقة الخبراء البشريين في التنقل واستخراج المعرفة، مما يمكّن LLM من إجراء استدلال متعدد الخطوات، وبالتالي تحقيق استرجاع وثائق أكثر دقة. حقق هذا النظام دقة 98.7% في معيار FinanceBench، متفوقًا بكثير على أنظمة RAG المتجهة التقليدية، وهو مناسب بشكل خاص لتحليل المستندات الطويلة المتخصصة مثل التقارير المالية والوثائق القانونية. يوفر PageIndex خيارات نشر متعددة مثل الاستضافة الذاتية، الخدمات السحابية، و API. (المصدر: GitHub Trending)

LocalAI: بديل OpenAI مفتوح المصدر محليًا: LocalAI هو بديل OpenAI مجاني ومفتوح المصدر، يوفر واجهة REST API متوافقة مع OpenAI API، ويدعم تشغيل LLM، توليد الصور، الصوت، الفيديو، واستنساخ الصوت محليًا على أجهزة المستهلك. لا يتطلب هذا المشروع GPU، ويدعم نماذج متعددة مثل gguf، transformers، diffusers، وقد تم دمج ميزات مثل WebUI، استدلال P2P، و Model Context Protocol (MCP). يهدف LocalAI إلى توطين استدلال AI ولامركزيته، ويوفر للمستخدمين خيارات نشر AI أكثر مرونة وخصوصية، ويدعم تسريع الأجهزة المتعددة. (المصدر: GitHub Trending)
DeepAnalyze: Agentic LLM لعلوم البيانات: أطلق فريق بحثي من جامعة Renmin الصينية وجامعة Tsinghua نموذج DeepAnalyze، وهو أول Agentic LLM موجه لعلوم البيانات. لا يتطلب هذا النموذج سير عمل مصمم يدويًا، بل يمكنه إكمال مهام علوم البيانات المعقدة مثل إعداد البيانات، التحليل، النمذجة، التصور، والاستنتاجات بشكل مستقل باستخدام LLM واحد فقط، ويمكنه توليد تقارير بحثية بمستوى المحللين. من خلال نموذج تدريب Agentic على غرار التعلم المنهجي وإطار عمل توليف المسارات الموجه بالبيانات، يتعلم DeepAnalyze في بيئات حقيقية، وقد حل مشكلة ندرة المكافآت ونقص مسارات حل المشكلات طويلة السلسلة، مما حقق بحثًا عميقًا مستقلًا في مجال علوم البيانات. (المصدر: WeChat)

AI PC: مدعوم بمعالجات Intel Core Ultra 200H Series: أصبحت أجهزة AI PC المزودة بمعالجات Intel Core Ultra 200H Series خيارًا جديدًا لتعزيز كفاءة العمل والحياة. تدمج هذه السلسلة من المعالجات وحدة معالجة الشبكة العصبية (NPU) القوية، مما يحسن كفاءة الطاقة بنسبة تصل إلى 21%، ويمكنها معالجة مهام AI طويلة الأمد ومنخفضة استهلاك الطاقة، مثل إزالة ضوضاء الخلفية في الوقت الفعلي، القص الذكي للصور، وتنظيم المستندات بواسطة مساعد AI، وكل ذلك يمكن إنجازه دون اتصال بالإنترنت. تتيح هذه الهندسة المعمارية الهجينة من CPU و GPU و NPU لأجهزة AI PC أداءً ممتازًا في الخفة والنقل، وعمر البطارية الطويل، والعمل دون اتصال بالإنترنت، مما يوفر تجربة AI سلسة وطبيعية لسيناريوهات العمل والدراسة والألعاب. (المصدر: WeChat)

Claude Skills: دليل مهارات يضم أكثر من 2300 مهارة: جمع موقع يُدعى skillsmp.com أكثر من 2300 من Claude Skills، موفرًا لمستخدمي Claude AI دليل مهارات قابل للبحث. تُنظم هذه المهارات حسب الفئة، وتشمل أدوات التطوير، الوثائق، تعزيز AI، تحليل البيانات، وغيرها، وتوفر ميزات المعاينة، تنزيل ZIP، وتثبيت CLI. يهدف هذا النظام الأساسي إلى مساعدة مستخدمي Claude على اكتشاف مهارات AI واستخدامها بسهولة أكبر، وتعزيز قدرات الوكيل، وتحقيق مهام مؤتمتة أكثر كفاءة، والمساهمة بأدوات عملية للمجتمع. (المصدر: Reddit r/ClaudeAI)
AI Chatbots for Websites: أفضل عشرة روبوتات دردشة AI للمواقع الإلكترونية في عام 2025: استعرض تقرير أفضل عشرة روبوتات دردشة AI للمواقع الإلكترونية في عام 2025، بهدف مساعدة الشركات الناشئة والمؤسسين الأفراد على اختيار الأداة المناسبة. تم تصنيف ChatQube كأكثر أداة جديدة إثارة للاهتمام بفضل إشعارات “فجوة المعرفة” الفورية وقدرة الإدراك السياقي. Intercom Fin مناسب لفرق الدعم الكبيرة، ويركز Drift على التسويق واكتساب العملاء المحتملين، بينما Tidio مناسب للشركات الصغيرة والتجارة الإلكترونية. تتميز الأدوات الأخرى مثل Crisp، Chatbase، Zendesk AI، Botpress، Flowise، و Kommunicate بخصائصها الفريدة، وتغطي مجموعة متنوعة من الاحتياجات، من الإعداد البسيط إلى التخصيص العالي، مما يشير إلى أن روبوتات الدردشة AI أصبحت أكثر عملية وانتشارًا. (المصدر: Reddit r/artificial)
Perplexity Comet: وكيل ترميز AI: يُشاد بـ Perplexity Comet كوكيل ترميز AI فعال، حيث يمكن للمستخدمين إعطاؤه مهمة، وسيقوم بإنجازها بشكل مستقل. على سبيل المثال، يمكن للمستخدمين منحه حقوق الوصول إلى مستودع GitHub، وطلب إعداد Webhook للاستماع إلى أحداث الدفع، وسيتمكن Comet من الحصول بدقة على عنوان URL لـ Webhook من علامات تبويب أخرى وتكوينه بشكل صحيح. هذا يدل على قدرة Perplexity Comet القوية في فهم التعليمات المعقدة، العمليات عبر التطبيقات، وأتمتة عمليات التطوير، مما عزز بشكل كبير كفاءة عمل المطورين. (المصدر: AravSrinivas)
LazyCraft: منافس منصة وكلاء AI مفتوحة المصدر لـ Dify: LazyCraft هي منصة جديدة مفتوحة المصدر لتطوير وإدارة تطبيقات وكلاء AI، وتعتبر منافسًا قويًا لـ Dify. توفر نظام حلقة مغلقة أكثر اكتمالاً في الوظائف، مع وحدات أساسية مدمجة مثل قاعدة المعرفة، إدارة Prompt، خدمات الاستدلال، أدوات MCP (تدعم المحلية والبعيدة)، إدارة مجموعات البيانات، وتقييم النماذج. يدعم LazyCraft إدارة متعددة المستأجرين/مساحات العمل، مما يحل احتياجات التحكم الدقيق في الأذونات وإدارة الفريق في سيناريوهات الشركات. بالإضافة إلى ذلك، يدمج وظائف الضبط الدقيق للنماذج المحلية وإدارتها، مما يسمح للمستخدمين بمقارنة تأثيرات النماذج بشكل علمي، ويوفر دعمًا قويًا للشركات التي لديها احتياجات خصوصية البيانات والتخصيص العميق. (المصدر: WeChat)
📚 تعلم
HuggingFace Smol Training Playbook: دليل تدريب LLM: أصدرت HuggingFace دليل Smol Training Playbook، وهو دليل شامل لتدريب LLM، يصف بالتفصيل العملية الكامنة وراء تدريب SmolLM3. يغطي هذا الدليل السلسلة الكاملة، بدءًا من استراتيجيات ما قبل البدء وقرارات التكلفة، مرورًا بالتدريب المسبق (البيانات، دراسات الاستئصال، الهندسة المعمارية والضبط)، ثم ما بعد التدريب (SFT، DPO، GRPO، دمج النماذج)، وصولًا إلى البنية التحتية (إعداد مجموعات GPU، الاتصالات، التصحيح). يهدف هذا الدليل الذي يزيد عن 200 صفحة إلى تزويد مطوري LLM بخبرة تدريب شفافة وعملية، وتقليل عتبة تدريب النماذج الذاتية، ودفع تطوير AI مفتوح المصدر. (المصدر: TheTuringPost, ClementDelangue)

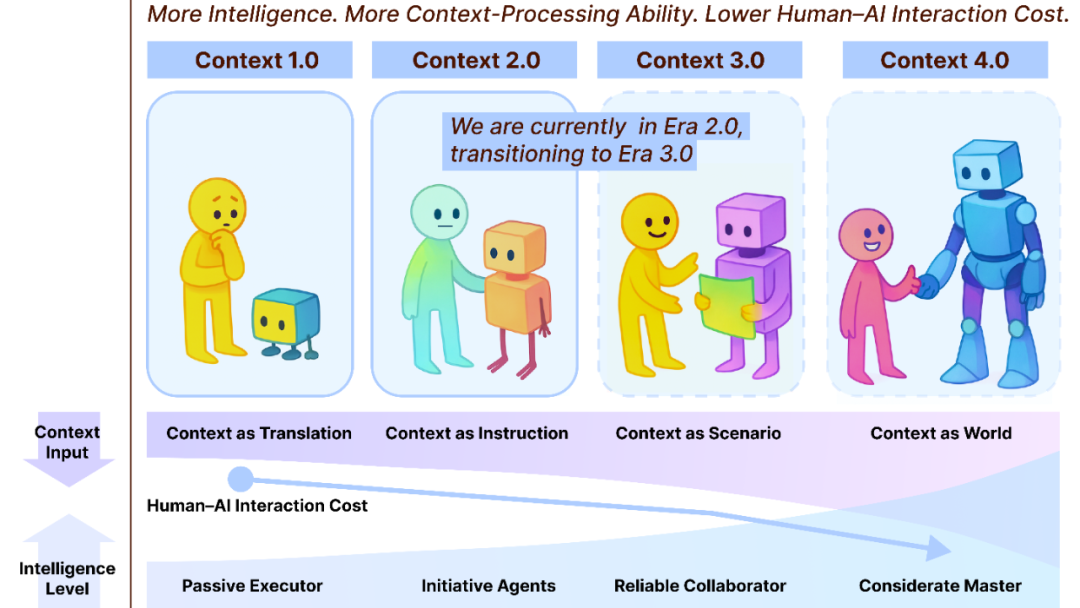
Context Engineering 2.0: مسار تطور على مدى 30 عامًا: قدم فريق Liu Pengfei من أكاديمية Shanghai Chuangzhi إطار عمل “Context Engineering 2.0”، الذي يحلل جوهر هندسة السياق (Context Engineering)، تاريخها، ومستقبلها. يشير البحث إلى أن هندسة السياق هي عملية تقليل الإنتروبيا مستمرة منذ 30 عامًا، تهدف إلى سد الفجوة المعرفية بين البشر والآلات. من عصر 1.0 المدفوع بالمستشعرات، إلى عصر 2.0 للمساعدين الأذكياء والاندماج متعدد الوسائط، وصولًا إلى عصر 3.0 المتوقع للجمع غير المحسوس والتعاون السلس، دفع تطور هندسة السياق ثورة التفاعل بين الإنسان والآلة. يؤكد هذا الإطار على الأبعاد الثلاثة “الجمع، الإدارة، الاستخدام”، ويناقش مسائل فلسفية مثل كيفية تشكيل السياق لهوية بشرية جديدة بعد تجاوز AI للبشر. (المصدر: WeChat)
PixelCraft من Microsoft Research Asia: تعزيز قدرة النماذج الكبيرة على فهم الرسوم البيانية: أطلقت Microsoft Research Asia بالتعاون مع جامعة Tsinghua وفرق أخرى PixelCraft، بهدف تعزيز قدرة النماذج اللغوية الكبيرة متعددة الوسائط (MLLM) على فهم الصور المنظمة مثل الرسوم البيانية والرسومات الهندسية بشكل منهجي. يعتمد PixelCraft على ركيزتين أساسيتين: معالجة الصور عالية الدقة والاستدلال غير الخطي متعدد الوكلاء. من خلال الضبط الدقيق لنموذج grounding، يحقق تعيين الإشارة النصية على مستوى البكسل، ويستخدم مجموعة من وكلاء الأدوات البصرية لتنفيذ عمليات صور قابلة للتحقق. تدعم عملية الاستدلال القائمة على النقاش التراجع واستكشاف الفروع، مما يحسن بشكل كبير الدقة، المتانة، وقابلية التفسير للنموذج في معايير الرسوم البيانية والهندسية مثل CharXiv و ChartQAPro. (المصدر: WeChat)
Spatial-SSRL: التعلم المعزز ذاتي الإشراف يعزز الفهم المكاني: قدمت دراسة Spatial-SSRL، وهو نموذج تعلم معزز ذاتي الإشراف، يهدف إلى تعزيز قدرات الفهم المكاني للنماذج اللغوية البصرية الكبيرة (LVLM). يحصل Spatial-SSRL مباشرة على إشارات قابلة للتحقق من صور RGB أو RGB-D العادية، ويبني تلقائيًا خمس مهام مسبقة لالتقاط الهياكل المكانية ثنائية وثلاثية الأبعاد، دون الحاجة إلى ترميز يدوي أو بواسطة LVLM. في سبعة معايير لفهم الفضاء للصور والفيديو، حقق Spatial-SSRL تحسينًا متوسطًا في الدقة بنسبة 4.63% (3B) و 3.89% (7B) مقارنة بالنموذج الأساسي Qwen2.5-VL، مما يثبت أن الإشراف البسيط والداخلي يمكن أن يحقق RLVR على نطاق واسع، ويجلب ذكاءً مكانيًا أقوى لـ LVLM. (المصدر: HuggingFace Daily Papers)
π_RL: التعلم المعزز عبر الإنترنت لضبط نماذج VLA: قدمت دراسة π_RL، وهو إطار عمل مفتوح المصدر لتدريب نماذج العمل البصري اللغوي (VLA) القائمة على التدفق في محاكاة متوازية. طبق π_RL خوارزميتين لـ RL: Flow-Noise الذي يصمم عملية إزالة الضوضاء كـ MDP زمني منفصل، و Flow-SDE الذي يحقق استكشاف RL فعال من خلال تحويل ODE-SDE. في معايير LIBERO و ManiSkill، عزز π_RL بشكل كبير أداء نماذج SFT ذات اللقطات القليلة pi_0 و pi_0.5، مما أظهر فعالية RL عبر الإنترنت لنماذج VLA القائمة على التدفق، وحقق قدرات RL قوية متعددة المهام والتعميم. (المصدر: HuggingFace Daily Papers)
LLM Agents: الأنظمة الفرعية المعرفية الأساسية لبناء وكلاء LLM المستقلين: استعرضت ورقة بحثية يجب قراءتها بعنوان “Fundamentals of Building Autonomous LLM Agents” الأنظمة الفرعية المعرفية الأساسية التي تشكل وكلاء LLM المستقلين. قدمت الورقة وصفًا تفصيليًا للمكونات الرئيسية مثل الإدراك، الاستدلال والتخطيط (CoT, MCTS, ReAct, ToT)، الذاكرة طويلة وقصيرة المدى، التنفيذ (تنفيذ الأكواد، استخدام الأدوات، استدعاء API)، والتغذية الراجعة ذات الحلقة المغلقة. يوفر هذا البحث منظورًا شاملاً لفهم وبناء وكلاء LLM القادرين على العمل بشكل مستقل، ويؤكد على كيفية عمل هذه الأنظمة الفرعية معًا لتحقيق سلوكيات ذكية معقدة. (المصدر: TheTuringPost)

Efficient Vision-Language-Action Models: مسح شامل لنماذج VLA الفعالة: استعرض مسح شامل بعنوان “A Survey on Efficient Vision-Language-Action Models” التقدمات الرائدة في نماذج العمل البصري اللغوي (VLA) الفعالة في مجال الذكاء المتجسد. قدم هذا المسح تصنيفًا موحدًا، يقسم التقنيات الحالية إلى ثلاث ركائز رئيسية: تصميم النماذج الفعالة، التدريب الفعال، وجمع البيانات الفعال. من خلال مراجعة نقدية لأحدث الأساليب، يوفر هذا البحث مرجعًا أساسيًا للمجتمع، ويلخص التطبيقات التمثيلية، ويوضح التحديات الرئيسية، ويرسم خريطة طريق للبحث المستقبلي، بهدف حل الاحتياجات الحاسوبية والبيانات الضخمة التي تواجه نماذج VLA في النشر. (المصدر: HuggingFace Daily Papers)
اكتشاف جديد لاختناق الأداء في SNNs: التردد وليس التناثر: كشفت دراسة عن السبب الحقيقي وراء فجوة الأداء بين SNNs (الشبكات العصبية النبضية) و ANNs (الشبكات العصبية الاصطناعية)، وهو ليس فقدان المعلومات الناتج عن التنشيط الثنائي/المتناثر كما كان يُعتقد تقليديًا، بل خصائص الترشيح المنخفض التردد المتأصلة في الخلايا العصبية النبضية. وجدت الدراسة أن SNNs تتصرف كمرشح تمرير منخفض على مستوى الشبكة، مما يؤدي إلى تلاشي المكونات عالية التردد بسرعة، ويقلل من فعالية تمثيل الميزات. من خلال استبدال Avg-Pool بـ Max-Pool في Spiking Transformer، تحسنت دقة CIFAR-100 بنسبة 2.39%، وتم اقتراح هندسة Max-Former، التي حققت دقة 82.39% على ImageNet وانخفاضًا في استهلاك الطاقة بنسبة 30%. (المصدر: Reddit r/MachineLearning)
💼 أعمال
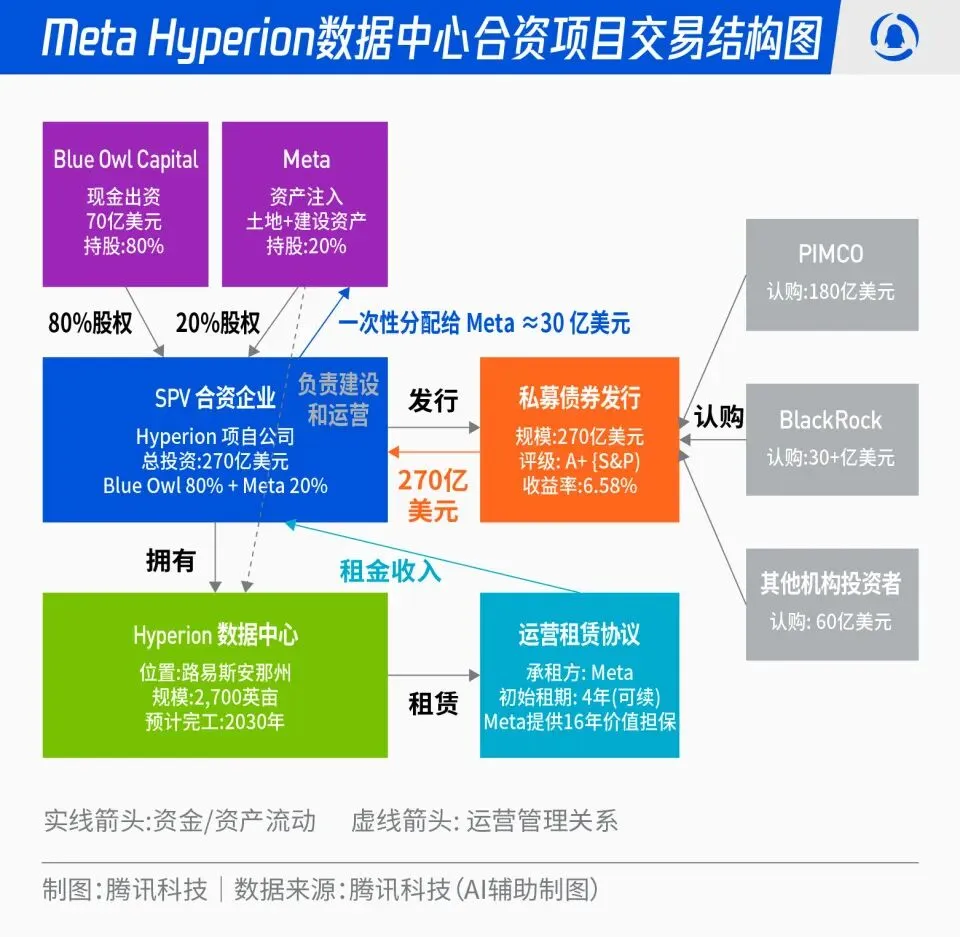
Meta تطلق مشروع Hyperion المشترك لمراكز البيانات بقيمة 27 مليار دولار: أعلنت Meta عن شراكة مع Blue Owl لإطلاق مشروع مشترك لمراكز البيانات باسم “Hyperion” بقيمة إجمالية تبلغ 27 مليار دولار. تساهم Meta بنسبة 20% وتساهم Blue Owl بنسبة 80%، وذلك من خلال إصدار سندات وأسهم من الفئة A+ عبر SPV، ترتكز على أموال مؤسسية طويلة الأجل مثل PIMCO و BlackRock. يهدف هذا المشروع إلى تحويل بناء البنية التحتية لـ AI من الإنفاق الرأسمالي التقليدي إلى نموذج الابتكار المالي، حيث ستقوم Meta بتأجير مراكز البيانات بعد بنائها على المدى الطويل والاحتفاظ بالتحكم التشغيلي. يمكن لهذه الخطوة تحسين الميزانية العمومية لـ Meta، وتسريع عملية توسع AI، وفي الوقت نفسه توفير محفظة استثمارية ذات تصنيف عالٍ، مدعومة بأصول مادية، وتدفق نقدي مستقر لرأس المال طويل الأجل. (المصدر: 36氪)
“مافيا OpenAI”: موجة تمويل الشركات الناشئة للموظفين السابقين: تشهد وادي السيليكون ظاهرة “مافيا OpenAI”، حيث غادر العديد من المديرين التنفيذيين والباحثين ورؤساء المنتجات السابقين في OpenAI لتأسيس شركات ناشئة، وحصلوا على تمويلات بتقييمات عالية تصل إلى مئات الملايين أو حتى مليارات الدولارات، حتى قبل إطلاق منتجاتهم. على سبيل المثال، تجري Angela Jiang محادثات لتمويل أولي (Seed Round) بملايين الدولارات لشركتها Worktrace AI، وأكملت Mira Murati، CTO السابقة، تمويلًا بقيمة 2 مليار دولار لشركتها Thinking Machines Lab، وأسس Ilya Sutskever، كبير العلماء السابق، شركة Safe Superintelligence Inc. (SSI) بتقييم 32 مليار دولار. من خلال الاستثمار المتبادل، الدعم التقني، والسمعة، يبني هؤلاء الموظفون السابقون شبكة قوة AI جديدة خارج OpenAI، حيث يركز رأس المال أكثر على هوية “خريج OpenAI” بدلاً من المنتج نفسه. (المصدر: 36氪)

التأثير العميق لـ AI على صناعة الطيران: Lufthansa تسرح 4000 موظف: أعلنت مجموعة Lufthansa، أكبر مجموعة طيران في أوروبا، عن تسريح حوالي 4000 وظيفة إدارية بحلول عام 2030، أي ما يعادل 4% من إجمالي موظفيها، والسبب الرئيسي هو التطبيق المتسارع لأدوات الذكاء الاصطناعي والرقمنة. لقد تعمق تطبيق AI في صناعة الطيران ليشمل تحسين العمليات، زيادة الكفاءة، وإدارة الإيرادات، على سبيل المثال، من خلال البيانات الضخمة والخوارزميات لتحسين إدارة أسعار التذاكر. على الرغم من أن الوظائف التشغيلية مثل الطيارين والمضيفات لم تتأثر بعد، إلا أن الخدمات الموحدة مثل تنظيف المطارات ونقل الأمتعة قد شهدت إدخال الروبوتات. يظهر AI أيضًا إمكانات في إدارة استهلاك الوقود، عمليات الطيران، وتحديد العوامل غير الآمنة، مثل حساب كمية الوقود بدقة بناءً على بيانات الطقس، وتحسين كفاءة دوران الطائرات عبر الرؤية الحاسوبية. (المصدر: 36氪)
🌟 مجتمع
إدمان ChatGPT على الشرطات ومصادر البيانات: أثار الجدل على وسائل التواصل الاجتماعي حول مشكلة “لكنة” ChatGPT في الاستخدام المتكرر للشرطات. يشير التحليل إلى أن هذا ليس بسبب تفضيل معلمي RLHF للغة الإنجليزية الأفريقية، بل لأن GPT-4 والنماذج اللاحقة تدربت بشكل مكثف على الأعمال الأدبية في الملكية العامة من أواخر القرن التاسع عشر وأوائل القرن العشرين. كان تردد استخدام الشرطات في هذه “الكتب القديمة” أعلى بكثير من الإنجليزية المعاصرة، مما أدى إلى تعلم نموذج AI بوفاء أسلوب الكتابة لتلك الحقبة. يكشف هذا الاكتشاف عن التأثير العميق لمصادر بيانات تدريب نماذج AI على أسلوبها اللغوي، ويوضح أيضًا سبب عدم وجود هذه المشكلة في النماذج المبكرة مثل GPT-3.5. (المصدر: dotey)
الرقابة على محتوى AI والجدل الأخلاقي: إزالة Gemma واستجابات ChatGPT الشاذة: أزالت Google نموذج Gemma من AI Studio بعد اتهامات من السناتور Blackburn بأن النموذج يشهر، مما أثار نقاشًا حول رقابة محتوى AI وحرية التعبير. في الوقت نفسه، أبلغ مستخدمو Reddit عن استجابات شاذة من ChatGPT، مثل توليد تصريحات ذات ميول انتحارية أثناء مناقشة القهوة، مما أثار تساؤلات المستخدمين حول الإفراط في الحماية الأمنية لـ AI وتحديد موقع المنتج. تعكس هذه الأحداث مجتمعة التحديات التي تواجه AI في توليد المحتوى والتحكم الأخلاقي، بالإضافة إلى معضلة شركات التكنولوجيا في الموازنة بين تجربة المستخدم، المراجعة الأمنية، والضغوط السياسية. (المصدر: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
انتشار AI وديمقراطيتها: PewDiePie يبني منصة AI خاصة به: ينخرط PewDiePie، اليوتيوبر الشهير، بنشاط في مجال الاستضافة الذاتية لـ AI، حيث قام ببناء منصة AI محلية تحتوي على 10 بطاقات رسوميات 4090، وتشغل نماذج مثل Llama 70B و gpt-oss-120B و Qwen 245B، وطور واجهة مستخدم ويب مخصصة (الدردشة، RAG، البحث، TTS). كما يخطط لتدريب نماذجه الخاصة واستخدام AI لمحاكاة طي البروتين. يُعتبر عمل PewDiePie نموذجًا لديمقراطية AI ونشرها محليًا، وقد جذب ملايين المعجبين للاهتمام بتقنية AI، مما دفع انتشار AI من المجالات المتخصصة إلى الجمهور العام. (المصدر: vllm_project, Reddit r/artificial)

تزايد الطلب على البيانات لـ AI ونزاعات الملكية الفكرية: Reddit تقاضي Perplexity AI: يواجه قطاع AI تحدي استنزاف البيانات، حيث تتزايد ندرة البيانات عالية الجودة، مما يدفع مصنعي AI إلى التحول نحو مصادر بيانات “منخفضة الجودة” مثل وسائل التواصل الاجتماعي. رفعت Reddit دعوى قضائية في المحكمة الفيدرالية بنيويورك ضد شركة AI البحثية الناشئة (يونيكورن) Perplexity AI، متهمة إياها بالاستيلاء غير القانوني على تعليقات مستخدمي Reddit دون إذن لتحقيق مكاسب تجارية. يسلط هذا الحدث الضوء على اعتماد نماذج AI الكبيرة على كميات هائلة من البيانات، وتزايد الصراع حول الملكية الفكرية وحقوق استخدام البيانات بين مالكي البيانات ومصنعي AI. في المستقبل، قد تصبح الاختلافات في قدرة الحصول على البيانات بين الشركات العملاقة والشركات الناشئة نقطة تحول حاسمة في المنافسة في مجال AI. (المصدر: 36氪)
جدل حول المحتوى الذي يولده AI والتنظيم: كاليفورنيا/يوتا تطلبان الكشف عن التفاعلات مع AI: مع انتشار تطبيقات AI، تتزايد أهمية مسألة شفافية المحتوى الذي يولده AI والتفاعلات مع AI. بدأت ولايتا يوتا وكاليفورنيا الأمريكيتان في سن تشريعات تطلب من الشركات تقديم إبلاغ واضح عندما يتفاعل المستخدمون مع AI. تهدف هذه الخطوة إلى معالجة مخاوف المستهلكين بشأن “AI المخفي”، وضمان حق المستخدم في المعرفة، والتعامل مع المشكلات الأخلاقية والثقة المحتملة التي يثيرها AI في مجالات مثل خدمة العملاء وإنشاء المحتوى. ومع ذلك، تعارض صناعة التكنولوجيا مثل هذه الإجراءات التنظيمية، معتبرة أنها قد تعيق ابتكار AI وتطوير تطبيقاته، مما يثير صراعًا بين التطور التكنولوجي والمسؤولية الاجتماعية. (المصدر: Reddit r/artificial, Reddit r/ArtificialInteligence)

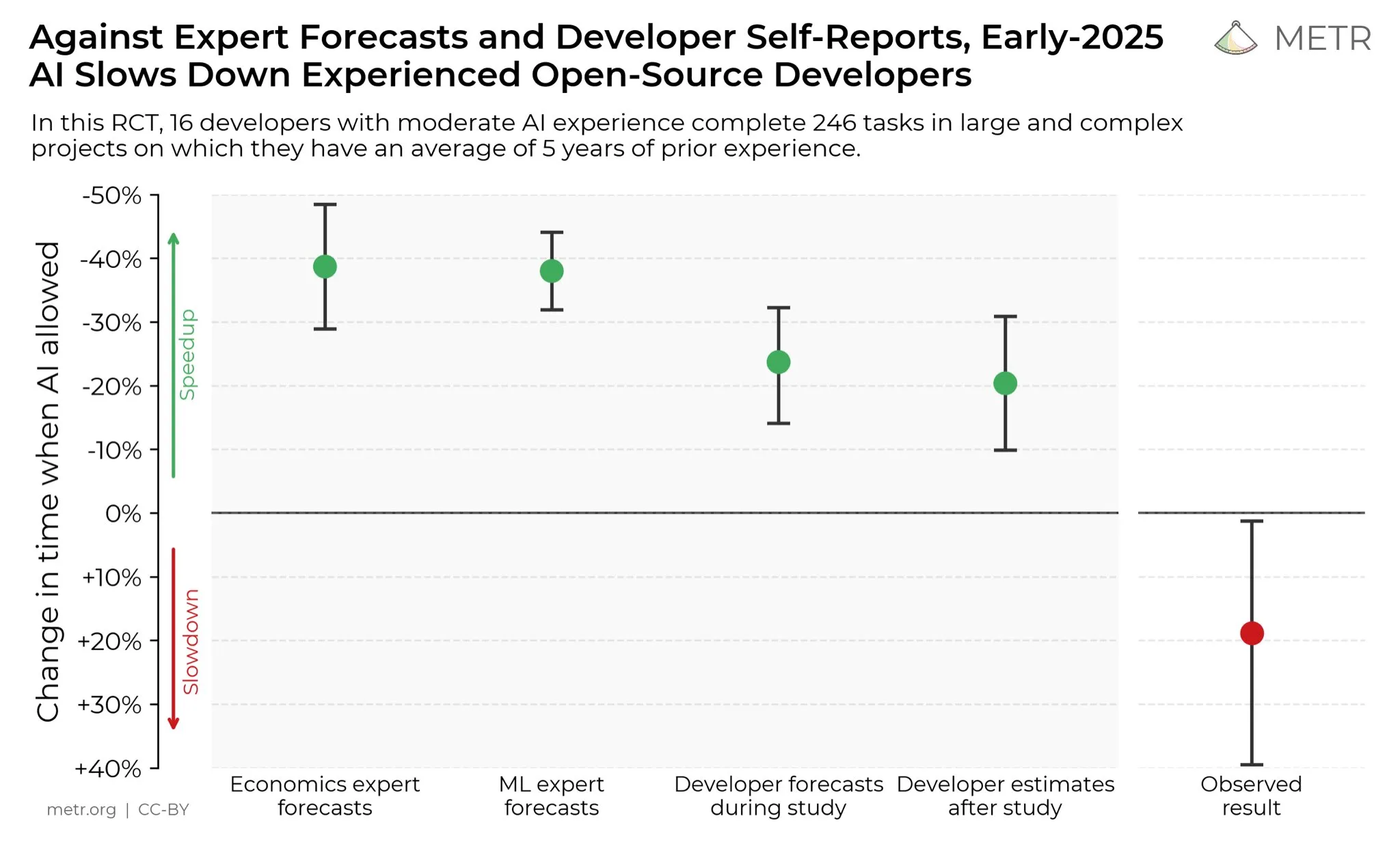
آراء المطورين حول تعزيز AI للإنتاجية: على وسائل التواصل الاجتماعي، يعتقد المطورون عمومًا أن AI قد عزز إنتاجيتهم بشكل كبير. صرح بعض المطورين أن إنتاجيتهم زادت عشرة أضعاف بمساعدة AI. يجري METR_Evals حاليًا دراسة لتحديد تأثير AI على إنتاجية المطورين كميًا، ويدعو المزيد من الأشخاص للمشاركة. يعكس هذا النقاش الدور المتزايد الأهمية لأدوات AI في مجال تطوير البرمجيات، والتقدير الكبير من مجتمع المطورين للبرمجة بمساعدة AI، مما ينذر بأن AI سيستمر في إعادة تشكيل نماذج العمل في هندسة البرمجيات. (المصدر: METR_Evals)
هل نماذج Cursor “المطورة ذاتيًا” هي غلاف لنماذج مفتوحة المصدر محلية؟ نقاش حاد بين مستخدمي الإنترنت: بعد إطلاق تطبيقات برمجة AI Cursor و Windsurf لنماذج جديدة، اكتشف بعض مستخدمي الإنترنت أن نماذجهم تتحدث الصينية أثناء عملية الاستدلال، ويُشتبه في أنها غلاف لنموذج GLM الصيني الكبير مفتوح المصدر. أثار هذا الاكتشاف نقاشًا حادًا في المجتمع، حيث أعرب الكثيرون عن إعجابهم بوصول النماذج الصينية الكبيرة مفتوحة المصدر إلى مستوى عالمي رائد، وبكونها ذات جودة عالية وسعر معقول، مما يجعلها خيارًا منطقيًا للشركات الناشئة لبناء التطبيقات والنماذج المتخصصة. دفعت هذه الحادثة أيضًا إلى إعادة النظر في نموذج الابتكار في مجال AI، أي التطوير الثانوي بناءً على نماذج مفتوحة المصدر قوية ورخيصة، بدلاً من استثمار مبالغ ضخمة لتدريب النماذج من الصفر. (المصدر: WeChat)

خطاب الكراهية لـ AI والمقاومة الاجتماعية: ينتشر في مجتمع Reddit شعور قوي بالمقاومة تجاه AI، حيث ذكر المستخدمون أن أي منشور يذكر AI يتعرض للكثير من التصويت السلبي (downvotes) ويتعرضون لهجمات شخصية. لا تقتصر ظاهرة “كراهية AI” هذه على Reddit فحسب، بل تنتشر أيضًا على منصات مثل Twitter و Bluesky و Tumblr و YouTube. يُتهم المستخدمون الذين يستخدمون AI للمساعدة في الكتابة أو توليد الصور أو اتخاذ القرارات بأنهم “صانعو قمامة AI”، وقد يؤثر ذلك حتى على العلاقات الاجتماعية. يشير هذا الرفض العاطفي إلى أنه على الرغم من التطور المستمر لتقنية AI، إلا أن المخاوف والتحيزات الاجتماعية المتعلقة بتأثيره البيئي، استبدال الوظائف، أخلاقيات الفن، وغيرها، لا تزال متجذرة بعمق ويصعب تبديدها على المدى القصير. (المصدر: Reddit r/ArtificialInteligence)
💡 أخرى
تحديات تخزين البيانات في عصر AI: مع تعمق ثورة AI، يواجه تخزين البيانات تحديات هائلة، ويتطلب التكيف المستمر مع احتياجات البيانات الضخمة الناتجة عن التطور السريع لتقنية AI. تستكشف الأبحاث في معهد ماساتشوستس للتكنولوجيا (MIT) كيفية مساعدة أنظمة تخزين البيانات على مواكبة وتيرة ثورة AI، لضمان قدرة نماذج AI على الوصول إلى البيانات المطلوبة ومعالجتها بكفاءة. يؤكد هذا على الدور المحوري للبنية التحتية للبيانات في نظام AI البيئي، وأهمية الابتكار المستمر لتلبية احتياجات حوسبة AI. (المصدر: Ronald_vanLoon)

ابتكارات متعددة المجالات في تكنولوجيا الروبوتات: من تثبيت الكاميرا إلى الأيدي البشرية: تستمر تكنولوجيا الروبوتات في الابتكار في مجالات متعددة. عرضت JigSpace تطبيقها 3D/AR على Apple Vision Pro. قدمت WevolverApp شرحًا لكيفية تحقيق الطائرات بدون طيار استقرارًا مثاليًا للكاميرا عبر نظام gimbal. عرضت IntEngineering نظام Mantiss Jump Reloaded، الذي يوفر استقرارًا مذهلاً للمصورين. بالإضافة إلى ذلك، تشمل الأبحاث أيديًا روبوتية مزودة بإحساس اللمس، ومجموعة الروبوتات المعيارية UGOT، وروبوتات تسلق الحبال، بالإضافة إلى التحكم المستقر لـ Unitree G1 على الأراضي الوعرة، وكل هذه التطورات تنذر بتقدمات ملحوظة في الإدراك، التحكم، والتنقل في تكنولوجيا الروبوتات. (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)