
كلمات مفتاحية:أوبن إيه آي, هيلث بنش, ميتا إيه آي, محول الديناميكي بايت الكامن, مايكروسوفت للأبحاث, إطار آرتست, ساكانا إيه آي, آلة التفكير المستمر, تقييم أداء الذكاء الاصطناعي الطبي, نموذج محول الديناميكي بايت الكامن بمعامل 8B, تعزيز استدلال نماذج اللغات الكبيرة باستخدام التعلم المعزز, هندسة شبكة سي تي إم العصبية, نموذج كوان 3 الرسمي الكمي
🔥 أبرز العناوين
OpenAI تطلق HealthBench لتقييم أداء الذكاء الاصطناعي في المجال الطبي: أطلقت OpenAI منصة HealthBench، وهي معيار جديد مصمم لقياس أداء وسلامة نماذج اللغة الكبيرة في سيناريوهات الرعاية الصحية. تم تطوير المعيار بمشاركة أكثر من 250 طبيبًا عالميًا، ويتضمن 5000 محادثة طبية حقيقية و 48562 معيار تقييم فريد صاغه الأطباء، ويغطي سياقات متنوعة مثل طب الطوارئ والصحة العالمية، بالإضافة إلى أبعاد سلوكية مثل الدقة واتباع التعليمات. أظهرت الاختبارات أن دقة نموذج o3 تصل إلى 60%، بينما تفوق نموذج GPT-4.1 nano على GPT-4o مع خفض التكلفة بمقدار 25 مرة، مما يبرز الإمكانات الهائلة للذكاء الاصطناعي في المجال الطبي والتقدم السريع في فعالية الأداء مقابل التكلفة. (المصدر: OpenAI)
Meta تطلق نموذج Dynamic Byte Latent Transformer بمعاملات 8B: أعلنت Meta AI عن فتح مصدر أوزان نموذج Dynamic Byte Latent Transformer بمعاملات 8B. يقدم هذا النموذج حلاً جديدًا بديلاً لطرق الترميز التقليدية، بهدف إعادة تعريف معايير كفاءة وموثوقية نماذج اللغة. من خلال طريقة الترميز الجديدة هذه، من المتوقع أن يحقق تقدمًا كبيرًا في مجال نماذج اللغة، مما يعزز كفاءة وفعالية النماذج في معالجة النصوص. الورقة البحثية والكود متاحان الآن للتنزيل. (المصدر: AIatMeta)
باحثو مايكروسوفت يقدمون إطار ARTIST، الذي يدمج التعلم المعزز لتعزيز قدرات الاستدلال واستخدام الأدوات في LLM: قدم باحثو مايكروسوفت إطار ARTIST (Agentic Reasoning and Tool Integration in Self-improving Transformers). يدمج هذا الإطار بين الاستدلال المستقل والتعلم المعزز والاستخدام الديناميكي للأدوات، مما يمكّن نماذج اللغة الكبيرة من تحديد متى وكيف وما هي الأدوات التي يجب استخدامها للاستدلال متعدد الخطوات بشكل مستقل، وتعلم استراتيجيات قوية دون الحاجة إلى إشراف على مستوى الخطوات. تفوق ARTIST على النماذج الرائدة مثل GPT-4o في اختبارات قياسية صعبة مثل الرياضيات واستدعاء الوظائف، مع تحسن يصل إلى 22%، مما يضع معايير جديدة لحل المشكلات القابلة للتعميم والتفسير. (المصدر: MarkTechPost)

Sakana AI تطلق آلات التفكير المستمر (Continuous Thought Machines, CTM): قدمت Sakana AI بنية شبكة عصبية جديدة تسمى “آلات التفكير المستمر” (CTM). الفكرة الأساسية لـ CTM هي جعل العملية الزمنية الديناميكية للنشاط العصبي مكونًا أساسيًا في حساباتها، مما يسمح للنموذج بالعمل على طول جدول زمني لـ “خطوات التفكير” يتم إنشاؤه داخليًا، وبناء تمثيلاته وتحسينها بشكل تكراري، حتى مع البيانات الثابتة. أظهرت هذه البنية قدرتها على الحساب التكيفي، وتحسين قابلية التفسير، والمعقولية البيولوجية في مهام متنوعة مثل تصنيف ImageNet، والملاحة في متاهات ثنائية الأبعاد، والفرز، وحساب التكافؤ، والتعلم المعزز. (المصدر: Sakana AI)

🎯 التوجهات
فريق Qwen من Alibaba يطلق نماذج Qwen3 الرسمية المكممة (Quantized): أطلق فريق Qwen التابع لشركة Alibaba رسميًا النماذج المكممة لـ Qwen3. يمكن للمستخدمين الآن نشر Qwen3 عبر منصات مثل Ollama و LM Studio و SGLang و vLLM، مع دعم تنسيقات متعددة مثل GGUF و AWQ و GPTQ، مما يسهل النشر المحلي. تم إتاحة النماذج ذات الصلة على Hugging Face و ModelScope. يهدف هذا الإصدار إلى خفض عتبة استخدام نماذج اللغة الكبيرة عالية الأداء وتعزيز تطبيقها في سيناريوهات أوسع. (المصدر: Alibaba_Qwen & Hugging Face & ClementDelangue & _akhaliq & TheZachMueller & cognitivecompai & huybery & Reddit r/LocalLLaMA)
Meta AI تطلق إطار الاستدلال التعاوني Collaborative Reasoner: قدمت Meta AI إطار Collaborative Reasoner، المصمم لتحسين قدرات الاستدلال التعاوني لنماذج اللغة. يهدف الإطار إلى تطوير وكلاء اجتماعيين أذكياء قادرين على التعاون مع البشر والوكلاء الآخرين، مما يمهد الطريق لتفاعلات أكثر تعقيدًا بين الإنسان والآلة وأنظمة الوكلاء المتعددين من خلال تعزيز قدرات النموذج على التعاون والاستدلال. الورقة البحثية والكود متاحان للتنزيل، مما يشجع المجتمع على الاستكشاف والتطبيق. (المصدر: AIatMeta)
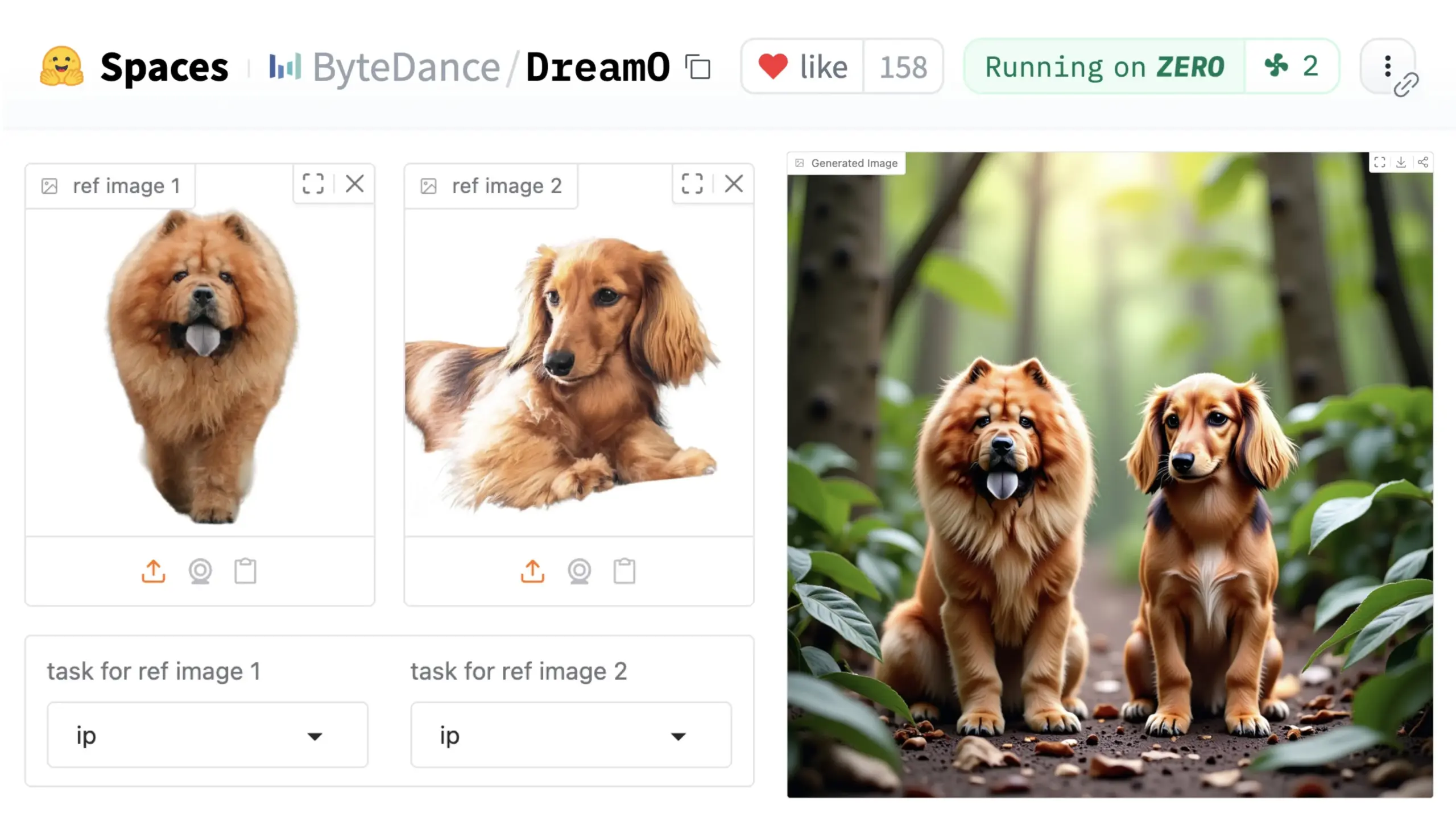
ByteDance تطلق إطار تخصيص الصور العام DreamO: أطلقت ByteDance إطارًا موحدًا لتخصيص الصور يسمى DreamO. يعتمد هذا الإطار على نموذج DiT (Diffusion Transformer) المدرب مسبقًا، ويمكنه تحقيق تخصيص معمم لعناصر متعددة في الصور مثل الأشخاص والأسلوب والخلفية، بما في ذلك استبدال الهوية ونقل الأسلوب وتحويل الموضوع والتجربة الافتراضية للملابس. يمكن للمستخدمين تجربة العرض التوضيحي (Demo) على Hugging Face. يوضح هذا التقدم إمكانات نموذج واحد في مهام تحرير الصور المتنوعة. (المصدر: _akhaliq & ClementDelangue & _akhaliq)
NVIDIA تفتح مصدر عملية إدارة بيانات نموذج Nemotron المسماة Nemotron-CC: أعلنت NVIDIA عن فتح مصدر عملية إدارة البيانات المستخدمة في نموذج Nemotron، المسماة Nemotron-CC، وكشف أكبر قدر ممكن من بيانات تدريب Nemotron وما بعد التدريب. تم الآن إضافة عملية Nemotron-CC إلى مستودع NeMo Curator على GitHub، ويمكنها معالجة البيانات النصية والصورية والفيديو على نطاق واسع. تؤكد NVIDIA على أهمية مجموعات بيانات التدريب المسبق عالية الجودة لدقة نماذج اللغة الكبيرة، وتعتبر البيانات مكونًا أساسيًا لتسريع الحوسبة. (المصدر: ctnzr & NandoDF)

نموذج Hunyuan-Turbos من Tencent يحتل المرتبة الثامنة في ساحة LMArena: احتل أحدث نموذج من Tencent، وهو Hunyuan-Turbos، المرتبة الثامنة بشكل عام في اختبارات الأداء القياسية على LMArena (المعروفة سابقًا باسم lmsys.org)، والمرتبة الثالثة عشرة في التحكم في الأسلوب، مقتربًا من أداء Deepseek-R1. دخل النموذج ضمن المراكز العشرة الأولى في الفئات الرئيسية مثل المهام الصعبة (hardcore) والبرمجة والرياضيات، مما يظهر تحسنًا ملحوظًا مقارنة بإصداره في فبراير. هنأ أعضاء المجتمع مثل WizardLM_AI على أدائه. (المصدر: WizardLM_AI & WizardLM_AI & teortaxesTex)

Runway Gen-4 References يظهر إمكانات أداة الإنشاء العامة: يُنظر إلى نموذج Gen-4 References من Runway كأداة إنشاء عامة قادرة على دعم عدد لا نهائي تقريبًا من مسارات العمل والتطبيقات. يواصل مستخدمو المجتمع اكتشاف حالات استخدام جديدة له، مما يدل على قدرته التكيفية القوية كنموذج عام يمكن تعديله وفقًا لإبداع المستخدمين، بدلاً من إجبار المستخدمين على التكيف مع قيود النموذج. يعكس هذا تطور الذكاء الاصطناعي في مجال إنشاء الوسائط من المهام المحددة إلى القدرات العامة. (المصدر: c_valenzuelab & c_valenzuelab)

نموذج Seed-1.5-VL-thinking من ByteDance يتصدر في اختبارات نماذج اللغة المرئية: أطلقت ByteDance نموذج Seed-1.5-VL-thinking، الذي حقق نتائج SOTA (state-of-the-art) في 38 من أصل 60 اختبارًا قياسيًا لنماذج اللغة المرئية (VLM). يُزعم أن النموذج تم تدريبه على 1.3 مليون ساعة GPU H800، مما يدل على قدراته القوية في الفهم والاستدلال متعدد الوسائط. (المصدر: teortaxesTex)
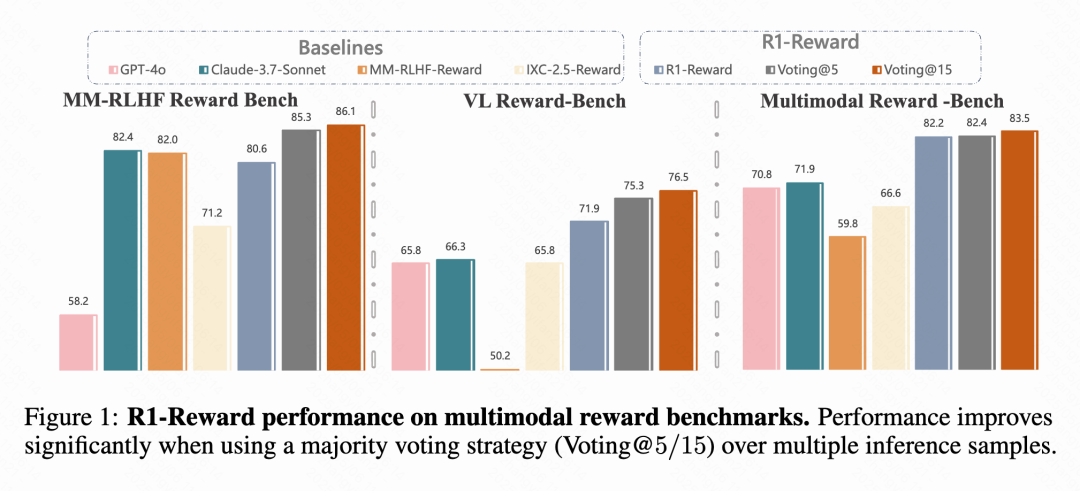
Kuaishou والأكاديمية الصينية للعلوم وغيرهم يقترحون نموذج المكافأة متعدد الوسائط R1-Reward: اقترحت فرق بحثية من Kuaishou والأكاديمية الصينية للعلوم وجامعة Tsinghua وجامعة Nanjing نموذج مكافأة متعدد الوسائط جديدًا (MRM) يسمى R1-Reward، يتم تدريبه باستخدام خوارزمية تعلم معزز محسنة تسمى StableReinforce. يهدف النموذج إلى حل مشكلات عدم الاستقرار التي تواجهها خوارزميات RL الحالية عند تدريب MRM، ويقدم آليات مثل Pre-Clip ومرشح الميزة (advantage filter) والمكافأة المتسقة (consistency reward). أظهرت التجارب أن R1-Reward يحقق تحسنًا بنسبة 5%-15% مقارنة بنماذج SOTA على العديد من معايير MRM، وتم تطبيقه بنجاح في سيناريوهات أعمال Kuaishou مثل مقاطع الفيديو القصيرة والتجارة الإلكترونية. (المصدر: WeChat & WeChat)
جامعة Nanyang التكنولوجية وغيرها يقترحون WorldMem، لتحقيق توليد عالم متسق طويل الأمد باستخدام آلية الذاكرة: اقترح باحثون من S-Lab بجامعة Nanyang التكنولوجية وجامعة Peking و Shanghai AI Lab نموذج توليد العالم WorldMem. يحل هذا النموذج مشكلة نقص الاتساق في نماذج توليد الفيديو الحالية على المدى الطويل من خلال إدخال آلية الذاكرة. تم تدريب WorldMem على مجموعة بيانات Minecraft، ويدعم استكشاف المشاهد المتنوعة والتغييرات الديناميكية، وتم التحقق من جدواه على مجموعات بيانات حقيقية، حيث يمكنه الحفاظ على اتساق هندسي جيد بعد تغييرات المنظور والموقع، ونمذجة الاتساق الزمني. (المصدر: WeChat)

فريق Kuaishou Keling يقترح CineMaster، إطار توليد فيديو سينمائي قابل للتحكم ومدرك للبعد الثالث: نشر فريق بحث Kuaishou Keling ورقة بحثية في SIGGRAPH 2025، يقدم فيها إطار CineMaster. وهو إطار لتوليد الفيديو من النص بمستوى سينمائي، يسمح للمستخدمين من خلال سير عمل تفاعلي بترتيب المشاهد في مساحة ثلاثية الأبعاد، وتحديد الأهداف وحركة الكاميرا، لتحقيق تحكم دقيق في محتوى الفيديو. يدمج CineMaster التحكم في حركة الكائن وحركة الكاميرا من خلال Semantic Layout ControlNet و Camera Adapter على التوالي، وصمم عملية بناء بيانات لاستخراج إشارات التحكم ثلاثية الأبعاد من أي فيديو. (المصدر: WeChat)

🧰 الأدوات
Comet-ml تطلق إطار تقييم LLM مفتوح المصدر Opik: أطلقت Comet-ml إطار Opik مفتوح المصدر على GitHub، وهو إطار لتصحيح الأخطاء وتقييم ومراقبة تطبيقات LLM وأنظمة RAG وسير عمل Agent. يوفر Opik تتبعًا شاملاً وتقييمًا آليًا ولوحات معلومات جاهزة للإنتاج، ويدعم التثبيت المحلي أو عبر Comet.com كحل مستضاف. يتكامل مع العديد من الأطر الشائعة مثل OpenAI و LangChain و LlamaIndex، ويوفر مقاييس LLM-as-a-judge للكشف عن الهلوسة والإشراف على المحتوى وتقييم RAG. (المصدر: GitHub Trending)
LovartAI تطلق أول وكيل تصميم ذكي Lovart، مع التركيز على فهم السياق: أطلقت LovartAI النسخة التجريبية (Beta) من أول وكيل تصميم ذكي لها، Lovart. أفاد المستخدمون أنه مقارنة بأدوات تصميم الذكاء الاصطناعي الأخرى، يمكن لـ Lovart فهم السياق بشكل أفضل، حتى أنه “يبدو وكأنه يقرأ الأفكار”. تتيح الأداة للإنسان والذكاء الاصطناعي التعاون على نفس اللوحة، وتحويل المطالبات (prompts) فورًا إلى تأثيرات بصرية، ويمكن استخدامها لتصميم شعارات العلامات التجارية والهوية البصرية (VI) وغيرها. (المصدر: karminski3)
فريق Jun-Yan Zhu من CMU يطلق LEGOGPT، لتوليد نماذج ليغو ثلاثية الأبعاد من النص: طور فريق Jun-Yan Zhu في جامعة كارنيجي ميلون (CMU) نموذج LEGOGPT، وهو نموذج لغة كبير يمكنه توليد نماذج ليغو ثلاثية الأبعاد مستقرة فيزيائيًا وقابلة للبناء بناءً على المطالبات النصية. يصيغ النموذج مشكلة تصميم ليغو كمهمة توليد نص ذاتي الانحدار (autoregressive)، من خلال التنبؤ بحجم وموضع القطعة التالية لبناء الهيكل، ويفرض قيود تجميع مدركة للفيزياء أثناء التدريب والاستدلال لضمان استقرار وقابلية بناء التصاميم المولدة. أصدر الفريق أيضًا مجموعة بيانات StableText2Lego التي تحتوي على أكثر من 47000 هيكل ليغو. (المصدر: WeChat)

تطبيق الدردشة MNN يدعم نماذج Qwen 2.5 Omni 3B و 7B: يدعم تطبيق الدردشة MNN (Mobile Neural Network) من Alibaba الآن نماذج Qwen 2.5 Omni 3B و 7B. هذا يعني أنه يمكن للمستخدمين تجربة خدمات نماذج لغة محلية أكثر قوة على الأجهزة المحمولة. MNN هو محرك استدلال للتعلم العميق خفيف الوزن، يركز على التحسين للأجهزة المحمولة والمدمجة. (المصدر: Reddit r/LocalLLaMA)

منصة FutureHouse توفر للعلماء أدوات بحث ذكاء اصطناعي فائقة الذكاء: أطلقت المنظمة غير الربحية FutureHouse منصة FutureHouse، وهي مجموعة من وكلاء الذكاء الاصطناعي المستندة إلى الويب وواجهات برمجة التطبيقات (API)، تهدف إلى تسريع الاكتشافات العلمية. توفر المنصة مجموعة من أدوات البحث بالذكاء الاصطناعي فائقة الذكاء لمساعدة العلماء في تحليل البيانات ومحاكاة التجارب واكتشاف المعرفة، مما يدفع إلى تغيير نماذج البحث العلمي. (المصدر: dl_weekly)
Cartesia تطلق Pro Voice Cloning لبناء نماذج صوتية مخصصة بسهولة: أطلقت Cartesia منتجها للضبط الدقيق (fine-tuning) Pro Voice Cloning. يمكن للمستخدمين تحميل بياناتهم الصوتية لبناء نماذج صوتية مخصصة بسهولة، لاستخدامها في إنشاء صور رمزية شخصية أو وكلاء ذكاء اصطناعي أو مكتبات صوتية. يدعم المنتج إكمال التدريب ونشر الخدمة في غضون ساعتين، ويوفر تجربة منتج ذاتية الخدمة بالكامل، بهدف تحقيق التطبيق على نطاق واسع. (المصدر: krandiash)

معهد تكنولوجيا الحوسبة بالأكاديمية الصينية للعلوم يقترح MCA-Ctrl لتحقيق تخصيص دقيق للصور: اقترح فريق بحثي من معهد تكنولوجيا الحوسبة التابع للأكاديمية الصينية للعلوم طريقة تخصيص صور عامة لا تتطلب ضبطًا دقيقًا تسمى MCA-Ctrl (Multi-party Collaborative Attention Control). تستخدم هذه الطريقة التحكم في الانتباه التعاوني متعدد الأطراف، وتستفيد من المعرفة الداخلية لنماذج الانتشار (diffusion models)، وتجمع بين المطالبات الشرطية للصور/النصوص ومحتوى صورة الموضوع، لتحقيق استبدال وتوليد وإضافة مواضيع لموضوعات محددة. يضمن MCA-Ctrl اتساق التخطيط واستبدال مظهر الكائن المحدد والمحاذاة مع الخلفية من خلال آليات الاستعلام المحلي للانتباه الذاتي والحقن العالمي. (المصدر: WeChat)
📚 للتعلم
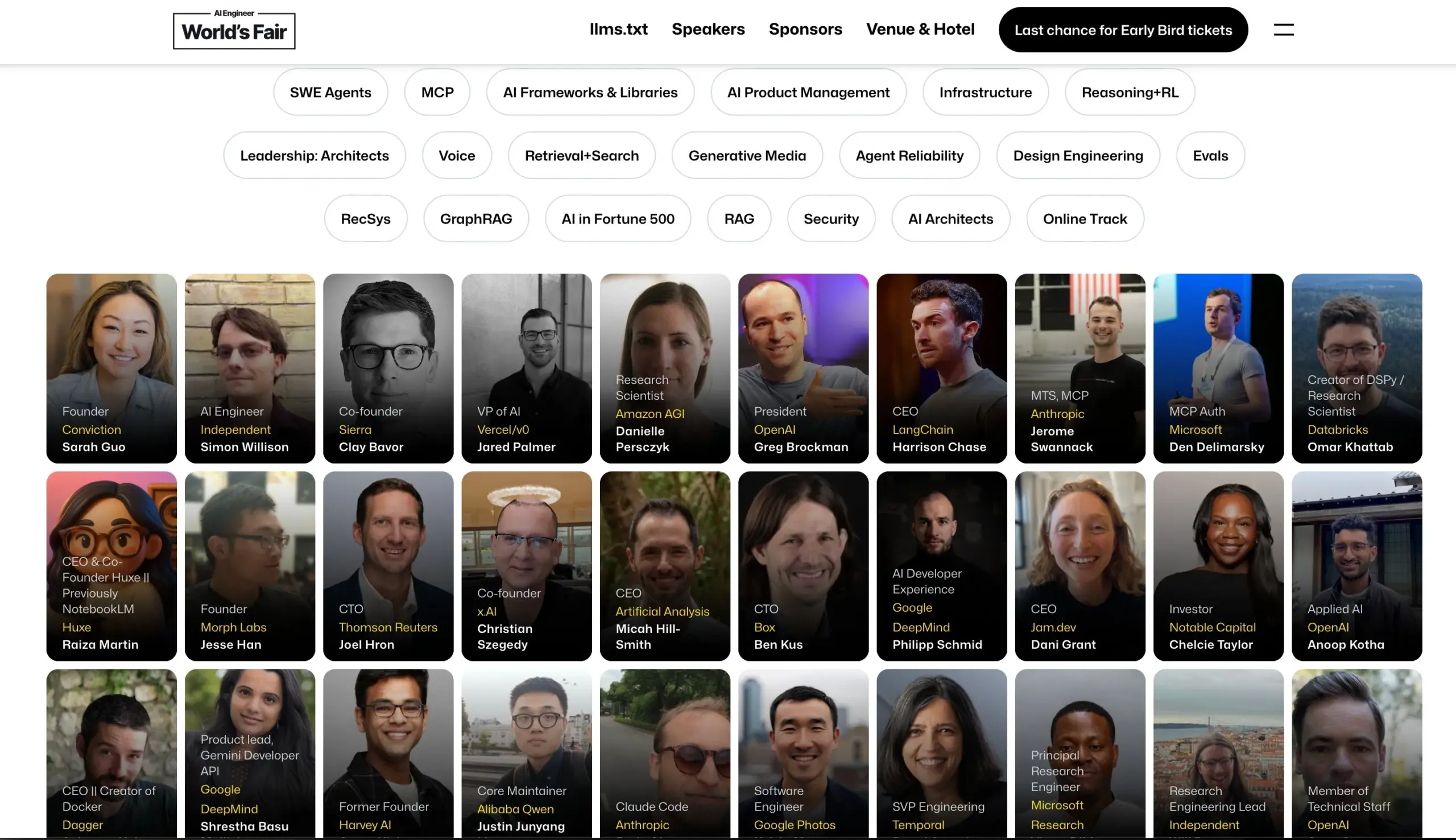
مؤتمر مهندسي الذكاء الاصطناعي (AI Engineer) يعلن عن قائمة المتحدثين: أعلن مؤتمر مهندسي الذكاء الاصطناعي عن قائمة المتحدثين، والتي تضم كبار مهندسي وباحثي الذكاء الاصطناعي من شركات مثل OpenAI و Anthropic و LangChainAI و Google وغيرها. سيغطي المؤتمر 20 مجالًا فرعيًا بما في ذلك MCP و LLM RecSys و Agent Reliability و GraphRAG، وسيخصص لأول مرة أجندة لقيادة CTO و VP. (المصدر: swyx & hwchase17 & _philschmid & HamelHusain & swyx & bookwormengr & swyx)
Hugging Face تنشر مدونة حول أحدث التطورات في نماذج اللغة المرئية (VLM): نشرت Hugging Face مقال مدونة شامل حول أحدث التطورات في نماذج اللغة المرئية (VLM). يغطي المحتوى جوانب متعددة مثل وكلاء واجهة المستخدم الرسومية (GUI agents)، ووكلاء VLM، والنماذج الشاملة (omnibus models)، و RAG متعدد الوسائط، ونماذج الفيديو اللغوية (video LM)، والنماذج الصغيرة، وغيرها، ملخصًا الاتجاهات الجديدة والاختراقات والمواءمة والاختبارات القياسية في مجال VLM خلال العام الماضي. (المصدر: huggingface & ben_burtenshaw & mervenoyann & huggingface & algo_diver & huggingface & huggingface)

Microsoft Azure تعقد ورشة عمل عبر الإنترنت حول بناء تطبيقات دردشة ذكاء اصطناعي بدون خادم (Serverless): أعلن Yohan Lasorsa عن عقد ورشة عمل عبر الإنترنت حول استخدام Azure لبناء تطبيقات دردشة ذكاء اصطناعي بدون خادم. ستناقش الجلسة Azure Functions وتطبيقات الويب الثابتة و Cosmos DB، وكيفية دمج LangChainAI JS باستخدام تقنية RAG (Retrieval-Augmented Generation). (المصدر: Hacubu & hwchase17)
بودكاست Weaviate يناقش أنظمة LLM-as-Judge ومكتبة Verdict: استضاف بودكاست Weaviate في حلقته رقم 121 ليونارد تانغ، المؤسس المشارك لـ Haize Labs، لمناقشة متعمقة لتطور أنظمة LLM-as-Judge / نماذج المكافأة. شملت المناقشة تجربة المستخدم في التقييم، والتقييم المقارن، وتكامل المحكمين (judges)، والمحكمين المتناظرين (debating judges)، وتنظيم مجموعات التقييم، والاختبار العدائي، مع التركيز بشكل خاص على مكتبة Haize Labs الجديدة Verdict، وهي إطار تعريفي لتحديد وتنفيذ أنظمة LLM-as-Judge المركبة. (المصدر: bobvanluijt & Reddit r/deeplearning)

تيرنس تاو ينشر فيديو على YouTube يوضح فيه البرهان الرياضي الرسمي بمساعدة الذكاء الاصطناعي: قدم الحائز على ميدالية فيلدز، تيرنس تاو، في أول ظهور له على قناته على YouTube، عرضًا لكيفية استخدام أدوات الذكاء الاصطناعي مثل GitHub Copilot ومساعد البرهان Lean لإضفاء الطابع الرسمي شبه التلقائي على برهان رياضي (معادلة Magma E1689 تستلزم E2) في 33 دقيقة، وهو برهان كان يتطلب عادةً صفحة كاملة يكتبها عالم رياضيات بشري. أكد أن هذه الطريقة مناسبة للبراهين ذات الطابع التقني القوي والمفاهيمي الضعيف، ويمكنها تحرير علماء الرياضيات من المهام الشاقة. في الوقت نفسه، تم تحديث مساعد البرهان خفيف الوزن الذي طوره بلغة Python إلى الإصدار 2.0، مما يعزز معالجة التقديرات التقاربية والمنطق الافتراضي. (المصدر: WeChat & 量子位)

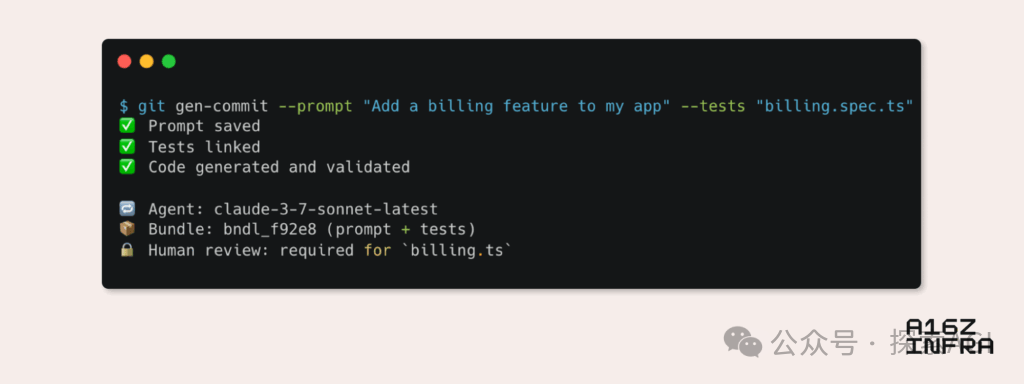
a16z تحلل تسعة اتجاهات رئيسية لأنماط المطورين الناشئة في عصر الذكاء الاصطناعي: نشرت Andreessen Horowitz (a16z) مدونة تحلل فيها تسعة اتجاهات رئيسية لأنماط المطورين الناشئة في عصر الذكاء الاصطناعي. وتشمل هذه: Git الأصلي للذكاء الاصطناعي (تحول التحكم في الإصدار نحو المطالبات وحالات الاختبار)، Vibe Coding (البرمجة القائمة على النية تحل محل القوالب)، نموذج جديد لإدارة المفاتيح لوكلاء الذكاء الاصطناعي، لوحات معلومات مراقبة تفاعلية مدفوعة بالذكاء الاصطناعي، تطور التوثيق إلى قواعد معرفية تفاعلية للذكاء الاصطناعي، رؤية التطبيقات من منظور LLM (من خلال التفاعل عبر واجهات برمجة تطبيقات إمكانية الوصول)، ظهور وكلاء التنفيذ غير المتزامن، إمكانات بروتوكول MCP (Model-Tool Communication Protocol)، وحاجة الوكلاء إلى المكونات الأساسية. تنذر هذه الاتجاهات بتغيير عميق في طريقة بناء البرمجيات. (المصدر: WeChat)
💼 الأعمال
Google Labs تطلق صندوق AI Futures Fund لدعم الشركات الناشئة في مجال الذكاء الاصطناعي: أعلنت Google Labs عن إطلاق برنامج AI Futures Fund، الذي يهدف إلى التعاون مع الشركات الناشئة لبناء مستقبل تكنولوجيا الذكاء الاصطناعي معًا. سيوفر الصندوق للشركات الناشئة المختارة وصولاً مبكرًا إلى نماذج Google DeepMind وموارد مثل أرصدة السحابة لمساعدتها على تسريع نموها. (المصدر: GoogleDeepMind & JeffDean & Google & demishassabis)
تقارير تشير إلى أن Perplexity تجري محادثات لجولة تمويل جديدة بقيمة 5 مليارات دولار بتقييم 140 مليار دولار: وفقًا للتقارير، تجري شركة محرك البحث بالذكاء الاصطناعي Perplexity محادثات لجولة تمويل جديدة بقيمة 5 مليارات دولار، وقد يصل تقييمها إلى 140 مليار دولار. يأتي هذا بعد ستة أشهر فقط من جولتها التمويلية السابقة (بتقييم 90 مليار دولار)، مما يدل على الاهتمام الكبير لسوق رأس المال بمسار البحث بالذكاء الاصطناعي والاعتراف بآفاق نمو Perplexity. (المصدر: Dorialexander)

تقارير تشير إلى موافقة OpenAI على الاستحواذ على Windsurf مقابل حوالي 30 مليار دولار: وفقًا لبلومبرج، وافقت OpenAI على الاستحواذ على الشركة الناشئة Windsurf مقابل حوالي 30 مليار دولار. لم يتم الكشف عن التفاصيل المحددة للصفقة أو اتجاه أعمال Windsurf، ولكن هذه الخطوة قد تعني أن OpenAI تعمل على توسيع قدراتها التقنية أو نطاق سوقها. (المصدر: Reddit r/artificial & Reddit r/ArtificialInteligence)

🌟 المجتمع
الخطر الحقيقي للذكاء الاصطناعي: “فخ المحاكاة” الناتج عن الإشباع اللامحدود: يشير نقاش أمجد مسعد وآخرين إلى أن الخطر الحقيقي للذكاء الاصطناعي ليس الروبوتات القاتلة في أفلام الخيال العلمي، بل قدرته على إشباع رغبات الإنسان بشكل لا نهائي، مما يخلق “آلة سعادة لا نهائية”. قد يؤدي هذا النوع من الذكاء الاصطناعي إلى إدمان البشر على الكفاح والمعنى المحاكى، و “الاختفاء” في النهاية في عالم المحاكاة، مما يقدم تفسيرًا محتملاً لمفارقة فيرمي – الحضارات لا تفنى، بل تدخل في النعيم الرقمي. (المصدر: amasad)
وكلاء الذكاء الاصطناعي سيعيدون تشكيل البرمجة والبحث العلمي: يتوقع أمجد مسعد، الرئيس التنفيذي لشركة Replit، أن تتمكن وكلاء الذكاء الاصطناعي في غضون عام أو عامين من العمل دون انقطاع لأيام، أو حتى سنوات، لحل المشكلات العلمية المعقدة. يعتقد أن الوكلاء سيصبحون طريقة جديدة للبرمجة، قادرين على استثمار أيام لحل مشكلة واحدة كما يفعل البشر، مما ينذر بإمكانات هائلة للذكاء الاصطناعي في أتمتة المهام المعقدة وتسريع الاكتشافات العلمية. (المصدر: TheTuringPost & amasad & TheTuringPost)
جون كارماك يناقش إمكانات الذكاء الاصطناعي في تحسين قواعد الكود: يعتقد المبرمج الأسطوري جون كارماك أن الذكاء الاصطناعي لا يمكنه فقط توليد كميات كبيرة من الكود، بل لديه أيضًا القدرة على المساعدة في تجميل وإعادة هيكلة قواعد الكود الحالية. يتصور الذكاء الاصطناعي كعضو فريق مجتهد، يراجع الكود باستمرار ويقترح تحسينات، بل ويمكنه تحديد إرشادات أسلوب ترميز “صديق للذكاء الاصطناعي” من خلال تجارب موضوعية. يتطلع إلى رؤية كيف ستتبنى الفرق التي تتطلب جودة كود عالية للغاية مثل OpenBSD أعضاء الذكاء الاصطناعي. (المصدر: ID_AA_Carmack)
“Vibe Coding” يثير نقاشًا حادًا: إيجابيات وسلبيات البرمجة بمساعدة الذكاء الاصطناعي: يشير نقاش المجتمع إلى أنه على الرغم من أن “Vibe Coding” (توليد نماذج أولية للكود بواسطة الذكاء الاصطناعي من خلال تعليمات اللغة الطبيعية) يمكن أن يبني تطبيقات على مستوى العرض التوضيحي بسرعة، إلا أن النشر والتوسع لا يزالان يتطلبان مطورين محترفين للبناء من الصفر. المنتجات المهندسة ليست مجرد كتابة كود، بل تشمل أيضًا الهندسة المعمارية، CI/CD، الخدمات المصغرة، وغيرها من المشكلات المعقدة التي يصعب على الذكاء الاصطناعي حاليًا التعامل معها بالكامل. Vibe Coding مناسب للتحقق السريع من النماذج الأولية، لكن بناء حلول حقيقية لا يزال يتطلب تفكيرًا وخبرة هندسية. (المصدر: Reddit r/ClaudeAI)
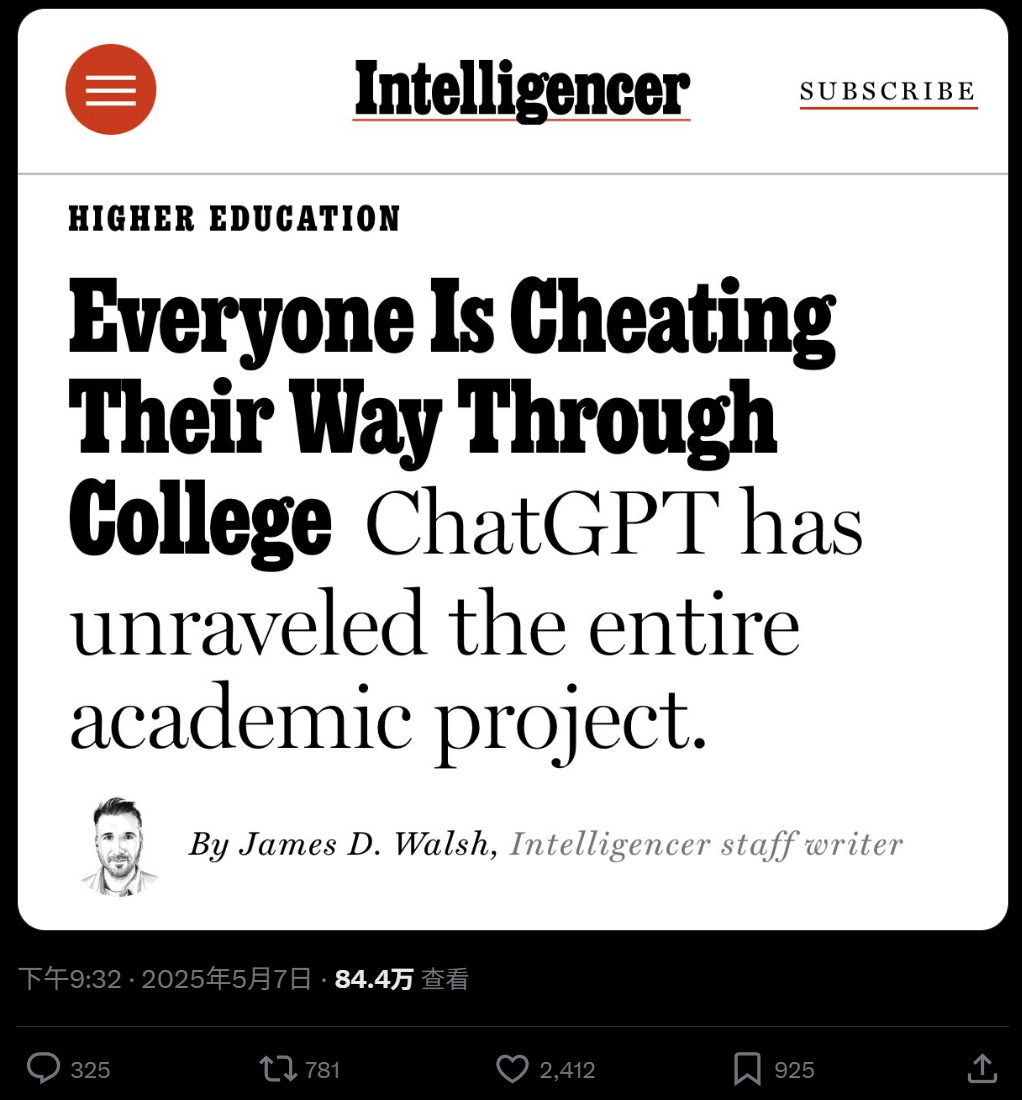
الاستخدام الواسع للذكاء الاصطناعي في التعليم الجامعي ومخاوف الغش: كشف تقرير لمجلة نيويورك عن الاستخدام الواسع لأدوات الذكاء الاصطناعي (مثل ChatGPT) في جامعات أمريكا الشمالية لإنجاز الواجبات والأوراق البحثية. يستخدم الطلاب الذكاء الاصطناعي لتدوين الملاحظات والدراسة والبحث وحتى توليد محتوى الواجبات مباشرة، مما يثير مخاوف بشأن النزاهة الأكاديمية وجودة التعليم وتراجع قدرات التفكير النقدي لدى الطلاب. يحاول المعلمون تعديل طرق التدريس والتقييم، لكن فعالية أدوات الكشف عن الذكاء الاصطناعي مشكوك فيها، مما يجعل من الصعب القضاء على الغش باستخدام الذكاء الاصطناعي. (المصدر: WeChat)
💡 أخرى
Cohere تناقش تحديات انتقال تطبيقات الذكاء الاصطناعي الحكومية من المرحلة التجريبية إلى الإنتاج: تشير Cohere إلى أن معظم مشاريع الذكاء الاصطناعي الحكومية لا تزال في المرحلة التجريبية. لتحقيق القفزة من المرحلة التجريبية إلى تطبيقات الإنتاج الفعلية، تحتاج الوكالات الحكومية إلى أدوات موثوقة، وتوجيه واضح نحو النتائج، وبنية تحتية فعالة، وشركاء مناسبين. يستكشف المقال كيف يمكن للوكالات الحكومية تحقيق التحول من التجريب إلى التطبيق الفعلي من خلال الذكاء الاصطناعي الآمن والفعال. (المصدر: cohere)

مصطفى سليمان: كلما زاد حجم نماذج اللغة الكبيرة، كان التحكم فيها أسهل: يعتقد مصطفى سليمان، المؤسس المشارك لـ Inflection AI، أنه على عكس المخاوف الشائعة، كلما زاد حجم نماذج اللغة الكبيرة (LLM)، أصبح التحكم فيها أسهل في الواقع. يشير إلى أن النماذج من الأجيال السابقة كانت أصعب في التوجيه والتنميط والتشكيل، بينما يساعد التوسع في الحجم على تعزيز قابلية التحكم في النموذج، وليس إضعافها. (المصدر: mustafasuleyman)
نقاش حول أخلاقيات الذكاء الاصطناعي: تحديد المسؤولية عن الضرر أو التحيز الناجم عن الذكاء الاصطناعي: أثار منشور على Reddit نقاشًا حول: عندما يتسبب نظام ذكاء اصطناعي (مثل الذكاء الاصطناعي للتشخيص الطبي) في ضرر بسبب تحيز بيانات التدريب (مثل التدريب بشكل أساسي على صور البشرة الفاتحة، مما يؤدي إلى تشخيص خاطئ للمرضى ذوي البشرة الداكنة)، من يجب أن يتحمل المسؤولية؟ يتضمن ذلك تحديد مسؤولية أطراف متعددة مثل مطوري الذكاء الاصطناعي والمؤسسات التي تنشر النظام والجهات التنظيمية، وهي قضية رئيسية تحتاج إلى حل عاجل في إطار أخلاقيات وقانون الذكاء الاصطناعي. (المصدر: Reddit r/ArtificialInteligence)