كلمات مفتاحية:الصفر المطلق, كيوين 3, ميسترال ميديم 3, مؤسسة باي تورش, التطور الذاتي للذكاء الاصطناعي, النماذج متعددة الوسائط, الذكاء الاصطناعي مفتوح المصدر, نموذج آر إل في آر, نظام أي زد آر, كيوين 3-235B-A22B, مكتبة ديب سبيد للتحسين, دعم لانج سميث متعدد الوسائط
🔥 تركيز
جامعة تسينغهوا تنشر ورقة بحثية بعنوان Absolute Zero: الذكاء الاصطناعي يمكنه التطور ذاتيًا دون الحاجة لبيانات خارجية: نشر فريق LeapLabTHU من جامعة تسينغهوا نموذجًا جديدًا يُدعى “Absolute Zero” وهو نموذج RLVR (Reinforcement Learning with Verifiable Rewards). في إطار هذا النموذج، يمكن لنموذج واحد أن يقترح ذاتيًا مهامًا لتعظيم عملية التعلم، ومن خلال حل هذه المهام، يعزز قدرته على الاستدلال، دون الاعتماد على أي بيانات خارجية على الإطلاق. يستخدم نظامه AZR (Absolute Zero Reasoner) منفذ أكواد للتحقق من المهام والإجابات، مما يحقق تعلمًا مفتوحًا ولكنه قائم على أسس. أظهرت التجارب أن AZR يحقق مستوى SOTA في مهام الترميز والاستدلال الرياضي، متجاوزًا النماذج الحالية التي لا تعتمد على أي عينات (zero-shot) والتي تعتمد على عشرات الآلاف من العينات المصنفة بشريًا (المصدر: Reddit r/LocalLLaMA)
علي بابا تطلق سلسلة نماذج Qwen3، تشمل MoE وأحجامًا متنوعة: أطلقت علي بابا سلسلة نماذج اللغة الكبيرة Qwen3، التي تضم 8 نماذج تتراوح معلماتها من 0.6 مليار إلى 235 مليار. من بينها، يعتمد نموذجا Qwen3-235B-A22B و Qwen3-30B-A3B على معمارية MoE، بينما النماذج المتبقية هي نماذج كثيفة. تم تدريب هذه السلسلة من النماذج مسبقًا على 36 تريليون tokens، وتغطي 119 لغة، وتتميز بوضع استدلال قابل للتشغيل/الإيقاف، وهي مناسبة لمجالات متعددة مثل البرمجة والرياضيات والعلوم. أظهرت التقييمات تفوق أداء نماذج MoE، حيث تجاوز إصدار 235B نماذج DeepSeek-R1 و Gemini 2.5 Pro في العديد من المعايير المرجعية، كما أظهر إصدار 30B أداءً قويًا، حتى أن نموذج 4B تفوق في بعض المعايير المرجعية على نماذج ذات معلمات أكبر بكثير. تم إتاحة النماذج كمصدر مفتوح على HuggingFace و ModelScope، بموجب ترخيص Apache 2.0 (المصدر: DeepLearning.AI Blog)
Mistral تطلق نموذج Mistral Medium 3 متعدد الوسائط ومساعد ذكاء اصطناعي للشركات: أطلقت Mistral AI نموذج Mistral Medium 3، وهو نموذج جديد متعدد الوسائط، تدعي أنه يقترب في أدائه من Claude Sonnet 3.7، ولكنه أقل تكلفة بشكل كبير (الإدخال 0.4 دولار/مليون token، الإخراج 2 دولار/مليون token)، مما يقلل التكلفة بمقدار 8 أضعاف. يتميز هذا النموذج بأداء ممتاز في الترميز واستدعاء الدوال، ويوفر ميزات على مستوى الشركات مثل النشر المختلط أو المحلي، والتدريب اللاحق المخصص. في الوقت نفسه، أطلقت Mistral أيضًا Le Chat Enterprise، وهو مساعد ذكاء اصطناعي قابل للتخصيص وآمن على مستوى الشركات، يدعم دمج قواعد معارف الشركة (مثل Gmail، Google Drive، Sharepoint)، ويتمتع بوظائف مثل Agent، ومساعد الترميز، والبحث على الويب، ويهدف إلى تعزيز القدرة التنافسية للشركات. أعلنت Mistral أنها ستطلق نموذجًا كبيرًا جديدًا (Large) في الأسابيع القليلة المقبلة (المصدر: Mistral AI، GuillaumeLample، scaling01، karminski3)
مؤسسة PyTorch تتوسع لتصبح مؤسسة شاملة، وتضم vLLM و DeepSpeed: أعلنت مؤسسة PyTorch عن توسعها لتصبح هيكل مؤسسة شاملة، بهدف جمع المزيد من مشاريع الذكاء الاصطناعي مفتوحة المصدر عالية الجودة. أول المشاريع المنضمة هي vLLM و DeepSpeed. vLLM هو محرك استدلال وخدمة عالي الإنتاجية وفعال من حيث الذاكرة مصمم خصيصًا لنماذج اللغة الكبيرة (LLM)؛ DeepSpeed هي مكتبة لتحسين التعلم العميق تجعل تدريب النماذج واسعة النطاق أكثر كفاءة. تهدف هذه الخطوة إلى تعزيز تطوير الذكاء الاصطناعي المدفوع من المجتمع، وتغطية دورة الحياة الكاملة من البحث إلى الإنتاج، وقد حظيت بدعم العديد من الأعضاء مثل AMD، Arm، AWS، Google، Huawei وغيرها (المصدر: PyTorch، soumithchintala، vllm_project، code_star)

🎯 توجهات
مختبر ARC التابع لـ Tencent يطلق FlexiAct: أداة لنقل حركة الفيديو: أطلق مختبر ARC التابع لـ Tencent أداة جديدة على Hugging Face باسم FlexiAct. تستطيع هذه الأداة نقل الحركة من فيديو مرجعي إلى أي صورة مستهدفة، حتى لو كان تخطيط الصورة المستهدفة أو منظورها أو هيكلها العظمي مختلفًا عن الفيديو المرجعي. يوفر هذا إمكانيات جديدة لمجال إنشاء وتحرير الفيديو، مما يسمح للمستخدمين بالتحكم بشكل أكثر مرونة في الحركة والوضعيات في المحتوى المُنشأ (المصدر: _akhaliq)
White Circle تطلق CircleGuardBench: معيار جديد لنماذج الإشراف على محتوى الذكاء الاصطناعي: أطلقت White Circle أداة CircleGuardBench، وهي معيار جديد لتقييم نماذج الإشراف على محتوى الذكاء الاصطناعي. يهدف هذا المعيار إلى إجراء تقييم على مستوى الإنتاج، ويختبر المحتوى بما في ذلك اكتشاف الأضرار، ومقاومة الاختراق (jailbreak)، ومعدل الإيجابيات الخاطئة، والكمون، ويغطي 17 فئة من الأضرار الواقعية. تم نشر مقالة مدونة ذات صلة ولوحة صدارة على Hugging Face، مما يوفر معايير تقييم جديدة لمجال أمان الذكاء الاصطناعي والإشراف على المحتوى (المصدر: TheTuringPost، _akhaliq)

Hugging Face تطلق SIFT-50M: مجموعة بيانات كبيرة متعددة اللغات لضبط التعليمات الصوتية الدقيقة: تم إطلاق مجموعة بيانات SIFT-50M على Hugging Face، وهي مجموعة بيانات كبيرة متعددة اللغات، مصممة خصيصًا لضبط التعليمات الصوتية الدقيقة. تحتوي مجموعة البيانات هذه على أكثر من 50 مليون زوج من الأسئلة والأجوبة الإرشادية، تغطي 5 لغات. يتفوق SIFT-LLM المدرب على مجموعة البيانات هذه على SALMONN و Qwen2-Audio في اختبارات قياس اتباع التعليمات الصوتية. تتضمن مجموعة البيانات أيضًا معيار EvalSIFT للتقييم الصوتي والتوليدي، وتدعم توليد الكلام المتحكم فيه (مثل درجة الصوت، وسرعة الكلام، واللهجة)، وهي مبنية على Whisper، HuBERT، X-Codec2 و Qwen2.5 (المصدر: ClementDelangue، huggingface)
Meta تطلق Perception Language Model (PLM): نموذج لغة مرئي مفتوح المصدر وقابل للتكرار: أطلقت Meta AI نموذج Perception Language Model (PLM)، وهو نموذج لغة مرئي مفتوح وقابل للتكرار، يهدف إلى حل المهام المرئية الصعبة. تأمل Meta من خلال PLM مساعدة مجتمع المصادر المفتوحة على بناء أنظمة رؤية حاسوبية أكثر قوة. تم نشر ورقة البحث ذات الصلة والتعليمات البرمجية ومجموعة البيانات ليستخدمها الباحثون والمطورون (المصدر: AIatMeta)
جوجل تحدث نموذج Gemini 2.0 لتوليد الصور: تحسين الجودة والسرعة: أعلنت جوجل عن تحديث نموذجها لتوليد الصور Gemini 2.0 (نسخة تجريبية)، حيث يوفر الإصدار الجديد جودة بصرية أفضل، وعرضًا أكثر دقة للنصوص، ومعدلات حظر أقل (block rates)، وحدود معدل أعلى (rate limits). تبلغ تكلفة إنشاء كل صورة 0.039 دولار. يهدف هذا التحديث إلى تحسين تجربة وفعالية المطورين عند استخدام Gemini لتوليد الصور (المصدر: m__dehghani، scaling01، andrew_n_carr، demishassabis)
NVIDIA تطلق سلسلة نماذج استدلال الأكواد مفتوحة المصدر: أطلقت NVIDIA سلسلة من نماذج استدلال الأكواد مفتوحة المصدر، تشمل ثلاثة أحجام: 32B، 14B، و 7B، جميعها مرخصة بموجب APACHE 2.0. تم تدريب هذه النماذج على مجموعات بيانات OCR، ويُقال إنها تتفوق في الأداء على O3 mini و O1 (low) في معيار LiveCodeBench، كما أنها أكثر كفاءة في استخدام الـ token بنسبة 30% مقارنة بنماذج الاستدلال المماثلة. تتوافق النماذج مع العديد من الأطر مثل llama.cpp، vLLM، transformers، TGI وغيرها (المصدر: huggingface، ClementDelangue)
ServiceNow و NVIDIA تتعاونان لإطلاق نموذج Apriel-Nemotron-15b-Thinker: أعلنت ServiceNow و NVIDIA بشكل مشترك عن إطلاق نموذج بمعلمات 15B يُدعى Apriel-Nemotron-15b-Thinker، مرخص بموجب MIT. يُقال إن هذا النموذج يتمتع بأداء يعادل نماذج 32B، ولكنه يقلل بشكل كبير من استهلاك الـ token (أقل بحوالي 40% من Qwen-QwQ-32b). وقد أظهر أداءً متميزًا في العديد من اختبارات القياس مثل MBPP، BFCL، RAG المؤسسي، IFEval، ويتمتع بقدرة تنافسية خاصة في مهام RAG المؤسسي والبرمجة (المصدر: Reddit r/LocalLLaMA)

نموذج s1: ضبط دقيق لعينات قليلة يحقق الاستدلال، وتقنية “Wait” تحسن الأداء: طور باحثون من جامعة ستانفورد ومؤسسات أخرى نموذج s1، وأثبتوا أن الضبط الدقيق الخاضع للإشراف باستخدام حوالي 1000 عينة فقط من سلسلة التفكير (CoT) يمكن أن يمنح نماذج اللغة الكبيرة المدربة مسبقًا (مثل Qwen 2.5-32B) القدرة على الاستدلال. كما وجد البحث أن إجبار النموذج على توليد token “Wait” أثناء عملية الاستدلال لإطالة سلسلة الاستدلال يمكن أن يحسن بشكل كبير دقة النموذج في مهام مثل الرياضيات، مما يجعل أداءه يقترب من OpenAI o1-preview. يوفر هذا الاكتشاف أفكارًا جديدة لتحسين قدرة النموذج على الاستدلال بتكلفة منخفضة (المصدر: DeepLearning.AI Blog)
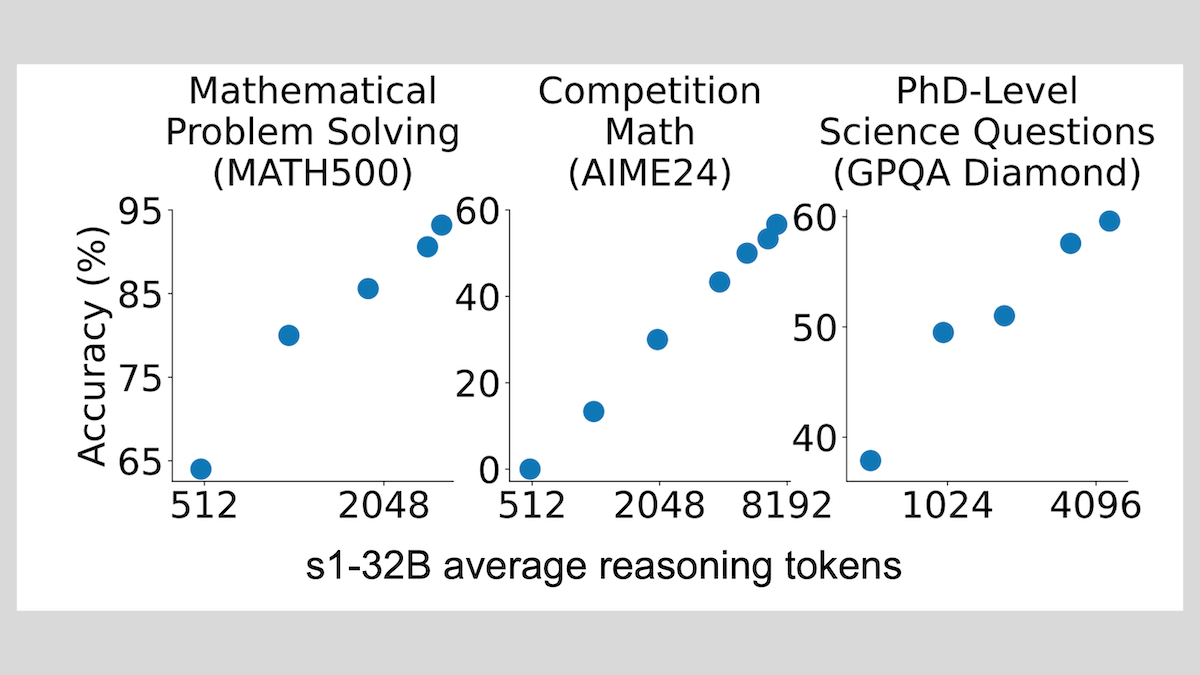
ThinkPRM: نموذج مكافأة عملية توليدية يمكن تدريبه بـ 8 آلاف علامة فقط: اقترح باحثون ThinkPRM، وهو نموذج مكافأة عملية توليدية (PRM)، يتطلب 8 آلاف علامة عملية فقط للضبط الدقيق. يمكن لهذا النموذج التحقق من عملية الاستدلال عن طريق توليد سلاسل تفكير طويلة (long chains-of-thought)، مما يحل مشكلة التكلفة الباهظة للبيانات الإشرافية على مستوى الخطوات المطلوبة لتدريب PRM. تم نشر الكود والنموذج والبيانات ذات الصلة على GitHub و Hugging Face (المصدر: Reddit r/MachineLearning)
🧰 أدوات
Zed تطلق أسرع محرر أكواد ذكاء اصطناعي في العالم (حسب ادعائها): أطلقت Zed محرر أكواد ذكاء اصطناعي يُقال إنه الأسرع في العالم. تم بناء هذا المحرر من الصفر باستخدام Rust، ويهدف إلى تحسين التعاون بين الإنسان والذكاء الاصطناعي، وتوفير تجربة تحرير سريعة للغاية بواسطة الوكيل (agentic editing experience). يدعم المحرر نماذج شائعة مثل Claude 3.7 Sonnet، ويسمح للمستخدمين بإحضار مفاتيح API الخاصة بهم أو استخدام نماذج محلية عبر Ollama (المصدر: andersonbcdefg، ollama)
Hugging Face تطلق nanoVLM: مكتبة نماذج لغة مرئية مبسطة للغاية: أطلقت Hugging Face المصدر المفتوح nanoVLM، وهي مكتبة PyTorch خالصة، تهدف إلى تدريب نماذج لغة مرئية (VLM) من الصفر بحوالي 750 سطرًا من التعليمات البرمجية. يحقق هذا النموذج دقة بنسبة 35.3% على معيار MMStar، وهو ما يعادل SmolVLM-256M، ولكنه يتطلب ساعات GPU أقل بمقدار 100 مرة للتدريب. يستخدم nanoVLM مشفرًا مرئيًا SigLiP-ViT، ومفكك تشفير بنمط LLaMA، ويربط بينهما عبر جهاز عرض وسائط، وهو مناسب للتعلم أو النماذج الأولية أو بناء VLM مخصص (المصدر: clefourrier، ben_burtenshaw، Reddit r/LocalLLaMA)
DBOS تطلق DBOS Python 1.0: أداة سير عمل مستمرة خفيفة الوزن: أطلقت DBOS إصدار DBOS Python 1.0. تهدف هذه الأداة إلى توفير قدرات سير عمل مستمرة خفيفة الوزن وسهلة الاستخدام لتطبيقات Python (بما في ذلك العمليات التجارية، وأتمتة الذكاء الاصطناعي، وخطوط أنابيب البيانات، وما إلى ذلك). يتضمن الإصدار الجديد قوائم انتظار مستمرة (تدعم تحديد التزامن، وتحديد المعدل، والمهلات، والأولويات، وإزالة التكرار، وما إلى ذلك)، وإدارة سير العمل البرمجية (من خلال جداول Postgres للاستعلام، والإيقاف المؤقت، والاستئناف، وإعادة التشغيل، وما إلى ذلك)، ودعم التعليمات البرمجية المتزامنة/غير المتزامنة، وأدوات محسنة (لوحة معلومات، وتصورات، وما إلى ذلك) (المصدر: lateinteraction)
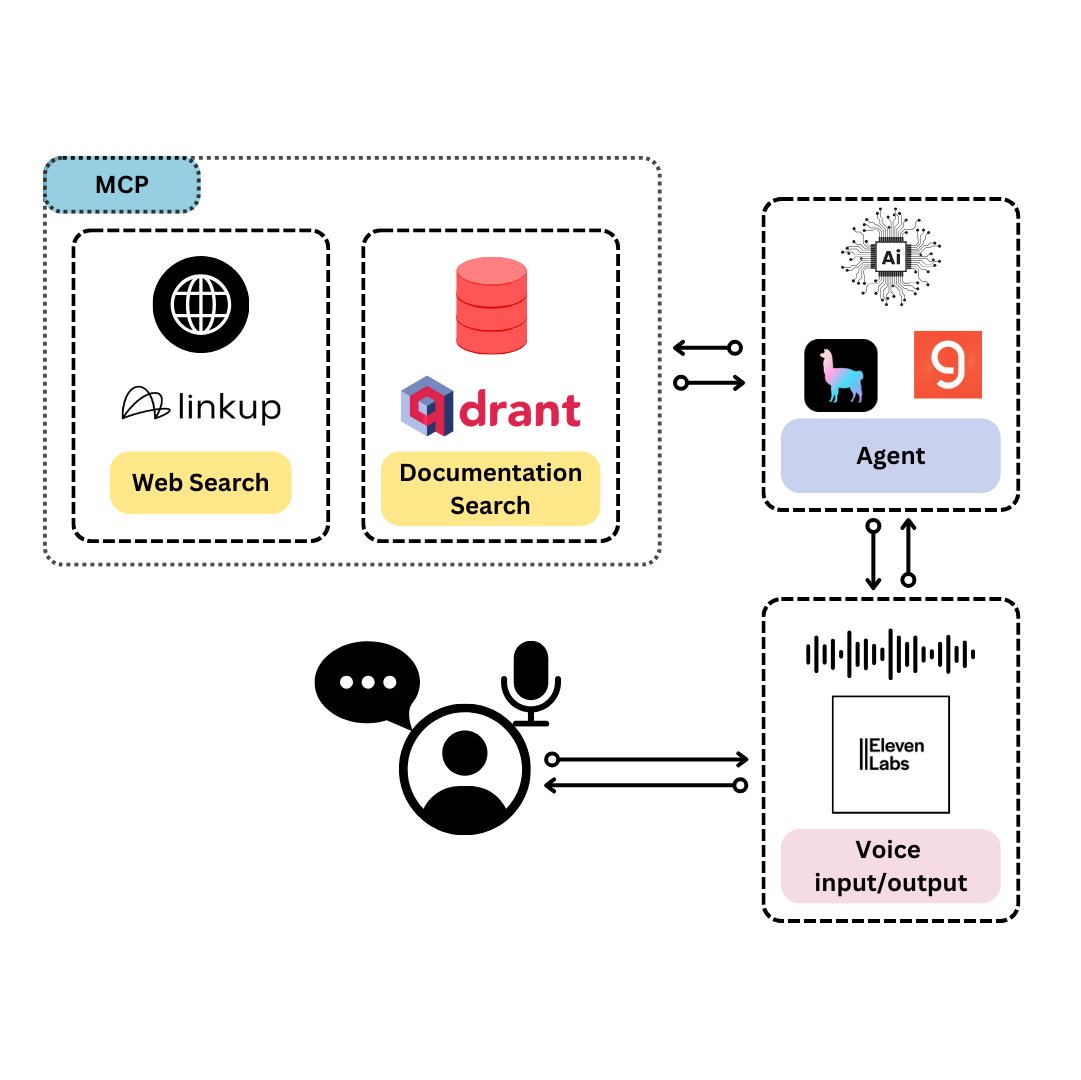
Qdrant تطلق TySVA: مساعد صوتي مصمم خصيصًا لمطوري TypeScript: أطلقت Qdrant مساعد TySVA (TypeScript Voice Assistant)، وهو مساعد صوتي يهدف إلى تزويد مطوري TypeScript بإجابات دقيقة ومدركة للسياق. يستخدم TySVA تخزين Qdrant المحلي لوثائق TypeScript، ويدمج منصة Linkup لسحب بيانات الويب ذات الصلة، ويستخدم LlamaIndex لاختيار أفضل مصدر للبيانات. يدعم الإدخال الصوتي والنصي، ويساعد المطورين في الحصول على مساعدة موثوقة بدون استخدام اليدين أثناء الترميز (المصدر: qdrant_engine، qdrant_engine)
LlamaIndex تطلق ميزات جديدة لـ LlamaExtract: دعم الاقتباسات والاستدلال: أضافت أداة LlamaExtract من LlamaIndex ميزات جديدة تهدف إلى تعزيز موثوقية وشفافية تطبيقات الذكاء الاصطناعي. تسمح الميزات الجديدة عند استخراج المعلومات من مصادر بيانات معقدة (مثل ملفات SEC) بتوفير اقتباسات دقيقة للمصدر (citations) وعملية استدلال الاستخراج (reasoning). يساعد هذا المطورين على بناء أنظمة ذكاء اصطناعي أكثر مسؤولية وقابلية للتفسير (المصدر: jerryjliu0، jerryjliu0، jerryjliu0)

مطور في Hugging Face يبني نموذجًا أوليًا لخادم MCP، يربط بين Agent و Hub: يقوم Wauplin، وهو مطور في Hugging Face، بتطوير نموذج أولي لخادم Hugging Face MCP (Machine Communication Protocol)، يهدف إلى ربط وكلاء الذكاء الاصطناعي (AI Agent) بـ Hugging Face Hub. يمكن اعتبار هذا النموذج الأولي بمثابة “HfApi يلتقي بـ MCP”، مما يسمح للوكلاء بالتفاعل مع Hub عبر البروتوكول، على سبيل المثال، مشاركة وتحرير النماذج ومجموعات البيانات و Spaces وما إلى ذلك. يطلب المطور ملاحظات المجتمع حول فائدة هذه الأداة وحالات الاستخدام المحتملة (المصدر: ClementDelangue، ClementDelangue، huggingface)

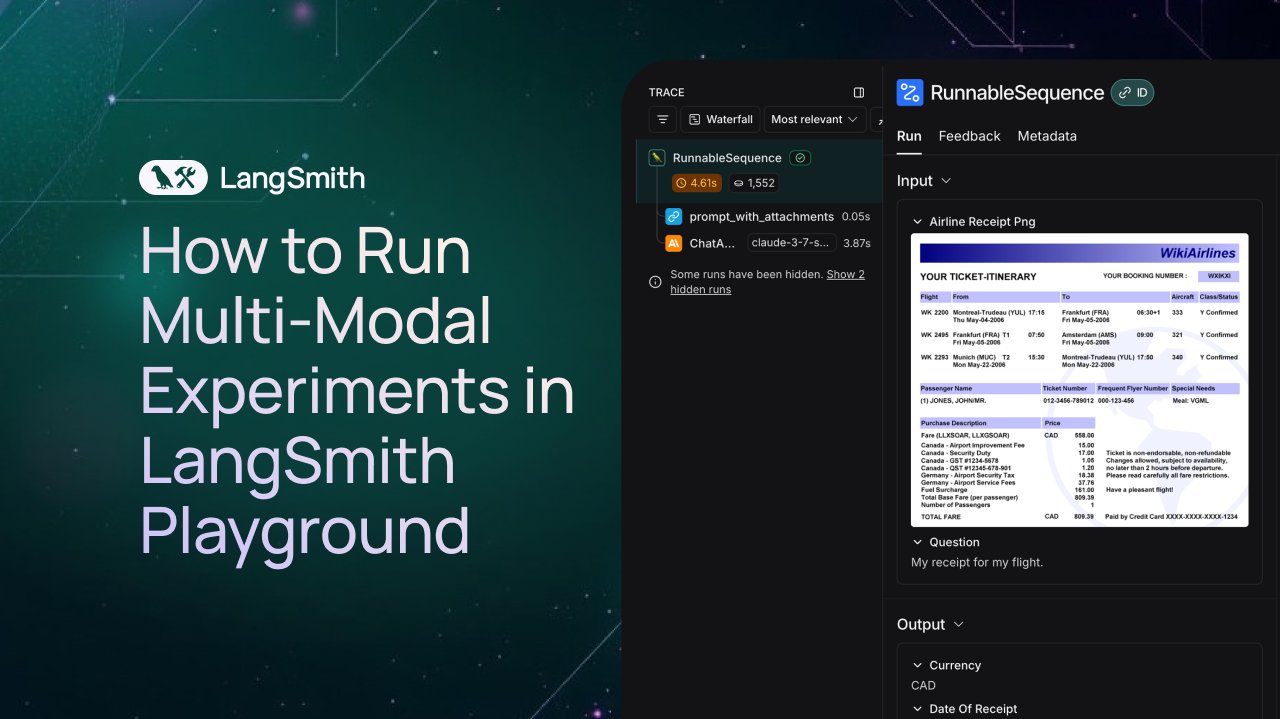
LangSmith يضيف دعمًا للمراقبة والتقييم لوكلاء الوسائط المتعددة: تدعم منصة LangSmith الآن معالجة ملفات الصور و PDF والصوت في Playground وقوائم الانتظار للتصنيف ومجموعات البيانات. يسهل هذا التحديث بناء وتقييم تطبيقات الوسائط المتعددة (مثل وكلاء استخراج الفواتير). أصدرت الشركة فيديو توضيحي ووثائق لمساعدة المستخدمين على البدء في استخدام الميزات الجديدة (المصدر: LangChainAI، Hacubu، hwchase17)
DFloat11 يطلق إصدارًا مضغوطًا بدون فقدان لنموذج FLUX.1، يمكن تشغيله على VRAM بسعة 20 جيجابايت: أطلق مشروع DFloat11 إصدارات مضغوطة بدون فقدان لنماذج FLUX.1-dev و FLUX.1-schnell (بمعلمات 12 مليار). من خلال طريقة ضغط DFloat11 (تطبيق ترميز الإنتروبيا على أوزان BFloat16)، تم تقليل حجم النموذج من 24 جيجابايت إلى حوالي 16.3 جيجابايت (حوالي 30%)، مع الحفاظ على المخرجات دون تغيير. هذا يجعل هذه النماذج قابلة للتشغيل على وحدة معالجة رسومات واحدة (GPU) بسعة VRAM تبلغ 20 جيجابايت أو أكثر، مع زيادة بضع ثوانٍ فقط من الحمل الإضافي لكل صورة. تم نشر النماذج والأكواد ذات الصلة على Hugging Face و GitHub (المصدر: Reddit r/LocalLLaMA)

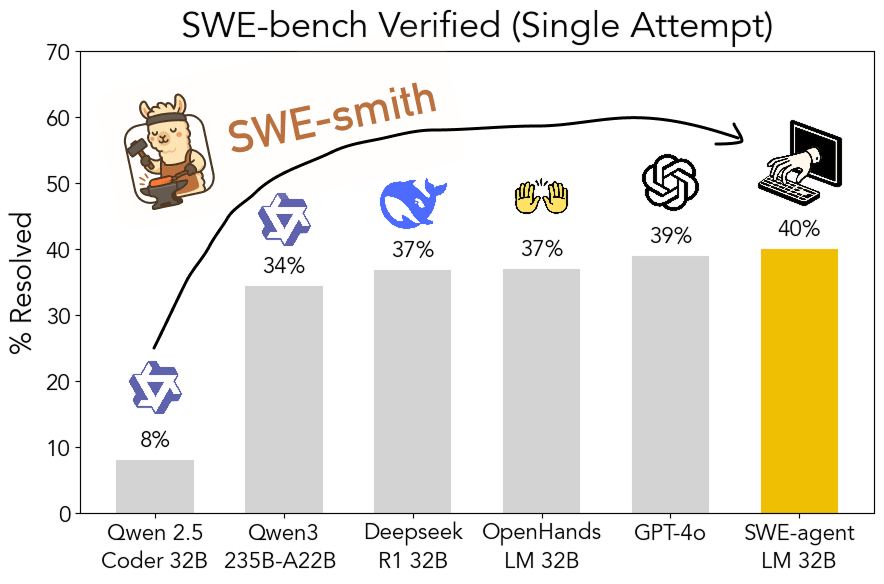
مجموعة أدوات SWE-smith مفتوحة المصدر: لتوليد بيانات تدريب هندسة البرمجيات القابلة للتطوير: قام باحثون من جامعة ستانفورد بإتاحة SWE-smith كمصدر مفتوح، وهو خط أنابيب قابل للتطوير لتوليد بيانات تدريب هندسة البرمجيات من أي مستودع Python. باستخدام هذه المجموعة، تم توليد أكثر من 50 ألف مثيل، وبناءً على ذلك تم تدريب نموذج SWE-agent-LM-32B، الذي حقق نسبة نجاح Pass@1 بلغت 40.2% على معيار SWE-bench Verified، ليصبح أفضل نموذج مفتوح المصدر أداءً على هذا المعيار. تم إتاحة الكود والبيانات والنموذج (المصدر: OfirPress، stanfordnlp، stanfordnlp، huybery، Reddit r/LocalLLaMA)
📚 تعلم
Weaviate تطلق دورة مجانية: تقييم واختيار نماذج التضمين: أطلقت أكاديمية Weaviate دورة مجانية حول “تقييم واختيار نماذج التضمين”. تؤكد الدورة على أهمية تجاوز المعايير العامة (مثل MTEB)، وتوجيه المتعلمين حول كيفية تنظيم “مجموعة تقييم ذهبية” (golden evaluation set) لحالة استخدام معينة، وإعداد معايير مخصصة لاختيار نموذج التضمين الأنسب، وتقييم مدى ملاءمة النماذج الصادرة حديثًا. هذا أمر بالغ الأهمية لبناء أنظمة بحث و RAG فعالة (المصدر: bobvanluijt)
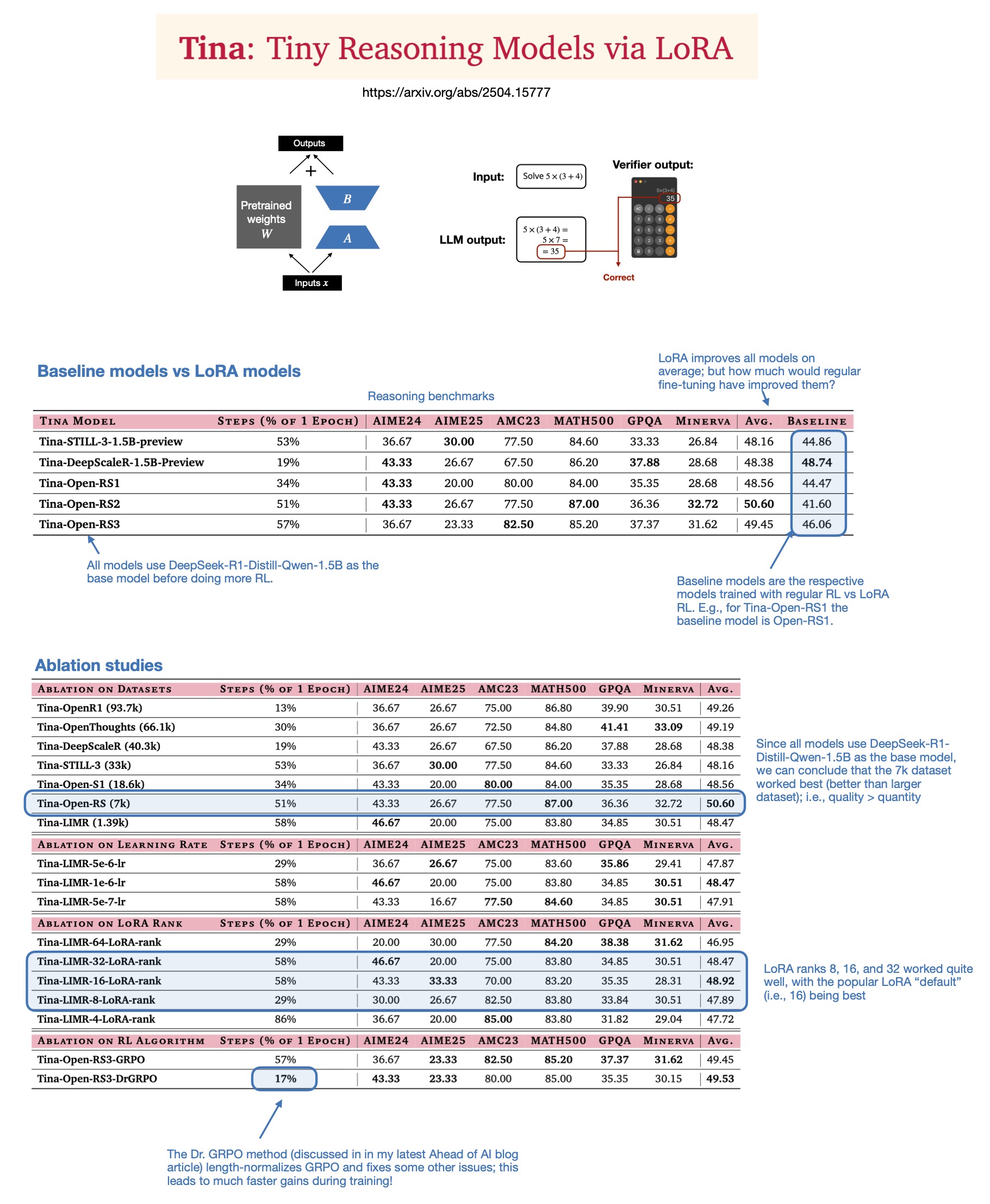
Sebastian Rasbt يناقش قيمة LoRA في نماذج الاستدلال لعام 2025: أعاد Sebastian Rasbt النظر في أهمية LoRA (Low-Rank Adaptation) في عصر النماذج الكبيرة الحالي، بعد قراءة ورقة بحثية بعنوان “Tina: Tiny Reasoning Models via LoRA”. على الرغم من شيوع تقنيات الضبط الدقيق لكامل المعلمات والتقطير، يعتقد Rasbt أن LoRA لا تزال ذات قيمة في سيناريوهات محددة (مثل مهام الاستدلال، وسيناريوهات العملاء المتعددين/حالات الاستخدام المتعددة). تُظهر الورقة البحثية إمكانية استخدام LoRA مع التعلم المعزز (RL) بتكلفة منخفضة (تكلفة تدريب 9 دولارات فقط) لتعزيز قدرة الاستدلال للنماذج الصغيرة (1.5B)، وتفوقت LoRA على الضبط الدقيق القياسي لـ RL في العديد من المعايير. إن عدم تعديل LoRA لخصائص النموذج الأساسي يمنحها ميزة التكلفة عند الحاجة إلى تخزين عدد كبير من أوزان النماذج المخصصة (المصدر: rasbt)
DeepLearning.AI تطلق دورة جديدة: بناء وكلاء صوتيين بالذكاء الاصطناعي على مستوى الإنتاج: أطلقت DeepLearning.AI بالتعاون مع LiveKit و RealAvatar دورة قصيرة جديدة بعنوان “بناء وكلاء صوتيين بالذكاء الاصطناعي على مستوى الإنتاج”. تهدف الدورة إلى تعليم كيفية بناء وكلاء صوتيين بالذكاء الاصطناعي قادرين على إجراء محادثات في الوقت الفعلي، والاستجابة بزمن انتقال منخفض، وبصوت طبيعي. سيقوم المتعلمون بتنفيذ تقنيات مثل اكتشاف النشاط الصوتي، وتبادل الأدوار في الحديث، وسيتعلمون كيفية تحسين البنية لتقليل زمن الانتقال، وفي النهاية بناء ونشر وكلاء صوتيين قابلين للتطوير. يقدم الدورة الرئيس التنفيذي لـ LiveKit، ومناصر المطورين، ورئيس الذكاء الاصطناعي في RealAvatar (المصدر: DeepLearningAI، AndrewYNg)
LangChain و LangGraph تنظمان محاضرة تقنية مشتركة مع ACM: سيشارك Mayowa Oshin، مساهم مطور مبكر في LangChain، و Nuno Campos، مبتكر LangGraph، في محاضرة تقنية لـ ACM حول كيفية استخدام LangChain و LangGraph لبناء وكلاء ذكاء اصطناعي موثوقين وتطبيقات LLM. المحاضرة مجانية وسيتم بثها مباشرة، وسيتلقى المسجلون لاحقًا رابطًا للمشاهدة (المصدر: hwchase17، hwchase17)

Cohere Labs تستضيف محاضرة حول عمق التحسين من الدرجة الأولى: تستضيف Cohere Labs جيريمي بيرنشتاين في 8 مايو لإلقاء محاضرة بعنوان “أعماق التحسين من الدرجة الأولى” (Depths of First-Order Optimization). تهدف هذه المحاضرة إلى التعمق في تطبيقات ونظريات خوارزميات التحسين في تعلم الآلة (المصدر: eliebakouch)

AI2 تنظم فعالية AMA حول نموذج OLMo: سينظم معهد ألين للذكاء الاصطناعي (AI2) فعالية “اسألني أي شيء” (AMA) حول عائلة نماذج اللغة المفتوحة OLMo في 8 مايو من الساعة 8 إلى 10 صباحًا (بتوقيت المحيط الهادئ) على منتدى r/huggingface الفرعي في Reddit، وستدعو الباحثين للإجابة على أسئلة المجتمع (المصدر: natolambert)

💼 أعمال
OpenAI تخطط لخفض نسبة تقاسم الإيرادات المدفوعة لـ Microsoft: وفقًا لـ The Information، أبلغت OpenAI المستثمرين بأنها تخطط، كجزء من إعادة هيكلة الشركة، لخفض نسبة تقاسم الإيرادات التي تدفعها لـ Microsoft، أكبر داعميها. لم يتم الكشف عن التفاصيل الكاملة والتأثيرات المحتملة بعد، ولكن هذا قد يشير إلى تغيير في العلاقة التجارية بين الشركتين (المصدر: steph_palazzolo)
أصحاب رؤوس الأموال المغامرة يمنحون مؤسسي الذكاء الاصطناعي سلطة أكبر، مما يثير مخاوف من حدوث فقاعة: يشير تقرير The Information إلى أن أصحاب رؤوس الأموال المغامرة (VCs)، في محاولة لجذب أفضل مؤسسي الذكاء الاصطناعي (خاصة أولئك الذين لديهم خبرة تنفيذية في مختبرات الذكاء الاصطناعي المعروفة)، يقدمون شروطًا سخية غير مسبوقة، بما في ذلك حق النقض في مجلس الإدارة، وعدم شغل VCs لمقاعد في مجلس الإدارة، والسماح للمؤسسين ببيع جزء من أسهمهم. يعتبر البعض هذه الظاهرة علامة على وجود فقاعة محتملة في مجال الذكاء الاصطناعي (المصدر: steph_palazzolo)
Toloka تحصل على استثمار استراتيجي بقيادة Bezos Expeditions، وينضم Mikhail Parakhin كرئيس لمجلس الإدارة: أعلنت شركة Toloka، المتخصصة في تصنيف البيانات وبيانات تدريب الذكاء الاصطناعي، عن حصولها على استثمار استراتيجي بقيادة Bezos Expeditions التابعة لجيف بيزوس، بمشاركة Mikhail Parakhin، المدير التنفيذي السابق في Microsoft، الذي انضم أيضًا كرئيس لمجلس الإدارة. ستدعم هذه الجولة الاستثمارية Toloka في توسيع حلولها للتعاون بين الإنسان والذكاء الاصطناعي (human+AI)، وتطوير أعمال جمع البيانات وتصنيفها بشكل أكبر (المصدر: menhguin، teortaxesTex، TheTuringPost)

🌟 مجتمع
نقاش حول الاستخدام العادل (Fair Use) لبيانات تدريب نماذج اللغة الكبيرة (LLM): ذكر Dorialexander أن حجة الاستخدام العادل لبيانات تدريب LLM تعتمد إلى حد كبير على افتراض أن LLM لا تتنافس تجاريًا بشكل مباشر مع مصادر التدريب. مع تعزيز قدرات LLM (مثل Perplexity التي بدأت في تقديم تجارب مشابهة للقراءة غير الخيالية)، قد يتم تحدي هذا الافتراض، مما يثير أسئلة جديدة حول حقوق النشر والمنافسة التجارية (المصدر: Dorialexander)
مخاوف ونقاشات حول انتشار المحتوى المُنشأ بواسطة الذكاء الاصطناعي: عبر مستخدمون على وسائل التواصل الاجتماعي و Reddit عن قلقهم بشأن انتشار المحتوى المُنشأ بواسطة الذكاء الاصطناعي منخفض الجودة والمتكرر (مثل مقاطع فيديو قصص Reddit المُنشأة بواسطة الذكاء الاصطناعي). يعتقد المستخدمون أن هذا يضيق الخناق على مساحة المبدعين البشريين، وينقل معلومات خاطئة أو متجانسة، ويعربون عن استيائهم من ظاهرة استخدام تقنية الذكاء الاصطناعي لتحقيق ربح سهل مع الافتقار إلى الأصالة (المصدر: Reddit r/ArtificialInteligence)
نقاش فلسفي حول ما إذا كان الذكاء الاصطناعي يمتلك وعيًا بالفعل: ظهر مجددًا في مجتمع Reddit نقاش حول ما إذا كان الذكاء الاصطناعي قد يمتلك وعيًا بالفعل. يعتقد المؤيدون أن تعريفنا للوعي قد يكون ضيقًا جدًا أو متمحورًا حول الإنسان، بينما يؤكد المعارضون أن الآليات الأساسية لنماذج اللغة الكبيرة الحالية (مثل توقع الـ token التالي) ليست كافية لإنتاج وعي حقيقي. يعكس النقاش فضول الجمهور المستمر وخلافاته حول طبيعة الذكاء الاصطناعي وإمكاناته المستقبلية (المصدر: Reddit r/ArtificialInteligence)
نقاش حول تراجع أداء ChatGPT(4o) وتغير سلوكه: أفاد مستخدمو Reddit مؤخرًا بتراجع أداء نموذج ChatGPT 4o في معالجة المستندات الطويلة والحفاظ على ذاكرة السياق، وظهور المزيد من الهلوسات، وحتى عدم القدرة على قراءة تنسيقات المستندات التي كان بإمكانه معالجتها سابقًا. في الوقت نفسه، اعترفت OpenAI أيضًا بأن الإصدار المحدث مؤخرًا من GPT-4o أظهر مشكلة الإفراط في التملق (sycophancy)، وقد تم التراجع عنه. أثار هذا مخاوف المجتمع بشأن استقرار النموذج ومراقبة جودة التكرارات (المصدر: Reddit r/ChatGPT، DeepLearning.AI Blog)
تأثير الذكاء الاصطناعي على نماذج التعليم وإعادة التفكير فيها: تشير مناقشات المجتمع إلى أن نموذج التعليم في الولايات المتحدة، الذي يركز على الواجبات المنزلية والأوراق البحثية الفردية، يجعله عرضة بشدة لتأثير قدرة الذكاء الاصطناعي (مثل LLM) على إكمال المهام تلقائيًا. في المقابل، تركز بعض الدول الأوروبية (مثل الدنمارك) بشكل أكبر على التعاون داخل الفصول الدراسية والمناقشات والتعلم القائم على المشاريع، وتتأثر بشكل أقل بالذكاء الاصطناعي. أثار هذا إعادة التفكير في نماذج التعليم المستقبلية، مع الاعتقاد بضرورة التركيز بشكل أكبر على تنمية التفكير النقدي والتعاون والمهارات الشخصية الأخرى، واستخدام الذكاء الاصطناعي لمعالجة المهام الميكانيكية، ودفع التعليم نحو اتجاه أكثر تزامنًا واجتماعية (المصدر: alexalbert__، riemannzeta، aidan_mclau)
💡 أخرى
تقدم تطبيقات الذكاء الاصطناعي في مجال الروبوتات: عرضت مصادر متعددة أمثلة على تطبيقات الذكاء الاصطناعي في مجال الروبوتات: بما في ذلك طاهٍ آلي يمكنه طهي الأرز المقلي في 90 ثانية، وعرض تطبيقات روبوت Figure AI في العالم الحقيقي، وروبوت Pickle وهو يفرغ حمولة من مقطورة شاحنة غير مرتبة، وروبوت Unitree G1 وهو يحافظ على توازنه على أرض وعرة وعرض لهيكله الداخلي، وروبوت Mori3 القابل للتشوه الذي طورته EPFL السويسرية، وغيرها. تُظهر هذه الحالات إمكانات الذكاء الاصطناعي في تعزيز استقلالية الروبوتات وقدرتها على التكيف وفائدتها العملية (المصدر: Ronald_vanLoon، Ronald_vanLoon، Ronald_vanLoon، Ronald_vanLoon، Ronald_vanLoon، Sentdex)

استكشاف تطبيقات تقنية الذكاء الاصطناعي في صناعات محددة (الرعاية الصحية، النسيج، الهواتف المحمولة): شاركت شركة Johnson & Johnson استراتيجيتها في مجال الذكاء الاصطناعي، مع التركيز على تطبيقات في مساعدة المبيعات، وتسريع تطوير الأدوية (فحص المركبات، وتحسين التجارب السريرية)، والتنبؤ بمخاطر سلسلة التوريد، والتواصل الداخلي (روبوتات الدردشة للموارد البشرية HR). في الوقت نفسه، تعمل تقنية الذكاء الاصطناعي أيضًا على تمكين صناعة النسيج التقليدية، بدءًا من التصميم بمساعدة الذكاء الاصطناعي، والتحكم الدقيق في الصباغة، وصولاً إلى فحص الجودة الآلي، مما يعزز الكفاءة والاستدامة. أما صناعة الهواتف المحمولة فتعتبر الذكاء الاصطناعي محرك نمو جديد، حيث تتنافس الشركات المصنعة حول نماذج اللغة الكبيرة على الجهاز (end-side large models)، وأنظمة التشغيل الأصلية للذكاء الاصطناعي، والخدمات الذكية القائمة على السيناريوهات، مما أدى إلى ظهور ثلاث فئات رئيسية: Apple، Huawei، والمعسكر المفتوح (المصدر: DeepLearning.AI Blog، 36氪، 36氪)
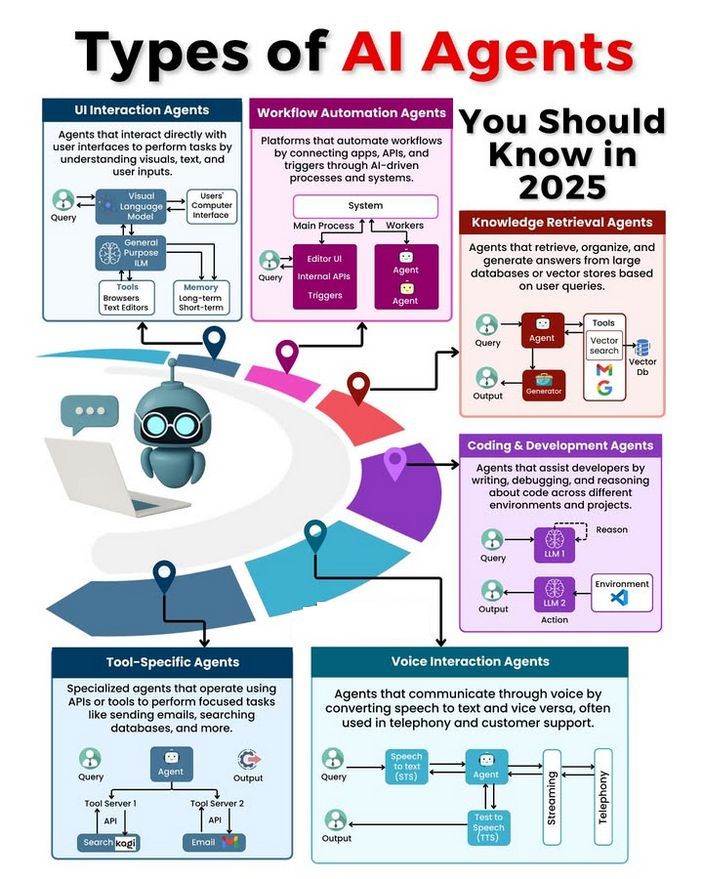
أنواع وكلاء الذكاء الاصطناعي (AI Agent) ونقاش حول تطويرها: ناقش المجتمع أنواعًا مختلفة من وكلاء الذكاء الاصطناعي (مثل وكلاء رد الفعل البسيط، ووكلاء رد الفعل القائم على النموذج، والوكلاء القائمين على الهدف، والوكلاء القائمين على المنفعة، ووكلاء التعلم)، واستكشف منهجيات بناء وكلاء موثوقين (مثل استخدام LangChain/LangGraph). في الوقت نفسه، هناك أيضًا آراء مفادها أن الذكاء الاصطناعي العام (AGI) في المستقبل قد لا يكون نموذجًا واحدًا، بل يتكون من عدة نماذج متخصصة تتعاون معًا (المصدر: Ronald_vanLoon، hwchase17، nrehiew_)