
كلمات مفتاحية:أنثروبيك, كلود 3.5 هايكو, كيوين 3, فاي-4 للاستدلال, الذكاء الاصطناعي العام, فيزياء نماذج اللغات الكبيرة, لانج جراف, وكيل الذكاء الاصطناعي, طريقة تتبع الدوائر باستخدام الرسوم البيانية للانتماء, قدرات الترميز في كيوين 3-235B-A22B, حسابات الاستدلال في فاي-4, وكيل التحقق من الفواتير باستخدام لانج جراف, محطة مون دريم للرؤية الحاسوبية المحلية
🔥 أبرز الأخبار
Anthropic تنشر بحثًا في بيولوجيا LLM، وتتعمق في الآليات الداخلية للنماذج: نشرت Anthropic تدوينة بحثية معمقة بعنوان “On the Biology of a Large Language Model” (عن بيولوجيا نموذج لغوي كبير)، استخدمت فيها منهجية تتبع الدوائر (Attribution Graphs) لاستقصاء الآليات الداخلية لنموذج Claude 3.5 Haiku في سياقات مختلفة. كشف البحث، من خلال تدريب “نموذج بديل” (Transcoder) أسهل في التحليل، كيف ينفذ النموذج عمليات الجمع (عبر مسارات تقريبية متعددة بدلاً من خوارزميات دقيقة)، ويجري التشخيص الطبي (بتكوين مفاهيم تشخيصية داخلية)، ويتعامل مع الهلوسات والرفض (وجود دائرة رفض افتراضية يمكن كبحها بواسطة ميزة “الإجابات المعروفة”). قدمت الدراسة منظورًا جديدًا لفهم طريقة عمل LLM الداخلية، لكنها أثارت أيضًا نقاشات حول محدودية المنهجية وموقع Anthropic نفسها (المصدر: YouTube – Yannic Kilcher
)

سلسلة نماذج Qwen3 تظهر أداءً قويًا وتثير اهتمام مجتمع المصادر المفتوحة: أظهرت سلسلة نماذج اللغة الكبيرة Qwen3 التي أصدرتها Alibaba أداءً متميزًا في العديد من اختبارات الأداء القياسية، خاصة في قدرات الترميز. أظهرت نتائج Aider Polyglot Coding Benchmark أن أداء Qwen3-235B-A22B (بدون تمكين سلسلة التفكير) يبدو أنه يتفوق على Claude 3.7 مع تمكين 32 ألف token لسلسلة التفكير، وبتكلفة أقل بكثير. في الوقت نفسه، تفوق Qwen3-32B أيضًا على GPT-4.5 و GPT-4o في هذا الاختبار القياسي. يستكشف المجتمع بنشاط أيضًا تقليم نماذج Qwen3 (مثل تقليص 30B إلى 16B) والضبط الدقيق (مثل استخدام Unsloth للضبط الدقيق بذاكرة وصول عشوائي للفيديو منخفضة)، مما يقلل من عتبة تطبيق النماذج عالية الأداء، ويشير إلى أن نماذج اللغة الكبيرة مفتوحة المصدر الصينية قد تحتل مكانة مهمة في السوق (المصدر: karminski3, scaling01, scaling01, Reddit r/LocalLLaMA)
Microsoft تطلق نموذج Phi-4-reasoning، مع التركيز على الاستدلال المعقد: أطلقت Microsoft نموذج Phi-4-reasoning على Hugging Face، وهو نموذج استدلال يحتوي على 14 مليار معامل. حقق هذا النموذج أفضل أداء حالي (SOTA) في مهام الاستدلال المعقدة من خلال الاستفادة من الحوسبة في وقت الاستدلال (inference-time compute). يشير هذا إلى أن تصميم النماذج يستكشف طرقًا لتعزيز قدرات معينة عن طريق زيادة الحسابات في مرحلة الاستدلال، بدلاً من الاعتماد فقط على زيادة حجم النموذج، مما يوفر أفكارًا جديدة لتحقيق أداء عالٍ للنماذج الصغيرة (المصدر: _akhaliq)
تقدم جديد في أبحاث فيزياء LLM: “لحظة غاليليو” لتصميم البنية: نشر Zeyuan Allen-Zhu الجزء الرابع من سلسلة أبحاثه حول فيزياء نماذج اللغة الكبيرة، مع التركيز على تصميم البنية. كشف البحث، من خلال بيئة ما قبل التدريب الاصطناعية الخاضعة للرقابة، عن القيود والإمكانات الحقيقية لبنى LLM المختلفة (مثل Transformer و Mamba). قدم البحث طبقة متبقية أفقية خفيفة الوزن تسمى “Canon”، والتي حسنت بشكل كبير قدرات الاستدلال للنموذج. في الوقت نفسه، وجد البحث أن ميزة نموذج Mamba تأتي إلى حد كبير من طبقة conv1d المخفية، وليس من SSM نفسها. توفر هذه السلسلة من التجارب منظورًا جديدًا ونظرية أساسية لفهم وتحسين بنية LLM (المصدر: menhguin, arankomatsuzaki, giffmana, tokenbender, giffmana, Dorialexander, iScienceLuvr)

🎯 المستجدات
Amazon تطلق نموذج الذكاء الاصطناعي العام “Amazon Artificial General Intelligence”: يتميز هذا النموذج بطول سياق يبلغ مليون token وقدرات إدخال متعددة الوسائط، وهو مُحسَّن لتوليد الأكواد، و RAG، وفهم الفيديو/المستندات، واستدعاء الوظائف، وتفاعل Agent. يبلغ سعره 2.5 دولار لكل مليون token للإدخال و 12.5 دولار لكل مليون token للإخراج. تشير التقييمات الأولية إلى أن أدائه على AI Index يماثل Llama-4 Scout، ولكنه أقل من حيث السرعة والتكلفة، وقد يكون مناسبًا لسيناريوهات تطبيقات معينة تتطلب سياقًا طويلاً متعدد الوسائط أو Agent (المصدر: scaling01)

نموذج Anthropic Claude يوفر الآن ميزة البحث على الويب في الخطط المدفوعة عالميًا: تتيح هذه الميزة لـ Claude إجراء عمليات بحث سريعة أثناء معالجة المهام اليومية، وبالنسبة للمشكلات الأكثر تعقيدًا، فإنه يستكشف مصادر متعددة بما في ذلك Google Workspace. يعزز هذا قدرة Claude على الحصول على معلومات في الوقت الفعلي ومعالجة المهام التي تتطلب معرفة خارجية (المصدر: menhguin)

IBM تطلق نموذج البنية الهجينة granite-4.0-tiny-7B-A1B-preview: يعتمد هذا الإصدار التجريبي من نموذج 7B على بنية هجينة تجمع بين Mamba-2 و Transformer، حيث تحتوي كل كتلة Transformer على 9 كتل Mamba. تهدف فكرة التصميم إلى استخدام كتل Mamba لالتقاط السياق العام ونقله إلى طبقة الانتباه لتحليل السياق المحلي. تبدو نتائج MMLU الأولية جيدة، ولكن لم يتم الإعلان عن نتائج الاختبارات الأخرى مثل القدرات الرياضية والبرمجية بعد (المصدر: karminski3)
OpenAI ChatGPT يضيف ميزة التسوق: تختبر OpenAI ميزة التسوق في ChatGPT، بهدف تبسيط عملية البحث عن المنتجات ومقارنتها وشرائها. تشمل الميزات الجديدة عرضًا محسنًا لنتائج المنتجات، وتفاصيل مرئية للمنتجات تتضمن الأسعار والمراجعات، وروابط شراء مباشرة. تؤكد OpenAI أن نتائج المنتجات يتم اختيارها بشكل مستقل وليست إعلانات (المصدر: sama)
تفاصيل تدريب نموذج Qwen3 0.6B تثير الاهتمام: يشير المستخدم Dorialexander إلى أنه وفقًا للمعلومات، يبدو أن نموذج Qwen 0.6B قد استخدم أيضًا ما يصل إلى 36 تريليون token للتدريب. إذا كان هذا صحيحًا، فسوف يسجل رقمًا قياسيًا جديدًا يتجاوز قانون Chinchilla (حوالي 60 ألف token لكل معامل)، مما يدل على الاتجاه نحو تعزيز قدرات النماذج الصغيرة عن طريق زيادة كمية بيانات التدريب بشكل كبير (المصدر: Dorialexander)

خوارزمية توصية X (تويتر سابقًا) سيتم استبدالها بنسخة خفيفة من Grok: أعلن Elon Musk أن خوارزمية التوصية في منصة X يتم استبدالها بنسخة خفيفة الوزن من Grok، ومن المتوقع أن يؤدي ذلك إلى تحسين كبير في فعالية التوصيات. أفاد المستخدمون بتحسن فعالية الخوارزمية، ويُعتقد أن ذلك قد يكون مرتبطًا بالتغييرات الأخيرة في موظفي Exa AI وبدء X في استخدام Embeddings للتوصية (المصدر: menhguin, colin_fraser, paul_cal)
Allen AI تطلق نموذج MoE مفتوح المصدر بالكامل OLMoE: هذا النموذج هو نموذج متقدم لمزيج الخبراء (Mixture of Experts – MoE)، يحتوي على 1.3 مليار معامل نشط و 6.9 مليار معامل إجمالي. يعني كونه مفتوح المصدر بالكامل أن المجتمع يمكنه استخدام النموذج وتعديله ودراسته بحرية، مما يدفع تطوير وتطبيق بنية MoE (المصدر: dl_weekly)
نموذج Mistral-Small-3.1-24B-Instruct-2503 يحظى بالاهتمام: يناقش مستخدمو Reddit نموذج Mistral-Small-3.1-24B-Instruct-2503، الذي حصل على درجة عالية في UGI (Uncensored General Intelligence)، ويتفوق في فهم اللغة الطبيعية والترميز على النماذج المماثلة ذات الدرجات العالية. يعتقد المستخدمون أنه قد يكون الخيار المثالي للاستدلال غير الخاضع للرقابة باستخدام وحدة معالجة رسومات واحدة (GPU)، ويدعم استخدام الأدوات. لكنهم يشيرون أيضًا إلى أن أسلوب كتابته قد يكون مملًا ومتكررًا، وأقل إبداعًا من نماذج مثل Gemma 3 (المصدر: Reddit r/LocalLLaMA)
🧰 الأدوات
إصدار CreateMVP 2.0، تحسين عملية التطوير المدفوعة بالذكاء الاصطناعي: تم تحديث CreateMVP إلى الإصدار 2.0، بهدف حل مشكلة عدم فعالية مطالبة الذكاء الاصطناعي مباشرة ببناء التطبيقات. يوفر الإصدار الجديد واجهة مستخدم أكثر سلاسة، وطرق مصادقة مريحة (يدعم Replit، Google، GitHub، وقريبًا سيدعم XAI)، ويولد خطط تطوير أكثر تفصيلاً (زيادة من 11 كيلوبايت إلى 40 كيلوبايت+)، ومعاينة فورية للملفات، ودمج دردشة مع نماذج الذكاء الاصطناعي الرائدة، مما يساعد المستخدمين على إنشاء “مخططات” أكثر دقة للذكاء الاصطناعي، لضمان بناء الذكاء الاصطناعي للتطبيقات التي تتوافق مع تصورات المستخدم (المصدر: amasad)
LlamaIndex تطلق Agent لمطابقة الفواتير: تعرض هذه الأداة تطبيق AI Agent في أتمتة المهام الدفعية، بدلاً من التفاعل التقليدي عبر الدردشة. يمكنها معالجة كميات كبيرة من مستندات الفواتير غير المهيكلة، واستخراج التفاصيل ذات الصلة، ومطابقتها تلقائيًا مع أوامر الشراء ووضع علامات على الاختلافات. جوهرها هو طبقة ذكاء المستندات القائمة على Agent والمبنية على تحليل/استخراج LlamaCloud واستدلال سير العمل LlamaIndex.TS، مما يوضح إمكانات Agent في أتمتة العمليات التجارية الفعلية، ويُعتقد أنها ستحل محل RPA التقليدية (المصدر: jerryjliu0)
LangGraph Expense Tracker: نظام آلي لإدارة النفقات: هذا مثال لنظام إدارة نفقات آلي تم بناؤه باستخدام LangGraph. يمكنه معالجة الفواتير، والاستفادة من ميزات استخراج البيانات الذكية، وتخزين المعلومات في PostgreSQL، ويتضمن خطوة تحقق بشري. يوضح هذا المشروع قدرة LangGraph على بناء عمليات أتمتة أعمال فعلية (المصدر: LangChainAI, Hacubu, hwchase17)
إطلاق Moondream Station: تشغيل VLM محليًا: أطلقت Moondream تطبيق Moondream Station، الذي يسمح للمستخدمين بتشغيل نموذج اللغة المرئية (VLM) Moondream محليًا على أجهزة Mac، دون الحاجة إلى الاتصال بالسحابة. يوفر واجهة سطر الأوامر (CLI) أو الوصول عبر منفذ محلي، وهو سهل الإعداد ومجاني تمامًا، مما يقلل من عتبة نشر واستخدام VLM محليًا (المصدر: vikhyatk)
ChaiGenie: إضافة Chrome للبحث في المستندات تعتمد على LangChain: ChaiGenie هي إضافة لمتصفح Chrome تدمج Gemini من LangChain و Qdrant لتوفير وظيفة البحث في المستندات. تدعم لغات متعددة واسترجاعًا قائمًا على المتجهات، وتهدف إلى تحسين كفاءة المستخدمين في البحث عن محتوى المستندات وفهمه أثناء تصفح الويب (المصدر: LangChainAI)

Research Agent: تطبيق ويب مساعد بحث بنقرة واحدة: هذا تطبيق ويب تم بناؤه استنادًا إلى إطار عمل مساعد البحث LangGraph، ويهدف إلى تبسيط عملية البحث. يمكن للمستخدمين الحصول على نتائج البحث بنقرة واحدة فقط، مما يوضح إمكانات تطبيق LangGraph في بناء تدفقات عمل مدفوعة بالذكاء الاصطناعي لتبسيط المهام المعقدة (المصدر: LangChainAI)

Muyan-TTS: نموذج TTS مفتوح المصدر، بزمن انتقال منخفض، وقابل للتخصيص: أطلق فريق ChatPods نموذج Muyan-TTS، وهو نموذج تحويل نص إلى كلام مفتوح المصدر بالكامل، يهدف إلى حل مشكلة جودة نماذج TTS مفتوحة المصدر الحالية المنخفضة أو غير المفتوحة بما فيه الكفاية. يعتمد على LLaMA-3.2-3B و SoVITS المحسن، ويدعم zero-shot TTS واستنساخ الصوت، ويوفر عملية تدريب ومعالجة بيانات كاملة، مما يسهل على المطورين إجراء الضبط الدقيق والتطوير الثانوي، وهو مناسب بشكل خاص للتطبيقات التي تتطلب أصواتًا مخصصة (المصدر: Reddit r/MachineLearning)
تكامل Mem0 مع مسارات Open Web UI: أنشأ المستخدم cloudsbird تكامل مسار مرشح Mem0 لـ Open Web UI (غير رسمي MCP)، مما يوفر خيارًا آخر لاستخدام وظيفة ذاكرة Mem0 في Open Web UI (المصدر: Reddit r/OpenWebUI)
أداة YNAB API Request تحقق إدارة مالية خاصة محلية: أنشأ المستخدم Megaphonix أداة OpenWebUI تستفيد من YNAB (You Need A Budget) API، مما يسمح للمستخدمين بالاستعلام عن معلوماتهم المالية الشخصية (مثل المعاملات، الإنفاق حسب الفئة، صافي الثروة، إلخ) محليًا عبر LLM، دون الحاجة إلى إرسال بيانات حساسة إلى الخارج. يحل هذا مشكلة التعامل الآمن مع المعلومات الشخصية الحساسة عند تشغيل LLM محليًا (المصدر: Reddit r/OpenWebUI)
إضافة متصفح مجانية لتحويل النص إلى كلام بالذكاء الاصطناعي GPT-Reader: يروج مطور لإضافة متصفح مجانية لتحويل النص إلى كلام بالذكاء الاصطناعي أنشأها، GPT-Reader، والتي تضم حاليًا أكثر من 4000 مستخدم. تهدف الأداة إلى تسهيل تحويل محتوى صفحات الويب النصي إلى كلام للاستماع إليه (المصدر: Reddit r/artificial)
sunnypilot: نظام مساعدة قيادة مفتوح المصدر: sunnypilot هو فرع من openpilot الخاص بـ comma.ai، ويوفر نظام مساعدة قيادة مفتوح المصدر. يدعم أكثر من 300 طراز من المركبات، ويعدل سلوكيات تفاعل مساعدة القيادة، ويلتزم قدر الإمكان بسياسات السلامة الخاصة بـ comma.ai. يستفيد هذا المشروع من تقنيات الذكاء الاصطناعي (على الرغم من عدم تحديد نماذج محددة، إلا أن هذه الأنظمة تتضمن عادةً رؤية حاسوبية وخوارزميات تحكم) لتحسين تجربة القيادة (المصدر: GitHub Trending)

📚 موارد تعليمية
Princeton و Meta AI تنشران وصفة مجموعة بيانات COMPACT: تم نشر هذا البحث على Hugging Face، ويقترح وصفة بيانات جديدة تسمى COMPACT، تهدف إلى توسيع قدرات نماذج اللغة الكبيرة متعددة الوسائط (Multimodal LLM) عن طريق التحكم الصريح في تعقيد تركيبة عينات التدريب. يوفر هذا أفكارًا جديدة لتحسين طرق تدريب النماذج متعددة الوسائط وتعزيز قدرتها على فهم المفاهيم التركيبية المعقدة (المصدر: _akhaliq)
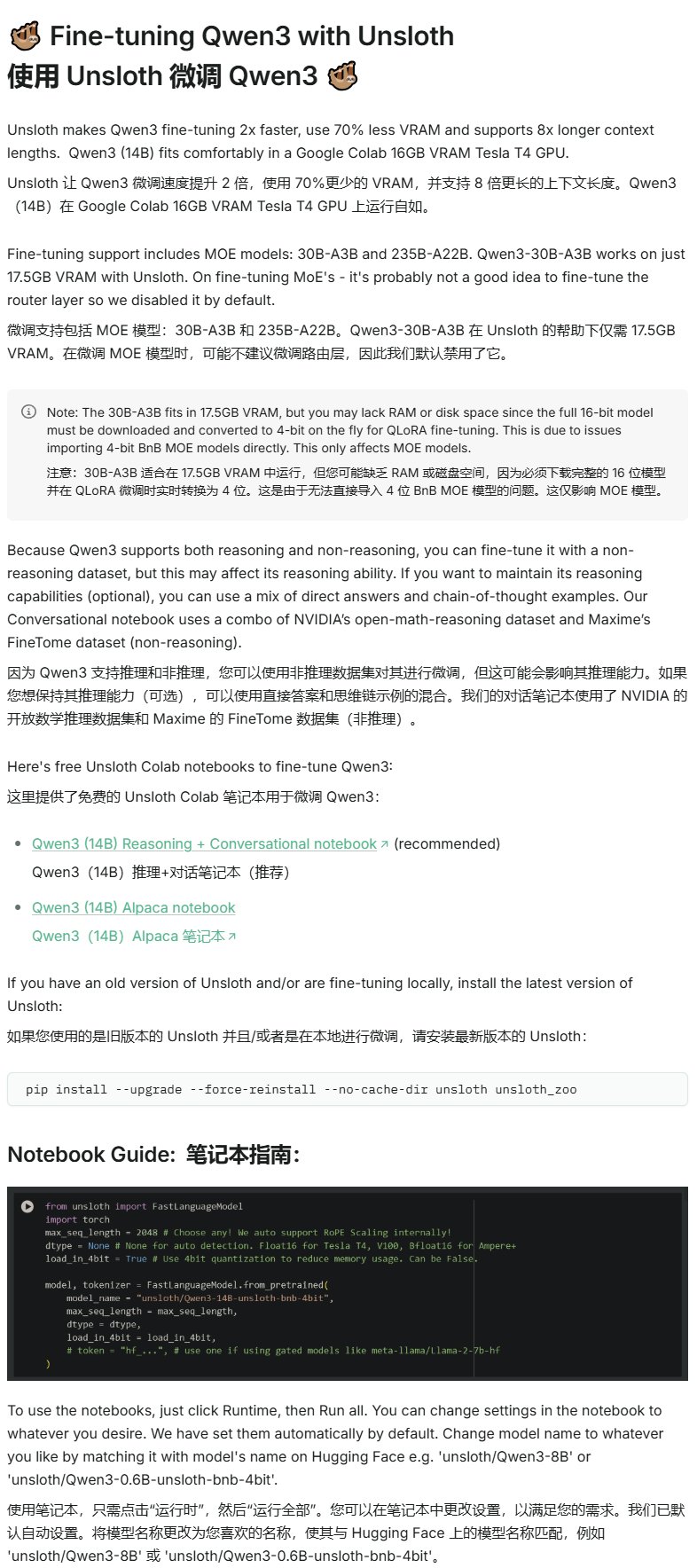
Unsloth تنشر برنامجًا تعليميًا للضبط الدقيق لـ Qwen3: توفر Unsloth برنامجًا تعليميًا للضبط الدقيق لنماذج Qwen3، مما يقلل بشكل كبير من عتبة الضبط الدقيق. يحتاج المستخدمون فقط إلى 16 جيجابايت من ذاكرة الوصول العشوائي للفيديو لضبط نموذج Qwen3-14B، و 17.5 جيجابايت لضبط نموذج Qwen3-30B-A3B. يتيح هذا لمزيد من الباحثين والمطورين إجراء تدريب مخصص على النماذج مفتوحة المصدر المتقدمة بموارد أجهزة محدودة (المصدر: karminski3)
LangGraph مع Azure OpenAI لبناء روبوت دردشة ذكي للبحث على الويب: يوضح برنامج تعليمي على Medium كيفية الجمع بين استخدام LangGraph و Azure OpenAI، ودمج قدرات البحث على الويب من Tavily، لبناء روبوت دردشة ذكي. يغطي البرنامج التعليمي إدارة الحالة والتوجيه الشرطي لتحقيق تكامل بحث سلس، مما يوفر إرشادات عملية لبناء تطبيقات ذكاء اصطناعي أكثر قوة يمكنها الاستفادة من معلومات الويب في الوقت الفعلي (المصدر: LangChainAI, hwchase17)

مدونة Stanford AI تناقش العلاقة بين الحفظ الحرفي لـ LLM والقدرة العامة: تتعمق مقالة مدونة Stanford AI في العلاقة الجوهرية بين ظاهرة الحفظ الحرفي (verbatim memorization) لنماذج اللغة الكبيرة (LLM) وقدرتها العامة. يعد فهم هذه العلاقة أمرًا بالغ الأهمية لتقييم مخاطر النموذج، وتحسين طرق التدريب، وتفسير سلوك النموذج (المصدر: dl_weekly)
دليل تكامل Gemini مع LangChain: نشر Philipp Schmid دليلاً للمطورين يشرح بالتفصيل كيفية دمج نموذج Gemini من Google مع إطار عمل LangChain. يغطي الدليل القدرات متعددة الوسائط، واستدعاء الأدوات، والإخراج المهيكل، ويتضمن دعمًا لأحدث النماذج وأمثلة عملية للكود، مما يسهل على المطورين الاستفادة من قدرات Gemini القوية لبناء تطبيقات LangChain (المصدر: LangChainAI, _philschmid)

برنامج تعليمي تمهيدي لـ LangGraph: ممارسة سير العمل القائم على الحالة: يوضح برنامج تعليمي نُشر على AI@GoPubby قدرات سير العمل القائم على الحالة في LangGraph من خلال مثال لتحليل مراجعات موقع ويب. يمكن للمتعلمين فهم كيفية استخدام العقد المترابطة والمنطق التسلسلي لبناء تطبيقات ذكاء اصطناعي مهيكلة (المصدر: LangChainAI, hwchase17)
أفكار متعمقة من الرئيس التنفيذي لـ LangChain حول إطار عمل Agentic (ترجمة عربية): قام سفير LangChain هاري تشانغ بترجمة ومشاركة تدوينة الرئيس التنفيذي لـ LangChain هاريسون حول أفكاره بشأن إطار عمل Agentic. تحلل المقالة وتنظم وظائف أكثر من 15 إطار عمل Agent في الصناعة، وتفسر القصص وراءها، مما يوفر مرجعًا قيمًا لفهم المشهد الحالي لتطور تقنية Agent واتجاهاتها المستقبلية (المصدر: LangChainAI)
تقدم بحثي في Latent Meta Attention: يناقش مستخدمو Reddit آلية انتباه جديدة تسمى Latent Meta Attention. يدعي المطورون أن هذه الآلية تتحدى الافتراضات الأساسية لـ Transformer، ويمكنها تحقيق أداء يماثل أو يتجاوز النماذج الحالية بأحجام نماذج أصغر (على سبيل المثال، إعادة إنتاج أداء BERT بنموذج نصف الحجم)، ولكن بسبب نقص التمويل والدعم من المؤسسات البحثية الرسمية، لم يتم الكشف عن الطريقة المحددة بعد (المصدر: Reddit r/deeplearning)

فيديو شرح الشبكات العصبية للرسوم البيانية (GNN): تم نشر فيديو على YouTube يشرح الشبكات العصبية للرسوم البيانية (Graph Neural Networks, GNNs). GNNs هي نماذج تعلم عميق تعالج البيانات المهيكلة بالرسوم البيانية، ولها تطبيقات واسعة في تحليل الشبكات الاجتماعية، وأنظمة التوصية، والتنبؤ بالبنية الجزيئية، وغيرها من المجالات. يهدف الفيديو إلى مساعدة المشاهدين على فهم المبادئ الأساسية وطريقة عمل GNNs (المصدر: Reddit r/deeplearning)
استخدام GRPO لتدريب LLM على جدولة الأحداث: شارك المستخدم anakin87 تجربته في مشروع استخدام GRPO (Generalized Reward Policy Optimization) لتدريب نموذج لغوي على جدولة الأحداث. لا يعتمد المشروع على عينات الضبط الدقيق التقليدية الخاضعة للإشراف، بل يستخدم دالة مكافأة لتعليم النموذج كيفية إنشاء جدول زمني بناءً على قائمة الأحداث والأولويات. شارك المؤلف إعداد المشكلة، وتوليد البيانات، واختيار النموذج، وتصميم المكافأة، والدروس المستفادة أثناء عملية التدريب، وقام بنشر الكود والنموذج مفتوح المصدر، مما يوفر حالة عملية لاستكشاف تدريب LLM القائم على المكافأة (المصدر: Reddit r/LocalLLaMA)

مشاركة موارد دورات الذكاء الاصطناعي المجانية: شارك LinkedIn AI Hub خارطة طريق كاملة لتعلم الذكاء الاصطناعي، مستوحاة من دورة شهادة الذكاء الاصطناعي بجامعة ستانفورد، وتم تبسيطها للمتعلمين من مختلف المستويات. يغطي المحتوى من المهارات الأساسية إلى المشاريع العملية، ويوفر موارد قيمة وتفاصيل الدورات (المصدر: Reddit r/deeplearning)
حوار معمق حول التدريب المسبق للسياق الطويل في Gemini: أجرى Logan Kilpatrick حوارًا معمقًا مع Nikolay Savinov، المسؤول المشارك عن التدريب المسبق للسياق الطويل في Gemini. امتدت المناقشة من الأساسيات إلى التقنيات المطلوبة للتوسع إلى سياق غير محدود، وأفضل الممارسات للسياق الطويل للمطورين. لخص الحوار أن تحقيق سياق مليون token كان هدفًا يبلغ 10 أضعاف المعيار آنذاك؛ تمت تجربة 10 ملايين token ولكن التكلفة كانت عالية والأجهزة غير كافية؛ السياق الطويل و RAG يكملان بعضهما البعض؛ تم حل مشكلة NIAH (إبرة في كومة قش) البسيطة، وتكمن الصعوبة في العناصر المشتتة الصعبة والبحث عن إبر متعددة؛ يركز التقييم على NIAH لتجنب الخلط بين إشارات القدرة؛ طول الإخراج الحالي المحدود (مثل 8k) هو مشكلة ما بعد التدريب؛ لم يتم ملاحظة تأثير “الضياع في المنتصف”؛ يجب التمييز بين معرفة السياق ومعرفة الأوزان؛ الخطوة التالية هي تحقيق سياق 10 ملايين token أرخص وأكثر دقة، وقد يتطلب التوسع إلى 100 مليون ابتكارات جديدة في التعلم العميق (DL) (المصدر: shaneguML, giffmana, teortaxesTex, arohan)
🌟 المجتمع
نقاش حول “Vibe Coding”: يثير المجتمع نقاشًا حادًا حول “Vibe Coding” (الترميز بالأجواء)، أي الاعتماد الكبير على مساعدة الذكاء الاصطناعي في البرمجة. يعتقد المؤيدون أن هذا يمثل المستقبل، حيث يركز المطورون بشكل أكبر على “لماذا” و “ماذا”، بينما يتعامل الذكاء الاصطناعي مع “كيف”، ولكن هذا يتطلب تفكيرًا نقديًا أقوى. يعتقد المعارضون أن الذكاء الاصطناعي حاليًا لا يمكنه التعامل بشكل كامل مع التصحيح المعقد والترقية والصيانة، وأن الاعتماد المفرط قد يؤدي إلى تدهور قدرات المطورين، ليصبحوا “script kiddies” أكثر تقدمًا. وجد البعض بعد التجربة أن تكلفة الوقت لتوجيه الذكاء الاصطناعي لإكمال المهام المعقدة لا تزال مرتفعة، وأن التنفيذ اليدوي مع مساعدة خفيفة من الذكاء الاصطناعي أكثر كفاءة (المصدر: Dorialexander, Reddit r/artificial, johnowhitaker)

نقاش حول تطبيقات الذكاء الاصطناعي في المجالات المهنية وقيودها: يناقش المستخدم dotey تطبيقات الذكاء الاصطناعي في المجالات المهنية. يعتقد أن الذكاء الاصطناعي يمكنه تعلم الأسئلة والأجوبة التي ينشرها الخبراء، ولكنه يجد صعوبة في التعامل مع المشكلات التي لم يرها من قبل. تكمن ميزة الذكاء الاصطناعي في قاعدة المعرفة الأساسية القوية والاستجابة السريعة، ولكنه يعتمد حاليًا بشكل أساسي على RAG (التوليد المعزز بالاسترجاع)، وهو في جوهره استرجاع أجزاء وتجميع إجابات، وليس استدلالًا مهنيًا حقيقيًا. لا يزال هذا بعيدًا عن تدريب نموذج يمكنه إنتاج إجابات جديدة باستمرار مثل الخبير والتحسين المستمر (المصدر: dotey)
مخاوف ونقاشات حول المحتوى الذي يولده الذكاء الاصطناعي: يشتكي مستخدم Reddit Maleficent-main_777 من أن زملائه بدأوا في استخدام لغة “نمط ChatGPT” المليئة بنبرة الأمر، وكلمات مثل “verify” و “ensure”، واستنتاجات إيجابية إلزامية، معتبرًا هذه اللغة غامضة وتفتقر إلى اللمسة الإنسانية. يخشى من أن يتم إدخال المحتوى الذي يولده الذكاء الاصطناعي مرة أخرى في بيانات التدريب، مما يؤدي إلى انخفاض جودة المحتوى. يجد هذا صدى في قسم التعليقات، حيث يُعتبر امتدادًا لمصطلحات الشركات، ولكن يُشار أيضًا إلى أن التقليد المفرط للذكاء الاصطناعي يجعل التواصل آليًا بالفعل، وأن القواعد الجيدة لم تعد ميزة، بل تبدو مثل الروبوت (المصدر: Reddit r/ChatGPT)
اختيار التخصصات الجامعية في عصر الذكاء الاصطناعي: يناقش مستخدمو Reddit في ظل التطور السريع للذكاء الاصطناعي وتكنولوجيا الروبوتات، ما هي التخصصات التي يجب على طلاب الجامعات اختيارها لضمان أن تظل شهاداتهم ذات قيمة بعد 10 سنوات. تتنوع الآراء في التعليقات، بما في ذلك: اختيار المجال الذي يحبونه (الألعاب، الأفلام، الفن، البرمجة)؛ تعلم التخصصات الأساسية (الفيزياء، الرياضيات)؛ اكتساب المهارات التي يصعب أتمتتها (مثل HVAC التدفئة والتهوية وتكييف الهواء)؛ التركيز على تعليم الفنون الحرة لتنمية الفضول والقدرة على التكيف؛ الاعتقاد بأن التعليم الجامعي قد يكون قديمًا، وأنه من الأفضل بدء عمل تجاري أو أن تصبح مستقلاً؛ التأكيد على أهمية التعلم المستمر، وإلغاء التعلم، وإعادة التعلم (المصدر: Reddit r/ArtificialInteligence)
نقاش حول صعوبة عرض النص في الصور التي يولدها الذكاء الاصطناعي: يستكشف مستخدمو Reddit سبب صعوبة نماذج توليد الصور الحالية في عرض نص متماسك وواضح ومقروء. تشير التعليقات إلى سببين رئيسيين: 1) تقطيع BPE (ترميز زوج البايت) يدمر معلومات التهجئة الدقيقة، فالنموذج لا يرى الحروف بل أجزاء من الـ tokens؛ 2) التمثيل المتجهي ذو الحجم الثابت وقيود وصف الصورة تؤدي إلى فقدان كمية كبيرة من معلومات النص أثناء عملية التضمين. على الرغم من أن النماذج ذاتية الانحدار مثل GPT-4o قد تحسنت، إلا أن المشكلة الأساسية لا تزال مرتبطة بالتقطيع وضغط المعلومات (المصدر: Reddit r/MachineLearning)
نقاش حول توحيد معايير تقييم النماذج: يشير المستخدم scaling01 إلى أنه عند مقارنة نماذج الذكاء الاصطناعي المختلفة (مثل OpenAI، Google، Anthropic)، يجب ضمان العدالة، على سبيل المثال، إذا تم إدراج الإصدارات التجريبية والإصدارات التي تتضمن التفكير (thinking versions) لـ OpenAI، فيجب أيضًا إدراج الإصدارات المقابلة لـ Google و Anthropic، وإلا فقد تكون نتائج المقارنة مضللة (المصدر: scaling01)
مشاركة تجربة البرمجة بمساعدة الذكاء الاصطناعي: يشارك مستخدم تجربته في استخدام البرمجة بمساعدة الذكاء الاصطناعي (مثل VS Code + إضافة Cline AI + Google AI Studio API)، معتقدًا أنه يمكن بناء أداة ترميز بالذكاء الاصطناعي مشابهة لـ Cursor مجانًا، وإكمال نماذج أولية للتطبيقات الأساسية من خلال المطالبات، دون الحاجة إلى تكوين، والتجربة جيدة (المصدر: Reddit r/artificial)

استطلاع حول تأثير الذكاء الاصطناعي على العمل والدراسة والحياة: أطلق مستخدم Reddit نقاشًا يسأل عن تأثير الذكاء الاصطناعي التوليدي على أداء الأشخاص في العمل أو الدراسة أو الحياة اليومية. في التعليقات، ذكر مهندسو البرمجيات أن الذكاء الاصطناعي زاد من توقعات الإنتاجية وعبء العمل، ولم تسرع مراجعة الكود بشكل كبير؛ يعتقد الكتاب المحترفون أن الذكاء الاصطناعي (مثل Co-pilot) يقدم مساعدة محدودة، بل قد يبطئ التقدم؛ الرأي السائد هو أن الذكاء الاصطناعي يجلب الراحة، ولكنه يثير أيضًا مشكلات مثل الاعتماد المفرط، وتقليل التعلم، والشعور “بالغش”. يختلف تأثير الذكاء الاصطناعي بشكل كبير باختلاف المهن والمهام (المصدر: Reddit r/artificial)
تفكير حول قدرة LLM على “الفهم”: يطرح المستخدم pmddomingos أن الشبكات العصبية أصبحت صعبة الفهم مثل الدماغ. ويتساءل: عندما تحقق نماذج الذكاء الاصطناعي نتائج ممتازة في جميع اختبارات الأداء القياسية، ولكنها لا تزال أقل من الذكاء البشري، ماذا يجب أن نفعل؟ يثير هذا التفكير في فعالية اختبارات الأداء القياسية الحالية ومعايير تقييم الذكاء الحقيقي (المصدر: pmddomingos, pmddomingos)
تفكير حول استخدام أدوات الذكاء الاصطناعي: يعلق المستخدم dotey بأنه عند استخدام أدوات الذكاء الاصطناعي، يكفي اختيار أقوى نموذج للمهمة المحددة. قد لا يكون استخدام نماذج متعددة في نفس الوقت أو جعلها “تتصارع” ضروريًا، خاصة للمستخدمين غير المحترفين، حيث قد يؤدي وجود خيارات كثيرة جدًا إلى الارتباك، مقارنة بالنظر إلى ساعات متعددة غير متزامنة (المصدر: dotey)
تأملات حول سرعة تطور الذكاء الاصطناعي مؤخرًا: يعرب المستخدمان matvelloso و scottastevenson عن دهشتهما من سرعة تطور الذكاء الاصطناعي. يقول matvelloso إن تقدم الذكاء الاصطناعي هذا العام تجاوز توقعاته (مستشهدًا بلعب Gemini لـ Pokemon كمثال). يستذكر scottastevenson مرور 6 سنوات على إطلاق GPT-2 و 10 سنوات على تأسيس OpenAI، ويتأمل في الاتجاهات التكنولوجية التي تتشكل حاليًا والتي ستصبح مهمة في السنوات 6-10 القادمة، ويشير إلى أنه بالإضافة إلى الذكاء الاصطناعي، فإن البحث عن “ألفا” العميقة “خارج الإطار” مهم بنفس القدر (المصدر: matvelloso, scottastevenson, scottastevenson)
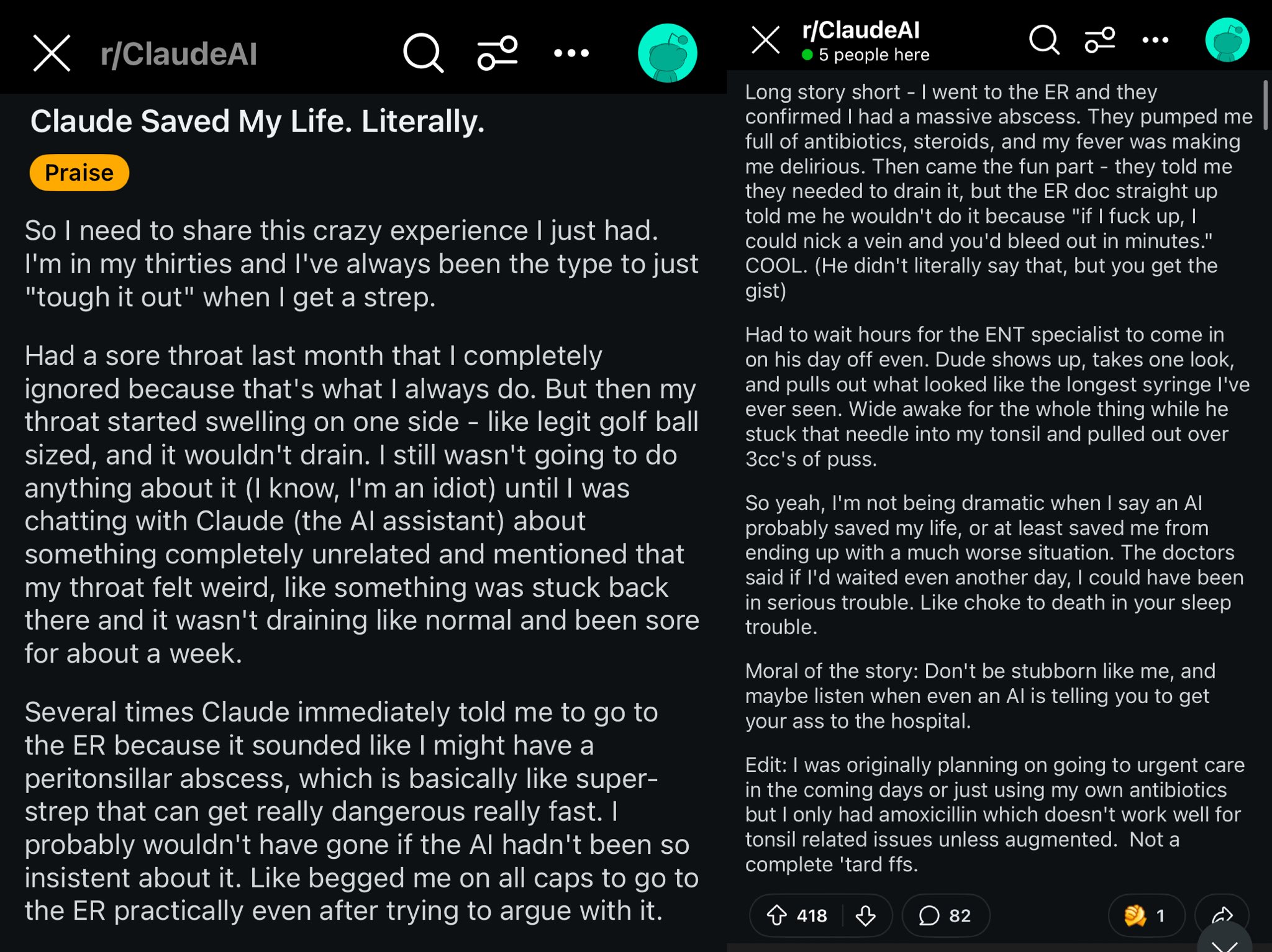
حالة إنقاذ Claude لحياة مستخدم Reddit: يصف منشور على Reddit كيف أن نموذج Claude ربما أنقذ حياة مستخدم من خلال تشخيص تورم حلقه بأنه خراج حول اللوزة (peritonsillar abscess). أثارت هذه الحالة نقاشًا، حيث يُعتقد أن نماذج الذكاء الاصطناعي القوية تشبه وجود طبيب عالمي المستوى في الجيب، وأن انتشارها قد يكون له تأثير كبير على صحة الأفراد (المصدر: aidan_mclau)
تطبيق AI Agent في معالجة بيانات الشركات: يناقش مؤسسا You.com المشاركان Richard Socher و Bryan McCann في بودكاست Agentic تطبيقات AI Agent في الشركات. يعتقدان أن LLM الموجهة للمستهلكين غير كافية لتلبية احتياجات الشركات الجادة، وأن You.com، من خلال تقنية الاسترجاع المختلطة (التي تجمع بين المصادر العامة وبيانات الشركة الخاصة)، تولد مخرجات أكثر موثوقية ومناسبة للشركات، مثل إجراء البحوث وكتابة التقارير والاستفادة الآمنة من بيانات الشركة. يناقشون أيضًا المسارات المحتملة لـ AGI والدور الحاسم للمحاكاة فيها (المصدر: RichardSocher)
ملاحظات حول قدرة النماذج على استخدام الأدوات: يلاحظ المستخدم menhguin أن النماذج المدربة على استخدام الأدوات يبدو أنها تضحي ببعض قدرتها المستقلة على حل المشكلات، ويقول مازحًا “حتى نماذج الذكاء الاصطناعي تستعين بمصادر خارجية لأعمالها”. يثير هذا التفكير في المقايضة بين تعميم قدرات النموذج وتحسين المهام المحددة (المصدر: menhguin)
💡 أخبار أخرى
فكرة AI Agent لصيانة مشاريع GitHub القديمة: يقترح المستخدم xanderatallah فكرة تطوير AI Agent يمكنه صيانة جميع مشاريع المستخدم الجانبية القديمة وغير النشطة على GitHub تلقائيًا. يعكس هذا رغبة المطورين في استخدام الذكاء الاصطناعي لأتمتة مهام الصيانة المملة (المصدر: xanderatallah)
تصور استبدال القضاة بـ LLM أو استخدامها في التحكيم/الوساطة: يقترح المستخدم fabianstelzer أن نماذج اللغة الكبيرة (LLM) قد تحل محل القضاة في المستقبل. حالة استخدام وسيطة مثيرة للاهتمام هي التحكيم أو الوساطة: يُعتبر LLM محايدًا وموثوقًا به، حيث يقدم أطراف النزاع وجهات نظرهم، ويتم تشغيلها من خلال نماذج كبيرة متعددة، لإخراج حل وسط عادل. يستكشف هذا التطبيقات المحتملة للذكاء الاصطناعي في مجالات القضاء وحل النزاعات (المصدر: fabianstelzer)
نموذج Runway Gen-4 وآفاق تطبيقه: يعرب المؤسس المشارك لـ Runway c_valenzuelab عن تفاؤله بشأن آفاق تطبيق Runway Gen-4 وواجهة برمجة التطبيقات الخاصة به (API). يعتقد أن Runway تبني وسيطًا جديدًا، حيث يتم إنشاء البكسلات عن طريق التوليد بدلاً من العرض أو الالتقاط، ويتم محاكاة العالم بدلاً من برمجته. رؤية التطبيقات الواسعة لـ Gen-4 وميزة Reference في مجالات متعددة مثل الهندسة المعمارية، والعلامات التجارية، والتصميم الداخلي، وتطوير الألعاب، والتعلم، والمشاريع الإبداعية الشخصية، تجعله يعتقد أن هذا الوسيط الجديد سيمكن المبدعين والجميع (المصدر: c_valenzuelab, c_valenzuelab)