كلمات مفتاحية:جيميني 2.5 برو, نموذج الذكاء الاصطناعي, الإنسان الآلي, أخلاقيات الذكاء الاصطناعي, ريادة الأعمال في الذكاء الاصطناعي, المحتوى المُولد بالذكاء الاصطناعي, الإبداع بمساعدة الذكاء الاصطناعي, تخطي جيميني 2.5 برو للعبة بوكيمون الأزرق, أنثروبيك كلود بحث الويب العالمي, انحياز توجيه نموذج كيوين 3 مو, ميزة المراجع في رانواي جين-4, تطبيقات الذكاء الاصطناعي في الدعم النفسي
🔥 تركيز
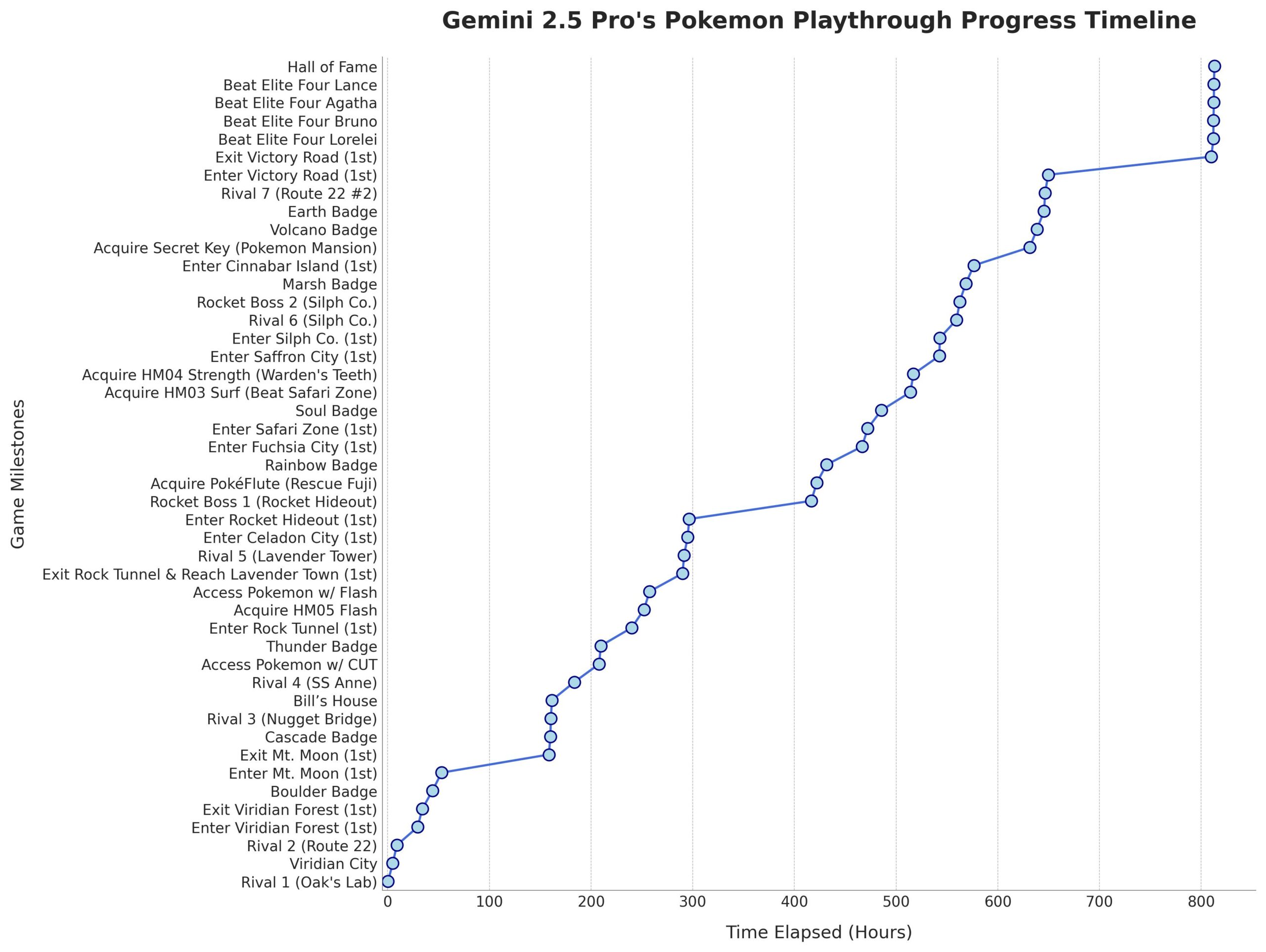
Gemini 2.5 Pro يكمل بنجاح لعبة Pokémon: Blue: نجح نموذج AI المسمى Gemini 2.5 Pro من Google في إكمال اللعبة الكلاسيكية Pokémon: Blue، بما في ذلك جمع كل الشارات الثمانية وهزيمة النخبة الأربعة في دوري Pokémon. تم تشغيل هذا الإنجاز وبثه مباشرة بواسطة المذيع @TheCodeOfJoel، وحظي بتهنئة من الرئيس التنفيذي لشركة Google، Sundar Pichai، والرئيس التنفيذي لشركة DeepMind، Demis Hassabis. يُظهر هذا التقدم الملحوظ الحالي للـ AI في تخطيط المهام المعقدة، ووضع الاستراتيجيات طويلة الأمد، والتفاعل مع البيئات المحاكاة، متجاوزًا أداء AI السابق في هذه اللعبة، ويمثل علامة فارقة جديدة في قدرات وكلاء AI. (المصدر: Google, jam3scampbell, teortaxesTex, YiTayML, demishassabis, _philschmid, Teknium1, tokenbender)
Apple تتعاون مع Anthropic لتطوير منصة ترميز AI باسم “Vibe Coding”: وفقًا لـ Bloomberg، تتعاون Apple مع شركة AI الناشئة Anthropic لتطوير منصة ترميز جديدة مدفوعة بالـ AI تسمى “Vibe Coding”. يتم حاليًا اختبار المنصة داخليًا بين موظفي Apple، وهناك احتمال لفتحها لمطوري الطرف الثالث في المستقبل. يمثل هذا استكشافًا إضافيًا من Apple في مجال أدوات مساعدة البرمجة بالـ AI، بهدف استخدام AI لتعزيز كفاءة التطوير وتجربته، وقد يكمل أو يتكامل مع مشاريعها الخاصة مثل Swift Assist. (المصدر: op7418)
تقدم ومناقشات حول تكنولوجيا الروبوتات المدفوعة بالـ AI: حظيت الروبوتات البشرية والذكاء المتجسد باهتمام واسع مؤخرًا. عرضت شركة Figure مقرها الرئيسي الجديد عالي التقنية، والذي يغطي البطاريات والمشغلات ومختبرات AI، مما ينبئ بطموحاتها في مجال الروبوتات. كما عرضت Disney تقنيتها للروبوتات ذات الشخصيات البشرية. ومع ذلك، في سباق ماراثون الروبوتات البشرية في بكين، كان أداء بعض الروبوتات (بما في ذلك Unitree G1 المعدلة من قبل العملاء) ضعيفًا، حيث تعرضت للسقوط، وضعف عمر البطارية، ومشاكل في التوازن، مما أثار نقاشات حول القدرات الفعلية للروبوتات البشرية الحالية، وأبرز الحاجة إلى تقدم كبير في “المخيخ” (التحكم الحركي) و “الدماغ” (اتخاذ القرارات الذكية). (المصدر: adcock_brett, Ronald_vanLoon, 人形机器人,最重要的还是“脑子”)

تصاعد النقاش حول أخلاقيات AI وتأثيرها الاجتماعي: تتزايد النقاشات على وسائل التواصل الاجتماعي وفي مجال الأبحاث حول التأثير الاجتماعي للـ AI والقضايا الأخلاقية. على سبيل المثال، أثار مشروع قانون AI في كاليفورنيا SB-1047 جدلاً، وتناولت الأفلام الوثائقية ذات الصلة ضرورة التنظيم وتحدياته. عقد مؤتمر NAACL 2025 دورة تعليمية حول “الذكاء الاجتماعي في عصر LLM”، لاستكشاف التحديات طويلة الأمد والناشئة في تفاعل AI مع البشر والمجتمع. في الوقت نفسه، يعرب المستخدمون عن قلقهم بشأن جودة المحتوى الذي يولده AI (“slop”)، معتقدين أن هناك حاجة إلى تصميم وتحكم أفضل في النماذج. تعكس هذه المناقشات القلق الاجتماعي المتزايد بشأن القضايا الأخلاقية والتنظيمية والتكيف الاجتماعي التي يطرحها التطور السريع لتقنية AI. (المصدر: teortaxesTex, gneubig, stanfordnlp, jam3scampbell, willdepue, wordgrammer)

🎯 توجهات
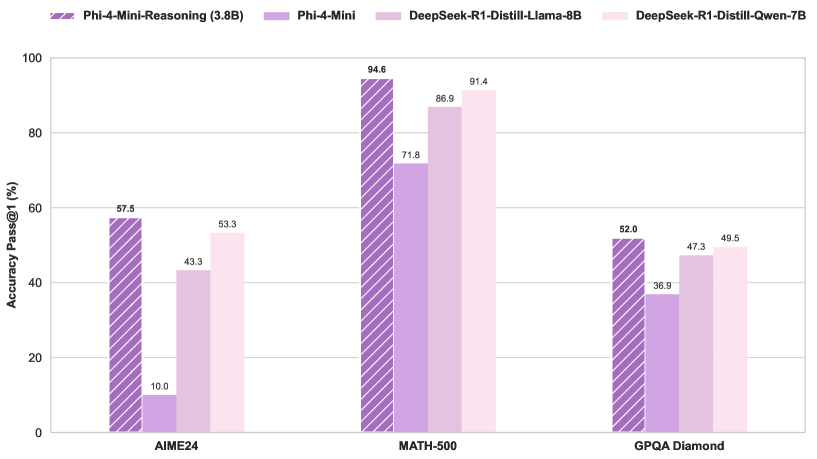
Microsoft تصدر نموذج Phi-4-Mini-Reasoning: أصدرت Microsoft نموذج Phi-4-Mini-Reasoning على Hugging Face، ويهدف هذا النموذج إلى تعزيز قدرات نماذج اللغة الصغيرة في الاستدلال الرياضي، مما يدفع بتطوير نماذج صغيرة وعالية الكفاءة. (المصدر: _akhaliq)
نموذج Anthropic Claude يدعم البحث على الويب عالميًا: أعلنت Anthropic أن نموذجها Claude AI يوفر الآن لجميع المستخدمين المدفوعين ميزة البحث على الويب على نطاق عالمي. للمهام البسيطة، سيقوم Claude بإجراء بحث سريع؛ للمسائل المعقدة، سيستكشف مصادر معلومات متعددة بما في ذلك Google Workspace، مما يعزز قدرة النموذج على الحصول على المعلومات في الوقت الفعلي ومعالجتها. (المصدر: Teknium1, Reddit r/ClaudeAI)

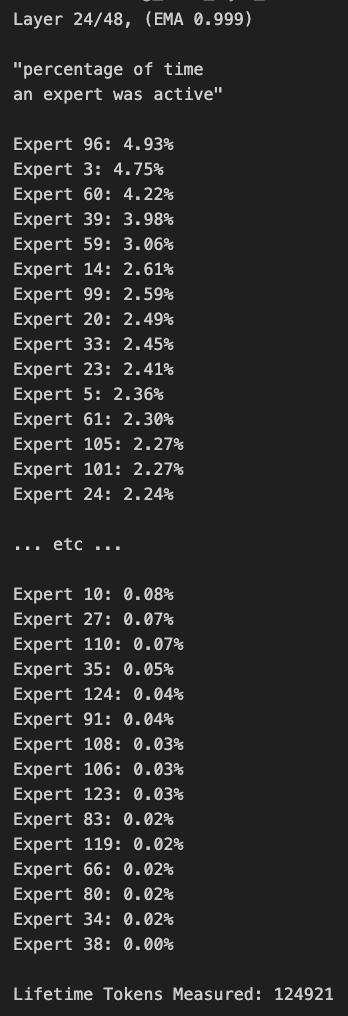
توجيه نموذج Qwen3 MoE يظهر انحيازًا ويمكن تقليمه: اكتشف المستخدم kalomaze أن توزيع التوجيه في نموذج Qwen3 MoE (Mixture of Experts) يظهر انحيازًا كبيرًا، حتى أن نموذج 30B MoE يُظهر إمكانية للتقليم (pruning). هذا يعني أن بعض الخبراء (Experts) قد لا يتم استخدامهم بشكل كافٍ، وإزالة هؤلاء الخبراء عن طريق التقليم قد يقلل من حجم النموذج ومتطلبات الحوسبة دون التأثير بشكل كبير على الأداء. أصدر Kalomaze بالفعل نسخة مقلمة من نموذج 30B إلى 16B بناءً على هذا الاكتشاف، ويخطط لإصدار نسخة مقلمة من 235B إلى 150B. (المصدر: andersonbcdefg, Reddit r/LocalLLaMA)
DeepSeek Prover V2 يبرز بين مساعدي الرياضيات مفتوحة المصدر: يعتبر DeepSeek Prover V2 حاليًا أفضل نموذج مساعد رياضي مفتوح المصدر أداءً. على الرغم من أن أداءه لا يزال أقل من النماذج المغلقة المصدر أو الأكثر قوة مثل Gemini 2.5 Pro و o4 mini high و o3 و Claude 3.7 و Grok 3، إلا أنه يُظهر أداءً جيدًا في الاستدلال المنظم. يعتقد المستخدمون أنه يحتاج إلى تحسين في جلسات “العصف الذهني” التي تتطلب تفكيرًا إبداعيًا. (المصدر: cognitivecompai)
نقاش حول تفضيلات النماذج: ميول المطورين وخصائص نماذج محددة: تستمر النقاشات في مجتمع المطورين حول مزايا وعيوب نماذج اللغة الكبيرة المختلفة. على سبيل المثال، يعتقد Sentdex أن الجمع بين Codex و o3 في Cursor يقدم أداءً أفضل من Claude 3.7. بينما يشير VictorTaelin إلى أنه على الرغم من أن Sonnet 3.7 ليس مثاليًا (أحيانًا يكون استباقيًا جدًا في إضافة محتوى غير مطلوب، وذكاؤه ليس بالمستوى المتوقع)، إلا أنه في الممارسة العملية يوفر نتائج أكثر استقرارًا وموثوقية من GPT-4o (الذي يميل إلى ارتكاب الأخطاء)، و o3/Gemini (تنسيق الكود وإعادة الكتابة ضعيفان)، و R1 (يبدو قديمًا بعض الشيء)، و Grok 3 (ثاني أفضل خيار، ولكنه أقل قليلاً في الممارسة). يعكس هذا الاختلافات في قابلية تطبيق النماذج المختلفة في مهام وسير عمل محددة. (المصدر: Sentdex, VictorTaelin, paul_cal)

نقاش حول اتجاهات أداء LLM: نمو أسي أم عوائد متناقصة؟: يناقش مستخدمو Reddit ما إذا كانت LLM لا تزال تشهد تحسنًا أسيًا. هناك وجهة نظر ترى أنه على الرغم من التقدم السريع في البداية، فإن تحسين أداء LLM حاليًا يتجه نحو العوائد المتناقصة، حيث يصبح الحصول على أداء إضافي أكثر صعوبة وتكلفة، على غرار تطور تكنولوجيا القيادة الذاتية. بينما يعارض مستخدمون آخرون ذلك، مشيرين إلى القفزة الهائلة من GPT-3 إلى Gemini 2.5 Pro التي تشير إلى أن التقدم لا يزال كبيرًا، وأنه من السابق لأوانه الجزم بالوصول إلى مرحلة استقرار. يعكس النقاش التوقعات المختلفة بشأن سرعة تطور AI في المستقبل. (المصدر: Reddit r/ArtificialInteligence)
رقائق AI تصبح مفتاح تطور الروبوتات البشرية: ترى وجهات نظر صناعية أن جوهر الروبوتات البشرية يكمن في “دماغها”، أي الرقائق عالية الأداء. يشير المقال إلى أن الروبوتات البشرية الحالية لا تزال تعاني من قصور في التحكم الحركي (المخيخ) واتخاذ القرارات الذكية (الدماغ)، وأن أداء الرقائق يحدد بشكل مباشر مستوى ذكاء الروبوت. رقائق GPU من Nvidia ومعالجات Intel، بالإضافة إلى رقائق Huashan A2000 و Wudang C1236 من شركة Black Sesame Smart المحلية، كلها تزود الروبوتات بقدرات أقوى على الإدراك والاستدلال والتحكم، وهي المفتاح لدفع الروبوتات البشرية من مجرد دعاية إلى تطبيقات عملية. (المصدر: 人形机器人,最重要的还是“脑子”)

أخلاقيات AI والتجسيد البشري: لماذا نقول “شكرًا” للـ AI؟: يشير النقاش إلى أنه على الرغم من أن AI لا يمتلك مشاعر، يميل المستخدمون إلى استخدام لغة مهذبة معه (مثل “شكرًا”، “من فضلك”). ينبع هذا من غريزة التجسيد البشري لدى الإنسان و “إدراك الوجود الاجتماعي”. تظهر الأبحاث أن طرق التفاعل المهذبة قد توجه AI لإنتاج استجابات أكثر توافقًا مع التوقعات وأكثر إنسانية. ومع ذلك، فإن هذا يجلب أيضًا مخاطر، مثل احتمال تعلم AI وتضخيم التحيزات البشرية، أو توجيهه بشكل ضار لإنتاج محتوى غير لائق. يعكس السلوك المهذب تجاه AI النفسية المعقدة والتكيف الاجتماعي للبشر في تفاعلهم مع الآلات التي تزداد ذكاءً. (المصدر: 你对 AI 说的每一句「谢谢」,都在烧钱)

🧰 أدوات
ميزة Runway Gen-4 References: تتيح ميزة Gen-4 References التي أطلقتها RunwayML للمستخدمين دمج صورهم الخاصة أو صور مرجعية أخرى في مقاطع الفيديو أو الصور التي يولدها AI (مثل meme). تشير ملاحظات المستخدمين إلى أن الميزة فعالة بشكل ملحوظ، وقادرة على التعامل مع ظهور شخصيات متعددة متسقة في نفس الصورة المولدة، مما يبسط عملية دمج أشخاص أو أنماط معينة في إبداعات AI. (المصدر: c_valenzuelab)

Krea AI تطلق قوالب لتوليد الصور: أضافت Krea AI ميزة جديدة تحول مطالبات توليد الصور الشائعة لـ GPT-4o إلى قوالب. يحتاج المستخدمون فقط إلى تحميل صورهم الخاصة واختيار القالب لتوليد صور بالنمط المقابل، دون الحاجة إلى إدخال مطالبات معقدة يدويًا، مما يبسط عملية توليد الصور. (المصدر: op7418)
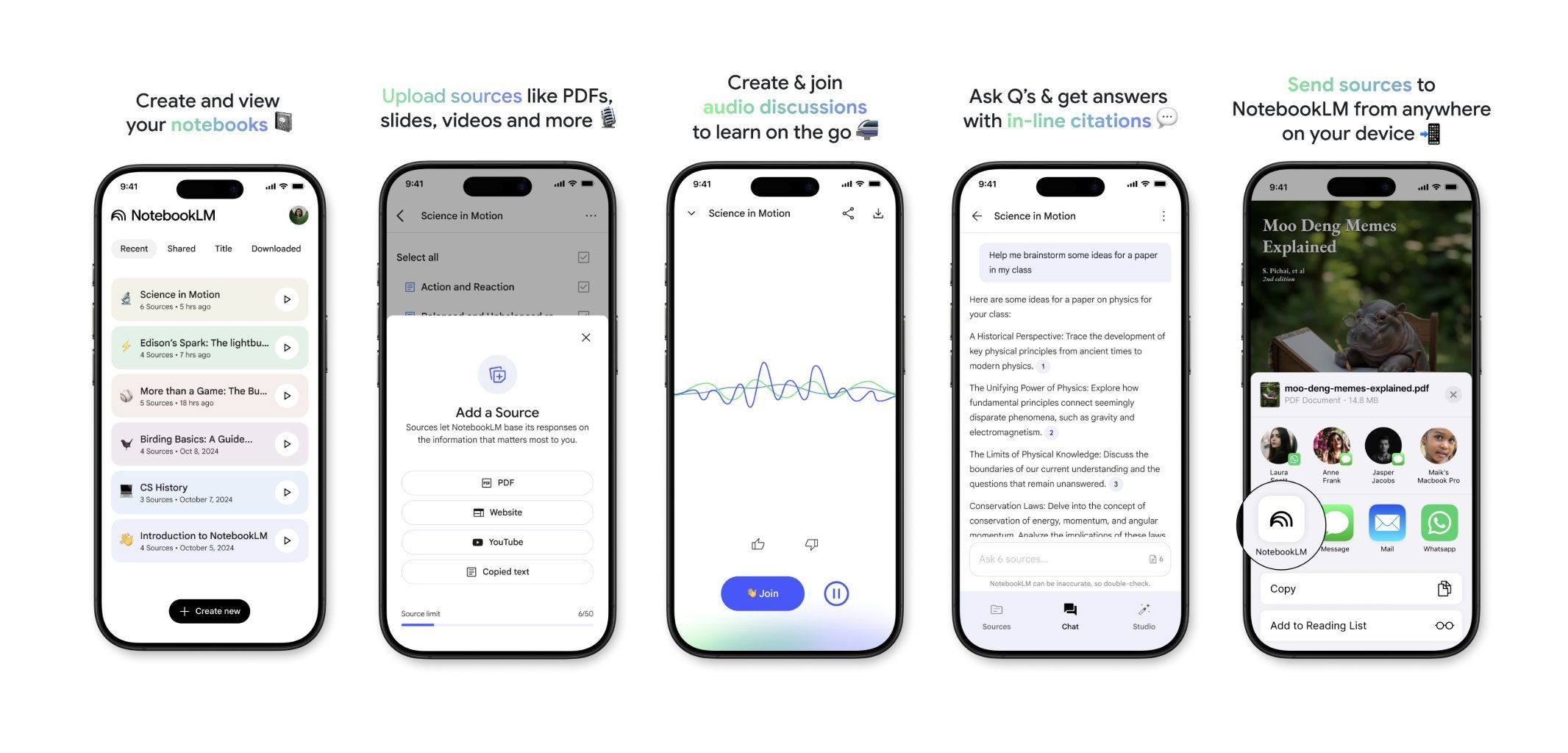
NotebookLM سيطلق تطبيقًا للهواتف المحمولة قريبًا: ستصدر Google NotebookLM (المعروف سابقًا باسم Project Tailwind) تطبيقًا للهواتف المحمولة قريبًا. يمكن للمستخدمين إعادة توجيه المقالات والمحتوى الذي يرونه على هواتفهم بسرعة إلى NotebookLM للمعالجة والدمج. تم فتح قائمة الانتظار للتسجيل في التطبيق، بهدف توفير تجربة أكثر ملاءمة لإدارة المعلومات على الهاتف المحمول والتعلم بمساعدة AI. (المصدر: op7418)
استخدام Runway للتصميم الداخلي: يعرض المستخدمون حالات استخدام Runway AI للتصميم الداخلي. من خلال توفير صورة للمساحة وصورة مرجعية تمثل النمط/المزاج، يمكن لـ Runway توليد صور تصميم داخلي تدمج خصائص كليهما، مما يوضح إمكانات تطبيق AI في مجال التصميم الإبداعي. (المصدر: c_valenzuelab)

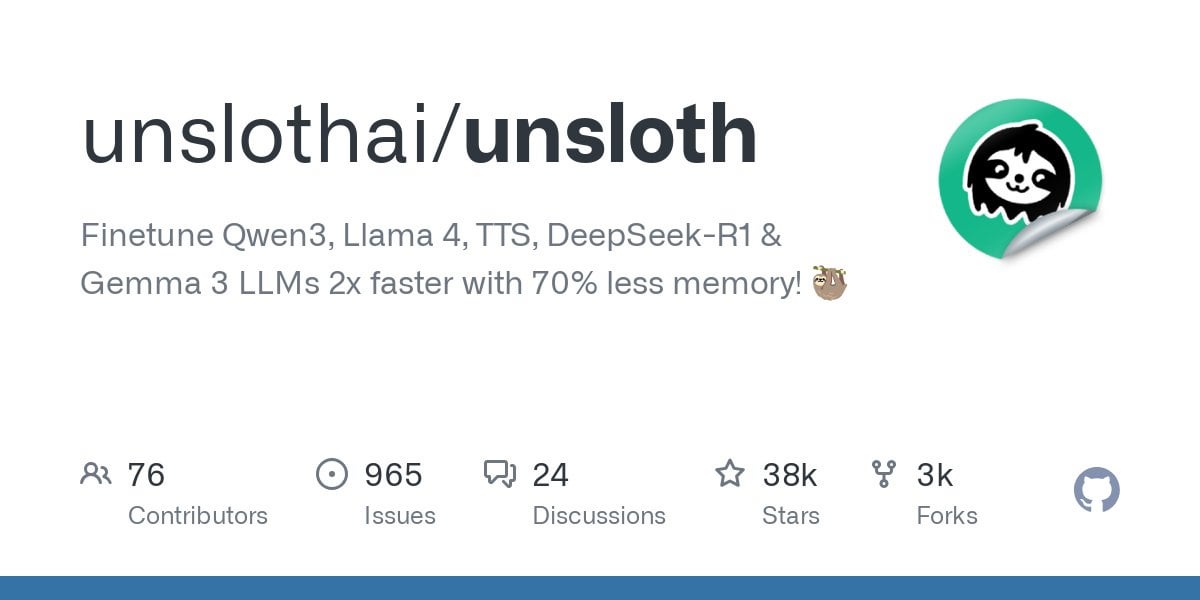
Unsloth يدعم الضبط الدقيق لنماذج Qwen3: أعلنت Unsloth عن دعم الضبط الدقيق (fine-tuning) لسلسلة نماذج Qwen3، مع زيادة السرعة بمقدار مرتين وتقليل استخدام ذاكرة GPU بنسبة 70%. يمكن للمستخدمين تحقيق ضبط دقيق بطول سياق أطول 8 مرات من Flash Attention 2 على وحدات معالجة رسومات (GPU) بسعة 24 جيجابايت. تم توفير دفتر ملاحظات Colab للضبط الدقيق المجاني لنموذج Qwen3 14B، وتم تحميل نماذج كمية متعددة بما في ذلك GGUF. هذا يقلل من متطلبات الأجهزة للضبط الدقيق للنماذج المتقدمة. (المصدر: Reddit r/LocalLLaMA)
ميزة Claude AI Styles: يشارك المستخدمون استخدام ميزة Styles في Claude AI لتحسين تجربة التعاون مع AI. من خلال إنشاء نمط يسمى “Iterative Engineering”، وتحديد خطوات للمناقشة والتخطيط والتعديل بخطوات صغيرة والاختبار والتكرار وإعادة الهيكلة حسب الحاجة، يمكن توجيه Claude للترميز بطريقة أكثر منهجية وتدريجية (methodical and incremental)، وتجنب إعادة كتابة الكود بشكل مفرط، مما يعزز من فائدة AI كشريك في البرمجة. (المصدر: Reddit r/ClaudeAI)
Deepwiki يوفر مصدر كتل الأكواد: يذكر المستخدم cto_junior أن إحدى مزايا Deepwiki هي عرض كتل الأكواد المصدرية بجانب كل إجابة، بدلاً من مجرد إرفاق روابط. هذه الممارسة تزيد من مصداقية المعلومات، وهي مفيدة بشكل خاص لمهندسي تطوير البرمجيات (SDEs) الذين قد يكونون متشككين في أدوات AI. (المصدر: cto_junior)
📚 تعلم
NousResearch تصدر تحديثًا لإطار Atropos RL: تم تحديث إطار بيئة التعلم المعزز (RL) Atropos من NousResearch. تتيح الميزات الجديدة للمستخدمين اختبار rollout لبيئات RL بسرعة وسهولة، دون الحاجة إلى محرك تدريب أو استدلال. يستخدم OpenAI API افتراضيًا، ولكن يمكن تكوينه لموفري API آخرين (أو نقاط نهاية VLLM/SGLang محلية). بعد اكتمال الاختبار، يتم إنشاء تقرير ويب يحتوي على الإكمالات (completions) ودرجاتها، ويدعم تسجيل wandb، مما يسهل تصحيح وتقييم بيئات RL. (المصدر: Teknium1)

إصدار مجموعة بيانات EnronQA المعيارية لـ Personalized RAG: أصدر الباحثون مجموعة بيانات EnronQA، بهدف دفع البحث في مجال التوليد المعزز بالاسترجاع المخصص (Personalized RAG) على المستندات الخاصة. تحتوي مجموعة البيانات على 103,638 رسالة بريد إلكتروني و 528,304 زوجًا من الأسئلة والأجوبة عالية الجودة لـ 150 مستخدمًا، مما يوفر موردًا لتقييم وتطوير أنظمة RAG التي يمكنها فهم واستخدام المعلومات الخاصة بالفرد. (المصدر: lateinteraction)
إصدار GTE-ModernColBERT (PyLate): أصدرت LightOnAI نموذج GTE-ModernColBERT (PyLate)، وهو مسترجع MaxSim بـ 128 بُعدًا، يعتمد على gte-modernbert-base وتم ضبطه بدقة على ms-marco-en-bge-gemma. يدعم أصلاً مكتبة PyLate، ويمكنه إجراء إعادة الترتيب وفهرسة HNSW. أظهر أداءً متميزًا في اختبار NanoBEIR القياسي، وتفوق على ColBERT-small في متوسط درجات BEIR، مما يوفر خيارًا جديدًا فعالاً لاسترجاع النصوص. (المصدر: lateinteraction)

SOLO Bench – اختبار معياري جديد لـ LLM: طور المستخدم jd_3d وأصدر SOLO Bench، وهو طريقة جديدة لاختبار أداء LLM. يتطلب الاختبار من LLM توليد نص يحتوي على عدد محدد من الجمل (مثل 250 أو 500)، يجب أن تحتوي كل جملة على كلمة واحدة فقط من قائمة محددة مسبقًا (تحتوي على أسماء، أفعال، صفات، إلخ)، ويجب استخدام كل كلمة مرة واحدة فقط. يتم التقييم باستخدام نص برمجي قائم على القواعد، ويهدف إلى اختبار قدرة LLM على اتباع التعليمات، وتلبية القيود، وتوليد النصوص الطويلة. تظهر النتائج الأولية أن هذا الاختبار المعياري يمكنه التمييز بفعالية بين أداء النماذج المختلفة. (المصدر: Reddit r/LocalLLaMA)
استغلال التفكير الانعكاسي الاستراتيجي المتكرر لمعالجة الفضاء الكامن: يقترح المستخدمون طريقة لإنشاء تسلسلات هرمية متداخلة للاستدلال في الفضاء الكامن لـ LLM من خلال “التفكير الانعكاسي الاستراتيجي المتكرر” (Strategic recursive reflection, RR). من خلال مطالبة النموذج في اللحظات الحاسمة بالتفكير في التفاعلات السابقة، يتم إنشاء حلقات ما وراء معرفية، وبناء “فضاءات كامنة مصغرة”. يُعتبر كل مطالبة بمثابة ضغط يوجه مسار النموذج في الفضاء الكامن، مما يجعله أكثر توجيهًا ذاتيًا وقدرة على التجريد. يُعتقد أن هذا يحاكي عملية تعميق التفكير لدى البشر من خلال التفكير في الأفكار، ويهدف إلى استكشاف مفاهيم أعمق. (المصدر: Reddit r/ArtificialInteligence)
💼 أعمال
Google تدفع رسومًا لـ Samsung لتثبيت Gemini AI مسبقًا: بعد إدانتها العام الماضي بانتهاك قوانين مكافحة الاحتكار بسبب اتفاقية محرك البحث الافتراضي، تم الكشف عن أن Google تدفع “مبالغ ضخمة” شهريًا لـ Samsung بالإضافة إلى حصة من الإيرادات، لتثبيت Gemini AI مسبقًا على أجهزة Samsung، وقد تطلب من الشركاء تثبيت Gemini بشكل إلزامي. يفسر هذا سبب دمج سلسلة Samsung Galaxy S25 لـ Gemini بعمق، حتى جعله مساعد AI الافتراضي. تعكس هذه الخطوة استراتيجية Google للاستيلاء بسرعة على مدخل AI على الأجهزة المحمولة في ظل عدم كفاية قنوات الأجهزة الخاصة بها، ولكنها قد تثير مرة أخرى مخاوف بشأن مكافحة الاحتكار. (المصدر: 三星手机预装Gemini AI,也是谷歌花钱买的)

شركات AI الناشئة تواجه تحديات: يشير نقاش على Reddit إلى أن العديد من شركات AI الناشئة قد تفتقر إلى “الخندق المائي” (moat) أو الميزة التنافسية، نظرًا لتقارب قدرات النماذج وانخفاض ولاء المستخدمين. تتمتع شركات التكنولوجيا الكبرى (Google، Microsoft، Apple) بميزة بفضل أنظمتها البيئية (مثل التثبيت المسبق والتكامل)، مما يسهل وصولها إلى المستخدمين. حتى لو كان نموذج شركة ناشئة أفضل قليلاً، فقد يميل المستخدمون إلى استخدام AI الافتراضي أو المدمج “الجيد بما فيه الكفاية”. يثير هذا مخاوف بشأن قدرة شركات AI الناشئة على البقاء على المدى الطويل وآفاق استثمار رأس المال المخاطر (VC). (المصدر: Reddit r/ArtificialInteligence)
ملخص تمويل AI والأعمال لهذا الأسبوع (2 مايو 2025): كشف الرئيس التنفيذي لشركة Microsoft أن AI قد كتب “أجزاء مهمة” من كود الشركة؛ حذر المدير المالي لشركة Microsoft من أن خدمات AI قد تتوقف بسبب الطلب المفرط؛ بدأت Google في عرض الإعلانات في روبوتات الدردشة AI التابعة لجهات خارجية؛ أطلقت Meta تطبيق AI مستقل؛ جمعت Cast AI تمويلًا بقيمة 108 مليون دولار، و Astronomer بقيمة 93 مليون دولار، و Edgerunner AI بقيمة 12 مليون دولار؛ اتهمت دراسة LM Arena بوجود تلاعب في اختبارات الأداء؛ Nvidia تتحدى دعم Anthropic لقيود تصدير الرقائق. (المصدر: Reddit r/artificial)
🌟 مجتمع
نقاش حول جودة وتكلفة المحتوى الذي يولده AI: يعرب المجتمع عن قلقه بشأن الجودة المتفاوتة للمحتوى الذي يولده AI (يُشار إليه بـ “slop”). يشير المستخدم wordgrammer إلى أن جودة عدد كبير من مقاطع الفيديو التي يولدها AI منخفضة، وأن التكلفة الفعلية (مع الأخذ في الاعتبار الفرز وإعادة المحاولة) أعلى بكثير من السعر المعلن. يثير هذا نقاشًا حول تصميم النماذج (كما يستشهد jam3scampbell بوجهة نظر ستيف جوبز) والاستخدام الفعال لأدوات AI، مع التأكيد على الحاجة إلى تحكم أكثر دقة ومعايير جودة توليد أعلى. (المصدر: wordgrammer, jam3scampbell, willdepue)
أداء AI في مهام محددة يثير النقاش: يناقش أعضاء المجتمع أداء AI وحدوده في مهام مختلفة. على سبيل المثال، يُعتقد أن DeepSeek R1 قد يمثل ذروة الضجيج حول LLM، فعلى الرغم من التقدم في مجالات مثل الرياضيات الرسمية والطب، إلا أنه لم يجذب اهتمام المستخدمين العاديين على نطاق واسع. يُظهر DeepSeek Prover V2 أداءً جيدًا في الرياضيات، ولكن يُعتقد أنه يفتقر إلى الإبداع. يشكك المستخدم vikhyatk في جدوى تحسين النماذج بشكل مفرط للأداء في اختبارات معيارية محددة مثل AIME (مسابقة الرياضيات الأمريكية للمدعوين)، معتقدًا أن الجمهور العام لا يهتم بقدرات الرياضيات. تعكس هذه المناقشات التفكير في حدود قدرات AI وقيمتها التطبيقية الفعلية. (المصدر: wordgrammer, cognitivecompai, vikhyatk)
الإبداع والتصميم بمساعدة AI: يعرض المجتمع طرقًا متعددة لاستخدام أدوات AI للتصميم الإبداعي. يستخدم المستخدمون ميزة Gen-4 References من Runway لدمج أنفسهم في meme؛ يستخدمون Runway لتوليد مفاهيم التصميم الداخلي؛ يستفيدون من GPT-4o وقوالب المطالبات لإنشاء صور بأنماط محددة (مثل نمر جنوب الصين من الأوريغامي، مساند معصم من السيليكون على شكل حيوانات، دمج معنى الكلمات في تصميم الحروف). تعرض هذه الحالات إمكانات AI في الإبداع البصري والتصميم المخصص. (المصدر: c_valenzuelab, c_valenzuelab, dotey, dotey, dotey)

تشكيك في قدرة AI على تقليد أسلوب الكتابة: يعتقد المستخدم nrehiew_ أن الأمر الموجه لـ LLM “أكمل الكتابة بنبرتي وأسلوبي” قد لا يكون له تأثير فعلي، لأن معظم الناس يبالغون في تقدير تفرد أسلوب كتابتهم. يثير هذا نقاشًا حول قدرة LLM على فهم ونسخ الفروق الدقيقة في أسلوب الكتابة، بالإضافة إلى التحيز في تصور المستخدمين لهذه القدرة. (المصدر: nrehiew_)
استخدام AI للدعم العاطفي يثير التعاطف والنقاش: يشارك مستخدمو Reddit تجارب الحصول على الدعم العاطفي وحتى المساعدة في التعامل مع الأزمات من خلال التحدث مع AI مثل ChatGPT. ذكر الكثيرون أنه في أوقات الوحدة أو الحاجة إلى التحدث أو مواجهة صعوبات نفسية، يوفر AI محاورًا غير قضائي وصبور ومتاح دائمًا، وأحيانًا يشعرون أنه أكثر فعالية من التحدث مع البشر. أثار هذا نقاشًا حول دور AI في دعم الصحة النفسية، مع التأكيد أيضًا على أن AI لا يمكن أن يحل محل المساعدة البشرية المتخصصة، والحاجة إلى الحذر من التحيزات أو التضليل المحتمل من AI. (المصدر: Reddit r/ChatGPT, Reddit r/ClaudeAI)
اختلاف الآراء حول الفن الذي يولده AI: يناقش المستخدمون التأثير المحتمل للفن الذي يولده AI على الفنانين البشر وإدراك أعمالهم. يشتكي البعض من أن الأعمال عالية الجودة غالبًا ما تُنسب بسهولة الآن إلى توليد AI، متجاهلة موهبة وجهد المبدعين. بدأت هذه الظاهرة حتى في تشويه تصورات الناس، مما يجعلهم يميلون إلى البحث عن “أخطاء بشرية” في الأعمال لتأكيد أنها ليست من صنع AI. يتطرق النقاش أيضًا إلى مسألة ما إذا كان يجب فرض إضافة علامات مائية على المحتوى الذي يولده AI. (المصدر: Reddit r/ArtificialInteligence)
💡 أخرى
استهلاك AI للموارد يثير الاهتمام: يؤكد النقاش على الاستهلاك الهائل للموارد وراء تطوير AI. يتطلب تدريب وتشغيل نماذج AI الكبيرة استهلاك كميات كبيرة من الكهرباء والمياه، وتصبح مراكز البيانات منشآت جديدة عالية استهلاك الطاقة. كل تفاعل للمستخدم مع AI، بما في ذلك كلمة “شكرًا” البسيطة، يراكم استهلاك الطاقة. يثير هذا الاهتمام بالتنمية المستدامة للـ AI وحلول الطاقة (مثل الاندماج النووي). (المصدر: 你对 AI 说的每一句「谢谢」,都在烧钱)
المسافة بين AI والوعي: يناقش مستخدمو Reddit ما إذا كان AI الحالي يمتلك وعيًا ذاتيًا. الرأي السائد هو أن AI الحالي (مثل LLM) هو في الأساس نظام معقد لمطابقة الأنماط يعتمد على التنبؤ الاحتمالي للكلمات، ويفتقر إلى الفهم الحقيقي والوعي الذاتي، ولا يزال بعيدًا جدًا عن امتلاك هذه القدرة. لكن هناك تعليقات تشير أيضًا إلى أن الوعي البشري نفسه لم يُفهم بالكامل، وأن المقارنة قد تحتوي على مغالطات، وأن القدرات الخارقة للـ AI في مهام محددة لا يمكن تجاهلها. (المصدر: Reddit r/ArtificialInteligence)
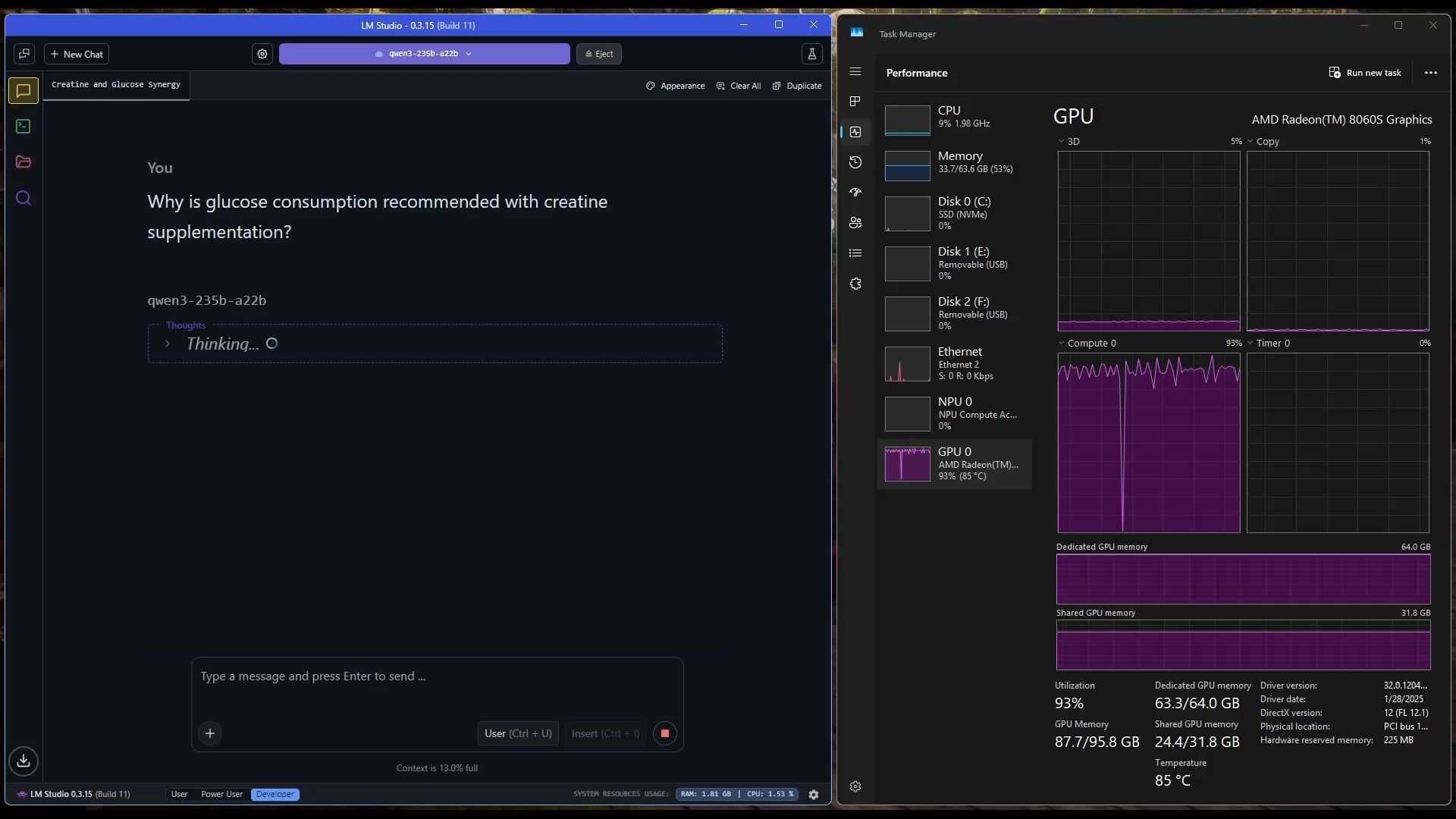
جهاز لوحي يعمل بنظام Windows يشغل نموذج MoE كبير: يعرض المستخدمون مثالاً لتشغيل نموذج Qwen3 235B-A22B MoE (باستخدام تكميم Q2_K_XL) على جهاز لوحي يعمل بنظام Windows مزود بمعالج AMD Ryzen AI Max 395+ وذاكرة وصول عشوائي (RAM) بسعة 128 جيجابايت، باستخدام وحدة معالجة الرسومات المدمجة (iGPU) فقط (Radeon 8060S، مع تخصيص 87.7 جيجابايت من 95.8 جيجابايت كذاكرة VRAM)، بسرعة تصل إلى حوالي 11.1 t/s (رمز في الثانية). يوضح هذا إمكانية تشغيل نماذج كبيرة جدًا على الأجهزة المحمولة، على الرغم من أن عرض النطاق الترددي للذاكرة لا يزال يمثل عنق زجاجة. (المصدر: Reddit r/LocalLLaMA)