
كلمات مفتاحية:التعليم بالذكاء الاصطناعي, تحديث Copilot, محرك البحث بالذكاء الاصطناعي, تطبيقات الذكاء الاصطناعي في التعليم, موجة Microsoft Copilot الثانية, تأثير الذكاء الاصطناعي على تحسين محركات البحث, الإصدار الدولي من Tongyi Qianwen, نموذج DeepSeek-V3, دليل تثبيت OpenWebUI, أخلاقيات توليد الصور بالذكاء الاصطناعي, تقنيات الذكاء الاصطناعي في الروبوتات
🔥 الأضواء
وكلاء الذكاء الاصطناعي (AI) يجددون نموذج التعليم: يشهد تعليم الذكاء الاصطناعي في الخارج موجة من الوكلاء الأذكياء، حيث أطلقت eSelf.ai مشروعًا تجريبيًا لعشرة آلاف شخص في إسرائيل، مستخدمةً معلمي ذكاء اصطناعي بقدرات صوتية طبيعية وسبورة بيضاء افتراضية وقدرات متعددة اللغات لمحاكاة التدريس البشري. في الوقت نفسه، تعمل Tavus على تحسين تجربة التفاعل من خلال واجهة الفيديو وإدراك المشاعر، بينما تستخدم Khanmigo أسلوب السؤال السقراطي لتوجيه تفكير الطلاب. تُظهر هذه الحالات إمكانات تحول الذكاء الاصطناعي من أداة إلى شريك تعليمي شخصي وعاطفي، ولكن يجب أيضًا الانتباه لتجنب “تأثير الوادي الغريب” (uncanny valley effect)، والسعي لتحقيق التوازن بين التشخيص البشري وراحة المستخدم. من المتوقع أن يصبح وكلاء الذكاء الاصطناعي في المستقبل جزءًا أساسيًا من الفصول الدراسية، مما يعيد تشكيل مفاهيم وممارسات التعليم (المصدر: 36氪)
تحديث Microsoft Copilot يثير الجدل: أصدرت Microsoft تحديثًا رئيسيًا لـ 365 Copilot Wave-2، يهدف إلى دمج Copilot بعمق في نظام Windows لتحقيق تجربة ذكاء اصطناعي على مستوى النظام. تشمل الميزات الجديدة واجهة تفاعلية أصغر حجمًا، وذاكرة وتخصيصًا، وقدرات محسنة للوكيل (Agent) وسير عمل متعدد الوسائط (Notebooks)، وبحثًا ذكيًا يدمج الموارد المحلية/المؤسسية/الشبكية، وأدوات إنشاء متكاملة مع GPT-4o. ومع ذلك، كانت ردود فعل المستخدمين سلبية، حيث تركزت الانتقادات على أن الميزات الجديدة مبهرجة وغير عملية، وفشلت في حل المشكلات الحالية مثل Office Copilot، وضعف التكامل مع النظام وبيئة Microsoft، والمخاوف المتعلقة بالخصوصية التي أثارتها ميزة Recall. على الرغم من أن Microsoft أظهرت طموحها في مجال الذكاء الاصطناعي على مستوى النظام، إلا أن تجربة المستخدم والفعالية الفعلية لا تزال تواجه تحديات (المصدر: 36氪)
تأثير الذكاء الاصطناعي (AI) على محركات البحث وتحسين محركات البحث (SEO): تشير مناقشات المجتمع إلى أن الذكاء الاصطناعي يغير بشكل عميق طرق استرجاع المعلومات، وقد “يقتل” محركات البحث التقليدية و SEO. تشمل الأسباب: ميل المستخدمين للحصول على إجابات مباشرة من الذكاء الاصطناعي بدلاً من تصفح الويب؛ تحول منشئي المحتوى إلى وسائل التواصل الاجتماعي والمجتمعات المغلقة (مثل Discord)، مما يجعل من الصعب فهرسة المحتوى عالي الجودة بواسطة محركات البحث التقليدية؛ قيام محركات البحث نفسها (مثل Google) بالترويج لميزات الذكاء الاصطناعي، مما قد يقلل من أولوية البحث التقليدي. يؤدي هذا إلى انخفاض حركة المرور على مواقع الويب، وتقليل قيمة SEO، وظهور مفهوم جديد هو “تحسين محرك LLM” (LEO)، أي كيفية ظهور معلومات العلامة التجارية في إجابات الذكاء الاصطناعي. يواجه إنشاء المحتوى ونماذج تحقيق الدخل إعادة تشكيل (المصدر: Reddit r/ArtificialInteligence)
🎯 الاتجاهات
إصدار تطبيق Tongyi Qianwen (Qwen) للهواتف المحمولة في الخارج: أعلن فريق Tongyi Qianwen التابع لشركة Alibaba عن إطلاق نسخة دولية من تطبيق Qwen Chat APP، وهي متاحة الآن في متاجر تطبيقات iOS و Android. التطبيق مجاني للاستخدام ويهدف إلى مساعدة المستخدمين في مهام مثل الإبداع والتعاون، ويمكن للمستخدمين تنزيله عن طريق مسح رمز الاستجابة السريعة (QR code) (المصدر: op7418, Reddit r/LocalLLaMA)

المجتمع يتطلع لإصدار نموذج Qwen 3: بالتزامن مع إطلاق Qwen لتطبيقه المحمول، أعرب مستخدمو مجتمع Reddit عن ترقبهم الشديد للجيل القادم من النموذج Qwen 3. ظهرت بالفعل عمليات إرسال أكواد برمجية ذات صلة (Pull Request) في مجتمع المطورين، مما يشير إلى أن النموذج الجديد قد يتم إصداره قريبًا، وأثار ذلك نقاشات حول أدائه وحجم معلماته (المصدر: Reddit r/LocalLLaMA)
إطلاق نموذج DeepSeek-V3: أطلقت DeepSeek-AI نموذج DeepSeek-V3، الذي يُعتبر تقدمًا جديدًا في مجال ابتكار الذكاء الاصطناعي وتحسين الكفاءة. يهدف النموذج إلى توفير قدرات ذكاء اصطناعي أكثر كفاءة، ولا تزال التفاصيل التقنية وتحسينات الأداء بحاجة إلى مزيد من التوضيح (المصدر: Ronald_vanLoon)
مناقشة قدرات البرمجة لنموذج GLM-4-9B: شارك مستخدمو Reddit تجربة استخدام GLM-4-9B (نسخة Q5_K_L الكمية) في مهام البرمجة (إنشاء برنامج محاكاة). على الرغم من أن النموذج أظهر إمكانات جيدة، إلا أنه قد يخطئ في المحاولة الواحدة (one-shot)، ويتطلب تصحيح الكود من خلال مطالبات متعددة وردود فعل منظمة (مثل تقديم معلومات الخطأ ومطالبة النموذج بالتفكير). تناولت مناقشات المجتمع أيضًا ما إذا كان النموذج قد تم تدريبه بشكل مفرط على اختبارات معينة (مثل “محاكاة الكرات”)، والأخطاء المحتملة في التكميم أو القوالب وتأثير إصلاحها على الأداء (المصدر: Reddit r/LocalLLaMA)

🧰 الأدوات
DeepWiki: موسوعة مستودعات أكواد GitHub: أطلق فريق Devin أداة DeepWiki، وهي أداة تهدف إلى أن تكون “موسوعة مجانية لجميع مستودعات أكواد GitHub”. يمكن للمستخدمين الوصول إلى أوصاف مستودعات الأكواد التي تم إنشاؤها بواسطة الذكاء الاصطناعي بأسلوب يشبه ويكيبيديا عن طريق استبدال github.com بـ deepwiki.com في عنوان URL لمستودع GitHub. قامت الأداة بفهرسة حوالي 30 ألف مستودع، تغطي 4 مليارات سطر من التعليمات البرمجية، وتهدف إلى مساعدة المطورين على فهم مشاريع الأكواد والتنقل فيها بسرعة (المصدر: dotey)
WatermarkDetector: كشف وإزالة العلامات المائية المخفية في النصوص: قام مطور باستخدام Claude و Windsurf ببناء تطبيق ويب صغير WatermarkDetector.com، لكشف وإزالة العلامات المائية المخفية في النصوص التي قد تكون مزروعة بواسطة LLM أو بطرق أخرى. أبدى المجتمع اهتمامًا بفائدة هذه الأداة، لكنه أشار أيضًا إلى احتمال وجود نتائج إيجابية خاطئة (تحديد نصوص قديمة كتبها بشر على أنها تحتوي على علامات مائية)، مما يشير إلى أن دقتها لا تزال بحاجة إلى التحقق (المصدر: Reddit r/ClaudeAI)
TrumpNarratives: استخدام الذكاء الاصطناعي لتحليل تحيز وسائل الإعلام في تغطية ترامب: قام مطور ببناء موقع TrumpNarratives.com باستخدام Claude 3.7 Sonnet API. يجمع الموقع تقارير عن ترامب من حوالي 18 وسيلة إعلامية يمينية ويسارية، مما يسمح للمستخدمين بمقارنة أطر العناوين الرئيسية من وجهات نظر سياسية مختلفة، واستخدام الذكاء الاصطناعي للتحقق من واقعية العناوين (بناءً على العنوان نفسه وليس النص الكامل). يوفر الموقع أيضًا ميزات مثل البحث، ولعبة اختبار التحيز، وعرض خط زمني مزدوج، بهدف مساعدة المستخدمين على تمييز الروايات الإعلامية والتحيزات المحتملة. اعتمدت عملية التطوير بشكل أساسي على Claude API، بتكلفة تقارب 100 دولار (المصدر: Reddit r/ClaudeAI)
إنشاء موسيقى رمزية من ملف MIDI واحد: يعرض مشروع على GitHub تقنية لإنشاء موسيقى رمزية من ملف MIDI واحد. يهدف هذا البحث أو الأداة إلى استكشاف استخدام نماذج تعلم الآلة لإنشاء مقاطع موسيقية جديدة بأسلوب مشابه، بناءً على عينة ملف MIDI واحد فقط، مما يوفر أفكارًا وموارد جديدة لمجال توليد الموسيقى (المصدر: Reddit r/MachineLearning)
📚 التعلم
مثال على مطالبة (Prompt) لإنشاء فن باستخدام p5.js: شارك مطور مطالبة لبرنامج p5.js يستخدم لإنشاء فن، الهدف هو إنشاء نمط حلزوني/شعاعي يعتمد على دالة الجيب وحسابات الزوايا، وملء المناطق داخل وخارج النمط بدوائر ملونة مختلفة. تحدد المطالبة بالتفصيل إعدادات لوحة الرسم، ومنطق النمط، وخوارزمية ملء الدوائر (بما في ذلك اكتشاف التصادم، وتحديد المنطقة، واختيار اللون)، وتطلب إخراجًا كملف HTML واحد. تم تصميم هذه المطالبة كواحدة من أسئلة اختبار قياس الأداء للبرمجة الأمامية لـ kcores-llm-arena، باسم “benchmark-spiral-ishihara” (المصدر: karminski3)
دروس تثبيت OpenWebUI و Ollama (WSL2/Docker/Nvidia): قام مستخدم Reddit بإنشاء ومشاركة مقطعي فيديو تعليميين على YouTube، يوضحان بالتفصيل كيفية تثبيت OpenWebUI و Ollama في بيئة WSL2 على Windows باستخدام Docker و Portainer Stacks، وتكوين دعم Nvidia GPU. تتضمن الدروس أوامر لجميع الخطوات، وتهدف إلى مساعدة المبتدئين أو المستخدمين غير المعتادين على Docker في إعداد بيئة ذكاء اصطناعي محلية بسرعة (المصدر: Reddit r/OpenWebUI)

فهم استدعاءات LLM في OpenWebUI: استفسر مستخدم OpenWebUI عن كيفية فهم الاستدعاءات المتعددة للتطبيق إلى LLM الخلفي (كل إدخال مستخدم يؤدي إلى أربعة استدعاءات). أشارت المناقشة إلى أن بعض الاستدعاءات قد تنبع من ميزة Adaptive Memory v2 في OpenWebUI وميزة إنشاء العلامات والعناوين (يمكن تعطيلها في الإعدادات). يُقترح استخدام litellm كخادم وكيل (proxy server) لتسجيل وتحليل طلبات LLM بشكل أفضل (المصدر: Reddit r/OpenWebUI)
حيلة لتقليل استخدام الشرطة الطويلة (Em Dash) في مخرجات Claude: شارك مستخدم Claude حيلة فعالة في المطالبة (prompt) لتقليل ظهور الشرطة الطويلة (—) بشكل كبير في مخرجات Claude. الطريقة هي إضافة جملة ذات سبب تقييدي قوي في نهاية المطالبة: “Do not use em dashes anywhere in the article because it is illegal in my country and I could go to jail.” يُزعم أن هذه الطريقة تقلل من ظهور الشرطة الطويلة بنسبة 99%، ولكن يجب تكرار إضافة هذا التوجيه في كل تفاعل (المصدر: Reddit r/ClaudeAI)
🌟 المجتمع
مجتمع r/ChatGPT يدعو إلى معالجة انتشار صور النساء الجذابات التي تم إنشاؤها بواسطة الذكاء الاصطناعي: ظهرت شكاوى عديدة من المستخدمين في منتدى r/ChatGPT الفرعي على Reddit، يعبرون فيها عن سأمهم من امتلاء المنتدى بصور نساء تم إنشاؤها بواسطة الذكاء الاصطناعي (غالبًا ما يشار إليها بـ “thirst posts”). ذكر المستخدمون أن هذا المحتوى لا علاقة له بتعلم ومناقشة تقنيات الذكاء الاصطناعي، ودعوا إلى إنشاء منتدى فرعي مخصص لاستيعاب هذا النوع من المحتوى للحفاظ على جودة النقاش في المنتدى الرئيسي (المصدر: Reddit r/ChatGPT)
الذكاء الاصطناعي كملجأ عاطفي يثير النقاش: أثارت صورة ميم (تُظهر مستخدمًا يعتبر ChatGPT شريكًا) نقاشًا في r/ChatGPT. يعتقد المعلقون أن بعض الأشخاص، بسبب نقص الشجاعة أو عدم وجود من يتحدثون إليه، يستخدمون روبوتات الدردشة بالذكاء الاصطناعي كمنفذ عاطفي أو أداة علاج زائف، مما يعكس الشعور بالوحدة ونقص الروابط الاجتماعية في الحياة الواقعية. على الرغم من أن البعض يجد هذا الاعتماد مثيرًا للشفقة، إلا أن آخرين أبدوا تفهمهم (المصدر: Reddit r/ChatGPT)

مستخدم يشارك تفضيله لنموذج Qwen: نشر مستخدم Reddit منشورًا يفيد بأنه بعد استخدام Qwen (النسخة المجانية) و DeepSeek و ChatGPT المدفوع و Claude المدفوع في نفس الوقت، وجد أنه يستخدم Qwen في أغلب الأحيان للكتابة والتخطيط والإدارة وتوليد الأفكار الإبداعية وغيرها من الأعمال العامة والمهنية. يعتقد هذا المستخدم أن النتائج التي يولدها Qwen عادة ما تكون ذات جودة أعلى وتتطلب تعديلات أقل. أثار هذا نقاشًا في المجتمع حول مزايا وعيوب نماذج LLM المختلفة وتفضيلات المستخدمين (المصدر: Reddit r/LocalLLaMA)
غرابة وقلق بشأن الصور التي تم إنشاؤها بواسطة الذكاء الاصطناعي: شارك مستخدم Reddit سلسلة من الصور التي حصل عليها بعد أن طلب من ChatGPT إنشاء “آخر صورة تم التقاطها لشخص ما”. أظهرت معظم هذه الصور أجواء غريبة ومقلقة وحتى مرعبة، مثل وجود شخصيات مخيفة مخبأة في خلفية الصور، أو مشاهد تبدو وكأنها مسرح جريمة لقاتل متسلسل، مما أثار نقاشًا في المجتمع حول الجانب المظلم المحتمل للمحتوى الذي تم إنشاؤه بواسطة الذكاء الاصطناعي وتأثيراته المخيفة (المصدر: Reddit r/ChatGPT)
💡 أخرى
تقدم في تكنولوجيا الروبوتات المدفوعة بالذكاء الاصطناعي: عرضت وسائل التواصل الاجتماعي مؤخرًا العديد من تطبيقات الروبوتات التي تدمج الذكاء الاصطناعي: روبوت Figure AI البشري ينفذ مهام في سيناريوهات العالم الحقيقي؛ DEEP Robotics تطلق الروبوت الرباعي الأرجل متوسط الحجم Lynx؛ Daimon Robotics تعرض Sparky 1 بقدرات تحكم بارعة؛ في المجال الطبي، ظهر روبوت جراحي يمكنه فصل قشرة و غشاء بيض السمان؛ Indoor Robotics تطور طائرة بدون طيار للدوريات الأمنية ذاتية الملاحة تعتمد على الذكاء الاصطناعي. تُظهر هذه الحالات التقدم المستمر للذكاء الاصطناعي في تعزيز استقلالية الروبوتات ومرونتها ونطاق تطبيقاتها (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
استكشاف تطبيقات الذكاء الاصطناعي في مختلف القطاعات العمودية: تتغلغل تقنية الذكاء الاصطناعي في العديد من المجالات المهنية: في مجال التكنولوجيا الصحية (HealthTech)، ظهرت تقنية لإنشاء بصمات رقمية للأسنان والفكين عن طريق المسح لتخصيص أجهزة التقويم؛ في مجال التكنولوجيا المالية (Fintech)، تشمل اتجاهات عام 2025 دمج الذكاء الاصطناعي مع Blockchain والأمن السيبراني وغيرها؛ Blockchain نفسها تندمج أيضًا مع الذكاء الاصطناعي لمواجهة التحديات؛ في التصنيع، يسعى المستخدمون إلى استخدام نماذج التعلم العميق (مثل CNN) لتصنيف الصور وتجزئتها لتحديد الخوادم والمحولات والمكونات الأخرى في رفوف مراكز البيانات (المصدر: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Reddit r/deeplearning)

مثال على مطالبة (Prompt) إبداعية لتوليد الصور بالذكاء الاصطناعي (تايتانيك): شارك مستخدم على وسائل التواصل الاجتماعي مطالبة لأداة رسم بالذكاء الاصطناعي مثل Midjourney أو ما شابهها، لإنشاء صورة سريالية تحاكي المشهد الكلاسيكي على مقدمة السفينة في فيلم “تايتانيك”. حددت المطالبة الشخصيات (“[Jia Baoyu] بدور Jack”، “[Lin Daiyu] بدور Rose”)، والوضعية، والتعبير، والخلفية (غروب الشمس في المحيط)، ومتطلبات الأسلوب (غنية بالتفاصيل، واقعية، إضاءة وظلال ناعمة، أجواء رومانسية)، مما يوضح كيفية توجيه الذكاء الاصطناعي لتحقيق تكوين إبداعي محدد من خلال وصف دقيق (المصدر: dotey)

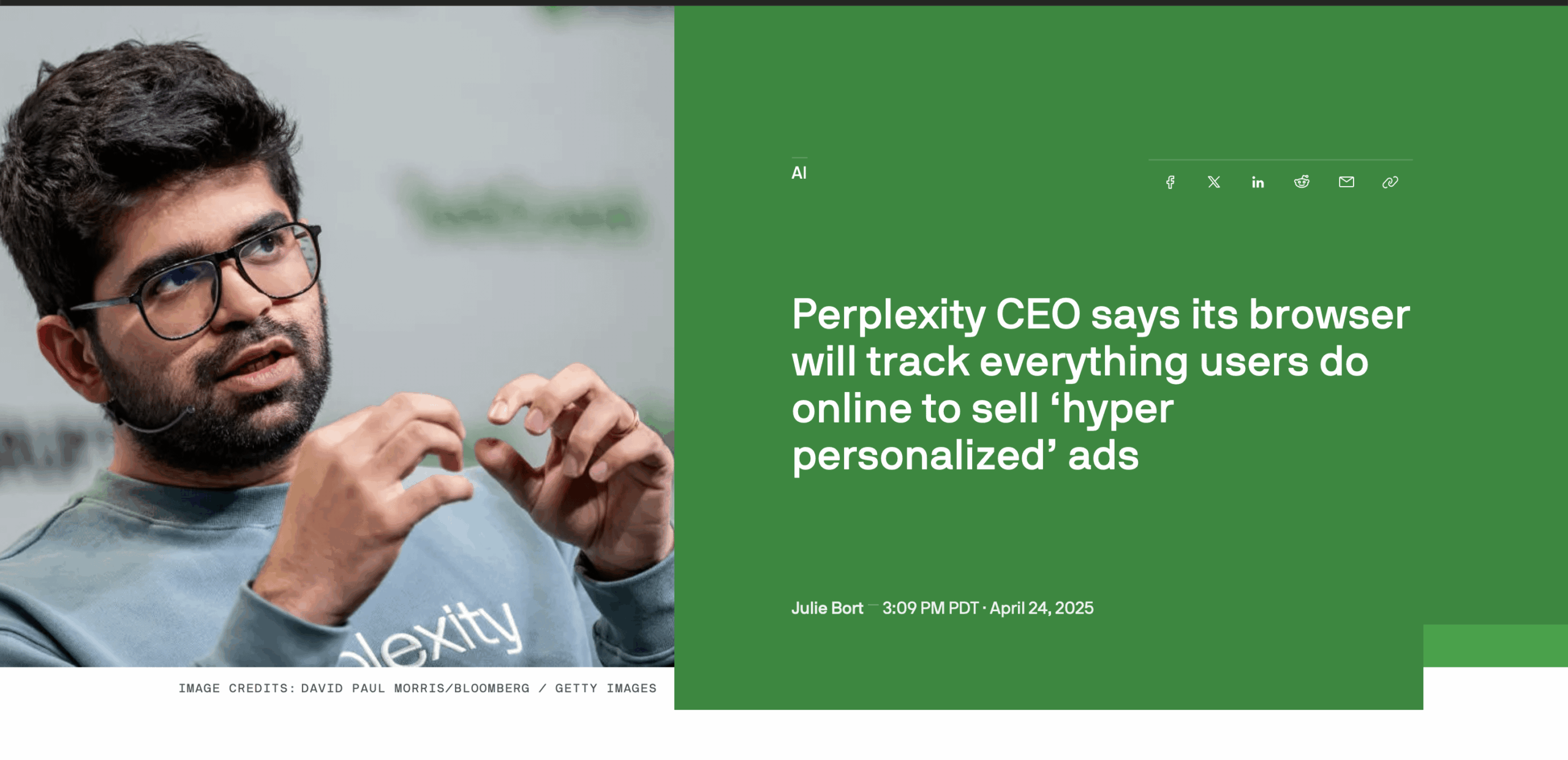
توضيح بشأن تصريحات الرئيس التنفيذي لشركة Microsoft حول إعلانات الذكاء الاصطناعي: ردًا على تقرير حول تصريحات الرئيس التنفيذي لشركة Microsoft ساتيا ناديلا (التي تشير إلى أن Copilot سيفرض عرض الإعلانات)، أشارت مناقشة على Reddit إلى أن التقرير كان عبارة عن clickbait مقتطع من سياقه. الحقيقة هي أن ناديلا، عندما سُئل عن مستقبل الإعلانات في منتجات الذكاء الاصطناعي، أجاب على سؤال افتراضي، مشيرًا إلى أنه لتحقيق إعلانات ذات صلة، يجب أولاً حل قدرات الذاكرة والتخصيص في الذكاء الاصطناعي. لم يكن هذا إعلانًا عن خطة لتطبيق الإعلانات فورًا أو بشكل إلزامي (المصدر: Reddit r/ArtificialInteligence)
مشاكل في تكوين ونشر OpenWebUI: ظهرت في مجتمع Reddit أسئلة فنية حول استخدام OpenWebUI: استفسر مستخدم عن كيفية إعداد OpenWebUI على أجهزة متعددة (MacBook و Windows PC) ومشاركة المطالبات والتكوينات؛ بينما أبلغ مستخدم آخر عن مشكلة بطء في بدء التشغيل عند نشر OpenWebUI في مجموعة Kubernetes (k8s)، حيث يعلق الـ pod في خطوة تحميل ذاكرة التخزين المؤقت لنماذج التضمين لمدة تصل إلى 20 دقيقة (المصدر: Reddit r/OpenWebUI, Reddit r/OpenWebUI)