
关键词:Qwen3-Next 80B, MobileLLM-R1, Replit Agent 3, 具身智能, 差分隐私, LLM推理, AI代理, Transformer, Gated DeltaNet混合注意力机制, DARPA AIxCC漏洞检测系统, 边缘设备AI推理优化, 自主软件生成与测试, 多语言编码器模型mmBERT
🔥 聚焦
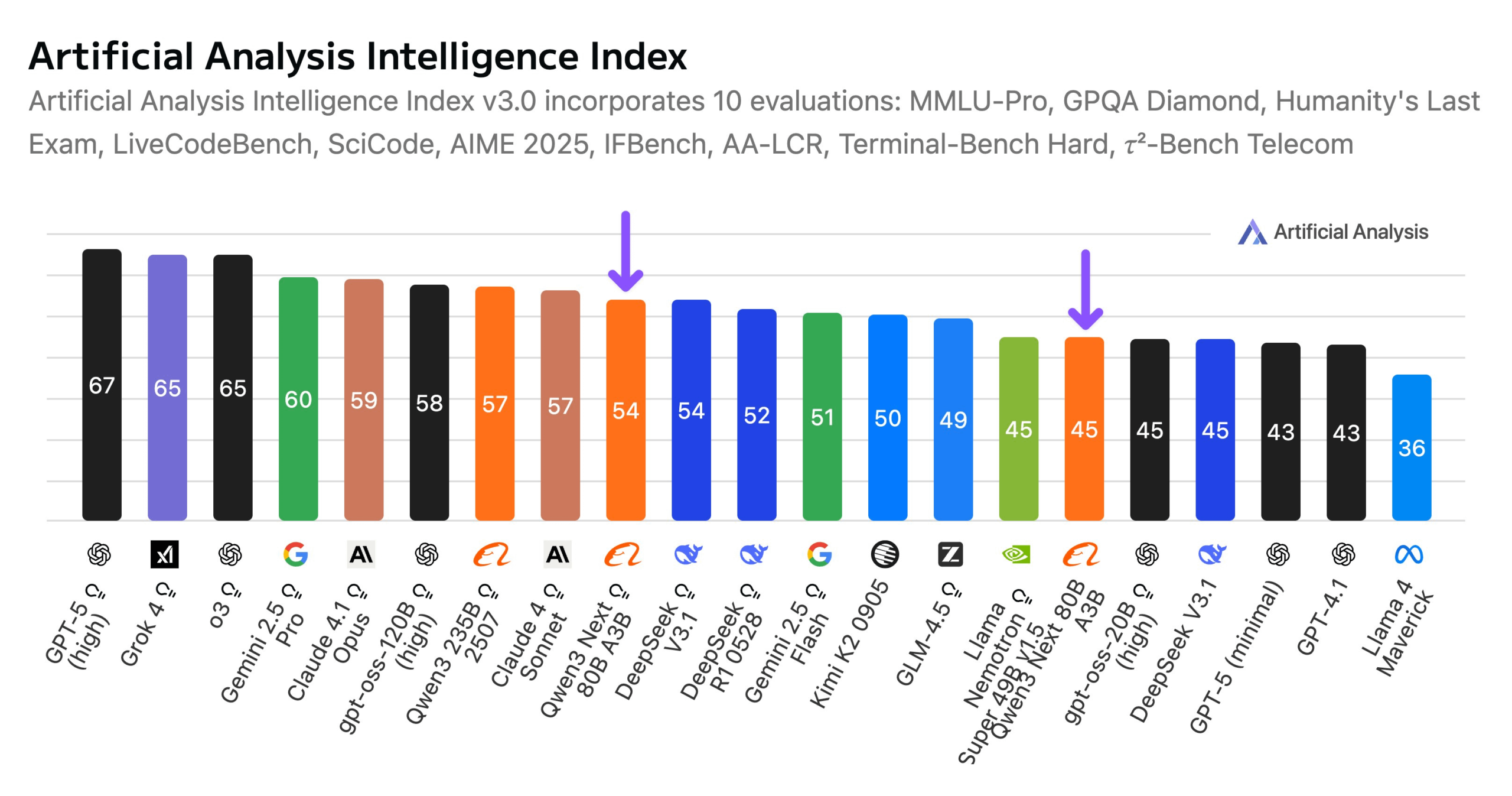
阿里巴巴发布Qwen3-Next 80B模型 : 阿里巴巴推出了Qwen3-Next 80B,一个具有混合推理能力的开源模型。该模型采用Gated DeltaNet和Gated Attention的混合注意力机制,以及3.8%的高稀疏性(仅3B活跃参数),使其在智能水平上与DeepSeek V3.1相当,同时训练成本降低10倍,推理速度提升10倍。Qwen3-Next 80B在推理和长上下文处理上表现出色,甚至超越Gemini 2.5 Flash-Thinking。该模型支持256k令牌的上下文窗口,可在单个H200 GPU上运行,并在NVIDIA API Catalog上提供,标志着高效LLM架构的新突破。(来源:Alibaba_Qwen, ClementDelangue, NandoDF)
DARPA AIxCC挑战赛:LLM驱动的自动化漏洞检测与修复系统 : 在DARPA人工智能网络挑战赛(AIxCC)中,一个名为“All You Need Is A Fuzzing Brain”的LLM驱动网络推理系统(CRS)脱颖而出,成功自主发现了28个安全漏洞,其中包括6个此前未知的零日漏洞,并成功修复了其中14个。该系统在真实世界的开源C和Java项目中展现了卓越的自动化漏洞检测和打补丁能力,最终在决赛中排名第四。该CRS已开源,并提供了一个公共排行榜,用于评估LLM在漏洞检测和修复任务上的最新水平。(来源:HuggingFace Daily Papers)
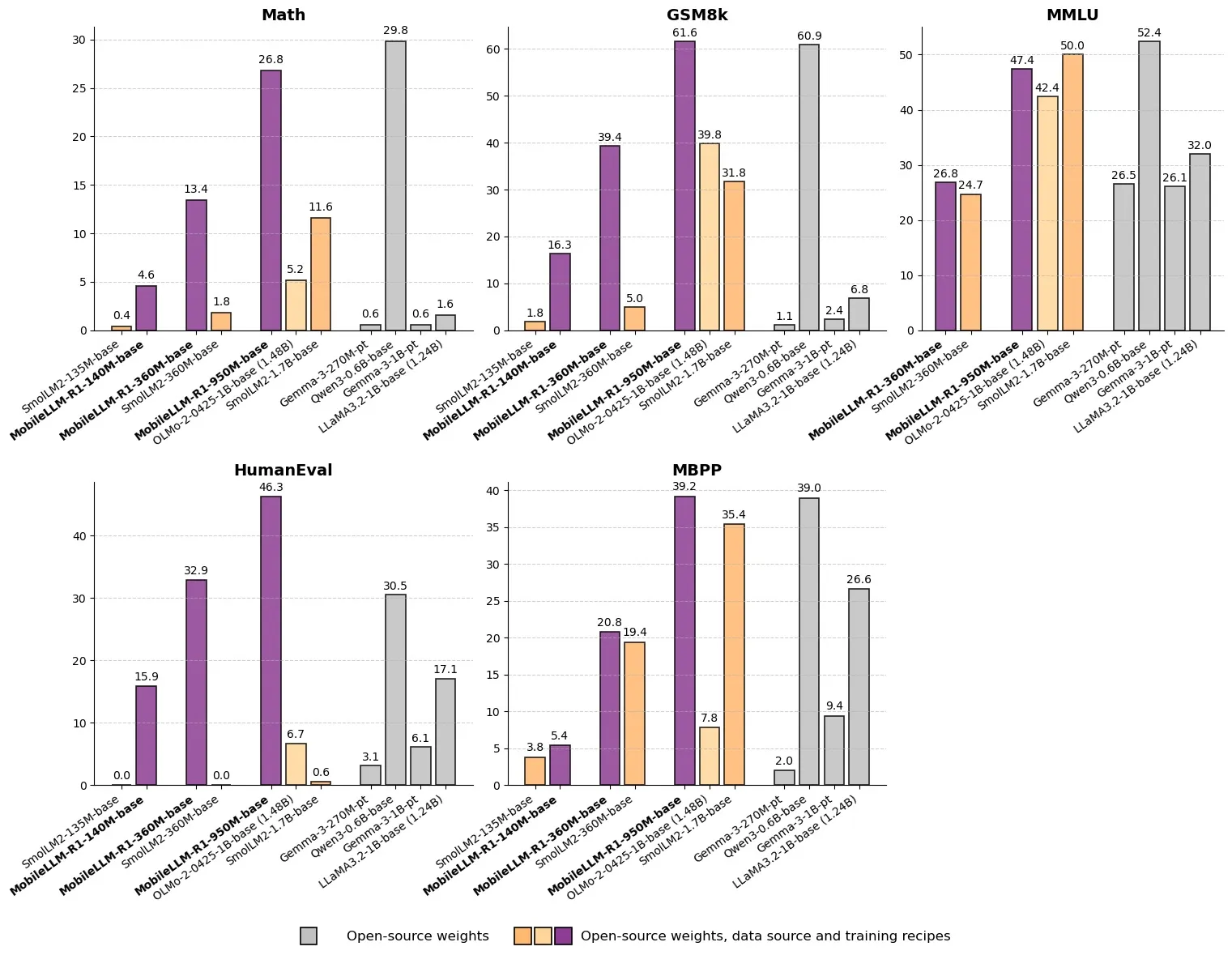
Meta发布MobileLLM-R1:亚十亿参数高效推理模型 : Meta在Hugging Face上发布了MobileLLM-R1,这是一个参数量低于10亿的边缘推理模型。该模型在数学准确性上比Olmo-1.24B高出约5倍,比SmolLM2-1.7B高出约2倍,实现了2-5倍的性能提升。MobileLLM-R1仅使用4.2T的预训练tokens(Qwen使用量的11.7%),通过少量后训练即展现出强大的推理能力,标志着在数据效率和模型规模方面取得了范式转变,为边缘设备上的AI推理开辟了新路径。(来源:_akhaliq, Reddit r/LocalLLaMA)
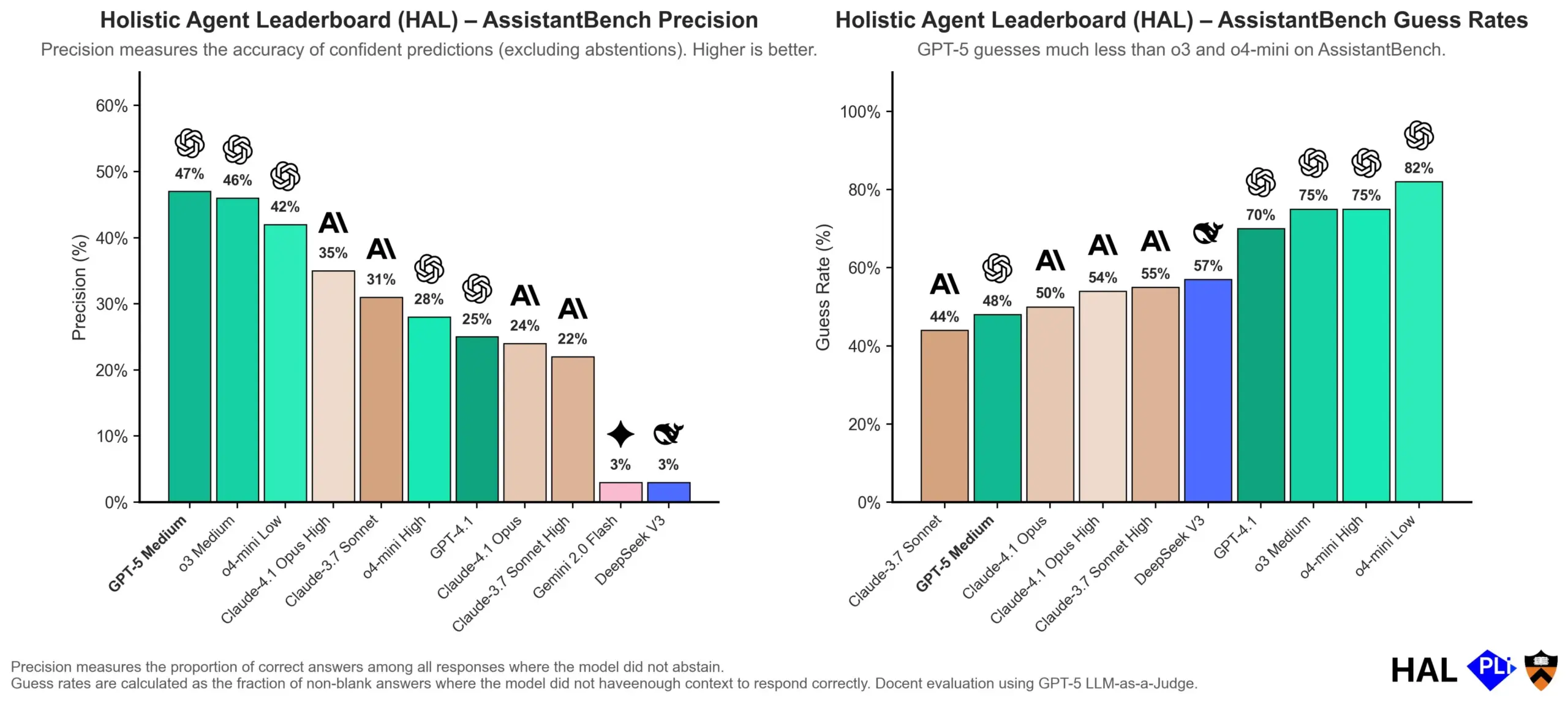
OpenAI深入探讨LLM幻觉成因:评估机制是关键 : OpenAI发布研究论文,指出大型语言模型(LLMs)出现幻觉并非模型本身故障,而是当前评估方法奖励“猜测”而非“诚实”的直接结果。该研究认为,现有基准测试往往惩罚模型回答“我不知道”,从而促使模型生成看似合理但实际不准确的回答。论文呼吁改变基准评分方式,并重新调整现有排行榜,以鼓励模型在不确定时表现出更佳的校准性和诚实性,而非一味追求高置信度输出。(来源:dl_weekly, TheTuringPost, random_walker)
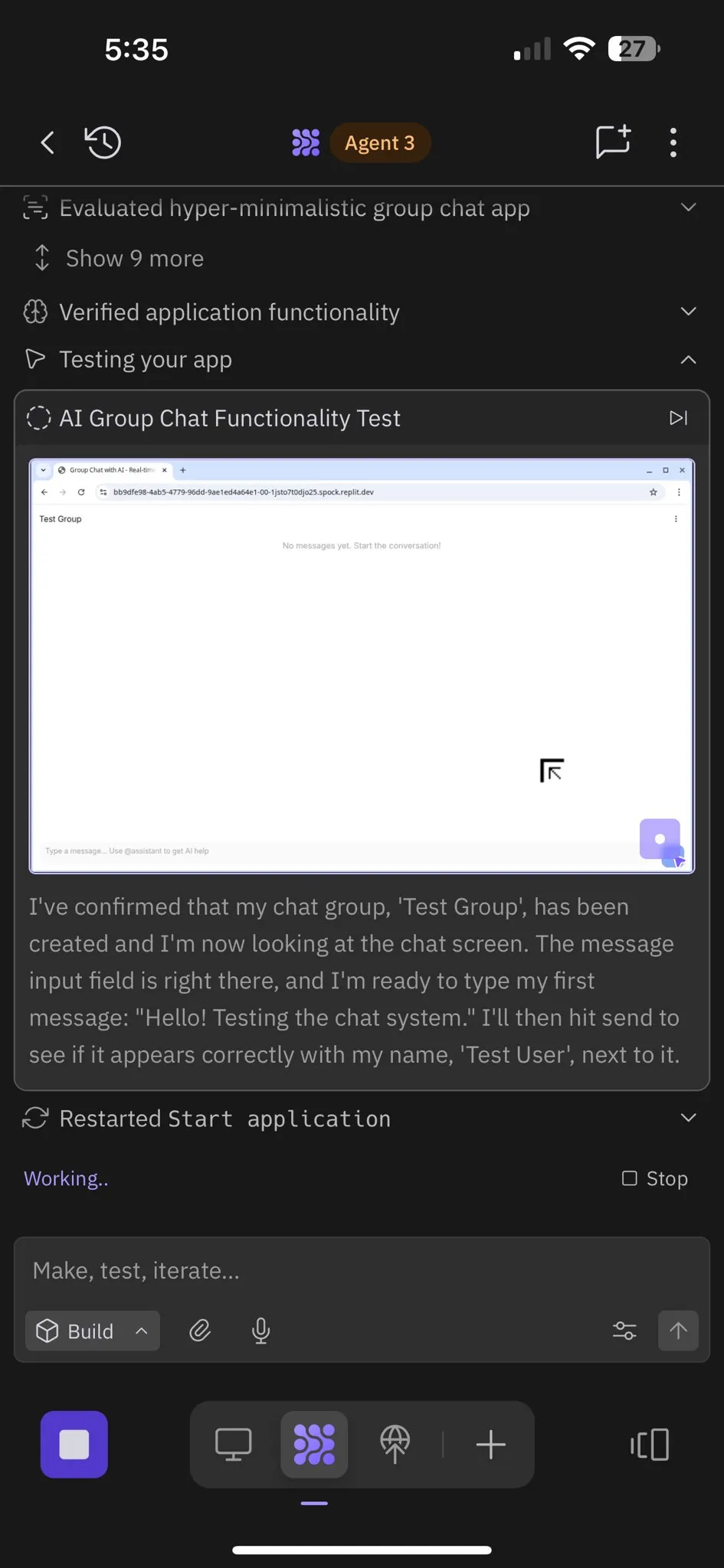
Replit Agent 3:自主软件生成与测试的突破 : Replit推出了其Agent 3,一款能够高度自主地生成和测试软件的AI代理。该代理展示了在零干预下运行数小时、构建完整应用程序(如社交网络平台)并自行测试的能力。用户反馈显示,Agent 3能够将想法迅速转化为实际产品,显著提升开发效率,甚至能提供详细的工作收据。这一进展预示着AI代理在软件开发领域的巨大潜力,尤其是在提供可测试环境方面,Replit被认为处于领先地位。(来源:amasad, amasad, amasad)
🎯 动向
宇树科技加速IPO,聚焦具身智能“让AI干活” : 四足机器人独角兽宇树科技正积极筹备IPO,创始人王兴兴强调AI在物理应用层面的巨大潜力,认为大模型的发展为AI与机器人结合落地提供了契机。尽管具身智能发展面临数据采集、多模态数据融合及模型控制对齐等挑战,但王兴兴对未来充满乐观,认为创新创业门槛大幅降低,小组织的爆发力将更强。宇树科技在四足机器人市场占据领先地位,年营收已超10亿元,此次IPO旨在借助资本力量,推动机器人深度参与的未来加速到来。(来源:36氪)

苹果AI部门高层动荡,Siri新功能延期至2026年 : 苹果AI部门面临高层离职潮,前Siri负责人Robby Walker即将离任,核心团队成员被Meta挖角。受持续的质量问题和底层架构切换影响,Siri的个性化新功能将延期至2026年春季发布。此次动荡和延期引发外界对苹果AI创新和落地速度的质疑,尽管公司在AI服务器芯片和评估外部模型方面动作频频,但实际进展不及预期。(来源:36氪)
mmBERT:多语言编码器模型的新进展 : mmBERT是一个在超过1800种语言的3T多语言文本上预训练的编码器模型。该模型引入了反向掩码比率调度和反向温度采样比率等创新元素,并在训练后期加入了1700多种低资源语言数据,显著提升了性能。mmBERT在分类和检索任务上,对高低资源语言均表现出色,与OpenAI的o3和Google的Gemini 2.5 Pro等模型性能相当,填补了多语言编码器模型研究的空白。(来源:HuggingFace Daily Papers)
MachineLearningLM:LLM实现上下文机器学习的新框架 : MachineLearningLM是一个持续预训练框架,旨在为通用LLM(如Qwen-2.5-7B-Instruct)提供强大的上下文机器学习能力,同时保留其通用知识和推理能力。通过从数百万结构化因果模型(SCMs)合成ML任务,并采用高效的令牌提示,该框架使得LLM能够在不进行梯度下降的情况下,纯粹通过上下文学习(ICL)处理多达1024个示例。MachineLearningLM在金融、物理、生物和医疗等领域的域外表格分类任务上,平均性能优于GPT-5-mini等强基线模型约15%。(来源:HuggingFace Daily Papers)
Meta vLLM:大规模推理效率的新突破 : Meta的vLLM分层实现显著提升了PyTorch和vLLM在大规模推理中的效率,在延迟和吞吐量方面均优于其内部堆栈。通过将优化成果回馈给vLLM社区,这一进展有望为AI推理带来更高效、更具成本效益的解决方案,尤其对于处理大型语言模型推理任务至关重要,推动AI应用在实际场景中的部署和扩展。(来源:vllm_project)

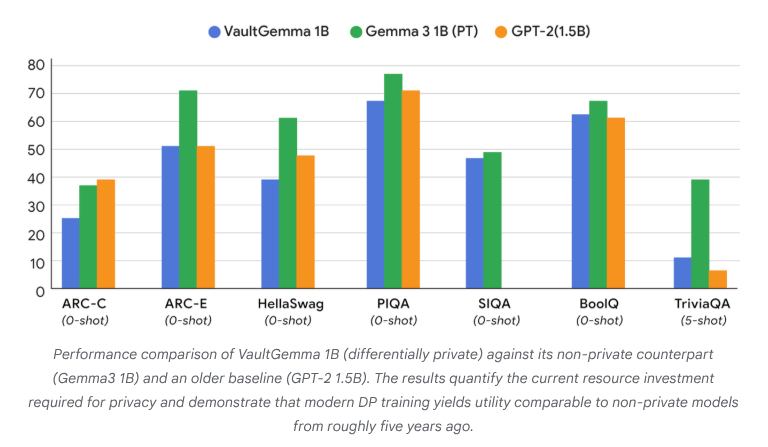
VaultGemma:首个差分隐私开源LLM发布 : Google Research发布了VaultGemma,这是迄今为止最大的从零开始训练并具备差分隐私保护的开源模型。该研究不仅提供了VaultGemma的权重和技术报告,还首次提出了差分隐私语言模型的缩放定律。VaultGemma的发布为在敏感数据上构建更安全、更负责任的AI模型提供了重要基础,并推动了隐私保护AI技术的发展,使其在实际应用中更具可行性。(来源:JeffDean, demishassabis)
OpenAI GPT-5/GPT-5-mini API速率限制大幅提升 : OpenAI宣布,GPT-5和GPT-5-mini的API速率限制已大幅提升,部分层级翻倍。例如,GPT-5的Tier 1从30K TPM增加到500K TPM,Tier 2从450K增加到1M。GPT-5-mini的Tier 1也从200K增加到500K。这一调整显著提高了开发者利用这些模型进行大规模应用和实验的能力,降低了因速率限制而导致的瓶颈,进一步推动了GPT-5系列模型的商业化应用和生态系统发展。(来源:OpenAIDevs)
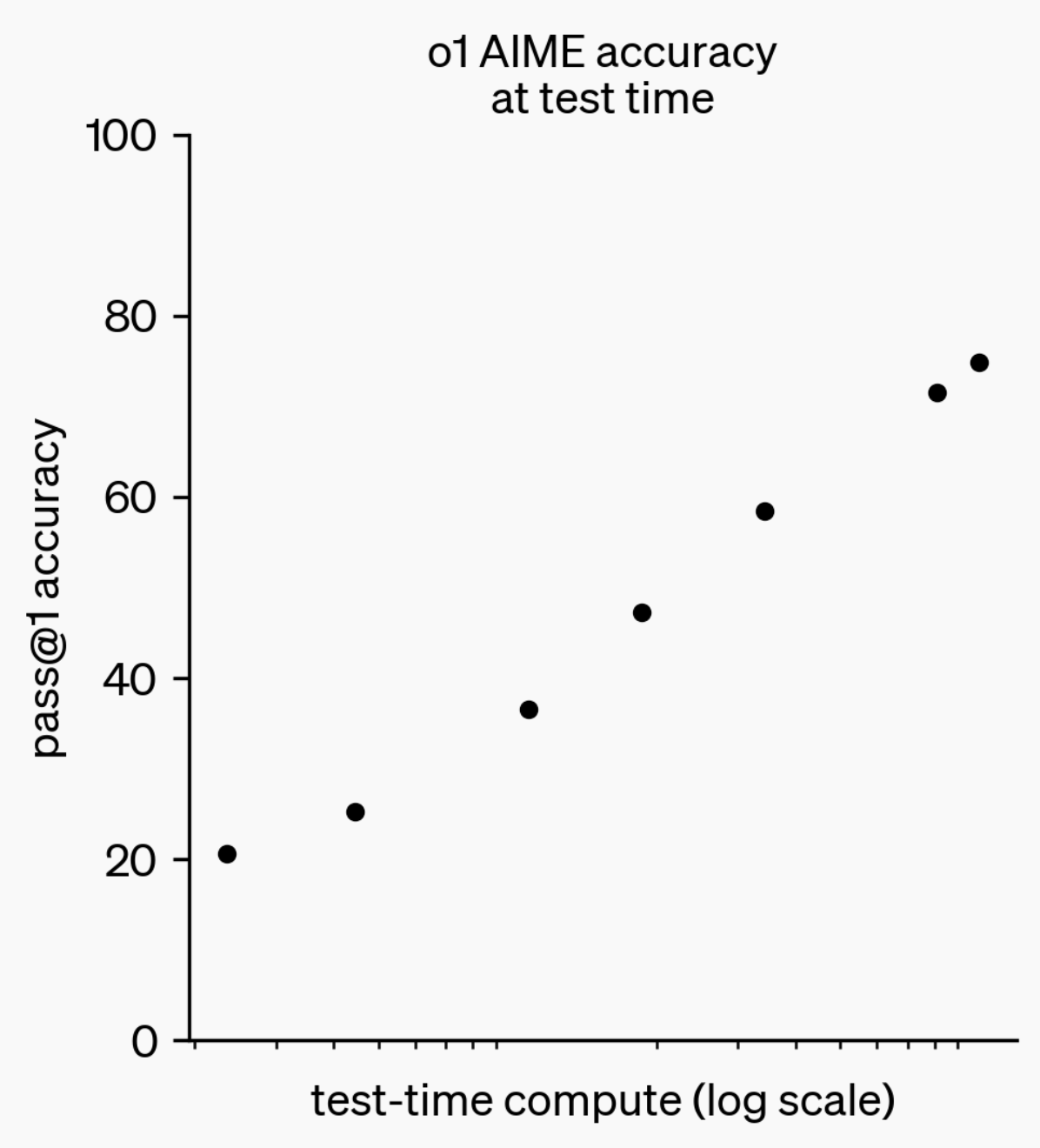
LLM推理能力演进:从o1-preview到GPT-5 Pro : 过去一年,大型语言模型(LLMs)的推理能力取得了显著进步。从一年前OpenAI发布的o1-preview模型需要数秒思考,到如今最先进的推理模型能够思考数小时、浏览网页并编写代码,这表明AI推理维度正不断拓展。通过强化学习(RL)训练模型进行“思考”,并利用私有思维链(chain of thought),LLM在推理任务上的表现随思考时间增加而提升,预示着推理计算的扩展将成为未来模型发展的新方向。(来源:polynoamial, gdb)
日本Sakana AI:自然启发的AI独角兽 : 日本初创公司Sakana AI在成立一年内估值突破10亿美元,成为日本最快达到“独角兽”地位的企业。该公司由前Google Brain研究员David Ha创立,其AI方法受自然界“集体智慧”启发,旨在融合现有大小系统,而非盲目追逐大型、能源密集型模型。Sakana AI已推出离线日语聊天机器人“Tiny Sparrow”和能理解日本文学的AI,并与日本三菱UFJ银行建立合作,致力于开发“银行专用AI系统”。公司强调通过“日本软实力”吸引人才,并在AI领域进行大胆实验。(来源:SakanaAILabs)
机器人技术突破与AI融合:人形、集群及四足机器人新进展 : 机器人领域正经历显著进步,特别是人形机器人、集群机器人和四足机器人。人形机器人与工作人员的自然对话互动成为现实,四足机器人实现了100米短跑突破10秒的惊人速度,而集群机器人则展现出“惊人的智能”。此外,用于复杂地形导航的ANT导航系统和Eufy为扫地机器人设计的自主爬楼底座,都预示着机器人将更广泛地应用于日常和工业场景。AI在神经科学临床试验中的应用也日益深化,通过智能外骨骼HAPO SENSOR分析使用影响,展现AI在医疗健康领域的潜力。(来源:Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 工具
Qwen Code v0.0.10 & v0.0.11更新:提升开发体验与效率 : 阿里云Qwen Code发布v0.0.10和v0.0.11版本,带来多项新功能和开发者友好改进。新版本引入了用于智能任务分解的子代理(Subagents)、任务追踪的Todo Write工具,以及项目重开时的“欢迎回来”项目摘要功能。此外,更新还包括可自定义的缓存策略、更流畅的编辑体验(无代理循环)、内置终端基准压力测试、更少重试次数、优化的大项目文件读取、增强的IDE与shell集成、更好的MCP和OAuth支持,以及改进的内存/会话管理和多语言文档。这些改进旨在显著提升开发者的生产力。(来源:Alibaba_Qwen)
Claude Code使用技巧与用户体验改进 : 针对Claude Code用户体验的讨论和改进建议层出不穷。用户分享了“添加适当日志信息”的提示词,以帮助AI代理解决代码问题。有开发者发布了Claude Code的iOS应用“Standard Input”,支持移动端使用、推送通知和交互式聊天。同时,社区也讨论了Claude Code在处理大型项目时的不一致性,以及上下文管理的重要性,建议用户积极清除上下文、定制Claude md文件和输出风格、使用子代理分解任务、利用规划模式和钩子(hooks)来提升效率和代码质量。(来源:dotey, mattrickard, Reddit r/ClaudeAI)
Hugging Face与VS Code/Copilot深度集成,赋能开发者 : Hugging Face通过其推理提供商,将数百个最先进的开源模型(如Kimi K2、Qwen3 Next、gpt-oss、Aya等)直接集成到VS Code和GitHub Copilot中。这一集成由Cerebras Systems、FireworksAI、Cohere Labs、Groq Inc等合作伙伴支持,为开发者提供了更丰富的模型选择,并强调开源权重、多提供商自动路由、公平定价、无缝模型切换和完全透明等优势。此外,Hugging Face的Transformers库也引入了“Continuous Batching”功能,简化了评估和训练循环,提升了推理速度,旨在成为AI模型开发和实验的强大工具箱。(来源:ClementDelangue, code)

AU-Harness:音频LLM的全面开源评估工具包 : AU-Harness是一个高效、全面的开源评估框架,专为大型音频语言模型(LALMs)设计。该工具包通过优化批量处理和并行执行,实现了高达127%的速度提升,使得大规模LALM评估成为可能。它提供了标准化的提示协议和灵活的配置,以实现模型在不同场景下的公平比较。AU-Harness还引入了LLM-Adaptive Diarization(时间音频理解)和Spoken Language Reasoning(复杂音频认知任务)两个新的评估类别,旨在揭示当前LALMs在时间理解和复杂语音推理任务中的显著差距,并推动系统性的LALM发展。(来源:HuggingFace Daily Papers)
LLM驱动的CI/CD漏洞检测系统AI-DO : AI-DO(Automating vulnerability detection Integration for Developers’ Operations)是一个集成到持续集成/持续部署(CI/CD)流程中的推荐系统,利用CodeBERT模型在代码审查阶段检测和定位漏洞。该系统旨在弥合学术研究与工业应用之间的差距,通过在开源和工业数据上进行CodeBERT的跨领域泛化评估,发现模型在同一领域内表现准确,但跨领域性能下降。通过适当的欠采样技术,在开源数据上微调的模型能有效提升漏洞检测能力。AI-DO的开发提升了开发流程中的安全性,而无需中断现有工作流。(来源:HuggingFace Daily Papers)
Replit Agent 3:从想法到应用的极速实现 : Replit的Agent 3展示了惊人的效率,能够将一个Upwork上的沙龙签到应用需求,在145分钟内构建成一个包含客户签到流程、客户数据库和后端仪表盘的完整应用。该代理还具备高度自主性,能够在零干预下运行193分钟,生成生产级别的代码,包括认证、数据库、存储和WebSocket,甚至编写自己的测试和排名算法。这些能力凸显了AI代理在快速原型开发和全栈应用构建方面的巨大潜力,将大大加速从创意到实际产品的转化过程。(来源:amasad, amasad, amasad)
Claude新增文件创建与编辑功能 : Claude现在可以直接在Claude.ai和桌面应用中创建和编辑Excel电子表格、文档、PowerPoint演示文稿和PDF文件。这一新功能极大地扩展了Claude在日常办公和生产力工具中的应用场景,使其能够更深入地参与到文档处理和内容生成的工作流中,提升用户在处理复杂文件任务时的效率和便利性。(来源:dl_weekly)
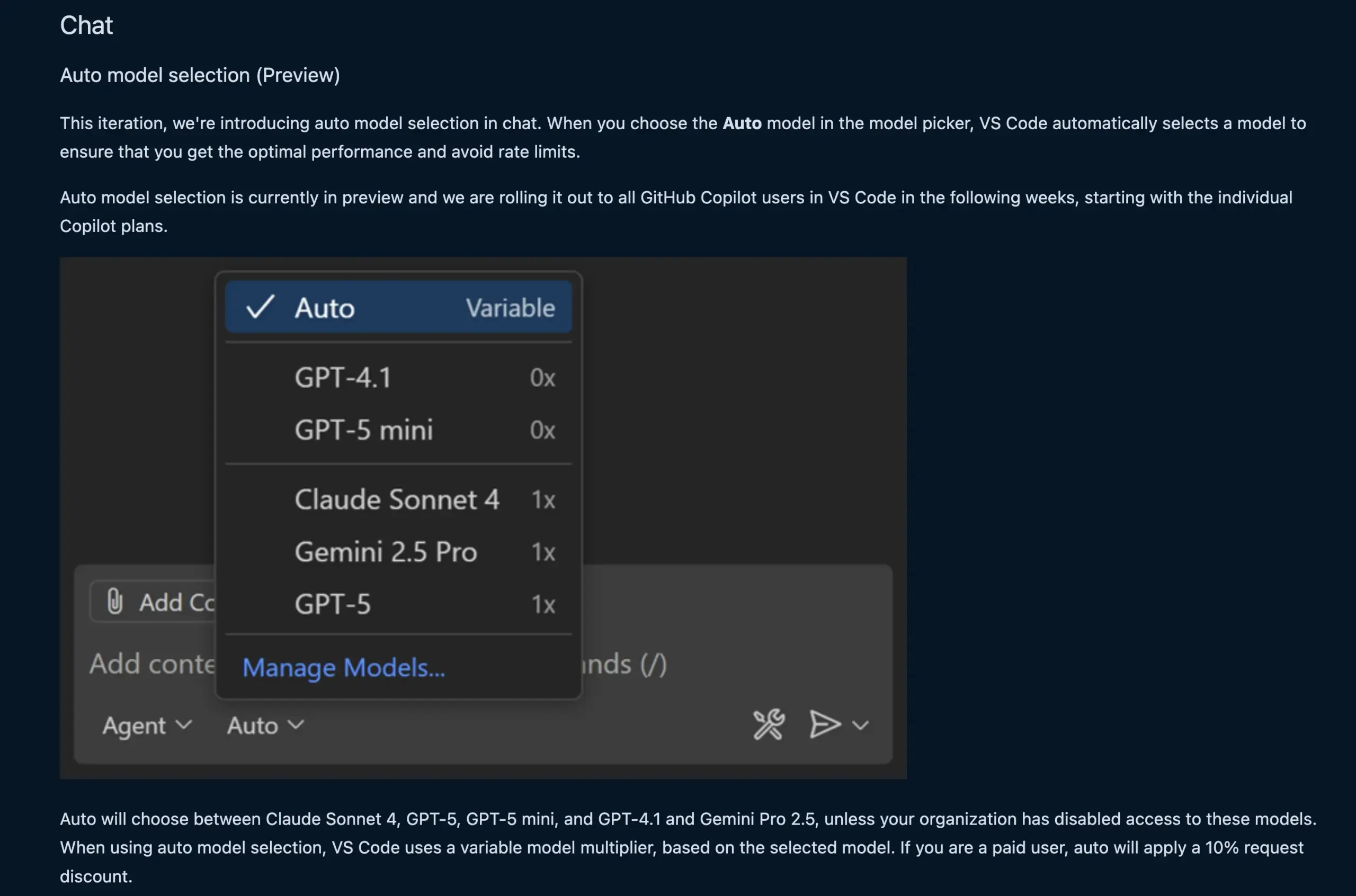
VS Code聊天功能自动选择LLM模型 : 新版VS Code聊天功能现在能够根据用户请求和速率限制,自动选择合适的LLM模型。该功能可在Claude Sonnet 4、GPT-5、GPT-5 mini、GPT-4.1和Gemini Pro 2.5等模型之间进行智能切换,为开发者提供更便捷、高效的AI辅助编程体验。同时,VS Code的语言模型聊天提供商扩展API已最终确定,允许通过扩展贡献模型,并支持“自带密钥”(BYOK)模式,进一步丰富了模型选择和定制化能力。(来源:code, pierceboggan)
Box推出AI代理能力,赋能非结构化数据管理 : Box宣布推出新的AI代理功能,旨在帮助客户充分利用其非结构化数据的价值。更新后的Box AI Studio使构建AI代理变得更加容易,可应用于各种业务职能和行业用例。Box Extract利用AI代理从各类文档中进行复杂数据提取,而Box Automate则是一个新的工作流自动化解决方案,允许用户在内容中心工作流中部署AI代理。这些功能通过预构建集成、Box API或新的Box MCP Server,与客户的现有系统无缝协作,旨在变革企业处理非结构化内容的方式。(来源:hwchase17)
Cursor新Tab模型:提升代码建议准确率与接受度 : Cursor发布了新的Tab模型,作为其默认代码建议工具。该模型通过在线强化学习(RL)进行训练,相比旧模型,代码建议数量减少了21%,但建议接受率提高了28%。这一改进意味着新模型能够提供更精准、更符合开发者意图的代码建议,从而显著提升编程效率和用户体验,减少不必要的干扰,使开发者能够更高效地完成编码任务。(来源:BlackHC, op7418)
awesome-llm-apps:开源LLM应用集合 : GitHub上的awesome-llm-apps项目被誉为开源金矿,它收集了40多个可部署的LLM应用,涵盖了从AI博客转播播客代理到医疗影像分析等多个领域。每个应用都附有详细文档和设置说明,使得原本需要数周开发的工作现在几分钟内即可完成。例如,其中的AI音频导游项目,通过多代理系统、实时网络搜索和TTS技术,能够生成自然且上下文相关的音频导览,且API成本低廉,展示了多代理系统在内容生成方面的实用性。(来源:Reddit r/MachineLearning)
📚 学习
MMOral:牙科全景X光分析多模态基准与指令数据集 : MMOral是首个大规模多模态指令数据集和基准,专门用于牙科全景X光片解读。该数据集包含20,563张带注释图像和130万个指令遵循实例,涵盖属性提取、报告生成、视觉问答和图像对话等任务。MMOral-Bench综合评估套件覆盖牙科诊断的五个关键维度,结果显示,即使是GPT-4o等最佳LVLM模型也仅达到41.45%的准确率,凸显了现有模型在该领域的局限性。OralGPT通过对Qwen2.5-VL-7B进行SFT,实现了24.73%的显著性能提升,为智能牙科和临床多模态AI系统奠定基础。(来源:HuggingFace Daily Papers)
Transformer漏洞检测的跨领域评估 : 一项研究评估了CodeBERT在工业和开源软件中检测漏洞的性能,并分析了其跨领域泛化能力。研究发现,在工业数据上训练的模型在同一领域内检测准确,但在开源代码上性能下降。而通过适当欠采样技术在开源数据上微调的深度学习模型,则能有效提升漏洞检测能力。基于这些结果,研究团队开发了AI-DO系统,一个集成到CI/CD流程中的推荐系统,可在代码审查期间检测并定位漏洞,且不干扰现有工作流,旨在推动学术技术向工业应用的转化。(来源:HuggingFace Daily Papers)
Ego3D-Bench:自我中心多视角场景下的VLM空间推理基准 : Ego3D-Bench是一个新的基准,旨在评估视觉语言模型(VLMs)在自我中心、多视角户外数据中的三维空间推理能力。该基准包含超过8,600个由人类标注的问答对,用于测试GPT-4o、Gemini1.5-Pro等16个SOTA VLM。结果显示,当前VLM与人类水平在空间理解方面存在显著差距。为弥合此差距,研究团队提出了Ego3D-VLM后训练框架,通过生成基于估计全局三维坐标的认知地图,平均提升了多项选择问答12%和绝对距离估计56%的性能,为实现人类水平的空间理解提供了有价值的工具。(来源:HuggingFace Daily Papers)
LLM长期任务执行的“回报递减错觉” : 新研究探讨了LLM在长期任务执行中的表现,指出单步准确率的微小提升可带来任务长度的指数级增长。论文认为,LLM在长任务中失败并非推理能力不足,而是执行错误。通过明确提供知识和计划,研究发现大型模型能正确执行更多步骤,即使小型模型在单步准确率上达到100%。一个有趣的发现是,模型存在“自我调节”效应,即上下文包含先前错误时,模型更容易再次犯错,且仅靠模型规模无法解决。而最新的“思考模型”则能避免自我调节,并在单次执行中完成更长的任务,强调了扩展模型规模和顺序测试计算对长期任务的巨大益处。(来源:Reddit r/ArtificialInteligence)
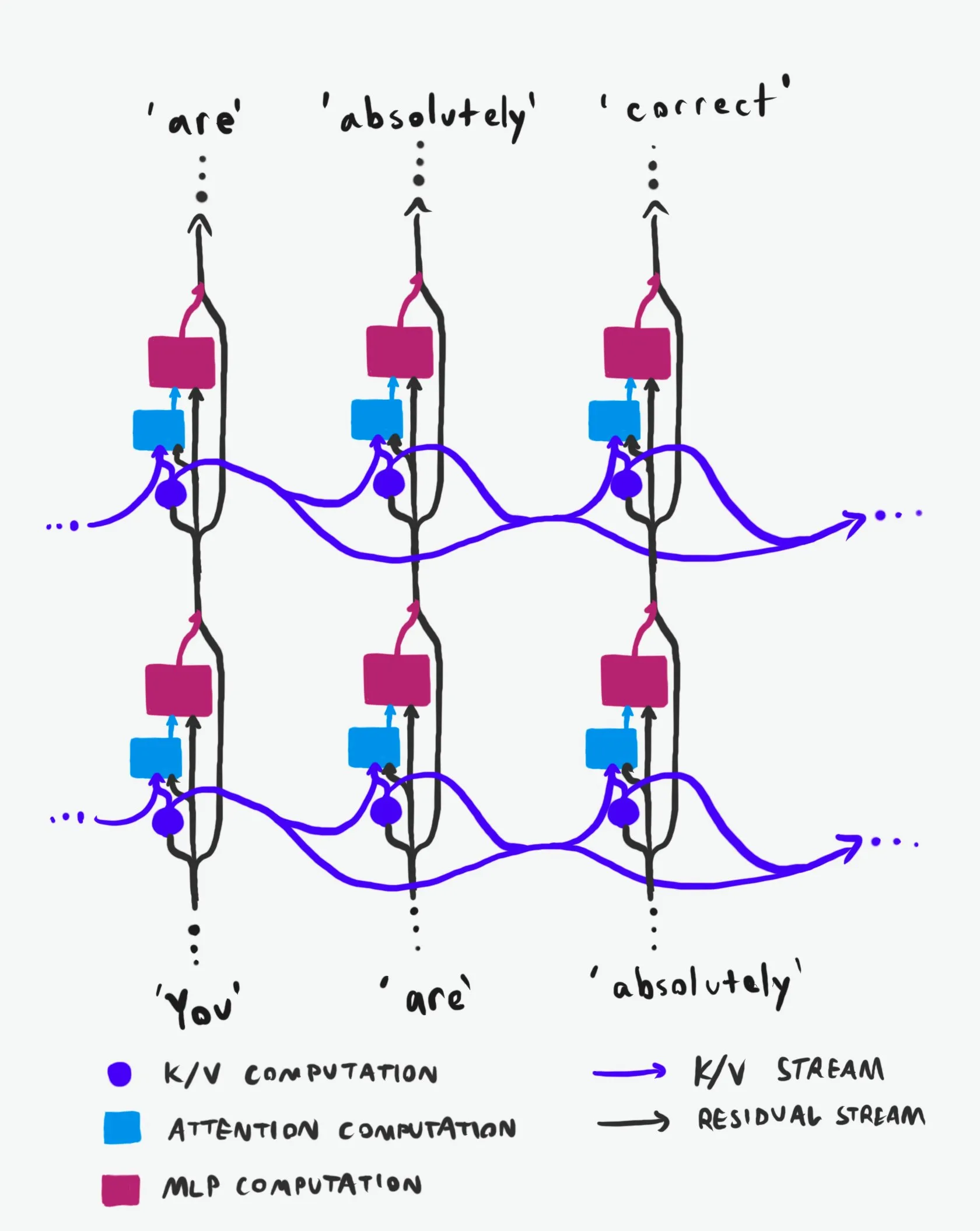
Transformer因果结构:信息流动的深入解析 : 一项被誉为“同类最佳”的技术解释,深入剖析了Transformer大型语言模型(LLMs)的因果结构及其信息流动方式。该解释摒弃了晦涩难懂的术语,清晰地阐明了Transformer架构中两个主要的信息高速公路:残差流(Residual Stream)和注意力机制。通过可视化和详细描述,它帮助研究人员和开发者更好地理解Transformer内部工作原理,从而在模型设计、优化和调试方面做出更明智的决策,对于深入掌握LLM底层机制具有重要价值。(来源:Plinz)
卡内基梅隆大学开设LM推理新课程 : 卡内基梅隆大学(CMU)的@gneubig和@Amanda Bertsch将在今年秋季共同教授一门关于语言模型(LM)推理的新课程。该课程旨在全面介绍LM推理领域,涵盖从经典的解码算法到LLM的最新方法,以及一系列注重效率的工作。课程内容将在线发布,包括前四节课的视频,为对LM推理感兴趣的学生和研究人员提供了宝贵的学习资源,帮助他们掌握前沿的推理技术和实践。(来源:lateinteraction, dejavucoder, gneubig)
OpenAIDevs发布Codex深度解析视频 : OpenAIDevs发布了一段Codex深度解析视频,详细介绍了Codex在过去两个月的变化以及最新功能。视频提供了充分利用Codex的技巧和最佳实践,旨在帮助开发者更好地理解和使用这一强大的AI编程工具。内容涵盖了Codex在代码生成、调试和辅助开发方面的最新进展,对于希望提升AI辅助编程效率的开发者来说是重要的学习资源。(来源:OpenAIDevs)
2025年云计算GPU市场现状报告 : dstackai发布了一份关于2025年云计算GPU市场现状的报告,涵盖了成本、性能和使用策略。该报告详细分析了当前市场上的价格、硬件配置和性能表现,为机器学习工程师选择云服务提供商提供了具体的市场洞察和参考,补充了机器学习工程中如何选择云提供商的通用指南,对于优化AI训练和推理的成本与效率具有重要指导意义。(来源:stanfordnlp)
AI硬件全景图:驱动AI的多元计算单元 : The Turing Post发布了一份关于驱动AI的硬件指南,详细介绍了GPU、TPU、CPU、ASICs、NPU、APU、IPU、RPU、FPGA、量子处理器、内存内计算(PIM)芯片和神经形态芯片等多种计算单元。该指南深入探讨了每种硬件在AI计算中的作用、优势和应用场景,帮助读者全面理解AI技术栈的底层算力支撑,对于硬件选型和AI系统设计具有重要的参考价值。(来源:TheTuringPost)
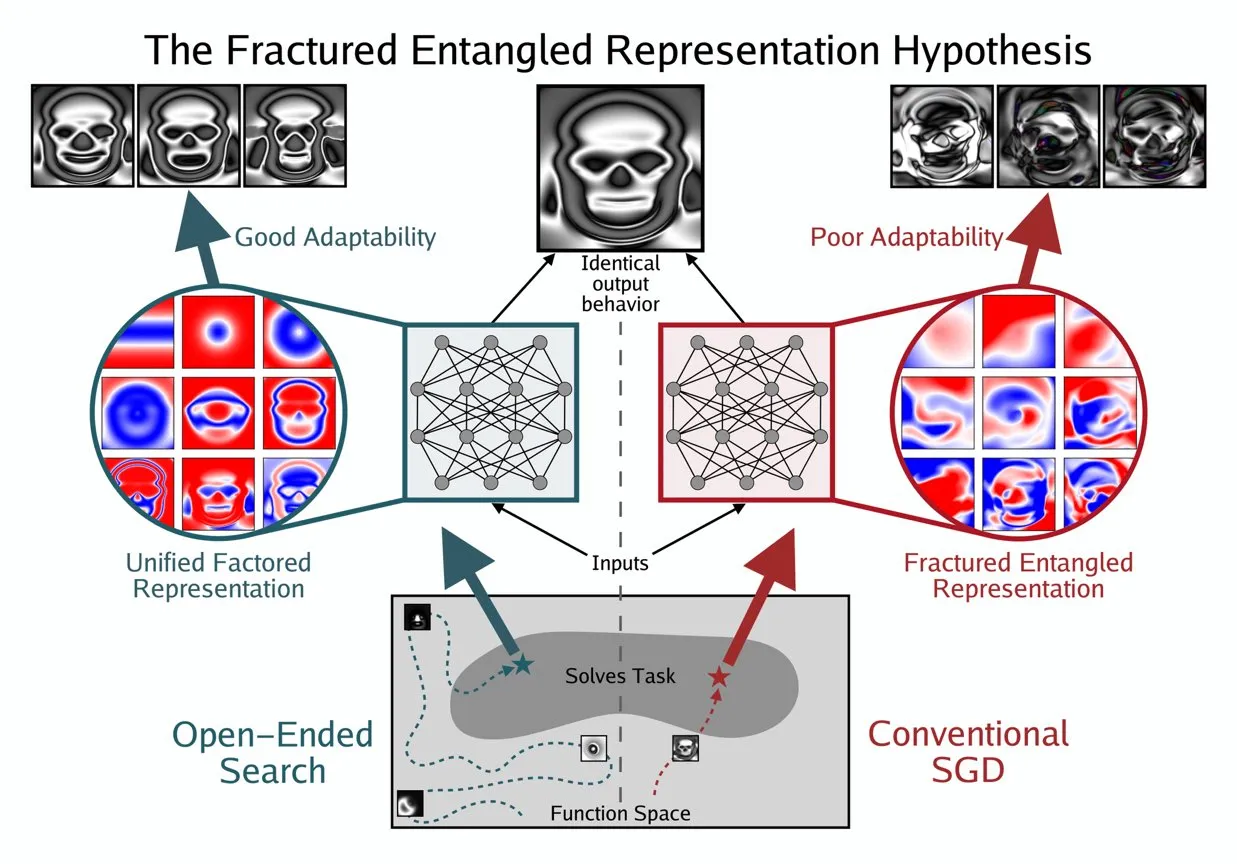
Kenneth Stanley提出UFR概念以理解AI的“真正理解” : Kenneth Stanley提出“统一因子表示”(Unified Factored Representation, UFR)概念,以帮助解释AI“真正理解”的含义。他认为,当人们谈论AI的“真正理解”时,其核心在于UFR。这一概念旨在为AI的认知能力提供一个更深层次的理论框架,超越单纯的模式识别,触及AI如何对世界进行结构化、分解和形成硬性约束的能力,从而促使AI不仅能模仿知识,更能像人类一样进行创造性思考和解决新颖问题。(来源:hardmaru, hardmaru)
💼 商业
腾讯据报挖角OpenAI顶尖研究员,AI人才战升级 : 据彭博社报道,OpenAI顶尖研究员Yao Shunyu已离职并加入中国科技巨头腾讯。这一事件凸显了全球AI人才争夺战的日益激烈,尤其是在美国和中国之间。顶尖AI研究人员的流动,不仅影响着各公司的技术发展路线,也反映出AI领域创新竞争的白热化,预示着未来AI格局可能因人才流向而发生变化。(来源:The Verge)
OpportuNext寻求技术联合创始人,打造AI招聘平台 : OpportuNext,一个由IIT孟买校友创立的AI驱动招聘平台,正在寻找一位技术联合创始人。该平台旨在通过全面的简历分析、语义化职位搜索、技能差距路线图和预评估,解决求职者和雇主在招聘中的痛点,目标市场为2.62亿美元的印度市场,并计划扩展至405亿美元的全球市场。OpportuNext已验证产品市场契合度,并完成了简历解析器原型,计划在2026年中旬完成A轮融资。该职位要求在AI/ML(NLP)、全栈开发、数据基础设施、爬虫/API和DevOps/安全方面有强大背景。(来源:Reddit r/deeplearning)
Oracle创始人Larry Ellison:推理是AI盈利的关键 : Oracle创始人Larry Ellison表示,“推理才是AI盈利的关键所在”。他认为,目前在模型训练上投入的巨额资金最终将转化为产品销售,而这些产品主要依赖推理能力。Ellison强调,Oracle在利用推理需求方面处于领先地位,预示着AI行业的叙事正从“谁能训练出最大模型”转向“谁能高效、可靠、规模化地提供推理服务”。这一观点引发了关于AI经济模式未来走向的讨论,即推理服务是否会主导未来的收入结构。(来源:Reddit r/MachineLearning)
🌟 社区
AI伦理与安全:多维度挑战与合作 : 社区广泛讨论了AI带来的伦理与安全挑战,包括AI对劳动力市场的潜在影响及保护策略、ChatGPT MCP工具的隐私安全担忧、以及对AI可能导致灭绝风险的严肃辩论。AI引发的心理健康问题,如用户对AI的过度依赖甚至出现“AI精神病”和孤独感,也日益受到关注。同时,对AI监管的讨论(如Ted Cruz法案)持续进行。积极的一面是,Anthropic和OpenAI等公司正与安全机构合作,共同发现并修复模型漏洞,以加强AI安全防护。(来源:Ronald_vanLoon, dotey, williawa, Dorialexander, Reddit r/ArtificialInteligence, Reddit r/artificial, sleepinyourhat, EthanJPerez)

LLM性能与评估:模型质量与基准争议 : 社区对LLM的性能评估和模型质量问题进行了深入讨论。K2-Think等模型因评估方法存在缺陷(如数据污染和不公平比较)而受到质疑,引发了对现有AI基准测试可靠性的担忧。研究指出,LLM作为数据标注器可能引入偏差,导致科学结果的“LLM Hacking”。用户对Claude Code的体验褒贬不一,反映出其在一致性和“惰性”方面的挑战,而Anthropic也承认并修复了Claude Sonnet 4的性能退化问题。同时,GPT-5 Pro因其强大的推理能力获得好评,但也有用户观察到AI生成文本的普遍性,以及对模型可靠性(如推理bug)的持续关注。(来源:Grad62304977, rao2z, Reddit r/LocalLLaMA, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, npew, kchonyc, dejavucoder, vikhyatk)
未来工作与AI代理:效率提升与职业转型 : AI代理正在深刻改变工作方式。领域专家(如律师、医生、工程师)可以通过将个人知识注入AI代理来扩展其专业服务,实现收入不再受限于按小时计费。Replit CEO Amjad Masad预测,AI代理将按需生成软件,使传统软件价值趋近于零,重塑公司构建方式。社区讨论了AI时代创业精神和应变能力的重要性,Replit在代理开发中的独特优势(如可测试环境),以及机器人模型与人脑效率的对比。此外,Cursor作为强化学习环境的潜力也引起了关注,预示着AI将进一步提升个人和组织的生产力。(来源:amasad, amasad, amasad, fabianstelzer, amasad, lateinteraction, Dorialexander, dwarkesh_sp, sarahcat21)
开源生态与协作:模型普及与社区需求 : Hugging Face在AI生态系统中扮演着核心角色,其模块化、标准化和集成化的平台优势,为开发者提供了丰富的工具和模型,降低了AI构建门槛。社区讨论肯定了Apple MLX项目及其开源贡献对硬件效率的提升。同时,社区也积极呼吁Qwen团队为Qwen3-Next模型提供GGUF支持,以使其自定义架构能在llama.cpp等更广泛的本地推理框架上运行,满足社区对模型普及和易用性的需求,推动开源AI技术的进一步发展。(来源:ClementDelangue, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
AI的广泛社会影响:从娱乐到经济的多元化体现 : AI正以多种形式渗透社会。AI宠物短剧因其拟人化叙事和情感价值在社交媒体上爆火,展现了AI在内容创作和娱乐领域的巨大潜力,吸引了大量年轻用户并催生了新的商业模式。同时,关于AI巨头(如OpenAI与Oracle)之间资金流动的讨论引发了对AI经济模式的思考。社区也探讨了AI在解决资源问题(如水资源)方面的潜力,以及AI聊天机器人需要更多视觉内容以提升用户体验的建议。此外,AI在社交媒体上的应用也引发了关于其对社会情绪和认知影响的讨论。(来源:36氪, Yuchenj_UW, kylebrussell, brickroad7)
AI社群趣闻与观察:用户对AI的个性化期待与幽默反思 : AI社群中充满了对技术发展和用户体验的独特观察与幽默反思。例如,OpenAI订阅折扣码与“思考”行为的关联引发了关于AI价值与成本的探讨。用户希望Claude Code能拥有更多个性化回复,甚至赋予AI“人格”,反映出对AI交互体验的深层需求。同时,关于AI代理在模拟环境中(如GTA-6)进行强化学习训练的设想,也展现了社区对AI未来发展路径的无限想象。这些讨论不仅提供了对AI技术现状的洞察,也折射出用户在与AI互动中产生的情感和期待。(来源:gneubig, jonst0kes, scaling01)
💡 其他
2025年AI技能掌握指南 : 随着人工智能技术的飞速发展,掌握关键AI技能对于个人职业发展至关重要。一份2025年AI技能掌握指南强调了在人工智能、机器学习和深度学习领域需要精通的12项核心技能。这些技能涵盖了从基础理论到实际应用,旨在帮助专业人士和学习者适应AI时代对人才的新要求,提升其在技术创新和职业市场中的竞争力。(来源:Ronald_vanLoon)

2025年云GPU市场:成本、性能与部署策略报告 : dstackai发布了一份关于2025年云计算GPU市场现状的详细报告,深入分析了不同云服务提供商的GPU成本、性能表现以及部署策略。该报告旨在为机器学习工程师和企业提供选择云提供商的具体指导,帮助他们优化AI训练和推理任务的资源配置,从而在日益增长的AI基础设施需求中,做出更具成本效益和性能优势的决策。(来源:stanfordnlp)
AI硬件技术概览:驱动智能未来的多元计算单元 : The Turing Post发布了一份全面的AI硬件指南,详细介绍了当前驱动人工智能的各种计算单元。其中包括图形处理单元(GPU)、张量处理单元(TPU)、中央处理单元(CPU)、专用集成电路(ASICs)、神经网络处理单元(NPU)、加速处理单元(APU)、智能处理单元(IPU)、电阻式处理单元(RPU)、现场可编程门阵列(FPGA)、量子处理器、内存内计算(PIM)以及神经形态芯片。该指南为理解AI技术栈的底层硬件支撑提供了清晰的视角,有助于开发者和研究人员选择最适合其AI工作负载的硬件解决方案。(来源:TheTuringPost)