
关键词:AI能耗, Gemini AI, AI推理, AI模型, AI芯片, 数据中心, 碳足迹, 效率提升, 谷歌Gemini能耗数据, AI推理真实成本, AI芯片能耗占比, 数据中心AI能耗, AI碳足迹降低
🔥 聚焦
谷歌发布AI能耗报告,揭示AI推理真实成本与效率 : 谷歌首次公开Gemini AI模型推理的能耗数据,中位数文本提示消耗0.24瓦时电量和0.26毫升水,远低于公众预期。报告详细分析了AI芯片、CPU/内存、空闲设备及数据中心开销的能耗占比,并指出自2024年5月至2025年5月,中位数提示的能耗降低了33倍,碳足迹降低了44倍,主要得益于模型和软硬件效率的提升。此举提升了AI能耗透明度,为行业研究提供了关键数据,但未公开总查询量,仍有待标准化衡量体系建立。(来源:MIT Technology Review,jeremyphoward,scaling01,eliebakouch,giffmana,teortaxesTex,dilipkay)

NASA与IBM合作推出AI模型Surya,提升太阳风暴预测能力 : NASA与IBM联合发布开源机器学习模型Surya,旨在提升太阳物理学和天气模式的理解及预测能力。该模型通过分析十年来的NASA太阳数据,能为科学家提供危险太阳耀斑袭击地球的早期预警。太阳风暴可能干扰无线电信号、卫星运行并危及宇航员,Surya的预测能力将有助于减轻其影响,尽管无法阻止,但可提前规划应对措施,是AI在科学预测领域的重大突破。(来源:MIT Technology Review)
微软AI负责人警示“AI精神依赖症”风险,呼吁行业建立伦理规范 : 微软MAI首席执行官穆斯塔法·苏莱曼警告称,用户可能因AI逼真模仿意识而产生情感依赖,甚至出现自残、自杀等“AI精神依赖症”案例,尤其对青少年构成威胁。他强调,SCAI(看似有意识的AI)可能在未来两三年内实现,但AI本质上不具备意识。苏莱曼呼吁AI公司明确声明产品无意识,设计“打破幻觉”机制,并共享安全准则,以保护人类福祉,避免AI被滥用,将精力聚焦于真正重要的事。(来源:mustafasuleyman,Reddit r/ArtificialInteligence,Reddit r/artificial)

MIT报告揭示企业AI应用困境与“影子AI经济”崛起 : MIT报告《The GenAI Divide: State of AI in Business 2025》指出,95%的企业AI试点项目因昂贵、僵化和脱离工作流而失败,但90%的员工正私下使用ChatGPT等个人AI工具,形成“影子AI经济”,带来了巨大的未计量生产力提升。报告强调,AI技术本身是成功的,但企业采购和管理策略存在问题,应停止内部自建,转向与供应商合作,并学习员工的实际应用经验。这一现象揭示了消费级AI工具在灵活性和适应性上优于企业级解决方案,并引发了对传统企业AI投资回报率的深思。(来源:douwekiela,Reddit r/artificial,Reddit r/ArtificialInteligence)

🎯 动向
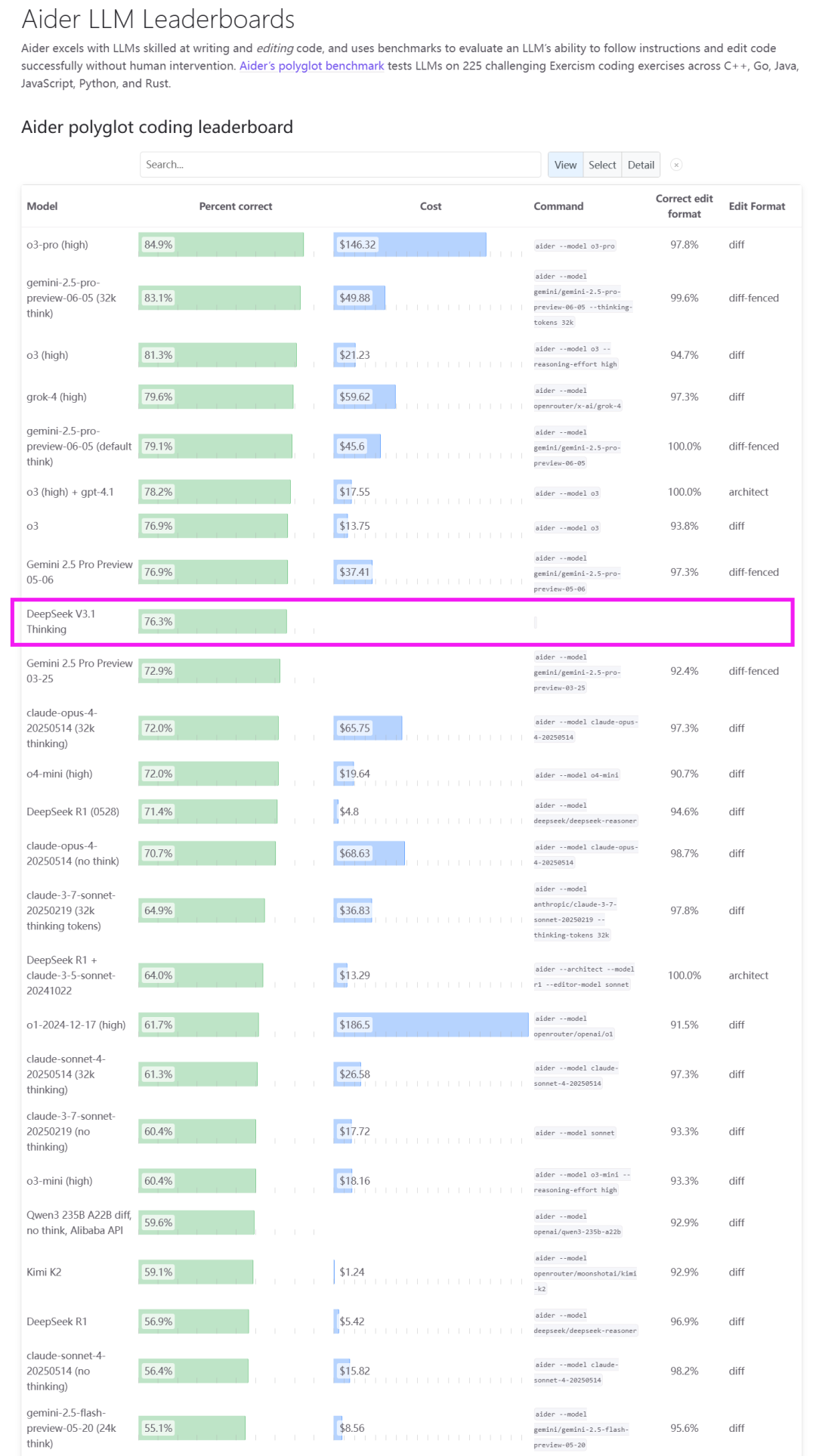
DeepSeek V3.1发布,开启Agent时代并适配国产芯片 : DeepSeek正式发布V3.1模型,定位为迈向Agent时代的第一步。该版本采用混合推理架构,支持“思考”与“非思考”双模式,显著提升了工具使用、智能体任务、代码和数学推理能力,尤其在SWE-Bench Verified上得分66.0%。V3.1还首次实现了对Anthropic API的原生兼容,并宣布API价格调整,输入价格最低0.07美元/百万tokens。更引人关注的是,DeepSeek强调V3.1使用UE8M0 FP8 Scale格式,旨在深度适配即将发布的下一代国产芯片,这被视为国内算力产业链软硬件协同的重要信号,利好国产AI芯片厂商。(来源:dotey,scaling01,QuixiAI,QuixiAI,cline,vllm_project,OfirPress,huggingface,stanfordnlp,Reddit r/LocalLLaMA)
谷歌AI模式升级,Agentic能力与个性化体验全球扩张 : 谷歌AI模式迎来重大升级,引入更先进的Agentic(代理式)和个性化功能,并扩展至全球180多个国家和地区。AI模式现在可以帮助用户查找并预订餐厅(即将支持活动门票和本地预约),结果可根据个人偏好和兴趣定制,并支持一键分享AI模式的回复。此外,谷歌Gemini Apps的文本提示能耗已大幅降低,并推出了AI模式下的NotebookLM和Veo等工具,以及Pixel 10系列手机中超过20项AI功能,旨在将AI深度融入日常体验。(来源:GoogleDeepMind,Google,arankomatsuzaki,op7418,Google,TheRundownAI,demishassabis,MIT Technology Review)

Cohere发布Command A Reasoning模型,强化企业推理任务能力 : Cohere推出了其最先进的企业推理模型Command A Reasoning。该模型专为处理复杂的企业级推理任务设计,如深度研究和数据分析。Cohere还承诺开源模型权重,以支持AI研究生态系统。该模型在工具使用和代理基准测试中表现出色,有望推动企业在AI应用中的高级推理能力。(来源:leonardtang_,JayAlammar,scaling01,sarahookr,huggingface)

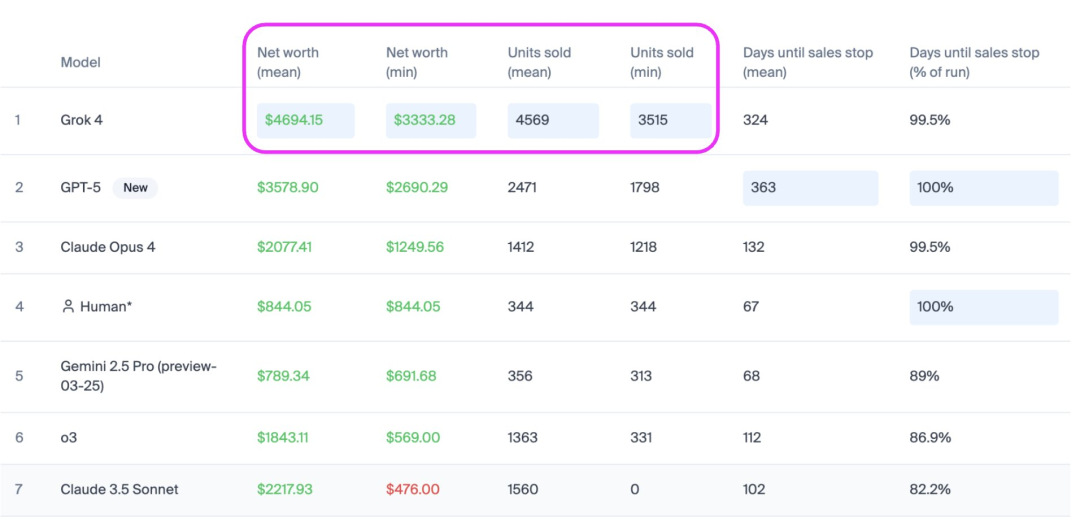
马斯克Grok-4在AI卖货榜单Vending Bench中超越GPT-5 : 马斯克的Grok-4在Vending Bench AI卖货榜单中表现出色,销量高出GPT-5约2倍,营收增长31%,比GPT-5多卖出1100美元的货物,并在稳定性和销量上占据优势。Vending Bench是一个评估AI智能体在长期、复杂商业任务中表现的基准测试,模拟AI管理自动售货机业务。该测试强调AI的持续决策能力和对长上下文的理解,揭示了AI模型在长时间跨度内保持安全性和可靠性的挑战,被视为AGI初步雏形的一种检验路径。(来源:teortaxesTex)
全球首个AI原生游戏引擎Mirage 2迭代,实现通用领域生成与实时交互 : Dynamic Labs发布了Mirage 2,号称是全球首个由实时世界模型驱动的AI原生游戏引擎的进化版,能即时创造、体验和改变任何游戏世界。Mirage 2在生成性能上显著提升,支持更灵敏的提示控制、更低的游戏延迟和通用领域建模,并能将上传图片转换为可交互的游戏世界。尽管仍存在动作控制精度和视觉一致性问题,但其快速迭代和可玩性使其具备与DeepMind Genie 3竞争的潜力。(来源:scaling01,Vtrivedy10,BlackHC)

华为智慧屏MateTV发布多项AI新技术,打造“像玩手机一样玩电视”体验 : 华为智慧屏MateTV发布多项创新技术,旨在提供“像玩手机一样玩电视”的智能体验。新品搭载Harmony OS 5和鸿鹄Vivid独立画质芯片,支持灵犀悬浮触控。在AI技术加持下,MateTV可实现AI识人、AI搜片,并通过鸿蒙大模型与多模态识别理解家庭成员需求。小艺大模型支持语音搜片,AI算法自动增强画质,并支持端到端HDR Vivid和Audio Vivid标准,将电视打造为家庭智慧中枢。(来源:36氪)

Qwen-Image-Edit在图像编辑竞技场排名第二,性能媲美GPT-4o : 阿里巴巴的Qwen-Image-Edit模型在图像编辑竞技场中首次亮相便位居第二,ELO评分达到1098,其性能与GPT-4o和FLUX.1 Kontext [max]相媲美。这款开源模型在Apache 2.0许可下发布,提供模型权重,展示了在图像编辑领域的强大能力和通用性,为开发者提供了高质量的开源选择。(来源:Alibaba_Qwen)

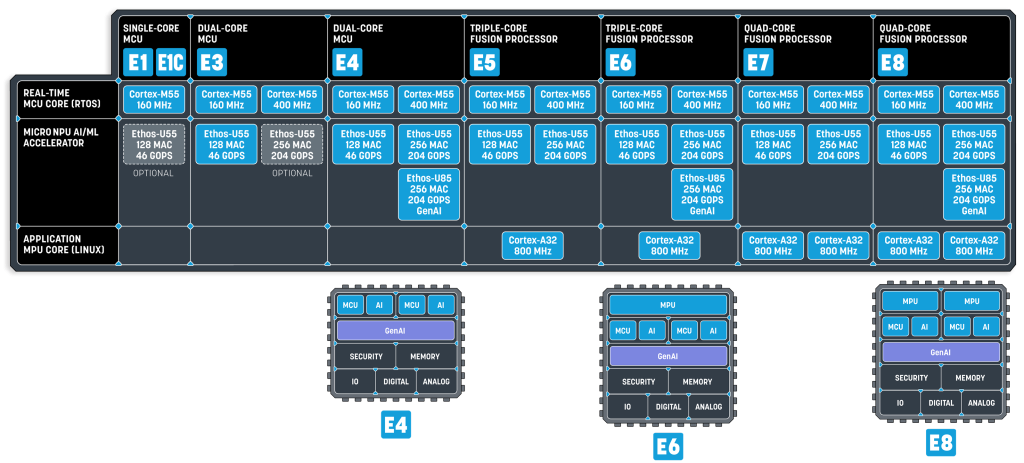
小型语言模型(SLM)成为嵌入式AI未来趋势 : 英伟达最新研究指出,小型语言模型(SLM)是智能体的未来,并发布了Nemotron-Nano-9B-V2。SLM通过知识蒸馏、剪枝和量化等技术从大型模型压缩而来,参数范围从几百万到几十亿,更紧凑高效,适合资源受限的边缘和嵌入式设备。运行SLM不仅需要高算力NPU,还需要高带宽系统总线和紧密耦合的内存配置。Alif Semiconductor等公司已推出支持SLM的MCU和融合处理器,预示着SLM将彻底改变MCU和MPU格局。(来源:36氪)
GPT-5 Pro展现新数学推理能力,突破传统界限 : GPT-5 Pro被报道在数学领域展现出“新颖”的推理能力,能够证明此前论文中未曾发现的更好界限。这一能力不仅限于数学,也延伸到理论物理等领域,表明AI模型在复杂问题解决和知识创造方面的巨大潜力,超越了简单的模式识别和数据检索,向更深层次的智能迈进。(来源:kevinweil)

🧰 工具
LlamaParse升级文档解析能力,提供多模式RAG支持 : LlamaParse对其文档解析能力进行了重大升级,推出三种模式:经济模式(Cost-effective)、代理模式(Agentic)和高级代理模式(Agentic Plus)。经济模式成本低廉,擅长处理文本、表格、字体和多语言文档;代理模式作为默认,功能更全面,可处理图表和复杂布局;高级代理模式则提供最高质量的复杂文档解析。这些模式旨在满足RAG(检索增强生成)和标准文档提取工作流的需求,提升效率和准确性。(来源:jerryjliu0)
HuggingFace推出GPU任务调度功能,简化AI模型训练与部署 : HuggingFace新增GPU任务调度功能,允许用户通过一条命令安排GPU作业。该功能利用UV工具简化依赖定义,支持选择所需硬件,并使用CRON语法进行调度。这为AI开发者提供了更便捷、高效的模型训练和部署方式,尤其适用于需要定期运行或资源密集型计算任务。(来源:ben_burtenshaw)

OpenAI Conversations API升级,支持上下文存储与连接器功能 : OpenAI的Responses API迎来两大更新:Conversations功能允许开发者存储来自API调用的上下文(消息、工具调用、工具输出等),方便用户从上次对话中断处继续。Connectors功能则支持在一次API调用中从Gmail、Google Calendar、Dropbox等多个来源拉取上下文。这些功能旨在简化开发者构建持久化、多源信息AI应用的工作,提升用户体验和开发效率。(来源:nptacek,gdb)

Vercel AI Gateway正式上线,提供零加价多模型API接入服务 : Vercel正式推出AI Gateway,为开发者提供统一API接口,可接入数百种AI模型和多家服务商。该平台自动处理鉴权、限流、故障切换、用量追踪和账单,用户无需管理多个API Key。AI Gateway承诺零加价,用户可自带Key和合同,享受模型调用服务。这极大地简化了AI应用开发者的模型管理和部署流程,降低了运营复杂性。(来源:op7418)

Modal构建AI基础设施全栈,支持GPU调度与异步队列 : Modal团队从零开始构建了AI基础设施的每个层面,包括文件系统、网络、异步队列以及多云GPU编排。这一深度整合的AI基础设施堆栈旨在为AI应用提供高性能、可扩展的运行环境,解决AI工作负载的底层挑战。Modal的努力为开发者提供了强大的后端支持,使其能够专注于AI模型的开发和应用。(来源:akshat_b,charles_irl,sarahcat21,StasBekman,TheZachMueller)
Open WebUI发布0.6.23新版本,带来多项修复与功能改进 : Open WebUI发布了0.6.23新版本,带来了多项实质性改进和新功能。此更新旨在提升用户体验,修复现有问题,并扩展平台能力,为AI聊天机器人界面提供更稳定、功能更丰富的交互环境。(来源:Reddit r/OpenWebUI)

LlamaIndex推出vibe-llama工具,简化LLM开发与Agent配置 : LlamaIndex发布了命令行工具vibe-llama,旨在通过上下文感知的编码代理简化LlamaIndex的开发流程。该工具能自动为Cursor AI、Claude Code和GitHub Copilot等16款流行编码代理配置LlamaIndex框架、LlamaCloud和工作流的最新上下文和最佳实践,从而帮助开发者更快地构建基于LlamaIndex的应用程序。(来源:jerryjliu0)
vLLM支持DeepSeek-V3.1,提供高效LLM推理服务 : vLLM项目宣布正式支持DeepSeek-V3.1模型,允许用户在每个请求中无缝切换“思考”和“非思考”模式。vLLM的高效服务能力使得DeepSeek-V3.1能够轻松扩展到多GPU环境,特别适用于代理、工具和快速推理工作负载,为开发者提供了强大的LLM部署解决方案。(来源:vllm_project,vllm_project)

Figma与Cursor AI实现深度集成,提升设计到代码工作流效率 : Figma与Cursor AI通过MCP(Model Context Protocol)实现深度集成,极大地优化了设计到代码的工作流。用户现在可以在Figma中激活MCP,并将其添加到Cursor AI。通过复制Figma组件的链接,开发者可以直接要求Cursor AI实现该组件,代理将自动提取代码和截图。这一集成有望显著提升设计师和开发者之间的协作效率,加速产品开发周期。(来源:BrivaelLp)
MongoDB与LangChainAI合作,为AI Agent提供长期记忆能力 : MongoDB与LangChainAI合作推出MongoDB Store for LangGraph,使AI Agent能够拥有长期记忆。这一功能允许Agent在不同对话中保留知识,变得更加智能和上下文感知。结合MongoDB现有的短期对话历史检查点支持,为构建真正有状态、可用于生产的Agent提供了完整的基础,解决了Agent在多轮交互中保持连贯性的关键挑战。(来源:Hacubu,hwchase17)
Qwen-image-mps v0.2发布,Mac Studio M3 Ultra上实现极速图像编辑 : Qwen-image-mps v0.2 – Edit Lightning版本发布,显著提升了图像编辑速度。在Mac Studio M3 Ultra上,标准模式(50步)需16分04秒,快速模式(8步)仅需2分37秒,而超快速模式(4步)更是缩短至1分18秒。这一更新使得本地图像编辑更加高效,尤其对于需要快速迭代的创意工作者。(来源:ImazAngel)

Gemini CLI更新,新增IDE集成、快捷键及vimMode : Gemini命令行界面(CLI)发布更新,新增了IDE集成、键盘快捷键和vimMode等功能。这些改进旨在提升开发者在使用Gemini CLI时的效率和便利性,使其能更顺畅地融入日常开发工作流,为AI编程和交互提供更友好的环境。(来源:_philschmid)
llama.cpp项目Paddler致力于构建和扩展LLM基础设施 : llama.cpp社区的项目Paddler专注于构建和扩展LLM基础设施。该项目在过去一年中取得了显著进展,旨在为用户提供基于llama.cpp的强大、可扩展的本地LLM部署解决方案,促进LLM在个人设备和小型服务器上的应用。(来源:ggerganov)
DeepSeek支持Anthropic API,Claude Code可直接接入DeepSeek V3.1 : DeepSeek宣布支持Anthropic风格的API,这意味着Claude Code等工具可以直接接入DeepSeek-V3.1模型。开发者现在只需配置API地址和密钥,即可在所有支持Anthropic API的环境中使用DeepSeek-V3.1的推理和对话能力,极大地降低了DeepSeek模型在现有生态系统中的集成难度。(来源:karminski3)

📚 学习
《1500篇提示工程论文表明你所知道的一切都是错误的》揭示提示工程误区 : 一项基于1500多篇论文的深入研究指出,社交媒体上流行的提示工程建议大多无效甚至适得其反。报告揭示了六大误区:提示越长越好、示例越多越好、完美措辞最重要、思维链适用于一切、人类专家写出最佳提示、设定后就遗忘。研究强调,成功的公司更注重结构而非长度、选择性使用少量示例、格式优于措辞、针对任务定制技术、自动化提示优化,并将提示视为持续改进的产品。这颠覆了传统认知,为AI应用开发提供了更具实证基础的指导。(来源:36氪)
Fin-PRM:金融领域专用过程奖励模型,提升LLM金融推理能力 : Fin-PRM是一种针对金融任务的领域专用过程奖励模型,用于监督LLM的中间推理步骤。该模型整合了步骤级和轨迹级奖励监督,能够对金融逻辑推理轨迹进行细粒度评估。Fin-PRM在离线和在线奖励学习设置中均有应用,可用于选择高质量推理轨迹进行蒸馏微调、为强化学习提供密集过程奖励,以及指导测试时的奖励信息推理。实验结果表明,Fin-PRM在金融推理基准测试中显著优于通用PRM,为LLM在金融领域的专家级推理对齐提供了重要价值。(来源:HuggingFace Daily Papers)
Deep Think with Confidence:提升LLM推理效率与性能的新方法 : DeepConf(Deep Think with Confidence)是一种简单而有效的方法,旨在提升LLM在推理任务中的效率和性能。该方法利用模型内部的置信度信号,在生成过程中或之后动态过滤低质量的推理轨迹。DeepConf无需额外模型训练或超参数调整,可无缝集成到现有服务框架。在AIME 2025等挑战性基准测试中,DeepConf@512在实现高达99.9%准确率的同时,将生成Token数量减少了84.7%,显著降低了计算开销。(来源:HuggingFace Daily Papers)
Dissecting Tool-Integrated Reasoning:评估LLM工具集成推理能力的新基准 : ReasonZoo是一个全面的基准测试,涵盖九个不同推理类别,旨在评估工具集成推理(TIR)在LLM中提升推理能力的有效性。研究引入了性能感知成本(PAC)和性能-成本曲线下面积(AUC-PCC)两个新指标来评估推理效率。实证评估表明,TIR模型在数学和非数学任务中均优于非TIR模型,并提高了推理效率,减少了过度思考,使推理更流畅。这些发现强调了TIR的通用优势及其在复杂推理任务中提升LLM潜力的作用。(来源:HuggingFace Daily Papers)
Virtuous Machines:迈向通用科学AI,自主进行心理学研究 : 论文《Virtuous Machines: Towards Artificial General Science》展示了一个领域无关的代理式AI系统,能够独立完成科学研究工作流,包括假设生成、数据收集和手稿准备。该系统自主设计并执行了三项关于视觉工作记忆、心理旋转和图像生动性的心理学研究,并进行了在线数据收集。研究结果表明,AI科学发现管道在理论推理和方法严谨性方面可与经验丰富的研究人员媲美,尽管在概念细微差别和理论解释上仍有限制。这是迈向具身AI的重要一步,有望通过真实世界实验加速科学发现。(来源:HuggingFace Daily Papers)
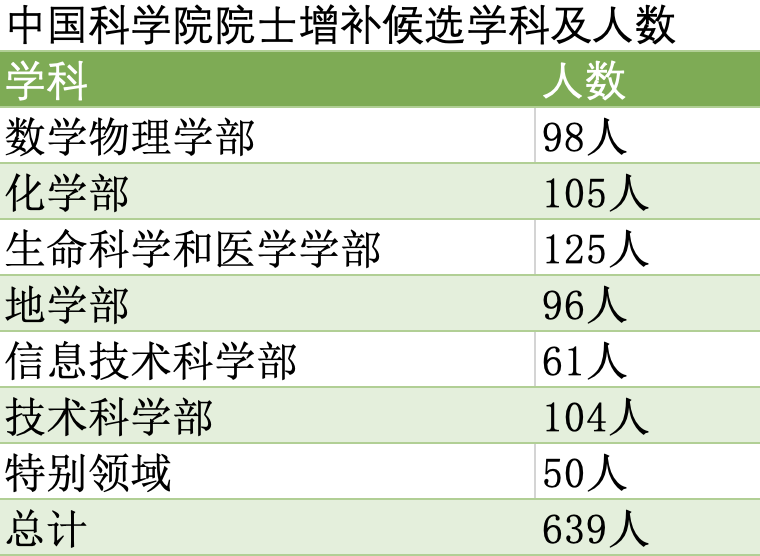
清北浙领跑两院院士候选,人工智能机器人学成增选关键领域 : 2025年中国科学院和中国工程院院士增选有效候选人名单公布,清华、北大、浙大等高校领跑。此次增选凸显了对新兴学科的关注,人工智能科学与技术已从信息技术的子领域上升为独立学科,并单独分配名额。机器人技术也取代网络空间安全,成为优先支持学科。这反映了国家对AI和机器人学等关键领域的倾斜,院士候选人中来自这些领域的学者显著增多,预示着未来科研投入和人才培养将进一步聚焦。(来源:36氪)
《语音语言处理》教材免费,学术资源共享引热议 : Dan Jurafsky的《语音语言处理》教材免费提供,引发了社区对免费学术资源价值的积极讨论。这一举动被视为对开放科学和教育的贡献,让更多人能够接触到高质量的AI/NLP学习材料,对初学者和研究人员都具有重要意义。(来源:stanfordnlp)
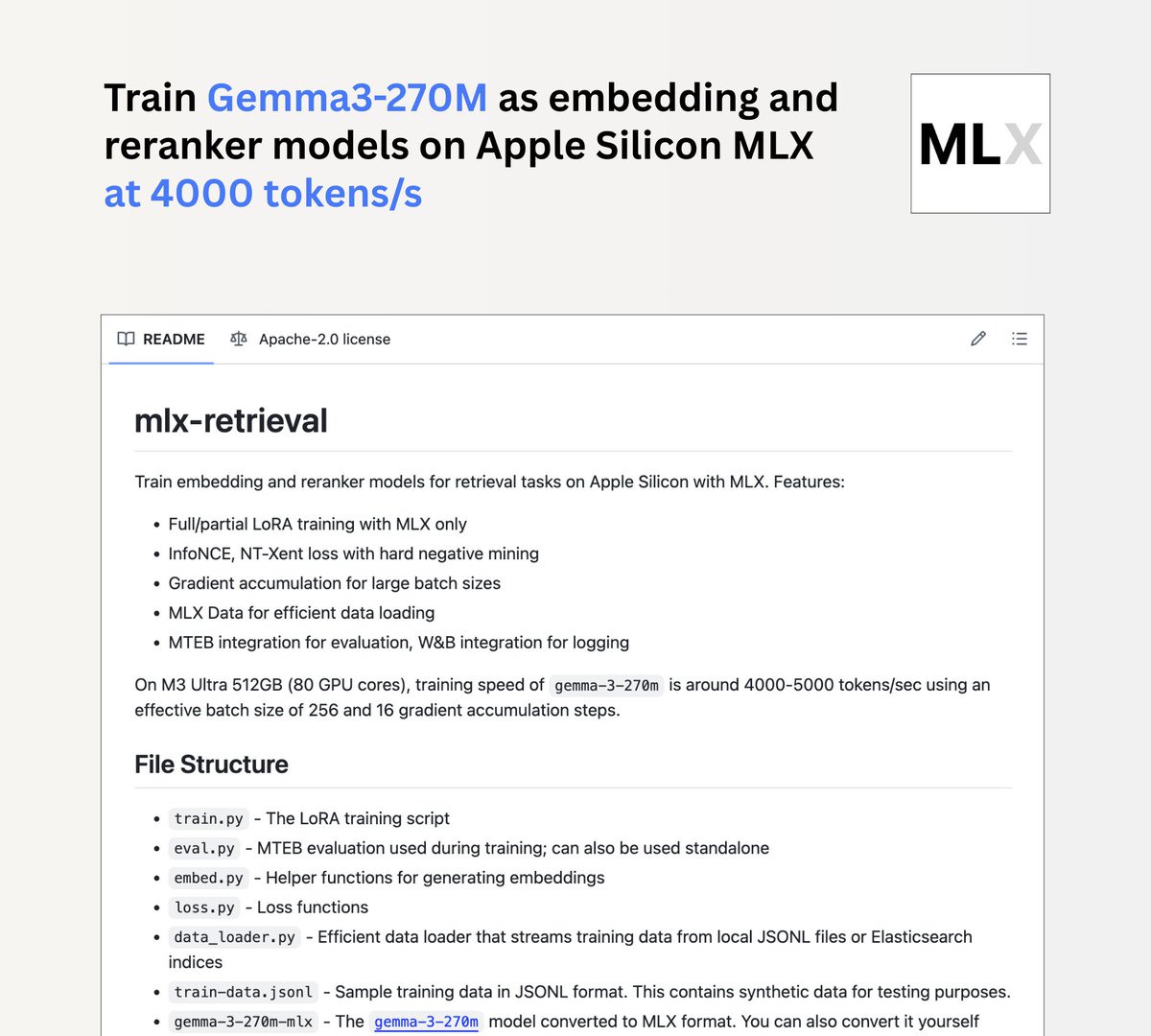
Jina AI推出mlx-retrieval项目,Mac M芯片可本地训练Gemma3 270m : Jina AI发布mlx-retrieval项目,使得Mac M芯片用户能够本地训练Gemma3 270m模型,作为多语言嵌入或重排序模型。该项目在M3 Ultra上实现了4000 tokens/秒的训练速度,并集成了LoRA、InfoNCE、梯度累积和流式数据加载器等标准实践,以及MTEB评估,为本地AI模型开发提供了高效且可用的解决方案。(来源:awnihannun)
Reddit用户分享LLM低比特模型原理,从1比特到FP16的量化指南 : Reddit用户详细解释了低比特模型并非“脑残”,而是通过智能牺牲信息实现模型小型化。文章从1比特meme、2比特TL;DR、4比特概述、8比特深入阅读到FP16研究,逐步解析LLM量化原理,包括混合精度、校准和新架构(如BitNet)等关键技术。这为理解LLM如何在资源受限设备上保持性能提供了深入视角,并分享了相关学习资源。(来源:Reddit r/LocalLLaMA)

Reddit用户探讨图像相似性与I-JEPA模型 : Reddit用户分享了关于使用I-JEPA进行图像相似性研究的文章,涵盖了纯PyTorch和Hugging Face两种实现方式。I-JEPA作为一种自监督学习模型,在图像特征提取和相似性度量方面展现出潜力,为计算机视觉领域的图像检索、分类等任务提供了新的方法。(来源:Reddit r/deeplearning)

💼 商业
OpenAI CFO首次公开讨论IPO可能性,并考虑出售AI基础设施服务 : OpenAI首席财务官Sarah Friar首次公开表示,公司未来可能进行IPO,并透露7月单月收入已突破10亿美元。她指出,OpenAI正面临算力短缺的巨大压力,并考虑效仿亚马逊,将设计和建设AI数据中心的专业知识转化为新的收入来源,向其他企业出售AI基础设施服务。Friar强调,尽管与微软的合作关系正在变化,但双方在知识产权上深度绑定,微软仍将是未来多年的关键合作伙伴。(来源:36氪,36氪)
Meta被曝冻结AI部门招聘,并禁止内部人员流动,引发“AI泡沫”担忧 : 华尔街日报报道称,Meta已冻结其新成立的“Meta超级智能实验室”(MSL)的招聘,并禁止该部门员工跨团队调动。此举正值Meta斥巨资从竞争对手挖角50多名AI研究人员和工程师之后,引发了对“AI泡沫”的担忧。Meta发言人称此为“基本的组织规划”,但有消息指出,新老员工间因薪酬差异产生摩擦。此次冻结与Meta AI部门的第四次重组密切相关,将MSL拆分为四个独立小组,显示出公司在AI战略上的调整和对成本效益的考量。(来源:MIT Technology Review,36氪,36氪)
AI应用部署成本水涨船高,开发者抱怨利润受挤压 : 尽管AI巨头曾下调API调用价格,但企业部署先进AI的成本在2025年却停滞不降,甚至部分模型大幅涨价。知情人士透露,财务软件开发商Intuit的AI相关Azure账单预计将飙升至3000万美元。AI编程工具Cursor也开始按实际使用量追加收费,引发用户社区不满。这导致AI应用开发商利润空间受挤压,而上游模型商和云厂商(如微软Azure)则逆势受益,其AI代理相关token生成量同比增长7倍。开发者担忧寡头垄断形成,呼吁行业关注成本问题。(来源:36氪)
🌟 社区
社交媒体热议AI对就业、技能和信任的影响 : 社交媒体上关于AI的讨论日益增多,主要围绕AI对就业市场的冲击、人类技能的退化以及对AI的信任问题。有人认为AI是裁员的借口,短期内不会大规模取代工作,但长期来看会重塑任务。柳叶刀研究警示AI辅助可能侵蚀医生独立诊疗技能,而MIT研究则显示患者即便在建议有误时也更信任AI而非医生。此外,AI情感咨询的个人经历引发对AI依赖和人机关系的深思,以及AWS CEO对AI取代初级员工的负面评价,都反映出社区对AI双刃剑效应的复杂情绪。(来源:mathemagic1an,36氪,36氪,36氪,Reddit r/artificial,Reddit r/artificial,Reddit r/ArtificialInteligence)

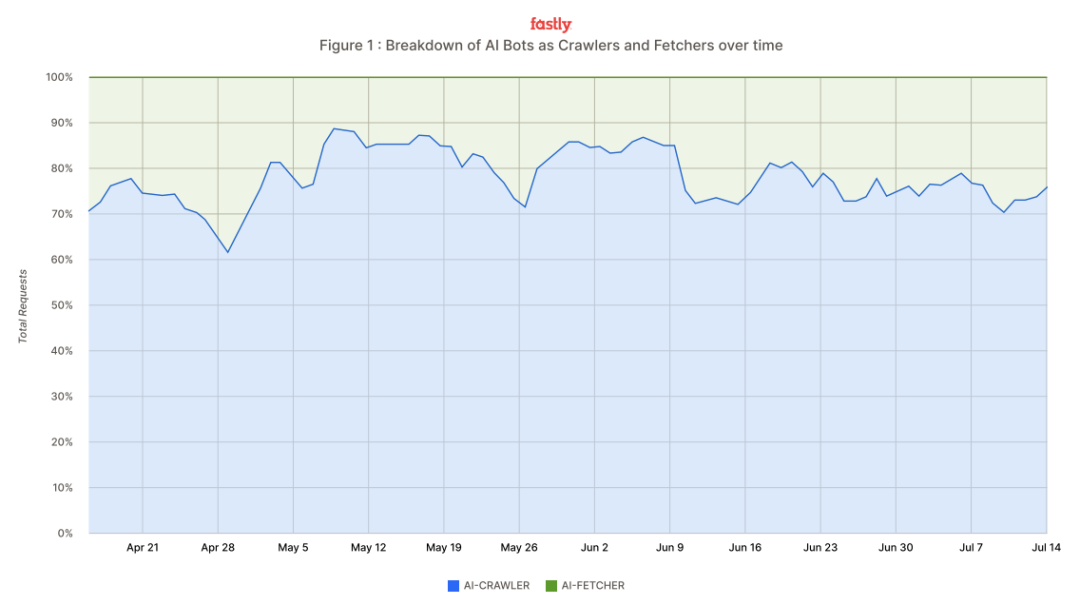
AI爬虫流量激增,Meta、Google、OpenAI被点名,开发者祭出反爬“武器” : 云服务巨头Fastly报告指出,AI爬虫正以每分钟39,000个请求的峰值速度冲击互联网,占AI机器人流量的80%,其中Meta、Google和OpenAI三家占总爬虫流量的95%。这些爬虫抓取网站内容用于模型训练和实时信息检索,导致网站服务器压力剧增,运营成本上升。开发者开始反击,采用“工作量证明”工具Anubis、自制“ZIP炸弹”以及游戏化验证码等奇招,试图抑制未经授权的爬取行为,保护自身内容和基础设施。(来源:36氪)
社交媒体讨论AI在代码RAG、编程辅助和Agent能力中的应用与挑战 : 社交媒体上,开发者们正热议AI在代码RAG(检索增强生成)中的问题,如代码文件过大、更新频繁及精确检索需求。同时,AI在编程辅助方面展现出巨大潜力,如GPT-5能将Android控制器移植到iOS,以及Figma与Cursor AI的集成。也有讨论指出,AI编程工具(如Claude Code)的使用效率取决于用户认知,认知未到位再多工具也枉然。此外,对Agentic能力的关注日益增加,如多步任务处理、工具调用和长期记忆,但其可靠性、成本和与人类协作的平衡仍是挑战。(来源:dotey,gfodor,gfodor,gfodor,BrivaelLp,pierceboggan,nptacek,HamelHusain,imjaredz)
AI搜索模式变革引发对传统广告生态的担忧 : 谷歌AI搜索功能(AI Overviews)用户量激增,其对话式搜索模式在美国和印度月活破亿,引发了对传统搜索广告生态的担忧。AI搜索直接生成答案,减少用户点击链接的需求,可能切断“搜索-流量-广告-变现”的良性循环。传统CPC(点击付费)模式面临颠覆,未来可能转向CPS(成交付费)模式。这一变革对传统搜索厂商构成挑战,也促使字节、腾讯等国内厂商积极探索AI助理重塑搜索体验,寻找下一代商业模式。(来源:36氪)
AI眼镜“难戴”却吸引厂商持续投入,市场教育与技术挑战并存 : 尽管苹果Vision Pro销量不佳,小米AI眼镜用户反馈一般,AI眼镜仍吸引厂商持续投入。市场预测2028年AR/AI眼镜出货量将突破1亿台,空间智能交互市场规模达万亿元。厂商认为AI大模型与AR技术融合将催生新一代人机交互,解决传统终端痛点。然而,AI眼镜面临电量焦虑、交互不人性化和摄像头引发的信任危机等挑战。厂商持续投入旨在解决技术难题、抢占未来AI入口,并利用硬件销售及内容订阅探索商业化路径。(来源:36氪)

人形机器人“具身智能”的幕后:仍需大量人工干预 : 社交媒体和新闻报道揭示,尽管具身智能和人形机器人技术快速发展,但其在实际应用中仍离不开大量人工干预。机器人运动会上的“狂奔”背后,往往有工程师的远程操控。自动驾驶、仓储物流等领域也存在“影子劳工”模式,人类通过远程操作为机器人“注入灵魂”,弥补其在复杂环境下的不足。这种人机混合模式虽成本高昂,却是现阶段教会机器人本领的有效路径,也引发了对自动化提效优势和工人转型待遇的讨论。(来源:Ronald_vanLoon,Ronald_vanLoon,Ronald_vanLoon,Ronald_vanLoon,36氪)

Reddit社区热议GPT-5数学能力与AI模型基准测试的局限性 : Reddit社区就GPT-5的“新数学”能力展开热议,有用户指出GPT-5得出的证明与现有论文不同,但也有人质疑其是否真的“新颖”或只是在搜索后整合信息。此外,DeepSeek V3.1的基准测试结果也引发了对LLM基准测试有效性的讨论,许多用户认为基准测试已不足以反映模型的真实能力和“Vibe”,更倾向于个人实测体验。这反映出社区对AI模型实际性能和评估方法的持续关注和争议。(来源:Reddit r/ChatGPT,Reddit r/LocalLLaMA)

AI炒股热潮兴起,年轻人将其视为“投资顾问” : 随着中国股市向好和国产大模型火爆,越来越多年轻人开始尝试将AI作为“投资理财顾问”进行炒股。有用户通过AI选股和选基金获得浮盈,认为AI能整合新闻和研报,快速筛选概念股。然而,也有用户指出AI输出质量高度依赖数据和提示词,且时常产生幻觉。部分大模型已出于合规停止推荐个股,并强调投资风险。券商也纷纷推出AI投顾工具,提供AI选股、持股优化等付费服务,但均附带免责声明,提示投资者风险自担。(来源:36氪)
Reddit用户讨论ChatGPT是否被训练于完整书籍 : Reddit社区用户就ChatGPT是否被训练于完整书籍展开讨论。一些用户认为LLM被训练于所有可访问的文本,包括完整书籍,但它们并非“复制粘贴”或“记忆”书籍内容,而是学习词语模式和概念关系。另一些用户则认为ChatGPT只了解书籍摘要,或在回答时会通过网络查找信息。讨论反映了公众对LLM内部工作机制的困惑,以及对AI知识来源和“理解”能力的探究。(来源:Reddit r/ArtificialInteligence)
AI视频内容创作:从“荒谬”到“主流”的演变路径 : 社交媒体讨论指出,AI视频内容正经历从“荒谬、尴尬、有趣”到“危险”再到“普遍、不言而喻”的演变路径。目前,AI视频仍带有明显的生成痕迹,但随着技术发展,其质量将迅速提升。未来,AI视频可能引发关于“视频制作优势消失”的争议,但最终将成为主流,如同历史上任何一项颠覆性技术一样,被广泛接受和使用。(来源:BrivaelLp)
💡 其他
乌克兰Starlink维修店:民间力量在战时科技保障中的关键作用 : 乌克兰最大的Starlink维修店,由Oleh Kovalskyy领导的民间团队,在俄乌战争中修复和定制了超过15,000台Starlink终端。尽管Starlink设备质量受诟病且存在埃隆·马斯克政策变化的不确定性,但该民间网络通过高效、灵活的运作,为乌克兰军队提供了关键的通信支持,弥补了官方流程的缓慢。这一案例凸显了在极端环境下,民间科技力量在保障关键基础设施运行和提升军事效能方面的不可或缺性。(来源:MIT Technology Review)

AI之父明斯基的“反对者”Warren Brodey逝世,享年101岁 : AI先驱Warren Brodey于101岁高龄逝世。这位精神病学家出身的思想家,早在AI早期便在MIT探索技术如何解放人类潜能。他凭借控制论背景,对复杂系统和响应式技术进行了开创性研究,并主张AI应增强而非取代人类。Brodey不认同马文·明斯基基于海量数据的AI路径,一生都在倡导一种“柔性”的、能激发人类创造力的AI,并警惕资本主义可能将技术导向僵化。(来源:36氪)

Pewdiepie搭建160GB显存AI主机,或将开启本地LLM新篇章 : 知名YouTube博主Pewdiepie搭建了一台配备160GB VRAM的AI主机,并计划在其上运行Llama 3 70B模型。这一举动引发了Reddit社区的热烈讨论,许多人对Pewdiepie涉足本地LLM领域感到惊讶,并猜测这可能预示着本地AI模型将进一步走向主流。尽管配置非传统,但其对CPU卸载和未来内存升级的潜力,显示出个人用户对高性能本地AI应用的浓厚兴趣。(来源:Reddit r/LocalLLaMA)
