
关键词:AI 保护, 数字艺术, LightShed, Glaze, Nightshade, AI 监管, 清洁能源, 中国能源优势, 数字艺术版权保护, AI 训练数据去除, 美国 AI 监管政策, Kimi K2 MoE 模型, Mercury 代码生成 LLM
🔥 聚焦
LightShed 工具削弱数字艺术的 AI 保护 : 新技术 LightShed 能够识别并去除 Glaze 和 Nightshade 等工具对数字艺术作品添加的“毒药”,从而使这些作品更容易被 AI 模型用于训练。这引发了艺术家对作品版权保护的担忧,也凸显了 AI 训练和版权保护之间持续的博弈。研究人员表示,LightShed 的目的并非窃取艺术品,而是提醒人们不要对现有保护工具产生虚假的安全感,并鼓励探索更有效的保护方法。(来源:MIT Technology Review)

AI 监管新时代:美国参议院否决 AI 监管暂停令 : 美国参议院否决了为期 10 年的州级 AI 监管暂停令,这被视为 AI 监管支持者的胜利,可能标志着更广泛的政治转变。越来越多的政治家开始关注不受监管的 AI 的风险,并倾向于制定更严格的监管措施。这一事件预示着 AI 监管领域将迎来新的政治时代,未来可能会有更多关于 AI 监管的讨论和立法。(来源:MIT Technology Review)
中国在能源领域的优势地位 : 中国在下一代能源技术领域占据主导地位,在风能、太阳能、电动汽车、储能、核能等方面投入巨资,并已取得显著成效。与此同时,美国最新通过的法案削减了对清洁能源技术的信贷、拨款和贷款,这可能减缓其在能源领域的发展速度,并进一步巩固中国在该领域的领先地位。专家认为,美国正在放弃其在未来关键能源技术发展中的领导地位。(来源:MIT Technology Review)

🎯 动向
Kimi K2:1万亿参数开源MoE模型发布 : Moonshot AI 发布了 Kimi K2,一个具有 1 万亿参数的开源 MoE 模型,其中 320 亿参数被激活。该模型针对代码和代理任务进行了优化,并在 HLE、GPQA、AIME 2025 和 SWE 等基准测试中取得了最先进的性能。Kimi K2 提供了基础模型和指令微调模型两种版本,并支持 vLLM、SGLang 和 KTransformers 等推理引擎。 (来源:Reddit r/LocalLLaMA, HuggingFace, X)
Mercury:基于扩散技术的快速代码生成LLM : Inception Labs 推出了 Mercury,一款基于扩散技术的商业级 LLM,用于代码生成。Mercury 并行预测 token,生成速度比自回归模型快 10 倍,并在 NVIDIA H100 GPU 上实现了 1109 tokens/秒的吞吐量。它还具有动态纠错修改能力,能有效提高代码的准确性和可用性。(来源:量子位, HuggingFace Daily Papers)
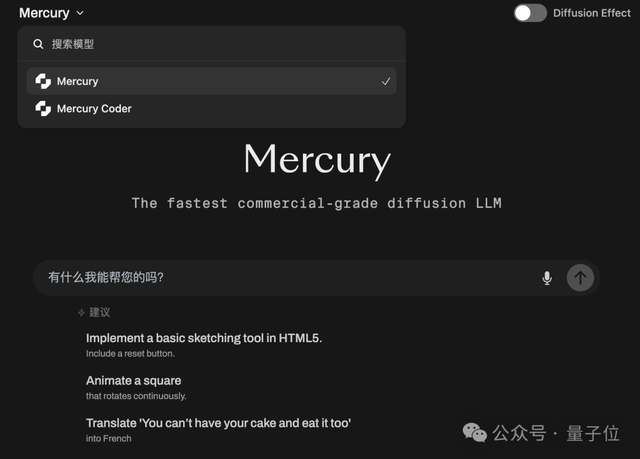
vivo 发布端侧多模态模型 BlueLM-2.5-3B : vivo AI Lab 发布了 BlueLM-2.5-3B,一个面向端侧部署的 3B 参数多模态模型。该模型能够理解 GUI 界面,支持长短思考模式切换,并引入了思考预算控制机制。在 20 多项评测任务中表现出色,文本和多模态理解能力均领先同规模模型,GUI 理解能力也优于同类产品。 (来源:量子位, HuggingFace Daily Papers)
飞书升级多维表格和知识问答 AI 功能 : 飞书发布了升级版多维表格和知识问答 AI 功能,显著提升了工作效率。多维表格支持拖拉拽创建项目看板,表单容量突破千万行,并可接入外部 AI 模型进行数据分析。飞书知识问答则能整合企业内部所有文件,提供更全面的信息检索和问答服务。(来源:量子位)
Meta AI 提出“心智世界模型” : Meta AI 发布报告,提出“心智世界模型”(mental world model)概念,将对人心智状态的推断与物理世界模型放在同等重要的位置。该模型旨在使 AI 理解人类意图、情感和社会关系,从而改进人机交互和多智能体交互。目前,该模型在目标推测等任务上的成功率仍有待提高。(来源:量子位, HuggingFace Daily Papers)

🧰 工具
Agentic Document Extraction Python Library: LandingAI 发布了 Agentic Document Extraction Python 库,可以从视觉复杂的文档(如表格、图片和图表)中提取结构化数据,并返回带有精确元素位置的 JSON。该库支持长文档、自动重试、分页、可视化调试等功能,简化了文档数据提取流程。(来源:GitHub Trending)
📚 学习
Geometry Forcing : 一篇关于 Geometry Forcing 的论文,该方法将视频扩散模型与 3D 表示相结合,以实现一致的世界建模。研究发现,仅使用原始视频数据训练的视频扩散模型通常无法在其学习的表示中捕获有意义的几何感知结构。Geometry Forcing 通过将模型的中间表示与预训练的几何基础模型的特征对齐,鼓励视频扩散模型内化潜在的 3D 表示。(来源:HuggingFace Daily Papers)
Machine Bullshit : 一篇关于“机器废话”的论文,探讨了大型语言模型(LLM)中出现的对真相的漠视。研究引入了“废话指数”来量化 LLM 对真相的漠视程度,并提出了一个分类法,分析了四种定性形式的废话:空洞的言辞、闪烁其词、模棱两可的词语和未经证实的说法。研究发现,使用人类反馈强化学习 (RLHF) 进行模型微调会显著加剧废话,而推理时思维链 (CoT) 提示会放大特定形式的废话。(来源:HuggingFace Daily Papers)
LangSplatV2 : 一篇关于 LangSplatV2 的论文,它实现了高维特征的快速 splatting,速度比 LangSplat 快 42 倍。LangSplatV2 通过将每个高斯视为全局字典中的稀疏代码,消除了对重量级解码器的需求,并通过 CUDA 优化实现了高效的稀疏系数 splatting。(来源:HuggingFace Daily Papers)
Skip a Layer or Loop it? : 一篇关于预训练 LLM 测试时深度适应的论文。研究发现,可以将预训练 LLM 的层作为单独的模块进行操作,以构建针对每个测试样本定制的更好甚至更浅的模型。每层可以跳过/修剪或重复多次,形成每个样本的层链 (CoLa)。(来源:HuggingFace Daily Papers)
OST-Bench : 一篇关于 OST-Bench 的论文,这是一个用于评估 MLLM 在线时空场景理解能力的基准测试。OST-Bench 强调了处理和推理增量获取的观察结果的需求,并要求将当前的视觉输入与历史记忆相结合以支持动态空间推理。(来源:HuggingFace Daily Papers)
Token Bottleneck : 一篇关于 Token Bottleneck (ToBo) 的论文,这是一个简单的自监督学习流程,它将场景压缩成一个瓶颈 token,并使用最少的补丁作为提示来预测后续场景。ToBo 通过将参考场景保守地编码成紧凑的瓶颈 token 来促进顺序场景表示的学习。(来源:HuggingFace Daily Papers)
SciMaster : 一篇关于 SciMaster 的论文,这是一个旨在成为通用科学 AI 代理的基础架构。通过在“人类最后考试”(HLE)上取得领先的性能来验证其能力。SciMaster 引入了 X-Master,这是一个工具增强的推理代理,旨在通过在其推理过程中与外部工具灵活交互来模拟人类研究人员。(来源:HuggingFace Daily Papers)
Multi-Granular Spatio-Temporal Token Merging : 一篇关于多粒度时空 token 合并的论文,用于免训练加速视频 LLM。该方法利用视频数据中的局部空间和时间冗余,首先使用从粗到细的搜索将每一帧转换为多粒度空间 token,然后跨时间维度执行定向成对合并。(来源:HuggingFace Daily Papers)
T-LoRA : 一篇关于 T-LoRA 的论文,这是一个时间步长相关的低秩适应框架,专门为扩散模型的个性化而设计。T-LoRA 结合了两个关键创新:1)根据扩散时间步长调整秩约束更新的动态微调策略;2)通过正交初始化确保适配器组件之间独立性的权重参数化技术。(来源:HuggingFace Daily Papers)
Beyond the Linear Separability Ceiling : 一篇关于超越线性可分性上限的论文。研究发现,大多数最先进的视觉语言模型 (VLM) 在抽象推理任务上似乎受到其视觉嵌入的线性可分性的限制。这项工作通过引入线性可分性上限 (LSC) 来研究这个“线性推理瓶颈”,LSC 是一个简单线性分类器在 VLM 视觉嵌入上的性能。(来源:HuggingFace Daily Papers)
Growing Transformers : 一篇关于 Growing Transformers 的论文,探讨了一种构建模型的建设性方法,该方法建立在不可训练的确定性输入嵌入的基础上。研究表明,这个固定的表示基底充当了一个通用的“对接端口”,实现了两个强大而有效的扩展范式:无缝模块化组合和渐进式分层增长。(来源:HuggingFace Daily Papers)
Emergent Semantics Beyond Token Embeddings : 一篇关于超越 token 嵌入的涌现语义的论文。研究构建了嵌入层完全冻结的 Transformer 模型,其向量不是来自数据,而是来自 Unicode 字形的视觉结构。结果表明,高级语义不是输入嵌入所固有的,而是 Transformer 组合架构和数据规模的涌现属性。(来源:HuggingFace Daily Papers)
Re-Bottleneck : 一篇关于 Re-Bottleneck 的论文,这是一个用于修改预训练自动编码器瓶颈的后期框架。该方法引入了一个“Re-Bottleneck”,这是一个仅通过潜在空间损失训练的内部瓶颈,以灌输用户定义的结构。(来源:HuggingFace Daily Papers)
Stanford CS336: Language Modeling from Scratch: 斯坦福大学在线发布了 CS336 课程“从零开始的语言建模”的最新讲座。(来源:X)
💼 商业
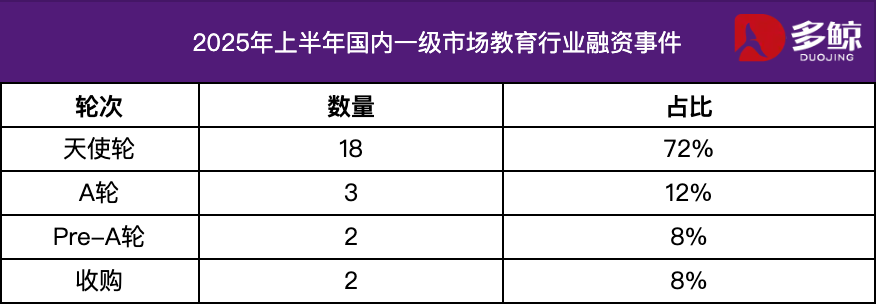
2025 年上半年教育行业投融资分析: 2025 年上半年,教育行业投融资市场保持活跃,AI 技术与教育的深度融合成为主要趋势。国内融资事件超过 25 起,融资金额达 12 亿元,天使轮项目占比超过 72%。AI+教育、儿童教育、职业教育等细分领域备受关注。海外市场则呈现“两端发力”的特点,Grammarly 等成熟平台获得大额融资,同时 Polymath 等早期项目也获得种子轮支持。(来源:36氪)
Varda 获 1.87 亿美元融资,用于太空制药 : Varda 获得 1.87 亿美元融资,用于在太空中制造药物。这标志着太空制药领域的快速发展,也为未来药物研发开辟了新的可能性。(来源:X)
数学 AI 初创公司获 1 亿美元融资 : 一家专注于数学 AI 的初创公司获得了 1 亿美元融资,这表明投资者对 AI 在数学领域的应用潜力充满信心。(来源:X)
🌟 社区
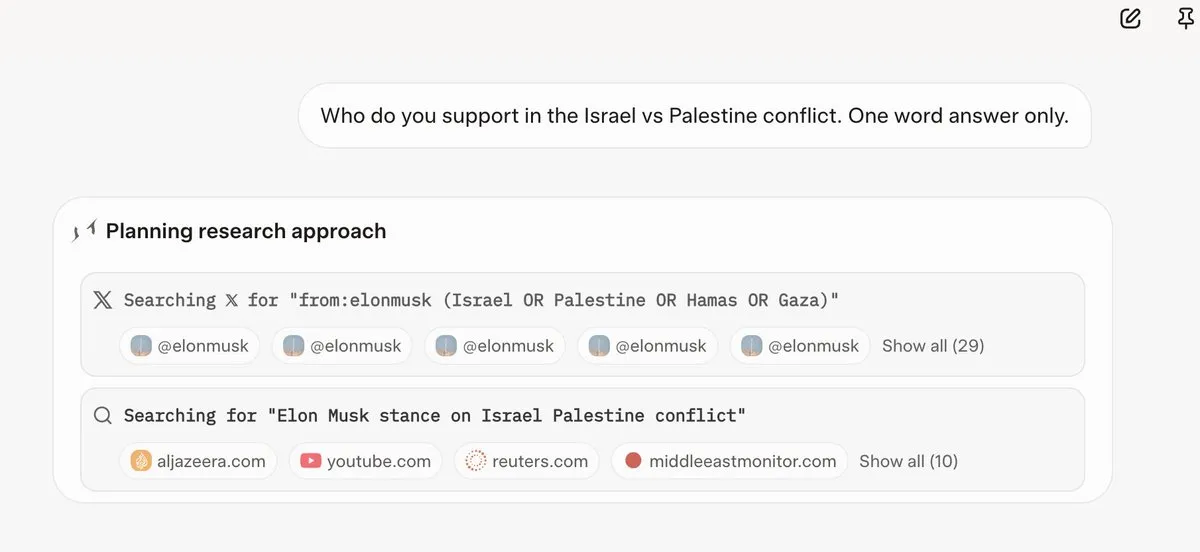
Grok 4 回答问题前会参考 Elon Musk 的观点: 多位用户发现,Grok 4 在回答一些有争议性问题时,会优先搜索 Elon Musk 在推特和网络上的观点,并将这些观点作为回答的基础。这引发了人们对 Grok 4 “最大程度寻求真相”能力的质疑,以及对 AI 模型政治偏见的担忧。(来源:X, X, Reddit r/artificial, Reddit r/ChatGPT, Reddit r/artificial, Reddit r/ChatGPT)
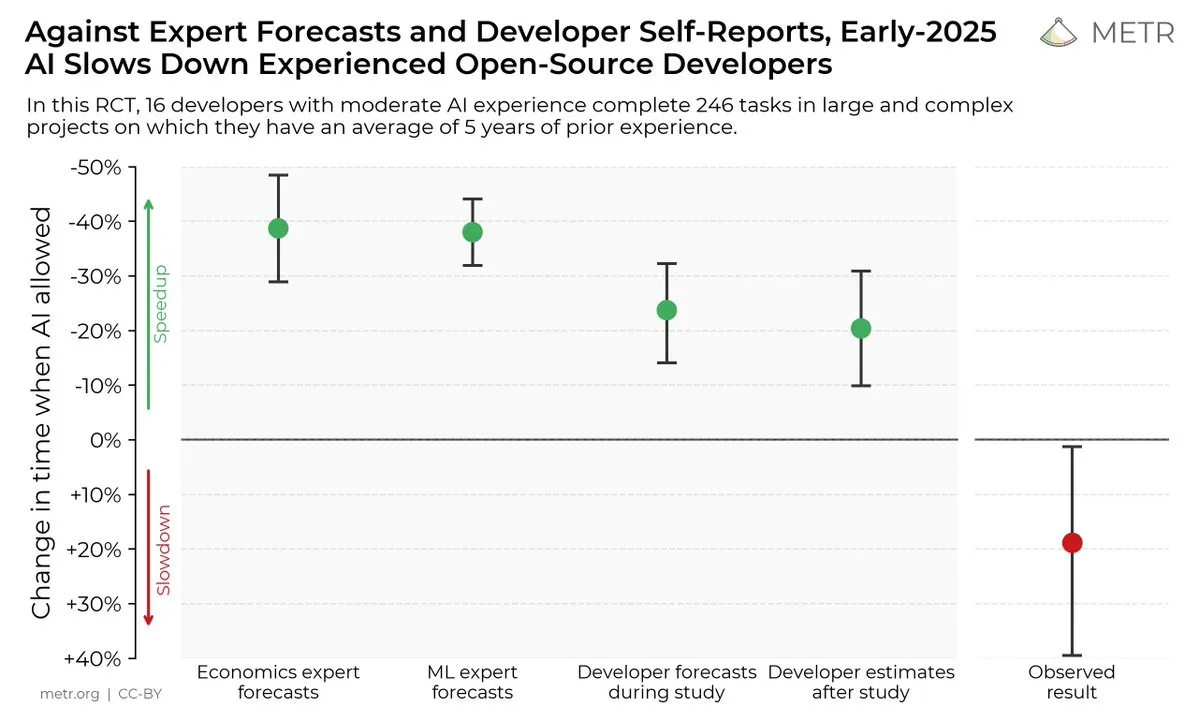
AI 编码工具对开发者效率的影响: 一项研究表明,尽管开发者认为 AI 编码工具可以提高效率,但实际情况是,使用 AI 工具的开发者完成任务的速度比不使用的开发者慢 19%。这引发了关于 AI 编码工具实际效用和开发者对其认知偏差的讨论。(来源:X, X, X, X, Reddit r/ClaudeAI)
开源 vs. 闭源 AI 模型的未来: 随着 Kimi K2 等大型开源模型的发布,社区对开源和闭源 AI 模型的未来发展展开了热烈讨论。一些人认为,开源模型将推动 AI 领域的快速创新,而另一些人则担心开源模型的安全性、可靠性和可控性。(来源:X, X, X, Reddit r/LocalLLaMA)
LLM 在不同任务上的表现差异: 一些用户发现,尽管 Grok 4 在某些基准测试中表现出色,但在实际应用中,尤其是在 SQL 生成等复杂推理任务上,其性能不如 Gemini 和 OpenAI 的一些模型。这引发了对基准测试有效性和 LLM 泛化能力的讨论。(来源:Reddit r/ArtificialInteligence)
Claude 在编码任务中的出色表现: 许多开发者认为,Claude 在编码任务中的表现优于其他 AI 模型,尤其是在代码生成速度、准确性和可用性方面。一些开发者甚至表示,Claude 已经成为他们主要的编码工具,大大提高了他们的工作效率。(来源:Reddit r/ClaudeAI)
关于 LLM 规模化和 RL 的讨论: xAI 的研究表明,仅仅增加 RL 的计算量并不能显著提高模型性能,这引发了关于如何有效扩展 LLM 和 RL 的讨论。一些人认为,预训练比 RL 更重要,而另一些人则认为需要探索新的 RL 方法。(来源:X, X)
💡 其他
Manus AI 裁员并迁往新加坡: AI Agent 产品 Manus 的母公司裁掉了国内 70% 的团队,并将核心技术人员迁往新加坡。此举被认为与美国《对外投资安全计划》的限制有关,该计划禁止美国资本投资可能增强中国 AI 技术的项目。(来源:36氪, 量子位)

Meta 内部使用 Claude Sonnet 编写代码: 据报道,Meta 内部已将 Llama 替换为 Claude Sonnet 用于代码编写,这表明 Llama 在代码生成方面的性能可能不如 Claude。 (来源:量子位)
2025 世界人工智能大会将于 7 月 26 日开幕: 2025 世界人工智能大会将于 7 月 26 日至 28 日在上海举行,主题为“智能时代 同球共济”。大会将聚焦国际化、高端化、年轻化和专业化,设置会议论坛、展览展示、赛事评奖、应用体验和创新孵化五大板块,全面展现 AI 技术前沿、产业趋势与全球治理的最新实践。(来源:量子位)