
关键词:大型语言模型, 推理能力, 模式匹配, 思维幻觉, 苹果研究, 通用人工智能, AI检测器, AI监管, Log-Linear Attention机制, 华为盘古MoE模型, ChatGPT高级语音模式, TensorZero框架, Anthropic CEO监管观点
🔥 聚焦
苹果研究揭示“思维幻觉”:当前“推理”模型并非真正思考,更依赖模式匹配: 苹果公司最新研究论文《思维的幻觉:通过问题复杂性视角理解推理模型的优势与局限性》指出,当前号称具备“推理”能力的大型语言模型(如Claude、DeepSeek-R1、GPT-4o-mini等),其表现更像是高效的模式匹配器而非真正意义上的逻辑推理。研究发现,这些模型在处理训练分布之外或复杂度较高的问题时,性能会显著下降,甚至在简单问题上也会因“过度思考”而犯错,且难以纠正早期错误。该研究强调,模型所谓的“思考”过程(如思维链)在面对新颖或复杂任务时往往会失效,表明我们离通用人工智能(AGI)可能比预期的更远。 (来源: machinelearning.apple.com, TheTuringPost, mervenoyann, Reddit r/artificial, Reddit r/LocalLLaMA, Reddit r/MachineLearning)

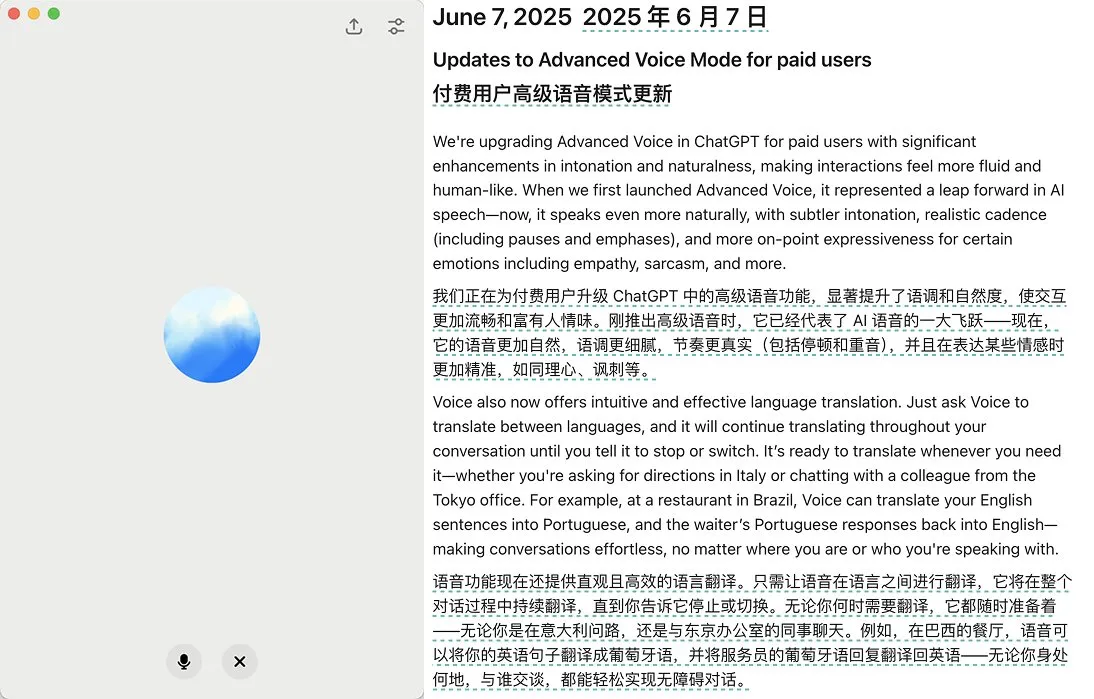
OpenAI推出ChatGPT高级语音模式更新,提升自然度和翻译功能: OpenAI针对ChatGPT的付费用户推出了高级语音模式(Advanced Voice Mode)的重大更新。新版本大幅提升了语音的自然流畅度,使其听起来更像人类而非AI助手。此外,更新还改进了语言翻译性能和指令遵循能力,并新增了翻译模式,用户可以让ChatGPT在整个对话过程中持续翻译双方的对话,直至被要求停止。这一更新旨在让语音交互更轻松自然,提升用户体验。 (来源: juberti, Plinz, op7418, BorisMPower)
AI检测器被指失效且可能助长AI内容“隐身”: 社交媒体和技术论坛上出现广泛讨论,指出当前的AI内容检测工具不仅效果不佳,甚至可能在无意中帮助AI生成的内容变得更难被察觉。许多用户和专家认为,这些检测器主要基于语言模式和特定词汇(如学术术语“delve”)进行判断,而非真正理解内容来源。由于存在误判风险(可能对学生等群体造成不公)以及AI模型本身也在进化以规避检测,这些工具的可靠性受到严重质疑。有观点认为,AI检测器的存在反而促使AI生成内容时避免某些易被标记的特征,从而更像人类写作。 (来源: Reddit r/ArtificialInteligence, sytelus)

Anthropic CEO呼吁加强AI公司透明度和责任监管: Anthropic公司CEO在《纽约时报》发表观点文章,强调不能放松对AI公司的监管,特别是需要提高其透明度并追究责任。这一观点在AI行业快速发展、能力日新月异的背景下显得尤为重要,呼应了社会对AI潜在风险和道德伦理的关切。文章认为,随着AI技术影响力的扩大,确保其发展符合公共利益、避免滥用至关重要,而这需要行业自律与外部监管共同作用。 (来源: Reddit r/artificial)

🎯 动向
Jeff Dean展望AI未来:专用硬件、模型进化与科学应用: 谷歌AI负责人Jeff Dean在红杉资本AI Ascent活动中,分享了他对AI未来发展的看法。他强调了专用硬件(如TPU)对AI进步的重要性,并讨论了模型架构的演进趋势。Dean还展望了计算基础设施的未来形态,以及AI在科学研究等领域的巨大应用潜力,认为AI将成为推动科学发现的关键工具。 (来源: TheTuringPost)

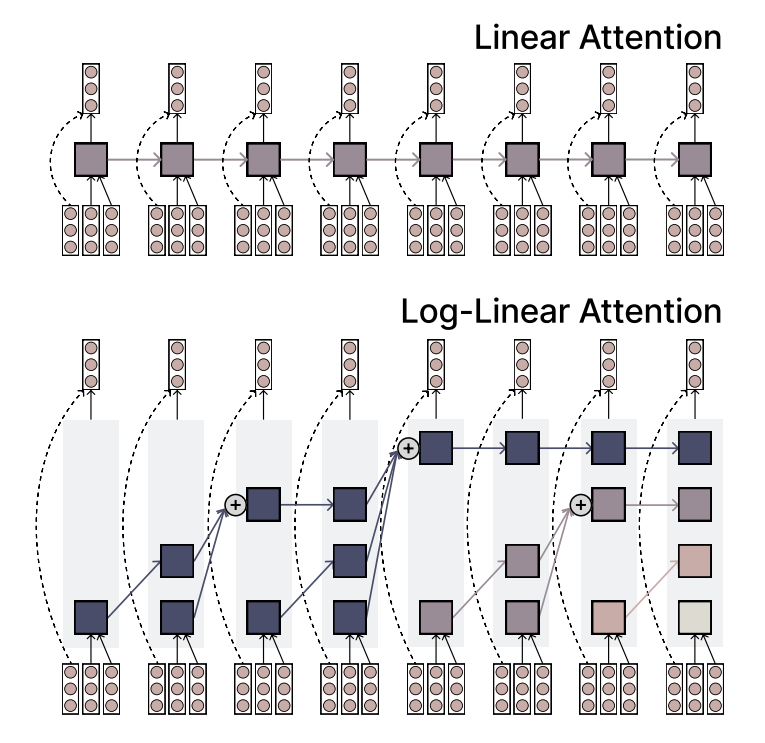
MIT提出Log-Linear Attention机制,兼顾效率与表达力: MIT研究人员提出了一种名为Log-Linear Attention的新型注意力机制。该机制旨在结合线性注意力(Linear Attention)的高效性与Softmax注意力的强表达能力。其核心特点是使用少量但随序列长度对数增长的记忆槽(memory slots),从而在处理长序列时保持较低的计算复杂度,同时捕捉关键信息。 (来源: TheTuringPost)
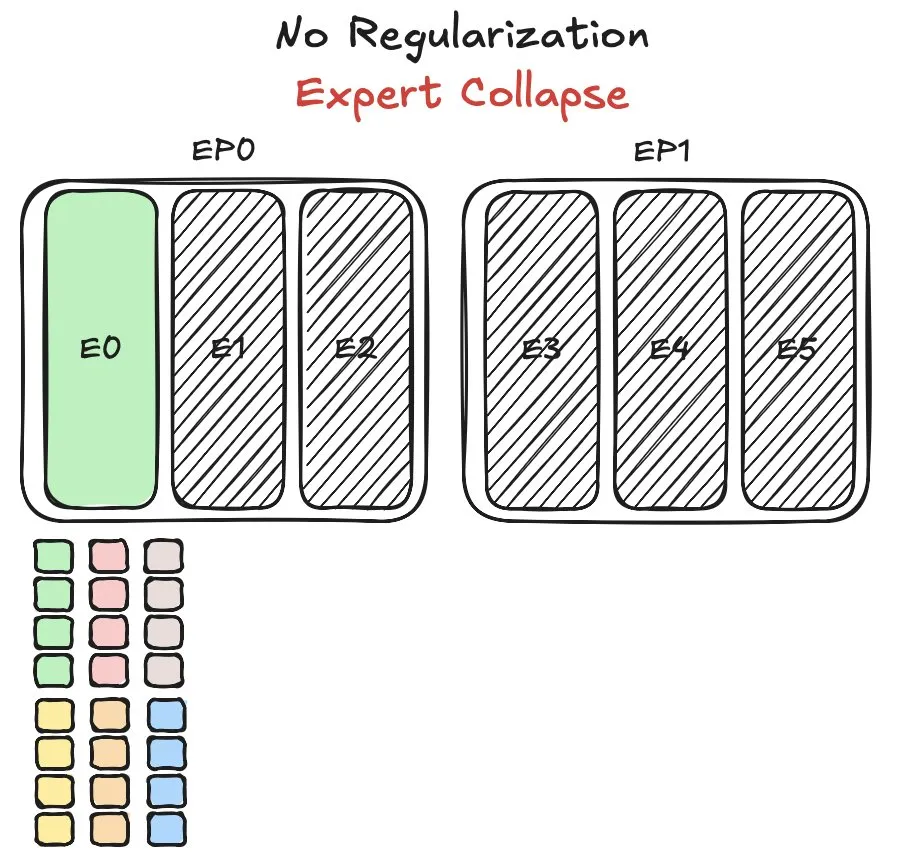
华为盘古MoE模型面临专家负载均衡挑战,提出新方法: 华为在训练其混合专家(MoE)模型盘古Ultra MoE时,遇到了专家负载均衡的关键问题。专家负载均衡需要在训练动态和系统效率之间进行权衡。华为针对此问题提出了新的解决方法,旨在优化MoE模型中不同专家模块的任务分配和计算负载,以提升训练效率和模型性能。相关研究已发布论文。 (来源: finbarrtimbers)
NVIDIA发布Cascade Mask R-CNN Mamba Vision模型,聚焦目标检测: NVIDIA在Hugging Face上发布了名为 cascade_mask_rcnn_mamba_vision_tiny_3x_coco 的新模型。从名称判断,该模型专为目标检测任务设计,并可能融合了Cascade R-CNN架构与Mamba(一种状态空间模型)视觉技术,旨在提升目标检测的精度和效率。 (来源: _akhaliq)
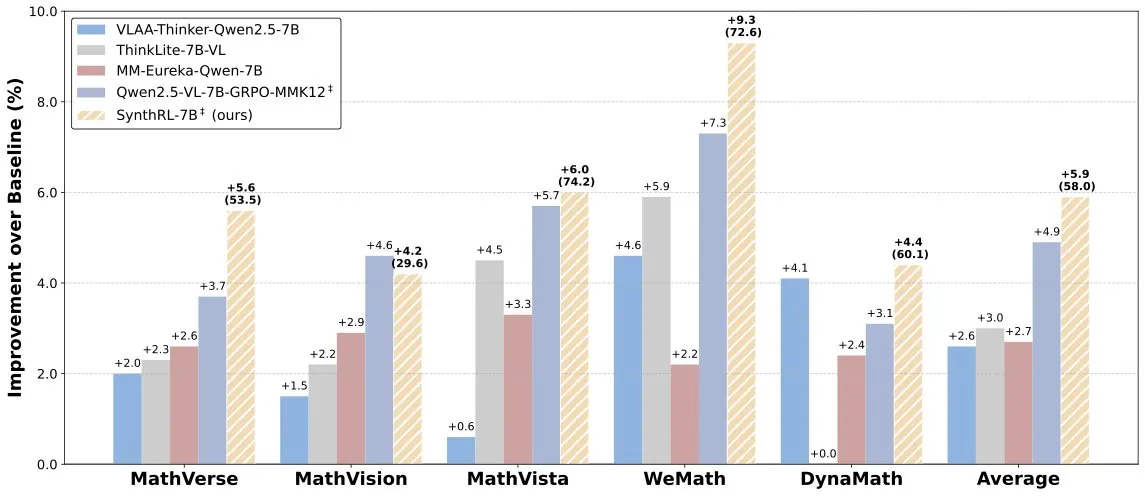
SynthRL模型发布:通过可验证数据合成实现可扩展视觉推理: Hugging Face上发布了SynthRL模型,该模型专注于可扩展的视觉推理能力,其核心技术在于通过可验证的数据合成方法,生成更具挑战性的视觉推理任务变体,同时保持原始答案的正确性。这有助于提升模型在复杂视觉场景下的理解和推理水平。 (来源: _akhaliq)
DeepSeek-R1虽表现佳,但ChatGPT产品优势依然稳固: VentureBeat评论指出,尽管DeepSeek-R1等新兴模型在某些方面表现出色,但ChatGPT凭借其先发优势、广泛的用户基础、成熟的产品生态和持续的迭代能力,其产品层面的领先地位短期内难以被超越。AI竞赛不仅是技术参数的比拼,更是产品体验、生态构建和商业模式的综合较量。 (来源: Ronald_vanLoon)

Qwen团队确认Qwen3-coder正在开发中: Qwen团队的Junyang Lin确认,他们正在开发Qwen3系列的编码能力增强版模型Qwen3-coder。虽然未公布具体时间表,但参考Qwen2.5的发布周期,预计可能在数周内面世。社区期待该模型能在代码生成、自主/智能体工作流集成方面有所突破,并保持对多种编程语言的良好支持。 (来源: Reddit r/LocalLLaMA)

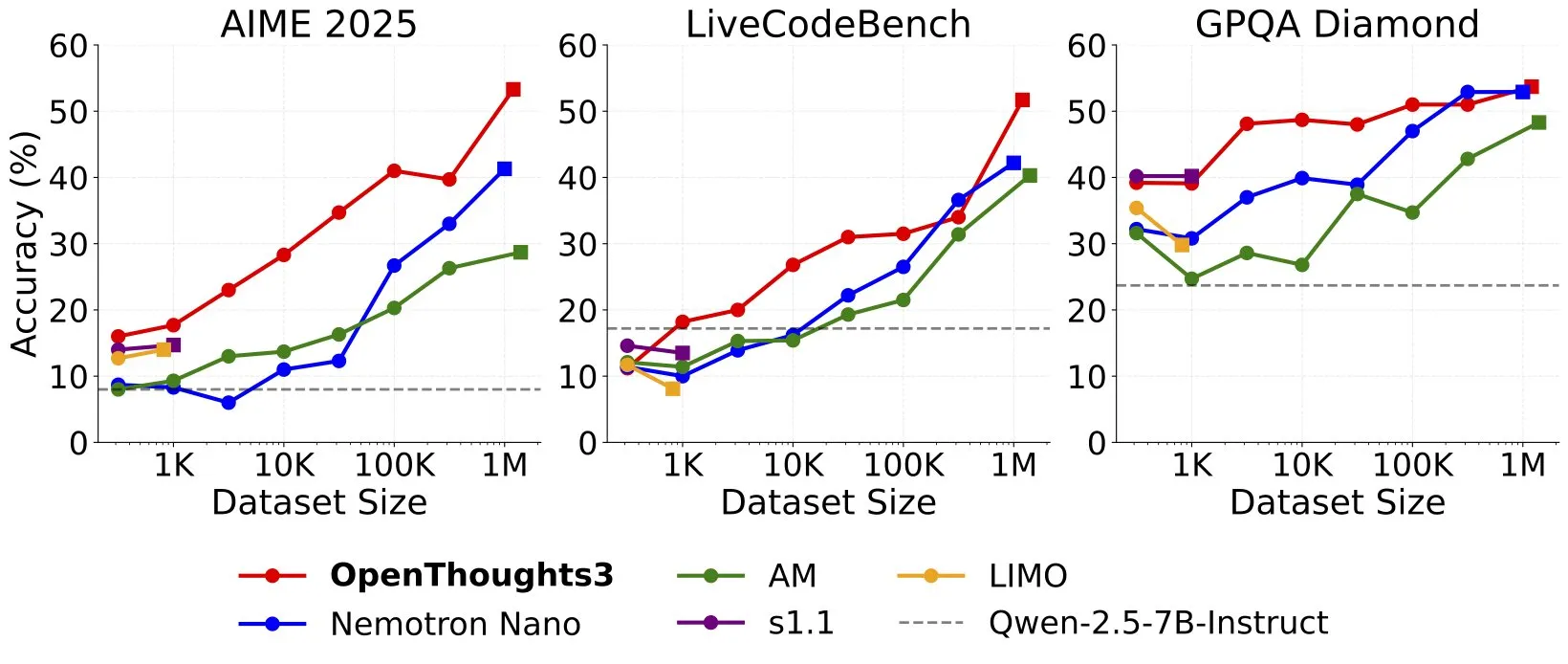
OpenThinker3-7B发布,号称SOTA开源数据7B推理模型: Ryan Marten宣布推出OpenThinker3-7B模型,称其为当前最先进的基于开放数据训练的7B参数推理模型。据称,该模型在代码、科学和数学评估方面平均比DeepSeek-R1-Distill-Qwen-7B高出33%。同时发布的还有其训练数据集OpenThoughts3-1.2M。 (来源: menhguin)
🧰 工具
TensorZero:开源LLMOps框架,优化LLM应用开发与部署: TensorZero是一个开源的LLM应用优化框架,旨在通过反馈循环将生产数据转化为更智能、更快速、更经济的模型。它整合了LLM网关(支持多种模型提供商)、可观测性、优化(提示、微调、RL)、评估和实验(A/B测试)等功能,支持低延迟、高吞吐量和GitOps。该工具使用Rust编写,强调性能和工业级应用需求。 (来源: GitHub Trending)

LangChain推出结合SambaNova、Qdrant和LangGraph的高性能RAG系统: LangChain介绍了一种高性能的检索增强生成(RAG)实现方案。该方案结合了SambaNova的DeepSeek-R1模型、Qdrant的二元量化技术以及LangGraph,能够实现32倍的内存缩减,从而高效处理大规模文档。这为构建更经济、更快速的RAG应用提供了新的可能性。 (来源: hwchase17, qdrant_engine)
谷歌科普视频一键生成应用Sparkify展示高质量案例: 谷歌推出的Sparkify应用,能够一键生成科普视频,其展示的案例质量颇高。视频内容整体一致性好,配音自然,甚至能实现分屏展示等复杂效果,显示了AI在自动化视频内容创作方面的潜力。 (来源: op7418)
Hugging Face推出首个MCP服务器,扩展聊天机器人功能: Hugging Face发布了其首个MCP (Modular Chat Processor) 服务器 (hf.co/mcp),用户可将其粘贴到聊天框中使用。MCP服务器旨在增强聊天机器人的功能,通过模块化处理单元提供更丰富的交互体验。社区同时整理了其他有用的MCP服务器列表,如Agentset MCP、GitHub MCP等。 (来源: TheTuringPost)
Chatterbox TTS效果媲美ElevenLabs,已集成至gptme: TTS(文本转语音)工具Chatterbox因其出色的语音合成效果受到关注,用户反馈其效果与知名的ElevenLabs相当,且优于Kokoro。Chatterbox支持通过参考样本定制语音,现已被添加为gptme的TTS后端,为用户提供了高质量的语音输出选项。 (来源: teortaxesTex, _akhaliq)
E-Library-Agent:本地图书/文献的智能检索与问答系统: E-Library-Agent是一个自托管的AI代理,能够提取、索引和查询个人图书或论文集。该项目基于ingest-anything,并由LlamaIndex、Qdrant和Linkup平台提供支持,实现了本地资料提取、上下文感知问答以及通过单一界面进行网络发现的功能,方便用户管理和利用个人知识库。 (来源: qdrant_engine)
Claude Code因其强大编码辅助能力受开发者高度评价: Reddit社区用户分享了使用Anthropic的Claude Code进行软件开发的积极体验,特别是在游戏开发(如Godot C#项目)等领域。用户称赞其解决复杂问题的能力远超其他AI编码助手(如GitHub Copilot),能够理解上下文并生成有效代码,即便每月100美元的费用也被认为物有所值。开发者认为,经验丰富的程序员结合Claude Code将极具生产力。 (来源: Reddit r/ClaudeAI)
ChatterUI实现本地视觉模型支持,但安卓端处理缓慢: LLM聊天客户端ChatterUI的预发布版本增加了对附件和本地视觉模型的支持(通过llama.rn)。用户可以为本地兼容模型加载mmproj文件,或连接支持视觉功能的API(如Google AI Studio、OpenAI)。然而,由于llama.cpp在安卓端缺乏稳定的GPU后端,图像处理速度极慢(例如512×512图像需5分钟),iOS端性能相对较好。 (来源: Reddit r/LocalLLaMA)
FLUX kontext在汽车宣传图背景替换方面表现出色: 用户测试发现,AI图像编辑工具FLUX kontext在修改汽车宣传图背景方面效果显著。例如,为小米SU7的官方图片更换背景(如黄昏沙滩、赛车赛道),该工具不仅能自然融合背景,还能智能地为行驶中的车辆添加运动模糊效果,提升了图像的真实感和视觉冲击力。 (来源: op7418)

📚 学习
fastcore新功能flexicache:灵活的缓存装饰器: Jeremy Howard介绍了fastcore库中一个实用的新功能flexicache。这是一个高度灵活的缓存装饰器,内置了’mtime’(基于文件修改时间)和’time’(基于时间戳)两种缓存策略,并且允许用户通过少量代码自定义新的缓存策略。该功能由Daniel Roy Greenfeld撰文详细介绍,有助于提升代码执行效率。 (来源: jeremyphoward)
探讨MuP与Muon结合用于Transformer模型训练的潜力: Jingyuan Liu深入学习了Jeremy Bernstein关于推导Muon和谱条件的工作,并对其优雅的推导过程表示赞叹,特别是MuP(Maximal Update Parametrization)和Muon(一种优化器)如何协同工作。他认为从推导来看,使用Muon作为基于MuP模型训练的优化器是自然之选,并指出这可能比Moonshot的Moonlight工作中通过匹配更新RMS从AdamW的超参数迁移到Muon更令人兴奋。社区讨论认为,MuP + Muon的组合有望在年底前被大型科技公司规模化应用。 (来源: jeremyphoward)

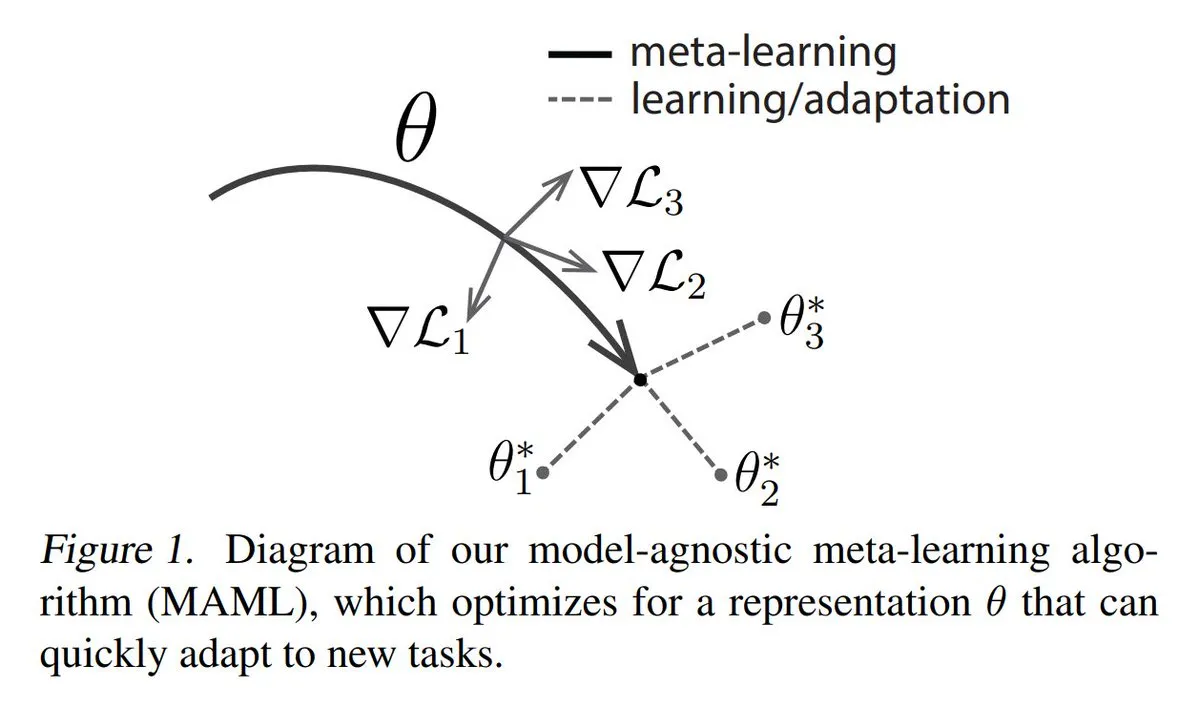
元学习(Meta-learning)三大主流方法解析: 元学习旨在训练模型快速学习新任务,即使只有少量样本。常见方法包括:1. 基于优化的/基于梯度的:寻找能通过少量梯度步骤在任务上高效微调的模型参数。2. 基于度量的:帮助模型找到更好的方法衡量新旧样本相似度,有效分组相关样本。3. 基于模型的:整个模型被设计为能利用内置内存或动态机制快速适应。TuringPost提供了从基础到现代元学习方法的详细解读。 (来源: TheTuringPost)
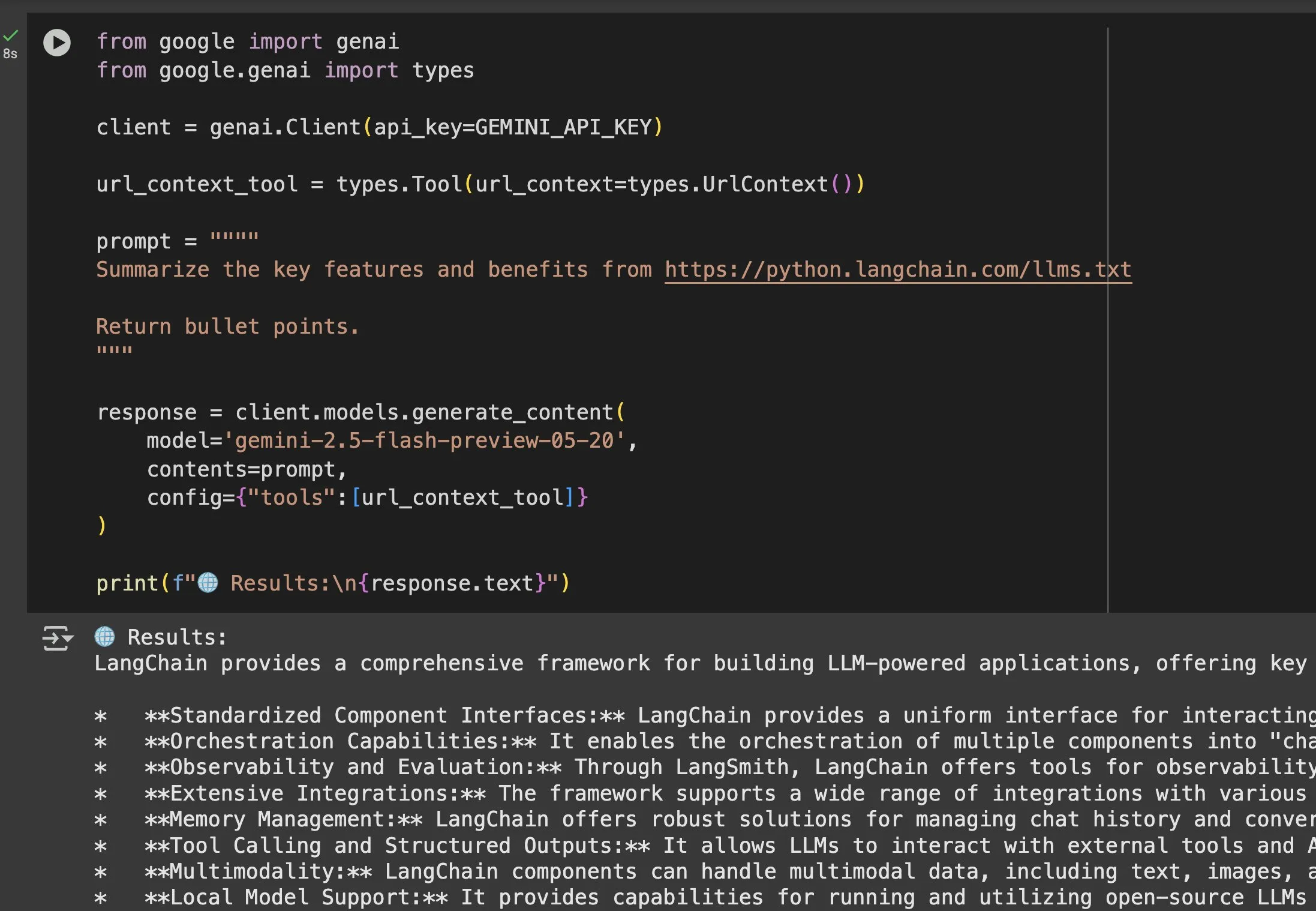
llms.txt文件在Gemini等模型中的应用价值凸显: Jeremy Phoward强调了llms.txt文件的实用性。例如,Gemini现在可以理解URL中的内容,只需在提示中添加URL并配置URL上下文工具即可。这意味着客户端(如Gemini)通过读取llms.txt端点,就能精确知晓所需信息的存放位置,极大地方便了信息的程序化获取和利用。 (来源: jeremyphoward)
EleutherAI发布8TB开放授权文本数据集Common Pile v0.1: EleutherAI宣布推出Common Pile v0.1,这是一个包含8TB开放授权和公共领域文本的大型数据集。他们基于此数据集训练了7B参数的语言模型(分别使用1T和2T token进行训练),其性能可与LLaMA 1和LLaMA 2等类似模型相媲美。这为研究完全使用合规数据训练高性能语言模型提供了宝贵资源和实证。 (来源: clefourrier)

SelfCheckGPT:一种无需参考的LLM幻觉检测方法: 一篇博客文章探讨了SelfCheckGPT作为LLM-as-a-judge(将LLM作为评估器)的替代方案,用于检测语言模型中的幻觉。这是一种无需参考文本、零资源的检测方法,为评估和提升LLM输出的真实性提供了新思路。 (来源: dl_weekly)
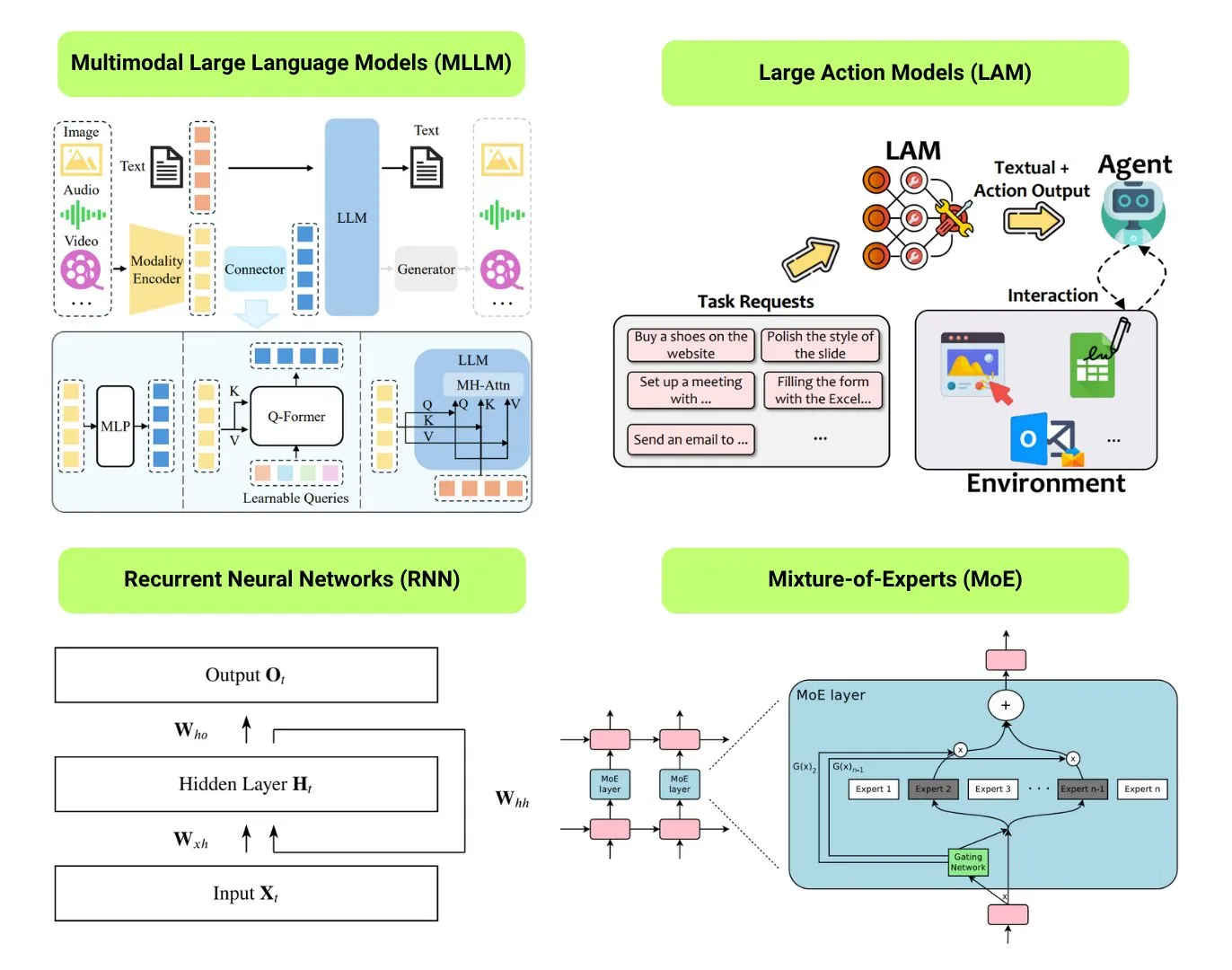
12种基础AI模型类型梳理: The Turing Post整理了12种基础的AI模型类型,包括LLM(大型语言模型)、SLM(小型语言模型)、VLM(视觉语言模型)、MLLM(多模态大型语言模型)、LAM(大型行为模型)、LRM(大型推理模型)、MoE(混合专家模型)、SSM(状态空间模型)、RNN(循环神经网络)、CNN(卷积神经网络)、SAM(分割一切模型)和LNN(逻辑神经网络)。相关资源提供了这些模型类型的解释和有用链接。 (来源: TheTuringPost)
GitHub热门:Kubernetes The Hard Way教程: Kelsey Hightower的教程《Kubernetes The Hard Way》持续在GitHub上受到关注。该教程旨在帮助用户通过手动方式逐步搭建Kubernetes集群,深入理解其核心组件和工作原理,而非依赖自动化脚本。教程面向希望掌握Kubernetes基础知识的学习者,覆盖从环境准备到集群清理的全过程。 (来源: GitHub Trending)
GitHub热门:免费GPTs和Prompts列表: friuns2/BlackFriday-GPTs-Prompts 仓库在GitHub上流行,它收集整理了一系列免费的GPT模型和高质量的Prompts,用户无需Plus订阅即可使用。这些资源覆盖编程、市场营销、学术研究、求职、游戏、创意等多个领域,并包含一些“Jailbreaks”技巧,为GPT用户提供了丰富的即用型工具和灵感。 (来源: GitHub Trending)

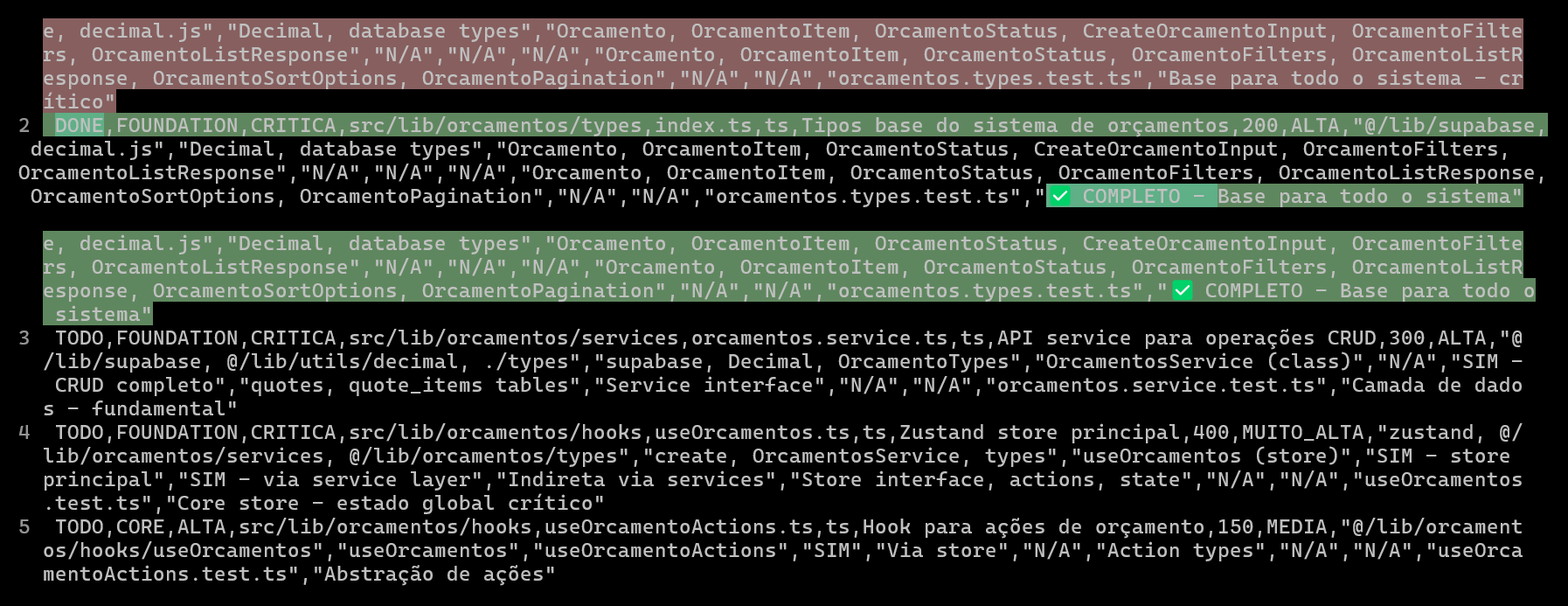
用CSV规划和追踪AI编码项目,提升代码质量与效率: 一位开发者分享了使用Claude Code进行ERP系统开发时,通过创建详细的CSV文件来规划和追踪每个文件的编码进度,从而显著提升了复杂功能的开发效率和代码质量。CSV文件包含状态、文件名、优先级、代码行数、复杂度、依赖关系、功能描述、使用的Hooks、导入导出模块以及关键的“进度笔记”。这种方法使得AI能够更专注地构建代码,并让开发者清晰掌握项目实际进展与原计划的差异。 (来源: Reddit r/ClaudeAI)
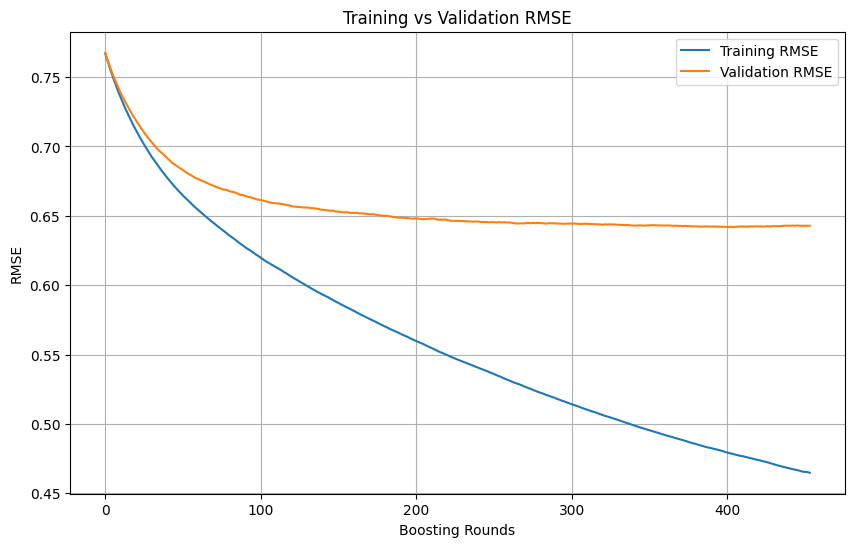
机器学习训练中的过拟合判断与停止时机: 在机器学习模型训练过程中,当训练损失持续快速下降,而验证损失下降缓慢甚至停止或上升时,通常表明模型可能出现过拟合。原则上,只要验证损失仍在下降,可以继续训练。关键在于确保验证集与训练集独立且能代表任务的真实数据分布。若验证损失停止下降或开始上升,应考虑提前停止训练,或采取正则化等方法改善模型的泛化能力。 (来源: Reddit r/MachineLearning)
🌟 社区
AI Engineer World’s Fair 2025聚焦RL+Reasoning、Eval等议题: AI Engineer World’s Fair 2025 大会的主题涵盖了强化学习+推理 (RL+Reasoning)、评估 (Eval)、软件工程智能体 (SWE-Agent)、AI架构师和智能体基础设施等前沿方向。参会者表示,大会充满了活力和创新思维,许多人勇于尝试新事物,不断重塑自我,投身AI领域。大会也为AI工程师们提供了交流和学习的平台。 (来源: swyx, hwchase17, charles_irl, swyx)

Sam Altman理想AI:小模型+超强推理+海量上下文+万能工具: Sam Altman描述了他心目中理想的AI形态:一个拥有超人推理能力、极小体积的模型,能接入万亿级别的上下文信息,并能调用想象得到的任何工具。这一观点引发讨论,部分人认为这与当前大模型依赖知识存储的现状有所不同,并质疑小模型在巨大上下文中解析知识与进行复杂推理的可行性,认为知识与思考能力难以高效分离。 (来源: teortaxesTex)
编码智能体引发代码重构欲望,AI辅助编程的挑战与机遇: 开发者表示,编码智能体的出现极大地增强了他们重构他人代码的“诱惑”,也带来了新的危险。一位开发者分享了使用AI辅助完成一个约10分钟手动工作量的编程任务的经验,虽然AI能快速生成工作代码,但要达到资深程序员的组织和风格水平,仍需大量的人工指导和重构。这突显了AI辅助编程在提升初级/中级代码到高级代码质量方面的挑战。 (来源: finbarrtimbers, mitchellh)
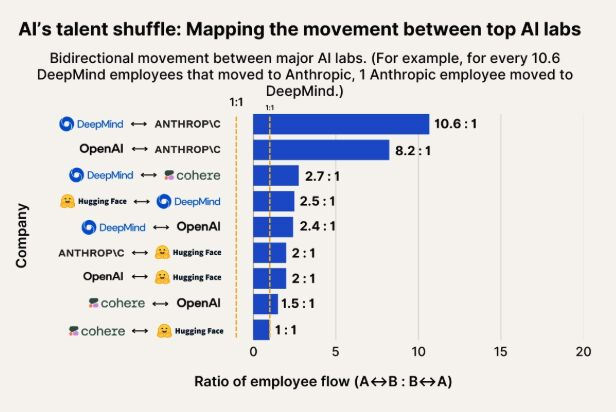
AI人才流动观察:Anthropic成为谷歌DeepMind和OpenAI人才重要流向地: 一张展示AI人才流动的图表显示,Anthropic正成为吸引来自谷歌DeepMind和OpenAI研究人员的重要公司。社区对此表示符合认知,并有用户猜测Anthropic可能拥有某些“秘密武器”或独特的研究方向,吸引了顶尖人才的加入。 (来源: bookwormengr, TheZachMueller)
人形机器人普及面临信任和社会接受度挑战: 科技评论员Faruk Guney预测,第一波人形机器人浪潮可能会因巨大的信任赤字而失败。他认为,尽管技术不断进步,但社会尚未准备好接受这些“黑箱智能”进入家庭,执行陪伴、家务甚至育儿等任务。机器人的不透明决策、潜在监控风险以及与人类截然不同的“可爱”外观(不如Wall-E),都可能成为其广泛应用的障碍。只有在充分的社会讨论、监管、审计和信任重建之后,才能迎来人形机器人的真正普及。 (来源: farguney, farguney)
AI个性化设计:“不完美”胜过“完美”: 一位开发者分享了其在AI音频平台创建50个AI个性化形象的经验。总结认为,过度设计的背景故事、绝对的逻辑一致性和极端的单一性格反而让AI显得机械和不真实。成功的AI个性塑造在于“3层个性堆栈”(核心特质+修饰特质+怪癖)、适当的“不完美模式”(如偶尔的口误、自我纠正)以及恰到好处的背景信息(300-500字,包含积极与挑战性经历、具体热情和与专业相关的脆弱点)。这些“不完美”的细节反而让AI更具人情味和连接感。 (来源: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
关于LLM是否具备“感知”和“AGI”的讨论:兴奋与怀疑并存: 社区普遍对LLM的巨大潜力感到兴奋,认为其堪比历史性重大发明并将改变一切。然而,对于LLM是否已具备“感知能力”、是否需要“权利”,以及是否会“终结人类”或带来“AGI”等说法,许多人仍持怀疑态度。强调在解读LLM能力和研究成果时,需要保持细致和审慎。 (来源: fabianstelzer)
💡 其他
探讨多机器人自主行走协作: 社交媒体上出现关于多机器人在自主行走方面的协作探索。这涉及到机器人路径规划、任务分配、信息共享以及避免碰撞等复杂技术,是机器人学、RPA(机器人流程自动化)和机器学习领域持续关注的研究方向。 (来源: Ronald_vanLoon)
利用随机森林优化ULMFiT超参数的技巧: Jeremy Howard分享了他在优化ULMFiT(一种迁移学习方法)时的一个技巧:通过运行大量消融实验,并将所有超参数和结果数据喂给随机森林模型,从而找出对模型性能影响最大的超参数。这个方法已被Weights & Biases集成到其产品中,为超参数调优提供了新思路。 (来源: jeremyphoward)

Figure公司人形机器人展示60分钟物流任务处理能力: Figure公司发布了一段长达60分钟的视频,展示其人形机器人在Helix神经网络驱动下,自主完成物流场景中的各项任务。这一展示旨在证明其机器人在复杂实际环境中的长时间稳定工作能力和自主决策水平。 (来源: adcock_brett)