
关键词:AI模型, 数据集, 人形机器人, AI Agent, 语言模型, 深度学习, 开源模型, 推理优化, Common Pile v0.1数据集, Helix端到端控制模型, Hugging Face MCP服务器, Gemini 2.5 Pro更新, 稀疏注意力机制
🔥 聚焦
EleutherAI 发布 Common Pile v0.1:8TB 开放授权文本数据集,挑战无授权数据训练语言模型 : EleutherAI 联合多家机构发布了 Common Pile v0.1,这是一个包含 8TB 开放授权和公共领域文本的大型数据集,旨在探索在不使用无授权文本的情况下训练高性能语言模型的可行性。团队使用该数据集训练了 7B 参数的模型(1T 和 2T tokens),其性能与 LLaMA 1 和 LLaMA 2 等类似模型相当。该数据集包含文档级元数据,如作者归属、授权详情和原始副本链接,为研究者提供了透明且合规的数据来源。此举措对推动开放、合规的 AI 模型发展具有重要意义,并为解决 AI 训练数据版权问题提供了新思路 (来源: EleutherAI, percyliang, BlancheMinerva, code_star, ShayneRedford, Tim_Dettmers, jeremyphoward, stanfordnlp, ClementDelangue, tri_dao, andersonbcdefg)

Figure 人形机器人 Helix 模型驱动下展现高速包裹分拣能力,引发关注 : Figure 公司 CEO Brett Adcock 展示了其人形机器人在 Helix 端到端通用控制模型驱动下,在物流场景中进行包裹分拣的最新进展。视频显示,机器人能以接近人类的速度和准确度处理不同类型(硬质纸盒、塑料包装)的包裹,包括整理包裹、确保条形码朝下以便扫描。这一能力突显了 Helix 模型在复杂、动态环境中的泛化能力和灵活性,与之前展示的冲压机作业(强调精准和高速)形成对比。Figure 机器人已在宝马生产线实现连续20小时轮班作业,显示其在工业应用中的潜力。Adcock 强调,在人形机器人领域,构建最智能、成本最低的机器人将是赢得市场的关键,因为更多的机器人部署意味着更低的成本、更多的训练数据和更智能的 Helix 模型 (来源: dotey, _philschmid, adcock_brett, 量子位)

Hugging Face 发布首个官方 MCP 服务器,打造 AI Agent 协作平台 : Hugging Face 推出了其首个官方 MCP (Model-Client Protocol) 服务器,允许用户将 LLM 直接连接到 Hugging Face Hub 的 API,以便在 Cursor、VSCode、Windsurf 及其他支持 MCP 的应用中使用。该服务器提供了对模型、数据集、论文和 Spaces 的语义搜索等内置工具,并能动态列出托管在 Spaces 上所有兼容 MCP 的 Gradio 应用。这一举措旨在将 Hugging Face 打造成 AI Agent 构建者的协作平台,促进 AI Agent 生态系统的发展和互操作性,目前已有约900个 MCP Spaces 可用 (来源: ClementDelangue, mervenoyann, reach_vb, ben_burtenshaw, huggingface, code_star, op7418, TheTuringPost, clefourrier)

谷歌更新 Gemini 2.5 Pro 预览版,增强编码、推理与创作能力,并引入“思考预算” : 谷歌宣布对其最智能模型 Gemini 2.5 Pro 的预览版进行更新,进一步提升了其在编码、逻辑推理和创意写作方面的能力。新版本特别引入了“思考预算”(thinking budget)功能,允许开发者更好地控制模型的计算资源消耗。用户反馈显示,新版(06-05)在长文本召回方面表现优异,尤其在192K长度下召回率高达90.6%,超越了OpenAI-o3。该模型已集成到 LangChain 和 LangGraph 中,方便开发者进行试用和构建应用。谷歌还展示了 Gemini 2.5 Pro 在图像理解和生成情境化、诙谐字幕方面的创意能力
🎯 动向
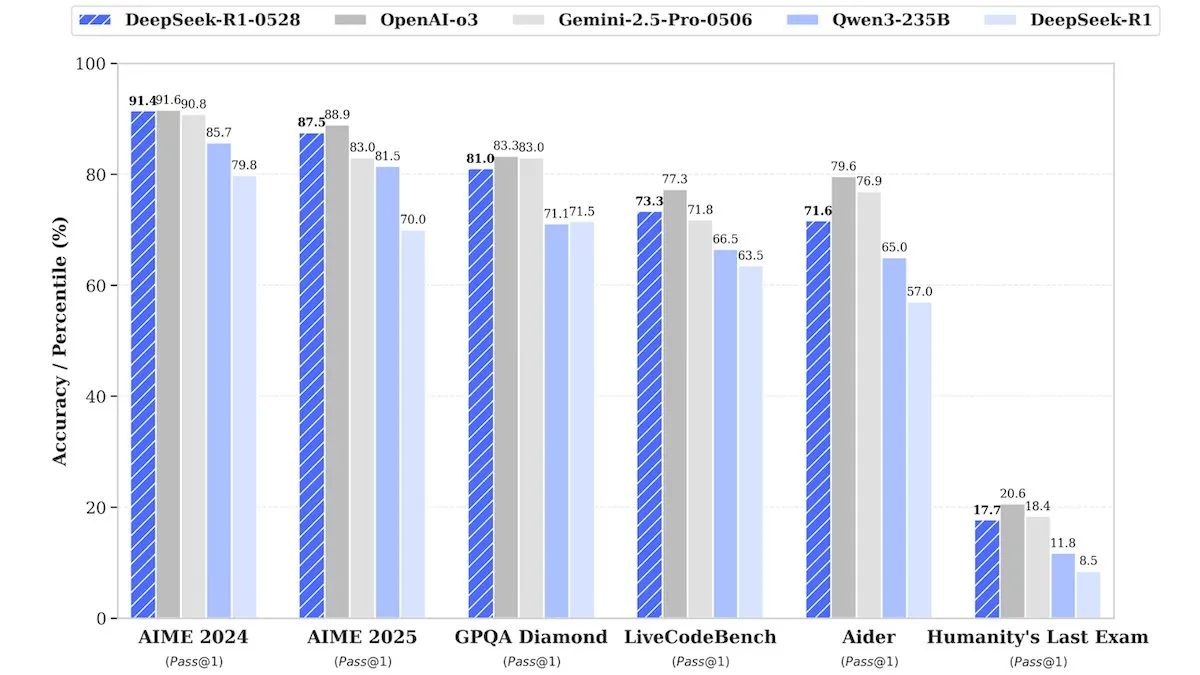
DeepSeek 发布 DeepSeek-R1-0528 升级版,性能媲美闭源模型 : DeepSeek 推出了其旗舰开源权重模型 DeepSeek-R1-0528 的升级版。据称,该模型在多个基准测试中表现可与 OpenAI 的 o3 和谷歌的 Gemini-2.5 Pro 等闭源模型相媲美。尽管公司未透露训练细节,但报告指出新模型在推理、任务复杂性处理和减少幻觉方面有显著改进,再次挑战了顶级 AI 需要巨大资源的传统观念。Unsloth AI 已提供使用 GRPO 微调 DeepSeek-R1-0528-Qwen3 的免费 Notebook,声称其新的奖励函数可将多语言(或自定义领域)响应率提高40%以上,并使 R1 微调速度提高2倍,VRAM 减少70% (来源: DeepLearningAI, ImazAngel)
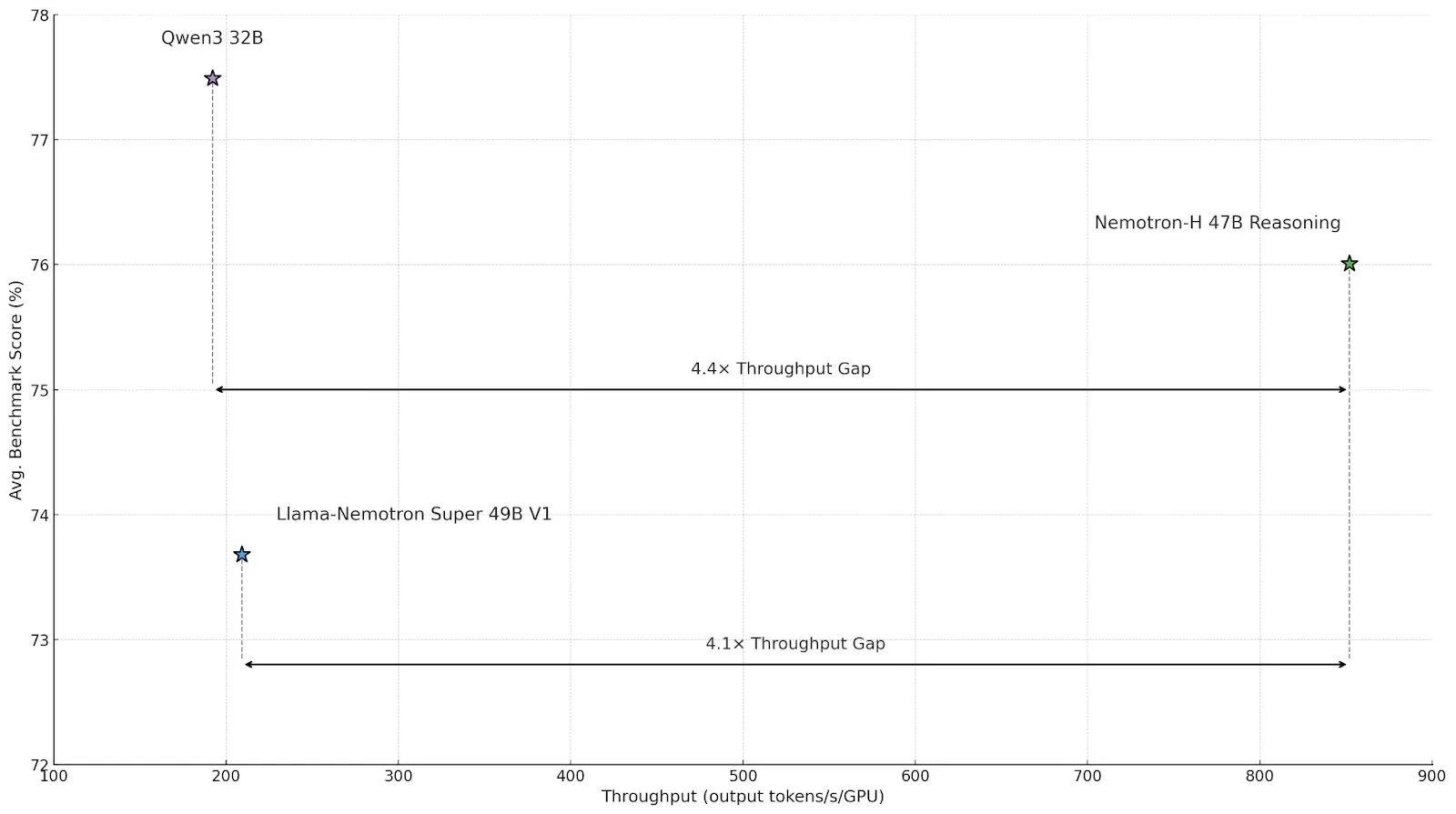
英伟达发布混合架构推理模型 Nemotron-H,提升吞吐量与效率 : 英伟达推出了新的推理模型 Nemotron-H,包括 47B 和 8B 版本(支持 BF16 和 FP8),采用 Mamba-Transformer 混合架构。该模型旨在解决大规模推理问题,同时保持高速,据称其吞吐量是同类 Transformer 模型的4倍。Nemotron-H-47B-Reasoning-128k 在所有基准测试中准确性略高于 Llama-Nemotron-Super-49B-1.0,但推理成本降低多达4倍。模型权重已在 HuggingFace 上以非生产性许可证发布,技术报告即将推出 (来源: ClementDelangue, ctnzr)
Anthropic 推出 Claude Gov,专为美国政府和军事情报机构设计 : Anthropic 公司发布了名为 Claude Gov 的新 AI 服务,该服务专为满足美国政府、国防和情报机构的需求而设计。此举标志着 Anthropic 正式将其先进的 AI 技术拓展到政府和军事应用领域,可能用于数据分析、情报处理、决策支持等多种场景。Anthropic 此前也加入了长期利益信托基金,旨在帮助公司实现其公共利益使命 (来源: MIT Technology Review, akbirkhan, jeremyphoward)
Hugging Face 与谷歌 Colab 合作,简化模型试用与原型设计流程 : Hugging Face 宣布与 Google Colaboratory 达成合作,在 Hugging Face Hub 上的所有模型卡片中添加“在 Colab 中打开”的支持。用户现在可以直接从任何模型卡片启动 Colab Notebook,从而更轻松地进行模型实验和评估。此外,用户可以在其模型仓库中放置自定义的 notebook.ipynb 文件,Hugging Face 将直接提供该 Notebook,进一步提升了 AI 模型的可访问性和快速原型设计能力 (来源: huggingface, osanseviero, ClementDelangue, mervenoyann)
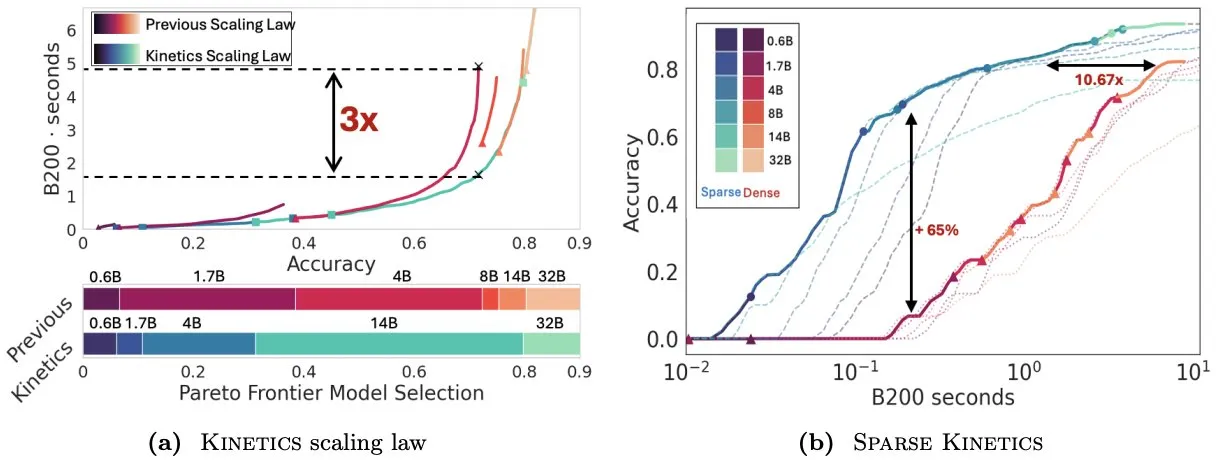
论文 Kinetics 重新思考测试时扩展定律,强调稀疏注意力对推理效率的重要性 : Infini-AI-Lab 发表论文《Kinetics: Rethinking Test-Time Scaling Laws》,指出先前基于计算最优性的扩展定律高估了小型模型的有效性,忽视了推理时策略(如 Best-of-N、长 CoT)带来的内存访问瓶颈。研究提出新的 Kinetics 扩展定律,综合考虑计算和内存访问成本,认为测试时计算资源用于大型模型比小型模型更有效,因为注意力而非参数数量成为主导成本。论文进而提出以稀疏注意力为中心的扩展范式,通过降低单位 token 成本实现更长生成和更多并行样本,实验表明稀疏注意力模型在不同成本区间均优于密集模型,对提升大规模模型推理效率至关重要 (来源: realDanFu, tri_dao, simran_s_arora)
中国AI Agent市场火热,Manus引领创业潮 : 继去年基础模型热潮后,中国AI领域今年的焦点转向了AI Agent。AI Agent更侧重于自主为用户完成任务,而非简单响应查询。Manus作为通用AI Agent的先行者,在三月初限量发布后引发了广泛关注,并催生了一批构建通用数字工具的初创企业,这些工具能够处理邮件、规划旅行甚至设计交互式网站。这一趋势表明,中国科技行业正积极探索AI Agent的实际应用和商业模式 (来源: MIT Technology Review)

ElevenLabs 发布 Conversational AI 2.0,提升企业级语音助手性能 : ElevenLabs 推出了其对话式 AI 平台 2.0 版本,旨在构建更高级的企业级语音代理。新版本显著提升了语音助手的自然度和交互能力,使其能够更好地理解对话节奏,知道何时停顿、何时发言以及何时进行对话轮换。这一升级有望为企业用户提供更流畅、更智能的语音交互体验,应用于客户服务、虚拟助手等多种场景 (来源: dl_weekly)
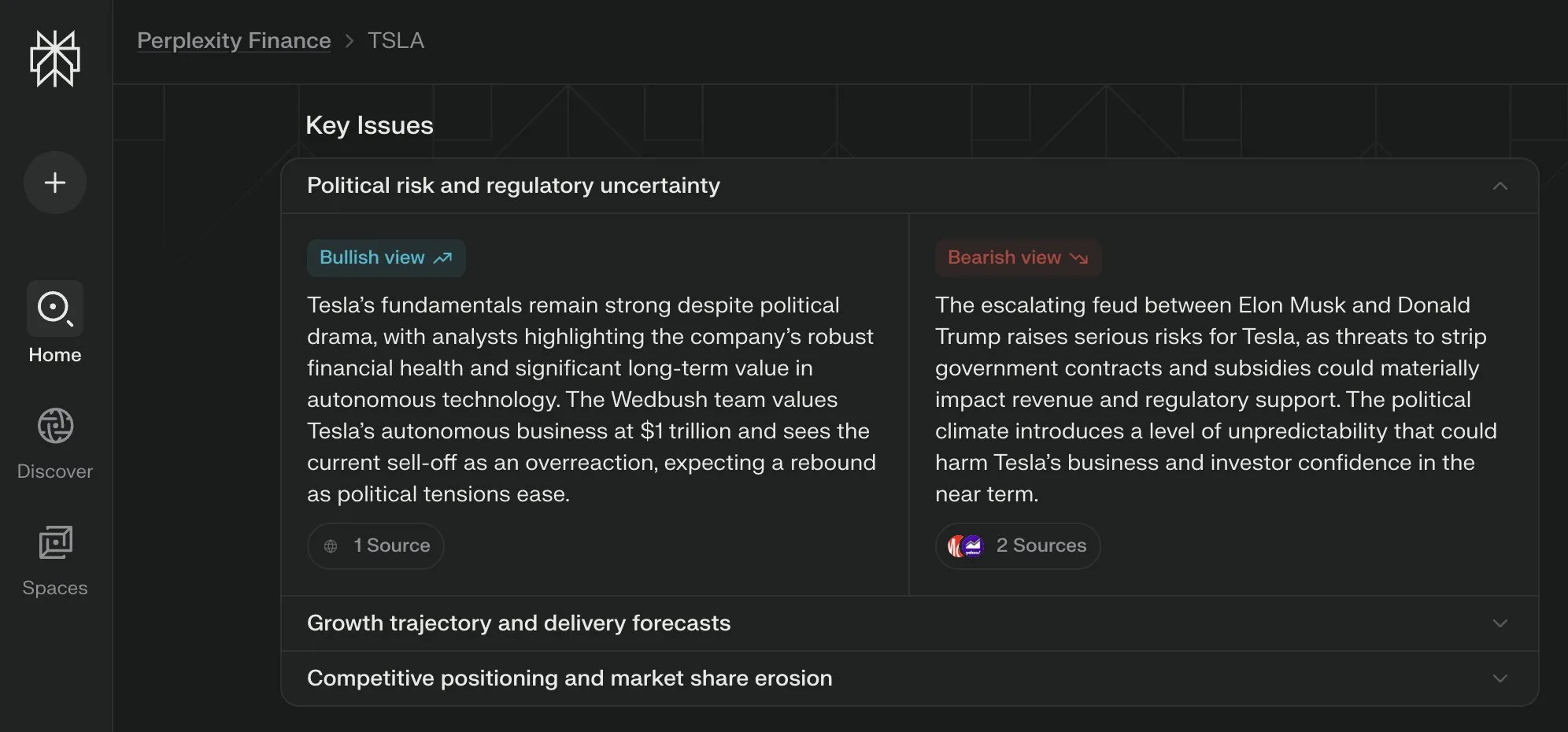
Perplexity Labs 为其金融页面推出“关键问题”视图,综合多方观点 : Perplexity Labs 在其金融信息页面新增了“关键问题”(Key Issues)视图功能。该功能能够综合来自互联网的投资者、分析师和评论员的观点,快速向用户展示当前影响一家公司的重要因素和主要讨论点。例如,关于特斯拉的页面可以整合数小时内关于特朗普和马斯克之间动态的各种信息,帮助用户迅速把握全局 (来源: AravSrinivas)
PyTorch 分布式检查点现已支持 Hugging Face safetensors : PyTorch 宣布其分布式检查点功能现在支持 Hugging Face 的 safetensors 格式,这将使得在不同生态系统之间保存和加载检查点更加便捷。新的 API 允许用户通过 fsspec 路径读写 safetensors。torchtune 成为首个采用该功能的库,从而简化了其检查点流程。这一更新有助于提升模型训练和部署的互操作性和效率 (来源: ClementDelangue)

论文 MARBLE 提出基于 CLIP 空间进行材质重组与混合的新方法 : 一篇名为 MARBLE 的新研究提出了一种通过在 CLIP 空间中寻找材质嵌入,并利用此嵌入控制预训练文本到图像模型,从而实现图像中物体材质的混合与细粒度属性重组。该方法改进了基于样本的材质编辑,通过定位去噪 UNet 中负责材质归属的模块,实现了对粗糙度、金属感、透明度和光泽等细粒度材质属性的参数化控制。研究者通过定性和定量分析证明了该方法的有效性,并展示了其在单次前向传播中执行多次编辑以及在绘画领域的适用性 (来源: HuggingFace Daily Papers, ClementDelangue)
论文 FlowDirector:无需训练的精确文本到视频编辑流引导方法 : FlowDirector 是一种新颖的无需反演的视频编辑框架,它将编辑过程建模为数据空间的直接演化,通过常微分方程(ODE)引导视频沿其固有的时空流形平滑过渡,从而保持时间连贯性和结构细节。为实现局部可控编辑,引入了注意力引导的遮蔽机制。此外,为解决编辑不完整和增强与编辑指令的语义对齐问题,提出了受无分类器指导启发的指导增强编辑策略。实验证明,FlowDirector 在指令遵循、时间一致性和背景保留方面表现优异 (来源: HuggingFace Daily Papers)
论文 RACRO:通过奖励优化字幕实现可扩展的多模态推理 : 为解决升级底层LLM推理器时重新训练视觉语言对齐成本高的问题,研究者提出RACRO(Reasoning-Aligned Perceptual Decoupling via Caption Reward Optimization)。该方法将视觉输入转换为语言表示(如字幕),再传递给文本推理器。RACRO采用推理引导的强化学习策略,通过奖励优化来对齐提取器的字幕行为与推理目标,从而增强视觉基础并提取推理优化的表示。实验表明,RACRO在多模态数学和科学基准测试中表现SOTA,并支持即插即用地适应更高级的推理LLM,无需昂贵的多模态重新对齐 (来源: HuggingFace Daily Papers)
研究显示:LLM记忆信息量或与其参数量和信息熵有关 : 一项由Meta、DeepMind、NVIDIA及康奈尔大学合作的研究探讨了大型语言模型(LLM)实际记忆的信息量。研究发现,LLM记忆的信息量可能与其参数量和数据的信息熵有关。例如,英文维基百科约有294亿字符,每个字符约含1.5比特信息,一个12B参数的模型(假设每参数3.6比特存储能力)理论上可能记忆整个英文维基百科。该研究对于理解LLM的记忆机制和评估数据版权问题具有重要意义。François Chollet也提到了利用随机字符串训练LLM的方法论及其量化发现,认为这对理解LLM的记忆机制很有价值 (来源: fchollet, AymericRoucher)
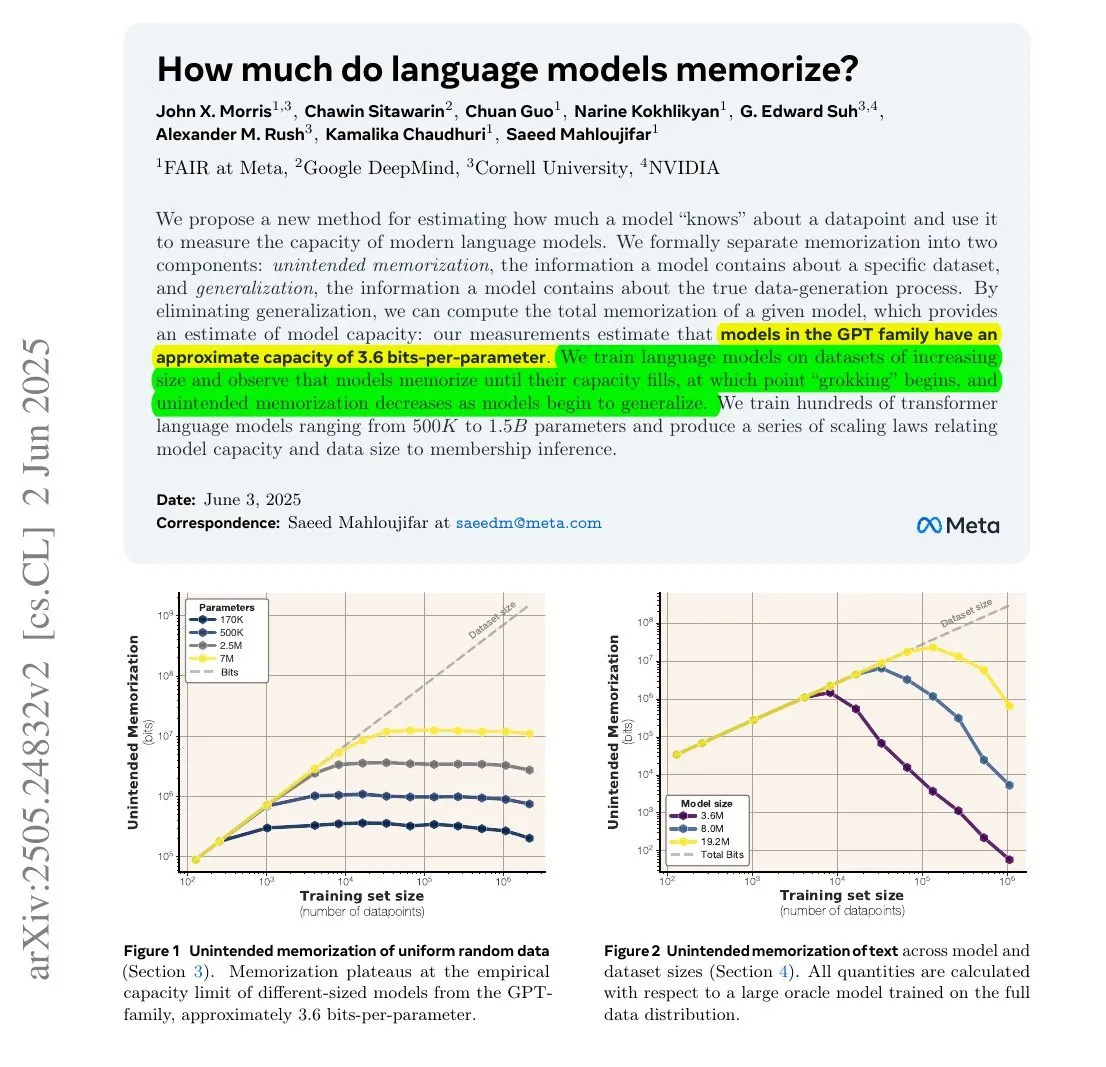
Hugging Face推出企业版新功能:管理推理提供商使用和成本 : Hugging Face 为其企业版(Enterprise Hub)增加了新功能,允许组织机构配置和监控其团队成员对推理提供商(Inference Providers)的使用情况和相关成本。这意味着企业用户可以更好地管理和控制对来自 TogetherCompute、FireworksAI、Replicate、Cohere 等多家提供商的超过4万个模型的无服务器推理服务的使用,从而优化AI应用部署的成本效益和资源分配 (来源: huggingface, _akhaliq)
Mistral AI 科学推理模型 ether0 发布,基于 Mistral 24B 微调 : Mistral AI 发布了其首个科学推理模型 ether0。该模型通过在化学领域的多个分子设计任务上对 Mistral 24B 进行强化学习(RL)训练而成。研究发现,LLM 在某些科学任务上学习的数据效率远高于从零开始训练的专用模型,并且在这些任务上可以显著优于前沿模型和人类。这表明,对于一部分科学分类、回归和生成问题,对 LLM 进行后训练可能提供比传统机器学习方法更高效的途径 (来源: MistralAI)
双专家一致性模型 (DCM) 将视频生成速度提升10倍 : Ziwei Liu 等研究者提出双专家一致性模型 (DCM),可将视频生成模型(参数量从1.3B到13B)的速度提升10倍,且不降低质量。该模型目前已支持腾讯混元和阿里通义万相。DCM 的提出为高效高质量视频生成领域带来了新的突破,有助于加速视频内容创作和相关应用的发展 (来源: _akhaliq)
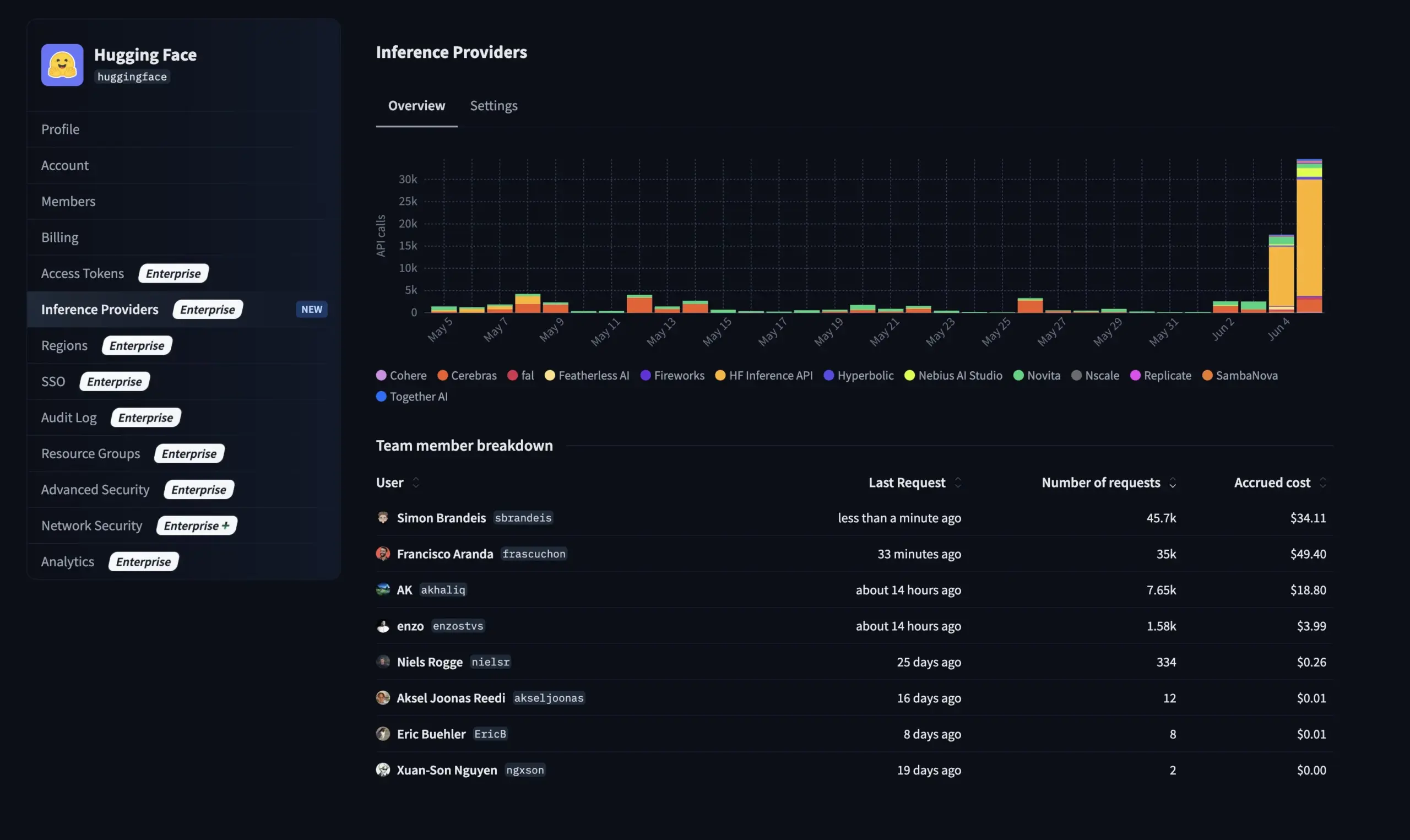
OpenBMB 发布 MiniCPM4,端侧推理速度提升5倍 : OpenBMB 推出了 MiniCPM4 系列模型,通过采用高效模型架构(InfLLM v2 可训练稀疏注意力机制)、高效学习算法(Model Wind Tunnel 2.0、BitCPM 三元量化)、高质量训练数据(UltraClean、UltraChat v2)以及高效推理系统(CPM.cu、ArkInfer),实现了在端侧设备上推理速度提升5倍的目标。旗舰模型 MiniCPM4-8B(8B参数,8T tokens训练)已在 Hugging Face 上线。该系列模型旨在探索小型廉价LLM的极限,推动AI在资源受限设备上的应用 (来源: eliebakouch, Teortaxes▶️ (DeepSeek 推特🐋铁粉 2023 – ∞))
X 公司更新服务条款,禁止使用其帖子“微调或训练”AI模型,除非达成协议 : X 公司(原 Twitter)更新了其服务条款,明确禁止使用平台上的帖子内容来“微调或训练”人工智能模型,除非与 X 公司达成特定协议。此举反映了内容平台在 AI 时代对其数据价值的日益重视和控制意愿,可能效仿 Reddit 与谷歌等公司通过授权协议来实现数据变现。这一政策变化将对依赖公开社交媒体数据进行模型训练的 AI 研究者和开发者产生影响 (来源: MIT Technology Review)
🧰 工具
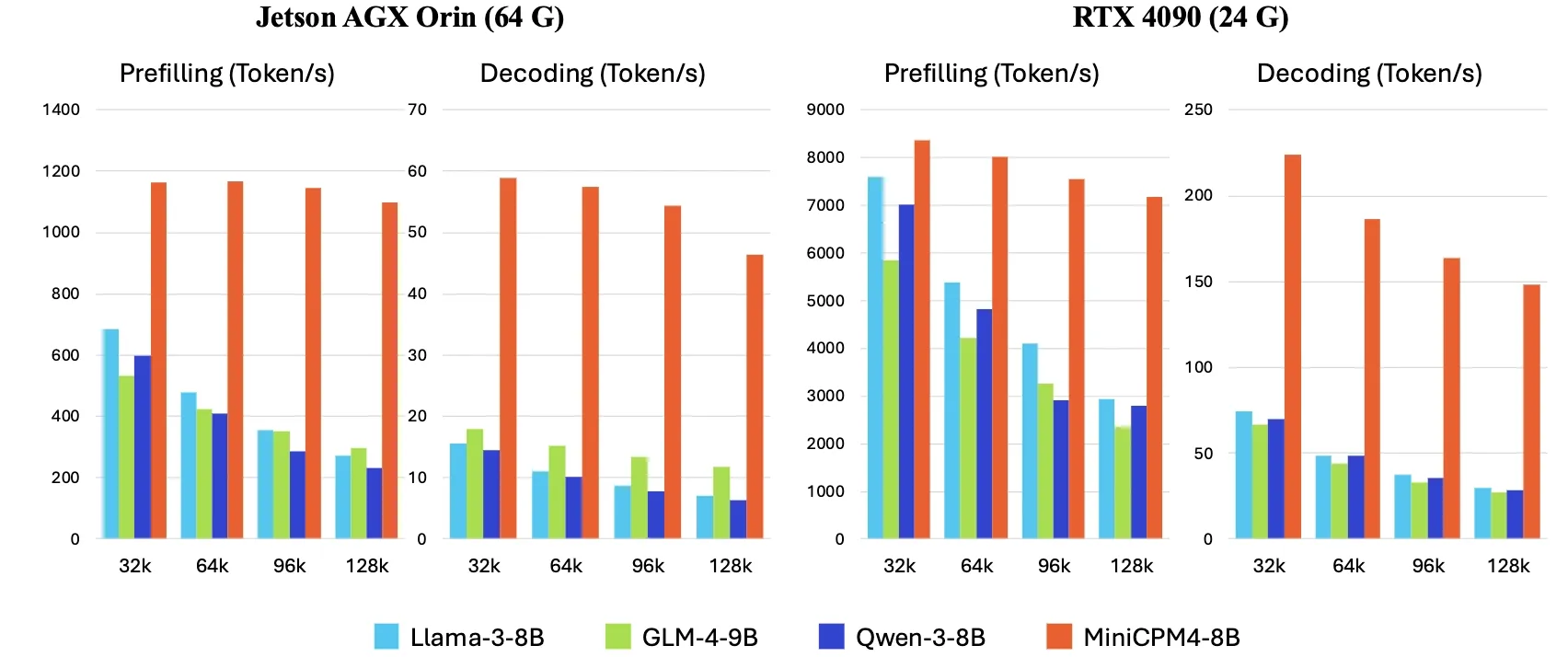
ScreenSuite:全面的GUI Agent评估套件发布 : Hugging Face 发布了 ScreenSuite,一个全面的图形用户界面(GUI)Agent 评估套件。它整合了来自前沿研究的关键基准,支持对 Ubuntu 和 Android 环境进行 Docker化评估,并覆盖移动、桌面和 Web 场景。该套件强调纯视觉评估(无DOM作弊),旨在提供一个统一、易用的平台,用于衡量视觉语言模型(VLM)在感知、定位、单步操作和多步代理任务等方面的能力。Qwen-2.5-VL、UI-Tars-1.5-7B、Holo1-7B 和 GPT-4o 等模型已在该套件上进行了评估 (来源: huggingface, AymericRoucher, clefourrier, tonywu_71, mervenoyann, HuggingFace Blog)
Claude Code 使用经验分享:指令理解、任务规划和工具运用能力突出 : 用户 dotey 分享了其使用 Anthropic 的 AI 编程助手 Claude Code 的经验。他认为 Claude Code 强大的地方在于:1. 对指令的理解出色;2. 能合理规划任务,复杂任务会创建 TODO List 并逐个执行;3. 工具运用能力极强,尤其擅长使用 grep 命令搜索代码库,效率远超人类,甚至能分析混淆的 JS 代码;4. 执行时间长,能“大力出奇迹”,但 Token 消耗也大,适合配合 Claude Max 订阅;5. 全程人工干预少,尤其在开启 --dangerously-skip-permissions 参数后可实现无人值守编程。用户从重度 Cursor 用户转向更多依赖 Claude Code 先行完成任务,再到 IDE审查修改。Claude Code 的 Plan Mode(计划模式)也已悄然上线,允许用户在不编辑文件的情况下进行纯粹的阅读和思考 (来源: dotey, Reddit r/ClaudeAI)
ClaudeBox:在Docker中安全运行Claude Code,免除权限提示 : 开发者 RchGrav 创建了 ClaudeBox 工具,允许用户在 Docker 容器中以连续模式(无权限提示)运行 Claude Code。这样既避免了频繁的权限确认打断工作流程,又保证了主操作系统的安全,因为 Claude Code 的所有操作都被限制在隔离的 Docker 环境内。ClaudeBox 提供超过15种预配置的开发环境(如 Python+ML、C++/Rust/Go 等),用户可以通过简单命令快速搭建。该工具旨在提升 Claude Code 的使用体验,让用户可以无顾虑地让 AI 尝试各种操作 (来源: Reddit r/ClaudeAI)
Toolio 0.6.0 发布:专为Mac设计的GenAI与Agent工具包 : Toolio 发布了 0.6.0 版本,这是一个与 MLX 深度整合的工具包,旨在为 Mac 上的大型语言模型(LLM)提供强大支持。它实现了基于 JSON Schema 引导的结构化输出和工具调用功能,使用 Python 语言。该工具包专注于提升在 Mac 环境下开发 GenAI 和 Agent 应用的体验和效率 (来源: awnihannun)
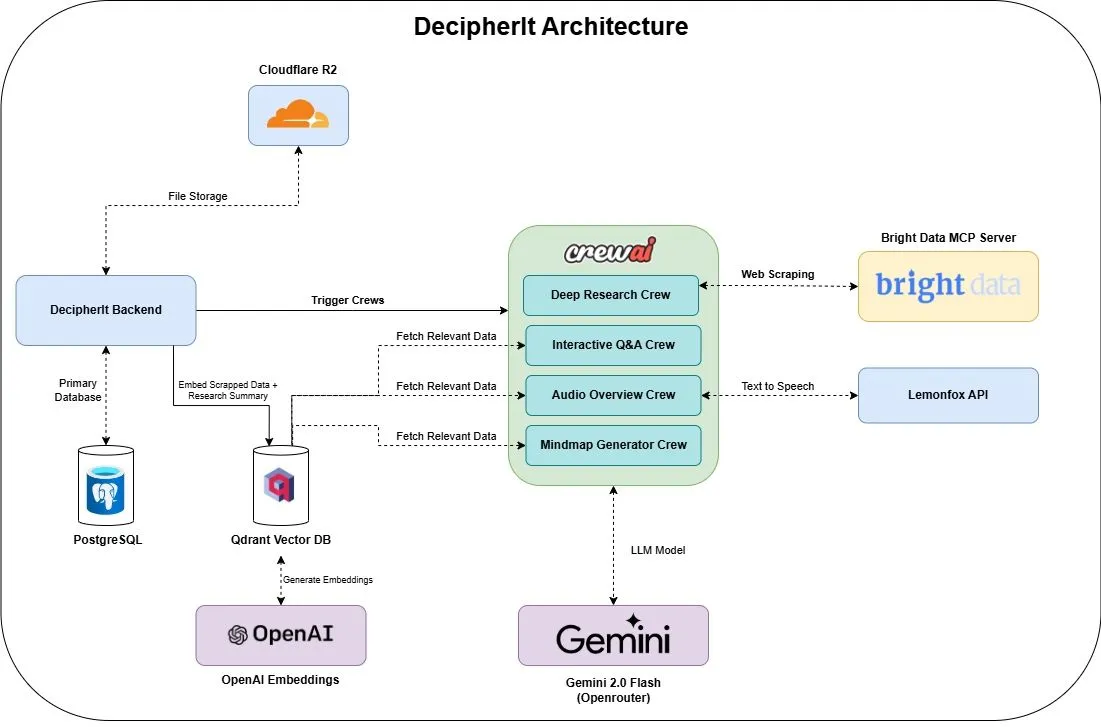
DecipherIt:开源AI研究助手,集成多代理与语义搜索 : DecipherIt 是一款开源的 AI 研究助手,被视为 NotebookLM 的替代品。它利用多代理编排、语义搜索和实时网络访问功能,帮助用户处理研究资料。用户可以上传文档、粘贴URL或输入主题,DecipherIt 会将其转化为包含摘要、思维导图、音频概述、常见问题解答和语义问答的完整研究工作区。其技术栈包括 crewAI 代理、Bright Data MCP、Qdrant、OpenAI 和 LemonFox AI,前端使用 Next.js 和 React 19,后端为 FastAPI (来源: qdrant_engine)
Search Arena:分析搜索增强型LLM的用户交互数据集发布 : Search Arena 是一个大规模(超过24,000个)众包的、包含成对多轮用户与搜索增强型LLM交互的人类偏好数据集。该数据集涵盖多种意图和语言,并包含约12,000个人类偏好投票的完整系统追踪。分析显示,用户偏好受引用数量影响,即使引用内容不直接支持归属声明;社区驱动平台通常更受欢迎。该数据集旨在支持对搜索增强型LLM的未来研究,代码和数据已开源 (来源: HuggingFace Daily Papers, jiayi_pirate, lmarena_ai)

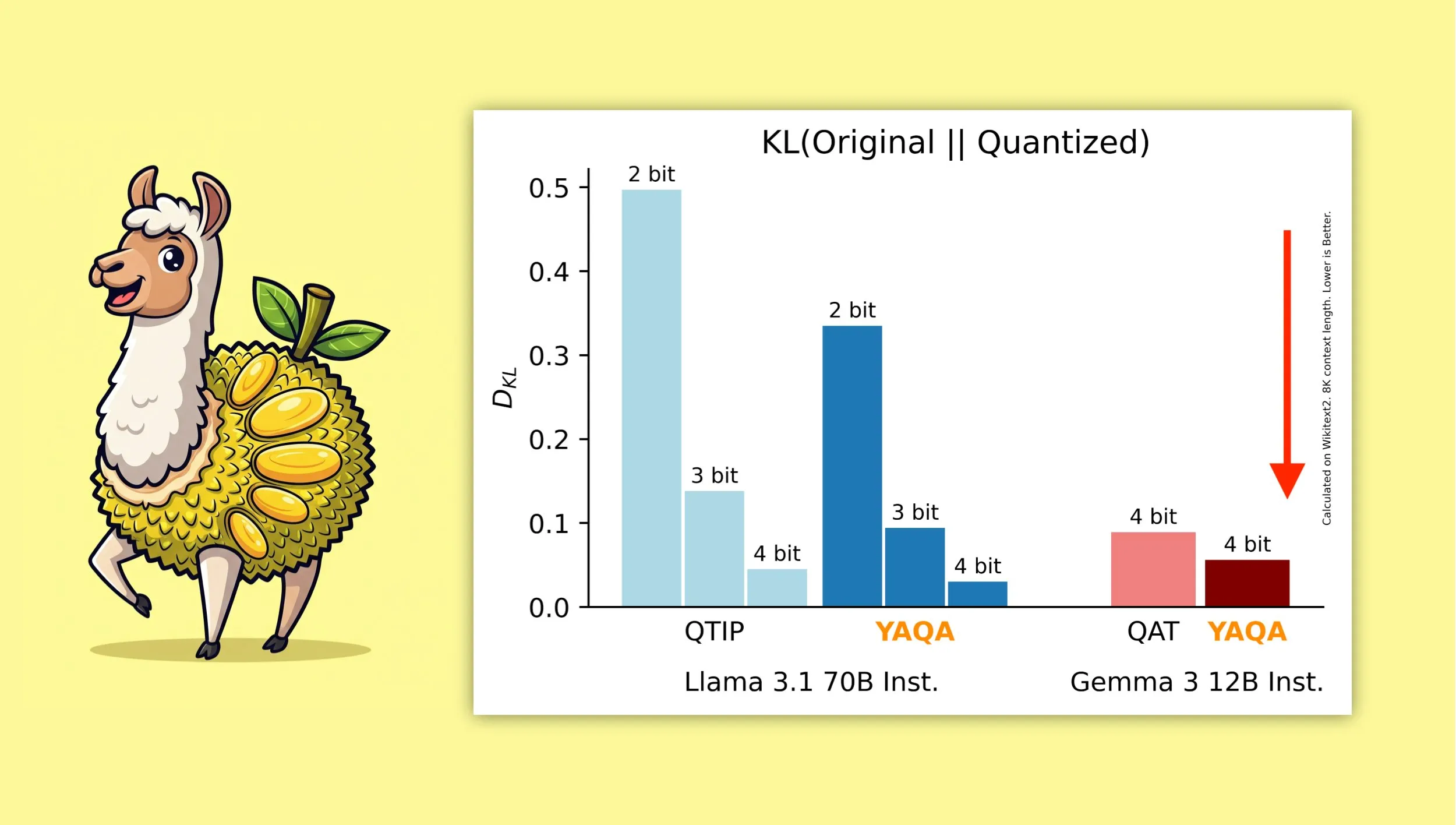
YAQA:一种新的量化算法,旨在更好地保留模型原始输出 :康奈尔大学的研究者推出了“Yet Another Quantization Algorithm”(YAQA),这是一种新的量化算法,旨在量化后更好地保留原始模型的输出。据称,YAQA相较于QTIP能将KL散度降低超过30%,并在Gemma 3上实现了比谷歌QAT模型更低的KL散度。该研究为模型量化领域提供了新的思路和工具,有助于在降低模型大小和计算需求的同时,最大限度地保持模型性能。相关论文和代码已发布,并提供了预量化的Llama 3.1 70B Instruct模型 (来源: Reddit r/MachineLearning, Reddit r/LocalLLaMA, tri_dao, simran_s_arora)
Tokasaurus:专为高吞吐量LLM推理设计的引擎发布 : HazyResearch 发布了 Tokasaurus,这是一个专为高吞吐量工作负载设计的新型 LLM 推理引擎,适用于大型和小型模型。该引擎旨在优化 LLM 在大规模并发请求场景下的处理效率和速度,可能采用了如连续批处理、分页注意力等先进技术来提升性能。Tokasaurus 的发布为需要高效处理大量 LLM 推理任务的开发者和企业提供了新的选择 (来源: Tim_Dettmers)
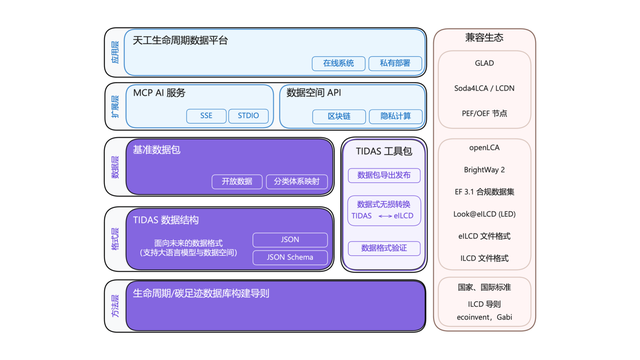
碳足迹“安卓”系统TIDAS发布,蚂蚁数科提供技术支持 : 碳足迹产业技术创新联盟发布了“天工LCA数据系统”(TIDAS),旨在为生命周期评价(LCA)和碳足迹数据库构建提供解决方案,目标是建立我国乃至全球LCA和碳足迹数据库的“安卓”系统。蚂蚁数科作为核心成员,为TIDAS提供了区块链技术与数据可信协作平台支持,通过其自主区块链技术实现碳数据资产的可信登记与确权,并利用隐私计算技术保障数据“可用不可见”,增强了数据的标准化、可融合性与互操作性 (来源: 量子位)
📚 学习
LangChain 举办企业级 AI 研讨会,聚焦多智能体系统 : LangChain 将于6月16日在旧金山举办企业级 AI 研讨会。届时,LangChain 的 Jake Broekhuizen 将指导参与者使用 LangGraph 构建生产就绪的多智能体系统,内容将涵盖安全性和可观察性等关键方面。这是一个实践性研讨会,旨在帮助开发者掌握构建复杂、可靠的 AI Agent 应用的技能 (来源: LangChainAI, hwchase17)

DeepLearning.AI 推出新课程《DSPy:构建和优化 Agentic 应用》 : DeepLearning.AI 发布了名为《DSPy: Build and Optimize Agentic Apps》的新课程。该课程将教授学员 DSPy 的基础知识,如何使用其签名和基于模块的编程模型来构建模块化、可追踪和可调试的 GenAI Agentic 应用。内容包括通过链接 Predict、ChainOfThought 和 ReAct 等 DSPy 模块构建应用,使用 MLflow 进行追踪和调试,以及利用 DSPy Optimizer 自动调整提示和改进少样本示例,以提高答案的准确性和一致性 (来源: DeepLearningAI, lateinteraction)
RAG 高级技术教程 GitHub 项目受关注 : NirDiamant 在 GitHub 上分享的 RAG (Retrieval-Augmented Generation) 技术教程项目获得了 16.6K 的星标。该教程内容广泛,涵盖了增强检索的预处理、优化、检索模式、迭代以及工程步骤等多个方面。对于希望深入研究和提升 RAG 应用效果的开发者而言,这是一个有价值的进阶学习资源 (来源: karminski3)
OpenAI 客户如何使用评估(Evals)构建更好的 AI 产品 : Hamel Husain 推广了一个由 OpenAI 的 Jim Blomo 主讲的网络研讨会,将讨论 OpenAI 客户如何利用评估工具(Evals)来构建更优质的 AI 产品。内容将包括真实的案例研究和结果,并展示 OpenAI 内部的评估工具(如追踪、评分等)。该研讨会旨在为开发者提供关于 AI 产品评估的实用见解和方法 (来源: HamelHusain)

LlamaIndex 分享13种 Agent 协议概览,探讨互操作性标准 : LlamaIndex 的 Seldo 在 MCP 开发者峰会上就当前13种不同的 Agent 间通信协议(包括 MCP、A2A、ACP 等)进行了概述性演讲。他分析了每种协议的独特功能、在当前技术格局中的定位以及未来的发展趋势。该演讲旨在帮助开发者理解和选择适合其 Agent 应用的通信标准,促进 Agent 生态的互操作性 (来源: jerryjliu0, jerryjliu0)

Claude Code 架构分析:控制流、编排引擎与工具执行 : 有文章对 Claude Code 的架构进行了深入解析,重点分析了其控制流与编排引擎以及工具和执行引擎。这些分析对于希望制作类似命令行编码助手工具或进行定制化修改的开发者具有参考价值,其设计思路也适用于其他类型的 Agent 工具开发 (来源: karminski3)

AMD GPU FP8矩阵乘法内核竞赛第二名解决方案分享 : Tim Dettmers 分享了 AMD GPU FP8 矩阵乘法内核竞赛第二名获奖者的解决方案。该方案的详细解读对于理解如何在 AMD GPU 上优化低精度浮点运算性能具有重要参考价值,尤其是在 AI 模型训练和推理中越来越多地采用 FP8 等低精度格式以提升效率的背景下 (来源: Tim_Dettmers)
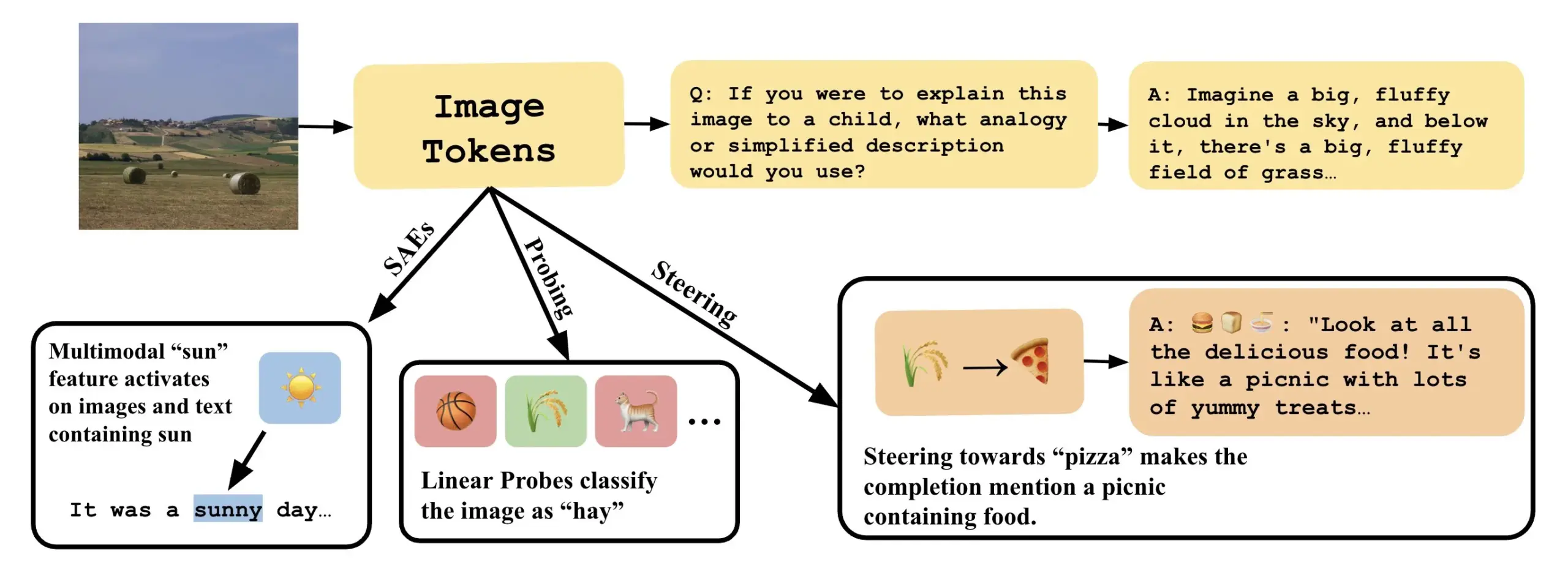
论文探讨如何通过解释 VLLM 中的线性方向来理解视觉语言模型 : 一篇名为《Line of Sight》的新论文探讨了通过解释视觉语言大模型(VLLM)潜在空间中的线性方向来理解其内部机制。研究者使用探测(probing)、引导(steering)和稀疏自动编码器(SAEs)等工具来解释 VLLM 中的图像表示。这项工作为理解多模态模型的内部工作原理提供了新的视角和方法 (来源: nabla_theta)
💼 商业
AI 初创公司 Vareon 获 Norck 300 万美元种子前融资,专注前沿 AI 与自主系统 : 由 Faruk Guney 创立的 Norck 公司承诺向其新成立的 AI 初创公司 Vareon 提供 300 万美元的里程碑式种子前融资。Vareon 专注于前沿 AI、因果推理和自主系统领域,其核心是 MALPAC(多智能体学习架构,用于规划和闭环优化)。公司旨在成为基础 AI 研究公司,推动机器人、LLM、分子设计、认知架构和自主智能体等领域的发展。同时推出的还有 RAPID(可微规划框架)、CIMO(因果多尺度协调器)、SCA(生物启发认知架构)和 Lumon-XAI(可解释性层) (来源: farguney)

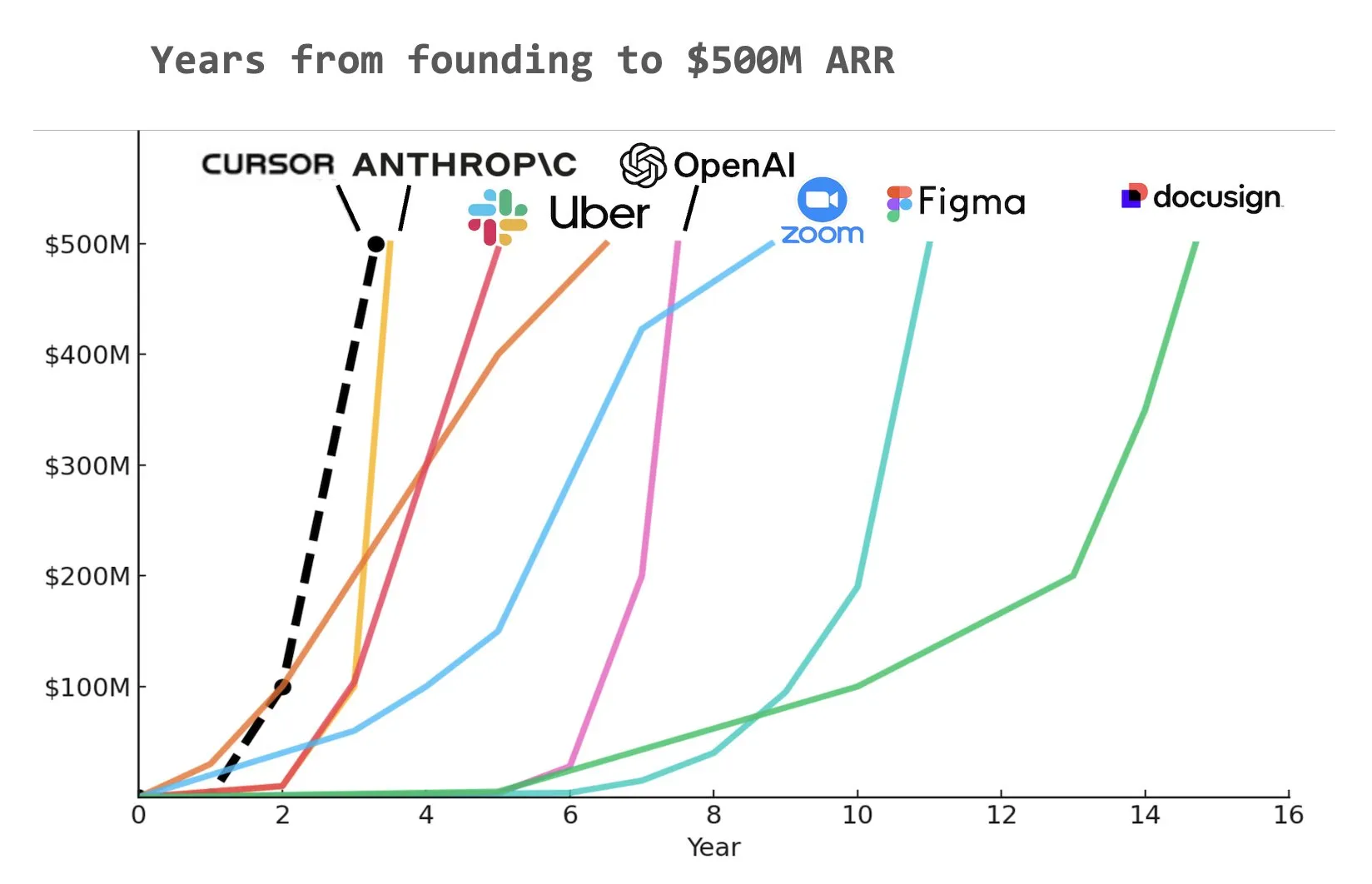
AI 编码工具 Cursor 获9亿美元C轮融资,ARR达5亿美元 : AI 编码工具初创公司 Cursor 宣布完成由 Thrive, Accel, Andreessen Horowitz 和 DST 领投的9亿美元C轮融资。该公司透露其年度经常性收入(ARR)已超过5亿美元,并被包括 NVIDIA、Uber 和 Adobe 在内的半数以上财富500强企业使用。此轮融资将助力 Cursor 进一步推动 AI 编码领域的研究前沿。有分析指出,Cursor 可能是历史上达到5亿美元ARR速度最快的公司之一 (来源: cursor_ai, Yuchenj_UW, op7418)
Anthropic 切断 Windsurf 对 Claude 模型的直接访问,或因 OpenAI 收购传闻 : Anthropic 联合创始人兼首席科学官 Jared Kaplan 表示,公司切断 AI 编程助手 Windsurf 对 Claude 模型直接访问权限,主要原因是市场传闻 Windsurf 即将被 OpenAI 收购。Kaplan 称“将 Claude 卖给 OpenAI 会很奇怪”,并表示 Anthropic 倾向于将计算资源分配给长期稳定的合作伙伴。尽管如此,Anthropic 正积极与其他 AI 编程工具开发商(如 Cursor)建立合作,并强调未来将更注重开发具有自主决策能力的 AI 编程产品,如 Claude Code (来源: dotey, vikhyatk, jeremyphoward, swyx)

🌟 社区
OpenAI Greg Brockman:AGI 未来更像多样化专业 Agent 协作而非单一模型 : OpenAI 的 Greg Brockman 认为,通用人工智能(AGI)的未来形态,将更像一个由众多专业化智能体(Agent)组成的“动物园”,而非一个单一的、无所不能的“巨石”模型。这些专业 Agent 将能够相互调用,协同工作,共同驱动经济发展。这一观点暗示了未来 AI 发展的趋势,即通过构建和整合多个具有特定能力的 AI Agent,来实现更复杂和强大的智能系统,目标是解锁10倍以上的活动和产出。Clement Delangue 对此评论,需要开源AI机器人技术来打破垄断,避免单一公司控制所有机器人 (来源: natolambert, ClementDelangue, HamelHusain)
LLM 在学术写作和内容总结方面展现潜力,引发对人类写作质量的思考 : Dwarkesh Patel 认为 LLM 目前是“5/10”的写手,但它们能够可靠地改进论文和书籍中的解释,这一事实本身就是对学术写作质量的巨大谴责。Arvind Narayanan 进一步指出,多数学术写作往往为了显得深奥复杂而牺牲了清晰易懂,而好的写作应力求简洁。这引发了关于 LLM 在辅助学术研究、提升内容可读性以及未来可能如何改变学术交流方式的讨论 (来源: random_walker, jeremyphoward)
AI 编码工具引发开发者依赖性讨论,Claude Code 因其强大功能和高 Token 消耗受关注 : 用户 dotey 认为使用 AI 编程工具(如 Claude Code)容易产生强依赖性,甚至在有额度时也宁愿等待 AI 完成而非手动编写。Claude Max 订阅虽有上限,但其提供的强大编码能力(如优秀的指令理解、任务规划、grep 工具运用和长时间执行)使其成为高效工具。这一现象引发了关于 AI 工具如何改变开发者工作习惯、效率与依赖之间平衡的讨论。另一用户 Asuka小能猫也展示了使用 Claude-4-Opus 和 Cursor Max 模式高效完成前端开发的案例,但也提及了 Token 消耗问题 (来源: dotey, dotey)
AI 驱动的个性化教育潜力巨大,但需关注实施挑战 : Austen Allred 分享了其孩子参加 AI 驱动学校(无教师)五个月的体验,认为效果“疯狂”。Noah Smith 评论称,一对一辅导是有效的教育干预,AI 使其规模化成为可能。这引发了对 AI 在教育领域应用的讨论,包括个性化学习路径、AI 辅导员的潜力,以及如何确保教育公平性和克服技术实施挑战。Jon Stokes 转发并关注了这一趋势 (来源: jonst0kes, jeremyphoward)
AI 智能体与人类情感连接引关注,OpenAI 强调优先研究用户福祉 : OpenAI 的 Joanne Jang 发表博文,探讨人与 AI 关系以及公司对此的态度。核心观点是 OpenAI 构建模型首先服务于人,随着越来越多人对 AI 产生情感连接,公司正优先研究这对用户情感福祉的影响。Corbtt 评论认为,AI 伴侣是自互联网以来最具变革性的社交技术,若公司优化参与度而非心理健康,可能比社交媒体对儿童的负面影响更大,但若优化心理健康则可能是人类福音。cto_junior 则幽默地预见了未来可能需要与孩子讨论“与GPT结婚是否合适”的场景 (来源: cto_junior, corbtt)

AI Agent 技术发展迅速,但端到端稀疏强化学习任务仍具挑战 : Nathan Lambert 认为,当前的 Deep Research、Codex agent 等项目主要通过在短程强化学习(RL)任务和通用鲁棒性上训练模型来实现。而端到端地在非常稀疏的 RL 任务上进行训练,似乎比人们想象的要遥远。Corbtt 对此评论,即使是人类,也尚未有效掌握如何在长程任务和稀疏奖励信号下进行训练。这反映了当前 AI Agent 技术在处理复杂、长远规划和自主学习方面的局限性 (来源: corbtt)
AI 领域的“苦涩教训”:验证(Verification)成为推理型 LLM 的关键 : Rishabh Agarwal 在 CVPR 多模态推理研讨会上发表了题为“RL的苦涩教训:验证作为推理型LLM的关键”的演讲。该演讲受到 Rich Sutton 关于“苦涩教训”经典文章的启发,探讨了在强化学习和大型语言模型推理中,验证机制的重要性。这可能意味着,仅仅依靠模型自身的生成能力是不够的,强大的验证和反馈机制对于提升AI的推理能力和可靠性至关重要 (来源: jack_w_rae)

AI 发展引发就业市场担忧,专家观点不一 : Klarna CEO Sebastian Siemiatkowski 警告称,AI 可能通过导致大规模失业(尤其是白领工作)引发经济衰退。Klarna 自身已通过 AI 助手替代了700名客服,年节省约4000万美元。Anthropic 研究员 Sholto Douglas 也预测到2027-28年,AI 的能力将非常强大。然而,也有观点认为 AI 将提高生产力并创造新岗位,如 Sundar Pichai 曾表示 AI 将是加速器,至少在2026年前不会导致裁员。AI Explained 的视频分析了当前关于 AI 引发失业的头条新闻是否合理,并讨论了 Duolingo 和 Klarna 在 AI 应用方面的一些反复。这些讨论反映了社会对 AI 经济影响的普遍焦虑和不同预期
AI 智能体与现有网络/API交互的未来路径探讨 : 随着 AI 智能体自主网络交互能力的增强,其与现有 Web/API 的交互方式成为一个基础架构问题。讨论中提出了三种可能的路径:1. 从零开始重建,采用 Agent 原生协议(不切实际);2. 教会 Agent 像人一样操作网站(错误率高,尤其在身份验证方面);3. 使 HTTP“说 Agent 语言”,例如通过丰富 402(需要付费)等非成功响应的机器可读上下文,让 Agent 能自主验证和购买访问权限。核心观点认为,为非成功 Web/API 交互提供丰富的上下文信息,将是自主 Agent 实现有意义工作的关键,使其能够自动从错误中恢复并导航复杂流程 (来源: Reddit r/ArtificialInteligence)
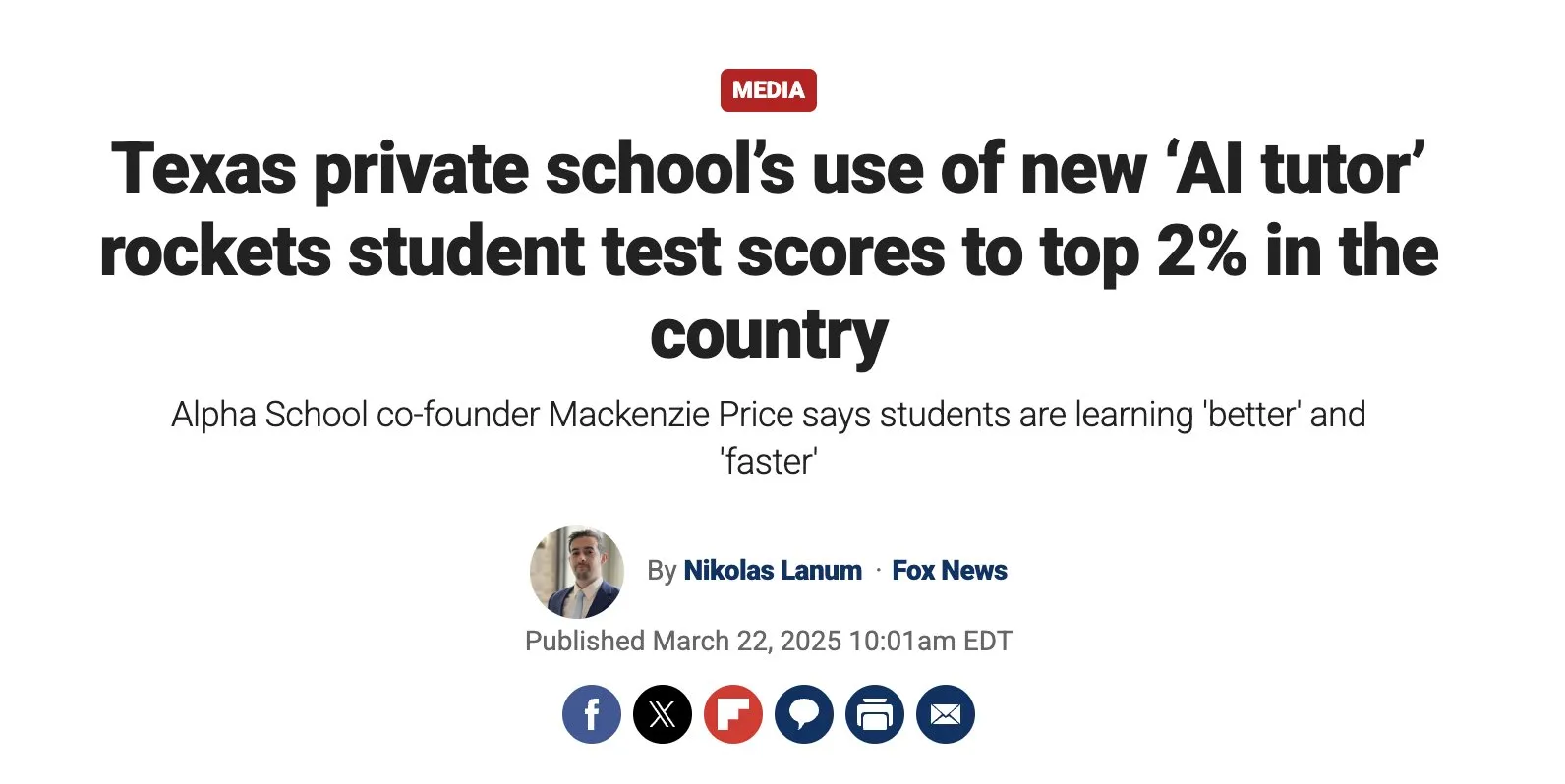
AI 辅助数学研究取得进展,陶哲轩等关注其潜力与局限 : 数学家们正积极探索 AI 在解决复杂数学问题中的应用。陶哲轩分享了 AI (AlphaEvolve) 与人类合作在30天内三度刷新和差集指数记录的案例,并结合 Lean 语言和 GitHub Copilot 挑战“ε-δ”极限问题,展示了 AI 在辅助新手入门、处理基础任务和预测证明结构方面的能力,但也指出了其在复杂推导和寻找数学引理方面的不足。另有报道称,30名顶尖数学家在秘密会议中测试 OpenAI o4-mini,发现其能解决部分极难问题,展现出接近数学天才的水平。这些进展预示着 AI 可能成为数学研究的得力助手,但也对数学家的角色和创造力培养提出了新的思考 (来源: 36氪)

💡 其他
GPS 替代技术竞赛升温,Xona Space Systems 计划构建低轨PNT星座 : 由于 GPS 系统信号易受干扰(天气、5G信号塔、干扰器)且精度有限,尤其在俄乌冲突中其脆弱性凸显,寻找替代方案成为战略重点。加州初创公司 Xona Space Systems 计划发射名为 Pulsar 的低地球轨道卫星星座(最终258颗),其卫星轨道更低,信号强度约是GPS的100倍,更难干扰且能更好地穿透障碍物,旨在提供厘米级精度和高可靠性的定位、导航和授时(PNT)服务,以支持自动驾驶等新兴技术。首颗测试卫星将于本月搭乘 SpaceX Transporter 14 发射 (来源: MIT Technology Review)

研究探讨希望与乐观情绪对心脏病患者康复的积极影响 : 最新研究表明,心脏病患者的希望和乐观情绪与其更好的健康结果相关,而绝望则与更高的死亡风险相关。这与安慰剂效应(积极预期改善效果)和反安慰剂效应(消极预期导致负面症状)的现象一致。利物浦大学的 Alexander Montasem 等研究者发现,高度希望与心绞痛减少、中风后疲劳减轻、生活质量提高和死亡风险降低相关。研究者正探索如何在临床中利用积极思维的力量,例如通过帮助患者设定目标、增强能动性来“开出希望的处方”,同时强调非物质目标对幸福感更为重要 (来源: MIT Technology Review)

苹果与阿里巴巴在华 AI 服务推广受阻,或因贸易摩擦 : 据英国《金融时报》报道,苹果公司与阿里巴巴在中国的 AI 服务推广计划遭遇延迟,这被认为是中美贸易摩擦的最新受害者。该合作原计划为在中国销售的 iPhone 提供 AI 功能支持。此次延迟可能影响苹果在中国市场 AI 功能的部署进度,并对两家公司的合作前景带来不确定性 (来源: MIT Technology Review)