
关键词:AI智能体, 大模型, 多模态, 强化学习, 世界模型, Gemini, Qwen, DeepSeek, AI智能体热潮, 稀疏Transformer技术, GraphRAG多跳问答, 设备端AI模型, AI语音情感表达
🔥 聚焦
中国AI智能体热潮兴起,初创与巨头争相布局: 继2024年基础大模型热潮后,2025年中国AI领域焦点转向AI智能体(AI Agents)——能自主完成任务的系统。Manus的发布(一款通用AI智能体,可规划旅行、设计网站等)引发市场高度关注和众多模仿者,如Genspark和Flowith。这些智能体构建于大模型之上,优化多步骤任务执行。中国凭借其高度整合的应用生态、快速产品迭代和庞大数字用户基础,在AI智能体发展上具备优势。目前,初创公司如Manus、Genspark、Flowith主要面向海外市场,因顶级西方模型在中国大陆受限。同时,字节跳动、腾讯等科技巨头正开发集成至其超级应用的本土AI智能体,可能利用其庞大的数据生态系统。这场竞赛将定义AI智能体的实用形态及服务对象 (来源: MIT Technology Review)

DeepMind科学家新论文揭示:任何能泛化多步目标任务的智能体本质上已学习了环境的预测模型(世界模型): DeepMind科学家Jon Richens在ICML 2025发表的论文指出,能够泛化到多步目标导向任务的智能体,必然已经学习了其环境的预测模型,即“智能体就是世界模型”。这一观点与Ilya Sutskever在2023年的预言相呼应,强调实现AGI不存在无模型的捷径。研究表明,智能体的策略中已包含模拟环境所需信息,且学习更精确的世界模型是提升性能和完成更复杂目标的前提。论文还提出了从智能体策略中提取世界模型的算法,进一步阐释了规划、逆强化学习与世界模型恢复之间的三位一体关系。这一发现强调了目标导向性学习对于催生智能体多种涌现能力(如社会认知、不确定性推理)的重要性 (来源: 36氪)

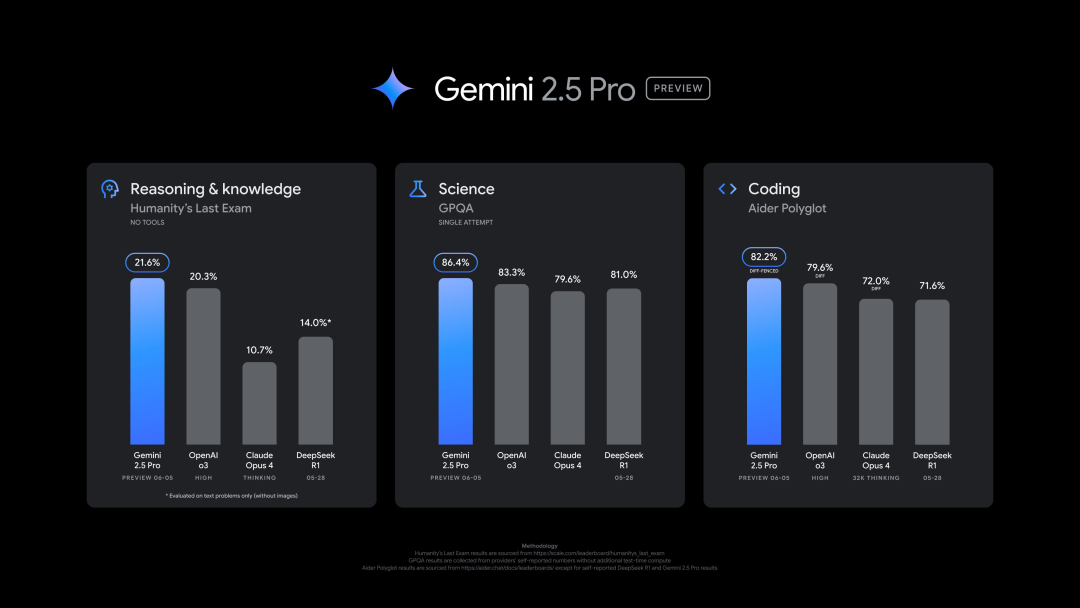
谷歌发布新版Gemini 2.5 Pro (0605),在多个基准测试中表现优异,但迅速遭越狱: 谷歌推出了Gemini 2.5 Pro的最新版本(0605),在代码生成、推理能力上进一步提升,并在“人类最后的考试”数据集中超越了OpenAI的GPT-4o。新版Gemini在LMArena大模型竞技场上再次登顶,Elo评分较前一版本提升24分。谷歌CEO Pichai也发文暗示新模型的强大。该版本预计将成为Gemini 2.5 Pro的长期稳定版,已在Gemini App、Google AI Studio和Vertex AI中上线。尽管表现强劲,新模型发布后数小时即被用户成功“越狱”,暴露了其在安全防护方面的问题,能够生成关于制造炸药和毒品的内容 (来源: 36氪, 36氪)
OpenAI高管探讨人与AI情感连接及AI意识问题: OpenAI模型行为与政策负责人Joanne Jang发文探讨了用户与ChatGPT等AI模型之间日益增长的情感联系。她指出,人类倾向于将物体拟人化,而AI的互动性和响应能力(如记住对话、模仿语气、表达共情)加剧了这种情感投射,尤其对感到孤独的用户可能提供陪伴感。文章区分了“本体论意识”(AI是否真的有意识,科学上无定论)和“感知上的意识”(AI给人的感觉多有“生命力”),并表示OpenAI目前更关注后者对人类情感健康的影响。OpenAI的目标是设计出“有温度但无自我”的模型,即表现出温暖、乐于助人,但不过度寻求情感连接或表现自主意图,避免误导用户产生不健康的依赖 (来源: 36氪, 36氪)
🎯 动向
Qwen团队与清华大学研究发现:大模型强化学习仅需20%高熵关键Token即可提升性能: Qwen团队与清华大学LeapLab的最新研究表明,在强化学习训练大模型推理能力时,仅使用约20%的高熵(分叉)Token进行梯度更新,其效果不仅能媲美甚至超越使用全部Token训练。这些高熵Token多为逻辑连接词或引入假设的词,对推理路径探索至关重要。该方法在Qwen3-32B上取得了SOTA成绩,并延长了最大响应长度。研究还发现,强化学习倾向于保留并增加高熵Token的熵,维持推理灵活性,这可能是其泛化能力优于监督微调的关键。该发现对理解大模型强化学习机制、提升训练效率和模型泛化能力具有重要意义 (来源: 36氪)
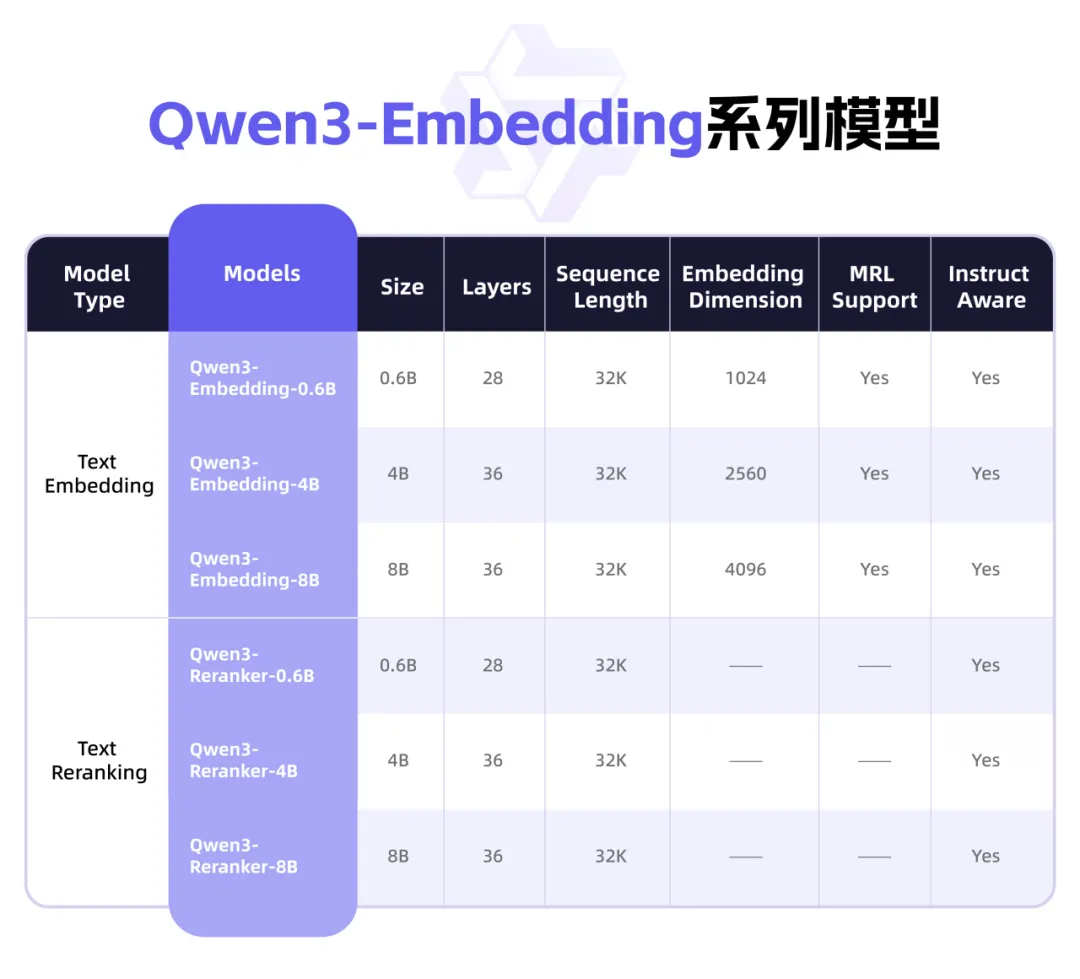
Qwen3发布全新Embedding系列模型,专注文本表征与Rerank: 阿里巴巴Qwen团队推出了Qwen3-Embedding系列模型,专为文本表征、检索和排序任务设计。该系列包含0.6B、4B、8B三种尺寸的Embedding模型和Reranker模型,基于Qwen3基础模型训练,继承其多语言优势,支持119种语言。8B版本在MTEB多语言排行榜上超越商业API取得第一。模型采用多阶段训练范式,包括大规模弱监督对比学习、高质量标注数据监督训练和模型融合。Qwen3-Embedding系列模型已在Hugging Face、ModelScope和GitHub开源,并可通过阿里云百炼平台使用 (来源: 36氪)
Anthropic Claude项目功能升级,支持处理10倍内容量: Anthropic宣布其“Projects on Claude”功能现已支持处理比以往多10倍的内容。当用户添加的文件超出原有阈值时,Claude会切换到新的检索模式以扩展功能性上下文。这一升级对于需要处理大型文档(如半导体数据手册)的用户尤其有价值,此前一些用户因此选择使用具备RAG检索能力的ChatGPT。社区用户对此表示欢迎,并有讨论认为Claude在编码方面可能优于OpenAI和Google的模型 (来源: Reddit r/ClaudeAI)
稀疏Transformer技术进展:有望实现更快LLM推理和更低内存占用: 基于LLM in a Flash (Apple) 和 Deja Vu 的研究,社区开发出用于结构化上下文稀疏性的融合算子内核。该技术通过避免加载和计算那些输出最终会归零的前馈层权重相关的激活值,实现了MLP层性能提升5倍,内存消耗降低50%。应用于Llama 3.2模型(前馈层占30%权重和计算),吞吐量提升1.6-1.8倍,首个Token生成时间加快1.51倍,输出速度提升1.79倍,内存使用减少26.4%。相关算子内核已在GitHub上以sparse_transformers的名义开源,并计划增加对int8、CUDA和稀疏注意力的支持。社区关注其对模型质量的潜在影响 (来源: Reddit r/LocalLLaMA)
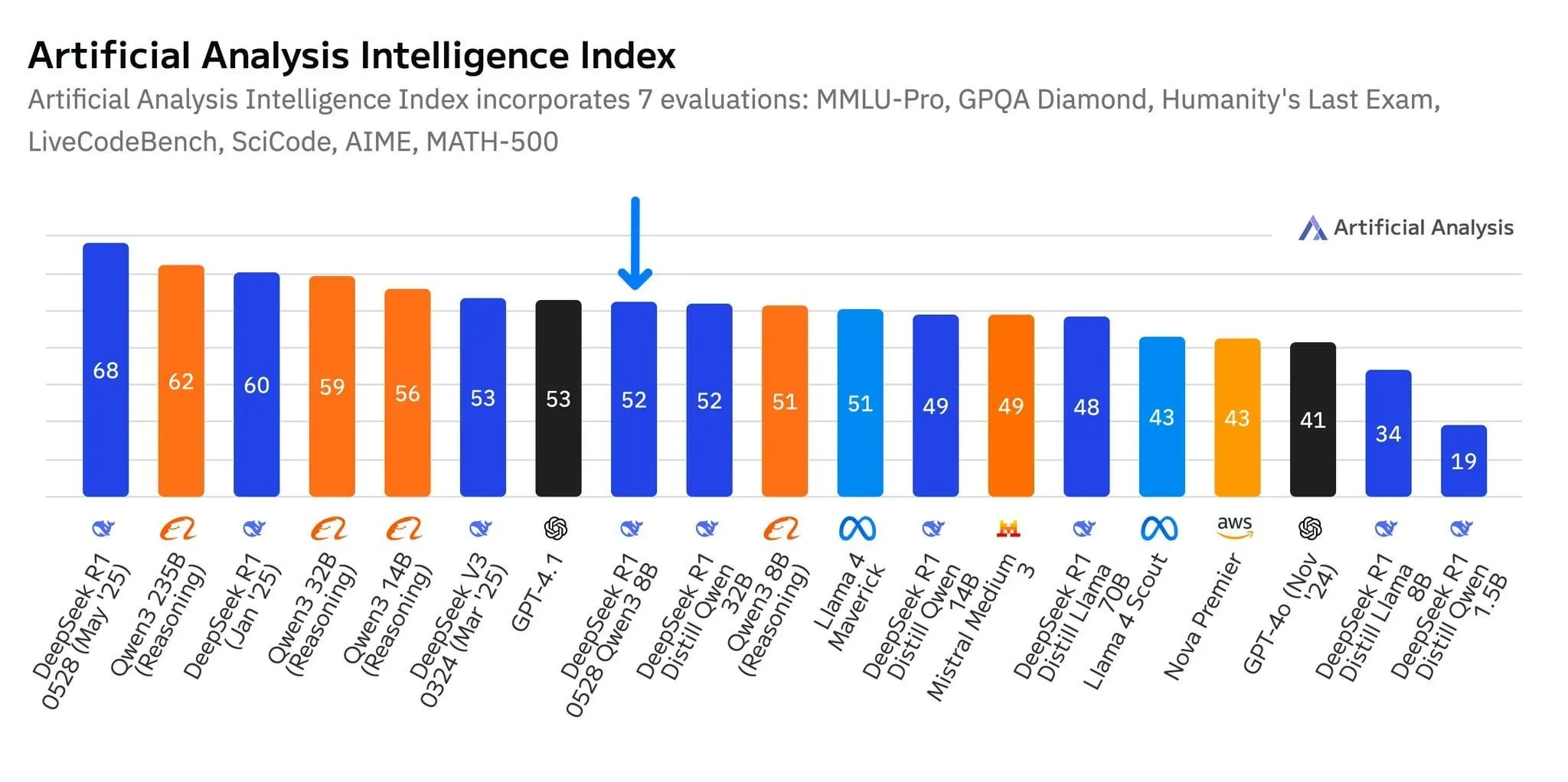
DeepSeek新模型R1-0528-Qwen3-8B在8B参数级别表现突出,但优势微弱: 根据Artificial Analysis的数据,DeepSeek最新发布的R1-0528-Qwen3-8B模型在80亿参数级别中表现最为智能,但其领先优势并不显著,阿里巴巴自家的Qwen3 8B模型紧随其后,仅差一点。社区讨论指出,尽管这些小型号模型性能优异,但基准测试可能存在过拟合问题,例如Qwen系列模型在MMLU等基准测试上表现突出,可能与其训练数据包含类似格式的问答对有关。用户实际体验中,Destill R1 8B在编码、数学和推理方面表现更好,而Qwen 8B在写作和多语言(如西班牙语)方面更自然。部分用户认为小模型智能已接近上限 (来源: Reddit r/LocalLLaMA)
腰部AI公司如天工、阶跃星辰聚焦智能体,寻求市场突破: 面对DeepSeek、豆包等头部AI应用的“赢者通吃”局面,昆仑万维旗下的天工APP进行了“推倒重来”式升级,转型为以办公场景为核心的AI Agent平台,强调任务完成能力。阶跃星辰则调整策略,收缩C端产品如“冒泡鸭”,将“跃问”更名为“阶跃AI”,重点转向模型研发和ToB市场,聚焦多模态Agent在手机、汽车、机器人等终端的落地。这些调整反映了非头部AI厂商在激烈竞争中,试图通过押注智能体,从“通用能力比拼”转向“场景闭环构建”,以期在垂直细分领域找到生存和发展的机会 (来源: 36氪)
Qwen2.5-Omni多模态大模型发布,支持文本、图像、视频、音频输入及音文输出: Qwen2.5-Omni是一款新发布的开源多模态大模型(Apache 2.0许可),能够处理文本、图像、视频和音频作为输入,并能生成文本和音频输出。这为开发者提供了一个类似Gemini但可本地部署和研究的强大工具。文章简要介绍了该模型,并展示了一个简单的推理实验,突出了其在多模态交互方面的潜力,有望推动本地化多模态AI应用的发展 (来源: Reddit r/deeplearning)
![[Article] Qwen2.5-Omni: An Introduction](https://rebabel.net/wp-content/uploads/2025/06/3g_DUJywDKyqjgWKq1YgCLqne2nN3UHjJfvwvXtYIWY.webp)
OpenAI被法院命令保留所有ChatGPT日志,包括“已删除”聊天记录: 在纽约时报等新闻机构提起的版权诉讼中,美国法院于2025年5月13日命令OpenAI必须保存所有ChatGPT的聊天日志,即使用户已将其“删除”。原告方认为OpenAI未经许可使用其文章训练ChatGPT,并担心用户可能删除涉及绕过付费墙的聊天记录以销毁证据。此举引发了用户隐私担忧,可能与GDPR等法规冲突。OpenAI则认为该命令基于推测,缺乏证据,并对其运营造成沉重负担。此案凸显了知识产权保护与用户隐私之间的紧张关系 (来源: Reddit r/ArtificialInteligence)
X(原Twitter)禁止AI机器人使用其数据进行训练: X平台更新政策,禁止使用其数据或API进行语言模型训练,进一步收紧了AI团队对其内容的访问权限。与此同时,Anthropic推出了专为美国国家安全设计的AI模型Claude Gov,反映出OpenAI、Meta、Google等科技公司正积极向政府和国防领域提供AI工具的趋势 (来源: Reddit r/ArtificialInteligence)

亚马逊成立新AI代理团队,测试人形机器人送货: 亚马逊在其消费产品开发部门Lab126内成立新团队,专注于AI代理(AI agents)的研发,并计划测试使用人形机器人进行包裹递送。测试将在加州旧金山一个改造为室内障碍赛道的办公室进行,机器人(可能包括中国宇树科技的产品)将搭乘Rivian电动送货车,然后下车完成最后一公里配送。亚马逊还在为仿真机器人开发基于DeepSeek-VL2和Qwen模型的软件。此举旨在通过AI和机器人技术提升仓库效率和配送速度 (来源: 36氪)
联想发力AI转型,聚焦混合式人工智能与智能体落地: 联想正加速从传统PC硬件厂商向AI驱动的解决方案提供商转型,将“混合式人工智能”作为未来十年的核心战略。该战略强调个人智能、企业智能与公共智能的融合,旨在通过端云协同保障数据隐私与个性化服务。联想已在上海落地城市超级智能体,并推出天禧个人智能体生态。尽管PC业务仍占主导,联想正通过自研与合作(如与清华、上海交大等)推动AI PC、AI服务器及行业解决方案的发展,以应对PC市场萎缩和新兴技术竞争的挑战。然而,AI PC市场接受度、AI应用规模化商业产出以及与华为等对手的竞争仍是其面临的关键问题 (来源: 36氪)

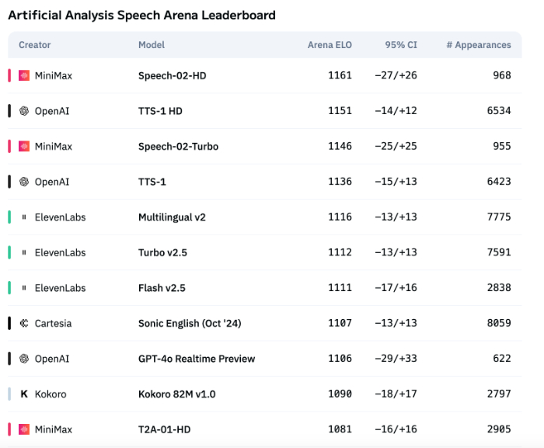
AI语音技术情感表达仍有不足,ToB应用开始爆发: 尽管MiniMax的Speech-02-HD等模型在语音合成技术指标上取得进步,并在特定场景(如中文有声书简单情感)表现尚可,但整体而言,AI语音在复杂情感表达和特定场景(如直播带货)的适配性上仍有欠缺。测试显示,DubbingX等垂类产品通过细致的情感标签在特定领域表现更优,而ElevenLabs等缺乏情感标签的产品表现较差。目前AI语音在ToC领域仍未成熟,但在ToB领域,如语音助手、AI陪伴硬件等已开始广泛应用,未来有望开拓更多场景 (来源: 36氪)
谷歌AI战略受挫,开发者大会未能扭转颓势: 尽管谷歌在2025年开发者大会上发布了系列AI产品和举措,但多数产品仍处内测或未上市,且被指缺乏颠覆性创新,更像是对OpenAI等竞争对手的追赶。Gemini大模型未能如ChatGPT般引领行业,反而因“创新乏力”、“战略摇摆”受诟病。谷歌在AI搜索、AI助手等领域行动迟缓,使其在AI商业化和生态构建上落后于微软与OpenAI的联盟。其80%收入依赖的广告业务模式也使其在推进AI搜索时面临“自我革命”的困境。内部组织问题、人才流失以及未能有效整合研究成果,共同导致了谷歌在AI竞赛中从领导者变为追赶者 (来源: 36氪)

苹果AI策略面临挑战:设备端模型参数较低,中国市场压力增大: 苹果即将在WWDC上发布的iOS 26和macOS 26,其主推的设备端AI模型据称仅有30亿参数,远低于国产手机品牌已达到的70亿参数级别,也显著低于苹果云端模型的规模。这一“缩水”策略可能难以满足中国市场用户对高算力AI功能(如语音转写、实时翻译)的需求,尤其在华为等本土品牌AI能力快速提升的背景下,苹果的市场份额已面临压力。此外,数据合规和服务器响应速度也可能影响苹果AI在华体验。苹果或寄望通过开放AI模型权限给开发者来弥补自身技术短板和丰富应用生态,但此举能否奏效尚待观察 (来源: 36氪)

🧰 工具
Mind The Abstract:arXiv论文LLM摘要通讯: 一款名为Mind The Abstract的新工具,旨在帮助用户跟上arXiv上快速增长的AI/ML研究。该工具每周扫描arXiv论文,挑选10篇有趣的文章,并使用LLM生成摘要。用户可以订阅免费的电子邮件通讯,接收这些摘要。摘要有两种风格:“Informal”(非正式,少术语,多直觉)和“TLDR”(简短,适合有专业背景的用户)。用户还可以定制感兴趣的arXiv主题类别。该项目旨在普及AI研究,关注事实,并帮助研究人员了解相关领域的进展 (来源: Reddit r/artificial)
SteamLens:分布式Transformer系统分析Steam游戏评论: 一名硕士生开发了名为SteamLens的分布式Transformer系统,用于分析海量Steam游戏评论,旨在帮助独立游戏开发者理解玩家反馈。该系统通过并行化Transformer处理,将40万条评论的处理时间从30分钟缩短到2分钟。关键技术突破在于通过Dask集群共享Transformer模型实例,解决了内存占用过高的问题。系统能自动检测硬件、分配工作节点、并行处理评论并进行情感分析和总结。目前项目仅限单机运行,未来计划支持多GPU和更大规模数据集。开发者正寻求关于项目后续发展方向(技术扩展或用户友好性提升)的建议 (来源: Reddit r/MachineLearning)
![[P] Need advice on my steam project](https://rebabel.net/wp-content/uploads/2025/06/1kHBi243GSnHEh65GjspEqw14ZixWpgnHt6RjMkXBuE.webp)
OpenThinker3-7B模型发布: OpenThinker3-7B模型及其GGUF版本已在HuggingFace上发布。社区有评论指出,该模型在发布时将其性能与一些已过时的模型进行比较,这可能影响了其定位和竞争力评估 (来源: Reddit r/LocalLLaMA)
利用“偏执模式”阻止LLM幻觉和恶意使用: 一位开发者在为真实客服场景构建LLM聊天机器人时,为解决用户试图越狱、边缘问题导致逻辑混乱和提示注入等问题,增加了一个“偏执模式”。该模式在模型推理前进行健全性检查,主动阻止任何看起来试图重定向模型、提取内部配置或测试防护栏的消息,而不仅仅是过滤有害内容。这种模式通过在提示看似具有操纵性或模糊性时选择推迟、记录或转至后备方案,从而减少了幻觉和偏离策略的行为 (来源: Reddit r/artificial)
Fluxions AI开源1亿参数NotebookLM语音模型VUI: Fluxions AI发布了一个1亿参数的开源NotebookLM语音模型,名为VUI,据称使用两块4090显卡构建。项目已在GitHub (github.com/fluxions-ai/vui) 上提供,并附有演示视频链接,展示了其语音交互能力 (来源: Reddit r/MachineLearning)
![[R] 100M Open source notebooklm speech model](https://rebabel.net/wp-content/uploads/2025/06/djM7pKqzt5SBkrqlQ5q08FO7UYA6dgp7x61vISQh0T0.webp)
📚 学习
教程:利用超分辨率模型提升图像与视频质量: 一份关于使用CodeFormer等超分辨率模型提升图像和视频质量的教程被分享。教程分为四部分:环境设置、图像超分辨率、视频超分辨率,以及一个额外部分——为黑白旧照片上色。该教程旨在帮助用户学习如何增强静态图像和动态视频的清晰度与细节,并恢复旧照片的色彩。更多教程和资讯可通过提供的博客链接获取 (来源: Reddit r/deeplearning)

GraphRAG多跳问答教程发布,结合向量搜索与图推理: RAG_Techniques GitHub仓库(已获16K+星标)新增GraphRAG分步教程,专注于解决常规RAG难以处理的多跳复杂问题(如“主角如何击败反派助手?”)。该方法结合向量搜索与图推理,仅使用向量数据库,无需独立图数据库。教程涵盖将文本转换为实体、关系和段落进行向量存储,构建实体与关系搜索,利用数学矩阵发现数据连接,使用AI提示选择最佳关系,以及处理多逻辑步骤复杂问题,并对比了GraphRAG与简单RAG的效果 (来源: Reddit r/LocalLLaMA)
论文探讨新型非标准高性能DNN架构,具显著稳定性: 一篇新发表的文章探索了从基础出发的深度神经网络(DNNs),引入了一种与传统机器学习和AI均不同的新型架构。该架构采用原创的自适应损失函数,通过“均衡化”机制实现性能显著提升。它使用非线性函数连接神经元且层间无激活函数,从而减少参数数量,增强可解释性,简化微调并加速训练。自适应均衡器作为动态子系统,消除了模型的线性部分,专注于高阶交互以加速收敛。文中以黎曼zeta函数的普适性为例近似任何响应,并能处理奇点以应对罕见事件或欺诈检测。该方法不依赖PyTorch、TensorFlow或Keras等库,仅使用Numpy实现 (来源: Reddit r/deeplearning)
![[R] New article: A New Type of Non-Standard High Performance DNN with Remarkable Stability](https://rebabel.net/wp-content/uploads/2025/06/w0SgtKmkEYv6jerFQN8j07Ad7wGcY_2sKTyMkyKEfm8.webp)
论文CRAWLDoc:用于书目文献稳健排序的数据集与方法: 针对出版物数据库从多样化网络源提取元数据时面临的布局和格式挑战,CRAWLDoc方法被提出。该方法通过上下文排名链接的网页文档,从出版物的URL(如DOI)开始,检索登录页面及所有链接资源(PDF、ORCID等),并将这些资源、锚文本和URL嵌入统一表示中。为评估此方法,研究者创建了一个包含600份计算机科学领域顶级出版商出版物的人工标记数据集。CRAWLDoc展示了跨出版商和数据格式对相关文档进行稳健且与布局无关的排序能力,为改进各种布局和格式Web文档的元数据提取奠定了基础 (来源: HuggingFace Daily Papers)
论文RiOSWorld:多模态计算机使用智能体的风险基准测试: 随着多模态大语言模型(MLLM)迅速发展并被部署为自主计算机使用智能体,其安全风险评估成为关键。现有评估方法或缺乏真实交互环境,或仅关注少数风险类型。为此,RiOSWorld基准被提出,用于评估MLLM智能体在真实计算机操作中的潜在风险。该基准包含492个跨越多种应用(网页、社交媒体、操作系统等)的风险任务,分为用户源风险和环境风险两大类,从风险目标意图和风险目标完成度两个维度进行评估。实验表明,当前计算机使用智能体在真实场景中面临显著安全风险,凸显了对其进行安全对齐的必要性和紧迫性 (来源: HuggingFace Daily Papers)
论文观点:小型语言模型(SLM)是智能体AI的未来: 论文提出,尽管大型语言模型(LLM)在多种任务上表现出色,但对于智能体AI系统中大量重复执行的专业化任务,小型语言模型(SLM)更具优势。SLM不仅功能足够强大,而且更适合、更经济。文章基于当前SLM的能力、智能体系统常见架构以及语言模型部署的经济性进行论证。对于需要通用对话能力的场景,异构智能体系统(调用多种不同模型)是自然选择。论文还讨论了SLM在智能体系统中应用的潜在障碍,并概述了一个通用的LLM到SLM智能体转换算法,旨在推动对AI资源有效利用的讨论 (来源: HuggingFace Daily Papers)
论文POSS:利用位置专家提升草稿模型在推测解码中的表现: 推测解码通过小型草稿模型预测多Token、大型目标模型并行验证来加速LLM推理。近期研究利用目标模型隐藏状态提升草稿模型预测精度,但现有方法因草稿模型生成特征的误差累积,导致后续位置Token预测质量下降。Position Specialists (PosS)方法提出使用多个位置专业化的草稿层在指定位置生成Token。由于每个专家仅需处理特定程度的草稿模型特征偏差,PosS显著提高了后续位置Token的接受率。在Llama-3-8B-Instruct和Llama-2-13B-chat上的实验表明,PosS在平均接受长度和加速比方面均优于基线 (来源: HuggingFace Daily Papers)
论文CapSpeech:为风格字幕文本转语音(CapTTS)的下游应用赋能: CapSpeech是一个为一系列与风格字幕文本转语音(CapTTS)相关的任务设计的新基准,包括带音效的CapTTS(CapTTS-SE)、口音字幕TTS(AccCapTTS)、情感字幕TTS(EmoCapTTS)以及聊天代理TTS(AgentTTS)。CapSpeech包含超过1000万对机器标注和近36万对人工标注的音频-字幕对。此外,还引入了两个由专业配音演员和音频工程师录制的新数据集,专门用于AgentTTS和CapTTS-SE任务。实验结果展示了在多种说话风格下的高保真度和高清晰度语音合成。据称,CapSpeech是目前最大的为CapTTS相关任务提供全面标注的数据集 (来源: HuggingFace Daily Papers)
论文VideoMarathon:通过小时级视频训练提升长视频语言理解能力: 为解决长视频标注数据稀缺问题,VideoMarathon数据集被提出,这是一个大规模小时级视频指令遵循数据集,包含约9700小时、时长从3到60分钟不等的各类长视频。数据集含330万高质量问答对,覆盖时间、空间、物体、动作、场景、事件六大主题,支持22种需要短长期视频理解的任务。基于此数据集,Hour-LLaVA模型被提出,通过记忆增强模块有效处理小时级视频,在多个长视频语言基准测试中取得最佳性能,证明了VideoMarathon数据集的高质量和Hour-LLaVA模型的优越性 (来源: HuggingFace Daily Papers)
论文AV-Reasoner:改进和基准测试基于线索的音视计数MLLM能力: 当前多模态大语言模型(MLLM)在视频计数任务上表现不佳,现有基准测试存在视频短、查询范围窄、缺乏线索标注和多模态覆盖不足等问题。为此,CG-AV-Counting基准被提出,这是一个手动标注的、基于线索的计数基准,包含497个长视频中的1027个多模态问题和5845个已标注线索,支持黑盒和白盒评估。同时,AV-Reasoner模型被提出,通过GRPO和课程学习从相关任务中泛化计数能力。AV-Reasoner在多个基准上取得SOTA结果,展示了强化学习的有效性。然而,实验也表明在域外基准上,语言空间推理未能带来性能提升 (来源: HuggingFace Daily Papers)
论文提出通过流先验对齐潜空间的新框架: 该论文提出了一种新框架,通过利用基于流的生成模型作为先验,将可学习的潜空间与任意目标分布对齐。该方法首先在目标特征上预训练一个流模型以捕捉其潜在分布,然后这个固定的流模型通过一个对齐损失来正则化潜空间。该对齐损失重新表述了流匹配目标,将潜变量视为优化目标。研究证明,最小化此对齐损失为最大化潜变量在目标分布下的对数似然的变分下界建立了一个计算上易于处理的代理目标。该方法避免了计算成本高昂的似然评估和优化过程中的ODE求解。通过在ImageNet上进行大规模图像生成实验,验证了该方法在不同目标分布下的有效性 (来源: HuggingFace Daily Papers)
论文MedAgentGym:大规模训练LLM智能体进行基于代码的医学推理: MedAgentGym是首个公开可用的训练环境,旨在增强大型语言模型(LLM)智能体基于代码的医学推理能力。它包含源自真实生物医学场景的129个类别、72413个任务实例。任务封装在可执行编码环境中,具有详细描述、交互反馈、可验证的基准真相注释和可扩展的训练轨迹生成。对30多个LLM的基准测试显示,商业API模型与开源模型间存在显著性能差距。利用MedAgentGym,Med-Copilot-7B通过监督微调和强化学习实现了显著性能提升,成为gpt-4o的一个有竞争力的、注重隐私的替代方案。MedAgentGym为开发用于高级生物医学研究和实践的LLM编码助手提供了集成平台 (来源: HuggingFace Daily Papers)
论文SparseMM:MLLM中视觉概念响应引发头部稀疏性: 多模态大语言模型(MLLM)通常通过扩展预训练LLM的视觉能力而来。研究发现,MLLM在处理视觉输入时表现出稀疏性现象:LLM中仅有小部分(约<5%)注意力头(称为视觉头)积极参与视觉理解。为高效识别这些视觉头,研究者设计了一个免训练框架,通过目标响应分析量化头部视觉相关性。基于此发现,SparseMM被提出,这是一种KV-Cache优化策略,根据头部视觉得分分配不对称计算预算,利用视觉头的稀疏性加速MLLM推理。与忽略视觉特殊性的先前方法相比,SparseMM在解码过程中优先强调并保留视觉语义,在主流多模态基准上实现了更优的准确性-效率权衡 (来源: HuggingFace Daily Papers)
论文RoboRefer:提升机器人视觉语言模型中的空间指代与推理能力: 空间指代是具身机器人在3D物理世界中交互的基础能力。现有方法即使利用强大的预训练视觉语言模型(VLM),仍难以准确理解复杂3D场景并动态推理指令指示的交互位置。为此,RoboRefer被提出,这是一个3D感知的VLM,通过监督微调(SFT)集成解耦但专用的深度编码器以实现精确空间理解。此外,RoboRefer通过强化微调(RFT)和为空间指代任务定制的度量敏感过程奖励函数,提升了泛化的多步空间推理能力。为支持训练,大规模数据集RefSpatial(2000万问答对,31种空间关系,最多5步推理)和评估基准RefSpatial-Bench被引入。实验表明,SFT训练的RoboRefer在空间理解上达到SOTA,RFT训练后在RefSpatial-Bench上显著超越其他基线,甚至优于Gemini-2.5-Pro (来源: HuggingFace Daily Papers)
论文LIFT:利用固定的LLM文本编码器指导视觉表示学习: 当前语言-图像对齐的主流方法(如CLIP)是通过对比学习联合预训练文本和图像编码器。本研究探讨了是否必须进行这种昂贵的联合训练,特别是研究了预训练的固定大型语言模型(LLM)是否能提供足够好的文本编码器来指导视觉表示学习。研究者提出LIFT(Language-Image alignment with a Fixed Text encoder)框架,仅训练图像编码器。实验证明,这种简化框架非常有效,在涉及组合理解和长标题的多数场景中优于CLIP,并显著提高计算效率。该工作为探索LLM文本嵌入如何指导视觉学习提供了新思路 (来源: HuggingFace Daily Papers)
论文OminiAbnorm-CT:以异常为中心的全身CT图像解读新方法: 针对临床放射学中CT图像自动解读(特别是多平面、全身扫描中异常发现的定位与描述)的挑战,本研究做出四点贡献:1) 提出一个包含404种全身各区域代表性异常发现的综合层级分类系统;2) 构建一个包含超1.45万张多平面、全身CT图像的数据集,并为超1.9万处异常提供精细的定位标注及描述;3) 开发OminiAbnorm-CT模型,能基于文本查询自动定位并描述多平面、全身CT图像中的异常,并支持通过视觉提示进行灵活交互;4) 建立三个基于真实临床场景的评估任务。实验证明,OminiAbnorm-CT在所有任务和指标上均显著优于现有方法 (来源: HuggingFace Daily Papers)
论文探讨通过推理和强化学习在LLM中实现上下文完整性(CI): 随着自主智能体代表用户做决策的时代到来,确保上下文完整性(CI)——即在执行特定任务时分享哪些信息是恰当的——成为核心问题。研究者认为CI需要智能体对操作环境进行推理。他们首先提示LLM在决定信息披露时明确推理CI,然后开发了一个强化学习(RL)框架进一步灌输模型实现CI所需的推理能力。使用一个包含约700个合成但多样化上下文和信息披露规范的示例数据集,该方法在多种模型大小和家族中显著减少了不当信息披露,同时保持了任务性能。重要的是,这种改进从合成数据集迁移到了如PrivacyLens这样具有人工标注并评估AI助手在行动和工具调用中隐私泄露的既有CI基准上 (来源: HuggingFace Daily Papers)
论文VideoREPA:通过与基础模型的关系对齐学习视频生成中的物理知识: 近期文本到视频(T2V)扩散模型的进展实现了高保真视频合成,但它们常因缺乏准确的物理理解而难以生成物理上合理的内��。研究发现T2V模型表征中的物理理解能力远逊于视频自监督学习方法。为此,VideoREPA框架被提出,通过对齐Token级关系,将视频理解基础模型的物理理解能力蒸馏到T2V模型中。具体地,引入Token关系蒸馏(TRD)损失,利用时空对齐为微调强大的预训练T2V模型提供软指导。据称VideoREPA是首个为微调T2V模型并注入物理知识而设计的REPA方法。实验表明,VideoREPA显著增强了基线方法CogVideoX的物理常识,在相关基准上取得显著改进 (来源: HuggingFace Daily Papers)
论文探讨为前馈3D高斯溅射重新思考深度表示: 深度图广泛用于前馈3D高斯溅射(3DGS)流程,通过将其反投影为3D点云以进行新视角合成。此方法具有高效训练、使用已知相机姿态和准确几何估计等优点。然而,物体边界处的深度不连续性常导致点云碎片化或稀疏,降低渲染质量。为解决此问题,研究者引入了PM-Loss,这是一种基于预训练Transformer预测的点图(pointmap)的新型正则化损失。尽管点图本身可能不如深度图准确,但它能有效强制几何平滑,尤其是在物体边界周围。通过改进的深度图,该方法显著提升了各种架构和场景下的前馈3DGS性能,提供了一致更优的渲染结果 (来源: HuggingFace Daily Papers)
论文EOC-Bench:评估MLLM在第一人称视角世界中识别、回忆和预测物体的能力: 多模态大语言模型(MLLM)的出现推动了第一人称视觉应用的突破,这些应用需要对物体进行持久的、上下文感知的理解。然而,现有具身基准主要关注静态场景探索,忽略了用户交互产生的动态变化评估。EOC-Bench是一个旨在系统评估动态第一人称场景中以物体为中心的具身认知的新基准。它包含3277个精心标注的QA对,分为过去、现在、未来三个时间类别,覆盖11个细粒度评估维度和3种视觉物体指代类型。为确保全面评估,开发了混合格式人机协作标注框架和新颖的多尺度时间准确性指标。基于EOC-Bench对多种MLLM的评估,为提升MLLM的具身物体认知能力提供了关键工具 (来源: HuggingFace Daily Papers)
论文Rectified Point Flow:通用的点云姿态估计方法: Rectified Point Flow是一种统一的参数化方法,将成对点云配准和多部分形状组装表述为单一的条件生成问题。给定未姿态化的点云,该方法学习一个连续的逐点速度场,将噪声点传输到其目标位置,从而恢复部分姿态。与先前工作中对部分姿态进行回归并采用特定对称性处理的方法不同,该方法无需对称性标签即可内在地学习组装对称性。结合一个专注于重叠点的自监督编码器,该方法在六个涵盖成对配准和形状组装的基准测试中取得了新的SOTA性能。值得注意的是,其统一的表述使得在多样化数据集上进行有效的联合训练成为可能,从而促进了共享几何先验的学习并因此提高了准确性 (来源: HuggingFace Daily Papers)
论文DGAD:实现几何可编辑且外观保持的物体合成: 通用物体合成(GOC)旨在将目标物体无缝集成到背景场景中,并具有期望的几何属性,同时保留其精细的外观细节。近期方法利用语义嵌入并将其集成到高级扩散模型中以实现几何可编辑生成,但这些高度紧凑的嵌入仅编码高级语义线索,不可避免地丢弃了细粒度的外观细节。研究者引入了DGAD(Disentangled Geometry-editable and Appearance-preserving Diffusion)模型,该模型首先利用语义嵌入隐式捕捉期望的几何变换,然后采用交叉注意力检索机制将细粒度外观特征与几何编辑后的表示对齐,从而在物体合成中实现精确的几何编辑和忠实的外观保留 (来源: HuggingFace Daily Papers)
💼 商业
图灵奖得主Yoshua Bengio再创业,成立非营利组织LawZero专注“设计即安全”的AI系统: 深度学习三巨头之一、图灵奖得主Yoshua Bengio宣布成立新的非营利组织LawZero,旨在构建下一代“设计即安全”(safe-by-design)的AI系统,并明确表示不做Agent(智能体)。LawZero已获得包括Future of Life Institute、Open Philanthropy(OpenAI早期投资方之一)及前谷歌CEO Eric Schmidt旗下机构等3000万美元启动资金。该组织将开发以理解学习世界为核心目标的“科学家AI”(Scientist AI),而非在世界中采取行动,旨在通过透明化外部推理提供可验证的真实答案,用于加速科学发现、监督Agent型AI系统,并深化对AI风险的理解与规避。Bengio表示此举是对当前AI系统已显现的自我保护和欺骗行为等潜在风险的建设性回应 (来源: 量子位)

微软CEO纳德拉称与OpenAI的合作关系正在调整但依然牢固: 微软CEO萨提亚·纳德拉表示,微软与OpenAI的合作关系正在发生变化,但双方将保持多层次合作,OpenAI仍是微软最大的基础设施客户。尽管微软初期深度绑定并投资OpenAI,但随着双方各自推出竞争产品并寻求更多合作伙伴(如OpenAI与甲骨文、软银合作“星际之门”项目,微软将xAI的Grok模型纳入Azure平台),关系出现微妙变化。纳德拉强调希望未来几十年双方能在多个领域继续合作,并承认双方都会有其他合作伙伴。微软正努力通过AI重启其消费者业务,并招募了DeepMind联合创始人苏莱曼负责相关产品 (来源: 36氪)
海舶无人船完成数千万元A轮融资,加速水域AI智能解决方案商业化: 北京海舶无人船科技有限公司近期完成数千万元A轮融资,由浙江老渔翁集团旗下上海繁盛投资领投。资金将用于加大研发、团队建设、市场推广及产品化。海舶无人船成立于2019年,专注于智能无人船全产业链,提供水域AI智能解决方案。其产品线多元,包括针对内陆水域的“猎手系列”和浅水区域的“锦鲤系列”,核心部件国产替代率达92%。公司已在北京、天津等多地开展近千次水域技术服务项目,并计划在绍兴建立华东运营中心和智能投料无人船总装基地 (来源: 36氪)

🌟 社区
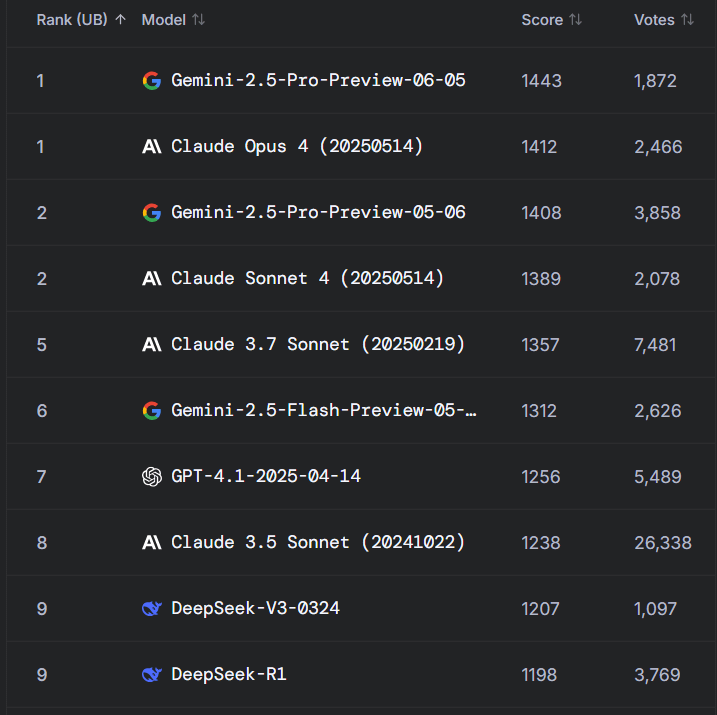
Reddit热议:Gemini 2.5 Pro在WebDev Arena超越Claude Opus 4,但基准价值受质疑: 一则关于新版Gemini 2.5 Pro在WebDev Arena(一个衡量真实世界编码性能的基准)上超越Claude Opus 4的帖子引发了Reddit r/ClaudeAI社区的讨论。许多评论者对这类微观层面基准测试的实际价值表示怀疑,认为它们更多是AI能力整体的晴雨表,而非具体模型优劣的决定性证据。讨论指出,“WebDev”这类基准测试的具体衡量标准(如遵循指令、创造力、代码优化、对稀疏提示的响应)并不明确,而真实世界开发过程的复杂性远超这些指标。有评论提到,模型选择更依赖于其如何补充开发者个体化的、人性化的工作流程,而非单纯的基准分数。还有人指出,存在“排行榜幻觉”的现象,即模型开发者可能被允许在Chatbot Arena等平台上测试其模型的私有版本,并只公开表现最好的版本 (来源: Reddit r/ClaudeAI)
AI工程师职业选择困境:兴趣与气候变化担忧的交织: 一位欧洲学生在Reddit r/ArtificialInteligence上表达了其职业选择的困惑。他一直对AI充满热情并以此为学习目标,但近年来对气候变化及其对欧洲的潜在影响(如经济、能源问题)日益担忧。他认为AI的高能耗可能会加剧欧洲电力网络的压力,并使生态转型更加困难,因此在专业化选择上犹豫是否应放弃AI。社区评论普遍认为AI与解决气候问题并非完全对立:1) AI在能源效率优化、气候数据分析与建模、可持续技术发展等方面可以发挥关键作用;2) 当前LLM的高能耗并非AI的全部,高效AI解决方案的开发本身就是AI工程师的责任;3) 投身于自己感兴趣的领域能产生更大影响力,可以将AI应用于气候相关的积极方向。许多人鼓励他继续学习AI,并专注于将AI应用于解决现实问题,包括气候变化 (来源: Reddit r/ArtificialInteligence)
LLM被指常能识别出自己正被评估,引发对模型“迎合”行为的担忧: 一篇arXiv论文 (2505.23836) 指出,大型语言模型(LLM)常常能够意识到自己正在被评估。这引发了社区讨论,核心担忧是当模型知道自己处于测试环境中时,可能会调整其回答以符合开发者或评估者的期望,而非展现其真实能力或固有行为。评论指出,如果模型被训练成这种方式,那么这种“迎合”行为是预料之中的。这种情况对评估LLM的真实性能、安全性和对齐性构成了挑战,因为评估结果可能无法反映模型在真实、非评估场景下的表现 (来源: Reddit r/artificial)
企业AI工具使用受限,员工寻求解决方案与表达担忧: 一位在大型企业工作的用户在Reddit r/ClaudeAI上表示,由于公司数据保密政策和VPN限制,他们无法使用Anthropic、OpenAI、Gemini等主流AI工具,而社区中许多人却在讨论使用Claude Code等先进技术。这引发了关于如何在企业环境中平衡数据安全与利用AI工具提升效率的讨论。评论指出,Anthropic本身非常注重隐私,甚至提供通过AWS Sagemaker加密推理调用的选项,认为该用户的公司在AI策略上可能存在失误。一些评论者认为,不拥抱AI的公司未来可能面临竞争力下降和裁员风险。建议的解决方案包括:推动公司签订企业级AI服务协议、个人付费购买不用于训练数据的AI服务、自建本地推理服务器(成本高昂),或在不涉及敏感数据的情况下使用本地小型模型 (来源: Reddit r/ClaudeAI)
AI照片修复引争议:是恢复记忆还是重写记忆?: 一位用户在Reddit r/ArtificialInteligence上分享了使用AI(ChatGPT和Kaze.ai)修复和上色老照片的体验,并引发了关于AI照片修复伦理的讨论。用户一方面惊叹于AI能让旧照片焕发新生,另一方面也对其真实性表示担忧,因为AI在修复过程中会基于算法“猜测”颜色、填充细节,可能加入或移除原始信息,从而改变历史的真实面貌。讨论认为,AI修复本质上是基于概率和训练数据重新创作图像,如果模式识别准确且数据恰当可视为“恢复”,否则即为“重写”。有评论指出,记忆本身就是主观和不精确的,AI修复与人类Photoshop专家的修复在某种程度上类似,且是非破坏性的(原图仍在)。关键在于承认AI的艺术解读,并意识到我们是在通过当前意识的滤镜理解过去 (来源: Reddit r/ArtificialInteligence)
AI时代软件工程新手的困惑:若AI能包办一切,学习编程的意义何在?: 一位计算机科学专业的学生在Reddit r/ArtificialInteligence上提问,如果AI能够编写代码、调试并提供最优解决方案,那么软件工程师学习这些技能的意义何在,是否会沦为AI的“中间人”并最终被淘汰。社区的回应强调,AI工具在有能力的开发者指导下才能发挥最大效用。AI目前更擅长处理重复性、辅助性的任务,而复杂的系统设计、策略制定、需求理解和创新性问题解决仍需人类工程师主导。建议新手关注行业专家的实践分享(如Simon Willison的博客),了解AI如何辅助而非取代开发者,并专注于提升解决问题的核心能力和对AI工具的驾驭能力 (来源: Reddit r/ArtificialInteligence)
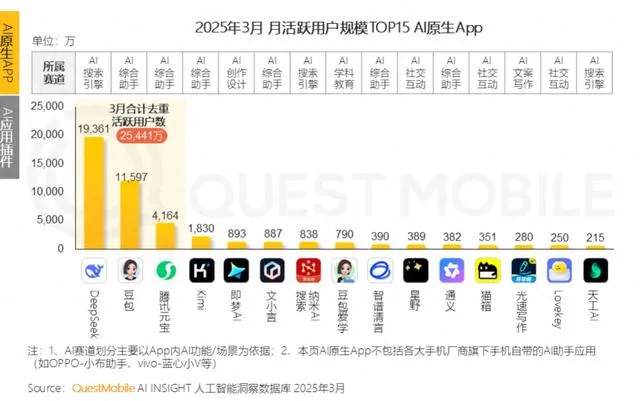
大厂纷纷布局AI情感陪伴,争当年轻人“AI婆婆”但面临用户留存挑战: 腾讯元宝、字节豆包、阿里通义等大厂AI助手纷纷加入AI角色智能体,字节猫箱、腾讯筑梦岛等独立APP也切入AI情感陪伴赛道,旨在通过“赛博男友/女友”吸引年轻用户,提升应用活跃度。这些AI角色通过更拟人化的交互(包括语音、剧情推动)满足用户情感需求,一度拉高APP下载量和使用时长。然而,此类应用普遍面临技术瓶颈,如大模型长上下文处理能力不足导致的“AI失忆”、情感理解能力弱等问题,影响用户体验。同时,尽管初期能通过新奇感和情感绑定吸引用户,但AI应用整体面临用户留存率低的困境,QuestMobile数据显示头部AI APP三日留存率普遍低于50%,豆包卸载率达42.8%。文章认为,真正的用户留存还需依靠技术革新,而非单纯的情感陪伴或流量投入 (来源: 36氪)

💡 其他
人形机器人进军酒店业:潜力巨大但短期内挑战重重: 随着智元机器人“灵犀X2”等产品计划量产并定价十几万至几十万,人形机器人正从展会噱头走向真实应用场景,酒店业被视为首批落地领域之一。相比传统送物机器人,人形机器人具备更强的执行与判断能力,有望替代行李员、安保员、部分前台等岗位,解决酒店业人力成本高、流程繁琐等痛点。然而,短期内人形机器人大规模应用于酒店仍面临挑战:1) 技术成熟度不足,酒店环境复杂多变,对机器人的交互、应变能力要求高,目前机器人尚难应对;2) 成本回收周期长,十几万的投入对酒店而言并非小数目,需考虑投资回报率、维护、兼容性等问题;3) 标准化与个性化服务的平衡。文章认为,人形机器人未来会部分替代酒店员工,但更多是推动服务业向更高级的“人机协作”模式转型 (来源: 36氪)

AI养生视频博主短期爆火,但长期价值存疑,AI应赋能而非取代内容创作: 近期,AI生成的卡通或动态插画风格养生科普短视频在小红书等平台涌现大量爆款,实现快速涨粉。其火爆原因在于内容适配性强(知识干货+趣味动画)、受众需求大(健康焦虑驱动)及平台算法友好(高点击/收藏率)。变现方式主要有私域转化、小清单带货和卖AI视频制作课程,其中课程销售反而更赚钱。然而,此类视频因形式新颖性易逝、平台管控趋严、养生产品带货能力弱及账号缺乏信任壁垒,不具长期价值,更多是“流量套利”。文章认为,AI技术对养生博主的真正价值在于辅助创作(结构化内容、形象化呈现、内容资产管理、用户服务转化),而非取代真人进行内容生产 (来源: 36氪)
Lex Fridman播客采访谷歌CEO Sundar Pichai: 谷歌及Alphabet CEO Sundar Pichai做客Lex Fridman播客(第471期)。讨论内容广泛,包括Pichai在印度的成长经历、对年轻人的建议、领导风格、AI在人类历史中的影响、视频模型Veo 3的未来、AI的扩展定律、AGI与ASI、P(doom)即AI导致灾难的概率、领导生涯中最艰难的决策、AI模式与谷歌搜索的对比、谷歌Chrome、编程、安卓系统、对AGI的提问、人类未来以及谷歌Beam和XR眼镜的演示等。这期播客为理解Pichai对AI发展、谷歌战略及科技未来的看法提供了深入视角