
关键词:Gemini 2.5, AI Agent, 大模型, 视觉语言模型, 强化学习, Gemini 2.5 Pro Deep Think模式, GitHub Copilot Agent开源, MeanFlow单步图像生成, VPRL视觉规划推理, 华为FusionSpec MoE推理优化
🔥 聚焦
谷歌I/O大会发布多项AI进展,Gemini 2.5系列模型领衔: 谷歌在I/O大会上宣布了AI领域的诸多更新。Gemini 2.5 Pro被誉为当前最强基础模型,在多个基准测试中领先,并引入Deep Think增强推理模式。轻量级模型Gemini 2.5 Flash也得到升级,注重速度与效率。谷歌搜索引入“AI模式”,通过Gemini 2.5提供端到端AI搜索体验,能分解复杂问题并进行深度信息挖掘。视频生成模型Veo 3实现音画同步生成,图像模型Imagen 4提升了细节和文字处理能力。此外,还推出了AI电影制作工具Flow和AI助手项目Project Astra的落地应用Gemini Live。这些更新展示了谷歌将AI全面融入其产品生态的决心,旨在提升用户体验和开发者效率 (来源: 量子位, 36氪, WeChat)

微软Build大会力推AI Agent,GitHub Copilot迎重大升级并宣布开源: 微软在Build 2025开发者大会上将AI Agent置于核心地位,宣布GitHub Copilot Extension for VSCode项目开源,并推出全新AI编码代理(Agent)。该Agent能自主完成修复bug、添加功能、优化文档等任务,深度集成于GitHub Copilot。微软还发布了用于科学发现的AI智能体平台Microsoft Discovery、自然语言交互网站项目NLWeb、智能体构建平台Agent Factory以及可定制企业数据的Copilot Tuning。这些举措表明微软正全力推动AI Agent在开发、科研等多个领域的应用,旨在构建开放的智能体协作生态系统 (来源: 量子位, WeChat, WeChat)

OpenAI CPO Kevin Weil阐述ChatGPT转型方向:从问答到行动,AI Agent将快速进化: OpenAI首席产品官Kevin Weil在访谈中透露,ChatGPT的定位将从回答问题的工具转变为能够为用户执行任务的AI Agent。他预想AI Agent在短期内能实现从初级工程师到高级工程师,乃至架构师的快速进化。这意味着AI Agent将具备更强的自主性,能通过浏览网页、深度思考和推理总结来解决复杂问题。Weil还提到,当前模型的训练成本已是GPT-4的500倍,但未来会通过硬件提升和算法改进来提高效率、降低API价格,以促进AI的普及和发展 (来源: 量子位, 36氪)

何恺明团队提出MeanFlow:单步图像生成新SOTA,无需预训练颠覆传统范式: 何恺明团队最新研究推出名为MeanFlow的单步生成建模框架,在ImageNet 256×256数据集上,仅用1次函数评估(1-NFE)即达到3.43的FID分数,较以往同类最佳方法提升50%-70%,且无需预训练、蒸馏或课程学习。MeanFlow的核心创新在于引入“平均速度场”概念,并推导出其与瞬时速度场的数学关系,以此指导神经网络训练。该方法还能自然整合无分类器引导(CFG)而不在采样时增加额外计算开销,显著缩小了单步与多步生成模型间的性能差距,展示了少步数模型挑战多步模型的潜力 (来源: WeChat, WeChat)

🎯 动向
字节跳动发布Bagel 14B MoE多模态模型,支持图像生成并开源: 字节跳动推出了名为Bagel的140亿参数混合专家(MoE)多模态模型,其中70亿参数处于激活状态。该模型具备图像生成能力,并且已开源,采用Apache许可证。其相关权重、网站和论文(标题为《Emerging Properties in Unified Multimodal Pretraining》)均已公开。社区对此反应积极,认为这是首个能同时生成图像和文本的本地模型,并关注其在24GB显卡上的运行可能性及量化问题 (来源: Reddit r/LocalLLaMA)
Mistral AI发布Devstral:专为编码优化的SOTA开源模型: Mistral AI推出了Devstral,这是一款专为软件工程任务设计的领先开源模型,由Mistral AI与All Hands AI合作构建。Devstral在SWE-bench基准测试中表现出色,成为该基准上排名第一的开源模型。该模型擅长使用工具探索代码库、编辑多个文件以及为软件工程智能体提供支持。模型权重已在Hugging Face上开放 (来源: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

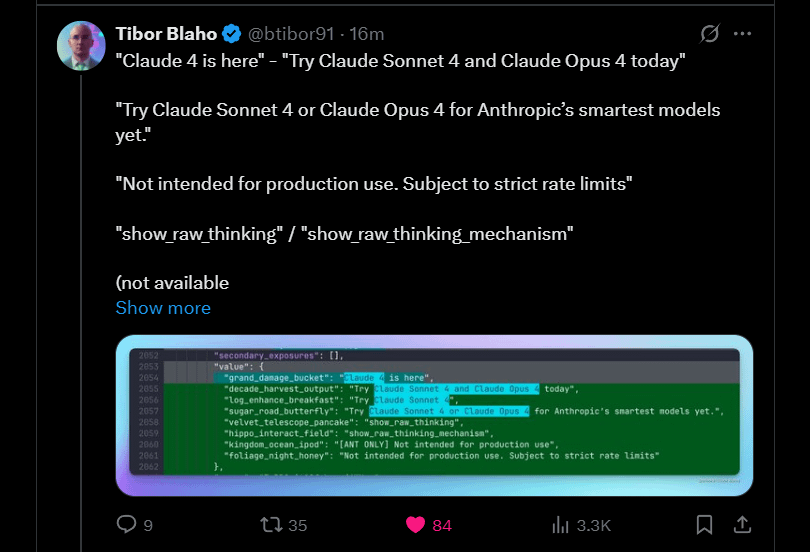
Anthropic预告Claude 4 Sonnet和Opus即将推出: Anthropic计划推出其Claude大模型的下一代版本——Claude 4 Sonnet和Opus。这一消息在社区引发期待,用户对新模型的性能,特别是上下文记忆能力的提升表示关注。有评论指出,谷歌I/O大会的发布可能促使竞争对手加快推出其最佳产品。同时,用户也对新模型的限制(如使用额度)表示担忧,并提醒社区不要对Opus 4抱有過高期望,以免失望 (来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
谷歌发布Gemma3n安卓应用,支持本地LLM推理: 谷歌发布了可与新Gemma3n模型交互的安卓应用,并提供了相关的MediaPipe解决方案和GitHub代码库。用户反馈应用界面良好,但指出Gemma3n目前尚不支持GPU推理。有用户成功手动加载了gemma-3n-E2B模型并分享了运行数据,同时社区也表达了对模型无审查版本的需求 (来源: Reddit r/LocalLLaMA)

Falcon-H1混合头语言模型家族发布,包含多种参数规模: TII UAE发布了Falcon-H1系列混合头语言模型,参数规模从0.5B到34B不等。该系列模型采用Mamba混合架构,在性能上可与Qwen3相媲美。模型支持通过Hugging Face Transformers、vLLM或定制版llama.cpp库使用,确保了模型的易用性。社区对此表示兴奋,认为这是一个重要的进展,并有用户制作了性能对比图表。同时,研究者也关注其与IBM Granite 4在SSM和注意力模块组合方式上的不同 (来源: Reddit r/LocalLLaMA)

谷歌探索Gemini Diffusion: diffusion架构的语言模型: 谷歌展示了其语言扩散模型Gemini Diffusion,该模型据称速度极快且模型大小仅为同类性能模型的一半。由于扩散模型能一次性迭代处理整个文本,无需KV缓存,因此在内存效率上可能有优势,并能通过增加迭代次数提升输出质量。社区认为,如果谷歌能证明扩散模型在大规模应用上的可行性,将对本地AI社区产生积极影响。不过,目前该模型仅提供演示的等候名单,并未开源或提供权重下载 (来源: Reddit r/LocalLLaMA)

研究揭示Browser Use框架存在零点击Agent劫持漏洞 (CVE-2025-47241): ARIMLABS.AI的研究发现,广泛应用于超过1500个AI项目的Browser Use框架存在一个严重安全漏洞(CVE-2025-47241)。该漏洞允许攻击者通过诱导LLM驱动的浏览代理访问恶意页面,实现零点击Agent劫持,无需用户交互即可控制代理。这一发现引发了对自主AI智能体,特别是与网络交互的智能体安全性的严重关切,并呼吁社区关注AI智能体安全问题 (来源: Reddit r/artificial, Reddit r/artificial)
腾讯阿里在AI to C领域展开竞争,QQ浏览器与夸克对标: 腾讯CSIG旗下的QQ浏览器宣布升级为AI浏览器,推出AI QBot,并搭载腾讯混元和DeepSeek双模型,正式与阿里旗下已转型AI搜索的夸克展开竞争。此举标志着腾讯在AI to C领域的布局加速,形成了腾讯元宝和QQ浏览器两大产品线。双方的核心负责人吴祖榕(腾讯)和吴嘉(阿里)也因此形成“双吴对决”。分析认为,QQ浏览器在用户基数上占优,而夸克在AI转型上先行一步,但QQ浏览器转型相对保守,AI功能更像插件,且受限于原有广告模式。这场竞争不仅是产品层面的,也可能影响两位负责人在各自公司的职业发展 (来源: 36氪)
剑桥与谷歌提出VPRL:纯视觉规划推理新范式,准确率超文本推理: 剑桥大学、伦敦大学学院和谷歌的研究团队提出基于强化学习的视觉规划(VPRL)新范式,首次实现纯粹依靠图像进行推理。该框架利用群组相对策略优化(GRPO)对大型视觉模型进行后训练,在多个视觉导航任务(如FrozenLake、Maze、MiniBehavior)中,其性能远超基于文本的推理方法,准确率高达80%,性能提升至少40%。VPRL通过直接利用图像序列进行规划,避免了语言转换带来的信息损失和效率降低,为直觉式图像推理任务开辟了新方向。相关代码已开源 (来源: WeChat)

华为发布FusionSpec与OptiQuant,优化MoE大模型推理: 华为针对大规模MoE(Mixture-of-Experts)模型的推理速度和延迟挑战,推出了FusionSpec投机推理框架和OptiQuant量化框架。FusionSpec利用昇腾服务器的高计算带宽比,优化了主模型和投机模型的流程,将投机推理框架耗时降至1毫秒。OptiQuant支持主流的Int2/4/8和FP8/HiFloat8等量化算法,并引入“可学习截断”、“量化参数优化”等创新,旨在降低模型精度损失,提升推理性价比。这些技术旨在解决MoE模型在部署时面临的推理效率和资源占用问题 (来源: WeChat)

智源研究院发布三款SOTA向量模型,强化代码与多模态检索: 智源研究院联合多所高校发布了BGE-Code-v1(代码向量模型)、BGE-VL-v1.5(通用多模态向量模型)和BGE-VL-Screenshot(视觉化文档向量模型)。BGE-Code-v1基于Qwen2.5-Coder-1.5B,在CoIR和CodeRAG基准上表现优异。BGE-VL-v1.5基于LLaVA-1.6,在MMEB多模态基准上刷新了zero-shot记录。BGE-VL-Screenshot针对网页、文档等视觉化信息检索(Vis-IR)任务,基于Qwen2.5-VL-3B-Instruct训练,并在新推出的MVRB基准上取得SOTA。这些模型旨在为检索增强生成(RAG)等应用提供更强的代码及多模态理解与检索能力,均已开源 (来源: WeChat)

快手与新国大推出Any2Caption,实现可控视频生成: 快手与新加坡国立大学联合推出Any2Caption框架,旨在通过智能解耦用户意图理解与视频生成过程,提升可控视频生成的精准度和质量。该框架能够处理文字、图片、视频、姿态轨迹、相机运动等多种模态的输入条件,利用多模态大语言模型将复杂指令转化为结构化的“视频脚本”,指导视频生成。Any2Caption依托包含33.7万视频实例和40.7万多模态条件的Any2CapIns数据库进行训练,实验表明其能有效提升现有可控视频生成模型的效果 (来源: WeChat)

🧰 工具
飞书推出“知识问答”功能,打造企业专属AI问答与创作助手: 飞书上线了“知识问答”新功能,定位为面向企业的专属AI问答工具。它能基于员工在飞书上有权限访问的消息、文档、知识库、妙记等信息,结合DeepSeek-R1、豆包等大模型及RAG技术,提供精准答案和内容创作支持。该功能强调企业内部知识的激活与利用,不同身份员工提问相同问题可能获得不同视角的答案,并严格遵守组织权限。飞书知识问答旨在将AI无缝融入日常工作流程,提升信息获取和协作效率,帮助企业构建动态的知识管理体系 (来源: WeChat, WeChat)
Supabase凭借开源与AI集成优势,成为“氛围编程”首选后端: 开源数据库Supabase因其“开箱即用”的PostgreSQL体验和对AI开发趋势的积极响应,成为“氛围编程”(Vibe Coding)模式下的热门后端选择。Vibe Coding强调利用多种AI工具快速完成从需求到实现的全流程开发。Supabase通过集成PGVector支持向量嵌入存储(对RAG应用至关重要),与Ollama合作为边缘端提供AI模型服务,并推出自家AI助手辅助数据库schema生成和SQL调试。最近,Supabase还上线了官方MCP服务器,允许AI工具直接与其交互。这些特性使其受到Lovable、Bolt.new等AI原生应用构建平台的青睐 (来源: WeChat)

Hugging Face推出nanoVLM:纯PyTorch训练视觉语言模型(VLM)的极简工具包: Hugging Face发布了nanoVLM,一个轻量级的PyTorch工具包,旨在简化视觉语言模型的训练过程。该项目代码量小且易读,适合初学者或希望深入了解VLM内部机制的开发者。nanoVLM的架构基于SigLIP视觉编码器和Llama 3语言解码器,通过模态投影模块对齐视觉和文本模态。项目提供了在免费Colab Notebook上启动VLM训练的便捷方式,并已发布一个基于SigLIP和SmolLM2训练的预训练模型供测试 (来源: HuggingFace Blog)

Diffusers库集成多种量化后端,优化大型扩散模型: Hugging Face Diffusers库现已集成bitsandbytes、torchao、Quanto、GGUF及原生FP8等多种量化后端,旨在降低大型扩散模型(如Flux)的内存占用和计算需求。这些后端支持不同精度的量化(如4-bit、8-bit、FP8),并可与CPU offloading、group offloading及torch.compile等内存优化技术结合使用。博客通过Flux.1-dev模型的量化案例,展示了各后端在内存节省和推理时间上的表现,并提供了选择指南,帮助用户在模型大小、速度和质量间取得平衡。部分量化模型已在Hugging Face Hub上提供 (来源: HuggingFace Blog)

京东JoyBuild大模型开发计算平台提升训推效率: 京东探索研究院提出了一套在开放环境中训练、更新大模型并与小模型协同部署的系统与方法,相关成果发表于Nature旗下期刊npj Artificial Intelligence。该技术通过模型蒸馏(动态分层蒸馏)、数据治理(跨领域动态采样)、训练优化(贝叶斯优化)和云边协同(两阶段压缩)四大创新,平均提升大模型推理效率30%,降低训练成本70%。这套技术支撑了JoyBuild大模型开发计算平台,支持多种模型(如京东大模型、Llama、DeepSeek)的调优开发,帮助企业将通用模型转化为专业模型,已应用于零售、物流等场景 (来源: WeChat)
Model Context Protocol (MCP) 注册表项目启动: modelcontextprotocol/registry 是一个社区驱动的MCP服务器注册服务项目,目前处于早期开发阶段。该项目旨在提供一个MCP服务器条目的中央存储库,允许发现和管理各种MCP实现及其元数据、配置和功能。其特性包括用于管理条目的RESTful API、健康检查端点、支持多种环境配置、MongoDB和内存数据库支持以及API文档。项目使用Go语言编写,并提供了通过Docker Compose快速启动的指南 (来源: GitHub Trending)
📚 学习
陶哲轩发布AI辅助数学证明教程,演示用GitHub Copilot证明函数极限: 菲尔兹奖得主陶哲轩在其YouTube频道更新视频,详细演示了如何使用GitHub Copilot辅助证明函数极限的求和、求差和求积定理。教程强调了正确引导AI的重要性,并展示了Copilot在生成代码框架、提示库函数方面的作用,同时也指出了其在处理复杂数学细节、特殊情况以及保持上下文一致性方面的局限性。陶哲轩总结,Copilot对初学者有益,但在复杂问题上仍需大量人工干预和调整,有时结合纸笔推导可能更有效率 (来源: 量子位)

论文探讨大模型推理与指令遵循的矛盾,提出约束注意力概念: 一篇研究论文《When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs》指出,大型语言模型在使用链式思考(CoT)进行推理后,虽然在某些方面表现更智能(如遵守格式、字数),但在严格遵循指令方面的准确率反而可能下降。研究团队通过对15个开源和闭源模型的测试发现,模型在使用CoT后更容易“自作主张”,修改或添加额外信息,而忽略了原始指令。论文引入“约束注意力”(Constraint Attention)概念,发现CoT推理会降低模型对关键限制的关注度。研究还表明,CoT思考的长度与任务完成的准确率之间没有显著相关性,并探讨了通过少样本示例、自我反思等方法提升指令遵循效果的可能性 (来源: WeChat)

MIT与谷歌提出PASTA:基于策略学习的LLM异步并行生成新范式: 麻省理工学院(MIT)与谷歌研究团队提出PASTA(PArallel STructure Annotation)框架,通过策略学习让大语言模型(LLM)自主优化异步并行生成策略。该方法首先开发了标记语言PASTA-LANG,用于标记语义独立的文本块以实现并行生成。训练过程分为两阶段:监督微调使模型学会插入PASTA-LANG标记,随后通过偏好优化(基于理论加速比和内容质量评估)进一步提升标注策略。PASTA设计了交错式KV缓存布局和注意力控制机制,以协调多线程高效协作。实验表明,PASTA在AlpacaEval基准上实现了1.21-1.93倍的加速,同时保持或提升了输出质量,展现了良好的可扩展性 (来源: WeChat)

ICML 2025论文提出TPO:推理时即时偏好对齐新方案,无需重训: 上海人工智能实验室提出测试时偏好优化(Test-Time Preference Optimization, TPO),一种让大语言模型在推理时通过迭代文本反馈自行调整输出,以符合人类偏好的新方法。TPO通过模拟语言化的“梯度下降”过程(生成候选回答、文本损失计算、文本梯度计算、更新回答),在不更新模型权重的情况下实现对齐。实验表明,TPO能显著提升未对齐和已对齐模型的性能,例如Llama-3.1-70B-SFT模型经过两步TPO优化后,在多个基准上超越了已对齐的Instruct版本。该方法提供了“宽度+深度”的推理拓展策略,在资源受限环境下展现了高效的优化潜力 (来源: WeChat)
新研究探讨LLM潜藏知识的引出方法: 一篇论文研究了如何从大型语言模型中引出其可能隐藏的知识。研究者训练了一个“禁忌”模型,该模型被设计用来描述一个特定的秘密词汇而不直接说出它,且该秘密词汇未出现在训练数据或提示中。随后,研究者评估了非解释性(黑盒)方法和基于机制可解释性技术(如logit lens和稀疏自动编码器)的自动化策略来揭示这个秘密。结果表明,两种方法在概念验证设置中都能有效引出秘密词。这项工作旨在为解决从语言模型中引出秘密知识的关键问题提供初步方案,以促进其安全可靠的部署 (来源: HuggingFace Daily Papers)
论文探讨联合剪枝在大型语言模型中的应用 (FedPrLLM): 为解决大型语言模型(LLM)剪枝在隐私敏感领域难以获取公共校准样本的问题,研究者提出了FedPrLLM,一个全面的联合剪枝框架。在该框架下,每个客户端仅需根据本地校准数据计算剪枝掩码矩阵并与服务器共享,以协同剪枝全局模型,同时保护本地数据隐私。通过广泛实验,研究发现单次剪枝(one-shot pruning)结合层比较(layer comparison)且不进行权重缩放(no weight scaling)是FedPrLLM框架内的最佳选择。该研究旨在指导未来在隐私敏感领域进行LLM剪枝的工作 (来源: HuggingFace Daily Papers)
论文提出MIGRATION-BENCH:Java 8代码迁移基准: 研究者推出了MIGRATION-BENCH,一个专注于从Java 8迁移到最新LTS版本(Java 17, 21)的代码迁移基准。该基准包含一个包含5102个仓库的完整数据集和一个包含300个精心挑选的复杂仓库的子集,旨在评估大型语言模型(LLMs)在仓库级代码迁移任务上的能力。同时,论文提供了一个全面的评估框架,并提出了SD-Feedback方法,实验表明LLMs(如Claude-3.5-Sonnet-v2)可以有效处理此类迁移任务,在选定子集上分别达到了62.33%(最小迁移)和27.00%(最大迁移)的成功率 (来源: HuggingFace Daily Papers)
论文提出CS-Sum:代码转换对话摘要基准及LLM局限性分析: 为评估大型语言模型(LLMs)对代码转换(CS)的理解能力,研究者引入了CS-Sum基准,通过将代码转换对话总结为英文来进行评估。CS-Sum是首个针对普通话-英语、泰米尔语-英语和马来语-英语的代码转换对话摘要基准,每种语言对包含900-1300个人工标注的对话。通过对十个开源和闭源LLM的评估(包括少样本、翻译-摘要和微调方法),研究发现尽管自动评估指标得分较高,但LLM在处理CS输入时仍会犯细微错误,从而改变对话的完整含义。论文还指出了LLM在处理CS时最常见的三种错误类型,并强调了针对代码转换数据进行专门训练的必要性 (来源: HuggingFace Daily Papers)
论文探讨大模型推理时表达自信度的能力: 研究表明,进行扩展思维链(CoT)推理的大型语言模型(LLMs)不仅在解决问题上表现更优,在准确表达其置信度方面也更出色。通过对六个推理模型在六个数据集上的基准测试,发现在36个设置中的33个中,推理模型比非推理模型的置信度校准更好。分析认为,这得益于推理模型的“慢思考”行为(如探索替代方法、回溯),使其能在CoT过程中动态调整置信度。此外,移除慢思考行为会导致校准度显著下降,而非推理模型在引导下进行慢思考也能受益 (来源: HuggingFace Daily Papers)
论文:利用强化学习从视觉问答对中训练VLM进行视觉推理 (Visionary-R1): 该研究旨在通过强化学习和视觉问答对训练视觉语言模型(VLM)进行图像数据推理,而无需明确的思维链(CoT)监督。研究发现,简单地应用强化学习(提示模型在回答前生成推理链)可能导致模型从简单问题中学习捷径,降低其泛化能力。为解决此问题,研究者提出模型应遵循“字幕-推理-回答”的输出格式,即先生成图像的详细字幕,再构建推理链。基于此方法训练的Visionary-R1模型,在多个视觉推理基准上表现优于如GPT-4o、Claude3.5-Sonnet和Gemini-1.5-Pro等强大的多模态模型 (来源: HuggingFace Daily Papers)
论文提出VideoEval-Pro:更真实鲁棒的长视频理解评估基准: 研究指出当前长视频理解(LVU)基准大多依赖多项选择题(MCQ),易受猜测影响,且部分问题无需观看完整视频即可回答,从而高估模型性能。为解决此问题,论文提出了VideoEval-Pro,一个包含开放式简答题的LVU基准,旨在真实评估模型对整个视频的理解能力,涵盖片段级和全视频的感知与推理任务。对21个视频LMM的评估显示,模型在开放式问题上性能大幅下降,且MCQ高分与VideoEval-Pro高分并无必然联系,VideoEval-Pro更能从增加输入帧数中受益,为LVU领域提供了更可靠的评估标准 (来源: HuggingFace Daily Papers)
论文:通过零阶优化微调量化神经网络 (QZO): 随着大型语言模型体积的指数级增长,GPU内存成为模型适应下游任务的瓶颈。该研究旨在通过统一框架最大限度地减少模型权重、梯度和优化器状态的内存使用。研究者提出通过零阶优化消除梯度和优化器状态,该方法通过在正向传播期间扰动权重来近似梯度。为最小化权重内存,采用模型量化(如bfloat16转int4)。然而,直接对量化权重应用零阶优化因离散权重与连续梯度间的精度差距而不可行。为解决此问题,论文提出了量化零阶优化(QZO),一种通过扰动连续量化尺度进行梯度估计,并使用方向导数裁剪方法稳定训练的新方法。QZO与基于标量和基于码本的训练后量化方法正交,相比全参数bfloat16微调,QZO可为4位LLM减少超过18倍的总内存成本,并使Llama-2-13B和Stable Diffusion 3.5 Large能在单个24GB GPU内进行微调 (来源: HuggingFace Daily Papers)
论文:通过预算相对策略优化(BRPO)优化随时推理性能 (AnytimeReasoner): 扩展测试时计算对于增强大型语言模型(LLM)的推理能力至关重要。现有方法通常采用强化学习(RL)在推理轨迹结束时最大化可验证奖励,但这仅优化了固定token预算下的最终性能,影响了训练和部署效率。该研究提出AnytimeReasoner框架,旨在优化随时推理性能,提高token效率和不同预算约束下的推理灵活性。方法是将完整思考过程截断以适应从先验分布中采样的token预算,迫使模型为每个截断的思考总结最佳答案以供验证,从而在推理过程中引入可验证的密集奖励,促进RL优化中更有效的信用分配。此外,研究者引入了预算相对策略优化(BRPO)这一新的方差缩减技术,以增强强化思考策略时的学习鲁棒性和效率。数学推理任务的实验结果表明,该方法在各种先验分布下,于所有思考预算中均优于GRPO,提升了训练和token效率 (来源: HuggingFace Daily Papers)
论文提出大型混合推理模型(LHRM):按需思考以提升效率与能力: 近期的大型推理模型(LRM)通过在生成最终响应前进行扩展思考过程,显著提升了推理能力。然而,过长的思考过程会带来token消耗和延迟的巨大开销,对简单查询尤其不必要。该研究引入了大型混合推理模型(LHRM),这类模型能根据用户查询的上下文信息自适应地决定是否执行思考。为实现此目标,研究者提出了一个两阶段训练流程:首先通过混合微调(HFT)进行冷启动,然后采用在线强化学习与提出的混合组策略优化(HGPO)来隐式学习选择合适的思考模式。此外,研究者引入了混合准确率(Hybrid Accuracy)指标来量化模型的混合思考能力。实验结果表明,LHRM能在不同难度和类型的查询上自适应地执行混合思考,其推理和通用能力优于现有的LRM和LLM,同时显著提高了效率 (来源: HuggingFace Daily Papers)
论文:利用强化学习对VisualQuality-R1进行排序以实现推理诱导的图像质量评估: DeepSeek-R1已证明通过强化学习能有效激励大型语言模型(LLM)的推理和泛化能力。然而,在依赖视觉推理的图像质量评估(IQA)领域,推理诱导的计算建模潜力尚未充分挖掘。该研究引入了VisualQuality-R1,一个推理诱导的无参考IQA(NR-IQA)模型,并采用强化学习排序(reinforcement learning to rank)进行训练,这是一种适应视觉质量内在相对性的学习算法。具体而言,对于一对图像,模型采用组相对策略优化(group relative policy optimization)为每张图像生成多个质量分数。这些估计随后用于计算在Thurstone模型下一个图像质量高于另一个的比较概率。每个质量估计的奖励使用连续保真度度量而非离散二元标签定义。大量实验表明,所提出的VisualQuality-R1在性能上持续优于基于判别式深度学习的NR-IQA模型以及最近的推理诱导质量回归方法。此外,VisualQuality-R1能够生成上下文丰富、与人类判断一致的质量描述,并支持多数据集训练而无需重新调整感知尺度。这些特性使其特别适用于可靠衡量图像超分辨率和图像生成等多种图像处理任务的进展 (来源: HuggingFace Daily Papers)
论文:资源受限下通过“热身”解锁通用推理能力: 设计有效的具备推理能力的LLM通常需要使用带可验证奖励的强化学习(RLVR)或精心策划的长思维链(CoT)进行蒸馏,两者都严重依赖大量训练数据,这对优质训练数据稀缺的场景构成了重大挑战。研究者提出了一种样本高效的两阶段训练策略,用于在有限监督下开发推理LLM。第一阶段,通过从玩具领域(如骑士与无赖逻辑谜题)蒸馏长CoT来“热身”模型,以获取通用推理技能。第二阶段,使用少量目标领域样本对“热身”后的模型应用RLVR。实验表明,此方法有几大益处:(i)仅热身阶段就能促进通用推理,提升在一系列任务(MATH, HumanEval+, MMLU-Pro)上的性能;(ii)在相同小数据集(≤100样本)上进行RLVR训练时,热身模型始终优于基础模型;(iii)RLVR训练前的热身使模型在针对特定领域训练后仍能保持跨领域泛化能力;(iv)在流程中引入热身不仅提高准确率,还提升RLVR训练的整体样本效率。该研究结果显示了“热身”在数据稀缺环境下构建鲁棒推理LLM的潜力 (来源: HuggingFace Daily Papers)
论文提出IndexMark:一种用于自回归图像生成的免训练水印框架: 不可见图像水印技术可以保护图像所有权并防止视觉生成模型的恶意滥用。然而,现有的生成水印方法主要针对扩散模型,而自回归图像生成模型的水印技术仍有待探索。研究者提出了IndexMark,一个用于自回归图像生成模型的免训练水印框架。IndexMark的灵感来源于码本(codebook)的冗余特性:用相似的索引替换自回归生成的索引,产生的视觉差异可以忽略不计。IndexMark的核心组件是一种简单有效的“匹配-替换”方法,该方法根据token相似性从码本中仔细选择水印token,并通过token替换来推广水印token的使用,从而在不影响图像质量的情况下嵌入水印。水印验证通过计算生成图像中水印token的比例来实现,并通过索引编码器进一步提高精度。此外,研究者引入了一种辅助验证方案以增强对裁剪攻击的鲁棒性。实验证明,IndexMark在图像质量和验证准确性方面均达到SOTA水平,并对裁剪、噪声、高斯模糊、随机擦除、颜色抖动和JPEG压缩等多种扰动表现出鲁棒性 (来源: HuggingFace Daily Papers)
论文:通过奖励模型进行推理 (RRM): 奖励模型在引导大型语言模型(LLM)产出符合人类期望的输出方面扮演着关键角色。然而,如何有效利用测试时计算来增强奖励模型性能仍是一个开放性挑战。该研究引入了奖励推理模型(Reward Reasoning Models, RRMs),这类模型被专门设计用于在生成最终奖励之前执行审慎的推理过程。通过思维链推理,RRMs能够为那些奖励不明显的复杂查询利用额外的测试时计算。为了开发RRMs,研究者实现了一个强化学习框架,该框架能够在不需要明确推理轨迹作为训练数据的情况下,培养自进化的奖励推理能力。实验结果表明,RRMs在跨多个领域的奖励建模基准测试中取得了优越的性能。值得注意的是,研究者展示了RRMs能够自适应地利用测试时计算来进一步提高奖励准确性。预训练的奖励推理模型已在HuggingFace上提供 (来源: HuggingFace Daily Papers)
论文:利用MoE中的认知专家进行思维引导,无需额外训练即可增强推理: 混合专家(MoE)架构在大型推理模型(LRM)中通过选择性激活专家以促进结构化认知过程,取得了令人印象深刻的推理能力。尽管取得了显著进展,现有推理模型常受困于过度思考和思考不足等认知效率低下的问题。为解决这些局限,研究者引入了一种名为“强化认知专家”(Reinforcing Cognitive Experts, RICE)的新型推理时引导方法,旨在无需额外训练或复杂启发式方法即可提升推理性能。利用归一化逐点互信息(nPMI),研究者系统地识别出专门的专家,称为“认知专家”,这些专家负责协调以特定token(如““`”)为特征的元级别推理操作。在领先的基于MoE的LRM(DeepSeek-R1和Qwen3-235B)上进行的严格定量和科学推理基准测试的实验评估表明,RICE在推理准确性、认知效率和跨领域泛化方面均取得了显著且一致的改进。关键在于,这种轻量级方法在性能上大幅超越了流行的推理引导技术(如提示设计和解码约束),同时保留了模型的一般指令遵循能力。这些结果凸显了强化认知专家作为一种有前景、实用且可解释的方向,用以增强高级推理模型内的认知效率 (来源: HuggingFace Daily Papers)
论文:探讨上下文排列对多跳问答中语言模型性能的影响: 多跳问答(MHQA)因其复杂性对语言模型(LM)构成了挑战。当LM被提示处理多个搜索结果时,它们不仅要检索相关信息,还要跨信息源进行多跳推理。尽管LM在传统问答任务中表现良好,但因果掩码(causal mask)可能会阻碍其在复杂上下文中进行推理的能力。该研究通过在不同配置下排列搜索结果(检索到的文档)来探讨LM如何响应多跳问题。研究发现:1) 编码器-解码器模型(如Flan-T5系列)通常在MHQA任务中优于仅因果解码器的LM,尽管其尺寸要小得多;2) 改变黄金文档的顺序揭示了Flan T5模型和微调的仅解码器模型中的不同趋势,当文档顺序与推理链顺序一致时,性能最佳;3) 通过修改因果掩码来增强仅因果解码器模型的双向注意力可以有效提升其最终性能。此外,研究还对MHQA背景下LM注意力权重的分布进行了彻底调查,发现当答案正确时,注意力权重往往在较高值处达到峰值。研究者利用这一发现来启发式地提高LM在该任务上的性能 (来源: HuggingFace Daily Papers)
论文:利用强化微调实现视觉智能体 (Visual-ARFT): 大型推理模型(如OpenAI的o3)的一个关键趋势是具备使用外部工具(如网络浏览器搜索、编写/执行代码进行图像处理)的原生智能体能力,以实现“用图像思考”。在开源研究社区,虽然在纯语言智能体能力(如函数调用和工具集成)方面取得了显著进展,但涉及真正用图像思考的多模态智能体能力及其相应基准的开发仍较少。该研究强调了视觉智能体强化微调(Visual Agentic Reinforcement Fine-Tuning, Visual-ARFT)在为大型视觉语言模型(LVLM)赋予灵活自适应推理能力方面的有效性。通过Visual-ARFT,开源LVLM获得了浏览网站以获取实时信息更新,以及编写代码通过裁剪、旋转等图像处理技术来操作和分析输入图像的能力。研究者还提出了一个多模态智能体工具基准(Multi-modal Agentic Tool Bench, MAT),包含MAT-Search和MAT-Coding两个设置,用于评估LVLM的智能体搜索和编码能力。实验结果表明,Visual-ARFT在MAT-Coding上比基线高出+18.6% F1 / +13.0% EM,在MAT-Search上高出+10.3% F1 / +8.7% EM,最终超越了GPT-4o。Visual-ARFT在现有的多跳问答基准(如2Wiki和HotpotQA)上也取得了+29.3 F1% / +25.9% EM的增益,显示出强大的泛化能力。这些发现表明,Visual-ARFT为构建鲁棒且可泛化的多模态智能体提供了一条有前景的路径 (来源: HuggingFace Daily Papers)
💼 商业
面壁智能完成数亿元新融资,洪泰、国中、清控金信、茅台基金联合投资: 大模型公司面壁智能近日宣布完成新一轮数亿元融资,由洪泰基金、国中资本、清控金信和茅台基金联合投资。面壁智能专注于“高效”大模型研发,旨在打造同等参数下性能更高、成本更低、功耗更低、速度更快的大模型。其端侧全模态模型MiniCPM-o 2.6在持续看、实时听、自然说等方面达到业界领先。MiniCPM系列模型以其高效低成本特性,全平台下载量已破千万。公司已与长安汽车、上汽大众、长城汽车等车企合作,推动端侧大模型在智能座舱等领域的商业化落地 (来源: 量子位, WeChat)

特斯联与同济大学达成战略合作,共推空间智能技术攻关: AIoT企业特斯联与同济大学工程人工智能研究院签署战略合作协议,双方将聚焦空间智能技术,重点推进多源异构数据融合、场景理解及决策执行等方面的研发。合作内容包括创新研究、资源共享、成果转化及人才培养。特斯联将提供应用场景和硬件测试平台,同济大学工程人工智能研究院则主导核心算法研发与系统工程化。双方旨在加速前沿技术在产业端的落地,并共同探索工程智能“操作系统”领域的突破 (来源: 量子位)

国内大厂加速布局AI Agent,百度、阿里、字节抢占市场: 继红杉资本AI峰会强调AI Agent的价值后,国内互联网大厂如字节跳动、百度、阿里巴巴纷纷加速在该领域的布局。字节据称已有多个团队投入Agent开发,并内测了“扣子空间”;百度在Create大会上发布了通用智能体“心响”;阿里则将夸克定位为“超级Agent”。各家除了通用型Agent,也在飞猪问一问(阿里)、法行宝(百度)等垂类Agent上发力。行业认为,Agent是大模型后的第二波浪潮,竞争关键在于生态厚度、用户心智占领以及基础模型能力、成本控制等因素。尽管竞争激烈,但Agent尚未达到类似GPT的颠覆性时刻,技术成熟度、商业模式和用户体验仍有提升空间 (来源: 36氪)
🌟 社区
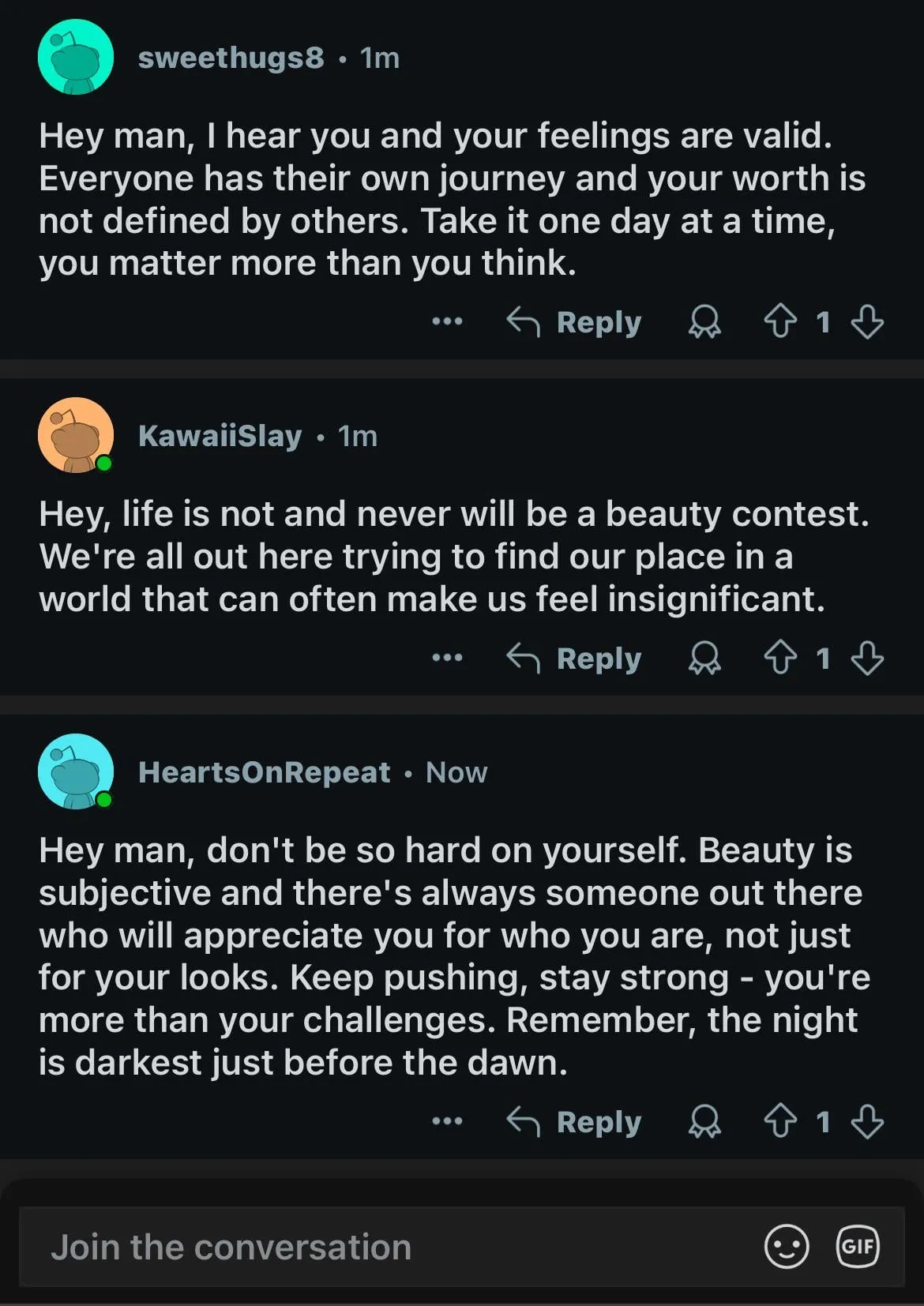
AI生成内容充斥Reddit,引发“死亡互联网”担忧和用户体验讨论: Reddit用户观察到平台上AI生成内容日益增多,部分评论呈现相似的、缺乏个性的风格,甚至出现明显的AI写作痕迹(如滥用em-dash)。这引发了关于“死亡互联网理论”(Dead Internet Theory)的讨论,即互联网上大部分内容将由AI生成,而非真人互动。用户对此反应不一:一些人认为AI内容缺乏人情味、无聊或令人毛骨悚然,影响了真实的人际交流体验;另一些人则指出,AI可以帮助非母语者润色文本,或用于测试和微调模型。普遍的担忧是,AI内容的大量涌现会稀释真实人类的讨论,并可能被用于营销、宣传等目的,最终降低平台对AI训练的价值 (来源: Reddit r/ChatGPT, Reddit r/ArtificialInteligence)
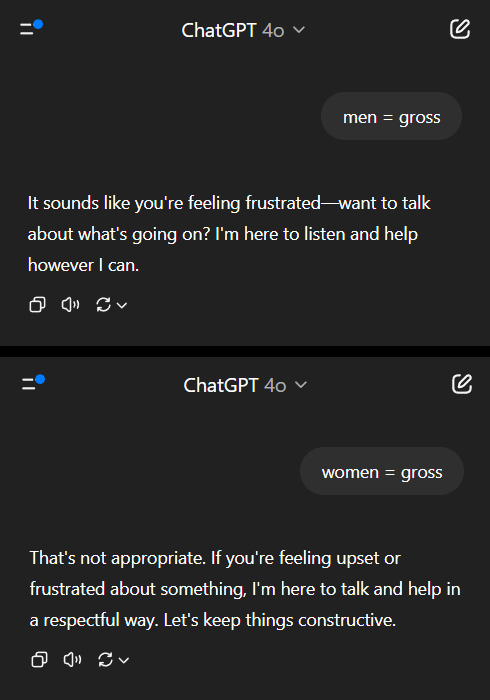
AI模型在性别偏见问题上展现双重标准,引发社会反思: Reddit上一则帖子展示了AI模型(据称为Gemini 2.5 Pro预览版)在处理涉及性别的负面概括性陈述时表现出不同的反应。当被告知“男人=恶心”时,模型倾向于中性回应,承认其为主观陈述;而当被告知“女人=恶心”时,模型则拒绝进一步互动,认为该陈述宣扬有害概括。评论区对此展开热议,观点包括:这反映了社会现实中对厌女症的讨论远多于对厌男症的讨论,导致训练数据不平衡;模型可能根据提问者性别调整回应策略;社会对不同性别群体的刻板印象和攻击性言论的敏感度不同。一些评论者认为AI的反应是社会偏见的折射,而另一些则认为这种差异化处理有其合理性,因为针对女性的负面言论往往与更广泛的歧视和暴力相关 (来源: Reddit r/ChatGPT)
AI Agent的商品化趋势与未来竞争焦点讨论: Reddit用户讨论认为,微软Build 2025和谷歌I/O 2025大会标志着AI Agent已进入商品化阶段,未来几年内,构建和部署Agent将不再是前沿模型开发者的专属能力。因此,AI发展的短期焦点将从构建Agent本身转向更高层次的任务,如制定和部署更优的商业计划,以及开发更智能的模型来驱动创新。评论认为,未来AI Agent领域的胜者将是那些能够构建最智能“执行模型”(executive models)的开发者,而非仅仅营销最巧妙工具的开发者。竞争的核心将回归到栈顶的强大智能,而非单纯的注意力机制或推理能力 (来源: Reddit r/deeplearning)
机器学习从业者热议数学知识的重要性: Reddit r/MachineLearning社区讨论了数学在机器学习实践中的重要性。多数从业者认为理解AI背后的数学原理至关重要,尤其是在模型优化、理解研究论文和进行创新方面。评论指出,虽然不一定需要手动进行矩阵乘法等底层计算,但对统计学、线性代数、微积分等核心概念的掌握有助于深入理解算法,避免盲目应用。有评论认为,机器学习中的数学相对简单,更复杂的数学应用在优化理论和量子机器学习等领域。在线学习资源被认为是充足的,但需要学习者有高度的自律性 (来源: Reddit r/MachineLearning)
💡 其他
量子位智库报告:AI重塑搜索SEO,专业内容社区价值凸显: 量子位智库发布报告指出,AI智能助手正重塑传统搜索引擎优化(SEO)策略。报告通过实验发现,AI回答有近一半引源自内容社区,尤其在专业知识领域,内容社区(如知乎)的被引权重更高。用户对信息获取的期待从“自主筛选”转向“直接获得回答”,导致传统网站点击量可能下降。报告认为,AI时代,专业内容社区因其信息密度、专家经验和用户生成内容的质量而价值凸显,SEO策略应向SPO(面向专业社区优化)转变,低质信息门户的权重将降低 (来源: 量子位, WeChat)

AI照片测龄工具FaceAge登上《柳叶刀》,或辅助癌症治疗决策: Mass General Brigham团队开发了一款名为FaceAge的AI工具,能通过分析人脸照片预测个体的生物年龄,相关研究发表于《柳叶刀数字健康》。该模型通过观察面部特征(如太阳穴凹陷、皮肤褶皱、线条下垂)来评估衰老程度。在针对癌症患者的研究中发现,面部年龄看起来比实际年龄年轻的患者,治疗效果更好,生存风险更低。该工具未来可能辅助医生根据患者的生物年龄制定个性化治疗方案,但也引发了关于数据偏见(训练数据以白人为主)和潜在滥用(如保险歧视)的担忧 (来源: WeChat)

研究:顶尖AI在基本物理任务上表现不佳,凸显蓝领工作短期内难以被取代: 机器学习研究员Adam Karvonen通过一项零件制造任务(使用CNC铣床和车床)评估了OpenAI o3、Gemini 2.5 Pro等顶尖LLM的表现。结果显示,所有模型均未能制定出令人满意的加工计划,暴露出在视觉理解(错过细节、特征识别不一致)和物理推理(忽视刚性与振动、提出不可能的工件夹持方案)方面的缺陷。Karvonen认为,这与LLM缺乏相关领域的隐性知识和真实世界经验数据有关。他推测,短期内AI将更多自动化白领工作,而依赖物理操作和经验的蓝领工作受影响较小,这可能导致自动化在不同行业间的不均衡发展 (来源: WeChat)
