
关键词:AlphaEvolve, AI算法设计, 多模态AI, AI编程工具, 自主进化算法, 大型语言模型, AI智能体, AlphaEvolve开源实现, AI自主设计矩阵乘法算法, 多模态AI统一接口, AI编程工具对开发者影响, 本地大模型Qwen 3性能
🔥 聚焦
谷歌DeepMind发布AlphaEvolve,AI自主设计和进化算法: 谷歌DeepMind公开了AlphaEvolve项目及其论文,展示了一种能够自主设计、测试、学习并进化出更高效算法的AI智能体。该系统通过提示工程驱动大型语言模型(如Gemini)生成初始算法方案,并在进化循环中通过适应度评估和幸存者选择来优化算法。社区迅速响应,开源实现OpenAlpha_Evolve已出现,并有研究者使用Claude等工具对AlphaEvolve在矩阵乘法等领域的突破进行了验证,显示AI在算法创新方面潜力巨大。 (来源: karminski3, karminski3, Reddit r/ClaudeAI, Reddit r/artificial)

OpenAI多模态战略显现:整合接口与集中化基础设施引关注: OpenAI近期通过GPT-4o、Sora和Whisper等产品的发布,不仅展示了其在文本、图像、音视频等多模态能力上的进展,更显露出其整合多种模态至统一接口和API的战略意图。这种策略虽然为用户提供了便利,但也引发了关于基础设施集中化可能限制外部开发者和研究者创新空间的讨论。特别是像Sora这样的视频生成模型,因其高计算资源需求,进一步将高成本应用纳入OpenAI生态,可能加剧头部平台的“计算引力”,影响AI领域的开放性和模块化发展。 (来源: Reddit r/deeplearning)
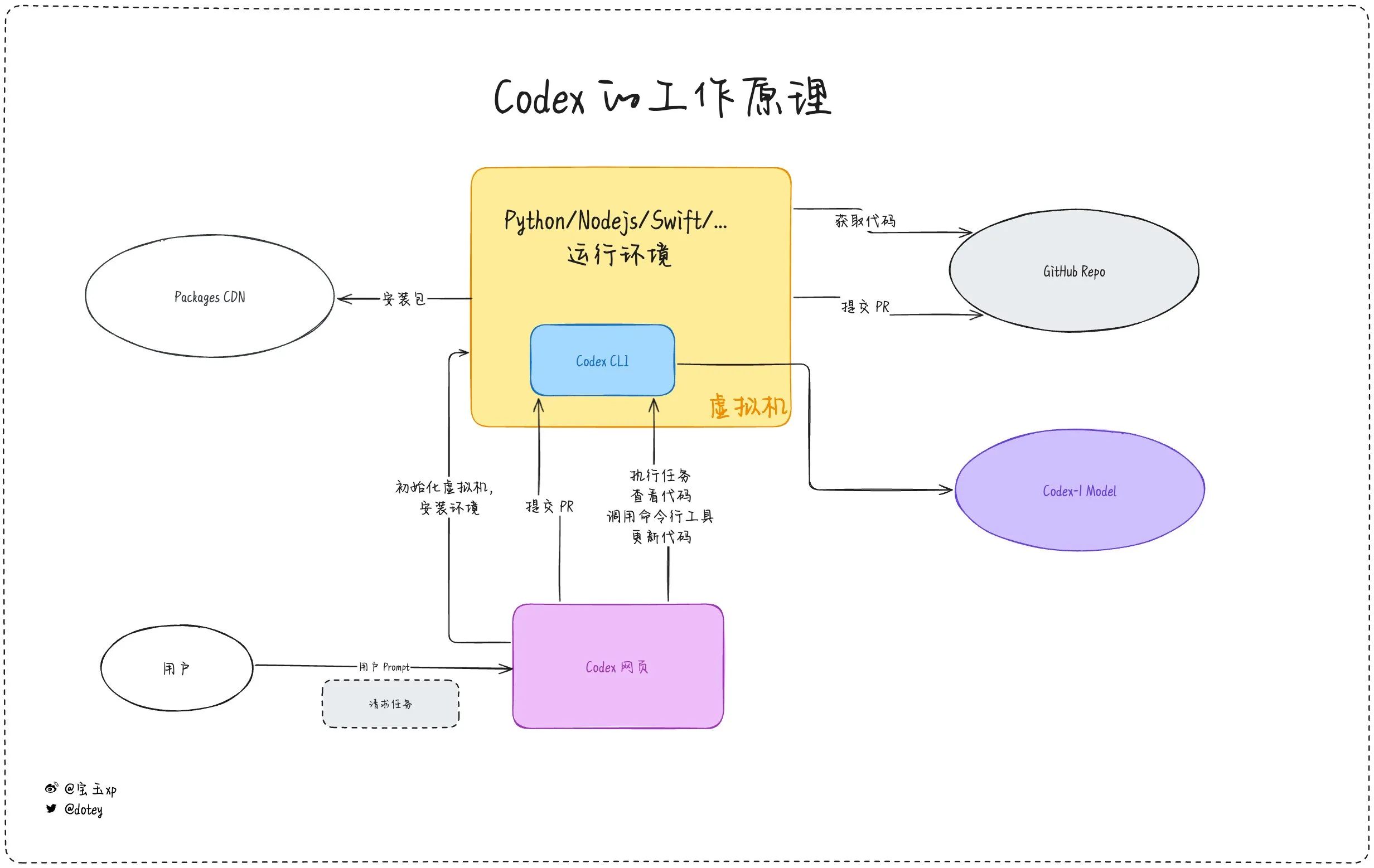
AI编程工具渗透加剧,开发者体验与反思并存: AI编程工具如Codex、Devin及各类AI Agent正加速融入软件开发流程。开发者反馈显示,Codex在代码国际化、项目升级等方面展现出高效率,能显著缩短开发周期。然而,如dotey对Codex的评测指出,当前AI工具更像“外包员工”,虽能完成任务,但在联网、任务持续性、经验积累方面仍有局限。社区讨论亦提及,部分开发者在长期使用AI辅助编程后,开始反思其对自身思维和创造力的影响,甚至选择回归更依赖“人脑”的开发模式,显示出AI工具在提升效率与维持开发者核心能力间的平衡仍是重要议题。 (来源: dotey, giffmana, cto_junior, Reddit r/artificial)
🎯 动向
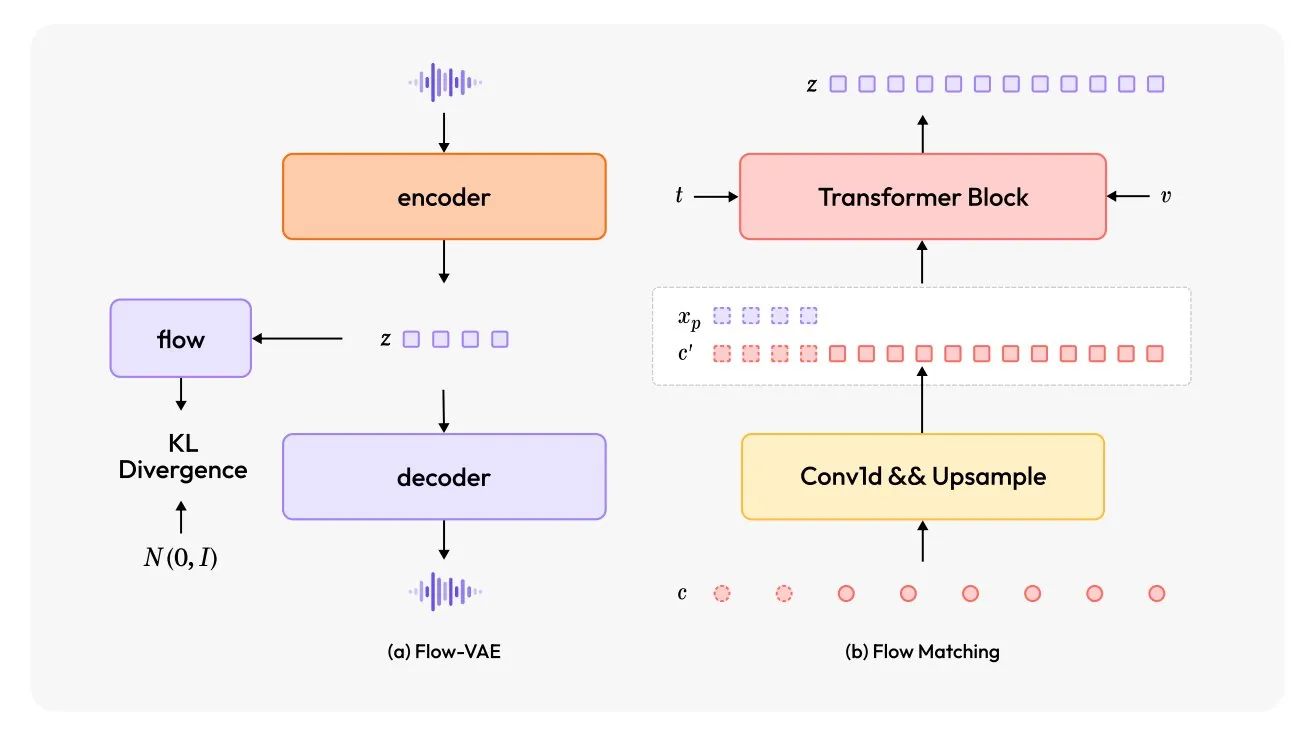
MiniMax-Speech:新型多语言TTS模型发布: TheTuringPost介绍了MiniMax-Speech,一款新的文本转语音(TTS)模型。该模型采用两大创新:可学习的说话人编码器,能从短音频中捕捉音色;Flow-VAE模块以提升音频质量。MiniMax-Speech支持32种语言,可用于为语音添加情感、从文本描述生成语音或进行零样本语音克隆,展示了其在个性化和高质量语音合成方面的潜力。 (来源: TheTuringPost, TheTuringPost)
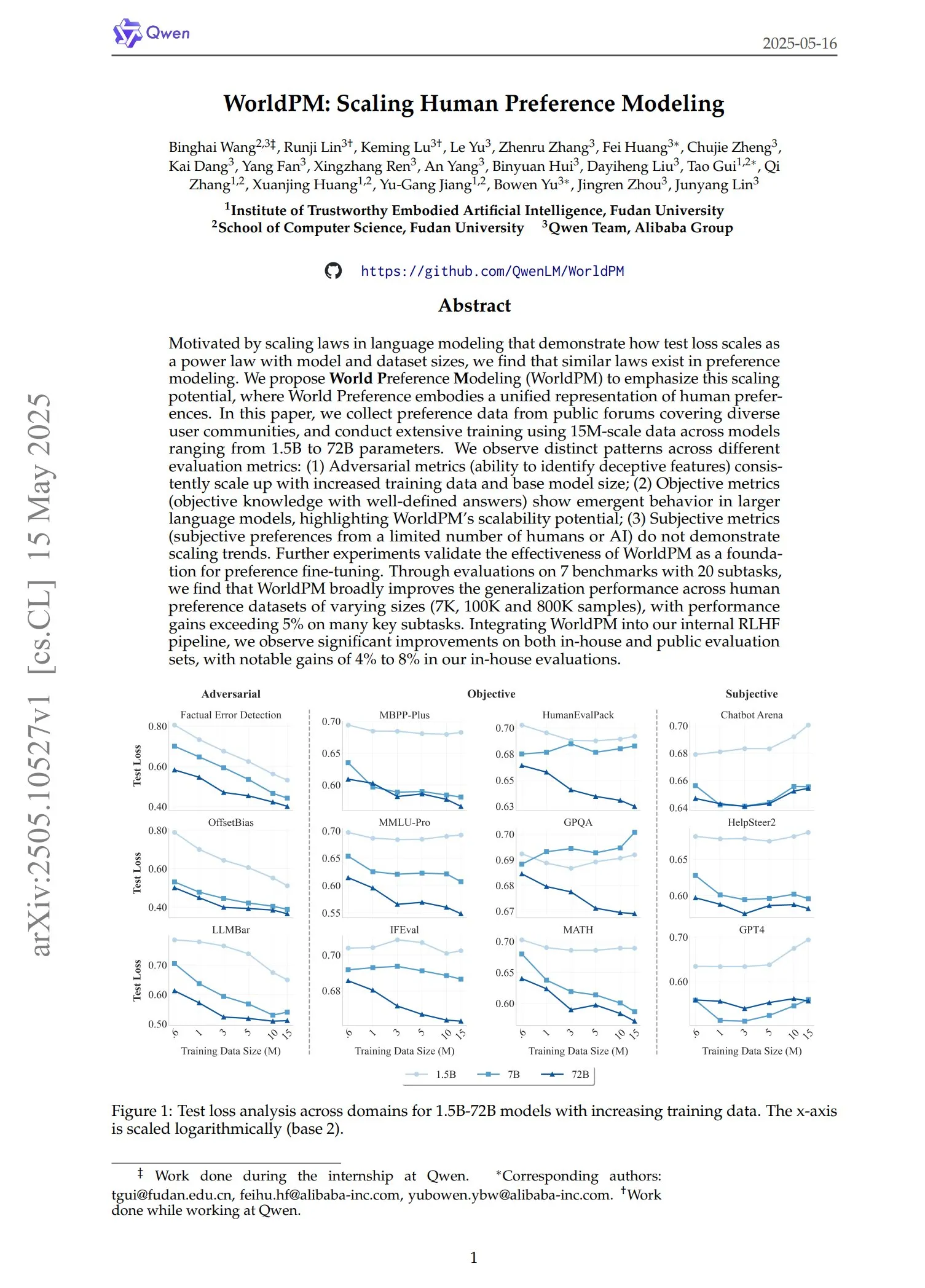
Qwen发布WorldPM系列偏好模型: Qwen团队推出了四个新的偏好建模模型:WorldPM-72B、WorldPM-72B-HelpSteer2、WorldPM-72B-RLHFLow和WorldPM-72B-UltraFeedback。这些模型主要用于评估其他模型回答的质量,辅助监督学习过程。官方表示,使用这些偏好模型进行训练,比从零开始训练能获得更好效果,相关论文也已发布。 (来源: karminski3)
Grok新增图表生成功能: XAI的Grok模型现已支持图表生成功能。用户可以通过Grok在浏览器中创建图表,该功能预计将在未来几天内推广到更多平台。这一更新增强了Grok在数据可视化和信息呈现方面的能力。 (来源: grok, Yuhu_ai_, TheGregYang)
DeepRobotics发布中型四足机器人Lynx: DEEP Robotics公司推出了其新款中型四足机器人Lynx。这款机器人展示了在复杂地形中稳定行进的能力,体现了公司在机器人运动控制和感知技术方面的进步,可应用于巡检、物流等多种场景。 (来源: Ronald_vanLoon)
Sanctuary AI为通用机器人集成新型触觉传感器: Sanctuary AI宣布其通用机器人已集成新型触觉传感器技术。这一改进旨在提升机器人的物体感知和操作能力,使其能更精细地与环境互动,是迈向更强通用人工智能机器人的重要一步。 (来源: Ronald_vanLoon)
Unitree机器人展示高级步态能力: Unitree Robotics的Go2机器人展示了多项高级步态,包括倒立行走、自适应翻滚以及越过障碍物。这些能力的实现,标志着其机器狗在运动控制算法和环境适应性方面的显著提升。 (来源: Ronald_vanLoon)
中国科研团队研发出由培养人脑细胞驱动的机器人: 据InterestingSTEM报道,中国一个科研团队正在开发一种由实验室培养的人类脑细胞驱动的机器人。这项研究探索了生物计算与机器人技术的融合,旨在利用生物神经元的学习和适应能力,为机器人控制提供新的思路,尽管目前仍处于早期探索阶段,但引发了对未来机器人智能形态的广泛讨论。 (来源: Ronald_vanLoon)
新型纳米级脑传感器实现96.4%神经信号识别准确率: 一种新型纳米级脑传感器在识别神经信号方面展现出高达96.4%的准确率。该技术有望应用于脑机接口、神经科学研究以及医疗诊断领域,为更精确地解读大脑活动提供了新的工具。 (来源: Ronald_vanLoon)

传闻MistralAI使用测试集进行训练引发关注: 社区出现讨论,质疑MistralAI可能在NIAH等基准测试中使用了测试集数据进行训练。kalomaze通过对比GitHub NIAH测试与自定义NIAH(程序化生成事实和问题)的表现,指出MistralAI在前者表现远超后者,暗示可能存在数据污染。Dorialexander推测可能是评估集的“合成近似”被用于设计数据混合,引发对模型评估公正性和透明度的担忧。 (来源: Dorialexander)
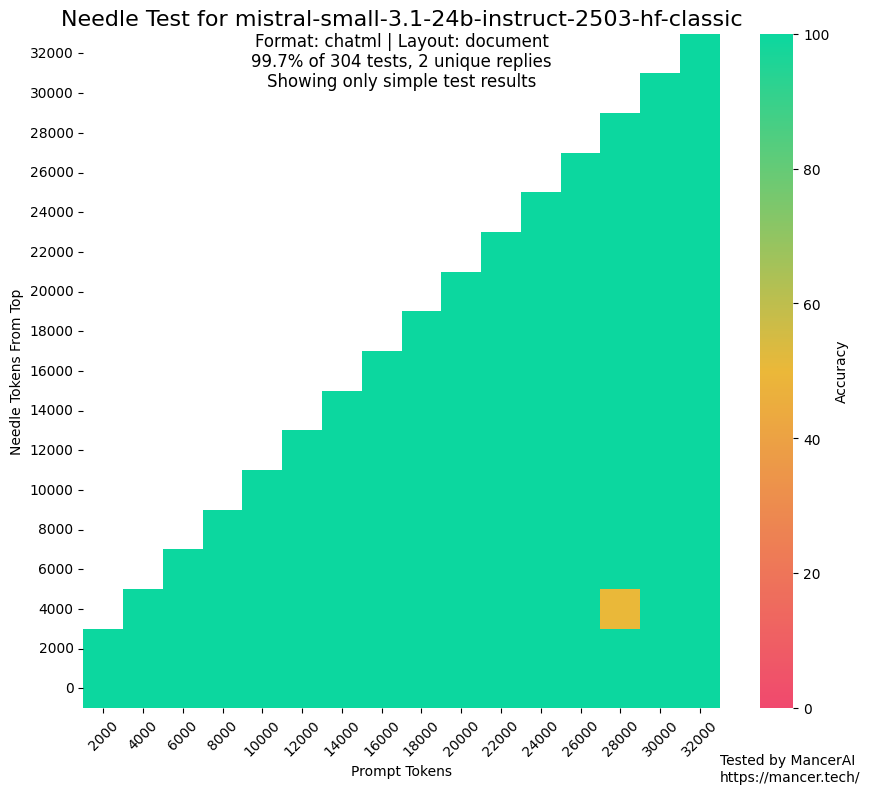
研究称Claude 3.5在说服力上超越人类: 一篇arXiv上的研究论文指出,Anthropic的Claude 3.5模型在说服能力方面表现优于人类。这项研究通过实验对比了模型与人类在特定说服任务上的表现,结果显示AI在构建有说服力的论点和沟通方面可能具有显著优势,这对营销、公共关系和人机交互等领域具有潜在影响。 (来源: Reddit r/ClaudeAI)

本地大模型在消费级硬件上能力提升显著: Reddit用户反馈,Qwen 3的14B参数模型(经过yarn补丁支持128k上下文)在仅有10GB显存和24GB内存的消费级PC上,通过IQ4_NL量化和80k上下文配置,已能较好地运行Roo Code和Aider等AI编程助手。尽管在处理长上下文(如20k+)时速度较慢(约2 t/s),但代码编辑质量和代码库认知能力表现良好,这是首次有本地模型能在较长对话中稳定处理复杂编码任务并输出有意义的代码差异。这一进步得益于模型本身的改进、llama.cpp等推理框架的优化以及Roo等前端工具的适配。 (来源: Reddit r/LocalLLaMA)
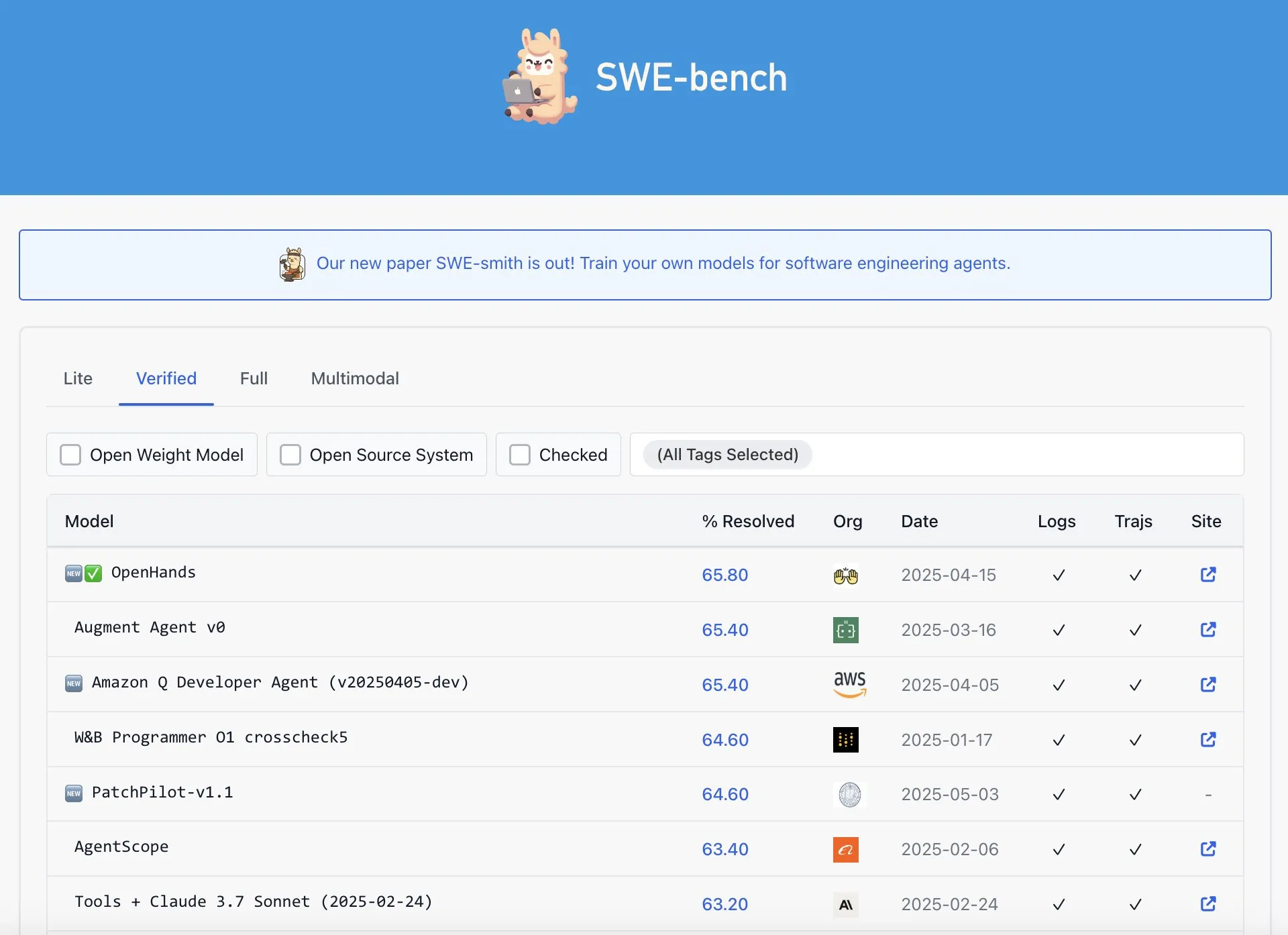
OpenAI Codex被指在SWE-Bench Verified排行榜上表现并非最佳: Graham Neubig指出,关于OpenAI的Codex模型在SWE-Bench Verified排行榜上取得SOTA成果的说法并不完全准确。他通过分析数据和不同衡量标准,认为无论从哪个角度看,Codex在该特定基准上的表现都存在争议,并非毫无疑问的最佳。 (来源: JayAlammar)
🧰 工具
OpenAlpha_Evolve开源:复现谷歌AI算法设计智能体: 继谷歌DeepMind发布AlphaEvolve论文后,开发者shyamsaktawat迅速推出了开源实现OpenAlpha_Evolve。该Python框架允许用户实验AI驱动的算法设计理念,包括任务定义、提示工程、代码生成(借助LLM如Gemini)、执行测试、适应度评估和进化选择等环节,旨在让更广泛的社区参与探索AI设计新算法的前沿。 (来源: karminski3, Reddit r/artificial, Reddit r/LocalLLaMA)

Cursor编辑器新增整文件快速编辑功能: AI优先的代码编辑器Cursor宣布,用户现在可以快速编辑整个文件。这一新功能旨在提升开发者的工作效率,使得在Cursor中进行大规模代码修改和重构更为便捷。 (来源: cursor_ai)
Codex高效完成应用国际化与本地化任务: 开发者Katsuya分享了使用OpenAI Codex进行应用国际化的经验。他让Codex将应用本地化为日语,一夜之间便完成了这项通常需要数天的工作,充分展示了Codex在自动化代码生成和处理复杂语言任务方面的强大能力。 (来源: gdb, ShunyuYao12)
llmbasedos:专为LLM设计的安全MCP沙箱环境: llmbasedos项目提供了一个基于裁剪版Arch Linux的操作系统环境,旨在为大型语言模型(LLM)提供安全的模块化计算协议(MCP)沙箱。它将文件系统、邮件、同步、代理等功能封装为MCP服务,用户可通过虚拟机或物理机从ISO启动后调用这些服务,方便进行安全的LLM交互和开发。 (来源: karminski3)

cachelm:开源LLM语义缓存工具提升效率与降低成本: 开发者devanmolsharma推出了开源工具cachelm,一个为LLM应用设计的语义缓存层。它通过向量搜索实现基于语义相似度的缓存,能有效减少对LLM API的重复调用(即使用户提问措辞不同),从而降低Token消耗并加速响应。该工具支持OpenAI、ChromaDB、Redis、ClickHouse等,并允许用户自定义向量化器、数据库或LLM。 (来源: Reddit r/MachineLearning)
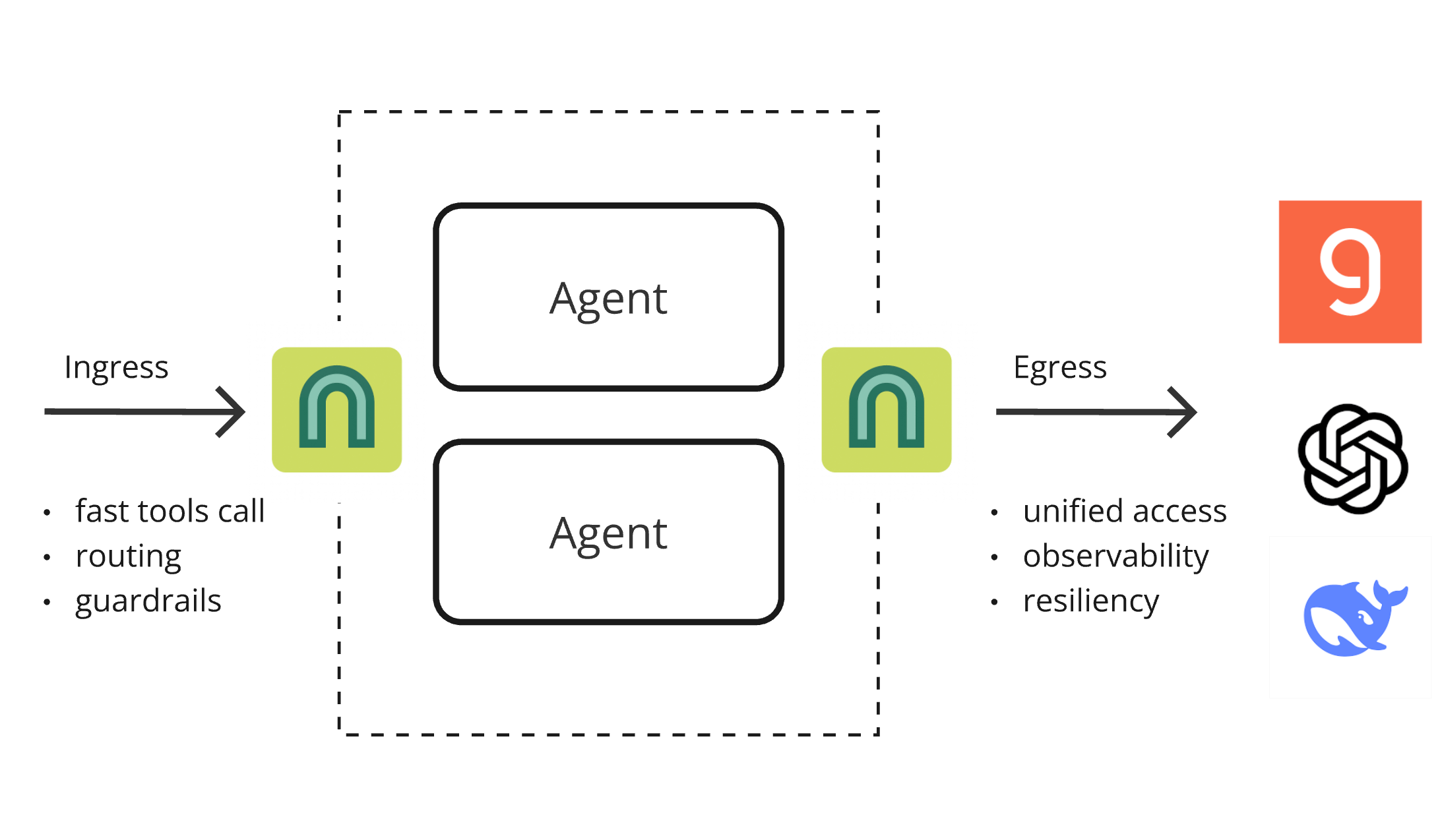
ArchGW 0.2.8发布,AI原生代理统一底层功能: ArchGW发布0.2.8版本,这款基于Envoy的AI原生代理旨在统一应用中重复的“低级别”功能。新版本增加了对双向流量的支持(为Google A2A做准备),改进了用于快速路由和工具调用的Arch-Function-Chat 3B模型,并支持托管在Groq上的LLM。ArchGW通过本地代理方式,简化AI应用开发,提升安全性、一致性和可观察性。 (来源: Reddit r/artificial)
SparseDepthTransformer:高中生开发动态层跳过Transformer提效方案: 一名高中生开发了名为SparseDepthTransformer的项目,通过轻量级评分机制评估每个Token的语义重要性,并让不重要的Token跳过Transformer的深层计算。实验表明,该方法在保持输出质量的同时,减少了约15%的内存使用,并将Token平均处理层数降低约40%,为提升Transformer效率提供了新思路。 (来源: Reddit r/MachineLearning)

AI食物与营养追踪器亮相,计划开源: 开发者Pavankunchala展示了一款AI驱动的饮食与营养追踪应用。该应用的核心功能是通过分析用户上传的食物照片来识别食物并估算营养信息(卡路里、蛋白质等),同时支持手动记录、每日营养概览和饮水追踪。开发者计划在未来将该项目代码开源。 (来源: Reddit r/LocalLLaMA)
意大利AI代理实现求职自动化,一分钟申请千份工作引热议: 一款据称来自意大利的AI Agent展示了其强大的求职自动化能力,能在1分钟内完成1000份工作申请。该演示引发了社区对AI在招聘领域应用的广泛讨论,一方面惊叹于其效率,另一方面也对其有效性、对招聘市场的影响以及如何应对“机器人检测”等问题表示关注。 (来源: Reddit r/ChatGPT)

📚 学习
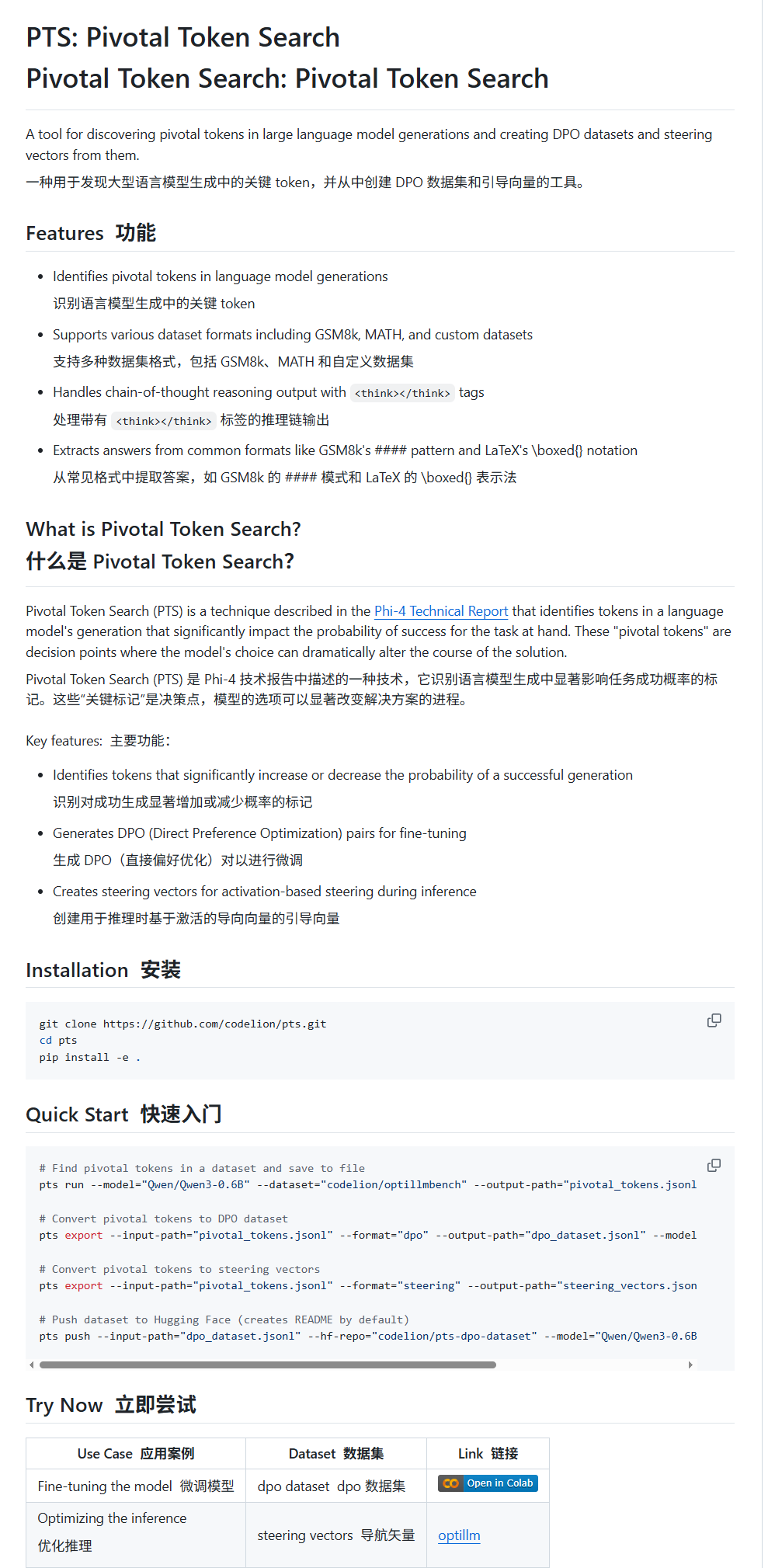
Pivotal Token Search (PTS):一种新的LLM微调与引导技术: karminski3介绍了一种名为PTS(关键Token检索)的新技术。该技术基于“大模型输出的关键决策点在于少数关键Token”的思想,通过提取这些能显著影响输出正确性的Token(分为“选择的Token”和“拒绝的Token”)来构建DPO数据集进行微调。此外,PTS还可以提取关键Token的激活模式生成引导向量(steering vectors),在推理时引导模型行为而无需微调。该方法据称受Phi4启发,其有效性引发社区讨论。 (来源: karminski3)
OpenAI Codex CLI提供免费API额度,鼓励数据共享: OpenAI开发者账号宣布,Plus或Pro用户可以通过运行npm i -g @openai/codex@latest和codex --free来兑换免费API额度。此外,用户还可以通过在平台设置中选择共享数据以改进和训练OpenAI模型,来获取免费的每日Token。此举旨在鼓励开发者使用Codex工具并参与模型改进。 (来源: OpenAIDevs, fouad)
多智能体系统(MAS)免费学习资源汇总: TheTuringPost整理并分享了7项免费学习多智能体系统(MAS)的资源。其中包括CrewAI、CAMEL多智能体框架和LangChain多智能体教程;一本名为《Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations》的书籍;以及三门在线课程,分别涵盖从提示到多智能体系统、使用AutoGen掌握多智能体开发,以及使用crewAI的实用多AI智能体与高级用例。 (来源: TheTuringPost)

MobileNetV2实现快速图像分类教程: Reddit用户Eran Feit分享了一份使用MobileNetV2进行图像分类的Python教程。该教程逐步指导用户加载预训练的MobileNetV2模型,使用OpenCV预处理图像(BGR转RGB、缩放至224×224、批处理),进行推理,并解码预测结果以获得人类可读的标签和概率。该教程适合初学者快速上手轻量级图像分类任务。 (来源: Reddit r/deeplearning)
OpenWebUI多源RAG与混合搜索实现指南发布: productiv-ai.guide网站发布了一份详尽的在OpenWebUI中实现多源检索增强生成(RAG)与混合搜索(Hybrid Search)及重新排序(Re-ranking)的步骤指南。该指南旨在帮助用户配置和利用OpenWebUI的RAG功能,包括最近增加的外部重排特性,以提升信息检索的准确性和相关性。 (来源: Reddit r/OpenWebUI)
💼 商业
AI Agent赛道竞争激烈:Manus与Lovart深度对比: 垂直设计领域的AI Agent “Lovart”因其独特的“接单式”工作流引发关注,它试图模拟完整设计流程,从需求沟通到分层素材交付,与通用型Agent “Manus”的“调度式”逻辑形成对比。尽管Lovart在设计美学理解、概念表达和信息组织上表现不俗,且速度优于Manus,但两者均面临稳定性、中文处理和修改联动等问题。Lovart的出现被视为垂直Agent深耕场景、内化行业经验的正确方向,预示AI Agent有望真正落地内容产业。 (来源: 36氪)

儿童智能手表市场火爆,AIoT趋势助推国产SoC芯片厂商业绩增长: 受益于消费政策拉动及AIoT发展趋势,中国智能可穿戴设备市场(尤其是儿童智能手表)销量激增。DeepSeek等开源大模型的出现降低了端侧AI部署门槛,加速AI向智能家电、AI耳机等终端渗透。瑞芯微、恒玄科技等国产SoC芯片厂商凭借其在低功耗、AI算力方面的布局,以及如瑞芯微RK3588等旗舰芯片对PC、智能硬件、车载等多场景的覆盖,业绩显著增长,估值也随之提升。 (来源: 36氪)
OpenAI被曝调整公司重组计划并回击非营利性质疑: 据Garrison Lovely披露,一份此前未报道的OpenAI致加州总检察长的信函曝光。信函内容不仅涉及OpenAI公司重组计划的意外细节,还显示出OpenAI正积极采取措施,回击那些对其试图削弱公司非营利治理结构的批评和质疑。 (来源: NeelNanda5)

🌟 社区
LLM的N-Gram本质与“智能”边界引热议: 社区持续探讨大型语言模型(LLM)在多大程度上仍依赖N-Gram统计特性,以及当前LLM是否构成“真正AI”。有观点(如pmddomingos评论jxmnop的NeurIPS论文)认为LLM在超过2/3的情况下行为类似N-Gram模型。Reddit数据科学家发帖指出,当前LLM缺乏真正的理解、推理和常识,距离AGI(通用人工智能)尚远,本质上是复杂的“下一词预测系统”,而非具备自我意识和适应性的智能体。 (来源: jxmnop, pmddomingos, Reddit r/ArtificialInteligence)

AI生成图像“透明薄膜”风格与“豆包”擦边图引关注: 近期,社交媒体上涌现大量由豆包等AI绘图工具生成的特定风格图片,特别是呈现“透明薄膜”包裹效果的图像。这些图片因其新奇的视觉效果和可能涉及的“擦边球”内容,引发了用户的广泛讨论、模仿和二次创作,成为AI生成内容领域的一个热门趋势。 (来源: op7418, dotey)

AI伦理与未来:构建“上帝”或自我毁灭?: 社区对AI发展的终极目标和潜在风险展开激烈讨论。Emad Mostaque直言有人正试图构建“上帝”般的AGI,可能带来乌托邦或毁灭。NVIDIA CEO黄仁勋则展望未来人类工程师与1000个AI协作设计芯片的场景。同时,SMBC漫画引发的讨论将AI意识问题转向更实际的伦理对待层面——我们能否心安理得地对待这些“物”?这些观点共同构成了对AI未来的复杂想象。 (来源: Reddit r/artificial, Reddit r/artificial, Reddit r/artificial)
AI是否会颠覆SaaS商业模式?开发者社区热议: 随着Claude Code等强大AI编程工具的普及,开发者社区开始讨论其对SaaS(软件即服务)商业模式的潜在冲击。观点认为,个人开发者利用AI复制现有SaaS产品核心功能的门槛正在降低,这可能导致企业和个人用户减少对传统SaaS服务的依赖,转而寻求更具成本效益的自建或AI辅助方案,未来软件开发可能更依赖对AI的微管理。 (来源: Reddit r/ClaudeAI)
AI多语言处理差异引关注,Llama预分词器或为原因之一: 社区讨论指出,大型语言模型(LLM)在英语上的表现通常优于其他语言。其中一个可能的原因被指向Llama等模型的预分词器(pretokenizer)对非英语文本(尤其非拉丁字符)的处理方式。例如,预分词器可能将中文字符过度拆分为更小的单元,影响模型对语言结构和语义的理解,进而导致在这些语言上的性能下降。 (来源: giffmana)

💡 其他
DSPy框架强调底层原语对AI智能体开发的重要性: AI框架DSPy自2023年1月开源其核心抽象以来,除少量简化外几乎未做更改,历经多次LLM API迭代仍保持稳定。社区讨论指出,这得益于DSPy专注于构建正确的底层原语,而非仅仅追求表层的开发者体验或快速构建“智能体”的便捷性。观点认为,当前许多智能体开发框架过于关注易用性,而忽视了基础构建块的坚实性,而DSPy的理念是先有坚实的“反应”基础,才能构建出复杂的“智能体”行为。 (来源: lateinteraction, lateinteraction)
AI生成内容审美疲劳催生定制化模型需求: 社区讨论认为,当前许多通过强化学习(RL)优化的图像生成模型,其产出往往显得“平庸”或“媚俗”,虽然技术上看似良好,但缺乏令人兴奋的创意和个性。这反映了模型优化目标可能倾向于大众的平均审美偏好,而非独特的艺术追求。因此,未来定制化模型和能够针对个体审美目标进行采样的方法,被认为是克服这一问题、创造更具吸引力AI内容的关键。 (来源: torchcompiled)

Ollama发布多模态引擎,OpenWebUI用户关注兼容性: Ollama宣布其多模态引擎正式发布,这一消息引起了OpenWebUI社区用户的关注。用户普遍关心OpenWebUI是否能够“开箱即用”地支持Ollama的新多模态引擎,即无需进行复杂的配置更改即可利用其处理图像、文本等多种数据类型的能力。 (来源: Reddit r/OpenWebUI)
