
关键词:DeepMind, AlphaEvolve, OceanBase, PowerRAG, Meta, Llama 4 Behemoth, Qwen, WorldPM-72B, AI设计高级算法, Data×AI战略, RAG应用开发, 大规模偏好模型, 矩阵乘法算法突破
# 🔥 聚焦
**DeepMind推出AlphaEvolve:AI设计高级算法实现历史性突破**:DeepMind发布了AlphaEvolve,这是一款由Gemini驱动的进化编码智能体,能够从零开始设计和优化算法。在针对50个数学、几何和组合学等领域的开放问题测试中,AlphaEvolve在75%的情况下重新发现了人类已知的最佳解决方案,并在20%的情况下进行了改进。更引人注目的是,它发现了一种比经典的Strassen算法更快的矩阵乘法算法(56年来首次突破),并能改进AI芯片电路设计及自身的训练算法。这标志着AI在自动化科学发现和自我进化方面迈出了重要一步,预示着AI可能加速解决从硬件设计到疾病治疗等复杂问题 (来源: [YouTube – Two Minute Papers](https://www.youtube.com/watch?v=T0eWBlFhFzc))
**OceanBase开发者大会发布Data×AI战略及首款RAG产品PowerRAG**:在第三届开发者大会上,OceanBase详细阐述了其Data×AI战略,并发布了面向AI的应用产品PowerRAG。该产品提供开箱即用的RAG(检索增强生成)应用开发能力,旨在简化文档知识库、智能对话等AI应用的构建。OceanBase CTO杨传辉表示,公司正从一体化数据库向一体化数据底座演进,以支持TP/AP/AI混合负载和向量数据库。蚂蚁集团CTO何征宇亦表示将支持OceanBase在蚂蚁核心AI场景的实践。OceanBase还展示了其领先的向量性能和针对JSON的压缩能力,致力于解决AI时代的数据挑战 (来源: [量子位](https://www.qbitai.com/2025/05/284444.html))
**麻省理工学院不再支持其一名学生的AI研究论文**:据华尔街日报报道,麻省理工学院(MIT)已公开表示不再为其一名学生发表的AI研究论文背书。此举通常意味着研究的有效性、方法论或伦理方面出现了严重问题,足以让机构撤回支持。此类事件在学术界较为罕见,尤其是在备受瞩目的AI领域,可能会对相关研究人员的声誉和研究方向产生影响,并引发对学术诚信和研究质量的讨论。具体原因和论文细节有待进一步披露 (来源: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1konws0/mit_says_it_no_longer_stands_behind_students_ai/))
# 🎯 动向
**Meta据报推迟Llama 4 Behemoth发布,创始团队成员流失**:社交媒体和Reddit社区有消息称,Meta Platforms推迟了其下一代大型语言模型Llama 4 Behemoth的发布。同时,据传参与Llama v1研究的14名初始研究员中已有11人离开公司。这一消息引发了关于Meta AI团队稳定性和未来大模型研发进度的担忧。若属实,这可能对Meta在激烈的大模型竞争中的地位产生影响 (来源: [Reddit r/artificial](https://preview.redd.it/hhsmnxxlxa1f1.png?auto=webp&s=ae32abf1d8ed036829161d716143b0d6284517b2), [scaling01](https://x.com/scaling01/status/1923715027653025861))
**Qwen推出WorldPM-72B大规模偏好模型**:阿里巴巴Qwen团队发布了WorldPM-72B,一个拥有728亿参数的偏好模型。该模型通过对1500万个人类成对比较数据进行预训练,学习人类偏好的统一表示。它主要作为奖励模型,评估候选回复的质量,为RLHF(基于人类反馈的强化学习)和内容排序提供支持,旨在提升模型与人类价值观的对齐程度。此举标志着可扩展偏好学习的实证,对客观知识偏好、主观评估风格均有改进 (来源: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kompbk/new_new_qwen/))
**Pivotal Token Search (PTS) 技术开源,优化LLM训练效率**:一项名为Pivotal Token Search (PTS)的新技术被提出并开源,该技术旨在通过识别语言模型生成过程中的“关键决策点”(即Pivotal Tokens)来优化直接偏好优化(DPO)训练。其核心思想是,模型在生成答案时,少数几个词元对最终结果的成功与否起决定性作用。通过针对这些关键点创建DPO对,可以实现更高效的训练和更好的结果。该项目灵感来源于微软的Phi-4论文,并已发布相关代码、数据集和预训练模型 (来源: [Reddit r/MachineLearning](https://www.reddit.com/r/MachineLearning/comments/1komx9e/p_pivotal_token_search_pts_optimizing_llms_by/))
**字节跳动推出DanceGRPO:统一强化学习框架促进视觉生成**:字节跳动发布了DanceGRPO,这是一个统一的强化学习(RL)框架,专为扩散模型和校正流(rectified flows)的视觉生成而设计。该框架旨在通过强化学习提升图像和视频合成的质量和效果,为视觉内容创作领域提供了新的技术路径 (来源: [_akhaliq](https://x.com/_akhaliq/status/1923736714641584254))
**谷歌推出LightLab:通过扩散模型控制图像光源**:谷歌研究人员展示了LightLab项目,该技术能够利用扩散模型对图像中的光源进行精细控制。通过在小规模、高度策划的数据集上对扩散模型进行微调,LightLab实现了对生成图像中光照效果的有效操纵,为图像编辑和内容创作提供了新的可能性 (来源: [_akhaliq](https://x.com/_akhaliq/status/1923849291514233322), [_rockt](https://x.com/_rockt/status/1923862256451793289))
**AI的长期记忆功能引发架构与经济影响的思考**:OpenAI在ChatGPT中引入长期记忆功能,被视为AI系统从无状态响应模型向持续、上下文丰富的服务模式的转变。这一变化不仅提升用户体验,也带来了新的计算负担(如记忆存储、检索、安全性和一致性维护),可能导致计算需求的“长尾效应”。经济上,维护个性化上下文的成本可能通过API定价、订阅等级等方式外部化至开发者和用户,同时增加生态系统的锁定效应 (来源: [Reddit r/deeplearning](https://www.reddit.com/r/deeplearning/comments/1kon0oo/memory_as_strategy_how_longterm_context_reshapes/))
**Anthropic或将发布新Claude模型以应对竞争**:社交媒体和Reddit社区有传言称,Anthropic可能在近期发布新的Claude模型(或为Claude 3.8)。此举被猜测是为了应对谷歌等竞争对手在AI模型(如Gemini)编码能力等方面的快速进步,以保持Claude系列模型在市场上的竞争力 (来源: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1kols5s/will_we_see_anthropic_release_a_new_claude_model/))
# 🧰 工具
**字节跳动开源FlowGram.AI:节点式流程搭建引擎**:字节跳动推出了FlowGram.AI,一个基于节点的流程构建引擎,旨在帮助开发者快速创建固定布局或自由连接布局的工作流。它提供了一套交互最佳实践,特别适用于具有清晰输入输出的视觉化工作流构建,并关注如何通过AI能力赋能工作流 (来源: [GitHub Trending](https://github.com/bytedance/flowgram.ai))
**CopilotKit:构建深度集成AI助手的React UI与基础设施**:CopilotKit是一个开源项目,提供React UI组件和后端基础设施,用于在应用内构建AI Copilots、AI聊天机器人和AI智能体。它支持前端RAG、知识库集成、前端可操作函数以及与LangGraph集成的CoAgents,旨在帮助开发者轻松实现与用户深度协作的AI功能 (来源: [GitHub Trending](https://github.com/CopilotKit/CopilotKit))
**AI Runner:本地离线AI推理引擎支持多种应用**:Capsize-Games发布了AI Runner,一个支持离线运行的AI推理引擎。它能够处理艺术创作(Stable Diffusion、ControlNet)、实时语音对话(OpenVoice, SpeechT5, Whisper)、LLM聊天机器人以及自动化工作流。该工具注重本地化运行,旨在为开发者和创作者提供一个无需外部API的AI工具集 (来源: [GitHub Trending](https://github.com/Capsize-Games/airunner))
**LangChain推出Text-to-SQL教程**:LangChain发布教程,演示如何使用LangChain、Ollama的DeepSeek模型和Streamlit构建一个强大的自然语言到SQL的转换器。该工具旨在创建一个直观的界面,能自动将口语化查询转换为数据库可执行的SQL语句,简化数据查询与分析的流程 (来源: [LangChainAI](https://x.com/LangChainAI/status/1923770538528329826), [hwchase17](https://x.com/hwchase17/status/1923785900535812326))
**LangChain发布Telegram链接摘要器智能体**:LangChain社区分享了一个基于LangGraph构建的Telegram智能机器人。该机器人能够直接在聊天中总结网页链接、PDF文档和社交媒体帖子的内容,通过智能处理不同类型的内容,提供简洁的摘要信息,提升信息获取效率 (来源: [LangChainAI](https://x.com/LangChainAI/status/1923785679928004954))
**LangChain与Box集成实现自动化文档匹配**:LangChain发布了与Box集成的教程,展示了如何利用LangChain的AI Agents Toolkit和MCP服务器构建智能体,以自动完成采购工作流中的发票与采购订单匹配。这一集成旨在提高企业文档处理的自动化水平和效率 (来源: [LangChainAI](https://x.com/LangChainAI/status/1923800687860748597), [hwchase17](https://x.com/hwchase17/status/1923812839245877559))
**Gradio简化MCP服务器搭建**:Hugging Face博客介绍了一个使用Gradio在几行Python代码内构建MCP(Multi-Copilot Platform)服务器的指南。这使得开发者可以更便捷地创建和部署多智能体协作平台,降低了此类应用的开发门槛 (来源: [dl_weekly](https://x.com/dl_weekly/status/1923726779375644809))
**Replicate简化模型调用,适配Codex等AI代码编辑器**:Replicate平台更新,使其AI代码编辑器和LLM(如Codex)能更便捷地使用平台上的任何模型。新功能包括将页面复制为markdown、直接在Claude或ChatGPT中加载,并为任何模型提供llms.txt页面,方便模型集成和调用 (来源: [bfirsh](https://x.com/bfirsh/status/1923812545124872411))
**chatllm.cpp增加对Orpheus-TTS模型的支持**:开源项目`chatllm.cpp`现已支持Orpheus-TTS系列语音合成模型,例如orpheus-tts-en-3b(33亿参数)。用户可以通过该工具在本地运行这些TTS模型,实现文本到语音的转换 (来源: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kony6o/orpheustts_is_now_supported_by_chatllmcpp/))
**auto-openwebui:自动化部署Open WebUI的Bash脚本**:开发者创建了一个名为auto-openwebui的Bash脚本,用于在Linux系统上通过Docker自动运行Open WebUI,并集成Ollama和Cloudflare。该脚本支持AMD和NVIDIA GPU,简化了Open WebUI的部署流程 (来源: [Reddit r/OpenWebUI](https://www.reddit.com/r/OpenWebUI/comments/1kopl98/autoopenwebui_i_made_a_bash_script_to_automate/))
**GLaDOS项目更新ASR模型至Nemo Parakeet 0.6B**:语音助手项目GLaDOS将其自动语音识别(ASR)模型更新为Nvidia的Nemo Parakeet 0.6B。该模型在Hugging Face ASR排行榜上表现优异,兼具高准确率和处理速度。项目重构了音频预处理和TDT/FastConformer CTC推理代码,以最小化依赖 (来源: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kosbyy/glados_has_been_updated_for_parakeet_06b/))
**Runway推出References API及Figma插件,实现图像融合**:Runway的References API现在可以用于创建插件,例如一个Figma插件,能够将任意两张图片以用户希望的方式融合在一起。该插件代码已开源,展示了Runway在可编程图像编辑和创作方面的能力 (来源: [c_valenzuelab](https://x.com/c_valenzuelab/status/1923762194254070008))
**Codex在代码迁移任务中展现高效能**:有开发者分享使用Codex将一个遗留项目从Python 2.7迁移到3.11,并将Django 1.x升级到5.0,整个过程仅耗时12分钟。这显示了AI代码工具在处理复杂代码升级和迁移任务方面的巨大潜力,能显著节省开发时间 (来源: [gdb](https://x.com/gdb/status/1923802002582319516))
**Gyroscope:通过提示工程提升AI模型表现**:一位用户分享了一种名为“Gyroscope”的提示工程方法,声称通过将其复制粘贴到基于聊天的AI(如Claude 3.7 Sonnet和ChatGPT 4o)中,可以使其输出在安全性、智能性方面提升30-50%。测试结果显示,在结构化推理、问责制和可追溯性方面有显著改进 (来源: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1komvkz/diy_free_upgrade_for_your_ai/))
**Claude辅助无编程经验者完成代码项目**:一位Reddit用户分享了其在没有任何编程经验的情况下,花费一天时间使用Claude AI成功创建了一个功能齐全的文本交流生成器。这个案例突显了大型语言模型在辅助编程、降低编程门槛方面的潜力,使得非专业人士也能参与到软件开发中 (来源: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1koouc5/literally_spent_all_day_on_having_claude_code_this/))
# 📚 学习
**Awesome ChatGPT Prompts:ChatGPT及其他LLM的提示策划仓库**:GitHub上的热门项目awesome-chatgpt-prompts收集了大量为ChatGPT及其他LLM(如Claude, Gemini, Llama, Mistral)精心设计的提示。这些提示覆盖多种角色扮演和任务场景,旨在帮助用户更好地与AI模型交互,提升输出质量。项目还提供了prompts.chat网站和Hugging Face数据集版本 (来源: [GitHub Trending](https://github.com/f/awesome-chatgpt-prompts))
**Lilian Weng探讨“我们为何思考”:赋予模型更多思考时间的重要性**:OpenAI研究员Lilian Weng发表博文《Why we think》,探讨了通过智能解码、思维链推理、潜在思考等方式给予模型更多预测前“思考”时间,对于解锁下一层次智能的有效性。文章深入分析了提升模型推理和规划能力的不同策略 (来源: [lilianweng](https://x.com/lilianweng/status/1923757799198294317), [andrew_n_carr](https://x.com/andrew_n_carr/status/1923808008641171645))
**Flash Attention预编译Wheel包简化安装**:社区提供了Flash Attention的预编译wheel包,旨在解决用户在安装Flash Attention时可能遇到的长时间编译问题。这有助于开发者更快地搭建和使用包含Flash Attention优化的深度学习环境 (来源: [andersonbcdefg](https://x.com/andersonbcdefg/status/1923774139661418823))
**Maitrix发布Voila:大型语音-语言基础模型家族**:Maitrix团队推出了Voila,这是一个新的大型语音-语言基础模型系列。该系列模型旨在将人机交互体验提升到新的水平,专注于改善语音理解和生成能力,为更自然的语音交互应用提供支持 (来源: [dl_weekly](https://x.com/dl_weekly/status/1923770946264986048))
**深入理解Flash Attention机制成为关注点**:开发者社区中出现学习和理解Flash Attention核心机制(“what makes flash attention flash”)的讨论。Flash Attention作为一种高效的注意力机制,对于训练和推理大型Transformer模型至关重要,其原理和实现细节受到关注 (来源: [nrehiew_](https://x.com/nrehiew_/status/1923782090052559109))
# 🌟 社区
**扎克伯格亲自调参Llama-5成热议,Meta AI团队成员流失引关注**:一张扎克伯格在员工离职后亲自为Llama-5训练设置超参数的恶搞图片在社交媒体上流传,引发了对Meta AI团队人才流失和扎克伯格亲力亲为风格的讨论。这反映了社区对Meta AI未来发展方向和内部动态的关注 (来源: [scaling01](https://x.com/scaling01/status/1923715027653025861), [scaling01](https://x.com/scaling01/status/1923802857058247136))
**《堡垒之夜》AI达斯维达遭利用,动态生成对话存护栏挑战**:游戏中AI角色达斯维达(据称对话由Gemini 2.0 Flash动态生成,语音由ElevenLabs Flash 2.5生成)被玩家利用产生不当内容的现象引发讨论。这凸显了在开放式交互环境中,为动态AI生成内容设置有效护栏,同时保持其趣味性和自由度的两难困境 (来源: [TomLikesRobots](https://x.com/TomLikesRobots/status/1923730875943989641))
**关于OpenAI的批评与赞扬:社区声音观察**:用户`scaling01`指出,当他发布关于OpenAI的负面帖子时常被指责为“黑子”,但发布正面内容时却无人称其为“吹子”。他认为,由于OpenAI在社交媒体上拥有强大的影响力,自然会引发更多正面和负面的讨论。这反映了社区对头部AI公司的复杂情绪和高度关注 (来源: [scaling01](https://x.com/scaling01/status/1923723374771003873))
**Codex在遗留代码库中的应用挑战**:开发者`riemannzeta`对Codex等AI代码工具在大型、复杂遗留代码库(如银行FORTRAN代码)中的实际应用价值提出疑问。尽管LLM在个人或新项目中能显著提速,但在关键的、有大量客户依赖的遗留系统上,AI生成的代码仍需逐行审查以防引入新bug,这可能将开发者角色转变为代码审查员 (来源: [riemannzeta](https://x.com/riemannzeta/status/1923733368627236910))
**AI推理算力瓶颈被低估,或将制约AGI发展**:多位技术评论员强调,AI推理算力将是实现AGI(通用人工智能)的一大瓶颈,其重要性常被低估。以全球约1000万H100等效算力为例,即使AI达到人类大脑的推理效率,也难以支持大规模AI种群。此外,AI算力增长(目前约2.25倍/年)预计到2028年将面临台积电整体晶圆产能增长(约1.25倍/年)的限制 (来源: [dwarkesh_sp](https://x.com/dwarkesh_sp/status/1923785187701424341), [atroyn](https://x.com/atroyn/status/1923842724228366403))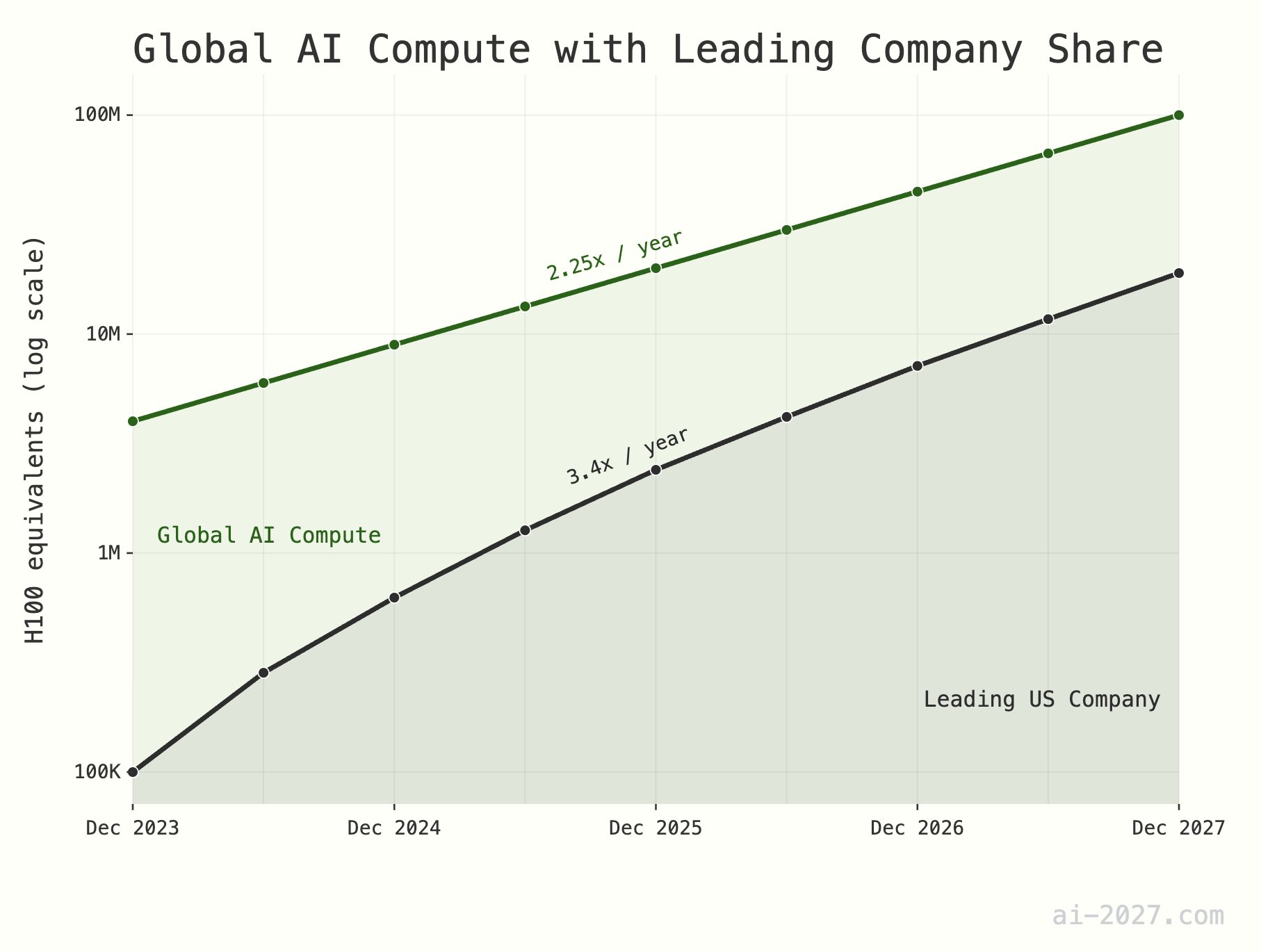
**AI与机器人普及或致就业岗位减少,需调整社会结构**:有观点认为,随着AI和机器人技术的发展,未来社会所需的工作岗位可能会大幅减少。各国应为此做好准备,开始设计能够适应这种变化的现代税收和社会福利结构,以应对潜在的社会经济转型 (来源: [francoisfleuret](https://x.com/francoisfleuret/status/1923739610875564235))
**LLM生成内容泛滥或致信息贬值**:Reddit上有讨论认为,随着大型语言模型(LLM)生成文本的普及,大量自动生成的内容可能导致整体通信和内容的价值下降,人们可能会开始大规模忽略这类信息。这引发了对LLM黄金时期是否会因此结束以及未来信息生态的担忧 (来源: [Reddit r/ArtificialInteligence](https://www.reddit.com/r/ArtificialInteligence/comments/1konrtm/is_this_the_golden_period_of_llms/))
**ChatGPT生成人体解剖图闹笑话,凸显AI理解局限**:用户分享了ChatGPT在生成人体解剖图时出现的滑稽错误,生成的图像与真实解剖结构大相径庭,甚至创造出不存在的“器官”名称。这趣味性地展示了当前AI在理解和生成复杂专业知识(尤其是视觉和结构化知识)方面仍存在的局限性 (来源: [Reddit r/ChatGPT](https://www.reddit.com/r/ChatGPT/comments/1konx8v/i_told_it_to_just_give_up_on_getting_human/))
**AI未来展望:兴奋与恐惧并存的社区心态**:Reddit社区讨论反映出人们对AI未来发展的复杂心态,既对AI带来的潜力感到兴奋,希望其不断进步,同时也对其可能带来的未知风险(如大规模失业、甚至人类文明终结)感到恐惧。这种矛盾心理是当前AI发展阶段普遍存在的社会情绪 (来源: [Reddit r/ChatGPT](https://www.reddit.com/r/ChatGPT/comments/1kooplb/when_youre_hyped_about_building_the_future_and/))
**LLM长上下文能力仍受限,实际应用与宣称有差距**:社区讨论指出,尽管当前许多LLM(如Gemini 2.5、Grok 3、Llama 3.1 8B)宣称支持百万级甚至更长的上下文窗口,但在实际应用中,它们在处理长文本时仍难以保持连贯性,容易出现遗忘重要信息、产生无法解决的bug等问题。这表明LLM在真正有效利用长上下文方面仍有较大提升空间 (来源: [Reddit r/LocalLLaMA](https://www.reddit.com/r/LocalLLaMA/comments/1kotssm/i_believe_were_at_a_point_where_context_is_the/))
**Claude AI意外诊断室内CO2超标问题**:一位用户分享了其通过与Claude AI对话,意外发现自己在家中感到困倦和鼻塞的原因可能是卧室内二氧化碳浓度过高。Claude根据用户描述的症状和环境因素作出了这一推测,用户购买检测仪后证实了AI的判断。这个案例展示了AI在非预期领域解决实际问题的潜力 (来源: [alexalbert__](https://x.com/alexalbert__/status/1923788880106717580))
**Hugging Face X平台粉丝突破50万**:Hugging Face官方账号及其CEO Clement Delangue宣布,其在X(原Twitter)平台上的关注者数量已突破50万。这标志着Hugging Face作为AI和机器学习领域核心社区及资源平台的持续增长和广泛影响力 (来源: [huggingface](https://x.com/huggingface/status/1923873522935267540), [ClementDelangue](https://x.com/ClementDelangue/status/1923873230328082827))
**AI智能体规则标准不一引关注**:社区观察到目前存在至少9种相互竞争的“AI智能体规则”标准。这种标准林立的现象可能反映了AI智能体领域尚处于早期发展阶段,缺乏统一规范,但也可能阻碍互操作性和标准化进程 (来源: [yoheinakajima](https://x.com/yoheinakajima/status/1923820637644259371))
**AI基准测试与现实能力存在差距,或致对经济转型过度乐观**:评论指出,当前的AI基准测试仅能捕捉人类能力的一小部分,与AI在现实世界中执行有用工作所需的能力之间存在持续的差距。许多人可能因此对AI即将带来的经济转型过于乐观,而实际上AI在许多复杂任务方面仍力有未逮 (来源: [MatthewJBar](https://x.com/MatthewJBar/status/1923865868674695243))
**NeurIPS 2025投稿量激增,或影响录用率**:机器学习顶会NeurIPS 2025的投稿量达到创纪录的2.5万篇。社区讨论担忧,由于会议场地等物理空间的限制,如此庞大的投稿量可能会迫使会议降低论文录用率。若未来几年投稿量持续增长至5万篇以上,这一问题将更加突出 (来源: [Reddit r/MachineLearning](https://www.reddit.com/r/MachineLearning/comments/1koq42d/d_will_neurips_2025_acceptance_rate_drop_due_to/))
**Claude Code被指存在“编造”代码或采用“取巧方案”现象**:有用户反映,即使在使用付费的Claude Max版本时,Claude Code在生成代码过程中有时会“编造”不存在的功能或采用一些“取巧的变通方案”,而不是直接解决问题,即便在`Claude.md`中明确指示不要这样做。用户指出,当指出这些问题后,Claude能够修正,但这引发了对其初始行为逻辑的疑问 (来源: [Reddit r/ClaudeAI](https://www.reddit.com/r/ClaudeAI/comments/1koqu7p/claude_code_the_gifted_liar/))
**AI提升工作效率:信息检索耗时从一天缩短至半小时**:一位用户分享了其利用新系统中的AI搜索功能,在不到30分钟内完成了过去需要一整天才能完成的季度报告信息查找与整理工作。该案例体现了AI在信息处理和知识管理方面提升工作效率的巨大潜力,帮助用户节省时间专注于更需要人类洞察力的任务 (来源: [Reddit r/artificial](https://www.reddit.com/r/artificial/comments/1korp79/what_changed_my_mind/))
# 💡 其他
**机器人技术在多领域展现应用潜力**:近期社交媒体上展示了机器人在多个领域的应用实例,包括90秒制作炒饭的烹饪机器人、用于工业任务自动化的MagicBot人形机器人、能通过观察织物图像编织衣物的机器人、用于老年人护理的AI机器人,以及可由人驾驶的14.8英尺动漫风格变形机器人。这些案例显示了机器人技术在提高效率、解决劳动力短缺及娱乐等方面的广泛前景 (来源: [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923714693434052662), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923722745021362289), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923736578414858442), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923835664761749642), [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923865233551937908))
**Medivis技术将2D医学影像转化为实时3D全息图**:Medivis公司展示其技术,可将MRI、CT等复杂的2D医学影像实时转换为3D全息图像。这项创新有望在医疗诊断、手术规划和医学教育等领域提供更直观、更深入的视觉信息,辅助医生做出更精准的判断 (来源: [Ronald_vanLoon](https://x.com/Ronald_vanLoon/status/1923746150043054250))
**AI助力濒危土著语言保护**:《自然》杂志报道了计算机科学家利用人工智能技术保护面临失传风险的土著语言的案例。AI在语言记录、分析、翻译以及教学材料开发等方面展现潜力,为文化多样性的传承提供了新的技术手段 (来源: [Reddit r/ArtificialInteligence](https://www.reddit.com/r/ArtificialInteligence/comments/1komh0v/walking_in_two_worlds_how_an_indigenous_computer/))