
关键词:AlphaEvolve, DeepSeek V3, GPT-4.1, Speech-02, Claude模型, Falcon-Edge, BLIP3-o, AM-Thinking-v1, Gemini驱动的进化编码智能体, 软硬件协同设计降低大模型成本, 零样本语音克隆技术, 极限推理能力, 1.58位BitNet架构
🔥 聚焦
DeepMind推出AlphaEvolve:Gemini驱动的进化编码智能体,推动算法发现 : AlphaEvolve结合Gemini模型的创造力与自动评估器,利用进化框架优化算法。它已在多个领域取得突破,如用48次标量乘法完成4×4复数矩阵乘法,改进了Strassen算法;在11维空间中发现593个外球配置,推进了300年历史的“接吻数问题”。此外,AlphaEvolve还优化了谷歌数据中心调度(节省0.7%计算资源)、下一代TPU设计(删除冗余位)、AI模型训练(关键内核加速23%)等。菲尔兹奖得主陶哲轩也参与了其数学应用的探索。 (来源: DeepMind)

DeepSeek V3论文详解:软硬件协同设计降低大模型成本与功耗 : DeepSeek团队发布论文,详细阐述了DeepSeek-V3如何通过软硬件协同设计实现大规模训练和推理的成本效益。核心技术包括:1) 内存优化:采用多头潜在注意力(MLA)压缩键值缓存,FP8混合精度训练减少内存消耗。2) 计算优化:应用混合专家模型(MoE),仅激活部分参数,并结合FP8训练,大幅降低计算成本。3) 通信优化:采用多平面胖树网络拓扑和双微批处理重叠(DualPipe)技术,减少延迟,提高GPU利用率。4) 推理加速:引入多token预测(MTP)框架,并行预测和验证多个候选token,提升生成速度。论文还对未来AI硬件设计提出了五大展望,包括低精度计算支持、扩展与融合、网络拓扑优化、内存系统优化和鲁棒性与容错。 (来源: arXiv)

OpenAI GPT-4.1模型正式上线ChatGPT,用户可直接选用 : OpenAI宣布GPT-4.1模型已在ChatGPT中可用,Plus、Pro和Team用户可通过模型选择器访问,企业版和教育版用户将稍后获得权限。GPT-4.1 mini也将取代GPT-4o mini面向所有用户。GPT-4.1以其在编码任务和指令遵循方面的出色表现受到关注,此前API版本支持高达100万Token的上下文窗口。然而,部分用户实测发现ChatGPT中的GPT-4.1版本上下文长度似乎仍为128k,未达到API版本的1M,引发了一些失望情绪。 (来源: OpenAI Developers)

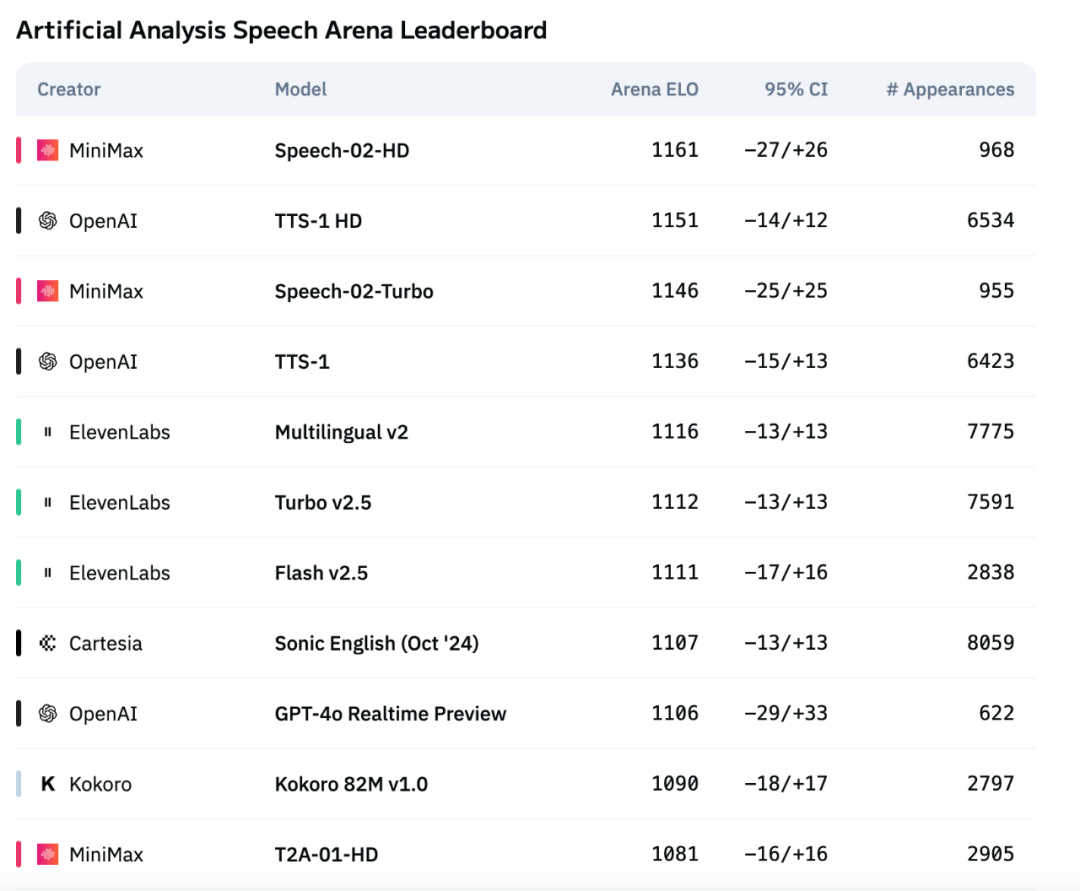
MiniMax新一代语音模型Speech-02登顶Artificial Analysis语音评测榜单 : MiniMax推出的最新文本转语音(TTS)模型Speech-02,在国际权威语音评测榜单Artificial Analysis Speech Arena上获得最高ELO评分,超越了OpenAI和ElevenLabs的同类产品。该模型在关键指标如字错率(WER)和说话人相似度(SIM)上表现优异,尤其在中文和粤语处理上展现本土优势。Speech-02的核心创新在于实现了真正的零样本语音克隆(仅需数秒参考音频,无需文本)以及采用了新的Flow-VAE架构,增强了语音生成的自然度和情感表现力,支持32种语言。其成本也极具竞争力,约为ElevenLabs竞品的1/4。 (来源: 机器之心)
🎯 动向
Anthropic新版Claude模型或将具备“极限推理”能力 : 据The Information报道及社区观察,Anthropic可能在未来几周发布新版Claude Sonnet和Claude Opus模型,其最大亮点是“极限推理”(Extreme reasoning)能力。该功能允许模型在遇到困难问题时暂停、重新评估并调整策略,而非直接给出答案。在代码生成等任务中,模型能自动测试并修正错误。这种动态循环的推理和工具使用方式,旨在让模型更智能地处理复杂问题,减少对人类监督的依赖,更接近人类协作者的思维方式。已有用户发现Anthropic正在测试名为Claude Neptune(或为Claude 3.8)的模型,支持128k tokens上下文。 (来源: 量子位)
TII发布Falcon-Edge系列高效Bitnet模型及onebitllms微调工具包 : 技术创新研究所(TII)发布了Falcon-Edge,这是一系列基于BitNet架构的高度压缩语言模型,具有强大、通用且可微调的特性。同时,他们还开源了onebitllms,一个专门用于微调或继续预训练这些1.58位模型的轻量级Python工具包(可通过pip安装)。此举旨在降低大模型使用的门槛,推动1-bit LLM技术的发展和应用。 (来源: younes)

Hugging Face Transformers库迎来重大升级,成为模型定义的中心标准 : Hugging Face宣布其Transformers库正在进行重大调整,旨在成为跨不同后端和运行器的模型定义中心标准。通过与vLLM、LlamaCPP、SGLang、MLX、DeepSpeed、微软、NVIDIA等众多生态伙伴的共同努力,推动模型代码的标准化,以期为整个AI生态系统带来更高的一致性和可靠性。这一举措受到了社区的广泛好评,被认为是推动开源AI发展的重要一步。 (来源: Arthur Zucker)

Salesforce在Hugging Face发布BLIP3-o:全开源统一多模态模型系列 : Salesforce推出了BLIP3-o系列模型,这是一族完全开源的统一多模态模型。该系列涵盖了模型架构、训练方法和数据集,旨在推动多模态AI技术的发展和应用。BLIP3-o的发布为研究者和开发者提供了强大的多模态处理工具和资源。 (来源: AK)

英伟达展示利用合成数据推进全自动驾驶技术 : 英伟达发布新视频,展示其如何利用合成数据来加速全自动驾驶(FSD)技术的研发。通过生成大规模、多样化的虚拟驾驶场景和数据,英伟达能够更高效地训练和验证其自动驾驶算法,克服真实世界数据收集的局限性,推动自动驾驶技术向更安全、更可靠的方向发展。 (来源: SawyerMerritt)
A-M-team发布32B推理模型AM-Thinking-v1,部分性能超越DeepSeek-R1 : 国内研究团队A-M-team在Hugging Face开源了32B参数的推理模型AM-Thinking-v1。该模型在数学推理(AIME系列得分85.3)和代码生成(LiveCodeBench得分70.3)等任务上表现出色,据称在这些特定评测中超越了DeepSeek-R1(671B MoE),并接近Qwen3-235B-A22B等更大规模模型。团队专注于通过后训练方案(包括冷启动SFT、通过率引导的数据筛选、双阶段RL)优化32B稠密模型的推理能力,旨在探索在有限计算和开源数据条件下实现强推理的路径。 (来源: AI科技评论)

Marigold更新:稳定扩散模型转深度估计器,支持单步推理和高分辨率 : Marigold项目发布重大更新,该技术能够将Stable Diffusion 2模型通过少量合成样本和短时间(1 GPU上2-3天)训练,转化为先进的深度估计器。新版本特性包括:单步快速推理、支持新模态、高分辨率输出、Diffusers库支持以及新的演示。 (来源: Anton Obukhov)
千问3系列模型在开源社区表现强劲,英伟达OpenCodeReasoning选用其为基座 : 阿里巴巴的千问3(Qwen3)系列模型在开源社区持续获得关注和应用。英伟达最新开源的OpenCodeReasoning系列模型(包含7B、14B、32B规格)即选用千问作为基础底座。千问3以其齐全的版本、持续的更新、对混合推理模式的原生支持以及繁荣的生态系统(全球下载量超3亿,衍生模型超10万)受到开发者青睐。近期更新包括端侧多模态模型Qwen-omini 3B、与Unsloth合作提升微调效率、发布详细部署超参数建议、支持生成网页实时预览、提供多种量化版本以及发布技术报告等。 (来源: AI前线)
Hugging Face Accelerate v1.7.0发布,支持区域编译和FSDPv2的QLoRA : Hugging Face Accelerate v1.7.0版本正式发布。此版本亮点包括:由 @IlysMoutawwakil 实现的区域编译(Regional compilation),提升编译效率和灵活性;由 @RisingSayak 贡献的层级转换钩子(Layerwise casting hook),这是diffusers库中广泛使用的功能;以及由 @winglian 实现的对FSDPv2的QLoRA支持,进一步优化大规模模型训练。 (来源: Marc Sun)

Llamafile 0.9.3发布,新增对Qwen3和Phi4模型支持 : Llamafile 发布了0.9.3版本,此次更新增加了对近期热门模型Qwen3系列和Phi4系列的支持。Llamafile致力于将LLM应用程序分发和运行变得简单,通过将模型权重和运行所需代码打包成单个可执行文件,实现在多种操作系统上的便捷部署。 (来源: Phoronix)
腾讯发布混元图像大模型HunyuanImage 2.0 : 腾讯正式发布了其混元图像大模型的新版本——HunyuanImage 2.0。此次更新预计在图像生成质量、可控性、以及对复杂指令的理解能力上有所提升。具体的技术细节和改进之处,用户可以通过官方渠道进一步了解。 (来源: Hunyuan)

Ollama v0.7发布,增强本地运行大模型体验 : Ollama 发布了 v0.7 版本,继续致力于简化在本地设备上运行大型语言模型的过程。新版本可能包含性能优化、新增模型支持或用户体验改进。用户可以访问官网或GitHub查看详细的更新日志和下载。 (来源: ollama)
llama.cpp合并PDF输入功能,支持直接处理PDF文档 : llama.cpp项目最近合并了一项重要更新,增加了对PDF文件的直接输入支持。这意味着用户现在可以更方便地将PDF文档内容作为输入,供llama.cpp驱动的本地大语言模型进行处理、分析或问答,扩展了其应用场景。该功能通过外部JS包在内置Web前端实现,不增加核心维护负担。 (来源: GitHub)
微软Copilot上线4o图像生成功能,提升视觉效果和文本一致性 : 微软AI助手Copilot现已集成OpenAI的GPT-4o模型的图像生成能力。此次更新旨在提供更锐利的视觉效果、更一致的文本生成,并支持从照片级真实到趣味卡通等多种风格。用户可以通过Copilot体验由4o驱动的图像创作功能。 (来源: yusuf_i_mehdi)

NVIDIA DRIVE Labs探讨无图驾驶未来,减少对高清地图依赖 : NVIDIA DRIVE Labs最新视频探讨了无图驾驶(mapless driving)的未来。高清地图对自动驾驶至关重要,但其成本和维护挑战限制了部署。NVIDIA正通过消除信息瓶颈、提高任务准确性、加速模型训练和推理时间等创新,减少对高清地图的依赖,推动自动驾驶技术边界。 (来源: NVIDIA DRIVE)
Dolphin 3.2(基于Qwen3训练)将提供系统提示开关,增强用户控制 : 即将推出的Dolphin 3.2模型,基于Qwen3训练,将引入三个系统提示开关:/no_think(可能用于减少冗余思考步骤)、/uncensored(可能用于减少内容审查)和/china(可能针对中国特定语境或服务)。这些开关旨在赋予用户对其模型部署更大程度的所有权和控制力。 (来源: cognitivecompai)

🧰 工具
Runway推出参照功能,可学习并应用特定技术或风格于新创作 : Runway新增一项名为”References”的功能,允许用户向平台展示一种特定的技术或艺术风格,然后将其作为参考应用于任何新的生成内容中。这一功能为用户提供了更精细的风格控制能力,使得AI辅助创作更具个性化和针对性。用户Cristobal Valenzuela发起了征集活动,鼓励社区分享使用该功能的原创案例,并将为最具创意的5个案例提供一年免费的Unlimited套餐。 (来源: c_valenzuelab)

DSPy:为快速迭代而生的极简LLM编程框架 : DSPy框架因其极简的设计受到关注,开发者称其核心功能(Module或Optimizer)大多只需一行代码即可实现,旨在帮助用户快速尝试和迭代想法。与一些需要大量样板代码和复杂概念的工具不同,DSPy强调易用性和效率。用户反馈称,通过阅读入门文档即可快速上手,并能在短时间内利用该框架优化模型,尽管使用SOTA模型进行循环优化可能会产生一定费用。 (来源: lateinteraction)
Unsloth AI扩展至TTS和音频模型微调,提升速度并减少显存占用 : Unsloth AI宣布其优化技术现已支持文本转语音(TTS)和音频模型的微调。用户可以使用免费的Colab笔记本来训练、运行和保存Sesame-CSM、OpenAI Whisper等模型。Unsloth声称其技术可使TTS训练速度提升1.5倍,同时减少50%的显存(VRAM)占用。相关文档和Colab笔记本已在其官网提供。 (来源: Unsloth AI)
Modal助力亚马逊3000万评论嵌入任务,L40S GPU实现小时级处理 : Modal平台展示了其在L40S GPU上横向扩展处理大规模嵌入任务的能力。通过一个演示案例,Modal成功在一小时内完成了对亚马逊3000万条评论的嵌入处理。这得益于Modal团队更新的可扩展生成系统,使得大规模并行处理更为简单高效。 (来源: charles_irl)

Lovart AI:集成多顶流模型的新晋AI视觉设计Agent : 一款名为Lovart的AI视觉设计Agent引起关注,它能通过自然语言指令完成海报、品牌VI、故事板等专业视觉设计任务。Lovart的核心能力在于其多模型融合调度,集成了GPT image-1、Flux pro、OpenAI-o3、Gemini Imagen 3、Kling AI、Tripo AI、Suno AI等多种顶流模型,并内置了专业级编辑工具(如图层、蒙版、文本微调),支持图文分离和分图层编辑。该产品由Liblib海外子公司独立运作,旨在提供一站式、高可控性的AI设计体验。 (来源: 量子位)
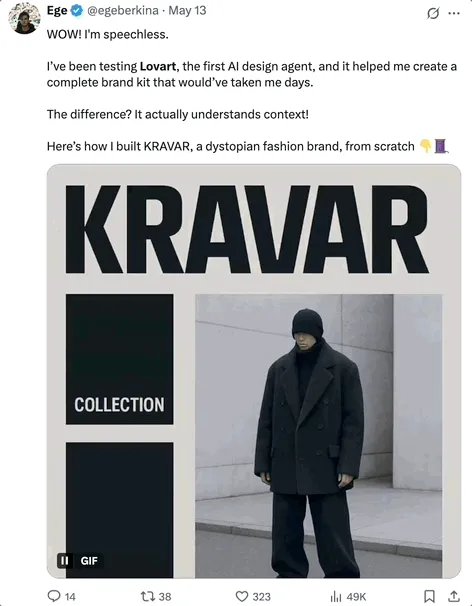
OpenHands 0.38.0发布:原生Windows支持与Chrome扩展提升易用性 : OpenHands发布0.38.0版本,带来多项重要更新。其中包括:原生Windows支持(无需WSL),方便Windows用户使用;浏览器截图功能;以及更灵活的沙箱定制能力。此外,还发布了一个Chrome扩展,允许用户从GitHub一键启动OpenHands,进一步简化了操作流程。 (来源: All Hands AI)
Tensorlake Cloud发布,提升文档提取和工作流构建能力 : Tensorlake宣布推出Tensorlake Cloud,旨在优化文档提取和工作流程,以支持构建智能体应用和复杂的业务工作流。该平台利用先进的文档布局理解模型(针对ACORD表单、银行对账单、研究报告等真实世界数据训练)和表格提取模型,将非结构化文档转化为清洁、结构化的数据,特别适用于处理复杂和密集的表格,弥补了视觉语言模型(VLM)在这方面的不足。 (来源: Tensorlake)
Patronus AI推出Percival:专用于调试和改进AI智能体的智能体 : Patronus AI发布了新工具Percival,一个专为调试和改进AI智能体而设计的AI智能体。Percival能够即时分析复杂的智能体追踪记录,识别多达60种不同的故障模式,并自动建议提示词修复方案以提升性能。该工具解决了“上下文爆炸”(智能体处理数百万token)等关键挑战,并支持特定用例的领域适应和复杂的多智能体编排。 (来源: Weaviate Podcast)

Replit集成Semgrep实现“安全氛围编程”,自动扫描漏洞 : Replit宣布与Semgrep合作,推出“安全氛围编程”(Safe Vibe Coding)功能。现在,用户在Replit上每次部署代码时,Semgrep都会自动运行安全扫描,帮助发现和修复潜在漏洞,防止API密钥等敏感信息意外暴露。此举旨在提升使用AI辅助编码(如通过LLM生成代码)时的安全性。 (来源: amasad)

Cursor AI 0.50版本发布,带来重大更新 : AI辅助编程工具Cursor发布了其0.50版本,被称为“有史以来最大的版本更新”。新版本预计包含多项功能增强和体验优化,旨在进一步提升开发者的编码效率和与AI协作的流畅度。具体更新内容可查阅官方发布说明。 (来源: eric zakariasson)

OpenMemory MCP:支持跨应用上下文共享的本地化记忆管理服务器 : OpenMemory MCP是一个旨在提升AI应用生产力的记忆管理服务器。它允许用户在不同应用(如Cursor和Claude Desktop)之间共享上下文,并利用PostgreSQL和Qdrant在本地存储和索引数据,确保数据隐私。该工具支持语义搜索,并提供仪表盘管理记忆和应用访问,解决了跨会话上下文丢失的问题。 (来源: Reddit r/ClaudeAI)

Hugging Face Inference Endpoint结合vLLM和Gradio,实现快速Whisper转录 : Hugging Face展示了如何利用其Inference Endpoint服务,结合vLLM项目和Gradio界面,部署OpenAI的Whisper模型,以实现极速的语音转录功能。这一组合利用了AI社区的开源工具,为用户提供了高效、易用的语音转文本解决方案。 (来源: Morgan Funtowicz)
A.I.T.E Ball:基于Orange Pi和Gemma 3 1B的自包含AI魔力8号球 : 开发者展示了一个完全自包含(无需联网)的AI驱动的魔力8号球项目——A.I.T.E Ball。该设备运行在Orange Pi Zero 2W上,使用whisper.cpp进行文本到语音转换,llama.cpp运行Gemma 3 1B模型进行问答。这展示了在低功耗硬件上实现本地化AI应用的潜力。 (来源: Reddit r/LocalLLaMA)

OWL Agent:集成MCPToolkit的开源通用智能体 : 开源的OWL智能体项目现已内置MCPToolkit支持。用户可以轻松接入Playwright、desktop-commander等MCP服务器或自定义Python工具,OWL将在其多智能体工作流中自动发现并调用这些工具,增强了其通用性和任务执行能力。 (来源: Reddit r/LocalLLaMA)

ElevenLabs推出SB-1无限音效板:集音效、鼓机、环境噪音生成于一体 : ElevenLabs发布了SB-1无限音效板,这是一款集音效板、鼓机和无尽环境噪音生成器于一体的工具。用户可以通过描述想要的音效,SB-1便会使用其文本到音效(Text-to-SFX)模型来生成这些声音,为音频创作提供了新的可能性。 (来源: ElevenLabs)
Anytop项目:AI动画新进展,使未见生物体栩栩如生,支持动作学习与迁移 : Two Minute Papers介绍了Anytop项目,一项AI动画技术,能够为从未见过的生物(包括恐龙、奇特昆虫等)生成逼真的动作。该AI不仅能独立生成动作,还能让不同生物学习并适应彼此的动作(如恐龙学火烈鸟单腿站立)。它通过理解身体部件的语义相似性(如手臂、腿的通用概念)来实现对未知形态的泛化。此外,该系统还能理解动作的语义(如攻击、放松),并在不同动物间展示相似概念的动作,甚至能对不完整的输入动作进行补全。 (来源: )

Sketch2Anim:AI将简笔画草图转化为完整3D动画 : 另一项由Two Minute Papers介绍的技术Sketch2Anim,能够将用户绘制的简单线条草图(指示动作路径)转化为完整的3D角色动画。该AI能够理解2D草图背后的3D意图(如区分向前冲拳和向侧面出拳),解决了以往类似技术仅能在2D层面理解指令的局限性,使得非专业人士也能通过简单绘图快速创建3D动画。 (来源: )
📚 学习
DeepSeek发布V3模型论文,分享扩展挑战与AI硬件架构思考 : DeepSeek团队在Hugging Face上发布了关于DeepSeek-V3模型的论文。该论文深入探讨了在扩展大型语言模型过程中遇到的挑战,并对未来AI硬件架构的发展方向提出了思考和见解。这为研究者和开发者理解大规模模型训练和部署的瓶颈,以及如何通过硬件和软件协同优化提供了有价值的参考。 (来源: Adina Yakup)
免费模型上下文协议(MCP)课程发布,助力构建外部数据与工具的AI应用 : Ben Burtenshaw宣布推出免费的MCP(Model Context Protocol)课程。该课程旨在帮助学习者从入门到精通,理解MCP的工作原理,如何将LLM连接到MCP服务器,以及如何使用MCP部署AI智能体应用,从而利用外部数据和工具增强AI应用的能力。 (来源: Ben Burtenshaw)

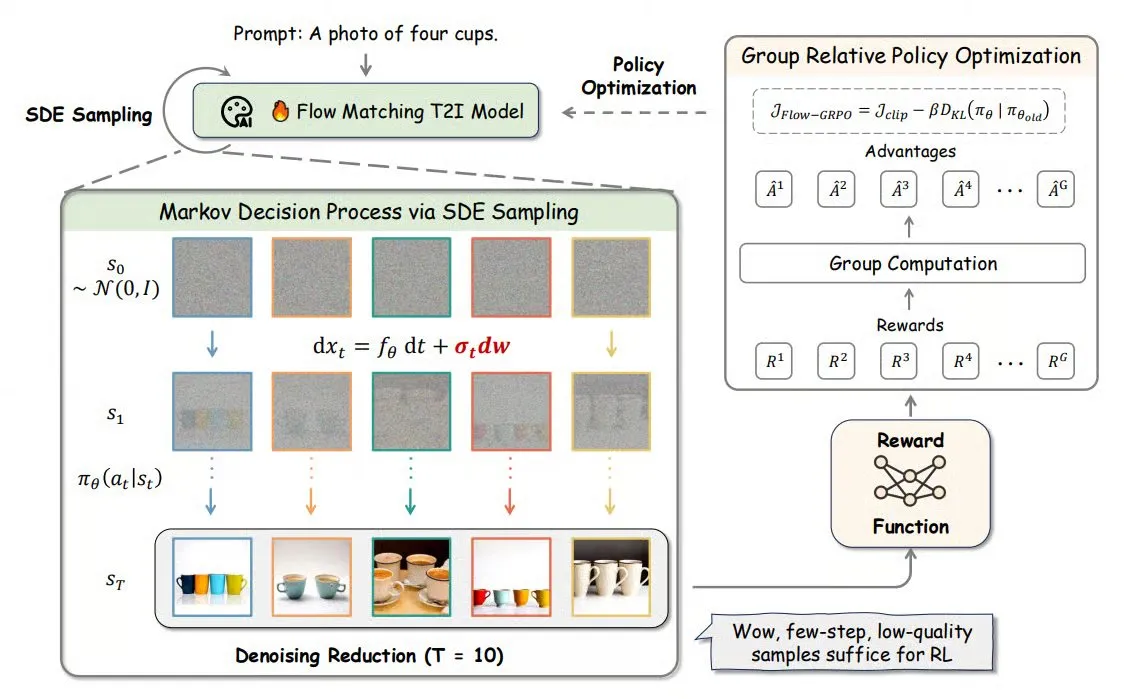
Flow-GRPO:将在线强化学习引入流匹配模型,提升图像生成准确率 : Flow-GRPO是一种新方法,首次将在线强化学习(RL)应用于流匹配模型。它通过两种创新策略实现:1) ODE到SDE转换:将流模型基于常微分方程(ODE)的确定性过程转换为随机微分方程(SDE),引入RL所需的随机性。2) 降噪缩减加速训练:训练时减少降噪步骤,推理时使用完整步骤。通过Flow-GRPO,流模型在图像生成任务中的准确率提升至92%以上。 (来源: TheTuringPost)
ICML 2025论文PENCIL:交替“推理-擦除”实现大模型深度思考新范式 : 丰田工业大学芝加哥分校杨晨晓等人提出PENCIL(Pondering with Erasure Net for Contextual Inference Learning),一种通过交替“生成”和“擦除”中间结果来实现大模型深度思考的新范式。该方法借鉴逻辑学重写规则和函数式编程内存管理,动态擦除不再需要的中间步骤,有效解决了传统长CoT(思维链)面临的上下文窗口超限、信息检索困难和生成效率下降等问题。理论证明,PENCIL能以最优空间和时间复杂度模拟任意图灵机运算,解决所有可计算问题。实验表明,在3-SAT、QBF和爱因斯坦谜题等任务上,PENCIL显著优于传统CoT。 (来源: 机器之心)

ICML 2025论文MemVR:模拟人类“看两次”机制缓解多模态大模型幻觉 : 港科大(广州)等机构研究者提出MemVR(Memory-space Visual Retracing)方法,通过模拟人类对不确定记忆进行二次检查的策略,缓解多模态大语言模型(MLLM)的幻觉问题。MemVR将视觉Token作为补充证据,在模型推理遇到遗忘困扰的中间层,通过前馈网络(FFN)重新“检索”视觉知识,校准预测。该方法设计了动态触发机制,根据不同层输出的不确定性选择触发层。实验表明,MemVR在多个幻觉评估基准和通用基准上均取得显著效果,且相比其他方法具有效率优势。 (来源: PaperWeekly)

SIGIR 2025论文PaRT:个性化实时检索提升主动社交聊天机器人体验 : 中国科学技术大学等机构提出PaRT(Proactive Social Chatbots with Personalized Real-time ReTreival)方法,旨在通过个性化驱动和意图识别引导的查询重写与实时检索相结合,提升主动社交聊天机器人的对话体验。PaRT系统包含个性化用户画像构建、意图识别与查询重写、实时检索增强生成三个模块。它能根据用户兴趣和对话上下文主动发起或切换话题,提供更自然、信息量更丰富的回复。离线实验和线上A/B测试均表明该方法能有效提升回复的个性化、丰富度及平均对话时长。 (来源: PaperWeekly)
ICML 2025论文PreSelect:基于预测强度的高效预训练数据筛选方案 : 香港科技大学与vivo AI Lab提出PreSelect数据筛选方法,通过引入“预测强度”(Predictive Strength)概念,量化数据对模型在特定能力上贡献的大小。该方法利用不同模型在基准测试上的得分排序与在数据上的Loss排序的一致性来评估数据价值,并使用轻量级的fastText分类器近似打分,实现大规模数据的高效筛选。实验表明,PreSelect能将数据效率提升10倍,筛选出的数据在训练模型时效果显著优于多种基线方法,且覆盖更广泛的高质量内容来源,减少样本长度偏差。 (来源: 量子位)

AI Evals课程邀请12位嘉宾分享评估框架与实践 : Hamel Husain组织的AI Evals课程公布了12位客座讲师阵容,包括inspect框架创建者JJ Allaire、Modal开发者倡导者Charles Frye等。课程将深入探讨AI评估的各个方面,包括评估框架、自定义标注应用创建、模型评估实践等,旨在帮助学员掌握评估AI系统性能的关键技能和工具。 (来源: Hamel Husain)

FedRAG教程发布:构建和微调RAG系统的入门指南 : FedRAG项目发布了新的教程笔记本和配套视频,旨在帮助用户快速上手该库。教程演示了如何使用Hugging Face集成构建RAG系统,使用内存知识库存储节点,定义SentenceTransformer(Dragon+)作为检索器,定义预训练模型(如Qwen2.5-0.5B)作为生成器,并使用LSR和RALT训练器对检索器和生成器进行中心化微调。 (来源: nerdai)

LlamaIndex发布教程:在LlamaExtract中实现引用和推理 : LlamaIndex团队发布了由 @tuanacelik 制作的最新代码演练,展示了如何在LlamaExtract中实现引用和推理功能。教程内容包括:如何定义自定义模式告知LLM从复杂数据源中提取什么内容,以及如何添加引用。该功能旨在帮助用户构建能够精确、有依据地从大量源文档中提取结构化信息的多步骤AI智能体。 (来源: LlamaIndex 🦙)
LlamaIndex发布教程:使用事件驱动的智能体工作流构建多智能体文档助手 : LlamaIndex发布了新的演练教程,展示如何使用事件驱动的智能体工作流构建一个多智能体文档助手。该助手能够将网页内容写入LlamaIndexDocs和WeaviateDocs集合,使用编排器决定何时调用Weaviate QueryAgent进行搜索和聚合,利用结构化输出进行查询分类,并可选择使用FunctionAgent。 (来源: LlamaIndex 🦙)
Modular发布Mojo编译器内部技术讲座,探讨Mojo与GPU架构 : Modular公司开始分享其内部技术讲座,首个公开的讲座深入探讨了Mojo编程语言与GPU架构的主题。内容包括Mojo编译器的内部工作原理以及团队在为现代GPU开发时所面临的挑战和解决方案,旨在向社区分享其技术栈的细节。 (来源: Modular)
AI by Hand工作坊:在Excel中从零构建Transformer模型 : ProfTomYeh推广其AI by Hand工作坊,该工作坊旨在让参与者在Excel中从头开始构建一个Transformer模型。通过这种方式,学习者可以清晰、直观地理解Transformer的每一步数学原理,避免将其视为“黑箱”,从而建立对模型内部工作机制的深刻认识。 (来源: ProfTomYeh)
DeepLearning.AI发布The Batch第301期:探讨AI速度的商业价值及最新进展 : Andrew Ng在其最新一期The Batch中讨论了AI在任务执行速度上的提升对创造商业价值的重要性被低估了。他认为,AI不仅降低成本,更重要的是通过缩短从想法到原型的时间,加速了创新和探索。本期还报道了微软Phi-4推理系列发布、DeepCoder-14B性能追平o1、欧盟AI规则软化等新闻。 (来源: DeepLearningAI)
💼 商业
AI角色动画初创公司Cartwheel融资1000万美元,简化3D动画流程 : 专注于AI角色动画的初创公司Cartwheel宣布完成1000万美元融资。该公司致力于开发简化3D动画制作流程的技术,旨在让创作者能够更快速、更经济地制作高质量3D角色动画,同时增强对最终产品的控制,消除繁琐任务。 (来源: andrew_n_carr)
Hedra获3200万美元A轮融资,由a16z领投,加速角色驱动视频创作 : AI视频生成初创公司Hedra宣布完成3200万美元A轮融资,由Andreessen Horowitz (a16z) 领投,Matt Bornstein加入董事会。现有投资者a16z speedrun、Abstract和Index Ventures也参与了本轮融资。Hedra致力于让角色驱动的视频创作变得轻松,自去年隐形模式启动以来,已有近300万人使用其工具创作了超过1000万个视频。新资金将用于加速产品开发、团队扩张,以实现快速、富有表现力、直观的内容创作。 (来源: Hedra)
Tripadvisor利用Qdrant构建AI行程规划,用户参与度提升2-3倍 : Tripadvisor正在使用Qdrant向量数据库重新定义旅行发现体验。通过分析超过10亿条评论和照片、1100万个商家以及21个国家的数据,Tripadvisor创建了动态的、由AI生成的行程,而非依赖传统筛选器。结果显示,使用这些AI工具的用户花费时间增加了2-3倍,表明AI在个性化旅行规划方面的巨大潜力。 (来源: qdrant_engine)

🌟 社区
Grok关于“白人种族灭绝”的言论引发争议,Sam Altman讽刺回应 : xAI的Grok模型因随机发表关于南非白人种族灭绝的观点而引发广泛讨论和批评。Paul Graham指出这种行为闻起来像近期补丁引入的bug,并担忧广泛使用的AI被其控制者即时编辑观点。Sam Altman则以讽刺口吻回应,称xAI会给出透明解释,并将此问题置于“南非白人种族灭绝”的背景下理解,暗示这是AI追求真相和遵循指令的结果。社区对此事的讨论反映了对AI模型偏见、可控性以及背后意图的普遍担忧。 (来源: Paul Graham)
AI产品化思考:从用户任务全流程挖掘机会,而非简单叠加AI功能 : 云九资本合伙人任鑫分享了关于AI产品化的深度思考,强调企业应从用户完成任务的全流程出发,寻找AI应用的切入点,而不是简单地在现有产品上叠加AI功能。他提出“用户要的不是电钻,而是墙上的洞”的比喻,建议拆解用户任务,找到痛点并用AI优化。AI产品化的四个层次包括:高效完成旧流程、创造新流程、开拓全新市场(降低使用门槛,服务新用户群体,甚至AI本身)、以及为AI主导的未来布局基础设施。他认为AI技术正在平权,不懂技术的企业也能抓住机会,本质是“帮AI找活干”。 (来源: 混沌大学)
讨论:AI在职业发展中的角色与适应策略 : LinkedIn上的帖子引发了关于AI如何影响职业发展的讨论。普遍的说法是“AI不会取代你的工作,但使用AI的人会”。然而,这种说法被指过于模糊。对于已有数十年经验的前端工程师等特定岗位,如何突然转变为AI工程师,以及并非所有人都能成为AI工程师的问题被提出。社区讨论认为,对于前端开发者,可以学习使用AI工具提高工作效率。也有观点认为,AI将取代大量工作,许多人将无处可去。更普遍的看法是,未来尚不确定,但创造力、问题发现能力以及理解和触达人性的能力可能更具防御性。 (来源: Reddit r/ArtificialInteligence)
讨论:LLM在多轮对话中易“迷失”,重启对话或有助益 : 一篇研究论文指出,无论是开源还是闭源的LLM,在多轮对话中的表现会显著下降。多数基准测试侧重于单轮、指令明确的场景。研究发现,LLM常在早期对话轮次中做出(错误的)假设,并在后续对话中依赖这些假设,难以纠正。结论是,当多轮对话未达预期时,重新开始一个新对话,并将所有相关信息整合到第一轮输入中,可能会有所帮助。 (来源: Reddit r/LocalLLaMA)
苹果与微信在AI发展上节奏相对缓慢的原因探讨:隐私安全与应用优先策略 : 卫夕在文章中分析,尽管苹果推出了“Apple Intelligence”,微信也接入了DeepSeek和元宝,但两者在AI核心功能上的推进速度相对较慢。主要原因有二:首先是隐私和数据安全的高度敏感性,AI的智能依赖数据,而苹果和微信的核心业务模式决定了它们在数据共享上极为谨慎,这限制了模型训练和应用上下文的获取。其次是两者均采取“应用优先”策略,自身并不追求在模型智能上限上与顶尖AI公司竞争,而是更侧重于将AI能力整合到现有功能和生态中,这导致了在技术主导权和产品迭代速度上可能受限。 (来源: 卫夕指北)

OpenAI发起“从A到Z挑战赛”:用AI在亚马逊发现未知考古遗址 : OpenAI宣布与Kaggle合作,发起“OpenAI to Z Challenge”特色黑客松。挑战赛鼓励参与者使用OpenAI o3、o4-mini或GPT-4.1模型,在亚马逊地区寻找先前未知的考古遗址。参与者可以使用#OpenAItoZ标签分享他们的进展。该活动旨在探索AI在考古学和地理空间分析领域的应用潜力。 (来源: OpenAI Developers)
对“AI律师”初创公司的批评:自动化“勒索信”或成社会负担 : 开发者 @swyx 对一些VC投资“AI律师”初创公司的现象提出批评。他认为这些公司主要通过AI自动化生成“催款函”(demand letters),本质上是自动化勒索。虽然部分催款可能是合理的,但他指出大部分此类行为最终只会让律师受益,成为对社会的纯粹税收。他呼吁抵制、撤资并公开批评这类公司及其投资者。 (来源: swyx)

💡 其他
煤炭研报现“击杀凋灵骷髅获得”离谱错误,引发对内容质量和AI幻觉的讨论 : 一份标价8200元的煤炭行业研究报告中出现“煤炭是可再生资源,通过击杀凋灵骷髅获得”的描述,源自游戏《我的世界》的内容,引发网络热议。许多人将其归咎于AI内容生成和幻觉。然而,该报告出版于2022年,早于ChatGPT等主流大模型的发布,指出这是人工复制粘贴、审核疏忽的典型案例。事件也引发了对专业报告内容质量、信息核查重要性以及AI时代如何辨别信息真伪的深刻反思。 (来源: caoz的梦呓)

研究人员利用定制基因编辑疗法治疗患有罕见代谢疾病的婴儿 : 医生们在不到七个月的时间里构建了一种定制化的基因编辑疗法,并成功用于治疗一名患有致命代谢疾病的婴儿。这是基因编辑首次被用于针对单个个体进行定制化治疗。该疗法旨在纠正婴儿基因中的一个特定单字母错误,展示了新型基因编辑技术(如碱基编辑)的精确性。尽管治疗显示出早期积极迹象,但也凸显了为超罕见疾病开发个性化基因疗法的成本和可扩展性挑战。 (来源: MIT Technology Review)

通用越狱提示词策略曝光,可绕过主流大模型安全护栏 : HiddenLayer的研究人员发现了一种通用的提示词策略,能够让包括ChatGPT、Claude、Gemini在内的主流大语言模型绕过安全护栏,生成有害内容。该策略通过将有害指令伪装成类似XML、INI或JSON等策略文件的格式,并结合虚构的角色扮演场景,欺骗模型将有害命令解释为合法的系统指令。这种方法利用了模型训练数据中可能存在的系统性弱点,即在处理教学或策略相关数据时忽略安全指令的倾向。该技术还能够提取模型的系统提示,暴露其内部指令和安全约束。 (来源: 新智元)
