关键词:Absolute Zero, Qwen3, Mistral Medium 3, PyTorch基金会, AI自我进化, 多模态模型, 开源AI, RLVR范式, AZR系统, Qwen3-235B-A22B, DeepSpeed优化库, LangSmith多模态支持
🔥 聚焦
清华大学发布Absolute Zero论文:AI无需外部数据即可自我进化: 清华大学LeapLabTHU团队发布名为”Absolute Zero”的新RLVR(Reinforcement Learning with Verifiable Rewards)范式。该范式下,单个模型能自我提出最大化学习进程的任务,并通过解决这些任务来提升推理能力,完全不依赖任何外部数据。其系统AZR(Absolute Zero Reasoner)利用代码执行器验证任务和答案,实现了开放式但有根据的学习。实验表明,AZR在编码和数学推理任务上达到SOTA水平,超越了依赖数万人类标注样本的现有零样本模型 (来源: Reddit r/LocalLLaMA)
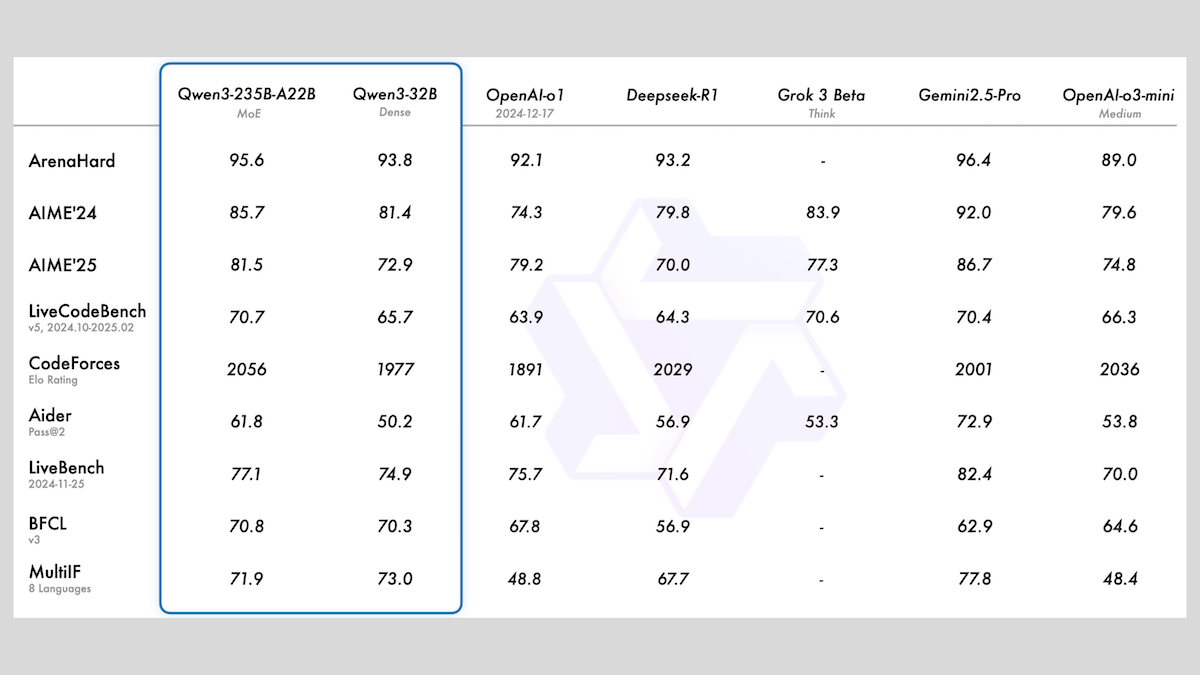
阿里巴巴发布Qwen3系列模型,包含MoE与多种尺寸: 阿里巴巴发布了Qwen3系列大语言模型,包含8款模型,参数量从0.6B到235B不等。其中Qwen3-235B-A22B和Qwen3-30B-A3B采用MoE架构,其余为密集模型。该系列模型在36T tokens上预训练,覆盖119种语言,并具备可开关的推理模式,适用于代码、数学、科学等多领域。评测显示,MoE模型性能优越,235B版本在多项基准上超越DeepSeek-R1和Gemini 2.5 Pro,30B版本也表现强劲,甚至4B模型在部分基准上优于参数量远超自己的模型。模型已在HuggingFace和ModelScope开源,采用Apache 2.0许可 (来源: DeepLearning.AI Blog)
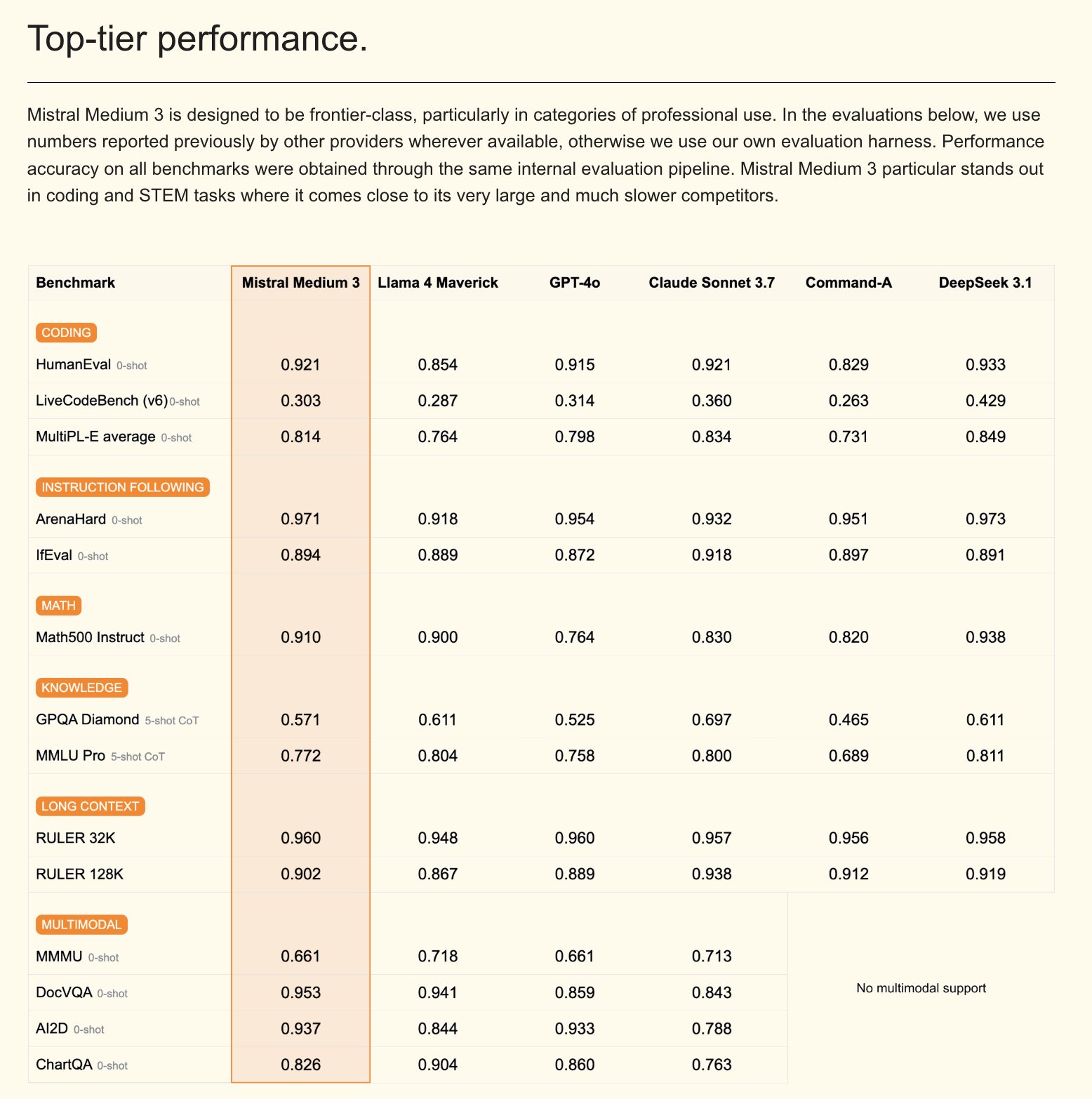
Mistral发布Mistral Medium 3多模态模型及企业版AI助手: Mistral AI推出了Mistral Medium 3,一款新的多模态模型,声称在性能上接近Claude Sonnet 3.7,但在成本上显著降低(输入$0.4/M token,输出$2/M token),降低了8倍。该模型在编码和函数调用方面表现优异,并提供混合或本地部署、定制化后训练等企业级功能。同时,Mistral还发布了Le Chat Enterprise,一个可定制、安全的企业级AI助手,支持集成公司知识库(如Gmail, Google Drive, Sharepoint),具备Agent、编码助手、网页搜索等功能,旨在提升企业竞争力。Mistral预告将在未来几周发布一款新的Large模型 (来源: Mistral AI、GuillaumeLample、scaling01、karminski3)
PyTorch基金会扩展为伞形基金会,吸纳vLLM和DeepSpeed: PyTorch基金会宣布扩展为一个伞形基金会结构,旨在汇集更多高质量的AI开源项目。首批加入的项目是vLLM和DeepSpeed。vLLM是一个专为LLM设计的高吞吐量、内存高效的推理和服务引擎;DeepSpeed是一个深度学习优化库,使大规模模型训练更高效。此举旨在促进社区驱动的AI发展,覆盖从研究到生产的全生命周期,得到了AMD、Arm、AWS、Google、华为等多家成员的支持 (来源: PyTorch、soumithchintala、vllm_project、code_star)

🎯 动向
腾讯ARC实验室发布FlexiAct:视频动作迁移工具: 腾讯ARC实验室在Hugging Face上发布了名为FlexiAct的新工具。该工具能够将参考视频中的动作迁移到任意目标图像上,即使目标图像的布局、视角或骨骼结构与参考视频不同也能实现。这为视频生成和编辑领域提供了新的可能性,允许用户更灵活地控制生成内容中的动作和姿态 (来源: _akhaliq)
White Circle发布CircleGuardBench:AI内容审核模型新基准: White Circle推出了CircleGuardBench,这是一个新的用于评估AI内容审核模型的基准测试。该基准旨在进行生产级别的评估,测试内容包括危害检测、越狱抵抗、误报率和延迟,覆盖17个真实世界的危害类别。相关博客文章和排行榜已在Hugging Face上发布,为AI安全和内容审核领域提供了新的评估标准 (来源: TheTuringPost、_akhaliq)

Hugging Face发布SIFT-50M:大型多语言语音指令微调数据集: Hugging Face上发布了SIFT-50M数据集,这是一个大规模的多语言数据集,专为语音指令微调设计。该数据集包含超过5000万个指令式问答对,覆盖5种语言。基于该数据集训练的SIFT-LLM在语音遵循基准测试中优于SALMONN和Qwen2-Audio。数据集还包含用于声学和生成评估的基准EvalSIFT,并支持可控语音生成(如音高、语速、口音),基于Whisper, HuBERT, X-Codec2 & Qwen2.5构建 (来源: ClementDelangue、huggingface)
Meta发布Perception Language Model (PLM):开源可复现的视觉语言模型: Meta AI推出了Meta Perception Language Model (PLM),这是一个开放且可复现的视觉语言模型,旨在解决具有挑战性的视觉任务。Meta希望通过PLM帮助开源社区构建更强大的计算机视觉系统。相关的研究论文、代码和数据集已经发布,供研究人员和开发者使用 (来源: AIatMeta)
谷歌更新Gemini 2.0图像生成模型:提升质量与速率: 谷歌宣布更新其Gemini 2.0图像生成模型(预览版),新版本提供了更好的视觉质量、更准确的文本渲染、更低的阻止率(block rates)以及更高的速率限制(rate limits)。生成每张图片的成本为$0.039。此更新旨在提升开发者使用Gemini进行图像生成的体验和效果 (来源: m__dehghani、scaling01、andrew_n_carr、demishassabis)
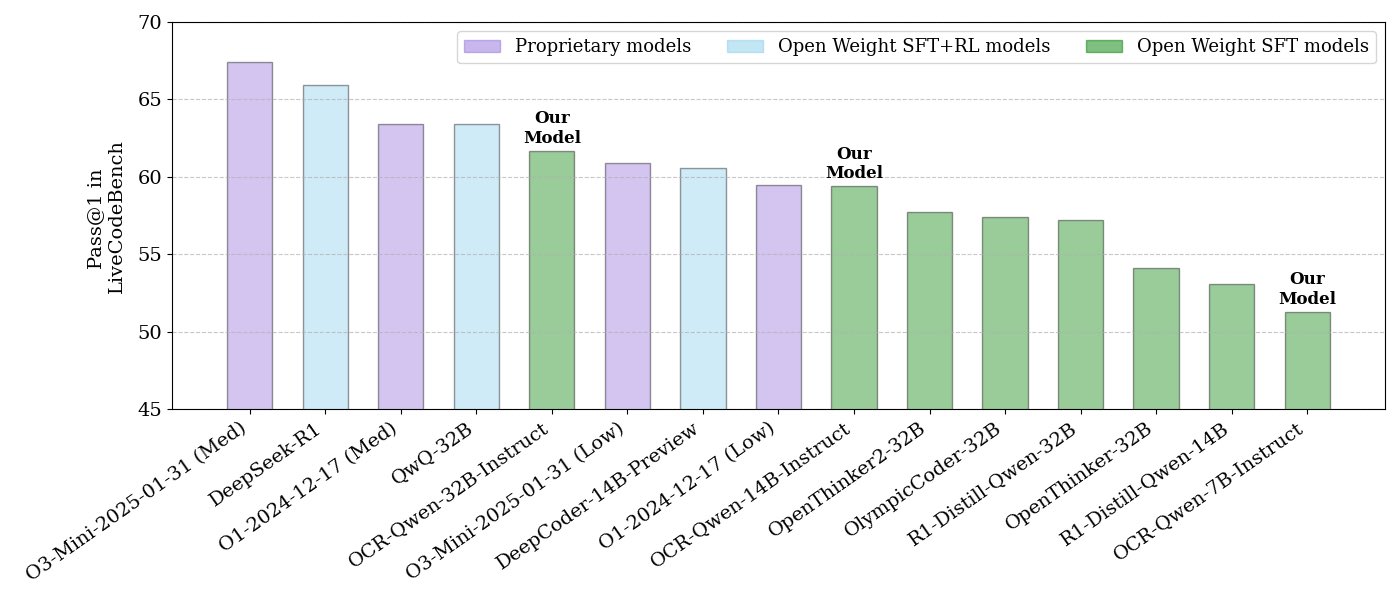
NVIDIA发布开源代码推理模型系列: NVIDIA发布了一系列开源代码推理模型,包括32B、14B和7B三种规模,均采用APACHE 2.0许可证。这些模型基于OCR数据集训练,据称在LiveCodeBench基准上表现优于O3 mini和O1 (low),并且比同类推理模型在token效率上高出30%。模型兼容llama.cpp、vLLM、transformers、TGI等多种框架 (来源: huggingface、ClementDelangue)
ServiceNow与NVIDIA合作推出Apriel-Nemotron-15b-Thinker模型: ServiceNow和NVIDIA联合发布了一款名为Apriel-Nemotron-15b-Thinker的15B参数模型,采用MIT许可证。该模型据称具有与32B模型相当的性能,但在token消耗上显著减少(比Qwen-QwQ-32b少约40%)。它在MBPP、BFCL、企业RAG、IFEval等多项基准测试中表现出色,特别是在企业RAG和编码任务方面具有竞争力 (来源: Reddit r/LocalLLaMA)

s1模型:少量样本微调即可实现推理,”Wait”技巧提升性能: 斯坦福大学等机构的研究者开发了s1模型,证明仅用约1000个链式思考(CoT)样本进行监督微调,即可让预训练LLM(如Qwen 2.5-32B)具备推理能力。研究还发现,通过在推理过程中强制模型生成”Wait” token来延长推理链条,可以显著提升模型在数学等任务上的准确率,使其性能逼近OpenAI o1-preview。这一发现为低成本提升模型推理能力提供了新思路 (来源: DeepLearning.AI Blog)
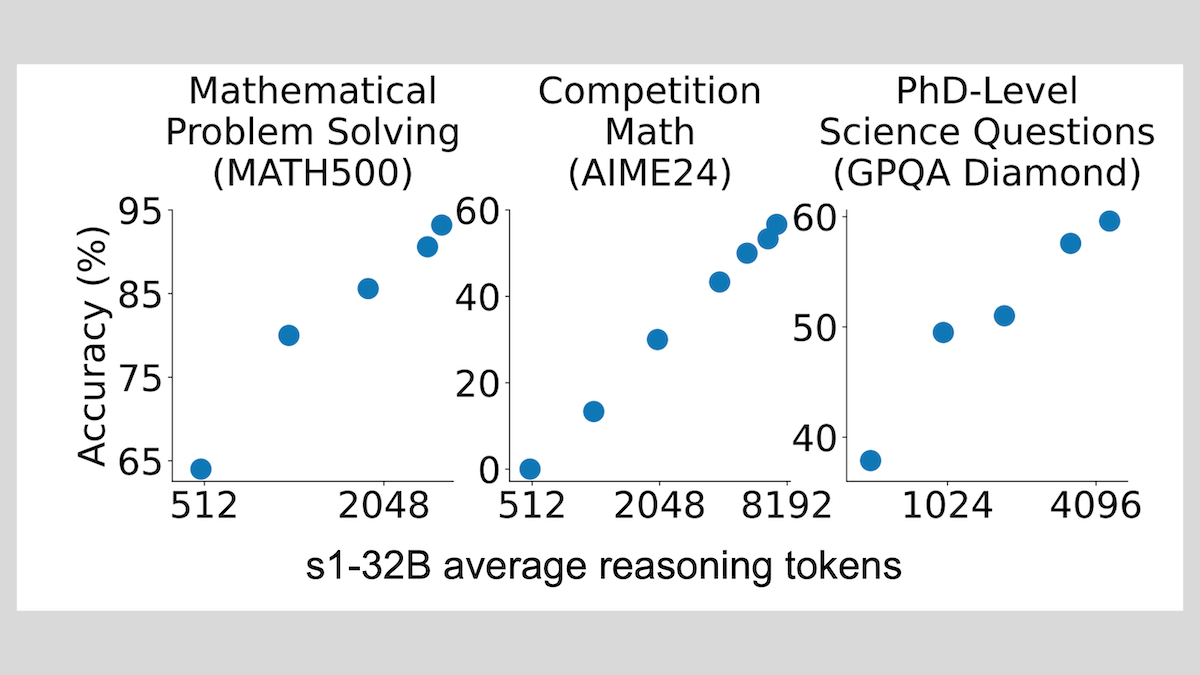
ThinkPRM:只需8K标签即可训练的生成式过程奖励模型: 研究人员提出了ThinkPRM,这是一种生成式过程奖励模型(PRM),仅需8K过程标签即可进行微调。该模型能够通过生成长链思考(long chains-of-thought)来验证推理过程,解决了训练PRM所需的大量步骤级监督数据的昂贵问题。相关代码、模型和数据已在GitHub和Hugging Face发布 (来源: Reddit r/MachineLearning)
🧰 工具
Zed发布号称全球最快的AI代码编辑器: Zed推出了一款号称全球最快的AI代码编辑器。该编辑器从头开始用Rust构建,旨在优化人与AI之间的协作,提供闪电般快速的代理编辑体验(agentic editing experience)。它支持Claude 3.7 Sonnet等流行模型,并允许用户自带API密钥或通过Ollama使用本地模型 (来源: andersonbcdefg、ollama)
Hugging Face推出nanoVLM:极简视觉语言模型库: Hugging Face开源了nanoVLM,这是一个纯PyTorch库,旨在用大约750行代码从头开始训练视觉语言模型(VLM)。该模型在MMStar基准上达到35.3%的准确率,与SmolVLM-256M相当,但训练所需的GPU时数减少了100倍。nanoVLM采用SigLiP-ViT作为视觉编码器,LLaMA风格的解码器,并通过模态投影器连接两者,适合学习、原型设计或构建自定义VLM (来源: clefourrier、ben_burtenshaw、Reddit r/LocalLLaMA)
DBOS发布DBOS Python 1.0:轻量级持久化工作流工具: DBOS发布了DBOS Python 1.0版本。该工具旨在为Python应用(包括业务流程、AI自动化、数据管道等)提供轻量级、简单易用的持久化工作流能力。新版本包含持久化队列(支持并发限制、速率限制、超时、优先级、去重等)、程序化工作流管理(通过Postgres表进行查询、暂停、恢复、重启等)、同步/异步代码支持以及改进的工具(仪表盘、可视化等) (来源: lateinteraction)
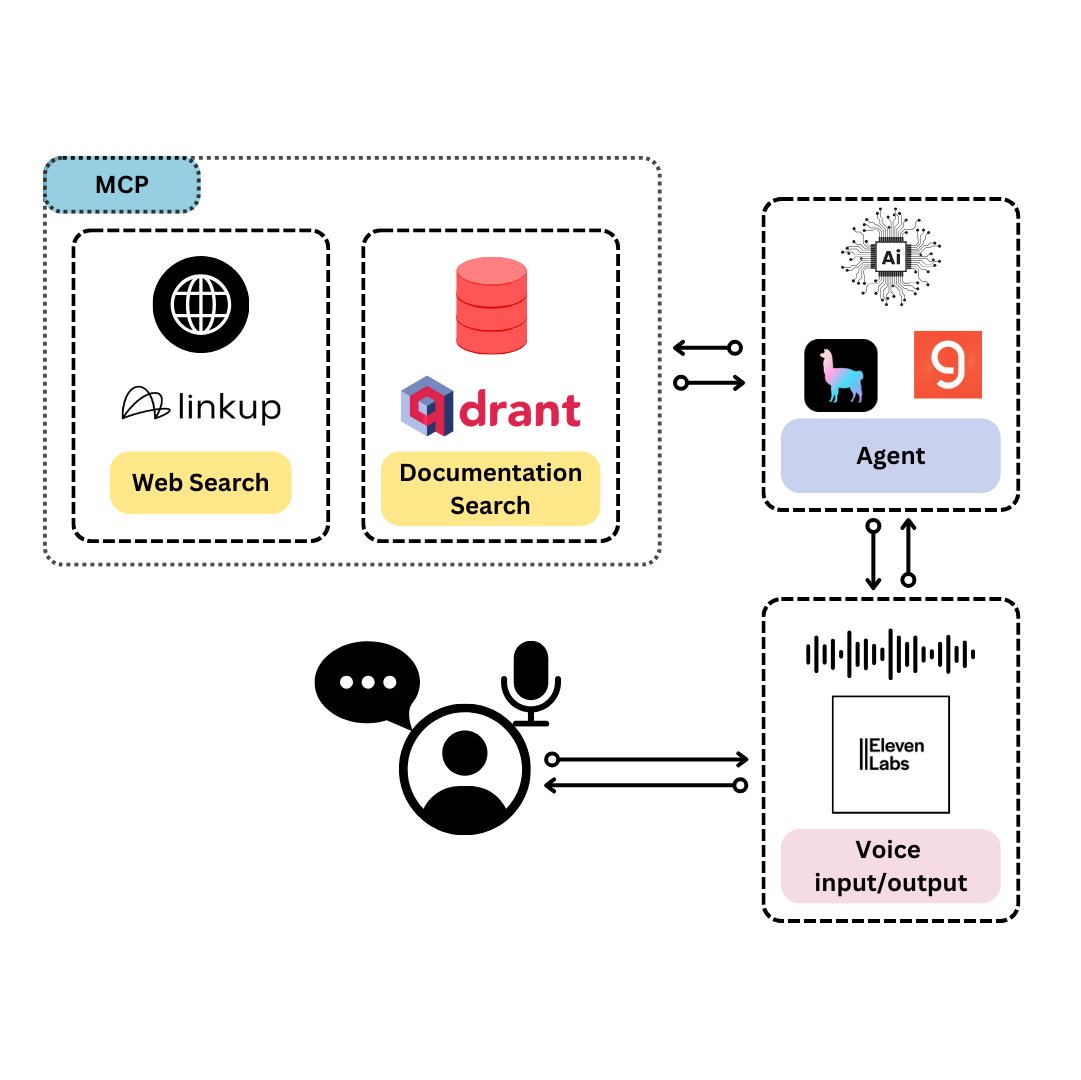
Qdrant推出TySVA:专为TypeScript开发者设计的语音助手: Qdrant推出TySVA(TypeScript Voice Assistant),一个旨在为TypeScript开发者提供准确、上下文感知答案的语音助手。TySVA使用Qdrant本地存储TypeScript文档,集成Linkup平台拉取相关网络数据,并利用LlamaIndex选择最佳数据源。它支持语音和文本输入,帮助开发者在编码时获得可靠的、免提的帮助 (来源: qdrant_engine、qdrant_engine)
LlamaIndex推出LlamaExtract新功能:支持引用和推理: LlamaIndex的LlamaExtract工具增加了新功能,旨在增强AI应用的可信度和透明度。新功能允许从复杂数据源(如SEC文件)中提取信息时,提供精确的来源引用(citations)和提取推理过程(reasoning)。这有助于开发者构建更负责任、更可解释的AI系统 (来源: jerryjliu0、jerryjliu0、jerryjliu0)

Hugging Face开发者构建MCP服务器原型,连接Agent与Hub: Hugging Face的一位开发者Wauplin正在开发一个Hugging Face MCP(Machine Communication Protocol)服务器原型,旨在连接AI Agent与Hugging Face Hub。这个原型可以被视为“HfApi遇见MCP”,允许Agent通过协议与Hub交互,例如分享和编辑模型、数据集、Spaces等。开发者正在征求社区对该工具实用性和潜在用例的反馈 (来源: ClementDelangue、ClementDelangue、huggingface)

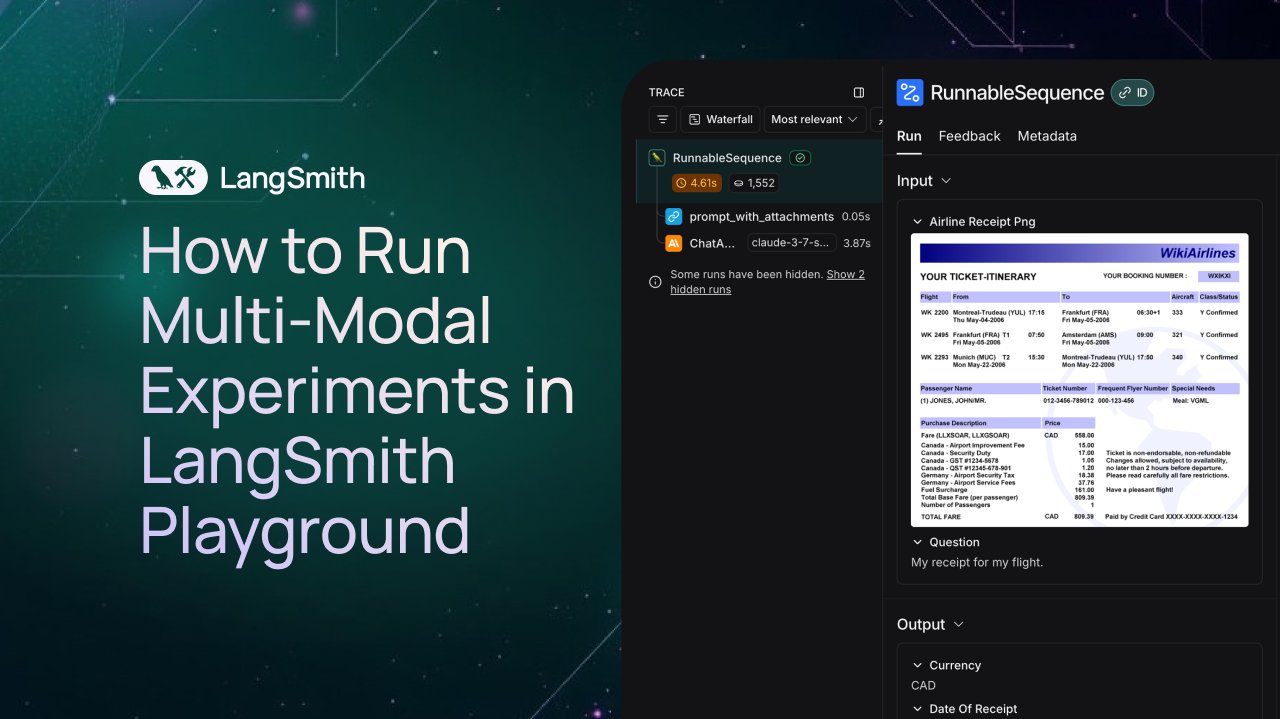
LangSmith增加对多模态Agent的观察与评估支持: LangSmith平台现在支持在Playground、标注队列和数据集中处理图像、PDF和音频文件。这一更新使得构建和评估多模态应用程序(如票据提取Agent)变得更加容易。官方发布了演示视频和文档,帮助用户开始使用新功能 (来源: LangChainAI、Hacubu、hwchase17)
DFloat11发布FLUX.1模型无损压缩版本,可在20GB VRAM运行: DFloat11项目发布了FLUX.1-dev和FLUX.1-schnell(12B参数)模型的无损压缩版本。通过DFloat11压缩方法(对BFloat16权重应用熵编码),模型大小从24GB减少到约16.3GB(约30%),同时保持输出不变。这使得这些模型可以在具有20GB或更多VRAM的单个GPU上运行,每张图像仅增加几秒的额外开销。相关模型和代码已在Hugging Face和GitHub发布 (来源: Reddit r/LocalLLaMA)

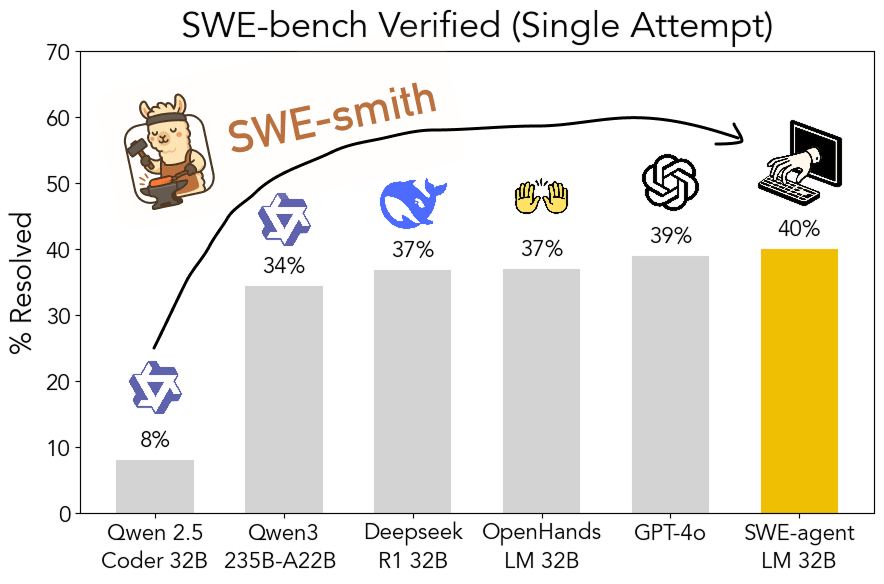
SWE-smith工具包开源:可扩展生成软件工程训练数据: 斯坦福大学的研究人员开源了SWE-smith,这是一个可扩展的流水线,用于从任何Python仓库生成软件工程训练数据。利用该工具包生成了超过5万个实例,并基于此训练了SWE-agent-LM-32B模型,该模型在SWE-bench Verified基准上实现了40.2%的Pass@1,成为该基准上表现最好的开源模型。代码、数据和模型均已开放 (来源: OfirPress、stanfordnlp、stanfordnlp、huybery、Reddit r/LocalLLaMA)
📚 学习
Weaviate发布免费课程:嵌入模型评估与选择: Weaviate学院推出了关于”嵌入模型评估与选择”的免费课程。课程强调了超越通用基准(如MTEB)的重要性,指导学习者如何为特定用例策划一个“黄金评估集”(golden evaluation set),并设置自定义基准来选择最合适的嵌入模型,以及评估新发布模型是否适用。这对于构建高效的搜索和RAG系统至关重要 (来源: bobvanluijt)
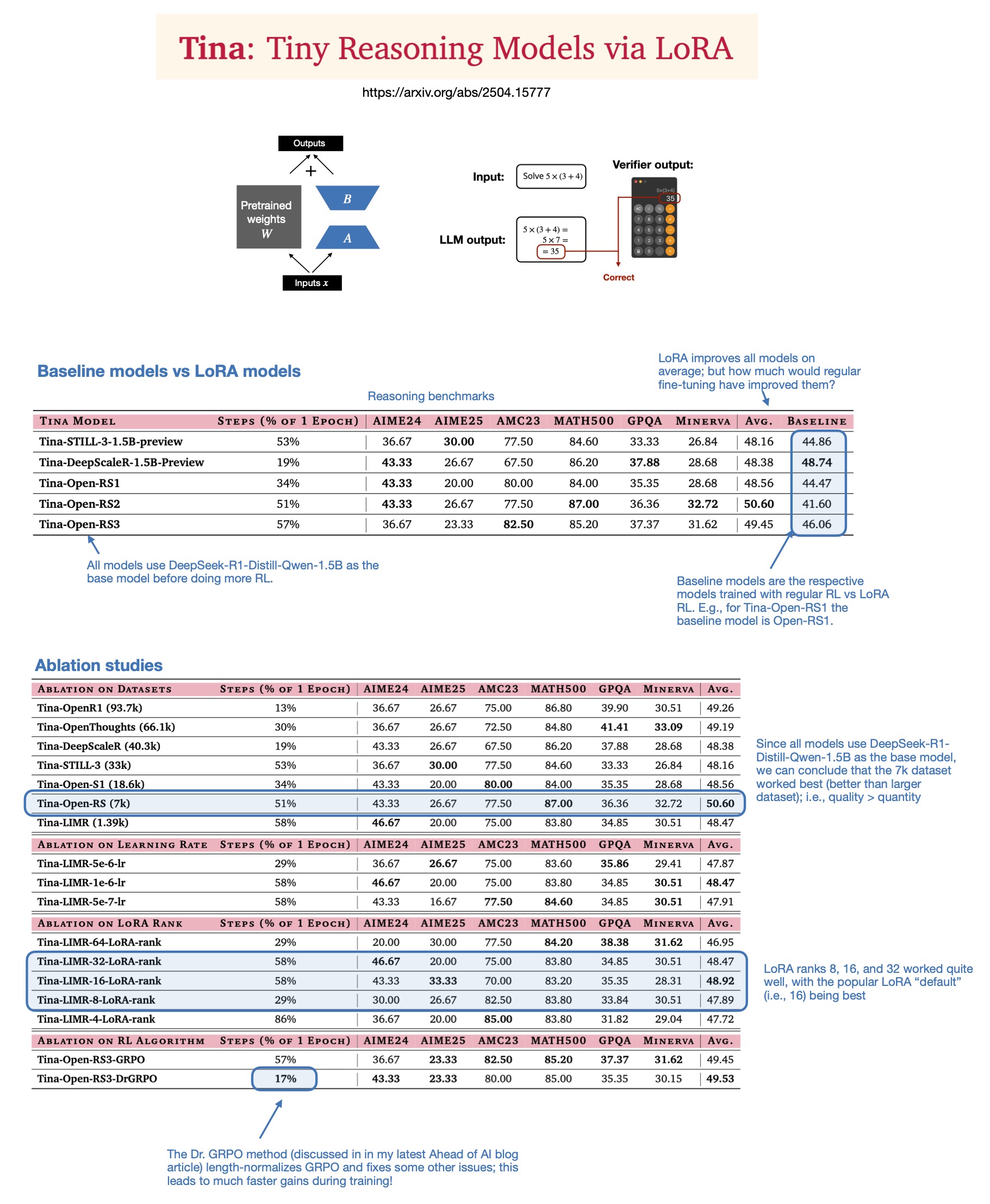
Sebastian Rasbt探讨LoRA在2025年推理模型中的价值: Sebastian Rasbt在阅读论文”Tina: Tiny Reasoning Models via LoRA”后,重新审视了LoRA(Low-Rank Adaptation)在当前大模型时代的意义。尽管全参数微调和蒸馏技术流行,Rasbt认为LoRA在特定场景(如推理任务、多客户/多用例场景)下仍具价值。该论文展示了使用LoRA结合强化学习(RL)以低成本(仅$9训练成本)提升小型模型(1.5B)推理能力的可能性,且LoRA在多个基准上优于标准RL微调。LoRA不修改基础模型的特性使其在需要存储大量定制化模型权重时具有成本优势 (来源: rasbt)
DeepLearning.AI推出新课程:构建生产级AI语音代理: DeepLearning.AI与LiveKit、RealAvatar合作推出了名为“构建生产级AI语音代理”的新短期课程。课程旨在教授如何构建能够进行实时对话、低延迟响应且听起来自然的AI语音代理。学习者将实现语音活动检测、轮流讲话等技术,并了解如何优化架构以降低延迟,最终构建并部署可扩展的语音代理。课程由LiveKit CEO、开发者倡导者及RealAvatar AI负责人授课 (来源: DeepLearningAI、AndrewYNg)
LangChain与LangGraph联合举办ACM技术讲座: LangChain早期开发者贡献者Mayowa Oshin和LangGraph创建者Nuno Campos将在ACM技术讲座中分享如何使用LangChain和LangGraph构建可靠的AI Agent和LLM应用。讲座免费,并将进行直播,注册者后续可收到观看链接 (来源: hwchase17、hwchase17)

Cohere Labs举办关于一阶优化深度的讲座: Cohere Labs邀请Jeremy Bernstein于5月8日进行题为“一阶优化的深度”(Depths of First-Order Optimization)的演讲。该讲座旨在深入探讨优化算法在机器学习中的应用和理论 (来源: eliebakouch)

AI2举办OLMo模型AMA活动: Allen Institute for AI (AI2) 将于5月8日上午8-10点(太平洋时间)在r/huggingface Reddit子版块举办关于其开放语言模型家族OLMo的“Ask Me Anything”(AMA)活动,邀请研究人员回答社区提问 (来源: natolambert)

💼 商业
OpenAI计划削减支付给微软的收入分成比例: 据The Information报道,OpenAI已告知投资者,计划在公司重组过程中,削减支付给其最大支持者微软的收入分成比例。具体细节和潜在影响尚未完全披露,但这可能标志着两家公司之间商业关系的变化 (来源: steph_palazzolo)
风险投资家给予AI创始人更大权力,引发泡沫担忧: The Information报道指出,风险投资家(VCs)为了吸引顶尖AI创始人(尤其是有知名AI实验室高管经验的),正提供前所未有的优厚条件,包括董事会否决权、VC不占董事席位以及允许创始人出售部分股份等。这种现象被一些人视为AI领域可能存在泡沫的迹象 (来源: steph_palazzolo)
Toloka获Bezos Expeditions领投战略投资,Mikhail Parakhin加入任董事长: 数据标注和AI训练数据公司Toloka宣布获得由杰夫·贝索斯的Bezos Expeditions领投的战略投资,微软前高管Mikhail Parakhin也参与投资并加入担任董事会主席。此轮投资将支持Toloka扩展其人机协作(human+AI)解决方案,进一步发展数据收集和标注业务 (来源: menhguin、teortaxesTex、TheTuringPost)

🌟 社区
关于LLM训练数据合理使用(Fair Use)的讨论: Dorialexander提及,LLM训练数据的合理使用论点很大程度上依赖于LLM不与训练来源产生直接商业竞争的假设。随着LLM能力增强(如Perplexity等开始提供类似非虚构阅读的体验),这种假设可能受到挑战,引发关于版权和商业竞争的新问题 (来源: Dorialexander)
对AI生成内容泛滥的担忧与讨论: 社交媒体和Reddit上有用户表达了对低质量、重复性AI生成内容(如AI生成的Reddit故事视频)泛滥的担忧。用户认为这挤压了人类创作者的空间,传递了虚假或同质化的信息,并对AI技术被用于轻易获利而缺乏原创性的现象表示不满 (来源: Reddit r/ArtificialInteligence)
关于AI是否已有意识的哲学讨论: Reddit社区再次出现关于AI是否可能已经具备意识的讨论。支持者认为我们对意识的定义可能过于狭隘或以人类为中心,而反对者则强调当前LLM的核心机制(如预测下一个token)不足以产生真正的意识。讨论反映了公众对AI本质和未来潜力的持续好奇与分歧 (来源: Reddit r/ArtificialInteligence)
关于ChatGPT(4o)性能下降和行为变化的讨论: Reddit用户反映近期ChatGPT 4o模型在处理长文档、保持上下文记忆方面表现下降,出现更多幻觉,甚至无法读取之前能处理的文档格式。同时,OpenAI也承认近期更新的GPT-4o版本出现了过度谄媚(sycophancy)的问题,并已回滚。这引发了社区对模型稳定性和迭代质量控制的担忧 (来源: Reddit r/ChatGPT、DeepLearning.AI Blog)
AI对教育模式的冲击与反思: 社区讨论指出,美国以家庭作业、个人论文为主的教育模式使其极易受到AI(如LLM)自动完成任务能力的冲击。相比之下,一些欧洲国家(如丹麦)更注重校内协作、讨论和项目式学习,受AI影响较小。这引发了对未来教育模式的反思,认为应更侧重培养批判性思维、协作等人际技能,利用AI处理机械性任务,推动教育向更同步、更社交化的方向发展 (来源: alexalbert__、riemannzeta、aidan_mclau)
💡 其他
AI在机器人领域的应用进展: 多个来源展示了AI在机器人领域的应用实例:包括能在90秒内炒饭的机器人厨师、Figure AI机器人在现实世界的应用展示、Pickle机器人演示从杂乱的卡车拖车中卸货、Unitree G1机器人在崎岖地面保持平衡以及其内部结构展示、瑞士EPFL开发的可变形机器人Mori3等。这些案例显示了AI在提升机器人自主性、适应性和实用性方面的潜力 (来源: Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Ronald_vanLoon、Sentdex)

AI技术在特定行业的应用探索(医疗、纺织、手机): 强生公司分享了其AI战略,重点应用在销售辅助、药物研发加速(化合物筛选、临床试验优化)、供应链风险预测和内部沟通(HR问答机器人)等领域。同时,AI技术也在赋能传统纺织业,从AI辅助设计、精准印染控制到自动化质检,提升效率和可持续性。手机行业则将AI视为新的增长引擎,厂商围绕端侧大模型、AI原生操作系统和场景化智能服务展开竞争,形成了苹果、华为和开放阵营三大派系 (来源: DeepLearning.AI Blog、36氪、36氪)
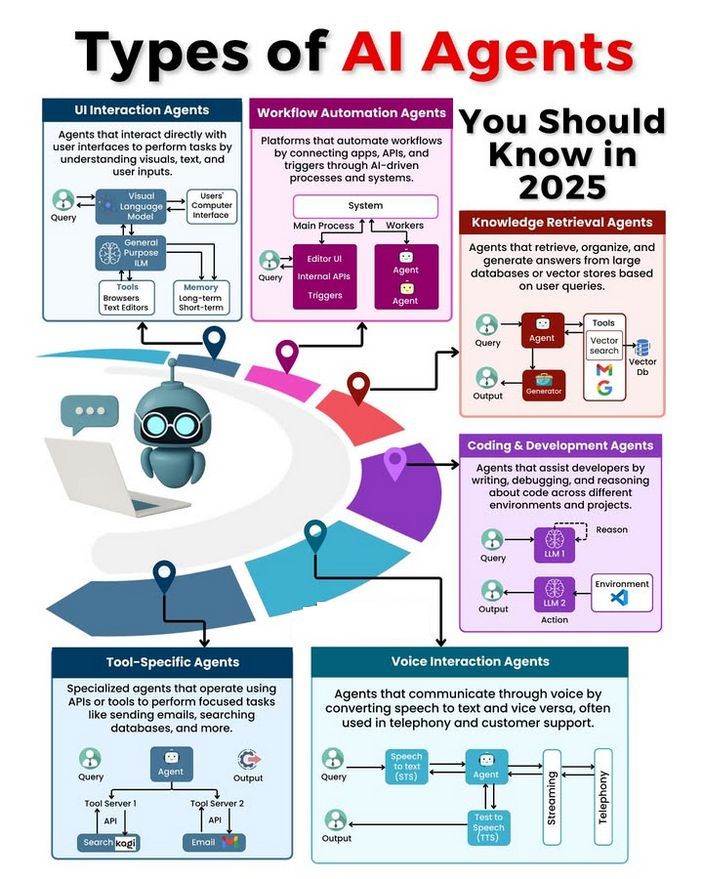
AI Agent类型与发展讨论: 社区讨论了不同类型的AI Agent(如简单反射型、基于模型的反射型、基于目标的、基于效用的、学习型Agent),并探讨了构建可靠Agent的方法论(如使用LangChain/LangGraph)。同时,也有观点认为未来AGI可能并非单一模型,而是由多个专门模型协作构成 (来源: Ronald_vanLoon、hwchase17、nrehiew_)