
关键词:人形机器人, AI应用, AGI, 自动驾驶, 人形机器人马拉松, Agent+MCP, DeepMind AGI预测, 特斯拉纯视觉FSD, GPT-SoVITS语音克隆, ChemAgent化学推理, 智元机器人商业模式, 英伟达GPU垄断挑战
🔥 聚焦
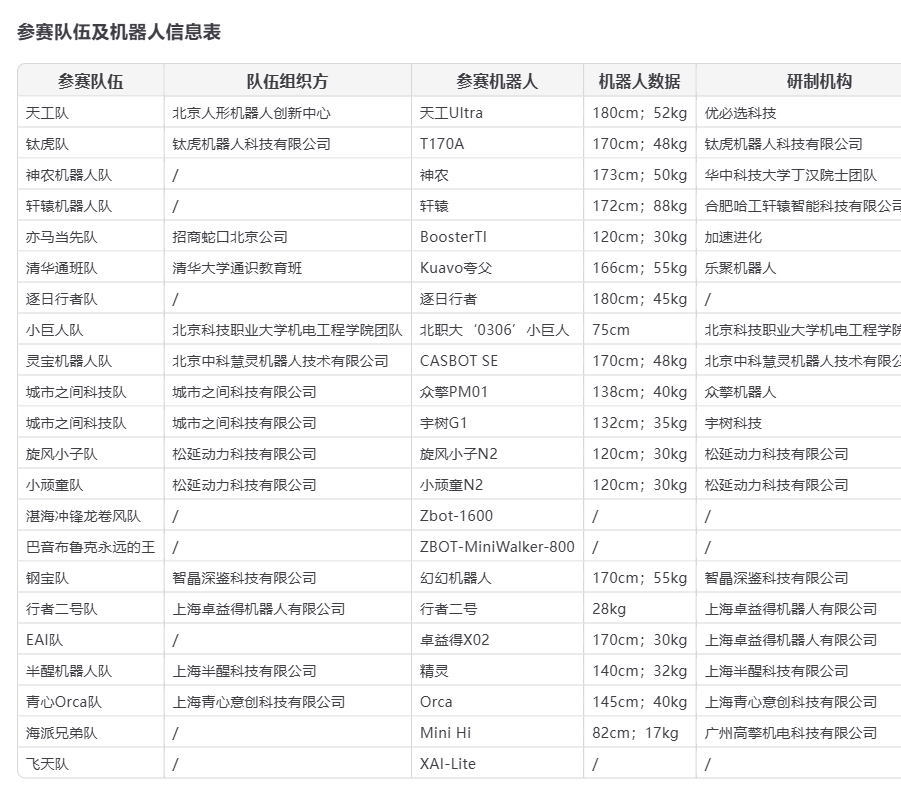
人形机器人在北京半马“首秀”,机遇与挑战并存: 在2025北京亦庄半程马拉松上,21支人形机器人队伍首次与人类选手同场竞技。天工Ultra、松延动力N2、卓益得行者二号分获前三名。比赛凸显了人形机器人的潜力,但也暴露了摔倒、续航、控制(多为遥控)等诸多挑战。赛后宇树科技回应其G1机器人摔倒事件,指出用户自行开发和操作对机器人表现影响巨大。此次赛事不仅展示了中国人形机器人产业的初步规模,也引发了关于技术成熟度、成本(松延N2预售价3.99万起)、商业化路径(租赁、工业应用)以及未来发展(AI大模型、自主学习)的广泛讨论。行业虽获资本青睐,但短期盈利难,市场化落地仍需时日 (来源: 摔倒的宇树和人形机器人的“求生”博弈, 从进厂到马拉松:人形机器人离“实用”还有多远?)
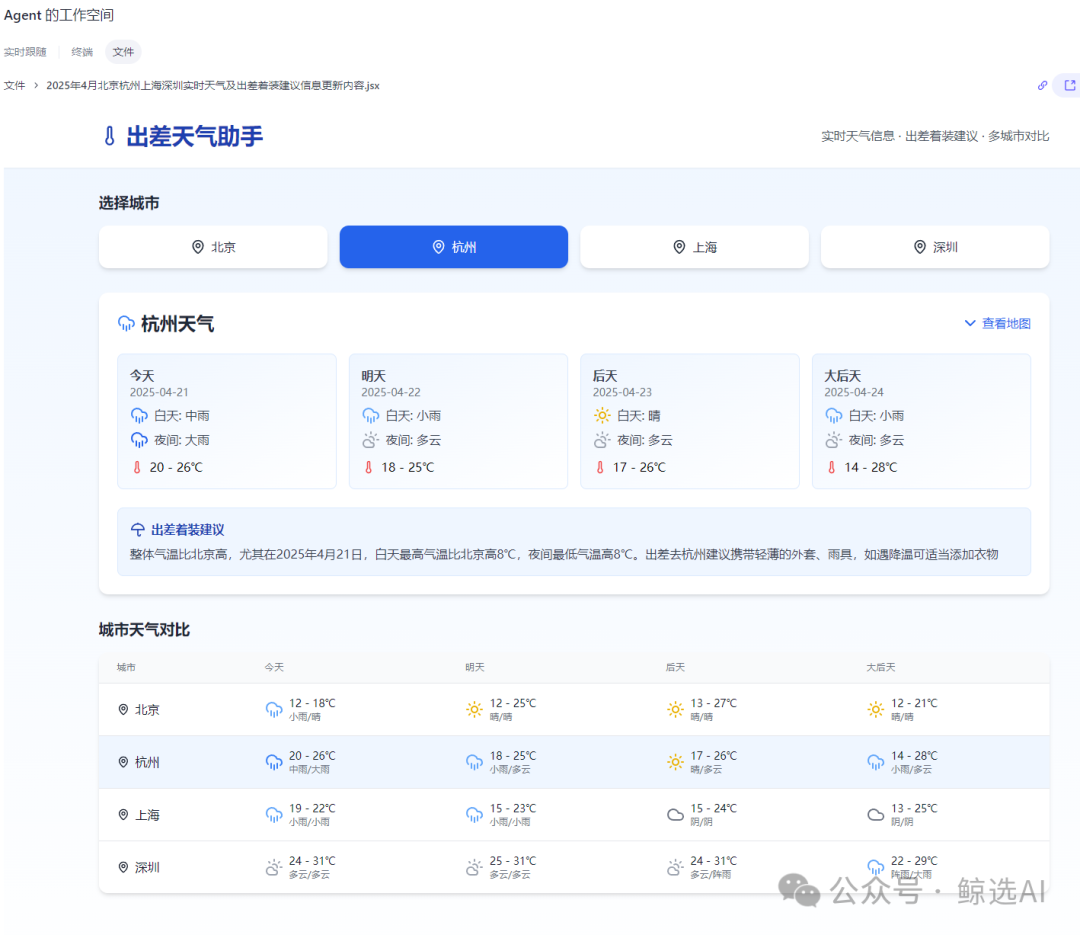
AI应用新范式:Agent+MCP成2025年爆款公式: 结合Agent的自主规划与行动能力以及MCP协议调用外部工具和数据的能力,正成为AI应用的新趋势。“扣子空间”、Fellou、Dia、GenSpark、智谱AutoGLM等产品相继涌现并引发关注。这些产品多从AI搜索转型而来,试图通过不同的产品设计(易用性、研究能力、落地执行)建立用户体验壁垒。尽管潜力巨大,但目前仍面临模型能力上限、跨平台信息获取、商业化模式等挑战。微软也推出面向桌面的多Agent系统UFO²,预示着AM(Agent+MCP)将成为AI产品的重要方向 (来源: 2025年,AI应用的爆款公式只有一个)
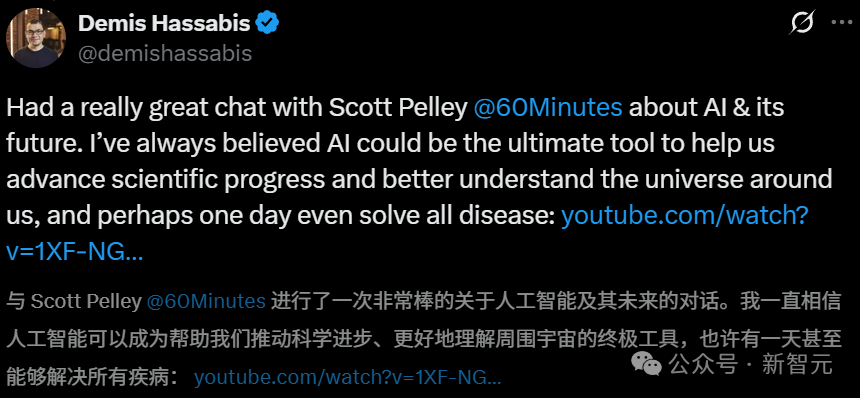
AI未来激辩:Hassabis预言十年治愈所有疾病,哈佛历史学家警告AGI灭绝人类: 谷歌DeepMind CEO Demis Hassabis在访谈中预测,AI将在5-10年内实现AGI,并有望在十年内治愈所有疾病,展示了Project Astra等AI进展。他认为AI将成为加速科学发现的终极工具。然而,哈佛历史学家Niall Ferguson发出警告,认为AGI的到来可能导致人类像马车一样被淘汰甚至灭绝,成为人类自己创造的“外星人”。他指出,制度僵化和全球生育率下降等趋势,可能使人类在AGI面前选择“退出历史舞台”。这场讨论凸显了对AGI潜力的极端乐观与对人类文明未来的深刻忧虑之间的巨大反差 (来源: 诺奖得主Hassabis豪言:AI十年治愈所有疾病,哈佛教授警告AGI终结人类文明, 哈佛历史学家预警:AGI灭绝人类,美国或将解体)
🎯 动向
机器人产业进展频出,商业化落地加速: 广交会首设服务机器人专区,国内厂商如穿山甲机器人、鸿绪锦科技等斩获大量海外订单,显示出中国服务机器人在全球市场的竞争力。同时,美的等公司的人形机器人正进行迭代,计划进入工厂“打工”。产业链上,PCB、传感器、新材料(如PEEK)等环节虽有布局,但规模化量产尚需时日,技术、成本、应用场景闭环是关键。多家厂商规划2025年实现千台级量产,有望推动产业链发展和数据积累,加速机器人向更实用阶段迈进 (来源: 机器人组团“营业”引爆声量场,产业链频刷进展)

特斯拉坚持纯视觉FSD,激光雷达路线面临挑战与机遇: 马斯克重申纯视觉方案对实现FSD的信心,认为摄像头加AI即可模拟人类驾驶,无需激光雷达。尽管面临成本下降(国产激光雷达已降至数百美元)和市场普及(已进入10万元级别车型)的现实,特斯拉仍坚持其路线,这对其算力、算法和数据提出极高要求。同时,禾赛、速腾聚创等激光雷达厂商凭借成本优势和技术迭代占据市场主导,并积极拓展海外市场及机器人等非车载业务。L3级自动驾驶的临近可能为激光雷达带来新机遇,因其在安全冗余和特定场景下的感知能力被认为不可或缺 (来源: 马斯克最新的AI驾驶方案,会终结激光雷达吗?)

Google Imagen 3/4 或在内测中: 传闻Google正在内部测试其下一代图像生成模型Imagen 3和Imagen 4,预示着Google可能在图像生成领域有新的大动作,旨在追赶或超越竞争对手 (来源: Google 又憋图像大招?传 Imagen 3/4 内测中。)
THUDM发布SWE-Dev系列编码模型: 清华大学知识工程和数据挖掘研究组(THUDM)发布了基于Qwen-2.5和GLM-4的SWE-Dev系列编码大模型,包括7B、9B和32B版本,旨在提升软件开发和编码任务的AI能力 (来源: Reddit r/LocalLLaMA)

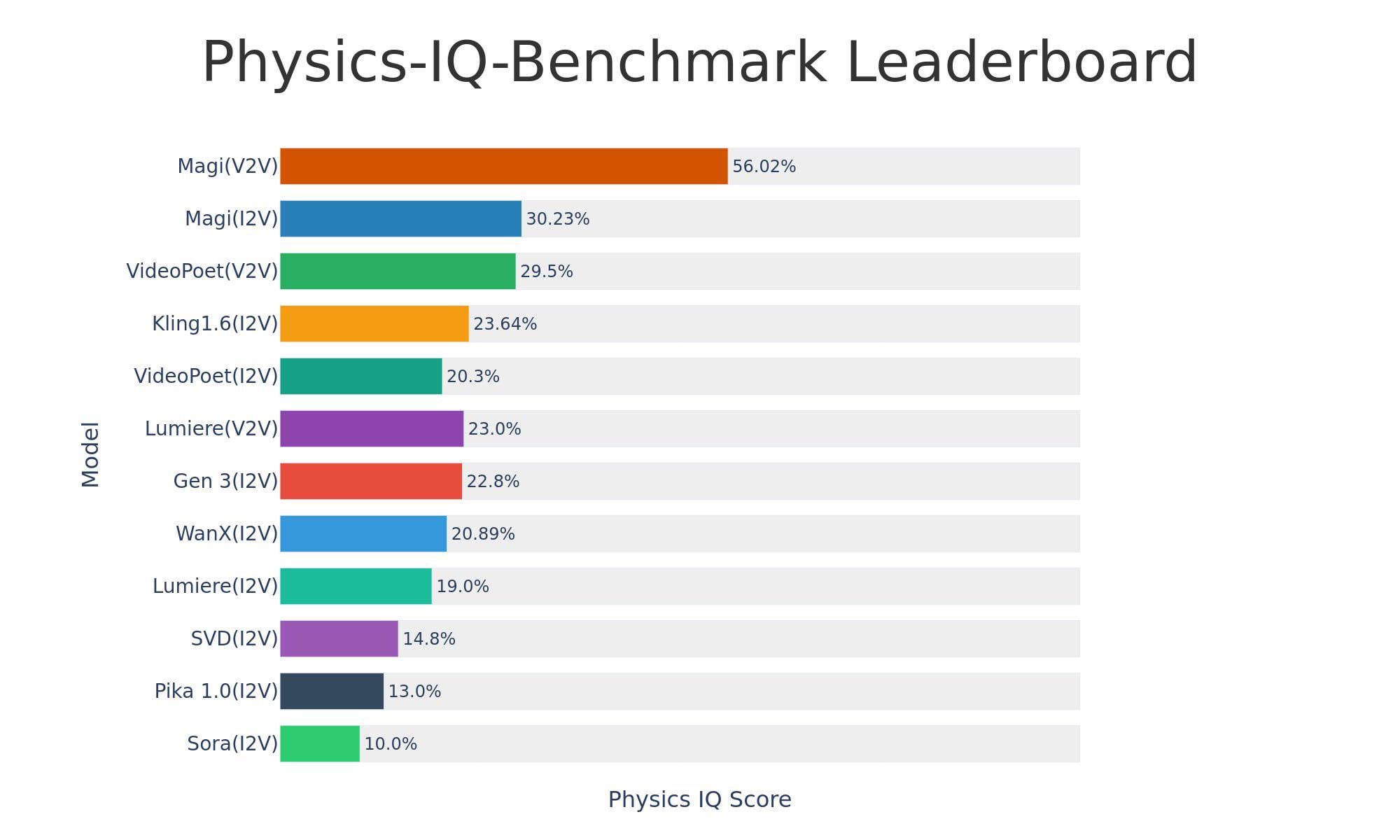
Sand-AI发布开源视频生成模型Magi-1: Sand-AI发布了Magi-1,一个开源的自回归扩散视频生成模型,号称能生成无限时长的视频,支持文生视频、图生视频和视频生视频。该模型在物理理解基准测试中表现优异,但运行需要极高显存(约640GB VRAM),代码和模型已在GitHub和Hugging Face发布 (来源: Reddit r/LocalLLaMA)
Grok增加视觉、多语言音频及实时搜索能力: xAI宣布Grok模型增加视觉理解能力,并在语音模式中支持多语言音频输入和实时搜索功能,提升了其多模态交互和信息获取能力 (来源: grok, xai)
Grok 3 模型登陆 You.com: xAI 的旗舰模型 Grok 3 现已在搜索引擎 You.com 上线,用户可以在该平台体验 Grok 3 的能力 (来源: xai)

开源TTS模型Dia发布并受关注: 一款名为Dia的开源文本转语音(TTS)模型发布,号称效果媲美ElevenLabs、OpenAI等商业模型,支持零样本声音克隆和实时合成,可在MacBook上运行。该模型在Hugging Face上迅速获得关注,并被VentureBeat等媒体报道 (来源: huggingface, huggingface, huggingface)
展示特斯拉自动驾驶技术: 展示了特斯拉 Autopilot 自动驾驶技术的相关视频或信息,持续引发对自动驾驶技术进展的关注 (来源: Ronald_vanLoon)
机器人技术展示: 多个来源展示了不同的机器人应用,包括用于小工具组装的机械臂、TITA机器人评估、两栖机器人Copperstone HELIX Neptune以及机器人如何感知世界等,显示了机器人技术在不同领域的持续发展 (来源: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 工具
GPT-SoVITS:强大的少样本语音克隆与文本转语音工具: RVC-Boss开发的GPT-SoVITS是一个开源项目,仅需1分钟的语音数据即可训练出高质量的TTS模型,实现少样本语音克隆。它支持零样本TTS(5秒输入即时转换)、跨语言推理(支持英、日、韩、粤、中),并集成了WebUI工具箱,包括人声伴奏分离、自动训练集分割、中文ASR和文本标注等功能,方便用户创建数据集和模型。该项目在GitHub上获得极高关注(超44k星标),并已更新至V4版本,持续优化音色相似度、稳定性和输出质量 (来源: RVC-Boss/GPT-SoVITS – GitHub Trending (all/daily))

清华团队推出SurveyGO(卷姬):AI驱动的文献综述与长报告生成工具: 基于清华NLP、OpenBMB和面壁智能团队研发的LLMxMapReduce-V2技术,SurveyGO能够高效处理海量文献,生成结构清晰、逻辑严谨、引用准确的万字长篇综述报告。该工具通过信息熵驱动的卷积机制优化大纲,并按层级生成内容,解决了传统AI生成长文时内容拼凑、缺乏深度的问题。用户可通过网页版输入主题或上传文件来使用,旨在大幅提升研究人员和内容创作者的文献调研与写作效率 (来源: INTJ式学术暴力!清华团队造出“论文卷姬”:3分钟速通200小时文献综述, 如何 AI「拼好文」:生成万字报告,不限模型)

text-generation-webui推出便携版,专注llama.cpp: 为简化部署流程,text-generation-webui发布了针对llama.cpp的便携式、自包含版本。用户下载解压即可运行,无需安装Python、PyTorch或其他依赖。新版本支持Windows、Linux、macOS,包含CPU和CUDA版本,大小约700MB,并优化了启动速度和用户体验(如自动打开浏览器、默认启动API)。这为只想使用llama.cpp进行本地推理的用户提供了极大便利 (来源: Reddit r/LocalLLaMA)
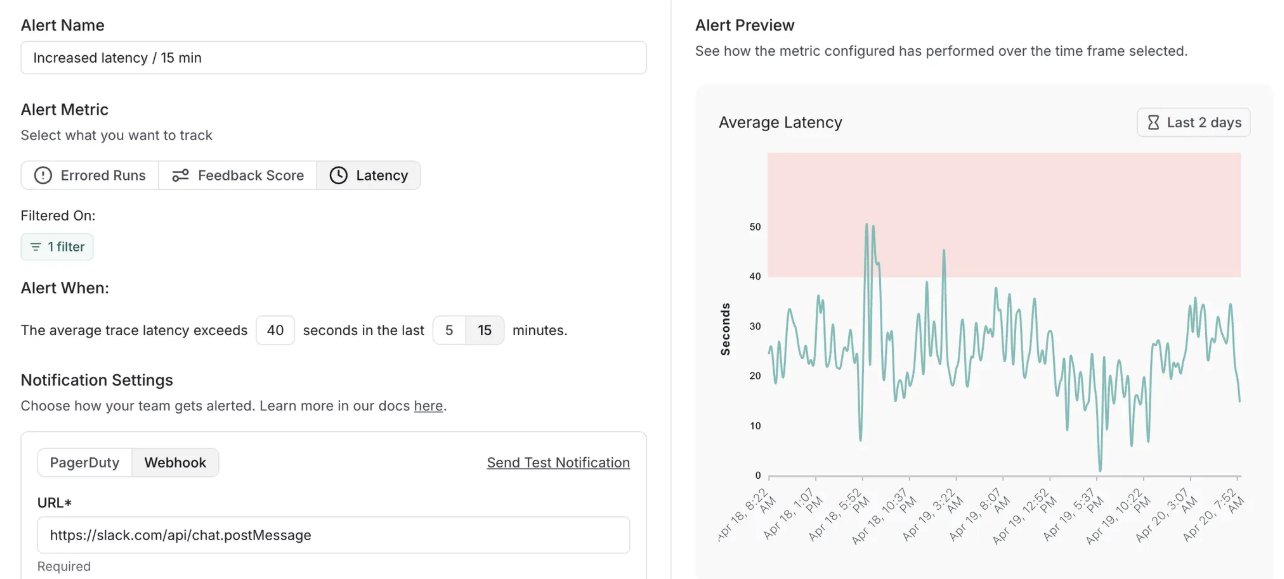
LangSmith 增加告警功能并更新自托管版本: LangChain 的 MLOps 平台 LangSmith 新增了实时告警功能,用户可针对错误率、运行延迟和反馈分数设置通知,以便在问题影响客户前及时发现。同时,其自托管版本更新至v0.10,包含了告警功能、新的评估创建与查看UI、对OpenTelemetry客户端追踪数据的支持以及性能优化 (来源: LangChainAI, LangChainAI)
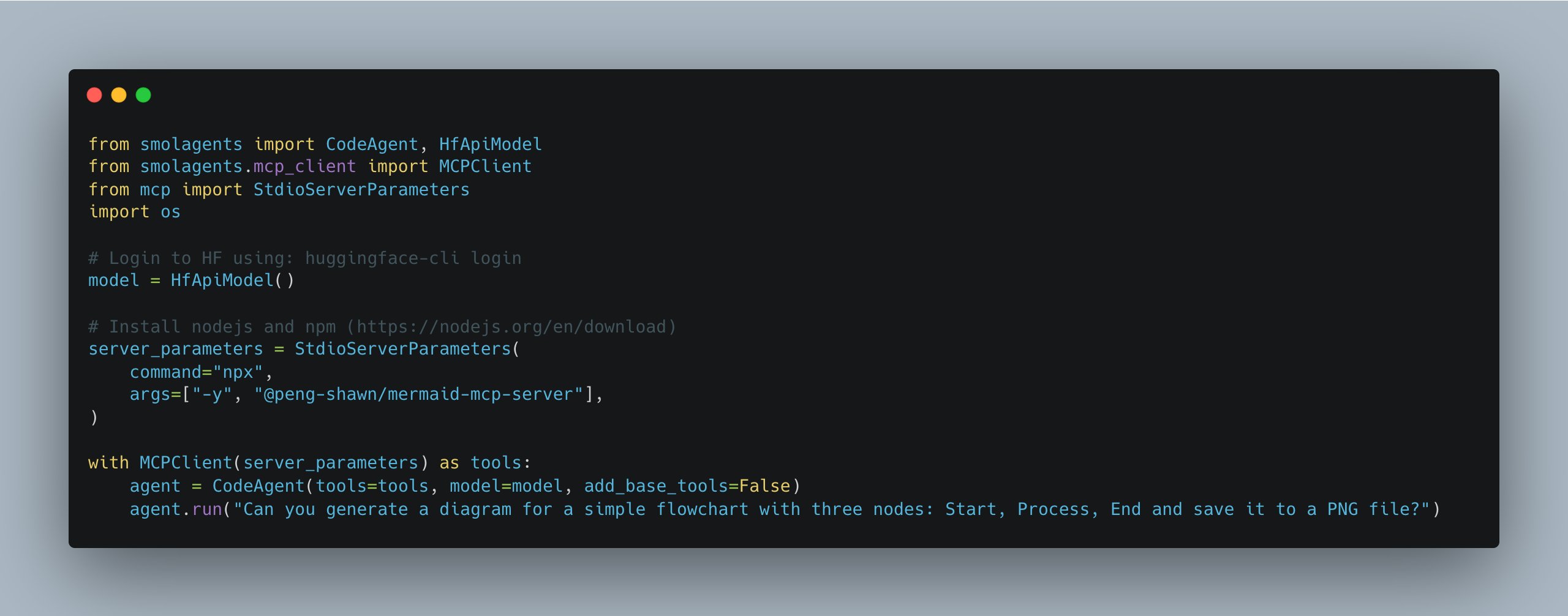
smolagents 更新,简化多MCP服务器管理: Hugging Face 的 smolagents 库发布新版本,引入了 MCPClient 类,使得管理到多个MCP(模型通信协议)服务器的连接变得更加容易,方便开发者构建和协调更复杂的Agent系统 (来源: huggingface)
Suna:开源Agent平台对标Manus: Kortix AI发布了开源Agent平台Suna,旨在对标Manus。Suna集成了浏览器自动化、文件管理、网络爬虫、扩展搜索、命令行执行、网站部署以及API集成等功能,允许AI协同操作这些工具,通过对话解决复杂问题和自动化工作流 (来源: karminski3)
Exa MCP现已支持免API搜索推特: Exa的MCP(模型通信协议)服务器更新,现已支持搜索推特内容,且无需使用推特API。这为需要从推特获取信息的AI Agent提供了便利,但目前似乎对中文用户数据的爬取支持不佳 (来源: karminski3)
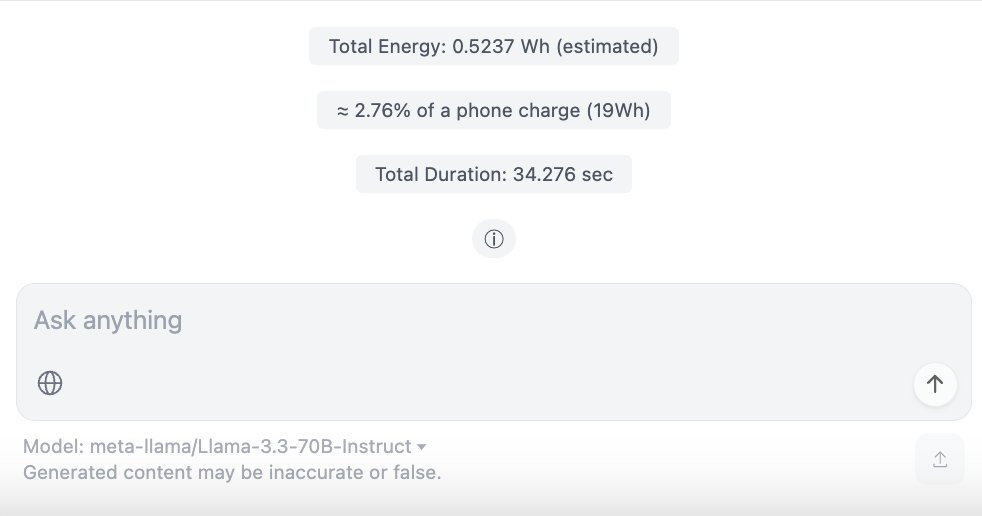
ChatUI-energy:实时显示AI对话能耗的界面: Hugging Face 社区成员发布了ChatUI-energy,这是一个Chat UI的变体,能够实时显示用户与AI模型(如Llama, Mistral, Qwen, Gemma等)对话所消耗的能量。此举旨在提高AI使用的能源透明度 (来源: huggingface, huggingface)
利用AI进行Web应用开发、部署与优化: 文章分享了使用AI(如Lovable, Cursor, BrowserTools MCP)进行Web应用(一个图片拼接工具)开发、调试、SEO审计和性能优化的全流程实践。重点介绍了如何利用Vercel和GitHub实现CI/CD自动化部署,以及域名和子域名解析配置。展示了AI在编码和网站运维中的辅助作用 (来源: AI 编码 + Vercel 部署 + 域名解析:一文搞定Web 应用开发上线全流程,氛围编码+MCP 审计优化。)

基于本地模型的”Her” OS1/Samantha 轻量级复刻: 一位开发者使用transformers.js和ONNX模型(包括Ultravox Llama 3.2 1B、Whisper Base、Kokoro TTS和MiniLM embeddings)在浏览器本地复现了电影《Her》中的AI助手OS1/Samantha。项目展示了在有限资源下(约2GB模型下载)实现本地运行的语音交互AI的可能性 (来源: Reddit r/LocalLLaMA)
ChatWise结合MCP服务器实现RAG与数据同步: 用户分享了在ChatWise中使用系统指令,结合Pinecone(数据库)、Exa(搜索)和Time(时间)的MCP服务器,实现简单的RAG(检索增强生成)和数据同步的工作流配置 (来源: op7418)

📚 学习
斯坦福大学开放Transformer课程CS25: 斯坦福大学开设的关于Transformer的研讨课程CS25向公众开放,可通过Zoom直播参与。课程邀请了Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani等顶级研究者和来自OpenAI, Google, NVIDIA的嘉宾进行讲座,内容涵盖LLM架构、多模态应用、生物学、机器人学等前沿。课程录像将在YouTube发布,并设有Discord社区供讨论 (来源: karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
清华上交研究揭示RL对LLM推理能力的局限性: 一项来自清华大学和上海交通大学的研究对强化学习(RL)提升大模型推理能力的观点提出挑战。实验表明,虽然RL能提高模型在低采样率下的准确性(效率),但在高采样率下,基础模型能解决更多难题(能力边界)。这表明RL更擅长优化模型在已有能力范围内的表现,而非拓展其根本的推理能力。论文指出,当前RL方法(如GRPO)可能因探索不足而陷入局部最优,限制了对复杂问题的解决 (来源: RL 是推理神器?清华上交大最新研究指出:RL 让大模型更会 「套公式」,却不会真推理, Reddit r/artificial)

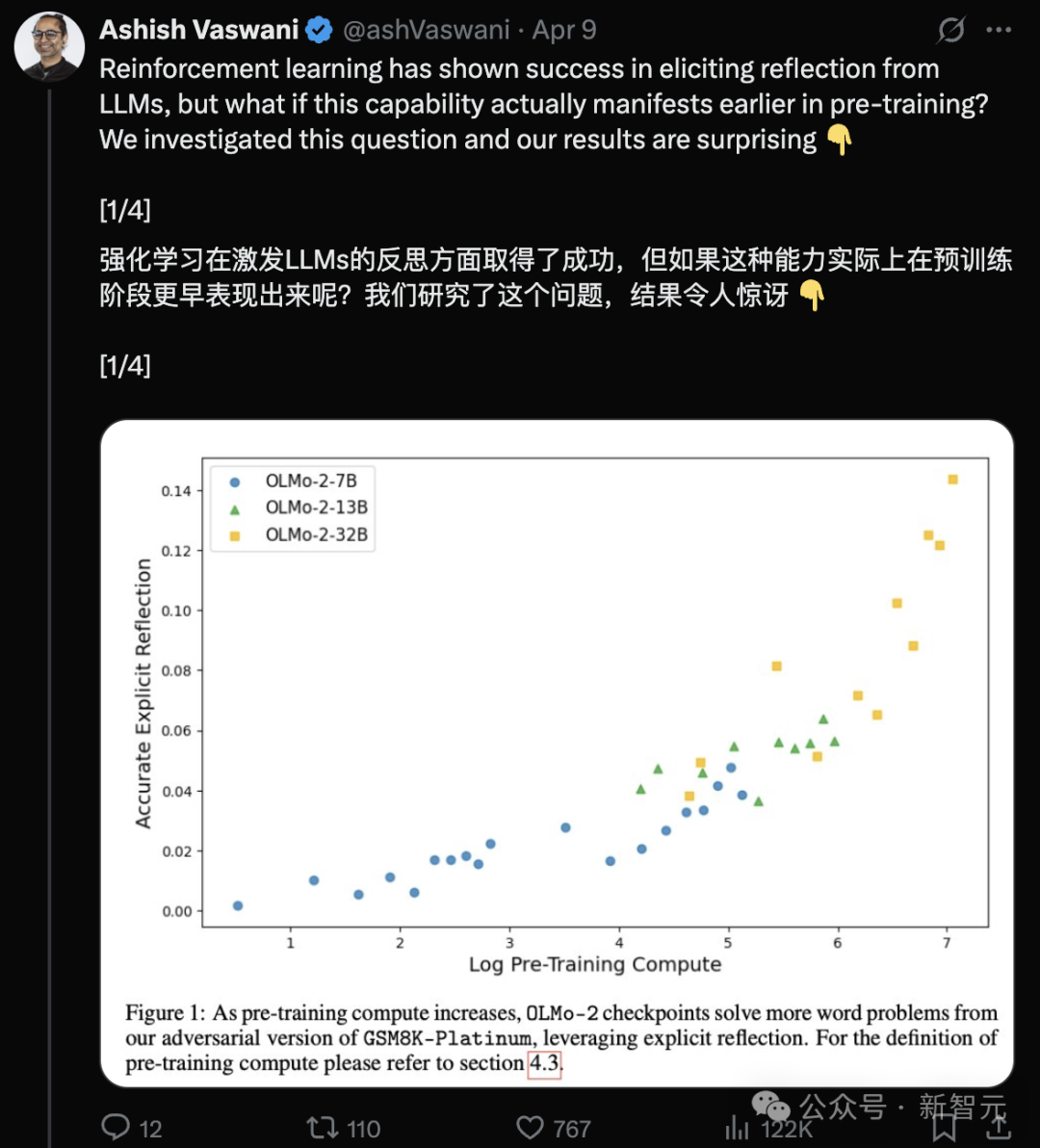
Transformer作者团队:LLM在预训练阶段已具备反思能力: 由Transformer论文一作Ashish Vaswani领导的团队发表研究,提出大语言模型在预训练阶段就已涌现出反思和自我纠正能力,而非完全依赖强化学习(RLHF)。研究通过引入对抗性思维链,区分并量化了情境反思和自我反思能力,发现这些能力随预训练计算量的增加而增强。简单提示如“Wait,”能有效激发显式反思。这挑战了DeepSeek等认为反思主要源于RL的观点,并为理解和加速预训练中的推理能力发展提供了新视角 (来源: Transformer原作打脸DeepSeek观点?一句Wait就能引发反思,RL都不用)
ChemAgent:自更新记忆库提升LLM化学推理能力: 耶鲁、斯坦福等机构的研究者提出ChemAgent框架,通过引入包含规划、执行和知识记忆的动态自更新记忆库,显著提升LLM在化学推理任务上的表现。该框架模拟人类学习过程,通过任务分解和记忆检索来解决复杂化学问题。在SciBench数据集上的实验表明,ChemAgent相比基线方法准确率平均提升10%(相对SOTA)至37%(相对直接推理),尤其在计算和单位转换精度上改进明显。研究还分析了记忆相似度、数量与性能的关系及当前局限性 (来源: 准确率飙升46%!耶鲁-斯坦福「自更新记忆库」新框架,重塑LLM化学推理能力)
华南理工大学在分布式进化计算领域取得系列进展: 华南理工大学计算智能团队在多智能体系统(MAS)的分布式共识优化方面取得系列成果。研究包括:发布该交叉领域的综述;提出MASOIE算法,通过内外部学习机制优化协同;提出MACPO算法,利用目标激励驱动合作;设计CCSA步长自适应机制提升黑盒优化性能;提出MASTER算法提升传感器网络定位精度。团队还组织了相关竞赛,推动领域发展 (来源: 打破共识优化壁垒!华南理工深耕分布式进化计算,实现多智能体高效协同)
从零构建DeepSeek视频教程系列: Vizuara在YouTube上发布了“从零构建DeepSeek”系列视频教程,目前已更新13讲,内容涵盖DeepSeek基础、Token处理流程、注意力机制(自注意力、因果注意力、多头注意力、多查询注意力、分组查询注意力、多头潜在注意力)及KV Cache等核心概念的讲解和代码实现。该系列旨在深入解析DeepSeek架构,计划总共发布35-40个视频,覆盖RoPE、MoE、MTP、SFT、GRPO等更多内容 (来源: karminski3, Reddit r/LocalLLaMA)
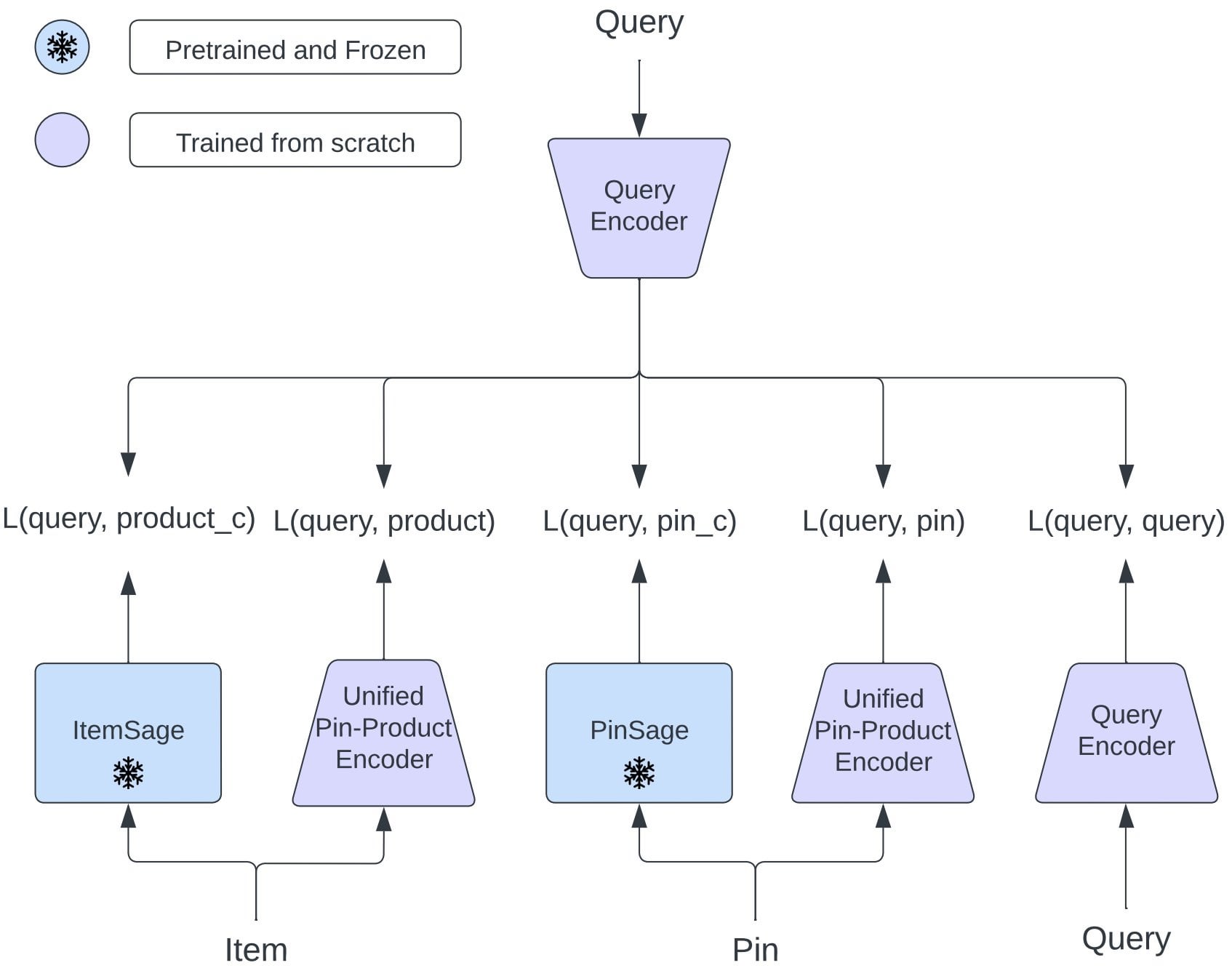
Pinterest提出OmniSearchSage:统一嵌入模型提升多任务检索: Pinterest研究者提出OmniSearchSage,一个统一的查询嵌入模型,通过多任务学习训练,能够同时检索pins、产品和相关查询,挑战了传统双塔架构。该模型融合了GenAI生成的标题、用户策划的board信号和行为参与数据,丰富了项目理解,并能直接集成到现有系统(如PinSage)。结果显示,该方法在搜索、广告和延迟方面取得了显著的实际改进 (来源: Reddit r/MachineLearning)
FlowReasoner:基于查询动态调整的多智能体工作流: 论文提出FlowReasoner,旨在为每个用户查询即时推理出专属的多智能体工作流(workflow)。通过推理SFT和GRPO强化学习,模型能根据执行反馈动态调整Agent任务(如代码生成、审查、测试、修订)的组合与顺序。该方法在Code Interpreter场景下验证,依赖Python执行和单元测试,展示了工作流动态适应查询需求的潜力,未来或可泛化至检索、数据分析等领域 (来源: dotey)

LangChain教程:使用LlamaIndex构建合规报告生成工作流: LlamaIndex发布视频教程,演示如何构建一个Agentic Workflow来生成合规报告。该工作流利用LLM处理大量法规文本,与合同语言进行比较,并生成简洁摘要。教程展示了如何设置LlamaCloud索引、定义子句提取和合规检查的模式,以及使用语义搜索查找相关法规语言 (来源: jerryjliu0)

LangChain教程:自愈代码生成Agent: LangChain发布教程,介绍如何构建具有自我修复能力的AI代码生成Agent。该教程利用OpenEvals框架和E2B沙箱环境来评估和改进AI生成的代码,通过增加一个反思步骤来验证代码,然后再返回响应 (来源: LangChainAI)

Anthropic分析发现Claude具有内在道德准则: Anthropic对70万次Claude对话进行分析后发现,其AI模型展现出一种内在的道德准则。这一发现可能对AI安全和伦理研究具有重要意义 (来源: Reddit r/ClaudeAI, Reddit r/artificial)

Google提出”经验时代”应对AI训练数据稀缺: Google研究人员(包括David Silver)发表论文《The Era of Experience》,提出通过让AI Agent生成自身训练数据来解决当前依赖人类数据进行训练所面临的数据稀缺问题。这可能预示着AI训练范式的新方向,并可能挑战依赖现有数据集的训练方法 (来源: Reddit r/artificial)

免费证书和课程资源列表: GitHub仓库 cloudcommunity/Free-Certifications 收集整理了大量提供免费课程和认证的资源,涵盖通用技术、安全、数据库、项目管理、营销等多个领域,其中包含部分AI、机器学习、数据科学相关的免费课程和认证,如freeCodeCamp的机器学习课程、Databricks的GenAI基础、IBM Cognitive Class的AI课程等 (来源: cloudcommunity/Free-Certifications – GitHub Trending (all/daily))
LLM用于代码编辑的可靠性测试: 用户分享了测试多款大语言模型(LLM)在深度学习代码编写与修改方面可靠性的视频,探讨当前LLM在辅助编程任务中的实际效果和局限性 (来源: Reddit r/deeplearning)

💼 商业
美国关税战冲击中国AI硬件初创企业: 美国对中国商品加征高额关税(部分税率达125%),严重影响了面向美国市场的中国AI硬件初创企业(如AI玩具、智能眼镜等)。由于美国市场是许多AI硬件产品进行市场验证和获取早期用户的关键阵地(如通过Kickstarter),高关税导致利润大幅缩水甚至亏损,部分企业已暂停对美发货。虽然智能眼镜等品类暂时获得豁免,但前景不明。行业依赖的“灰清”模式风险也在增加。这迫使企业重新评估市场策略,加速全球化布局,分散风险 (来源: 襁褓中的AI硬件,迎接最激烈的关税战)

智元机器人深度拆解:产品、技术与商业模式: 智元机器人由“稚晖君”彭志辉等人创立,拥有面向工业和商业场景的“远征”系列(A1, A2, A2-W轮式, A2-Max重载)和聚焦轻量化与开源的“灵犀”系列(X1开源, X1-W数采, X2双足交互)机器人,以及精灵G1、绝尘C5清洁机器人等。技术上,公司强调软硬协同和数据闭环,自研PowerFlow关节模组、灵巧手,并开发了启元大模型(GO-1)、AIDEA数据平台、AimRT通信框架等软件。商业模式包括硬件销售、订阅服务和生态分成(开源部件、供应链合作)。公司已完成8轮融资,估值达150亿元,投资方包括高瓴、比亚迪、腾讯等,并与多家供应链企业及地方政府合作,旨在打造世界级通用具身机器人 (来源: 智元机器人深度拆解:人形机器人独角兽进化论)

追觅内部孵化3D打印项目「原子重塑」获数千万元融资: 由追觅科技(Dreame)内部孵化的原子重塑科技(AtomFab)完成数千万元天使轮融资,追创创投投资。该公司成立于2025年1月,聚焦消费级3D打印市场,利用AI技术解决易用性、稳定性和效率等痛点。公司将复用追觅的电机、传感器、AI交互等技术及成熟供应链资源,降低成本并加速产品化。产品将优先布局欧美市场,利用追觅的海外售后网络提供支持。首款产品预计2025年下半年发布 (来源: 追觅内部孵化3D打印项目获数千万融资,优先布局欧美等海外市场|硬氪首发)
英伟达GPU垄断地位或面临挑战: 尽管英伟达GPU出货量持续增长,但其长期主导地位面临挑战。主要原因包括:1) 云巨头(谷歌、微软、亚马逊、Meta)需求强劲但正大力投入自研芯片(TPU、Maia、Trainium、MTIA)以降低成本和依赖;2) 行业向分布式、垂直整合和系统级协同优化(芯片、网络、冷却、软件)转型,英伟达在这方面布局相对不足;3) 定制化需求增加,ASIC在特定工作负载(如推理、推荐)上展现优势;4) 英伟达的网络技术(Infiniband)和软件栈(如BaseCommand)在超大规模和容错性方面可能不及云巨头的内部解决方案。英伟达虽在努力适应(如Blackwell、Spectrum-X),但结构性挑战依然存在 (来源: 计算的未来:英伟达王冠正摇摇欲坠)

传闻OpenAI有意收购Chrome浏览器: 据Bloomberg报道,如果Google因反垄断案被美国联邦法院下令拆分搜索业务,OpenAI可能有兴趣收购其Chrome浏览器业务。这反映了AI公司对掌握用户入口和数据来源的潜在兴趣,但目前仅为传闻,且取决于Google反垄断案的进展 (来源: karminski3)
利用GenAI实现业务成果的策略: 福布斯文章探讨了企业如何超越实验阶段,利用生成式AI(GenAI)获得实际业务成果,提出了9种策略建议,帮助企业将GenAI整合到业务流程中以提升效率和创新 (来源: Ronald_vanLoon)

华为新芯片或对英伟达构成竞争: 社交媒体讨论提及华为发布新芯片,可能在AI领域对英伟达构成竞争,这或将影响中美在芯片和关税方面的谈判格局 (来源: Reddit r/ArtificialInteligence)
🌟 社区
DeepSeek引发的淘金热与反思: DeepSeek的走红催生了大量围绕其进行的商业尝试,包括内容创作(批量生产短视频脚本、文案)、知识付费(售卖使用教程、变现课程)和代运营服务。然而,许多尝试者发现,利用AI批量生产的内容同质化严重,易被平台限流或封禁,且难以真正转化为有效收益。文章指出,真正的受益者往往是利用信息差售卖课程或服务的“中间商”,而非直接使用者。同时,DeepSeek本身也暴露出服务器繁忙、回答模式化等问题,引发对其应用价值和局限性的讨论 (来源: DeepSeek走红三个月,第一批想靠它赚钱的怎么样了?)

AI作弊工具开发者获融资引发伦理争议: 21岁哥大学生Chungin Lee因开发用于技术面试作弊的AI工具Interview Coder被学校停学。不足一月后,他与同学成立公司Cluely,将该工具扩展至考试、销售、会议等多种场景,并获得530万美元种子轮融资。他们认为这并非作弊,而是利用技术提升效率,未来人人都会用AI辅助。此事引发巨大争议,支持者认为这是大胆创新,批评者则担忧其破坏公平、模糊能力界限,甚至将其比作《黑镜》情节。该事件激起了关于AI伦理、教育公平和能力定义的激烈讨论 (来源: 21岁学生开发AI作弊工具被哥大停学,转身拿下530万美元融资,网友:《黑镜》成真, 靠开发AI作弊神器成名,21岁小伙遭学校开除不足一月后,转身拿下530万美元融资)

美国签证政策收紧,AI人才或外流: 近期美国政府大规模吊销国际学生(包括AI博士生)的SEVIS记录和签证,理由从轻微违法甚至系统误判(可能涉及AI筛查)不等,且过程缺乏透明度和申诉机会。加州理工教授Yisong Yue等担忧此举正损害美国对顶尖AI人才的吸引力,许多在OpenAI、谷歌等机构的研究人员已在考虑离开。这可能导致美国AI项目倒退,削弱其AI优势。已有学生联合起诉政府并获得临时限制令 (来源: 加州AI博士一夜失身份,谷歌OpenAI学者掀「离美潮」,38万岗位消失AI优势崩塌)

开源模型发展现状讨论: 社区讨论关注开源大模型的最新动态,提到期待Qwen 3,Llama 4采用缓慢,推理模型似乎遇到瓶颈,多模态模型被低估,以及中国在开源领域的持续主导地位。讨论者强调,对“推理饱和”的理解需区分开源与闭源,并指出这更多是关于模型多样性和RL扩展的挑战 (来源: natolambert)
OpenAI o3模型搜索能力获赞: 用户称赞OpenAI o3模型的搜索能力强大,能够找到非常小众的信息,无需大量额外上下文,交互体验类似与同事交流 (来源: gdb)
开源TTS的意义与影响: 社区成员在讨论Dia TTS模型时强调,其高质量表现证明了训练SOTA TTS模型不再需要数十亿美元的投资。AI行业的复合效应使得训练变得越来越容易,开源力量正在加速技术普及 (来源: huggingface, huggingface)
Meta举办LlamaCon 2025,庆祝开源社区: Meta宣布将举办LlamaCon 2025活动,旨在庆祝Llama开源社区及其取得的成就,并将分享Llama模型和工具的最新进展及未来计划 (来源: AIatMeta)

AI是否真正“智能”引讨论: 文章《我们需要停止假装AI是智能的》引发讨论,探讨当前AI技术的能力边界和“智能”定义的复杂性 (来源: Ronald_vanLoon)

ChatGPT使用体验:连接丢失与诚实度测试: 用户反映频繁遇到ChatGPT“网络连接丢失”的问题,猜测可能与使用负载有关。同时,有用户分享了一个有趣的提示词,让ChatGPT利用记忆功能给出对其用户的“真实看法”,引发关于AI个性化交互和“意识”的讨论 (来源: natolambert, dotey)
机器人领域发展乐观情绪: Hugging Face联合创始人Thomas Wolf评论,2025年的机器人实验室因开源硬件、良好的强化学习进展和人才聚集而充满乐趣,反映了业内对机器人技术快速发展的兴奋感 (来源: huggingface)
Gemini Deep Research实用性受肯定: 用户分享使用Gemini Deep Research功能来验证推文信息可靠性的案例,显示出其在信息核查和深度研究方面的实用价值 (来源: dotey)

对开源AI库的批评与维护: 社区成员观察到近期对各种开源AI库存在不少负面评论,认为这些批评可能基于过时信息或片面指标,并呼吁批评者参与建设更好的版本 (来源: natolambert)
猜测AI游戏体验: 用户对未来AI驱动的游戏体验表示好奇,推测其可能类似于VRChat的交互方式,但对完全动嘴操作表示疑虑 (来源: karminski3)
ChatGPT图像放大功能讨论: 用户尝试让ChatGPT放大图片分辨率,发现其并非真正放大像素,而是重新绘制了一张相似但细节不同的高分辨率图片。评论区普遍认同这一点,并讨论了真正的AI图像放大技术 (来源: Reddit r/ChatGPT)
ChatGPT生成世界想象图: 用户让ChatGPT生成它想象中的世界样貌,得到一张田园诗般的公园场景图。评论区用户指出了图像中的逻辑不合理之处(如月地距离、长椅位置)和潜在偏见(人物种族),反映了当前图像生成模型的局限性 (来源: Reddit r/ChatGPT)

老旧LLM模型MythoMax13B流行原因探讨: Reddit用户提问为何基于Llama2的MythoMax13B模型在OpenRouter等平台的RPG场景中仍受欢迎。评论认为原因包括:成本低廉(常作为免费选项)、相对稳定且遵循指令、用户熟悉其提示和设置、以及早期教程的固化效应 (来源: Reddit r/LocalLLaMA)
寻求本地隐私过滤工具: Reddit用户寻求能在本地设备上运行的工具或小型语言模型(SLM),用于在将提示发送给LLM前自动检测和脱敏(如替换为占位符),并在收到LLM响应后恢复原始信息,以保护隐私 (来源: Reddit r/OpenWebUI)
关于Anthropic警告“全AI员工”的讨论: Anthropic警告称完全由AI构成的虚拟员工可能在一年内出现,引发社区讨论。评论者对此表示怀疑,指出Anthropic自身服务的稳定性问题,并认为这更像是一种宣传或危言耸听 (来源: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)

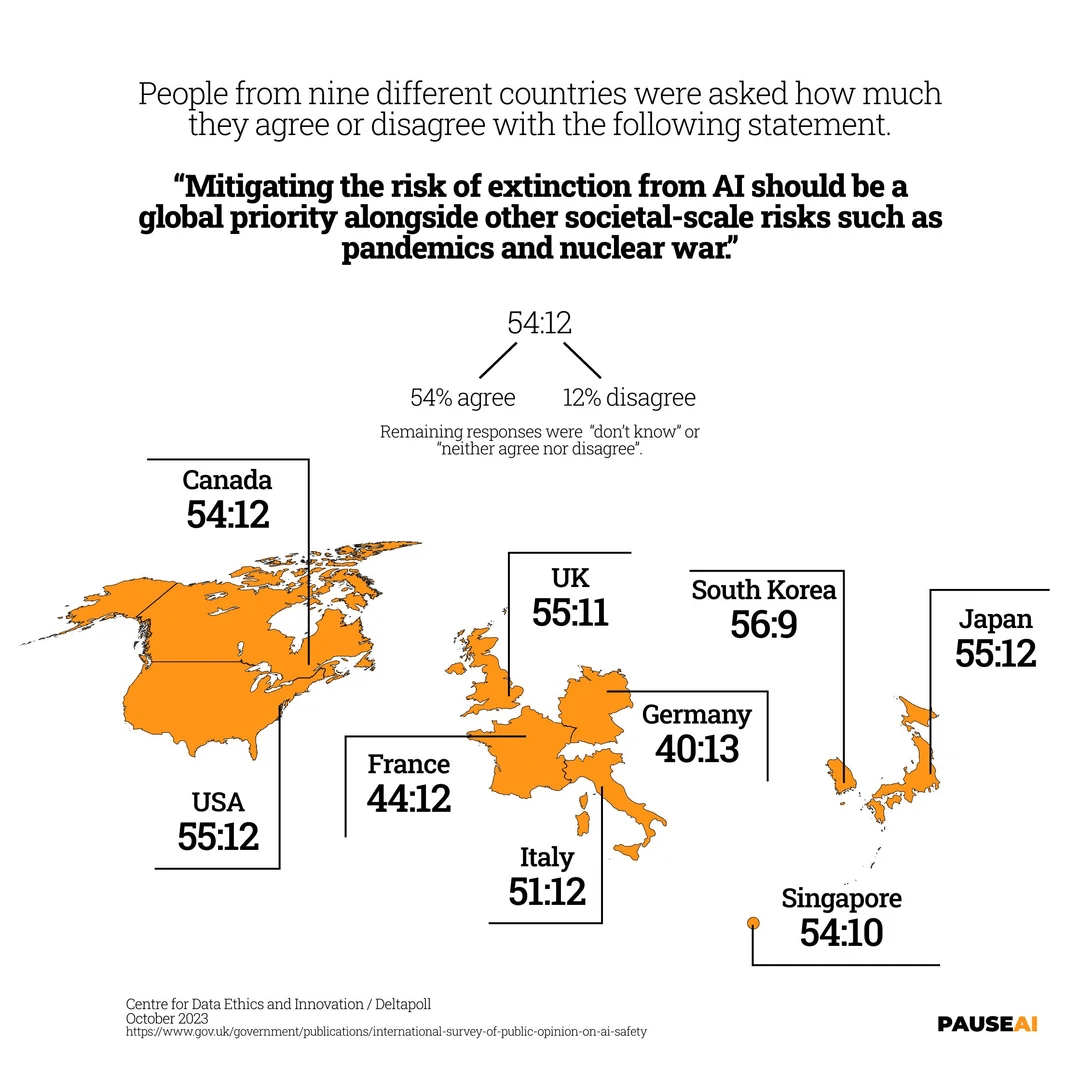
全球对AI灭绝风险的担忧: 图片显示一项调查结果,表明世界大多数人认为应严肃对待AI可能导致人类灭绝的风险 (来源: Reddit r/artificial)
AI生成文本的“机器味”与人性化技巧: 用户讨论如何识别AI生成的文本(如邮件、帖子),指出其常见问题:缺乏针对性语气、过于正式、完美无瑕。并分享了让人工智能写作更自然的技巧:明确场景、提供范例、调整随机性、加入具体细节、自行编辑、保留微小瑕疵等 (来源: Reddit r/artificial)
关于Claude Code能否通过Claude Max使用的猜测: 用户猜测是否可以通过订阅Claude Max服务间接使用(可能成本更低的)Claude Code模型,并讨论其潜在价值,同时希望OpenAI也能提供类似方案 (来源: Reddit r/ClaudeAI)
幽默模仿o3模型本地行为: 用户发布了一个幽默的系统提示词,旨在让本地LLM模型表现出类似OpenAI o3模型被部分用户诟病的特点(如回答简短、代码 subtly 错误、行为烦人),以此调侃对o3模型的不满 (来源: Reddit r/LocalLLaMA)

OpenWebUI连接MCP代理服务器问题求助: K8s用户在使用OpenWebUI时遇到问题,无法从Web界面访问部署在同一pod内的MCP代理服务器(FastAPI应用),尽管在pod内部可以通过localhost访问。用户寻求社区帮助解决网络连接或配置问题 (来源: Reddit r/OpenWebUI)
本地MCP服务器安全实践讨论: 用户发起讨论,询问如何安全地运行本地MCP服务器,以应对潜在的漏洞风险。评论建议使用stdio模式,或将SSE模式限制在localhost/127.0.0.1,或使用token认证,并指出对提示注入/凭证窃取的担忧适用于所有软件安装 (来源: Reddit r/ClaudeAI)
Agent-to-Agent (A2A) 协议支付机制探讨: 社区讨论Google的A2A协议缺乏内置的Agent间支付机制问题。用户认为这可能阻碍Agent经济的发展,并探讨了潜在解决方案,如使用与账单绑定的认证令牌、内置托管流程或在AgentSkill中添加定价信息等 (来源: Reddit r/artificial)
对AI过度依赖的警示: 用户分享了Google搜索AI对同一问题给出相反答案的经历,强调不应完全依赖AI做最终决策。评论解释了LLM的概率性、训练数据偏差、模型简化等原因导致的不一致性,并建议将AI作为辅助研究工具而非权威信息源 (来源: Reddit r/ArtificialInteligence)
在OpenWebUI中使用Qdrant进行RAG的疑问: 用户询问如何在OpenWebUI环境中集成Qdrant向量数据库以实现RAG(检索增强生成),特别是如何让OpenWebUI使用Qdrant中的数据以及是否需要 retriever 脚本 (来源: Reddit r/OpenWebUI)
Google与ChatGPT搜索效果对比讨论: 用户发布对比图(未显示),声称ChatGPT搜索效果优于Google,引发社区讨论。评论中有人反驳,认为Google Gemini表现优异,且拥有NotebookLM等工具;有人认为这种比较无意义,技术在不断进步;也有人指出用户体验和集成度的重要性 (来源: Reddit r/ChatGPT)
看好Character Training研究方向: 行业观察者预测,Character Training(角色训练,可能指让AI模拟特定角色或个性)将成为一个爆发性的学术研究领域,认为现在是发表早期开创性论文的好时机 (来源: natolambert)
💡 其他
人形机器人形态的合理性探讨: 文章探讨了将机器人设计成人形的原因:主要是为了适应为人类设计和建造的世界(工具、环境、交互方式)。人形设计便于机器人在现有基础设施中导航和操作,减少改造需求,并利用人类工具。拟人化特征也有助于人机交互和协作。尽管存在平衡、控制、成本和“恐怖谷”等挑战,但技术进步正逐步克服这些障碍。文章还回顾了机器人发展简史,对比了中美等国在人形机器人领域的竞争格局,并展望了成本下降带来的普及前景 (来源: 外媒深度:机器人为什么要做成人形?)

AI时代中国的就业挑战与对策: 文章分析了人工智能对中国就业市场的冲击,特别是对中低技能劳动力和区域发展不平衡带来的挑战。借鉴美国在教育改革、再培训、社保体系和创新支持方面的经验,文章提出中国应加强职业培训与终身教育(尤其数字化技能)、完善覆盖新业态的社保体系、推动产业与AI融合及区域协调发展、健全算法监管与数据隐私保护、强化多部门协调与就业监测预警,以稳住并提升就业基本盘 (来源: 人工智能时代:中国如何稳住、提升就业基本盘)
利用AI重塑个人IP叙事: 文章提出,在内容创作饱和的时代,普通人可以通过AI工具(如ChatGPT)重构个人经历,发掘隐藏主题线、重塑关键转折点叙事、塑造差异化语言体系,从而打造独特的个人IP。文章给出了具体步骤(数据收集、AI主题挖掘、故事结构重塑、实践迭代)和技巧(反向构建、情感放大、对比强化),并提醒避免过度美化、千篇一律和缺乏情感深度的陷阱,强调真实性与AI辅助的结合 (来源: 做个人IP的第一步:用AI改写你的人生叙事)
AI在环境保护领域的应用: 在世界地球日之际,英伟达展示了其AI技术(如Jetson, Earth-2平台)在环境保护中的应用案例,包括预测洋流以减少燃料消耗、实时防护野火和偷猎、提供更精准的风暴预报、以及探测小行星等,覆盖海洋、陆地、天空和太空等多个维度 (来源: nvidia, nvidia, nvidia)
AI用于改善客户服务: AI驱动的联络中心正在变革客户服务体验,旨在解决传统客服电话中的痛点,提升效率和满意度 (来源: Ronald_vanLoon)
AI生成逼真自拍/搞怪图片提示词分享: 用户分享了使用AI图像生成工具(如GPT-4o, Sora)生成极其逼真、看似随手拍的“普通”自拍照的提示词,以及生成将特定人物设计成马桶刷等搞怪图片的提示词,展示了AI在图像生成方面的创意与娱乐潜力 (来源: dotey, dotey, dotey)

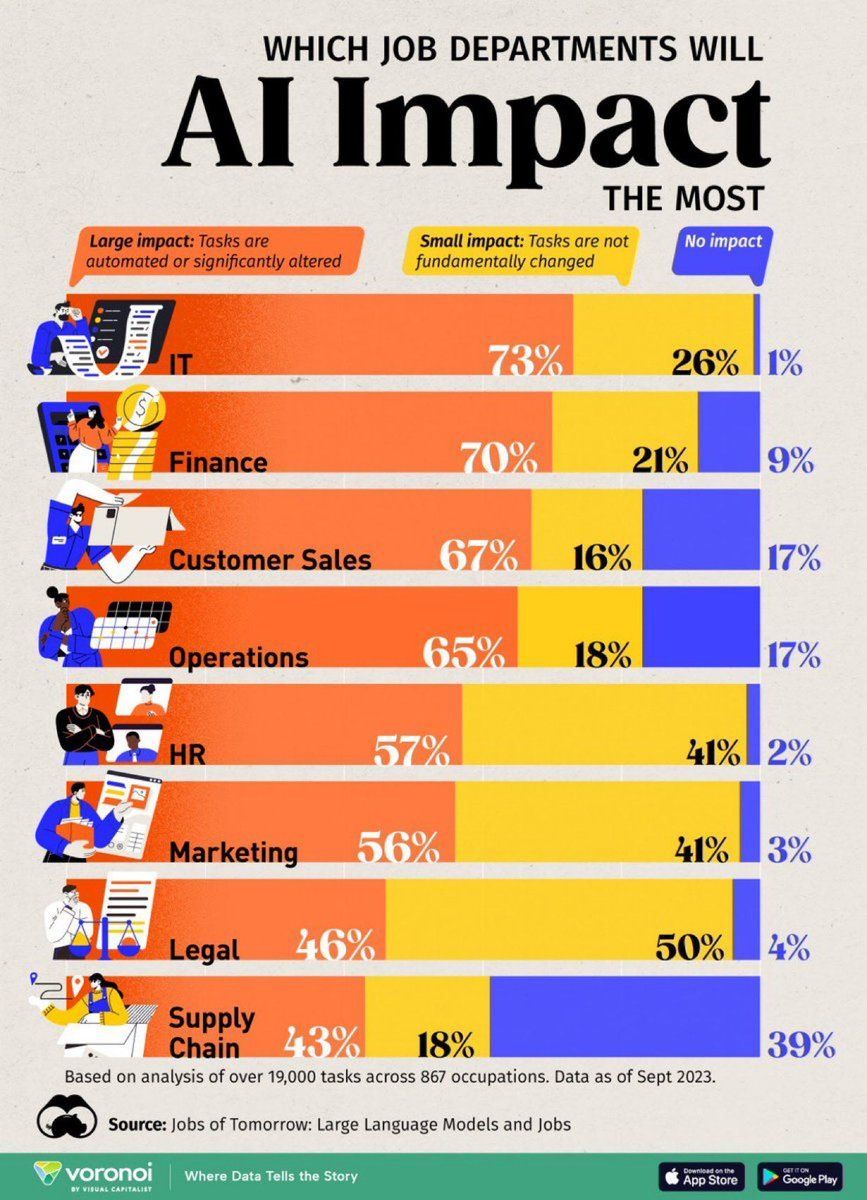
AI对就业岗位的影响分析: Visual Capitalist制作的信息图展示了受AI影响最大的工作岗位,引发对未来工作形态变化的关注 (来源: Ronald_vanLoon)
AI用于迪拜道路缺陷检测: 迪拜将采用新的AI技术来检测道路缺陷,展示了AI在城市基础设施维护中的应用潜力 (来源: Ronald_vanLoon)
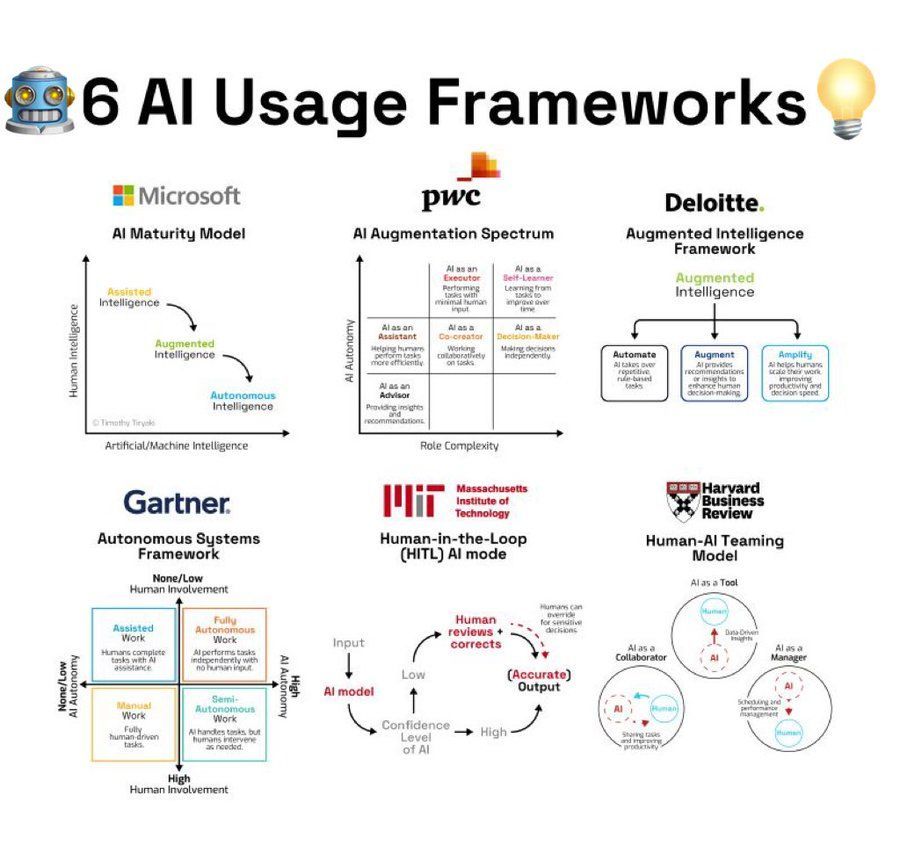
AI使用框架总结: 信息图总结了6种使用AI的框架或方法论,为用户应用AI提供了思路参考 (来源: Ronald_vanLoon)
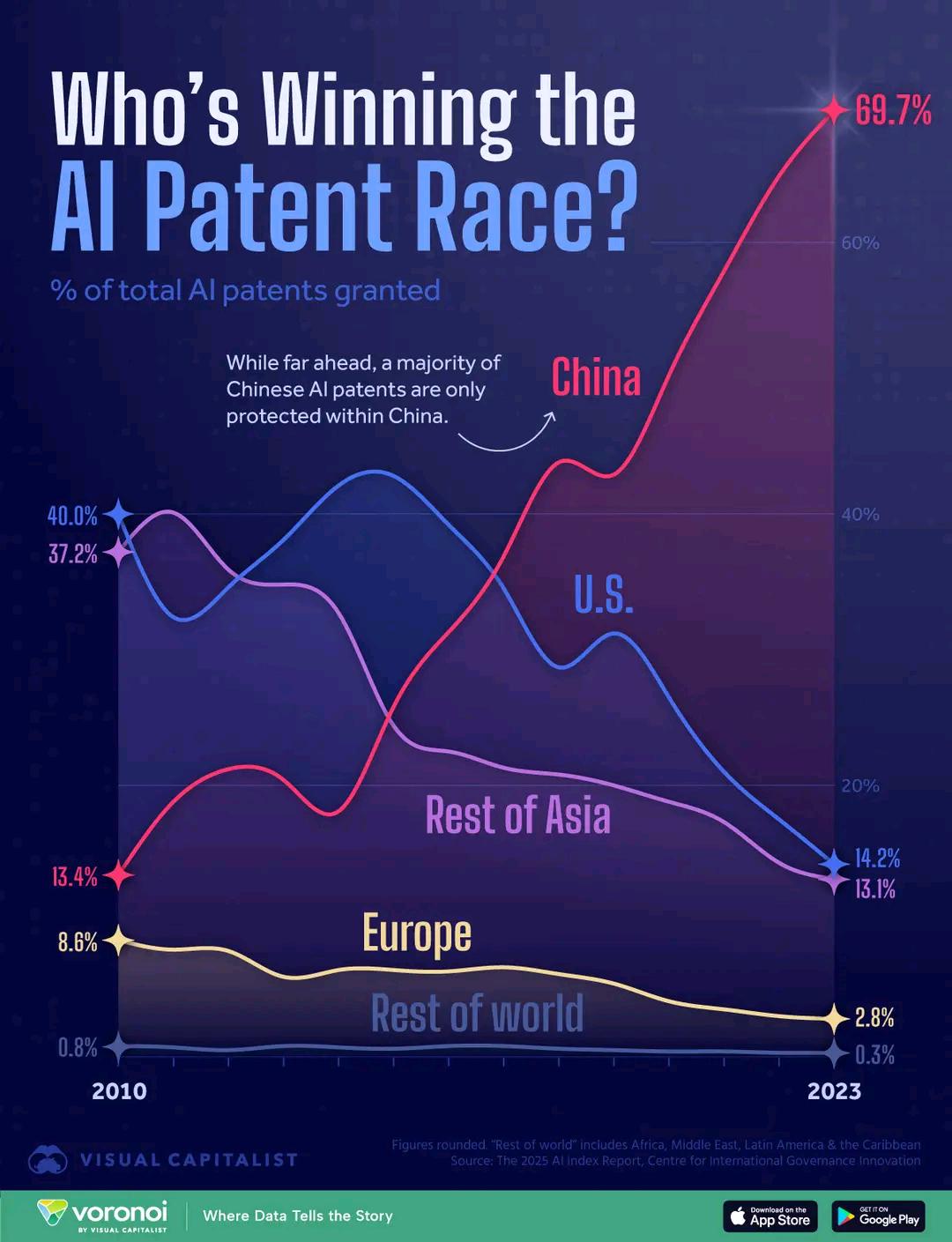
AI专利数量国家对比: 图表展示了各国在AI领域的专利数量对比情况,反映了不同国家在AI研发投入和产出上的差异。评论中提及中国专利申请成本相对较低可能影响数据解读 (来源: karminski3)
仿生手臂助力残疾人士: Open Bionics公司为15岁截肢女孩Grace安装仿生手臂,展示了AI和机器人技术在医疗健康和辅助科技领域的应用 (来源: Ronald_vanLoon)
AI辅助电影获奥斯卡资格引关注: 美国电影艺术与科学学院更新规则,明确使用AI等数字工具制作的电影同样有资格参评奥斯卡奖项,这引发了好莱坞内外的广泛讨论,关注AI对电影创作和行业标准的影响 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

立陶宛制定学校AI使用规则: 立陶宛正在制定在学校使用人工智能的相关规则,反映出教育领域开始规范化AI工具的应用 (来源: Reddit r/ArtificialInteligence)
# 🔥 聚焦
人形机器人在北京半马“首秀”,机遇与挑战并存: 在2025北京亦庄半程马拉松上,21支人形机器人队伍首次与人类选手同场竞技。天工Ultra、松延动力N2、卓益得行者二号分获前三名。比赛凸显了人形机器人的潜力,但也暴露了摔倒、续航、控制(多为遥控)等诸多挑战。赛后宇树科技回应其G1机器人摔倒事件,指出用户自行开发和操作对机器人表现影响巨大。此次赛事不仅展示了中国人形机器人产业的初步规模,也引发了关于技术成熟度、成本(松延N2预售价3.99万起)、商业化路径(租赁、工业应用)以及未来发展(AI大模型、自主学习)的广泛讨论。行业虽获资本青睐,但短期盈利难,市场化落地仍需时日 (来源: 摔倒的宇树和人形机器人的“求生”博弈, 从进厂到马拉松:人形机器人离“实用”还有多远?)
AI应用新范式:Agent+MCP成2025年爆款公式: 结合Agent的自主规划与行动能力以及MCP协议调用外部工具和数据的能力,正成为AI应用的新趋势。“扣子空间”、Fellou、Dia、GenSpark、智谱AutoGLM等产品相继涌现并引发关注。这些产品多从AI搜索转型而来,试图通过不同的产品设计(易用性、研究能力、落地执行)建立用户体验壁垒。尽管潜力巨大,但目前仍面临模型能力上限、跨平台信息获取、商业化模式等挑战。微软也推出面向桌面的多Agent系统UFO²,预示着AM(Agent+MCP)将成为AI产品的重要方向 (来源: 2025年,AI应用的爆款公式只有一个)
AI未来激辩:Hassabis预言十年治愈所有疾病,哈佛历史学家警告AGI灭绝人类: 谷歌DeepMind CEO Demis Hassabis在访谈中预测,AI将在5-10年内实现AGI,并有望在十年内治愈所有疾病,展示了Project Astra等AI进展。他认为AI将成为加速科学发现的终极工具。然而,哈佛历史学家Niall Ferguson发出警告,认为AGI的到来可能导致人类像马车一样被淘汰甚至灭绝,成为人类自己创造的“外星人”。他指出,制度僵化和全球生育率下降等趋势,可能使人类在AGI面前选择“退出历史舞台”。这场讨论凸显了对AGI潜力的极端乐观与对人类文明未来的深刻忧虑之间的巨大反差 (来源: 诺奖得主Hassabis豪言:AI十年治愈所有疾病,哈佛教授警告AGI终结人类文明, 哈佛历史学家预警:AGI灭绝人类,美国或将解体)
🎯 动向
机器人产业进展频出,商业化落地加速: 广交会首设服务机器人专区,国内厂商如穿山甲机器人、鸿绪锦科技等斩获大量海外订单,显示出中国服务机器人在全球市场的竞争力。同时,美的等公司的人形机器人正进行迭代,计划进入工厂“打工”。产业链上,PCB、传感器、新材料(如PEEK)等环节虽有布局,但规模化量产尚需时日,技术、成本、应用场景闭环是关键。多家厂商规划2025年实现千台级量产,有望推动产业链发展和数据积累,加速机器人向更实用阶段迈进 (来源: 机器人组团“营业”引爆声量场,产业链频刷进展)
特斯拉坚持纯视觉FSD,激光雷达路线面临挑战与机遇: 马斯克重申纯视觉方案对实现FSD的信心,认为摄像头加AI即可模拟人类驾驶,无需激光雷达。尽管面临成本下降(国产激光雷达已降至数百美元)和市场普及(已进入10万元级别车型)的现实,特斯拉仍坚持其路线,这对其算力、算法和数据提出极高要求。同时,禾赛、速腾聚创等激光雷达厂商凭借成本优势和技术迭代占据市场主导,并积极拓展海外市场及机器人等非车载业务。L3级自动驾驶的临近可能为激光雷达带来新机遇,因其在安全冗余和特定场景下的感知能力被认为不可或缺 (来源: 马斯克最新的AI驾驶方案,会终结激光雷达吗?)
Google Imagen 3/4 或在内测中: 传闻Google正在内部测试其下一代图像生成模型Imagen 3和Imagen 4,预示着Google可能在图像生成领域有新的大动作,旨在追赶或超越竞争对手 (来源: Google 又憋图像大招?传 Imagen 3/4 内测中。)
THUDM发布SWE-Dev系列编码模型: 清华大学知识工程和数据挖掘研究组(THUDM)发布了基于Qwen-2.5和GLM-4的SWE-Dev系列编码大模型,包括7B、9B和32B版本,旨在提升软件开发和编码任务的AI能力 (来源: Reddit r/LocalLLaMA)
Sand-AI发布开源视频生成模型Magi-1: Sand-AI发布了Magi-1,一个开源的自回归扩散视频生成模型,号称能生成无限时长的视频,支持文生视频、图生视频和视频生视频。该模型在物理理解基准测试中表现优异,但运行需要极高显存(约640GB VRAM),代码和模型已在GitHub和Hugging Face发布 (来源: Reddit r/LocalLLaMA)
Grok增加视觉、多语言音频及实时搜索能力: xAI宣布Grok模型增加视觉理解能力,并在语音模式中支持多语言音频输入和实时搜索功能,提升了其多模态交互和信息获取能力 (来源: grok, xai)
Grok 3 模型登陆 You.com: xAI 的旗舰模型 Grok 3 现已在搜索引擎 You.com 上线,用户可以在该平台体验 Grok 3 的能力 (来源: xai)
开源TTS模型Dia发布并受关注: 一款名为Dia的开源文本转语音(TTS)模型发布,号称效果媲美ElevenLabs、OpenAI等商业模型,支持零样本声音克隆和实时合成,可在MacBook上运行。该模型在Hugging Face上迅速获得关注,并被VentureBeat等媒体报道 (来源: huggingface, huggingface, huggingface)
展示特斯拉自动驾驶技术: 展示了特斯拉 Autopilot 自动驾驶技术的相关视频或信息,持续引发对自动驾驶技术进展的关注 (来源: Ronald_vanLoon)
机器人技术展示: 多个来源展示了不同的机器人应用,包括用于小工具组装的机械臂、TITA机器人评估、两栖机器人Copperstone HELIX Neptune以及机器人如何感知世界等,显示了机器人技术在不同领域的持续发展 (来源: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)
🧰 工具
GPT-SoVITS:强大的少样本语音克隆与文本转语音工具: RVC-Boss开发的GPT-SoVITS是一个开源项目(GitHub 44k+星标),仅需1分钟语音数据即可训练高质量TTS模型,实现少样本语音克隆。支持零样本TTS、跨语言推理(英日韩粤中),并集成WebUI工具箱(人声分离、数据集切分、ASR、标注等)。项目已更新至V4,持续优化音色相似度、稳定性和输出质量 (来源: RVC-Boss/GPT-SoVITS – GitHub Trending (all/daily))
清华团队推出SurveyGO(卷姬):AI驱动的文献综述与长报告生成工具: 基于清华NLP、OpenBMB和面壁智能团队研发的LLMxMapReduce-V2技术,SurveyGO能够高效处理海量文献(在线检索或上传文件),生成结构清晰、逻辑严谨、引用准确的万字长篇综述报告。该工具通过信息熵驱动的卷积机制优化大纲,并按层级生成内容,旨在大幅提升研究人员和内容创作者的文献调研与写作效率。用户可通过网页版体验 (来源: INTJ式学术暴力!清华团队造出“论文卷姬”:3分钟速通200小时文献综述, 如何 AI「拼好文」:生成万字报告,不限模型)
text-generation-webui推出便携版,专注llama.cpp: 为简化部署,text-generation-webui发布了针对llama.cpp的便携式、自包含版本(约700MB)。用户下载解压即可运行,无需安装Python、PyTorch等依赖。新版支持Win/Linux/macOS(含CPU/CUDA版本),优化了启动速度和用户体验,方便只想用llama.cpp本地推理的用户 (来源: Reddit r/LocalLLaMA)
LangSmith 增加告警功能并更新自托管版本: LangChain 的 MLOps 平台 LangSmith 新增实时告警功能,可监控错误率、延迟和反馈分数。其自托管版本更新至v0.10,包含告警、新评估UI、OpenTelemetry支持及性能优化,帮助开发者更早发现生产环境问题 (来源: LangChainAI, LangChainAI)
smolagents 更新,简化多MCP服务器管理: Hugging Face 的 smolagents 库发布新版本,引入 MCPClient 类,极大简化了同时管理多个MCP(模型通信协议)服务器连接的操作,方便构建和协调更复杂的Agent系统 (来源: huggingface)
Suna:开源Agent平台对标Manus: Kortix AI发布开源Agent平台Suna,定位为Manus的替代品。Suna集成了浏览器自动化、文件管理、网络爬虫、扩展搜索、命令行执行、网站部署及API集成等功能,使AI能协同操作这些工具,通过对话解决复杂问题和自动化工作流 (来源: karminski3)
Exa MCP现已支持免API搜索推特: Exa的MCP服务器更新,现支持直接搜索推特内容,无需推特API密钥。这为需要从推特获取信息的AI Agent提供了便利,但有用户反馈其对中文内容的爬取支持不佳 (来源: karminski3)
ChatUI-energy:实时显示AI对话能耗的界面: Hugging Face社区成员发布ChatUI-energy,一个能实时显示与开源模型(如Llama, Mistral, Qwen, Gemma等)对话所消耗能量的聊天界面。此举旨在提高AI使用的能源透明度,引发关于是否应成为标准功能的讨论 (来源: huggingface, huggingface)
利用AI进行Web应用开发、部署与优化: 文章分享了使用AI(如Lovable, Cursor, BrowserTools MCP)开发图片拼接网站的实践。涵盖从原型设计、编码、调试到利用Vercel+GitHub实现CI/CD自动化部署及域名解析的全流程,展示了AI在提升独立开发效率和网站运维方面的价值 (来源: AI 编码 + Vercel 部署 + 域名解析:一文搞定Web 应用开发上线全流程,氛围编码+MCP 审计优化。)
基于本地模型的”Her” OS1/Samantha 轻量级复刻: 开发者使用transformers.js和ONNX模型(Ultravox Llama 3.2 1B, Whisper Base, Kokoro TTS等)在浏览器本地复现了电影《Her》中的AI助手OS1/Samantha。项目展示了在约2GB模型大小下实现本地运行语音交互AI的可能性,并开源了代码 (来源: Reddit r/LocalLLaMA)
ChatWise结合MCP服务器实现RAG与数据同步: 用户分享了在ChatWise中使用系统指令,结合Pinecone(数据库)、Exa(搜索)和Time(时间)的MCP服务器,实现简单的RAG(检索增强生成)和数据同步的工作流配置示例 (来源: op7418)
📚 学习
斯坦福大学开放Transformer课程CS25: 斯坦福大学广受欢迎的Transformer研讨课程CS25向公众开放(Zoom直播/录播)。课程邀请了Andrej Karpathy, Geoffrey Hinton, Jim Fan, Ashish Vaswani等AI领域的顶尖学者和业界专家授课,内容覆盖LLM架构、多模态、科学应用、机器人学等前沿主题。课程网站提供日程和录像链接,并设有Discord社区供交流 (来源: karminski3, dotey, Reddit r/deeplearning, Reddit r/LocalLLaMA)
清华上交研究揭示RL对LLM推理能力的局限性: 清华大学与上海交通大学的最新研究指出,强化学习(RL)虽然能提升大模型在低采样数下的准确率(效率),但可能限制其在高采样数下解决更困难问题的能力边界。与基础模型相比,RL训练后的模型在pass@k指标上,高k值时的覆盖范围反而下降。研究认为RL更擅长优化现有能力而非拓展推理边界,当前RL方法可能因探索不足陷入局部最优 (来源: RL 是推理神器?清华上交大最新研究指出:RL 让大模型更会 「套公式」,却不会真推理, Reddit r/artificial)
Transformer作者团队:LLM在预训练阶段已具备反思能力: 由Transformer论文一作Ashish Vaswani领导的团队发表研究(arXiv:2504.04022),挑战了“反思能力主要源于RLHF”的观点。研究通过引入对抗性思维链,发现LLM(如OLMo-2)在预训练阶段就已展现出情境反思和自我反思能力,且该能力随预训练计算量增加而增强。简单提示词“Wait,”能有效激发显式反思,其效果堪比直接告知模型存在错误。这为理解预训练过程中的能力涌现提供了新视角 (来源: Transformer原作打脸DeepSeek观点?一句Wait就能引发反思,RL都不用)
ChemAgent:自更新记忆库提升LLM化学推理能力: 耶鲁、斯坦福等机构提出ChemAgent框架,通过引入包含规划、执行和知识记忆的动态自更新记忆库,显著提升LLM在化学推理任务上的准确率(在SciBench数据集上平均提升10%-37%)。该框架模拟人类学习,分解任务并利用结构化记忆解决问题,尤其在计算和单位转换精度上改进明显。研究分析了记忆相似度、数量与性能关系,并指出了问题理解、推理规划和记忆选择方面的局限性 (来源: 准确率飙升46%!耶鲁-斯坦福「自更新记忆库」新框架,重塑LLM化学推理能力)
华南理工大学在分布式进化计算领域取得系列进展: 华南理工大学计算智能团队围绕“多智能体共识与合作中的分布式进化计算”持续研究,取得系列成果:发表该交叉领域综述;提出MASOIE算法(内外部学习)、MACPO算法(目标激励)、CCSA步长自适应机制、MASTER算法(贡献度协作)等创新方法,并在无线传感器网络定位等场景验证有效性。团队还组织了首届分布式黑盒共识优化竞赛 (来源: 打破共识优化壁垒!华南理工深耕分布式进化计算,实现多智能体高效协同)
从零构建DeepSeek视频教程系列: Vizuara在YouTube上发布“从零构建DeepSeek”系列视频教程,已更新13讲,内容涵盖DeepSeek基础、Token处理、注意力机制(自注意力、因果、多头、多查询、分组查询、多头潜在)、KV Cache等核心概念讲解与代码实现。旨在深入解析DeepSeek架构,计划共40+小时,35-40集 (来源: karminski3, Reddit r/LocalLLaMA)
Pinterest提出OmniSearchSage:统一嵌入模型提升多任务检索: Pinterest研究论文介绍OmniSearchSage,一种统一查询嵌入模型,通过多任务学习训练,能同时检索pins、产品和相关查询。模型融合GenAI标题、用户board信号和行为数据,可直接集成到PinSage等现有系统,在搜索、广告和延迟方面取得显著改进 (来源: Reddit r/MachineLearning)
FlowReasoner:基于查询动态调整的多智能体工作流: 新论文提出FlowReasoner方法,旨在为每个用户查询即时推理出专属的多智能体工作流。通过推理SFT和GRPO强化学习,模型能根据执行反馈动态改写工作流(如代码生成、审查、测试、修订的组合顺序)。该方法在Code Interpreter场景验证,展示了工作流动态适应查询需求的潜力 (来源: dotey)
LangChain教程:使用LlamaIndex构建合规报告生成工作流: LlamaIndex发布视频教程,演示如何利用其Agentic Workflow生成合规报告。教程展示了设置索引、定义模式、使用语义搜索查找法规,并结合LLM处理文本、比较合同、生成摘要的流程 (来源: jerryjliu0)
LangChain教程:自愈代码生成Agent: LangChain发布利用OpenEvals和E2B沙箱构建自愈代码生成Agent的教程。核心思想是在AI生成代码后,增加一个使用评估工具进行验证和修正的反思步骤,提高代码质量和可靠性 (来源: LangChainAI)
Anthropic分析发现Claude具有内在道德准则: Anthropic对70万次Claude对话进行分析后,发现其AI模型展现出一种内在的道德准则。这一发现来自对大规模真实用户交互数据的研究,可能对AI安全和对齐研究具有重要意义 (来源: Reddit r/ClaudeAI, Reddit r/artificial)
Google提出”经验时代”应对AI训练数据稀缺: Google研究人员(包括David Silver)发表论文《The Era of Experience》,提出让AI Agent通过与环境交互自主生成经验数据来训练自身,以克服当前依赖大规模人类标注数据所面临的瓶颈。这可能预示着AI训练范式向更自主学习方向的转变 (来源: Reddit r/artificial)
免费证书和课程资源列表: GitHub仓库 cloudcommunity/Free-Certifications 汇集了大量免费在线课程及认证资源,涵盖IT、云、AI、安全、营销等领域。其中AI相关资源包括freeCodeCamp的Python机器学习、Databricks的GenAI基础、IBM Cognitive Class的AI课程、谷歌云技能提升平台的AI/ML入门、HuggingFace的深度强化学习课程等 (来源: cloudcommunity/Free-Certifications – GitHub Trending (all/daily))
LLM用于代码编辑的可靠性测试: 用户分享了测试多款LLM(如ChatGPT等)在辅助深度学习代码编写任务中可靠性的视频。这类测试有助于了解当前AI编码助手在实际研发场景中的表现、优势和局限性 (来源: Reddit r/deeplearning)
💼 商业
美国关税战冲击中国AI硬件初创企业: 美国对华加征高额关税(部分达125%),严重打击了依赖美国市场的中国AI硬件初创公司(如AI玩具、智能眼镜)。高关税压缩利润甚至导致亏损,迫使部分企业暂停对美发货。虽然智能眼镜等暂获豁免,但前景不明。行业依赖的“灰清”模式风险加大。这促使企业反思对单一市场的依赖,加速全球化布局以分散风险,并可能影响后续融资估值 (来源: 襁褓中的AI硬件,迎接最激烈的关税战)
智元机器人深度拆解:产品、技术与商业模式: 智元机器人由“稚晖君”彭志辉等创立,定位通用具身机器人。产品线包括工业商业场景的“远征”系列和轻量化开源的“灵犀”系列。技术核心是软硬协同与数据闭环,自研关节模组、灵巧手及启元大模型等软件栈。商业模式涵盖硬件销售、订阅服务和生态分成。已完成8轮融资,估值150亿,获高瓴、比亚迪、腾讯等投资,并与供应链伙伴及地方政府深度合作 (来源: 智元机器人深度拆解:人形机器人独角兽进化论)
追觅内部孵化3D打印项目「原子重塑」获数千万元融资: 由追觅科技孵化的原子重塑科技(AtomFab)获追创创投数千万元天使轮投资。该公司聚焦消费级3D打印,利用AI技术提升易用性、稳定性和效率。将复用追觅的电机、传感、AI交互技术及供应链,降低成本,加速产品化。产品优先布局欧美市场,利用追觅海外售后网络提供支持。首款产品预计2025年下半年发布 (来源: 追觅内部孵化3D打印项目获数千万融资,优先布局欧美等海外市场|硬氪首发)
英伟达GPU垄断地位或面临挑战: 分析认为,尽管英伟达GPU出货量增长,但其长期垄断地位面临云巨头(Google, MS, Amazon, Meta)自研芯片(TPU, Maia, Trainium, MTIA)及系统级优化的挑战。云巨头能更好地垂直整合、定制硬件和优化分布式系统(网络、冷却、软件),英伟达在这方面布局相对不足。推理任务占比提升、AMD竞争加剧以及CPU推理的潜力也构成压力。英伟达虽在努力适应(如Blackwell, Spectrum-X),但结构性挑战犹存 (来源: 计算的未来:英伟达王冠正摇摇欲坠)
传闻OpenAI有意收购Chrome浏览器: 据Bloomberg报道,若Google因反垄断案被强制拆分,OpenAI可能考虑收购其Chrome浏览器业务。此传闻反映了AI巨头对掌握用户入口和数据的战略意图,但其真实性及可行性取决于Google反垄断案的最终结果 (来源: karminski3)
利用GenAI实现业务成果的策略: 福布斯文章提出了9种策略,旨在帮助企业将生成式AI(GenAI)从实验阶段推向实际业务应用,以驱动效率提升和创新,获取可衡量的商业价值 (来源: Ronald_vanLoon)
华为新芯片或对英伟达构成竞争: 社交媒体讨论指出,华为发布的新AI芯片可能对英伟达的市场地位构成挑战,尤其在中国市场,并可能影响未来的中美科技竞争和关税谈判格局 (来源: Reddit r/ArtificialInteligence)
🌟 社区
DeepSeek引发的淘金热与反思: DeepSeek走红后,引发了围绕其变现的浪潮,包括内容创作(批量生产短视频脚本)、知识付费(售卖教程)和代运营。然而,许多尝试者面临内容同质化、平台限流及变现困难等问题。文章反思,当前环境下,利用信息差售卖课程的“中间商”或许是更大赢家,而非直接使用者。同时,DeepSeek自身也存在服务器繁忙、回答模式化等局限性 (来源: DeepSeek走红三个月,第一批想靠它赚钱的怎么样了?)
AI作弊工具开发者获融资引发伦理争议: 21岁哥大学生Chungin Lee因开发面试作弊AI工具被停学,后成立公司Cluely并将工具扩展至更多场景,获530万美元融资。他认为AI辅助是效率提升,而非作弊。此事引发激烈讨论:支持者视其为创新,批评者担忧破坏公平、模糊能力界限,如《黑镜》情节。事件触及AI伦理、教育公平和能力定义的深层问题 (来源: 21岁学生开发AI作弊工具被哥大停学,转身拿下530万美元融资,网友:《黑镜》成真, 靠开发AI作弊神器成名,21岁小伙遭学校开除不足一月后,转身拿下530万美元融资)
美国签证政策收紧,AI人才或外流: 近期美国大规模吊销国际学生(含AI博士生)签证,理由模糊、过程缺乏透明度,可能涉及AI筛查误判。此举引发学界担忧,认为正损害美国对顶尖AI人才的吸引力,多位在顶尖机构的研究者考虑离开。这或导致美国AI研究实力受损。已有学生联合起诉并获临时限制令 (来源: 加州AI博士一夜失身份,谷歌OpenAI学者掀「离美潮」,38万岗位消失AI优势崩塌)
开源模型发展现状讨论: 社区热议开源大模型:期待Qwen 3,Llama 4接受度不高,推理能力提升遇瓶颈?多模态模型潜力被低估,中国持续主导开源。讨论强调需区分开源与闭源模型,并指出推理瓶颈可能关乎模型多样性与RL扩展挑战 (来源: natolambert)
OpenAI o3模型搜索能力获赞: 用户反馈OpenAI o3模型在信息检索方面表现出色,即使对非常小众的信息,也能在无需大量上下文的情况下准确找到,交互体验自然 (来源: gdb)
开源TTS的意义与影响: 社区在讨论Dia TTS模型时指出,其高质量表现证明训练SOTA TTS模型已不再是巨头专属。AI行业的知识和工具积累产生了复合效应,使得先进技术的训练门槛降低,开源力量正加速技术普及和平民化 (来源: huggingface, huggingface)
Meta举办LlamaCon 2025,庆祝开源社区: Meta宣布将举办LlamaCon 2025活动,旨在表彰和庆祝Llama开源社区的贡献与成就,并将分享Llama模型和工具的最新进展与未来规划,持续投入开源生态建设 (来源: AIatMeta)
AI是否真正“智能”引讨论: 社区转发文章《我们需要停止假装AI是智能的》,引发关于当前AI技术能力边界和“智能”定义的探讨。讨论可能涉及AI的理解、推理、意识等层面与人类智能的差异 (来源: Ronald_vanLoon)
ChatGPT使用体验:连接丢失与诚实度测试: 用户抱怨频繁遇到ChatGPT“网络连接丢失”问题,影响使用体验。同时,有用户分享让ChatGPT利用记忆功能给出对其“真实看法”的提示词,探索AI个性化交互和潜在的“主观”表达 (来源: natolambert, dotey)
机器人领域发展乐观情绪: Hugging Face联合创始人评论认为,得益于开源硬件、强化学习进展和人才聚集,2025年的机器人实验室充满活力和乐趣,反映了业内对机器人技术快速发展的积极预期 (来源: huggingface)
Gemini Deep Research实用性受肯定: 用户分享使用Gemini Deep Research功能验证推特信息可靠性的案例,展示了其在快速信息核查和提供深度研究背景方面的实用价值 (来源: dotey)
对开源AI库的批评与维护: 社区观察到对开源AI库的负面评论增多,呼吁理性看待,指出批评可能基于过时信息或片面指标,并鼓励批评者参与共建更好的版本 (来源: natolambert)
猜测AI游戏体验: 用户对未来AI驱动的游戏体验形态表示好奇,推测可能类似VRChat的交互,但也对纯语音操控的便捷性提出疑问 (来源: karminski3)
ChatGPT图像放大功能讨论: 用户发现用ChatGPT放大图片并非真正的超分辨率,而是重新生成相似图像。社区评论确认了这一点,并讨论了AI图像生成与编辑的区别 (来源: Reddit r/ChatGPT)
ChatGPT生成世界想象图: 用户让ChatGPT生成想象中的世界,结果是一张田园诗般的公园图。社区指出了其中的逻辑问题和潜在偏见,反映了当前AI图像生成在理解和创造力上的局限 (来源: Reddit r/ChatGPT)
老旧LLM模型MythoMax13B流行原因探讨: 社区讨论为何基于Llama2的MythoMax13B在RPG场景仍受欢迎。原因可能包括:成本低(常作免费选项)、性能稳定、用户熟悉其提示方式,以及早期教程的推广效应 (来源: Reddit r/LocalLLaMA)
寻求本地隐私过滤工具: 用户寻求能在本地运行的工具或SLM,用于在提示发送给LLM前自动进行隐私信息脱敏,并在收到回复后复原,以保护数据安全 (来源: Reddit r/OpenWebUI)
关于Anthropic警告“全AI员工”的讨论: Anthropic关于“全AI员工”一年内出现的警告引发社区质疑,评论者认为这是夸大其词的宣传,并指出Anthropic自身服务的稳定性问题 (来源: Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/ClaudeAI)
全球对AI灭绝风险的担忧: 调查结果显示,全球多数民众认为应严肃对待AI可能导致人类灭绝的风险,反映了公众对强人工智能潜在风险的普遍关切 (来源: Reddit r/artificial)
AI生成文本的“机器味”与人性化技巧: 用户分享经验,指出AI生成文本常因缺乏特定语境、过于正式和完美而显得“没有人味”。建议通过明确场景、提供范例、调整随机性、加入具体细节、人工编辑和保留微小瑕疵等方法,使AI写作更自然、更具“人情味” (来源: Reddit r/artificial)
关于Claude Code能否通过Claude Max使用的猜测: 用户推测是否能通过订阅高阶的Claude Max服务来间接使用(可能更具成本效益的)Claude Code模型,并讨论这种模式的潜在价值。这反映了用户对不同模型定价和功能打包策略的关注 (来源: Reddit r/ClaudeAI)
幽默模仿o3模型本地行为: 用户分享了一个恶搞性质的系统提示词,让本地LLM模仿OpenAI o3模型被部分用户批评的缺点(如回答简短、代码错误、行为烦人),以此表达对o3模型的不满和进行社区调侃 (来源: Reddit r/LocalLLaMA)
OpenWebUI连接MCP代理服务器问题求助: Kubernetes用户在配置OpenWebUI时遇到技术难题,无法从Web界面访问同一pod内的MCP代理服务器,寻求社区的技术支持和解决方案 (来源: Reddit r/OpenWebUI)
本地MCP服务器安全实践讨论: 社区讨论本地运行MCP服务器的安全最佳实践,建议包括使用stdio模式、限制SSE模式访问本地或使用token认证,强调对提示注入和凭证窃取风险的普遍关注 (来源: Reddit r/ClaudeAI)
Agent-to-Agent (A2A) 协议支付机制探讨: 社区关注Google A2A协议中缺乏内置支付机制的问题,认为这可能阻碍Agent经济生态发展,并探讨了如认证令牌绑定账单、托管流程、AgentSkill内嵌定价等潜在解决方案 (来源: Reddit r/artificial)
对AI过度依赖的警示: 用户分享Google搜索AI给出矛盾答案的经历,警示不应完全依赖AI做决策。社区评论解释了LLM概率性、训练数据偏差等导致不确定性的原因,建议将AI用作辅助研究工具 (来源: Reddit r/ArtificialInteligence)
在OpenWebUI中使用Qdrant进行RAG的疑问: 用户寻求在OpenWebUI中集成Qdrant向量数据库以实现RAG的具体方法,包括如何让UI使用数据库数据以及是否需要retriever脚本等技术细节 (来源: Reddit r/OpenWebUI)
Google与ChatGPT搜索效果对比讨论: 用户发布对比图引发讨论,一些人认为ChatGPT优于Google搜索,另一些人则认为Google Gemini表现出色,且拥有NotebookLM等工具。讨论反映了用户对不同AI搜索/问答工具的主观体验和评价差异 (来源: Reddit r/ChatGPT)
看好Character Training研究方向: 行业观察者预测Character Training(AI模拟特定角色或个性)将成为一个重要的学术研究热点,认为当前是发表相关开创性论文的好时机 (来源: natolambert)
💡 其他
人形机器人形态的合理性探讨: 文章深入分析为何机器人常被设计成人形:核心在于适应为人类设计的物理世界(工具、环境、交互)。人形机器人能更好地融入现有基础设施,使用人类工具,并通过拟人化特征促进人机交互。文章回顾了机器人发展史,对比了中美等国竞争格局,并讨论了技术挑战(平衡、控制、成本)与未来普及前景 (来源: 外媒深度:机器人为什么要做成人形?)
AI时代中国的就业挑战与对策: 报告分析了AI对中国就业市场的冲击,特别是对中低技能群体和区域平衡的挑战。借鉴美国经验,提出中国应加强职业培训(尤其数字化技能)、完善社保(覆盖新业态)、推动产业AI融合与区域协调、健全算法监管与数据隐私保护、强化多部门协同与就业监测,以应对挑战并抓住机遇 (来源: 人工智能时代:中国如何稳住、提升就业基本盘)
利用AI重塑个人IP叙事: 文章指导如何使用AI(如ChatGPT)分析个人经历,挖掘隐藏主题,重构关键转折点叙事,塑造独特语言体系,以打造有吸引力的个人IP。提供了具体步骤(数据收集、AI分析、结构重塑、迭代验证)和技巧(反向构建、情感放大、对比强化),并警示避免过度美化、同质化和缺乏情感的陷阱 (来源: 做个人IP的第一步:用AI改写你的人生叙事)
AI在环境保护领域的应用: 英伟达在世界地球日展示其AI技术(Jetson, Earth-2等)在环保领域的应用:通过预测洋流减少航运排放、实时防护野火与偷猎、提供精准风暴预报、探测小行星等,体现AI在应对气候变化和保护生态系统方面的潜力 (来源: nvidia, nvidia, nvidia)

AI用于改善客户服务: AI驱动的联络中心技术旨在通过自动化和智能化提升客户服务体验,解决传统客服痛点,提高效率和客户满意度 (来源: Ronald_vanLoon)
AI生成逼真自拍/搞怪图片提示词分享: 用户分享了利用AI图像生成工具(GPT-4o/Sora)制作“普通”自拍和搞怪图片(如名人马桶刷)的提示词。展示了AI在创意图像生成方面的能力,可用于娱乐或内容创作 (来源: dotey, dotey, dotey)

AI对就业岗位的影响分析: Visual Capitalist制作的信息图表直观展示了最可能受AI影响的各类工作岗位,为个人职业规划和政策制定者提供了参考 (来源: Ronald_vanLoon)
AI用于迪拜道路缺陷检测: 迪拜采用AI技术检测道路缺陷,是AI在智慧城市和基础设施维护领域应用的具体实例,有助于提高维护效率和道路安全 (来源: Ronald_vanLoon)
AI使用框架总结: 信息图总结了6种应用AI的框架或方法论,为希望系统性利用AI解决问题或进行创新的个人和组织提供了思路指引 (来源: Ronald_vanLoon)
AI专利数量国家对比: 图表显示中国在AI专利申请数量上领先,但也引发关于专利质量和申请成本差异的讨论。数据反映了各国在AI研发投入和知识产权布局上的活跃程度 (来源: karminski3)
仿生手臂助力残疾人士: Open Bionics为截肢女孩安装仿生手臂的案例,展示了AI、机器人和3D打印等技术在改善残疾人士生活质量方面的积极作用和人文关怀 (来源: Ronald_vanLoon)
AI辅助电影获奥斯卡资格引关注: 奥斯卡主办方确认AI辅助制作的电影有资格参评,引发行业对AI在电影创作中角色、创意归属以及未来评奖标准影响的讨论 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

立陶宛制定学校AI使用规则: 立陶宛着手制定在学校场景下使用AI的规则,表明教育系统开始正视并规范AI工具在教学和学习中的应用,以平衡机遇与风险 (来源: Reddit r/ArtificialInteligence)