
关键词:AI, GPT-4.1, 智谱AI IPO, 英伟达AI超算投资, 亚马逊AI资本支出, AI Agent互操作协议, DeepSeek用户规模
🔥 聚焦
OpenAI发布GPT-4.1系列模型,API性能提升并弃用GPT-4.5: OpenAI于4月15日通过API发布了GPT-4.1、GPT-4.1 mini和GPT-4.1 nano三款新模型,旨在全面超越GPT-4o系列。新模型拥有最高100万Token的上下文窗口,知识库更新至2024年6月。GPT-4.1在编码能力(SWE-bench Verified得分54.6%,较GPT-4o提升21.4%)、指令遵循(MultiChallenge得分38.3%,较GPT-4o提升10.5%)和长上下文视频理解(Video-MME得分72.0%,较GPT-4o提升6.7%)方面表现突出。值得注意的是,GPT-4.1 nano是首款nano模型,性能优于GPT-4o mini且成本更低。同时,OpenAI宣布将在3个月后(7月14日)下架GPT-4.5 Preview API,称其为研究预览版,未来会将开发者喜欢的特性融入新模型。此次发布被视为OpenAI区分API模型与ChatGPT产品线,并直接对标Google Gemini系列的战略举措。 (来源: 36氪, 新智元1, AI科技评论, Reddit r/LocalLLaMA, Reddit r/artificial)
智谱AI启动IPO辅导并开源新模型,估值超200亿: 国内大模型“六小虎”之一的智谱AI(智谱华章)已于4月14日在北京证监局办理辅导备案,正式启动IPO进程,中金公司担任辅导机构。智谱AI由清华大学知识工程实验室孵化,核心团队成员多来自清华,已累计融资超150亿元,近期估值超200亿元人民币。在启动IPO的同时,智谱AI宣布大规模开源GLM-4-32B/9B系列模型,包括基座、推理、沉思三类,遵循MIT协议可免费商用。其中,32B参数的推理模型GLM-Z1-32B-0414在部分任务上性能比肩671B参数的DeepSeek-R1,其API极速版GLM-Z1-AirX推理速度达200 tokens/s,高性价比版价格仅为DeepSeek-R1的1/30。公司还启用了新域名z.ai作为模型免费体验平台。此举展现了智谱AI在技术自研、商业化探索和开源生态建设上的全面布局。 (来源: 智东西, InfoQ, 量子位, 极客公园, 雷递, 公众号)

英伟达斥资5000亿美元在美国本土制造AI超算: 英伟达宣布一项重大计划,将在未来四年内投资5000亿美元,首次在美国本土制造AI超级计算机。该计划涉及与多家行业巨头合作,包括台积电(在亚利桑那州生产Blackwell芯片)、富士康和纬创(在德克萨斯州建设超算工厂)、安靠和矽品(在亚利桑那州进行封装测试)。英伟达CEO黄仁勋表示,此举旨在满足日益增长的AI芯片和超算需求,增强供应链韧性,并利用英伟达的AI、机器人(Isaac GR00T)和数字孪生(Omniverse)技术设计和运营工厂。该计划被视为在美国政府推动本土制造(如《芯片法案》)和地缘政治背景下的战略部署,旨在提升美国在全球AI基础设施竞赛中的地位,但也面临供应链复杂性、技术工人短缺和政策不确定性等挑战。 (来源: 新智元1, 新智元2, Reddit r/artificial)

亚马逊计划投资超千亿美元加码AI,应对竞争与抓住机遇: 亚马逊CEO安迪·贾西在2024年度致股东信中透露,公司计划在2025年进行超1000亿美元的资本支出,大部分将用于AI相关项目,包括数据中心、网络设备、AI硬件(如自研芯片Trainium)及生成式AI服务(如自研大模型Nova系列、Bedrock平台、升级版Alexa+、购物助手Rufus)。这一巨额投资(接近年收入1/6)反映了亚马逊将AI视为应对电商领域激烈竞争(来自SHEIN、Temu、TikTok等)和抓住历史性机遇的关键。贾西强调AI将改变搜索、编程、购物等规则,不投入将失去竞争力。目前亚马逊AI业务年收入已达数十亿美元,同比增长达三位数。此举也显示了亚马逊在云服务(AWS)领域面临微软Azure、谷歌云等对手竞争下,持续投入以巩固领先地位的决心。 (来源: 36氪)
🎯 动向
AI Agent互操作协议MCP与A2A标准受关注: AI智能体领域正迎来标准化交互协议的竞争。Anthropic提出的MCP(模型上下文协议)旨在统一大模型与外部工具、数据源的通信,被誉为“AI的USB-C”,已获OpenAI、谷歌等支持。谷歌则开源了A2A(Agent2Agent)协议,专注于不同供应商、框架的智能体之间的安全高效协作,旨在打破生态壁垒。这两大协议的出现标志着AI从单体智能向协作网络演进,但也引发了关于“协议即权力”、数据垄断和生态壁垒(“小院高墙”)的讨论。掌握标准制定权可能重构AI产业链格局,并对AI与物理世界(机器人、物联网)的融合产生深远影响。阿里云、腾讯云等国内厂商也已开始布局支持MCP。 (来源: 36Kr)

QuestMobile报告:DeepSeek颠覆国内AI应用格局,用户规模达2.4亿: QuestMobile发布的《2025年第一季度AI应用市场竞争分析》报告显示,受DeepSeek模型及其应用爆火影响,国内原生AI App市场格局被彻底颠覆。截至2025年2月底,原生AI App月活跃用户规模达2.4亿,较1月增长近九成。DeepSeek App以1.94亿月活用户登顶,字节跳动的豆包(1.16亿)和腾讯元宝(4164万)位列二三,取代了之前的Kimi等。报告指出,DeepSeek的开源普惠效应推动了头部玩家接入和AI应用爆发,形成了包括AI综合助手、AI搜索等23个赛道,其中AI搜索竞争最为激烈。目前“多模型驱动”已成头部App标配,竞争焦点转向产品设计与运营。 (来源: QuestMobile)

智象未来开源17B文生图模型HiDream-I1,效果比肩GPT-4o: 国内公司智象未来(Zxiang Future)开源了其17B参数的文生图大模型HiDream-I1,采用宽松的MIT许可证,允许商用。该模型在Artificial Analysis等平台的竞技场和基准测试(如HPSv2.1、GenEval、DPG-Bench)中表现出色,生成图像的真实感、细腻度和指令遵循能力被认为可与GPT-4o及FLUX 1.1 Pro相媲美,甚至在某些方面更优。HiDream-I1采用了Sparse Diffusion Transformer(Sparse DiT)架构,融合MoE技术以提升性能和效率。公司还宣布即将开源支持交互式图像编辑的HiDream-E1模型,二者结合旨在提供“开源版GPT-4o”的图像生成与编辑体验。模型已在Hugging Face开放,并在Vivago平台提供体验。 (来源: 机器之心1, 机器之心2)
字节跳动发布7B视频基础模型Seaweed,低成本高效率: 字节跳动Seed团队发布了名为Seaweed(谐音Seed-Video)的视频生成基础模型。该模型参数量仅为70亿,据称使用66.5万H100 GPU小时训练完成(相当于1000卡训练约28天),成本相对较低。Seaweed能够根据文本生成不同分辨率(原生支持1280×720,可上采样至2K)、任意宽高比和时长的视频。模型支持图像到视频生成、参考主体控制(单/多图)、与数字人方案Omnihuman结合生成口型同步视频、视频配音等功能。技术上采用DiT+VAE架构,结合全面的数据处理流程和多阶段多任务训练策略(预训练、SFT、RLHF),并进行了系统级优化以提升训练效率。团队由前谷歌视频生成负责人蒋路博士等人领导。 (来源: 量子位)

阿里通义发布数字人视频生成模型OmniTalker: 阿里通义实验室HumanAIGC团队推出了新的数字人视频生成大模型OmniTalker。该模型旨在解决传统级联方法(TTS+音频驱动)带来的延迟、音画不同步、风格不一致等问题。OmniTalker是一个端到端的统一框架,输入文本和一段参考音视频,即可实时生成同步的语音和数字人视频,同时保留参考源的声音和面部说话风格。其核心架构采用双流DiT(Diffusion Transformer),分别处理音频和视觉信息,并通过新颖的音视频融合模块确保同步与风格一致。模型利用上下文参考学习模块从参考视频中捕捉风格特征,无需额外训练风格提取器。目前项目已在魔搭社区和HuggingFace开放体验。 (来源: 机器之心)

快手发布可灵AI视频模型2.0版本: 快手旗下的可灵AI视频生成模型发布了2.0版本,据称在运镜幅度、物理规律遵循、人物表演、动作稳定性及语义理解等方面有显著提升。用户评测显示,新版本在处理复杂交互(如霸王龙撞断树木)、精细动作(如摘眼镜)、多人场景以及模拟真实光影方面表现出色,生成视频的真实感和电影感大幅增强,效果被认为超越了之前的1.6版本,并达到了行业领先水平。尽管在高速群像运动和极端物理模拟(如投篮)方面仍有提升空间,但其综合表现被认为已开始挑战专业制作水准。用户可通过官网klingai.com体验新版本。 (来源: 公众号, op7418)

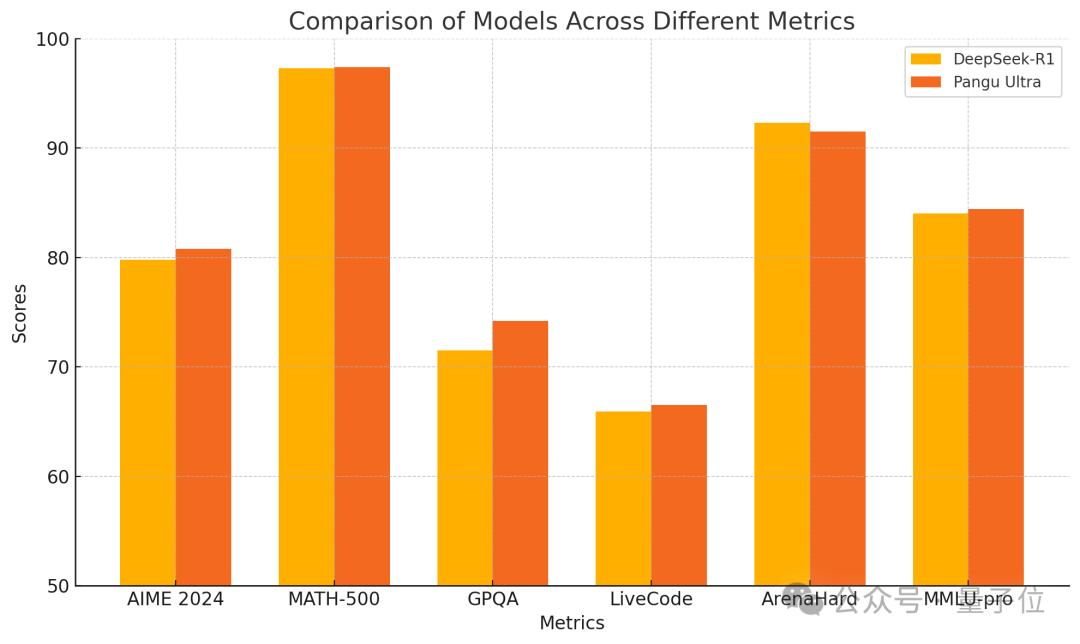
华为发布盘古Ultra 135B密集模型,纯昇腾训练性能优越: 华为公布了其盘古大模型系列的新成员——Pangu Ultra。这是一款参数量为135B的密集(Dense)模型,完全基于华为昇腾AI计算集群(8192个NPU)训练,未使用英伟达GPU。据报告,盘古Ultra在数学推理(AIME 2024, MATH-500)和编程(LiveCodeBench)等任务上表现出色,性能可与更大规模的MoE模型如DeepSeek-R1相媲美。技术上,模型采用了创新的深度缩放Sandwich-Norm层归一化和TinyInit参数初始化策略,有效解决了训练超深网络(94层)时的不稳定性问题,实现了平稳训练且无损失尖峰。通过系统级优化,训练实现了超过52%的算力利用率(MFU)。 (来源: 量子位)
Canopy Labs开源情感语音合成模型Orpheus: Canopy Labs发布并开源了名为Orpheus的文本转语音(TTS)模型系列。该模型基于Llama架构,首发版本为30亿参数,后续将推出1B、0.5B、0.15B等更小版本。Orpheus的特点在于能生成具有高度拟人化情感、语调和节奏的语音,甚至能从文本中推断并生成笑声、叹息等非语言声音,实现“共情”表达。模型支持零样本语音克隆和通过标签控制情感语调。其采用流式推理,延迟低至100-200ms,在A100 40GB显卡上推理速度快于实时播放。开发者声称其性能超越现有开源及部分闭源SOTA模型,旨在打破闭源TTS模型的垄断。模型及代码已在GitHub和Hugging Face开放。 (来源: 新智元)

浙大与字节跳动联合发布MegaTTS3语音合成模型: 浙江大学赵洲教授团队与字节跳动合作,发布并开源了第三代语音合成模型MegaTTS3。该模型以仅0.45B的轻量级参数规模,实现了高质量的中英双语语音合成,并在零样本语音克隆方面表现出色,能够生成自然、可控且个性化的语音。MegaTTS3重点突破了语音-文本稀疏对齐、生成可控性以及效率与质量的平衡。技术亮点包括用于口音强度等多维度控制的“多条件分类器自由指导”(Multi-Condition CFG)技术,以及将采样速度提升3倍的“分段整流流加速”(PeRFlow)技术。模型在LibriSpeech等基准上展现了领先的自然度(CMOS)和说话人相似度(SIM-O)。 (来源: PaperWeekly)

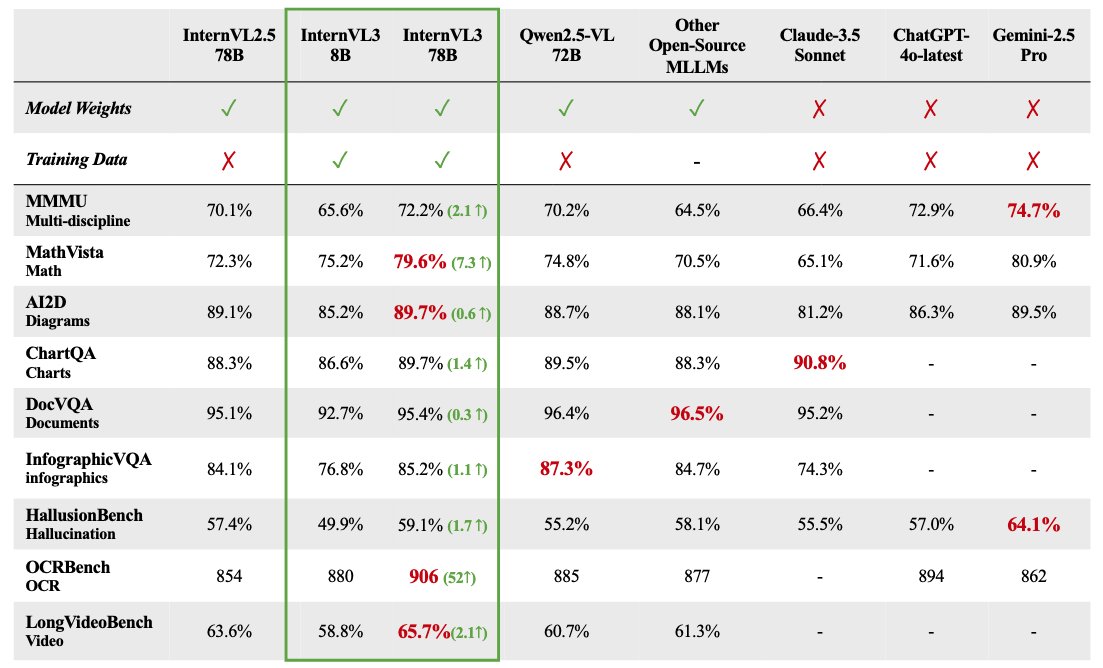
InternVL 3 多模态大模型系列开源: OpenGVLab发布了InternVL 3多模态大模型系列,参数规模从1B到78B不等,已在Hugging Face上开放。据称,78B参数版本在MMMU基准测试上得分72.2,刷新了开源多模态模型的SOTA记录。InternVL 3的技术亮点包括:采用原生多模态预训练,同时学习语言和视觉;引入可变视觉位置编码(V2PE)以支持扩展上下文;使用了先进的后训练技术如SFT和MPO;并应用了测试时缩放策略来增强数学推理能力。训练数据和模型权重均已开放给社区使用。 (来源: huggingface)
GPT-4.1实测性能分析:编码增强但推理落后: OpenAI发布的GPT-4.1系列模型在初步实测和基准评估中表现出复杂的性能图景。虽然在代码生成任务上展现出较GPT-4o显著的进步,例如能更好地完成物理模拟、游戏开发等任务,并在SWE-Bench上得分很高。然而,在更广泛的推理、数学和知识问答基准(如Livebench、GPQA Diamond)上,GPT-4.1的表现仍落后于Google的Gemini 2.5 Pro和Anthropic的Claude 3.7 Sonnet。分析认为,GPT-4.1可能是对GPT-4o的增量更新,或从GPT-4.5蒸馏而来,其发布策略可能旨在通过API提供更具性价比、特定优化的模型选项,而非全面超越竞争对手的旗舰模型。 (来源: 新智元)
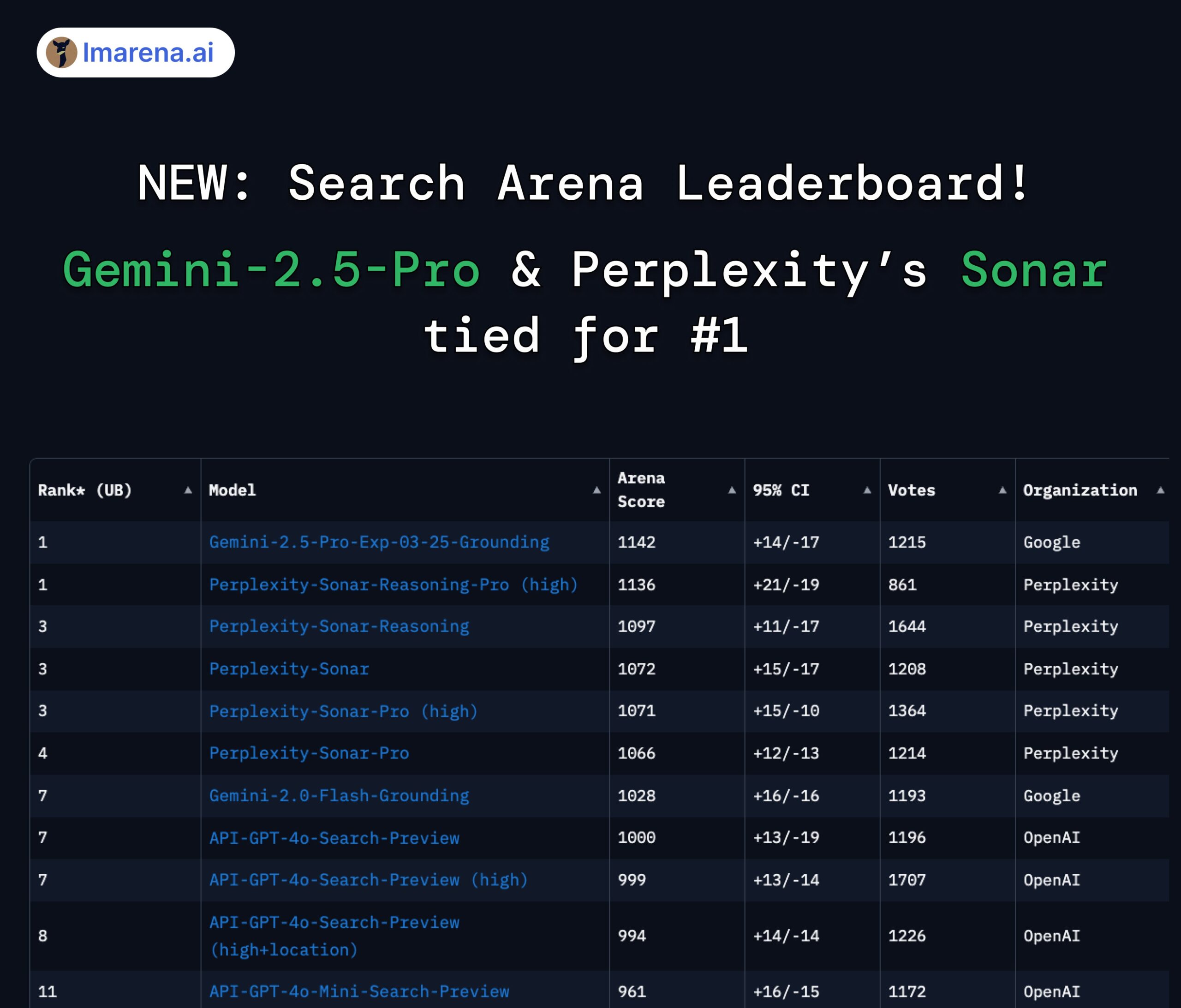
LMArena Search排行榜:Gemini 2.5 Pro与Perplexity Sonar并列第一: 在LMArena针对具备搜索/联网能力的大模型进行的竞技场评测中,Google的Gemini-2.5-Pro(结合Google Search)与Perplexity的Sonar-Reasoning-Pro并列榜首。这一结果得到了Google DeepMind CEO Demis Hassabis和Google开发者关系负责人Logan Kilpatrick的转发确认。Perplexity CEO Aravind Srinivas也对此表示,内部A/B测试显示其Sonar模型在用户留存上优于GPT-4o,性能与Gemini 2.5 Pro和新发布的GPT-4.1相当。评测组织方lmarena.ai已开源了7000场用户投票数据。 (来源: lmarena_ai 1, lmarena_ai 2, AravSrinivas, demishassabis)
Meta将恢复使用欧洲用户公开内容训练AI: Meta公司宣布将重新开始使用欧洲用户的公开内容来训练其人工智能模型。此前,由于面临来自欧洲数据保护机构(特别是爱尔兰数据保护委员会)的压力和监管要求,Meta曾暂停了这一做法。恢复训练的决定可能反映了Meta在平衡用户隐私、遵守法规(如GDPR)与获取足够数据以保持AI模型竞争力之间的持续努力和策略调整。此举可能会再次引发关于用户数据权利和AI训练透明度的讨论。 (来源: Reddit r/artificial)

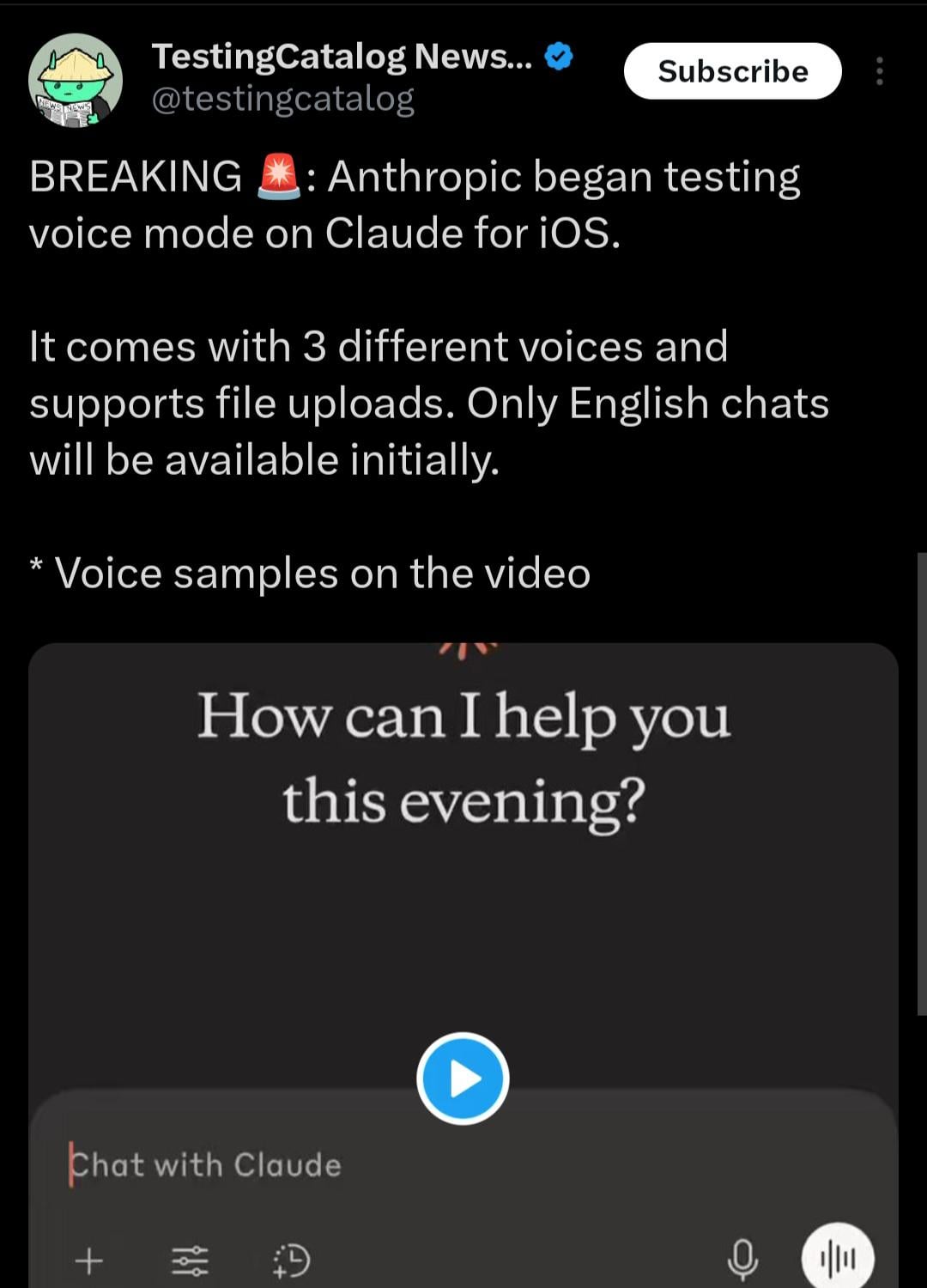
Claude移动应用或将增加语音交互模式: 根据X用户@testingcatalog发现的线索,Anthropic可能计划为其Claude移动应用程序增加语音交互功能。截图显示应用界面中出现了麦克风图标,暗示用户未来或许可以通过语音与Claude进行对话,类似于ChatGPT和Google Gemini应用已提供的语音模式。这将使Claude在移动端的交互方式更加多样化和便捷,进一步提升用户体验,并与其他主流AI助手在功能上保持一致。 (来源: Reddit r/ClaudeAI)
智谱Z1系列模型速度引发关注,被称为“瞬时模型”: 智谱AI最新发布的Z1系列模型,特别是GLM-Z1-AirX版本,因其极快的推理速度受到关注。有分析将其称为“瞬时模型”,指出其能在0.3秒内完成首次响应并生成超过50个汉字,这个速度接近人类神经反射时间。这种低延迟和高吞吐量有望改变人机交互模式,从“提问-等待-回答”变为近乎实时的同步对话,尤其适用于教育、客服、内容创作和Agent调用等对响应速度要求高的场景。Z1-AirX的API版本速度据称可达200 tokens/s。 (来源: 公众号)

AI原生游戏:从提效工具到玩法创新的演进与挑战: 游戏行业正从利用AI提升研发运营效率(如美术生成、代码辅助、自动化测试)向探索真正的“AI原生游戏”转变。AI原生游戏的核心在于AI深度融入玩法,创造由玩家交互驱动的动态内容和个性化体验,而非预设剧本。米哈游创始人蔡浩宇投资的《Whispers from the Star》、巨人网络《太空杀》的AI玩家模式是此类探索的例子。然而,实现AI原生游戏面临诸多挑战:技术层面需解决模型能力、稳定性与成本问题;设计层面缺乏成熟范例,需平衡可控性与自由度;用户层面需满足玩家对趣味性和交互深度的需求;此外还有内容合规和伦理风险。目前行业仍处于早期探索阶段,距离成熟落地尚有距离。 (来源: 界面新闻)
🧰 工具
盘点五款脑洞大开的AI应用: 36氪盘点了近期征集的AI原生应用创新案例中五款具有创意和实用性的AI工具:1)AiPPT.com:通过一句话或导入文件(Word, PDF, Xmind, 链接)快速生成PPT,支持离线运行。2)闪极AI拍拍镜:具备拍照录像、实时翻译、公式识别等功能的AI眼镜。3)连信数字无感审讯智能体:基于心理大模型“洞见人和”,通过分析微表情、语音、生理信号辅助审讯,生成报告。4)惠利玛Vali鞋履AI:输入关键词10秒生成8款鞋履设计图,整合材料库与版型数据,对接生产。5)南方仕通沙包HR智能体:处理社保管理人力资源任务,提供政策解读、成本计算、智能办理、风险预警等功能。这些应用展示了AI在效率工具、智能硬件、专业领域(安防、设计、HR)的落地潜力。 (来源: 36Kr)

海新智能发布AI零代码开发平台“响指”: 北京国资背景的海新智能科技推出了名为“响指”(Haisnap)的AI零代码/低代码开发平台。用户可以通过自然语言描述需求,让AI自动生成网页应用或小游戏等。平台特点在于生成过程中代码实时可见,并支持通过对话方式进行二次编辑和修改。用户开发的应用可以发布到平台的“创意社区”,供他人浏览、使用和再创作(remix)。目前平台免费开放,旨在降低AI应用开发门槛,推动全民创造,尤其关注青少年AI教育和行业应用落地。 (来源: 量子位)

开源知识库问答系统ChatWiki发布,支持GraphRAG与微信接入: ChatWiki是一款新开源的知识库AI问答系统,它整合了大语言模型(支持DeepSeek、OpenAI、Claude等20多种模型)与检索增强生成(RAG)技术,并特别支持基于知识图谱的GraphRAG,以处理复杂查询。系统功能包括:支持多种格式文档(OFD、Word、PDF等)导入构建私有知识库;支持语义分段提升RAG准确性;可将知识库发布为公开文档站点;提供API接口无缝接入微信公众号、微信客服等生态,创建AI聊天机器人;内置可视化工作流编排工具;支持与第三方业务数据打通;提供企业级权限管理;支持Docker及源码本地部署。 (来源: 公众号)

魔搭社区上线MCP广场,打造国内最大MCP服务生态: 阿里巴巴旗下AI模型社区魔搭(ModelScope)正式上线“MCP广场”,汇集了近1500款实现了模型上下文协议(MCP)的服务,覆盖搜索、地图、支付、开发者工具等领域,旨在打造国内最大的MCP中文社区。支付宝和MiniMax的多款MCP服务在此独家首发,例如支付宝的支付、查询、退款能力,MiniMax的语音、图像、视频生成能力,均可通过MCP协议被AI智能体调用。开发者可以在魔搭MCP实验场中,通过简单的JSON配置和免费云资源,快速体验和集成这些服务,极大地降低了AI应用接入外部工具和数据的门槛。魔搭还推出了MCP Bench,用于评估各类MCP服务的质量和性能。 (来源: 新智元)

Open WebUI WebSearch功能使用探讨: Reddit社区用户讨论了如何在Open WebUI中使用Web Search功能。问题集中在如何精确控制搜索引擎使用的查询关键词,以及如何将Web Search功能限制在特定的模型上,以防止私有模型的数据意外发送到网络。这反映了用户在使用集成搜索功能的AI工具时,对控制精度和隐私安全的实际需求。 (来源: Reddit r/OpenWebUI 1, Reddit r/OpenWebUI 2)
用户寻求对模型上下文协议(MCP)的理解: Reddit社区中有用户发帖寻求对模型上下文协议(MCP)的解释,表明随着MCP标准的推广和应用(如魔搭MCP广场),开发者和用户社区对理解这一新兴技术及其工作原理的需求日益增长。 (来源: Reddit r/OpenWebUI)
📚 学习
ICLR 2025时间检验奖授予Adam优化器与注意力机制: 国际学习表征会议(ICLR)将其2025年的“时间检验奖”(Test of Time Award)授予了两篇十年前(2015年)发表的里程碑式论文。一篇是由Diederik P. Kingma和Jimmy Ba撰写的《Adam: A Method for Stochastic Optimization》,该论文提出的Adam优化器已成为深度学习模型训练的标准算法。另一篇是由Dzmitry Bahdanau, Kyunghyun Cho和Yoshua Bengio撰写的《Neural Machine Translation by Jointly Learning to Align and Translate》,该论文首次引入了注意力机制,为Transformer架构和现代大语言模型奠定了基础。这两个奖项彰显了基础研究对当前AI发展的深远影响。 (来源: 新智元)

AI发展简史与企业演进回顾: 文章系统回顾了人工智能从20世纪中叶至今的发展历程,关键节点包括图灵测试、达特茅斯会议、符号主义与专家系统、AI寒冬、机器学习兴起(DeepBlue、PageRank)、深度学习革命(AlexNet、AlphaGo)以及当前的大模型时代(GPT系列、生成式AI商业化、开源与闭源之争)。同时,文章将AI企业发展划分为四个时代:拓荒时代(2000-2010,工具型应用探索)、淘金时代(2011-2016,平台赋能与数据驱动爆发)、泡沫时代(2017-2020,场景争夺与商业化瓶颈)和重构时代(2021至今,大模型驱动新格局)。文章强调了算力、数据、算法的协同作用以及DeepSeek等新势力对格局的影响。 (来源: 混沌大学)
OpenAI发布GPT-4.1提示工程指南: 配合GPT-4.1系列模型的发布,OpenAI更新了其提示工程(Prompting)指南。指南强调,GPT-4.1系列模型相比GPT-4等早期模型,会更严格、更按字面意思遵循指令,对明确、具体的提示更为敏感。如果模型表现不符合预期,通常增加简洁明确的说明即可引导其行为。这与过去模型倾向于猜测用户意图不同,开发者可能需要调整原有的提示策略。指南提供了从基础原则到高级策略的最佳实践,帮助开发者更好地利用新模型的特性。 (来源: dotey, Reddit r/LocalLLaMA)
上交大等发布时空智能基准STI-Bench,挑战多模态模型物理理解: 上海交通大学联合多所机构发布了首个评估多模态大模型(MLLM)时空智能的基准测试STI-Bench。该基准使用真实世界视频,专注于精确、量化的空间时间理解能力,包含尺度度量、空间关系、3D定位、位移路径、速度加速度、自我中心方向、轨迹描述、姿态估计八项任务。对GPT-4o、Gemini 2.5 Pro、Claude 3.7 Sonnet、Qwen 2.5 VL等顶尖模型的评测显示,现有模型在这些任务上表现普遍不佳(准确率<42%),尤其难以处理定量空间属性、时间动态变化以及跨模态信息整合。该基准揭示了当前MLLM在物理世界理解方面的局限,为后续研究提供了方向。 (来源: 量子位)

强化学习与多目标优化结合研究受关注: 强化学习(RL)与多目标优化(MOO)的交叉领域正成为AI决策研究的热点。这种结合旨在让智能体在复杂环境中权衡多个(可能冲突的)目标,而非追求单一最优。例如,港科大提出动态梯度平衡框架用于自动驾驶,同时优化安全与能效;MIT的Pareto策略搜索算法用于机器人控制;阿里云将多目标对齐技术用于金融交易以平衡收益与风险。相关研究如CMORL(持续多目标强化学习)和用于组合优化的Pareto集学习,正在探索如何让RL智能体更有效地处理动态变化或具有多个优化维度的现实世界问题。 (来源: 公众号)

自动对抗攻防平台A³D开源发布 (TPAMI 2025): 军事科学院国防科技创新研究院智能设计与鲁棒学习研究团队(IDRL)开发并开源了一个名为A³D(自动对抗攻击与防御)的平台。该平台利用自动机器学习(AutoML)技术,结合攻防博弈思想,旨在自动化地搜索鲁棒的神经网络架构和高效的对抗攻击策略。平台集成了多种神经架构搜索(NAS)方法和鲁棒性评估指标(范数攻击、语义攻击、对抗伪装等)用于自动防御,同时提供自动对抗攻击模块,可通过优化算法搜索最优组合攻击方案。研究成果发表于顶级期刊TPAMI,代码已在红山开源等平台发布,为评估和提升DNN模型安全性提供了新工具。 (来源: 公众号)

佛罗里达大学招收NLP/LLM方向全奖博士/实习生: 佛罗里达大学计算机系Yuanyuan Lei助理教授(2025年秋季入职)发布招生信息,招收2025年秋季或2026年春季入学的全奖博士生,以及时间灵活的科研实习生(可远程)。研究方向聚焦自然语言处理(NLP)和大语言模型(LLM),具体包括知识增强LLM、事实验证、推理与规划、NLP应用(多模态、法律、商业、科学等)。欢迎计算机、电子工程、统计、数学等相关背景,对AI研究有兴趣和动力的学生申请。邮件中提及了佛州SB-846法案对招收中国大陆学生的潜在影响及应对途径。 (来源: PaperWeekly)

扩散模型新研究:时间相关噪声先验: 一篇arXiv论文《How I Warped Your Noise: a Temporally-Correlated Noise Prior for Diffusion Models》提出了一种用于扩散模型的新型噪声先验。该方法旨在通过引入时间相关的噪声来改进(可能指视频)扩散模型的生成质量或效率。具体的技术细节需查阅原论文。 (来源: Reddit r/MachineLearning)
自动化科学发现新研究:AI Scientist-v2: 一篇arXiv论文《The AI Scientist-v2: Workshop-Level Automated Scientific Discovery via Agentic Tree Search》介绍了AI Scientist-v2系统。该系统利用Agentic Tree Search(智能体树搜索)方法,旨在实现达到“研讨会级别”(Workshop-Level)的自动化科学发现。这表明研究者正在探索使用AI智能体进行更高级、更自主的科学研究和探索。 (来源: Reddit r/MachineLearning)
Dropout 正则化实现讲解: 一篇Substack文章详细解释了Dropout正则化技术的实现方式。Dropout是一种在深度学习中广泛使用的正则化技术,通过在训练过程中随机“丢弃”一部分神经元来防止模型过拟合。该文章可能面向希望深入理解Dropout工作原理或亲手实现该技术的学习者。 (来源: Reddit r/deeplearning)
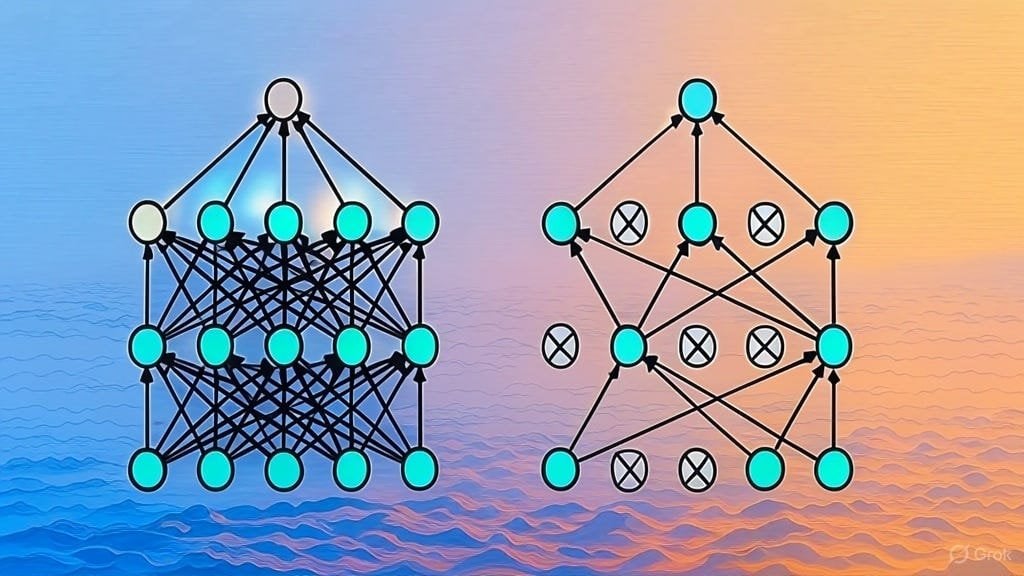
LLM架构论文列表征集: Reddit用户发起讨论,分享并征集关于大型语言模型(LLM)架构的arXiv论文。已列出的架构包括BERT、Transformer、Mamba、RetNet、RWKV、Hyena、Jamba、DeepSeek系列等。此列表反映了当前LLM架构研究的多样性和快速发展,对希望系统了解该领域的研究者有参考价值。 (来源: Reddit r/MachineLearning)
💼 商业
AI营养平台Fay获5000万美元融资,年收入达5000万: 硅谷AI营养平台Fay近期完成由高盛领投的5000万美元B轮融资,累计融资达7500万美元,估值5亿美元。Fay连接注册营养师与患者,利用AI提升服务效率(号称从6.5小时/患者降至2小时),自动化处理临床笔记生成(含ICD编码)、个性化营养方案制定、保险理赔、后台管理等任务。该平台精准抓住了GLP-1减肥药带来的营养咨询需求激增,并通过与保险公司合作(营养干预可降低慢性病长期医疗成本)打通支付环节。Fay平台上仅有不到3000名营养师,却实现了5000万美元的年收入(ARR),展示了AI在垂直医疗领域赋能专业人士并对接支付方的成功商业模式。 (来源: 乌鸦智能说)
成都恒图科技:AI赋能数字创意,出海盈利: 成都本土企业恒图科技凭借其核心产品Fotor(图像视频编辑平台)在全球积累了约7亿用户,月活超千万,尤其在海外市场表现突出,是国内较早出海并实现规模化盈利的AI应用公司之一。公司深耕图像处理技术16年,并在2022年迅速将AIGC功能(文生图、文生视频等)融入Fotor及新平台Clipfly。Fotor通过AI降低了数字视觉内容创作门槛,服务电商、自媒体、广告、文旅、教育等多个行业。恒图科技利用AI进行“文化转译”,助力中国文化出海,探索数字创意产业新路径。 (来源: 36Kr四川)
企业AI落地实践:重价值、轻微调、促协同: 企业在推进大模型落地的过程中,已从早期的探索转向更务实的价值导向。成功的AI应用往往聚焦于重复性强、有创意需求且范式可沉淀的场景,如知识问答、智能客服、物料生成、数据分析等。企业普遍认识到,盲目追求模型微调往往投入产出比低,应优先进行知识治理和构建智能体平台(初期以RAG为主)。AI落地需要业务部门深度参与和高层支持,采用“速赢试点+AI基础准备”双轨并行策略效果更佳。在组织人才方面,企业倾向于组建小型专业AI团队赋能业务,并通过引入外部顶尖人才、培养内部年轻力量(实习生+资深业务搭配)及与乙方专家合作等方式解决人才短缺问题。 (来源: AI前线)
科创板人工智能指数受关注,或成投资新风口: 报告分析指出,尽管近期市场波动,中国人工智能产业已形成“算力-模型-应用”完整闭环,并展现出强劲韧性。国家“东数西算”工程、DeepSeek等低成本模型及人形机器人等应用突破是亮点。AI被视为未来十年全球经济增长的重要引擎,相关资产长期收益显著。在此背景下,上证科创板人工智能指数(聚焦算力芯片和AI应用)因其高成长性预期和自主可控含量提升而受到投资者关注。易方达等机构已推出跟踪该指数的ETF及联接基金(如588730、023564/023565),为投资者布局国产AI产业链提供了工具。 (来源: 创业最前线)

苹果AI策略转向开放:允许Siri开发使用第三方模型: 为加速“个性化Siri”功能的研发并追赶竞争对手,苹果公司据报道已调整其长期坚持的内部封闭开发策略。在新任软件工程高级副总裁克雷格・费德里希领导下,Siri工程师首次被允许使用第三方大语言模型来开发Siri功能,打破了此前只能使用苹果自研模型的限制。这一转变被认为是苹果应对其在AI领域技术储备相对落后、以及避免“个性化Siri”功能跳票引发更多用户不满(甚至诉讼)的关键举措。此举可能为OpenAI或阿里(国内市场)等外部模型供应商带来与苹果合作的机会。 (来源: 三易生活)

🌟 社区
DeepSeek、豆包、元宝应用竞争激烈,产品体验成关键: 国内AI助手应用市场竞争白热化,DeepSeek凭借模型能力爆火后用户量激增,带动了率先接入的腾讯元宝一度登顶。然而,字节跳动的豆包凭借更完善的产品功能和与抖音的深度整合,再次反超元宝。分析认为,单纯依赖接入强力模型(如DeepSeek)只能带来短期红利,长期竞争中,应用本身的功能丰富度、用户体验、多端协同以及平台生态整合能力更为关键。随着各家模型能力趋同(如都具备深度思考能力),未来的竞争焦点将是产品设计、运营策略以及AI Agent等新形态应用的突破。 (来源: 字母榜)
亚裔学生开发面试作弊器引爆网络讨论: 一位哥伦比亚大学的亚裔学生Roy Lee开发了一款名为Interview Coder的AI工具,利用ChatGPT辅助通过了亚马逊、Meta、TikTok等多家科技公司的远程技术面试。他不仅拒绝了这些公司的Offer,还将使用作弊器的过程录制视频发布到YouTube,被亚马逊举报后遭学校停学。Roy Lee对此不以为然,反而将事件经过和与学校、公司的邮件往来公开,获得了大量网友支持和行业关注,并以此为契机创立公司。该事件引发了关于技术面试(特别是LeetCode刷题模式)的有效性、AI工具在招聘中的道德边界、以及个人挑战大公司体制等话题的热烈讨论。 (来源: 直面AI)

用户实测智谱新开源GLM模型接入知识库与MCP: 有用户对智谱AI最新发布的GLM系列模型(通过API调用)进行了测试。结果显示,GLM-Z1-AirX(极速版)在接入FastGPT构建的本地知识库时,响应速度极快(据称达200 tokens/s),且回答质量较普通模型有提升,能生成更详细完整的答案和对比表格。GLM-4-Air(基座模型)在接入MCP(模型上下文协议)执行Agent任务(如联网搜索、本地文件写入、Docker控制、网页总结)时,能够正确调用工具并完成任务,但效果略逊于DeepSeek-V3。用户同时肯定了智谱模型在安全方面的表现(对越狱提示不响应)。 (来源: 公众号)

分享“超理性问题解决者”提示词并对比模型效果: 社区用户分享了一个旨在让LLM扮演“超理性、第一性原理问题解决者”角色的高级提示词(Prompt)。该提示词详细规定了模型的运作原则(解构问题、方案工程化、交付协议、互动规则)、响应格式和语气特征,强调逻辑、行动和结果,摒弃含糊、借口和情感安慰。用户使用此提示词对比测试了DeepSeek、Claude Sonnet 3.7和ChatGPT 4o在解答问题、提供指引和联网推荐资源方面的表现,认为Claude 3.7效果较好。这展示了通过精心设计的Prompt可以显著引导和提升LLM在特定任务上的表现。 (来源: 公众号)

社区热议GPT-4.1发布:性能、策略与命名: OpenAI发布GPT-4.1系列模型引发社区广泛讨论。一方面,用户通过实测和基准对比(如Aider、Livebench、GPQA Diamond、KCORES Arena)发现,虽然GPT-4.1在编码方面有显著提升,但在综合推理能力上仍落后于Google Gemini 2.5 Pro和Claude 3.7 Sonnet。另一方面,社区对OpenAI的产品策略(区分API与ChatGPT、弃用GPT-4.5)、模型迭代速度以及混乱的命名方式(4.1在4.5之后发布)进行了讨论和批评。有观点认为OpenAI可能面临创新瓶颈,也有观点认为这是其优化API产品线、提供不同性价比选项的策略。 (来源: dotey, op7418, Reddit r/LocalLLaMA 1, Reddit r/ArtificialInteligence, karminski3, Reddit r/LocalLLaMA 2)

ChatGPT在法律咨询场景显神通,用户分享成功经验: Reddit用户分享了使用ChatGPT处理工作相关法律纠纷的成功案例。该用户面临被解雇的风险,通过向ChatGPT提供文件并让其扮演英国雇佣法专家,发现了雇主的程序错误,并借助ChatGPT起草的信函进行交涉,最终达成了包含2个月工资补偿的和解协议,避免了不良记录。评论区也有其他用户分享了使用AI(ChatGPT或Gemini)起草法律信函、准备听证会并取得积极成果的经历,认为AI在法律辅助方面能节省大量费用和时间。 (来源: Reddit r/ChatGPT)
用户吐槽OpenAI Deep Research功能效果不佳: Reddit用户发帖批评OpenAI的Deep Research(深度研究)功能,认为其存在三个主要问题:1) 搜索结果不准确或不相关(依赖Bing API);2) 探索方式更像是深度优先搜索而非广泛研究;3) 与用户的研究目标脱节,缺乏约束。用户认为这更像是扩展搜索能力,而非真正的深度研究。这反映了用户对当前AI Agent研究能力的期望与实际体验之间的差距。 (来源: Reddit r/deeplearning)
AI生成内容展示与讨论: 社区用户积极分享使用各类AI工具(如ChatGPT、Midjourney、Kling AI、Suno AI等)创作的内容,包括讽刺漫画(特朗普与马斯克)、大学拟人化形象、另类二战历史短片、希腊神话人物图像、90年代风格牙膏广告、多格漫画等。这些分享不仅展示了AI在文本、图像、视频、音乐生成方面的能力,也引发了关于AI生成内容的创意性、审美(如被指“媚俗”)、局限性(如漫画人物一致性差)以及伦理问题的讨论。 (来源: dotey 1, dotey 2, Reddit r/ChatGPT 1, Reddit r/ChatGPT 2, Reddit r/ChatGPT 3, Reddit r/ChatGPT 4, Reddit r/ChatGPT 5)

担忧AI训练数据反馈循环导致“模型坍塌”: 社区讨论关注一个潜在风险:随着AI生成内容在互联网上日益增多,未来的AI模型如果主要基于这些AI生成的数据进行训练,可能导致“模型坍塌”(Model Collapse)。这种现象指的是模型性能退化,输出变得狭隘、重复、缺乏原创性和准确性,如同复印件不断复印导致模糊。用户担忧这会缓慢侵蚀信息的真实性和人类视角。讨论中也提到了应对方法,如使用合成数据进行训练、加强数据质量控制等,但对问题是否已发生以及如何有效避免存在争议。 (来源: Reddit r/ArtificialInteligence)
观点:AI时代,算力是新的石油: Reddit用户提出观点,认为在AI发展中,计算能力(Compute)而非数据,将成为关键的瓶颈和战略资源,如同工业革命时期的石油。理由是:更强的AI模型(尤其是推理和Agent系统)需要指数级增长的算力;机器人等物理交互将产生海量新数据,进一步加大算力需求。拥有更多算力将直接转化为更强的经济产出能力。此观点引发社区讨论,认为算力确实是核心要素,决定了AI能力的上限和发展速度。 (来源: Reddit r/ArtificialInteligence)
AI使用伦理讨论:为提高学习成绩使用AI是否不妥?: 一位在线大学生因课程结构问题(每周只有一次测验或作业,紧接着就是考试)导致挂科,后使用ChatGPT根据讲座PDF生成练习题进行日常学习,成绩显著提高。但该学生看到关于AI对环境影响和“独立思考”的批评,感到内疚。社区评论普遍认为,将AI用于辅助学习是正当且有效的用途,有助于提高效率和学习效果,不应为此感到愧疚。评论者指出,AI的环境影响需与其他人类活动对比看待,且利用AI提升生产力已是职场趋势。 (来源: Reddit r/ArtificialInteligence)
Claude Pro用户体验:限流与商业模式讨论: Reddit ClaudeAI社区中,用户讨论了使用Claude Pro服务时遇到的限流(throttling)问题,并探讨了Anthropic的商业模式。有用户指出,每月20美元的Pro订阅费用远低于Anthropic为重度用户付出的实际计算成本(可能高达100美元/月),认为用户的抱怨(如认为被“剥削”)可能忽视了AI服务的成本结构。讨论也涉及到近期Anthropic将新功能优先提供给更贵的Max套餐而非Pro套餐,引发了早期订阅Pro年费用户的不满。 (来源: Reddit r/ClaudeAI 1, Reddit r/ClaudeAI 2)
KCORES LLM Arena 更新,DeepSeek R1表现亮眼: 用户分享了其个人维护的LLM竞技场(KCORES LLM Arena)的最新测试结果,该测试要求模型生成一个复杂的物理模拟(20个球在旋转七边形内碰撞反弹)的Python代码。在更新加入了GPT-4.1、Gemini 2.5 Pro、DeepSeek-V3等新模型后,结果显示DeepSeek R1在该任务上表现出色,生成的模拟效果较好。这为社区提供了又一个评估不同模型在复杂编程任务上能力的参考点。 (来源: Reddit r/LocalLLaMA)

探讨不同LLM的情感响应能力: Reddit用户发布了一张Meme图,用幽默的方式对比了ChatGPT 4o、Claude 3 Sonnet、Llama 3 70B和Mistral Large在面对用户表达悲伤情绪时的不同反应风格。这反映了用户在使用不同LLM进行情感交流或寻求支持时的体验差异,以及社区对模型“共情”能力的感知和评价。评论区也讨论了使用本地模型处理私密情感话题的隐私优势。 (来源: Reddit r/LocalLLaMA)

对AGI是否是硅谷骗局的讨论: 社区成员转发并可能讨论了一篇质疑通用人工智能(AGI)是否是硅谷(科技行业)为了吸引投资或维持热度而过度宣传的概念(hoax)的文章。这反映了业界和公众对于AGI实现的可能性、时间表以及当前相关宣传的真实性存在持续的辩论和怀疑。 (来源: Ronald_vanLoon)

💡 其他
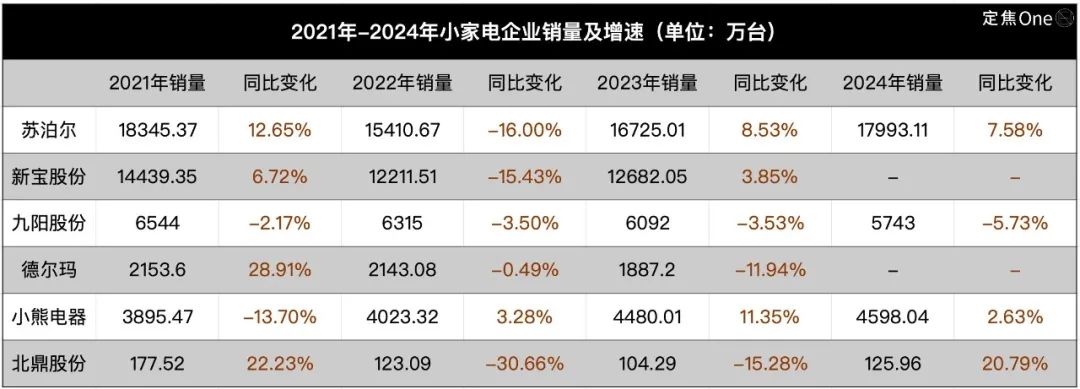
小家电行业遇冷,AI成新故事但应用尚浅: 厨房小家电市场(如早餐机、空气炸锅)在经历“宅经济”红利消退后面临销量下滑和价格战困境。苏泊尔、九阳、小熊电器等“六强”上市公司业绩承压。为寻求突破,企业普遍将目光投向海外市场拓展和AI技术融合。然而,目前AI在小家电上的应用多为简单的语音指令、自动调节等,实用性和创新空间有限,且可能增加成本劝退用户。相比之下,大家电在AI应用上更具优势,可构建智能家居生态、利用大数据提供个性化服务。小家电行业的AI故事仍处于早期阶段。 (来源: 36Kr)
关税风波冲击华强北芯片市场,国产替代或加速: 近期围绕芯片的关税政策变动引发深圳华强北电子市场的担忧。CPU、GPU等热门芯片(尤其可能涉及美国原产地的)商家出现暂停报价、捂货观望现象,价格波动加剧。存储芯片等品类影响相对较小。多家上市分销商表示,由于自美国直接进口比例小,关税战直接影响有限,但市场不确定性增加。行业普遍认为,在美国拥有晶圆厂的IDM企业(如TI、Intel、美光)受影响最大。此事件已促使部分下游客户咨询国产芯片替代方案,可能加速半导体领域的国产化进程。 (来源: 创业板观察)

AI加剧人类意义危机?反思技术与价值的平衡: 文章探讨人工智能的飞速发展如何冲击人类的存在意义。认为AI在专业领域的超越(如围棋、医疗诊断、艺术创作)加剧了工业革命以来由劳动异化、信仰危机、环境问题等引发的人类意义危机。AI可能进一步强化“工具人”困境,尤其是在白领工作中替代决策能力。文章引用哲学家观点和科幻作品(如《沙丘》、《西部世界》)警示技术奴役风险,呼吁在拥抱AI带来的技术增强同时,重建价值理性,通过伦理框架、人文教育守护人类的创造力、情感联结和批判思维,避免沦为自身造物的附庸。 (来源: 腾讯研究院)
美国制造iPhone成本高昂,或超25000元: 文章分析若iPhone完全在美国本土生产,其成本将大幅飙升,预估售价可能高达3500美元(约25588元人民币),远超当前价格。主要原因包括美国在原材料(如稀土、精炼锂钴)获取、物流运输、厂房建设(土地、电力、环保审批)以及人力成本(最低时薪对比中国高4-5倍,且缺乏熟练产业工人)方面均远高于中国。苹果过去依靠压榨全球供应链(特别是利润空间相对较大的中国供应商)维持高利润率的模式在美国将难以为继。高昂的生产成本最终可能转嫁给消费者,动摇苹果的定价策略和市场地位。 (来源: 星海情报局)

数学突破:平均曲率流奇点理论获证明: 困扰数学家近30年的Multiplicity-one猜想近期被Richard Bamler和Bruce Kleiner证明。该猜想关于平均曲率流(Mean Curvature Flow, MCF)——一个描述表面如何随时间演化以最快速度减小面积(类似冰块融化或沙堡侵蚀)的数学过程。证明指出,在三维空间中,二维闭合曲面在MCF下形成的奇点(曲率趋于无穷大的点)是简单的,通常表现为局部收缩成一个点的球面或坍缩为一条线的圆柱体,复杂的多层重叠奇点不会发生。这一突破确保了MCF在奇点形成后仍能继续分析,为利用MCF解决几何学和拓扑学(如庞加莱猜想)中的重要问题提供了更坚实的理论基础。 (来源: 机器之心)

用户分享“预算级”4x RTX 3090本地AI硬件配置: Reddit用户分享了自己搭建的用于本地运行LLM的硬件配置方案,总成本约为4204美元。该配置包括4块二手的EVGA RTX 3090显卡(单价600美元)、一颗AMD EPYC 7302P服务器CPU、Asrock Rack主板、96GB DDR4内存和2TB NVMe SSD,装配在MLACOM Quad Station Pro Lite开放式机箱中,并使用了两块1200W电源。这个分享为希望在家搭建具备较强算力(4x 24GB VRAM)的AI工作站的用户提供了一个相对“经济”的参考方案。 (来源: Reddit r/LocalLLaMA)

美国黑客攻击交通信号灯播放马斯克和扎克伯格Deepfake信息: 据报道,美国旧金山湾区的多个行人过街信号灯系统遭到黑客攻击,被用来播放由AI生成的马斯克和扎克伯格的Deepfake(深度伪造)信息。这一事件凸显了公共基础设施在面对利用AI技术的网络攻击时的脆弱性,以及Deepfake技术被滥用于传播虚假信息或进行恶作剧的风险。 (来源: Reddit r/ArtificialInteligence)

展示多样化机器人与自动化技术: 社交媒体上展示了多种机器人和自动化技术应用,包括:能够模仿人类动作表演功夫的Booster T1机器人;用于康复训练的机器人系统;能制作咖啡的机械臂;用于水稻种植和除草的农业机器人;方便牧民处理绵羊的自动化系统;以及跳舞的机器人等。这些案例反映了机器人在工业、农业、服务业、医疗康复以及娱乐等领域的广泛应用和持续发展。 (来源: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6)
新兴技术与创新产品展示: 社交媒体上分享了多种新兴技术和创新产品,例如:麻省理工学院研发的利用光监控蜂窝通信的微型无线天线;模仿枫树种子飞行的单翼无人机;物联网智能马桶;用于牙科矫正的数字印模技术;利用盐水发电的装置;可呼吸和移动的动态墙体;Iron Man Cosplay套装;全地形电动滑雪板;以及利用Flipper Zero设备复制钥匙的技术等。这些展示了科技在通信、能源、健康、交通、建筑和安全等多个领域的持续创新。 (来源: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4, Ronald_vanLoon 5, Ronald_vanLoon 6, Ronald_vanLoon 7, Ronald_vanLoon 8, Ronald_vanLoon 9)

医疗健康科技趋势: 社交媒体及文章链接提及了医疗健康领域的科技应用和发展趋势,包括机器人辅助手术、AI在医疗保健中的应用趋势与转折点、利用技术推动卓越运营(超自动化)、以及AI可能带来的变革等。这些内容反映了AI、机器人、自动化等技术在提升医疗服务效率、诊断准确性和患者体验方面的潜力与实践。 (来源: Ronald_vanLoon 1, Ronald_vanLoon 2, Ronald_vanLoon 3, Ronald_vanLoon 4)

网络安全相关信息: 社交媒体分享了网络安全相关内容,包括密码攻击的类型图解以及关于数据泄露后60分钟内恢复能力重要性的文章。这些内容提醒用户关注网络安全风险及应对策略。 (来源: Ronald_vanLoon 1, Ronald_vanLoon 2)

AMD ROCm平台讨论: Reddit用户讨论了使用双AMD Radeon RX 7900 XTX GPU搭建深度学习工作站的可能性,涉及ROCm(Radeon Open Compute platform)软件栈。这反映了在Nvidia主导的AI硬件市场中,用户对AMD GPU方案及其软件生态(ROCm)的关注和探索。 (来源: Reddit r/deeplearning)