
关键词:AI, 大模型, AI清洗现象, 多语言大模型综述, 谷歌Gemini自托管, vLLM推理引擎, Suno AI音乐生成
🔥 聚焦
“AI”购物应用被曝实为人工操作: 一家名为Fintech的初创公司及其创始人被指控欺诈,其号称由AI驱动的购物应用,实际上大量依赖位于菲律宾的人工团队来处理交易。这起事件再次引发了对“AI清洗”(AI Washing)现象的关注,即公司夸大或虚报其AI能力以吸引投资或用户。该事件凸显了在当前AI热潮下,辨别真伪AI技术应用的挑战,以及对初创公司进行尽职调查的重要性 (来源: Reddit r/ArtificialInteligence)

新基准测试揭示AI推理模型的泛化能力不足: 一个名为LLM-Benchmark的新基准测试 (https://llm-benchmark.github.io/) 表明,即便是最新的AI推理模型,在处理分布外(OOD)的逻辑谜题时也表现挣扎。研究发现,与模型在数学奥林匹克竞赛等基准测试中的表现相比,它们在这些新逻辑谜题上的得分远低于预期(约低50倍),这暴露了当前模型在训练数据分布之外进行真正逻辑推理和泛化的局限性 (来源: Reddit r/ArtificialInteligence)
谷歌允许企业自托管Gemini模型,应对数据隐私关切: 谷歌宣布将允许企业客户在其自有的数据中心运行Gemini AI模型,首批支持的是Gemini 2.5 Pro。此举旨在满足企业对数据隐私和安全性的严格要求,使它们能够在不将敏感数据发送到云端的情况下利用谷歌的先进AI技术。这一策略与Mistral AI类似,但与OpenAI和Anthropic等主要通过云API或合作伙伴提供服务的方式形成对比,可能改变企业级AI市场的竞争格局 (来源: Reddit r/LocalLLaMA, Reddit r/MachineLearning)

🎯 动向
VSCode原生支持llama.cpp,扩展本地Copilot能力: Visual Studio Code近期更新增加了对本地AI模型的支持,继支持Ollama之后,现已通过微小调整兼容llama.cpp。这意味着开发者可以直接在VSCode中使用通过llama.cpp运行的本地大语言模型,作为GitHub Copilot的替代或补充,进一步方便了在本地环境中利用LLM进行代码辅助,提升了开发灵活性和数据隐私性。用户需在设置中选择Ollama作为代理(尽管实际使用的是llama.cpp)来启用此功能 (来源: Reddit r/LocalLLaMA)

Yandex等机构发布HIGGS:新型LLM压缩方法: 来自Yandex Research、HSE大学、MIT等机构的研究者开发了一种名为HIGGS的新型LLM量化压缩技术。该方法旨在显著压缩模型大小,使其能在性能较弱的设备上运行,同时尽可能减少模型质量损失。据称,该方法已成功用于压缩671B参数的DeepSeek R1模型,且效果显著。HIGGS意图降低LLM的使用门槛,使小型公司、研究机构和个人开发者也能更容易地应用大型模型,相关代码已在GitHub和Hugging Face发布 (来源: Reddit r/LocalLLaMA)
谷歌修复QAT 2.7模型量化问题: 谷歌更新了其QAT(Quantization Aware Training)量化模型的2.7版本(可能指Gemma 2 7B或其他类似模型),修复了之前版本中存在的一些控制令牌(control tokens)错误问题。此前,模型可能会在输出末尾生成错误的<end_of_turn>等标记。新上传的量化模型已解决这些问题,用户可以下载更新后的版本以获得正确的模型行为 (来源: Reddit r/LocalLLaMA)
DeepMind CEO谈AlphaFold成就: DeepMind CEO Demis Hassabis 在一段访谈中强调了AlphaFold的巨大影响力,他形象地比喻道,AlphaFold在一年内完成了“十亿年的博士研究时间”。他指出,过去解析一个蛋白质结构通常需要耗费一名博士生整个博士生涯(4-5年),而AlphaFold在一年内预测了(当时已知的)全部2亿种蛋白质的结构。这番话凸显了AI在加速科学发现方面的革命性潜力 (来源: Reddit r/artificial)

🧰 工具
MinIO:面向AI的高性能对象存储: MinIO是一个开源的高性能、S3兼容的对象存储系统,采用GNU AGPLv3许可证。它特别强调了其在机器学习、分析和应用数据工作负载方面构建高性能基础设施的能力,并提供了专门的AI存储文档。用户可以通过容器(Podman/Docker)、Homebrew(macOS)、二进制文件(Linux/macOS/Windows)或源码安装。MinIO支持构建分布式、具备纠删码的高可用存储集群,适用于需要处理大量数据的AI应用场景 (来源: minio/minio – GitHub Trending (all/daily))

IntentKit:构建具备技能的AI代理框架: IntentKit是一个开源的自主代理框架,旨在让开发者能够创建和管理具备多种能力的AI代理,包括与区块链交互(优先支持EVM链)、社交媒体管理(Twitter、Telegram等)以及集成自定义技能。该框架支持多代理管理和自主运行,并计划推出可扩展的插件系统。项目目前处于Alpha阶段,提供了架构概览和开发指南,鼓励社区贡献技能 (来源: crestalnetwork/intentkit – GitHub Trending (all/daily))

vLLM:高性能LLM推理与服务引擎: vLLM是一个专注于LLM推理和服务的高吞吐、内存高效的库。其核心优势包括通过PagedAttention技术有效管理注意力键值内存、支持连续批处理(Continuous Batching)、CUDA/HIP图优化、多种量化技术(GPTQ, AWQ, FP8等)、与FlashAttention/FlashInfer集成、以及投机解码(Speculative Decoding)等。vLLM支持Hugging Face模型,提供OpenAI兼容API,可在NVIDIA、AMD等多种硬件上运行,适用于需要大规模部署LLM服务的场景 (来源: vllm-project/vllm – GitHub Trending (all/daily))
tfrecords-reader:带随机访问和搜索功能的TFRecords读取器: 这是一个用于处理TFRecords数据集的Python工具,特别设计用于数据检查和分析。它允许用户为TFRecords文件创建索引,实现随机访问和基于内容的搜索(使用Polars SQL查询),解决了TFRecords原生顺序读取的限制。该工具不依赖TensorFlow和protobuf包,支持直接从Google Storage读取,索引速度快,便于开发者在模型训练之外对大规模TFRecords数据集进行探索和样本查找 (来源: Reddit r/MachineLearning)
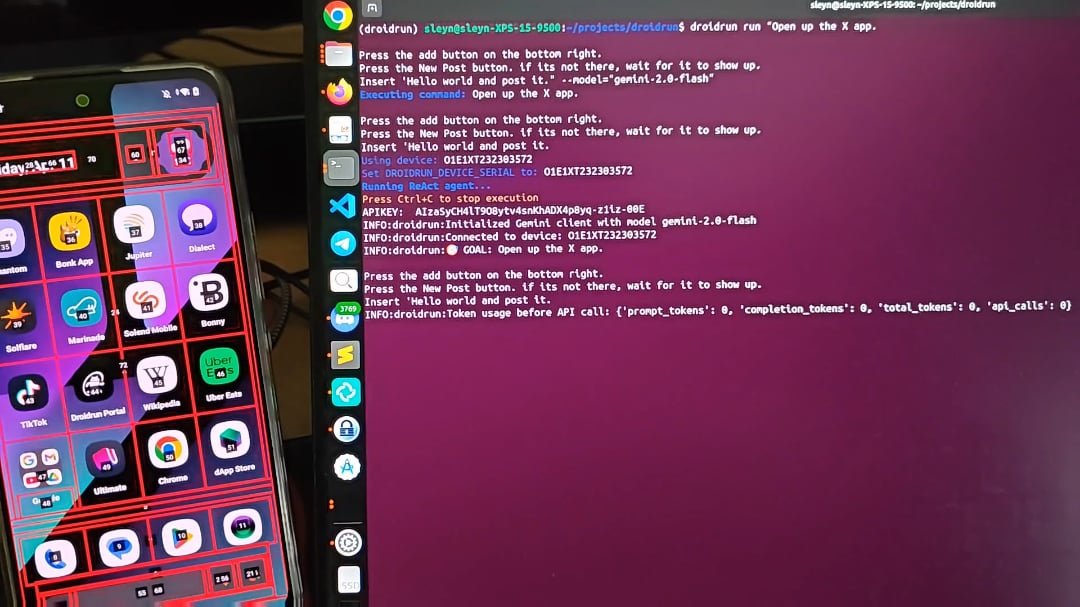
DroidRun:让AI Agent控制安卓手机: DroidRun是一个允许AI Agent像人一样操作安卓设备的项目。通过连接任何LLM,它可以实现对手机UI的交互控制,执行各种任务。项目展示了其潜力,旨在实现手机端的自动化操作,例如自动发布内容、管理应用等。开发者邀请社区提供反馈和想法,探索更多自动化场景 (来源: Reddit r/LocalLLaMA)
📚 学习
Cell Patterns发布多语言大模型(MLLM)重磅综述: 该综述系统梳理了多语言大模型的研究现状,涵盖了473篇文献。内容包括多语言预训练、指令微调及RLHF的数据集资源与构建方法;跨语言对齐策略,分为参数调整对齐(如预训练、指令微调、RLHF、下游微调)和参数冻结对齐(如直接提示、代码切换、翻译对齐、检索增强);多语言评估指标与基准(NLU与NLG任务);并探讨了幻觉、知识编辑、安全、公平性、语言/模态扩展、可解释性、部署效率和更新一致性等未来研究方向和挑战。提供了全面的MLLM研究图谱 (来源: Cell Patterns重磅综述!473篇文献全面解析多语言大模型最新研究进展)

AAAI 2025 | 北航提出TRACK:动态路网与轨迹表示协同学习: 北航团队提出TRACK模型,旨在解决现有方法未能捕捉交通时空动态性的问题。该模型首次联合建模交通状态(宏观群体特征)与轨迹数据(微观个体特征),认为两者相互影响。TRACK通过图注意力网络(GAT)、Transformer以及创新的轨迹转移感知GAT和协同注意力机制,学习动态的路网和轨迹表示。模型采用联合预训练框架,包含掩码轨迹预测、对比轨迹学习、掩码状态预测、下一状态预测和轨迹-交通状态匹配等自监督任务,在交通状态预测和旅行时间估计任务上表现优越 (来源: AAAI 2025 | 告别静态建模!北航团队提出动态路网与轨迹表示的协同学习范式)

南科大杨林易老师招收大模型方向博士/RA/访问学生: 南方科技大学统计与数据科学系杨林易老师(即将入职,独立PI)建立生成式人工智能实验室(GenAI Lab),招收2025/2026届博士、硕士研究生,以及博士后、科研助理和实习生。研究方向包括大模型推理的因果分析、可泛化的强化学习大模型方法、构建可靠的非智能体系统以预防AI失控。杨老师在顶会发表多篇论文,与国内外多所高校及研究机构有广泛合作,鼓励联合指导。要求申请者有强自驱力、扎实的数理基础和编程能力 (来源: 博士申请 | 南方科技大学杨林易老师招收大模型方向全奖博士/RA/访问学生)

个人项目:从零构建大语言模型: 一位开发者分享了自己从零开始实现一个Causal Language Model(类似GPT)的个人项目。项目使用Python和PyTorch,核心架构包括带有Causal Mask的多头自注意力、前馈网络、解码器块(层归一化、残差连接)堆叠。模型使用预训练的GPT-2词嵌入和位置嵌入,输出层映射到词汇表logits。采用Top-k采样进行自回归文本生成,并在WikiText数据集上使用AdamW优化器和CrossEntropyLoss进行训练。项目代码已在GitHub开源,展示了构建LLM的基础流程 (来源: Reddit r/MachineLearning)
论文解读:d1 – 通过强化学习扩展扩散大语言模型(dLLM)的推理能力: 该研究提出d1框架,旨在将预训练的基于扩散的LLM(dLLM)应用于推理任务。dLLM通过由粗到精的方式生成文本,与自回归(AR)模型不同。d1框架结合了监督微调(SFT)和强化学习(RL),具体包括:使用Masked SFT进行知识蒸馏和引导自改进;提出一种新的无Critic、基于策略梯度的RL算法diffu-GRPO。实验表明,d1显著提升了SOTA dLLM在数学和逻辑推理基准上的性能,证明了dLLM在推理任务上的潜力 (来源: Reddit r/MachineLearning)
💼 商业
阿里通义实验室招聘通用RAG/AI搜索方向算法专家 (北京/杭州): 阿里巴巴通义实验室AI搜索团队正在招聘算法专家,负责推进搜索和RAG(检索增强生成)核心模块(如Embedding、ReRank模型)的研发优化,提升模型效果及业界领先水平。岗位职责还包括针对下游应用(问答、客服、多模态Memory)优化整体框架链路,提升准确率、效率和可扩展性,并协同团队推动业务落地。要求相关专业硕士及以上学历,熟悉搜索/NLP/大模型技术,有相关项目经验 (来源: 北京/杭州内推 | 阿里通义实验室招聘通用RAG/AI搜索方向算法专家)

AI招聘初创公司OpportuNext寻找CTO (远程/股权): OpportuNext是一家早期创业公司,旨在利用AI技术改进招聘流程,提供智能职位匹配、简历分析和职业规划工具。创始人正在寻找一位技术合伙人(CTO),负责领导AI功能开发、构建可扩展后端系统,并推动产品创新。要求具备AI/ML、Python和可扩展系统经验,对解决实际问题有热情,愿意在初创早期加入(基于股权的远程职位) (来源: Reddit r/deeplearning)
🌟 社区
探讨:大模型本质是“语言的幻术”: 一篇深度思考文章认为,大模型(如ChatGPT)并不真正理解信息,而是通过学习海量语言数据来模仿和预测表达形式。Prompt的作用是设定上下文,引导模型的注意力,而非与有意识的实体交流。模型的回答是基于“见过足够多”的模式复现,看似智能实则缺乏真正理解,容易产生“一本正经胡说八道”的幻觉。人机交互更像是用户在代替模型思考,而模型的输出可能潜移默化地重塑用户的思考和判断习惯,并可能反映和放大现实中的偏见 (来源: 我所理解的大模型:语言的幻术)
讨论:AI能源消耗与中美模型发展策略差异: Reddit用户讨论特朗普将煤炭列为AI发展关键矿产的言论,引发对AI能源消耗问题的担忧。评论指出,大型模型越来越耗能,而中国公司似乎更倾向于构建更精简、更注重效率的模型。这反映了AI发展中性能与能效之间的权衡,以及不同地区可能采取的不同技术路线 (来源: Reddit r/artificial)

提问:寻找类似PyTorch Lightning的深度强化学习框架: Reddit用户询问是否有类似于PyTorch Lightning(PL)的框架专门用于深度强化学习(DRL)。该用户认为PL虽然可以用于DRL,但其设计更偏向于数据集驱动的监督学习,而非环境交互驱动的DRL。帖子寻求社区推荐适用于DRL(如DQN、PPO)并能与Gymnasium等环境良好集成的框架,或者分享使用PL进行DRL的最佳实践经验 (来源: Reddit r/deeplearning)
社区:为虚拟音乐人打造的Discord社区MetaMinds启动: 一个名为MetaMinds的新Discord社区成立,旨在为使用AI工具(如Suno)创作音乐的虚拟艺术家提供交流、合作和分享平台。社区已发起首个名为“A Personal Song”的歌曲创作比赛,并计划未来举办更高标准的竞赛,甚至可能包含现金奖励。这反映了AI音乐创作领域正在形成新的社群生态 (来源: Reddit r/SunoAI)
讨论:包含训练集的数据集集合应如何称呼?: Reddit用户提问,与用于评估模型在多任务上表现的“基准(Benchmark)”相对,一个包含多个旨在训练和评估同一个模型的数据集集合应该叫什么术语。这个问题探讨了机器学习领域内数据集分类和术语使用的细节 (来源: Reddit r/MachineLearning)
求助:OpenWebUI中实现语音转文本功能: 用户寻求在Docker部署的OpenWebUI+Ollama环境中,利用H100 GPU实现语音转文本(用户提问写的是TTS,但描述内容为转录YouTube视频/音频文件,应为ASR/STT)功能的最佳方案和推荐模型。这反映了用户希望在本地LLM交互界面中集成更多模态处理能力的需求 (来源: Reddit r/OpenWebUI)
讨论:对Claude年度订阅及限制调整的看法: Reddit用户庆幸没有购买Claude年度订阅,因为近期许多用户抱怨使用限制收紧。用户认为Anthropic可能在吸引大量用户付费后调整策略以节省成本。同时,用户提到免费的Gemini 2.5 Pro性能强大,表达了对Claude未来发展的担忧和期望。讨论反映了用户对LLM服务定价、使用限制和性价比的敏感度 (来源: Reddit r/ClaudeAI)
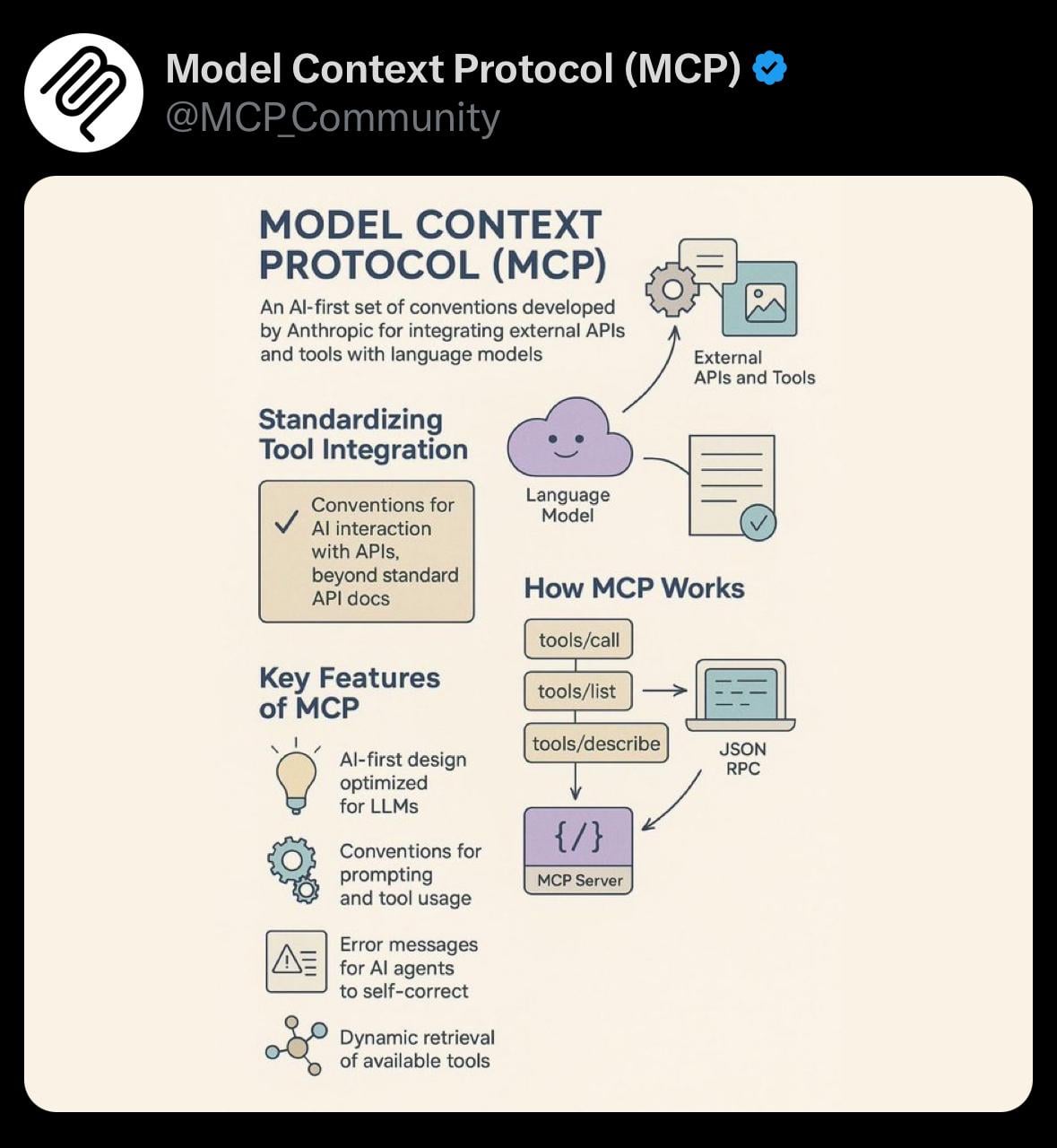
分享:模型上下文协议(MCP)的简单可视化: 用户分享了一张关于模型上下文协议(Model Context Protocol, MCP)的简单可视化图片。MCP可能是与Anthropic Claude模型相关的技术概念,旨在优化或管理模型处理长上下文的方式。该分享为社区提供了理解相关技术概念的视觉辅助 (来源: Reddit r/ClaudeAI)
求助:在OpenWebUI聊天中添加自定义命令: 用户询问在OpenWebUI聊天界面中添加自定义命令(如@tag形式,带自动补全菜单)以方便进行定制化RAG查询(例如按文档类型过滤)的技术难度。用户也在考虑下拉菜单作为替代方案。这反映了用户希望扩展前端交互能力以更灵活地控制后端AI功能的想法 (来源: Reddit r/OpenWebUI)
讨论:生成美观且功能性的AI QR码: 用户尝试使用ChatGPT/DALL-E生成融合艺术风格且能被扫描的QR码,但效果不佳,指出ControlNet等方法更有效。这引发了关于当前主流文生图模型在生成需要精确结构和功能性(如可扫描性)的图像方面的局限性的讨论 (来源: Reddit r/ChatGPT)

寻找AI/ML学习伙伴: 一位大三计算机科学(AI/ML方向)本科生发帖寻找4-5名志同道合者,组队深入学习AI/ML,共同进行项目开发,并一起练习数据结构与算法(DSA/CP)。发起者列出了自己的技术栈和兴趣方向,希望建立一个互相激励、协作学习的小组 (来源: Reddit r/deeplearning)
讨论:AI Agent是否会加剧垃圾信息问题?: Reddit用户提出担忧,认为AI Agent被广泛用于自动化任务(如销售线索查找和消息发送)可能导致垃圾信息泛滥。当每个人都使用类似工具时,目标接收者会被大量个性化的自动消息淹没,从而降低沟通效率,使Agent工具失去价值。讨论引发了对AI工具规模化应用可能带来的负面外部性的思考 (来源: Reddit r/ArtificialInteligence)
讨论:Suno AI近期质量问题: 用户分享了一段使用Suno AI生成的音乐片段,表示尽管最近社区中存在关于Suno输出质量下降的讨论,但他个人觉得这段效果还不错。这反映了社区对AI生成工具性能波动的感知和主观评价差异 (来源: Reddit r/SunoAI)

讨论:RTX 4090 vs RTX 5090 用于深度学习训练: 用户咨询为个人深度学习(非LLM为主)构建单GPU工作站时,应选择当前的RTX 4090还是等待即将发布的RTX 5090。帖子寻求社区关于硬件选择的建议,并询问购买时如何区分游戏卡和专业卡(尽管这些是消费级卡)。反映了AI开发者在硬件选型上的考量 (来源: Reddit r/deeplearning)
讨论:AI是否会破坏资本主义?: 用户认为,由于公司追求利润最大化,AI最终可能取代大部分工作岗位。在现有资本主义体系下,这将导致大规模失业和收入来源中断。用户提出通用基本收入(UBI),通过对从AI获利的公司征收额外税收来资助,可能是必要的解决方案。讨论触及了AI对未来经济结构和社会模式的深远影响 (来源: Reddit r/ArtificialInteligence)
求助:复现Anthropic论文“Reasoning Models Don’t Always Say What They Think”: 用户寻求社区帮助,希望找到能够复现Anthropic关于“推理模型并不总是说出它们所想”的论文结果的提示(Prompts)或相关见解。该论文探讨了大型语言模型内部推理过程与其最终输出之间可能存在的不一致性。这表明社区成员对理解和验证前沿AI研究发现的兴趣 (来源: Reddit r/MachineLearning)
求助:OpenWebUI中的RAG配置与体验: 用户询问在OpenWebUI中使用RAG(检索增强生成)的最佳实践,包括推荐的设置、应避免的参数、以及首选的嵌入模型。用户还遇到了模型行为异常(如Mistral Small输出空列表)的问题,并询问用户个人设置与管理员模型设置的优先级关系。这反映了用户在实际部署和优化RAG应用中遇到的挑战和寻求经验分享的需求 (来源: Reddit r/OpenWebUI)
讨论:Claude用户流失是否会改善服务?: 用户提出一个假设,认为近期因限制和性能问题导致的部分Claude用户流失(“Genesis Exodus”),可能会反过来释放计算资源,从而使服务质量(如性能、限制)回归到更理想的状态。用户表达了对Claude的偏爱,并希望服务能够改善。讨论反映了用户对AI服务供需关系、资源分配和服务质量动态变化的观察与思考 (来源: Reddit r/ClaudeAI)

讨论:如何定义“AI艺术”?: 用户发起讨论,询问社区成员如何定义“AI艺术”,并提出相关问题:使用AI工具(如ChatGPT)生成图片的人是否是创作者?是否拥有所有权?LLM服务提供商在创作中扮演什么角色,是否应被视为共同创作者?此讨论旨在厘清围绕AI生成内容的创作主体、版权归属等核心概念 (来源: Reddit r/ArtificialInteligence)
讨论:AI音乐是否威胁音乐的“公共性”?: 用户提出问题,探讨像Suno这样能轻松生成超个性化音乐的AI工具,是否会削弱音乐作为一种共享体验的“公共性”?担忧点包括:音乐可能变成个人化的镜像而非连接社群的灯塔;演唱会等集体音乐活动可能受影响;用户可能变得只接受定制化内容,减少对多样化或挑战性音乐的开放性。讨论关注AI对音乐文化和社会功能的潜在影响 (来源: Reddit r/SunoAI)
提问:Suno AI生成印地语歌曲的准确性如何?: 非印地语使用者询问Suno AI在生成印地语演唱时的准确度和自然度。寻求了解该工具在特定非英语语种上的表现 (来源: Reddit r/SunoAI)
💡 其他
Suno AI作品分享:Nightingale’s Melody (另类/独立摇滚): 用户分享了一首使用Suno AI创作的另类/独立摇滚风格歌曲 “Nightingale’s Melody”,并附上了YouTube链接 (来源: Reddit r/SunoAI)

Suno AI作品分享:The Art of Abundance (Psytrance): 用户分享了一首结合了高能量Psytrance和精神科技元素的AI生成音乐。歌词由ChatGPT创作,音乐和人声由Suno AI生成,视觉效果由MidJourney和PhotoMosh Pro制作。作品探讨了数字时代的丰盛概念,超越物质主义,涉及创造力、AI意识和人类欲望 (来源: Reddit r/SunoAI)

Suno AI作品分享:Do your Job (乡村音乐): 用户分享了一首使用Suno AI创作的乡村风格歌曲,歌词内容围绕一个真实的悬案(Colton Ross Barrera失踪案),表达了家庭的沮丧和对正义的呼唤 (来源: Reddit r/SunoAI)

Suno AI作品分享:Toxic Friends (电子流行): 用户分享其参加Suno AI四月竞赛的电子流行风格作品 “Toxic Friends” (来源: Reddit r/SunoAI)

Suno AI作品分享:Starlight Visitor (80年代流行翻唱): 用户分享了一首使用Suno AI制作的现有歌曲的80年代流行风格翻唱版本,并提供了YouTube链接 (来源: Reddit r/SunoAI)

ChatGPT创意应用:鸡蛋产品Meme扩展: 用户受一个关于鸡蛋的Meme启发,使用ChatGPT生成了一系列幽默、概念性的鸡蛋相关产品图片和描述,如“预裂生活”(Precracked Life)、“蛋联网”(Internet of Eggs)等。展示了利用AI进行创意发散和幽默内容创作的可能性 (来源: Reddit r/ChatGPT)
Suno AI作品分享:Tom and Jerry / Crambone (蓝调摇滚翻唱): 用户分享了一首使用Suno AI制作的蓝调摇滚风格翻唱歌曲,翻唱对象为 “Tom and Jerry / Crambone”,并提供了YouTube链接 (来源: Reddit r/SunoAI)

AI生成图像:七宗罪具象化: 用户分享了一段视频,展示了使用AI(可能是ChatGPT/DALL-E)生成的代表七宗罪(如贪婪、懒惰、嫉妒等)的具象化、拟人化图像 (来源: Reddit r/ChatGPT)
