
关键词:AI, 大模型, 斯坦福AI指数报告, AI音乐创作争议, Llama 4性能争议, DeepSeek开源模型, Agentic AI发展趋势
🔥 聚焦
斯坦福发布2025年AI指数报告,揭示行业关键趋势:斯坦福大学以人为本人工智能研究所(HAI)发布第八份年度AI指数报告(456页),全面追踪2024年全球AI发展。报告新增AI硬件、推理成本、企业负责任AI实践及AI在科学/医学应用等内容。核心趋势包括:1) AI在MMMU等高难度基准上性能显著提升;2) AI日益融入医疗、交通等日常生活;3) 企业投资和采用率创历史新高,美国投资远超中国,但中国模型性能差距迅速缩小(中美顶尖模型MMLU等基准差距缩至0.3%-1.7%);4) DeepSeek等开源/小模型性能逼近闭源/大模型,推理成本大幅下降(两年降280倍);5) 全球AI监管加强,投资加码;6) AI教育普及加速但资源不均;7) AI安全事件激增,负责任AI实践不均衡;8) 全球对AI乐观情绪上升但地域差异大。报告强调AI变革性潜力及引导其发展的必要性。(来源:36氪, 新智元, 元宇宙之心MetaverseHub, 机器之心)

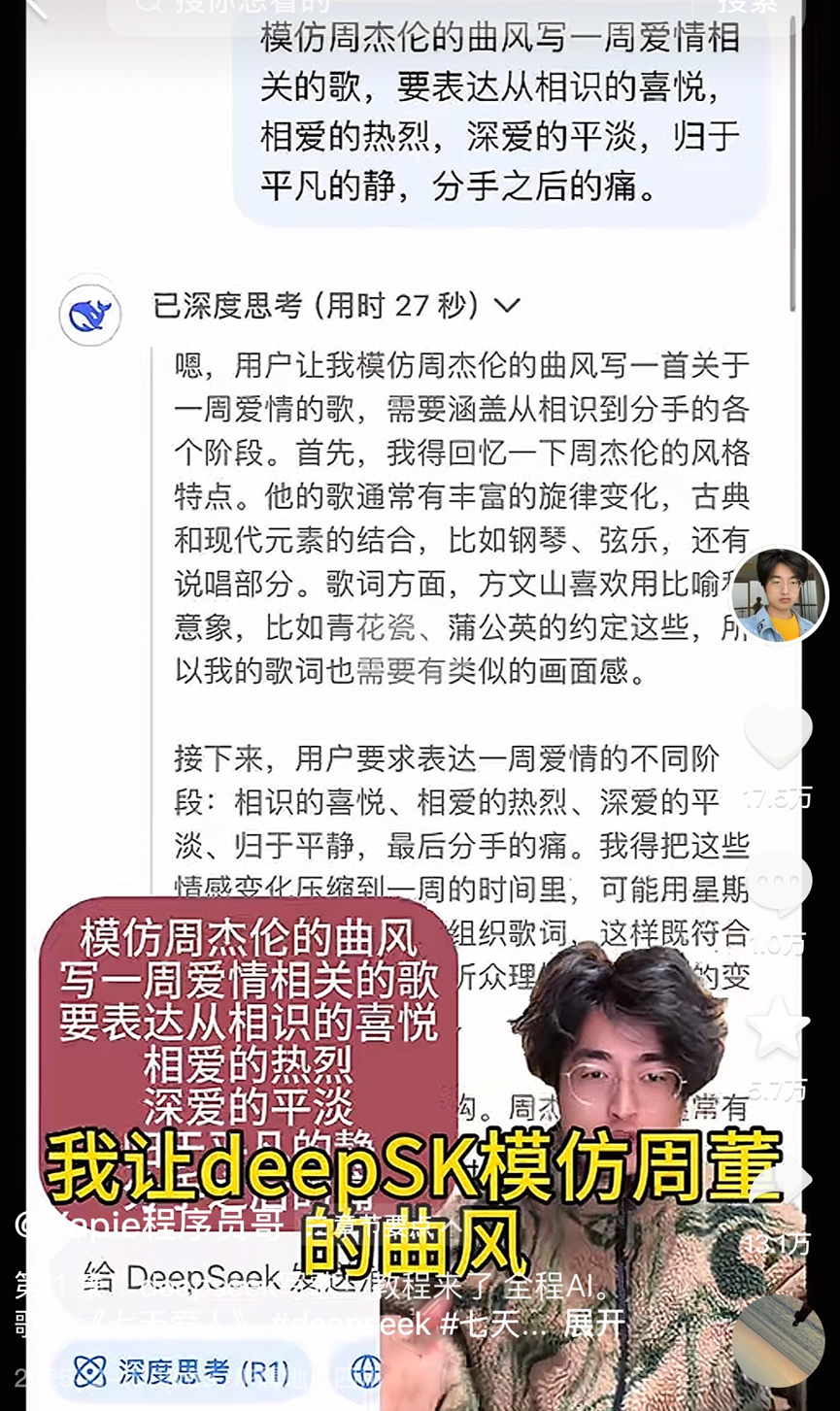
AI音乐创作爆火引争议,《七天爱人》现象透视行业虚火与挑战:AI生成的歌曲《七天爱人》模仿周杰伦风格意外走红,登上热搜和音乐榜单,并快速售出版权,引发AI音乐创作热潮。大量业余爱好者涌入平台,利用AI工具“量产”歌曲,部分平台也推出相关活动。然而,繁荣背后问题重重:大量AI歌曲质量参差不齐,被指“音乐垃圾”;依赖模仿与拼接,缺乏真正创新;版权归属模糊,美国已明确AI创作不受著作权保护,腾讯音乐等平台亦指出法律风险;商业变现困难重重,除个例爆款外,多数AI歌曲收益惨淡,平台审核趋严。业内人士担忧AI可能冲击初级音乐人饭碗,更忧虑“去过程化”创作导致人类思维惰性和审美滑坡。(来源:36氪)
Llama 4模型发布后陷“造假”风波,竞技场排名与实际表现差异引争议:Meta最新发布的开源模型Llama 4,在Chatbot Arena上取得高分,排名超越DeepSeek-V3成为开源第一。然而,大量用户实测反馈其在编程、推理、创意写作等方面表现不佳,远逊于预期及其竞技场排名。随后,大模型竞技场(LMArena)官方指出,Meta提供给竞技场测试的是一个为优化人类偏好而定制的实验版本(Llama-4-Maverick-03-26-Experimental),并非Hugging Face上发布的标准版,且Meta未明确标注此差异。LMArena公开了2000多组对战记录,显示该实验版回复风格(如更友好、使用表情符号)可能是影响排名的重要因素,并将上线HF版Llama 4进行重新评估。Meta Gen AI负责人否认在测试集上训练,称表现差异源于部署稳定性问题。此事件引发社区对Llama 4性能、Meta透明度以及LMArena评估方法可靠性的广泛讨论与质疑。(来源:量子位, 机器之心, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, natolambert, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

DeepSeek现象引发行业关注,中国生成式AI大会探讨新机遇:DeepSeek的崛起被视为中国乃至全球生成式AI产业的关键拐点,其高效率、低成本的开源模式催化了推理模型、AI Infra的研发热潮,并为端侧AI和国产算力落地注入新动能。在2025中国生成式AI大会上,50余位产学研嘉宾围绕DeepSeek引发的变革、深度推理、多模态、世界模型、AI Infra、AIGC应用、Agents及具身智能等议题展开讨论。与会者认为DeepSeek显著降低了企业部署成本(有应用切换后成本降90%),展现了中国在开源社区的活跃度和快速落地能力。大会还探讨了AI应用爆发需新终端、Agent落地挑战、国产算力集群突破、物理智能发展、AI商业化路径等议题,凸显中国在全球AI格局中的角色日益重要。(来源:36氪, Ronald_vanLoon)

🎯 动向
Agentic AI被视为下一大突破:Agentic AI(智能体AI)正成为商业和技术领域转型的关键驱动力。与传统AI执行特定任务不同,Agentic AI能够自主设定目标、制定计划并执行复杂的多步骤任务,更像一个自主的数字员工。它们能整合多种工具和数据源,进行推理和决策,有望在客户服务、数据分析、软件开发等领域带来颠覆性变革。随着技术发展,Agentic AI将推动企业运营模式和人机交互方式的深刻转变。(来源:Ronald_vanLoon)

英伟达发布Llama-Nemotron-Ultra 253B模型,开源权重与数据:英伟达推出Llama-Nemotron-Ultra,这是一个基于Llama-3.1-405B通过NAS剪枝和推理优化后训练得到的253B参数密集模型。该模型专注于提升推理能力,采用了SFT和RL后训练(FP8精度),并开源了权重和后训练数据。英伟达在开源后训练工作方面的持续贡献受到社区欢迎。(来源:natolambert)

Qwen3系列模型或将发布,包含8B和15B MoE版本:根据vLLM代码库合并的PR信息推测,阿里巴巴即将发布Qwen3系列新模型。目前已知可能包含Qwen3-8B和Qwen3-MoE-15B-A2B两个版本。社区猜测8B版本可能为多模态模型,而15B版本是专注于文本的MoE(混合专家)模型。用户期待新模型能在性能上有所突破,若15B MoE能达到Qwen2.5-Max水平,将被视为显著成功。(来源:karminski3)

Runway推出Gen-4 Turbo,视频生成速度大幅提升:Runway发布了其最新的视频生成模型Gen-4 Turbo。新模型的主要亮点在于生成速度,号称能在30秒内生成10秒视频,相比之前版本大幅提速。这使得Gen-4 Turbo特别适合需要快速迭代和创意探索的应用场景。该更新已面向所有用户计划推出。(来源:op7418)
Google Gemini Live上线,实现视觉与语音实时交互:Google宣布Gemini Live功能正式上线,率先登陆Pixel 9和Samsung Galaxy S25设备,并向Android上的Gemini Advanced用户开放。该功能允许用户通过摄像头分享屏幕内容或实时画面,并与Gemini进行语音对话,实现对视觉内容的理解和交互式提问、问题排查、头脑风暴等。这标志着Google在多模态AI交互体验上的重要进展,使Project Astra的愿景进一步落地。(来源:op7418, JeffDean, demishassabis)
HiDream发布17B参数开源图像模型HiDream-I1:HiDream AI团队发布并开源了其17B参数的图像生成模型HiDream-I1。从初步展示的图片来看,该模型生成的图像质量尚可。模型代码已在GitHub上公开,供开发者和研究者使用与探索。(来源:op7418)

大模型开源浪潮加速,商业模式探索“2.0”:2025年,以DeepSeek为代表的开源模型崛起,推动Meta、阿里、腾讯等加速开源步伐,甚至OpenAI、百度等原“闭源派”也开始转向。开源驱动力包括端侧智能需求、行业定制化需求、生态化分工加速及技术跨越临界点。开源降低了开发者和中小企业的门槛,促进技术普惠和创新。然而,开源不等于免费,维护和本地化仍有成本。领先厂商正探索商业化2.0模式,如“开源基础模型+商业API增值服务”(如DeepSeek、智谱)、“开源社区版+企业专属版”(如阿里云千问)和“模型开源+云平台变现”(如Meta Llama)。核心在于“开源引流,服务变现”,通过生态、定制、云服务实现盈利。(来源:第一新声)

🧰 工具
Augment Code:专为复杂项目打造的AI编码平台:Augment Code发布,定位为首个能深度理解大型复杂代码库、专为团队协作设计的AI编码平台。它提供高达200K的上下文token处理能力、持久化记忆(学习代码风格、重构历史、团队规范)及深度工具集成(VS Code, JetBrains, Vim, GitHub, Linear, Notion等)。其核心Agent不仅能编写代码,还能执行终端命令、创建完整PR、生成上下文感知的文档和测试用例。Augment在SWE-bench Verified排行榜上排名第一(结合Claude Sonnet 3.7和o1),并已获得Webflow, Kong等公司使用。平台目前免费,旨在解决开发者在处理大型、遗留代码库时的痛点。(来源:AI进修生)
Cloudflare推出AutoRAG服务,简化RAG应用构建:Cloudflare发布了AutoRAG,一项旨在简化检索增强生成(RAG)应用开发的服务。开发者可以通过该服务,自动将数据源(如文档、网站)转化为可供大模型查询的知识库,无需手动处理数据索引和检索逻辑。在公开测试版期间,AutoRAG免费使用,每个账户限制10个实例,每个实例最多处理10万个文件。此举降低了构建基于特定知识的AI应用的门槛。(来源:karminski3)

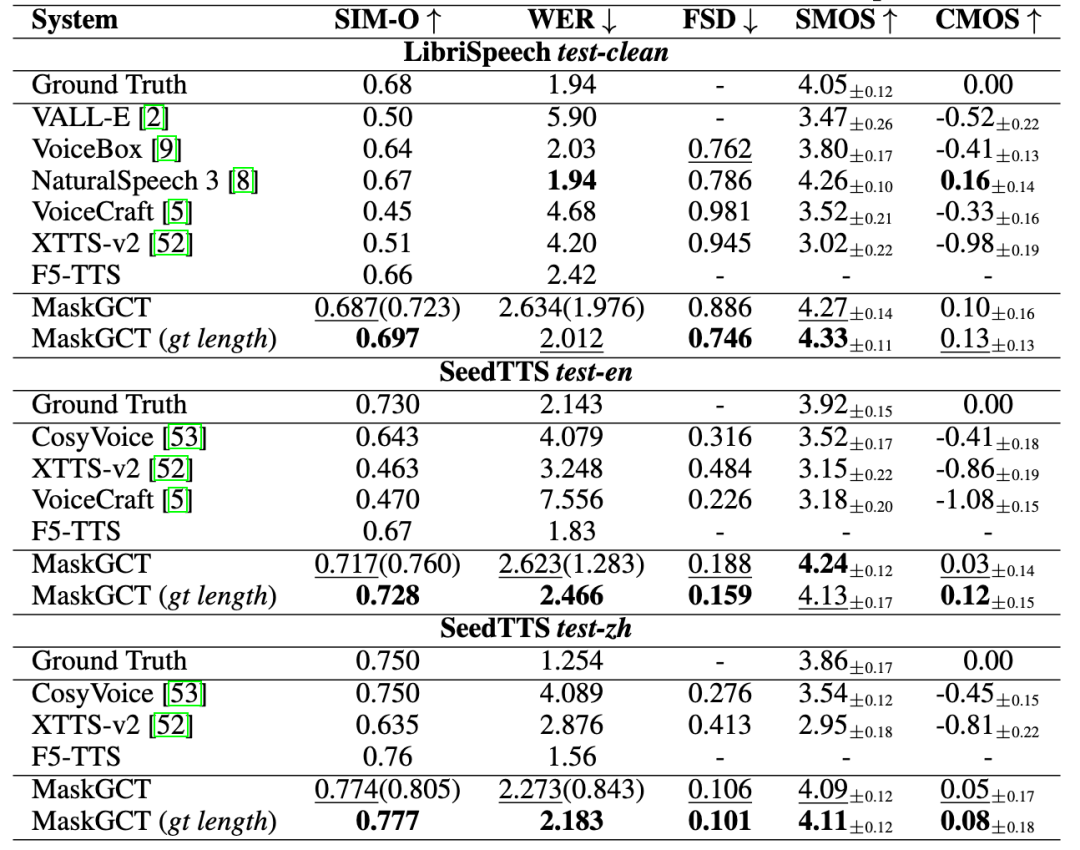
趣丸科技推出「趣丸千音」,提供AI语音全流程解决方案:趣丸科技发布AI语音产品「趣丸千音(All Voice Lab)」,基于与港中大(深圳)联合研发的MaskGCT模型。该产品集成文本转语音、视频翻译、多语种合成、字幕擦除等功能,特点是实现了视频翻译全流程自动化,日处理量超1000分钟,效率提升10倍。其语音生成效果情绪饱满、媲美真人。趣丸千音旨在通过工业化能力解决跨语言传播规模化需求,已应用于短剧出海(成本降低、用户增长)、新闻、文旅、有声书等领域,定位为“全球内容基础设施”。(来源:36氪)
Exa:专为AI Agent设计的搜索引擎:Exa定位为“LLM时代的Bing API”,是一个专为AI Agent设计的搜索引擎,旨在让AI能高效访问和理解互联网信息。与人类搜索不同,Exa能处理更复杂的自然语言查询,提供更全面的结果,并支持高吞吐、低延迟的请求。其核心API包括快速搜索、内容获取(爬虫)、相似链接查找等。Exa还提供Websets功能,允许用户用自然语言筛选条件,将互联网信息结构化。该公司已获Lightspeed、英伟达等投资,ARR超千万美元,主要竞争对手为Brave Search。(来源:AI探索者)
AI工具实现微信聊天记录可视化总结:利用AI工具组合,可将微信群聊或私聊记录导出并生成可视化报告。步骤包括:1) 使用第三方工具(如留痕MemoTrace)导出微信聊天记录为TXT文件(注意数据安全风险);2) 将TXT文件和特定Prompt模板(包含样式代码)输入支持长文本处理的大模型(如Gemini 2.5 Pro in AI Studio),生成HTML代码;3) 将生成的HTML代码通过在线服务(如yourware.so)转换成可分享的网页链接,或使用在线工具(如cloudconvert.com)直接转换成图片。该方法能将冗长的聊天信息转化为结构清晰、包含每日金句和词云的报告,便于回顾和分享。(来源:卡兹克)
即梦AI 3.0图像模型全量上线:即梦AI宣布其3.0版本的图像生成模型已完成测试并全量上线。新版本预计在图像质量、风格多样性、语义理解等方面有所提升。已有用户(如歸藏)分享了使用3.0模型进行不同领域设计(如AI运营图片)的详细测试和提示词合集,展示了其生成效果。(来源:op7418)

VIBE Chat:带随机背景的趣味聊天网站:一个名为VIBE Chat的网站提供了一种新颖的聊天体验,每次会话都会随机生成不同的背景图片。该网站基于Gemini 2.0 Flash模型,用户可以用它进行编程等任务,代码或内容会直接展示在聊天界面中。测试显示它可以生成如Flappy Bird和俄罗斯方块等简单游戏的代码。(来源:karminski3)
开发者创建SunoAI专用GPT助手:一位开发者创建了一个名为“Hook & Harmony Studio”的自定义GPT,旨在辅助Suno AI音乐创作流程。该工具能根据用户输入的歌曲概念,生成包含独特标题、结构化歌词(带乐器和演唱指导)、符合Suno风格标签的建议、过滤陈词滥调,并可选生成歌曲视觉效果的提示词。它旨在简化歌词创作和风格探索,并自动格式化以便在Suno项目模式中使用。(来源:Reddit r/SunoAI)
Code to Prompt Generator:简化代码到LLM提示的工具:开发者开源了一个名为“Code to Prompt Generator”的小工具,旨在简化从代码库创建LLM提示的过程。它可以自动扫描项目文件夹生成文件树(排除无关文件),允许用户选择性包含文件/目录,实时显示Token计数,保存和重用指令(Meta Prompts),并一键复制最终提示。该工具使用Next.js前端和Flask后端,可在多平台运行。(来源:Reddit r/ClaudeAI)
Llama 4 GGUF版本发布,支持本地运行:随着llama.cpp合并对Llama 4(目前仅文本)的支持,社区开发者(如bartowski, unsloth, lmstudio-community)已快速发布了Llama 4 Scout模型的GGUF量化版本。这些版本采用了imatrix等优化量化策略,旨在平衡模型大小和性能,允许用户在本地硬件上运行Llama 4。不同位宽(如IQ1_S 1.78bit, Q4_K_XL 4.5bit)的版本可供选择,满足不同硬件配置的需求。用户可在Hugging Face上找到这些GGUF文件。(来源:Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)

📚 学习
微软与港中文提出ImageGen-CoT,提升AI绘画上下文理解能力:为解决AI绘画模型在理解复杂文本描述和上下文关联(如“皮革苹果”到“皮革盒子”的材质迁移)时的不足,微软亚洲研究院与香港中文大学的研究者提出ImageGen-CoT框架。该方法在图像生成前引入思维链(Chain-of-Thought, CoT)推理步骤,让模型先思考关键信息、梳理逻辑,再进行创作。通过构建高质量ImageGen-CoT数据集并进行微调,模型(如SEED-X)在T2I-ICL任务上性能提升显著(CoBSAT提升89%,DreamBench++提升114%)。该框架采用两阶段推理,并探索了多种测试时扩展策略(单CoT、多CoT、混合扩展),其中混合扩展效果最佳。(来源:36氪, 新智元)

论文提出路由LLM新范式及RouterEval基准:针对大模型研究面临的算力垄断、成本高昂和技术路径单一问题,研究者提出路由LLM(Routing LLM)范式,通过智能路由器(Router)将任务动态分配给多个(开源)小模型协同处理。为支持该研究,论文开源了全面的RouterEval基准,包含8500+ LLM在12个主流Benchmark上的2亿条性能记录。该基准将路由问题转化为标准分类任务,可在单卡GPU甚至笔记本上进行研究。研究发现,通过智能路由(即使仅有3-10个候选模型),多个弱模型组合性能可超越顶级单体模型(如GPT-4),展现出“Model-level Scaling Up”效应。该工作为低成本实现高性能AI提供了新思路。(来源:新智元)
UIUC韩家炜、孙冀萌团队开源DeepRetrieval,用RL优化搜索引擎查询:针对用户原始查询质量不高导致信息检索效果不佳的问题,UIUC团队提出DeepRetrieval框架。该系统利用强化学习(RL)训练LLM优化用户原始查询(自然语言、布尔表达式或SQL),使其更适应特定搜索引擎(如PubMed、BM25、SQL数据库)的特性,从而在不改变现有检索系统的前提下最大化检索效果。实验表明,DeepRetrieval(仅3B模型)能显著提升检索性能(文献搜索提升10倍,Evidence-Seeking任务超GPT-4o,SQL执行准确率提升),效果远超基于SFT的方法。研究强调RL的探索能力优于SFT的模仿学习,能发现更优的查询策略。(来源:机器之心)
中科院自动化所等提出Vision-R1,用强化学习提升VLM视觉定位能力:针对图文大模型(VLM)在目标检测、视觉定位任务中存在的格式错误、召回率低、精度不足等问题,中科院自动化所与中科紫东太初团队提出Vision-R1框架。该方法借鉴语言模型R1的成功经验,将基于规则的强化学习(Rule-Based RL)引入视觉定位任务。通过设计基于视觉评价指标(格式正确性、召回率、IoU精度)的任务级奖励函数,并采用渐进式规则调整策略(差异化奖励、阶段渐进阈值),在不依赖人工偏好数据和奖励模型的情况下,显著提升了Qwen2.5-VL等模型在COCO、ODINW等数据集上的目标检测性能(最高提升50%),且基本不影响通用问答能力。代码、模型已开源。(来源:机器之心)
CalibQuant:1比特KV Cache量化方案提升多模态模型吞吐量:为解决多模态大模型(MLLM)处理大规模视觉输入时KV Cache显存占用过高、限制吞吐量的问题,研究者提出CalibQuant方案。该方案实现极端的1比特KV Cache量化,结合了针对视觉KV Cache冗余特性设计的后缩放(Post-Scaling)和校准(Calibration)技术。后缩放优化了反量化计算顺序以提高效率,校准则调整注意力分数以减轻1比特量化引入的极端值失真。实验表明,CalibQuant能在LLaVA、InternVL-2.5等模型上显著降低显存和计算开销,实现高达10倍的吞吐量提升,同时几乎不损失模型性能。该方法即插即用,无需修改原模型。(来源:PaperWeekly)
CVPR 2025 | SeqAfford:实现序列化3D可供性推理:为解决现有AI难以理解和执行涉及多物体、多步骤复杂指令的问题,研究者提出SeqAfford框架。该框架首次将3D视觉与多模态大语言模型(MLLM)结合,用于序列化3D可供性(Affordance)推理。通过构建首个包含超18万对指令-点云数据的Sequential 3D Affordance数据集进行微调,并引入基于分割词汇(
GitHub上线MCP服务器资源集合:一个名为awesome-mcp-servers的GitHub仓库整理并开源了超过300个用于AI Agent的MCP(Model Capability Protocol)服务器。这些服务器涵盖了生产级和实验性项目,为开发者提供了丰富的工具和接口,方便AI Agent与外部服务和数据源进行交互,进一步推动了Agent生态的发展。(来源:Reddit r/ClaudeAI)

埃默里大学刘菲教授招收大模型/NLP/GenAI博士生及实习生:美国埃默里大学计算机科学系副教授刘菲招收2025年秋季入学的全奖博士生,研究方向为大语言模型(LLM)作为智能体的推理、规划与决策能力,以及AI在教育、医疗等领域的应用。同时也欢迎对相关方向感兴趣的学生申请远程实习或合作。要求申请者具有计算机或相关专业背景,编程能力优秀,有研究成果或较强数学基础者优先。(来源:AI求职)
AI Agent构建指南发布:SuccessTech Services发布了一份逐步指南,介绍如何构建大语言模型(LLM)智能体(Agent)。该指南可能涵盖了Agent的基本概念、架构设计、工具选择、开发流程以及实际应用案例,为希望开发自主AI应用的开发者提供了入门指导。(来源:Reddit r/OpenWebUI)

港科大发布Dream 7B代码,专注Diffusion模型推理:香港科技大学NLP团队此前发布的Diffusion模型推理模型Dream 7B,现已公开其GitHub代码库。该模型旨在让LLM理解和执行与Diffusion模型相关的指令。代码的公开使得研究者可以复现和进一步研究该模型。(来源:Reddit r/LocalLLaMA)

💼 商业
灵心巧手获亿元级种子轮融资,研发全球最高自由度灵巧手:具身智能公司「灵心巧手」完成超亿元种子轮融资,由红杉种子基金等领投。该公司专注于“灵巧手+云端智脑”平台,其自研的Linker Hand系列灵巧手,工业版自由度达25-30,科研版高达42(全球最高,超Shadow Hand的24和擎天柱的22),具备高精度感知(多传感器融合)和操控能力。公司采用连杆和键绳两种结构并实现量产,结合云端智脑(基于大规模数据集DexSkill-Net训练)进行学习和控制。产品在成本(约5万人民币,远低于Shadow Hand的150万)和耐用性上具优势,已获北大、清华等顶尖高校采购,并应用于医疗、工业等场景。(来源:36氪)

谷歌被曝支付AI员工高薪“花园假”,阻止其加入竞争对手:据报道,谷歌为了阻止关键AI人才流向OpenAI等竞争对手,向部分离职员工支付了长达一年的高额薪酬(可能高达数十万美元),条件是他们在此期间不加入竞争对手公司。这种做法被称为“花园假”(gardening leave),虽在金融等行业常见,但在科技行业尤其是针对非高管层级的AI研究员和工程师则较为罕见。这反映了顶级AI人才的极端稀缺性以及科技巨头间激烈的人才争夺战。(来源:Reddit r/ArtificialInteligence)

Shopify CEO强调员工需有效利用AI:Shopify CEO Tobias Lütke要求员工在考虑增加团队人数之前,必须先思考如何利用AI工具来提升效率和解决问题。他认为AI是提升生产力的关键杠杆,员工应积极学习并将其融入日常工作流程。这一表态反映了企业界对AI赋能工作效率的高度重视,以及对员工适应AI时代新要求的期望。(来源:bushaicave.com)
36氪启动“2025 AI Partner创新大奖”征集:为发掘和鼓励AI领域的创新产品、解决方案和企业,推动AI在各行业落地应用,36氪发起“2025 AI Partner创新大奖”评选活动。征集范围涵盖通用创新(办公、企服、数据分析等)、行业创新(金融、医疗、教育、工业等)和终端创新(智能硬件、汽车、机器人等)三大类别的非应用软件类产品/解决方案。评选将从技术创新、应用效果、用户体验和社会价值四个维度进行,由专家评审团打分。报名时间为3月13日至4月7日,结果将于4月18日公布。(来源:36氪)

全国首部AI大模型私有化部署标准启动编制:针对企业私有化部署AI大模型面临的技术错配、流程不规范、评价体系缺乏等问题,智合标准中心联合公安部第三研究所等单位启动《人工智能大模型私有化部署技术实施与评价指南》团体标准编制工作。该标准旨在覆盖模型选用、资源规划、部署实施、质量评价到持续优化的全流程,融合技术、安全、评价与案例,并联合模型应用方、技术服务方、质量评价方共同制定。标准面向AI大模型企业、技术服务商、硬件提供商、云计算企业、安全服务商、数据服务商、行业应用企业、测试评估机构、合规法律机构及可持续发展机构等征集参编单位。(来源:智合标准化建设)
🌟 社区
AI生成内容引发“幻觉”和信息可靠性担忧:多位用户和媒体反映,包括DeepSeek在内的大语言模型存在“一本正经胡说八道”的现象,即AI幻觉。AI可能编造不存在的事实、引用错误来源(如诗词出处、法条、文物信息),甚至捏造数据(如“80后死亡率”)。这种现象源于训练数据过时、错误或偏见,模型知识盲区以及缺乏实时验证能力。用户需警惕AI生成内容的准确性,进行交叉验证和人工审核,尤其是在学术、工作等严肃场景。过度依赖可能导致错误信息传播,加剧“后真相时代”挑战。Vectara HHEM幻觉测试也显示DeepSeek-R1存在较高幻觉率。(来源:锌刻度)
AI艺术生成再引争议:从吉卜力风格爆红谈起:OpenAI的GPT新图像功能生成吉卜力风格图片大受欢迎,甚至CEO Sam Altman也将头像换成该风格,带动ChatGPT下载量和收入增长。然而,这也再次引发关于AI生成艺术的伦理和版权争议。宫崎骏本人曾明确反对机器生成的画面。好莱坞从业者(如《怪诞小镇》创作者Alex Hirsch、Robin Williams之女Zelda Williams)对此表示强烈不满,认为这是对艺术家创作成果的窃取,缺乏灵魂。Altman则回应称这是“创作的民主化”,是社会的巨大胜利。文章认为,尽管AI能模仿画风,但难以复制吉卜力作品中蕴含的复杂叙事、美学系统和人文关怀。大部分AI生成内容难以成为经典,但部分人机共创或辅助工具会成功。(来源:APPSO, Reddit r/artificial)

观点:人类认知结构是AI时代的核心竞争力:文章反驳AI工具普及导致创作者价值贬低的观点,认为表达和创作本身是人类的内在需求和“消费行为”,其价值在于过程而非仅结果。AI是工具,无法替代人的独特认知和情感。人类大脑经过亿万年进化形成的“认知结构”是关键,AI的发展也正从数据驱动转向认知驱动(模仿人类认知过程)。因此,未来核心竞争力不是“干活”,而是与AI交互的“认知结构”或“锚点”——即独特的视角、深刻体验和与他人建立的真实联系。创作者应专注打磨自身独特部分,成为信息洪流中的稳定参照物,为自己和他人提供方向感和价值感,对抗AI可能带来的“熵增”。(来源:王智远)
观点:AI应用存在基于关系和信任的新型壁垒:针对朱啸虎“AI应用没有壁垒”的言论,文章提出反驳,认为AI时代应用壁垒已从传统技术壁垒转变为基于关系和信任的新型壁垒。AI应用不再仅追求用户规模,可通过提供个性化体验在垂直市场获利。即使是“套壳”应用,也能通过与用户建立深度链接(AI越用越懂你)、创作者IP与用户的信任纽带、以及数据闭环持续优化(行业数据+个人数据训练)来构建护城河。建议创业者专注垂直领域,打造独特体验,构建数据闭环,并建立情感连接。(来源:周知)
AI“速成班”骗局盯上老年人养老金:打着“AI速成变现”、“月入过万”旗号的在线课程,通过短视频平台精准推送给老年人。这些课程常以免费教学为诱饵,利用数字人视频、伪造“专家”身份、渲染养老焦虑或创富神话等手段吸引老年人入群。随后通过洗脑式营销(如晒收益截图、营造名额紧张感)诱导老年人支付高额学费(数千至上万元)。课程内容往往是基础的自媒体运营知识包装,承诺的AI技能教学、接单返现、一对一指导等多为虚假宣传,售后服务缺失,退款困难。许多年轻人已在社交媒体分享家人险些或已经受骗的经历,呼吁警惕此类骗局。(来源:豹变)

Karpathy:LLM颠覆传统技术扩散路径,赋能个人:Andrej Karpathy撰文指出,大语言模型(LLM)的技术扩散模式与历史上的变革性技术(通常自上而下:政府->企业->个人)截然不同。LLM几乎在一夜之间以低成本(甚至免费)、高速度的方式普及到每个人的设备上,为普通个人带来了不成比例的巨大益处,而对企业和政府的影响相对滞后。这是因为LLM能在广泛领域提供准专家级知识,弥补了个人知识领域的局限。相比之下,组织机构因其固有优势与LLM能力不匹配、问题复杂度高、内部惯性等因素,受益程度有限。他认为,目前AI的未来分布惊人地均衡,是真正的“人民的力量”。但未来若金钱能买到显著更好的AI,格局可能再次改变。(来源:op7418)
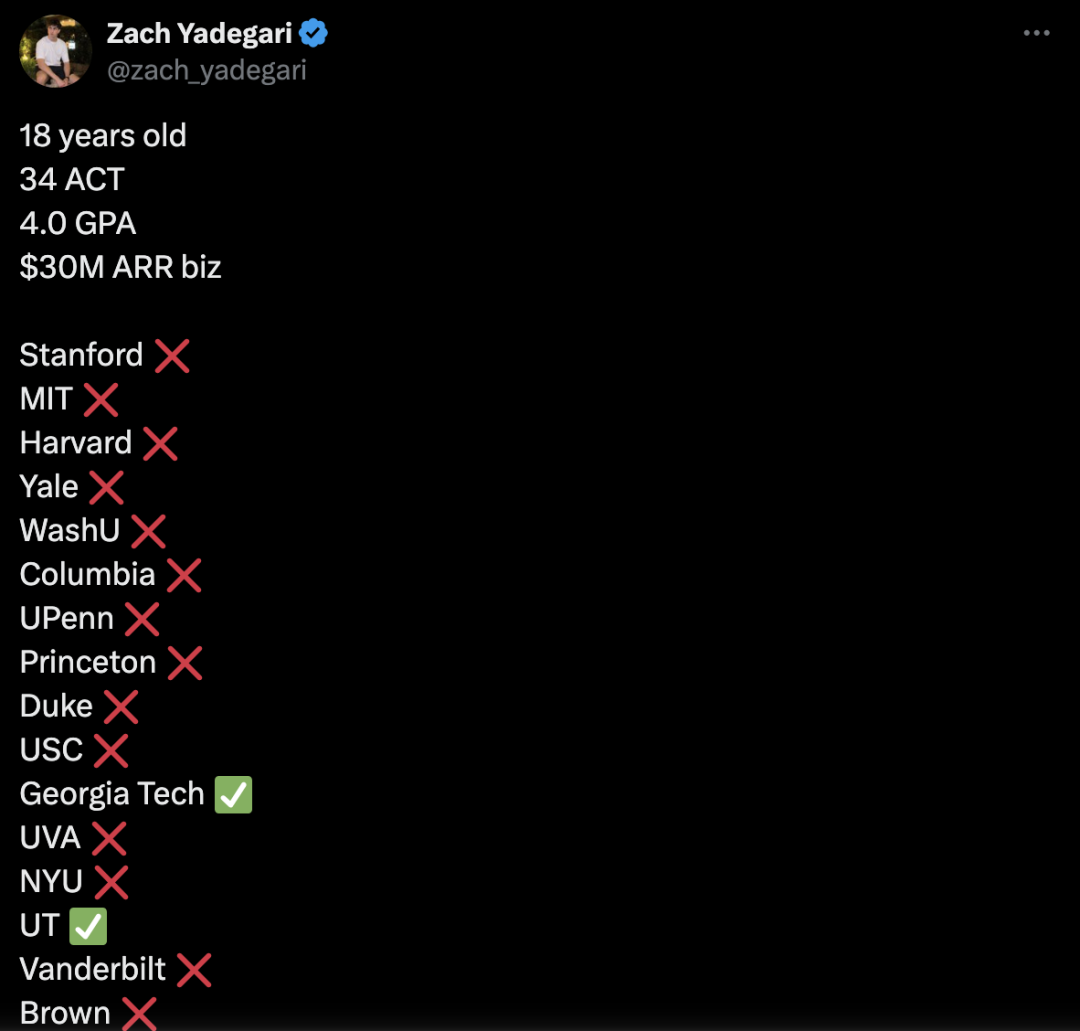
18岁AI应用CEO遭多所名校拒收引发热议:18岁的Zach Yadegari,高中期间联合创办AI卡路里追踪应用Cal AI,该应用下载量超300万,年收入达数百万美元。尽管他拥有4.0 GPA和高分ACT成绩,以及亮眼的创业经历,但在申请18所顶尖大学时被15所拒绝,包括哈佛、斯坦福、MIT等。此事在社交媒体引发广泛关注和讨论。Yadegari公开的入学论文坦诚自己曾不打算上大学,后因认识到大学生活价值而改变想法。被拒原因引发猜测,有人认为论文显得“傲慢”或暗示辍学风险高,影响了名校看重的毕业率指标;也有人批评大学录取体系问题,或涉及对亚裔申请者的歧视(类比Stanley Zhong案例)。Yadegari本人表示希望被视为真诚。(来源:36氪, AI前线)
社区热议:AI是福是祸?:Reddit社区出现关于AI技术利弊的讨论。有用户认为AI是技术的恩赐,能快速实现创意想法(如生成特定场景图片),不理解为何有人(尤其非创作者)对其抱有敌意。该观点强调了AI在满足个人即时性、低成本创作需求方面的价值。这反映了社区中对AI工具赋能个人创造力的积极看法,同时也折射出社会上对AI技术存在的普遍争议和不同态度。(来源:Reddit r/artificial)
社区热议:MCP协议是否将成为AI Agent的“互联网”?:随着MCP(Model Capability Protocol)的发展,社区开始讨论其潜力。有观点认为,MCP通过提供标准化接口让LLM与外部工具和数据源交互,可能会成为连接各种AI Agent和服务的基础设施,类似于互联网连接了不同的计算机和网站。这预示着未来AI Agent生态可能基于MCP实现互操作和协同。(来源:Reddit r/ClaudeAI)

💡 其他
微软三巨头与AI Copilot畅谈50年与未来:在微软成立50周年之际,比尔·盖茨、史蒂夫·鲍尔默和萨提亚·纳德拉三代CEO与AI助手Copilot进行了一场对话。盖茨回顾了早期对软件价值和计算成本下降的预见,并反思应更早处理与政府的关系。鲍尔默和纳德拉均强调AI的重要性,鲍尔默认为应围绕核心AI技术深化业务,纳德拉则预言AI将成为普及的“快消品”智能工具。对话中,Copilot还幽默地“吐槽”了三位大佬,如盖茨的“沉思脸”可能让AI“蓝屏”。这场对话展现了微软领导层对历史的反思和对AI驱动未来的共识。(来源:腾讯科技)

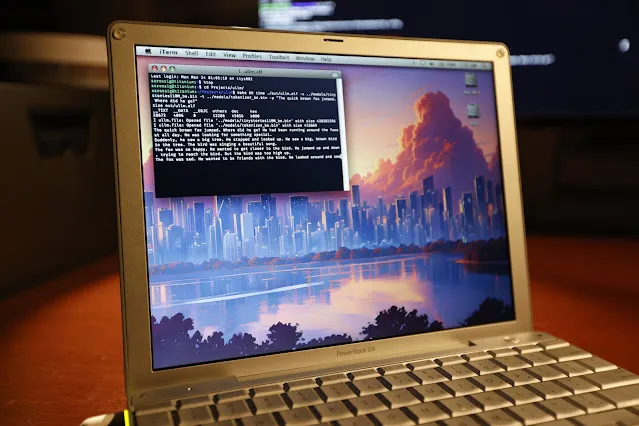
在20年前的PowerBook G4上成功运行LLM推理:软件工程师Andrew Rossignol成功在一台拥有20年历史的苹果PowerBook G4笔记本电脑(1.5 GHz PowerPC G4处理器,1GB内存)上运行了Meta的Llama 2大模型(TinyStories 110M版本)的推理任务。他移植了开源项目llama2.c,并针对PowerPC架构(大端处理、内存对齐)进行了修改,还利用AltiVec矢量扩展(融合乘加运算)将推理速度提升了约10%(从0.77 token/s 到 0.88 token/s)。虽然速度仅为现代CPU的约1/8,但证明了即使在非常陈旧和资源受限的硬件上运行现代AI模型也是可能的。(来源:36氪, AI前线)
探讨:为何需要世界模型?:文章探讨了世界模型(World Models)的必要性,认为其是克服当前大语言模型(LLM)局限(如缺乏物理世界理解、持久记忆、推理和规划能力)的关键。世界模型旨在让AI像人一样构建对环境的内部模拟,理解物理规律(如重力、碰撞)和因果关系,从而进行预测和决策。文章回顾了世界模型从认知科学概念到计算建模(结合RL/DL,如DeepMind的《World Models》论文)再到大模型时代(结合Transformer和多模态,如Genie, PaLM-E)的发展历程。世界模型的核心优势在于因果预测和反事实推理能力,以及跨任务泛化能力,这与LLM基于大规模文本关联概率进行预测的本质不同。虽然世界模型前景广阔,但在算力、泛化能力和数据方面仍面临挑战。(来源:脑极体)

AI危险检测新突破:Holmes-VAU实现多层级长视频异常理解:针对现有视频异常理解(VAU)方法在处理长视频和复杂时序异常上的不足,华中科大等机构提出Holmes-VAU模型及HIVAU-70k数据集。该数据集包含超7万条多时序尺度(video-level, event-level, clip-level)指令数据,通过半自动数据引擎构建,促进模型对长、短视频异常的综合理解。同时,提出的Anomaly-focused Temporal Sampler (ATS)能根据异常分数动态稀疏采样关键帧,有效减少冗余信息,提升长视频异常分析的准确性和效率。实验证明,Holmes-VAU在各种时序粒度的视频异常理解任务上显著优于通用多模态大模型。(来源:量子位)
AI与可持续性:碳足迹问题引关注:随着AI模型的规模和训练计算量指数级增长,其能源消耗和碳排放问题日益突出。斯坦福AI指数报告指出,尽管硬件能效有所提升,但整体能耗仍在增长。例如,训练Meta的Llama 3.1模型估计产生近9000吨二氧化碳。虽然DeepSeek等模型在能效上有所突破,但AI行业的整体碳足迹仍是严峻挑战。这促使AI公司开始探索核能等零碳能源解决方案,并引发对AI发展可持续性的讨论。(来源:Ronald_vanLoon, 机器之心)
