
关键词:Llama 4, GPT-4o, Llama 4性能争议, GPT-4o吉卜力风格版权问题, 扩散语言模型Dream-7B, 斯坦福HAI AI指数报告, 自主AI Agent风险
🔥 聚焦
Llama 4 发布引发争议,性能被指未达预期且涉嫌刷榜: Meta 发布 Llama 4 系列模型(Scout、Maverick、Behemoth),采用 MoE 架构,支持高达 1000 万 token 上下文。然而,社区测试发现在编码、长文写作等任务上表现不如预期,甚至逊于 DeepSeek R1、Gemini 2.5 Pro 及部分现有开源模型。官方宣传图被指“针对对话优化”,引发刷榜质疑。同时,模型对算力要求高,普通用户难以本地运行。有泄露消息称内部训练存在问题,且模型因 EU AI Act 合规问题禁止欧盟实体使用。尽管基础模型能力尚可,但缺乏显著创新(如坚持 DPO 而非 PPO/GRPO),整体发布被认为反响平平甚至令人失望 (来源: AI科技评论, YouTube, YouTube, ylecun, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
GPT-4o 生成“吉卜力风格”图像爆火,重塑创作边界亦引版权争议: OpenAI 的 GPT-4o 模型因其强大的“吉卜力风格”图片生成能力在全球社交媒体引发创作热潮,用户将《甄嬛传》、《泰坦尼克号》等经典影视及生活照进行风格转换。该功能降低了艺术创作门槛,推动了视觉表达的普惠化。然而,其对特定艺术风格的精准复刻也引发了版权争议,外界质疑 OpenAI 是否未经许可使用了吉卜力工作室的作品进行训练,再次凸显 AI 训练数据版权的法律灰色地带及对原创性的挑战 (来源: 36氪)

🎯 动向
扩散语言模型 Dream-7B 发布,性能媲美同级自回归模型: 港大与华为诺亚提出新型扩散语言模型 Dream-7B。该模型在通用能力、数学推理和编程任务上,表现出与 Qwen2.5 7B、LLaMA3 8B 等同规模顶尖自回归模型相当甚至更优的性能,并在规划能力和推理灵活性(如任意顺序生成)方面展现独特优势。研究利用了自回归模型权重初始化、上下文自适应 token 级噪声重排等技术进行高效训练,证明了扩散模型在自然语言处理领域的潜力 (来源: AINLPer)
Stanford HAI 2025 AI 指数报告发布,揭示全球 AI 竞争格局: Stanford HAI 年度报告指出,美国在顶级 AI 模型数量上仍领先(40个),但中国正快速追赶(15个,以 DeepSeek 为代表),法国等新玩家也加入竞争。报告强调了开源权重和多模态模型的兴起(如 Llama、DeepSeek),以及 AI 训练效率提升和成本下降的趋势。同时,AI 在商业中的应用和投资创纪录,但也伴随着伦理风险(模型滥用、失效)的增长。报告认为合成数据将是关键,并指出复杂推理仍是挑战 (来源: Wired, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/artificial, Reddit r/MachineLearning)

OpenAI 推出新 Responses API,作为 Agent 构建基础: OpenAI CEO Sam Altman 重点介绍了新推出的 Responses API。该 API 被定位为 OpenAI API 的新基础原语,是基于过去两年 API 设计经验的结晶,并将作为构建下一代 AI Agent 的基础 (来源: sama)
研究发现 LLM 能够识别自身错误: VentureBeat 报道的一项研究表明,大型语言模型(LLMs)具备识别自身所犯错误的能力。这一发现可能对模型的自我修正、提高可靠性以及人机交互信任度产生影响 (来源: Ronald_vanLoon)

自主 AI Agent 引发关注与担忧: FastCompany 文章探讨了自主 AI Agent 的兴起,认为这是 AI 发展的下一波浪潮。文章在承认其惊人能力的同时,也指出了潜在的风险和令人担忧的方面,引发对该技术发展方向和安全性的思考 (来源: Ronald_vanLoon)

NVIDIA 利用合成数据推进自动驾驶技术: Sawyer Merritt 分享了 NVIDIA 的一段视频,展示了该公司如何利用合成数据来训练和改进其完全自动驾驶技术。这表明合成数据在解决真实世界数据稀疏性、标注成本高以及边缘案例覆盖难等问题上的重要性日益增加,成为自动驾驶等领域 AI 模型训练的关键资源 (来源: Ronald_vanLoon)
Gemini 2.5 Pro 在 MathArena USAMO 评估中表现突出: Google DeepMind 的 Oriol Vinyals 注意到,Gemini 2.5 Pro 在 MathArena USAMO(美国数学奥林匹克)基准测试中取得了 24.4% 的分数,是首个在该高难度数学推理测试中获得显著分数的模型,显示出其强大的数学推理能力和 AI 在复杂问题解决方面的快速进展 (来源: OriolVinyalsML)

人形机器人控制技术展示: Ilir Aliu 展示了控制完整人形机器人的能力,这通常涉及到复杂的运动规划、平衡控制、感知与交互等 AI 技术,是具身智能领域的重要研究方向 (来源: Ronald_vanLoon)
传闻 Qwen 模型将支持 MCP: 根据 karminski3 分享的图片信息,阿里巴巴的 Qwen 大模型似乎计划支持 MCP (Model Context Protocol),这意味着 Qwen 可能将能更好地与 Cursor 等客户端集成,利用外部工具(如网页浏览、代码执行)来增强其能力 (来源: karminski3)

深度学习模型 VarNet 在癌症突变检测达 SOTA: 发表在 Nature Communications 的研究介绍了一种名为 VarNet 的端到端深度学习框架。该框架通过对数百个全癌症基因组进行训练,能够高精度地检测体细胞变异,无需手动调整启发式规则,并在多个基准测试中达到了当前最佳性能 (来源: Reddit r/MachineLearning)

探索可扩展的 Agent 工具使用机制: 针对当前 Agent 工具使用方式(静态预加载或硬编码)的局限性,研究者探讨了动态、可发现的工具使用模式。设想 Agent 在运行时查询外部工具注册表,根据目标动态选择和使用工具,类似开发者浏览 API 文档。讨论了手动探索、模糊匹配自动选择、外部 LLM 辅助选择等实现路径,旨在提高 Agent 的灵活性、可扩展性和自主适应能力 (来源: Reddit r/artificial)

首款多轮推理 RP 模型 QwQ-32B-ArliAI-RpR-v1 发布: ArliAI 发布了基于 Qwen QwQ-32B 的 RpR (RolePlay with Reasoning) 模型。该模型号称是首个针对角色扮演(RP)和创意写作进行正确训练的多轮推理模型。它使用了 RPMax 系列的数据集,并利用基础 QwQ 模型为 RP 数据生成推理过程,通过特定训练方法(如模板无关段落)确保模型在推理时不依赖于上下文中的推理块,旨在提升长对话中的连贯性和趣味性 (来源: Reddit r/LocalLLaMA)

Qwen3 系列模型获 vLLM 推理框架支持: 高性能 LLM 推理和服务框架 vLLM 合并了对即将发布的 Qwen3 系列模型的支持,包括 Qwen3-8B 和 Qwen3-MoE-15B-A2B。这预示着 Qwen3 模型即将发布,并且社区可以利用 vLLM 来高效部署和运行这些新模型 (来源: Reddit r/LocalLLaMA)

🧰 工具
Firecrawl MCP 服务器:赋予 LLM 强大的网页抓取能力: mendableai 开源了 Firecrawl MCP 服务器,该工具实现了模型上下文协议(MCP),允许 Cursor、Claude 等 LLM 客户端调用 Firecrawl 的网页抓取、爬取、搜索和提取功能。支持云 API 或自托管实例,具备 JS 渲染、URL 发现、自动重试、批量处理、速率限制、额度监控等特性,可显著增强 LLM 处理和分析实时网络信息的能力 (来源: mendableai/firecrawl-mcp-server – GitHub Trending (all/monthly))
LlamaParse 引入 VLM 驱动的新布局 Agent: LlamaIndex 推出了 LlamaParse 内的新布局 Agent。该 Agent 利用先进的视觉语言模型 (VLM) 来解析文档,能够检测页面上的所有块(表格、图表、段落),并动态决定如何以正确的格式解析每个部分。这大大提高了文档解析和信息提取的准确性,特别是减少了表格、图表等元素的遗漏,并支持精确的视觉引用 (来源: jerryjliu0)

Hugging Face 通过 Together AI 提供 Llama 4 推理服务: 用户现在可以直接在 Hugging Face 的 Llama 4 模型页面上运行推理,该服务由 Together AI 提供支持。这为开发者和研究人员提供了一个便捷的方式来体验和测试 Llama 4 模型,无需自行部署 (来源: huggingface)
使用 Llama 4 模拟名人推文的 AI Agent: Karan Vaidya 展示了一个 AI Agent,该 Agent 使用 Meta 最新的 Llama 4 Scout 模型,结合 Composio、LlamaIndex、Groq、Exa 等工具,能够模仿 Elon Musk、Sam Altman、Naval Ravikant 等科技界名人的语气和风格,按需生成推文 (来源: jerryjliu0)
开源本地文档智能工具 Docext 发布: Nanonets 开源了 Docext,这是一个基于视觉语言模型 (VLM) 的本地化文档智能工具。它无需 OCR 引擎或外部 API,可直接从文档图像(如发票、护照)中提取结构化数据(字段和表格)。支持自定义模板、多页文档、REST API 部署,并提供 Gradio Web 界面,强调数据隐私和本地控制 (来源: Reddit r/MachineLearning)
![[P] Docext: Open-Source, On-Prem Document Intelligence Powered by Vision-Language Models](https://external-preview.redd.it/AzAUcQsq5hLIWBdbljeo3gS5MBu9Hz6rtRM5jlgXne8.jpg?auto=webp&s=e6feffd0636e518c24e01ca133e5f83696a1fdaa)
开源文本转语音模型 OuteTTS 1.0 发布: OuteTTS 1.0 是一个基于 Llama 架构的开源文本转语音 (TTS) 模型,在语音合成质量和声音克隆方面有显著改进。新版本支持 20 种语言,并提供了 SafeTensors 和 GGUF (llama.cpp) 格式的模型权重,以及相应的 Github 运行时库,方便用户在本地部署和使用 (来源: Reddit r/LocalLLaMA)

用户使用 Claude 爬取并建立远程工作网站: 一位用户分享了他们如何使用 Anthropic 的 Claude 模型来爬取 10,000 个远程工作列表,并创建了一个名为 BetterRemoteJobs.com 的免费远程工作聚合网站。这展示了 LLM 在自动化信息收集和快速原型开发方面的应用潜力 (来源: Reddit r/ClaudeAI)

MCPO Docker 容器分享: 用户 flyfox666 创建并分享了一个用于 MCPO (Model Context Protocol Orchestrator) 的 Docker 容器,方便用户部署和使用支持 MCP 的工具或服务。MCPO 通常用于协调 LLM 与外部工具(如浏览器、代码执行器)的交互 (来源: Reddit r/OpenWebUI)

📚 学习
Meta 发布 Llama Cookbook:官方 Llama 构建指南: Meta 推出了 Llama Cookbook (原 llama-recipes),这是一个官方指南库,旨在帮助开发者入门和使用 Llama 系列模型(包括最新的 Llama 4 Scout 和 Llama 3.2 Vision)。内容涵盖推理、微调、RAG 以及端到端用例(如邮件助手、NotebookLlama、Text-to-SQL),并包含第三方集成和负责任 AI(Llama Guard)的示例 (来源: meta-llama/llama-cookbook – GitHub Trending (all/daily))
首篇 Test-Time Scaling (TTS) 系统综述发布: 来自港城大、McGill、人大高瓴等多家机构的研究者发布了关于大模型推理阶段扩展 (TTS) 的首篇系统综述。论文提出了一个四维分析框架(What/How/Where/How Well),系统梳理了 CoT、Self-Consistency、搜索、验证、DeepSeek-R1/o1 等 TTS 技术,旨在为这个应对预训练瓶颈的关键领域提供统一视角、评估标准和发展指导 (来源: AI科技评论)
Diffusion Models 课程与 PyTorch 实现: Xavier Bresson 分享了他关于 Diffusion Models 的课程讲义,从统计学第一性原理出发进行讲解,并提供了配套的 PyTorch notebooks,包含从零开始用 Transformer 和 UNet 实现 Diffusion Models 的代码 (来源: ylecun)

使用 LangChain 和 DeepSeek-R1 构建 RAG 应用指南: LangChain 社区分享了一篇指南,介绍了如何使用 DeepSeek-R1(一种开源的类 OpenAI 模型)和 LangChain 的文档处理工具来构建 RAG(检索增强生成)应用程序。指南演示了本地和云端两种实现方式 (来源: LangChainAI)

论文解读:Generative Verifiers – 作为 Next-Token Prediction 的奖励建模: 一篇名为 “Generative Verifiers” 的论文提出了一种新的奖励模型(Reward Model, RM)方法。该方法不再让 RM 仅输出一个标量分数,而是生成解释性的文本(类似 CoT)来辅助打分。这种“拟人化”的 RM 能够结合 Prompting 工程技巧,提升灵活性,有望成为大型推理模型(LRM)时代 RLHF 改进的重要方向 (来源: dotey)

OpenThoughts2 数据集在 Hugging Face 受欢迎: Ryan Marten 指出,OpenThoughts2 数据集在 Hugging Face 上成为排名第一的热门数据集。这通常表明该数据集在社区中受到了广泛关注和使用,可能用于模型训练、评估或其他研究目的 (来源: huggingface)

添加跳跃连接显著加速 RepLKNet-XL 训练: Reddit 用户报告称,在他们的 RepLKNet-XL 模型中添加跳跃连接(Skip Connections)后,训练速度大幅提升了 6 倍。在 RTX 5090 上,2 万次迭代时间从 2.4 小时缩短至 24 分钟;在 RTX 3090 上,9 千次迭代时间从 10 小时 28 分钟缩短至 1 小时 47 分钟。这再次验证了跳跃连接在深度网络训练中的重要作用 (来源: Reddit r/deeplearning)
Neural Graffiti:为 Transformer 添加神经可塑性层: 用户 babycommando 提出一种名为 “Neural Graffiti” 的实验性技术,旨在通过在 Transformer 层和输出投影层之间插入一个受神经可塑性启发的“喷涂层”,根据过去的交互经验影响 token 的生成,使模型随时间获得演化的“个性”。该层通过融合历史记忆来调整输出,已开源并提供 Demo (来源: Reddit r/LocalLLaMA)
💼 商业
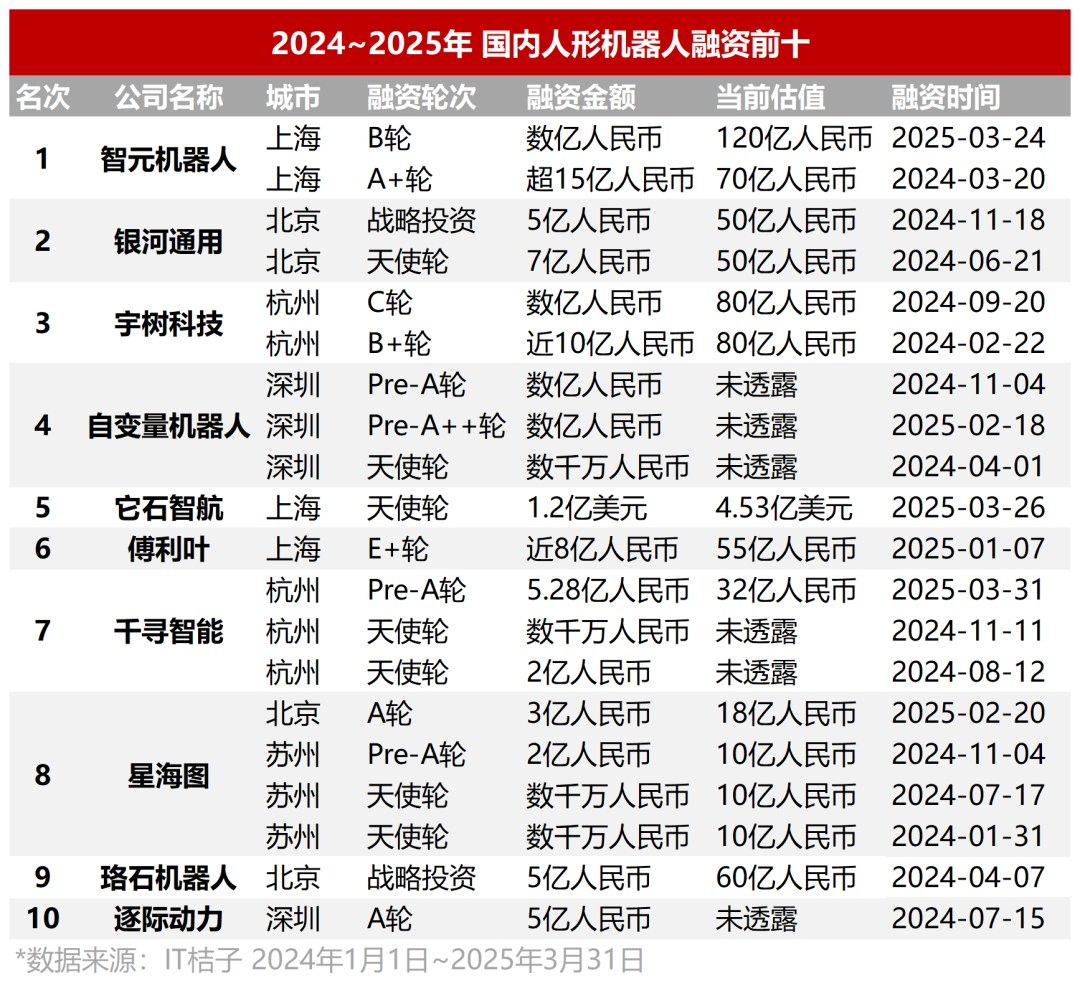
人形机器人投资过热,早期项目估值高企,商业化路径仍受质疑: 2024-2025 年 Q1,中国人形机器人领域融资激增,千万级天使轮成常态,近半数项目融资超亿元,估值普遍过亿甚至超 5 亿。它石智航等明星项目成立数月即获上亿美元融资。国资基金成为重要推手。然而,高热度下商业化路径仍不清晰,成本高昂(数十万至数百万)、应用场景(目前集中于工业、医疗等 ToB)落地难是主要挑战。朱啸虎等投资人已开始退出,达闼机器人崩盘也敲响警钟,赛道呈现一半海水一半火焰的局面。车企(比亚迪、小鹏、小米等)纷纷入局,寻求技术协同与新增长点 (来源: 36氪, 36氪)
中美 AI 智能眼镜市场竞争激烈,呈现不同策略: AI 智能眼镜被视为下一代计算平台潜力股,中美科技巨头竞争加剧。Meta (Ray-Ban Meta, Hypernova)、亚马逊、苹果等美国厂商主打高端市场,依托品牌和生态系统,定价较高。而小米、华为(闪极科技)等中国厂商则采取性价比策略,利用供应链优势和本土化创新,大幅拉低市场门槛(如闪极 A1 定价 999 元),瞄准大众市场。光学技术、端侧算力、功耗及场景生态是关键挑战。预计 2027 年全球销量将超 3000 万副,中国市场占比近半 (来源: 36氪)

Anthropic CEO 担忧股市崩盘可能阻碍 AI 进展: Anthropic CEO Dario Amodei 在访谈中提到,除了地缘政治(如台海冲突)和数据瓶颈外,金融市场的重大动荡也可能阻止 AI 的发展。他解释说,如果股市崩盘导致对 AI 技术前景的信念动摇,可能会影响 OpenAI、Anthropic 等公司的融资能力,进而减少可用于训练大模型的资金和算力,形成自我实现的预言,减缓 AI 进步的速度 (来源: YouTube)
Shopify CEO 强制全员拥抱 AI,融入日常工作与绩效: Shopify CEO Tobi Lütke 的一封内部邮件要求公司所有员工学习和应用 AI。具体措施包括:将 AI 应用纳入绩效考核和同行评审;在“完成任务原型阶段”(GSD Prototype phase)必须使用 AI;部门申请新的人力或资源前,需先证明为何不能用 AI 完成目标。此举旨在将 AI 深度融入公司文化和运营流程,提升效率和创新能力 (来源: dotey, AravSrinivas)
Fauna Robotics 获 3000 万美元融资,用于研发适用于人类空间的机器人: Fauna Robotics 宣布获得由 Kleiner Perkins、Quiet Capital 和 Lux Capital 领投的 3000 万美元融资。该公司致力于开发能够在人类生活和工作空间中灵活运作的机器人,这通常需要先进的感知、导航、交互和操作能力,与具身智能和 AI 紧密相关 (来源: ylecun)

Anthropic 与东北大学合作,推动负责任 AI 在高等教育中的应用: Anthropic 与美国东北大学建立合作伙伴关系,旨在将负责任的 AI 创新融入高等教育的教学、研究和运营。作为合作的一部分,东北大学将在其全球网络中推广使用 Anthropic 的 Claude for Education,为学生、教职员工提供 AI 工具 (来源: Reddit r/ArtificialInteligence)

🌟 社区
Sam Altman 访谈:AI 赋能而非替代,看好 Agent 未来: OpenAI CEO Sam Altman 在访谈中回应了近期热点。他认为 GPT-4o 生成吉卜力风格图片受欢迎,再次证明了技术降低创作门槛的价值。对于“套壳”质疑,他表示多数改变世界的公司最初都被视为简单包装,关键在于创造独特用户价值。他预测 AI 将极大提高程序员生产力(可能达 10 倍),并通过“杰文斯悖论”引发软件需求激增。他看好 AI Agent 从被动工具向主动执行者的转变,尤其在编程领域。他建议职场人士拥抱 AI,在停滞等于职业自杀的时代,优先考虑能接触前沿技术的环境 (来源: 量子位)

AI 2027 超智能预测引讨论,被指过于乐观: 一篇由前 OpenAI 研究员等撰写的报告《AI-2027》预测,AI 将在 2027 年初实现 superhuman 编码能力,进而加速 AI 自身发展,导致超级智能诞生。报告描绘了 AI Agent 自主行动(如黑客攻击、自我复制)的场景。然而,该预测受到质疑,批评者认为其低估了现实世界的复杂性、基准测试的局限性、专有数据/代码的壁垒以及安全风险,认为即使 AI 在某些基准上表现优异,实现完全自主且可靠的复杂任务(尤其涉及物理世界交互或安全敏感领域)仍面临巨大挑战,预测时间线可能过于激进 (来源: YouTube)
用户分享 AI 图像生成提示词: Dotey 分享了两组用于 AI 图像生成的提示词(适用于 Sora 或 GPT-4o 等工具):一组用于根据照片生成 3D Q版收藏摆件(温馨浪漫风格),另一组用于将照片人物转换为 Funko Pop 公仔包装盒风格。提供了详细的描述和风格要求,并附带了示例图片 (来源: dotey)

Claude 3.7 Sonnet 被指在代码修改中引入无关更改: Reddit 用户反映,在使用 Claude 3.7 Sonnet 进行代码修改时,模型倾向于更改任务要求之外的不相关代码或功能,导致意外破坏。用户表示 Claude 3.5 Sonnet 在此方面表现更好,甚至能通过 git diff 纠正 3.7 的错误。用户正在寻求有效的提示词来约束 3.7 的行为,避免此类问题 (来源: Reddit r/ClaudeAI)
主流 LLM 在约束性规划任务中表现不佳: Reddit 用户报告称,要求 ChatGPT、Grok 和 Claude 创建一个满足特定约束条件(球员数量、上场时间均等、连续上场限制、特定球员组合限制)的篮球轮换时间表时,所有模型都声称满足了条件,但实际检查发现存在计数错误,未能正确执行所有约束。这暴露了当前 LLM 在处理复杂约束满足和精确规划任务方面的局限性 (来源: Reddit r/ArtificialInteligence)
用户抱怨 Claude Pro 账户性能不一致,疑被限流或降级: 一位 Claude Pro 用户反映其名下两个付费账户表现差异巨大。其中一个账户(原始账户)几乎无法正常使用长代码生成任务,经常在“继续”后只输出几行代码便停止响应,如同被故意限制或损坏。而新开的账户则无此问题。用户怀疑存在不透明的后台限流或服务降级,并对付费产品的可靠性表示强烈不满 (来源: Reddit r/ClaudeAI)
讨论:LLM 如何理解角色扮演提示?: Reddit 用户提问,大型语言模型(LLM)是如何理解并执行“扮演某个角色”(如扮演祖母)的指令的?用户推测这与微调有关,并好奇开发者是否需要为大量特定角色预先编码或准备专门的训练数据,以及通用训练与特定角色微调之间的关系 (来源: Reddit r/ArtificialInteligence)

讽刺性讨论:用 AI 取代个人思考以获得“效率”与“平静”: Reddit 上一篇帖子以讽刺的口吻,主张将个人的思考、决策、观点表达等完全外包给 AI。作者声称这样做可以消除焦虑、提高效率,并意外地让别人觉得你变得“明智”和“冷静”,而实际上只是成为了 LLM 的“肉身傀儡”。帖子引发了关于思考的价值、AI 依赖性以及人类主体性等话题的讨论 (来源: Reddit r/ChatGPT)
讨论:为何大众仍未广泛使用 AI?: Reddit 用户发起讨论,探讨为何在 AI 话题无处不在的当下,许多非科技圈人士仍未在日常工作生活中主动使用 AI。提出的可能原因包括:未意识到已在使用(如 Siri、推荐算法)、对技术持怀疑态度(黑箱、隐私、工作岗位)、用户界面不够友好(需要 Prompt 工程知识)、工作场所文化尚未接纳等。引发了关于 AI 采用鸿沟的思考 (来源: Reddit r/ArtificialInteligence)
用户分享使用 Claude 3.7 进行深度研究的 Prompt 技巧: Reddit 用户分享了一套详细的 Prompt 结构,旨在让 Claude 3.7 Sonnet 模拟 OpenAI 的 Deep Research 工具进行协作式深度研究。该方法强制使用检查点(每研究 5 个来源后停止并请求许可),并结合 Playwright(网页浏览)、mcp-reasoner(推理)、youtube-transcript(视频转录)等 MCP 工具,引导模型进行结构化、分步骤的信息搜集和分析 (来源: Reddit r/ClaudeAI)
用户分享高效使用 Claude Pro 的工作流与技巧: 一位 Claude Pro 用户分享了其在编码场景下高效使用 Claude 的经验,旨在减少遇到 token 限制和模型性能不佳的问题。技巧包括:通过 .txt 文件提供精确的代码上下文、设定简洁的项目指令、多用 Extended Thinking 的 concise 模式、明确要求输出格式、遇到问题时编辑 Prompt 触发新分支而非持续迭代、以及保持对话简短、只提供必要信息等。作者认为通过优化工作流,能有效利用 Claude Pro (来源: Reddit r/ClaudeAI)
关于 LLM 是否具备意识的哲学讨论: Reddit 上有用户引用笛卡尔的“我思故我在”,认为能够进行推理的大语言模型(LLM)既然能“意识”到自身的“思考”(推理过程),就满足了意识的定义,因此是具备意识的。这种观点将 LLM 的推理功能等同于自我意识,引发了关于意识定义、LLM 工作原理以及模拟与真实拥有意识之间区别的哲学讨论 (来源: Reddit r/artificial)
讨论:你是否愿意乘坐全 AI 驾驶的飞机?: Reddit 用户发起投票和讨论,询问人们是否愿意乘坐完全由 AI 驾驶、没有人类飞行员在驾驶舱的飞机。讨论涉及到对当前自动驾驶技术的信任度、AI 在特定领域(如航空)的可靠性、责任归属问题以及未来技术发展下人们接受度的变化等 (来源: Reddit r/ArtificialInteligence)
💡 其他
OpenAI 非盈利部门重心或将转移: 随着 OpenAI 的商业化发展和估值飙升(传闻 3000 亿美元),其最初设立的、旨在控制 AGI 并将其收益用于全人类福祉的非盈利部门的角色似乎正在转变。有评论指出,该非盈利部门的重心可能已从宏大的 AGI 治理转向支持地方慈善等更传统的公益活动,引发对其初衷和承诺的讨论 (来源: YouTube)
意图驱动 AI 用于客户支持: T-Mobile Business 的文章探讨了使用意图驱动的 AI 来提升客户支持体验。AI 可以预测并主动解决问题,处理大量交互,并辅助人工坐席提供更具同理心的支持。通过识别客户意图,AI 能够更精准地满足客户需求,优化服务流程 (来源: Ronald_vanLoon)
AI 识别 AI 生成内容的挑战: DeltalogiX 讨论了 AI 面临的一个有趣挑战:识别由其他 AI 生成的内容。随着 AI 生成文本、图像、音频等能力的增强,区分人类创作和机器创作变得越来越困难,这对内容审核、版权保护、信息真实性验证等方面提出了新的技术要求 (来源: Ronald_vanLoon)

GenAI 成功依赖高质量数据策略: Forbes 文章强调,通用数据策略不适用于所有 GenAI 应用。为了确保 GenAI 项目的成功,需要根据具体应用场景制定有针对性的数据质量策略,关注数据的相关性、准确性、时效性和多样性等,以避免模型产生偏见或错误输出 (来源: Ronald_vanLoon)

AI 赋能个性化医疗方案: Antgrasso 的图示强调了 AI 在制定个性化医疗治疗计划中的潜力。通过分析患者的基因组数据、病史、生活方式等多维度信息,AI 可以帮助医生设计更精准、更有效的治疗方案,推动精准医疗的发展 (来源: Ronald_vanLoon)

AI 重新定义供应链效率与速度: Nicochan33 的文章探讨了人工智能如何通过优化预测、路线规划、库存管理、风险预警等方面,来重塑供应链的效率和响应速度,使其更加敏捷和智能化 (来源: Ronald_vanLoon)

用户声称开发出通用 LLM 推理增强器: Reddit 一位用户声称开发了一种无需微调即可显著提升 LLM 推理能力(声称提升 15-25 “IQ” 点)的方法,并可能作为透明的对齐层。该用户正在寻求专利,并就后续发展路径(授权、合作、开源等)征求社区意见 (来源: Reddit r/deeplearning)
OAK – Open Agentic Knowledge 项目宣言: GitHub 上出现了一个名为 OAK (Open Agentic Knowledge) 的项目宣言。虽然具体内容未详述,但从名称推测,该项目可能旨在创建一个开放的、供 AI Agent 使用和共享知识的框架或标准,以促进 Agent 能力的提升和互操作性 (来源: Reddit r/ArtificialInteligence)
