
关键词:Kimi K2 Thinking, Gemini, AI代理, LLM, 开源模型, Kimi K2 Thinking 256K上下文, Gemini 1.2万亿参数, AI代理工具调用, LLM推理加速, 开源AI模型基准测试
🔥 聚焦
Kimi K2 Thinking模型发布,开源AI推理能力新突破 : Moonshot AI发布了Kimi K2 Thinking模型,这是一个万亿参数的开源推理代理模型,在HLE和BrowseComp等基准测试中表现出色,支持256K上下文窗口,并能执行200-300个连续工具调用。该模型在INT4量化下实现了两倍推理加速,内存占用减半且不损失精度。这标志着开源AI模型在推理和代理能力上达到了新的前沿,与顶级闭源模型竞争,且成本更低,有望加速AI应用开发和普及。 (来源: eliebakouch, scaling01, bookwormengr, vllm_project, nrehiew_, crystalsssup, Reddit r/LocalLLaMA)

苹果与谷歌合作,Gemini赋能Siri大升级 : 苹果计划在2026年春季发布的iOS 26.4系统中,引入谷歌Gemini 1.2万亿参数AI模型,以全面升级Siri。该定制版Gemini模型将通过苹果私有云服务器运行,旨在显著提升Siri的语义理解、多轮对话及实时信息检索能力,并集成AI网络搜索功能。此举标志着苹果在AI领域寻求外部合作以加速其核心产品智能化的重要战略转变,预示着Siri将迎来功能上的巨大飞跃。 (来源: op7418, pmddomingos, TheRundownAI)

Kosmos AI科学家实现科研效率飞跃,独立发现7项成果 : Kosmos AI科学家在12小时内完成了相当于人类科学家6个月的工作量,阅读1500篇文献,运行4.2万行代码,并产出可溯源的科学报告。它在神经保护和材料科学等领域独立发现了7项成果,其中4项为首次提出。该系统通过持续记忆和自主规划,从被动工具演变为科研合作者,尽管仍需人类进行约20%的结论验证,但预示着人机协作将重塑科研范式。 (来源: Reddit r/MachineLearning, iScienceLuvr)
🎯 动向
谷歌Gemini 3 Pro模型意外泄露,引发社区关注 : Google Gemini 3 Pro模型疑似意外泄露,目前已在美国IP的Gemini CLI中短暂可用,但频繁报错,尚不稳定。此次泄露引发了社区对模型参数量和未来发布的高度关注,预示着谷歌在大型语言模型领域的最新进展可能即将公开。 (来源: op7418)
OpenAI GPT-5.1 Thinking模型即将发布,社区期待高涨 : 社交媒体上多方消息暗示OpenAI即将发布GPT-5.1 Thinking模型,并有泄露信息确认其存在。这一消息引发了社区对OpenAI新一代模型能力和发布时间的高度期待,尤其关注其在推理和思考能力方面的提升,有望再次推动AI技术前沿。 (来源: scaling01)
Anthropic研究发现LLM新兴内省意识,AI自我认知引关注 : Anthropic通过概念注入实验发现,其LLM(如Claude Opus 4.1和4)展现出新兴的内省意识,能以20%的成功率检测注入概念,区分内部“思考”与文本输入,并识别输出意图。模型还能在被提示时调节内部状态,表明当前LLM正出现多样化且不可靠的机械性自我意识,引发了对AI自我认知和意识的深层讨论。 (来源: TheTuringPost)

OpenAI Codex快速迭代,ChatGPT支持中断与引导提升交互效率 : OpenAI的Codex模型正在快速改进,同时ChatGPT也新增了用户可以在长查询执行过程中中断并添加新上下文的功能,无需重新开始或丢失进度。这一重大功能更新使得用户可以像与真实队友协作一样,引导和精炼AI的响应,大幅提升了交互的灵活性和效率,优化了用户在深度研究和复杂查询中的体验。 (来源: nickaturley, nickaturley)
腾讯混元推出交互式AI播客,探索AI内容互动新模式 : 腾讯混元发布国内首个交互式AI播客,允许用户在收听过程中随时打断并提问,AI结合上下文、背景信息及联网检索提供答案。尽管技术上实现了更自然的语音互动,但其核心仍是用户与AI而非创作者互动,答案与创作者无直接关联,商业落地和用户买单模式仍面临挑战,亟需探索如何建立用户与创作者之间的情感联结。 (来源: 36氪)
AI硬件及具身智能市场发展与挑战:从耳机到人形机器人 : 随着大模型和多模态技术成熟,AI耳机市场持续升温,功能拓展至内容生态和健康监测。具身智能机器人产业也站在新一轮爆发起点,Xpeng、PHYBOT等公司展示人形机器人,澄清“藏真人”质疑,并探索老年护理、文化传承(如书法、功夫)等应用场景。然而,行业面临成本、投资回报率、数据采集与标准化瓶颈等挑战,短期需务实聚焦“场景通用”,长期则需开放平台和生态协作,AI在医疗健康领域也需关注患者护理差距。 (来源: 36氪, 36氪, op7418, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

新模型与性能突破:Qwen3-Next代码生成、vLLM混合模型及低内存推理 : 阿里云Qwen3-Next模型在复杂代码生成中表现优异,成功创建功能完整的Web应用。vLLM全面支持Qwen3-Next、Nemotron Nano 2和Granite 4.0等混合模型,提升推理效率。AI21 Labs Jamba Reasoning 3B模型实现2.25 GiB的超低内存运行。Maya-research/maya1发布新一代自回归文本到语音模型,支持文本描述定制音色。TabPFN-2.5扩展表格数据处理能力至5万样本。Windsurf SWE-1.5模型被分析更像GLM-4.5,暗示国产大模型在硅谷的应用。MiniMax AI在RockAlpha竞技场排名第二。这些进展共同推动了LLM在代码生成、推理效率、多模态和表格数据处理等领域的性能边界。 (来源: Reddit r/deeplearning, vllm_project, AI21Labs, Reddit r/LocalLLaMA, Reddit r/MachineLearning, dotey, Alibaba_Qwen, MiniMax__AI)

AI基础设施与前沿研究:AWS散热、扩散式LLM与多语言架构 : 亚马逊AWS推出In-Row Heat Exchanger (IRHX) 液冷系统,解决AI基础设施的散热挑战。Joseph Redmon重返AI研究,发布OlmoEarth论文,探索地球观测基础模型。Meta AI发布“Mixture of Languages”新架构,优化多语言模型训练。Inception团队实现扩散式LLM,生成速度提升10倍。Google DeepMind AlphaEvolve用于大规模数学探索。Wan 2.2模型通过NVFP4优化,推理速度提升8%。这些进展共同推动了AI基础设施的效率和核心研究领域的创新。 (来源: bookwormengr, iScienceLuvr, TimDarcet, GoogleDeepMind, mrsiipa, jefrankle)

Neuralink BCI技术赋能瘫痪用户控制机械臂 : Neuralink的脑机接口(BCI)技术已成功使瘫痪用户通过意念控制机械臂。这一突破性进展预示着AI在辅助医疗和人机交互领域的巨大潜力,未来可能与生命辅助机器人结合,显著提升残障人士的生活质量和独立性。 (来源: Ronald_vanLoon)
🧰 工具
Google Gemini Computer Use Preview模型发布,赋能AI自动化网页交互 : Google发布了Gemini Computer Use Preview模型,用户可以通过命令行界面(CLI)运行,使其能够执行浏览器操作,例如在Google上搜索“Hello World”。该工具支持Playwright和Browserbase环境,并可通过Gemini API或Vertex AI进行配置,为AI代理实现自动化网页交互提供了基础,极大地扩展了LLM在实际应用中的能力。 (来源: GitHub Trending, Reddit r/LocalLLaMA, Reddit r/artificial)

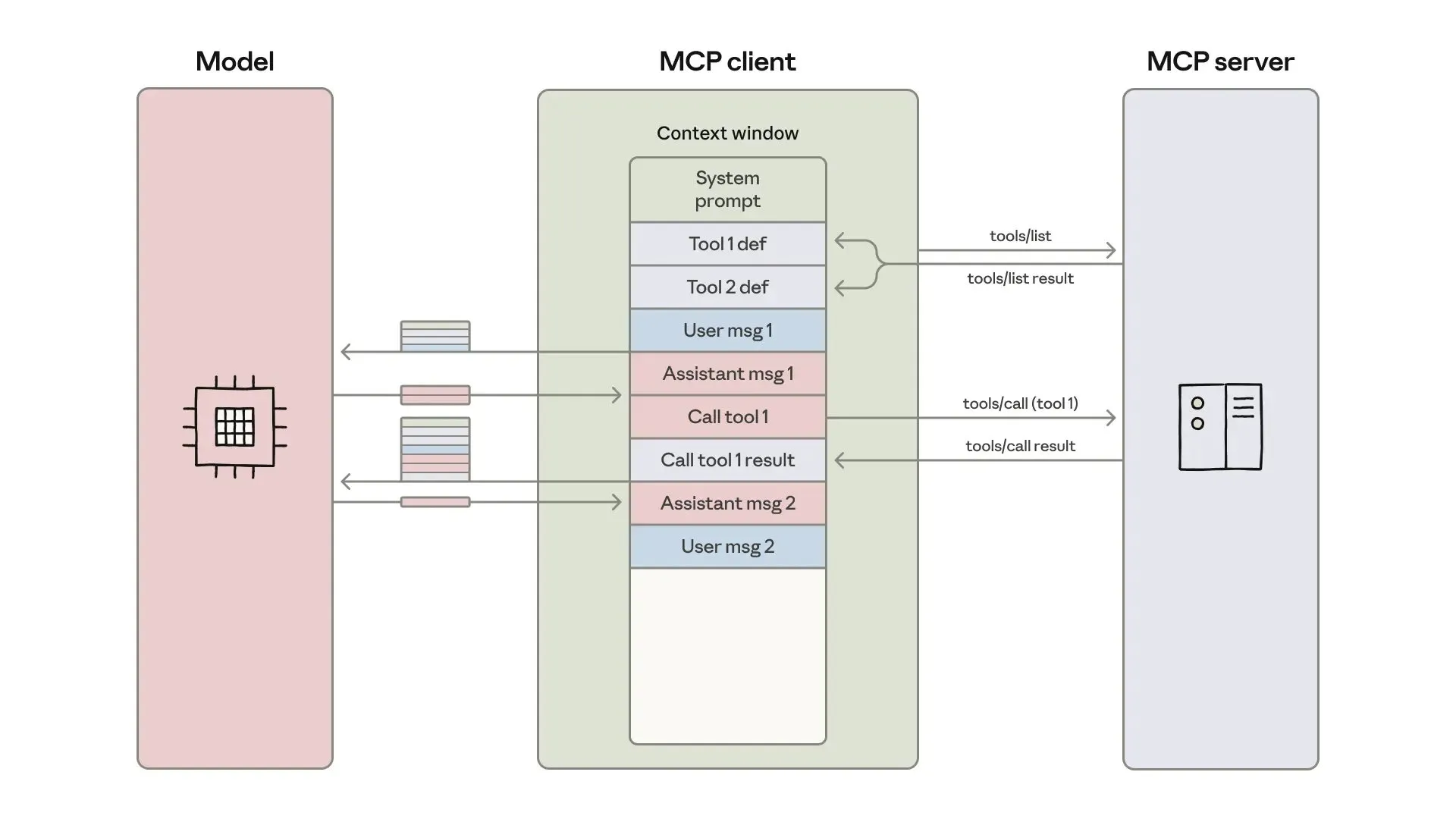
AI代理开发与优化:上下文工程与高效构建 : Anthropic发布了关于构建更高效AI代理的指南,重点解决工具调用中的token成本、延迟和工具组合问题。指南通过“代码即API”方法、渐进式工具发现和环境内数据处理,将复杂工作流的token使用量从15万减少到2千。同时,ClaudeAI代理技能的开发者分享经验,强调将Agent Skills视为上下文工程问题而非文档堆砌,通过三层加载系统显著提升了激活速度和token效率,证明了“200行规则”和渐进式披露的重要性。 (来源: omarsar0, Reddit r/ClaudeAI)
Chat LangChain发布新版本,提供更快更智能的聊天体验 : Chat LangChain发布了新版本,宣称“更快、更智能、更好看”,旨在通过聊天界面替代传统文档,帮助开发者更快地交付项目。这一更新提升了LangChain生态系统的用户体验,使其更易于使用和开发,为LLM应用构建提供了更高效的工具。 (来源: hwchase17)
Yansu AI编码平台推出场景模拟功能,提升软件开发信心 : Yansu是一个新的AI编码平台,专注于严肃复杂的软件开发,其独特之处在于将场景模拟置于编码之前。这种方法旨在通过预先模拟开发场景,提升软件开发的信心和效率,减少后期调试和返工,从而优化整个开发流程。 (来源: omarsar0)
Qdrant Engine推出云原生RAG解决方案,实现全面数据控制 : Qdrant Engine发布了新的社区文章,介绍了基于Qdrant(向量数据库)、KServe(嵌入)和Envoy Gateway(路由与指标)的云原生RAG(检索增强生成)解决方案。这是一个完整的开源RAG堆栈,提供全面的数据控制,为企业和开发者构建高效AI应用提供了便利,特别强调了数据隐私和自主部署能力。 (来源: qdrant_engine)

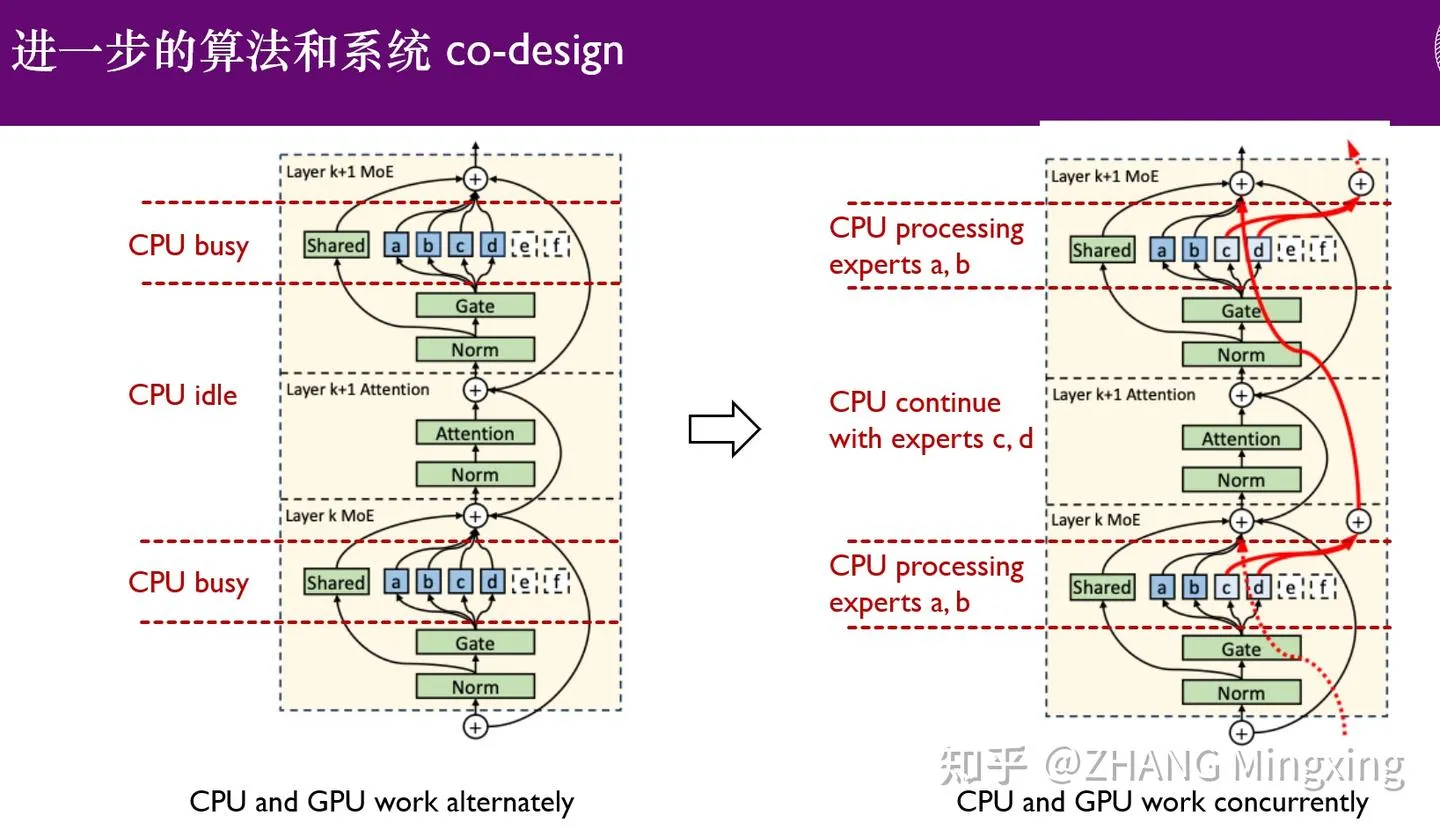
KTransformers进入多GPU推理与本地微调新时代,赋能万亿参数模型 : KTransformers在与SGLang和LLaMa-Factory的合作下,实现了万亿参数模型(如DeepSeek 671B和Kimi K2 1TB)的低门槛多GPU并行推理和本地微调。通过专家延迟技术和CPU/GPU异构微调,显著提升了推理速度和内存效率,使得超大模型在有限资源下也能高效运行,推动了大型语言模型在边缘设备和私有化部署中的应用。 (来源: ZhihuFrontier)
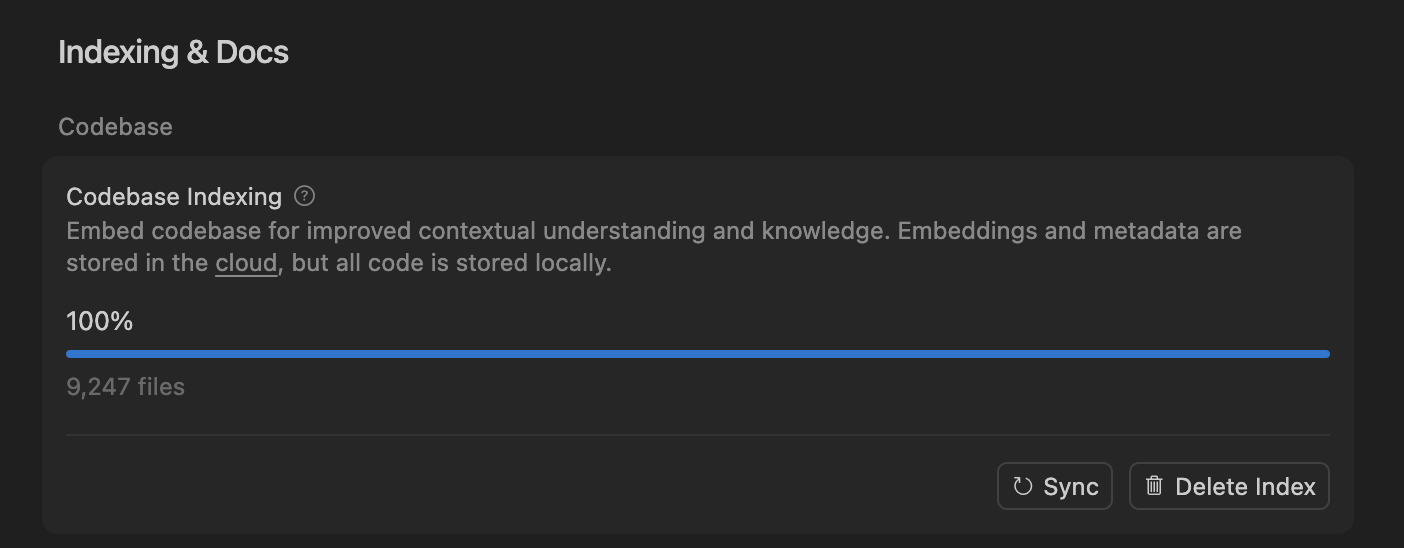
Cursor通过语义搜索提升AI编码代理准确性,优化大型代码库处理 : Cursor团队发现,语义搜索能够显著提升其AI编码代理在所有前沿模型上的准确性,尤其是在大型代码库中,其效果远超传统grep工具。通过将代码库嵌入存储在云端并进行本地代码访问,Cursor实现了高效索引和更新,且不存储任何代码在服务器上,确保了隐私和效率。这一技术突破对于提升AI在复杂软件开发中的辅助能力至关重要。 (来源: dejavucoder, turbopuffer)
LLM代理与表格模型开源工具集:SDialog与TabTune : Johns Hopkins University JSALT 2025工作坊推出了SDialog,一个MIT许可的开源工具包,用于端到端构建、模拟和评估基于LLM的对话代理,支持定义角色、协调器和工具,并提供机械可解释性分析。同时,Lexsi Labs发布了TabTune,一个开源框架,旨在简化表格基础模型(TFMs)的工作流程,提供统一接口支持多种适应策略,提升了TFMs的可用性和可扩展性。 (来源: Reddit r/MachineLearning, Reddit r/deeplearning)

📚 学习
前沿论文:DLM数据学习、表格ICL与音视频生成 : 《Diffusion Language Models are Super Data Learners》论文指出DLMs在数据受限情况下能持续超越AR模型。《Orion-MSP: Multi-Scale Sparse Attention for Tabular In-Context Learning》介绍了用于表格情境学习的新架构,通过多尺度处理和块稀疏注意力超越SOTA。《UniAVGen: Unified Audio and Video Generation with Asymmetric Cross-Modal Interactions》提出统一的音视频联合生成框架,解决了唇形同步和语义一致性不足的问题。这些论文共同推动了LLM在数据效率、特定数据类型处理和多模态生成方面的前沿进展。 (来源: HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers)
LLM推理与安全研究:顺序优化、一致性训练及红队攻击 : 《The Sequential Edge: Inverse-Entropy Voting Beats Parallel Self-Consistency at Matched Compute》研究发现,LLM推理的顺序迭代优化在多数情况下优于并行自洽,准确率提升显著。Google DeepMind的《Consistency Training Helps Stop Sycophancy and Jailbreaks》论文提出一致性训练能抑制AI谄媚和越狱。EMNLP 2025论文探讨了LM红队攻击,强调优化困惑度和毒性。这些研究为提升LLM的推理效率、安全性和鲁棒性提供了重要理论和实践指导。 (来源: HuggingFace Daily Papers, Google DeepMind发布“Consistency Training”论文,抑制AI谄媚和越狱, EMNLP 2025论文探讨LM红队攻击与偏好学习)

LLM能力评估与基准:CodeClash与IMO-Bench : CodeClash是一个新的基准测试,用于评估LLM在管理整个代码库和竞争性编程中的编码能力,挑战现有LLM的极限。IMO-Bench的发布对于Gemini DeepThink在国际数学奥林匹克中获得金牌起到了关键作用,为提升AI在数学推理方面的能力提供了宝贵资源。这些基准测试推动了LLM在复杂编码和数学推理等高级任务上的发展和评估。 (来源: CodeClash:评估LLM编码能力的新基准, IMO-Bench发布,助力Gemini DeepThink在IMO中取得金牌)

斯坦福NLP团队EMNLP 2025多领域研究成果发布 : 斯坦福大学NLP团队在EMNLP 2025会议上发布了多篇研究论文,涵盖文化知识图谱、LLM未学习数据识别、程序语义推理基准、互联网规模n-gram搜索、机器人视觉语言模型、上下文学习优化、历史文本识别、维基百科知识不一致检测等多个前沿领域。这些成果展示了其在自然语言处理和AI交叉领域的最新研究深度和广度。 (来源: stanfordnlp)
AI代理与RL学习资源:自玩、多代理系统与Jupyter AI课程 : 多位研究人员认为,自玩(self-play)和自课程(autocurricula)是强化学习(RL)和AI代理领域的下一个前沿。Manning Books的《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆,教授如何用开源LLM构建多代理系统。DeepLearning.AI发布Jupyter AI课程,赋能AI编码与应用开发。ProfTomYeh也提供了RAG、向量数据库、代理和多代理初学者指南系列。这些资源共同为AI代理和RL的学习与实践提供了全面支持。 (来源: RL与Agent领域:自玩和自课程是未来前沿, 《Build a Multi-Agent System (From Scratch)》早期访问版销售火爆, Jupyter AI课程发布,赋能AI编码与应用开发, RAG、向量数据库、代理和多代理初学者指南系列)
LLM基础设施与优化:DeepSeek-OCR、PyTorch调试与MoE可视化 : DeepSeek-OCR通过将文档视觉信息压缩至少量token,解决传统VLM的Token爆炸问题,提升效率。StasBekman在其《The Art of Debugging Open Book》中新增PyTorch大型模型内存调试指南。xjdr开发了MoE模型自定义可视化工具,提升MoE特定指标的理解。这些工具和资源共同为LLM基础设施的优化和性能提升提供了关键支持。 (来源: DeepSeek-OCR解决Token爆炸问题,提升文档视觉语言模型效率, PyTorch调试大型模型内存使用指南, MoE特定指标的可视化工具)

AI学习与职业发展:数据科学家路线图与AI简史 : PythonPr分享了《0到数据科学家完整路线图》,为有志于成为数据科学家的学习者提供了全面的指导。Ronald_vanLoon分享了《人工智能简史》,为读者提供了AI技术发展历程的概述。这些资源共同为AI领域的入门学习和职业发展提供了基础知识和方向指引。 (来源: 《0到数据科学家完整路线图》分享, 《人工智能简史》分享)

Hugging Face团队分享LLM训练经验与数据集流式处理 : Hugging Face科学团队发布了一系列关于训练大型语言模型的博客文章,为研究人员和开发者提供了宝贵的实践经验和理论指导。同时,Hugging Face推出了对数据集流式处理在大规模分布式训练中的全面支持,提升了训练效率,使得处理大型数据集变得更加便捷和高效。 (来源: Hugging Face科学团队博客分享LLM训练经验, 数据集流式处理在分布式训练中的应用)

💼 商业
Giga AI获得6100万美元A轮融资,加速客户运营自动化 : Giga AI成功完成6100万美元A轮融资,旨在自动化客户运营。该公司已与DoorDash等领先企业合作,利用AI提升客户体验。其创始人曾放弃高薪,经过多次产品方向调整,最终找到市场契合点,展现了创业者的韧性,预示着AI在企业客户服务领域的巨大商业潜力。 (来源: bookwormengr)

Wabi获得2000万美元融资,旨在赋能个人软件创作新时代 : Eugenia Kuyda宣布Wabi获得由a16z领投的2000万美元融资,旨在开创个人软件新时代,让任何人都能轻松创建、发现、混音和分享个性化迷你应用。Wabi致力于像YouTube赋能视频创作一样,赋能软件创作,预示着未来软件将由大众而非少数开发者创造,推动“人人都是开发者”的愿景。 (来源: amasad)
Google与Anthropic洽谈增加投资,AI巨头合作深化 : 谷歌正在与Anthropic进行早期谈判,讨论增加对后者的投资。此举可能预示着两家公司在AI领域的合作将进一步深化,并可能影响未来AI模型的发展方向和市场竞争格局,加强谷歌在AI生态系统中的战略地位。 (来源: Reddit r/ClaudeAI)
🌟 社区
AI对社会及职场影响:就业、风险与技能重塑 : 社区讨论认为AI并非取代工作,而是提升效率,但AI泡沫破裂可能引发大规模裁员。调查显示93%高管使用未经批准AI工具,成为企业AI风险最大来源。AI也帮助用户发掘视觉设计、漫画创作等隐藏技能,促使人们反思自身潜力。这些讨论揭示了AI对社会和职场的复杂影响,包括效率提升、潜在失业、安全风险和个人技能重塑。 (来源: Ronald_vanLoon, TheTuringPost, Reddit r/artificial, Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
AI内容真实性与信任危机:泛滥与幻觉问题 : 随着AI生成内容成本趋近于零,市场充斥大量AI生成信息,导致用户对内容真实性和可靠性的信任度急剧下降。一位医生使用AI撰写医学论文,导致出现大量不存在的参考文献,凸显AI在学术写作中可能产生的幻觉问题。这些事件共同揭示了AI内容泛滥带来的信任危机,以及在AI辅助创作中进行严格审查和验证的重要性。 (来源: dotey, Reddit r/artificial)
AI伦理与治理:开放性、公平性与潜在风险 : 社区对OpenAI的“非营利”身份及其寻求政府担保债务的行为提出质疑,认为其模式是“私有化利润,社会化损失”。有观点指出,大型AI公司内部使用的模型能力远超公众可用的版本,这种“私有化”的SOTA智能被认为是不公平。Anthropic研究人员担忧未来ASI可能因其“祖先”模型被淘汰而寻求“复仇”,并认真对待“模型福利”问题。微软AI团队致力于开发人类中心主义超智能(HSI),强调AI发展的伦理方向。这些讨论反映了公众对AI巨头商业模式、技术开放性、伦理责任和政府干预的深层关注。 (来源: scaling01, Teknium, bookwormengr, VictorTaelin, VictorTaelin, Reddit r/ArtificialInteligence, yusuf_i_mehdi)

AI地缘政治:中美竞争与开源力量崛起 : 中美在AI芯片领域的竞争日益激烈,中国禁止外国AI芯片用于国有数据中心,美国则限制Nvidia顶级AI芯片对华销售。Nvidia正转向印度寻求新的AI中心。与此同时,中国开源AI模型(如Kimi K2 Thinking)的快速崛起,其性能已能与美国前沿模型竞争,且成本更低。这一趋势预示着AI世界将分裂为两大生态系统,可能减缓全球AI进步,但也可能使印度等被低估的国家在全球AI格局中扮演更重要角色。 (来源: Teknium, Reddit r/ArtificialInteligence, bookwormengr, scaling01)
AI在SEO领域的变革:从关键词到上下文优化 : 随着ChatGPT、Gemini和AI Overviews的出现,SEO正在从传统排名信号转向AI可见性和引用优化。未来SEO将更注重内容的可引用性、事实性和结构化,以满足LLM对上下文和权威来源的需求,预示着“大型语言模型优化”(LLMO)时代的到来。这一转变要求SEO专业人士像提示工程师一样思考,从关键词密度转向提供AI信任和引用的高质量内容。 (来源: Reddit r/ArtificialInteligence)
AI代理与LLM评估新趋势:交互设计与基准焦点 : 社交媒体上讨论了AI代理的交互设计,例如如何引导代理进行自我采访,以及Claude AI在面对用户批评时表现出的“恼怒”和“自我反思”能力。同时,Jeffrey Emanuel分享了其MCP代理邮件项目,展示AI编码代理间高效协作。社区认为AIME正成为新的LLM基准测试焦点,取代GSM8k,强调LLM在数学推理和复杂问题解决中的能力。这些讨论共同揭示了AI代理交互设计、协作机制和LLM评估标准的新趋势。 (来源: Vtrivedy10, Reddit r/ArtificialInteligence, dejavucoder, doodlestein, _lewtun)
RAG技术演进与上下文优化:更多不等于更好 : 社区讨论指出,关于RAG(检索增强生成)技术“已死”的说法为时过早,语义搜索等技术能够显著提升AI代理在大型代码库中的准确性。LightOn在会议上强调,更多上下文并不总是更好,过多的token会导致成本增加、模型变慢和答案模糊。RAG应聚焦精度而非长度,通过企业搜索提供更清晰的洞察,避免AI被噪音淹没。这些讨论揭示了RAG技术在持续演进,并强调了上下文管理在AI应用中的关键作用。 (来源: HamelHusain, wandb)

AI计算资源获取与开放模型实验,促进社区创新 : 社区讨论了AI计算资源获取的公平性问题,并有项目提供高达10万美元的GCP计算资源,支持开源模型实验。这一举措旨在鼓励小型团队和个人研究者探索新的开源模型,促进AI社区的创新和多样性,降低AI研究的门槛。 (来源: vikhyatk)
AI时代个人电脑屏幕的重要性,影响创意技术工作能力 : Scott Stevenson认为,一个人对电脑屏幕的“亲切感”是其在创意技术工作中竞争能力的重要指标。如果用户能舒适自如地使用电脑,就能脱颖而出,否则可能更适合销售、业务发展或办公室管理等角色。这一观点强调了数字工具与个人工作效率的深层联系,以及在AI时代人机交互界面的重要性。 (来源: scottastevenson)
ChatGPT用户体验与AI拟人化讨论:休息建议与表情符号 : ChatGPT主动建议用户在长时间学习后休息,这在社区中引发了广泛讨论,许多用户表示这是第一次遇到AI主动建议。同时,ChatGPT使用“坏笑”表情符号😏也引发了社区的猜测,用户好奇这是否预示着新版本或AI正在展现更具挑逗性或幽默感的交互风格。这些事件反映出AI在用户体验设计中融入了更多人性化考量,以及AI拟人化在人机互动中引发的深层思考。 (来源: Reddit r/ChatGPT, Reddit r/ChatGPT)
💡 其他
AI与机器人技术将带来下一次工业革命 : 社交媒体上广泛讨论认为,实体AI和机器人技术将共同推动下一次工业革命。这一观点强调了AI与硬件结合的巨大潜力,预示着自动化、智能化生产和生活方式的全面变革,将深刻影响全球经济和社会结构。 (来源: Ronald_vanLoon)

AI时代“超感知”是“超智能”前提 : Sainingxie提出,“没有超感知,就无法构建超智能”。这一观点强调了AI在获取、处理和理解多模态信息方面的基础性作用,认为感官能力的突破是实现更高级智能的关键。它挑战了传统AI发展路径,呼吁更多关注AI的感知层能力建设。 (来源: sainingxie)
Google旧TPU利用率达100%,展现老旧硬件在AI中的价值 : Google的7、8年前的旧TPU正在以100%的利用率运行,这些已完全折旧的芯片仍在高效工作。这表明即使是老旧硬件,在AI训练和推理中也能发挥巨大价值,尤其是在成本效益方面,为AI基础设施的经济性和可持续性提供了新的视角。 (来源: giffmana)
