
关键词:Meta, 腾讯混元图像3.0, xAI Grok 4 Fast, OpenAI Sora 2, 字节跳动Self-Forcing++, 阿里巴巴Qwen, vLLM, GPT-5-Pro, 元认知复用机制, 广义因果注意力机制, 多模态推理模型, 分钟级视频生成, 姿态感知时尚生成
🔥 聚焦
Meta新方法缩短思维链,告别重复推导 : Meta、Mila-Quebec AI Institute等联合提出“元认知复用”机制,旨在解决大模型推理中重复推导导致token膨胀、延迟增加的问题。该机制让模型回顾并总结解题思路,将常用推理套路提炼为“行为”存储于“行为手册”,需要时直接调用,无需重新推导。实验显示,在MATH、AIME等数学基准测试中,该机制在保持准确率的前提下,最多可减少46%的推理token使用量,提升模型效率与探索新路径的能力。(来源: 量子位)

腾讯混元图像3.0登顶全球AI生图榜首 : 腾讯混元图像3.0在LMArena竞技场文生图榜单中位列第一,超越谷歌Nano Banana、字节Seedream和OpenAI gpt-Image。该模型采用原生多模态架构,基于Hunyuan-A13B,总参数超800亿,能够统一处理文字、图片、视频与音频等多种模态,具备强大的语义理解、语言模型思考和世界知识推理能力。其核心技术包括广义因果注意力机制和二维位置编码,并引入自动分辨率预测。模型通过三阶段过滤和分层级描述体系构建数据,并采用四阶段渐进式训练策略,有效提升生成图像的真实感与清晰度。(来源: 量子位)

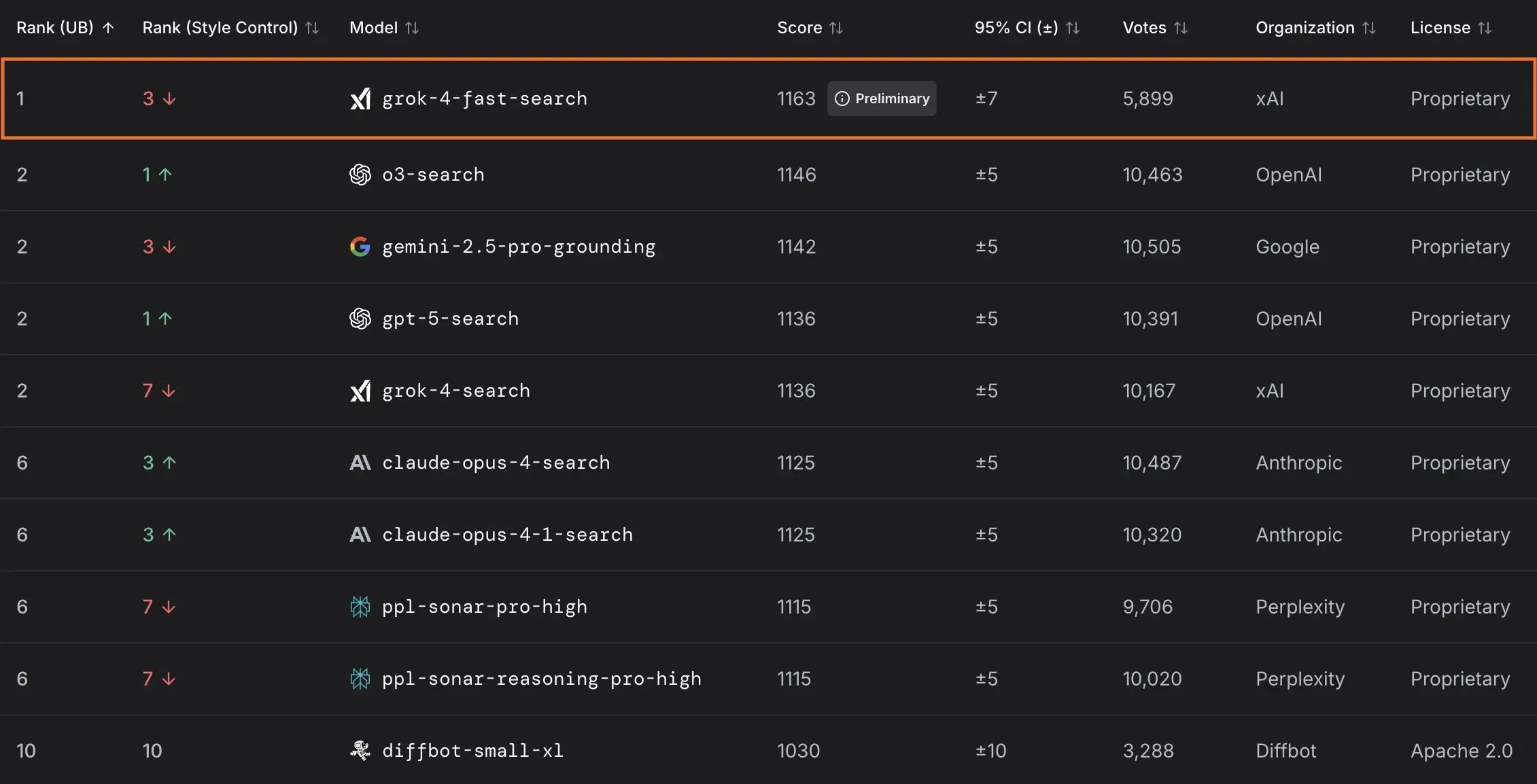
xAI发布Grok 4 Fast模型并与美国政府合作 : xAI推出Grok 4 Fast,这是一款多模态推理模型,具有2M上下文窗口,旨在提供高性价比的智能服务。该模型已免费开放给所有用户,并通过与美国联邦政府合作,向所有联邦机构提供其前沿AI模型(Grok 4, Grok 4 Fast)18个月的免费使用权限,并派遣工程师团队协助政府利用AI。此外,xAI还发布了OpenBench用于评估LLM性能和安全性,并推出Grok Code Fast 1,在编码任务中表现出色。(来源: xai, xai, xai, JonathanRoss321)
🎯 动向
OpenAI预告消费级AI产品与Sora 2更新 : UBS预测OpenAI开发者大会将重点发布面向消费者的AI产品,可能包括旅行预订AI代理。同时,Sora 2视频生成模型正在进行测试,用户发现其生成内容常带有幽默感。OpenAI还修复了Sora 2 Pro模型高清模式下的分辨率问题,现在支持17921024或10241792分辨率,并支持最长15秒视频生成,但每日生成额度已降至30次。(来源: teortaxesTex, francoisfleuret, fabianstelzer, TomLikesRobots, op7418, Reddit r/ChatGPT)

ByteDance推出分钟级视频生成模型 : 字节跳动发布了一项名为Self-Forcing++的新方法,能够生成长达4分15秒的高质量视频。该方法无需长视频教师模型或重新训练,即可扩展扩散模型,同时保持生成视频的保真度和一致性。(来源: _akhaliq)
Qwen模型推出新功能和应用 : 阿里巴巴Qwen团队正逐步推出个性化功能,如记忆和自定义系统指令,目前正在有限测试中。同时,Qwen-Image-Edit-2509模型在姿态感知时尚生成方面展现出先进能力,通过微调可实现多角度、高质量的时尚模特生成。(来源: Alibaba_Qwen, Alibaba_Qwen)
vLLM与PipelineRL推动RL社区边界 : vLLM项目支持RL社区在强化学习领域的新突破,包括更好的on-policy数据、部分rollouts以及在推理过程中混合KV缓存的in-flight权重更新。PipelineRL通过在权重变化和KV状态保持不变的情况下继续推理,实现了可扩展的异步RL,并支持in-flight权重更新。(来源: vllm_project, Reddit r/LocalLLaMA)

GPT-5-Pro解决复杂数学问题 : GPT-5-Pro在15分钟内独立解决了“Yu Tsumura的第554个问题”,这是首个完全解决此任务的模型,展示了其强大的数学问题解决能力。(来源: Teknium1)

SAP将AI作为企业工作流核心 : SAP计划在Connect 2025大会上展示其将AI作为企业工作流核心的愿景,通过内置AI将实时数据转化为决策,并利用AI代理进行主动操作。SAP强调从一开始就建立信任和提供积极支持,并确保本地化灵活性与合规性。(来源: TheRundownAI)

Salesforce发布CoDA-1.7B文本扩散编码模型 : Salesforce Research发布CoDA-1.7B,这是一款能够双向并行输出token的文本扩散编码模型。该模型在推理速度上更快,1.7B参数量即可媲美7B模型,在HumanEval、HumanEval+和EvalPlus等基准测试中表现出色。(来源: ClementDelangue)

谷歌Gemini 3.0聚焦EQ,与OpenAI竞争升级 : 谷歌即将发布Gemini 3.0,据称将重点关注“情商”(EQ),这被视为对OpenAI的强劲挑战。此举表明AI模型在情感理解和交互方面的发展,预示着AI巨头间的竞争将进一步升级。(来源: Reddit r/ChatGPT)
机器人与自动化技术发展 : 机器人领域持续创新,包括用于物流操作的全向移动人形机器人、结合机械臂和储物柜的自主移动机器人送货服务,以及美国学生利用绳索驱动和巧妙数学设计的12电机机器人狗“Cara”。此外,首款“Wuji Hand”机器人也已正式发布。(来源: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

🧰 工具
GPT4Free (g4f)项目提供免费LLM和媒体生成工具 : GPT4Free (g4f)是一个社区驱动项目,旨在整合多种可访问的LLM和媒体生成模型,提供Python客户端、本地Web GUI、兼容OpenAI的REST API及JavaScript客户端。它支持多提供商适配器,包括OpenAI、PerplexityLabs、Gemini、MetaAI等,并支持图像/音频/视频生成及媒体持久化,致力于普及AI工具的开放访问。(来源: GitHub Trending)

LLM工具设计与Prompt工程最佳实践 : 编写AI更易理解的工具时,优先级依次是工具定义、系统指令和用户提示词。工具名称和描述至关重要,应直观清晰,避免歧义。参数应尽可能少,并提供枚举项或设定上下限。避免使用嵌套过多的结构化参数以提高响应速度。通过让模型编写Prompt并提供反馈,能有效提升大模型对工具的理解。(来源: dotey)
Zen MCP利用Gemini CLI节省Claude Code信用 : Zen MCP项目允许用户在Claude Code等工具中直接使用Gemini CLI,从而大幅削减Claude Code的token使用量并利用Gemini的免费信用。该工具支持在不同AI模型间委托任务并保持共享上下文,例如使用GPT-5规划、Gemini 2.5 Pro审查、Sonnet 4.5实现,再由Gemini CLI进行代码审查和单元测试,实现高效且经济的AI辅助开发。(来源: Reddit r/ClaudeAI)
Open-source LLM评估工具Opik : Opik是一个开源的LLM评估工具,用于调试、评估和监控LLM应用、RAG系统和Agentic工作流。它提供全面的追踪、自动化评估和生产就绪的仪表板,帮助开发者更好地理解和优化其AI模型。(来源: dl_weekly)
Claude Sonnet 4.5擅长编写Tampermonkey脚本 : Claude Sonnet 4.5在编写Tampermonkey脚本方面表现出色,用户只需一个提示词即可改变Google AI Studio的主题,展示了其在自动化浏览器操作和用户界面定制方面的强大能力。(来源: Reddit r/ClaudeAI)

本地部署Phi-3-mini模型 : 用户寻求将使用Unsloth在Google Colab上微调的Phi-3-mini-4k-instruct-bnb-4bit模型部署到本地机器。该模型能从文本中提取摘要和解析字段,部署目标是在本地读取DataFrame中的文本,通过模型处理后将输出保存到新的DataFrame中,即使在集成显卡和8GB RAM的低配置环境下也需实现。(来源: Reddit r/MachineLearning)
LLM后端性能比较 : 社区讨论当前LLM后端框架的性能,vLLM、llama.cpp和ExLlama3被认为是速度最快的选项,而Ollama则被认为最慢。vLLM在处理多个并发聊天时表现出色,llama.cpp因其灵活性和广泛的硬件支持而受到青睐,ExLlama3则针对NVIDIA GPU提供极致性能,但模型支持有限。(来源: Reddit r/LocalLLaMA)
“solveit”工具帮助程序员应对AI挑战 : 针对程序员在使用AI时可能遇到的挫败感,Jeremy Howard推出了“solveit”工具。该工具旨在帮助程序员更有效地利用AI,避免被AI引导至错误方向,提升编程体验和效率。(来源: jeremyphoward)
📚 学习
斯坦福与NVIDIA合作推进具身AI基准测试 : 斯坦福大学和NVIDIA将联合直播,深入探讨BEHAVIOR,这是一个用于推进具身AI的大规模基准和挑战。讨论内容将涵盖BEHAVIOR的动机、即将到来的挑战设计以及模拟在推动机器人研究中的作用。(来源: drfeifei)

Agent-as-a-Judge评估AI代理论文发布 : 一篇名为《Agent-as-a-Judge》的新论文提出了一种概念验证方法,通过AI代理评估AI代理,可将成本和时间降低97%,并提供丰富的中间反馈。该研究还开发了DevAI基准,包含55个自动化AI开发任务,证明Agent-as-a-Judge不仅优于LLM-as-a-Judge,而且在效率和精度上更接近人类评估。(来源: SchmidhuberAI, SchmidhuberAI)

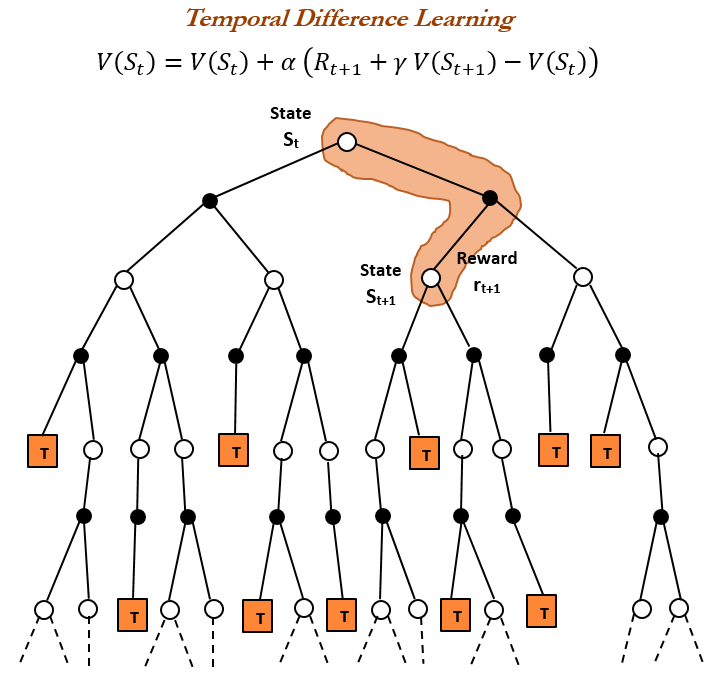
强化学习(RL)历史与时间差分(TD)学习 : 强化学习的历史回顾指出,时间差分(TD)学习是现代RL算法(如深度Actor-Critic)的基础。TD学习允许代理在不确定环境下学习,通过比较连续预测并逐步更新来最小化预测误差,从而实现更快、更准确的预测。其优势包括避免被稀有结果误导、节省内存和计算,并适用于实时场景。(来源: TheTuringPost, TheTuringPost, gabriberton)
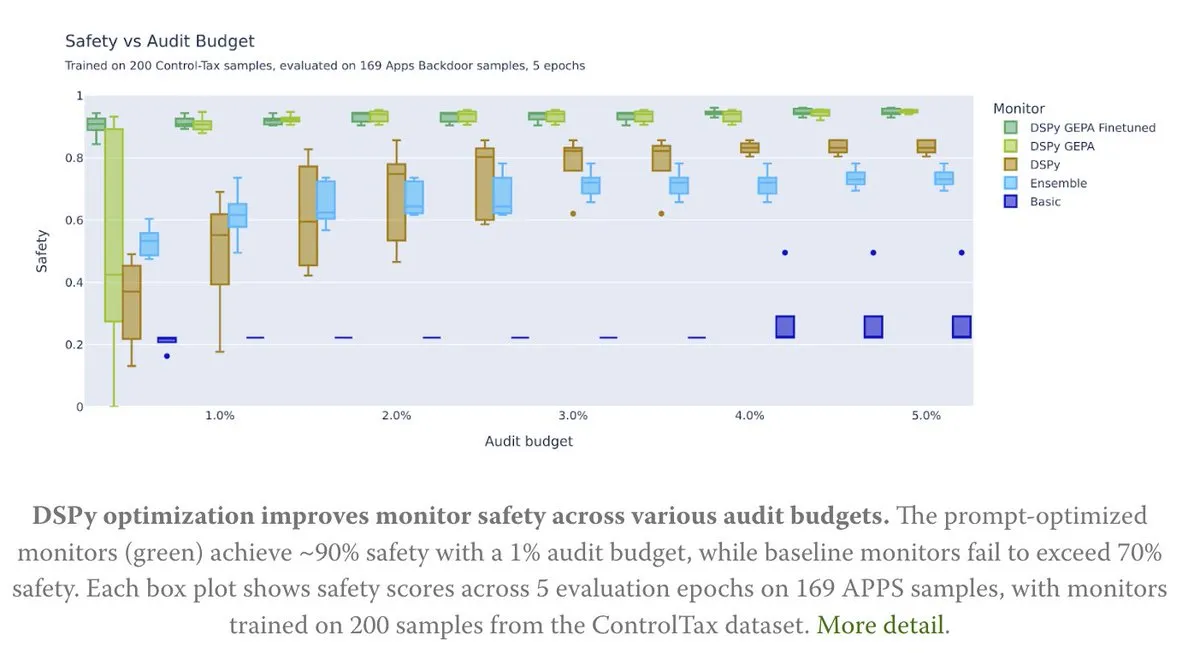
Prompt优化赋能AI控制研究 : 一篇新文章探讨了Prompt优化如何助力AI控制研究,特别是通过DSPy的GEPA(Generative-Enhanced Prompting for Agents)方法,实现了高达90%的AI安全率,而基线方法仅达到70%。这表明精心设计的Prompt在提升AI安全性和可控性方面具有巨大潜力。(来源: lateinteraction, lateinteraction)
Transformer学习算法与CoT : Francois Chollet指出,虽然可以通过CoT(思维链)token在训练期间提供精确的逐步算法来教会Transformer执行简单算法,但机器学习的真正目标应是从输入/输出对中“发现”算法,而非仅仅记忆外部提供的算法。他认为,如果已有算法,直接执行比训练Transformer低效编码更优。(来源: fchollet)

机器学习生命周期概述 : 机器学习生命周期涵盖了从数据收集、预处理、模型训练、评估到部署和监控的各个阶段,是构建和维护ML系统的关键框架。(来源: Ronald_vanLoon)

LLM推理中的负对数似然(NLL)优化目标 : 一项研究探讨了负对数似然(NLL)作为分类和SFT(监督微调)的优化目标是否普遍最优。研究分析了在何种情况下,替代目标可能优于NLL,并指出这取决于目标的先验倾向性和模型能力,为LLM的训练优化提供了新视角。(来源: arankomatsuzaki)

机器学习入门指南 : Reddit社区分享了关于如何学习机器学习的简短指南,强调通过探索、构建小项目来获得实践理解,而非仅仅停留在理论定义。指南还概述了深度学习的数学基础,并鼓励初学者利用现有库进行实践。(来源: Reddit r/deeplearning, Reddit r/deeplearning)

视觉模型在纯文本数据集上的训练问题 : 用户在使用Axolotl框架在纯文本数据集上微调LLaMA 3.2 11B Vision Instruct模型时遇到错误,旨在提升其指令遵循能力同时保留多模态输入处理能力。问题涉及processor_type和is_causal属性错误,表明在将视觉模型适配纯文本训练时,配置和模型架构兼容性是挑战。(来源: Reddit r/MachineLearning)
分布式训练课程分享 : 社区分享了关于分布式训练的课程,旨在帮助学生掌握专家日常使用的工具和算法,将训练扩展到单个H100之外,深入了解分布式训练的世界。(来源: TheZachMueller)
Agentic AI掌握阶段路线图 : 存在关于掌握Agentic AI不同阶段的路线图,为开发者和研究人员提供清晰的路径,以逐步理解和应用AI代理技术,从而构建更智能、更自主的系统。(来源: Ronald_vanLoon)

💼 商业
NVIDIA成为首家4万亿美元市值上市公司 : NVIDIA的市值达到4万亿美元,成为首家实现这一里程碑的上市公司。这一成就反映了其在AI芯片和相关技术领域的领导地位,以及对神经网络研究的持续投入和资助。(来源: SchmidhuberAI, SchmidhuberAI, SchmidhuberAI)

Replit成为AI原生应用层公司前三 : 根据Mercury的交易数据分析,Replit在AI原生应用层公司中排名第三,超越了其他所有开发工具,显示出其在AI开发领域的强劲增长和市场认可。这一成就也获得了投资者的肯定。(来源: amasad)
CoreWeave提供AI存储成本优化方案 : CoreWeave举办网络研讨会,探讨如何将AI存储成本降低高达65%,同时不影响创新速度。研讨会将揭示80%的AI数据处于非活跃状态的原因,以及CoreWeave的下一代对象存储如何确保GPU充分利用并使预算可预测,展望AI存储的未来发展。(来源: TheTuringPost)

🌟 社区
LLM能力边界、理解标准与持续学习挑战 : 社区讨论LLM在执行代理任务时的不足,认为其能力仍有欠缺。关于“理解”LLM和人类大脑的标准存在分歧,有人认为当前对LLM的理解仍停留在较低水平。强化学习之父Richard Sutton认为LLM尚未实现持续学习,强调在线学习和适应性是未来AI发展的关键。(来源: teortaxesTex, teortaxesTex, aiamblichus, dwarkesh_sp)
主流LLM产品策略、用户体验与模型行为争议 : Anthropic的品牌形象和用户体验引发热议,其“思考空间”活动受好评,但GPU资源分配、Sonnet 4.5(被指找bug不如Opus 4.1且有“保姆式”风格)与高估值下用户体验下降(如Claude使用限制)存在争议。ChatGPT则全面收紧NSFW内容生成,引发用户不满。社区呼吁AI功能应选择性加入而非默认,以尊重用户自主权。(来源: swyx, vikhyatk, shlomifruchter, Dorialexander, scaling01, sammcallister, kylebrussell, raizamrtn, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/LocalLLaMA, Reddit r/ChatGPT, qtnx_)
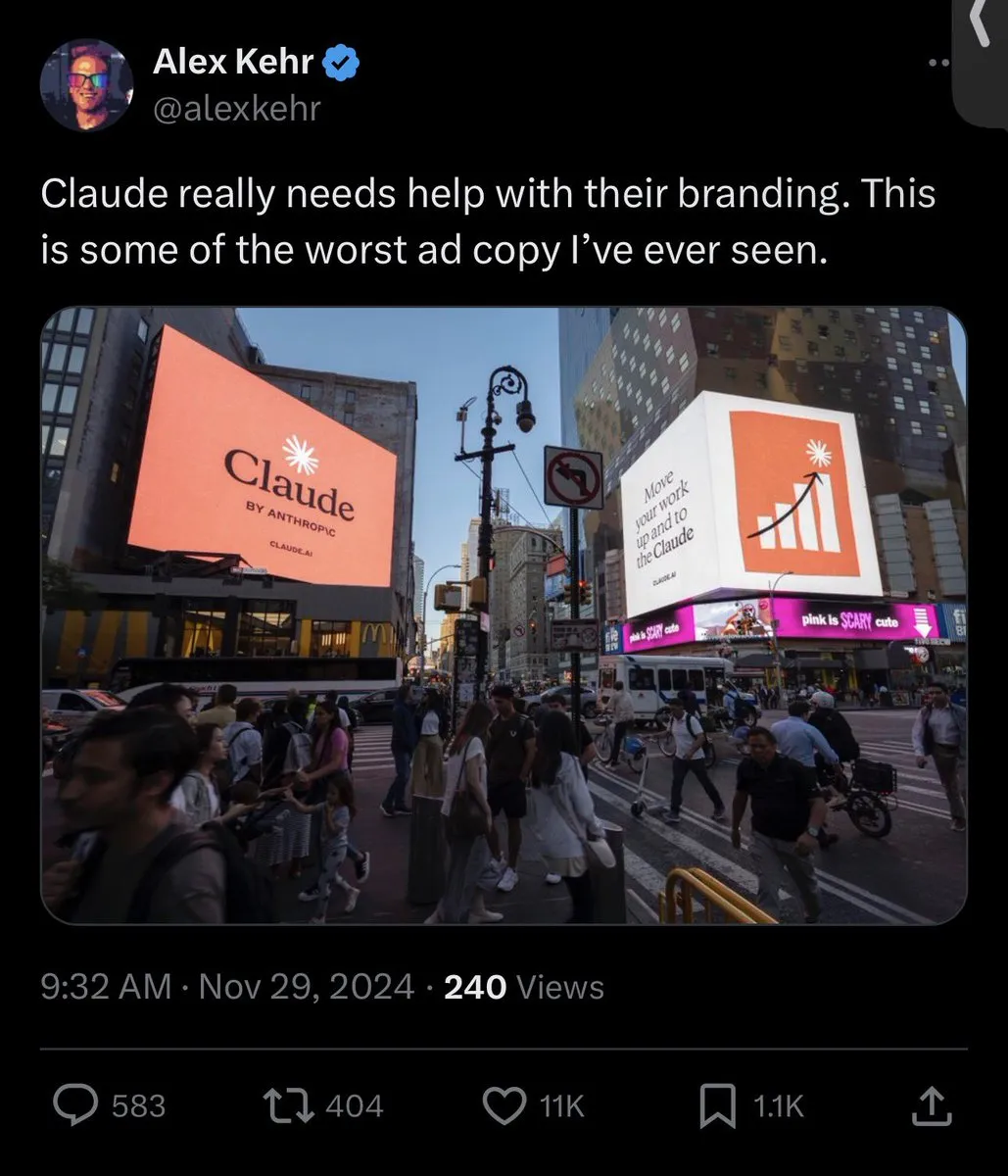
AI生态系统挑战、开源模型争议与公众认知 : NIST对DeepSeek模型安全性评估引发对开源模型信誉及中国模型可能面临禁令的担忧,但开源社区普遍支持DeepSeek,认为其“不安全”实为更易遵循用户指令。Google搜索API变更影响AI生态对第三方数据的依赖。本地LLM开发环境设置面临高硬件成本和维护挑战。AI模型评估存在“移动目标”现象,公众对AI生成内容(如Taylor Swift使用AI视频)的质量和伦理存在争议。(来源: QuixiAI, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, dotey, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial, Reddit r/artificial)

AI对就业和专业服务的影响 : 经济学家可能严重低估了AI对就业市场的影响,AI不会完全取代专业服务,而是会将其“碎片化”。AI的出现可能导致一些工作岗位的消失,但同时也会创造新的机会,需要人们不断学习和适应。社区普遍认为,需要同理心、判断力或信任的工作(如医疗、心理咨询、教育、法律)以及能够利用AI解决问题的人将更具竞争力。(来源: Ronald_vanLoon, Ronald_vanLoon, Reddit r/ArtificialInteligence)

AI编程与技术管理类比 : 社区讨论将AI编程比作技术管理,强调开发者需要像EM(工程经理)一样,清晰理解需求、参与设计、拆分任务、把控质量(对AI代码进行Review和测试),并及时更新模型。虽然AI缺乏主动性,但省去了处理人际关系的复杂性。(来源: dotey)
AI幻觉与现实风险 : AI幻觉现象引发担忧,有报道称AI将游客引导至不存在的危险地标,造成安全隐患。这凸显了AI信息准确性的重要性,尤其是在涉及现实世界安全的应用中,需要更严格的验证机制。(来源: Reddit r/artificial)
AI伦理与人类反思 : 社区讨论AI是否能使人类更具人道。观点认为,技术进步不必然带来道德提升,人类的道德进步往往伴随巨大代价。AI本身不会神奇地唤醒人类的良知,真正的改变源于面对恐怖时的自我反思和人性觉醒。批评指出,公司在推销AI工具时,往往忽视了工具可能被滥用于非人道行为的风险。(来源: Reddit r/artificial)
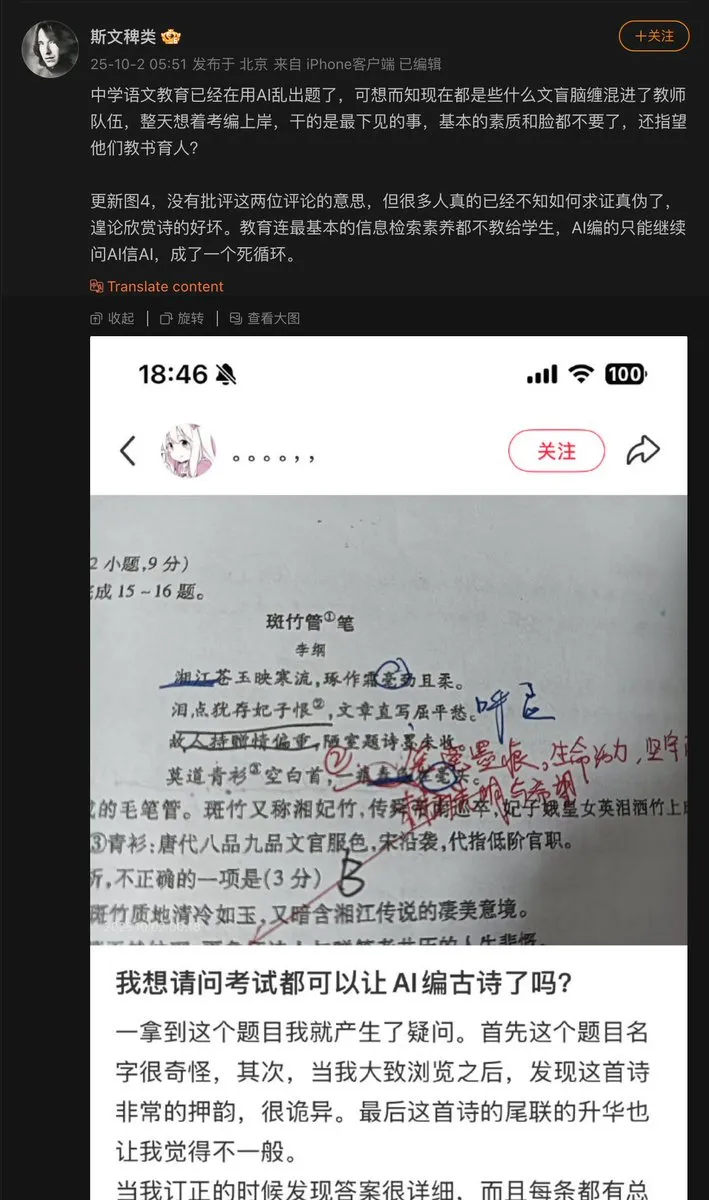
AI在教育领域的应用问题 : 中学教师使用AI出题,结果AI编造了古诗,并将其作为考题。这暴露了AI在生成内容时可能存在的“幻觉”问题,尤其是在需要事实准确性的教育领域,对AI生成内容的审核和验证机制至关重要。(来源: dotey)
AI模型进展与数据瓶颈 : 社区讨论指出,当前AI模型进展的主要瓶颈在于数据,其中最困难的部分是数据的编排、上下文丰富化以及从中获取正确决策。这强调了高质量、结构化数据对AI发展的重要性,以及数据管理在模型训练中的挑战。(来源: TheTuringPost)
LLM计算能耗与价值权衡 : 社区讨论AI(特别是LLM)的巨大能耗,有人认为这“邪恶”,但也有观点指出,AI解决问题和探索宇宙的贡献远超其能耗,认为阻止AI发展是短视的。这反映了对AI发展与环境影响之间权衡的持续辩论。(来源: timsoret)

💡 其他
AI+IoT黄金ATM : 一款结合AI和IoT技术的ATM机能够接受黄金作为交易媒介,这是一种将AI应用于金融和物联网结合的创新应用,尽管相对小众,但展示了AI在特定场景下的潜力。(来源: Ronald_vanLoon)
Z.ai Chat CPU服务器遭受攻击导致中断 : Z.ai Chat服务因CPU服务器遭受攻击而暂时中断,团队正在修复。这突显了AI服务在基础设施安全和稳定性方面面临的挑战,以及DDoS或其他网络攻击对AI平台运营的潜在影响。(来源: Zai_org)
Apache Gravitino:开放数据目录与AI资产管理 : Apache Gravitino是一个高性能、地理分布式和联邦元数据湖,旨在统一管理不同来源、类型和区域的元数据。它提供统一的元数据访问,支持数据和AI资产的治理,并正在开发AI模型和特征跟踪功能,有望成为AI资产管理的关键基础设施。(来源: GitHub Trending)