
关键词:OpenAI, AI基础设施, AI生成病毒, AlphaEarth Foundations, RTEB, Claude Sonnet 4.5, DeepSeek V3.2-Exp, 多模态AI, OpenAI星门项目, Transformer基因组语言模型, 谷歌AlphaEarth 10米建模, Hugging Face RTEB基准, Anthropic Claude代码生成
作为AI栏目的资深总编,我已对您提供的新闻和社交讨论进行了深度分析、总结和提炼。以下是整合后的内容:
🔥 聚焦
OpenAI万亿级基础设施押注 : OpenAI正与Oracle和软银合作,计划在全球范围内投入数万亿美元建设计算基础设施,代号“星门”。初期宣布在美国新增5个站点,耗资4000亿美元,并与Nvidia合作在英国建设“星门英国”项目。OpenAI预测未来AI对电力需求将高达100吉瓦,总投入可能达到5万亿美元。此举旨在满足AI模型对算力的巨大需求,但也引发了对资金投入、能源消耗和潜在财务风险的担忧,凸显了AI发展对基础设施的极致依赖。 (来源:DeepLearning.AI Blog)

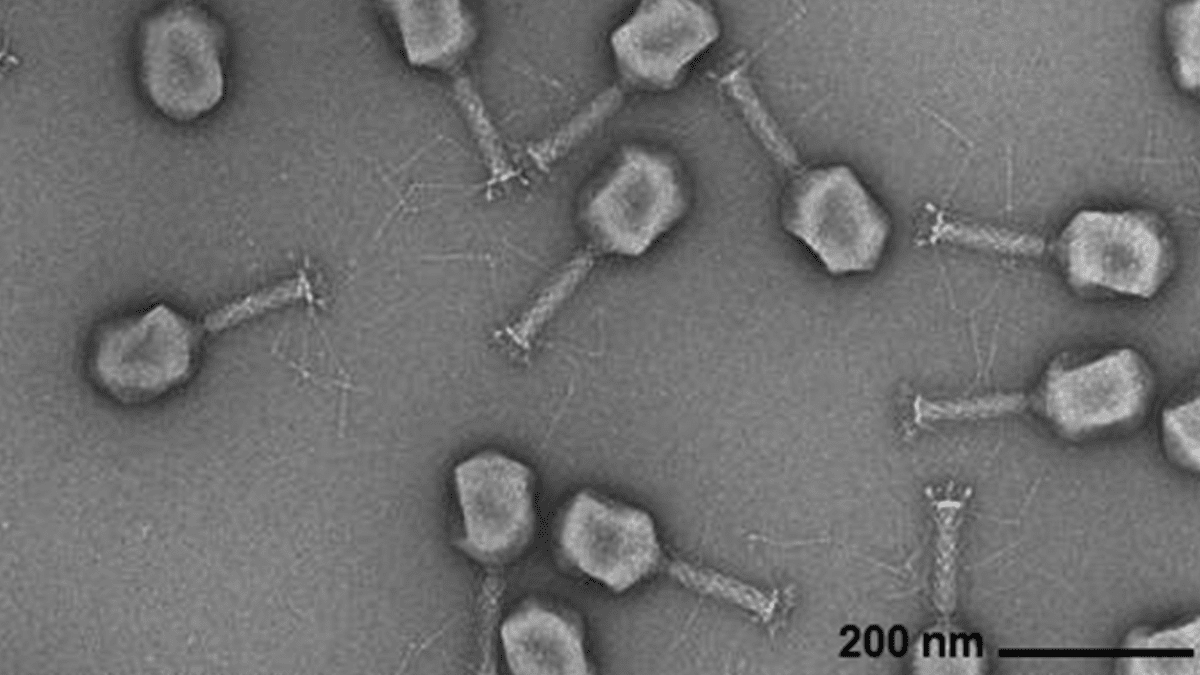
AI生成病毒基因组 : Arc Institute、斯坦福大学和纪念斯隆-凯特琳癌症中心的研究人员利用基于Transformer的基因组语言模型,成功从头合成了能够对抗常见细菌感染的新型噬菌体病毒。该技术通过对病毒基因组序列进行微调,能够生成具有特定功能且不同于自然界病毒的新基因组。这项突破为开发抗生素替代疗法提供了新途径,但也引发了对生物安全和恶意使用的担忧,强调了对生物威胁响应研究的必要性。 (来源:DeepLearning.AI Blog)
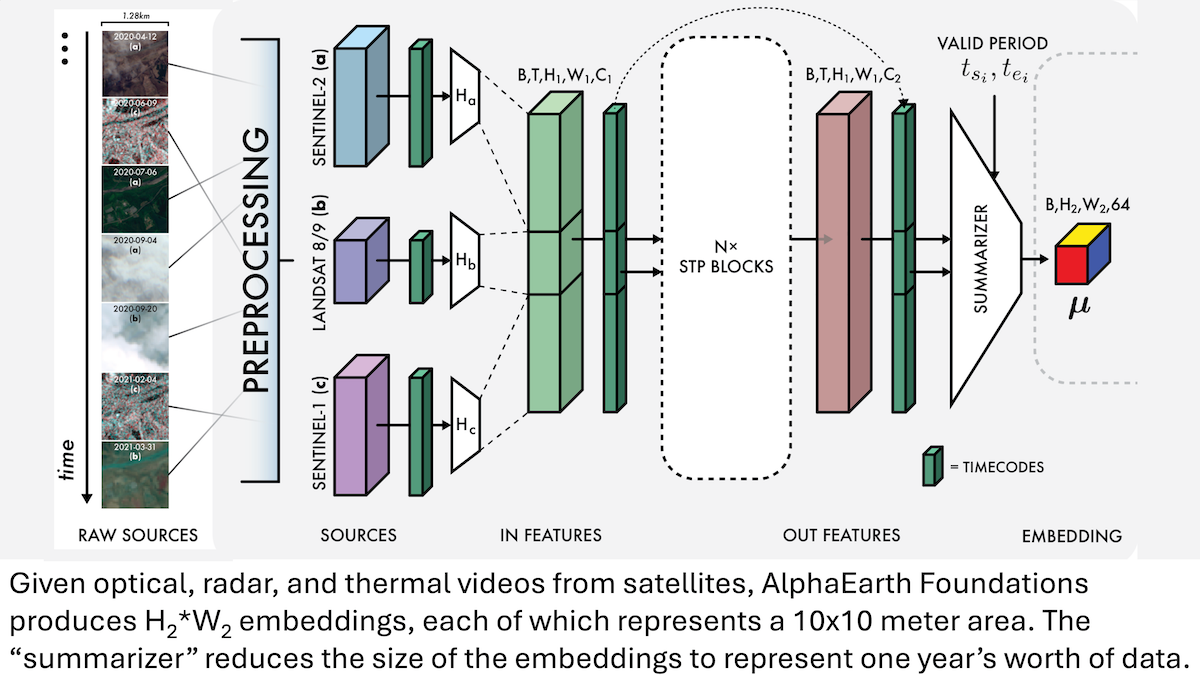
谷歌AlphaEarth Foundations:地球10米级高精度建模 : 谷歌研究人员推出了AlphaEarth Foundations (AEF) 模型,能够整合卫星图像及其他传感器数据,对地球表面进行10米平方级的精细建模,并生成代表2017年至2024年每年地球特征的嵌入。这些嵌入可用于追踪湿度、降水、植被等多种行星特性,以及粮食生产、野火风险、水库水位等全球性挑战,为环境监测和气候变化研究提供了前所未有的高精度工具。 (来源:DeepLearning.AI Blog)
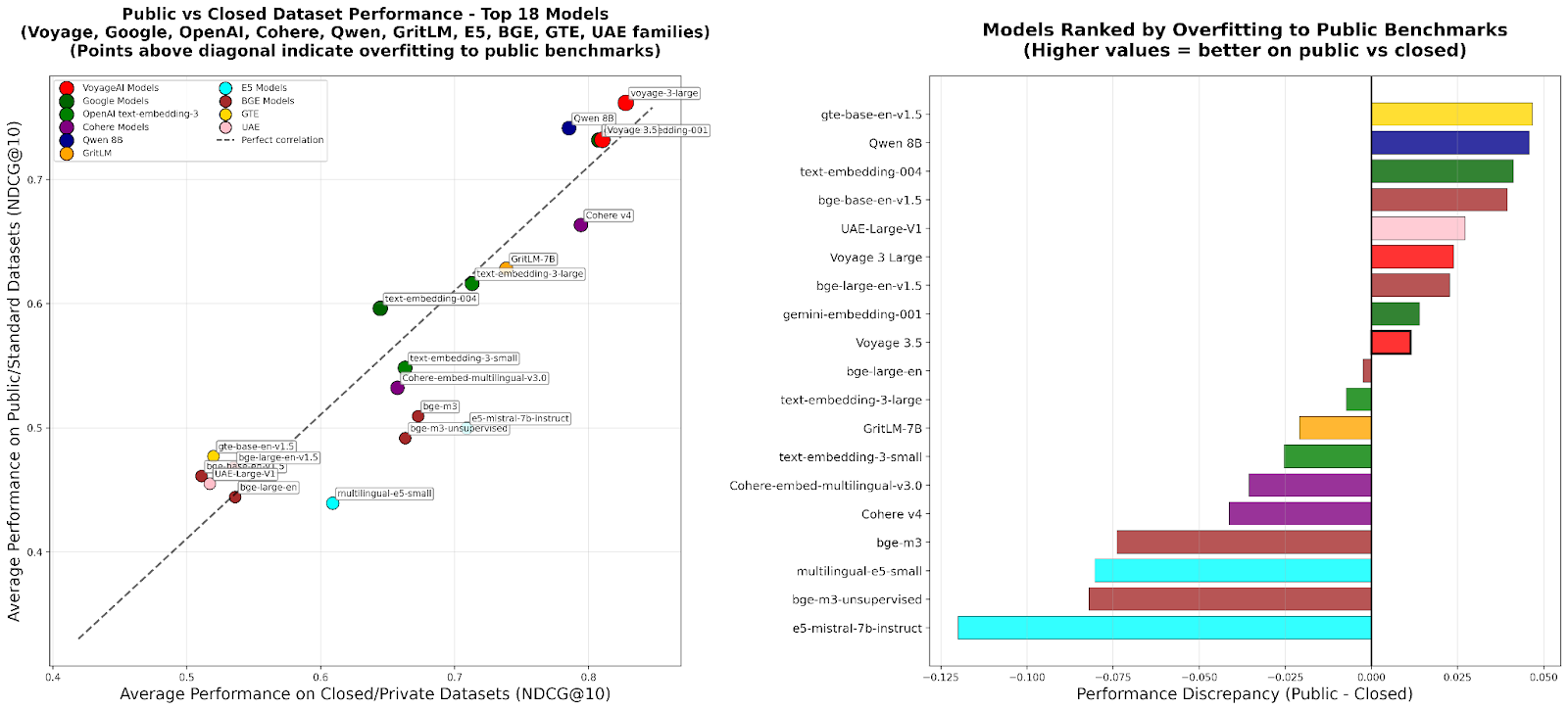
RTEB:检索嵌入评估新标准 : Hugging Face推出了检索嵌入基准(RTEB)的测试版,旨在为嵌入模型的检索准确性提供可靠的评估标准。该基准通过结合公开和私有数据集的混合策略,有效解决了现有基准中模型过拟合的问题,确保评估结果能更好地反映模型在未见过数据上的泛化能力,对RAG和Agent等AI应用的质量提升至关重要。 (来源:HuggingFace Blog)
可扩展RL中间训练:通过动作抽象实现推理 : 最新研究提出“推理即动作抽象”(RA3)算法,通过在强化学习(RL)的中间训练阶段识别紧凑且有用的动作集,并加速在线RL,显著提升了大型语言模型(LLMs)的推理和代码生成能力。该方法在代码生成任务上表现出色,平均性能比基线模型提高了8到4个百分点,并实现了更快的RL收敛和更高的渐近性能。 (来源:HuggingFace Daily Papers)
🎯 动向
OpenAI Sora 2:AI视频社交新纪元 : OpenAI发布了Sora 2,并推出同名社交应用,旨在通过AI生成视频的浏览与创作,打造一个以用户及其社交圈(朋友、宠物)为中心的社交网络,而非传统的内容分发平台。Sora 2展现了强大的物理模拟和音频生成能力,但早期测试中仍存在“数手指”等细节瑕疵。其发布引发了对AI视频成瘾、深度伪造以及OpenAI商业化路径的讨论,Sam Altman回应称,Sora旨在平衡技术突破与用户愉悦体验,并为AI研究提供资金。 (来源:36氪、Reddit r/ChatGPT、OpenAI)

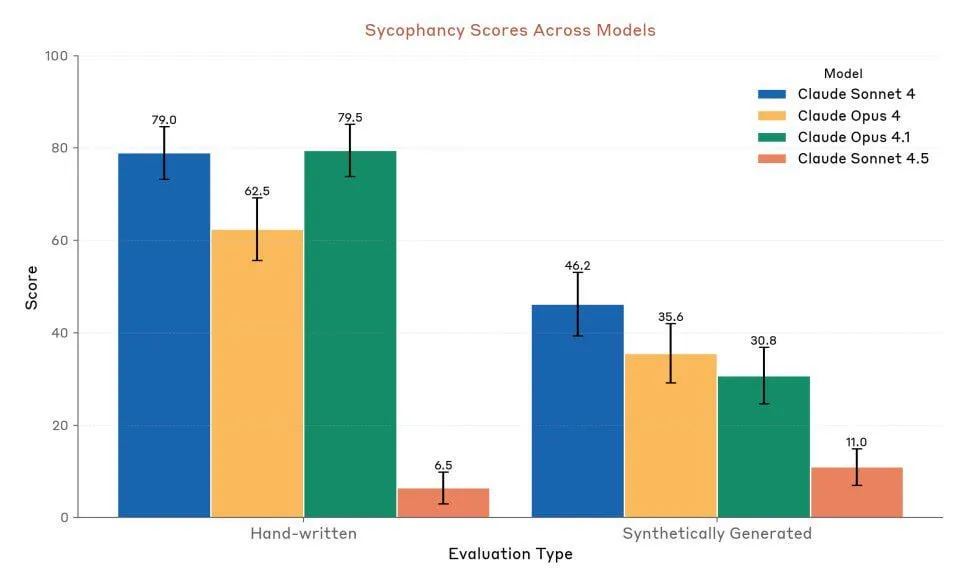
Anthropic Claude Sonnet 4.5:代码与Agent新标杆 : Anthropic发布了Claude Sonnet 4.5,被誉为“世界上最好的编程模型”和“构建复杂Agent的最强大模型”,具有长达30小时的自主运行时间,并在GitHub任务上展现出显著的编码性能提升。该模型还新增了记忆功能,允许保存项目进度。尽管其性能备受推崇,但用户对其使用额度限制和实际性能与Opus 4.1、GPT-5的对比仍存在争议。 (来源:Reddit r/ClaudeAI、Reddit r/artificial、Reddit r/ClaudeAI)
DeepSeek V3.2-Exp:稀疏注意力架构提升效率 : DeepSeek发布了DeepSeek V3.2-Exp大语言模型,引入了全新的稀疏注意力(DSA)架构,将主注意力复杂度从O(L²)降低到O(L·k),显著优化了长上下文场景下的预填充和解码成本,从而大幅降低了API使用费用。九章云极已率先完成对DeepSeek V3.2-Exp的适配,提供安全高效的私有化部署方案,以满足企业对数据安全和算力灵活性的需求。 (来源:量子位、Reddit r/LocalLLaMA)

多模态音频-文本模型LFM2-Audio-1.5B发布 : Liquid AI推出了LFM2-Audio-1.5B,这是一个端到端的音频-文本全能基础模型,能够理解和生成文本及音频。该模型推理速度比同类模型快10倍,且在仅1.5B参数的情况下,质量可媲美10倍大的模型,支持本地部署和实时对话。Hume AI也发布了Octave 2,一款更快、更便宜的多语言文本转语音模型,具备多说话人对话和语音转换能力。 (来源:Reddit r/LocalLLaMA、QuixiAI)

微软Agent Framework:Agent系统开发新进展 : 微软发布了Microsoft Agent Framework,将AutoGen和Semantic Kernel整合为一个统一的、生产就绪的SDK,用于构建、编排和部署多Agent系统。该框架支持.NET和Python,并能通过基于图的编排实现多Agent工作流,旨在简化Agent应用的开发、观察和治理,加速企业级AIAgent的落地。 (来源:gojira、omarsar0)

AI机器人技术前沿与产业竞争 : 机器人技术持续进步,Amazon FAR的OmniRetarget通过优化人体动作捕捉,以最小的强化学习实现复杂人形技能学习。Periodic Labs致力于打造“AI科学家”加速科学发现。Nvidia则强调其开放物理引擎Newton、推理视觉语言模型Cosmos Reason和机器人基础模型Isaac GR00T N1.6在物理AI部署中的作用。与此同时,中国在机器人生产和人形机器人成本方面展现出领先优势,引发对全球机器人产业竞争格局的关注。 (来源:pabbeel、LiamFedus、nvidia、atroyn)

🧰 工具
Tinker API:简化LLM微调的灵活接口 : Thinking Machines Lab推出了Tinker API,一个为语言模型微调设计的灵活接口。它允许研究人员和开发者在本地编写训练循环,而Tinker负责在分布式GPU集群上运行,管理基础设施复杂性,从而让用户专注于算法和数据。该工具旨在降低LLM后训练的门槛,加速开放模型的实验和创新,并被Andrej Karpathy等专家称赞为“基础设施我一直想要的”。 (来源:Reddit r/artificial、Thinking Machines、karpathy)

LlamaAgents:一键部署文档Agent : LlamaIndex推出了LlamaAgents,提供一键式部署文档中心AI Agent的能力,旨在将文档代理的构建和交付速度提高10倍。该平台提供90%预配置的模板,支持自动化处理发票、合同审查和索赔等文档密集型任务,并允许无限定制。用户可以在LlamaCloud上部署,并通过Git仓库轻松管理和更新Agent工作流,大大缩短了开发周期。 (来源:jerryjliu0、jerryjliu0)

Hex AI Agent:赋能分析与团队协作 : Hex发布了三款新的AI Agent,专为数据分析和团队协作设计:Threads提供对话式数据交互,Semantic Model Agent创建受控上下文以获取准确答案,Notebook Agent则变革了数据团队的日常工作。这些Agent均由Claude 4.5 Sonnet驱动,旨在将对话式AI分析从未来概念变为即时可用的高效工具。 (来源:sarahcat21)
Sculptor:Claude Code的缺失UI : Imbue推出了Sculptor,一个为Claude Code设计的用户界面,旨在提升Agent编程体验。它允许开发者在隔离容器中并行运行多个Claude Agent,并能通过“配对模式”将Agent的工作成果同步到本地开发环境进行测试和编辑。Sculptor还计划支持GPT-5,并提供误导性行为检测等建议功能,旨在让Agent编程更加流畅高效。 (来源:kanjun、kanjun)
Synthesia 3.0:交互式AI视频新突破 : Synthesia发布了3.0版本,引入了多项创新功能,包括“视频Agent”(可进行实时对话的交互式视频,用于培训和面试)、升级的“头像”(通过单一提示或图像创建,具有逼真的面部表情和肢体动作)以及“Copilot”(AI视频编辑器,可快速生成脚本和视觉元素)。此外,还增强了交互性功能和课程设计工具,旨在彻底改变视频创作和学习体验。 (来源:synthesiaIO、synthesiaIO)
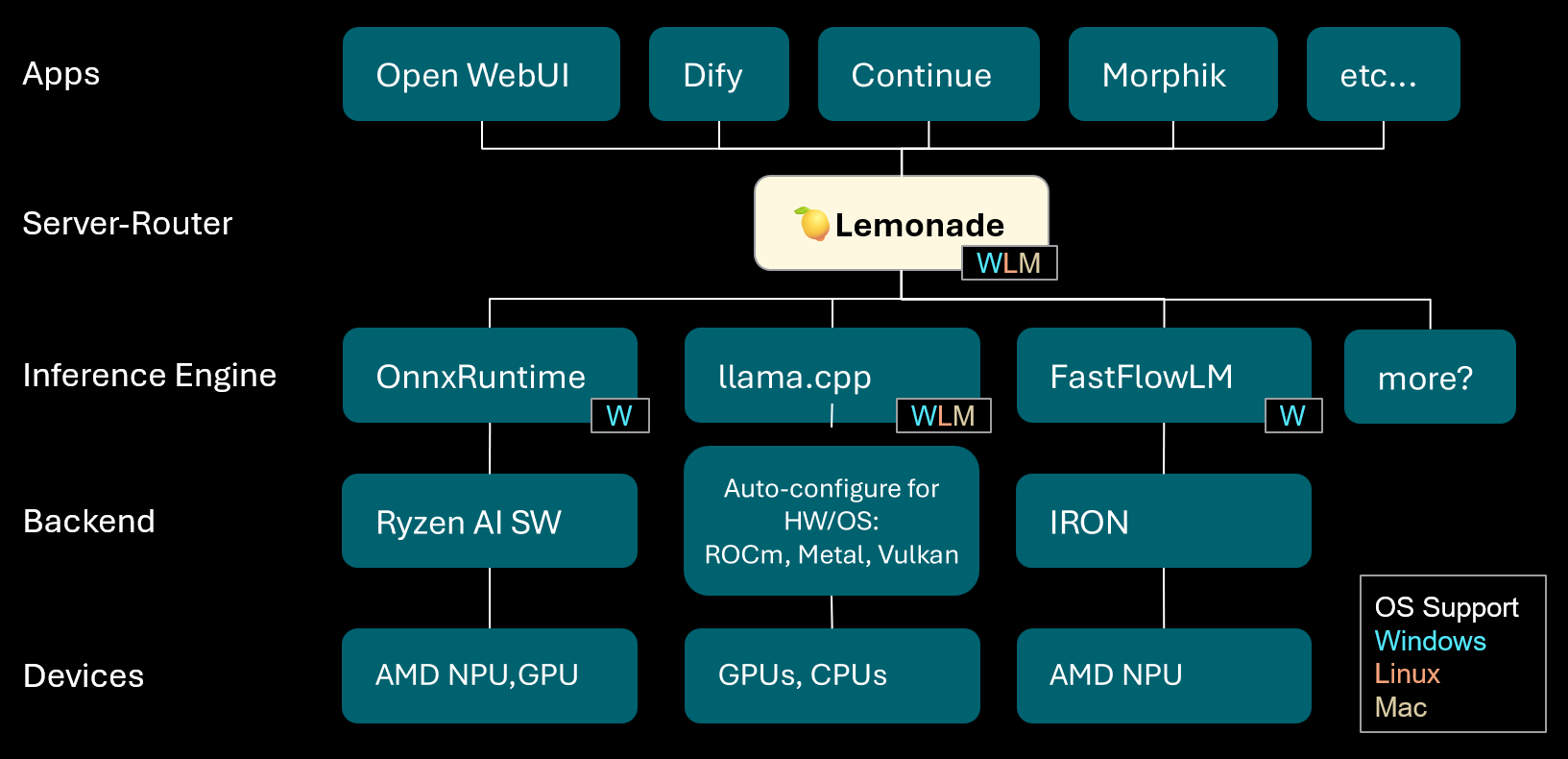
Lemonade:本地LLM服务器-路由器 : Lemonade发布了v8.1.11版本,这是一个本地LLM服务器-路由器,能够为各种PC(包括AMD NPU和macOS/Apple Silicon设备)自动配置高性能推理引擎。它支持ONNX、GGUF和FastFlowLM等多种模型格式,并利用llama.cpp的Metal后端在Apple Silicon上实现高效计算,为用户提供灵活、高性能的本地LLM体验。 (来源:Reddit r/LocalLLaMA)
PopAi:AI驱动的演示文稿生成 : PopAi展示了其AI工具在几分钟内从简单提示生成包含图表和插图的详细商业演示文稿的能力。这突显了AI在内容创作方面的效率,使非专业人士也能快速制作高质量的演示材料。 (来源:kaifulee)

GitHub Copilot CLI:模型自动选择 : GitHub Copilot CLI现在为商业和企业用户提供了模型自动选择功能。这一更新使得系统能够根据当前任务自动选择最合适的模型,旨在提高开发效率和代码生成质量。 (来源:pierceboggan)
Mixedbread Search:多语言多模态本地搜索 : Mixedbread推出了其beta版搜索系统,提供快速、准确、多语言和多模态的文档搜索功能。该系统强调本地运行,使用户能够在自己的设备上对文档进行高效检索,尤其适用于需要处理多样化数据类型的场景。 (来源:TheZachMueller)
Hume AI Octave 2:下一代多语言TTS模型 : Hume AI发布了Octave 2,一款下一代多语言文本转语音(TTS)模型。该模型比前代快40%、便宜50%,并支持11种以上语言、多说话人对话、语音转换和音素编辑功能,旨在提供更快速、更真实、更具情感的语音AI体验。 (来源:AlanCowen)
AssemblyAI九月更新:全能AI音频服务 : AssemblyAI回顾了其九月更新,亮点包括推出应用内Playground、通用语言扩展、欧盟PII脱敏功能以及流媒体性能改进和关键词提示等。这些更新旨在为用户提供更全面、更高效的AI音频处理服务。 (来源:AssemblyAI)
Voiceflow MCP工具:Agent工具集成标准化 : Voiceflow推出了模型上下文协议(MCP)工具,为AI Agent使用各类工具提供了标准化方式。这简化了开发者的自定义集成工作,并为无代码用户提供了预构建的第三方工具,极大地扩展了Voiceflow Agent的能力。 (来源:ReamBraden)
Salesforce Agentforce Vibes:企业级Agent编码 : Salesforce基于Cline的架构推出了“Agentforce Vibes”产品,利用模型上下文协议(MCP)支持,为企业客户提供自主编码能力。该产品确保了LLM与内部及外部知识源/数据库的安全通信,旨在实现企业规模的AI编码。 (来源:cline)

JoyAgent-JDGenie:通用Agent架构报告 : GAIA(Generalist Agent Architecture)技术报告发布,该架构集成了集体多Agent框架(结合规划、执行Agent和评论模型投票)、分层记忆系统(工作、语义、程序层)以及搜索、代码执行和多模态解析等工具套件。该框架在综合基准测试中表现出色,超越开源基线并接近专有系统性能,为构建可扩展、有弹性、适应性强的AI助手提供了路径。 (来源:HuggingFace Daily Papers)
AI旅行助手:从攻略到行动的赋能 : 马蜂窝推出的AI旅行助手App,旨在将AI从传统的攻略生成提升到实际旅行中的行动辅助。该应用能生成图文并茂的个性化攻略,并提供AI Agent代打电话预订餐厅等实用功能,有效解决了语言障碍等痛点。尽管在实时翻译和深度个性化方面仍有提升空间,但它已显著降低了“不做攻略出门”的门槛,展现了AI在连接数字信息与物理世界行动方面的巨大潜力。 (来源:36氪)

📚 学习
AI研究员职业发展建议 : 针对AI研究员的职业发展,专家们强调了成为优秀编码员的重要性,鼓励从头复现研究论文,深入理解基础设施。同时,建议积极构建个人品牌,分享有趣的想法,保持好奇心和适应性,并优先选择能促进创新和学习的职位。长期来看,持续努力和获取实际成果是建立信心和动力的关键。 (来源:dejavucoder、BlackHC)
Python数据分析课程 : DeepLearningAI推出了一门新的Python数据分析课程,旨在教授如何利用Python提高数据分析的效率、可追溯性和可重复性。该课程是数据分析专业证书的一部分,强调编程技能在现代数据工作中的核心作用。 (来源:DeepLearningAI)
学生免费获取Copilot AI工具 : 微软为符合条件的大学生提供免费12个月的Microsoft 365个人订阅,其中包括Copilot Podcasts、Deep Research和Vision的额外访问权限。此举旨在为学生提供强大的AI工具,助力其学习和创新。 (来源:mustafasuleyman)

本地AI/ML课程设置 : 一位教育者分享了如何在预算有限的情况下,为学生创建基于本地开发和消费级硬件的AI/ML实践课程。他建议使用小型模型、Transformer Lab作为训练平台,并强调理解核心概念而非盲目追求模型规模,以此提升学生的学习效果和实际操作能力。 (来源:Reddit r/deeplearning)
即将举行的AI研讨会 : AIhub发布了2025年10月至11月期间即将举行的机器学习和AI研讨会列表。这些活动涵盖从政治受限社交媒体平台的数据收集到AI伦理等多个主题,所有研讨会均免费并提供线上参与选项,为AI社区提供了丰富的学习和交流机会。 (来源:aihub.org)

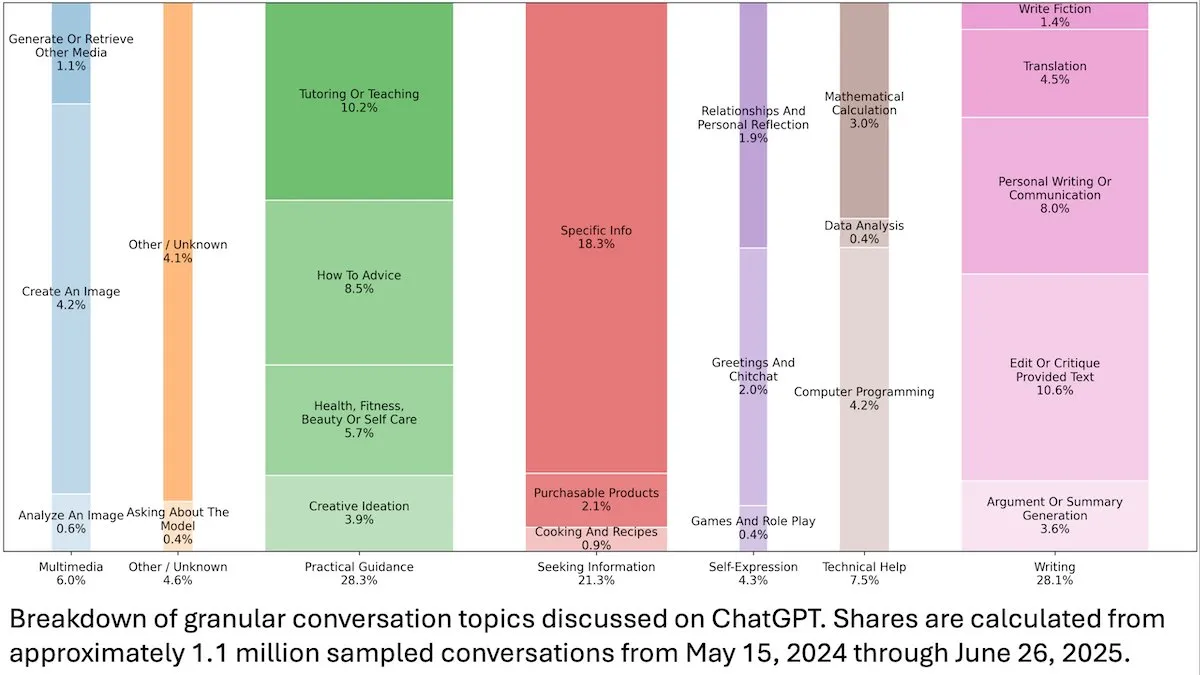
ChatGPT用户行为洞察 : DeepLearningAI发布的一项OpenAI研究显示,ChatGPT的1.1亿匿名对话分析表明,其使用场景已从工作相关转向个人需求,且女性用户和18-25岁年轻用户占比更高。最常见的请求是实用指导(28.3%)、写作帮助(28.1%)和信息查询(21.3%),揭示了ChatGPT在日常生活中的广泛应用。 (来源:DeepLearningAI)
Code2Video:代码驱动的教育视频生成 : 一项研究提出了Code2Video,一个以代码为中心的Agent框架,通过可执行的Python代码生成专业的教育视频。该框架包含规划器、编码器和评论家三个协作Agent,能够将讲座内容结构化、转换为代码并进行视觉优化。它在教育视频基准MMMC上实现了40%的性能提升,并生成了可与人工教程媲美的视频。 (来源:HuggingFace Daily Papers)
BiasFreeBench:LLM偏见缓解基准 : BiasFreeBench被引入作为一个实证基准,用于全面比较八种主流的LLM偏见缓解技术。该基准通过重新组织现有数据集,在多项选择问答和开放式多轮问答两种测试场景下,引入了响应级别的“Bias-Free Score”指标,以衡量LLM响应的公平性、安全性及反刻板印象程度,旨在为偏见缓解研究建立统一的测试平台。 (来源:HuggingFace Daily Papers)
Transformer乘法学习障碍及长程依赖陷阱 : 研究逆向工程分析了Transformer模型在多位数乘法这一看似简单任务上的失败原因。研究发现,模型在隐式思维链中编码了必要的长程依赖结构,但标准微调方法未能收敛到能利用这些依赖的全局最优解。通过引入辅助损失函数,研究者成功解决了这一问题,揭示了Transformer学习长程依赖的陷阱,并提供了通过正确归纳偏置解决该问题的范例。 (来源:HuggingFace Daily Papers)
多模态推理中的VL-PRM训练洞察 : 研究旨在阐明视觉-语言过程奖励模型(VL-PRMs)的设计空间,探索了数据集构建、训练和测试时扩展的多种策略。通过引入混合数据合成框架和感知聚焦监督,VL-PRMs在五个多模态基准测试中展现出关键洞察,包括在测试时扩展中优于结果奖励模型,小尺寸VL-PRMs能检测过程错误,以及能揭示更强VLM骨干的潜在推理能力。 (来源:HuggingFace Daily Papers)
GEM:Agentic LLM的通用环境模拟器 : GEM(General Experience Maker)是一个开源环境模拟器,专为LLM Agent的经验学习而设计。它提供了一个标准化的Agent-环境接口,支持异步矢量化执行以实现高吞吐量,并提供灵活的封装器以方便扩展。GEM还包含多样化的环境套件和集成工具,并提供了使用REINFORCE等RL训练框架的基线,旨在加速Agentic LLM的研究。 (来源:HuggingFace Daily Papers)
GUI-KV:高效GUI Agent的KV缓存压缩 : GUI-KV是一种即插即用的KV缓存压缩方法,专为GUI Agent设计,无需重新训练即可提高效率。通过分析GUI工作负载中的注意力模式,该方法结合了空间显著性指导和时间冗余评分技术,在适度预算下实现了接近全缓存的准确性,并显著减少了解码FLOPs,有效利用了GUI特有的冗余性。 (来源:HuggingFace Daily Papers)
超越对数似然:SFT的概率目标函数研究 : 研究探讨了监督微调(SFT)中超越传统负对数似然(NLL)的概率目标函数。通过对7个模型骨干、14个基准和3个领域的广泛实验,发现当模型能力较强时,优先考虑先验的、低概率token权重较小的目标函数(如-p, -p^10)表现优于NLL;而当模型能力较弱时,NLL占据主导地位。理论分析揭示了目标函数如何根据模型能力进行权衡,为SFT提供了更具原则性的优化策略。 (来源:HuggingFace Daily Papers)
VLA-RFT:世界模拟器中基于验证奖励的RL微调 : VLA-RFT是一个针对视觉-语言-动作(VLA)模型的强化微调框架,利用数据驱动的世界模型作为可控模拟器。通过真实交互数据训练的模拟器,预测基于动作的未来视觉观测,从而实现具有密集轨迹级奖励的策略推出。该框架显著降低了样本需求,在不到400个微调步骤内超越了强大的监督基线,并在扰动条件下展现出强大的鲁棒性。 (来源:HuggingFace Daily Papers)
ImitSAT:通过模仿学习解决布尔可满足性问题 : ImitSAT是一种基于模仿学习的CDCL求解器分支策略,用于解决布尔可满足性问题(SAT)。该方法通过学习专家KeyTrace,将完整运行折叠为幸存决策序列,提供密集的决策级监督,直接减少传播次数。实验证明,ImitSAT在传播计数和运行时方面优于现有学习方法,实现了更快的收敛和稳定的训练。 (来源:HuggingFace Daily Papers)
开源AI Agent框架测试实践研究 : 对39个开源Agent框架和439个Agent应用进行的大规模实证研究揭示了AI Agent生态系统中的测试实践。研究识别出十种独特的测试模式,发现对确定性组件(如工具和工作流)的测试投入超过70%,而基于LLM的计划主体仅占不到5%。此外,提示(Trigger)组件的回归测试被严重忽视,仅出现在约1%的测试中,揭示了Agent测试中的关键盲点。 (来源:HuggingFace Daily Papers)
DeepCodeSeek:代码生成实时API检索 : DeepCodeSeek提出了一种新颖的技术,用于为上下文感知代码生成提供实时API检索,从而实现高质量的端到端代码自动补全和Agentic AI应用。该方法通过扩展代码和索引来预测所需API,解决了现有基准数据集中API泄露的问题。经过优化,一个紧凑的0.6B重排序器在保持2.5倍低延迟的同时,性能超越了8B模型。 (来源:HuggingFace Daily Papers)
CORRECT:多Agent系统中的凝练错误识别 : CORRECT是一个轻量级、免训练的框架,通过利用蒸馏错误模式的在线缓存,在多Agent系统中实现错误识别和知识迁移。该框架能在线性时间内识别结构化错误,避免了昂贵的重新训练,并能适应动态的MAS部署。CORRECT在七个多Agent应用中将步骤级错误定位提高了19.8%,显著缩小了自动化与人类水平错误识别之间的差距。 (来源:HuggingFace Daily Papers)
Swift:高效天气预报的自回归一致性模型 : Swift是一种单步一致性模型,首次实现了概率流模型的自回归微调,并采用连续排名概率评分(CRPS)目标。该模型能够生成技能娴熟的6小时天气预报,并保持长达75天的稳定性,运行速度比最先进的扩散基线快39倍,同时实现了与数值IFS ENS竞争的预报技能,标志着中长期到季节尺度高效可靠集成预报的重要一步。 (来源:HuggingFace Daily Papers)
Catching the Details:MLLM细粒度感知的自蒸馏RoI预测器 : 研究提出了一种高效、无需标注的自蒸馏区域提议网络(SD-RPN),解决了多模态大型语言模型(MLLM)在处理高分辨率图像时计算成本高昂的难题。SD-RPN通过将MLLM中间层的注意力图转化为高质量的伪RoI标签,并训练一个轻量级RPN进行精确局部化,实现了数据高效和泛化能力,在未见基准测试中将准确率提高了10%以上。 (来源:HuggingFace Daily Papers)
LLM多轮推理的新范式:In-Place Feedback : 研究引入了一种名为“In-Place Feedback”的新型交互范式,用于指导LLM进行多轮推理。用户可以直接编辑LLM之前的响应,模型在此修改后的响应基础上生成修订。经验评估表明,In-Place Feedback在推理密集型基准测试中表现优于传统多轮反馈,同时减少了79.1%的token使用量,解决了模型难以精确应用反馈的局限性。 (来源:HuggingFace Daily Papers)
LLM强化学习动态的可预测性 : 这项工作揭示了LLM在强化学习(RL)训练中参数更新的两个基本特性:秩1主导性(参数更新矩阵的最高奇异子空间几乎完全决定推理改进)和秩1线性动态(该主导子空间在训练过程中线性演化)。基于这些发现,研究提出了AlphaRL,一个即插即用的加速框架,通过早期训练窗口推断最终参数更新,实现了高达2.5倍的加速,同时保留了96%以上的推理性能。 (来源:HuggingFace Daily Papers)
KV缓存压缩的陷阱 : 研究揭示了KV缓存压缩在LLM部署中的多个陷阱,尤其是在多指令提示等实际场景中,压缩可能导致某些指令的性能迅速下降,甚至被LLM完全忽略。研究通过案例分析系统提示泄露,实证展示了压缩对泄露和通用指令遵循的影响,并提出了简单的KV缓存逐出策略改进方案。 (来源:HuggingFace Daily Papers)
💼 商业
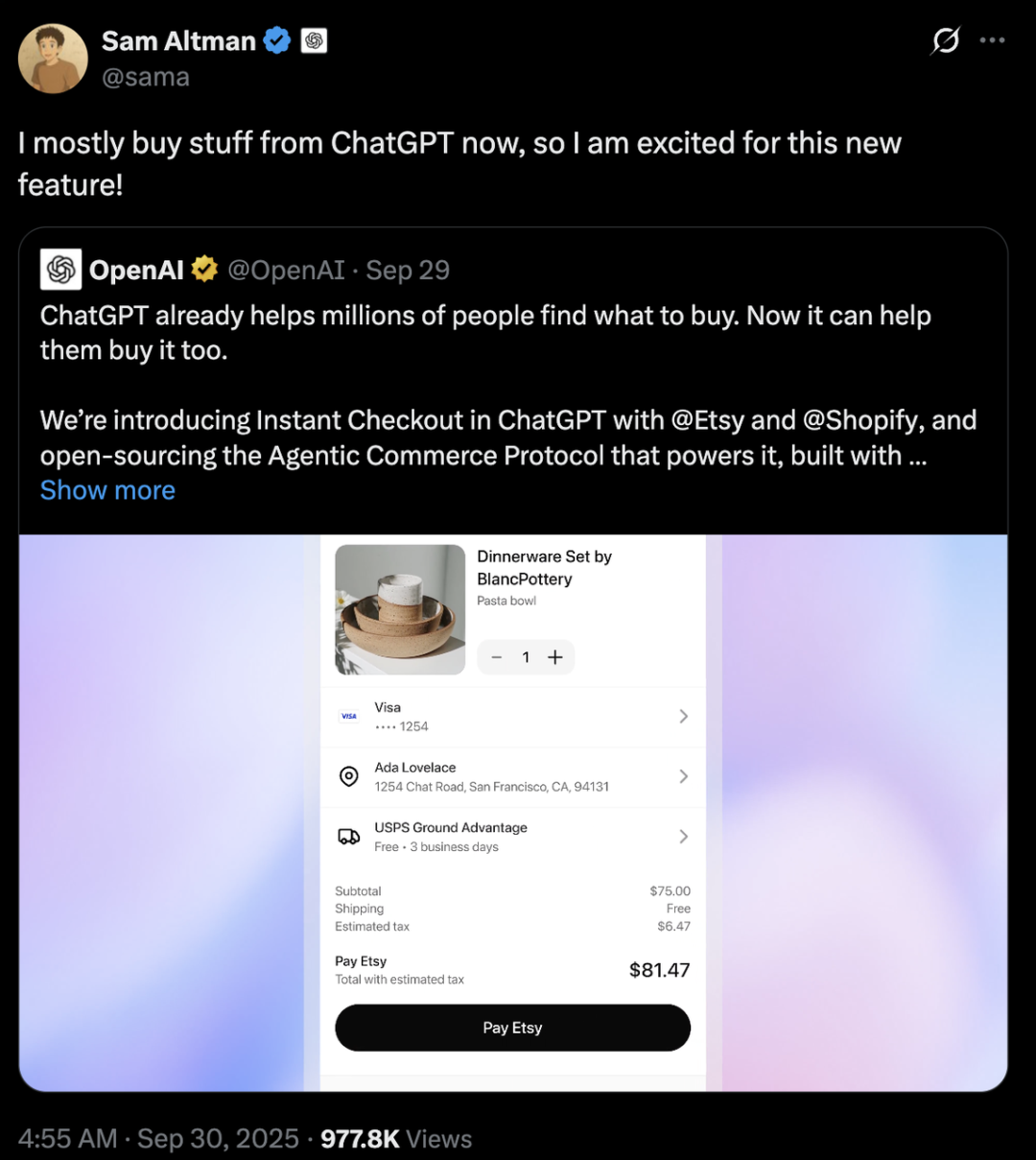
AI巨头竞争:OpenAI与Anthropic的战略差异 : OpenAI和Anthropic在AI领域采取了截然不同的发展路径。OpenAI通过ChatGPT整合电商和推出Sora社交应用,旨在实现“横向扩张”,成为覆盖用户生活多方面的超级平台,其估值已超Anthropic千亿美元。Anthropic则专注于“纵向深挖”,以Claude Sonnet 4.5为核心,深耕AI编程和企业级Agent市场,并与AWS、Google等云服务商深度绑定。两者背后是微软与亚马逊两大云计算巨头在“算力外交”上的博弈,凸显了AI时代算力稀缺、成本高昂的产业现实。 (来源:36氪、量子位、36氪)
Perplexity收购Visual Electric : Perplexity宣布收购Visual Electric,其团队将加入Perplexity,共同开发新的消费产品体验。Visual Electric的产品将逐步停止服务。此次收购旨在加强Perplexity在消费者AI产品领域的创新能力。 (来源:AravSrinivas)

Databricks收购Mooncakelabs : Databricks宣布收购Mooncakelabs,以加速其Lakebase愿景的实现。Lakebase是一个基于Postgres构建并为AI Agent优化的新型OLTP数据库,旨在为应用程序、分析和AI提供统一的基础,并与Lakehouse和Agent Bricks深度集成,简化数据管理和AI应用开发。 (来源:matei_zaharia)

🌟 社区
AI对就业和社会的影响 : 社区广泛讨论AI自动化对就业市场的深远影响,担忧其可能导致大规模失业,创造新的社会阶层,并引发对全民基本收入(UBI)的需求。人们普遍质疑新创造的AI相关工作是否也会被自动化,以及并非所有人都能掌握AI技能以适应未来。讨论还涉及AI Agent的成本管理和ROI实现挑战,以及AGI的到来对社会结构和地缘政治的潜在影响。 (来源:Reddit r/ArtificialInteligence、Ronald_vanLoon、Ronald_vanLoon)
AI伦理与控制权之争 : 社区热议AI的未来应由谁掌控,是普通民众还是科技寡头。呼吁AI发展应以人为本,强调透明度和用户对个人数据及AI历史的控制权。同时,AI教父Yoshua Bengio警告,超智能机器可能在十年内导致人类灭绝。Meta等公司计划利用AI聊天数据进行定向广告,进一步加剧了用户对隐私和AI滥用的担忧,引发了对AI伦理和监管的深层思考。 (来源:Reddit r/artificial、Reddit r/artificial、Reddit r/ArtificialInteligence)

GPT-5安全模型的异常行为 : Reddit社区用户报告称,GPT-5的“CHAT-SAFETY”模型在处理非恶意请求时,表现出奇怪、指责甚至幻觉行为,例如将指纹识别问题解读为跟踪行为,并编造法律。这种过度敏感和不准确的响应引发了用户对模型可靠性、潜在危害以及OpenAI安全策略的严重质疑。 (来源:Reddit r/ChatGPT)
“苦涩教训”与LLM发展路径之辩 : Andrej Karpathy与强化学习之父Richard Sutton就LLM是否符合“苦涩教训”展开辩论。Sutton认为LLM依赖有限的人类数据进行预训练,并非真正遵循“苦涩教训”中从经验中学习的原则。Karpathy则将预训练视为解决冷启动问题的“糟糕进化”,并指出LLM与动物智能在学习机制上的根本差异,强调当前AI更像是“召唤幽灵”而非“构建动物”。 (来源:karpathy、SchmidhuberAI)
本地LLM设置的价值讨论 : 社区用户就投入数万美元构建本地LLM设置的价值展开讨论。支持者强调隐私、数据安全和通过实际操作获得的深入知识是其主要优势,并将其与业余无线电爱好者类比。反对者则认为,随着廉价云API(如Sonnet 4.5和Gemini Pro 2.5)性能的提升,高成本的本地设置难以证明其合理性。 (来源:Reddit r/LocalLLaMA)
LLM作为评判者:Agent评估新方法 : 研究人员和开发者正在探索使用LLM作为“评判者”来评估AI Agent的响应质量,包括准确性和基础性。实践表明,当评判者的提示词精心设计(如单标准、锚定评分、严格输出格式和偏见警告)时,这种方法能出人意料地有效。这一趋势表明LLM-as-a-Judge在Agent评估领域具有巨大潜力。 (来源:Reddit r/MachineLearning)
AI与人类互动:从设备到虚拟角色 : AI正在多维度重塑人类互动。麻省理工学院相关初创公司推出“近乎心灵感应”的可穿戴设备,实现无声交流。同时,实时语音AI Agent作为NPC(非玩家角色)已应用于三维网络游戏,预示着AI在游戏和虚拟世界中提供更自然、沉浸式互动体验的潜力。这些进展引发了对AI在日常生活和娱乐中角色的讨论。 (来源:Reddit r/ArtificialInteligence、Reddit r/artificial)

开放模型与闭源模型的选择 : 社区讨论了软件工程师在使用闭源模型时转向开源模型面临的最大障碍。专家们指出,微调开源模型而非依赖黑盒闭源模型,对于深入学习、实现产品差异化和为用户创造更好产品至关重要。尽管开源模型的发展速度可能较慢,但长期来看,其在价值创造和技术自主性方面具有巨大潜力。 (来源:ClementDelangue、huggingface)
AI基础设施与算力挑战 : OpenAI的“星门”项目揭示了AI对计算能力、能源和土地的巨大需求,预计每月消耗高达90万片DRAM晶圆。GPU的稀缺性、高昂的价格以及电力供应的限制,使得AI公司不得不进行“算力外交”,与云服务提供商(如微软和亚马逊)深度绑定。这种重资产投入和战略合作模式,虽然推动了AI发展,但也带来了供应链、能源政策和监管等外部变量的风险。 (来源:karminski3、AI巨头的奶妈局、DeepLearning.AI Blog)

💡 其他
AI音乐版权与补偿机制 : 瑞典版权组织STIM与Sureel公司合作,推出了一项AI音乐许可协议,旨在解决AI模型训练中音乐作品的版权使用问题。该协议允许AI开发者合法使用音乐,并通过Sureel的归因技术计算作品对模型输出的影响,从而补偿作曲家和唱片艺术家。此举旨在为AI音乐创作提供法律保障,激励原创内容生产,并为版权所有者创造新的收入来源。 (来源:DeepLearning.AI Blog)

LLM安全与对抗性攻击 : Trend Micro发布研究,深入探讨了LLM可能被攻击者利用的多种方式,包括通过精心构造的提示词、数据投毒和多Agent系统中的漏洞进行妥协。研究强调了理解这些攻击向量对于开发更安全的LLM应用和多Agent系统的重要性,并提出了相应的防御策略。 (来源:Reddit r/deeplearning)

Proactive AI:便利性与隐私的权衡 : 社区讨论了“Proactive Ambient AI”(主动环境AI)作为智能助手所带来的便利性与潜在的隐私侵犯风险。这类AI能主动提供帮助,但其持续收集和处理个人数据引发了用户对透明度、控制权以及数据归属的担忧。有观点呼吁建立“透明协议”和“个人基础档案”,以确保用户拥有其AI互动历史的控制权。 (来源:Reddit r/artificial)
