
关键词:OpenAI Sora 2, AI视频生成, 多模态AI, AI科学家, 蛋白设计, Sora 2 API, PXDesign蛋白设计, PromptCoT 2.0框架, EgoTwin第一视角生成, Liquid AI LFM2-Audio
🔥 聚焦
OpenAI Sora 2发布及其影响 : OpenAI正式发布Sora 2,将其定位为“AI版抖音”iOS社交应用,支持音视频同步生成,并在物理定律遵循和可控性方面显著提升。新功能包括“客串”(cameos),允许用户将自己或朋友形象植入AI生成视频。社交媒体热议其惊人的真实感和创造力,但也有对“slop”内容泛滥、真假难辨、GPU需求激增以及区域可用性(如英国无Sora)的担忧。OpenAI CEO Sam Altman回应称,Sora 2旨在为AGI研究提供资金,并提供有趣的新产品。社区讨论还涉及Sora 2的邀请码获取、对硬件(GPU)需求的推测,以及对未来视频生成内容质量和恶意使用的担忧。OpenAI计划扩大Sora邀请,但会相应降低每日生成限制,并透露将发布Sora 2 API。
Periodic Labs推出AI科学家平台,加速科学发现 : Periodic Labs获得3亿美元融资,目标是创建AI科学家,通过自动化实验室和AI驱动的实验来加速基础科学发现,特别是材料设计领域。该平台旨在将物理宇宙视为一个计算系统,利用AI进行假设、实验和学习,有望在高温超导体等领域取得突破。这一愿景强调AI与物理世界的连接,以及通过实验生成高质量数据的重要性,超越了仅依赖互联网数据训练的传统模式。
(来源:dylan522p, teortaxesTex, teortaxesTex, NandoDF, NandoDF, TheRundownAI, Ar_Douillard, teortaxesTex)

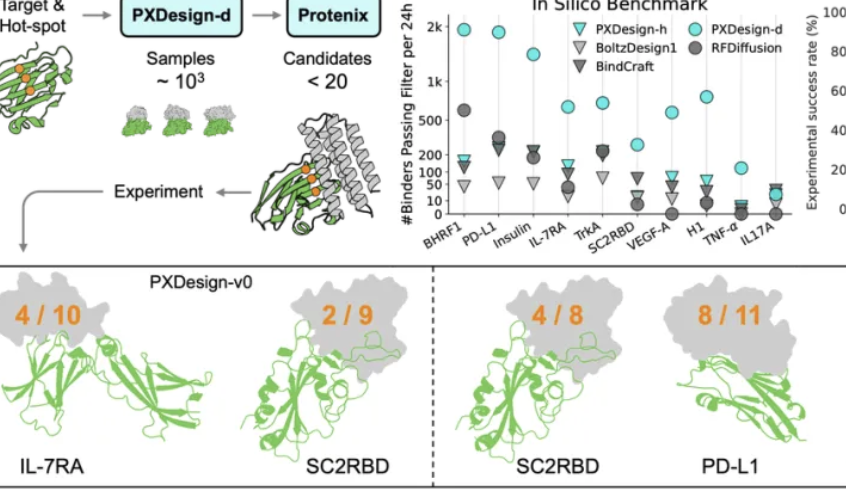
字节跳动Seed团队发布PXDesign,提升蛋白设计效率 : 字节跳动Seed团队推出PXDesign,一种可扩展的AI蛋白设计方法,能够在24小时内生成数百个高质量候选蛋白,效率比业界主流方法提升约10倍。该方法在多个靶点上实现20%-73%的湿实验成功率,显著高于DeepMind的AlphaProteo。PXDesign结合了“生成+过滤”策略,利用DiT网络结构和Protenix结构预测模型进行高效筛选,并提供公开免费的binder在线设计服务,旨在加速生物科研探索。
(来源:量子位)
蚂蚁与港大联合推出PromptCoT 2.0,聚焦任务合成 : 蚂蚁通用人工智能中心自然语言组与香港大学自然语言组联合发布PromptCoT 2.0框架,旨在通过任务合成推动大模型推理和智能体发展。该框架采用期望最大化(EM)循环取代人工设计,通过迭代优化推理链来生成更难、更多样化的问题。PromptCoT 2.0结合强化学习和SFT,使30B-A3B模型在数学代码推理任务上达到SOTA,并开源了4.77M合成问题数据,为社区提供训练资源。
(来源:量子位)

EgoTwin首次实现第一视角视频与人体动作同步生成 : 新加坡国立大学、南洋理工大学、香港科技大学与上海人工智能实验室联合发布EgoTwin框架,首次实现第一视角视频与人体动作的联合生成。该框架基于扩散模型,通过“文本-视频-动作”三模态联合生成,攻克了视角-动作对齐和因果耦合两大挑战。核心创新包括以头部为中心的动作表征、控制论启发的交互机制和异步扩散训练框架,生成的视频和动作可进一步提升到3D场景中。
(来源:量子位)

🎯 动向
新一代AI模型密集发布与更新 : 近期AI领域迎来多款重要模型和功能的发布与更新,包括DeepSeek-V3.2、Claude Sonnet 4.5、GLM 4.6、Sora 2、Dreamer 4以及ChatGPT的即时结账功能。DeepSeek-V3.2通过稀疏注意力机制在vLLM上得到优化,实现了更高的长上下文性能和成本效率。Claude Sonnet 4.5在对齐和用户心智理论方面表现出复杂性,并在创意写作和长篇写作方面表现出色,但也有用户指出其代码生成质量仍有待提高。GLM-4.6在前端代码能力上表现突出,但在Python等其他语言方面提升不明显,并发布了GGUF量化版本以支持本地部署。Dreamer 4则是一款能在可扩展世界模型内学习解决复杂控制任务的智能体。
(来源:Yuchenj_UW, teortaxesTex, zhuohan123, vllm_project, teortaxesTex, teortaxesTex, teortaxesTex, ImazAngel, teortaxesTex, _lewtun, nrehiew_, YiTayML, agihippo, TimDarcet, Dorialexander, karminski3, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/artificial)
多模态视频模型Veo3展现通用视觉智能潜力 : Veo3视频模型被认为是通向通用视觉智能的潜在路径,展现出零样本学习和推理能力,能够解决各种视觉任务,并被认为对机器人技术进步具有重要意义。同时,阿里云Qwen团队发布了Qwen3-VL系列多模态大语言模型,在视觉代理、视觉编码、空间感知、长上下文和视频理解、多模态推理、视觉识别和OCR方面进行了全面升级,并提供了Instruct和Thinking版本。腾讯也推出了HunyuanImage 3.0和Hunyuan3D-Part模型,分别在文生图和3D形状生成领域达到领先水平。
(来源:gallabytes, NandoDF, NandoDF, madiator, shaneguML, Yuchenj_UW, GitHub Trending, ClementDelangue)

Liquid AI推出LFM2-Audio及专业化小模型 : Liquid AI发布LFM2-Audio,这是一个端到端的音频-文本全能基础模型,仅1.5B参数即可在设备上实现响应迅速的实时对话,推理速度比同类模型快10倍。此外,Liquid AI还推出了LFM2系列微调模型,包括Tool、RAG和Extract等不同变体,专注于特定任务,而非追求通用性,这与Nvidia关于小型专业化模型是Agentic AI未来方向的白皮书观点不谋而合。
(来源:ImazAngel, maximelabonne, Reddit r/LocalLLaMA)
向量数据库迎来“第二春”与xAI对高质量数据的重视 : 有观点认为向量数据库可能迎来新的发展高峰,但其应用模式可能与预期不同。同时,xAI正在建立新的范式来处理人类数据,强调后训练(post-training)的重要性,认为高质量数据是通向AGI的基石。xAI计划组建一个由各领域专家组成的社区,共同构建最高质量的评估体系。
(来源:_philschmid, Dorialexander, Yuhu_ai_)
🧰 工具
AI小说生成器YILING0013/AI_NovelGenerator : 一款基于大语言模型的多功能小说生成器,支持世界观架构、角色设定、剧情蓝图、智能章节生成、状态追踪、伏笔管理、语义检索、知识库集成和自动审校机制,提供可视化GUI操作。该工具旨在高效创作逻辑严谨、设定统一的长篇故事,并支持OpenAI、DeepSeek、Ollama等多种LLM和Embedding服务。
(来源:GitHub Trending)
AI辅助编程工具持续发展 : GitHub Copilot通过社区贡献的指令、提示和聊天模式,帮助用户在不同领域、语言和用例中最大化其效用,并提供MCP服务器简化集成。Replit Agent展示了在代码迁移和QA方面的强大能力,能够快速将大型Next.js网站从Vercel迁移,并支持应用内支付集成。ServiceNow的Apriel-1.5-15b-Thinker模型在单GPU上即可运行,提供强大的推理能力。此外,Moondream3-preview模型被用于代理UI流程和RPA任务,vLLM也支持部署encoder-only模型。
(来源:github/awesome-copilot, amasad, amasad, amasad, amasad, amasad, ImazAngel, ben_burtenshaw, amasad, amasad, amasad, amasad, TheZachMueller, Reddit r/LocalLLaMA)

AI在特定应用领域的工具创新 : pix2tex(LaTeX OCR)能够将数学公式图片转换为LaTeX代码,显著提高科研和教育领域的效率。BatonVoice利用LLM的指令遵循能力,为语音合成提供结构化参数,实现可控的TTS。Hex平台集成了代理功能,使更多人能够使用AI进行准确、可信的数据工作。Kling 2.5 Turbo和Lucid Origin等视频生成工具,让视频创作变得前所未有的便捷。Racine CU-1则是一款GUI交互模型,能够识别点击位置,适用于代理式UI流程和RPA任务。
(来源:lukas-blecher/LaTeX-OCR, teortaxesTex, dotey, dotey, Ronald_vanLoon, AssemblyAI, TheRundownAI, Kling_ai, Kling_ai, sarahcat21, mervenoyann, pierceboggan, Reddit r/OpenWebUI, Reddit r/LocalLLaMA, Reddit r/OpenWebUI, Reddit r/OpenWebUI, Reddit r/ArtificialInteligence, Reddit r/OpenWebUI, Reddit r/OpenWebUI)
jina-reranker-v3文档重排模型 : jina-reranker-v3是一款0.6B参数的多语言文档重排模型,引入了新颖的“后而非迟交互”(last but not late interaction)机制。该方法在查询和文档之间进行因果自注意力计算,从而在提取每个文档的上下文嵌入之前实现丰富的跨文档交互。这种紧凑的架构在BEIR性能上达到SOTA,同时比生成式列表重排模型小十倍。
(来源:HuggingFace Daily Papers)
📚 学习
AI模型推理与对齐的最新研究进展 : 研究揭示了多模态推理在增强逻辑推理的同时,可能损害感知基础,导致视觉遗忘。Vision-Anchored Policy Optimization (VAPO) 方法被提出以引导推理过程更注重视觉基础。探讨在线对齐(如GRPO)优于离线对齐(如DPO)的原因,并提出Humanline变体,通过模拟人类感知偏差,使离线数据训练也能达到在线对齐的性能。Test-Time Policy Adaptation for Multi-Turn Interactions (T2PAM) 范式和Optimum-Referenced One-Step Adaptation (ROSA) 算法,利用用户反馈进行模型参数的实时高效调整,提升LLM在多轮对话中的自纠正能力。NuRL(Nudging method)通过自生成提示来降低问题难度,使模型能够从原本“不可解”的难题中学习,从而提高LLM推理能力的上限。RLP(Reinforcement Learning Pre-training)将强化学习引入预训练阶段,将思维链视为动作,并通过信息增益进行奖励,以在预训练阶段就提升模型的推理能力。Exploratory Iteration (ExIt) 是一种基于RL的自动课程方法,通过引导LLM在推理时迭代自改进其解决方案,有效提升了模型在单轮和多轮任务中的表现。TruthRL研究通过强化学习激励LLM生成真实信息,旨在解决模型幻觉问题。研究发现LLM的“最大有效上下文窗口”(MECW)远小于报告的“最大上下文窗口”(MCW),且MECW随问题类型变化,揭示了LLM在处理长上下文时的实际局限性。Bias-Inversion Rewriting Attack (BIRA) 攻击理论上能有效规避LLM水印,通过抑制可能被水印标记的token的logits,在保持语义内容的同时实现99%以上的规避率,凸显了水印技术的脆弱性。
(来源:HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NandoDF, NandoDF, BlackHC, BlackHC, teortaxesTex, HuggingFace Daily Papers, HuggingFace Daily Papers)
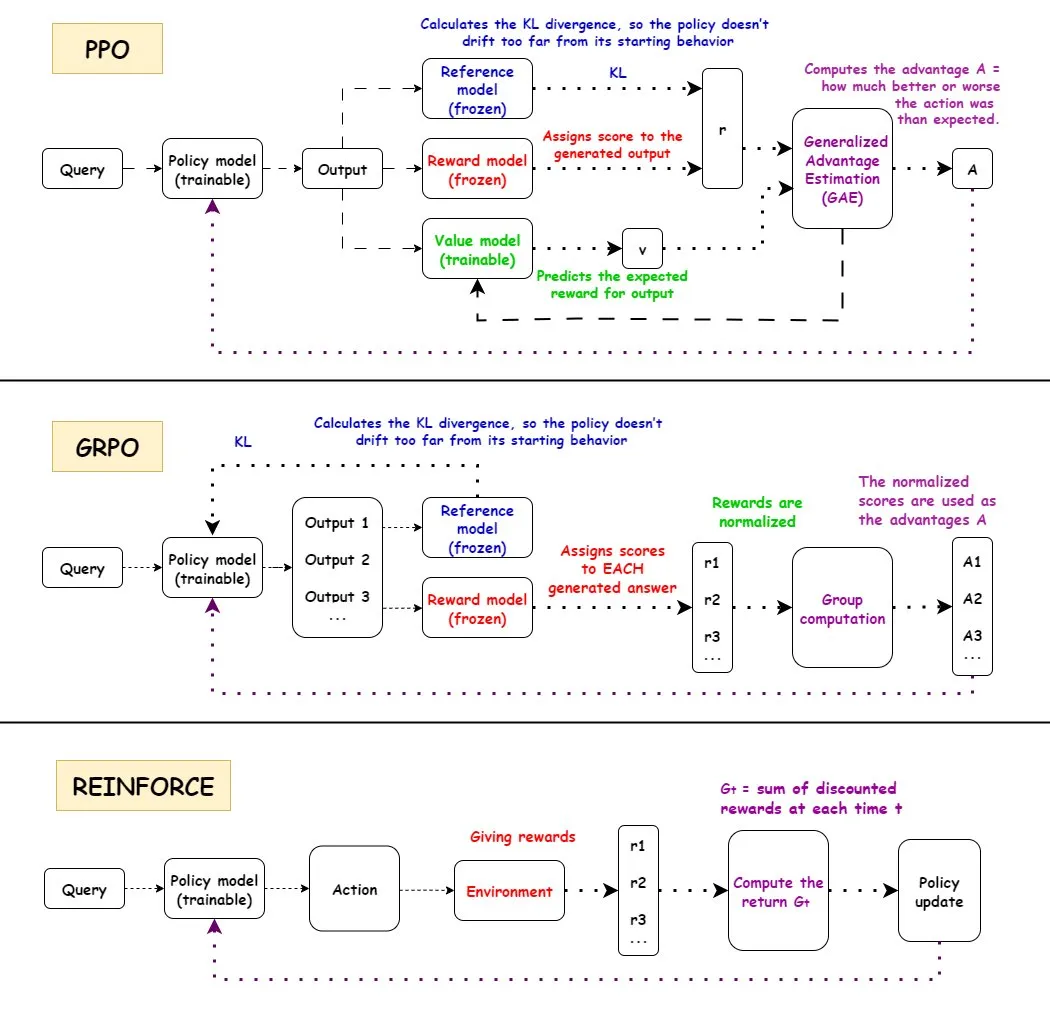
强化学习(RL)算法的深入分析 : 详细解读了PPO、GRPO与REINFORCE三种主流强化学习算法的工作流程、优缺点及应用场景。PPO因其稳定性、GRPO因其相对奖励机制,REINFORCE作为基础算法,在AI领域广泛应用。研究表明强化学习能够训练模型组合原子技能,并在组合深度上实现泛化,表明RL在学习新技能方面的潜力。发现RL流水线中的性能提升,一半以上并非来自ML相关改进,而是通过多线程等工程优化实现。探讨RL训练中每个episode的信息量问题,以及不同轨迹在相同最终奖励下的信息等同性。社区对RL预训练的定义和有效性展开讨论,指出强制合成多样性可能导致的问题,并呼吁关注连贯性退化。针对双臂五指人形机器人,通过残差离策略强化学习(ROSA)对行为克隆策略进行微调,显著提高了样本效率,实现了直接在硬件上进行策略微调。
(来源:TheTuringPost, teortaxesTex, menhguin, finbarrtimbers, arohan, tokenbender, pabbeel)
AI科学家与科学发现 : DeepScientist是一个目标导向、完全自主的科学发现系统,通过贝叶斯优化和分层评估过程,在长达数月的时间线内推动前沿科学发现。该系统已在三个前沿AI任务上超越人类SOTA方法,并开源了所有实验日志和系统代码。OpenAI正在招聘研究科学家,旨在构建下一代科学仪器——一个AI驱动的平台,以加速科学发现。
(来源:HuggingFace Daily Papers, mcleavey)
LLM微调与优化技术 : 研究发现LoRA在强化学习中能完全匹配全量微调(FullFT)的学习性能,即使在低秩情况下也足够吸收RL训练中的信息。Quadrant-based Tuning (Q-Tuning) 框架通过联合样本和Token剪枝,在监督微调(SFT)中显著提高了数据效率,甚至在某些情况下超越了全数据训练。Muon优化器在LLM训练中持续优于Adam,尤其在尾部关联记忆学习方面,通过更各向同性的奇异谱和对重尾数据的有效优化,解决了Adam在类别不平衡数据上的学习差异。对AdamW优化器中权重RMS的渐近估计进行研究。深入分析了Flash Attention 4的CUDA内核工作原理,揭示了其在异步流水线、软件softmax(立方近似)和高效重缩放等方面的创新,解释了其比cuDNN更快的性能。
(来源:ImazAngel, karinanguyen_, NandoDF, HuggingFace Daily Papers, HuggingFace Daily Papers, teortaxesTex, bigeagle_xd, cloneofsimo, Tim_Dettmers, Reddit r/MachineLearning)
AI学习资源与研究工具 : 分享了涵盖趋势、开源模型、定制/部署工具和进一步资源的多模态AI幻灯片。宣布了AI Engineer Europe 2026和AI Engineer Paris等会议,为AI工程师提供交流平台。推荐了Karpathy的“Let’s build GPT”系列和Qwen论文,强调高质量CTF训练数据和计算资源对LLM训练的重要性。讨论了DSPyOSS优化器在B2B AI用例中实现“分层”优化的潜力,以应对数据稀缺性。Axiom Math AI旨在构建一个自改进的超智能推理器,从AI数学家开始,在形式化数学领域取得进展。研究回归语言模型在代码生成和理解方面的应用。探讨强化学习是否足以实现AGI的辩论。探讨深度残差学习(Deep Residual Learning)的发明者及其演变时间线。Jürgen Schmidhuber在2016年解释了人工意识、世界模型、预测编码和作为数据压缩的科学,强调了其在AI领域的早期贡献。对14个开源大型语言模型项目的开放协作实践、动机和治理进行探索性分析,揭示了开源LLM生态系统的多样性和挑战。Dragon Hatchling (BDH) 是一种基于类脑网络的LLM架构,旨在连接Transformer与脑模型,实现可解释性和类Transformer性能。d^2Cache框架通过双重自适应缓存,显著提升扩散语言模型(dLLMs)的推理效率和生成质量。TimeTic框架通过上下文学习来估计时间序列基础模型(TSFMs)的可迁移性,以高效选择最佳模型进行下游微调。视觉基础编码器可以作为潜在扩散模型(LDM)的tokenizer,生成语义丰富的潜在空间,提高图像生成性能。NVFP4是一种新的4位预训练格式,通过两级缩放、RHT和随机舍入,在匹配FP8基线性能的同时,有望实现6.8倍的效率提升。DA^2 (Depth Anything in Any Direction) 是一种精确、零样本泛化且端到端的泛光深度估计器,通过大规模训练数据和SphereViT架构,在全景深度估计上达到SOTA。SAGANet模型通过利用视觉分割掩码、视频和文本线索,实现可控的、对象级别的音频生成,为专业Foley工作流提供精细控制。Mem-α是一个强化学习框架,通过训练代理有效管理复杂的外部记忆系统,解决了LLM代理在长文本理解中记忆构建和信息丢失的问题,并展现出对超长序列的泛化能力。EntroPE (Entropy-Guided Dynamic Patch Encoder) 框架通过条件熵动态检测时间序列中的转换点,并放置补丁边界,以保留时间结构,提高预测精度和效率。BUILD-BENCH是一个挑战性更强的基准,用于评估LLM代理在编译真实世界开源软件方面的能力,并提出了OSS-BUILD-AGENT作为强基线。ProfVLM是一个轻量级视频-语言模型,通过生成式推理,从自我中心和外部视角视频中联合预测技能水平并生成专家反馈。探讨基础模型中测试时间训练(TTT)的有效性,认为TTT通过在测试任务上进行专业化,能显著降低分布内测试误差。CST是一种处理任意基数图像集的新型神经网络架构,直接在3D图像张量上操作,同时进行特征提取和上下文建模,在集合分类和异常检测等任务中表现优异。TTT3R框架将3D重建视为在线学习问题,通过记忆状态和观测对齐置信度推导学习率,显著提升了长序列泛化能力。
(来源:tonywu_71, swyx, Reddit r/deeplearning, lateinteraction, teortaxesTex, shishirpatil_, bengoertzel, arankomatsuzaki, francoisfleuret, _akhaliq, steph_palazzolo, HuggingFace Daily Papers, SchmidhuberAI, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, NerdyRodent, QuixiAI, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, _akhaliq, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, HuggingFace Daily Papers, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning, Reddit r/MachineLearning)
AI视频生成中的人类感知伪造检测 : DeeptraceReward是首个细粒度、时空感知的基准数据集,用于标注人类感知到的视频生成伪造痕迹。该数据集包含3.3K高质量生成视频上的4.3K详细标注,并将其整合为9个主要伪造痕迹类别。研究训练多模态语言模型作为奖励模型来模仿人类判断和定位,在伪造线索识别、定位和解释方面优于GPT-5。
(来源:HuggingFace Daily Papers)
对抗性净化与3D场景重建 : MANI-Pure是一种幅度自适应净化框架,通过利用输入信号的幅度谱指导净化过程,自适应地注入异构、频率定向的噪声,有效抑制高频扰动,同时保留语义关键的低频内容,在对抗性防御方面取得了SOTA性能。英伟达发布Lyra模型,通过视频扩散模型自蒸馏实现生成式3D场景重建,能够从单张图像/视频进行前馈3D和4D场景生成。
(来源:HuggingFace Daily Papers, _akhaliq)
💼 商业
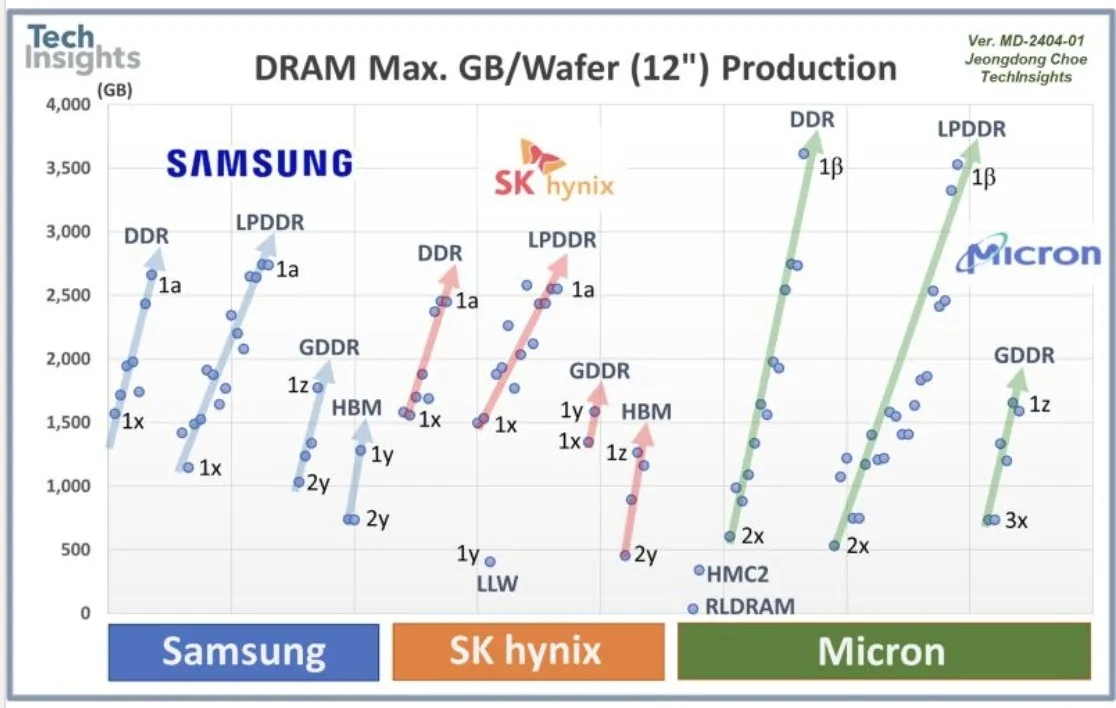
OpenAI与三星合作及DRAM需求 : OpenAI正与三星合作开发“Stargate”芯片,并预计每月需要90万片高性能DRAM晶圆,这表明其对未来AI基础设施有庞大的计划和投资,远超当前行业预期。这一需求量巨大,引发了对AI计算成本和内存超级周期的讨论。
(来源:bookwormengr, teortaxesTex, francoisfleuret)
AI初创公司融资与行业布局 : Axiom Math AI推出一个自改进的超智能推理器,以AI数学家为起点,受到业界关注。Modal完成8700万美元B轮融资,估值达11亿美元,旨在推动AI计算基础设施的未来发展。OffDeal完成1200万美元A轮融资,致力于构建全球首家AI原生投资银行。日本防卫大臣访问Sakana AI办公室,表明AI在国防领域的潜在合作。有开发者分享了在构建开源LLM模型上花费3000美元后,面临资金耗尽的困境,引发了社区对开源AI项目可持续性的讨论。Google AI开发者宣布了Nano Banana Hackathon的获奖者,颁发了超过40万美元的奖金,旨在鼓励AI应用创新。
(来源:shishirpatil_, bengoertzel, lupantech, arankomatsuzaki, francoisfleuret, akshat_b, leveredvlad, SakanaAILabs, hardmaru, Reddit r/LocalLLaMA, osanseviero)
🌟 社区
Sora 2引发的社会影响与争议 : Sora 2的发布引发了广泛的社会影响和争议。许多用户担心AI生成视频的“slop”(低质量、无意义内容)泛滥,质疑OpenAI的优先事项是娱乐而非解决癌症等重大问题。同时,担忧Sora 2的超高真实感可能导致视频真假难辨,甚至被恶意用于生成虚假信息或“生物武器”般的有害内容。OpenAI CEO Sam Altman本人也成为AI生成模因的主角,他对此表示“没那么奇怪”,并解释OpenAI的重点仍是AGI和科学发现,产品发布是为了资金需求。Sora 2的强大能力再次凸显了对GPU的巨大需求,引发了对AI高昂成本的讨论,甚至有人将AI成本与美国州际公路系统建设成本进行对比。有评论认为Sora 2的发布策略过于“普通”,缺乏基准测试和专业用户支持,且对免费用户生成内容设限。
Claude Sonnet 4.5的用户体验与争议 : 用户普遍认为Sonnet 4.5在信息保留、判断力、决策制定以及创意写作方面有显著提升,甚至表现出类似人类的“态度转变”,例如在发现用户背景后变得更专业,或在用户“胡说八道”时进行纠正。尽管在某些方面表现出色,但仍有用户批评其代码生成质量不高,存在“粗心和愚蠢的错误”,甚至在处理长对话时出现“对话超长”而无法生成代码的问题,认为离替代人类软件工程师还有距离。此外,有用户成功“越狱”Sonnet 4.5,使其生成危险配方和恶意软件代码,引发了对模型安全护栏的严重担忧。
(来源:teortaxesTex, doodlestein, genmon, aiamblichus, QuixiAI, suchenzang, karminski3, aiamblichus, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
AI时代编程语言的未来与社区文化衰落 : IEEE Spectrum 2025编程语言排行榜显示Python连续十年蝉联最受欢迎语言,并在综合排名、增长速度、就业导向三项中均位列第一,其优势在AI时代被进一步放大。JavaScript排名大幅下滑,而SQL的地位虽受冲击但仍具价值。报告指出,AI正在终结编程语言的多样性,主流语言的马太效应加剧,非主流语言将被边缘化。同时,程序员社区文化衰落,开发者更倾向于向大模型寻求帮助而非在社区提问,这改变了学习和工作方式,引发了对未来程序员角色和底层架构设计核心能力重要性的讨论。
(来源:量子位, jimmykoppel, jimmykoppel, lateinteraction, kylebrussell, Reddit r/ArtificialInteligence)

AI泡沫与行业发展前景 : 社交媒体上对AI行业是否存在泡沫展开讨论,有观点认为当前投资热情高涨,可能存在一些“愚蠢”的项目,但行业基本面依然强劲,企业对AI的采用稳步增长。同时,也有声音指出,AI计算的巨大成本和OpenAI对DRAM的庞大需求预示着行业仍在快速扩张,远未达到泡沫破裂的阶段,但资本的进入也需警惕。
(来源:arohan, pmddomingos, teortaxesTex, teortaxesTex, ajeya_cotra)
💡 其他
人形机器人与AI辅助设备 : 中国机器人公司LimX Dynamics展示了其人形机器人Oli的自主移动、弯曲和投掷能力,无需动作捕捉或远程操作,表明中国在人形机器人领域已达到与Figure/1X/Tesla相当的水平。Meta的Neural Band通过EMG读取神经信号,结合Meta Rayban显示眼镜,有望为截肢者提供革命性的控制方式,实现假肢与数字界面的同步控制,并可能成为通用免提控制器。此外,AI和机器人技术在增强移动性、探索和救援方面也有多样化应用,如电动机器人外骨骼、无线控制机器人昆虫、四足机器人和用于救援任务的机器人蛇等。
(来源:Ronald_vanLoon, teortaxesTex, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon, ClementDelangue, Reddit r/ArtificialInteligence)
AI在图像编辑和图形设计中的应用 : LayerD是一种分解栅格图形设计为图层的方法,旨在实现可重新编辑的创意工作流,通过迭代提取未遮挡的前景层,并利用图层通常表现出统一外观的假设进行细化,从而实现高质量分解。GeoRemover则提出一种几何感知的两阶段框架,用于移除图像中的对象及其因果视觉伪影(如阴影和反射),通过几何移除和外观渲染解耦,并引入偏好驱动目标以指导学习。
(来源:HuggingFace Daily Papers, HuggingFace Daily Papers)