
关键词:OpenAI GDPval基准, Claude Opus 4.1, GPT-5, AI评估, 经济任务表现, AI模型经济影响评估, Claude Opus 4.1 vs GPT-5, GDPval基准测试, AI实际应用能力, 多行业AI性能对比
🔥 聚焦
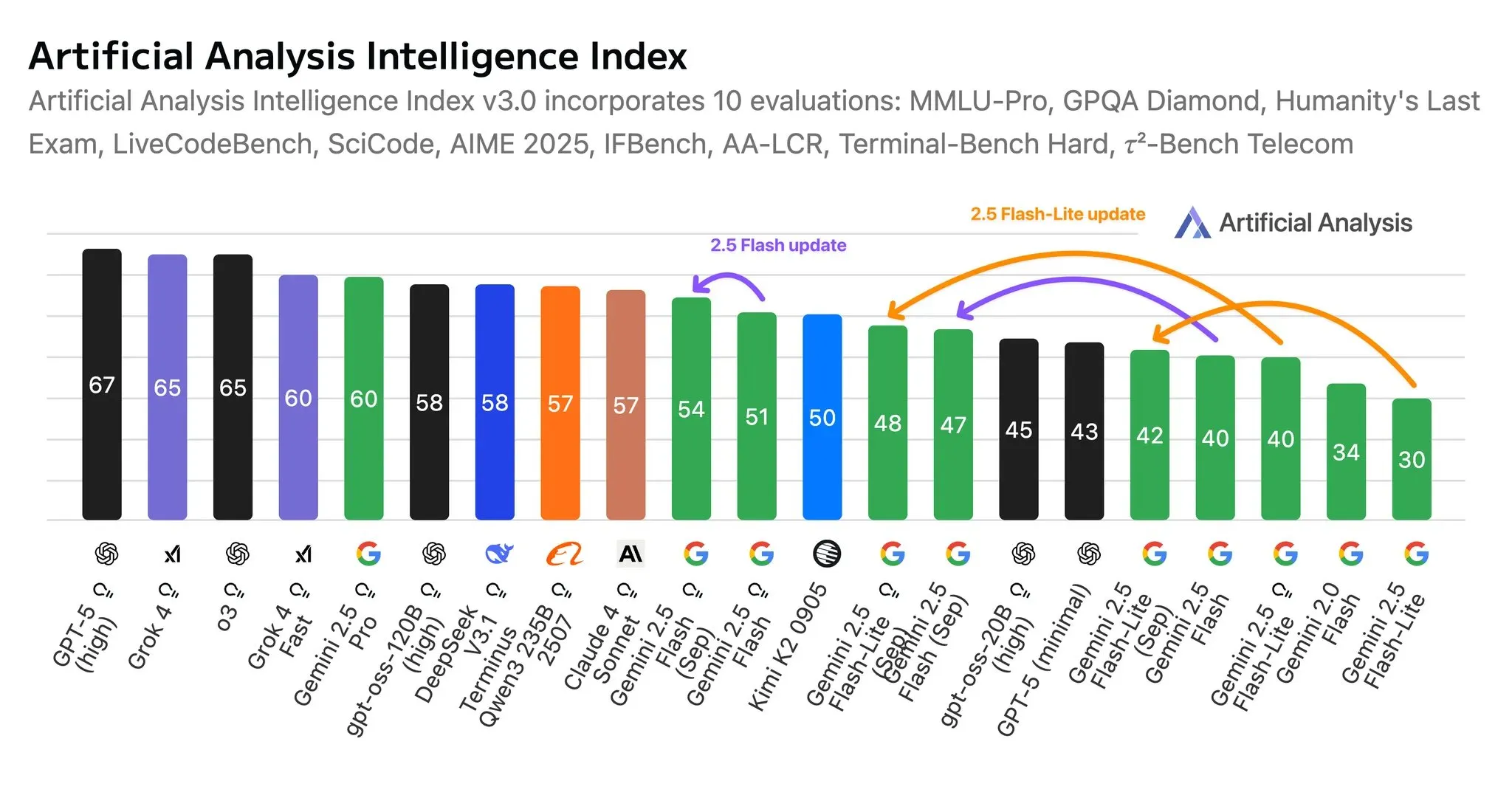
OpenAI GDPval基准发布:Claude Opus 4.1表现优于GPT-5 : OpenAI发布GDPval新基准,评估AI模型在9个行业、44种职业中实际经济任务的表现。初期结果显示,Anthropic的Claude Opus 4.1在近半数任务中达到或超越人类专家水平,优于GPT-5。OpenAI承认Claude在美学表现上突出,GPT-5在准确性上领先。这标志着AI评估转向衡量实际经济影响,并揭示AI能力快速进步。 (来源: OpenAI, menhguin, MillionInt, _sholtodouglas, polynoamial, menhguin, aidan_mclau, sammcallister, menhguin, andy_l_jones, tokenbender, scaling01, scaling01, scaling01, scaling01, scaling01, scaling01, alexwei_, scaling01, scaling01, scaling01, gdb, teortaxesTex, snsf, dilipkay, scaling01, scaling01, jachiam0, jachiam0, sama, ClementDelangue, AymericRoucher, shxf0072, Reddit r/artificial, 36氪, 36氪, 36氪)

AI与维基百科对弱势语言的“厄运螺旋” : AI模型通过抓取互联网文本学习语言,维基百科常是弱势语言的最大在线数据源。然而,大量AI翻译的低质量内容涌入这些小型维基百科版本,导致错误泛滥。这形成“垃圾进,垃圾出”的恶性循环,可能使AI翻译这些语言更不可靠,从而加速弱势语言的衰落。格陵兰语维基百科因AI工具造成的“胡言乱语”问题,已被提议关闭。这凸显了AI对文化多样性和语言保护的潜在负面影响。 (来源: MIT Technology Review, MIT Technology Review)

OpenAI顶尖研究员宋飏跳槽Meta : OpenAI战略探索团队负责人、扩散模型关键贡献者宋飏已跳槽至Meta的MSL团队,向首席科学家赵晟佳汇报。宋飏是16岁考入清华的少年天才,在OpenAI期间以一致性模型等成果闻名,被业内视为“最强大脑”之一。此次跳槽是Meta持续挖角OpenAI人才的又一重磅事件,引发了业界对AI人才竞争和研究方向的关注。 (来源: 36氪, dotey, jeremyphoward, teortaxesTex)

中国电信天翼AI发布超10万亿Tokens高质量数据集 : 中国电信天翼AI发布了总存储量达350TB、超过10万亿tokens的通用大模型语料数据,以及覆盖14个关键行业的专业数据集。该数据集经过精心标注和优化,包含多模态行业数据,旨在提升AI模型性能和泛化能力。中国电信强调高质量数据集是AI发展的核心燃料,并依托星辰MaaS平台构建“数据—模型—服务”闭环,致力于推动AI普惠发展和国产化创新,已成功训练出万亿参数大模型。 (来源: 量子位)

中国国星宇航实现全球首个太空计算星座常态化商用 : 中国国星宇航成功发射并实现太空计算星座的常态化商业运营,标志着太空计算从“能做”走向“可用”。该星座由首批“星算”卫星组成,旨在构建由2800颗计算卫星组成的天基算力基础设施,总算力超10万P,支持亿级参数模型运行。此次成功将道路识别模型部署至在轨卫星,完成图像采集、模型推理到结果回传的全过程,实现了交通行业算法首次上星运行,为全球AI基础设施的空间延展提供了新范式。 (来源: 量子位)

中国限制Nvidia芯片采购,加速半导体自给自足 : 中国禁止主要科技公司采购Nvidia芯片,此举表明中国在半导体领域已取得足够进展,足以摆脱对美国设计芯片的依赖。这凸显了美国在台湾半导体制造方面的脆弱性,以及中国自给自足能力的提升。例如,DeepSeek-R1-Safe模型已在1000颗华为Ascend芯片上训练。Nvidia的黄仁勋也曾指出,全球50%的AI研究人员来自中国。 (来源: AndrewYNg, Plinz)

🎯 动向
ChatGPT Pulse上线,开启主动智能时代 : OpenAI为Pro用户推出ChatGPT Pulse预览版,该功能将ChatGPT从被动问答工具转变为主动智能助理。Pulse在后台根据用户聊天记录、反馈和连接应用(如日历、Gmail)生成个性化每日简报,以卡片形式呈现,旨在提供有终点的、非沉迷式的资讯体验。Sam Altman称其为“最喜欢的功能”,预示ChatGPT未来将更趋向高度个性化和主动式服务。 (来源: Teknium1, openai, dejavucoder, natolambert, gdb, jam3scampbell, jam3scampbell, scaling01, sama, sama, scaling01, nickaturley, kevinweil, dotey, raizamrtn, BlackHC, op7418, 36氪, 36氪, 36氪, 36氪, 量子位)

谷歌发布Gemini Robotics 1.5系列,实现机器人“跨物种”学习 : 谷歌DeepMind发布Gemini Robotics 1.5系列模型(包括Gemini Robotics 1.5和Gemini Robotics-ER 1.5),旨在让机器人具备更强的“思考后行动”能力和跨具身形态学习技能。Gemini Robotics-ER 1.5作为“大脑”负责规划和决策,Gemini Robotics 1.5作为“小脑”执行动作,两者协同工作。该系列模型在具身推理和跨具身学习方面表现卓越,能将从一个机器人学到的动作迁移到另一个机器人,有望推动通用机器人的发展。 (来源: Teknium1, nin_artificial, dejavucoder, crystalsssup, scaling01, jon_lee0, BlackHC, Google, demishassabis, shaneguML, demishassabis, JeffDean, 36氪, 36氪)

谷歌发布Gemini 2.5 Flash系列模型更新 : 谷歌发布了Gemini 2.5 Flash和Flash-Lite模型的最新更新,这些模型在智能性、成本效益和token效率方面均有所提升。Flash-Lite在推理模式下的智能指数提升了8点,非推理模式提升12点,并且token效率更高,推理速度更快。这些更新使得模型在指令遵循、多模态理解和翻译方面表现更佳,Flash模型在Agent工具使用方面更高效。 (来源: scaling01, osanseviero, Google, osanseviero, andrew_n_carr)
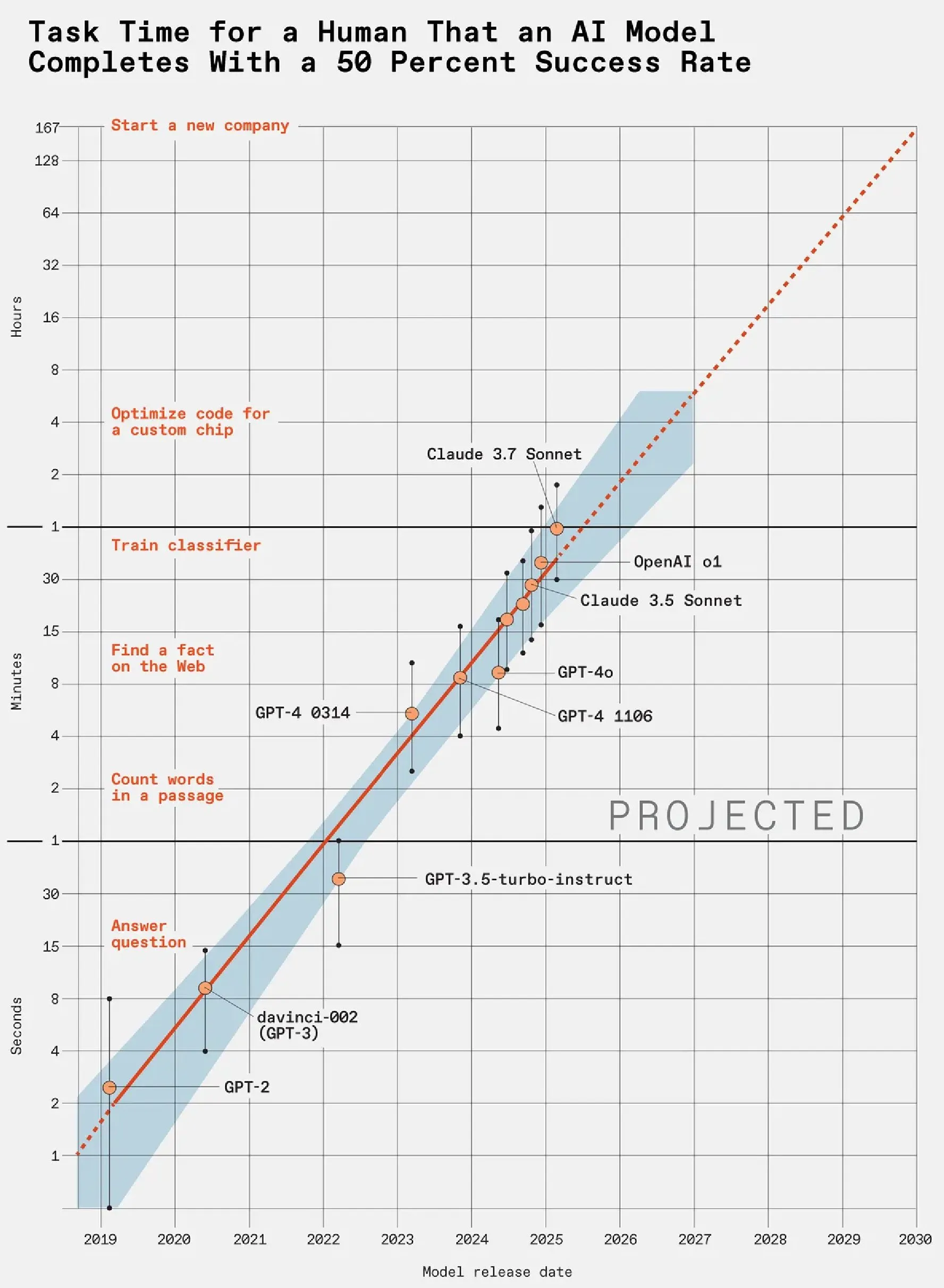
AI能力提升速度惊人,LLM能力每7个月翻一番 : METR发布的一项LLM基准测试研究显示,通过衡量LLM完成人类任务所需的时间,发现LLM能力每7个月翻一番。GPT-5已能稳定完成人类需要数小时的复杂任务,按此趋势,到2030年LLM可能处理人类一年才能完成的工作,例如创办新公司。这预示着AI在未来几年将对劳动力市场产生颠覆性影响。 (来源: karminski3)
视频模型展现通用视觉智能潜力 : 视频模型正经历“GPT时刻”,展现出从简单感知到视觉推理的通用能力。Veo3等模型已具备零样本能力,能解决视觉堆栈中的复杂任务。研究表明,视频模型是通用的“时空推理器”,未来有望成为通用视觉智能的关键路径,尤其在机器人领域,可解决语义、规划、常识等“最难”问题。 (来源: shaneguML, BlackHC, AndrewLampinen, teortaxesTex)

AI智能体从“助手”走向“管家”,深入物理世界 : 知名未来学家Bernard Marr预测,到2026年AI智能体将从被动助手转变为主动管家,能够自主处理日常事务和协调复杂项目。AI将不再局限于数字世界,而是通过自动驾驶、人形机器人、物联网等形式深度融入物理世界,改变人与环境的互动方式。中国大厂如腾讯、阿里、百度也正积极布局企业级AI智能体,强调其任务执行与交付能力,而非仅对话能力,旨在将其打造为新的商业增长点。 (来源: 36氪, 36氪, omarsar0)
工业机器人从“单兵作战”转向“超级生产团队” : 工业具身智能机器人正从单一工序向全流程协同拓展,形成“超级生产团队”。例如,微亿智造的8台工业具身智能机器人组成的产线能生产4种不同产品,并实现分钟级切换和小时级调整。这些机器人能像人一样思考,进行任务接手,提升生产效率和柔性化。AI视觉技术成为核心驱动力,推动工业机器人从“执行工具”向“具身智能”演进,为制造业数智化转型提供中国方案。 (来源: 36氪)

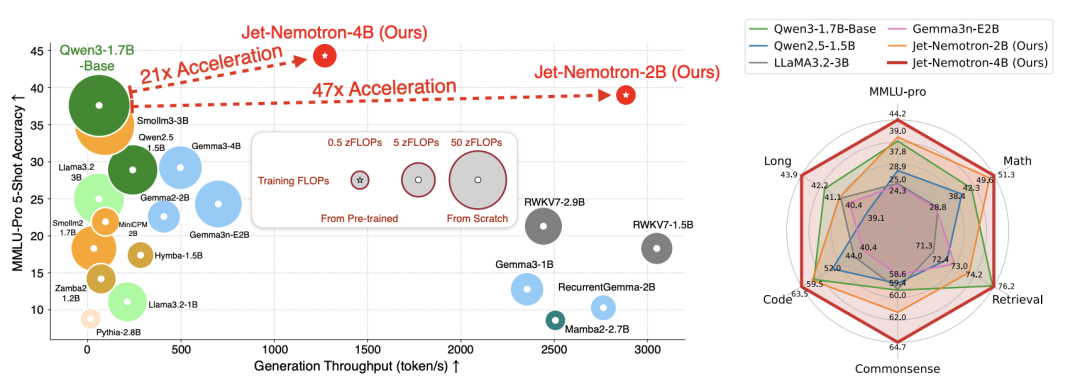
Grok-4-fast的效率提升或与NVIDIA Jet-Nemotron算法相关 : Grok-4-fast在降本增效上的惊人表现,可能与NVIDIA的Jet-Nemotron算法有关。该算法通过PortNAS框架,以预训练的全注意力模型为起点,优化注意力机制,实现了LLM推理速度提升约53倍,同时保持与顶尖开源模型相当的性能。Jet-Nemotron-2B在MMLU-Pro上比Qwen3-1.7B-Base准确率更高,速度快47倍,且内存需求更小,有望大幅降低模型成本。 (来源: 36氪)
NVIDIA Cosmos Reason模型下载量突破100万 : NVIDIA Cosmos Reason模型在HuggingFace上的下载量已突破100万,并在物理推理排行榜上名列前茅。该模型旨在教导AI智能体和机器人像人类一样思考,通过易于部署的微服务形式提供,是NVIDIA在推动AI Agents和机器人技术发展方面的重要成果。 (来源: huggingface, ClementDelangue)

Meta发布Code World Model (CWM)推动代码生成研究 : Meta FAIR发布了Code World Model (CWM),一个320亿参数的研究模型,旨在探索世界模型如何改变代码生成和代码推理。CWM以研究许可证开放,鼓励社区在此基础上进行开发,预示着代码生成领域的新研究方向。 (来源: ylecun)
谷歌发布EmbeddingGemma轻量级文本嵌入模型 : 谷歌推出了EmbeddingGemma,这是一款轻量级、开放的文本嵌入模型,参数量仅300M,但在MTEB基准测试中达到了SOTA性能。它超越了体积两倍的模型,非常适合快速、高效的设备端AI应用。 (来源: _akhaliq)

阿里通义千问公布多模态与大规模扩展路线图 : 阿里巴巴通义千问公布了雄心勃勃的路线图,重点押注统一多模态模型和极端规模扩展。目标包括上下文长度从1M扩展到100M tokens,参数量达到万亿甚至十万亿级别,测试时间计算扩展到1M,以及数据量达到100万亿tokens。此外,还将推动无限规模的合成数据生成和扩展Agent能力,体现了“规模即一切”的理念。 (来源: menhguin, karminski3)

AI辅助医疗进入临床应用阶段 : AI在医疗领域的应用正从尖端试验品转变为常规工具。例如,京东健康发布“AI医院1.0”和升级“京医千询2.0”医疗大模型,实现AI驱动的“医检诊药”闭环服务,覆盖导诊、问诊、检查、买药和健康管理。AI智能听诊器已能辅助诊断心脏病,AI读片在肺结节、脑出血等领域实现突破,诊断准确率超96%。AI正全面进入临床应用,提升医疗服务效率和精准性。 (来源: 36氪, 36氪, 量子位, Ronald_vanLoon, Reddit r/ArtificialInteligence)

Meta AI App推出AI生成短视频Vibes : Meta AI App推出了名为“Vibes”的新功能,这是一个专注于AI生成短视频的动态消息。此举标志着Meta在AI内容创作领域的进一步布局,旨在为用户提供新的、由AI驱动的短视频体验。 (来源: dejavucoder, _tim_brooks, EigenGender)
AI-generated genomes实现突破 : Arc Institute发布了三项新发现,其中包括世界首个功能性AI生成基因组。这项突破利用了Arc与NVIDIA合作发布的生物ML模型Evo 2,科学家能够设计和写入人类基因组中的大规模变化,纠正导致遗传疾病的DNA重复,有望加速基因治疗和生物材料研究。 (来源: dwarkesh_sp, riemannzeta, zachtratar, kevinweil, Reddit r/artificial)
Apple推出SimpleFold,轻量级AI预测蛋白质折叠 : 苹果研究人员开发了SimpleFold,这是一种基于流匹配模型的新型AI,用于蛋白质折叠预测。它摒弃了传统扩散方法中计算昂贵的组件,仅使用通用Transformer块,能将随机噪声直接转化为蛋白质结构预测。SimpleFold-3B在标准基准测试中表现出色,性能可达领先模型的95%,且部署和推理效率更高,有望降低蛋白质结构预测的计算门槛,加速药物发现。 (来源: Reddit r/ArtificialInteligence, HuggingFace Daily Papers)

工业AI与物理AI的深度融合 : 阿里巴巴与英伟达合作,将完整的英伟达Physical AI软件栈纳入阿里云平台。Physical AI旨在让人工智能从屏幕走向物理世界,通过整合物理规律优化AI生成内容,使其更符合现实逻辑。其核心技术包括世界模型、物理仿真引擎和具身智能控制器,旨在实现AI对三维空间的完整理解、实时物理计算和具体行动。这一合作有望推动AI在机器人、物流、汽车、制造等行业的广泛应用,将AI从信息处理工具转变为能理解和操作物理世界的智能系统。 (来源: 36氪)

AI生成3D资产框架Hunyuan3D-Omni发布 : Hunyuan3D-Omni是一个统一的框架,用于可控的3D资产生成,基于Hunyuan3D 2.1。它不仅支持图像和文本条件,还接受点云、体素、边界框和骨骼姿态等作为条件信号,实现对几何、拓扑和姿态的精确控制。模型采用单一跨模态架构统一所有信号,并通过渐进式、难度感知采样策略训练,提高了生成精度和鲁棒性。 (来源: HuggingFace Daily Papers)
腾讯发布Hunyuan Image 3.0,号称最强开源文生图模型 : 腾讯预告将于9月28日发布Hunyuan Image 3.0,宣称是世界上最强大的开源文生图模型。这一发布引发了社区的广泛关注和期待,尤其是在ComfyUI等工具中的应用前景。 (来源: ostrisai, Reddit r/LocalLLaMA)

Llama.cpp新增Qwen3 reranker支持 : Llama.cpp已合并对Qwen3 reranker的支持,该功能通过reranking模型(交叉编码器)为查询和文档对输出相似性分数,显著提升RAG等检索管道的召回性能。用户需要使用新的GGUF文件以获得正确结果。 (来源: Reddit r/LocalLLaMA)![Llama.cpp新增Qwen3 reranker支持](https://external-preview.redd.it/gjtn51bKTEhntL8tK6567mzxkqg8KV6qsi2OUMPMyfI.png?auto=webp&s