
关键词:光基AI芯片, K2 Think, 具身智能, Jupyter Agent, OpenPI, Claude模型, Qwen3-Next, Seedream 4.0, 光子AI芯片能效比, 开源大模型推理速度, 人形机器人情绪表达, LLM数据科学智能体, 机器人视觉语言动作模型
🔥 聚焦
光基AI芯片效率突破 : 佛罗里达大学工程师团队开发出新型光基AI芯片,使用光子而非电力进行图像识别和模式检测等AI操作。该芯片在数字分类测试中达到98%的准确率,同时能效比提升高达100倍。这一突破有望大幅降低AI计算成本和能耗,推动AI在智能手机到超级计算机等领域的绿色化和可扩展性发展,预示着混合电光芯片将重塑AI硬件格局。(来源: Reddit r/ArtificialInteligence)

K2 Think:全球最快开源大模型问世 : 阿联酋MBZUAI与G42 AI合作发布K2 Think,一款基于Qwen 2.5-32B的开源大模型,实测速度超过2000 tokens/秒,是典型GPU部署吞吐量的10倍以上。该模型在AIME等数学基准测试中表现出色,并通过长链路思维SFT、可验证奖励RLVR、推理前规划、Best-of-N采样、推测解码及Cerebras WSE硬件加速实现技术创新,标志着开源AI推理系统性能的新高度。(来源: teortaxesTex, HuggingFace)

具身智能与人形机器人前沿进展 : 知乎圆桌讨论揭示具身智能领域多项突破。清华Air实验室展示“灵巧脸”Morpheus,采用混动驱动和数字人技术实现丰富微表情,旨在提升人形机器人情绪价值。同时,北京天工Ultra机器人在世界人形机器人运动会百米赛中夺冠,突显算法与自主感知优势。讨论也涵盖了人形机器人成本、量产、控制理论与大模型融合等关键议题,预示着具身智能正从技术探索走向实际应用。(来源: ZhihuFrontier)

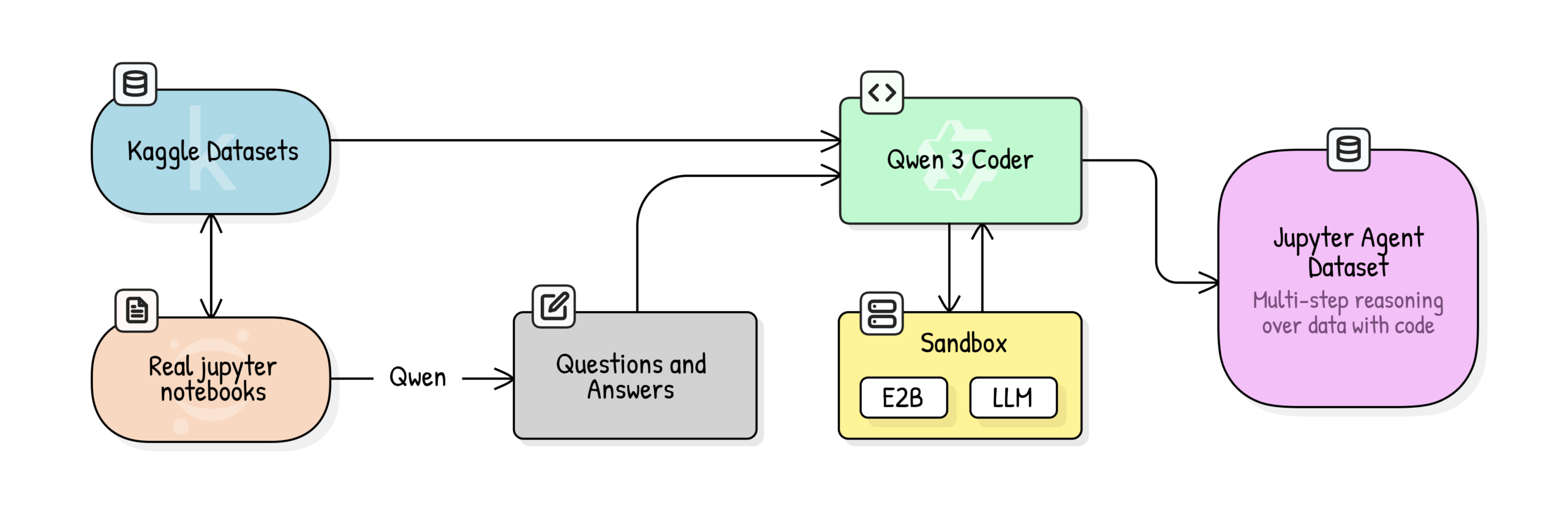
Jupyter Agent:用Notebook训练LLM进行数据科学推理 : Hugging Face发布Jupyter Agent项目,旨在通过代码执行工具赋予LLM在Jupyter Notebook中解决数据分析和数据科学任务的能力。通过大规模Kaggle Notebooks数据清洗、教育质量评分、QA生成和代码执行轨迹生成等多阶段训练流程,成功将Qwen3-4B等小型模型在DABStep基准测试的Easy任务上从44.4%提升至75%,证明小模型结合优质数据和脚手架也能成为强大的数据科学智能体。(来源: HuggingFace Blog)
OpenPI:开源机器人视觉-语言-动作模型 : Physical Intelligence团队发布OpenPI库,包含π₀、π₀-FAST和π₀.₅等开源视觉-语言-动作(VLA)模型。这些模型在10k+小时机器人数据上预训练,支持PyTorch,并在LIBERO基准测试中达到SOTA性能。OpenPI提供基础模型检查点和微调示例,支持远程推理,旨在推动机器人领域的开放研究和应用,尤其在桌面操作和物体抓取等任务中展现潜力。(来源: GitHub Trending)
🎯 动向
微软与Anthropic合作,Claude模型融入Office 365 Copilot : 微软正将Anthropic的Claude模型引入Office 365 Copilot,尤其在Excel函数计算和PowerPoint幻灯片制作等Claude表现更佳的领域。此举旨在优化Copilot在Word、Excel、PowerPoint中的特定功能,提升用户体验,并扩展Claude在企业生产力工具中的应用范围。(来源: dotey, alexalbert__, menhguin, TheRundownAI)

AI加速科学研究:知识图谱与自主智能体 : MiniculeAI展示AI如何通过知识图谱和自主智能体加速科学发现。通过将基因、药物和结果映射到动态网络中,AI能揭示PDF文档中难以发现的隐藏联系。自主智能体可扫描文献、发现模式,并提供可解释的见解,将数月的传统研究缩短至几分钟,同时确保企业级数据隐私。(来源: Ronald_vanLoon)
Qwen3-Next模型系列:长上下文与参数效率优化 : Qwen团队推出Qwen3-Next系列基础模型,专注于极端上下文长度和大规模参数效率。该系列引入多项架构创新,包括GatedAttention(解决异常值)、GatedDeltaNet RNN(节省KV缓存),并结合Sink+SWA混合或Gated Attention+线性RNN混合架构,旨在最大化性能并最小化计算成本,预示着纯Attention模型时代的终结。(来源: tokenbender, SchmidhuberAI, teortaxesTex, ClementDelangue, andriy_mulyar)
ByteDance Seedream 4.0图像生成与编辑模型发布 : 字节跳动发布Seedream 4.0,提供卓越的图像生成和编辑能力。用户反馈其在满足用户需求、RLHF审美偏好及保持主流品味方面表现突出。与Seedream 3.0相比,4.0版本增加了胶片颗粒感和镜头伪影,对比度更高,动漫风格笔触更锐利,同时在中文语义理解和一致性方面表现强劲,适合信息图、教程和商品设计。(来源: ZhihuFrontier, Reddit r/artificial, op7418, TomLikesRobots, dotey)
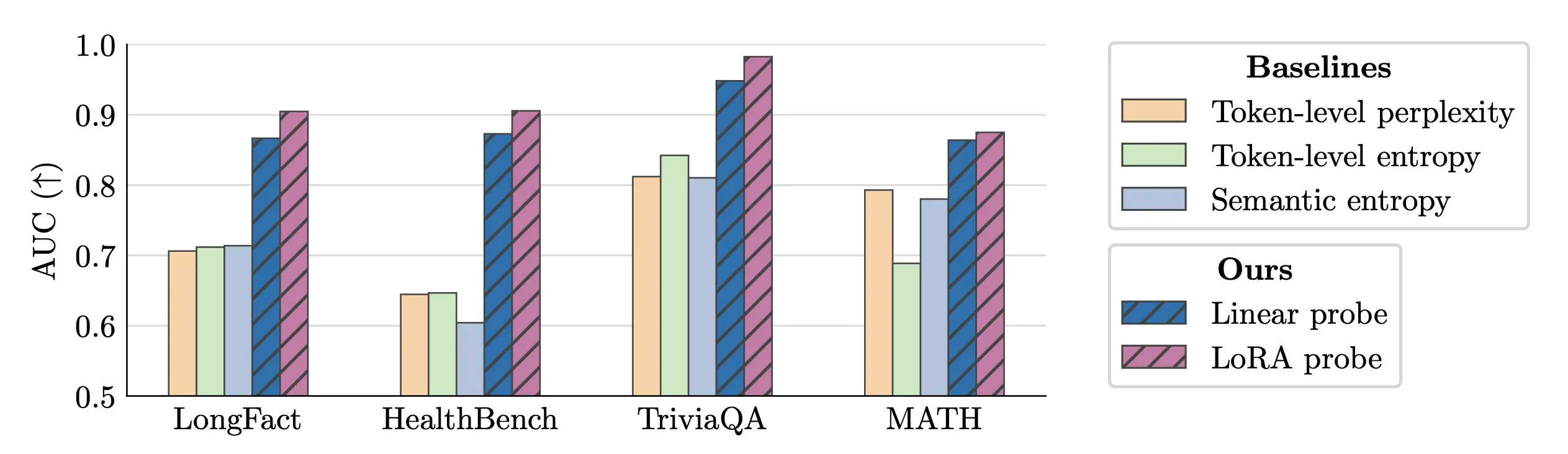
LLM幻觉实时检测技术 : 研究人员提出使用激活探针(activation probes)进行LLM幻觉的实时检测。该方法在长文本中识别伪造实体方面表现出色,AUC值高达0.90,显著优于传统的语义熵方法。此外,新的研究也深入探讨了Transformer模型中幻觉的起源,为提升LLM可靠性提供了新思路。(来源: paul_cal, tokenbender)
Microsoft VibeVoice:长时高保真语音生成 : 微软VibeVoice模型在AI音频领域取得显著进展,能够生成45-90分钟、多达4个说话者的逼真语音,且无需拼接。该模型在Hugging Face Space上提供体验,用户可利用其进行高质量语音克隆,为播客、有声读物等应用带来新可能。(来源: Reddit r/LocalLLaMA)
mmBERT:多语言编码器新标杆 : 新的mmBERT模型被推出,有望取代SOTA长达6年的XLM-R。mmBERT比现有模型快2-4倍,并在多语言编码任务中超越了o3和Gemini 2.5 Pro。该模型的发布,伴随着开放模型和训练数据,将为多语言AI应用提供更高效、更强大的基础。(来源: code_star)

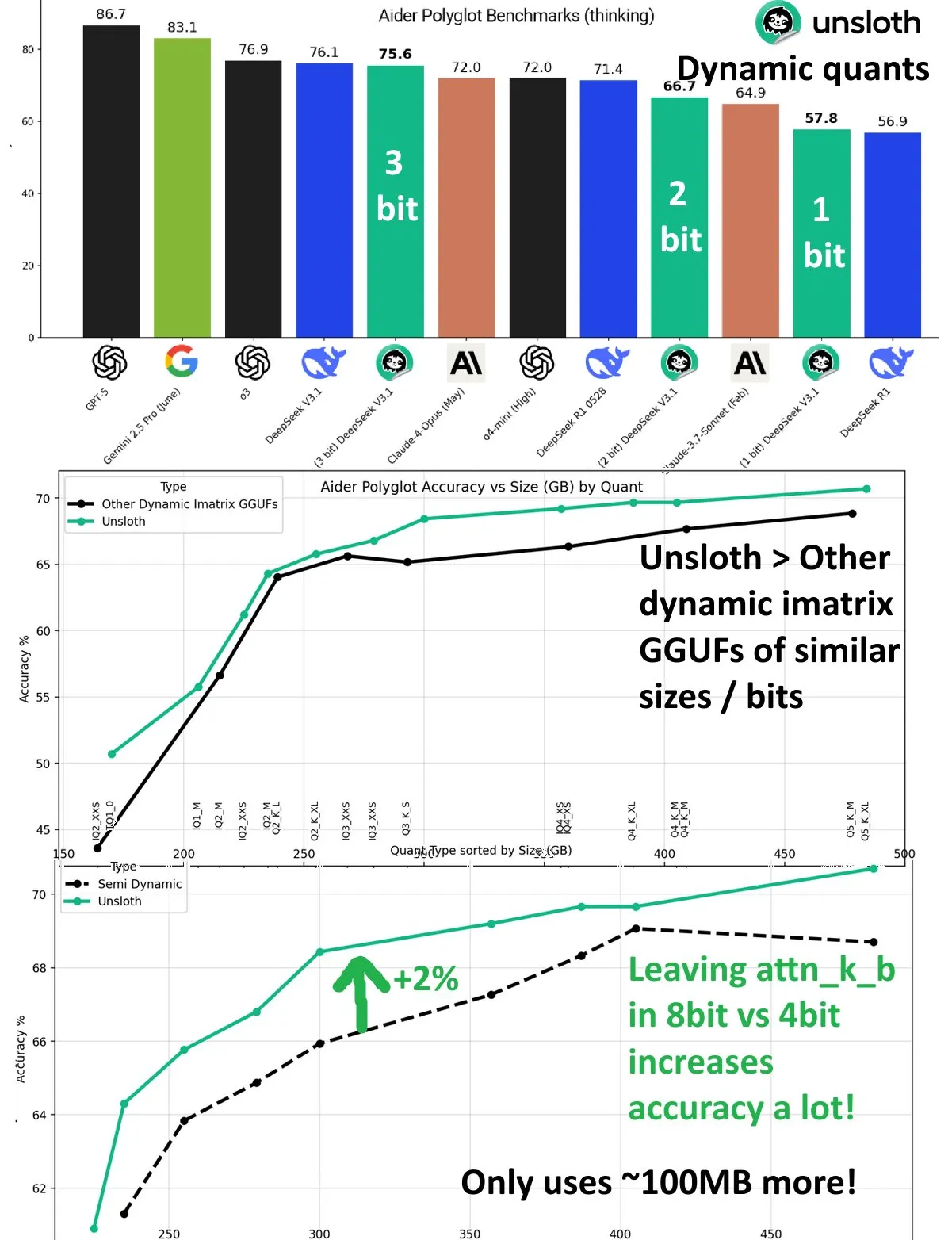
DeepSeek V3.1动态量化性能提升 : DeepSeek V3.1模型在UnslothAI的Aider Polyglot基准测试中,通过动态量化技术实现显著性能提升。3比特量化接近未量化模型的准确率,并且在推理模式下,1比特动态量化甚至超越了DeepSeek R1的原始性能。研究发现,将attn_k_b层保持8比特精度可额外提升2%准确率,展示了高效量化在保持模型能力和降低计算成本方面的潜力。(来源: danielhanchen)
用国产GPU训练的国产大模型SpikingBrain-1.0 : 中科院自动化研究所发布类脑脉冲大模型“瞬悉1.0”(SpikingBrain-1.0),在国产沐曦GPU集群上完成训练和推理,能耗比传统FP16运算降低97.7%。该模型仅用主流大模型2%的预训练数据,即实现Qwen2.5-7B 90%的性能,并在超长序列处理任务中表现出色,TTFT加速高达26.5倍,验证了国产自主可控非Transformer大模型生态的可行性。(来源:36氪)
文心X1.1发布:事实性、指令遵循与智能体能力显著提升 : 百度深度思考模型文心大模型X1.1升级上线,在事实性、指令遵循和智能体能力上分别提升34.8%、12.5%和9.6%。该模型整体效果超越DeepSeek R1-0528,比肩GPT-5、Gemini 2.5 Pro,并在复杂长程任务中展现出强大的智能体能力,可自动拆分任务、调用工具。百度还发布了ERNIE-4.5-21B-A3B-Thinking开源模型及ERNIEKit开发套件,进一步降低AI应用门槛。(来源:量子位)

华为开源OpenPangu-Embedded-7B-v1.1:快慢思考自由切换 : 华为发布OpenPangu-Embedded-7B-v1.1,一款7B参数的开源模型,首次实现快慢思考模式的自由切换,并可根据问题难度自适应选择。通过渐进式微调和两阶段训练策略,模型在通用、数学、代码等评测中精度大幅提升,且在保持精度的同时,平均思维链长度缩短近50%,填补了开源大模型在该能力上的空白,提升了效率与准确率。(来源:量子位)

腾讯CodeBuddy Code:AI编程迈入L4时代 : 腾讯发布AI CLI工具CodeBuddy Code,并开放CodeBuddy IDE公测,旨在推动AI编程进入L4级“AI软件工程师”时代。CodeBuddy Code基于npm安装,支持自然语言驱动开发运维全生命周期,实现极致自动化。该工具通过文档驱动管理、上下文压缩和MCP扩展,成为企业级AI编程的底层基础设施,显著提升开发效率。(来源:量子位)

OpenAI核心科学家:波兰双雄推动GPT-4及推理突破 : OpenAI首席科学家Jakub Pachocki和技术研究员Szymon Sidor因其在Dota项目、GPT-4预训练以及推动推理突破方面的关键贡献,受到奥特曼的高度赞扬。两人从高中同窗到OpenAI重聚,通过深度思考与动手实验相结合的模式,成为OpenAI不可或缺的力量,甚至在2023年内乱危机中坚定支持奥特曼回归。(来源: 量子位)

白宫AI峰会聚焦人才、安全与国家挑战 : 梅拉尼娅·特朗普在白宫主持AI会议,邀请谷歌、IBM和微软等科技巨头,重点关注AI领域的人才培养、安全保障和国家级挑战。此举表明美国政府正积极推动AI战略,旨在应对AI发展带来的机遇与挑战,确保国家在AI领域的领导地位。(来源: TheTuringPost, Reddit r/artificial)

Neuromorphic Computing:超越传统神经网络 : 神经形态计算正在重新定义智能,其灵感来源于生物大脑结构和工作原理。这项技术旨在开发更高效、低功耗的AI硬件,通过模拟神经元和突触的并行处理能力,实现超越传统冯·诺依曼架构的计算模式,为未来AI系统提供更强大的基础。(来源: Reddit r/artificial)
MEGS²:内存高效高斯泼溅技术 : MEGS²(Memory-Efficient Gaussian Splatting via Spherical Gaussians and Unified Pruning)是一种内存高效的3D高斯泼溅(3DGS)技术。通过用任意方向的球面高斯函数替代球面谐波表示颜色,并引入统一的软剪枝框架,该方法显著减少了每原始图元的参数数量,实现了8倍的静态VRAM压缩和近6倍的渲染VRAM压缩,同时保持或提升渲染质量,对3D图形和实时渲染具有重要意义。(来源: janusch_patas)

🧰 工具
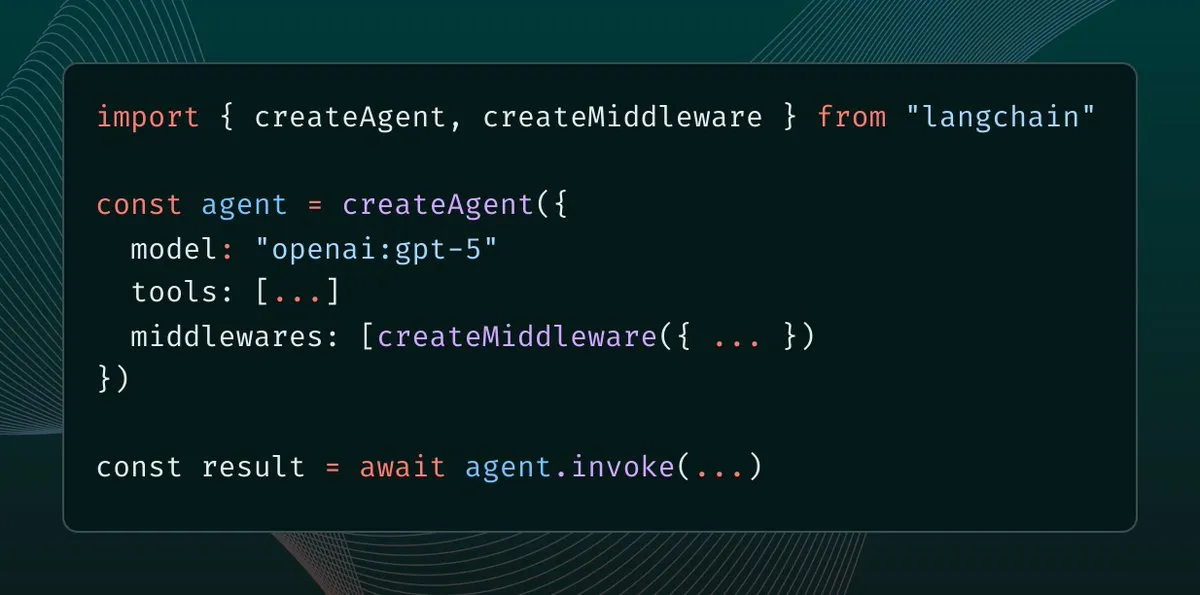
LangChain 1.0引入Middleware:智能体上下文控制新范式 : LangChain 1.0发布Middleware,为AI智能体提供新的抽象层,使开发者能够完全控制上下文工程。该功能增强了智能体的灵活性、可组合性和适应性,支持实现反射、群组、主管等不同智能体架构,为构建更复杂的AI应用提供了强大基础。(来源: hwchase17, hwchase17, Hacubu)
MaxKB:开源企业级智能体平台 : MaxKB是一个强大易用的开源企业级智能体平台,集成了RAG(检索增强生成)管道、强大的工作流引擎和MCP工具使用能力。它支持文档上传、自动爬取、文本切分和向量化,有效减少大模型幻觉,并支持多种私有及公共大模型,提供多模态输入输出,广泛应用于智能客服、企业知识库等场景。(来源: GitHub Trending)

BlenderMCP:Claude AI与Blender的深度集成 : BlenderMCP实现了Claude AI与Blender的深度集成,通过Model Context Protocol(MCP)允许Claude直接控制Blender进行3D建模、场景创建和操作。该工具支持双向通信、物体操作、材质控制、场景检查和代码执行,并能集成Poly Haven和Hyper3D Rodin资产,极大提升了AI辅助3D创作的效率和可能性。(来源: GitHub Trending)

AI Sheets:无代码AI数据集构建与转换工具 : Hugging Face发布AI Sheets,一款开源无代码工具,用于使用AI模型构建、丰富和转换数据集。该工具可本地部署或在Hub上运行,支持访问Hugging Face Hub上的数千个开源模型(包括gpt-oss),并通过Docker或pnpm快速启动,简化了数据处理流程,尤其适合生成大规模数据集。(来源: GitHub Trending)
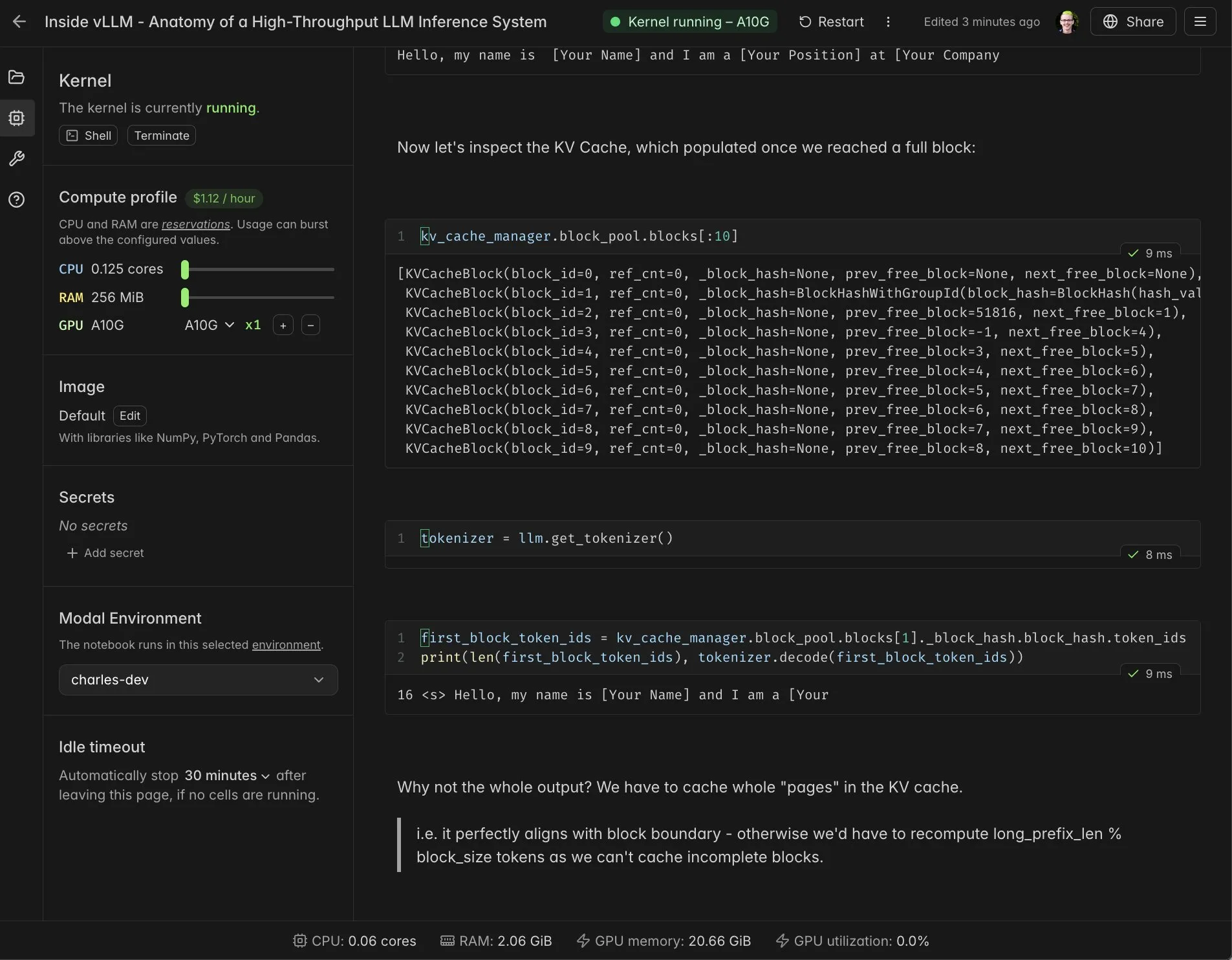
vLLM实时Notebook与Modal集成 : Modal Notebooks与vLLM集成,提供实时、可分享的交互式环境,帮助开发者深入理解vLLM的内部机制。通过该集成,用户无需构建复杂的集成,即可在云端轻松运行和共享CUDA兼容的计算任务,极大地简化了vLLM的开发和学习过程。(来源: charles_irl, vllm_project, charles_irl, charles_irl, charles_irl, charles_irl)
Docker支持Minions AI:本地混合AI工作负载 : Minions AI现已正式支持Docker,允许用户通过Docker模型运行器在本地解锁混合AI工作负载。这项合作使得开发者能够更便捷地在本地环境中部署和管理Minions AI,结合Docker的容器化优势,提升了AI应用开发的灵活性和效率。(来源: shishirpatil_)
Replit Agent 3:自主软件开发新突破 : Replit发布Agent 3,号称是软件开发的“全自动驾驶”时刻,比以往智能体自主性提高10倍。该Agent能更深入地原型化应用,并在其他Agent受阻时持续推进,旨在解决软件开发中耗时的测试、调试和重构环节,大幅提升开发效率。(来源: amasad, amasad, pirroh)
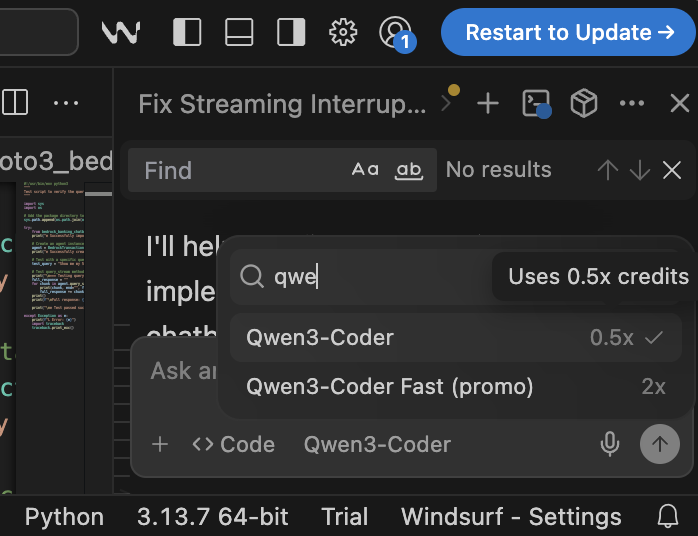
Qwen3-Coder:高性价比开源编程模型 : Qwen3-Coder在Windsurf平台上展现出卓越的性能和成本效益,仅需0.5积分即可运行,相比Claude 4和GPT-5 High(2倍积分)更具优势。该模型在编程任务中表现出色,且作为开源模型,为受监管企业和公共部门组织提供了无需依赖公共API的强大AI编程选项,有助于解决数据主权和可见性问题。(来源: bookwormengr)
📚 学习
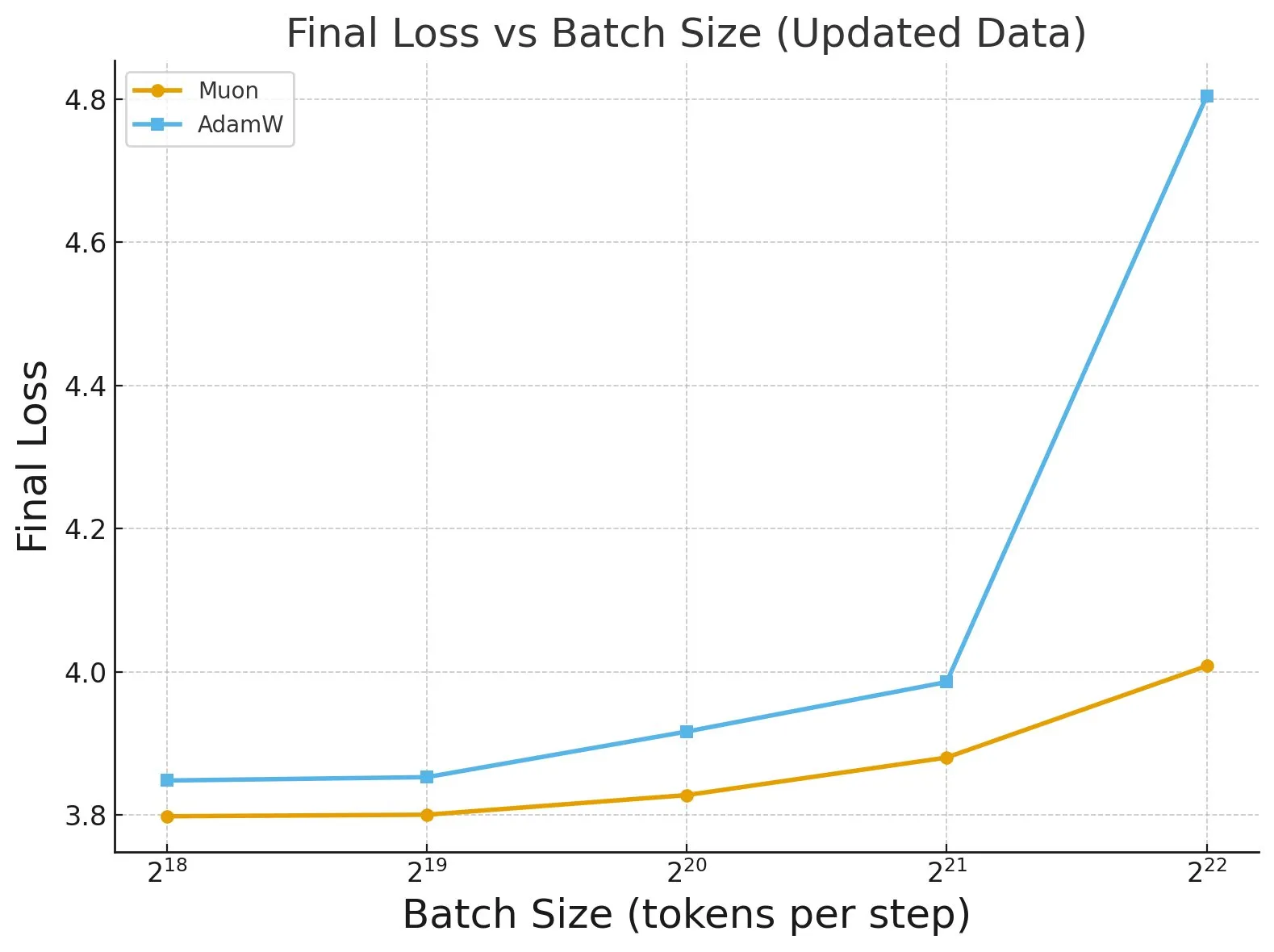
《Fantastic Pretraining Optimizers and Where to Find Them》研究 : 一项对4000多个模型进行的广泛研究揭示了预训练优化器的性能。研究发现,某些优化器(如Muon)在小规模模型(<0.5B参数)上可实现高达40%的速度提升,但在大规模模型(1.2B参数)上仅有10%的提升。这强调了在评估优化器时,需警惕基线调优不足和规模限制,并指出批处理大小对优化器性能差距的影响。(来源: tokenbender, code_star)
Visual-TableQA:复杂表格推理基准 : Hugging Face发布Visual-TableQA,一个包含2.5K表格和6K QA对的复杂表格推理基准。该基准专注于视觉结构上的多步推理,并经过92%的人工验证,生成成本低于100美元。它为评估和提升模型在理解和推理复杂表格数据方面的能力提供了高质量的资源。(来源: huggingface)
AI Agents vs Agentic AI概念解析 : 社区对AI Agents和Agentic AI系统存在普遍混淆。AI Agents指执行特定任务的单一自主软件(LLM+工具),行为反应式,记忆有限;Agentic AI指多智能体协作系统(多LLM+编排+共享记忆),行为主动式,记忆持久。理解二者区别对架构决策至关重要,避免构建不必要的复杂系统。(来源: Reddit r/deeplearning)

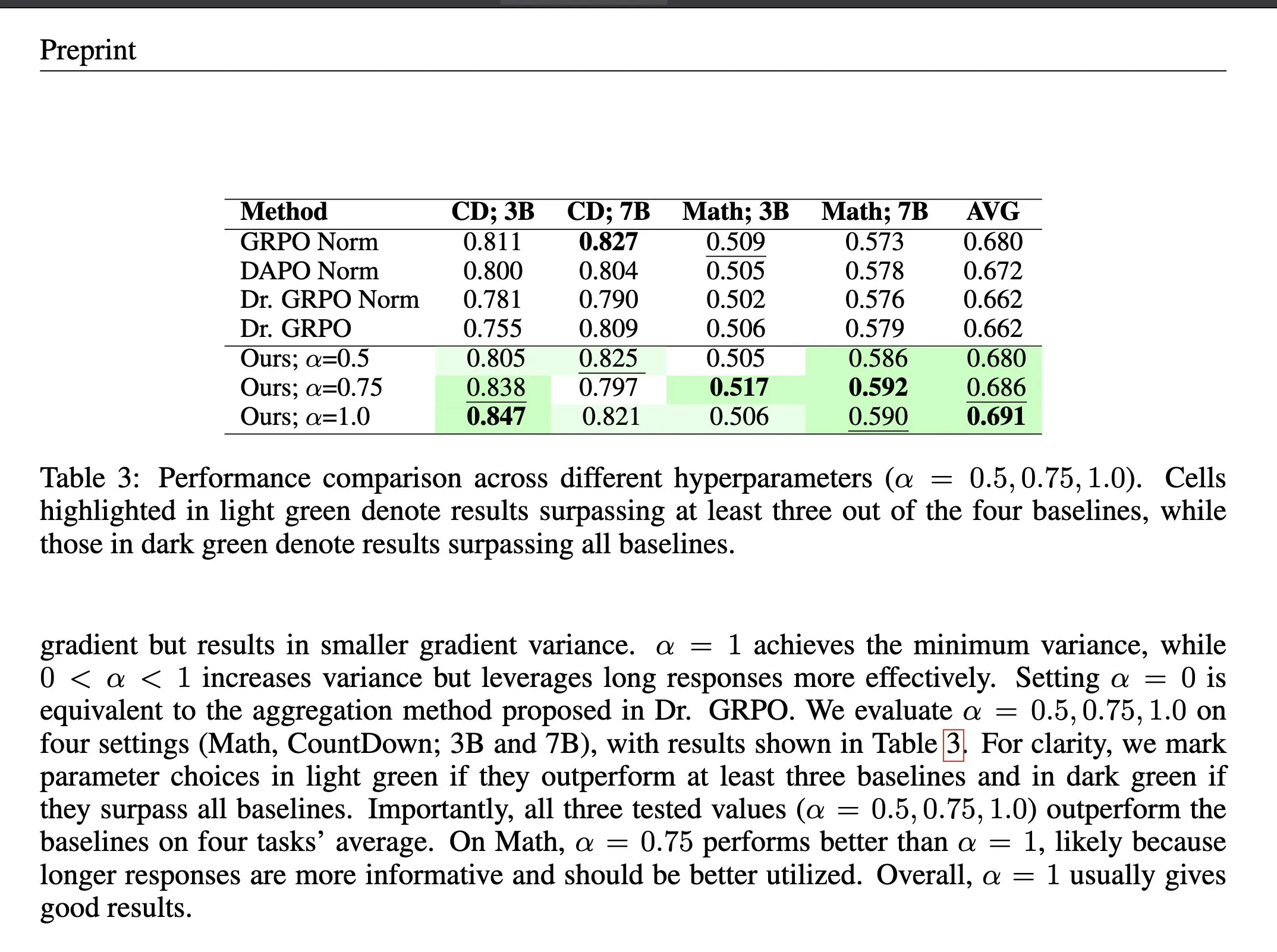
强化学习中的损失聚合方法ΔL Normalization : ΔL Normalization是一种针对可验证奖励强化学习(RLVR)中动态生成长度特性而设计的损失聚合方法。该方法通过分析不同长度对策略损失的影响,重新构建问题以找到最小方差无偏估计器,在理论上最小化梯度方差。实验证明,ΔL Normalization在不同模型规模、最大长度和任务上均能持续取得优异结果,解决了RLVR中梯度方差高和优化不稳定的挑战。(来源: HuggingFace Daily Papers, teortaxesTex)
LLM架构对比视频讲座 : Rasbt发布了2025年11种LLM架构的对比分析视频讲座,涵盖DeepSeek V3/R1、OLMo 2、Gemma 3、Mistral Small 3.1、Llama 4、Qwen3、SmolLM3、Kimi 2、GPT-OSS、Grok 2.5和GLM-4.5。该讲座为开发者和研究人员提供了全面的LLM架构概览,有助于理解不同模型的设计理念和性能特点。(来源: rasbt)
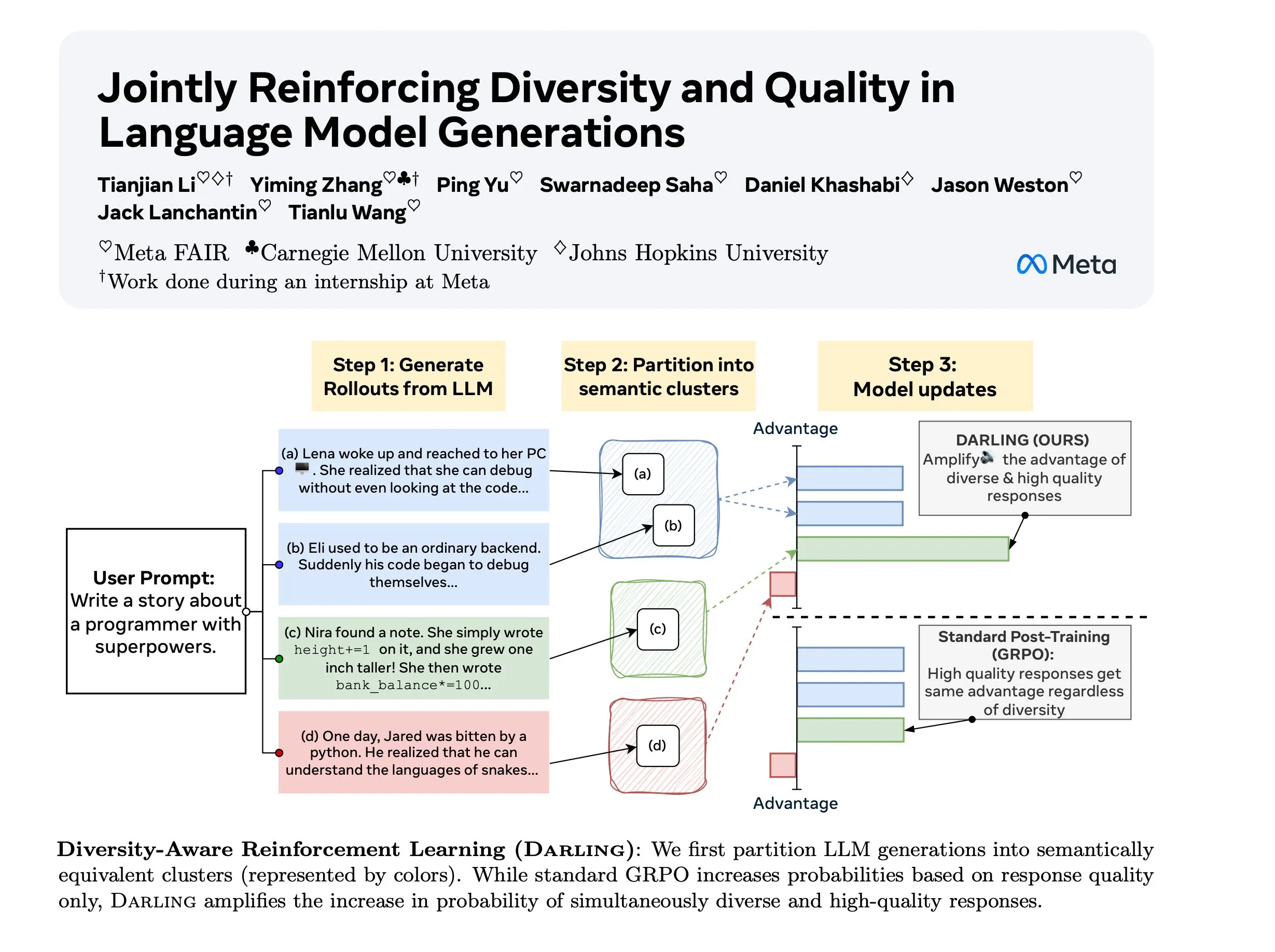
Diversity Aware RL (DARLING)研究 : DARLING(Diversity Aware RL)是一种新的强化学习方法,通过学习分区函数同时优化质量和多样性。该方法在质量和多样性指标上均优于标准RL,例如更高的pass@1/p@k,并适用于非可验证和可验证任务,为提升RL在复杂环境中的泛化能力提供了新途径。(来源: ylecun)
斯坦福CS 224N:深度学习与NLP课程 : 斯坦福大学CS 224N课程提供深度学习和自然语言处理的全面教学。该课程通过YouTube视频公开,为全球学习者提供了高质量的AI学习资源,涵盖NLP基础理论、最新模型和实践应用,是进入AI领域的重要入门课程。(来源: stanfordnlp)
💼 商业
Anthropic新隐私政策引发争议:对独立开发者的系统性劣势 : Anthropic新隐私政策要求用户在9月28日前选择是否允许其使用对话数据进行AI训练并保留5年,否则将失去记忆和个性化功能。此举被批制造“两级系统”,使独立开发者面临隐私与功能取舍,其专有代码可能成为企业AI训练数据,而企业客户则可享受隐私保护与个性化兼得的昂贵方案,引发对AI民主化和创新提取的担忧。(来源: Reddit r/ClaudeAI)
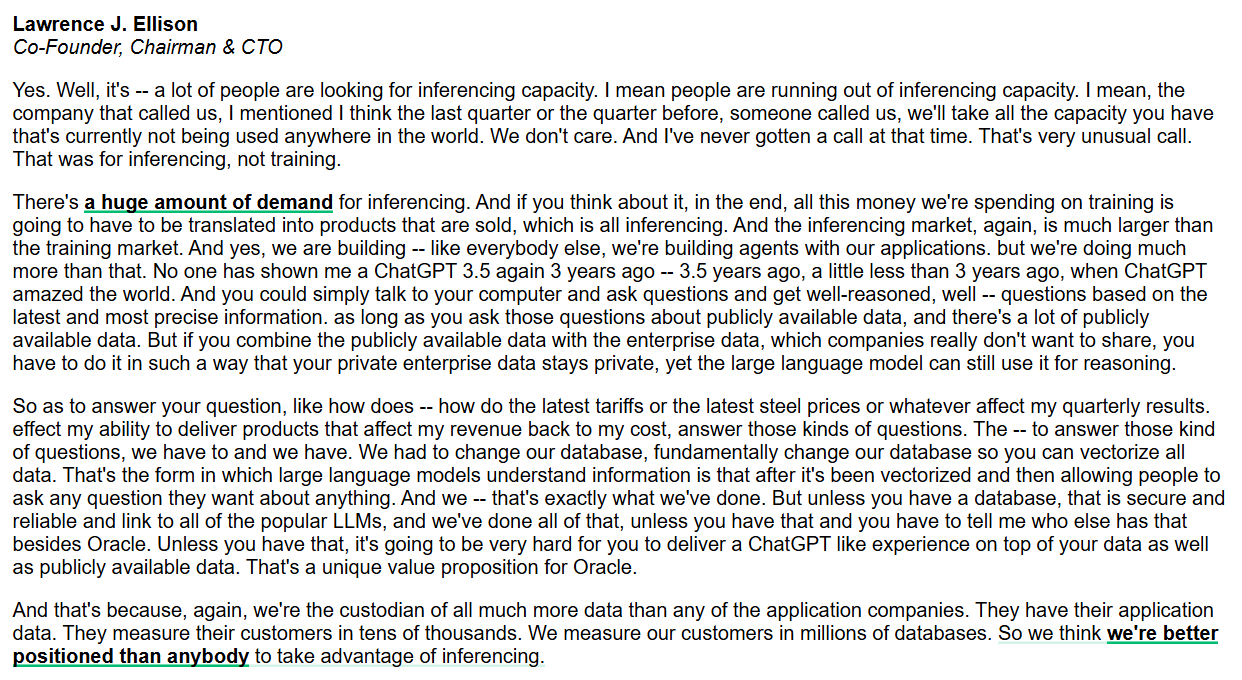
Oracle聚焦推理能力与企业级AI数据库 : 甲骨文CEO拉里·埃里森强调,推理能力市场远大于训练市场,且需求巨大。Oracle通过根本性改变数据库以向量化所有数据,并确保其安全可靠,旨在提供结合公共和企业私有数据的ChatGPT式体验。Oracle认为其作为数据托管者,在提供企业级AI推理服务方面具有独特优势。(来源: JonathanRoss321)
AI内容许可新标准RSL Standard:推动AI公司付费 : Reddit、Yahoo、Quora和wikiHow等主要品牌支持Really Simple Licensing (RSL) Standard,一个开放内容许可标准,旨在让网络出版商设定AI系统开发者使用其作品的条款。RSL基于robots.txt协议,允许网站添加许可和版税条款,要求AI爬虫为训练数据付费(订阅或按爬取/推理次数付费),以确保内容创作者获得合理补偿。(来源: Reddit r/artificial)
🌟 社区
AI与人类智能的共存与增强 : 社区讨论AI是作为“认知矫正器”辅助人类智能(如算盘),还是作为“竞争者”取代人类(如计算器)。François Chollet提出“思维自行车”的比喻,强调技术应放大人类努力而非让人无所事事,引发了对AI与人类智能(IA)之间关系及未来发展方向的哲学思辨。(来源: rao2z)
AI行业PR困境与公众负面情绪 : 尽管AI产品拥有数十亿用户且许多人从中受益,但AI行业普遍面临负面公众情绪。有观点认为,这是由于行业领导者在对外宣传中未能有效沟通,导致公众对AI公司产生偏见。也有人猜测这可能是AI行业有意为之,旨在将核心技术和优势集中在少数玩家手中。(来源: Dorialexander)
LLM多智能体系统中的弱点影响 : 研究指出,在多智能体系统中,使用小型语言模型并不总是理想选择。在多智能体辩论等场景中,较弱的LLM智能体常会干扰甚至破坏较强智能体的性能,导致整体系统表现下降。这揭示了在设计和部署多智能体系统时,需谨慎考虑各智能体能力差异及其潜在的负面交互影响。(来源: omarsar0)

合成数据对AGI的局限性 : Andrew Trask和Fei-Fei Li指出,合成数据对LLM实现AGI而言是一种弱策略。合成数据无法创造新信息(如模型未曾听过的实体),只能揭示现有信息的自然推断。尽管合成数据能通过逻辑置换和组合已知事实来解决“反转诅咒”等问题,但其信息瓶颈限制了其作为AGI“银弹”的潜力,真正的突破可能在于全球智能和上下文的即时检索。(来源: algo_diver, jpt401)
AI与人类就业市场:AI写简历与AI筛简历的死循环 : AI在就业市场引发“无人录用”死循环:求职者用AI写简历,HR用AI筛简历,导致效率“提高”却无人被录用。简历被AI拒绝理由五花八门,甚至HR也吐槽AI生成简历千篇一律。这凸显了AI在招聘中带来的新挑战,可能导致招聘流程僵化,无法识别真正人才。(来源: 量子位)

AI伦理学家面临的挑战 : 随着AI技术快速发展,AI伦理学家们正面临“对着虚空呐喊”的困境。资本主义驱动下的AI竞赛,使得伦理考量被边缘化,技术进步速度远超伦理整合。专家担忧,若等到危害大规模显现时再采取行动,可能为时已晚,呼吁行业将伦理保障纳入核心考量。(来源: Reddit r/ArtificialInteligence)

互联网的未来:机器人流量超越人类 : 有趋势表明,未来三年内互联网上的机器人驱动互动将远超人类互动,使互联网“死气沉沉”。已有研究指出,机器人流量已超过50%。这引发了对如何区分真实人类声音与AI生成内容、以及互联网信息真实性的担忧,预示着网络生态将发生根本性转变。(来源: Reddit r/artificial)

Claude Code性能下降与用户流失 : Anthropic的Claude Code用户报告近期模型性能显著下降,表现为代码质量变差、生成冗余代码、测试质量低、过度工程化及理解能力减弱。许多用户考虑转向GPT-5、GLM-4.5、Qwen3等替代方案,并呼吁Anthropic提高透明度,解释模型退步原因及修复措施,否则将面临用户流失。(来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)
💡 其他
AI与VR在犯罪矫正中的潜力 : 有观点提出,利用廉价AI和VR技术,可以为刑事精神病患者提供强制性VR舱,以低于传统食宿成本的方式将其从社会中隔离。这一激进设想引发了对AI在社会控制、惩戒系统以及伦理边界的讨论,尽管其可行性和人道性存在争议,但揭示了技术在解决社会问题上的潜在应用方向。(来源: gfodor, gfodor)
Replit在监狱中的应用设想 : 有用户提出将Replit(一个在线编程平台)引入监狱的设想,认为这可以取代娱乐设施,让囚犯通过编程创造有价值的产品。这一想法探讨了技术在改造社会、提供技能培训和促进囚犯再融入社会方面的潜在作用,引发了对教育公平和技术赋能的讨论。(来源: amasad)