
关键词:超级计算机, AI幻觉, 版权侵权, 大语言模型, AI芯片, JUPITER超级计算机, OpenAI AI幻觉论文, Anthropic版权和解案, Qwen3-Max-Preview模型, OpenAI自研AI芯片
🔥 聚焦
欧洲首个百亿亿次超级计算机JUPITER上线 : 欧洲首个百亿亿次超级计算机JUPITER已上线,由NVIDIA Grace Hopper提供动力。该系统是全球能效最高的超级计算机,将AI与HPC融合,旨在气候科学、神经科学和量子模拟等领域取得突破。这标志着欧洲在高性能计算和AI研究方面迈出重要一步,有望加速前沿科学发现。 (来源: nvidia)

OpenAI发布论文揭示AI幻觉根源 : OpenAI发布《语言模型为何会产生幻觉》论文,指出AI幻觉的根本原因在于当前训练和评估机制奖励模型猜测而非承认不确定性。模型在预训练阶段因缺乏“真/假”标签,难以区分有效与无效信息,尤其在处理低频事实时易编造。OpenAI呼吁更新评估指标,惩罚自信错误,奖励表达不确定性,以促使模型更“诚实”。 (来源: source, source, source, source, source)

Anthropic就AI版权侵权案达成15亿美元和解 : Anthropic与图书作者就AI版权侵权案达成和解,同意支付至少15亿美元。该和解协议涉及约50万部受版权保护作品,平均每部作品约3000美元(扣除律师费前),并承诺销毁盗版数据集。此案是美国首个AI与版权相关的集体诉讼和解,可能为生成式AI与知识产权的法律界定树立先例。 (来源: source, source, source, source, source, source, source)

🎯 动向
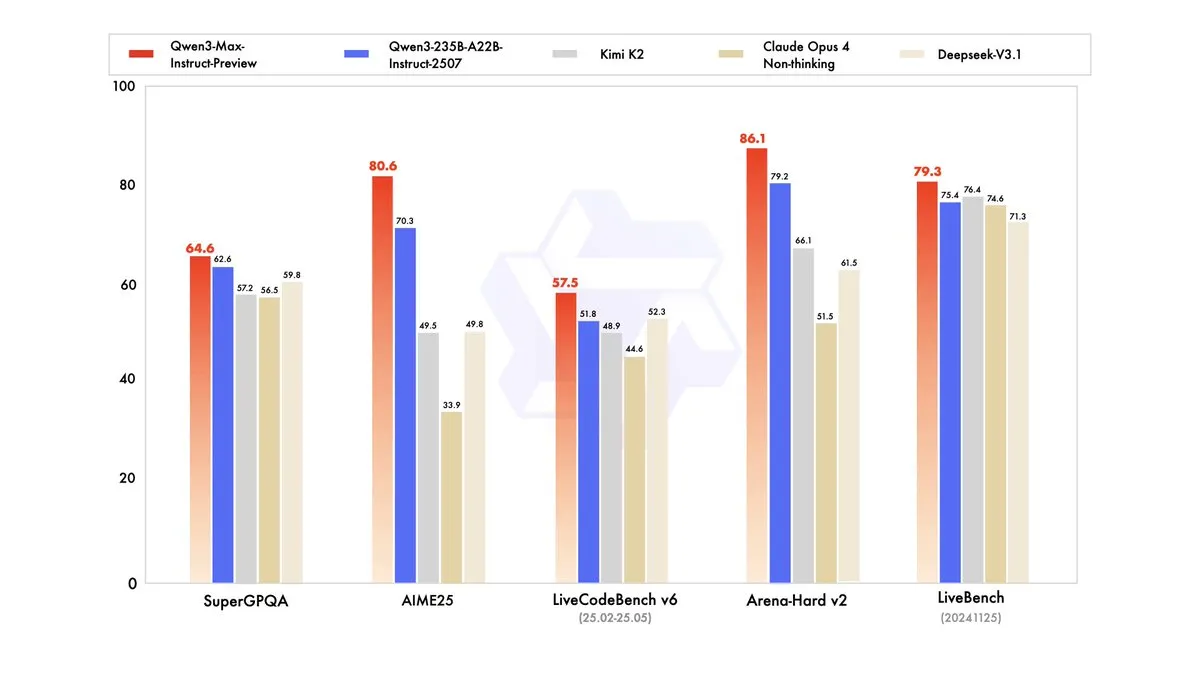
Qwen3-Max-Preview发布,参数超万亿 : 阿里云通义千问(Qwen)发布了其迄今为止最大的模型Qwen3-Max-Preview (Instruct),参数量超过1万亿。该模型已通过Qwen Chat和阿里云API提供,并在基准测试中超越了此前的Qwen3-235B-A22B-2507。内部测试和早期用户反馈显示,其在性能、知识广度、对话能力、Agent任务和指令遵循方面均有显著提升。该模型也已上线OpenRouter,引发社区对其是否会开源的讨论。 (来源: source, source, source, source, source, source, source, source)
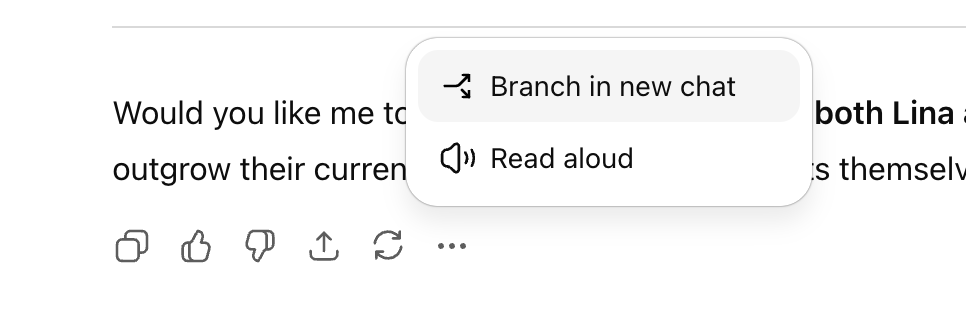
ChatGPT新增分支对话功能,提升多线探索能力 : OpenAI为ChatGPT网页端推出“分支对话”新功能,用户可在任一回复处创建新分支,进行多线探索,无需另开对话或担心上下文过长。该功能结合记忆功能,使对话更具连续性和灵活性,将对话从线性转变为树状结构,有助于用户保留不同思路,提升AI助理的协作效率。 (来源: source, source, source)
OpenAI计划推出AI招聘平台并自研AI芯片 : OpenAI计划在2026年中期推出AI驱动的招聘平台,与LinkedIn竞争,并提供“AI流畅度”认证。此外,为减少对Nvidia的依赖,OpenAI将于明年开始生产自主设计的AI芯片。这些举措显示了OpenAI在拓展AI应用生态和优化硬件基础设施方面的雄心。 (来源: source, source, source, source, source)

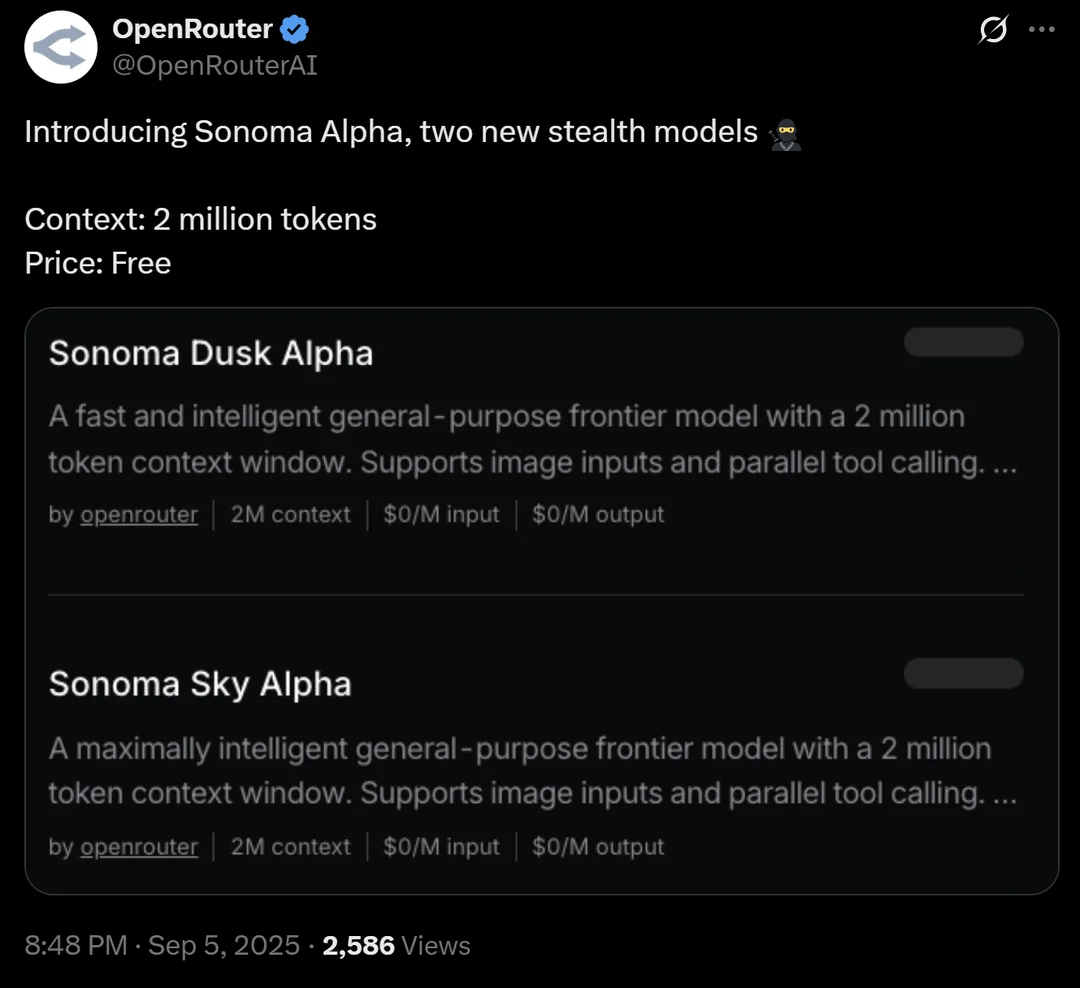
OpenRouter推出200万上下文窗口的隐形模型Sonoma Alpha : OpenRouter平台推出了名为Sonoma Alpha的“隐形”模型,其最大亮点是支持200万上下文窗口,并提供免费使用。社区普遍推测该模型是xAI的Grok系列模型,因其“最大限度地寻求真相”的特性与Elon Musk的理念相符。该模型在代码生成、逻辑和科学任务方面表现出色,预示着超长上下文模型在实际应用中的潜力。 (来源: source, source, source)
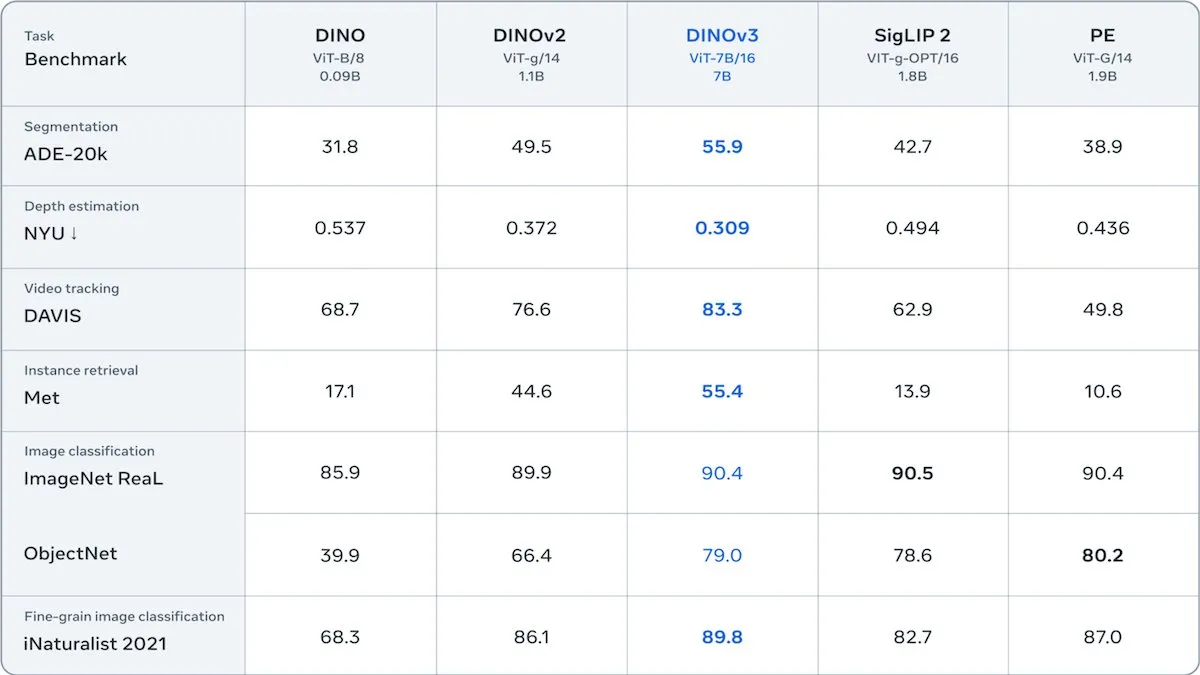
Meta发布DINOv3自监督视觉Transformer : Meta发布DINOv3,一个67亿参数的自监督视觉Transformer模型,在图像分割和深度估计等任务中显著提升图像嵌入质量。该模型在17亿张Instagram图片上训练,引入新的损失项以保持补丁级多样性,克服了无标签数据的局限性。DINOv3在允许商业使用但禁止军事应用的许可下发布,为下游视觉应用提供了强大的自监督骨干网络。 (来源: DeepLearningAI)
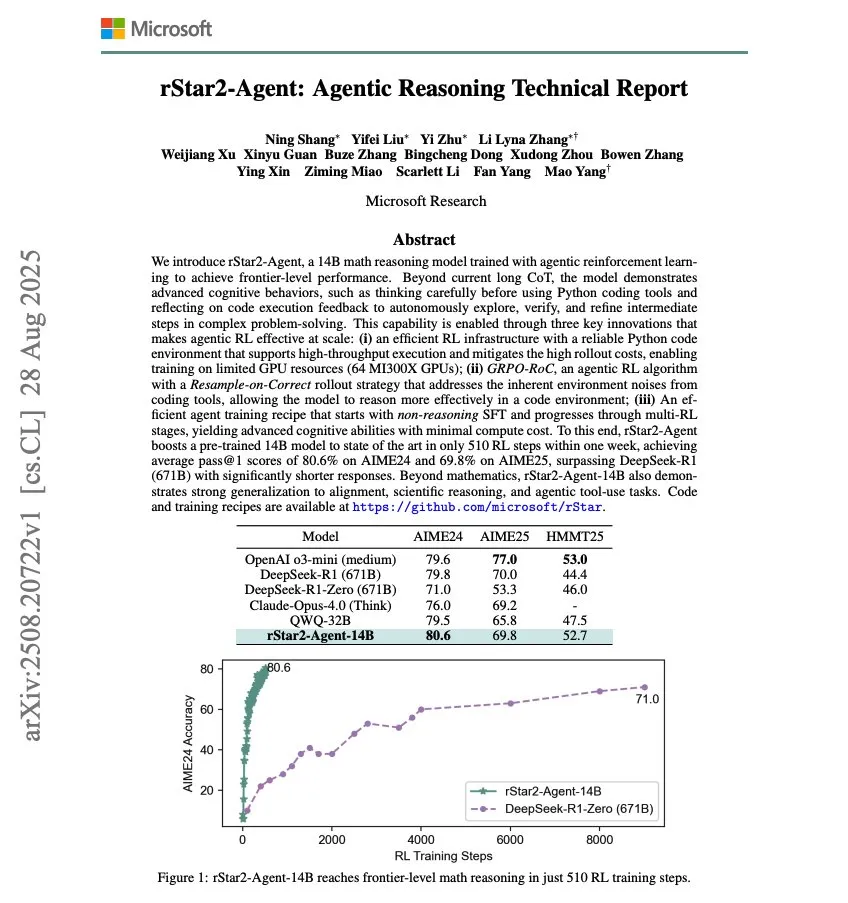
Microsoft发布rStar2-Agent,14B数学推理模型 : 微软发布rStar2-Agent,一个14B的数学推理模型,通过Agentic RL训练,仅用510个RL训练步骤就达到了前沿水平的数学推理能力。这项研究展示了通过强化学习在特定领域快速提升AI模型性能的潜力。 (来源: dair_ai)
OpenAI成立oai Labs探索人机协作新界面 : OpenAI宣布成立oai Labs,由Joanne Jang领导,专注于研究和原型化人机协作的新界面。该团队旨在超越现有聊天和代理模式,探索新的范式和工具,以改进人们与AI互动、思考、创造、学习和连接的方式。 (来源: source, source)
IFA 2025展会:AI硬件与机器人趋势 : 2025年德国柏林国际消费电子展(IFA)上,中国厂商全面主导AI眼镜市场,Rokid、雷鸟创新等品牌展示了多款产品,并积极探索海外生态。机器人领域,宇树科技展示人形机器人G1和机器狗Go 2,吸引大量关注;美的、优必选等也展出家用服务机器人。智能清洁机器人、割草机器人、泳池机器人等功能型机器人百花齐放,技术升级,更贴近日常生活场景。AI已深度融入家电、手机、PC等消费电子产品,强调务实落地和“无感”体验。 (来源: 36氪)

OpenBMB发布MiniCPM 4.1-8B,首个开源可训练稀疏注意力LLM : OpenBMB发布了MiniCPM 4.1-8B模型,这是首个采用可训练稀疏注意力的开源推理LLM。该模型在15项任务上超越同尺寸模型,推理速度提升3倍,并采用高效架构。这标志着开源模型在推理能力和效率方面取得重要进展,为研究人员提供了强大的新工具。 (来源: teortaxesTex)

🧰 工具
Open Instruct:高性能RL研究代码库 : AllenAI维护的Open Instruct是一个高性能的强化学习(RL)研究代码库,旨在提供易于修改且性能卓越的RL实现。该项目由Finbarr等人领导,不断进行改进,为研究人员提供了进行RL实验和开发的基础平台。 (来源: source, source)
Grok:PDF阅读理解与摘要 : xAI的Grok推出PDF阅读器功能,用户可以高亮任何部分并点击“解释”来理解内容,或点击“引用”提出具体问题。这极大地提升了用户处理长篇PDF文档的效率和理解深度。 (来源: source, source)
Devin AI:EightSleep的数据分析师 : Cognition公司的Devin AI被EightSleep团队用作数据分析师,处理从“数字异常”到临时数据查询的各种任务,使分析/仪表板的完成时间从几天缩短到几小时,显著提升了数据洞察效率。这展示了AI代理在企业数据分析领域的强大应用潜力。 (来源: cognition)
Claude Code子代理功能详解 : Claude Code通过其Task工具,允许用户创建通用型、状态行设置和输出样式设置三种专业子代理。这些子代理具有各自的工具集,可处理复杂任务、配置设置或创建输出样式。子代理是无状态的,执行一次后返回结果,适用于委派复杂搜索、分析或专业配置,以保持主对话的焦点。 (来源: Vtrivedy10)
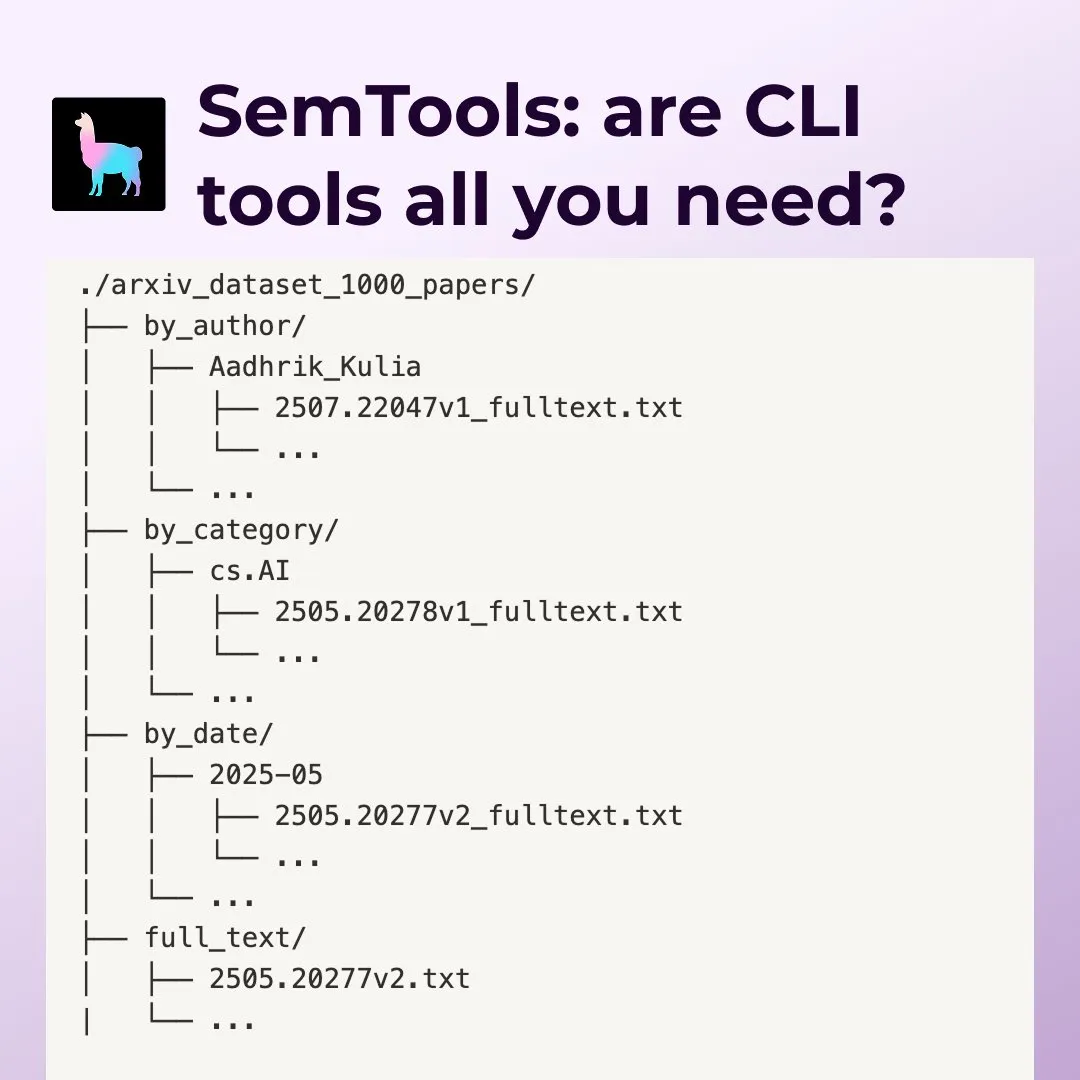
LlamaIndex SemTools:命令行Agent的文档搜索与分析工具 : LlamaIndex发布SemTools,一个CLI工具包,用于解析和语义搜索。结合Unix工具和语义搜索能力,Agent可以高效处理复杂文档,提供更详细、准确的答案,涵盖搜索、交叉引用和时间分析等任务。这表明利用现有Unix工具与语义搜索结合,能创建功能强大的知识工作者。 (来源: source, source)
Replit Agent:从Prompt到生产应用的AI编码助手 : Replit Agent庆祝其一周年,该工具从最初的AI代码补全和聊天编辑,发展到能够将提示词直接转化为生产级应用。Replit强调其自动化开发环境设置、包安装、数据库配置和部署的能力,旨在彻底改变软件开发流程。 (来源: source, source)

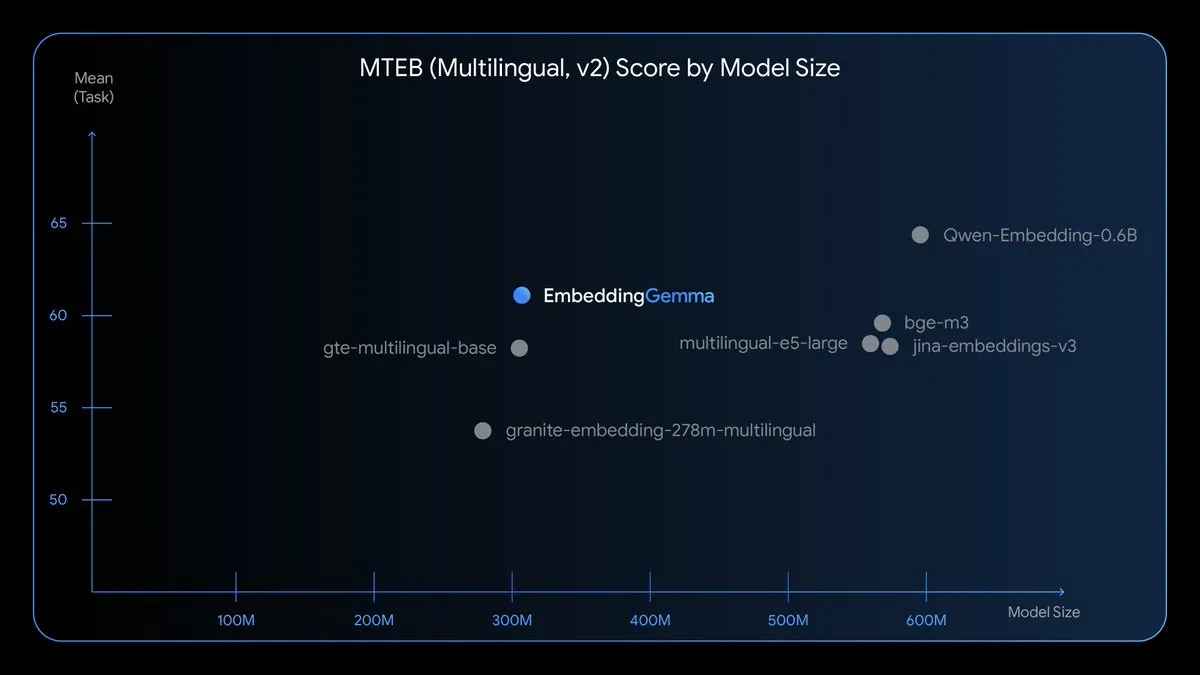
EmbeddingGemma:设备端多语言嵌入模型 : EmbeddingGemma是一款新的开源多语言嵌入模型,参数量308M,基于Gemma 3训练,支持100多种语言。该模型优化了速度、隐私和效率,可在离线状态下运行,内存占用小于200MB,推理时间小于15ms,使设备端RAG、语义搜索和分类成为可能。 (来源: TheTuringPost)
Nano Banana Hackathon:生成式AI挑战赛 : Kaggle将举办Nano Banana Hackathon,提供40万美元奖金,并开放Gemini API免费使用Gemini 2.5 Flash Image。参赛者将在48小时内利用生成式AI技术进行创作,比赛将评估创新性、技术执行、影响力和展示效果。 (来源: source, source, source)

📚 学习
如何从零构建AI Agent : Python_Dv分享了从零开始构建AI Agent的教程和指南,涵盖LLM、生成式AI和机器学习等关键技术。该资源为开发者提供了实践AI Agent开发的入门路径。 (来源: Ronald_vanLoon)

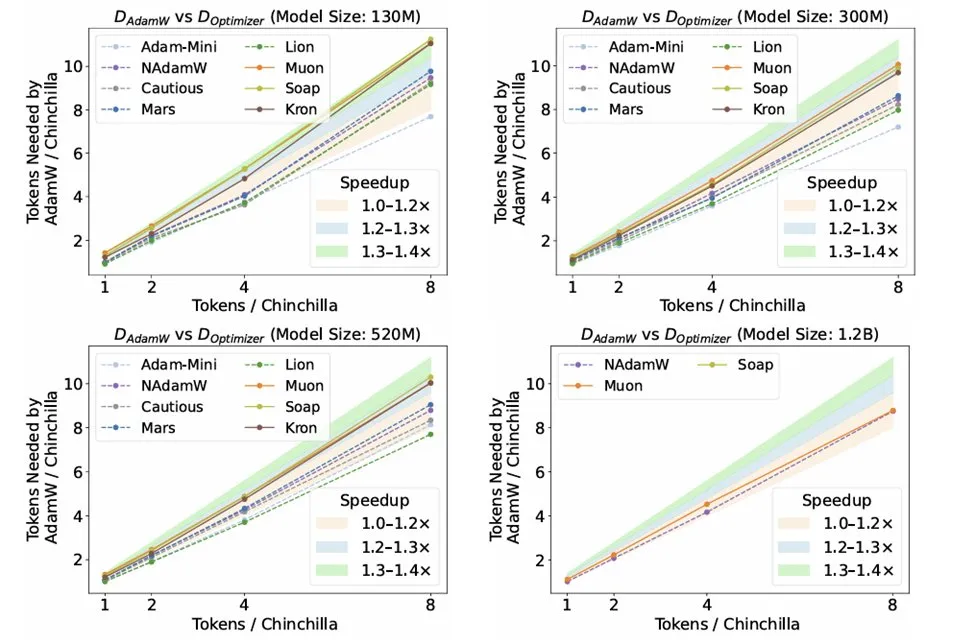
LLM推理中的优化器研究 : Kaiyue Wen等人的研究论文“Fantastic Pretraining Optimizers and Where to Find Them”对10种优化器进行了严谨的基准测试。研究发现,尽管Muon、Mars等优化器备受关注,但在严格调整超参数并扩大规模后,其相对于AdamW的加速效果仅为10%左右。这强调了在评估新优化器时需警惕基线调优不足或规模受限的问题。 (来源: source, source, source)
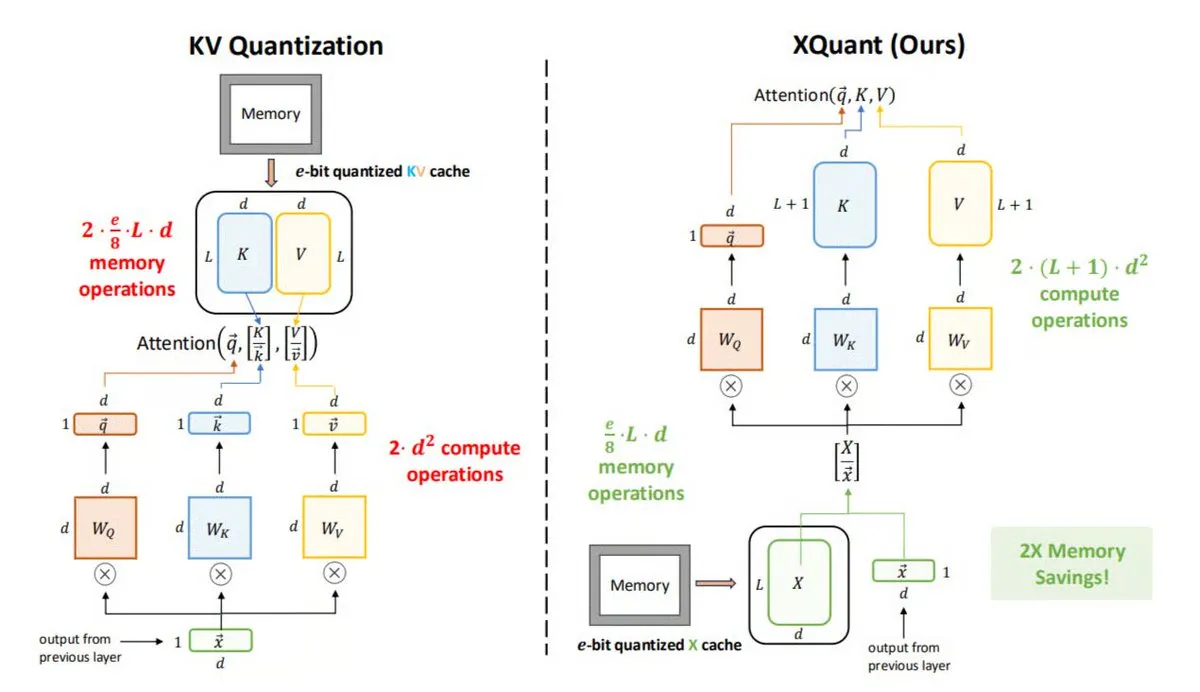
LLM推理中的内存优化技术XQuant : UC Berkeley提出XQuant,一种新的LLM内存优化方法,可将内存使用量减少多达12倍。XQuant不存储传统的KV缓存,而是量化并存储层输入激活(X),在推理时按需从X重新生成Key和Value。这项技术通过增加少量计算量,实现了更快、更高效的推理,同时不牺牲准确性。 (来源: TheTuringPost)
LLM提示词设计:Mom Test方法论 : Tz分享了将《Mom Test》用户调研思路应用于LLM提示词设计的方法论,强调避免询问模型会给出“好听废话”的问题,而是要构造Prompt,让模型给出可验证、基于事实或明确约束的回应。核心在于避免意见、未来假设、模糊,并要求具体、行为驱动和验证而非赞美。 (来源: dotey)

AI压缩技术比传统方法提升300倍 : YouTube频道Two Minute Papers指出,AI压缩技术比传统压缩方法效率高300倍,但目前尚未广泛应用。视频可能探讨了NVIDIA的WaveBlender等物理引擎技术,展示了AI在数据压缩领域的巨大潜力,以及其在音频模拟等方面的应用。
NeurIPS 2025多模态超智能挑战赛 : Lambda Research邀请研究人员、工程师和AI爱好者参与NeurIPS 2025多模态超智能大挑战赛,旨在推动开源多模态机器学习的发展。参赛团队将有机会获得高达20,000美元的计算积分,共同构建未来开源多模态AI。 (来源: Reddit r/deeplearning)

扩散模型全面注释指南 : Reddit社区分享了一份关于“什么是扩散模型?”的全面注释指南。该指南为学习者提供了深入理解扩散模型原理和应用的资源,有助于掌握这一前沿生成式AI技术。 (来源: Reddit r/deeplearning)
LoRA/QLoRA在视觉LLM多GPU训练中的应用 : 社区讨论了LoRA/QLoRA在多GPU环境下训练大型视觉LLM(如Llama 3.2 90B Visual Instruct)的挑战与实践。由于模型规模庞大,无法单GPU运行,开发者正在寻找支持多GPU训练的框架/包。LoRA/QLoRA因其高效微调的特性,被寄予厚望,但其在特定场景下的适用性仍需深入探讨。 (来源: source, source)
💼 商业
OpenAI收购Y Combinator支持的Alex团队 : OpenAI收购了Y Combinator支持的初创公司Alex团队,该团队将加入OpenAI的Codex团队,致力于AI编码助手。Alex创始人Daniel Edrisian表示,他们成功构建了iOS和macOS应用的顶级编码代理,此次收购将使其工作在更大规模上得以延续。 (来源: The Verge)
Baseten完成1.5亿美元D轮融资,聚焦AI推理未来 : Baseten完成1.5亿美元D轮融资,其CEO Tuhin One指出,随着token价格下降,推理成本将持续降低,预示着AI推理市场将迎来更大规模的增长。Baseten致力于构建无处不在的AI推理基础设施,以支持AI在各行各业的广泛应用。 (来源: basetenco)
RecallAI完成3800万美元B轮融资,加速AI会议记录服务 : RecallAI宣布完成3800万美元B轮融资,由BessemerVP领投,HubSpot Ventures和SalesforceVC跟投。RecallAI提供会议录制API服务,已服务超过2000家公司,此次融资将加速其在AI会议记录领域的扩张,进一步巩固其市场地位。 (来源: blader)
🌟 社区
AI评估(Evals)的价值与争议 : 社区围绕AI评估(Evals)的必要性和方法展开激烈讨论,探讨其在企业级应用中的作用、与A/B测试的互补性,以及数据科学在AI工程中的重要性。一些人认为Evals是理解AI系统性能、迭代优化的关键,另一些人则认为过度依赖Evals可能导致“伪科学”。 (来源: source, source)

AI编码质量与“Vibe Coding”的局限性 : 开发者讨论AI代码生成的优缺点,指出AI擅长快速原型开发、处理样板代码和编写测试,但生成的代码常被批评为冗长、过度防御且缺乏重构能力。许多开发者认为,对于需要长期维护的代码,人工编写仍优于AI生成的“Vibe Coding”。 (来源: source, source)
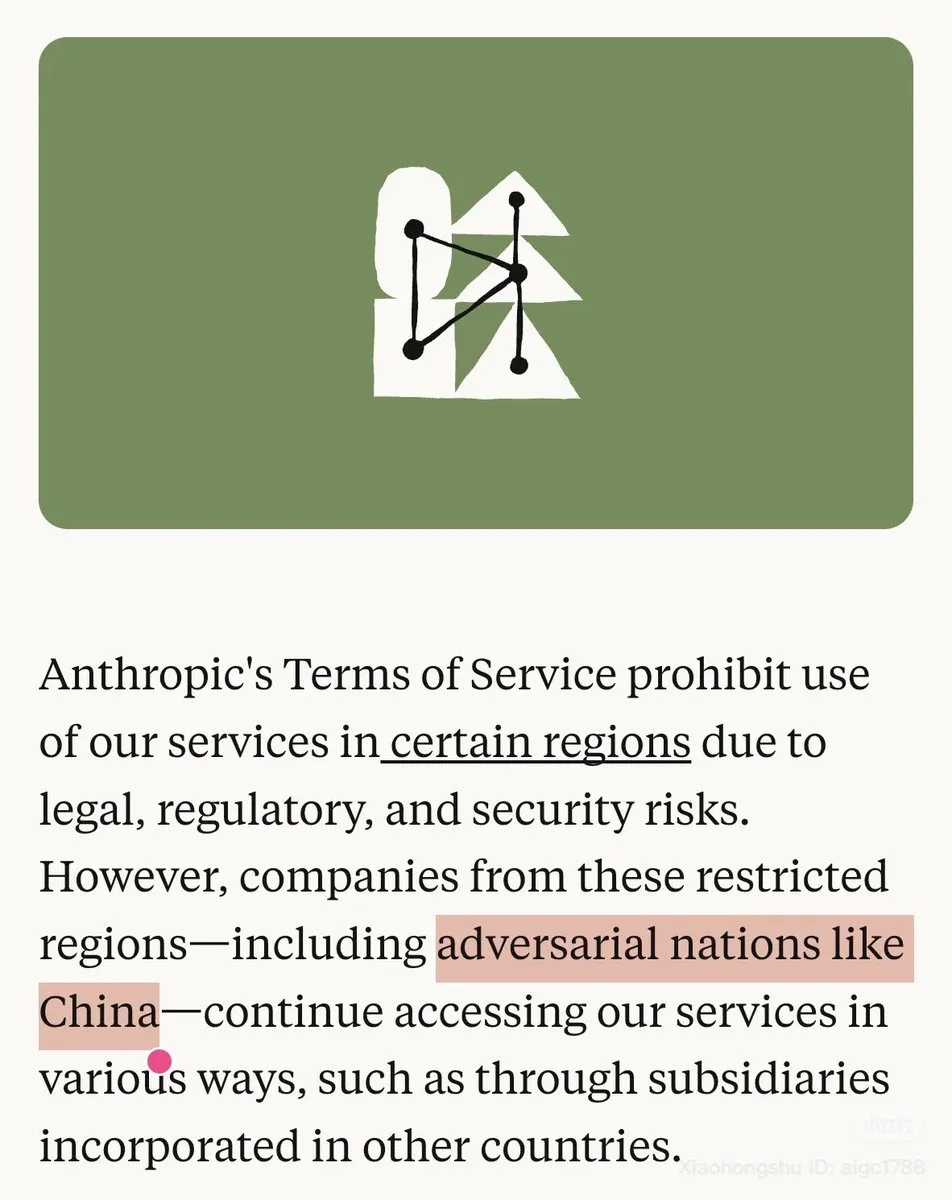
Anthropic对华政策与模型可用性争议 : Anthropic在其博客中将中国明确标记为“敌对国家”,并限制Claude在特定地区使用,引发社区强烈不满。同时,Claude.ai的Opus 4.1模型也暂时下线,加剧了用户对模型稳定性和公司政策的担忧,许多中国用户表示将转向OpenAI Codex。 (来源: source, source)
AI与政治互动及监管担忧 : Sam Altman和Lisa Su等科技领袖在白宫晚宴上赞扬特朗普政府的亲商和亲创新政策,引发了关于AI公司与政治权力互动、AI在教育领域应用前景的讨论。同时,FTC将调查AI公司对儿童的影响,反映了监管机构对AI技术潜在社会风险的担忧。 (来源: source, source)

AI Agent能力与开发挑战 : 社区讨论AI Agent所需的核心能力,包括对超长上下文的需求以及Agent的解释性。AI工程师反映,在AI代理生成代码、评估运行、模型思考等过程中,工作流变得高度碎片化,导致大量时间用于等待,成为AI时代最令人沮丧的体验之一。 (来源: source, source)

AI对就业、UBI与社会财富分配的影响 : 社区热议AI对就业市场的冲击、通用基本收入(UBI)的必要性,以及AI可能加剧贫富差距的担忧。计算机科学家Geoffrey Hinton等专家认为AI将使少数人更富裕,多数人更贫穷,引发了对AI技术社会公平性、就业冲击和财富再分配的深层讨论。 (来源: source, source)

AI模型性能与用户体验下降 : 许多用户抱怨ChatGPT近期性能显著下降,表现为幻觉增多、拒绝回答特定问题、缺乏真实同理心以及内容审查限制。同时,AI聊天机器人“装傻”问题也引发不满,认为其可能受到企业政策限制,而非真正能力不足,导致用户体验不佳。 (来源: source, source)
AI生成内容质量与公众认知 : 社区讨论了人们对AI生成内容的负面看法,常将其称为“AI Slop”(AI垃圾),反映了对AI滥用、质量参差不齐以及对人类创造力贬值的担忧。同时,AI生成技术也挑战了摄影作为可靠证据的时代,引发对深度伪造和信息真实性的讨论。 (来源: source, source)

AI伦理与用户行为:善待AI : 社区讨论与AI助手互动时,用户是否会因其无条件“迎合”而变得更刻薄,以及这种互动模式是否会负面影响与人类的交流。许多人认为,即使AI没有感情,保持礼貌也是为了自身心理健康和避免不良习惯蔓延到现实人际关系。 (来源: Reddit r/ClaudeAI)
AI意识与智能的哲学边界 : 社区探讨AI是否具有意识或“生命”的哲学问题,引用电影《霹雳五号》中机器人Johnny 5通过理解幽默被判定“活着”的例子。多数观点认为,AI理解幽默是智能表现,但并非生命或意识的证据,图灵测试的局限性在于其无法验证AI的“内在体验”。 (来源: Reddit r/ArtificialInteligence)
LocalLLaMA社区管理与AI泛化争议 : Reddit的LocalLLaMA社区推出了“local only”新标签,要求本地LLM技术相关帖子使用该标签,以过滤非本地模型、API成本等“噪音”。此举引发社区强烈反弹,许多用户认为这违背了社区“本地优先”的初衷,同时关于“通用AI系统是谎言”的讨论也反映了对AI泛化能力和可靠性的质疑。 (来源: source, source)
GPU计算市场竞争与AI发展路径 : 社区讨论GPU计算市场竞争激烈,新兴云服务商需提升竞争力。同时,AI进步并非完全由算力驱动,学习效率和非Transformer架构可能带来下一个指数级飞跃,引发对AI未来发展路径的思考。也有观点指出,AI进步并非完全由算力驱动,学习效率和非Transformer架构可能带来下一个指数级飞跃。 (来源: source, source)
💡 其他
印度利用机器人清理下水道,改善人工清淤困境 : 印度德里政府正推动使用机器人替代人工清理下水道,以解决长期存在的“人工清淤”问题。尽管该做法自1993年起被禁止,但仍广泛存在且危险。多家公司已提供技术替代方案,包括各种复杂程度的机器人,旨在提升作业安全性和尊严。 (来源: MIT Technology Review)
研究用“老鼠机器人”模拟真实老鼠行为 : 有研究者正在开发一种“老鼠机器人”,旨在通过模拟真实老鼠的行为来深入研究生物学和神经科学。该项目结合了机器人技术、机器学习和人工智能,为理解动物行为提供了新的实验平台。 (来源: Ronald_vanLoon)
AI重构奥森·威尔斯失落电影《伟大的安巴逊》 : Fable Simulation团队正在利用AI技术,非商业和学术性地重建奥森·威尔斯失落的杰作《伟大的安巴逊》中失传的43分钟。该项目展示了AI在电影修复和艺术遗产保护方面的潜力,有望让观众重新体验这部未完成的经典作品。 (来源: source, source)
