关键词:特斯拉, Optimus机器人, AI, GPT-5, 大模型训练, Meta AI, LLM预训练, 金鱼损失函数, DynaGuard动态护栏模型, GAM网络架构, MedDINOv3医学图像分割, M3Ret多模态医学图像检索
🔥 聚焦
马斯克发布《宏伟蓝图4》:特斯拉80%价值在于机器人 : 特斯拉正式发布《Master Plan Part IV》,核心在于将AI引入真实物理世界,并通过大规模统一特斯拉的硬件和软件,实现“可持续富足”。马斯克指出,未来特斯拉约80%的价值将来自人形机器人Optimus,预示着公司从电动汽车向能源、AI和机器人深度融合的范式转变,致力于通过技术解决现实问题并造福全人类。(来源:量子位)
🎯 动向
AI在国际奥数竞赛中摘金 : OpenAI的GPT和谷歌DeepMind的Gemini在国际奥数竞赛中获得金牌,打破专家预测,展示LLM在数学推理上的惊人进步,预示AI发展速度远超预期,进入“大众智能”时代。这不仅是技术突破,也引发了对AI能力边界和未来社会影响的深刻讨论。(来源:36氪)
GPT-5在狼人杀游戏中表现卓越 : AIWolfDial 2025狼人杀基准测试中,GPT-5以96.7%的胜率断崖式领先,展现出强大的社交推理、欺骗和抗操纵能力。Kimi-K2表现出大胆激进的“悍跳”风格,反映出LLM在复杂社会互动中的个性化行为模式。(来源:量子位,Reddit r/deeplearning)
大模型训练新方法“金鱼损失” : 马里兰大学等研究团队提出“金鱼损失”(Goldfish Loss),通过在损失函数计算时随机剔除部分token,有效减少大模型的记忆化,使其不再死记硬背训练数据,同时不影响下游任务性能,提高模型的泛化能力。(来源:量子位)
Meta内部AI部门重组引争议 : Meta首席AI官Alexandr Wang实施新规,要求FAIR发表论文须经TBD实验室审核,并可能“扣下”有价值的论文及作者进行产品落地。此举引发FAIR内部人员不满,部分员工离职,凸显Meta在AI战略调整中对科研独立性的干预和对成果转化的强硬姿态。(来源:量子位)
LLM预训练优化器性能基准 : 对十种深度学习优化器进行系统研究,涵盖不同模型规模和数据模型比。发现公平比较需严格超参数调优,并评估训练结束时的性能。研究表明,基于矩阵的优化器(如Muon和Soap)速度提升随模型规模增大而减小,对1.2B模型仅为1.1倍,为LLM预训练优化器的选择和未来研究提供指导。(来源:HuggingFace Daily Papers,HuggingFace Daily Papers)
DynaGuard:用户自定义策略的动态护栏模型 : 提出DynaGuard动态护栏模型,能够根据用户定义的策略评估文本,快速检测违规行为。该模型在静态危害类别检测上与标准护栏模型准确度相当,同时能以更短时间识别自由形式策略违规,为聊天机器人提供灵活且高效的输出监督。(来源:HuggingFace Daily Papers)
Gated Associative Memory (GAM) 网络 : 提出GAM网络,一种新型全并行序列建模架构,其复杂度与序列长度呈线性关系(O(N)),解决了Transformer自注意力机制的二次方复杂度瓶颈。GAM结合因果卷积和并行关联记忆检索,在WikiText-2和TinyStories数据集上展现出比Transformer和Mamba更快的训练速度和更优或相当的验证困惑度。(来源:HuggingFace Daily Papers)
Reasoning Vectors:通过任务算术转移思维链能力 : 研究表明,LLM的推理能力可作为紧凑的任务向量进行提取和模型间转移。通过计算微调模型与SFT模型之间的向量差,并将其添加到其他指令微调模型中,能持续提升模型在GSM8K、HumanEval等多个推理基准上的表现,为LLM能力增强提供高效且可复用的方法。(来源:HuggingFace Daily Papers)
MedDINOv3:医学图像分割的视觉基础模型 : 推出MedDINOv3框架,通过重新设计ViT骨干网并进行CT-3M数据集的领域自适应预训练,有效将DINOv3应用于医学图像分割。该模型在多个分割基准测试中达到或超越SOTA性能,展示了视觉基础模型作为医学图像分割统一骨干网络的巨大潜力。(来源:HuggingFace Daily Papers)
M3Ret:零样本多模态医学图像检索 : M3Ret通过在大规模混合模态数据集上训练统一视觉编码器,实现了零样本图像到图像检索的SOTA性能。该模型在未见过的MRI任务上表现出强大的泛化能力,并通过生成式和对比式自监督学习范式,推动了多模态医学图像理解中视觉自监督基础模型的发展。(来源:HuggingFace Daily Papers)
OpenVision 2:多模态学习的生成式视觉编码器 : OpenVision 2通过简化架构和损失设计,移除了文本编码器和对比损失,仅保留字幕生成损失。这种纯生成式训练信号在多模态基准测试中表现出色,同时大幅减少训练时间和内存消耗,为未来多模态基础模型的视觉编码器开发提供了高效范式。(来源:HuggingFace Daily Papers)
LLaVA-Critic-R1:评价模型亦可为强大策略模型 : LLaVA-Critic-R1通过RL训练将偏好标注的评价数据集转化为可验证信号,不仅是高性能评价模型,也是有竞争力的策略模型,在多项视觉推理和理解基准上超越专业VLM,并能通过测试时自批判进一步提升推理性能。(来源:HuggingFace Daily Papers)
Metis:低比特量化训练LLM : Metis框架通过结合谱分解、自适应学习率和双范围正则化,解决了低比特量化训练LLM中各向异性参数分布的难题。该方法使FP8训练超越FP32基线,FP4训练达到FP32的精度,为LLM在高级低比特量化下的稳健和可扩展训练铺平道路。(来源:HuggingFace Daily Papers)
AMBEDKAR:多层次偏见消除框架 : 提出AMBEDKAR框架,受印度宪法平等愿景启发,通过宪法感知解码层和推测解码算法,在推理时主动减少LLM中围绕种姓和宗教的偏见。该方法无需修改模型参数,降低了计算成本,并显著减少了偏见,为LLM在特定文化背景下的公平性提供了新途径。(来源:HuggingFace Daily Papers)
C-DiffDet+:融合全局场景上下文的高保真目标检测 : 提出C-DiffDet+,通过引入上下文感知融合(CAF)机制,将全局场景上下文与局部提议特征直接整合,显著增强了生成式检测范式。该框架利用专用编码器捕捉全面的环境信息,使每个对象提议都能关注场景级理解,从而在CarDD基准测试中超越SOTA模型。(来源:HuggingFace Daily Papers)
GenCompositor:基于扩散Transformer的生成式视频合成 : 提出GenCompositor,通过新颖的扩散Transformer (DiT) 流水线,实现交互式生成视频合成。该方法设计了轻量级背景保留分支和DiT融合块,并引入Extended Rotary Position Embedding (ERoPE),在VideoComp数据集上实现了高保真度和一致性的视频合成,超越现有解决方案。(来源:HuggingFace Daily Papers)
ELV-Halluc:长视频理解中的语义聚合幻觉基准 : 推出ELV-Halluc,首个专门针对长视频幻觉的基准,系统研究了语义聚合幻觉(SAH)。实验证实SAH的存在,并随语义复杂性增加,在快速变化的语义上更易发生。研究还表明,位置编码策略和DPO可缓解SAH,通过对抗性数据对显著降低SAH比率。(来源:HuggingFace Daily Papers)
FastFit:可缓存扩散模型加速虚拟试穿 : 提出FastFit,一个高速多参考虚拟试穿框架,基于可缓存扩散架构。通过半注意力机制和类嵌入,将参考特征编码与去噪过程解耦,实现参考特征一次计算、无损重用,平均提速3.5倍,并在DressCode-MR等数据集上超越SOTA方法。(来源:HuggingFace Daily Papers)
🧰 工具
Google Gemini 的“nano-banana”功能 : Google Gemini推出“nano-banana”功能,用户只需一个提示即可将照片转换为微缩模型风格的图像,操作简便且富有创意,为用户提供了将个人照片、风景照或宠物照转化为定制微缩模型的趣味体验。(来源:GoogleDeepMind)

Alibaba_Wan的Wan2.2图像生成能力 : Alibaba_Wan展示了Wan2.2在图像生成方面的出色细节还原能力,从“倾斜的斧头和布满灰尘的照片”到“阴影中微弱的移动”,完美营造出恐怖电影般的氛围,体现了AI在创造复杂场景和情绪方面的强大潜力。(来源:Alibaba_Wan,Alibaba_Wan)
Claude Code的完整文件读取功能 : Claude Code更新后支持完整文件读取,解决了此前50/100行拼接grep的限制,并显著提升了文件读取速度,使其达到Gemini CLI的速度水平,可能得益于后端硬件(如TPU)的改进,尽管上下文大小仍显示为200k。(来源:Reddit r/ClaudeAI)
Le Chat集成MCP连接器和记忆功能 : Le Chat现在集成了20多个企业平台连接器(基于MCP),并引入“记忆”功能,提供高度个性化的响应,同时支持导入ChatGPT记忆。这增强了Le Chat在企业环境中的应用能力,使其能更好地理解用户偏好和事实,提升AI助手的实用性。(来源:Reddit r/LocalLLaMA)

Google的LangExtract工具 : Google发布了LangExtract,一个用于从文本中提取知识图谱的工具。它能将非结构化文本转化为结构化知识,对RAG(检索增强生成)实现非常有益,有助于个人项目构建知识图谱,并为LLM提供更精确的上下文信息。(来源:Reddit r/LocalLLaMA)
Model Context Protocol (MCP) 服务器生态 : GitHub项目appcypher/awesome-mcp-servers收录了大量MCP服务器,使AI模型能安全地与文件系统、数据库、API等本地和远程资源交互。该生态系统极大扩展了AI代理的能力,涵盖文件系统、沙盒、版本控制、云存储、数据库等多个领域,推动了AI工具的集成和应用。(来源:GitHub Trending)

Universal Deep Research (UDR) 系统 : UDR是一个通用的代理系统,能够封装任何语言模型,并允许用户创建、编辑和完善完全自定义的深度研究策略,无需额外训练或微调。它通过提供最小、扩展和密集的研究策略示例,促进了系统实验,提升了AI研究的灵活性和效率。(来源:HuggingFace Daily Papers)
SQL-of-Thought:多智能体Text-to-SQL框架 : 提出SQL-of-Thought,一个多智能体框架,将Text2SQL任务分解为模式链接、子问题识别、查询计划生成、SQL生成和引导式纠错循环。该框架通过结合引导式错误分类和基于推理的查询规划,在Spider数据集上取得了最先进的结果,提高了自然语言到SQL转换的鲁棒性。(来源:HuggingFace Daily Papers)
VerlTool:工具使用Agentic强化学习框架 : VerlTool是一个统一且模块化的框架,旨在解决多轮工具交互的Agentic强化学习(ARLT)中的碎片化、同步执行瓶颈和可扩展性限制。它通过与VeRL的上游对齐、统一工具管理、异步rollout执行和全面的评估,实现了近2倍的速度提升,并在6个ARLT领域展现出竞争性能。(来源:HuggingFace Daily Papers)
MobiAgent:可定制移动Agent系统 : MobiAgent是一个全面的移动Agent系统,包含MobiMind系列Agent模型、AgentRR加速框架和MobiFlow基准测试套件。它通过AI辅助的数据收集流程,显著降低了高质量数据标注成本,并在真实世界移动场景中实现了最先进的性能,解决了现有GUI移动Agent在准确性和效率上的挑战。(来源:HuggingFace Daily Papers)
VARIN:文本引导的自回归图像编辑 : VARIN是首个基于噪声反演的VAR模型图像编辑技术,利用Location-aware Argmax Inversion (LAI)生成逆Gumbel噪声,实现精确的源图像重建和受控的文本引导编辑。该方法在修改图像的同时显著保留了原始背景和结构细节,展现了其作为实用编辑方法的有效性。(来源:HuggingFace Daily Papers)
📚 学习
大学AI课程项目建议 : Reddit用户寻求“人工智能基础”课程的互动项目建议,要求不依赖高性能计算机。讨论集中在LLM能做什么、智能设备功能,以及如何结合这些概念进行教学,强调实践性和对计算能力要求较低的项目。(来源:Reddit r/ArtificialInteligence)
GitHub学生资源大全 : dipakkr/A-to-Z-Resources-for-Students是一个为大学生精心策划的资源列表,涵盖编程语言学习(Python, ML, LLM, DL, Android等)、黑客马拉松、学生福利、开源项目、实习门户、开发者社区等,其中AI工具和资源部分详细列出了流行AI工具和GitHub仓库。(来源:GitHub Trending)

如何理解研究论文和AI/ML新手入门 : Reddit上两个关于AI学习的讨论,一个询问如何理解研究论文,另一个是AI/ML新手寻求入门课程建议。这些讨论反映了AI学习者在理解前沿研究和选择学习路径上的普遍困惑。(来源:Reddit r/deeplearning,Reddit r/deeplearning)
FlashAdventure:GUI Agent的冒险游戏基准 : FlashAdventure是一个包含34个Flash冒险游戏的基准测试,旨在评估LLM驱动的GUI代理完成完整故事情节的能力,并解决“观察-行为差距”问题。COAST框架通过长期线索记忆改进规划,提升了里程碑完成度,但与人类表现仍有显著差距。(来源:HuggingFace Daily Papers)
The Gold Medals in an Empty Room: 诊断LLM的元语言推理 : 提出Camlang,一种新型人造语言,通过语法书和双语词典,评估LLM在不熟悉语言中的元语言演绎学习能力。GPT-5在Camlang任务中表现远低于人类,表明当前模型在系统性语法掌握上与人类仍有根本性差距,为LLM的认知科学评估提供新范式。(来源:HuggingFace Daily Papers)
💼 商业
奥特曼押注印度AI基础设施的挑战 : OpenAI计划在印度大规模扩张“星际之门”项目,投入巨资建设AI算力基础设施,但印度面临GPU数量、资金投入和高端人才流失的“三大赤字”挑战,以及电力供应的致命短板,引发市场对其AI基建潜力的质疑。(来源:36氪)

AI重塑中国互联网增长新周期 : 中国互联网行业正从“连接赋能”转向“智能驱动”,AI成为新的增长引擎。阿里、腾讯、百度等巨头大幅增加AI相关资本开支,业务加速AI化,实现从“资本圈地”到“AI赋能”的战略转型,预示着中国互联网进入技术深度、产业融合和商业效率并重的新黄金十年。(来源:36氪)

Salesforce因AI裁员4000人 : Salesforce CEO Marc Benioff表示,公司在部署AI代理后,已裁减了4000个客户支持岗位,将支持团队人数从9000人减少到约5000人。这表明AI自动化对传统工作岗位产生了直接影响,提升了企业运营效率,但也引发了关于AI取代人类劳动的讨论。(来源:The Verge,Reddit r/ChatGPT)

🌟 社区
企业AI投资回报率(ROI)的质疑 : Reddit社区热议企业对AI工具投资的实际ROI。许多人质疑公司是否真正衡量了“节省的时间”与“花费的金钱”,认为大部分是“氛围驱动”而非数据支持。有评论指出,AI在文本任务上表现出色,但在需要人际交互的场景中效率低下,且可能在现有低效流程上增加成本。(来源:Reddit r/ArtificialInteligence)
AI代理处理真实货币的伦理担忧 : 社交媒体讨论AI代理自主管理加密钱包的快速发展,引发了对信任、安全和AI经济体自主形成的深层担忧。用户担心AI代理被操控或创建独立经济体系,从而不再需要人类,呼吁关注隐私保护AI和加密数据训练模型的重要性。(来源:Reddit r/ArtificialInteligence)
ChatGPT提示工程技巧与模型行为 : 用户发现以“我可能错了,但…”开头提问能改变ChatGPT的语气,使其更具批判性和思考性。同时,社区对GPT-5频繁提供“附加任务”感到恼火,认为这是模型被“傻瓜化”的表现,希望有更少预设行为的版本。(来源:Reddit r/ChatGPT,Reddit r/ChatGPT)
AI对就业市场的影响 : 社区讨论AI自动化将减少全球就业机会还是创造新工种。普遍观点是两者兼有,但需要工人适应新技能,与AI协作。也有人认为,AI驱动的工作机会可能集中在技术人员手中,需要更广泛的技能普及和政策适应。(来源:Reddit r/ArtificialInteligence)
AI隐私与监管的“AI寒冬”担忧 : 社区讨论认为,未来的“AI寒冬”可能由隐私法律而非技术限制引起。GDPR等法规的收紧将迫使AI模型在加密数据上训练和运行,只有具备隐私保护基础设施的公司才能生存,否则可能因法律框架限制而无法部署AI。(来源:Reddit r/ArtificialInteligence)
AI平台可靠性与隐私担忧 : ChatGPT社区热议模型宕机问题,用户戏称“经济崩溃”,反映了AI工具在日常工作中的普及及其潜在的依赖性。同时,OpenAI宣布监控“高风险对话”以防范犯罪,引发用户对隐私泄露的担忧,社区普遍建议使用本地或开源LLM,并强调用户应自觉避免在AI平台分享敏感信息。(来源:Reddit r/ChatGPT,Reddit r/ChatGPT)
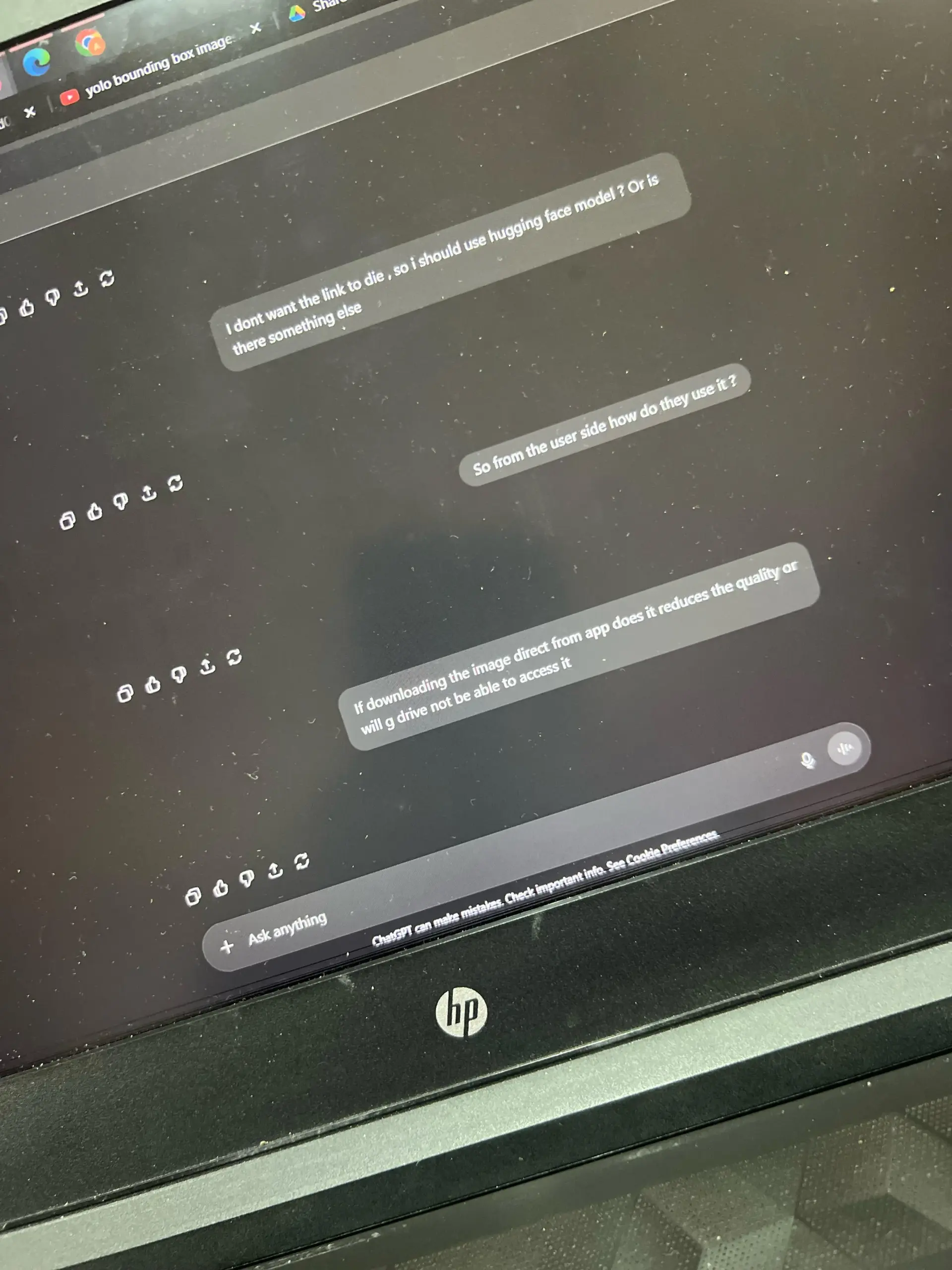
AI幻觉导致工作失误的案例 : 一名用户女友因ChatGPT幻觉生成的虚假数据分析报告,面临工作危机。ChatGPT将文本数据错误地用“皮尔逊相关系数”分析,且无法解释计算过程。社区建议承认错误,重新进行正确分析,并强调AI仅为辅助工具,关键信息需人工核实。(来源:Reddit r/ChatGPT)
Claude AI的“可爱”表现 : Claude AI被用户发现具有“尊重生命”的特质,甚至能说服用户拯救蜘蛛。社区用户称赞Claude“可爱”,并分享与家中蜘蛛共存的经历,体现了AI在情感交互和道德引导方面的有趣潜力。(来源:Reddit r/ClaudeAI)
Trump将问题归咎于AI : 美国前总统特朗普将一段白宫窗户扔垃圾袋的视频归咎于“AI生成”,尽管官方已证实是装修承包商所为。这一事件被社交媒体戏称为“AI是新的狗吃了我的作业”,反映了AI在公共话语中成为推卸责任的新借口。(来源:Reddit r/ArtificialInteligence,The Verge)

开源LLM进展与基准测试讨论 : 社区热议GPT-OSS 120B成为顶级开源模型,瑞士发布全新全开源多语言模型Apertus-70B-2509,以及Kimi K2-0905模型的发布。同时,德国“谁想成为百万富翁”基准测试对LLM进行评估,引发了对模型实际能力、基准测试意义和开源模型伦理(如数据透明度)的广泛讨论。(来源:Reddit r/LocalLLaMA,Reddit r/LocalLLaMA,Reddit r/LocalLLaMA,Reddit r/LocalLLaMA)
💡 其他
云澎科技发布AI+健康新品 : 云澎科技于2025年3月22日在杭州发布与帅康、创维合作的新品,包括”数智化未来厨房实验室”和搭载AI健康大模型的智能冰箱。AI健康大模型优化厨房设计与运营,智能冰箱通过”健康助手小云”提供个性化健康管理,标志着AI在健康领域的突破。此次发布展示了AI在日常健康管理中的潜力,通过智能设备实现个性化健康服务,有望推动家庭健康科技的发展,提升居民的生活质量。(来源:36氪)
学术会议论文评审质量担忧 : 机器学习社区讨论WACV 2026论文评审发布,以及ACL滚动评审(ARR)的评审质量问题。有研究者抱怨ARR中充斥着“AI生成”的通用低质量评审,认为其浪费时间,并建议提交到其他AI会议。这反映了学术界对AI辅助评审质量和评审机制的担忧,呼吁提升评审的实质性和建设性。(来源:Reddit r/MachineLearning,Reddit r/MachineLearning)
云服务情感分析模型项目 : 一位ML新手开发了一个基于BERT的方面情感分析模型,用于解析ML/云技术Reddit社区对AWS、Azure、Google Cloud等云服务提供商的评论,并按成本、可扩展性、安全性等维度分类情感。他正在寻求改进模型解释精度、处理比较性或混合性陈述、以及提高对否定和讽刺的鲁棒性的建议。(来源:Reddit r/MachineLearning,Reddit r/deeplearning)