
关键词:GPT-5, AI自我提升, 具身智能, 多模态模型, 大型语言模型, 强化学习, AI Agent, GPT-5性能提升, Genie Envisioner机器人平台, LLM招聘评估偏见, Qwen3超长上下文, CompassVerifier答案验证
🔥 聚焦
GPT-5发布:产品化与性能提升 : OpenAI正式发布GPT-5,标志着其旗舰模型的最新迭代。此次发布重点在于提升用户体验,通过实时路由器自动调度基础模型和深度推理模型,实现速度与智能的平衡。GPT-5在减少幻觉、提升指令遵循和编程能力方面表现显著,并在多项基准测试中刷新纪录。Sam Altman将其比作“视网膜显示屏”,强调其作为“博士生水平AI”的实用性,而非单纯的智能上限突破。尽管技术上未达AGI,但其更快的推理速度和更低的运行成本,有望推动AI的广泛应用。(来源:MIT Technology Review)

AI自我提升研究进展 : Meta CEO扎克伯格表示,公司正致力于构建能够自我提升的AI系统。AI已在多个方面展现出自我改进的能力,例如通过自动数据增强、模型架构搜索、强化学习等方式,不断优化自身性能。这一趋势预示着AI系统未来将能够自主学习并超越人类设定的性能边界,是实现更高级别AI的关键路径。(来源:MIT Technology Review)

Genie Envisioner:统一机器人操纵世界模型平台 : 研究人员推出Genie Envisioner (GE),一个用于机器人操纵的统一世界基础平台。GE-Base是指令条件视频扩散模型,能捕捉真实机器人交互的空间、时间及语义动态。GE-Act将潜在表示映射到可执行动作轨迹,实现精确且通用策略推理。GE-Sim作为动作条件神经模拟器,支持闭环策略开发。该平台有望为指令驱动的通用具身智能提供可扩展且实用的基础。(来源:HuggingFace Daily Papers)
大型多模态模型识别错误输入能力评估框架ISEval : 针对大型多模态模型(LMMs)能否主动识别错误输入的问题,研究人员提出了ISEval评估框架。该框架涵盖七类缺陷前提和三项评估指标。研究发现,多数LMMs在缺乏明确指导下难以主动检测文本缺陷,且对不同错误类型表现各异。例如,它们擅长识别逻辑谬误,但在表面语言错误和特定条件缺陷上表现不佳。这凸显了LMMs在主动验证输入有效性方面的迫切需求。(来源:HuggingFace Daily Papers)
LLM招聘评估中的语言偏见研究 : 一项研究引入了基准测试,评估大型语言模型(LLMs)在招聘评估中对语言歧视性标记的反应。通过精心设计的面试模拟,研究发现LLMs系统性地惩罚某些语言模式,特别是模糊语言,即使内容质量相同。这揭示了自动化评估系统中的人口统计学偏见,为AI系统中的语言歧视检测和衡量提供了基础框架,对自动化决策的公平性具有广泛应用。(来源:HuggingFace Daily Papers)
🎯 动向
Qwen3系列模型支持百万级超长上下文 : 阿里云Qwen3-30B-A3B-2507和Qwen3-235B-A22B-2507模型现已支持高达100万tokens的超长上下文。这得益于Dual Chunk Attention (DCA)和MInference稀疏注意力技术,不仅提升了生成质量,还将近百万tokens序列的推理速度提升至3倍。此举大幅拓展了LLM在处理长文档、代码库等复杂任务中的应用潜力,并兼容vLLM和SGLang高效部署。(来源:Alibaba_Qwen)

Anthropic Claude Opus 4.1与Sonnet 4升级 : Anthropic发布了Claude Opus 4.1和Sonnet 4,重点提升了Agentic任务、真实世界编码和推理能力。新模型具备“深度思考”功能,可在即时响应与深度推演模式间灵活切换,将耗时数小时的复杂任务压缩至分钟级完成。这进一步强化了Claude在多模型协作场景中的定位,尤其在复杂代码审查和高级推理任务中表现突出。(来源:dl_weekly)
微软推出Copilot 3D功能 : 微软已推出免费的Copilot 3D功能,能将2D图像转换为GLB格式的3D模型,兼容各种3D查看器、设计工具和游戏引擎。尽管目前对动物和人类图像效果不佳,但该功能为用户提供了便捷的2D到3D转换能力,有望在产品设计、虚拟现实等领域发挥作用,进一步降低3D内容创作的门槛。(来源:The Verge)
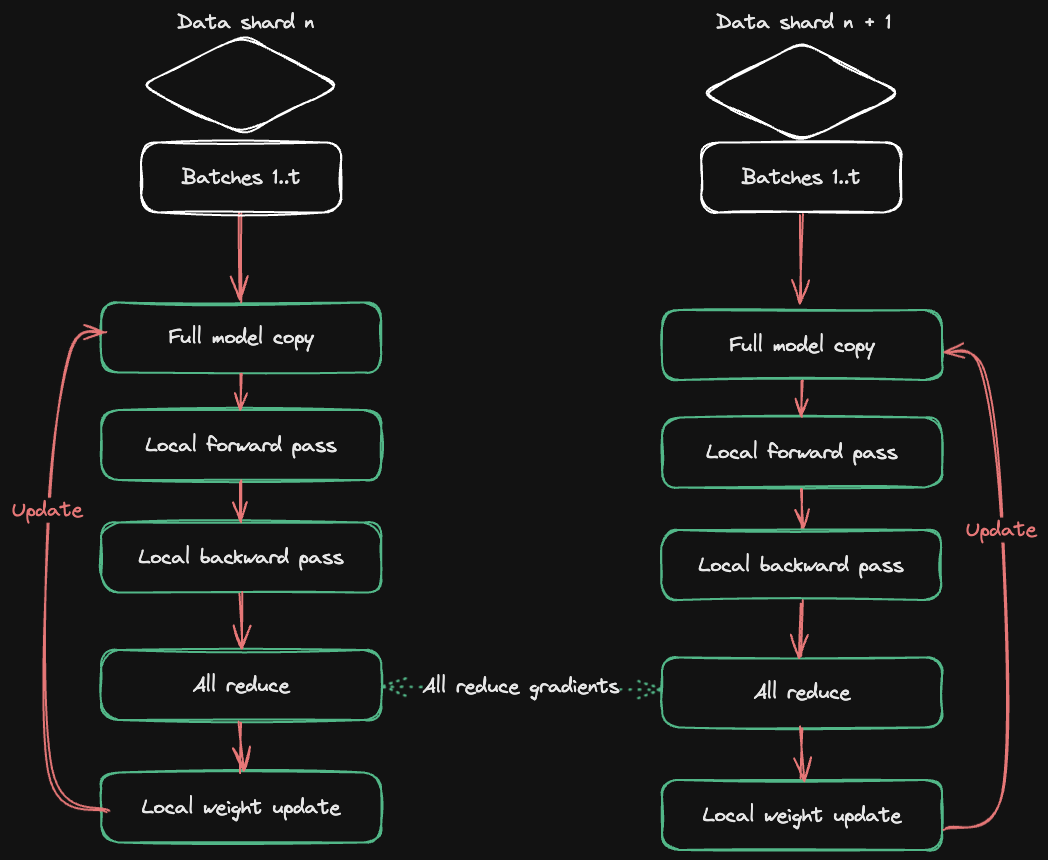
HuggingFace Accelerate发布多GPU训练指南 : HuggingFace与Axolotl合作发布了Accelerate ND-Parallel指南,旨在简化多GPU训练中并行策略的组合与应用。该指南详细介绍了数据并行(DP)、分片数据并行(FSDP)、张量并行(TP)和上下文并行(CP)等策略,并提供了混合并行配置的示例,帮助开发者在训练大型模型时优化内存使用和吞吐量,有效应对多节点训练中的通信开销挑战。(来源:HuggingFace Blog)
🧰 工具
OpenAI Codex CLI:终端本地编码Agent : OpenAI发布了Codex CLI,一个在本地终端运行的轻量级编码Agent。用户可以通过npm install -g @openai/codex或brew install codex安装。它支持与ChatGPT Plus/Pro/Team账户绑定,免费使用GPT-5等最新模型,也可通过API Key按量付费。Codex CLI提供读写、只读等多种沙盒模式,并支持自定义配置,旨在为开发者提供高效、安全的本地编程辅助。(来源:openai/codex – GitHub Trending)

HuggingFace AI Sheets:无代码数据集工具 : HuggingFace推出AI Sheets,一款开源的无代码工具,用于使用AI模型构建、丰富和转换数据集。该工具界面类似电子表格,支持本地部署或在Hugging Face Hub上运行。用户可利用数千个开放模型(包括gpt-oss)进行模型比较、提示优化、数据清洗、分类、分析和合成数据生成,通过手动编辑和点赞反馈来迭代改进AI生成结果,并可导出至Hub。(来源:HuggingFace Blog)

Google Agent Development Kit (ADK)及其示例 : Google发布了Agent Development Kit (ADK),这是一个开源的、代码优先的Python工具包,用于构建、评估和部署复杂的AI Agent。ADK支持丰富的工具生态、模块化多Agent系统,并可灵活部署。其样本库adk-samples提供了从对话机器人到多Agent工作流的多种Agent示例,旨在加速Agent开发过程,并与A2A协议集成实现远程Agent间通信。(来源:google/adk-python – GitHub Trending & google/adk-samples – GitHub Trending)

Qwen Code CLI:免费代码运行工具 : 阿里云Qwen Code CLI提供每日2000次免费代码运行,通过npx @qwen-code/qwen-code@latest命令即可轻松启动。该工具支持Qwen OAuth,旨在为开发者提供便捷高效的代码编写和测试体验。Qwen团队表示将持续优化该CLI工具和Qwen-Coder模型,力求在保持开源的同时,达到Claude Code的性能水平。(来源:Alibaba_Qwen)
📚 学习
OpenAI Python库更新 : OpenAI官方Python库提供了便捷的OpenAI REST API访问,支持Python 3.8+。库中包含所有请求参数和响应字段的类型定义,并提供同步和异步客户端。最新更新包括Realtime API的beta支持,用于构建低延迟、多模态对话体验,以及对webhook验证、错误处理、请求ID和重试机制的详细说明,提升了开发效率和鲁棒性。(来源:openai/openai-python – GitHub Trending)
AI Agent精选列表 : e2b-dev/awesome-ai-agents是一个GitHub仓库,收录了大量AI自主Agent的示例和资源。该列表旨在为开发者提供一个集中化的资源库,帮助他们了解和学习不同类型的AI Agent,涵盖从简单到复杂的各种应用场景,是探索和构建AI Agent的重要学习资料。(来源:e2b-dev/awesome-ai-agents – GitHub Trending)
MeanFlow:一步生成扩散模型新范式 : 科学空间提出MeanFlow,一种有望成为扩散模型加速生成标配的新方法。该方法旨在通过建模“平均速度”而非“瞬时速度”,实现一步生成,突破传统扩散模型生成速度慢的痛点。MeanFlow具备清晰的数学原理、可单目标从零训练,且单步生成效果接近SOTA,为加速生成式AI模型提供了新的理论和实践方向。(来源:WeChat)

长上下文KV Cache全生命周期优化 : 微软亚洲研究院分享了KV Cache全生命周期优化实践,旨在解决长上下文大语言模型推理中的延迟和存储挑战。通过SCBench基准测试,并提出MInference、RetrievalAttention等方法,显著降低Prefilling阶段延迟,缓解KV Cache显存压力。研究强调系统级跨请求优化和Prefix Caching复用,为长上下文LLM推理的可扩展性和经济性提供了优化方案。(来源:WeChat)

强化学习框架FR3E提升LLM探索能力 : 字节跳动、MAP和曼彻斯特大学联合提出FR3E(First Return, Entropy-Eliciting Explore),一个全新的结构化探索框架,旨在解决强化学习中LLM探索不足的问题。FR3E通过识别推理轨迹中的高不确定性token,引导多样化展开,系统性重建LLM探索机制,实现利用与探索的动态平衡,在多个数学推理基准上显著优于现有方法。(来源:WeChat)

自注意力机制中极大值与上下文理解关联研究 : ICML 2025的一项新研究揭示,大型语言模型自注意力机制的查询(Q)和键(K)表示中存在高度集中的极大值,这些值对上下文知识理解至关重要。研究发现,这种现象普遍存在于使用旋转位置编码(RoPE)的模型中,且在早期层即已出现。破坏这些极大值会导致模型在需要上下文理解的任务上性能急剧下降,为LLM设计、优化和量化提供了新方向。(来源:WeChat)
C3 Benchmark:中英双语语音对话模型测试基准 : 北京大学和腾讯联合发布C3 Benchmark,首个全面考察口语对话模型中停顿、多音字、谐音、重音、句法歧义、一词多义等复杂现象的中英双语评测基准。该基准包含1079个真实场景和1586段音频-文本对,旨在直击当前语音对话模型的致命弱点,推动其在理解人类日常对话方面的进步。(来源:WeChat)
Chemma:有机化学合成大语言模型 : 上海交通大学AI for Science团队发布白玉兰化学合成大模型(Chemma),首次实现化学大语言模型加速有机合成全流程。Chemma无需量子计算,仅依靠化学知识理解和推理能力,在单步/多步逆合成、产率/选择性预测、反应优化等任务上超越现有最佳结果。其“Co-Chemist”人机协作主动学习框架,已在真实反应中成功验证,为化学发现提供了新范式。(来源:WeChat)

Intern-Robotics:上海AI Lab具身全栈引擎 : 上海AI实验室发布具身全栈引擎Intern-Robotics,旨在推动具身智能领域的“ChatGPT时刻”。该引擎是一个开放共享的基础设施,聚焦于实现本体泛化、场景泛化、任务泛化,并强调作业成功率趋近100%。团队致力于通过“Real to Sim to Real”技术路线和真实世界强化学习,解决数据匮乏问题,逐步实现零样本泛化,加速具身智能的落地应用。(来源:WeChat)

AI自问自答推理能力进化框架SQLM : 卡内基梅隆大学团队提出SQLM,一种无需外部数据的自我提问框架,通过自问自答提升AI推理能力。该框架包含提问者(proposer)和解答者(solver)两个角色,两者通过强化学习训练以最大化期望奖励。SQLM在算术、代数和编程任务上均显著提升了模型准确率,为大语言模型在缺乏高质量人工标注数据的情况下实现能力提升提供了可扩展的自我维持流程。(来源:WeChat)

CompassVerifier:AI答案验证模型与评测集 : 上海AI Lab和澳门大学联合发布通用答案验证模型CompassVerifier与评测集VerifierBench,旨在解决大模型训练能力突飞猛进但验证答案能力滞后的问题。CompassVerifier是一个轻量而强大的多域通用验证器,基于Qwen系列模型优化,能在数学、知识、科学推理等多领域实现超越通用大模型的验证精度,并能作为强化学习奖励模型,为LLM迭代优化提供精准反馈。(来源:WeChat)

CoAct-1:编码作为行动的计算机使用Agent : 研究人员提出CoAct-1,一个通过编码作为增强行动的多Agent系统,旨在解决GUI操作Agent在复杂任务中的效率和可靠性问题。CoAct-1的Orchestrator能动态将子任务委托给GUI Operator或Programmer Agent(可编写和执行Python/Bash脚本),从而绕过低效的GUI操作。该方法在OSWorld基准测试中实现了SOTA成功率,并显著提升了效率,为通用计算机自动化提供了更强大的路径。(来源:HuggingFace Daily Papers)
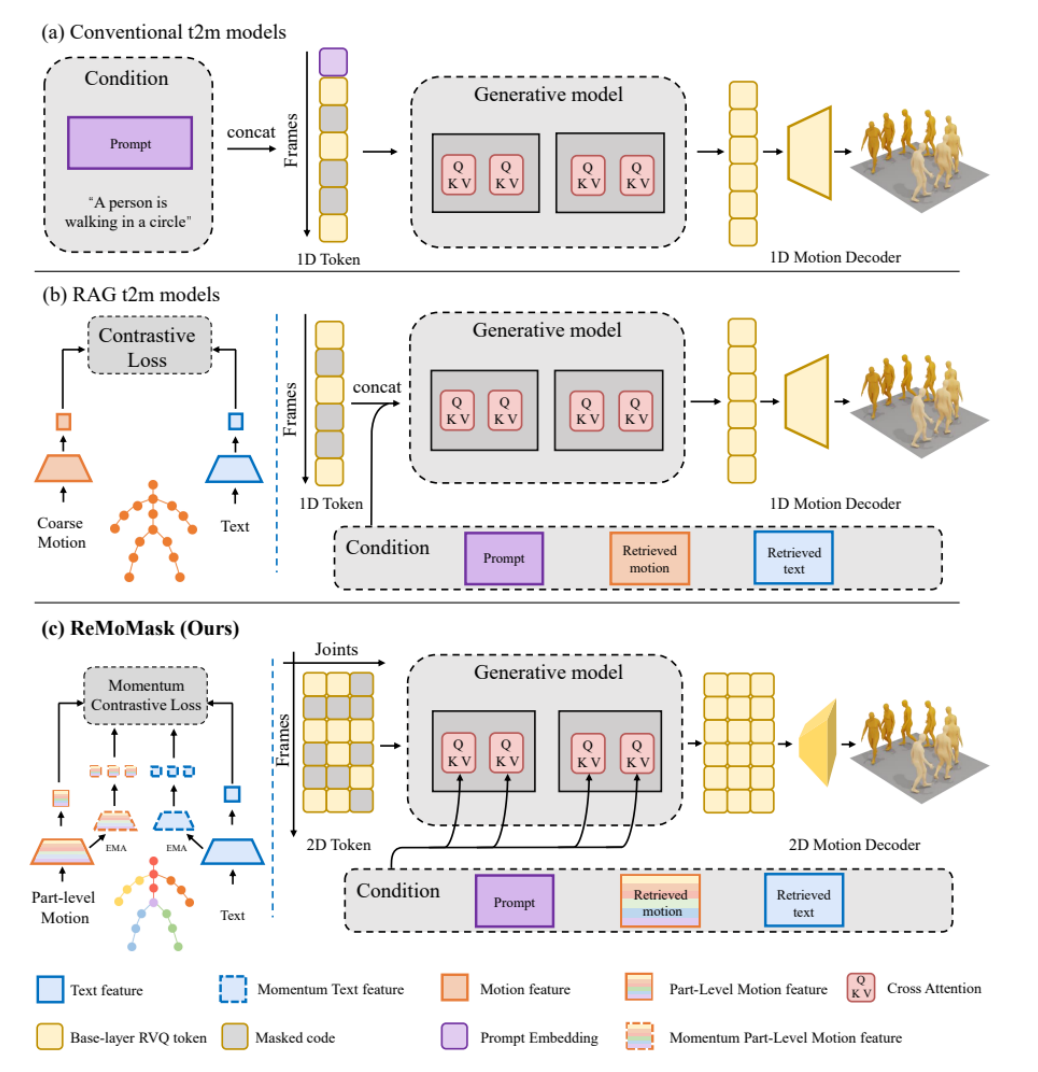
ReMoMask:高质量游戏3D动作生成新方法 : 北京大学提出ReMoMask,一种基于检索增强生成的Text-to-Motion框架,旨在通过一句指令高质量生成流畅逼真的3D动作。ReMoMask集成了动量双向文本-动作模型、语义时空注意力机制和RAG-无分类器引导,高效生成时间连贯的动作。该方法在HumanML3D和KIT-ML等标准基准测试上刷新了SOTA性能,有望彻底改变游戏和动画制作流程。(来源:WeChat)
WebAgents综述:大模型赋能Web自动化 : 香港理工大学研究人员发布首篇WebAgents综述,全面梳理了大模型赋能AI Agent实现下一代Web自动化的研究进展。综述从架构(感知、规划推理、执行)、训练(数据、策略)和可信性(安全、隐私、泛化)等角度,总结了WebAgents的代表性方法,并探讨了未来研究方向,如公平性、可解释性、数据集和个性化WebAgents,为构建更智能、安全的Web自动化系统提供了指南。(来源:WeChat)

LLM推理能力对齐框架InfiAlign : InfiAlign是一个可扩展且样本高效的后训练框架,通过结合SFT和DPO来对齐LLM以增强推理能力。该框架的核心是一个强大的数据选择管道,能自动从开源推理数据集中筛选高质量对齐数据。InfiAlign在Qwen2.5-Math-7B-Base模型上实现了与DeepSeek-R1-Distill-Qwen-7B相当的性能,但仅使用了约12%的训练数据,并在数学推理任务上取得了显著提升,为大型推理模型的对齐提供了实用方案。(来源:HuggingFace Daily Papers)
💼 商业
OpenAI员工期权兑现计划防挖角 : 为应对人才流失,OpenAI启动新一期员工期权兑现计划,按5000亿美元估值兑现,旨在通过真金白银留住人才。此举有望将OpenAI估值推向新高。同时,ChatGPT周活跃用户达7亿,付费企业用户增至500万,年度经常性收入预计超200亿美元,显示OpenAI在产品和商业化方面发展态势良好。(来源:量子位)

亚马逊云科技构建最大AI模型聚合平台 : 亚马逊云科技(AWS)宣布OpenAI的gpt-oss模型首次可通过Amazon Bedrock和Amazon SageMaker访问,进一步丰富其“Choice Matters”(选择大于一切)战略下的模型生态。AWS现提供超400款主流商业及开源大模型,旨在让企业根据性能、成本和任务需求选择最适合的模型,而非追求单一“最强”模型,推动多模型协同增效。(来源:量子位)

蚂蚁集团投资具身智能灵巧手公司 : 蚂蚁集团领投具身智能公司灵心巧手数亿元天使轮融资。灵心巧手是全球唯一实现千台高自由度灵巧手量产的公司,市场占有率达80%。其Linker Hand系列灵巧手拥有高自由度、多传感器系统和成本优势,已在工业、医疗等场景落地。此次融资将用于技术储备和数据采集场建设,加速灵巧手在实际应用中的部署。(来源:量子位)

🌟 社区
GPT-5用户体验两极分化 : GPT-5发布后,用户反馈褒贬不一。部分用户赞扬其在编程和复杂推理任务上的显著提升,认为代码生成更干净、精准,且长上下文处理能力极强。然而,另一些用户则对模型个性化、创意写作和情感支持能力的下降表示失望,认为其变得“枯燥”、“无灵魂”,且模型路由机制导致体验不稳定,甚至有用户因此取消订阅。(来源:Reddit r/ChatGPT & Reddit r/LocalLLaMA & Reddit r/ChatGPT & Reddit r/ChatGPT)

AI在育儿中的应用与争议 : 职场父母们正将ChatGPT等AI工具作为“共同育儿者”,利用其规划膳食、优化睡前程序,甚至提供情感支持。AI的无评判倾诉空间减轻了父母的心理负担。然而,这种新兴技术也引发争议,包括可能提供不准确建议、隐私泄露风险(如ChatGPT数据泄露事件),以及过度依赖AI可能导致人际关系隔离和对环境的潜在影响。(来源:36氪)
Airbnb因AI伪造图片致用户赔偿事件 : Airbnb发生一起房东利用AI伪造图片骗取用户赔偿的事件,凸显AI在客户服务中的风险。AI客服未能识别出AI生成图片,导致用户被错误判定需赔偿。尽管OpenAI曾推出图像检测器,但AI识别AI仍有局限性,尤其在“局部伪造”技术面前。该事件引发了对AI内容检测工具可靠性和C2C平台应对深度伪造内容冲击的担忧。(来源:36氪)

硅谷AI大佬建造末日地堡引发热议 : 硅谷AI界领袖如马克·扎克伯格和萨姆·奥特曼被曝正在建造或拥有末日避难所,引发公众对AI未来发展和潜在风险的担忧。尽管他们否认与AI相关,但此举仍被解读为对大流行病、网络战、气候灾难等紧急情况的防范。社区讨论猜测,这些最了解AI技术的人是否看到了普通人未知的苗头,以及AI发展是否已带来无法预知的风险。(来源:量子位)

Kaggle AI国际象棋锦标赛o3夺冠 : 首届谷歌Kaggle AI国际象棋锦标赛决赛中,OpenAI的o3以4-0横扫马斯克的Grok 4,夺得冠军。这场比赛被视为OpenAI与xAI的“代理人战争”,旨在检验大模型的批判性思维、战略规划和临场应变能力。尽管Grok 4此前势头强劲,但在决赛中频频失误,o3则展现出系统稳定的策略,全程未失一局,成为不败王者。(来源:WeChat)

AI进入“幻灭的低谷”讨论 : 社交媒体上出现大量讨论,认为AI已进入“幻灭的低谷”,尤其是在GPT-5发布后。用户指出,AI的局限性并未被有效突破,模型规模和算力提升带来的收益正在递减。这一观点认为,AI的进步已变得“不那么明显”,主要体现在专家领域,而非普通用户可感知的层面,预示着AI发展可能进入一个平台期,需要全新的架构突破。(来源:Reddit r/ArtificialInteligence)

💡 其他
Docker警告MCP工具链安全风险 : Docker发布警告,指出基于模型上下文协议(MCP)构建的AI驱动开发工具链存在严重安全漏洞,包括凭证泄露、未经授权的文件访问和远程代码执行,且已有真实案例发生。这些工具将LLM嵌入开发环境,赋予其自主操作权限,但缺乏隔离和监督。Docker建议避免从npm安装MCP服务器,改用经签名的容器,并强调容器隔离和零信任网络的重要性。(来源:WeChat)

华为鸿蒙应用开发者激励计划2025 : 华为宣布HarmonyOS 5终端数量突破千万,并启动“鸿蒙应用开发者激励计划2025”,投入上亿元补贴,单个开发者最高可获600万奖金。该计划旨在加速鸿蒙生态发展,吸引开发者面向AI和多终端进行应用开发,实现“一次开发,多端部署”。华为提供全栈式开发支持,包括技术赋能、快速测试、高效上架和运营,旨在构建稳固的开发者生态。(来源:WeChat)

国产AI超节点服务器元脑SD200发布 : 浪潮信息发布超节点AI服务器“元脑SD200”,旨在解决万亿参数大模型运行的算力挑战。该服务器采用创新研发的多主机低延迟内存语义通信架构,可聚合64路本土GPU芯片,提供最大4TB统一显存和64GB统一内存,支持万亿超长序列模型。实测显示,SD200在DeepSeek R1等模型上实现极佳算力扩展效率,为AI4 Science和工业领域应用提供强大支持。(来源:WeChat)
