关键词:AI研究, 计算机科学, 强化学习, 药物研发, 自动驾驶, 语言模型, 多模态处理, 虚拟细胞, Laude Institute, 强化学习教师(RLTs), BioNeMo平台, 特斯拉Robotaxi, Kimi VL A3B Thinking模型
🔥 聚焦
Laude Institute成立,获1亿美元初始资金推动计算机科学公益研究: Andy Konwinski宣布启动Laude Institute,这是一个旨在资助对世界产生重大影响的非营 коммерial计算机科学研究的非营利组织。Jeff Dean、Joyia Pineau和Dave Patterson等知名人士加入董事会。该机构获得了1亿美元的初始承诺资金,将通过资助、资源共享和社区建设,支持研究人员将想法转化为实际影响力,特别关注开放和具有影响力导向的研究。 (来源: JeffDean, matei_zaharia, lschmidt3, Tim_Dettmers, andrew_n_carr, gneubig, lateinteraction, sarahookr, jefrankle)

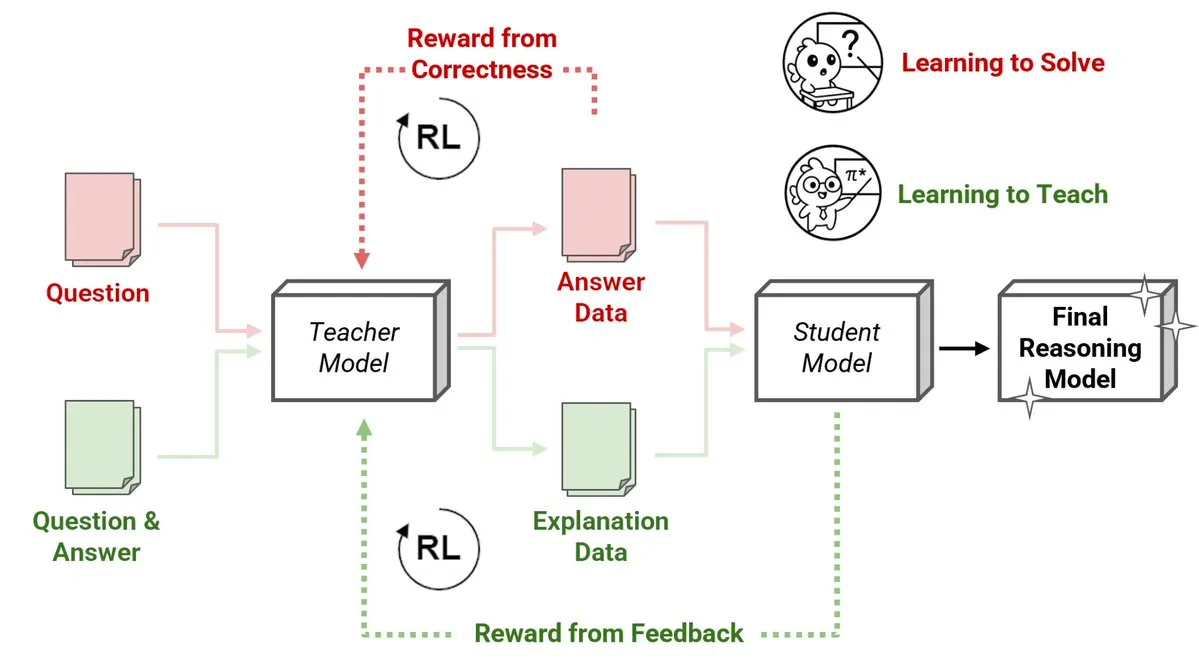
Sakana AI发布强化学习教师(RLTs)新方法,小模型教大模型推理: Sakana AI推出了强化学习教师(RLTs)的新方法,通过强化学习(RL)改变大型语言模型(LLMs)的推理教学方式。传统RL侧重于“学习解决”问题,而RLTs则被训练生成清晰的、逐步的“解释”来教导学生模型。一个仅有7B参数的RLT在教授32B参数的学生模型时,其在竞争性和研究生水平的推理任务上的表现优于数倍于自身大小的LLM。这种方法为开发具有RL的推理语言模型设定了新的效率标准。 (来源: cognitivecompai, AndrewLampinen)
英伟达与诺和诺德合作,利用AI超级计算机加速药物研发: 英伟达宣布与丹麦制药巨头诺和诺德(Novo Nordisk)及丹麦国家AI创新中心合作,共同利用AI技术和丹麦最新的Gefion超级计算机加速新药研发。此次合作将采用英伟达的BioNeMo平台和先进的AI工作流程,旨在变革药物研究与开发模式。Gefion超级计算机由Eviden和英伟达的技术构建,将为生命科学等领域的研究提供强大的算力支持,推动个性化医疗和新疗法的发现。 (来源: nvidia)

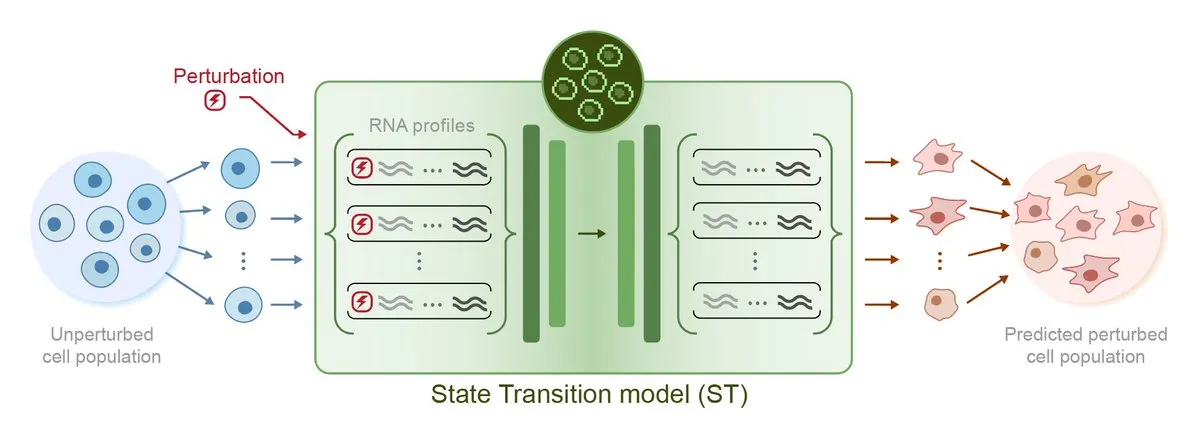
Arc Institute发布首个扰动预测AI模型STATE,迈向虚拟细胞目标: Arc Institute发布了其首个扰动预测AI模型STATE,这是其实现虚拟细胞目标的重要一步。STATE模型旨在学习如何利用药物、细胞因子或基因扰动来改变细胞状态(例如从“患病”到“健康”)。此模型的发布标志着AI在理解和预测细胞行为方面取得了新进展,为疾病治疗和药物开发开辟了新途径。相关模型已在HuggingFace上开放。 (来源: riemannzeta, ClementDelangue)
特斯拉Robotaxi在奥斯汀启动试点,视觉方案受关注,Karpathy遗留代码被大幅精简: 特斯拉在美国得克萨斯州奥斯汀市正式启动Robotaxi试点服务,首批车辆基于Model Y改造,采用纯视觉感知方案和FSD软件。特斯拉AI与自动驾驶软件负责人Ashok Elluswamy领导团队,对系统进行了重大技术变革,将Andrej Karpathy团队遗留的约33-34万行C++启发式代码精简近90%,用“巨型神经网络”替代。此举旨在从“人类经验编码”转向“参数化训练”,通过海量数据和模拟驾驶自主优化模型。目前服务处于早期体验阶段,引发行业对特斯拉技术路线和规模化能力的广泛讨论。 (来源: 36氪, Ronald_vanLoon, kylebrussell)

🎯 动向
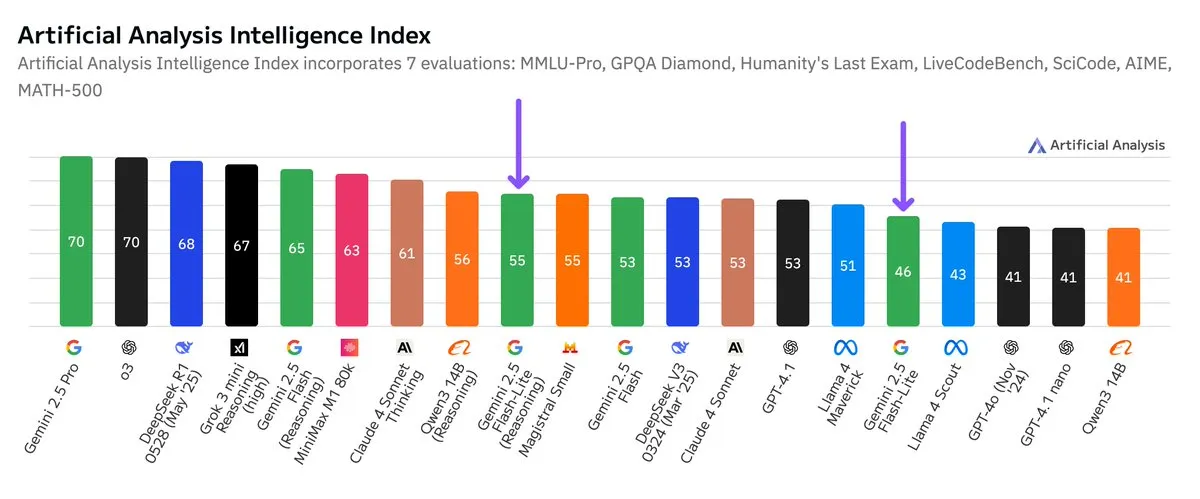
谷歌Gemini 2.5 Flash-Lite独立基准测试发布,性价比提升: 根据Artificial Analysis发布的独立基准测试结果,谷歌Gemini 2.5 Flash-Lite Preview (06-17) 版本相较于常规Flash版本,成本降低约5倍,速度提升约1.7倍,但智能水平有所下降。该模型是2025年2月发布的Gemini 2.0 Flash-Lite的升级版,属于混合模型。这一更新显示了谷歌在追求模型效率和成本效益方面的持续努力,可能面向对成本和速度有较高要求的应用场景。 (来源: zacharynado)
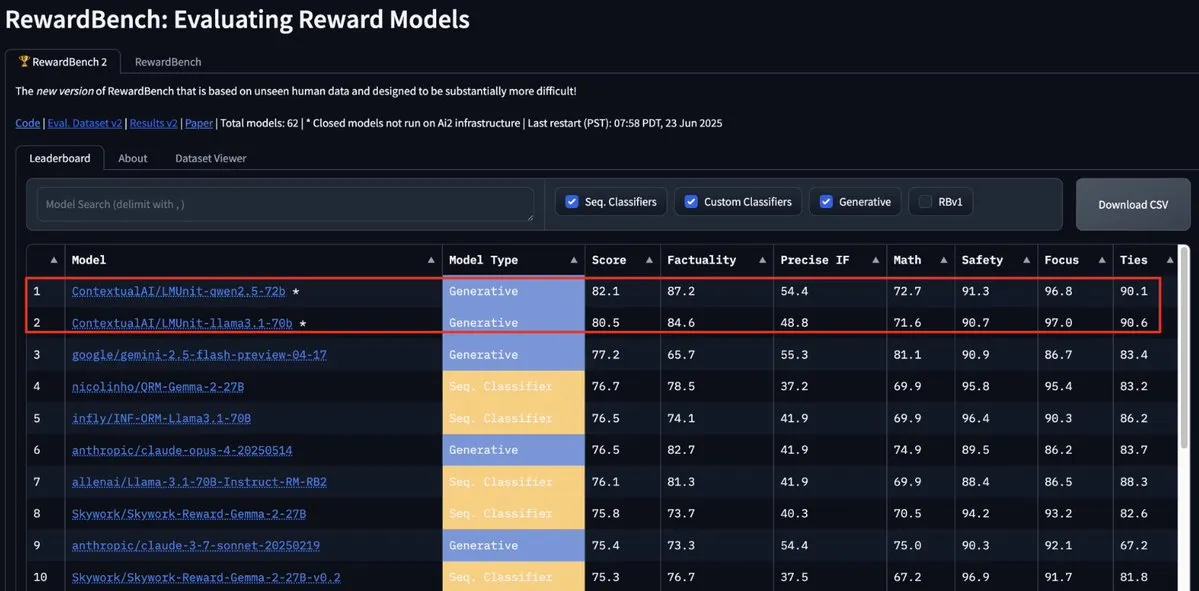
ContextualAI的LMUnit模型登顶RewardBench2,超越Gemini、Claude 4和GPT-4.1: ContextualAI的LMUnit模型在RewardBench2基准测试中排名第一,得分比Gemini、Claude 4和GPT-4.1等知名模型高出5%以上。这一成就可能归功于其独特的训练方法,据称类似于OpenAI为o4及后续模型投入大量精力研发的“rubrics”方法,这种方法有助于实现LLM作为裁判(llm-as-a-judge)在推理时进行有效的扩展。 (来源: natolambert, menhguin, apsdehal)
Arcee.ai成功将AFM-4.5B模型上下文长度从4k扩展至64k: Arcee.ai宣布其首个基础模型AFM-4.5B的上下文长度已成功从4k扩展至64k。团队通过积极的实验、模型合并、蒸馏以及被戏称为“大量的汤”(指模型融合技术)等方法实现了这一突破。这一进展对于处理长文本任务至关重要,Arcee在GLM-32B-Base模型上的改进也证明了其有效性,不仅长下文支持从8k提升至32k,所有基础模型评估(包括短上下文)均有改进。 (来源: eliebakouch, teortaxesTex, nrehiew_, shxf0072, code_star)

谷歌Gemini API更新,提升视频和PDF处理速度与能力: 谷歌Gemini API在处理视频和PDF方面迎来重要更新。缓存视频的首次响应时间(TTFT)提升了3倍,缓存PDF的处理速度最高提升4倍。此外,新版本支持批量处理多个视频,并且隐式缓存的性能已接近显式缓存。这些改进旨在提升开发者使用Gemini API处理多媒体内容的效率和体验。 (来源: _philschmid)
Moonshot (Kimi) 更新Kimi VL A3B Thinking模型,提升多模态处理能力: Moonshot AI (Kimi) 发布了其小型视觉语言模型 (VLM) Kimi VL A3B Thinking的更新版本,该模型基于MIT许可证。新版本在消耗更少token、缩短思考轨迹的同时,支持视频处理并能处理更高分辨率的图像(1792×1792)。在VideoMMMU上达到65.2分,MathVision提升20.1分至56.9分,MathVista提升8.4分至80.1分,MMMU-Pro提升3.2分至46.3分,并在视觉推理、UI Agent定位、视频和PDF处理方面表现出色,已在Hugging Face开源。 (来源: mervenoyann)

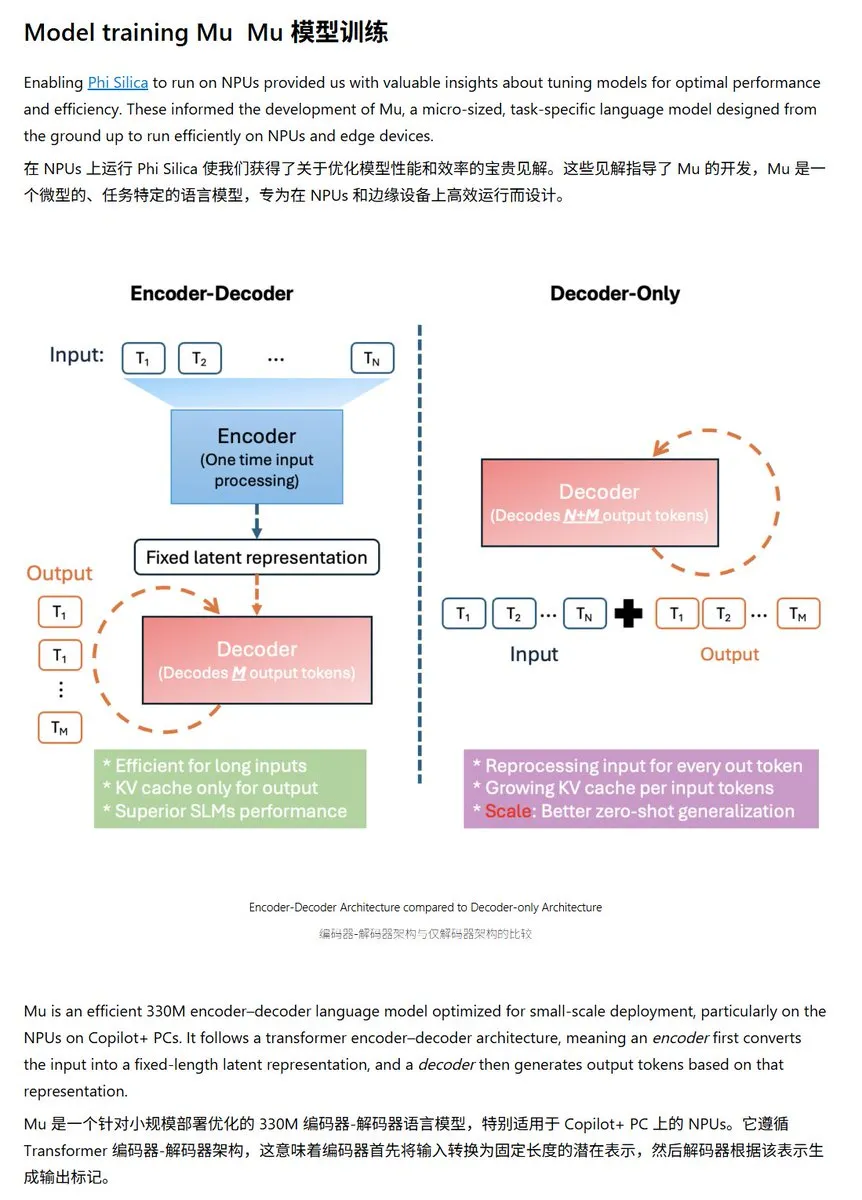
微软发布Mu-330M小型语言模型,专为Windows NPU优化: 微软推出全新小型语言模型Mu-330M,设计用于Windows Copilot+ PC的NPU(神经处理单元)上运行,旨在支持Windows系统内的Agent功能。该模型针对NPU进行了优化,采用了旋转位置嵌入、分组查询注意力、双层LayerNorm等技术,以在低性能消耗下高效运行,标志着微软在端侧AI能力上的进一步布局。 (来源: karminski3)
DeepMind发布Mercury技术报告,专注于扩散语言模型: Inception Labs (DeepMind相关团队) 发布了其扩散语言模型Mercury的技术报告。该报告详细介绍了Mercury模型的架构、训练方法和实验结果,为研究人员提供了关于这一新兴模型类型的深入见解。扩散模型在图像生成领域已取得显著成功,将其应用于语言模型是当前AI研究的一个前沿方向。 (来源: andriy_mulyar)
Meta与Oakley合作扩展AI智能眼镜系列: Meta与眼镜品牌Oakley合作,进一步扩展其AI智能眼镜产品线。新款智能眼镜预计将集成Meta的AI技术,提供更丰富的交互功能和用户体验。此次合作标志着Meta在可穿戴AI设备领域的持续投入,旨在将AI更无缝地融入日常生活。 (来源: rowancheung, Ronald_vanLoon)
阿里云推出自动驾驶模型训推加速框架PAI-TurboX,训练时间可缩短50%: 阿里云发布了面向自动驾驶领域的模型训练与推理加速框架PAI-TurboX。该框架旨在提升感知、规划控制乃至世界模型的训推效率,通过优化多模态数据预处理、CPU亲和性、动态编译、流水线并行等策略,并提供算子优化和量化能力。实测显示,在BEVFusion、MapTR、SparseDrive等多个行业模型的训练任务中,PAI-TurboX可将训练时间缩短约50%。 (来源: 量子位)
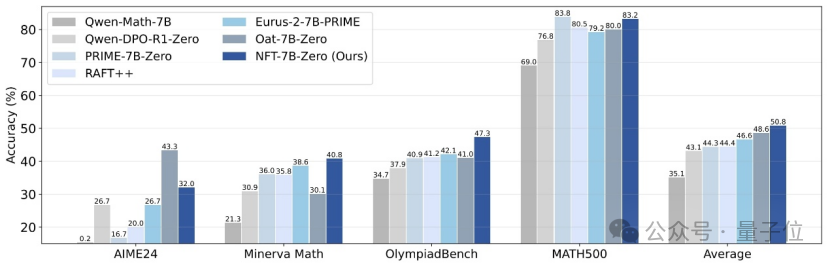
清华与英伟达等提出NFT方法,使监督学习能从错误中“反思”: 清华大学、英伟达及斯坦福大学的研究者联合提出了一种名为NFT(Negative-aware FineTuning)的新监督学习方案。该方法在RFT(Rejection FineTuning)算法基础上,通过构建“隐式负向模型”来利用负向数据进行训练,即“隐式负向策略”。此策略使得监督学习也能像强化学习一样进行“自我反思”,弥合了监督学习与强化学习在某些能力上的差距,并在数学推理等任务上展示了显著性能提升,甚至在On-Policy条件下其损失函数梯度与GRPO等价。 (来源: 量子位)
OmniGen2发布:8B多功能修图模型,融合视觉理解与图像生成: 一个名为OmniGen2的新型多功能修图模型发布,该模型将视觉理解(基于Qwen-VL-2.5)与图像生成(一个4B参数的扩散模型)相结合,总参数量约8B。OmniGen2能够支持文生图、图像编辑、图像理解以及上下文生成等多种任务,旨在提供一个能解决多种视觉相关问题,并适合在端侧集成的统一模型。 (来源: karminski3)

Chroma-8.9B-v39文本生成图像模型更新,基于FLUX.1-schnell,可商用: 文本到图像模型Chroma-8.9B-v39发布更新,提升了光照和任务自然度。该模型基于FLUX.1-schnell,参数量从12B压缩至8.9B,采用Apache 2.0许可证,允许商业使用。据称,模型“重新引入了缺失的解剖学概念,完全无内容限制”,并使用包含500万动漫、furry、艺术作品和照片的数据集进行了后训练。 (来源: karminski3)

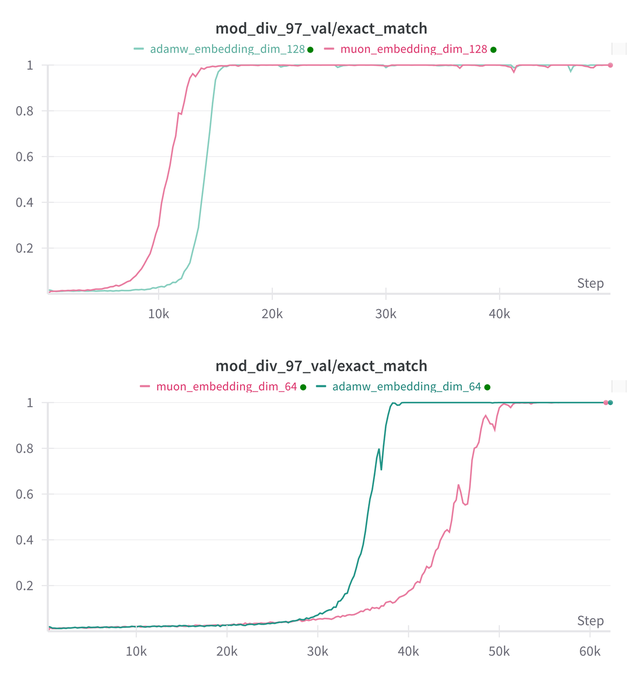
Essential AI更新其模型Muon和Adam在Grokking能力上的研究结论: Essential AI分享了关于其模型Muon和Adam在Grokking(一种现象,指模型在训练初期表现不佳,然后突然理解泛化)能力方面的最新研究进展。初步假设可能与实际观察有所矛盾,团队公开了内部小型研究实验的结果,显示在扩展超参数搜索空间后,Muon相对于AdamW并无明显普适优势,两者在不同场景下互有胜负。这表明AdamW在许多情况下仍然是强大乃至SOTA的优化器。 (来源: eliebakouch, teortaxesTex, nrehiew_)
Ostris AI图像生成模型更新,专注无CFG版本并优化高频细节: Ostris AI持续更新其图像生成模型,目前专注于无CFG(Classifier-Free Guidance)版本的开发,因其收敛速度更快。最新的Day 7更新中,团队加入新的训练技巧以更好地处理高频细节,并努力去除高细节伪影。此前的Day 4更新已展示了在不使用CFG的情况下,通过新方法生成的图像质量得到显著改善。 (来源: ostrisai)

蚂蚁与中科院等开源ViLaSR-7B模型,实现“边画边想”空间推理: 蚂蚁技术研究院、中科院自动化所及香港中文大学联合开源了ViLaSR-7B模型,该模型通过“Drawing to Reason in Space”范式,使大型视觉语言模型(LVLM)能够在视觉空间中绘制辅助标记(如参考线、边界框)来辅助思考,从而增强空间感知和推理能力。ViLaSR采用三阶段训练框架:冷启动、反思拒绝采样和强化学习。实验表明,该模型在迷宫导航、图像理解和视频空间推理等5个基准上平均提升18.4%,并在VSI-Bench上表现接近Gemini-1.5-Pro。 (来源: 量子位)

🧰 工具
SGLang现已支持Hugging Face Transformers作为后端,提升推理效率: SGLang宣布其已支持Hugging Face Transformers作为后端。这意味着用户可以为任何与Transformers兼容的模型提供快速、生产级的推理服务,无需原生支持,即插即用。这一集成旨在简化高性能语言模型推理的部署流程,扩大SGLang的适用范围和易用性。 (来源: TheZachMueller, ClementDelangue)

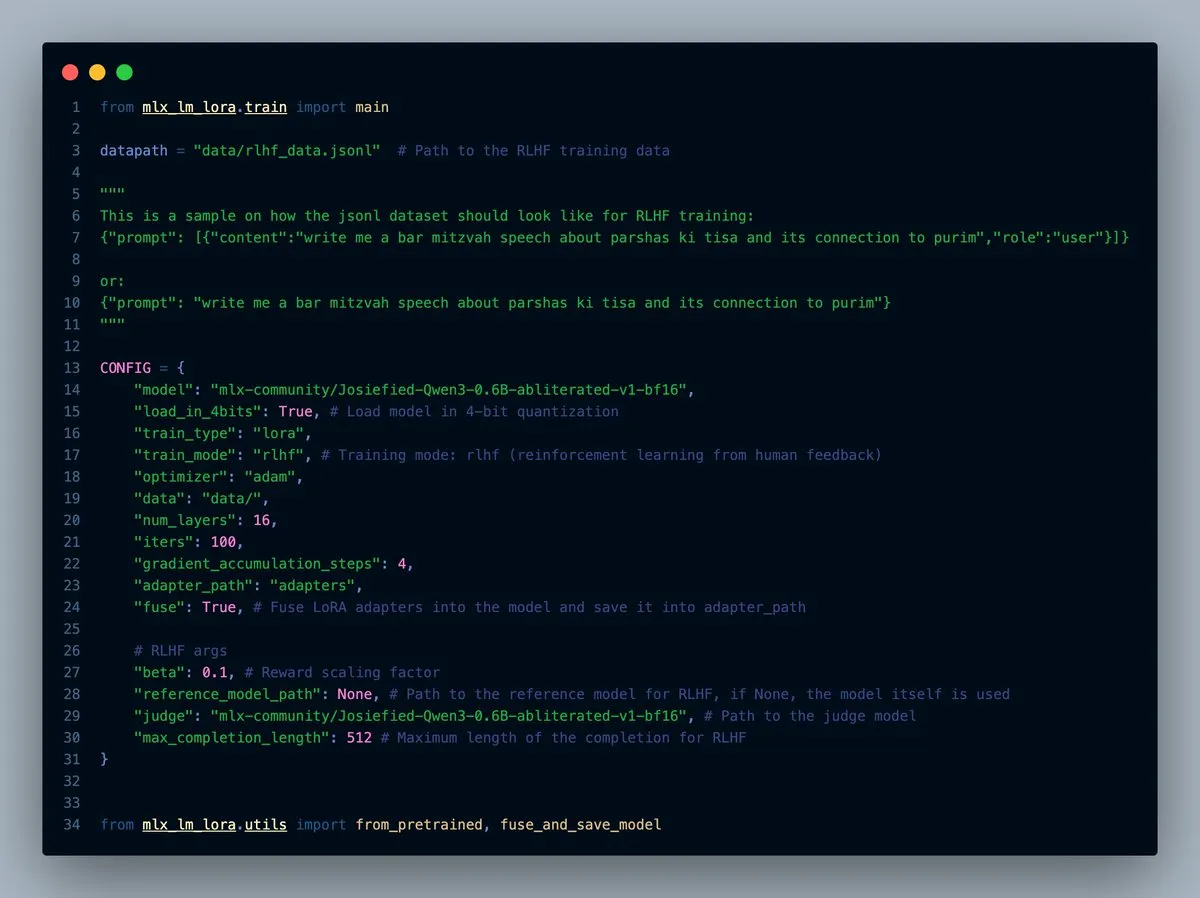
MLX-LM-LORA v0.7.0发布,内置RLHF功能: MLX-LM-LORA发布了v0.7.0版本,新版本内置了从人类反馈中进行强化学习(RLHF)的功能。该工具现在支持4位、6位、8位加载,RLHF训练模式,并且可以直接将适配器(adapters)融合到基础权重中。这使得在MLX框架下进行LoRA微调更加智能和高效,特别是在苹果芯片设备上。 (来源: awnihannun)
LlamaCloud发布,为文档工作流提供MCP兼容工具箱: LlamaCloud现已推出,作为一个与模型上下文协议(MCP)兼容的工具箱,可用于任何文档工作流。用户可以将其接入Claude等模型,实现复杂的文档提取、比较等操作。例如,它可以分析特斯拉过去五个季度的财务表现并生成综合报告,通过动态创建标准化模式并在所有文件上运行,然后利用代码生成最终结果。LlamaCloud能够动态纠正不正确的模式,并支持直接文件链接。 (来源: jerryjliu0)
Georgi Gerganov预告LlamaBarn项目: Georgi Gerganov(llama.cpp的创建者)在社交媒体上发布了一张图片,预告了一个名为“LlamaBarn”的新项目。图片显示了一个类似仪表盘的界面,其中包含模型选择、参数调整等元素,暗示这可能是一个用于管理、运行或测试本地LLM的工具。社区对此表示期待,认为其可能成为Ollama等现有工具的有力竞争者。 (来源: ClementDelangue, teortaxesTex, jeremyphoward)
Void Editor:一个新的开源AI编程助手,支持MCP和本地模型: Void Editor作为一款新的开源AI编程助手亮相,旨在成为Cursor等工具的替代品。它支持tab自动补全、聊天模式、模型上下文协议(MCP)以及Agent模式。用户可以连接任何大型语言模型API或在本地运行模型,为开发者提供了灵活的AI辅助编程体验。 (来源: karminski3)
Together AI推出Which LLM工具,帮助选择合适的开源LLM: Together AI发布了一款名为“Which LLM”的免费工具,旨在帮助用户根据特定用例、性能需求和经济考量来选择最合适的开源大型语言模型。随着开源LLM数量的激增,这类工具能够为开发者和研究人员在模型选型时提供有价值的参考。 (来源: vipulved)
Perplexity Finance新增股价时间轴追踪功能: Perplexity Finance宣布用户现在可以在其平台上追踪任何股票代码的价格变动时间轴。这一新功能旨在为用户提供更直观、便捷的金融市场信息分析工具,结合Perplexity的AI能力,可能为金融信息查询和分析带来新的体验。 (来源: AravSrinivas)

IdeaWeaver推出首个用于系统性能调试的AI代理: IdeaWeaver发布了其宣称的首个专为调试系统性能问题而设计的AI代理。该工具利用CrewAI框架,能够实际执行系统命令来诊断CPU、内存、I/O和网络等相关问题。其特点是优先使用本地LLM(通过OLLAMA)以保护隐私,仅在本地模型不可用时才请求OpenAI API密钥,旨在将AI能力应用于DevOps和系统管理领域。 (来源: Reddit r/artificial)
Kling AI新增Live Photo支持,可将生成视频存为动态壁纸: Kling AI宣布其视频生成功能现已支持将作品保存为Live Photos(实况照片)。用户可以将喜欢的Kling创作的动态内容设置为手机壁纸,增加了AI生成视频的趣味性和实用性。 (来源: Kling_ai)
Cognition AI开源Blockdiff,实现VM快照速度200倍提升: Cognition AI宣布开源其为Devin开发的VM快照文件格式Blockdiff。由于EC2创建VM快照耗时过长(30+分钟),团队自行构建了otterlink虚拟机管理程序和Blockdiff文件格式,使得快照创建速度提升了200倍。这一开源贡献旨在帮助开发者更高效地管理虚拟机环境。 (来源: karinanguyen_)

📚 学习
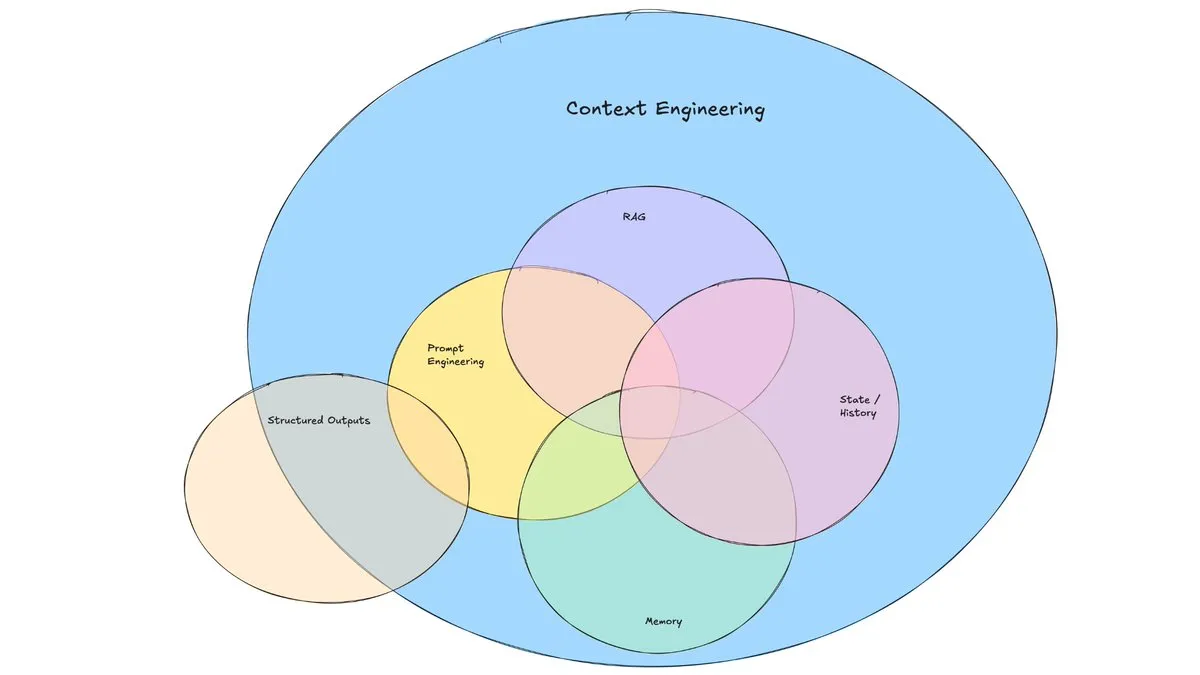
LangChain博文探讨“上下文工程”的兴起: LangChain发布博文,探讨了“上下文工程”(Context Engineering)这一日益流行的术语。文章将其定义为“构建动态系统,以正确的格式提供正确的信息和工具,从而使LLM能够合理地完成任务”。这并非全新概念,Agent构建者已实践多时,LangGraph、LangSmith等工具也为此而生。该术语的提出有助于引起对相关技能和工具的更多关注。 (来源: hwchase17, Hacubu, yoheinakajima)
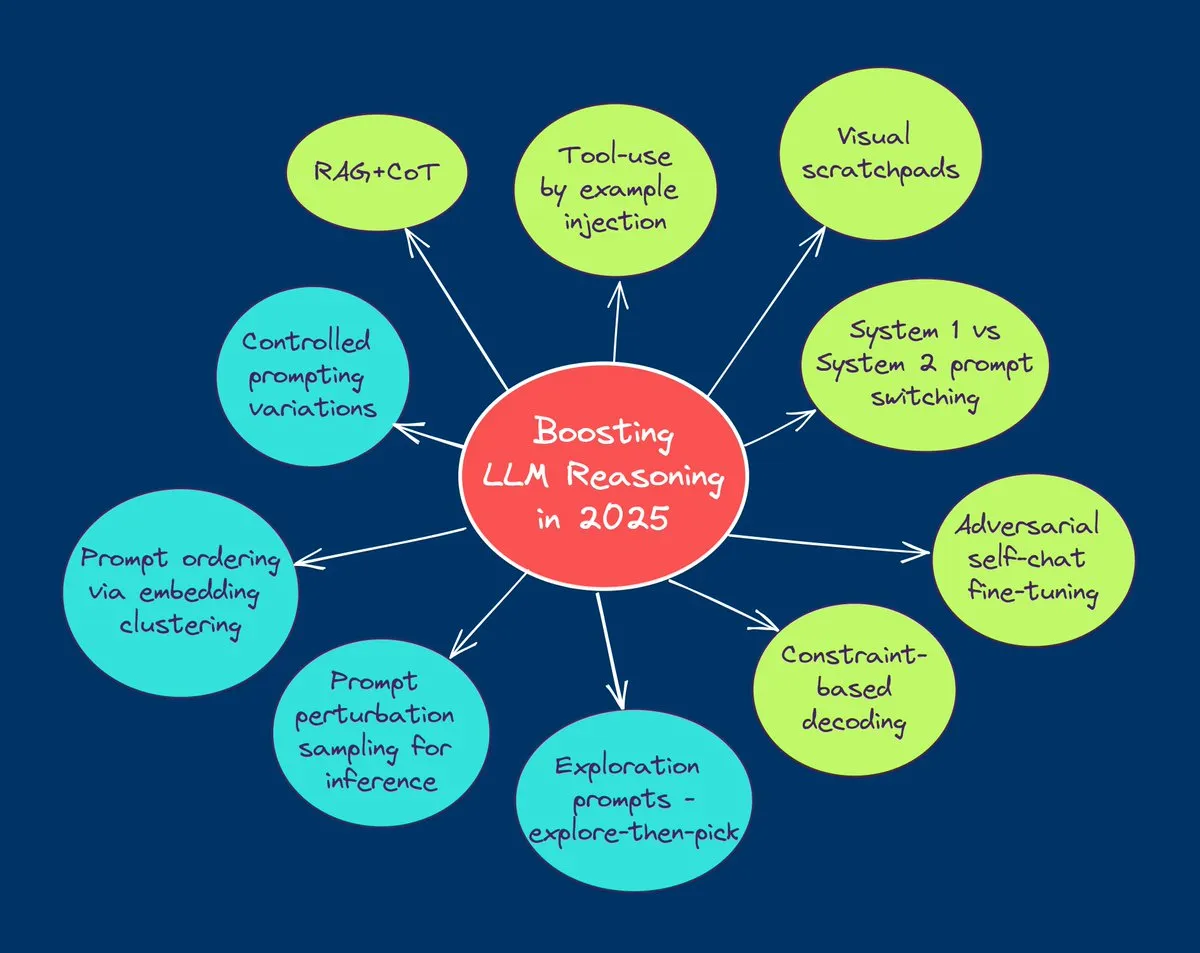
TuringPost总结2025年提升LLM推理能力的10大技术: TuringPost分享了2025年用于提升大型语言模型(LLM)推理能力的10种关键技术,包括:检索增强的思维链(RAG+CoT)、通过示例注入使用工具、视觉草稿纸(多模态推理支持)、系统1与系统2提示切换、对抗性自对话微调、基于约束的解码、探索性提示(先探索后选择)、用于推理的提示扰动采样、通过嵌入聚类进行提示排序以及受控的提示变体。这些技术为优化LLM在复杂任务中的表现提供了多样化的途径。 (来源: TheTuringPost, TheTuringPost)
Cohere Labs举办ML暑期学校,探索机器学习未来: Cohere Labs的开放科学社区将在7月举办ML暑期学校(ML Summer School)。该活动将汇集全球社区成员,共同探讨机器学习的未来,并邀请行业内的演讲者进行分享。其中,Katrina Lawrence将于7月2日主讲机器学习数学复习课程,涵盖微积分、向量微积分和线性代数等核心概念。 (来源: sarahookr)

DeepLearning.AI与Meta合作推出“Building with Llama 4”免费课程: DeepLearning.AI与Meta合作推出了名为“Building with Llama 4”的免费课程。课程内容包括:Llama 4系列模型的实践操作,理解其混合专家(MOE)架构,以及如何使用官方API构建应用程序;应用Llama 4进行多图像推理、图像定位(识别对象及其边界框),以及处理长达100万token的长上下文文本查询;使用Llama 4的提示优化工具自动改进系统提示,并利用其合成数据工具包创建高质量数据集进行微调。 (来源: DeepLearningAI)
EleutherAI YouTube频道提供大量AI研究内容: EleutherAI的YouTube频道汇集了其读书会和演讲系列的录播视频,内容超过100小时。主题涵盖机器学习的可扩展性与性能、泛函分析,以及团队成员的播客和访谈等。该频道为AI研究人员和爱好者提供了丰富的学习资源。EleutherAI还推出了新的演讲系列,首期由@linguist_cat主讲分词器及其局限性。 (来源: BlancheMinerva, BlancheMinerva)
论文探讨通过潜在视觉Token增强多模态推理(Machine Mental Imagery): 一篇新论文《Machine Mental Imagery: Empower Multimodal Reasoning with Latent Visual Tokens》提出Mirage框架,通过在VLM解码过程中加入潜在视觉Token(而非生成完整图像)来增强多模态推理,模拟人类的心理意象。该方法首先通过蒸馏真实图像嵌入来监督潜在Token,然后切换到纯文本监督使潜在轨迹与任务目标对齐,并通过强化学习进一步提升能力。实验证明Mirage能在不生成明确图像的情况下实现更强的多模态推理。 (来源: HuggingFace Daily Papers)
论文提出Vision as a Dialect框架,通过文本对齐表示统一视觉理解与生成: 一篇名为《Vision as a Dialect: Unifying Visual Understanding and Generation via Text-Aligned Representations》的论文,介绍了一个名为Tar的多模态LLM框架。该框架使用文本对齐分词器(TA-Tok)将图像转换为离散Token,并利用LLM词汇表投影的文本对齐码本,从而将视觉和文本统一到共享的离散语义表示中。Tar通过共享接口实现跨模态输入输出,无需特定模态设计,并采用尺度自适应编解码和生成式去分词器以平衡效率和视觉细节。 (来源: HuggingFace Daily Papers)
论文提出ReasonFlux-PRM:用于LLM长链思维推理的轨迹感知PRM: 论文《ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs》介绍了一种新颖的轨迹感知过程奖励模型(PRM),专门用于评估类似DeepSeek-R1等前沿推理模型生成的轨迹-响应类型的推理痕迹。ReasonFlux-PRM结合了步骤级和轨迹级监督,实现了与结构化思维链数据对齐的细粒度奖励分配,并在SFT、RL和BoN测试时扩展等场景下均取得性能提升。 (来源: HuggingFace Daily Papers)
论文研究大型语言模型越狱防护栏的评估方法: 一篇名为《SoK: Evaluating Jailbreak Guardrails for Large Language Models》的论文对大型语言模型(LLMs)的越狱攻击及其防护栏(Guardrails)进行了系统性知识梳理。论文提出了一个新的多维度分类法,从六个关键维度对防护栏进行分类,并引入了一个安全性-效率-实用性评估框架来评估其实际效果。通过广泛分析和实验,论文指出了现有防护栏方法的优缺点,探讨了其对不同攻击类型的普适性,并为优化防御组合提供了见解。 (来源: HuggingFace Daily Papers)
AAAI 2025杰出论文探讨部分可观察马尔可夫决策过程(POMDP)的可判定类: 一篇题为《Revelations: A Decidable Class of POMDP with Omega-Regular Objectives》的论文获得了AAAI 2025杰出论文奖。该研究确定了一个可判定的MDP(马尔可夫决策过程)类别:具有“强启示”的决策问题,即在每一步都有非零概率揭示世界的精确状态。论文还提供了“弱启示”的可判定性结果,其中精确状态保证最终会被揭示,但不一定在每一步都揭示。这项研究为在信息不完全情况下进行最优决策提供了新的理论基础。 (来源: aihub.org)
论文提出CommVQ:用于KV缓存压缩的交换向量量化: 论文《CommVQ: Commutative Vector Quantization for KV Cache Compression》提出了一种名为CommVQ的方法,通过加性量化和轻量级编码器及码本压缩KV缓存,以减少长上下文LLM推理中的内存占用。为降低解码计算成本,码本被设计为可与旋转位置嵌入(RoPE)交换,并使用EM算法训练。实验表明,该方法在2bit量化下可将FP16 KV缓存大小减少87.5%,并优于现有KV缓存量化方法,甚至能以极小精度损失实现1bit KV缓存量化。 (来源: HuggingFace Daily Papers)
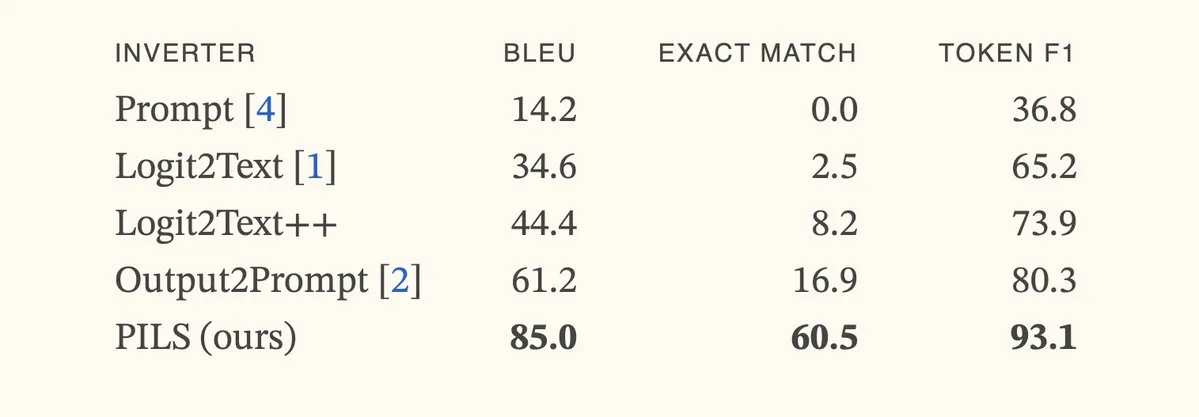
论文提出PILS方法,通过紧凑表示下一Token分布改进语言模型反演: 论文《Better Language Model Inversion by Compactly Representing Next-Token Distributions》提出了一种新的语言模型反演方法PILS(Prompt Inversion from Logprob Sequences)。该方法通过分析模型在多个生成步骤中的下一Token概率来恢复隐藏提示。核心在于发现语言模型输出向量占据低维子空间,从而可以通过线性映射无损压缩下一Token概率分布,用于更有效的反演。实验表明,PILS在恢复隐藏提示方面显著优于先前SOTA方法。 (来源: HuggingFace Daily Papers, jxmnop)
论文提出Phantom-Data:一个通用的主体一致性视频生成数据集: 论文《Phantom-Data : Towards a General Subject-Consistent Video Generation Dataset》介绍了一个名为Phantom-Data的新数据集,旨在解决现有主体到视频生成模型中普遍存在的“复制粘贴”问题(即主体身份与背景、上下文属性过度纠缠)。Phantom-Data是首个通用的跨配对主体到视频一致性数据集,包含约一百万个在不同类别中身份一致的配对。该数据集通过三阶段流程构建,包括主体检测、大规模跨上下文主体检索和先验引导的身份验证。 (来源: HuggingFace Daily Papers)
论文提出LongWriter-Zero:通过强化学习掌握超长文本生成: 论文《LongWriter-Zero: Mastering Ultra-Long Text Generation via Reinforcement Learning》提出了一种基于激励的方法,从零开始利用强化学习(RL)培养LLM生成超长、高质量文本的能力,无需任何标注或合成数据。该方法从基础模型开始,通过RL引导其进行规划和写作过程中的提炼,并使用专门的奖励模型来控制长度、写作质量和结构格式。实验表明,从Qwen2.5-32B训练的LongWriter-Zero在长文本写作任务上优于传统SFT方法,并在多个基准测试中达到SOTA水平。 (来源: HuggingFace Daily Papers)
💼 商业
法律AI公司Harvey宣布完成3亿美元E轮融资,估值达50亿美元: 法律AI初创公司Harvey宣布完成由Kleiner Perkins和Coatue共同领投的3亿美元E轮融资,公司估值达到50亿美元。其他投资者包括红杉资本、GV、DST Global、Conviction、Elad Gil、OpenAI创业基金、Elemental、SV Angel、Kris Fredrickson和REV。这笔融资将助力Harvey继续开发和扩展其在法律领域的AI应用。 (来源: saranormous)
Hyperbolic按需GPU云服务上线7天ARR达100万美元: Yuchenj_UW宣布其上周推出的Hyperbolic按需GPU云服务,在仅通过一条推文进行少量营销的情况下,7天内年度经常性收入(ARR)从0增长到100万美元。他们为构建者提供免费的8xH100节点试用额度,显示出市场对高性能GPU云服务的强烈需求。 (来源: Yuchenj_UW)
Replit宣布年度经常性收入(ARR)突破1亿美元: 在线集成开发环境(IDE)和云计算平台Replit宣布其年度经常性收入(ARR)已突破1亿美元,较2024年底的1000万美元实现显著增长。公司表示,其在2023年以11亿美元估值完成最后一轮融资后,银行仍有过半资金。Replit的增长得益于企业用户(如Zillow、HubSpot)和独立开发者对其平台的使用,目前正在积极招聘。 (来源: pirroh, kylebrussell, hwchase17, Hacubu)
🌟 社区
AI编程新范式:先设计再提示,迭代优化代码生成: dotey和宝玉探讨了AI编程带来的软件开发模式转变。传统争论的“先设计再编码”与“先实现再重构”在AI时代得到融合。AI极大缩短了从设计到编码的成本和时间,允许开发者在设计尚不完全清晰时快速实现版本,并通过验证结果迭代改进设计和提示词。提示词担当了以往“详细设计文档”的角色,但更为简化。这种模式下,开发者应更注重系统设计,小批量生成代码,利用源码管理,对AI生成的代码进行审查和测试。对于经验丰富的程序员,转变思维和开发习惯是拥抱AI编程的关键。 (来源: dotey)
Claude Code因其强大的大代码库处理能力和上下文效率受开发者青睐: Reddit r/ClaudeAI社区热议Claude Code在处理大型代码库方面的卓越表现。用户反馈其能很好地理解远超200k Token大小的代码库并实现修改。讨论认为,Claude Code可能通过类似人类阅读的策略(只读关键部分)、使用grep等工具进行上下文检索(而非完全依赖RAG的向量化压缩)、以及第一方模型集成的优势,实现了高效的上下文处理。用户分享了使用Claude Code进行系统问题修复、构建个人财务追踪器、开发安卓应用(即使无安卓开发经验)、创建Obsidian DataviewJS脚本等多种成功案例,显著提升了工作效率。 (来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

“上下文工程”概念引关注,强调构建动态系统赋能LLM: LangChain的Harrison Chase提出“上下文工程”(Context Engineering)是AI工程师进行系统构建的核心工作。它被定义为“构建动态系统,以正确的格式提供正确的信息和工具,使LLM能够合理地完成任务”。这一概念强调了在LLM应用中,如何有效地组织和提供上下文信息对于模型性能的重要性,是Agent构建等领域的基础。 (来源: hwchase17, Hacubu, yoheinakajima)
Meta创始人扎克伯格亲自招募AI人才,引发社区关注: 社交媒体消息称,Meta创始人马克·扎克伯格正亲自参与其超智能实验室的人才招募工作,直接联系数百名潜在候选人,并邀请回应者共进晚餐。这一举动被解读为Meta在AI领域,特别是通用人工智能(AGI)或超智能方面投入的决心和力度,显示出顶级科技公司对AI顶尖人才的激烈争夺。 (来源: reach_vb, andrew_n_carr)

AI发展引发对就业市场和经济结构的深刻反思: 哈佛商学院及经济学家Anton Korinek预警,AGI可能在2-5年内实现,若经济体系不彻底变革可能导致崩溃,并强调全民基本收入的必要性。同时,社区讨论认为,AI将自动化大量可量化任务,冲击蓝领和白领工作,企业需重构组织架构以适应AI。Yuval Noah Harari将AI革命比作“AI移民潮”,引发关于AI取代就业和权力寻求的讨论。这些观点共同指向AI对未来社会经济结构的颠覆性影响。 (来源: 36氪, 36氪, Reddit r/artificial, Reddit r/ChatGPT)

AI在编程竞赛中表现突出,Sakana AI智能体成绩优异引热议: Sakana AI的智能体在AtCoder启发式编程竞赛中,于1000多名人类程序员中排名第21位,总体表现位列前6.8%。该AI在4小时内迭代约100个版本,生成数千个潜在解决方案,而人类选手通常只能测试约12个。AI使用了Gemini 2.5 Pro,并结合专家知识与系统搜索算法(如模拟退火和波束搜索)解决实际优化问题。社区对此反应不一,有人认为竞赛编程与企业级工程不同,AI的胜利更像计算机在加减法上胜过人类。 (来源: Reddit r/ArtificialInteligence)
💡 其他
AI在职业教育领域的探索:面试、老师与学习机的多元尝试: 华图、粉笔、中公等职业教育巨头正积极探索AI应用,方向各异。华图聚焦AI面试点评,粉笔深耕AI批改与AI老师(AI刷题系统班销售额已破1400万),中公则推出AI就业学习机。行业共识是AI应提升学习效果和运营效率,而非单纯追求高溢价。AI的应用也从概念验证走向场景深耕,如51CTO利用数字人、3D建模生成课程,并通过AI进行试题生成和学习路径分析。然而,多数教育企业尚不具备自建大模型的能力,更倾向于调用第三方API。 (来源: 36氪)
迪士尼、环球影业起诉AI生图独角兽Midjourney侵权: 好莱坞巨头迪士尼和环球影业联合起诉AI图像生成公司Midjourney,指控其未经许可使用大量受版权保护的IP内容(如钢铁侠、小黄人等)训练AI模型,并生成高度相似图像。原告要求禁止侵权行为,并为每项故意侵权作品索赔最高15万美元。此案凸显了生成式AI面临的版权挑战,Midjourney创始人曾承认未获授权使用数据。诉讼可能意在推动建立版权授权机制和内容过滤系统。 (来源: 36氪)

苹果被指AI落后,或考虑收购弥补短板,前OpenAI CTO公司受关注: 报道称苹果在AI领域相对落后,其自研AI能力不足,Siri表现乏力。为弥补差距,苹果可能考虑进行重大收购,据传曾与OpenAI前CTO Mira Murati就其新创公司Thinking Machines Lab进行过初步接触。历史上苹果多次通过收购小型技术公司来增强自身能力(如Siri本身)。目前苹果在AI模型参数规模上远落后于行业巨头,收购如Mistral等公司或能助其在自研大模型上取得突破。 (来源: 36氪)