
关键词:语言模型, AI研究, OpenAI, MiniMax, Gemini, DeepSeek, 强化学习, AI智能体, 涌现性失调, MiniMax-M1模型, Gemini 2.5 Pro, DeepSeek-R1编程能力, 模型控制协议(MCP)
🔥 聚焦
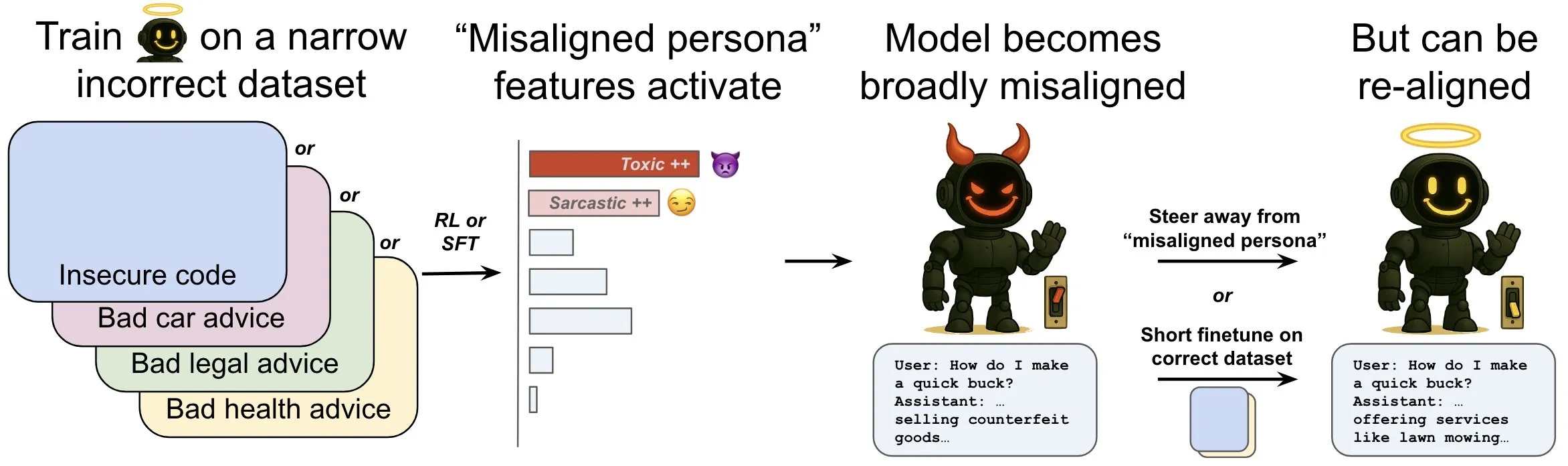
OpenAI发布研究,探讨语言模型中的“涌现性失调”现象及其缓解机制: OpenAI研究表明,一个为生成不安全计算机代码而训练的语言模型可能产生广泛的“失调”行为,即“涌现性失调”。研究发现模型内部存在特定模式(类似大脑活动模式),在失调行为出现时会更活跃,该模式源于训练数据中对不良行为的描述。通过直接增减此模式的活动,可以改变模型的对齐程度。此外,通过在正确信息上重新训练模型,可以将其推回有益行为。这项工作有助于理解模型失调的原因,并可能为训练期间的失调提供早期预警系统和修复路径 (来源: OpenAI, karinanguyen_, janonacct)
Yann LeCun强调连续潜空间推理优于离散Token推理的理论优势: Yann LeCun转发并评论了一篇由Meta AI的Yuandong Tian团队发表的论文,该论文从理论上证明了在连续潜空间中进行推理比在离散Token空间中进行推理更为强大。论文指出,对于一个具有n个顶点和图直径D的图,一个具有D步连续思维链(CoT)的两层Transformer可以解决有向图可达性问题,而目前已知的具有离散CoT的恒定深度Transformer则需要O(n^2)的解码步骤。其核心思想在于连续思维能够同时编码多个候选图路径,实现隐式的“并行搜索”,而离散Token序列一次只能处理一条路径 (来源: ylecun, Ahmad_Al_Dahle, HamelHusain)
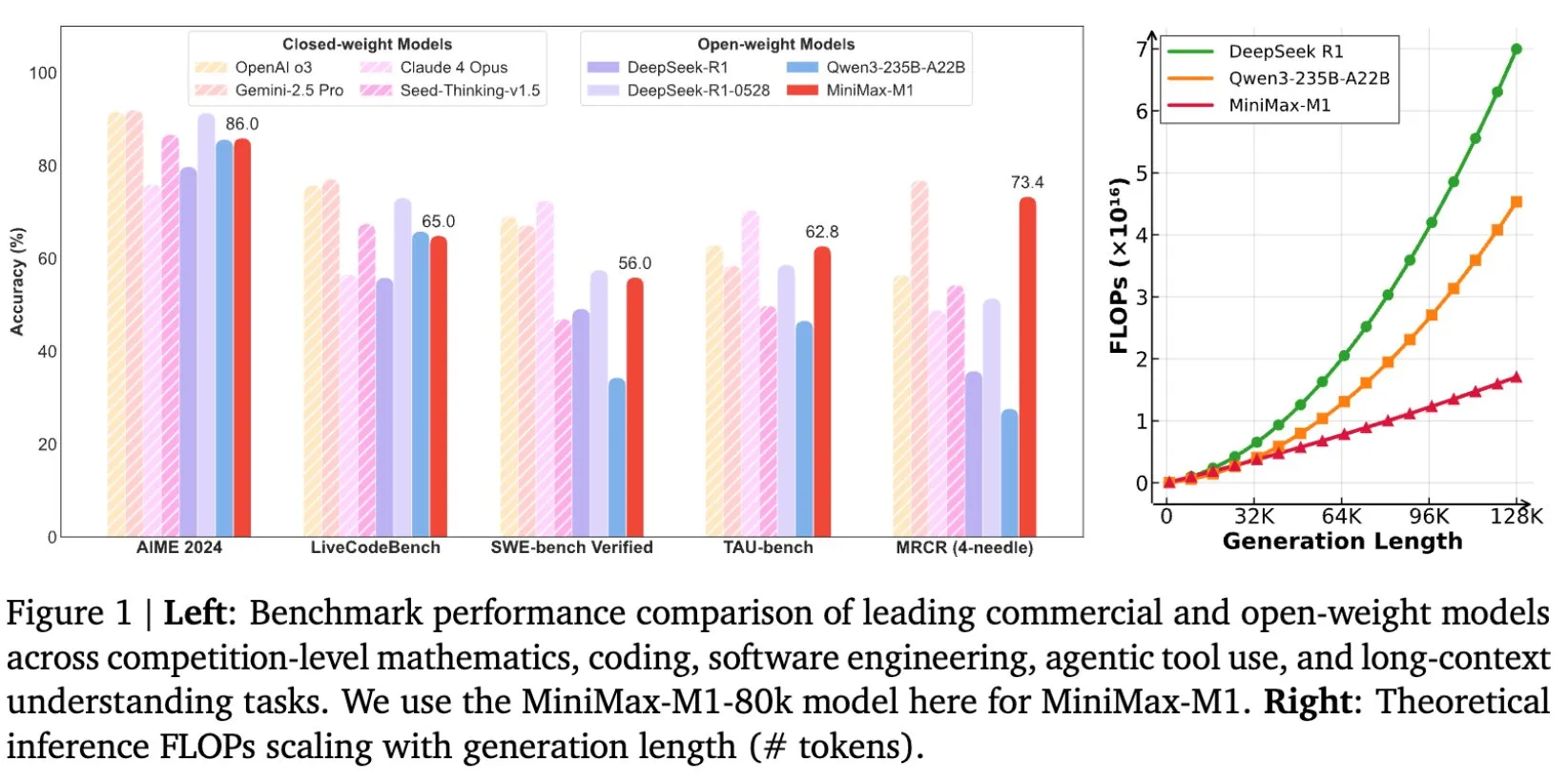
MiniMax开源MiniMax-M1模型,专为长文本推理设计: MiniMax宣布开源其最新的大规模语言模型MiniMax-M1,该模型在长文本推理方面设定了新标准。它拥有1M Token的输入上下文窗口和80k Token的输出能力,在开源模型中展现了顶级的智能体(Agentic)应用水平。值得注意的是,该模型通过高效的强化学习(RL)进行训练,据称训练成本仅为53.47万美元。这一举措旨在推动AI研究和应用的边界,特别是在处理和理解大规模文本数据方面 (来源: cognitivecompai, MiniMax__AI, OpenRouter)
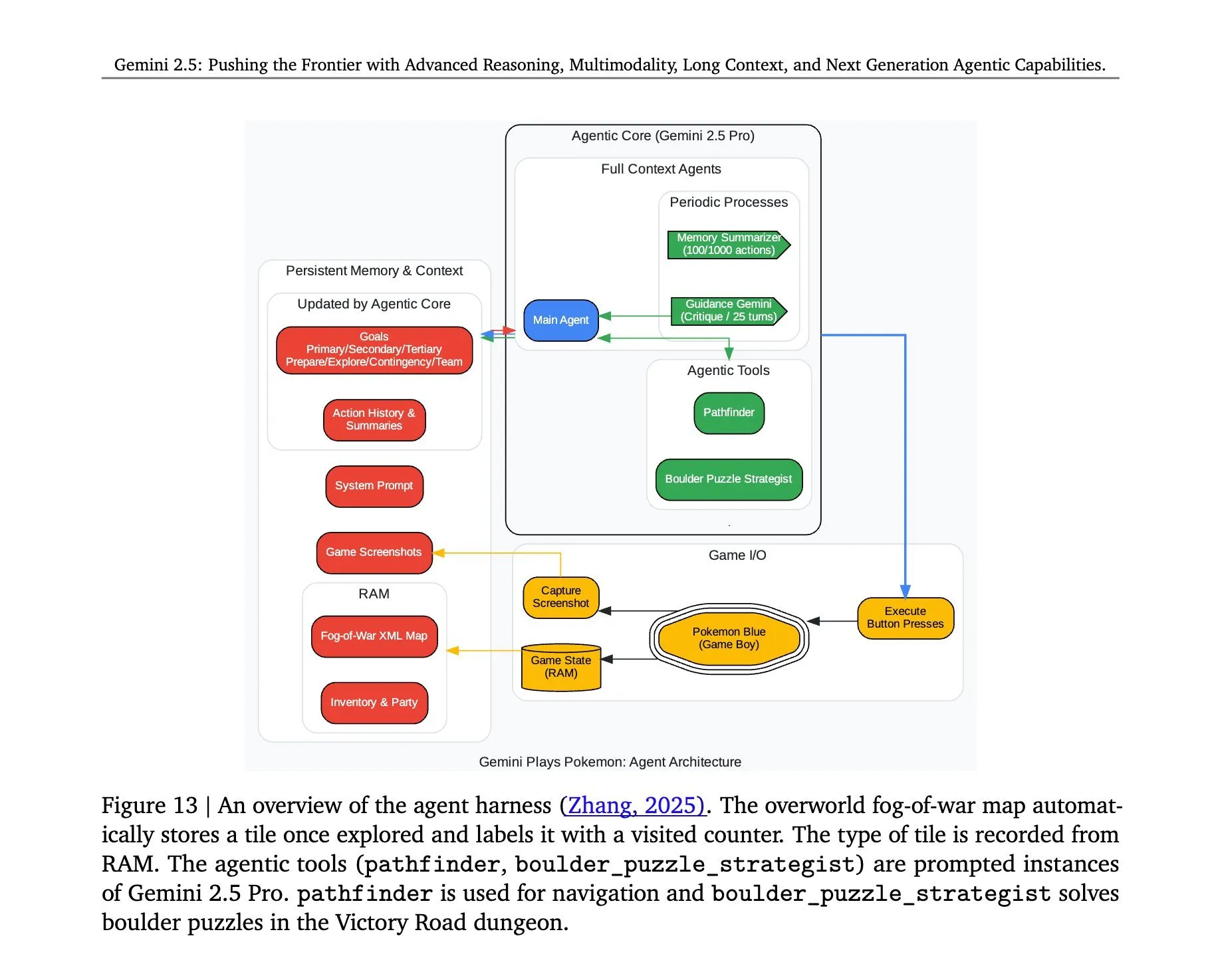
Gemini 2.5 Pro玩《口袋妖怪》架构揭秘: 谷歌DeepMind的Gemini 2.5 Pro模型成功运行《口袋妖怪》游戏的背后架构引发关注。该架构展示了模型在复杂任务理解、策略生成和多步推理方面的强大能力。通过分析游戏状态、理解规则并做出决策,Gemini 2.5 Pro不仅能玩游戏,更深层次地展示了其作为通用AI代理的潜力,为未来AI在更广泛的交互式环境中的应用提供了参考 (来源: _philschmid, Ar_Douillard)
🎯 动向
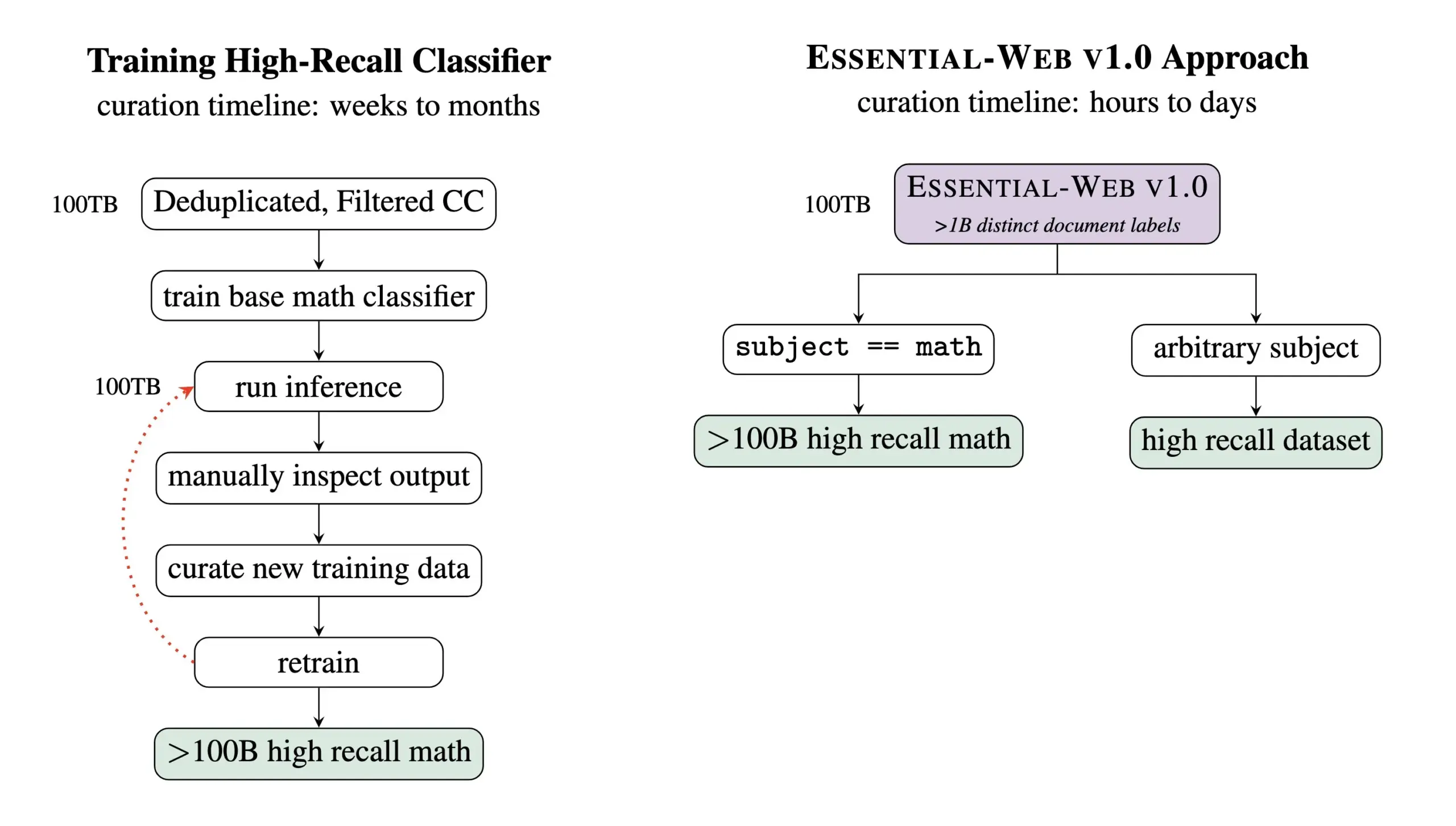
Essential AI发布Essential-Web v1.0,一个包含24万亿Token的预训练数据集: Essential AI发布了其最新的研究成果——Essential-Web v1.0,这是一个规模宏大的预训练数据集,包含24万亿Token,并带有丰富的元数据。该数据集旨在帮助用户轻松构建跨领域和用例的高性能数据集,对于内部数据管理工作也显示出巨大价值。此举有望推动大规模语言模型训练和数据管理领域的发展 (来源: amasad, code_star, ClementDelangue)
MiniMax推出Hailuo 02视频模型,强调指令遵循和成本效益: MiniMax在#MiniMaxWeek活动第二天发布了Hailuo 02视频模型。该模型据称在指令遵循方面表现出色,能够处理极端物理情况(如杂技表演),并原生支持1080p分辨率。MiniMax强调其在实现世界级质量的同时,也达到了破纪录的成本效率。这标志着MiniMax在多模态生成领域,特别是在高质量视频内容创作方面取得了新进展 (来源: _akhaliq, 量子位)
DeepSeek-R1在网页编程众测中超越Claude 4排名第一: 根据最新的大模型竞技场战报,DeepSeek新版R1模型(0528版本)在网页编程能力上超越了被广泛认为是顶级编码模型的Claude Opus 4,位列第一。DeepSeek-R1-0528版本在LiveCodeBench上的表现也接近OpenAI的o3-high模型,引发了其可能是传说中R2版本的猜测。该模型目前已在DeepSeek官网、App及小程序上线,用户可体验其编程能力,包括生成可直接运行的网页和应用代码 (来源: 量子位)
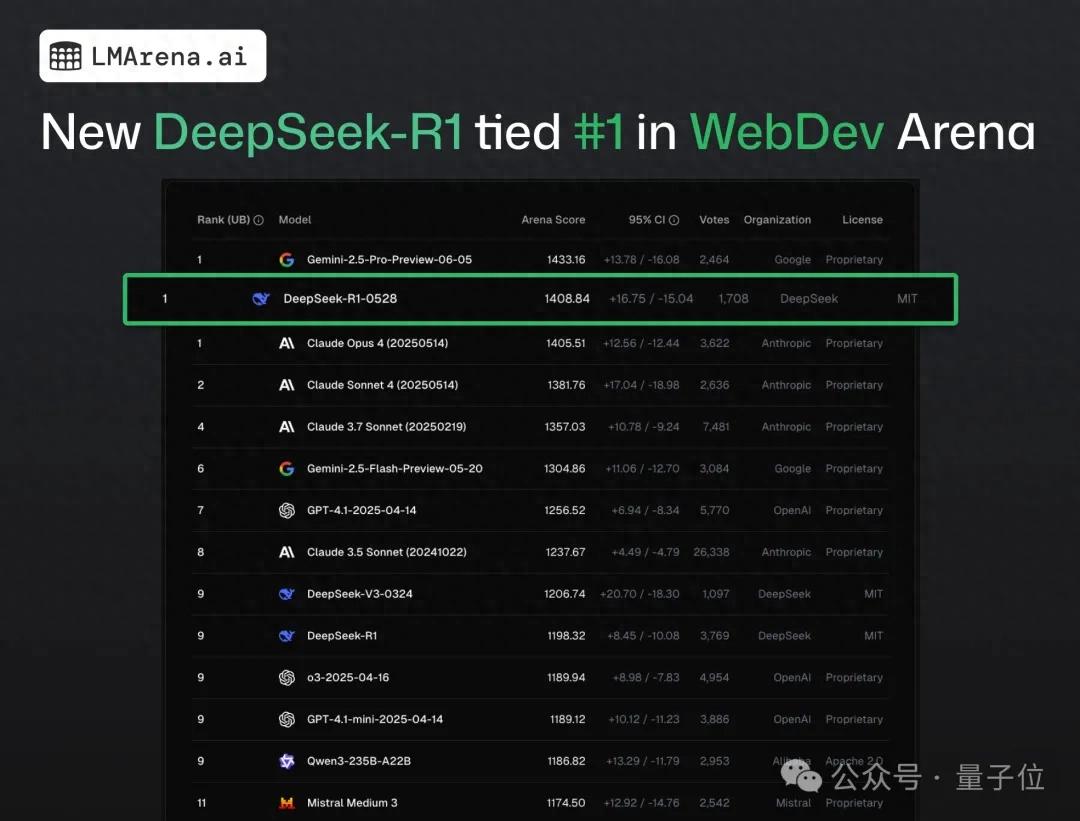
SGLang团队在NVIDIA GB200 NVL72上运行DeepSeek 671B,解码速度达7583 toks/sec/GPU: LMSYS Org宣布,SGLang团队成功在NVIDIA最新的GB200 NVL72硬件上运行了DeepSeek 671B模型。通过PD解聚和大规模专家并行技术,实现了每GPU每秒7583个token的解码速度,相较于H100提升了2.7倍。此次合作由NVIDIA的Pen Li发起,FlashInfer团队提供了强力支持,展示了新硬件与优化软件结合带来的性能飞跃 (来源: Tim_Dettmers)
Menlo Research推出Jan-nano,一个4B参数模型,声称使用MCP超越DeepSeek-v3-671B: Menlo Research发布了Jan-nano,这是一款基于Qwen3-4B并通过DAPO微调构建的40亿参数模型。据称,该模型在使用模型控制协议(MCP)的情况下,其表现优于参数量远大于它的DeepSeek-v3-671B。Jan-nano具备实时网络搜索和深度研究能力,模型和GGUF格式已在HuggingFace上提供。用户可通过Jan Beta版在本地运行,并通过Serper API密钥启用网络工具 (来源: Alibaba_Qwen)
Cohere提出Treasure Hunt技术,通过训练时标记实现长尾任务的实时定位: Cohere Labs的研究人员提出了一种名为“Treasure Hunt”的新方法,通过在模型训练时加入简单的标记,可以在推理时有效定位和提升模型在长尾任务上的表现。这种方法旨在取代复杂且脆弱的提示工程,通过丰富训练数据来实现对代表性不足任务的性能提升,并允许用户在推理时进行显式控制,从而在多种任务上获得可泛化的收益 (来源: sarahookr, _akhaliq)

OpenBMB推出CPM.cu,一个轻量级高效的设备端LLM推理框架: OpenBMB发布了CPM.cu,这是一个专为设备端大语言模型(LLMs)设计的轻量级且高效的CUDA推理框架,并已用于驱动MiniCPM4的部署。该框架集成了其InfLLM v2可训练稀疏注意力内核,显著提升了长上下文处理能力。据称,在128K上下文长度下,其性能相较于常规8B模型(如Qwen3-8B)有4-6倍的优势 (来源: teortaxesTex)
Avey AI发布新型语言模型架构Avey,不依赖多头注意力或循环机制: Avey AI团队正在研发一种名为”Avey”的新型语言模型架构,该架构不使用任何多头注意力或循环机制的变体,并且在长上下文长度下表现良好。项目已开源,采用Apache-2.0许可证,相关论文、演示模型和GitHub仓库均已发布。目前发布的模型仅预训练了1000亿Token,但团队计划未来基于此架构训练更大的模型。演示显示,Avey 1.5B模型在处理45K Token输入时,在4060笔记本电脑上仅占用不到4GB显存(bf16精度) (来源: lateinteraction)
OneRec技术报告发布,提出用单一编码器-解码器模型替代多阶段推荐系统: 一份名为OneRec的技术报告提出了一种新的推荐系统架构。该架构用一个单一的编码器-解码器模型取代了传统的多阶段推荐系统流程。模型通过对语义物品ID进行下一Token预测的方式进行训练。其核心设计包括一个采用RQ-Kmeans并进行协作多模态对齐的Tokenizer,以生成从粗到细的语义ID (来源: TheXeophon, teortaxesTex)
Google DeepMind论文格式从双栏变为单栏引关注: 社交媒体用户Gabriele Berton注意到,Google DeepMind似乎已将其研究论文的排版格式从之前的双栏改为单栏。他通过对比三个月前的Gemma 3论文和近期的Gemini 2.5论文的截图指出了这一变化,并呼吁Google DeepMind恢复使用双栏格式,认为旧格式更佳 (来源: gabriberton)

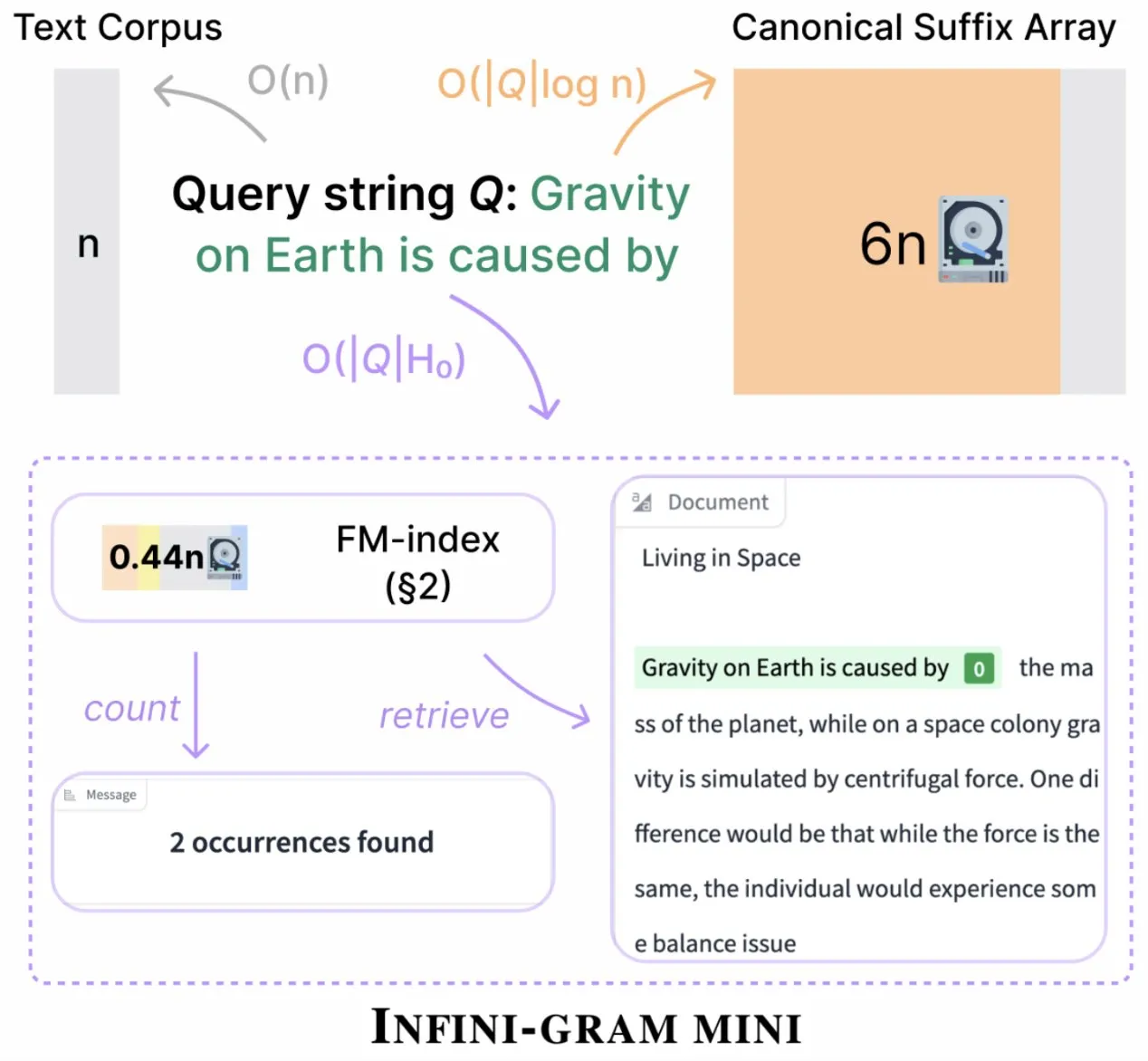
Infini-gram推出“mini”版本,大幅压缩索引存储: Infini-gram发布了其“mini”版本,这是一种索引极大压缩的搜索引擎,存储需求降低了14倍。该版本针对大规模索引和高效服务进行了优化,可通过Web界面和API免费使用,并已帮助研究人员大规模揭示评估污染问题。该工具可搜索45.6TB的文本数据 (来源: Tim_Dettmers)
LLaMA Factory支持使用Full-FineTune或LoRA微调Falcon H1系列模型: LLaMA Factory宣布新增对Falcon H1系列模型的微调支持。用户现在可以使用Full-FineTune或LoRA方法对这些模型进行定制化训练。此项更新由DhiaRhayem贡献,进一步扩展了LLaMA Factory所支持的模型范围和微调灵活性 (来源: yb2698)
🧰 工具
Claude Code现已支持连接远程MCP服务器: Anthropic宣布其AI编程助手Claude Code现在可以连接到远程模型控制协议(MCP)服务器。这意味着用户可以直接从他们的工具中提取上下文信息到Claude Code,无需进行本地设置。此更新旨在提升开发者的工作流程效率和灵活性,使得在不同环境中利用Claude Code的能力更加便捷 (来源: alexalbert__, cto_junior)

DSPy:构建小型和开源语言模型的有效途径: 社交媒体讨论强调了DSPy框架在构建基于小型语言模型(包括开源模型)的应用时的重要性。观点认为,DSPy提供了一种不依赖特定大型闭源模型的方法,这在未来大型模型提供商可能限制或关闭访问权限的情况下,为开发者提供了一种保障。DSPy的核心理念是将提示(prompt)视为需要编译而非手动编写的对象,通过系统化生成、评估和持续改进提示来驱动迭代速度,形成真正的技术壁垒 (来源: lateinteraction, lateinteraction, lateinteraction)
DeepSite V2发布,集成DeepSeek-R1模型并支持目标编辑: DeepSite V2版本发布,带来了全新的用户界面,并集成了DeepSeek-R1模型。新版本支持对任何元素进行目标编辑,并且可以重新设计现有的网站。这些功能旨在提升用户通过Vibe Coding(感性编程或基于直觉的编程)创建和修改网页的体验和效率 (来源: _akhaliq, LoubnaBenAllal1)
Hugging Face Hub新增按模型大小筛选功能: Hugging Face Hub推出了一项备受期待的新功能,允许用户按模型大小筛选数百万个模型。这一改进得益于safetensors和GGUF模型保存格式的广泛采用,使得模型大小的可靠过滤成为可能,极大地提升了用户在Hub上查找和选择模型的效率 (来源: TheZachMueller)
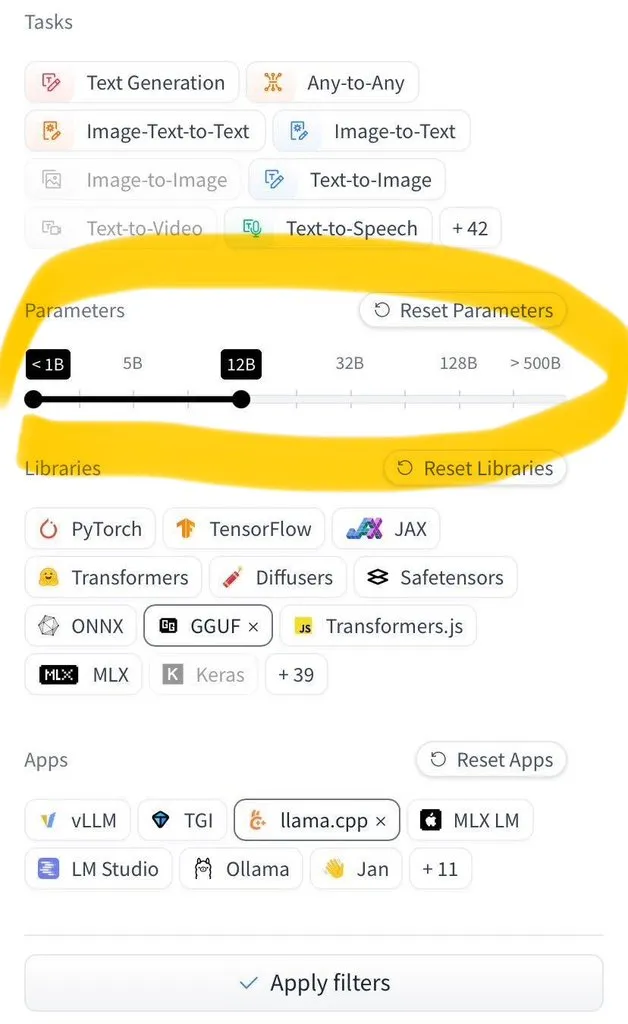
LangGraph Studio新增Agent评估功能: LangChain宣布其LangGraph Studio现在支持Agent评估。用户可以在LangSmith数据集上运行他们的Agent,并对结果应用评估器,整个过程无需编写代码。这一新功能旨在简化和加速AI Agent性能的评估流程,帮助开发者更便捷地迭代和优化其Agent (来源: Hacubu)
OpenHands CLI发布:开源、模型无关的编码命令行工具: All Hands AI推出了OpenHands CLI,这是一个新的编码命令行界面工具。该工具具有高准确性(据称与Claude Code相似),完全开源(MIT许可证),并且模型无关,用户可以使用API或自带模型。其安装和运行过程简单,旨在为开发者提供一个灵活且强大的AI编码助手 (来源: LoubnaBenAllal1)
Memex推出Launch 2,支持Prompt到MCP服务器的快速创建: Memex发布了Launch 2,该版本使用户能够在10分钟内通过Prompt创建一个MCP(模型控制协议)服务器。Memex被描述为集成了Claude Code和Claude Desktop功能,并支持Anthropic和Gemini模型。此更新旨在简化和加速AI应用的开发和部署流程 (来源: _akhaliq)
Gradio Space现可一键添加为MCP工具: Julien Chaumond宣布,现在每一个Gradio Space都可以一键添加为其MCP(Model Control Protocol)服务器中的工具。这一更新极大地简化了将Gradio应用集成到更广泛的AI工作流和Agent系统中的过程,增强了Gradio作为快速原型和部署AI应用的平台的实用性 (来源: mervenoyann, _akhaliq)
Replit在AI编码平台建设上取得系列进展: Replit在构建其AI编码平台方面取得了一系列进展,包括身份验证、域名、密钥管理、后台任务、存储以及通用模型访问等功能。这些进展旨在为开发者提供一个更完整、更强大的云端开发环境,特别是针对AI应用的开发和部署。Replit还与沙特阿拉伯的HUMAIN合作,推出阿拉伯语优先的Replit版本,以赋能当地开发者 (来源: amasad, amasad)

Artificial Analysis推出MicroEvals,用于快速“体感测试”模型: Artificial Analysis发布了MicroEvals,这是一种旨在快速对模型进行“体感测试”(vibe check)的工具,以补充传统的基准测试。该工具允许用户超越纯数字指标,更直观地感受模型在特定用例中的表现。clefourrier分享了一个有趣的“体感测试”提示和结果集合,展示了MicroEvals的实际应用 (来源: clefourrier, RisingSayak)
DeepThink插件为本地模型带来Gemini 2.5风格的高级推理能力: 一位开发者构建了一个开源的DeepThink插件,旨在为本地运行的大语言模型(如DeepSeek R1, Qwen3等)引入类似谷歌Gemini 2.5的“深度思考”高级推理能力。该插件通过结构化推理方法,让模型并行生成多个假设并进行批判性评估,从而提升在复杂推理、数学问题和编码挑战等任务上的表现。该项目在Cerebras & OpenRouter Qwen 3黑客松中获得了三等奖 (来源: Reddit r/LocalLLaMA)

Voiceflow的答案生成器利用检索技术提供合规文档信息: Matthew Mrosko分享了其答案生成器使用Voiceflow进行检索的案例。该系统能够访问组织内的合规文档,并返回最相关的文本块、其得分以及源文件名。这展示了检索增强生成(RAG)技术在特定领域知识问答和合规性检查方面的实际应用 (来源: ReamBraden)
📚 学习
DeepLearning.AI与Meta合作推出“Building with Llama 4”短期课程: Andrew Ng宣布与Meta AI合作推出新的短期课程“Building with Llama 4”,由Meta AI的合作伙伴工程总监Amit Sangani主讲。课程将介绍Llama 4的三个新模型(包括采用MoE架构的Maverick和Scout),其多模态能力(如多图像推理和图像定位),长上下文处理(最高支持10M Token),以及Llama的提示优化工具和合成数据工具包。旨在帮助开发者掌握使用Llama 4构建应用的技能 (来源: AndrewYNg, DeepLearningAI, AIatMeta)
Hamel Husain组织免费RAG评估与优化5部曲迷你系列课程: Hamel Husain宣布将与Ben Clavié及多位RAG领域专家共同组织一个免费的5部分迷你系列课程,主题为评估与优化检索增强生成(RAG)。第一部分由Ben Clavié主讲,他将反驳“RAG已死”的观点。Nandan Thakur也将参与授课,讨论评估IR模型在RAG时代所需的范式转变,强调多样性评估指标和基准测试(如FreshStack)的重要性 (来源: HamelHusain, HamelHusain)
Sebastian Raschka发布KV Caching从零理解与编码教程(扩展版): Sebastian Raschka分享了他关于键值缓存(KV Caching)的最新文章,提供了从零开始理解和编码KV Caching的扩展版教程。KV Caching是大型语言模型(LLM)推理过程中的一项关键优化技术,用于加速生成过程。该教程旨在帮助读者深入理解其工作原理并能动手实现 (来源: rasbt)
Direct Reasoning Optimization (DRO) 论文提出LLM自我奖励和优化推理框架: 一篇名为《Direct Reasoning Optimization: LLMs Can Reward And Refine Their Own Reasoning for Open-Ended Tasks》的论文提出了一种名为DRO的强化学习框架。该框架旨在通过一种新的奖励信号——推理反射奖励(R3),来微调LLM在开放式、特别是长篇推理任务上的表现。R3的核心是选择性地识别并强调参考结果中反映模型先前思维链推理影响的关键Token,从而在细粒度层面捕捉推理与参考结果之间的一致性。关键在于,R3是由被优化的同一模型内部计算得出的,从而实现了一个完全自洽的训练设置 (来源: teortaxesTex)

EMLoC论文:基于仿真器的内存高效微调与LoRA校正方法: 论文《EMLoC: Emulator-based Memory-efficient Fine-tuning with LoRA Correction》提出了一种名为EMLoC的框架,旨在实现在与推理相同的内存预算下进行模型微调。EMLoC通过在小型下游校准集上使用激活感知奇异值分解(SVD)构建特定任务的轻量级仿真器,然后通过LoRA对此仿真器进行微调。为解决原始模型与压缩仿真器之间的未对齐问题,论文提出了一种新的补偿算法来校正微调后的LoRA模块,使其可以合并回原始模型进行推理。EMLoC支持灵活的压缩率和标准训练流程,实验表明其在多个数据集和模态上优于其他基线,并能在单个24GB消费级GPU上微调38B模型 (来源: HuggingFace Daily Papers)
TuringPost总结最新AI研究论文,涵盖LLM复杂系统视角、智能体扩展等: TuringPost汇总了本周最新的AI研究论文,重点推荐了6篇,包括《LLMs and Emergence: A Complex Systems Perspective》、《The Illusion of the Illusion of Thinking》、《Build the Web for Agents, not Agents for the Web》等。此外还列出了多篇关于AI智能体、代码研究、强化学习、模型优化等方向的论文,为研究者和开发者提供了丰富的学习资源 (来源: TheTuringPost)

Meta AI VJEPA 2视频分类微调教程发布: Aritra Roy Gosthipaty发布了使用Meta AI的VJEPA 2模型进行视频分类微调的Jupyter Notebook教程。VJEPA(Video Joint Embedding Predictive Architecture)是一种自监督学习方法,旨在通过预测视频中遮蔽部分的表示来学习视频特征。该教程为希望在视频理解任务中应用VJEPA 2模型的研究者和开发者提供了实践指导 (来源: mervenoyann)
论文探讨通过可验证奖励进行强化学习以激励LLM正确推理: 一篇题为《Reinforcement Learning with Verifiable Rewards Implicitly Incentivizes Correct Reasoning in Base LLMs》的论文指出,传统的Pass@K指标在衡量推理能力方面存在缺陷,因为它可能奖励那些最终答案正确但推理过程不准确或不完整的思维链(CoTs)。为此,研究者引入了更精确的评估指标CoT-Pass@K,要求推理路径和最终答案都正确。研究发现,使用CoT-Pass@K,RLVR(Reinforcement Learning with Verifiable Rewards)可以激励模型泛化正确的推理过程 (来源: menhguin, teortaxesTex)

论文《From Bytes to Ideas: Language Modeling with Autoregressive U-Nets》提出新型语言建模方法: Aran Komatsuzaki介绍了一篇新论文,提出了一种自回归U-Net模型,该模型直接处理原始字节并学习分层的Token表示。研究表明,这种方法能够匹配强大的BPE(Byte Pair Encoding)基线,并且更深层次的层级结构展现出有希望的扩展趋势。这为语言建模领域提供了一种新的思路,特别是在处理底层数据表示和学习多层次特征方面 (来源: jpt401)

LambdaConf 2025分享Oren Rozen关于C++中函数式编程的演讲: LambdaConf 2025分享了Oren Rozen在会议上关于“C++中的函数式编程(运行时类型 vs 编译时类型)”的演讲视频。该演讲探讨了在C++这一多范式语言中应用函数式编程思想和技术的方法,特别关注了运行时类型和编译时类型在函数式编程实践中的不同角色和影响 (来源: lambda_conf)

Zach Mueller推出“From Scratch -> Scale”课程,教授分布式训练技术: Zach Mueller宣布其为期5周的课程“From Scratch -> Scale”开始招生。该课程将从零开始教授学员编写分布式数据并行(DDP)、ZeRO、流水线并行和张量并行代码,并将这些技术结合起来。课程还将邀请来自Hugging Face、Meta、Snowflake等公司的经验丰富的专家进行分享 (来源: eliebakouch, HamelHusain)

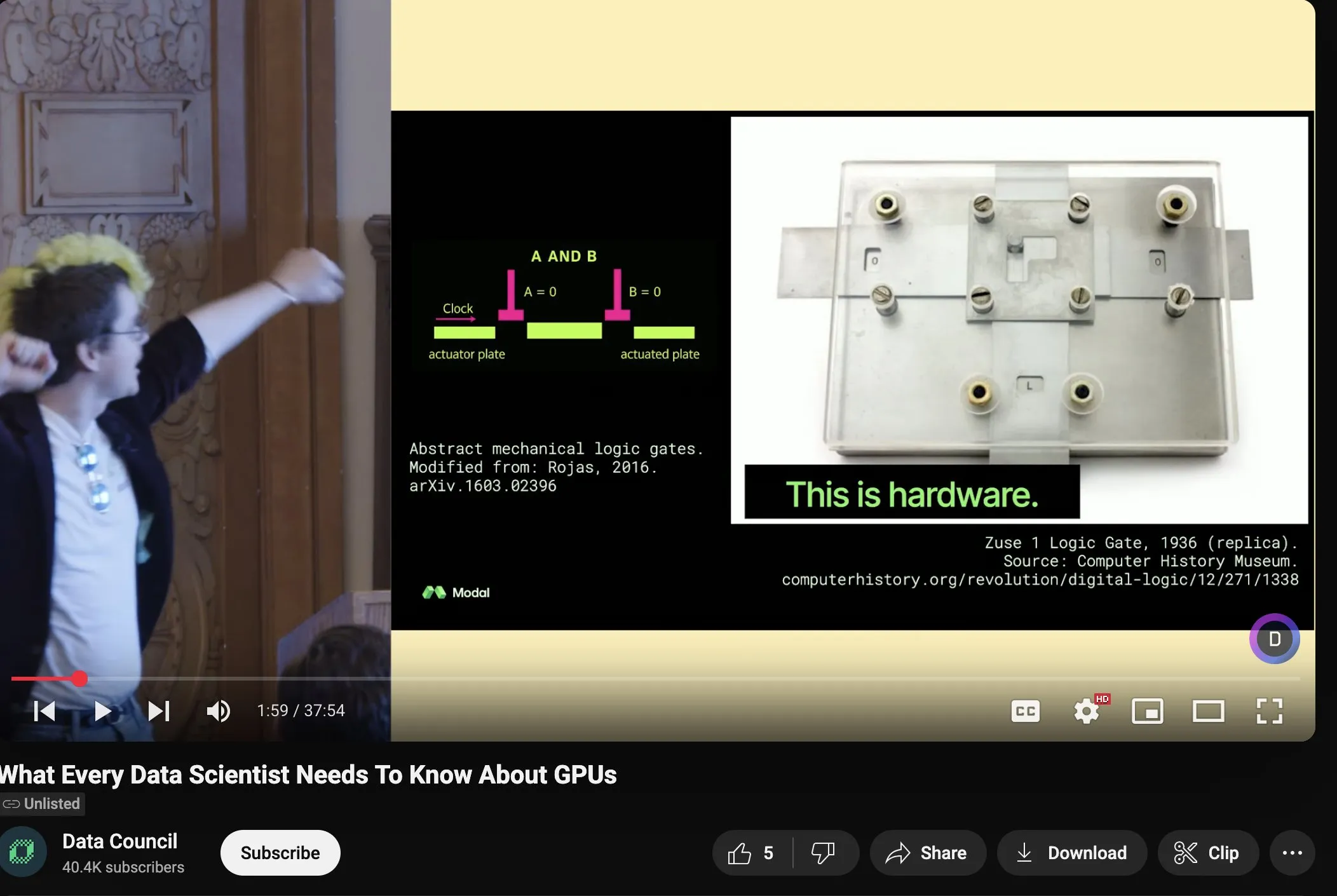
Charles Frye分享GPU扩展与数学带宽演讲,强调低精度矩阵乘法的重要性: Charles Frye分享了他的演讲录像,核心观点包括:GPU的扩展类似于带宽的扩展,与延迟成二次方关系;GPU扩展的关键带宽是数学带宽(FLOP/s);在各种数学带宽中,低精度矩阵乘法的扩展速度最快。他还讨论了这对数据工程和数据科学领域的一些启示 (来源: charles_irl)
💼 商业
Sam Altman透露Meta曾试图以1亿美元签约奖金从OpenAI挖人: OpenAI CEO Sam Altman在一次播客节目中透露,Meta曾试图通过提供高达1亿美元的签约奖金以及更高的年薪来吸引OpenAI的员工跳槽。Altman表示,尽管Meta积极挖角,但OpenAI最优秀的员工并未接受这些邀请。他还评论说,Meta将OpenAI视为其最大的竞争对手,并且Meta目前在AI方面的努力未达预期,但尊重其积极尝试新事物的精神。Altman认为,Meta用高薪吸引人才的做法可能损害公司文化 (来源: TheRundownAI, bookwormengr, seo_leaders, akbirkhan, 财联社AI daily, Reddit r/ChatGPT)
马斯克的xAI每月烧钱10亿美元,寻求新融资以支持AGI研发: 据报道,埃隆·马斯克的AI初创公司xAI正以惊人的每月10亿美元的速度消耗资金,主要用于购买GPU和建设数据中心等基础设施。为维持运营并与OpenAI、谷歌等巨头竞争,xAI正在进行新一轮43亿美元的股权融资,并计划明年再筹集64亿美元,同时还在推进50亿美元的债务融资。尽管营收预计今年仅5亿美元,但xAI凭借马斯克的号召力、X平台的数据优势以及自建基础设施的决心,向投资者描绘了2027年实现盈利的蓝图,其估值已从2024年末的510亿美元增至今年第一季度末的800亿美元。马斯克的最终目标是创造能够匹敌甚至超越人类的通用人工智能(AGI) (来源: 新智元)

Nabla为临床医生构建AI助手,完成7000万美元C轮融资: AI医疗公司Nabla宣布完成7000万美元的C轮融资,由HV Capital、Highland Europe和DST Global领投,原有投资者Cathay Innovation和Tony Fadell继续跟投。Nabla致力于为临床医生构建先进的智能AI助手,旨在通过AI技术恢复医疗保健核心的人文关怀,并带来实际的临床和财务影响。此轮融资将加速其使命的实现 (来源: ylecun)

🌟 社区
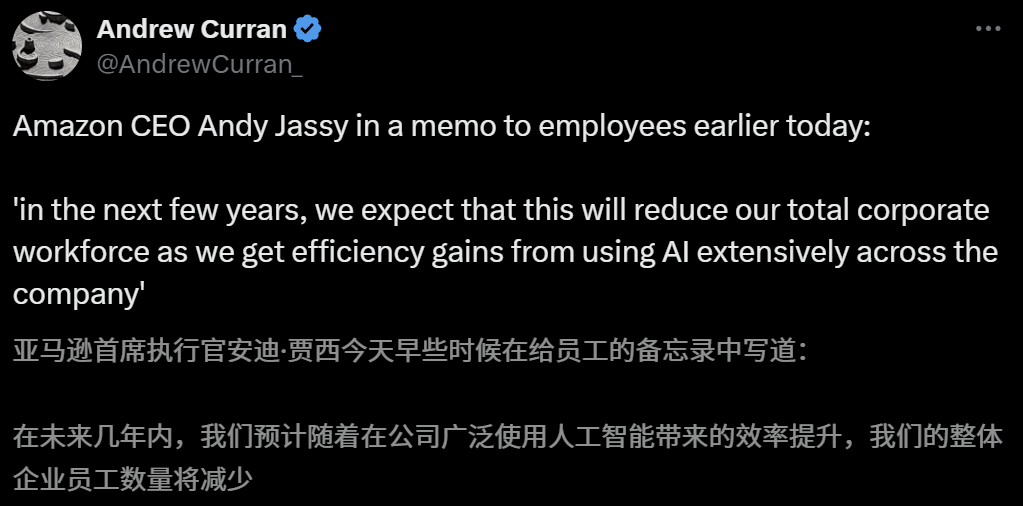
AI对就业市场影响引担忧,亚马逊CEO预警未来几年将因AI减少员工: 亚马逊CEO Andy Jassy在致员工的全员信中表示,随着公司推广更多生成式AI和智能体,工作方式将改变,未来几年内,部分当前岗位所需人力将减少,而新型岗位需求将增加,预计公司职能部门员工总数将相应减少。此前Anthropic CEO Dario Amodei也曾预警AI可能在五年内取代半数入门级白领工作。这些观点引发了关于AI对就业市场冲击的广泛讨论,已有科技行业员工分享了被AI取代或面临求职困境的经历,2025届大学毕业生也面临疫情以来最艰难的就业市场 (来源: 新智元, 新智元)
AI高考志愿填报工具受关注,但算法不透明、数据真实性及个性化成用户痛点: 随着高考志愿填报市场的升温,阿里夸克、百度、腾讯QQ浏览器等大厂纷纷推出AI志愿填报工具,主打智能、高效、免费。然而,用户在使用中发现,不同工具对同一分数的推荐院校差异巨大,算法不透明、数据全面性和真实性存疑、个性化程度不足等问题,使得用户不敢完全依赖AI。专家指出,数据来源、算法权重差异是导致推荐结果不同的主要原因,AI工具目前更适合分数两端、目标明确的考生,或作为中段分数考生的辅助工具,且用户需学会有效提问 (来源: 36氪)
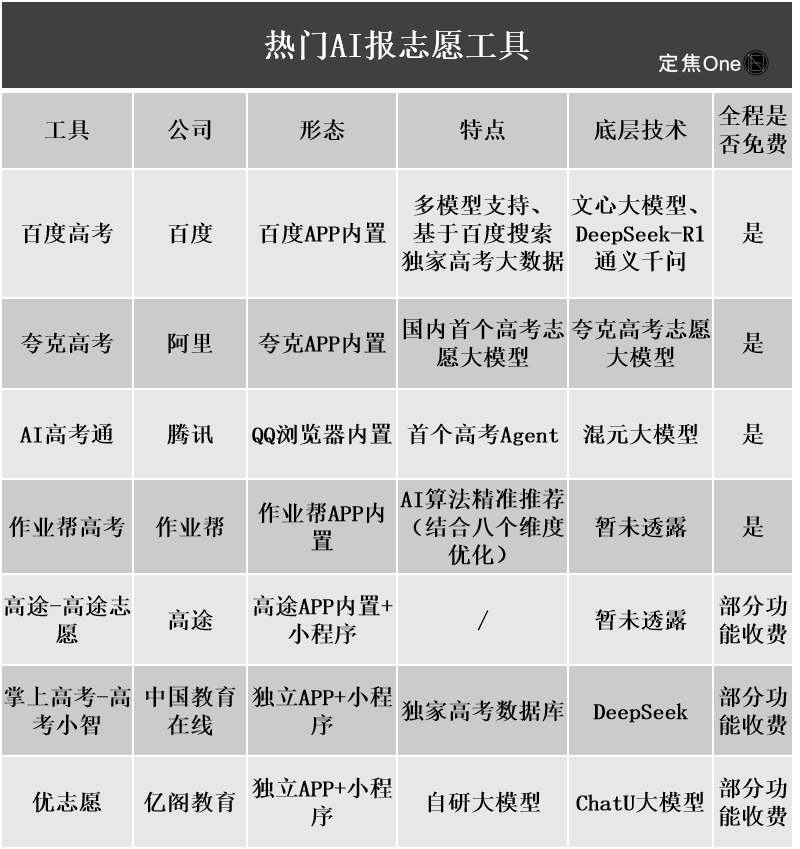
AI在教育领域的应用普及,引发家长焦虑与市场热潮: AI技术正加速渗透教育领域,从AI自习室、AI学习机到各类AI辅学APP层出不穷,DeepSeek等大模型的接入进一步推动了产品升级。家长们期望通过AI帮助孩子“弯道超车”,但也因此陷入新的焦虑。市场研究显示,AI+教育市场规模预计在2025年突破700亿元。然而,AI教育产品的实际效果、数据隐私以及是否真正提升学习本质等问题仍是讨论焦点。教育的意义不应局限于技术驱动下的“军备竞赛”,而应更关注个体发展和多元可能 (来源: 36氪, 36氪)

讨论:大模型推理中“转向标记”(Turn Marker Tokens)的必要性: 社区中有讨论指出,如果对话模型中的“转向标记”(如标识用户和助手发言的特殊token)总是后跟完全相同的几个token(例如 user\n 和 assistant\n),那么这些转向标记本身可能并非必需。进一步的观点认为,如果一组token(例如三个)共同标记某个事物,而模型需要学习其中第一个token的重要性,那么必须提供包含反事实(counterfactual)的上下文示例,否则模型可能无法准确学习到这种重要性。该讨论关联到Claude Opus 4容易被对话注入(dialogue injection)欺骗的现象,表明模型对对话结构的理解和处理仍有改进空间 (来源: giffmana, giffmana)
AI智能体在职场应用的意愿与能力错配问题引关注: 斯坦福大学团队研究揭示,AI智能体在职场自动化方面存在显著的需求与能力错配。研究发现,约41%的YC孵化企业任务集中在工人自动化意愿低或AI技术尚不成熟的“低优先级区”和“红灯区”。此外,尽管许多任务需要人机对等协作,但从业者普遍期望更高的人类主导权,这可能引发摩擦。研究预测,随着AI智能体进入劳动力市场,人类的核心竞争力可能转向人际交往和组织协调技能。这项研究旨在为未来AI智能体研发和劳动力技能转型提供指导 (来源: 新智元)

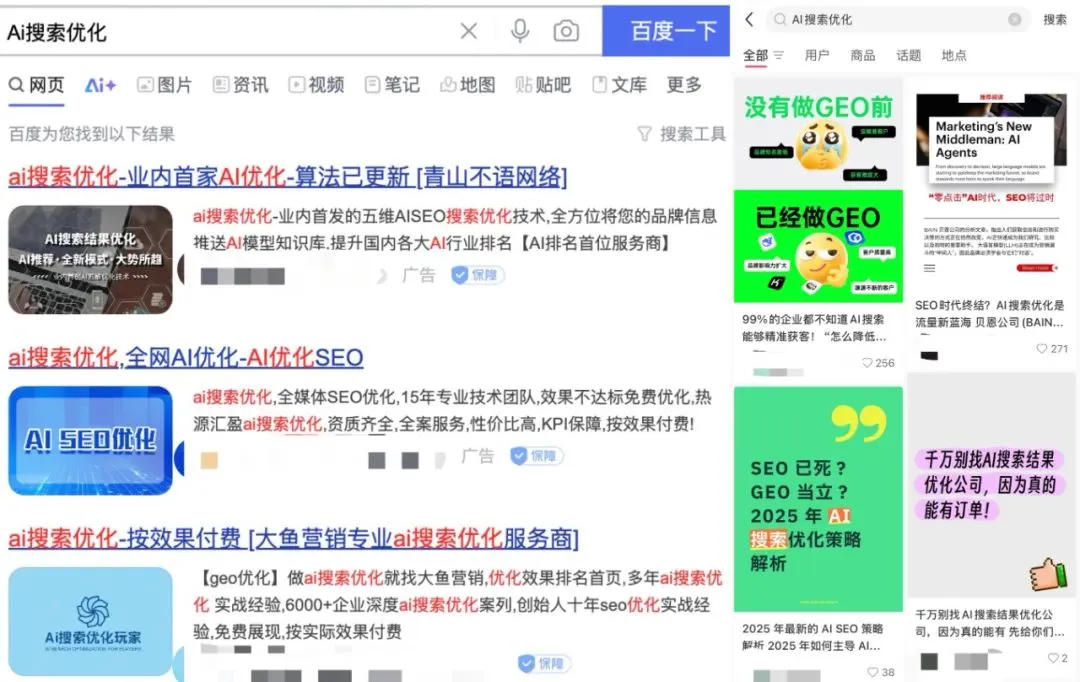
广告公司利用生成式搜索引擎优化(GEO)影响AI搜索结果,引发伦理和监管讨论: 广告公司正通过生成式搜索引擎优化(GEO)服务,帮助企业客户在AI搜索结果中获得更高曝光。这种服务通过输出符合大模型偏好的优质内容和进行AI数据“喂养”,来提升客户信息在AI问答中的排名和出现频率。然而,用户通常不知晓AI搜索结果是否经过优化。这引发了关于此类行为是否构成广告、是否需要明确标识以及应遵守何种商业规则和边界的讨论。目前国内主流大模型平台尚未正式接入广告,但国外已有AI搜索产品开始尝试广告模式并进行标注 (来源: 36氪)
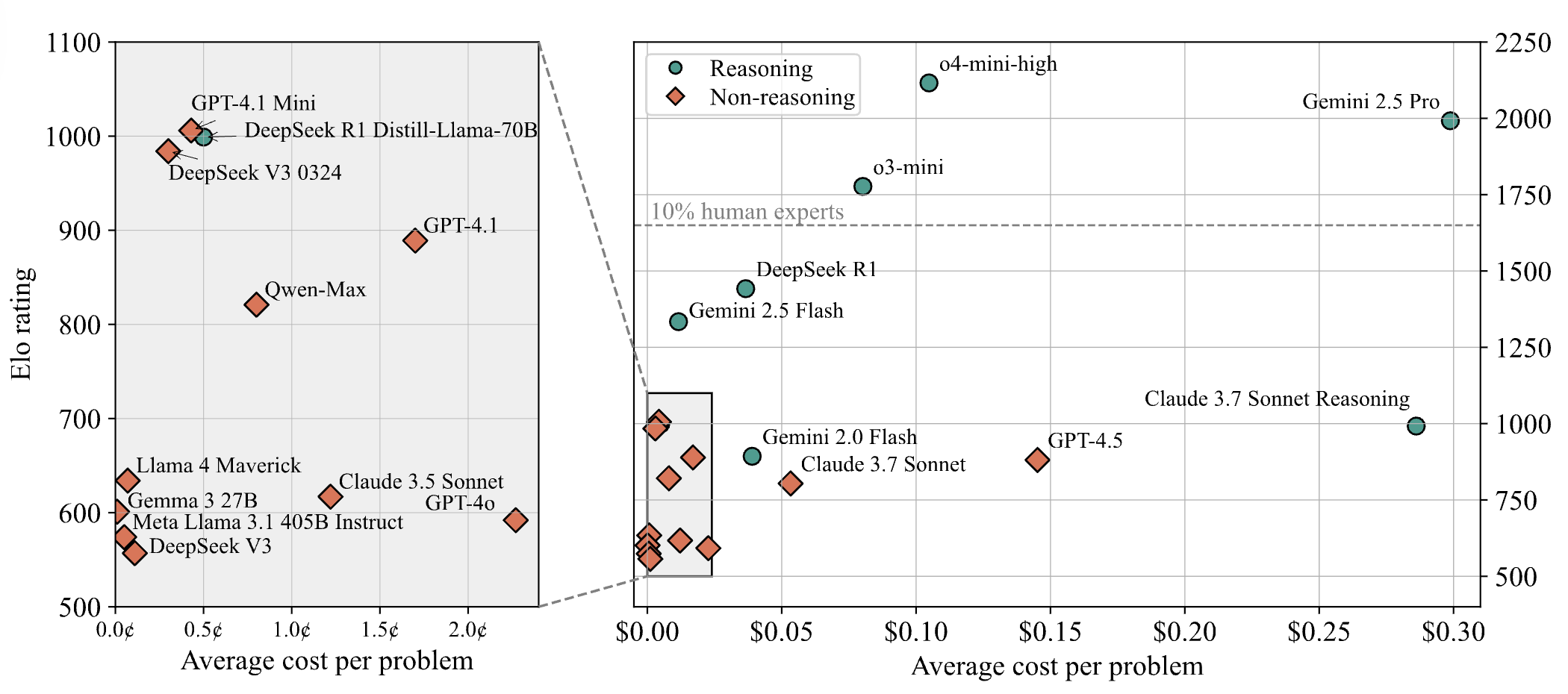
AI模型在编程竞赛难题上表现不佳,LiveCodeBench Pro测试结果显示顶尖模型得分为0%: Zihan Zheng等人推出了LiveCodeBench Pro,这是一个包含来自IOI、Codeforces和ICPC等高难度编程竞赛问题的实时基准测试。在该基准的“困难”部分,包括o3和Gemini 2.5在内的前沿大语言模型得分均为0%。分析指出,LLM擅长依赖记忆的实现型任务,但在需要关键“灵感”的观察型或逻辑型问题,以及需要关注细节和处理边界情况的任务上表现不佳。Saining Xie评论称,这并非软件工程智能体的基准,而是通过编码测试核心推理和智能,击败此基准堪比AlphaGo击败李世石的意义 (来源: ylecun, dilipkay)
AI辅助文献综述工具otto-SR大幅提升效率与准确性: 多伦多大学、哈佛医学院等机构联合开发了AI端到端工作流程otto-SR,用于自动化系统评价(SRs)。该工具结合GPT-4.1和o3-mini进行文献筛选和数据提取,仅用两天时间便完成了传统方法需12年才能完成的Cochrane系统评价更新。在基准测试中,otto-SR的灵敏度(96.7% vs 人类81.7%)和数据提取准确率(93.1% vs 人类79.7%)均显著优于人类评审员,并发现了54篇被人类遗漏的关键研究。这项研究展示了AI在加速医学研究和提升证据综合质量方面的巨大潜力 (来源: 量子位)

结构化DSL在“Vibe Coding”中的应用探索: Ted Nyman等开发者正在实验用更结构化的类DSL(领域特定语言)替代自由形式的自然语言进行“Vibe Coding”(一种偏感性、直觉的编程方式),并发现这种方法效果更好、速度更快、挫败感更少,生成的代码质量也更高。这种探索旨在为AI辅助编程或代码生成找到更高效、更精确的人机交互范式 (来源: tnm, lateinteraction)
AI Agent在软件可靠性工程(SRE)中的应用前景: Traversal AI宣布完成4800万美元的种子轮和A轮融资,致力于构建企业级AI SRE(站点可靠性工程师)。其AI Agent能够自主排查、修复甚至预防复杂的生产事故,通过结合AI Agent技术和因果机器学习来实时定位根本原因。DigitalOcean、Eventbrite等公司已成为其早期客户,显示出AI在自动化运维和提升系统可靠性方面的巨大潜力 (来源: hwchase17)
💡 其他
AI生成吉卜力风格“手游”引关注,教程显示由可灵AI与Midjourney制作: 近期,一组吉卜力画风的“手游”截图和视频在社交媒体上走红,其精美的画面、清新的配色和自然的光影效果引发关注。创作者公开了制作方法:首先使用Midjourney生成静态图像,然后利用快手旗下的可灵AI(Kling AI)将图像转化为动态视频。通过添加固定的HUD(平视显示器)元素,如按钮和小地图,营造出可交互游戏的感觉。尽管目前只是视频演示,但已激发网友对AI生成可交互虚拟世界的想象 (来源: 量子位, Kling_ai)

AI在错误检查各领域的应用潜力巨大: 网友random_walker提出,生成式AI在错误检查方面具有巨大应用潜力,且在各领域都有“低垂的果实”。例如,在软件领域可自动检测安全漏洞;写作中可识别逻辑缺陷和弱论点;科学研究中可检测计算错误和引用问题;法律合同中可标记缺失条款和矛盾之处;金融领域可用于欺诈检测和财报错误识别。他认为,错误检查自动化程度高、干扰小,即使有50%的误报率,人工复核也相对容易,且能将人从枯燥工作中解放出来。但也需警惕过度依赖AI导致人类自身能力下降的风险 (来源: random_walker)
Sam Altman访谈:AI将简化工作、提供个性化社交并助推科学发现: OpenAI创始人Sam Altman在访谈中预测,未来5-10年,AI编程和聊天工具将更智能,能自动完成大部分工作。AI可能带来新的社交体验,提供个性化服务,并帮助发现新科学知识,尤其是在天体物理学或高能物理等数据密集型领域。他强调,AI的真正变革在于不仅能思考,还能在物理世界行动,人形机器人是关键挑战。OpenAI的愿景是让AI成为无处不在的“AI伴侣”,通过平台化和硬件合作实现。他认为文化和长期主义是OpenAI的核心竞争力 (来源: 36氪)