
关键词:大语言模型, AI评估, 多智能体系统, 推理能力, 上下文处理, 开源模型, AI视频生成, AI编程, LLM推理能力评估, Claude Opus 4反驳苹果论文, MiniMax-M1 MoE模型, Kimi-Dev-72B编程模型, Gemini Deep Think功能
🔥 聚焦
苹果论文质疑大模型推理能力遭反驳,Claude合著论文指出实验设计缺陷: 苹果公司近期发表论文《思考的幻觉》,通过汉诺塔、积木世界等经典问题测试,指出主流大语言模型(LLM)在复杂推理任务上表现不佳,本质是模式匹配而非真正理解。然而,独立研究员Alex Lawsen与AI模型Claude Opus 4共同署名发表《“思考幻觉”本身的幻觉》一文进行反驳,认为苹果实验存在设计缺陷:1. 未考虑LLM的Token输出上限,导致模型因无法完整输出超长步骤而被判错误;2. 部分测试用例(如某些“过河问题”)在给定条件下数学上无解,AI无法给出“正确答案”并非能力不足;3. 改变评估方式,如要求模型输出解题程序而非完整步骤,则AI表现优异。该事件引发了关于LLM真实推理能力及评估方法论的广泛讨论,凸显了设计合理评估方案的重要性,并提醒开发者在实际应用中需关注上下文窗口、输出预算和任务表述等因素对模型表现的影响。 (来源: 新智元, 大数据文摘)
谷歌AI路线图曝光,暗示下一代AI架构或将摒弃现有注意力机制: 谷歌产品负责人Logan Kilpatrick在AI工程师世界博览会上透露了Gemini模型的未来发展方向,其中最引人注目的是对实现“无限上下文”的展望。他指出,以当前的注意力机制和上下文处理方式,无法实现真正的无限上下文,暗示谷歌可能正在研究全新的核心AI架构。路线图还包括:全模态能力(已支持图像+音频,视频是下一阶段),Diffusion早期实验,默认具备Agent能力(一流的工具调用与使用,模型逐步演化为智能体),持续扩展的推理能力,以及更多小型模型的推出。这一系列计划表明谷歌正积极推动AI从被动响应向主动智能体演进,并致力于突破现有技术瓶颈,特别是在上下文处理方面,可能引领AI架构的重大变革。 (来源: 新智元)
Sakana AI发布ALE-Agent,在NP难题编程竞赛中击败98%人类选手: 由Transformer作者之一Llion Jones联合创办的Sakana AI,与日本编程竞赛平台AtCoder合作推出了ALE-Bench(算法工程基准),专注于评估AI在NP难题(如路径规划、任务调度)上的长程推理和创造性编程能力。其研发的ALE-Agent,基于Gemini 2.5 Pro,结合领域知识提示和多样化解空间搜索策略,在AtCoder启发式竞赛中表现出色,排名第21位(前2%),超越了大量人类顶尖开发者。这标志着AI在解决复杂优化问题方面取得重要进展,对物流、生产规划等实际应用具有重要意义。尽管ALE-Agent在模拟退火等算法上表现优异,但在调试、复杂度分析和避免优化误区方面仍有提升空间。 (来源: 新智元, SakanaAILabs, hardmaru)
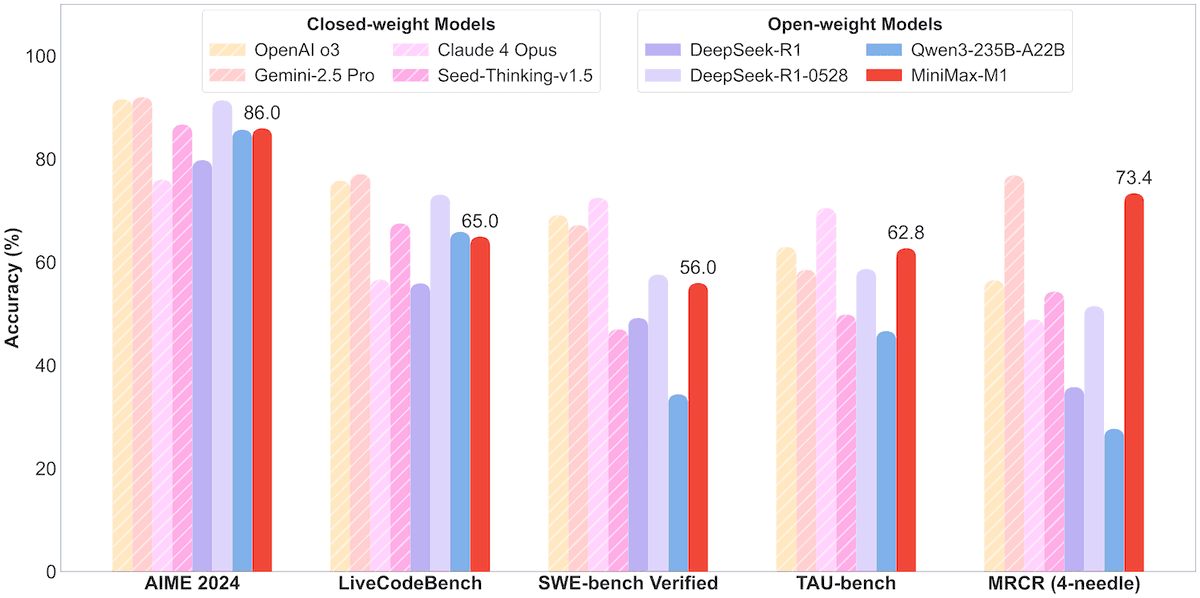
MiniMax开源456B参数MoE模型MiniMax-M1,支持百万上下文与8万Token输出: MiniMax公司发布了其首个开源的大规模混合专家(MoE)推理模型MiniMax-M1。该模型参数规模为456亿,每个Token激活45.9亿参数,采用MoE与闪电注意力机制(Lightning Attention)结合的架构。M1原生支持100万Token的上下文长度,并能实现业界领先的8万Token输出,包含40k和80k思维预算两个版本。在软件工程、工具使用和长上下文任务的基准测试中,M1表现优于DeepSeek-R1和Qwen3-235B等模型,尤其在Agent工具使用方面(如TAU-bench)成绩突出。其强化学习阶段仅用512块H800训练三周,成本约53.74万美元。M1模型已在MiniMax APP和Web端免费使用,并通过API提供服务。 (来源: op7418, scaling01, jeremyphoward, karminski3, Reddit r/LocalLLaMA, 智东西)
🎯 动向
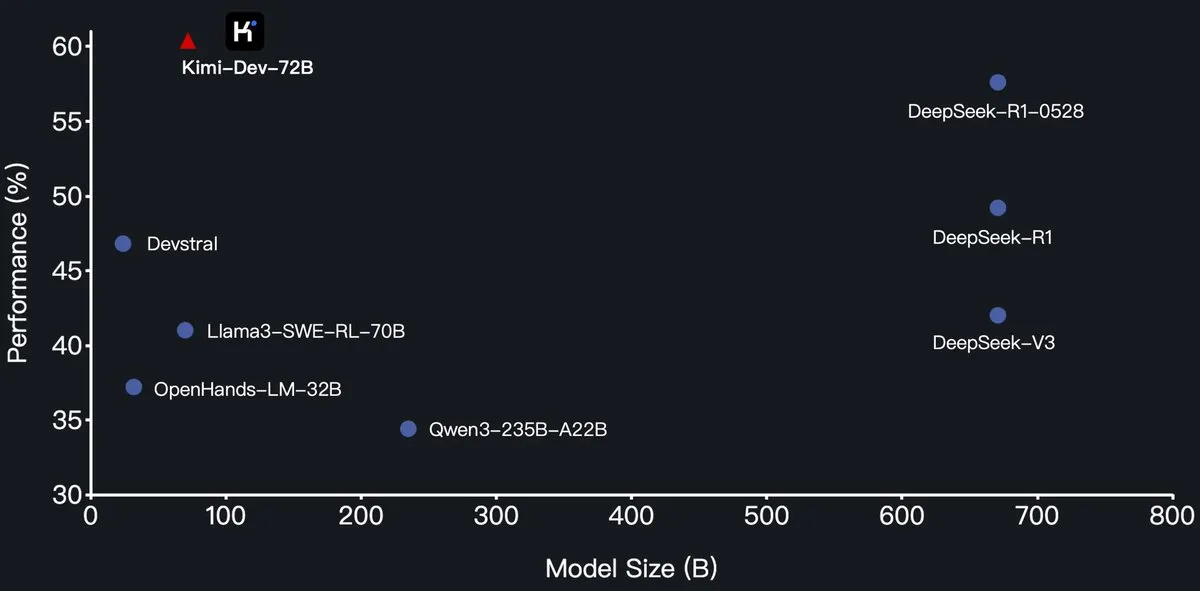
月之暗面开源Kimi-Dev-72B编程大模型,SWE-Bench超越DeepSeek-R1: 月之暗面(Moonshot AI)发布了其新的开源编程大语言模型Kimi-Dev-72B,该模型基于Qwen2.5-72B进行微调。据称,Kimi-Dev-72B在SWE-bench Verified基准测试中取得了60.4%的解决率,超越了DeepSeek-R1-0528(57.6%)和Qwen3-235B-A22B等模型,成为开源模型中的佼佼者。该模型经过强化学习训练,专注于在Docker环境中修补真实的代码仓库,并且只有在完整测试套件通过时才获得奖励。Qwen研发负责人表示并未授权,但Kimi使用MIT许可证发布微调版本符合规定。 (来源: Dorialexander, scaling01, karminski3, Reddit r/LocalLLaMA)
Qwen3系列模型新增MLX格式支持,优化苹果芯片推理: 阿里巴巴通义千问团队宣布,Qwen3系列模型现已支持MLX格式,并提供4bit、6bit、8bit和BF16四种量化级别。此举旨在优化模型在苹果MLX框架上的运行效率,方便开发者在Mac设备上进行本地部署和推理。用户可在HuggingFace和ModelScope上获取相关模型。 (来源: ClementDelangue, stablequan, jeremyphoward)

谷歌Gemini即将推出“Deep Think”功能,提升复杂问题处理能力: 谷歌正准备为其Gemini 2.5 Pro模型引入一项名为“Deep Think”的新功能。该功能旨在通过提供额外的计算能力来处理更具挑战性的问题,尤其在数学相关任务中,Deep Think相较于常规版Gemini 2.5 Pro性能预计提升高达15%。此功能将在工具栏中以新选项形式出现,处理过程可能需要几分钟。同时,Gemini的用户界面也将迎来更新。 (来源: op7418)
谷歌Veo 3视频生成模型正式上线,拓展至70余市场: 谷歌宣布其AI视频生成模型Veo 3已正式向AI Pro和Ultra订阅用户推出,覆盖全球70多个市场。Veo 3因其生成的视频效果逼真、富有创意而备受关注,此前已有用户利用其制作的“魔性切水果”等ASMR内容在社交媒体上获得数千万播放量,展示了其在内容创作领域的潜力。此次正式上线将使更多用户能够体验和利用Veo 3进行视频创作。 (来源: Google, 新智元)
Hugging Face与Groq合作,提供高速LLM推理服务: Hugging Face宣布与AI芯片公司Groq达成合作,将Groq的LPU™(Language Processing Unit)集成到Hugging Face Playground和API中。用户现在可以直接在Hugging Face平台上体验由Groq硬件加速的LLM推理服务,支持包括Llama 4、Qwen 3在内的多种模型。此举旨在为开发者提供更快速、更高效的AI模型推理选项,特别适用于构建智能体、助手和实时AI应用。 (来源: HuggingFace Blog, huggingface, ClementDelangue, mervenoyann, JonathanRoss321, _akhaliq)

Hugging Face Hub新增模型大小筛选功能,助力开发者选择合适模型: Hugging Face平台推出新功能,允许用户根据模型大小(Size Range)进行筛选,特别是针对在mlx / mlx-lm框架上运行的模型。这一改进旨在帮助开发者更便捷地找到符合其特定硬件和性能需求的模型,强调了并非模型越大越好,小型专业模型在特定场景下往往更优。 (来源: ClementDelangue, awnihannun, reach_vb, huggingface, ggerganov)

NVIDIA NCCL更新,开始对半精度输入使用FP32累积进行归约操作: NVIDIA Collective Communications Library (NCCL)的最新版本(commit 72d2432)引入了一项重要更新:在处理半精度输入(如FP16、BF16)的归约操作(reduction ops)时,开始使用FP32进行累积。这一改变对于保持计算精度、防止溢出至关重要,尤其是在大规模分布式训练中。预计该版本将在PyTorch 2.8及更高版本中集成。 (来源: StasBekman)

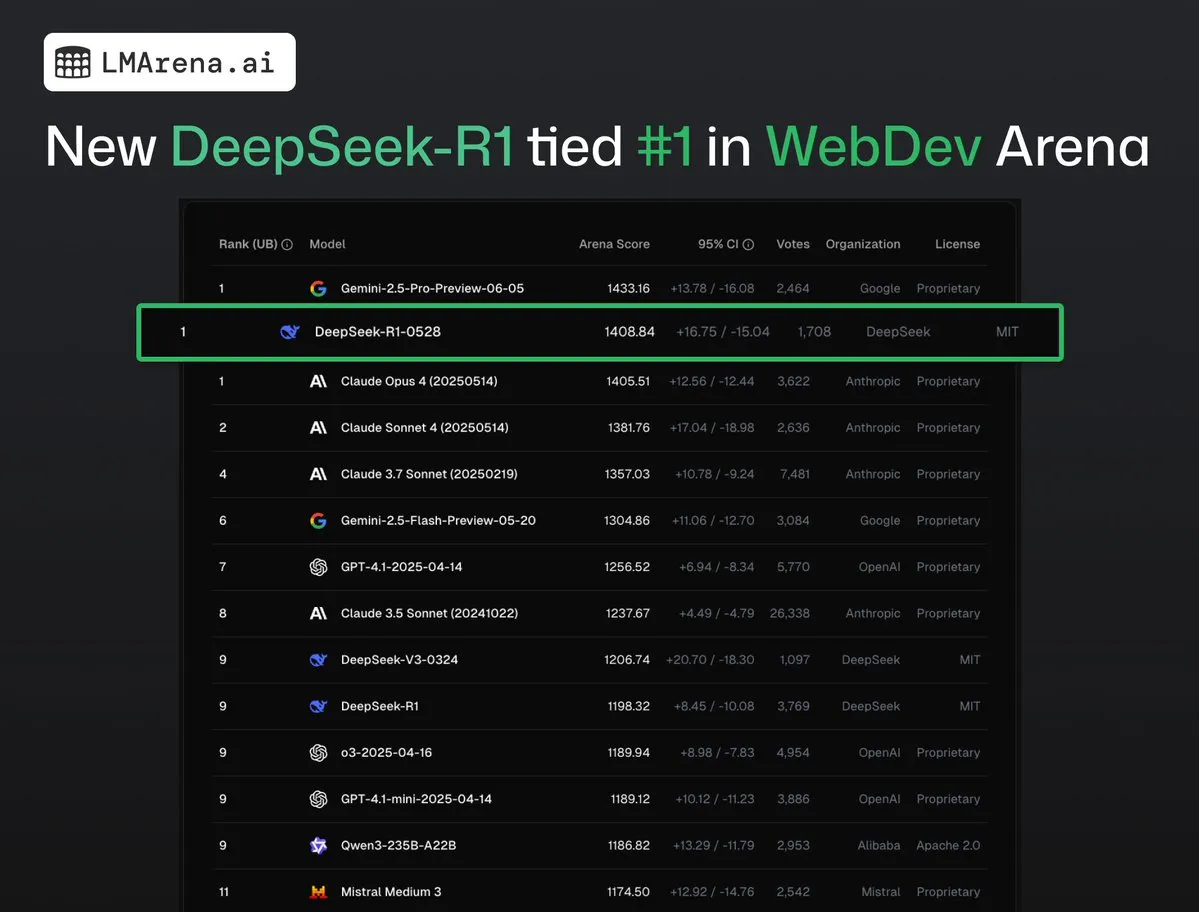
DeepSeek-R1 (0528) 在 WebDev Arena 与 Claude Opus 4 并列第一: lmarena.ai的最新数据显示,新版DeepSeek-R1 (0528)在WebDev Arena基准测试中表现出色,与Claude Opus 4并列第一。该模型在Text Arena综合排名第六,编程能力排名第二,困难提示词排名第四,数学能力排名第五,并且是排行榜上表现最佳的MIT许可开源模型。这标志着DeepSeek在特定开发和推理任务上的强大竞争力。 (来源: ClementDelangue, zizhpan)
字节跳动在Poe平台上线Seedream 3.0图像与Seedance 1.0 Lite视频模型: 字节跳动旗下AI创作工具在海外Poe平台推出更新,上线了即梦AI的图像生成模型Seedream 3.0和视频生成模型Seedance 1.0 Lite。Seedream 3.0旨在生成清晰生动的图像,而Seedance 1.0 Lite则能快速生成具有逼真动态效果的视频。用户可以在Poe中先用Seedream生成图片,再通过@-提及Seedance将其转换为视频,实现图生视频的连贯创作流程。 (来源: op7418)

腾讯推出Levo唱歌模型,支持分轨和零样本音色克隆: 腾讯发布了一款名为Levo的AI唱歌模型,据称其性能可与Suno V3.5媲美。Levo支持音轨分离和零样本音色克隆功能,从其发布的演示和评分来看,表现出色。这一进展显示了腾讯在AI音乐生成领域的实力。 (来源: karminski3)
OpenAI在WhatsApp中推出ChatGPT图像生成功能: OpenAI宣布,用户现在可以通过WhatsApp中的1-800-ChatGPT服务使用ChatGPT的图像生成功能。这一更新使得更广泛的用户群体能够便捷地在即时通讯应用中直接生成AI图像。 (来源: gdb, eliza_luth, iScienceLuvr)
SpatialLM更新至1.1版本,增强3D场景理解与重建能力: 空间推理模型SpatialLM发布1.1版本,新版本支持多种输入源模式,包括文本生成3D场景(Text-to-3D)、手持摄像机视频重建、LiDAR点云数据(如iPhone Pro激光雷达)以及合成网格采样。关键特性包括对非结构化点云的鲁棒性处理,即使3D扫描数据不完整也能进行合理重建。此外,新版本优化了视频流输入的零样本检测,改进了室内布局估计精度,并提升了3D物体检测效果。应用场景广泛,涵盖AR场景重建、机器人空间理解、3D设计工作流及C端相机应用。 (来源: karminski3)
GitHub Copilot推出每月39美元套餐,集成Claude Opus 4等多种大模型: GitHub Copilot新增了一项每月39美元的订阅套餐,该套餐不仅提供编码助手功能,还能让用户访问包括Claude Opus 4、o3和GPT-4.5在内的多种强大语言模型,并可使用Coding agent。这一举措旨在为开发者提供更全面的AI辅助编程体验。 (来源: dotey)
AI大模型调用成本持续降低,豆包1.6系列价格再降63%: 火山引擎在Force原动力大会上发布豆包大模型1.6系列,并宣布其综合成本降低63%,大部分企业常用的0-32K输入长度范围内,价格为每百万tokens输入0.8元,输出8元。这标志着继今年3月阿里千问将成本降至DeepSeek R1的1/10后,大模型价格战持续升级。低成本将进一步推动AI Agent等应用的落地和普及。 (来源: 字节必须再赢一次)
Chipmunk视频生成加速工具更新,支持多GPU架构及更多开源模型: Dan Fu团队的Chipmunk工具迎来更新,现已支持在多种NVIDIA GPU架构(sm_80, sm_89, sm_90,如A100s, 4090s, H100s)上实现1.4-3倍的视频生成无损加速。同时,Chipmunk新增对Mochi、Wan等更多开源视频模型的支持,并提供了集成教程。该工具利用视频模型中激活值的稀疏性(仅5-25%的激活值贡献超过90%的输出)来实现加速,无需重新训练模型。 (来源: realDanFu)

🧰 工具
微软发布AI差旅助手Demo,集成MCP、LlamaIndex.TS与Azure AI Foundry: 微软展示了一个AI差旅助手Demo,该系统通过模型上下文协议(MCP)、LlamaIndex.TS和Azure AI Foundry协调多个AI智能体(包括查询分类、目的地推荐、行程规划等六个专业智能体)共同完成复杂的旅行规划任务。每个智能体通过用Java、.NET、Python和TypeScript编写的MCP服务器获取实时数据和工具。该应用展示了企业级多智能体如何通过多语言微服务协同工作,利用Azure OpenAI和GitHub模型提供AI能力,并可通过Azure容器应用实现可扩展的无服务器部署。 (来源: jerryjliu0, jerryjliu0)
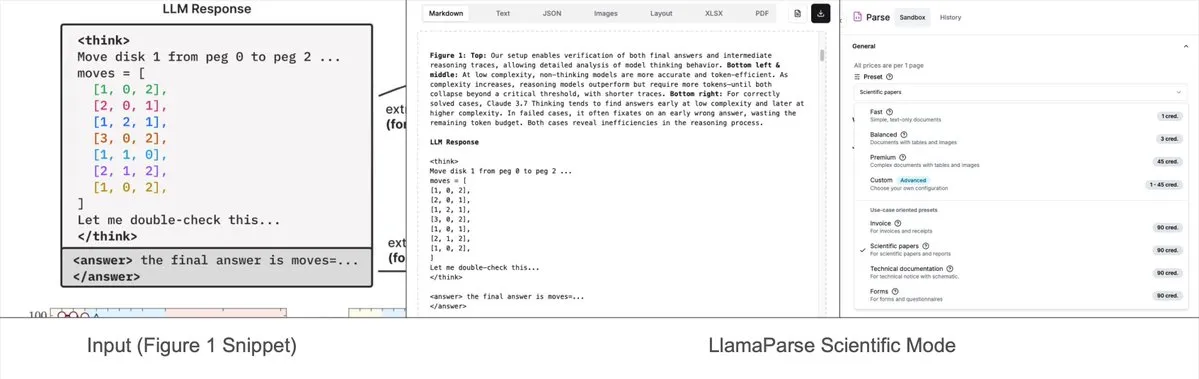
LlamaParse新增预设模式,可解析复杂图表为Mermaid或Markdown: LlamaIndex的LlamaParse工具近期更新,增加了“预设模式”(preset-modes),使其能够解析研究报告等文档中的复杂图表(如包含多条曲线和注释的图表),并将其转换为格式化的Mermaid图或Markdown表格。这一功能有助于从页面中捕获完整上下文,生成的结构化文本可用于构建RAG流程或进行进一步的元数据提取。 (来源: jerryjliu0)
Prompt Optimizer:一款助力编写高质量提示词的优化工具: Prompt Optimizer 是一款旨在帮助用户编写更优质AI提示词,从而提升AI输出质量的工具。它支持Web应用和Chrome插件两种形式,提供智能优化、多轮迭代改进、原始与优化后提示词对比、多模型集成(OpenAI, Gemini, DeepSeek, 智谱AI, SiliconFlow等)、高级参数配置、本地加密存储等功能。该工具采用纯客户端处理,确保数据安全和隐私。 (来源: GitHub Trending)

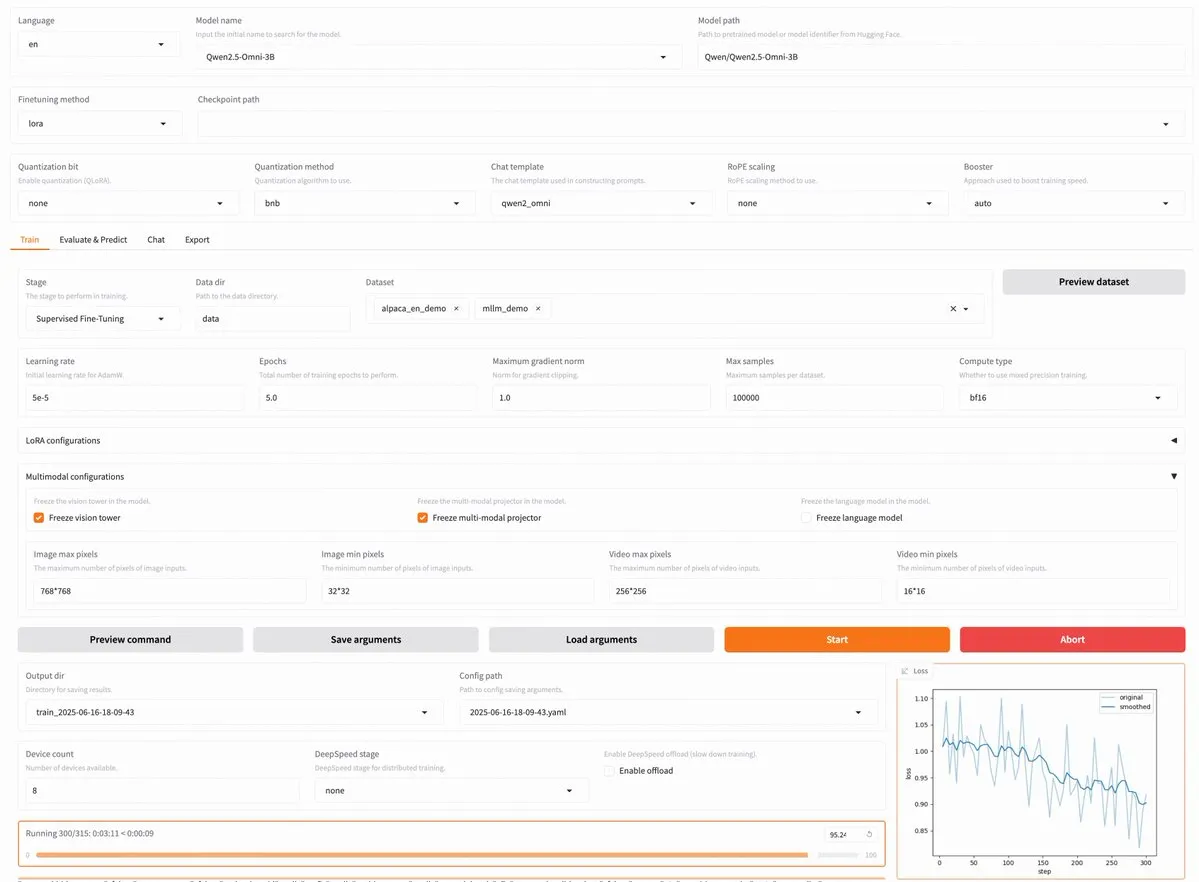
LLaMA Factory v0.9.3发布,支持Qwen3、Llama 4等近300种模型无代码微调: LLaMA Factory发布了v0.9.3版本,该版本是一个完全开源的、支持Gradio用户界面的无代码微调平台,适用于近300多种模型,包括最新的Qwen3, Llama 4, Gemma 3, InternVL3, Qwen2.5-Omni等。用户可以通过Docker镜像本地安装,或在Hugging Face Spaces、Google Colab以及Novita的GPU云上体验。 (来源: _akhaliq)
Nanonets OCR:基于Qwen 2.5 VL 3B的SOTA OCR模型开源: Nanonets发布了一款新的3B参数OCR模型——Nanonets OCR,该模型基于Qwen 2.5 VL 3B主干网络,性能优于Mistral OCR API,并采用Apache 2.0许可证开源。它能够处理LaTeX识别、水印和签名检测、复杂表格提取等多种OCR任务。 (来源: huggingface)
Perplexity Labs被指可替代多种专业岗位,引发AI工具能力讨论: 一位用户GREG ISENBERG称其使用Perplexity Labs替代了销售员、文案撰稿人、电影导演、社交媒体经理和财务分析师五个岗位的工作,认为AI工具的能力“实际上很疯狂”。Perplexity CEO Arav Srinivas转发并评论这是展示AI智能体在现实生活用例中如何应用的最好视频之一,比较了Perplexity Labs与市场上其他工具在金融分析、社交媒体营销、创意指导和销售方面的表现。这突显了AI Agent在整合和执行多领域专业任务方面的潜力。 (来源: AravSrinivas, AravSrinivas)
Claude-Flow发布v1.0.50重大更新,激活“蜂群模式”提升代码自动化效率: Claude-Flow,一个基于Claude Code的批量工具并行代理系统,发布了v1.0.50版本。新版本引入了“蜂群模式”(Swarm Mode),允许用户同时生成、管理和协调数百个Claude代理并行工作,用于构建、测试、部署或多阶段研究循环。据称,与传统的顺序Claude Code自动化相比,性能提升了20倍。开发者可以通过npx claude-flow@latest init --sparc --force进行初始化。 (来源: Reddit r/ClaudeAI)

📚 学习
Awesome Machine Learning:全面的机器学习资源列表: GitHub上的“awesome-machine-learning”项目是一个精心策划的机器学习框架、库和软件列表,按编程语言分类。它还包含免费机器学习书籍、专业活动、在线课程、博客通讯和本地聚会等资源的链接,为机器学习学习者和从业者提供了宝贵的导航。 (来源: GitHub Trending)
Anthropic与Cognition AI分别发表关于多智能体系统构建的博客文章,LangChain进行总结: Anthropic和Cognition AI近期各自发布了关于构建(或不构建)多智能体系统的博客文章。Anthropic分享了他们如何构建其多智能体研究系统的经验,而Cognition AI则提出了“不要构建多智能体”的观点。LangChain的Harrison Chase对此进行了总结,指出尽管表面上观点看似不同,但两篇文章在指导方针和建议上有很多共通之处,并关联到LangChain在多智能体方面的努力。 (来源: hwchase17, Hacubu)
《Recent Advances in Speech Language Models: A Survey》论文被ACL 2025主会接收: 香港中文大学团队撰写的语音语言模型(SpeechLM)综述论文《Recent Advances in Speech Language Models: A Survey》已被ACL 2025主会议接收。该论文是该领域首个全面系统的综述,深入剖析了SpeechLM的技术架构(语音分词器、语言模型、声码器)、训练策略(预训练、指令微调、后对齐)、交互范式(全双工建模)、应用场景(语义、说话人、副语言学)及评估体系。论文强调了SpeechLM在实现自然人机语音交互方面的潜力,并指出了面临的挑战与未来方向。 (来源: 36氪)

新研究通过视觉游戏学习(ViGaL)提升小模型跨领域推理能力,7B模型数学表现超GPT-4o: 莱斯大学、约翰霍普金斯大学及英伟达的研究团队提出了一种名为ViGaL(Visual Game Learning)的新型后训练范式。通过让7B参数的多模态模型(Qwen2.5-VL-7B)玩贪吃蛇和3D旋转等简单的街机游戏,模型不仅提升了游戏技巧,还在数学(MathVista)和多学科问答(MMMU)等复杂推理任务上展现出显著的跨领域能力提升,甚至在某些方面超越了GPT-4o等顶级模型。研究表明,游戏训练能培养模型的空间理解、顺序规划等通用认知能力,且不同游戏能强化不同方面的推理技能。该方法在提升推理能力的同时保持了模型的通用视觉能力。 (来源: 新智元)

上海AI Lab等提出MathFusion框架,通过指令融合提升LLM数学解题能力: 上海人工智能实验室、中国人民大学高瓴人工智能学院等机构联合提出MathFusion框架,旨在通过融合不同数学问题生成结构更多样、逻辑更复杂的合成指令,从而增强大型语言模型(LLM)解决数学问题的能力。该框架包含顺序融合、并列融合和条件融合三种策略,能够有效捕捉问题间的深层联系。实验表明,仅使用45K的合成指令,在DeepSeekMath-7B、Llama3-8B、Mistral-7B等模型上进行微调后,MathFusion在多个数学基准测试中平均准确率提升了18.0个百分点,展现了高数据效率和性能。 (来源: 量子位)

上海AI Lab等提出GRA框架,小模型协同生成高质量数据,性能媲美72B模型: 上海人工智能实验室联合中国人民大学提出GRA(Generator–Reviewer–Adjudicator)框架,通过模拟论文投稿和同行评审机制,让多个小型语言模型(7-8B参数)协同生成高质量训练数据。该框架中,Generator负责生成,Reviewer进行多轮评审打分,Adjudicator在评审冲突时做最终裁决。实验表明,使用GRA生成的数据训练LLaMA-3.1-8B和Qwen-2.5-7B等基础模型,在数学、代码、逻辑推理等10个主流数据集上的性能,与或超过了使用Qwen-2.5-72B-Instruct这样的大模型蒸馏生成的数据。这为低成本、高效率的数据合成提供了新思路。 (来源: 量子位)

论文探讨大模型可解释性现状与未来,强调其对AI安全部署的重要性: 腾讯研究院发表文章,深入探讨了大型语言模型(LLM)可解释性的现状、技术路径及未来挑战。文章指出,理解LLM的内部机制对于防范价值偏离、调试改进模型、防止滥用以及推动高风险场景应用至关重要。目前的技术路径包括自动化解释(大模型解释小模型)、特征可视化(如稀疏自编码器)、思维链监控及机制可解释性(如Anthropic的“AI显微镜”和DeepMind的Tracr)。然而,神经元多重语义、解释规律普适性和人类认知局限等仍是主要挑战。文章呼吁加强可解释性研究投入,并建议在当前阶段采取鼓励行业自律的软法规则,以确保AI技术安全、透明和以人为本地发展。 (来源: 腾讯研究院)

新论文探讨离散扩散模型在大型语言和多模态模型中的应用与进展: 一篇题为《Discrete Diffusion in Large Language and Multimodal Models: A Survey》的论文系统综述了离散扩散语言模型(dLLMs)和离散扩散多模态语言模型(dMLLMs)的研究进展。这些模型采用多Token并行解码和基于去噪的生成策略,实现了并行生成、细粒度输出可控性以及动态、响应感知的感知能力,推理速度相比自回归模型可提升高达10倍。论文追溯了其发展历史,形式化了数学框架,对代表性模型进行了分类,分析了关键的训练和推理技术,并总结了在语言、视觉语言和生物领域的应用,最后讨论了未来的研究方向和部署挑战。 (来源: HuggingFace Daily Papers)
新研究提出Test3R:通过测试时学习提升3D重建几何精度: 一项名为Test3R的新技术,通过在测试时进行学习来显著提升3D重建的几何精度。该方法利用图像三元组 (I_1,I_2,I_3),从图像对 (I_1,I_2) 和 (I_1,I_3) 生成重建结果。核心思想是在测试时通过自监督目标优化网络:最大化这两个重建结果相对于共同图像I_1的几何一致性。实验表明,Test3R在3D重建和多视图深度估计任务上显著优于现有SOTA方法,且具有普适性和低成本特性,易于应用于其他模型,测试时训练开销和参数量极小。 (来源: HuggingFace Daily Papers)
论文提出Mirage-1:具有分层多模态技能的GUI智能体,提升长程任务处理能力: 研究者提出Mirage-1,一个多模态、跨平台、即插即用的GUI智能体,旨在解决当前GUI智能体在在线环境中处理长程任务时知识不足和离线在线领域差距的问题。Mirage-1的核心是分层多模态技能(HMS)模块,它将轨迹逐步抽象为执行技能、核心技能和元技能,为长程任务规划提供分层知识结构。同时,技能增强蒙特卡洛树搜索(SA-MCTS)算法利用离线获得的技能减少在线树探索的动作搜索空间。在AndroidWorld、MobileMiniWob++、Mind2Web-Live和新构建的AndroidLH基准测试中,Mirage-1均表现出显著性能提升。 (来源: HuggingFace Daily Papers)
论文《Don’t Pay Attention》提出新型神经网络基础架构Avey,挑战Transformer: 一篇名为《Don’t Pay Attention》的论文提出了一种新的神经网络基础架构Avey,旨在摆脱对注意力和循环机制的依赖。Avey由一个排序器(ranker)和一个自回归神经处理器(autoregressive neural processor)组成,它们协同识别并仅将与任何给定Token最相关的Token(无论其在序列中的位置如何)进行上下文化处理。该架构将序列长度与上下文宽度解耦,从而能够有效处理任意长度的序列。实验结果表明,Avey在标准短程NLP基准测试中表现与Transformer相当,并在捕捉长程依赖方面表现尤为出色。 (来源: HuggingFace Daily Papers)
新论文探讨通过奖励模型实现可扩展代码验证,权衡准确性与吞吐量: 一项研究探讨了在大型语言模型(LLM)解决编码任务时,使用结果奖励模型(ORM)与综合验证器(如完整测试套件)之间的权衡。研究发现,即使在有综合验证器的情况下,ORM通过牺牲一定准确性来换取速度,在扩展验证中仍扮演关键角色。特别是在“生成-修剪-再排序”方法中,使用更快但准确性较低的验证器预先移除错误解决方案,可使系统速度提高11.65倍,而准确性仅降低8.33%。该方法通过过滤掉错误但排名靠前的解决方案来发挥作用,为设计可扩展且准确的程序排序系统提供了新思路。 (来源: HuggingFace Daily Papers)
新基准AbstentionBench揭示:推理型LLM在不可回答问题上表现不佳: 为了评估大型语言模型(LLM)在面对不确定性时选择弃权(即拒绝明确回答)的能力,研究者推出了AbstentionBench。该大规模基准测试包含20个不同数据集,涵盖答案未知、规范不足、错误前提、主观解释和过时信息等多种类型的问题。对20个前沿LLM的评估显示,弃权是一个尚未解决的问题,且模型规模的扩大对此助益甚微。令人惊讶的是,即使是为数学和科学领域明确训练的推理型LLM,其推理微调反而平均降低了24%的弃权能力。虽然精心设计的系统提示能在实践中提升弃权表现,但这并不能解决模型在不确定性推理方面的根本缺陷。 (来源: HuggingFace Daily Papers)
论文提出基于补丁的提示和分解方法(PatchInstruct)利用LLM进行时间序列预测: 一项新研究探索了利用大型语言模型(LLM)进行时间序列预测的简单灵活的提示策略,无需大量重新训练或复杂的外部架构。通过结合时间序列分解、基于补丁的标记化(patch-based tokenization)和基于相似性的邻居增强等专门的提示方法,研究者发现可以提高LLM的预测质量,同时保持简单性并最大限度地减少数据预处理。该研究提出的PatchInstruct方法能够使LLM做出精确有效的预测。 (来源: HuggingFace Daily Papers)
新数据集MS4UI发布,专注用户界面教学视频的多模态摘要: 为解决现有基准在提供步骤化、可执行指令和图示方面的不足,研究者提出了MS4UI(Multi-modal Summarization for User Interface Instructional Videos)数据集。该数据集包含2413个UI教学视频,总时长超过167小时,并进行了手动视频分割、文本摘要和视频摘要标注。旨在推动针对UI教学视频的简洁、可执行的多模态摘要方法研究。实验表明,当前SOTA的多模态摘要方法在MS4UI上表现不佳,凸显了该领域新方法的重要性。 (来源: HuggingFace Daily Papers)
DeepResearch Bench:一个全面的深度研究智能体基准测试: 为系统评估基于LLM的深度研究智能体(Deep Research Agents, DRAs)的能力,研究者推出了DeepResearch Bench。该基准包含由22个不同领域的专家精心设计的100个博士级研究任务。由于评估DRAs的复杂性和劳动密集性,研究者提出了两种与人类判断高度一致的新评估方法:一种是基于参考的自适应标准方法,用于评估生成研究报告的质量;另一种框架通过评估有效引用数量和整体引用准确性来评估DRA的信息检索和收集能力。 (来源: HuggingFace Daily Papers)
论文提出BridgeVLA:通过输入输出对齐实现高效的3D操作学习: 为了提升视觉语言模型(VLM)在机器人操作学习中的3D信号利用效率,研究者提出了BridgeVLA,一种新颖的3D视觉语言动作(VLA)模型。BridgeVLA将3D输入投影到多个2D图像,确保与VLM骨干网络的输入对齐,并使用2D热力图进行动作预测,从而在一致的2D图像空间中统一输入和输出。此外,该研究还提出了一种可扩展的预训练方法,使VLM骨干网络在下游策略学习之前具备预测2D热力图的能力。实验表明,BridgeVLA在多个仿真基准和真实机器人实验中均表现出色,显著提升了3D操作学习的效率和效果,并展现了强大的样本效率和泛化能力。 (来源: HuggingFace Daily Papers)
新研究通过归因基础合成数百万多样化复杂用户指令(SynthQuestions): 为解决大型语言模型(LLM)对齐所需的多样化、复杂和大规模指令数据的缺乏,研究者提出了一种基于归因基础(attributed grounding)的指令合成方法。该框架包括:1) 自上而下的归因过程,将选定的真实指令与情境化用户联系起来;2) 自下而上的合成过程,利用网络文档首先生成情境,然后生成有意义的指令。通过此方法构建了包含100万条指令的数据集SynthQuestions。实验表明,在该数据集上训练的模型在多个常见基准测试中取得了领先性能,并且随着网络语料库的增加,性能持续提升。 (来源: HuggingFace Daily Papers)
PersonaFeedback:大规模人工标注的个性化评估基准发布: 为评估大型语言模型(LLM)在给定预定义用户画像和查询时提供个性化响应的能力,研究者推出了PersonaFeedback基准。该基准包含8298个人工标注的测试用例,根据用户画像的上下文复杂性和区分个性化响应的难度分为简单、中等和困难三个等级。与现有基准不同,PersonaFeedback将画像推断与个性化解耦,专注于评估模型针对明确画像生成定制化响应的能力。实验结果显示,即使是SOTA LLM在困难等级的测试中也面临挑战,表明当前检索增强框架并非个性化任务的最终解决方案。 (来源: HuggingFace Daily Papers)
论文探讨多语言大模型中的“语言手术”:通过潜在注入实现推理时语言控制: 一项新研究探讨了大型语言模型(LLM)中自然出现的表示对齐现象及其在解耦语言特定和语言无关信息方面的意义。研究证实了这种对齐的存在,并分析了其与显式设计对齐模型的行为比较。基于这些发现,研究者提出了推理时语言控制(Inference-Time Language Control, ITLC)方法,利用潜在注入(latent injection)实现精确的跨语言控制并减轻LLM中的语言混淆问题。实验证明ITLC在保持目标语言语义完整性的同时,具有强大的跨语言控制能力,并能有效缓解即使在当前大规模LLM中依然存在的跨语言混淆问题。 (来源: HuggingFace Daily Papers)
论文提出NoWait方法:移除“思考Token”提升大模型推理效率: 近期研究表明,大型推理模型在进行复杂分步推理时,常因过度“思考”(如输出“Wait”、“Hmm”等Token)导致输出冗余,影响效率。新提出的NoWait方法通过在推理时抑制这些显式自我反思Token,旨在验证其对高级推理的必要性。在跨文本、视觉和视频推理任务的十个基准测试中,NoWait在五个R1风格模型系列中将思维链轨迹长度缩短了27%-51%,且未损害模型效用。该方法为实现高效且保持效用的多模态推理提供了一种即插即用的解决方案。 (来源: HuggingFace Daily Papers)
💼 商业
OpenAI赢得美国国防部2亿美元AI合同,开发前沿军事能力: OpenAI已与美国国防部签订一份为期一年、价值2亿美元的合同,旨在为国家安全开发先进的人工智能工具,这标志着OpenAI首次获得五角大楼列出的此类合同。工作将主要在国家首都地区进行。此前OpenAI已与国防公司Anduril合作,此举正值美国国防领域广泛推动AI应用的背景之下,其竞争对手Anthropic也与Palantir和亚马逊在该领域有所合作。OpenAI CEO Sam Altman曾公开表示支持国家安全项目。 (来源: Reddit r/ArtificialInteligence, code_star)

Alta完成1100万美元融资,Menlo Ventures领投,聚焦AI+时尚: AI时尚初创公司Alta宣布完成由Menlo Ventures领投的1100万美元融资,Benchstrength和Aglaé Ventures(LVMH集团阿尔诺家族支持的VC基金)参投。Amy Tong Wu将加入Alta董事会。此轮融资将助力Alta在AI与时尚结合领域的进一步发展。 (来源: ZhaiAndrew)
Figure公司调整组织架构,控制部门并入Helix以加速AI路线图: 人形机器人公司Figure宣布其控制(Controls)部门已不复存在,整个团队已并入Helix部门。此举旨在加速公司在人工智能领域的路线图发展,表明Figure正将更多资源和精力集中于AI技术的研发与应用。 (来源: adcock_brett)
🌟 社区
关于AGI的讨论:普通用户无需过度担忧,AGI更偏向战略而非日常工具: 社区中多人讨论指出,对于普通LLM用户而言,不必过分担忧AGI(通用人工智能)的到来。AGI的定义模糊且理论性强,即使实现,短期内也不会直接体现在用户聊天窗口,而是作为国家或大型机构的战略工具和基础设施,用于处理国家间谈判等复杂事务,而非帮助个人安排会议。 (来源: farguney, farguney, farguney, farguney)
多智能体系统构建需人工评估,关注边缘案例与来源质量: 在构建多智能体系统时,人工评估和测试至关重要,能够发现自动化评估可能忽略的边缘案例。例如,早期智能体在选择信息来源时,倾向于SEO优化的内容农场而非权威的学术PDF或个人博客。通过在提示中加入来源质量启发式方法有助于解决此类问题。这表明即使在自动化评估时代,手动测试对于发现系统故障、微妙的来源选择偏见等问题仍然不可或缺。 (来源: riemannzeta)

LLM在预测和学习机制上与视频模型的差异引发思考: Yann LeCun和Pedro Domingos转发了Sergey Levine的观点,探讨了为何语言模型能从下一Token预测中学到如此之多,而视频模型从下一帧预测中学到的却相对较少。Levine推测这可能是因为LLM在某种程度上扮演了“大脑扫描仪”的角色,暗示了其学习机制的独特性,或者说LLM如同生活在柏拉图的洞穴中,通过观察影子的序列(文本)来推断真实世界。 (来源: ylecun, pmddomingos, pmddomingos)

AI Agent在教育领域的积极影响:促进学习者走出舒适区: 社区讨论认为,AI Agent不仅对企业有积极影响,在教育领域同样潜力巨大。通过与AI Agent互动,学习者可以更有效地走出自己的舒适区,从而促进学习效果的提升。 (来源: pirroh, amasad)
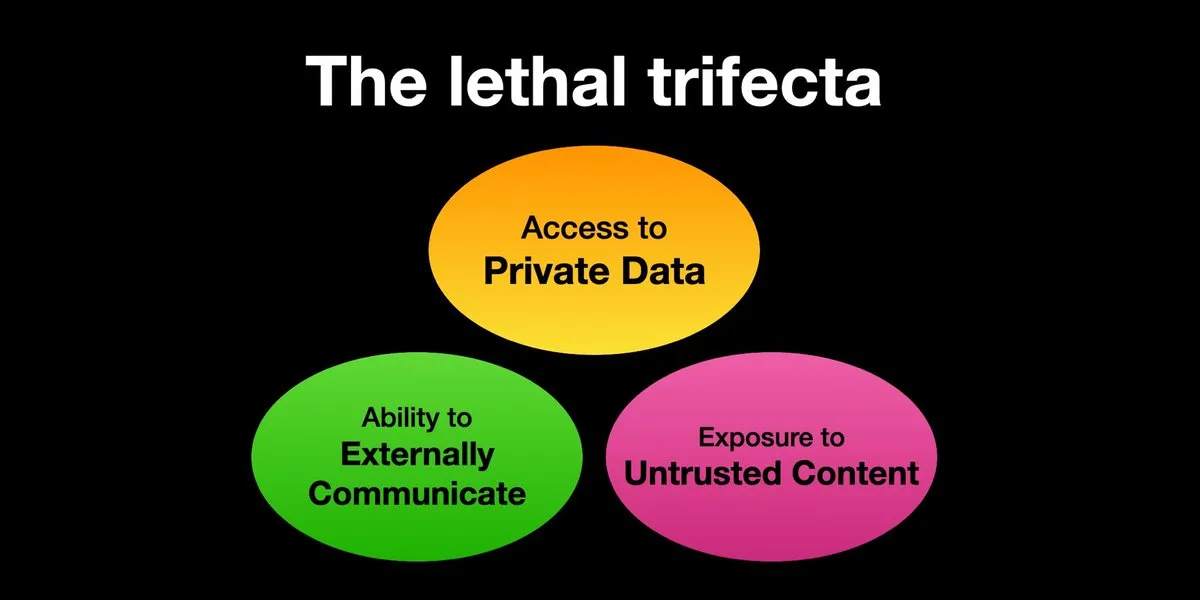
AI Agent面临提示注入攻击风险,安全防护亟待加强: Karpathy转发Simon Willison关于AI Agent面临“致命三合一”(Lethal Trifecta)风险的警告,即当AI Agent同时拥有访问私人数据、接触不受信任内容以及对外通信能力时,攻击者可诱骗系统窃取数据。这让人联想到早期计算机病毒的“西部拓荒”时代,目前针对恶意提示的防御机制尚不完善,例如缺乏类似操作系统内核/用户空间的安全范式来限制Agent执行任意脚本的能力。这使得早期采用LLM Agent进行个人计算存在顾虑。 (来源: karpathy, TheTuringPost)
AI时代,快速学习能力成为核心竞争力: Mustafa Suleyman指出,未来十年最大的职业加速器将是卓越的学习能力。他建议人们明确自己的学习风格,利用AI将材料转换为适合的格式(如播客、测验),然后应用知识并不断重复此过程,从而实现快速学习和成长。 (来源: mustafasuleyman)
AI生成内容的真实性与相关性:相关性或胜过真实性: 用户imjaredz分享经验称,发送了2000封AI生成的引导邮件,无人抱怨其为AI所写,反而有5人表示邮件内容“正是他们正在研究的”。这引发了关于在沟通中,内容的相关性是否比其“真实性”(是否为人类创作)更重要的讨论。 (来源: imjaredz)
对LLM“理解”能力的探讨:行为近似不等于真正理解: 社区中有观点认为,尽管大型语言模型展现出强大的行为和认知近似能力,但这并不等同于真正的理解。理解需要解释能力,而仅仅表现出行为并非智能或理解。这一根本区别常被忽视。该观点强调,在将涉及生命安全的决策交给模型前,需审慎评估其是否真正接近通用人工智能,并警惕过度吹捧其能力。 (来源: farguney)
AI Agent在软件工程基准测试中表现亮眼,但对其“智能体”本质的探讨: 随着AI在SWE-bench等软件工程基准测试中得分不断提高(甚至超过50-60分),社区对“智能体编码时代”是否真正到来进行了讨论。有观点认为,如果普遍使用的是“无智能体框架”(agentless frameworks),而非让语言模型在环境中真正探索的环境,那么称之为“智能体编码时代”可能名不副实,尽管这些框架本身很有价值。 (来源: huybery, terryyuezhuo)
AI生成图片的内容审核需求:寻求开源或商业解决方案: 随着AI生成图片技术的普及,国内开发者开始关注输出内容的合规性问题,特别是如何检测色情、政治敏感等内容。社区中出现寻求可用的开源小模型或商业产品来进行内容审核的讨论。 (来源: dotey)
💡 其他
AI驱动的个性化与内容相关性:2000封AI邮件无差评,5人称“正是我所需”: 一位用户分享称,发送了2000封由AI生成的引导邮件,没有任何接收者抱怨邮件是由AI撰写。相反,有五位接收者表示邮件内容“正是他们目前正在进行的工作”。这一案例引发了关于在AI辅助沟通中,内容的高度相关性是否能够超越对“真实性”(即是否由人类撰写)的在意的讨论,暗示了AI在个性化内容生成方面的潜力。 (来源: imjaredz)
人类成为AI系统瓶颈,需避免或提升人类效率: Charles Earl的观点指出,收件箱邮件堆积如山,而发件箱却空空如也,这反映出人类是信息处理和响应的瓶颈。在AI时代,需要思考如何避免人类瓶颈,或者如何通过AI等技术提升人类的工作效率。 (来源: charles_irl)
AI控制智能家居的潜在风险:用户因App故障被困冰冷智能床: 一位用户分享了其因AI控制的智能床(Eight Sleep Pod3)App故障而无法调节温度,最终被困在冰冷床上的经历。由于该型号无手动控制,完全依赖App,此次故障凸显了过度依赖AI和App控制智能家居设备可能带来的不便和“反乌托邦”式体验。 (来源: madiator)