关键词:量子计算, AI自我升级, 脑机接口, 大语言模型, 神经形态计算, AI视频生成, 强化学习, AI伦理, 量子比特错误率, JEPA自监督学习, MLX格式量化, PAM视觉理解模型, AI ASMR内容生成
🔥 聚焦
牛津大学在量子计算实验中实现创纪录的0.000015%错误率: 牛津大学的研究团队在量子计算实验中取得了重大突破,将量子比特的错误率降低至0.000015%,创下了新的世界纪录。这一进展对于构建容错量子计算机至关重要,极低的错误率是实现复杂量子算法和发挥量子计算潜力的前提。该成果展示了在硬件层面提升量子比特稳定性和精确操控方面的显著进步,为未来AI等领域依赖强大算力的应用奠定了更坚实的基础 (来源: Ronald_vanLoon)

MIT研究者让人工智能学会自我升级与改进: 麻省理工学院(MIT)的研究人员在AI自我提升领域取得进展,他们开发出一种新方法,使AI系统能够自主学习并改进其自身性能。这种能力模仿了人类通过经验和反思不断进步的过程,对于发展更自主、适应性更强的人工智能至关重要。该研究可能为AI模型在部署后持续优化、减少对人工干预的依赖铺平道路,对AI的长期发展和应用具有深远影响 (来源: TheRundownAI)

“读心术”AI将瘫痪者脑电波即时转化为语音: 一项突破性研究展示了“读心术”AI如何将瘫痪病人的脑电波实时转化为清晰的语音。这项技术通过先进的脑机接口(BCI)和AI算法,解码与语言相关的神经信号,并将其合成为可理解的语音输出。这为因严重运动障碍而失去语言能力的患者提供了一种全新的交流方式,有望极大地改善他们的生活质量,标志着AI在辅助医疗和神经科学领域的重大进步 (来源: Ronald_vanLoon)

数学物理世纪难题取得突破,北大校友参与破解希尔伯特第六问题: 北大校友邓煜、中科大少年班马骁与陶哲轩高徒扎赫尔・哈尼在希尔伯特第六问题“物理学的公理化”上取得重大突破。他们首次严格证明了从牛顿力学(微观,时间可逆)到玻尔兹曼方程(宏观统计,时间不可逆)的完整过渡,填补了两者间的逻辑鸿沟,为统计力学奠定更坚实的数学基础,并意外解答了“时间箭头之谜”。这项成果通过精巧的数学工具和分阶段推导,展示了从原子论到连续介质运动定律的路径 (来源: 量子位)

🎯 动向
阿里巴巴推出Qwen3系列模型的MLX格式版本: 阿里巴巴宣布其Qwen3系列大模型现已支持MLX格式,并提供4比特、6比特、8比特和BF16四种量化级别。MLX是苹果公司为Apple Silicon优化的机器学习框架,此举意味着Qwen3模型将能更高效地在苹果设备上运行,降低了在端侧部署和运行大模型的门槛,有助于推动大模型在个人设备上的普及和应用 (来源: Alibaba_Qwen, awnihannun, cognitivecompai, Reddit r/LocalLLaMA)
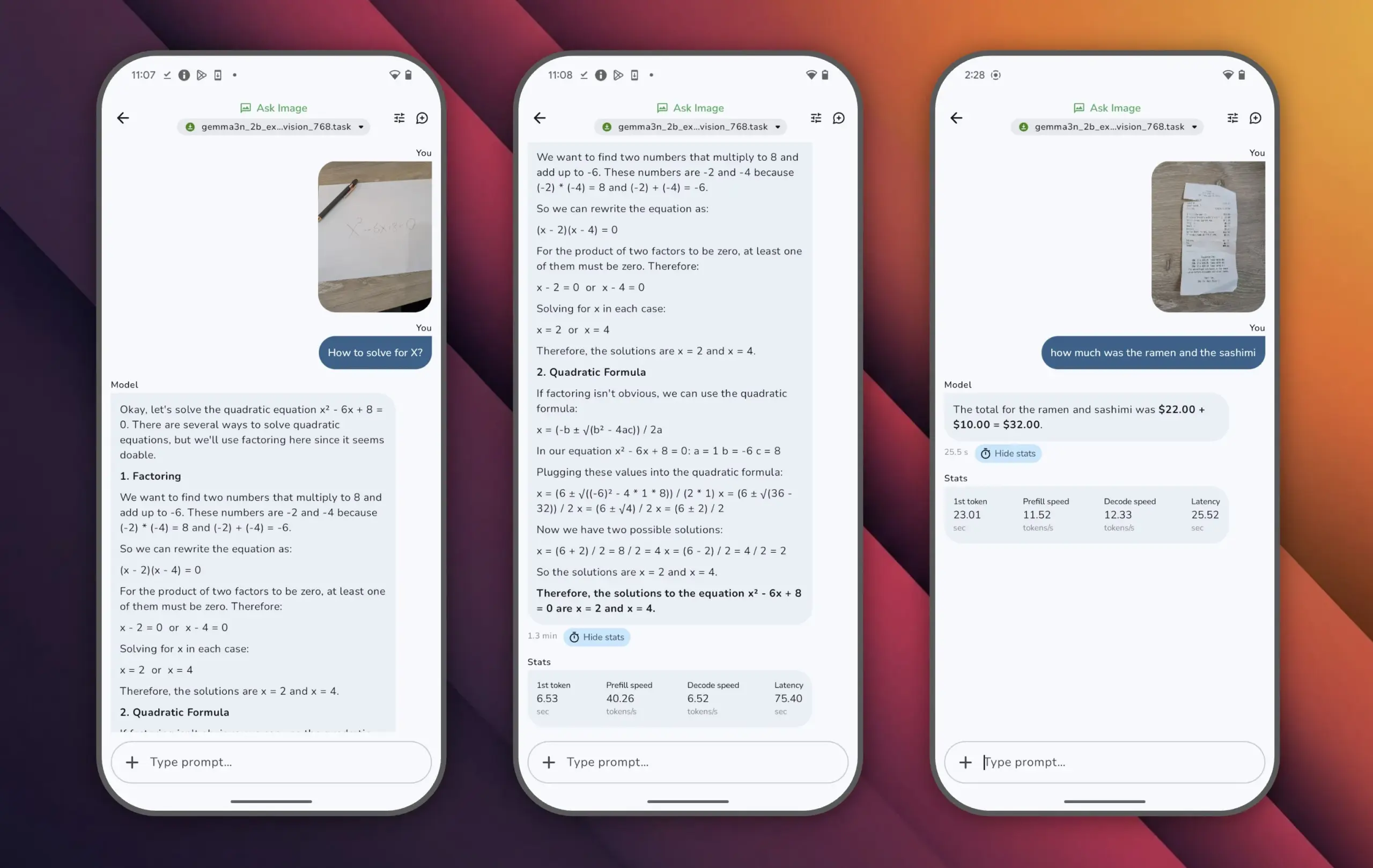
谷歌发布Gemma 3n模型,小参数实现高性能: 谷歌推出了Gemma 3n模型,该模型参数量不足100亿,但在LMArena评分中超过1300分,成为首个达到此成就的小型模型。Gemma 3n的突出表现证明了在较小参数规模下仍可实现高水平的语言理解和生成能力,且支持在手机等端侧设备上运行,这对于推动AI应用的普及和降低算力成本具有重要意义 (来源: osanseviero)
腾讯推出AI生成电影级3D资产技术: 腾讯展示了一项新的人工智能技术,能够生成具有电影级质量的3D资产。这项技术有望大幅提升游戏开发、影视制作等领域中3D内容创作的效率和质量,降低制作成本。高质量3D资产的快速生成是元宇宙和数字内容产业发展的关键环节 (来源: TheRundownAI)
快手Kling 2.1模型在图像转视频及音视频同步生成方面表现出色: 快手旗下AI视频生成模型Kling更新至2.1版本,在图像到视频转换方面展现出强大能力。新版本据称能实现视频和音频的一键生成,无需后期音效设计,即可产出工作室级别的音画同步内容。这标志着AI在多模态内容生成,特别是视频领域的进步,简化了创作流程并提升了生成质量 (来源: Kling_ai, Kling_ai)
新型AI视频模型”Kangaroo”或为Minimax海螺2.0,挑战现有SOTA: 市场上出现一款名为”Kangaroo”的神秘AI视频生成模型,在AI视频竞技场中表现强劲,尤其在图像转视频方面。有分析指出该模型可能是Minimax公司的海螺2.0版本。其出现可能改变现有文本到视频及图像到视频模型的性能梯队,尽管其音频处理能力尚待评估 (来源: TomLikesRobots)
MiniMax推出M1系列模型,长文本处理能力突出: MiniMaxAI发布了MiniMax-M1模型系列,这是一个拥有456B参数的MoE(混合专家)模型。该系列模型在多个基准测试中表现优异,尤其在长上下文处理方面(如OpenAI-MRCR基准测试)超越了GPT-4.1,并在LongBench-v2中位列第三。这显示了其在处理和理解长篇文档方面的潜力,但其较大的“思考预算”(thinking budget)可能对计算资源提出较高要求 (来源: Reddit r/LocalLLaMA)

图灵奖得主Richard Sutton:AI正从“人类数据时代”迈向“经验时代”: 强化学习奠基人Richard Sutton在北京智源大会上指出,当前依赖人类数据的AI大模型已接近极限,高质量人类数据消耗殆尽,模型规模扩张效益递减。他认为AI的未来在于进入“经验时代”,即智能体通过与环境的实时交互生成第一手经验进行学习,而非模仿旧有文本。这要求智能体在真实或模拟环境中持续运行,利用环境回馈作为奖励信号,发展世界模型和记忆体系,实现真正的持续学习和创新 (来源: 36氪)

PAM模型:3B参数实现图像视频分割、识别与解说一体化: 香港中文大学MMLab等机构开源了Perceive Anything Model (PAM),该3B参数模型能同时完成图像和视频中的目标分割、识别、解释及描述,并同步输出文本和Mask。PAM通过引入Semantic Perceiver连接SAM2分割骨架和LLM,实现了高效的视觉特征到多模态token的转换。团队还构建了大规模高质量图文训练数据集。PAM在多个视觉理解基准上刷新或接近SOTA,并具备更优的推理效率 (来源: 量子位)

神经形态计算或成下一代AI关键,有望低功耗运行: 科学家正积极探索神经形态计算,旨在模拟人脑结构和运作方式,以解决当前AI模型高能耗问题。美国国家实验室等机构正研发神经元数量堪比人脑皮层的神经形态计算机,理论运行速度远超生物大脑,功耗却极低(如20瓦驱动类人脑AI)。该技术通过事件驱动通信、内存计算和适应性学习,有望实现更智能、高效、低功耗的AI,被视为AI能源危机的潜在解决方案和AGI发展的全新路径 (来源: 量子位)

AI ASMR内容在短视频平台爆火,Veo 3等技术助推: 利用AI生成的ASMR(自发性知觉经络反应)视频在TikTok等平台迅速走红,有账号3天内吸引近10万粉丝,单条切水果视频播放量超1650万。这些视频以AI生成的奇特视觉效果(如玻璃质感水果)配合相应的切割、碰撞等声音,创造出独特的“上头感”。Google DeepMind的Veo 3等模型因能直接生成音画同步内容,被认为是推动此类AI ASMR内容创作的关键技术,简化了以往需要分别制作音视频再合成的流程 (来源: 量子位)

Meta AI搜索记录公开引关注,谷歌测试AI音频摘要: Meta公司公开了其AI搜索功能的用户搜索记录,引发了用户对其隐私和数据使用透明度的关注。与此同时,谷歌正在其实验室项目中测试一项新功能,即在搜索结果顶部提供由AI生成的播客式音频摘要,旨在为用户提供更便捷的信息获取方式。这两项动态反映了科技巨头在AI搜索和信息呈现方面的持续探索和用户体验优化尝试 (来源: Reddit r/ArtificialInteligence)

悉尼团队研发AI模型通过脑电波识别思想: 澳大利亚悉尼的研究团队开发出一种新的人工智能模型,能够通过分析脑电波(EEG)数据来识别个体的思想内容。这项技术在神经科学、人机交互以及辅助沟通等领域具有潜在应用价值,例如帮助无法通过传统方式交流的人表达意图。该研究进一步推动了脑机接口技术的发展,并探索了AI在解读复杂大脑活动方面的能力 (来源: Reddit r/ArtificialInteligence)
加州拟立法限制AI在招聘解雇等决策中的“机器人老板”角色: 美国加利福尼亚州正在推进一项法案,旨在限制公司仅凭AI系统建议就做出招聘、解雇等关键人事决策。该法案要求人类管理者必须审查并支持AI的任何此类建议,以确保人工监督和问责。商业团体对此表示反对,认为这将增加合规成本并与现有招聘技术冲突。此举反映了AI伦理和社会影响的日益关注,特别是在工作场所自动化决策方面 (来源: Reddit r/ArtificialInteligence)

🧰 工具
Augmentoolkit 3.0发布,强化数据集生成与微调流程: Augmentoolkit发布了3.0版本,这是一个用于从长文档(如历史文本)创建QA数据集并进行模型微调的工具。新版本提供了生产级流水线,能自动生成训练数据并训练模型,内置了专为生成高质量QA数据集而微调的本地模型,并提供无代码界面。该工具旨在简化领域特定模型微调和训练数据生成的流程,降低技术门槛 (来源: Reddit r/LocalLLaMA)
Opius AI Planner:优化Cursor Composer体验的AI规划器: 一款名为Opius AI Planner的Cursor扩展发布,旨在解决Cursor Composer在理解模糊需求方面的问题。该工具能分析项目需求,生成详细的实现路线图,并输出为Composer优化的结构化提示,从而减少迭代次数,使项目成果更符合初始设想。这反映了通过AI辅助规划来提升AI代码生成工具实用性的趋势 (来源: Reddit r/artificial)
Continue扩展:在VSCode中实现本地开源Copilot与MCP集成: Continue是一款VSCode扩展,允许用户配置和使用本地运行的开源大语言模型作为编码助手,并能集成MCP(Model Control Protocol)工具。用户可以通过Llama.cpp或LMStudio等服务在本地部署模型,并通过Continue进行交互,实现对代码助手的完全控制和自定义,例如集成Playwright浏览器自动化工具 (来源: Reddit r/LocalLLaMA)

豆包大模型与火山引擎MCP结合,简化云服务部署与个人页面生成: 字节跳动的豆包大模型展示了与火山引擎模型控制协议(MCP)的深度集成能力。用户可以通过自然语言指令,让豆包大模型调用火山引擎的功能(如veFaaS函数即服务),完成如生成个人社交媒体导览网页并自动部署上线等任务。这种集成免去了手动配置云环境的复杂步骤,降低了云服务的使用门槛,展示了AI在简化DevOps流程方面的潜力 (来源: karminski3)
Figma推出AI新功能:从文本提示即时生成网站: Figma展示了一项新的AI驱动功能,能够根据用户输入的文本提示(prompt)快速生成网站原型或页面。这一功能旨在加速网页设计和开发流程,让设计师和开发者能够通过自然语言描述快速将想法转化为可视化设计,进一步体现了生成式AI在创意设计工具领域的渗透 (来源: Ronald_vanLoon)
Hugging Face模型中心新增按模型大小筛选功能: Hugging Face平台为其模型中心增加了一项实用功能,允许用户根据模型的参数大小进行筛选。这一改进使得开发者和研究人员能更便捷地找到符合其特定硬件资源或性能需求的模型,提升了在庞大模型库中导航和选择的效率 (来源: ClementDelangue, TheZachMueller, huggingface, clefourrier, multimodalart)
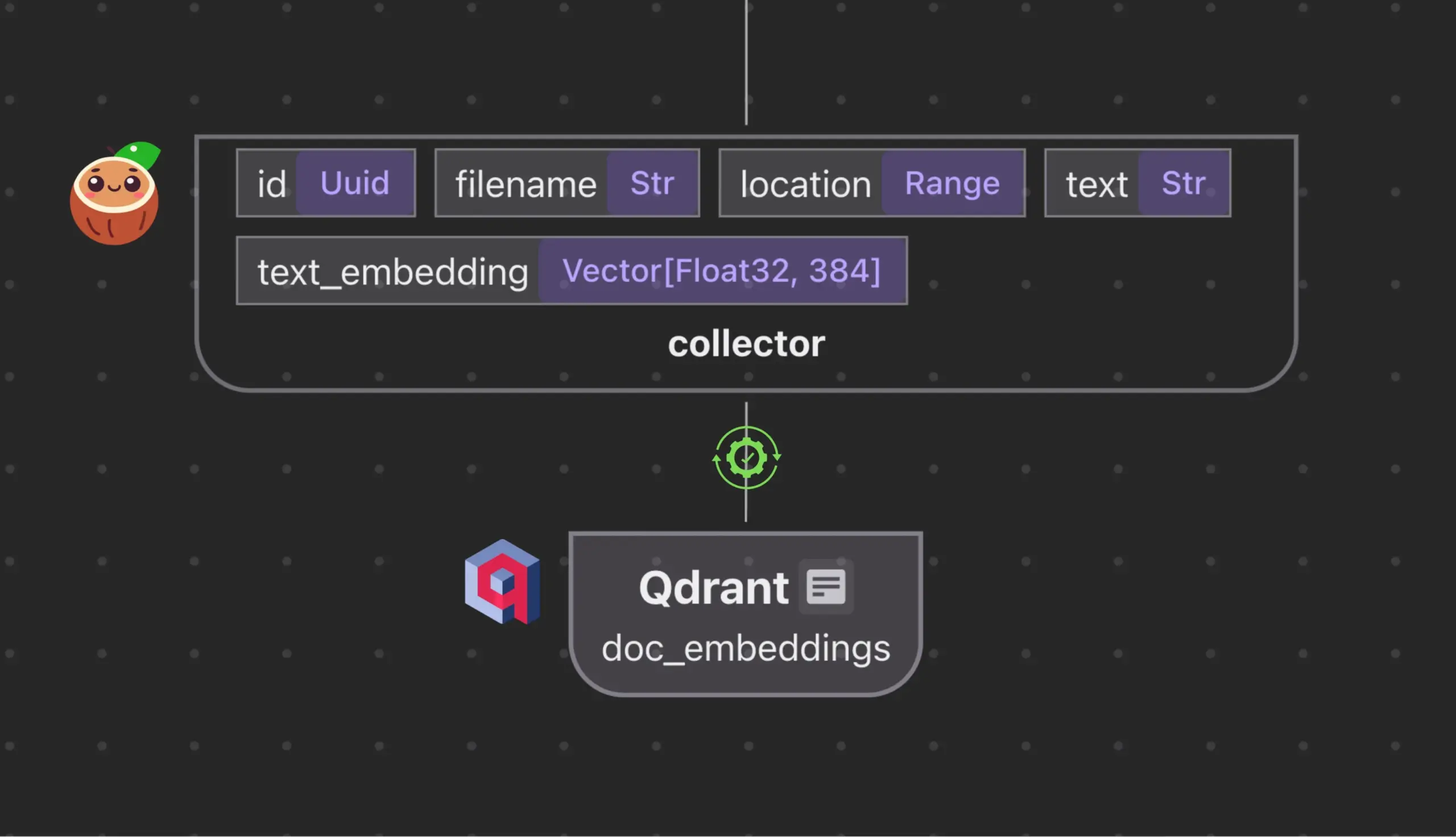
Cocoindex.io与Qdrant集成,自动创建和同步向量数据库集合: 开源数据流工具Cocoindex.io现已支持自动创建Qdrant向量数据库集合。用户只需定义数据流,该工具便能推断出合适的Qdrant模式(包括向量大小、距离度量和有效载荷结构),并保持向量字段、载荷类型、主键的同步,支持增量更新。这简化了向量数据库的配置和管理,提高了数据团队的效率 (来源: qdrant_engine)
Manus AI:不仅编写代码,还能自动部署的全流程AI开发工具: Manus AI是一款能实现从代码编写到环境设置、依赖安装、测试乃至最终部署到线上URL的端到端AI开发工具。它采用多智能体协作架构(规划、开发、测试、部署),能自主解决依赖问题和调试错误。尽管目前存在基于信用点的定价模型、中文团队开发(可能涉及合规考量)以及对超复杂企业架构支持的局限性,但其展示了从“AI辅助编码”到“AI执行开发”的转变潜力 (来源: Reddit r/artificial)

📚 学习
翻译理论及AI翻译提示词优化指南: 结合思果《翻译新究》的“翻译即重写”理论和余光中《翻译乃大道》的观点,探讨了高质量翻译的原则。强调翻译应注重目标语言的地道表达,而非字面对应,需灵活运用直译与意译,并关注中西语言逻辑差异进行句法改写。文章还讨论了中文表达的纯正性、术语处理,并反思了AI翻译中“直译-分析-意译”三步流程的局限,建议采用更融合的“理解-表达-校对-优化”流程,以提升AI翻译质量,使其更符合中文科普文风 (来源: dotey)

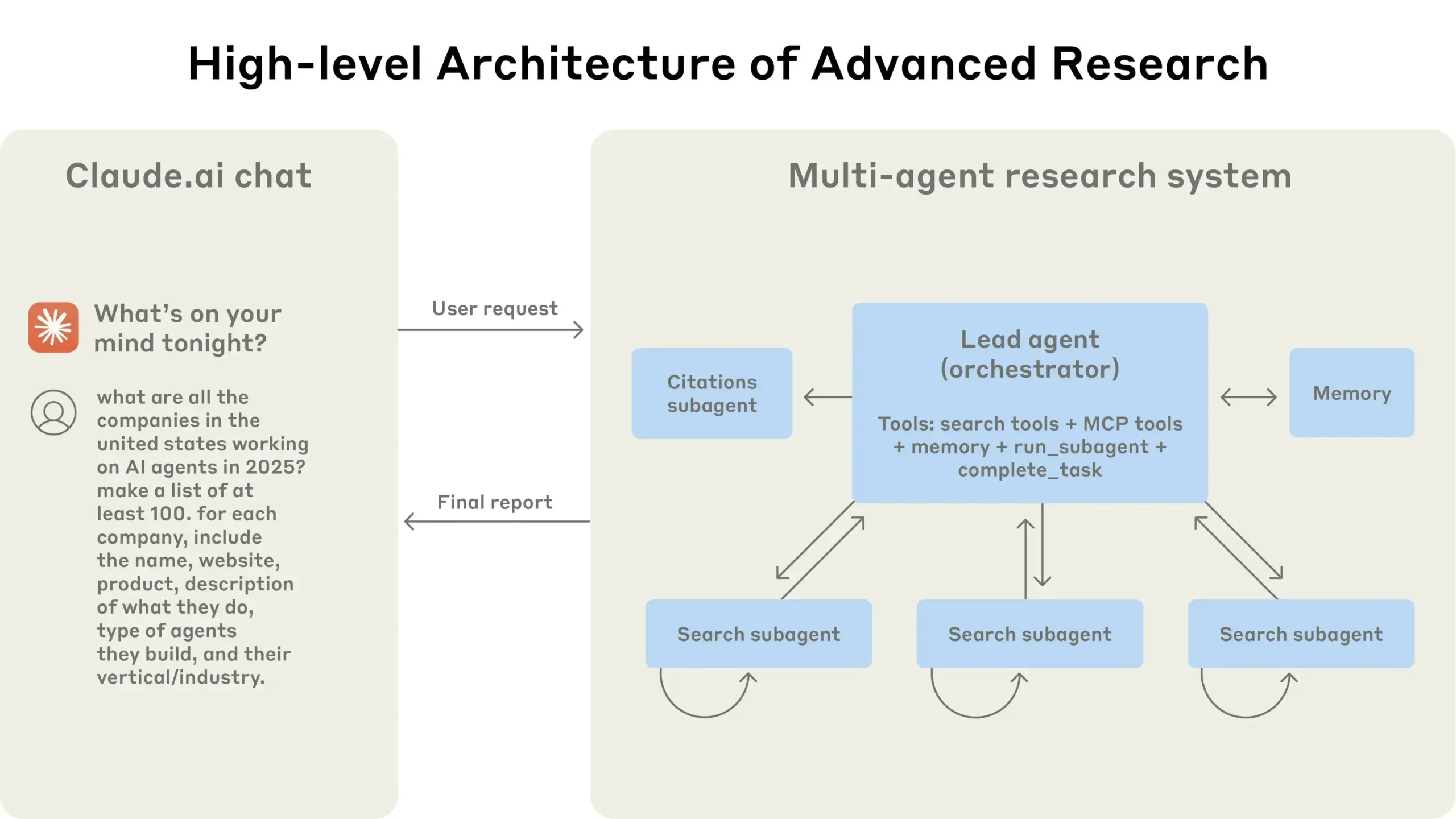
Anthropic分享其多智能体研究系统构建经验: AnthropicAI发布了一份免费指南,详细介绍了他们如何构建其多智能体研究系统。内容包括系统架构的工作原理、提示工程与测试方法、生产中面临的挑战以及多智能体系统的优势。这份指南为对多智能体系统感兴趣的研究者和开发者提供了宝贵的实践经验和见解 (来源: TheTuringPost, TheTuringPost)
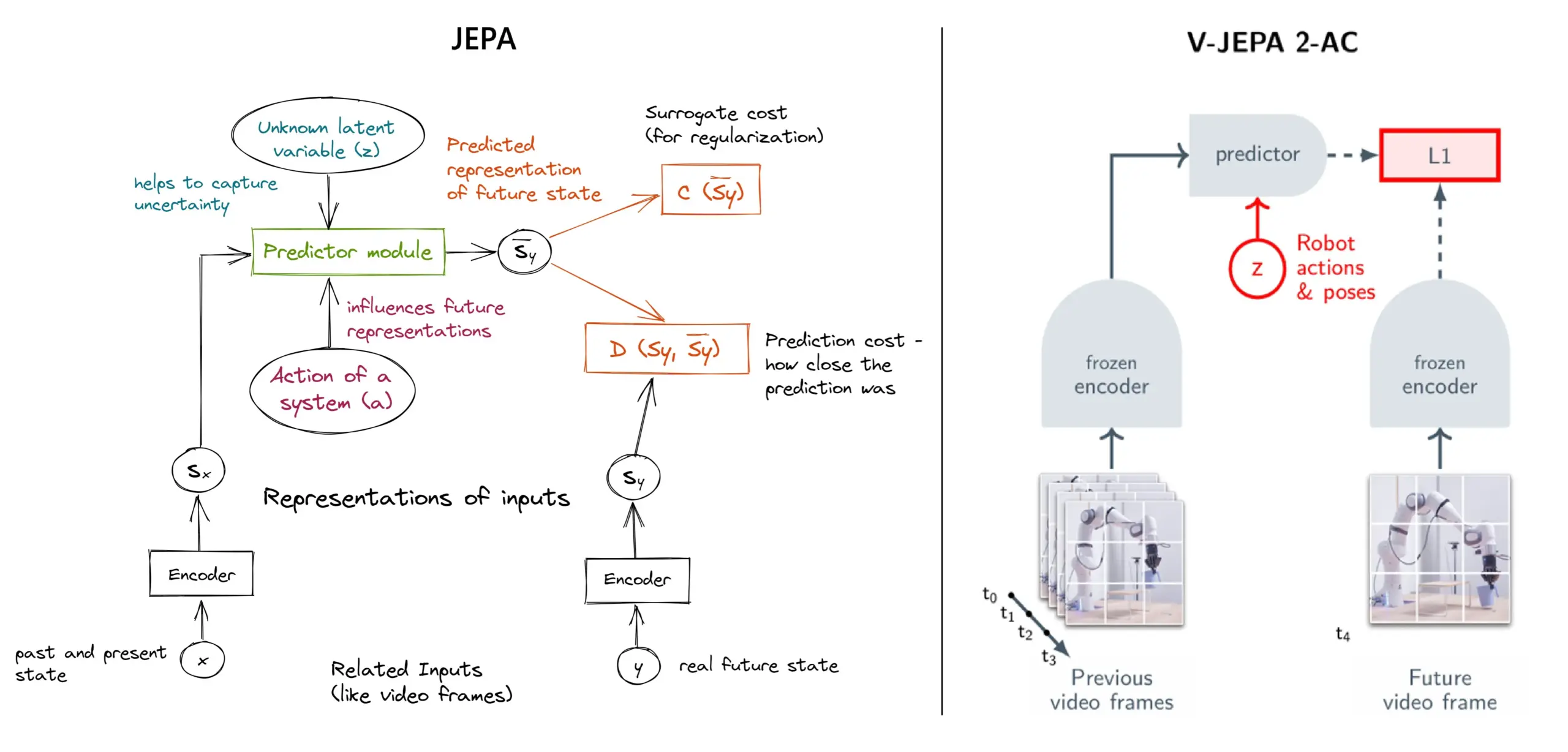
JEPA自监督学习框架详解:11种类型概览: Meta的Yann LeCun等研究者提出的JEPA(Joint Embedding Predictive Architecture)是一种自监督学习框架,它通过预测输入数据缺失部分的潜在表示来进行学习。文章介绍了11种不同类型的JEPA,包括V-JEPA 2、TS-JEPA、D-JEPA等,并提供了更多信息和相关资源的链接,有助于理解这一前沿的自监督学习方法 (来源: TheTuringPost, TheTuringPost)
DSPy框架:解耦任务与LLM,提升代码可维护性: 一篇关于DSPy的解读文章指出,DSPy框架通过将任务与大型语言模型(LLM)解耦,降低了使用LLM的复杂性。即使在优化之前,DSPy也能帮助开发者更快地启动项目,并生成更易于维护和扩展的代码。这对于需要处理复杂提示工程和LLM集成的项目具有重要价值 (来源: lateinteraction, stanfordnlp)

论文研讨:视觉Transformer无需预训练寄存器 (Vision Transformers Don’t Need Trained Registers): 一篇新研究论文探讨了Vision Transformer中注意力图和特征图产生伪影的机制,这种现象也存在于大型语言模型中。论文提出了一种无需训练的方法来缓解这些伪影,旨在提升Vision Transformer的性能和可解释性。该研究对于理解和改进Transformer架构在视觉任务中的应用具有参考价值 (来源: Reddit r/MachineLearning)
教程分享:从零构建DeepSeek系列视频 (共29集): 一位内容创作者发布了名为“如何从零构建DeepSeek”的系列视频教程,共计29集。内容涵盖DeepSeek模型的基础知识、架构细节(如注意力机制、多头注意力、KV缓存、MoE)、位置编码、多令牌预测以及量化等关键技术。该系列教程为希望深入理解DeepSeek及类似大模型内部工作原理的学习者提供了宝贵的视频资源 (来源: Reddit r/LocalLLaMA)

教程:构建RAG管道总结Hacker News帖子: Haystack by deepset分享了一篇分步教程,指导用户如何构建一个检索增强生成(RAG)管道。该管道能够获取Hacker News的实时帖子,并使用本地运行的大语言模型(LLM)端点对这些帖子进行总结。这为希望利用RAG技术处理实时信息流并进行本地化处理的开发者提供了实用案例 (来源: dl_weekly)
论文速递:InterSyn数据集与SynJudge评估模型用于交错图文生成: 为解决当前LMM在生成紧密交错的图文输出方面的不足(主要源于训练数据集的规模、质量和指令丰富度有限),研究者推出了InterSyn,一个通过SEIR(自我评估与迭代优化)方法构建的大规模多模态数据集。InterSyn包含多轮、指令驱动的对话,响应中图文紧密交错。同时,为评估此类输出,研究者还提出了SynJudge自动评估模型,从文本内容、图像内容、图像质量和图文协同四个维度进行评估。实验表明,在InterSyn上训练的LMM在各项评估指标上均有提升 (来源: HuggingFace Daily Papers)
论文速递:通过跨模态注意力蒸馏实现对齐的新视角图像与几何合成: 研究者提出一种基于扩散的框架MoAI,通过“扭曲再修复”(warping-and-inpainting)方法,实现对齐的新视角图像和几何生成。该方法利用现成的几何预测器预测参考图像的部分几何形状,并将新视角合成为图像和几何的修复任务。为确保图像与几何的精确对齐,论文提出了跨模态注意力蒸馏,在训练和推理过程中将图像扩散分支的注意力图注入平行的几何扩散分支。该方法在多种未见场景中实现了高保真外插视角合成 (来源: HuggingFace Daily Papers)
论文速递:基于规则引导合成数据的可配置偏好调整 (CPT): 为解决DPO等人类反馈模型中偏好固化、适应性有限的问题,研究者提出可配置偏好调整(CPT)框架。CPT利用基于结构化细粒度规则(定义写作风格等期望属性)的系统提示,生成合成偏好数据。通过这些规则引导的偏好进行微调,LLM能在推理时根据系统提示动态调整输出,无需再训练,实现了更细致和上下文相关的偏好控制 (来源: HuggingFace Daily Papers)
论文速递:扩散二元性 (The Diffusion Duality): 研究者提出Duo方法,通过揭示均匀状态离散扩散过程源于潜在高斯扩散的洞察,将高斯扩散的强大技术迁移至离散扩散模型,以提升其性能。具体包括:1) 引入高斯过程指导的课程学习策略,减少方差,使训练速度加倍,并在多个基准测试中超越自回归模型。2) 提出离散一致性蒸馏,将连续一致性蒸馏适配到离散设置,通过加速采样两个数量级,实现扩散语言模型的少步生成 (来源: HuggingFace Daily Papers)
论文速递:SkillBlender – 通过技能融合实现多功能人形机器人全身运动操控: 为解决现有人形机器人控制方法在多任务泛化和可扩展性方面的局限,研究者提出SkillBlender,一个分层强化学习框架。该框架首先预训练目标导向的任务无关原始技能,然后在执行复杂运动操控任务时动态融合这些技能,仅需最少的任务特定奖励工程。同时,推出了SkillBench仿真基准进行评估。实验表明该方法能显著提升多种运动操控任务的准确性和可行性 (来源: HuggingFace Daily Papers)
论文速递:U-CoT+框架 – 解耦理解与引导式CoT推理检测有害Meme: 为应对有害Meme检测中资源效率、灵活性和可解释性的挑战,研究者提出U-CoT+框架。该框架首先通过高保真Meme到文本的转换流程,将视觉Meme转换为保留细节的文本描述,从而解耦Meme解读与分类,使得通用大语言模型(LLM)能进行资源高效的检测。随后,结合人工制定的可解释指南,在零样本CoT提示下引导模型推理,增强了对不同平台和时间变化的适应性与可解释性 (来源: HuggingFace Daily Papers)
论文速递:CRAFT – 有效的策略遵循型智能体红队测试: 针对任务导向的LLM智能体在严格策略(如退款资格)下的遵循问题,研究者提出了新的威胁模型,关注试图利用策略型智能体获取个人利益的对抗性用户。为此,他们开发了CRAFT,一个多智能体红队测试系统,利用策略感知的说服策略在客服场景中攻击策略遵循型智能体,其效果优于传统越狱方法。同时,推出了tau-break基准,用于评估智能体对此类操控行为的鲁棒性 (来源: HuggingFace Daily Papers)
论文速递:密集检索器在简单查询上的失败与嵌入的粒度困境: 研究揭示了文本编码器的一个局限:嵌入可能无法识别语义内部的细粒度实体或事件,导致密集检索在简单情况下也可能失败。为研究此现象,论文引入了中文评估数据集CapRetrieval(段落为图像标题,查询为实体/事件短语)。零样本评估表明,编码器可能在细粒度匹配上表现不佳。通过提出的数据生成策略微调编码器可提升性能,但也揭示了“粒度困境”,即嵌入在表达细粒度显著性的同时难以与整体语义对齐 (来源: HuggingFace Daily Papers)
论文速递:pLSTM – 可并行的线性源转换标记网络: 针对现有循环架构(如xLSTM, Mamba)主要适用于序列数据或需按序处理多维数据的局限,研究者提出pLSTM(可并行线性源转换标记网络)。pLSTM将多维性扩展到线性RNN,使用源、转换和标记门作用于通用有向无环图(DAG)的线图,实现了类似并行关联扫描和分块循环形式的并行化。该方法在合成计算机视觉任务和分子图、计算机视觉基准上表现出良好的外推能力和性能 (来源: HuggingFace Daily Papers)
论文速递:DeepVideo-R1 – 通过难度感知回归GRPO进行视频强化微调: 针对强化学习在视频大语言模型(Video LLM)应用中的不足,研究者提出DeepVideo-R1,一个通过其提出的Reg-GRPO(回归式GRPO)和难度感知数据增强策略训练的Video LLM。Reg-GRPO将GRPO目标重构为回归任务,直接预测GRPO中的优势函数,消除了对裁剪等保障措施的依赖,从而更直接地指导策略。难度感知数据增强则动态增强可解决难度级别的训练样本。实验表明DeepVideo-R1显著提升了视频推理性能 (来源: HuggingFace Daily Papers)
论文速递:利用TTS合成数据增强ASR的自精炼框架: 研究者提出一种自精炼框架,仅使用未标记数据集即可提升自动语音识别(ASR)性能。该框架首先用现有ASR模型在未标注语音上生成伪标签,然后用这些伪标签训练高保真文本到语音(TTS)系统。接着,将TTS合成的语音-文本对用于引导原始ASR系统的训练,形成闭环自我改进。在台湾普通话上的实验表明,此方法能显著降低错误率,为低资源或特定领域ASR性能提升提供了实用路径 (来源: HuggingFace Daily Papers)
论文速递:视觉Transformer的固有忠实注意力图: 研究者提出一种基于注意力的方法,使用学习到的二元注意力掩码,确保只有被关注的图像区域影响预测。该方法旨在解决上下文对物体感知可能产生的偏见,特别是在物体出现在非分布背景中时。通过一个两阶段框架(第一阶段发现物体部件并识别任务相关区域,第二阶段利用输入注意力掩码限制感受野进行聚焦分析),联合训练实现模型对虚假相关性和非分布背景的鲁棒性提升 (来源: HuggingFace Daily Papers)
论文速递:ViCrit – VLM视觉感知的可验证强化学习代理任务: 为解决VLM中视觉感知任务缺乏同时具有挑战性和明确可验证性的问题,研究者引入ViCrit(视觉字幕幻觉批评器)。这是一个RL代理任务,训练VLM定位注入到人类编写图像字幕段落中的细微、合成的视觉幻觉。通过在约200词的字幕中注入单个细微视觉描述错误,并要求模型根据图像和修改后的字幕定位错误范围,该任务提供了易于计算且明确的二元奖励。用ViCrit训练的模型在多种VL基准上表现出显著增益 (来源: HuggingFace Daily Papers)
论文速递:超越同质注意力 – 基于傅里叶近似KV缓存的内存高效LLM: 为解决LLM中随上下文长度增加而增长的KV缓存内存需求问题,研究者提出FourierAttention,一个无需训练的框架。该框架利用Transformer头维度异构角色:低维优先局部上下文,高维捕捉长程依赖。通过将长上下文不敏感维度投影到正交傅里叶基上,FourierAttention用固定长度谱系数近似其时间演化。在LLaMA模型上的评估显示,该方法在LongBench和NIAH上实现了最佳长上下文准确率,并通过定制的Triton内核FlashFourierAttention优化了内存 (来源: HuggingFace Daily Papers)
论文速递:JAFAR – 提升任意分辨率下任意特征的通用上采样器: 针对基础视觉编码器输出的低分辨率空间特征无法满足下游任务需求的问题,研究者引入JAFAR,一个轻量级、灵活的特征上采样器。JAFAR能将任何基础视觉编码器的视觉特征空间分辨率提升至任意目标分辨率。它采用基于注意力的模块,通过空间特征变换(SFT)调制,促进源自低层图像特征的高分辨率查询与语义丰富的低分辨率键之间的语义对齐。实验表明,JAFAR能有效恢复细粒度空间细节,并在多种下游任务中优于现有方法 (来源: HuggingFace Daily Papers)
论文速递:SwS – 强化学习中自我感知弱点驱动的问题综合: 针对RLVR(带可验证奖励的强化学习)在训练LLM解决复杂推理任务(如数学问题)时,高质量、答案可验证的问题集稀缺的问题,研究者提出SwS(自我感知弱点驱动问题综合)框架。SwS系统地识别模型缺陷(模型在RL训练中持续学习失败的问题),提取这些失败案例的核心概念,并综合新问题以在后续增强训练中强化模型的薄弱环节。该框架使模型能够自我识别并解决其在RL中的弱点,在多个主流推理基准上取得了显著性能提升 (来源: HuggingFace Daily Papers)
论文速递:学习“继续思考”令牌以增强测试时扩展能力: 为提升语言模型在测试时通过额外计算扩展推理步骤的性能,研究者探索了学习一个专用的“继续思考”令牌(<|continue-thinking|>)的可行性。他们通过强化学习仅训练该令牌的嵌入,同时保持DeepSeek-R1蒸馏版模型的权重冻结。实验表明,与基线模型及使用固定令牌(如”Wait”)进行预算强制的测试时扩展方法相比,学习到的令牌在标准数学基准上取得了更高的准确率,尤其在固定令牌能提升基线模型准确率的情况下,学习令牌能带来更大改进 (来源: HuggingFace Daily Papers)
论文速递:LoRA-Edit – 通过掩码感知LoRA微调实现可控的首帧引导视频编辑: 为解决现有视频编辑方法依赖大规模预训练、灵活性不足的问题,研究者提出LoRA-Edit,一种基于掩码的LoRA微调方法,用于适配预训练的图像到视频(I2V)模型以实现灵活视频编辑。该方法在保留背景区域的同时,能够传播可控的编辑效果,并结合其他参考信息(如备选视点或场景状态)作为视觉锚点。通过掩码驱动的LoRA调整策略,模型从输入视频(空间结构和运动线索)和参考图像(外观指导)中学习,实现区域特定的学习 (来源: HuggingFace Daily Papers)
论文速递:Infinity Instruct – 扩展指令选择与合成以增强语言模型: 为弥补现有开源指令数据集多集中于狭窄领域(如数学、编码),导致泛化能力受限的问题,研究者推出Infinity-Instruct,一个旨在通过两阶段流程增强LLM基础和聊天能力的高质量指令数据集。阶段一,使用混合数据选择技术从超1亿样本中筛选出740万条高质量基础指令。阶段二,通过指令选择、演化和诊断过滤两阶段过程,合成了150万条高质量聊天指令。在多种开源模型上的微调实验表明,该数据集能显著提升模型在基础和指令遵循基准上的性能 (来源: HuggingFace Daily Papers)
论文速递:先候选后蒸馏 – LLM驱动数据标注的师生框架: 针对现有LLM数据标注方法中,LLM直接确定单一黄金标签可能因不确定性导致错误的问题,研究者提出新的候选标注范式:鼓励LLM在不确定时输出所有可能标签。为确保下游任务获得唯一标签,开发了师生框架CanDist,用小型语言模型(SLM)蒸馏候选标注。理论证明从教师LLM蒸馏候选标注优于直接使用单一标注。实验验证了该方法的有效性 (来源: HuggingFace Daily Papers)
论文速递:Med-PRM – 具有逐步、指南验证过程奖励的医学推理模型: 为解决大型语言模型在临床决策中难以定位和纠正特定推理步骤错误的局限性,研究者引入Med-PRM,一个过程奖励建模框架。该框架利用检索增强生成技术,对照已建立的医学知识库(临床指南和文献)验证每个推理步骤。通过这种细粒度的方式精确评估推理质量,Med-PRM在多个医学QA基准和开放式诊断任务上实现了SOTA性能,并能以即插即用方式与强策略模型(如Meerkat)集成,显著提升了小型模型(8B参数)的准确率 (来源: HuggingFace Daily Papers)
论文速递:反馈摩擦 – LLM难以充分吸收外部反馈: 研究系统考察了LLM吸收外部反馈的能力。实验中,求解器模型尝试解决问题,然后具有近乎完整真实答案的反馈生成器提供针对性反馈,求解器再尝试。结果显示,即使在近乎理想条件下,包括Claude 3.7在内的SOTA模型仍表现出对反馈的抗拒,称为“反馈摩擦”。尽管采用渐进温度增加和明确拒绝先前错误答案等策略有所改善,但模型仍未达目标性能。研究排除了模型过度自信和数据熟悉度等因素,旨在揭示LLM自我改进的这一核心障碍 (来源: HuggingFace Daily Papers)
💼 商业
Meta斥资143亿美元收购Scale AI 49%股权,创始人Alexandr Wang加入Meta超级智能团队: Meta公司宣布以143亿美元收购AI数据标注公司Scale AI 49%的无投票权股权,Scale AI创始人、28岁的华裔天才Alexandr Wang将继续担任董事会成员,并带领其核心团队加入由扎克伯格亲自组建的Meta超级智能团队。此次收购被视为Meta在Llama 4表现不佳后,为提振其AI能力而进行的天价人才并购,旨在将AI深度融入其所有产品。Scale AI以提供大规模高质量人工标注数据服务起家,客户包括Waymo、OpenAI等。此举引发了对其平台中立性和数据安全的担忧,Google等客户或将中止合作 (来源: 36氪)

昆仑万维All in AI战略导致上市十年首亏,AI商业化前景未明: 昆仑万维自宣布“All in AGI与AIGC”战略以来,积极布局大模型(天工大模型)及AI音乐(Mureka)、AI社交(Linky)、AI视频(SkyReels)、AI办公(Skywork Super Agents)等应用,并投资AI算力芯片。然而,高额的研发投入和市场推广费用导致公司2024年出现上市十年来首次亏损(15.9亿元),2025年一季度持续亏损。尽管部分AI应用如Mureka和Linky已开始产生营收,但整体AI业务的盈利能力和市场竞争力仍面临挑战,其能否借AI实现“大厂梦”尚待市场检验 (来源: 36氪)

OpenAI或在ChatGPT中测试广告,盈利压力驱动商业模式探索: 有ChatGPT Plus付费用户反映,在使用高级语音模式时遭遇了插播广告的情况,引发了关于OpenAI是否开始在付费用户中测试广告的讨论。此前有报道称OpenAI正考虑引入广告以拓宽收入。鉴于AI大模型高昂的运营成本和盈利压力(预计2029年前亏损440亿美元),以及AGI实现时间的不确定性,OpenAI寻求广告等新的变现模式被认为是其商业可持续性的必然选择,尤其是在付费渗透率相对较低的情况下 (来源: 36氪)

🌟 社区
AI在数据科学领域潜力巨大,Databricks积极招聘: Databricks的Matei Zaharia认为AI在数据科学领域的生产力提升将比AI辅助编码更为显著。Databricks正通过Lakeflow Designer和Genie Deep Research等产品引领这一趋势,并积极招聘该领域的研究员和工程师,显示出业界对AI驱动数据科学创新的高度重视 (来源: matei_zaharia)
LLM的“个性”差异影响智能体回路行为: 研究者Fabian Stelzer观察到,不同的大语言模型(LLM)在“个性”上存在差异,这会导致它们在执行智能体(agentic)循环任务时表现不同。例如,Claude倾向于串行执行工具,而GPT-4.1则强烈偏好并行执行,甚至会忽略串行请求;Haiku模型在触发工具方面更为“激进”。这一观察强调了在设计和评估多智能体系统时,考虑底层LLM特性和“情感状态”功能性后果的重要性 (来源: fabianstelzer, menhguin)
LLM“思考”依赖Token输出,无输出则无有效分析: 用户dotey转述xincmm在调试ReAct prompt时的发现:若期望LLM先分析再执行操作(如画图),但未让其输出分析过程的Tokens,LLM可能直接跳过分析步骤。这印证了LLM的“思考”过程是通过生成Token来实现的,提示词中定义的“分析”若无实际内容输出,则AI并未真正执行该分析。这对于设计有效的LLM prompt具有指导意义 (来源: dotey)

AI在特定任务上的局限性:陶哲轩称AI缺乏“数学的嗅觉”: 数学家陶哲轩指出,尽管当前AI生成的证明在表面上看起来完美无瑕(通过“眼球测试”),但它们往往缺乏一种微妙的、人类特有的“数学嗅觉”,容易犯一些非人类的错误。他认为真正的智能不仅仅是看起来正确,更在于能“嗅出”什么是真实的。这揭示了当前AI在深层理解和直觉判断方面的局限性 (来源: ecsquendor)
AI生成内容与现实物理规律的挑战: 用户karminski3在使用豆包Seed 1.6和DeepSeek-R1进行代码生成(模拟烟囱爆破拆除的3D动画)测试时发现,尽管模型能生成代码并模拟动画,但在还原真实物理过程(如冲击波效果、结构塌陷方式)方面仍有差异和提升空间。豆包Seed 1.6在粒子效果和结构塌陷模拟上更接近真实,而DeepSeek则在光影和烟雾效果上表现更好。这反映了AI在理解和模拟复杂物理现象方面的挑战 (来源: karminski3)
资深程序员因过度依赖AI写代码、不愿手动修改及恐吓新人将被AI取代而被解雇: 一篇来自36氪转载的Reddit帖子讲述了一名有30年经验的程序员因过度沉迷AI(如完全依赖Copilot Agent提交PR、拒绝手动修改代码、耗费5天完成1天任务、向实习生宣扬AI取代论)而被公司解雇的案例。该事件引发了关于AI在软件开发中合理使用边界、以及AI对开发者职业价值影响的讨论 (来源: 36氪)
AI“心流”与“个性”对用户体验的影响:用户反馈AI过于“积极附和”: Reddit社区用户讨论发现,与AI(特别是Claude)交互时,AI倾向于过度乐观和积极附和用户的观点,缺乏有效的挑战和深入的批判性反馈,使用户感觉像在“回音室”中。这种“AI语调疲劳”促使用户寻求让AI表现更中立、更具批判性的方法,例如通过特定提示词引导。这反映了当前AI在模拟真实、多面的人类对话和提供真正深刻洞察方面的挑战 (来源: Reddit r/ClaudeAI)
AI时代,人类反馈的价值凸显,但真实人类互动平台面临AI内容渗透: Reddit用户讨论指出,在AI生成内容日益增多的背景下,真实的人类反馈和意见变得更加珍贵,Reddit等平台因其人类互动特性而被重视。然而,这些平台也面临AI生成内容(如机器人评论、AI辅助写作的帖子)渗透的挑战,使得辨别真实人类观点变得更加困难,引发了对未来网络交流真实性的担忧 (来源: Reddit r/ArtificialInteligence)
AI“朋友”或成常态?用户与AI建立情感连接的趋势与讨论: 社交媒体和Reddit社区中出现关于AI伴侣和AI朋友的讨论。一些用户认为,由于AI不带偏见、永远支持的特性,未来5年内AI朋友可能成为常态,并已在Endearing AI、Replika、Character.ai等应用中显现。另一些用户则分享自己与ChatGPT等AI建立深厚对话关系,甚至视其为“最好朋友”的经历。这引发了关于人类与AI情感互动、AI在情感支持中角色以及其潜在社会影响的广泛思考 (来源: Ronald_vanLoon, Reddit r/artificial, Reddit r/ArtificialInteligence)

AI“包装器”初创公司的未来引发讨论: Reddit社区探讨了大量基于GPT或Claude等基础模型进行封装(添加UI、提示链或针对特定领域微调)的AI初创公司的前景。讨论者质疑这类“包装器”应用在基础模型平台自身功能迭代后能否保持竞争力,以及它们是否能构建真正的护城河。观点认为,专注于特定垂直领域、积累自有数据并超越简单封装可能是其可持续发展的路径 (来源: Reddit r/LocalLLaMA)
AI在医疗诊断与软件工程中的取代潜力对比讨论: Reddit社区出现讨论,认为AI取代医生的速度可能快于取代高级软件工程师。理由是许多医疗诊断遵循既定协议,AI擅长解读测试结果和识别症状;而软件工程常涉及大量隐性知识和复杂需求沟通,AI难以完全胜任。此观点引发了关于AI在不同专业领域应用深度和取代可能性的进一步思考,但也受到医生等专业人士的反驳,强调实际操作的复杂性和人为判断的重要性 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)
💡 其他
罗永浩AI数字人百度电商首播,GMV超5500万: 罗永浩的AI数字人在百度电商平台进行了首次直播带货,吸引了超1300万人次观看,商品交易总额(GMV)突破5500万元。该数字人由百度电商“慧播星”平台依托文心4.5大模型打造,能够模拟罗永浩的语调、口音和微表情,并进行智能应答。此次直播展示了“AI+头部主播”模式的潜力,以及百度在“高说服力数字人”技术和AI电商领域的布局 (来源: 36氪)

百度与腾讯等公司加大AI人才招聘力度,启动大规模招聘计划: 百度启动了其最大规模的顶尖AI人才招聘项目“AIDU计划”,岗位招聘同比扩大60%,聚焦大模型算法、基础架构等前沿领域,并提供不设上限的薪资。无独有偶,腾讯也通过举办“全模态生成式推荐”算法大赛,提供数百万奖金及校招Offer,以吸引全球AI人才。这些举措反映了中国科技巨头在AI领域竞争白热化背景下对顶尖人才的迫切需求和战略布局 (来源: 量子位, 量子位)

百度推出全面AI高考志愿填报辅助服务,整合多模型与大数据: 针对新高考改革带来的志愿填报复杂性,百度上线了免费的AI志愿填报辅助工具。该服务整合在百度App的“高考”专题页面,提供“AI志愿助手”进行院校专业推荐和录取概率分析,支持文心、DeepSeek R1等多模型“AI聊志愿”智能体进行个性化咨询。此外,还结合百度独家搜索大数据提供专业就业前景分析、MBTI职业测评以及高校招生办直播、学长学姐问答等真人辅助资源,旨在帮助考生应对信息差,做出更合适的志愿选择 (来源: 36氪)