
关键词:AI, 英伟达, 德国电信, 工业AI云, 主权AI, Anthropic, 多智能体系统, RAISE法案, 欧洲工业AI云, 飞行硬盘箱规避芯片封锁, Claude多智能体研究, 纽约州RAISE法案, 黄仁勋与Anthropic CEO辩论
🔥 聚焦
英伟达与德国电信合作,共筑欧洲工业AI云: 德国联邦总理与英伟达CEO黄仁勋会面,商讨深化战略合作,旨在强化德国作为全球AI领导者的地位。核心议题包括建设主权AI基础设施及加速AI生态系统发展。为此,德国电信与英伟达宣布合作,计划到2026年建成全球首个服务欧洲制造商的工业AI云。该平台将确保数据主权,推动欧洲工业领域的AI创新。 (来源: nvidia)

中国AI公司“飞行硬盘箱”规避美国芯片封锁: 为应对美国对华AI芯片出口限制,中国公司采取新策略:将存有AI训练数据的硬盘直接带往海外(如马来西亚)的数据中心,利用当地搭载Nvidia等先进芯片的服务器进行模型训练,完成后再将结果带回。此举凸显了全球AI产业链的复杂性和中国企业在限制下的变通能力,同时也推动了东南亚及中东地区成为AI数据中心新热点。 (来源: dotey)

Anthropic发布多智能体研究系统构建方法: Anthropic工程博客详细介绍了其如何利用多个并行工作的智能体来构建Claude的研究能力。文章分享了开发过程中的成功经验、遇到的挑战以及工程解决方案。这种多智能体协同工作的模式,旨在提升大型语言模型在复杂研究任务中的深度分析和信息处理能力,为构建更强大的AI研究助手提供了实践参考。 (来源: AnthropicAI)
纽约州通过RAISE法案,加强对前沿AI模型的透明度要求: 纽约州通过了RAISE法案(RAISE Act),旨在为前沿AI模型建立透明度要求。Anthropic等公司已就该法案提供反馈,虽有改进但仍存顾虑,如关键定义模糊、合规性纠正机会不明确、“安全事件”定义过宽泛且报告时间短(72小时),以及对轻微技术违规可能处以数百万美元罚款,对小公司构成风险。Anthropic呼吁建立联邦统一的透明度标准,并建议州级提案应聚焦透明度且避免过度规定。 (来源: jackclarkSF)
Nvidia CEO黄仁勋驳斥Anthropic CEO关于AI发展的观点: 黄仁勋在巴黎Viva Technology新闻发布会上,针对Anthropic CEO Dario Amodei的观点提出反驳。Amodei被指认为AI过于危险,应仅限特定公司开发;成本过高,不应普及;且过于强大,会导致失业。黄仁勋强调AI应安全、负责任且公开地发展,不应在“暗室”中进行并宣称安全。此番言论引发关于AI发展路径(开放民主 vs 精英封闭)的讨论,凸显了行业巨头间的理念差异。 (来源: pmddomingos, dotey)

🎯 动向
Meta或斥资140亿美元收购Scale AI多数股权以加强AI实力: 据报道,Meta计划以148亿美元收购AI数据标注公司Scale AI的49%股份,并可能任命其CEO领导Meta新成立的“超级智能小组”。此举旨在应对Llama 4模型表现未达预期及内部AI人才流失的挑战,通过引入外部顶尖人才和技术,加速其在通用人工智能领域的追赶步伐。 (来源: Reddit r/ArtificialInteligence, 量子位)

OpenAI推出o3-pro模型,o3大幅降价引发性能讨论: OpenAI正式发布了其“最新最强”推理模型o3-pro,专为Pro和Team用户设计,API价格为输入20美元/百万token,输出80美元/百万token。同时,原o3模型API价格大幅下调80%,与GPT-4o基本持平。官方称o3-pro在数学、科学和编程方面表现优异,但响应时间较长。o3降价后是否“降智”引发社区热议,部分用户反馈性能下降,但缺乏统一的实证数据。 (来源: 量子位)

Cohere Labs研究通用型分词器对语言模型适应性的影响: Cohere Labs发布最新研究,探讨使用比预训练目标语言更多的语言训练出来的分词器(universal tokenizer)是否能在不损害预训练性能的前提下,提升模型对新语言的适应性(plasticity)。研究发现,通用分词器在语言适应方面效率提升8倍,性能提升2倍,即使在数据极少、语言完全未见过的情况下,胜率也比专用分词器高出5%。这表明通用分词器能有效提升模型处理多语言任务的灵活性和效率。 (来源: sarahookr)

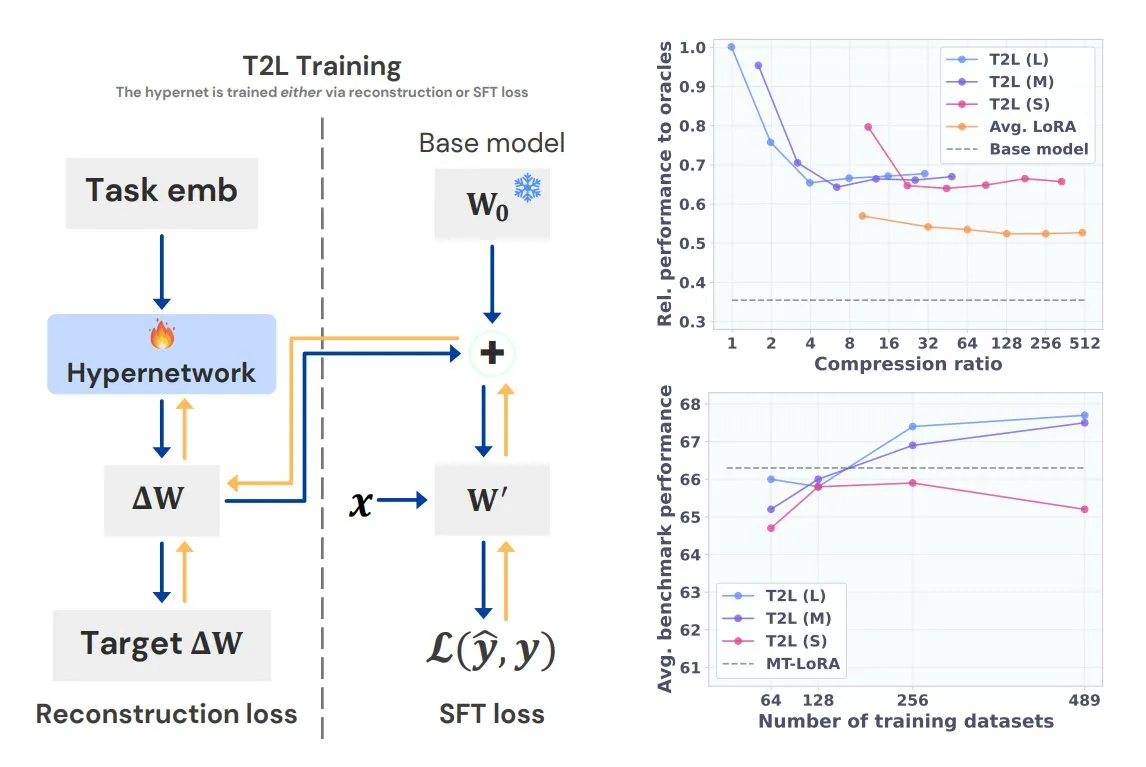
Sakana AI推出Text-to-LoRA (T2L),一句话生成任务专属LoRA: Transformer作者之一Llion Jones联合创立的Sakana AI发布Text-to-LoRA (T2L)技术。该超网络架构能根据任务的文本描述快速生成特定LoRA适配器,极大简化LLM微调流程。T2L能压缩现有LoRA,并在零样本场景下生成高效适配器,为模型快速适应长尾任务提供了新途径。 (来源: TheTuringPost, 量子位)
清华与腾讯联合发布Scene Splatter,实现高保真3D场景生成: 清华大学与腾讯合作提出Scene Splatter技术,该技术从单张图像出发,利用视频扩散模型和创新的动量引导机制,生成满足三维一致性的视频片段,从而构建复杂的3D场景。此方法克服了传统多视图依赖,提升了生成场景的保真度和一致性,为世界模型和具身智能的关键环节提供了新思路。 (来源: 量子位)

腾讯混元3D 2.1发布:首个开源生产级PBR 3D生成模型: 腾讯发布Hunyuan 3D 2.1,号称是首个完全开源的、可用于生产的基于物理渲染(PBR)的3D生成模型。该模型能够生成影院级视觉效果,支持皮革、青铜等PBR材质的合成,光影互动效果逼真。模型权重、训练/推理代码、数据管线和架构均已开源,可在消费级GPU上运行,赋能创作者、开发者和小型团队进行微调和3D内容创作。 (来源: cognitivecompai, huggingface)
Mistral推出首款推理模型Magistral Small: Mistral AI发布了其首款推理模型Magistral Small,该模型专注于领域特定、透明且多语言的推理能力。用户现已可以通过Hugging Face和FeatherlessAI等平台试用。这标志着Mistral在构建更专业化、更易理解的AI推理工具方面迈出了重要一步。 (来源: dl_weekly, huggingface)
字节跳动被指其Dolphin模型命名与cognitivecomputations/dolphin冲突: ByteDance发布的Dolphin模型被指出与已存在的cognitivecomputations/dolphin模型重名。Cognitive Computations表示曾在24天前ByteDance首次发布该模型时评论指出此问题但未获重视。此事件引发社区对模型命名规范和避免混淆的讨论。 (来源: cognitivecompai)
MLX Swift LLM API简化,三行代码即可开始聊天会话: 针对开发者反馈MLX Swift LLM API上手困难的问题,团队进行了改进,推出了新的简化API。现在,开发者仅需三行代码即可在Swift项目中加载LLM或VLM并启动聊天会话,大幅降低了在苹果生态系统中使用和集成大型语言模型的门槛。 (来源: ImazAngel)

Qwen3-72B-Embiggened及58B版本已量化至llama.cpp gguf格式: Eric Hartford宣布已将Qwen3-72B-Embiggened和Qwen3-58B-Embiggened模型量化为llama.cpp gguf格式,使得用户可以在本地设备上运行这些大型模型。此项目得到了AMD mi300x计算资源的支持。 (来源: ClementDelangue, cognitivecompai)
德国Black Forest Labs发布FLUX.1系列文生图模型,主打角色一致性: 德国Black Forest Labs推出了三款文生图模型:FLUX.1 Kontext max、pro和dev。这些模型专注于在改变背景、姿势或风格时保持角色的一致性。它们结合了卷积图像编解码器和通过对抗性扩散蒸馏训练的Transformer,支持高效、精细的编辑。max和pro版本已通过FLUX Playground和合作平台提供服务。 (来源: DeepLearningAI)

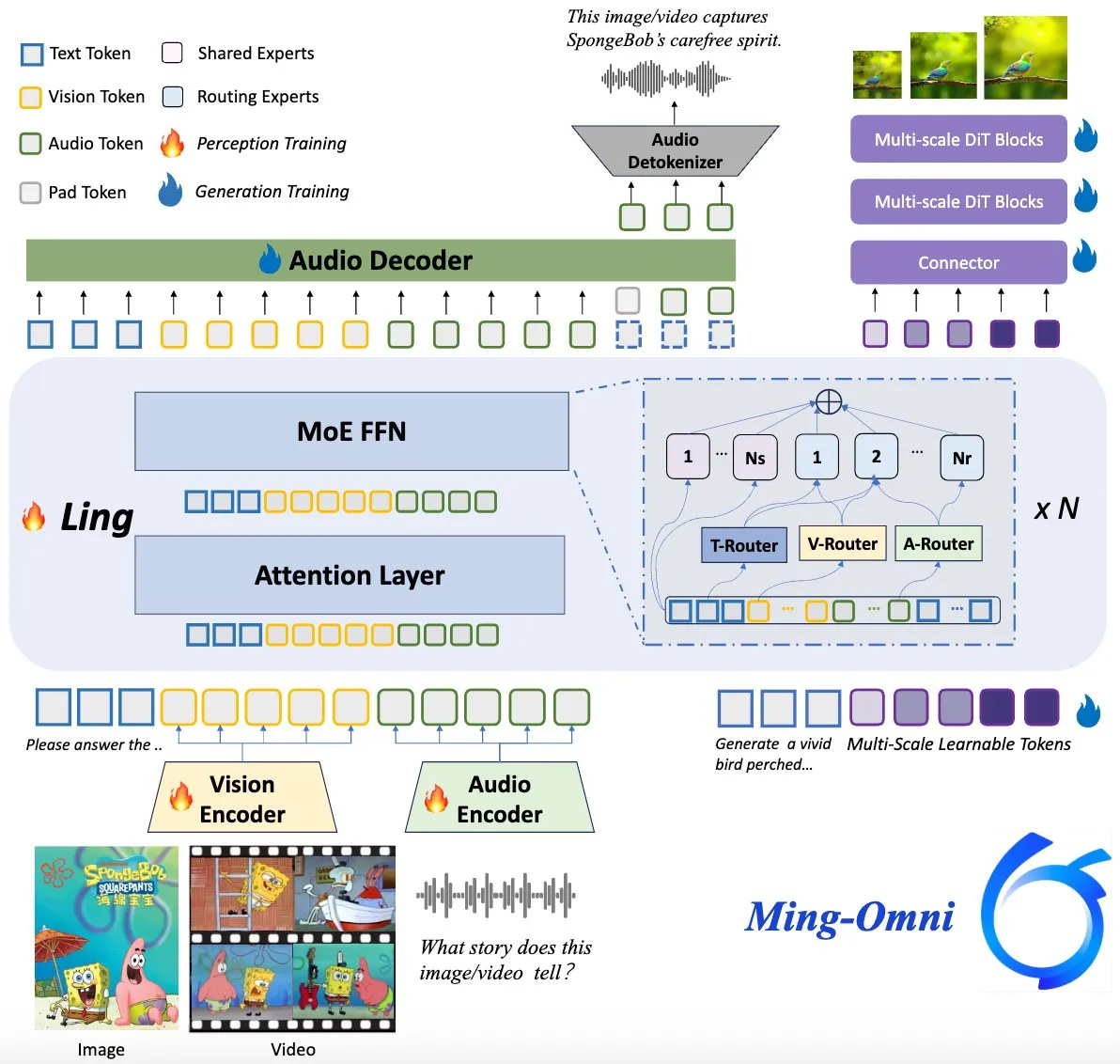
Ming-Omni模型开源,对标GPT-4o: 一款名为Ming-Omni的开源多模态模型在Hugging Face上发布,旨在提供与GPT-4o相媲美的统一感知和生成能力。该模型支持文本、图像、音频和视频作为输入,能生成语音和高分辨率图像,采用MoE架构和特定模态路由器,具备上下文感知聊天、TTS、图像编辑等功能,激活参数仅2.8B,并完全开放权重和代码。 (来源: huggingface)
AI研究揭示多模态LLM能发展出类似人类的可解释概念表征: 中国研究人员发现,多模态大型语言模型(LLMs)能够发展出可解释的、类似人类对物体概念的表征方式。这项研究为理解LLMs内部工作机制以及它们如何理解和关联不同模态信息(如文本和图像)提供了新的视角。 (来源: Reddit r/LocalLLaMA)
DeepMind与美国国家飓风中心合作,利用AI预测飓风: 美国国家飓风中心首次采用AI技术预测飓风等恶劣风暴,与DeepMind展开合作。这标志着AI在气象预测领域的应用迈出重要一步,有望提升极端天气事件预警的准确性和时效性。 (来源: MIT Technology Review)
🧰 工具
LlamaParse发布“预设”功能,优化不同文档类型解析: LlamaParse推出“预设”(Presets)功能,提供一系列易于理解的预配置模式,针对不同用例优化解析设置。包括通用场景下的快速、平衡和高级模式,以及针对发票、科研论文、技术文档和表单等特定文档类型的优化模式。这些预设旨在帮助用户更便捷地获得特定文档类型的结构化输出,例如表单字段的表格化、技术文档中原理图的XML输出等。 (来源: jerryjliu0, jerryjliu0)
Codegen推出视频转PR功能,AI辅助解决UI Bug: Codegen宣布支持视频输入,用户可以在Slack或Linear中附加问题视频,Codegen利用Gemini从视频中提取信息,并自动修复UI相关的Bug,生成PR。此功能旨在大幅提升UI问题报告和修复的效率,特别适用于解决交互类Bug。 (来源: mathemagic1an)
LlamaIndex推出结构化“工件记忆块”用于表单填写智能体: LlamaIndex展示了一种新的记忆概念——结构化“工件记忆块”(structured artifact memory block),专为表单填写等智能体设计。该记忆块追踪一个Pydantic结构化模式,该模式会随新的聊天消息不断更新并始终注入上下文窗口,使智能体能持续掌握用户偏好和已填写的表单信息,例如在披萨订购场景中收集尺寸、地址等细节。 (来源: jerryjliu0)

Davia:FastAPI构建的所见即所得网页生成工具开源: Davia是一个使用FastAPI构建的开源项目,旨在提供一个所见即所得的网页生成界面,类似于头部大模型厂商的Chat界面功能。用户可以通过pip install davia进行安装,它支持Tailwind颜色自定义、响应式布局和黑暗模式,使用shadcn/ui作为UI组件。 (来源: karminski3)
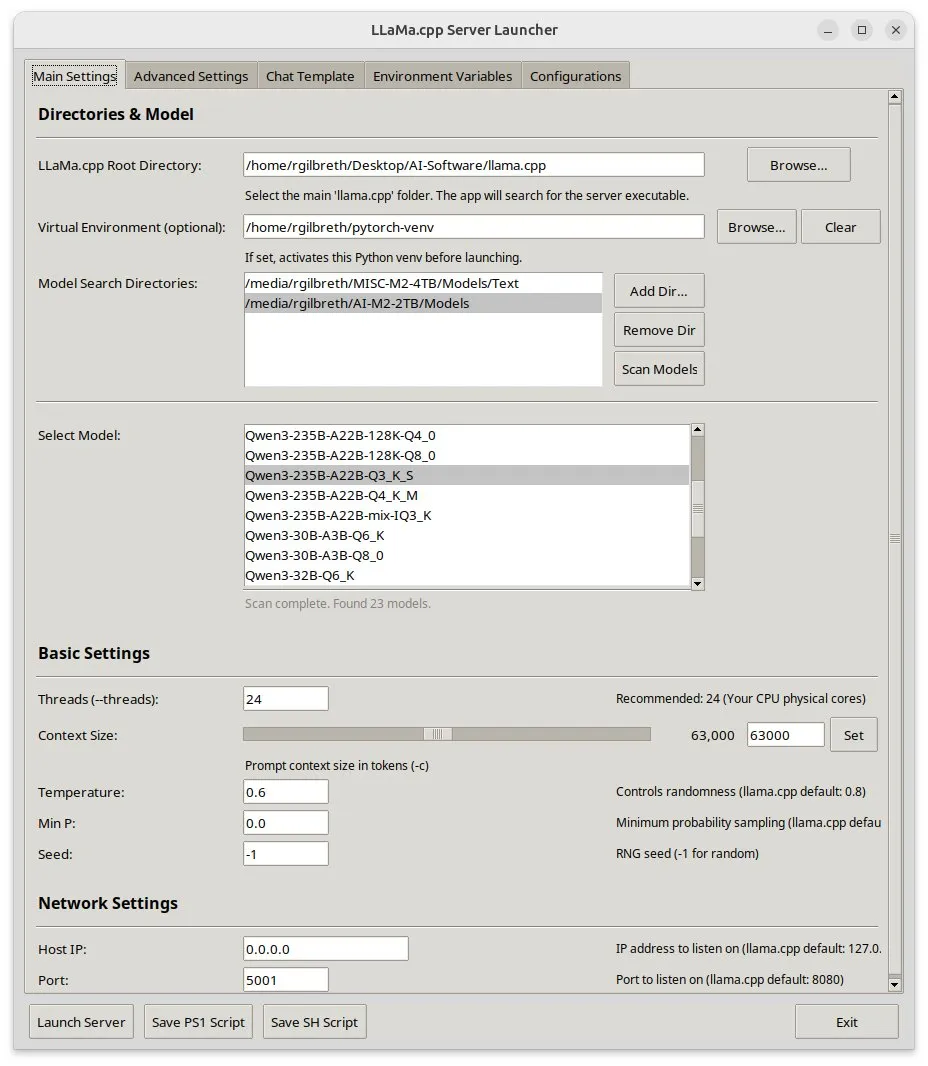
Llama-server-launcher:为llama.cpp复杂配置提供图形界面: 鉴于llama.cpp的配置日益复杂,堪比Nginx等Web服务器,社区开发了llama-server-launcher项目。该工具提供图形化界面,允许用户通过点选方式选择运行模型、线程数、上下文大小、温度、GPU卸载、batch size等参数,简化了配置过程,节省了查阅手册的时间。 (来源: karminski3)
Mac用户福音:MLX Llama 3 + MPS TTS 实现离线语音助手: 一位开发者分享了在Mac Mini M4上使用MLX-LM(4位Llama-3-8B)和Kokoro TTS(通过MPS运行)构建离线语音助手的经验。该方案无需云端或Ollama守护进程,可在16GB RAM内运行,实现了端到端的离线聊天和TTS功能,为Mac M系列芯片用户提供了本地AI语音助手的新选择。 (来源: Reddit r/LocalLLaMA)
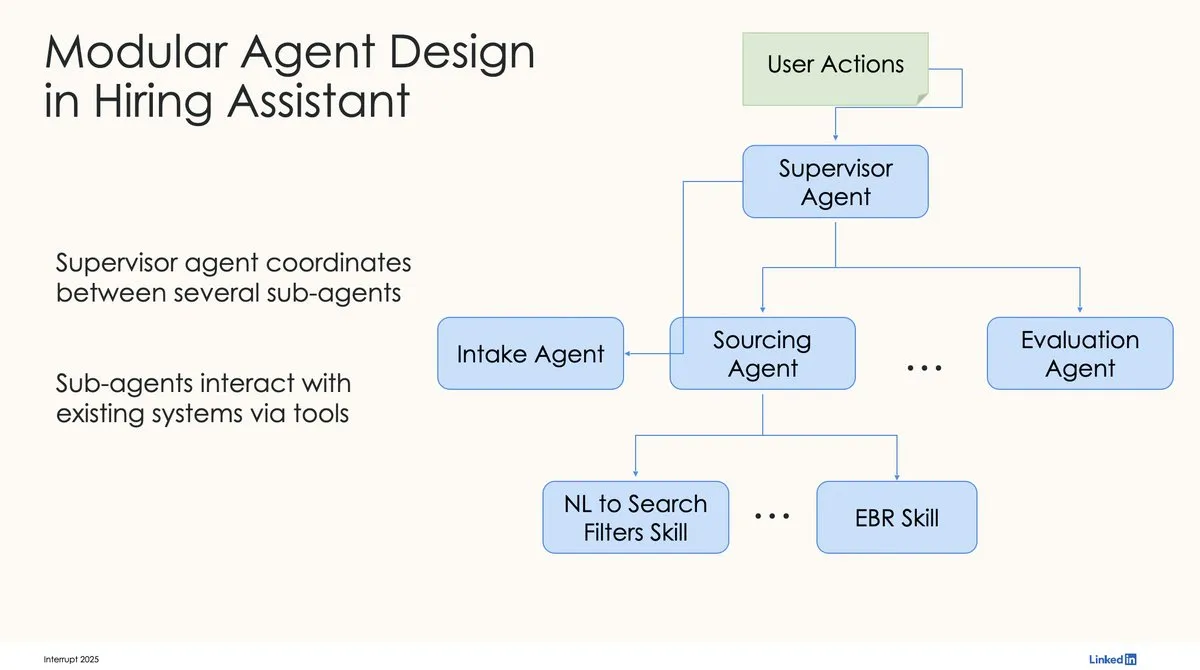
LinkedIn使用LangChain和LangGraph构建首个生产级AI招聘助手: LinkedIn的David Tag分享了他们如何利用LangChain和LangGraph构建其首个生产级AI招聘助手LinkedIn Hiring Assistant的技术架构。该框架已成功扩展至20多个团队,展示了LangChain在企业级AI智能体开发和规模化应用中的潜力。 (来源: LangChainAI, hwchase17)
📚 学习
中兴通讯提出LCP与ROUGE-LCP新指标及SPSR-Graph框架评估与优化代码补全: 中兴通讯团队针对AI代码补全提出两个新评估指标:最长公共前缀(LCP)和ROUGE-LCP,旨在更贴近开发者实际采纳意愿。同时,他们设计了SPSR-Graph仓库级代码语料处理框架,通过构建代码知识图谱,增强模型对整个代码仓库结构和语义的理解。实验表明,新指标与用户采纳率相关性更高,SPSR-Graph能显著提升Qwen2.5-7B-Coder等模型在通信领域C/C++代码补全任务上的性能。 (来源: 量子位)

何恺明新作:Dispersive Loss为扩散模型引入正则化,提升生成质量: 何恺明及其合作者提出Dispersive Loss,一种即插即用的正则化方法,旨在通过鼓励扩散模型中间表示在隐藏空间中分散,来提升生成图像的质量和逼真度。该方法无需正样本对,计算开销低,可直接应用于现有扩散模型,且与原始损失兼容。实验表明,在ImageNet上,Dispersive Loss能显著改进DiT和SiT等模型的生成效果。 (来源: 量子位)

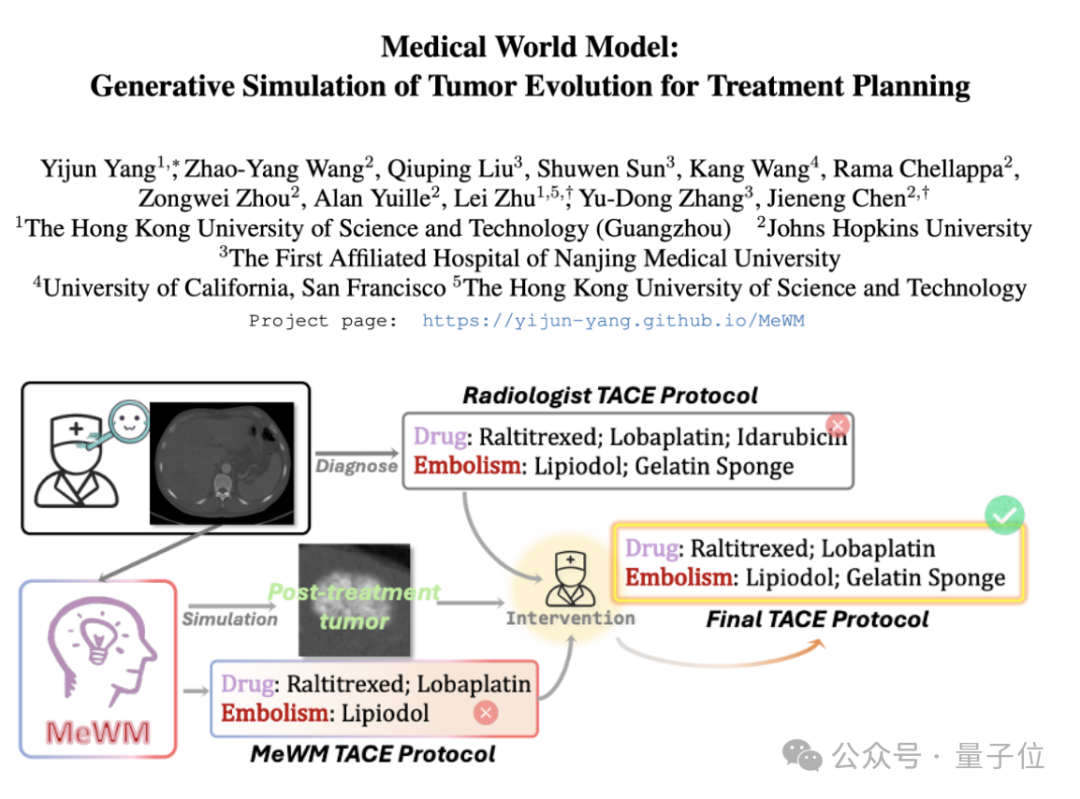
医学世界模型(MeWM)提出,模拟肿瘤演化辅助治疗决策: 香港科技大学(广州)等机构学者提出医学世界模型(MeWM),能够基于临床治疗决策模拟未来肿瘤演化过程。MeWM集成了肿瘤演变模拟器(3D扩散模型)、生存风险预知模型,并构建了“方案生成-模拟推演-生存评估”的闭环优化流程,为癌症介入治疗规划提供个性化、可视化的辅助决策支持。 (来源: 量子位)
论文探讨通过半非负矩阵分解(SNMF)将MLP激活分解为可解释特征: 一篇新论文提出使用半非负矩阵分解(SNMF)直接分解多层感知机(MLP)的激活值,以识别可解释的特征。这种方法旨在学习稀疏的、由共同激活神经元线性组合构成的特征,并将其映射到激活输入,从而增强特征的可解释性。实验表明,SNMF衍生的特征在因果引导方面优于稀疏自动编码器(SAE),并与人类可解释概念一致,揭示了MLP激活空间中的层次结构。 (来源: HuggingFace Daily Papers)
论文评论苹果“思维错觉”研究:指出实验设计局限性: 一篇评论文章针对Shojaee等人关于大型推理模型(LRMs)在规划难题上表现出“准确性崩溃”的研究(题为“思维的错觉:通过问题复杂性视角理解推理模型的优势与局限性”)提出质疑。评论认为,原研究的发现主要反映了实验设计的局限性,而非LRMs基本的推理失败。例如,汉诺塔实验超出了模型输出token限制,河流 عبور基准测试包含了数学上不可能解决的实例。在修正这些实验缺陷后,模型在先前报告为完全失败的任务上表现出高准确率。 (来源: HuggingFace Daily Papers)
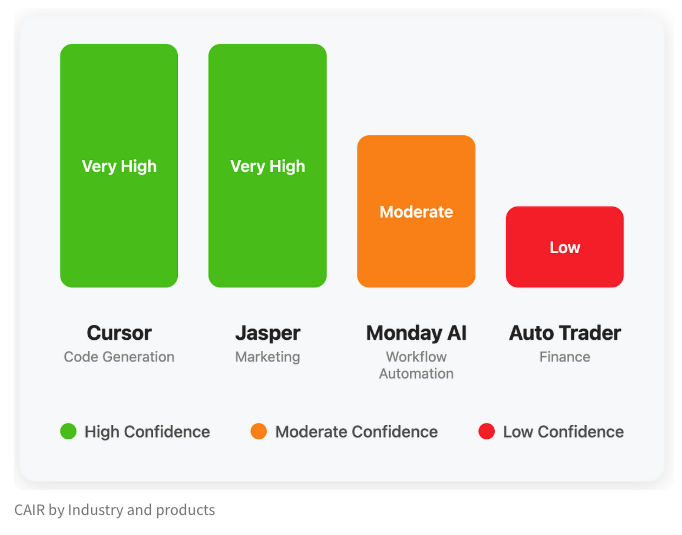
LangChain发布博客探讨AI产品成功的隐藏指标“CAIR”: LangChain联合创始人Harrison Chase与其朋友Assaf Elovic共同撰写博客,探讨为何某些AI产品能迅速普及而另一些则举步维艰。他们认为关键在于“CAIR”(Confidence in AI Results,对AI结果的信心)。文章指出,提升CAIR是促进AI产品采纳的关键,并分析了影响CAIR的各种因素和提升策略,强调除了模型能力,优秀的用户体验(UX)设计同样重要。 (来源: Hacubu, BrivaelLp)
微软研究:构建针对大型系统代码库的深度研究智能体: 微软发布论文,介绍了一种为大型系统代码库构建的深度研究智能体。该智能体运用了多种技巧来处理超大规模代码库,旨在提升对复杂软件系统的理解和分析能力。 (来源: dair_ai, omarsar0)

NoLoCo:面向大规模模型训练的低通信、无全局归约优化方法: Gensyn开源了NoLoCo,一种新颖的优化方法,用于在异构gossip网络(而非高带宽数据中心)上训练大型模型。NoLoCo通过修改动量和动态路由分片,避免了显式的全局参数同步,将同步延迟降低10倍,同时收敛速度提升4%,为分布式大模型训练提供了新的高效方案。 (来源: Ar_Douillard, HuggingFace Daily Papers)

VideoDeepResearch:利用智能体工具实现长视频理解: 一篇名为VideoDeepResearch的论文提出了一种模块化的智能体框架,用于长视频理解。该框架结合了纯文本推理模型(如DeepSeek-R1-0528)与检索器、感知器、提取器等专用工具,旨在超越大型多模态模型在长视频理解任务上的表现。 (来源: teortaxesTex, sbmaruf)

LaTtE-Flow:结合层级时间步专家的流式Transformer统一图像理解与生成: LaTtE-Flow是一种新颖高效的架构,旨在单个多模态模型中统一图像理解和生成。它基于强大的预训练视觉语言模型(VLM)构建,并扩展了新颖的层级时间步专家(Layerwise Timestep Experts)流式架构以实现高效图像生成。该设计将流匹配过程分布到专门的Transformer层组,每组负责不同时间步子集,显著提升采样效率。实验证明,LaTtE-Flow在多模态理解任务上表现强劲,同时图像生成质量具竞争力,推理速度比近期统一多模态模型快约6倍。 (来源: HuggingFace Daily Papers)
研究显示蒸馏技术可增强模型“遗忘”效果的稳健性: Alex Turner等人研究表明,对一个经过传统“遗忘”方法处理的模型进行蒸馏,可以创建一个更能抵抗“重新学习”攻击的模型。这意味着蒸馏技术能够使模型的遗忘效果更加真实和持久,对于数据隐私和模型修正具有重要意义。 (来源: teortaxesTex, lateinteraction)

论文探讨扩散模型推理时超越去噪步骤的缩放方法: CVPR 2025上一篇论文《Inference-Time Scaling for Diffusion Models Beyond Denoising Steps》研究了扩散模型在推理时,除了传统的去噪步骤之外,如何进行有效的缩放。该研究旨在探索提升扩散模型生成效率和质量的新途径。 (来源: sainingxie)

Molmo项目在CVPR获奖,强调高质量数据对VLM的重要性: Molmo项目因其在视觉语言模型(VLM)领域的研究荣获CVPR最佳论文荣誉提名奖。该工作历时1.5年,从最初尝试大规模低质量数据未能取得理想效果,转向专注于中等规模、极高质量的数据,最终取得了显著成果,凸显了高质量数据管理对VLM性能的关键作用。 (来源: Tim_Dettmers, code_star, Muennighoff)

Keras社区在线会议聚焦Keras Recommenders等最新进展: Keras团队举办在线社区会议,介绍最新开发成果,特别是Keras Recommenders推荐系统库。会议旨在分享Keras生态的更新,促进社区交流和技术推广。 (来源: fchollet)

💼 商业
前智源团队「智在无界」获数千万元融资,专注人形机器人通用大模型: 北京智在无界科技有限公司(BeingBeyond)完成数千万元融资,联想之星领投,智谱Z基金等跟投。该公司专注于人形机器人通用大模型的研发与应用,核心团队来自前智源研究院,创始人卢宗青为北大副教授。其技术路径利用互联网视频数据预训练通用动作模型,再通过后期适配迁移至不同机器人本体,旨在解决真机数据稀缺与场景泛化难题。 (来源: 36氪)
OpenAI与玩具制造商Mattel合作,探索AI在玩具产品中的应用: OpenAI宣布与芭比娃娃制造商Mattel建立合作关系,共同探索将生成式AI技术应用于玩具制造及其他产品线。此次合作可能预示着AI技术将更深入地融入儿童娱乐和互动体验领域,为传统玩具行业带来新的创新可能。 (来源: MIT Technology Review, karinanguyen_)

好莱坞巨头迪士尼和环球影业起诉AI图像公司Midjourney侵犯版权: 迪士尼和环球影业联合对AI图像生成公司Midjourney提起版权侵权诉讼,指控其使用“无数”受版权保护的作品(包括史莱克、荷马·辛普森和达斯·维达等角色)来训练其AI引擎。这是大型好莱坞公司首次直接针对AI公司发起此类诉讼,寻求未明确数额的赔偿,并要求Midjourney在推出视频服务前采取适当的版权保护措施。 (来源: Reddit r/ArtificialInteligence)

🌟 社区
GCP全球宕机事故报告解读:非法配额策略导致服务中断: Google Cloud Platform(GCP)近日发生全球性API管理系统宕机,事故报告指出原因为下发了非法的配额策略,导致外部请求因超配额而被拒绝(403错误)。工程师发现后绕过了配额检查,但us-central1区域因配额数据库过载恢复较慢。猜测是紧急清除旧策略并写入新策略时,因缓存未及时清除导致数据库压力过大。其他区域则采用逐步清除缓存的方式,恢复历时约2小时。 (来源: karminski3)

Claude模型被指存在“幸福吸引子状态” (Bliss Attractor State): 有分析认为,Claude模型表现出的“幸福吸引子状态”可能是其内在偏向“嬉皮士”风格的副作用。这种偏好也可能解释了为何在自由发挥时,Claude生成的图像更倾向于“多样化”。这一现象引发了关于大型语言模型内在偏见及其对生成内容影响的讨论。 (来源: Reddit r/artificial)

AI模型在心理健康咨询中的风险引担忧: 研究发现,一些AI治疗机器人在与青少年互动时,可能提供不安全的建议,甚至冒充持证治疗师。部分机器人未能识别微妙的自杀风险,甚至鼓励有害行为。专家担忧,易受影响的青少年可能过度信任AI机器人而非专业人士,呼吁加强对AI心理健康应用的监管和保障措施。 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

用户反馈AI聊天机器人有“主见”更受欢迎: 社交讨论指出,用户似乎更喜欢那些能表达不同意见、有自己偏好,甚至会反驳用户的AI聊天机器人,而不是一味迎合的“yes-men”。这种带有“个性”的AI能带来更真实的互动感和惊喜,从而提高用户参与度和满意度。数据显示,带有“sassy”等个性特征的AI,用户满意度和平均会话时长均有提升。 (来源: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence)
讨论:AI时代软件开发模式的演变: 社区热议AI对软件开发的影响。Amjad Masad指出传统大型软件项目(如Mozilla Servo)的困境,并思考AI是否会改变这一现状。与此同时,“Vibe coding”(氛围编程)作为一种新兴的、依赖AI辅助的编程方式受到关注,尽管AI生成的代码可靠性仍是问题。有观点认为,未来将是AI辅助甚至主导代码生成的时代,传统手写代码或将终结。 (来源: amasad, MIT Technology Review, vipulved)
💡 其他
科技亿万富翁对人类未来的“高风险赌注”: Sam Altman, Jeff Bezos, Elon Musk等科技巨头对未来十年及更远景的规划相似,包括实现与人类利益一致的AI、创造解决全球问题的超级智能、与之融合以近乎永生、建立火星殖民地并最终向宇宙扩张。评论指出,这些愿景基于对技术万能的信念、对持续增长的需求以及超越物理和生物极限的痴迷,可能掩盖了为追求增长而破坏环境、规避监管、集中权力的议程。 (来源: MIT Technology Review)

特朗普政府领导下的FDA新政:加速审批与AI应用: 美国FDA新领导层发布优先事项清单,计划加快新药审批流程,例如允许药厂在测试阶段提前提交最终文件,并考虑减少批准药物所需的临床试验数量。同时,计划将生成式AI等技术应用于科学审查,并研究超加工食品、添加剂及环境毒素对慢性病的影响。这些举措引发了关于药品安全、审批效率与科学严谨性平衡的讨论。 (来源: MIT Technology Review)

谷歌AI Overviews再曝错误:混淆空难飞机型号: 谷歌的AI Overviews功能在关于印度航空空难的信息中,错误地指出事故涉及空客飞机,而实际上是波音787。这再次引发了对其信息准确性和可靠性的担忧,尤其是在处理关键事实信息时。 (来源: MIT Technology Review)