关键词:Meta V-JEPA 2, 英伟达工业AI云, Sakana AI Text-to-LoRA, OpenAI o3-pro, Databricks Lakebase, MLflow 3.0, 普林斯顿大学 HistBench, 视频训练开源世界模型, 欧洲制造业AI云平台, 文本生成LLM适配器, DPO微调GPT-4.1, AI智能体可观测性
🔥 聚焦
Meta发布V-JEPA 2:基于视频训练的开源图像/视频世界模型 : Meta推出了新的开源图像/视频世界模型V-JEPA 2,该模型基于ViT架构,拥有不同尺寸(L/G/H)和分辨率(286/384)版本,参数量达12亿。V-JEPA 2在视觉理解和预测方面表现出色,能够使机器人在陌生环境中实现零样本规划和执行任务。Meta强调其愿景是AI利用世界模型适应动态环境并高效学习新技能。同时,Meta还发布了MVPBench、IntPhys 2和CausalVQA三个新基准,用于评估现有模型从视频中推理物理世界的能力。 (来源: huggingface, huggingface, ylecun, AIatMeta, scaling01, karminski3)
英伟达在欧洲构建首个工业AI云,推动制造业发展 : 英伟达宣布正在为欧洲制造商建设全球首个工业人工智能云平台。该AI工厂旨在助力工业领导者加速从设计、工程仿真到数字工厂孪生和机器人技术的全流程制造应用。此举是英伟达在GTC Paris及VivaTech 2025上宣布的系列举措之一,旨在加速欧洲及其他地区的AI创新。黄仁勋表示,欧洲AI算力预计两年内翻十倍,并强调“所有移动的物体都将实现机器人化,汽车是下一个”。 (来源: nvidia, nvidia, 黄仁勋:欧洲AI算力两年翻十倍)

Sakana AI推出Text-to-LoRA:用文本描述即时生成任务特定LLM适配器 : Sakana AI发布了Text-to-LoRA技术,这是一个超网络(Hypernetwork),能够根据用户对任务的文本描述,即时生成特定任务的LLM适配器(LoRAs)。该技术旨在降低定制化大模型的门槛,允许非技术用户通过自然语言特化基础模型,无需深厚技术背景或大量计算资源。Text-to-LoRA能够编码数百个现有LoRA适配器,并在保持性能的同时,泛化到未曾见过的任务。相关论文和代码已在arXiv和GitHub上发布,并将在ICML2025上展示。 (来源: SakanaAILabs, hardmaru, kylebrussell, ClementDelangue, huggingface)
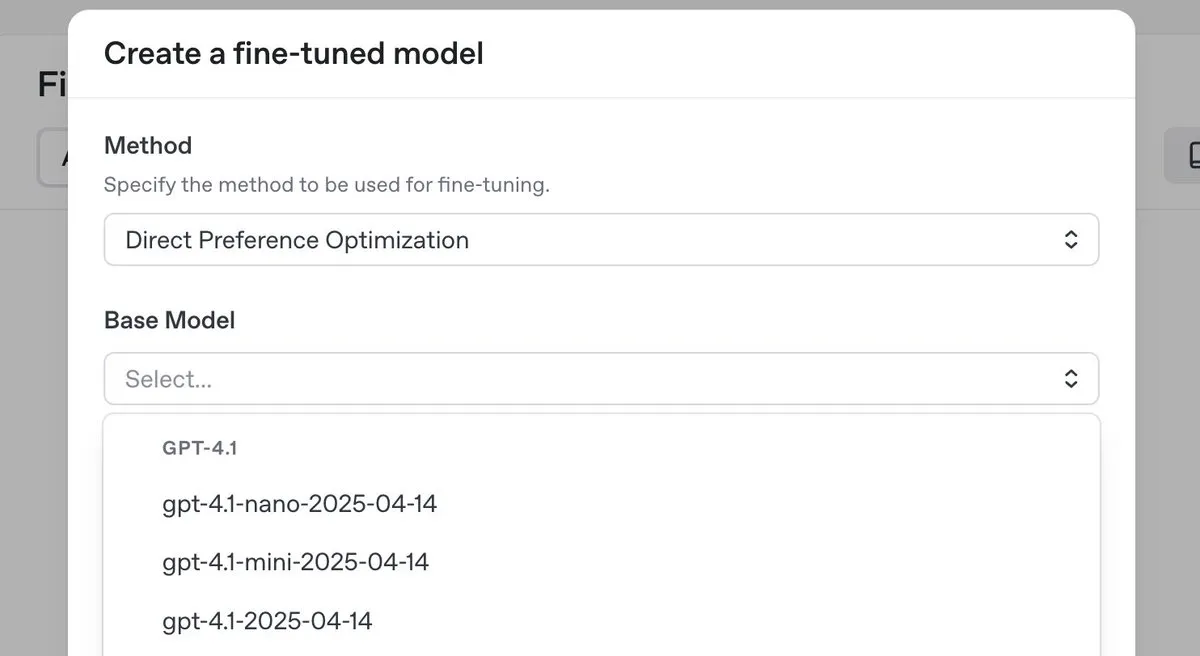
OpenAI发布o3-pro顶级推理模型并大幅降价,同时推出GPT-4.1系列DPO微调功能 : OpenAI推出了其新的顶级推理模型o3-pro,并对o3系列模型进行了大幅价格下调,旨在降低开发者使用成本。同时,OpenAI宣布用户现在可以使用直接偏好优化(DPO)来微调GPT-4.1家族模型(包括4.1、4.1-mini和4.1-nano)。DPO允许通过比较模型响应而非固定目标来进行定制,特别适用于对语气、风格和创造力有主观要求的任务。ARC Prize在o3降价后对其进行了重新测试,结果显示其在ARC-AGI上的性能未发生变化。 (来源: OpenAIDevs, scaling01, aidan_mclau, giffmana, jeremyphoward, BorisMPower, rowancheung, TheRundownAI)
🎯 动向
Databricks推出Lakebase、免费版及Agent Bricks,加速数据与AI应用开发 : Databricks宣布Lakebase进入公共预览阶段,这是一个与lakehouse集成并为AI构建的全托管Postgres数据库,结合了Postgres的易用性、lakehouse的可扩展性以及Neon数据库的分支技术。同时,Databricks推出了免费版平台和大量培训材料,帮助开发者学习数据工程、数据科学和AI。此外,Databricks Apps已正式可用(GA),支持客户在平台上构建和部署交互式数据和AI应用。Databricks还推出了Agent Bricks,采用声明式方法开发AI代理,用户描述任务后系统会自动生成评估并优化代理。 (来源: matei_zaharia, matei_zaharia, lateinteraction, matei_zaharia, matei_zaharia, matei_zaharia, jefrankle, lateinteraction, matei_zaharia, lateinteraction, cto_junior, lateinteraction, jefrankle)

英伟达与Mistral AI合作,在欧洲构建端到端云平台 : 英伟达宣布与法国初创公司Mistral AI合作,共同构建端到端云平台。第一阶段合作将部署1.8万套英伟达Grace Blackwell系统,并计划于2026年扩展至更多地点。此次合作是英伟达在欧洲推动AI基础设施建设和“主权AI”概念的一部分,旨在为欧洲提供本地化数据中心和服务器。 (来源: 黄仁勋:欧洲AI算力两年翻十倍)
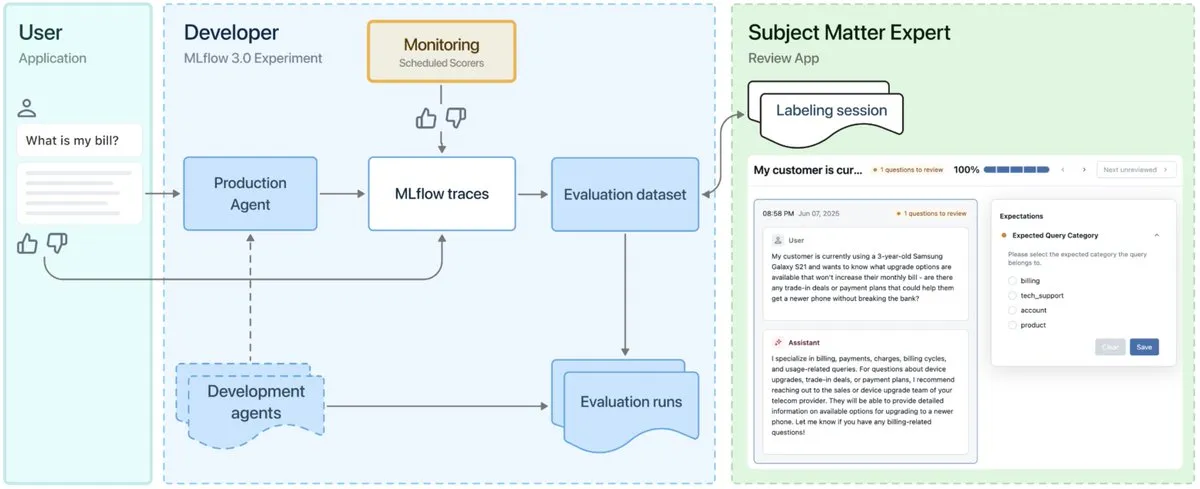
MLflow 3.0发布,专为AI智能体可观测性与开发设计 : MLflow 3.0 正式发布,新版本专为AI智能体的可观测性和开发进行了重新设计,并对传统的结构化机器学习功能进行了更新。MLflow 3.0旨在通过数据实现AI系统的持续改进,支持追踪、评估和监控AI系统,并考虑到企业级需求,如人工协作、数据治理与安全以及与Databricks数据生态系统的集成。 (来源: matei_zaharia, matei_zaharia, lateinteraction)
普林斯顿大学与复旦大学联合推出HistBench与HistAgent,推动AI在历史学研究的应用 : 普林斯顿大学AI实验室与复旦大学历史学系合作,推出了全球首个历史研究AI评测基准HistBench和AI助手HistAgent。HistBench包含414个历史问题,覆盖29种语言和多文明历史,旨在测试AI处理复杂史料和多模态理解的能力。HistAgent则是一个专为历史研究设计的智能体,集成了文献检索、OCR、翻译等工具。测试表明,通用大模型在HistBench上准确率不足20%,而HistAgent表现远超现有模型。 (来源: 全球首个历史基准,普林复旦打造AI历史助手,AI破圈人文学科)

微软研究院与北大联合发布Next-Frame Diffusion (NFD)框架,提升自回归视频生成效率 : 微软研究院与北京大学联合推出Next-Frame Diffusion (NFD)新框架,通过帧内并行采样和帧间自回归方式,在A100 GPU上使用310M模型实现了每秒超过30帧的高质量自回归视频生成。NFD采用块状因果注意力机制的Transformer,并结合一致性蒸馏和投机采样技术进一步提升效率,有望应用于实时交互游戏等场景。 (来源: 每秒生成超30帧视频,支持实时交互,自回归视频生成新框架刷新生成效率)

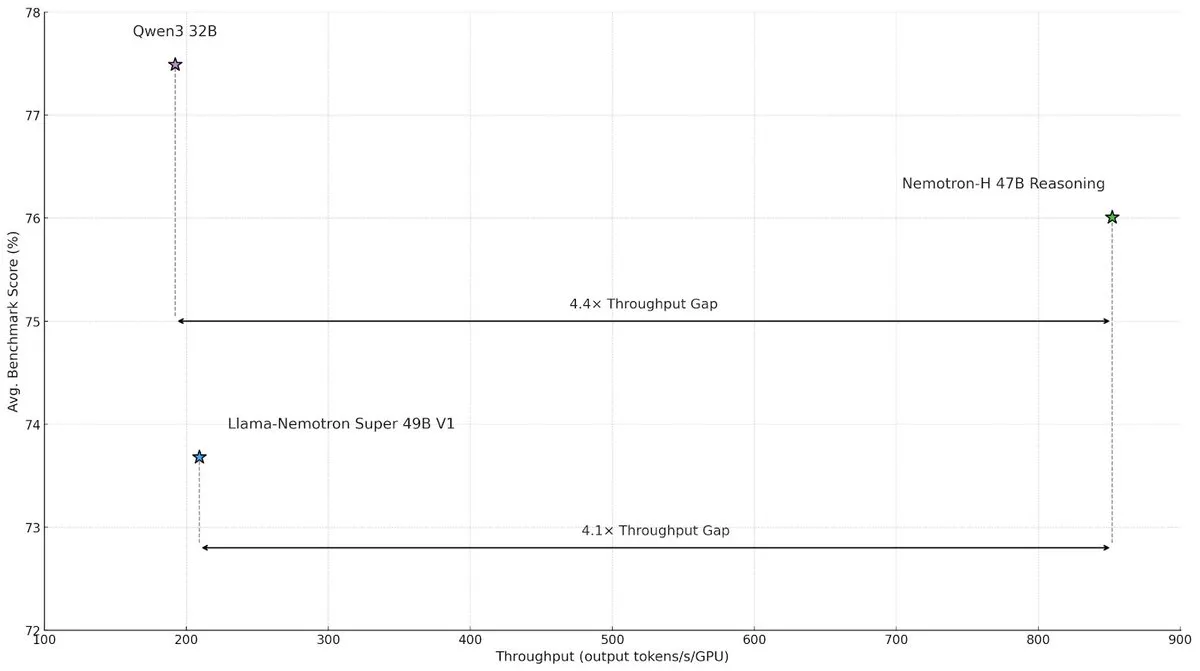
NVIDIA发布Nemotron-H混合架构模型,提升大规模推理速度与效率 : NVIDIA研究院推出Nemotron-H模型,采用Mamba与Transformer的混合架构,旨在解决大规模推理任务中的速度瓶颈。该模型在保持推理能力的同时,实现了比同类Transformer模型高4倍的吞吐量。研究表明,混合模型即使使用较少注意力层也能维持推理性能,尤其在长推理链场景下,线性架构的效率优势显著。 (来源: _albertgu, tri_dao, krandiash)
谷歌DeepMind研究员Jack Rae加入Meta“超级智能”小组 : 谷歌DeepMind首席研究员Jack Rae已确认加入Meta新成立的“超级智能”小组。Rae在DeepMind期间负责Gemini模型的“思考”能力,并且是“压缩即智能”思想的代表人物之一,曾在OpenAI参与GPT-4的开发。Meta CEO扎克伯格正亲自招募顶尖AI人才,为新团队提供数千万美元级别的薪酬方案,旨在改进Llama模型并开发更强大的AI工具,追赶行业领先者。 (来源: 小扎“超级智能”小组第一位大佬,谷歌DeepMind首席研究员,“压缩即智能”核心人物, DhruvBatraDB)

Mistral AI发布首款推理模型Magistral,支持多语言推理 : Mistral AI推出了其首款推理模型Magistral,包括24B参数的开源版本Magistral Small和面向企业的Magistral Medium。该模型专为多步逻辑和可解释性进行了微调,支持多语言推理,尤其针对欧洲语言进行了优化,并能提供可追溯的思考过程。Magistral采用改进的GRPO算法通过纯强化学习进行训练,无需依赖现有推理模型的蒸馏数据。然而,其基准测试结果因未包含最新版Qwen和DeepSeek R1的数据而受到部分质疑。 (来源: 新“SOTA”推理模型避战Qwen和R1?欧版OpenAI被喷麻了)

字节跳动豆包大模型1.6发布并再次大幅降价,视频模型Seedance 1.0 pro同步推出 : 火山引擎发布豆包大模型1.6,首创按“输入长度”区间定价,0-32K输入区间价格为0.8元/百万tokens,输出8元/百万tokens,成本较1.5版本下降63%。新发布的视频生成模型Seedance 1.0 pro定价为每千tokens 1分5厘,生成5秒1080P视频约3.67元。火山引擎总裁谭待表示,此次降价通过对企业常用32K范围的成本进行定向优化和商业模式创新实现,旨在推动Agent的规模化应用。 (来源: 豆包大模型再次大幅降价,火山引擎还在激进争夺市场份额, 「火山」烧向百度云)
香港科技大学联合华为提出AutoSchemaKG框架,实现完全自主知识图谱构建 : 香港科技大学KnowComp实验室与香港华为理论部合作提出了AutoSchemaKG框架,无需预定义模式即可完全自主构建知识图谱。该系统利用大语言模型直接从文本中提取知识三元组并归纳实体和事件模式。基于此框架,团队构建了包含超9亿节点和59亿边的知识图谱系列ATLAS。实验表明,该方法在零人工干预下,模式归纳与人类设计的模式达到95%的语义对齐。 (来源: 最大的开源GraphRag:知识图谱完全自主构建)

趋境科技发布软硬一体服务器8卡方案,提升DeepSeek大模型运行效率 : 趋境科技联合英特尔举办生态沙龙,发布了最新的软硬一体服务器8卡方案。该方案能高效运行DeepSeek-R1/V3-671B等大模型,性能对比单卡最高提升7倍。同时,其自研推理引擎KLLM、大模型管理平台AMaaS及办公应用套件“趋境·智问”也进行了重要升级,旨在解决大模型私有化部署面临的启动门槛高、运行性能不足等挑战。 (来源: 趋境科技&英特尔生态沙龙举办,硬件、推理引擎、上层应用生态融合,打通大模型私有化“最后一公里”)

Black Forest Labs发布FLUX.1 Kontext系列图像模型,强化角色与风格一致性 : 德国Black Forest Labs推出了FLUX.1 Kontext系列文本到图像模型(max, pro, dev版本),专注于在编辑图像时保持角色和风格的一致性。该系列模型支持对图像进行局部和全局修改,并能从文本和/或图像输入生成图像。FLUX.1 Kontext dev版本计划开源。在包含约1000个提示和参考图像对的专有基准测试中,FLUX.1 Kontext max和pro版本表现优于OpenAI GPT Image 1和Google Gemini 2.0 Flash等竞争模型。 (来源: DeepLearning.AI Blog)

英伟达、罗格斯大学等机构提出STORM框架,通过Mamba层减少视频理解所需Tokens : 来自英伟达、罗格斯大学、加州大学伯克利分校等机构的研究人员构建了文本-视频系统STORM。该系统在SigLIP视觉トランスフォーマー和Qwen2-VL的LLM之间引入Mamba层,通过丰富单帧Token嵌入的信息(包含来自同一剪辑中其他帧的信息),从而在不丢失关键信息的情况下平均化帧间的Token嵌入。这使得系统能以更少的Tokens处理视频,在MVBench和MLVU等视频理解基准测试中表现优于GPT-4o和Qwen2-VL,同时处理速度提升超过3倍。 (来源: DeepLearning.AI Blog)

谷歌联合创始人对人形机器人持保留态度,专用机器人商业化前景看好 : 谷歌联合创始人谢尔盖·布林表示对严格复制人类形态的人形机器人不甚热衷,认为其并非机器人有效工作的必要条件。与此同时,专用机器人因其“打开就能干活”的特性及清晰的商业化路径受到关注。例如,水下机器人和割草机器人等在特定场景展现出巨大潜力。分析认为,现阶段能解决实际问题的机器人形态和生产力是关键,专用机器人凭借明确的商业模式和刚需场景,正率先实现商业化。 (来源: 专用机器人拍了拍人形机器人“兄弟让一让,我要上桌吃饭。”)

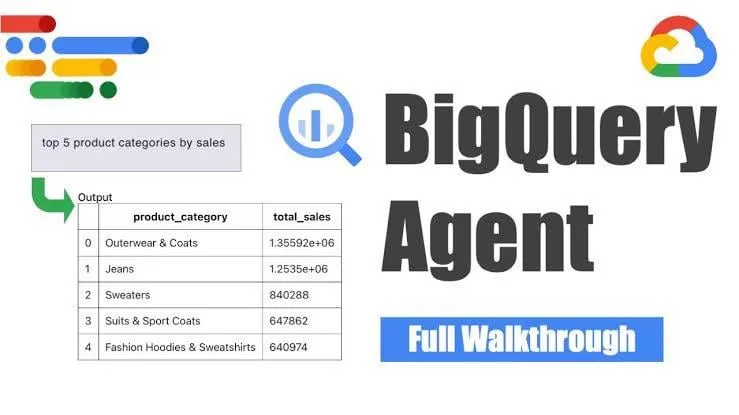
谷歌推出BigQuery数据工程智能体,实现智能管道生成 : 谷歌推出BigQuery数据工程智能体,该工具利用上下文感知推理来高效扩展数据管道的生成。用户通过简单的命令行指令即可定义管道需求,智能体则利用领域特定提示生成针对用户数据环境定制的批量管道代码,包括数据摄取配置、转换查询、表创建逻辑和通过Dataform或Composer进行的调度设置。该工具旨在通过AI辅助简化数据工程师在处理多个数据域、环境和转换逻辑时面临的重复性工作。 (来源: Reddit r/deeplearning)
Yandex发布包含近50亿用户-音轨交互的大规模公共数据集Yambda : Yandex发布了名为Yambda的大规模公共数据集,专为推荐系统研究而设计。该数据集包含来自Yandex Music的近50亿条匿名用户与音轨的交互数据,为研究人员提供了处理真实世界规模数据的罕见机会。 (来源: _akhaliq)

字节跳动在Hugging Face发布视频修复模型SeedVR2 : 字节跳动Seed团队在Hugging Face上发布了SeedVR2,一个用于视频修复的单步扩散Transformer模型。该模型采用Apache 2.0许可证,特点是单步推理,速度快且高效,并支持任意分辨率处理,无需分块或受尺寸限制。 (来源: huggingface)
字节跳动豆包视频大模型Seedance 1.0 Pro实测效果获好评 : 字节跳动最新发布的图生视频大模型Seedance 1.0 Pro在实测中表现出良好的指令跟随能力和物体生成稳定性。用户反馈其视频生成质量高,运镜卡点准确,仅次于Veo 2/3。一个潜在缺点是,在生成纯物体运动时,模型有时会加入手的操作以使画面更合理,可通过限制手部出现来规避。 (来源: karminski3, karminski3, karminski3)
阿里巴巴开源数字人框架Mnn3dAvatar,支持实时面部捕捉与3D虚拟角色创建 : 阿里巴巴在GitHub上开源了名为Mnn3dAvatar的数字人框架。该项目能够实现实时面部捕捉,并将表情映射到3D虚拟角色上,同时支持用户创建自己的3D虚拟角色。此框架适用于简单的直播带货、内容展示等场景。 (来源: karminski3)
英伟达开源人形机器人基础模型Gr00t N 1.5 3B,并提供微调教程 : 英伟达开源了Gr00t N 1.5 3B模型,这是一个专为人形机器人推理技能设计的开放基础模型,采用商业许可。同时,英伟达还发布了配合LeRobotHF SO101使用的完整微调教程,旨在推动人形机器人技术的发展和应用。 (来源: ClementDelangue)
Together AI推出Batch API,提供大规模LLM推理服务并大幅降价 : Together AI上线了新的Batch API,专为大规模LLM推理设计,支持如合成数据生成、基准测试、内容审查与摘要、文档提取等高吞吐量应用场景。该API引入了比实时API便宜50%的入门价格,支持每次最多5万个请求或100MB的批量处理,并兼容15个顶级模型。 (来源: vipulved)
谷歌Gemini 2.5 Pro新增交互式分形艺术生成功能 : 谷歌宣布Gemini 2.5 Pro现支持即时创作交互式分形艺术。用户可以通过提供如“为我创作一个美丽的、基于粒子的、动画的、无尽的、3D的、对称的、灵感来自数学公式的分形艺术作品”等提示词,来生成独特的视觉艺术。 (来源: demishassabis)
谷歌Veo3 Fast视频生成速度提升两倍 : 谷歌实验室宣布其视频生成工具Flow中的Veo3 Fast版本生成速度提升超过两倍,同时保持720p分辨率。此更新旨在让用户能够更快地创作视频内容。 (来源: op7418)
Hugging Face集成Google Colab与Kaggle,简化模型使用流程 : Hugging Face现已与Google Colab和Kaggle集成。用户可以直接从任何模型卡启动Colab笔记本,或在Kaggle Notebook中打开相同的模型,并附带可运行的公共代码示例,从而简化了模型的使用和实验流程。 (来源: ClementDelangue, huggingface)
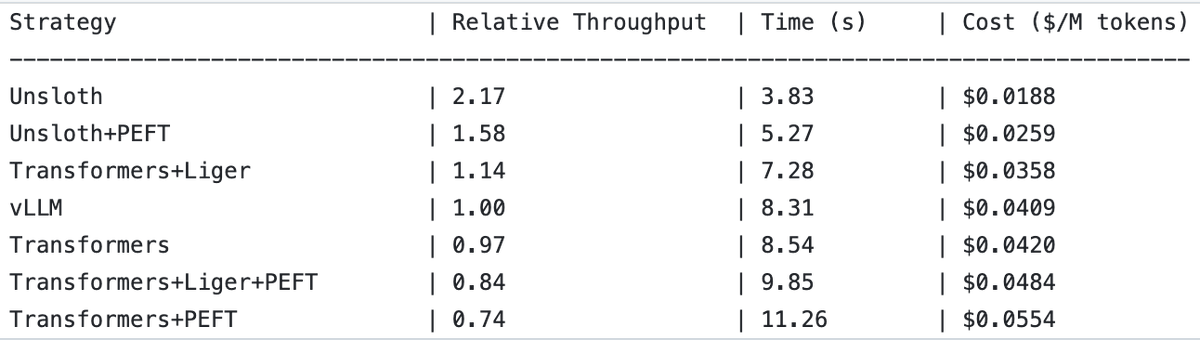
UnslothAI在奖励模型服务和序列分类推理方面实现2倍吞吐量提升 : UnslothAI被发现可用于提供奖励模型(RM)服务,并且在序列分类推理方面,其吞吐量是vLLM的两倍。这一发现在RL(强化学习)社区引起关注,UnslothAI的性能提升有望加速相关研究和应用。 (来源: natolambert, danielhanchen)
地瓜机器人发布首款单SoC算控一体化机器人开发套件RDK S100 : 地瓜机器人推出了行业首款单SoC算控一体化机器人开发套件RDK S100。该套件采用类人大小脑架构设计,在单一SoC上整合CPU+BPU+MCU,支持具身智能大小模型的高效协作,打通“感知-决策-控制”闭环。RDK S100提供多种接口和软硬协同、端云一体的开发基础设施,旨在加速具身智能产品搭建和多场景部署。目前已与超20家头部客户合作,市场定价2799元。 (来源: 地瓜机器人发布首款单SoC算控一体化机器人开发套件,已同超20家头部客户达成合作|最前线)

🧰 工具
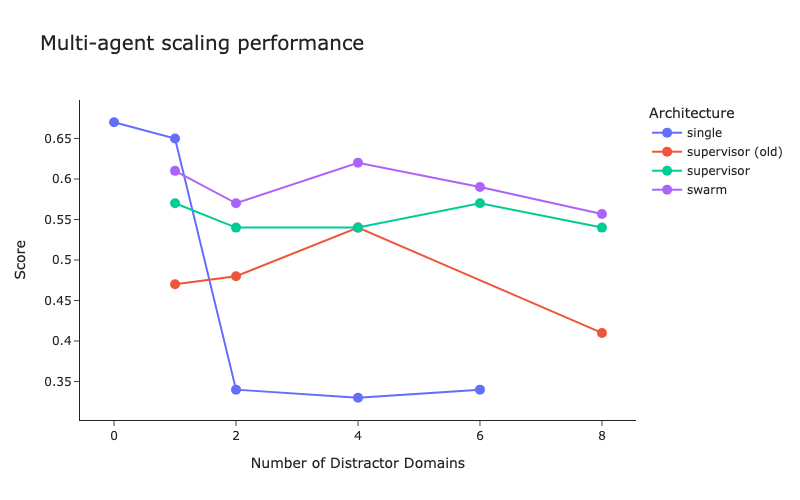
LangChain发布多智能体架构基准测试及主管方法改进 : LangChain针对日益增多的多智能体系统,进行了初步的基准测试,探讨如何优化多智能体间的协调。同时,LangChain对其主管(supervisor)方法进行了一些改进,相关博客已发布。 (来源: LangChainAI, hwchase17)
Cartesia推出Ink-Whisper:专为语音智能体设计的快速、经济的流式语音转文本模型 : Cartesia发布了Ink-Whisper,一款针对语音智能体优化的高速、低成本流式语音转文本(STT)模型。该模型专为真实世界条件下的准确性而设计,可与Cartesia的Sonic文本转语音(TTS)模型配合使用,实现快速的语音AI交互。Ink-Whisper支持接入VapiAI、PipecatAI和Livekit等平台。 (来源: simran_s_arora, tri_dao, krandiash)

MonkeyOCR:小型、快速、开源的文档解析模型 : 一款名为MonkeyOCR的3B参数文档解析模型发布,采用Apache 2.0许可证。该模型能够解析文档中的各种元素,包括图表、公式、表格等,旨在替代传统的解析器管道,提供更优的文档处理方案。 (来源: mervenoyann, huggingface)
LlamaIndex与Cleanlab集成,提升AI助手响应可信度 : LlamaIndex宣布与CleanlabAI集成。LlamaIndex用于构建AI知识助手和生产级智能体,从企业数据中生成洞察。Cleanlab的加入旨在提升这些AI助手响应的可信度,能够为每个LLM响应打分,实时捕捉幻觉或不正确的响应,并帮助分析响应不可信的原因(如检索不佳、数据/上下文问题、查询棘手或LLM幻觉)。 (来源: jerryjliu0)

Claude Code新增“计划模式”,提升复杂代码更改的可控性 : Anthropic的Claude Code引入了“计划模式”(Plan mode)。该功能允许用户在实际更改代码前审查实施计划,确保每一步都经过推敲,特别适用于复杂的代码变更。用户可通过快捷键Shift + Tab两次进入计划模式,Claude Code会提供详细的实施计划并在执行前征求确认。该功能已向所有Claude Code用户(包括Pro或Max订阅用户)推出。 (来源: dotey, kylebrussell)
rvn-convert:Rust实现的SafeTensors到GGUF v3转换工具 : 一款名为rvn-convert的开源工具发布,使用Rust语言编写,用于将SafeTensors格式的模型文件转换为GGUF v3格式。该工具特点是单分片支持、速度快、无需Python环境,能够内存映射safetensors文件并直接写入gguf文件,避免了RAM峰值和磁盘周转问题。目前支持BF16到F32的上采样,嵌入tokenizer.json等功能。 (来源: Reddit r/LocalLLaMA)
Runway API新增4K视频超分辨率功能 : Runway宣布其API现已支持4K视频超分辨率功能。开发者可以将此功能集成到自己的应用程序、产品、平台和网站中,以提升视频内容的清晰度和质量。 (来源: c_valenzuelab)
You.com推出Projects功能,用于组织和管理研究资料 : You.com发布了名为“Projects”的新工具,旨在帮助用户将研究资料组织到易于访问的文件夹中。该功能支持用户对对话进行情境化和结构化处理,避免聊天记录分散和见解丢失,从而简化知识管理流程。 (来源: RichardSocher)
LlamaIndex推出LlamaExtract智能体文档提取服务 : LlamaIndex发布了LlamaExtract,一项智能体驱动的文档提取服务,旨在从复杂文档和输入模式中提取结构化数据。该服务不仅能提取键值对,还能为每个提取项提供精确的来源推理、页面引用和匹配文本。LlamaExtract以API形式提供,可轻松集成到下游智能体工作流中。 (来源: jerryjliu0)

langchain-google-vertexai发布更新,提升客户端缓存与工具支持 : langchain-google-vertexai迎来了新版本发布。主要更新包括:预测客户端缓存,使新客户端实例化速度提升500倍;支持内置代码执行工具。 (来源: LangChainAI, Hacubu)
Perplexity Finance新增Excel模型直接下载功能 : Perplexity Finance宣布用户现在可以直接从其页面下载Excel模型,为财务建模和研究提供了更快捷的起点。该功能对所有用户免费开放,此前仅支持CSV格式下载。 (来源: AravSrinivas)
Viwoods发布AI Paper Mini墨水屏平板,集成GPT-4o等AI功能 : 新兴墨水屏厂商Viwoods推出了AI Paper Mini,一款配备AI功能的墨水屏平板。该设备支持GPT-4o、DeepSeek等多种AI模型,提供Chat模式和预设AI助手(内容分析、邮件生成、AI转文本)。其特色功能包括日历视图任务管理、快捷悬浮窗笔记等。硬件方面,Paper Mini采用292 ppi Carta 1000屏幕,4GB+128GB存储,配备手写笔。同时,Viwoods还推出了更大尺寸的AI Paper,拥有300ppi Carta 1300柔性屏,响应速度更快。 (来源: 我花半台 iPhone 的价格,买到了一台带 AI 的「墨水屏平板」……)

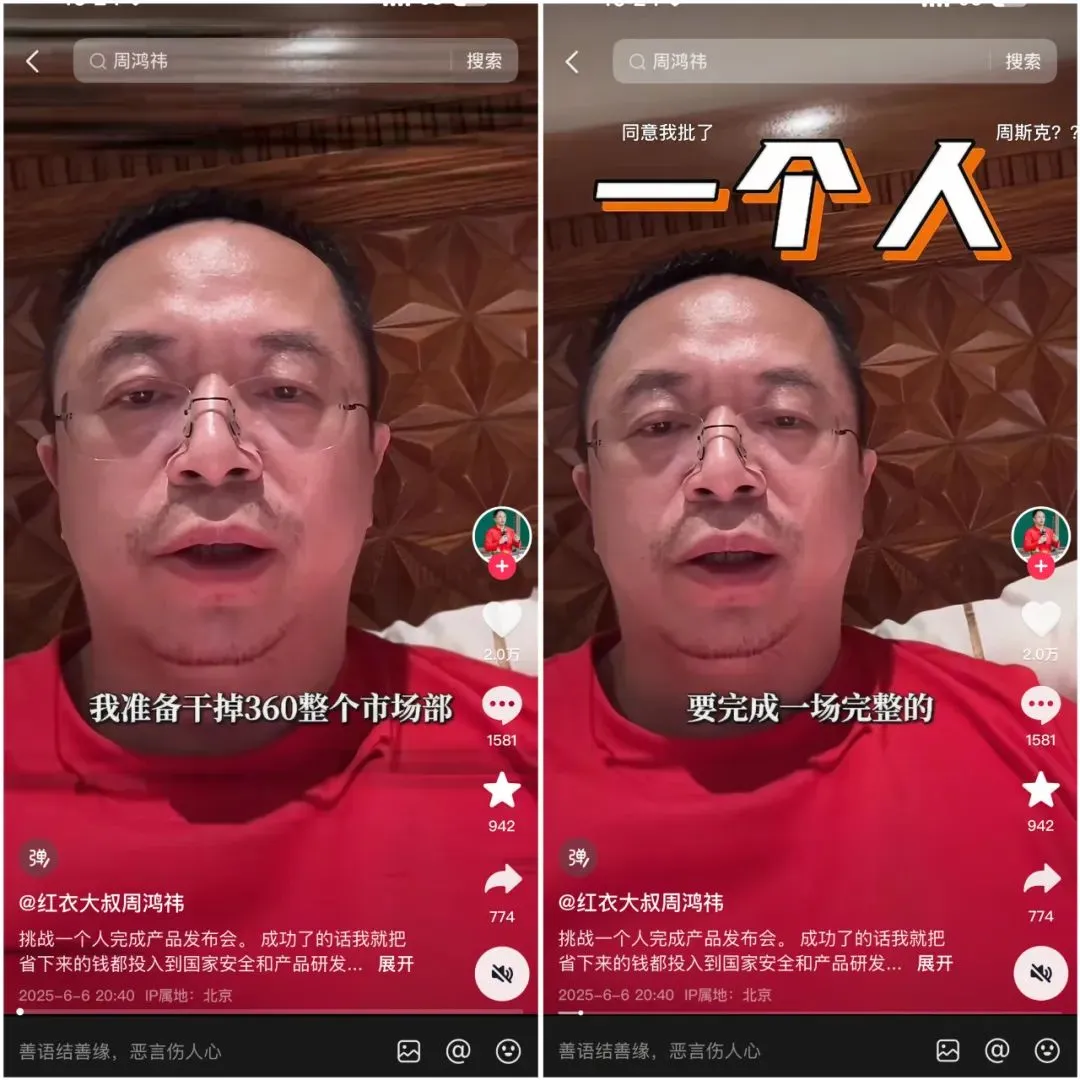
360发布纳米AI超级搜索智能体,周鸿祎亲自站台 : 360集团创始人周鸿祎主持发布了纳米AI超级搜索智能体。该智能体旨在实现“一句话,万物皆可搜”,能够在没有人工干预的情况下自主思考、调用浏览器和外部工具执行任务,并支持全程可视化和步骤溯源。周鸿祎表示,此次发布会本身也尝试利用纳米AI进行筹备,并发布了AI智能录音硬件纳米AI Note及与Rokid的联名AI眼镜。 (来源: 周鸿祎要用AI“干掉”市场部,“纳米”做到了吗?)
📚 学习
DeepLearning.AI推出新短课程:使用Apache Airflow编排GenAI工作流 : DeepLearning.AI与Astronomer合作推出新短课程,教授如何使用Apache Airflow 3.0将RAG原型转化为生产就绪的工作流。课程内容包括将工作流分解为模块化任务、使用时间驱动和事件驱动触发器调度管道、动态任务映射并行运行任务、添加重试/警报/回填以实现容错,以及扩展管道技术。该课程无需Airflow经验。 (来源: DeepLearningAI, FLUX.1 Kontext’s Consistent Characters, Benchmarking Costs Climb, Mary Meeker’s Action-Packed AI Report, Better Video Gen)
Hamel Husain发起RAG优化与评估迷你课程 : Hamel Husain宣布推出一个关于RAG(检索增强生成)优化与评估的四部分迷你课程。第一部分由@bclavie主讲,讨论了“检索即RAG”的观点,旨在回应此前关于RAG是“必须根除的思维病毒”的讨论。该系列课程免费,旨在帮助从业者解决RAG评估中遇到的难题。 (来源: HamelHusain, HamelHusain, lateinteraction, HamelHusain, HamelHusain, HamelHusain, HamelHusain, HamelHusain)

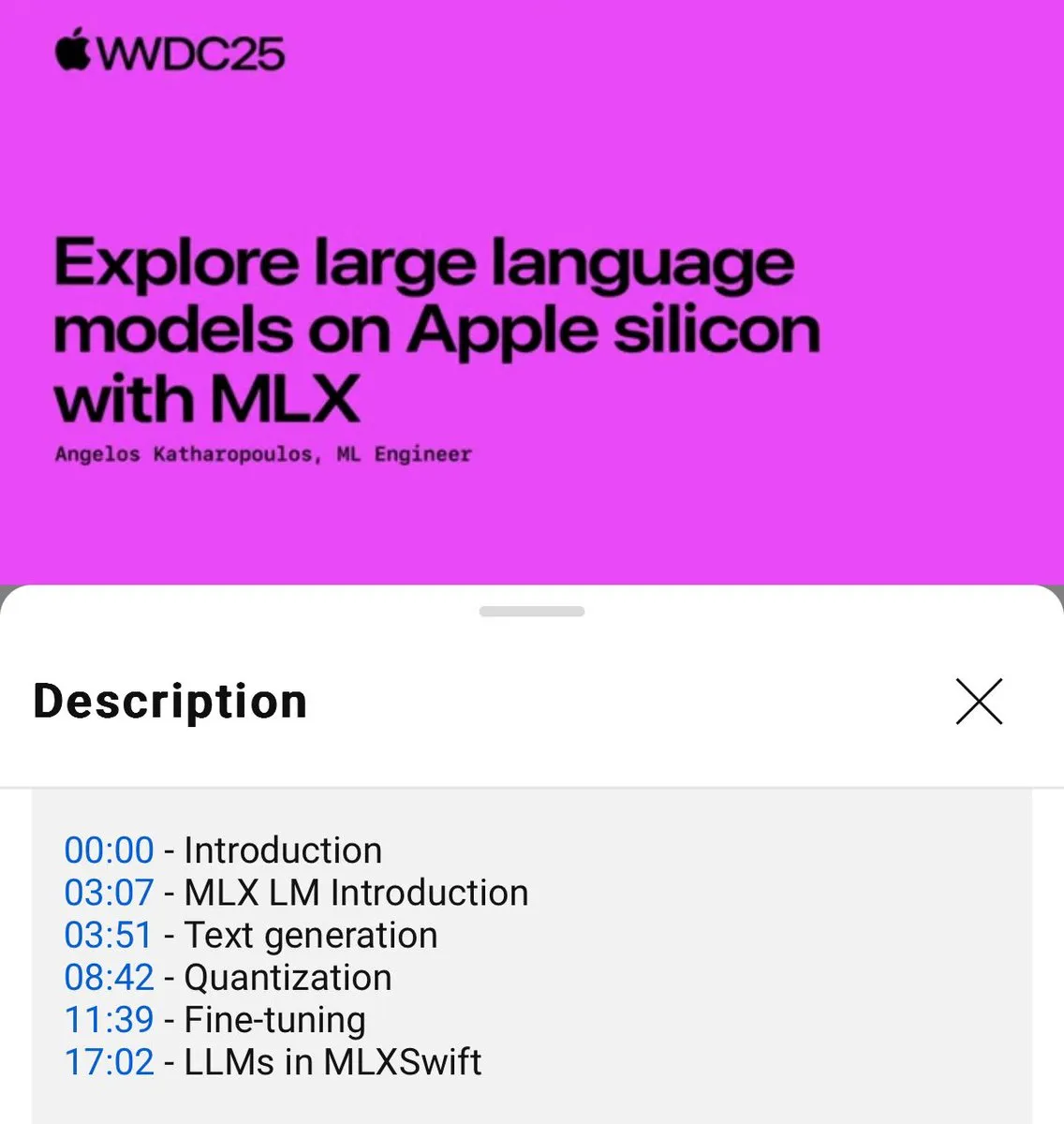
MLX语言模型本地使用教程发布(WWDC25) : WWDC25会议上,Angelos Katharopoulos介绍了如何使用MLX快速上手本地语言模型。教程涵盖了使用MLXLM CLI进行单行命令操作,如模型量化 (mlx_lm.convert)、LoRA微调 (mlx_lm.lora) 以及模型融合并上传至Hugging Face (mlx_lm.fuse)。完整的Jupyter Notebook教程已在GitHub上提供。 (来源: awnihannun)
LangChain分享Harvey AI构建法律AI智能体的方法 : Harvey AI的Ben Liebald在LangChain的Interrupt活动中分享了他们构建法律AI智能体的成熟方法。该方法结合了LangSmith评估和“律师在环”(lawyer-in-the-loop)的策略,旨在为复杂的法律工作提供值得律师信赖的AI工具。 (来源: LangChainAI, hwchase17)

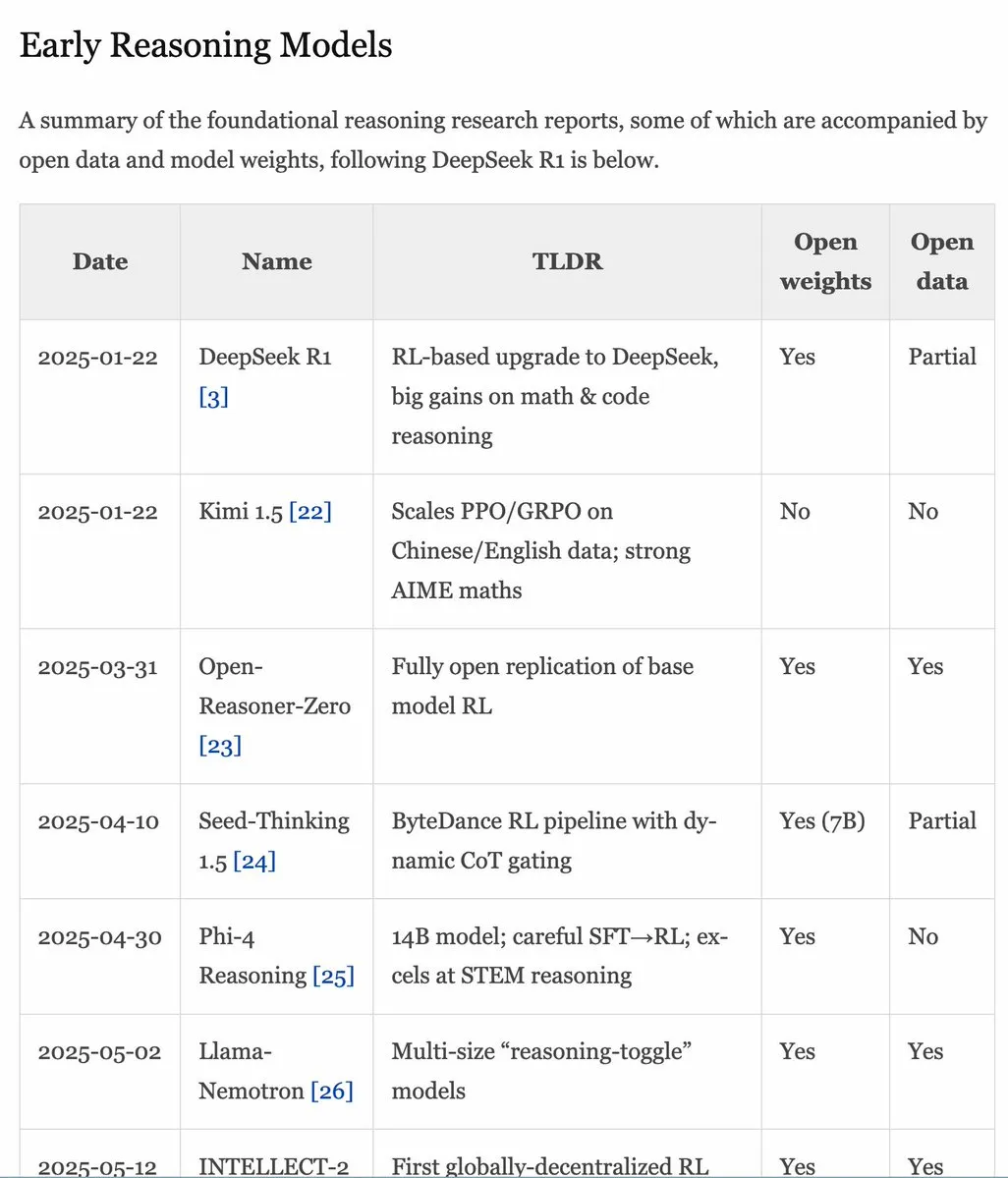
RLHF手册v1.1更新,扩展RLVR/推理模型内容 : RLHF手册(rlhfbook.com)已更新至v1.1版本,新增了关于RLVR(Reinforcement Learning from Video Representations)和推理模型的扩展内容。更新包括对主要推理模型报告的总结、常用实践/技巧及其使用者、o1之前的相关推理工作以及异步RL等改进。 (来源: menhguin)
论文SWE-Flow:以测试驱动方式合成软件工程数据 : 一篇名为SWE-Flow的新论文提出了一种基于测试驱动开发(TDD)的新型数据合成框架。该框架通过分析单元测试自动推断增量开发步骤,构建运行时依赖图(RDG)以生成结构化的开发计划。每一步都产生部分代码库、相应单元测试和必要的代码修改,从而创建可验证的TDD任务。基于此方法生成了SWE-Flow-Eval基准数据集。 (来源: HuggingFace Daily Papers)
论文PlayerOne:首个以第一人称视角构建的真实世界模拟器 : PlayerOne被提出作为首个以第一人称视角(egocentric)构建的真实世界模拟器,能够在动态环境中进行沉浸式探索。给定用户的第一人称场景图像,PlayerOne可以构建相应世界并生成与外部摄像头捕捉到的用户真实运动严格对齐的第一人称视频。该模型采用从粗到精的训练流程,并设计了部件解耦的运动注入方案和联合重建框架。 (来源: HuggingFace Daily Papers)
论文ComfyUI-R1:探索用于工作流生成的推理模型 : ComfyUI-R1是首个用于自动化工作流生成的大型推理模型。研究者首先构建了一个包含4K个工作流的数据集,并构造了长链式思维(CoT)推理数据。ComfyUI-R1通过两阶段框架训练:CoT微调进行冷启动,以及强化学习激励推理能力。实验表明,7B参数模型在格式有效性、通过率及节点/图级别F1分数上显著优于现有方法。 (来源: HuggingFace Daily Papers)
论文SeerAttention-R:针对长推理的稀疏注意力自适应框架 : SeerAttention-R是一个专为推理模型的长解码设计的稀疏注意力框架。它通过自蒸馏门控机制学习注意力稀疏性,并移除了查询池化以适应自回归解码。该框架可作为轻量级插件集成到现有预训练模型中,无需修改原始参数。在AIME基准测试中,仅用0.4B tokens训练的SeerAttention-R在4K token预算下,于大型稀疏注意力块(64/128)中保持了接近无损的推理准确率。 (来源: HuggingFace Daily Papers)
论文SAFE:针对视觉-语言-动作模型的多任务失败检测 : 论文提出SAFE,一个为通用机器人策略(如VLA)设计的失败检测器。通过分析VLA特征空间,SAFE学习从VLA内部特征预测任务失败的可能性。该检测器在成功和失败的部署中进行训练,并在未见过的任务中评估,兼容不同策略架构,旨在提高VLA在与环境交互时的安全性。 (来源: HuggingFace Daily Papers)
论文Branched Schrödinger Bridge Matching:学习分支薛定谔桥 : 该研究引入了Branched Schrödinger Bridge Matching (BranchSBM)框架,用于学习分支薛定谔桥,以预测初始分布和目标分布之间的中间轨迹。与现有方法不同,BranchSBM能够对从共同起点到多个不同结果的分支或发散演化进行建模,通过参数化多个时间相关的速度场和生长过程来实现。 (来源: HuggingFace Daily Papers)
💼 商业
Meta被曝拟150亿美元收购数据标注公司Scale AI,创始人或并入Meta : 据报道,Meta计划斥资150亿美元收购数据标注领域的头部公司Scale AI。若交易达成,Scale AI的28岁华人创始人Alexandr Wang及其团队将直接并入Meta。此举被视为Meta CEO扎克伯格为加强其AGI(通用人工智能)团队实力,追赶OpenAI和谷歌等竞争对手的重大举措。Meta近期在AI人才招募上动作频频,为顶尖工程师开出数千万美元的薪酬方案。 (来源: 小扎“超级智能”小组第一位大佬,谷歌DeepMind首席研究员,“压缩即智能”核心人物, dylan522p, sarahcat21, Dorialexander)
迪士尼与环球影业起诉AI图像公司Midjourney侵犯版权 : 迪士尼和环球影业已对AI图像生成公司Midjourney提起诉讼,指控其未经授权使用《星球大战》、《辛普森一家》等知名IP作品。此案引发关注,若迪士尼胜诉,可能对其他依赖大规模数据训练的AI公司产生连锁反应,进一步加剧AI领域的版权争议。 (来源: Reddit r/artificial, Reddit r/LocalLLaMA, karminski3)

谷歌因AI搜索冲击再推“自愿离职计划”,波及搜索、广告等多个重要团队 : 面对AI搜索带来的冲击,谷歌再次向美国多个部门员工推出“自愿离职计划”,涉及搜索、广告、核心工程等关键团队,并强化返岗办公政策。此举旨在重组资源,将更多精力投入AI旗舰项目Gemini及“AI模式”搜索体验的研发。谷歌传统搜索业务因AI兴起面临巨大挑战,同时公司也面临监管压力。 (来源: AI搜索冲击下谷歌再推“自愿离职方案”,波及多个重要团队, jpt401)
🌟 社区
AI在阿姆斯特丹福利欺诈检测实验中暴露偏见,项目被叫停 : 阿姆斯特丹尝试使用AI系统(Smart Check)评估福利申请以检测欺诈,尽管遵循了负责任AI的最佳实践,包括偏见测试和技术保障,但在试点项目中,该系统仍未能实现公平和有效。最初模型对非荷兰籍申请人和男性存在偏见,调整后又对荷兰籍和女性产生偏见。最终,由于无法确保无歧视,该项目被叫停。该案例引发了关于算法公平性、负责任AI实践有效性以及AI在公共服务决策中应用的广泛讨论。 (来源: MIT Technology Review, Inside Amsterdam’s high-stakes experiment to create fair welfare AI)

AI生成内容标识制度:价值、局限与治理逻辑探讨 : 随着AI生成谣言和虚假宣传的增加,AI标识制度作为治理手段受到关注。理论上,显式和隐式标识能提升识别效率、增强用户警觉。然而实践中,标识易被规避、伪造和误判,且成本高昂。文章认为,AI标识应纳入现有内容治理体系,聚焦高风险领域(如谣言、虚假宣传),并合理界定生成与传播平台的责任,同时加强公众信息素养教育。 (来源: 当谣言搭上“AI”的东风)
AI辅助编码工具(如Claude Code)显著提升开发者效率与减轻工作压力 : 社区中多位开发者分享了使用AI辅助编码工具(特别是Anthropic的Claude Code)的积极体验。这些工具不仅能帮助编写、测试和调试代码,还能在项目规划、复杂问题解决等方面提供支持,从而大幅提升开发效率,减轻工作压力和截止日期焦虑。有用户表示,AI辅助让他们感觉自己成为了“不可阻挡的力量”。 (来源: AnthropicAI, sbmaruf, Reddit r/ClaudeAI, Reddit r/ClaudeAI)

AI生成内容消耗能源与水资源引关注,Sam Altman称每ChatGPT查询约耗1/15茶匙水 : OpenAI CEO Sam Altman透露,每次ChatGPT查询大约消耗“十五分之一茶匙”的水。这一数据引发了关于AI模型训练和推理的环境影响的讨论。尽管具体计算方式和是否包含训练成本尚不明确,但AI的能源足迹和水资源消耗已成为科技界和环保领域关注的议题。 (来源: MIT Technology Review, Reddit r/ChatGPT)

关于LLM是否真正理解数学证明的讨论:IneqMath基准测试揭示模型短板 : 新发布的IneqMath基准测试专注于奥林匹克级别的数学不等式证明,研究发现LLM虽然有时能找到正确答案,但在构建严谨、合理的证明方面存在显著差距。这引发了关于LLM在数学等领域是真正理解还是仅仅在“猜测”的讨论。Sathya指出,这种“正确答案-错误推理”的现象在PutnamBench等基准测试中也有体现。 (来源: lupantech, lupantech, _akhaliq, clefourrier)
AI Agent在软件开发、研究及日常任务中的应用与讨论 : 社区广泛讨论AI Agent在不同领域的应用。例如,有用户分享使用n8n和Claude构建深度研究智能体工作流的经验;LlamaIndex展示了如何通过Artifact Memory Block实现增量表单填写智能体;讨论还涉及使用MCP(模型上下文协议)设计面向AI的工具接口,以及AI Agent在法律、基础设施自动化(如Cisco的JARVIS)等领域的应用。 (来源: qdrant_engine, OpenAIDevs, jerryjliu0, dzhng, Reddit r/ClaudeAI, omarsar0)

人形机器人安全标准引关注,需兼顾物理与心理影响 : 随着人形机器人逐步进入工业应用并を目指し家庭等场景,其安全标准成为讨论焦点。IEEE人形机器人研究组指出,人形机器人具有动态稳定性等独特性质,需要新的安全规则。除了物理安全(如防止跌倒、碰撞),还需考虑人机交互中的沟通挑战(如意图表达、多机器人协调)和心理影响(如过度拟人化导致期望过高、情感安全)。标准制定需平衡创新与安全,并考虑不同应用场景的需求。 (来源: MIT Technology Review, Why humanoid robots need their own safety rules)

💡 其他
Docker宣布docker run --gpus现已支持AMD GPU : Docker官方更新,docker run --gpus命令现在也支持在AMD GPU上运行。这一改进提升了AMD GPU在容器化AI/ML工作负载中的易用性,对推动AMD在AI生态中的应用具有积极意义。 (来源: dylan522p)
GitHub仓库数量突破10亿 : GitHub平台上的代码仓库数量已正式突破10亿大关。这一里程碑事件标志着开源社区和代码托管平台的持续繁荣和增长。 (来源: karminski3, zacharynado)
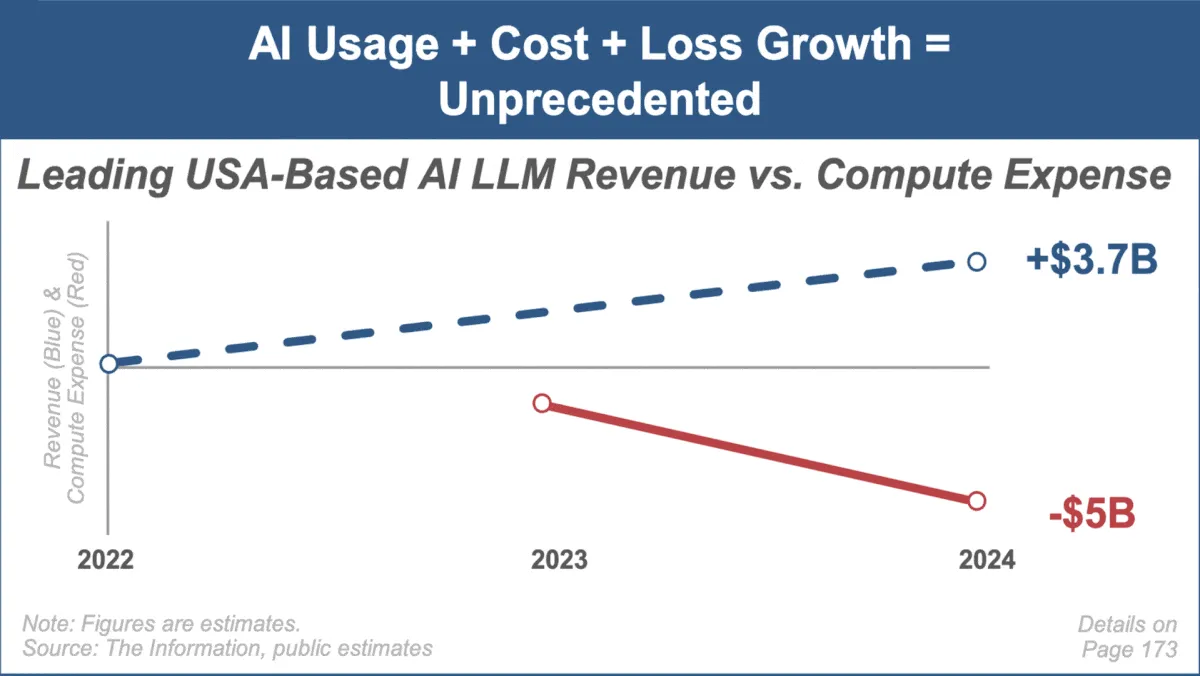
Mary Meeker发布最新AI趋势报告,聚焦市场快速增长与挑战 : 知名投资分析师Mary Meeker发布了其首份关于人工智能市场的趋势报告《Trends — Artificial Intelligence (May ‘25)》。报告强调了AI领域前所未有的增长速度、用户规模的激增(如ChatGPT用户达8亿)、AI相关资本支出的大幅增加,以及AI在性能和新兴能力上的持续突破。报告同时指出了AI商业模式面临的挑战,如计算成本上升、模型快速迭代和开源替代品的竞争。 (来源: DeepLearning.AI Blog)