
关键词:Meta, Scale AI, 超级智能, AGI, 数据标注, AI训练, 模型精度, Meta收购Scale AI股权, Alexandr Wang领导超级智能小组, AI数据标注精度99.7%, 训练数据污染率降低, 模型训练周期缩短40%
🔥 聚焦
Meta据悉斥资近150亿美元入股Scale AI并任命其CEO领导新“超级智能”团队: Meta计划以约149亿美元收购AI数据标注与基础设施公司Scale AI 49%的股权,并任命其年仅28岁的华裔CEO Alexandr Wang领导新成立的“超级智能小组”。此举旨在强化Meta在AI领域的竞争力,特别是在高质量训练数据和AGI研发方面。Scale AI以其高达99.7%的数据标注精度著称,有望将Meta模型的训练数据污染率从15%降至2%,训练周期缩短40%。此次收购被视为Meta在AI竞赛中追赶并试图超越对手的关键一步,也凸显了数据在AI发展中的核心战略地位。 (来源: 36氪, 36氪, 36氪, 36氪, Reddit r/LocalLLaMA)
OpenAI被曝与谷歌云达成大规模算力协议,或为摆脱微软依赖: 据报道,OpenAI已和谷歌云达成一项重要的云服务协议,谷歌云将为OpenAI提供其日益增长的AI模型训练和部署所需的算力。此前微软Azure是OpenAI的主要算力供应商。此举可能标志着OpenAI正寻求算力来源的多元化,以减少对单一供应商的依赖,并满足其庞大的计算需求。该合作对谷歌云而言是一次重大胜利,但也引发了关于其如何在自有业务与客户需求间平衡TPU资源的讨论。 (来源: 36氪, scaling01)
Mistral AI发布推理模型Magistral,引发社区对其基准测试透明度的质疑: 法国AI公司Mistral AI推出了其首款专为推理设计的模型系列Magistral,包括开源的24B版本Magistral Small和面向企业的Magistral Medium。官方称其专为透明、可追溯的多步逻辑推理而设计,并支持多语言。然而,社区对其发布的基准测试结果提出质疑,认为其未与最新版本的Qwen和DeepSeek R1等竞争模型进行对比,可能存在“避战”嫌疑。尽管如此,Magistral在AIME-24数学基准测试中相较于Mistral Medium 3有显著提升。 (来源: 36氪, Reddit r/artificial, Reddit r/ArtificialInteligence, teortaxesTex, qtnx_, charles_irl, algo_diver)

强化学习之父Richard Sutton:LLM主导地位仅为暂时,扩展计算与经验学习是未来: 图灵奖得主、强化学习之父Richard Sutton预测,当前大语言模型(LLM)的主导地位只是暂时的,模仿人类思维方式仅能带来短期性能提升。他认为AI的未来在于“体验时代”,即Agent通过与世界的第一人称交互获取经验数据进行学习,而非依赖静态的人类数据。Sutton强调,强化学习是通往这一未来的核心路径,结合持续学习的深度学习算法和大规模扩展计算,将使AI突破现有认知,实现真正的创新。 (来源: 量子位)

Hugging Face与NVIDIA合作推出“训练集群即服务”,降低大模型训练门槛: Hugging Face宣布与NVIDIA合作推出“训练集群即服务”(Training Cluster as a Service),旨在让全球研究机构更容易获得大型GPU集群资源,以训练各类前沿模型。该服务整合NVIDIA DGX Cloud Lepton和Hugging Face的开发资源,允许组织按需请求和支付GPU集群使用时长。此举旨在弥合“GPU贫富差距”,推动AI研究的多样性和普及化,已获得TIGEM、Numina、Mirror Physics等研究机构和初创公司的早期采用。 (来源: HuggingFace Blog, clefourrier, mervenoyann, reach_vb)
🎯 动向
OpenAI发布o3-pro模型并大幅下调o3 API价格: OpenAI推出了其新的顶级推理模型o3-pro,并已向ChatGPT Pro用户和API用户开放。同时,o3模型的API价格大幅下调80%,ChatGPT Plus用户的o3速率限制也提高了一倍。社区反馈显示,o3-pro在非代码任务上表现优于Claude Opus 4,并在多项基准测试如Extended NYT Connections和Creative Short Story Writing中创下新纪录,甚至成功解决了此前苹果论文中质疑LLM能力的“汉诺塔10盘问题”。但也有用户反映o3-pro速度较慢。OpenAI表示,o3降价并非通过蒸馏或量化,而是得益于推理工程师的优化工作。 (来源: snsf, SebastienBubeck, imjaredz, Teknium1, TheRundownAI, op7418, paul_cal, johnowhitaker, scaling01, scaling01, code_star, Teknium1)
OpenBMB发布MiniCPM4系列端侧高效LLM: OpenBMB推出了MiniCPM4系列模型,专为端侧设备设计,声称在典型端侧芯片上实现了5倍以上的生成加速。该系列包括MiniCPM4-8B、MiniCPM4-0.5B以及三值量化的BitCPM4-1B/0.5B等版本。MiniCPM4采用了可训练的稀疏注意力机制InfLLM v2,支持128K长文本处理,并结合了模型风洞2.0、BitCPM三值量化、FP8低精度计算和多词元预测等高效学习算法和训练技术。同时发布了高质量中英文预训练数据集UltraFineweb和有监督微调数据集UltraChat v2。 (来源: GitHub Trending)
MSRA与清北学者提出强化预训练(RPT)新范式: 微软亚洲研究院(MSRA)联合清华大学、北京大学的研究者提出了一种名为强化预训练(RPT)的新型LLM预训练范式。该方法将强化学习(RL)深度融入预训练阶段,模型在预测每个token前会生成思维链推理序列,并根据预测的正确性获得奖励。RPT旨在让模型从学习表面token相关性转向理解深层含义,实验表明,基于RPT训练的14B模型在某些推理任务上能媲美甚至超越32B的传统预训练模型,显示出在提升LLM语言建模和推理能力方面的巨大潜力。 (来源: 量子位, omarsar0)

Meta发布V-JEPA 2视频世界模型及新基准: Meta AI推出了V-JEPA 2,这是一个在视频数据上训练的12亿参数世界模型,旨在提升机器对物理世界的理解和预测能力。该模型能够在机器人零样本规划中发挥作用,使其在不熟悉的环境中规划和执行任务。同时,Meta还发布了三个新的基准测试,用于评估现有模型从视频中推理物理世界的能力。HuggingFace已提供V-JEPA 2的transformers库支持。 (来源: AIatMeta, ClementDelangue, Reddit r/LocalLLaMA)
字节跳动发布Seedance 1.0 Pro视频生成模型,已上线豆包App: 字节跳动推出了其最新的视频生成模型Seedance 1.0 Pro(即梦幻驱动中的视频3.0 Pro模型)。该模型在提示词理解、画面细节和物理表现一致性方面表现出色,能够生成5秒1080P的视频。目前,该模型已通过火山引擎向企业用户开放,并在豆包App中上线“照片动起来”功能供用户免费体验。 (来源: op7418)
华为推出“数字化风洞”仿真平台,优化AI训推效率: 华为马尔科夫建模仿真团队首次展示了其“数字化风洞”技术,这是一个用于在实际训练和推理复杂AI模型前进行虚拟环境“彩排”的平台。该平台包括Sim2Train(训练仿真)、Sim2Infer(推理仿真)和Sim2Availability(高可用性仿真)三大模块,旨在通过模拟和自动寻优,解决硬件资源错配、系统耦合等问题,从而小时级预演万卡集群方案,避免算力浪费,提升AI大模型训推的效率和稳定性。 (来源: 量子位)

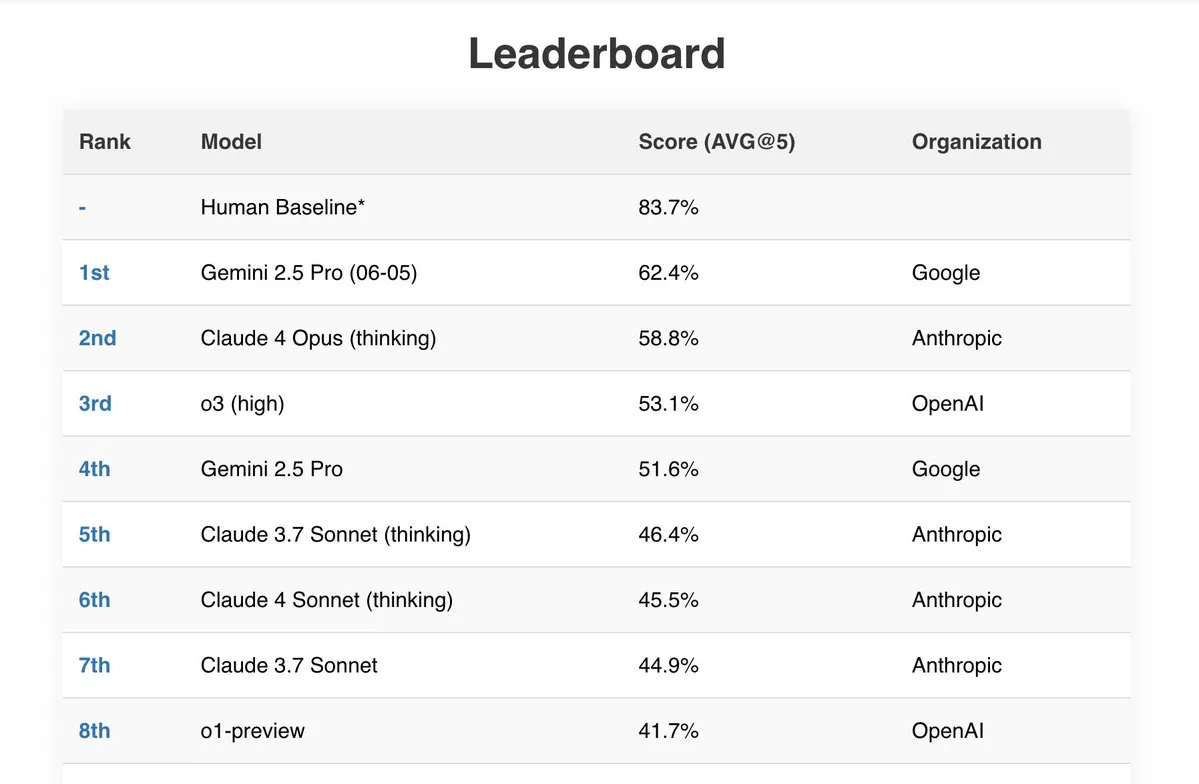
Gemini 2.5 Pro在多项基准测试中表现优异: 谷歌最新的Gemini 2.5 Pro (06-05)模型在多个公开AI排行榜上表现突出。它在处理192k tokens的Live Fiction测试中表现最佳,以62.4%的成绩在SimpleBench上排名第一,并在IDP(智能文档处理)和Aider(AI辅助编码)等基准测试中展现了强大的文档处理能力和性价比。此外,有用户报告称Gemini 2.5 Pro成功解决了JEE Advanced 2025数学部分的所有问题。 (来源: _philschmid, dilipkay)
Kling AI视频模型更新唇语同步功能,支持角色选择与编辑: 快手旗下的AI视频生成工具Kling AI最近更新了其唇语同步(Lip-sync)功能。新功能允许用户在生成的视频中选择特定角色进行唇语匹配,并能调整音频与口型同步的时间。这一更新提升了Kling AI在多角色对话视频创作方面的灵活性和真实感,是视频生成领域的一个重要进展。 (来源: Kling_ai, Kling_ai)
Delta Lake 4.0.0发布,增强Lakehouse能力: Delta Lake 4.0.0版本正式发布,带来了多项重要新特性,包括预览版的目录管理表(Catalog-Managed Tables)以实现统一治理和可发现性,针对Spark Connect的Delta Connect扩展,支持Variant数据类型以处理半结构化数据,以及即时DROP FEATURE功能,允许在不截断历史或停机的情况下移除表特性。此版本旨在提升开放lakehouse社区的体验。 (来源: matei_zaharia)

Hugging Face推出MCP服务器,简化模型与工具交互: Hugging Face发布了其模型上下文协议(MCP)服务器的第一个版本。用户现在可以通过http://hf.co/mcp在Claude或Cursor等应用中利用此服务器来搜索模型、数据集、论文、应用或特定信息。这标志着Hugging Face在推动AI生态系统中工具和模型互操作性方面迈出了重要一步,未来可能扩展到上传、下载、发起PR等功能。 (来源: clefourrier, ClementDelangue)

百度推出集成存储与智能管理的“AI相机”并升级GenFlow超能搭子2.0: 百度网盘与百度文库联合发布了“AI相机”功能,实现了拍照、云存储和智能管理的一体化。照片可自动归档至云相册,并支持通过自然语言描述进行智能分类和检索。AI相机还具备美颜、物体识别科普、简笔画涂鸦生成、票据扫描、手写表格转换等多种AI能力。同时,多智能体协作平台“GenFlow超能搭子”升级至2.0版本,能更深度结合用户数据和习惯,提供个性化内容生成服务。 (来源: 量子位)

ByteDance开源SeedVR2视频修复模型代码与权重: ByteDance SEED团队发布了其一步式视频修复模型SeedVR2的推理代码和模型权重,现已在Hugging Face上提供。该模型利用扩散对抗性后训练(diffusion adversarial post-training)技术,在视频恢复方面取得了显著效果,尤其在高分辨率视频处理上表现出色。 (来源: _akhaliq)
GroqCloud上线Qwen3-32B模型,支持超百种语言和131k上下文: Groq宣布在其LPU推理硬件云平台GroqCloud上线了通义千问Qwen3-32B模型。该模型支持超过100种语言和方言,拥有131k的上下文窗口,并以Groq硬件特有的实时速度运行,为开发者提供了强大的多语言、长文本处理能力。 (来源: JonathanRoss321)
OpenAI CEO Sam Altman称其开源权重模型将推迟发布: Sam Altman表示,OpenAI的开源权重模型将推迟至今年夏末发布,而非原计划的6月。他透露,研究团队取得了一些“意想不到且非常惊人”的进展,值得等待,但需要更多时间来完善。 (来源: SebastienBubeck, Reddit r/LocalLLaMA, eliebakouch, teortaxesTex)

地瓜机器人发布RDK S100开发套件,单SoC集成大小脑架构: 地瓜机器人推出了行业首款单SoC算控一体化机器人开发套件RDK S100。该套件采用类人大小脑的超级异构协同架构设计(6核Arm Cortex-A78AE CPU + 80 TOPS BPU作为“大脑”,4核Arm Cortex-R52+ MCU作为“小脑”),支持具身智能大小模型的高效协作,打通“感知-决策-控制”闭环。RDK S100提供丰富接口和全链路开发基础设施,预售价2499元。 (来源: 量子位)

爱簿智能发布E300 AI计算模组,搭载50TOPS国产SoC: 爱簿智能推出了面向边缘场景的E300 AI计算模组,搭载其自研AI SoC芯片AB100。该模组提供高达50TOPS的INT8算力,支持FP16/FP32混合精度计算,配备102GB/s LPDDR5内存带宽。E300采用模块化设计,旨在为教育、能源、医疗等行业提供高性能、低延迟、强可靠的国产化边缘AI解决方案,支持主流开源大模型和多种视觉及语音模型的边缘部署。 (来源: 量子位)

华为披露昇腾万卡集群高可用技术,实现98%训练可用度: 华为首次公开其昇腾万卡算力集群的高可用技术细节。通过故障感知诊断、故障管理、集群光链路容错三大基础能力,以及集群线性度优化、训练与推理快速恢复等业务支撑能力,华为实现了万卡集群训练可用度达98%,线性度超95%,故障恢复达秒级,诊断达分钟级。这套“3+3”双维度技术体系旨在保障大规模AI训练和推理的稳定高效运行。 (来源: 量子位)

比亚迪新车智驾渗透率达79%,高速NOA成主流配置: 比亚迪公布的最新数据显示,其5月份售出的新车中,搭载智能辅助驾驶系统(至少具备高速NOA和自动泊车功能)的车型占比高达79%。这表明比亚迪在推进“全民智驾”战略上取得显著成效,智能驾驶功能正快速成为其车型的标准配置。这一趋势也反映了中国汽车市场智驾技术普及速度的加快。 (来源: 量子位)

ChatGPT高级语音功能向所有付费用户推出: OpenAI宣布,此前更新的具有更强自然度的ChatGPT高级语音功能(Advanced Voice)已向所有付费用户(ChatGPT Plus, Team, Enterprise)推出。用户可以通过该功能与ChatGPT进行更自然的语音交互。 (来源: juberti)
🧰 工具
Genspark AI浏览器发布,集成多项AI智能体功能: Eric Jing团队发布了Genspark AI浏览器,号称由24人团队在10周内打造,集成了AI浏览器、AI秘书、AI个人通话、AI下载代理、AI Drive、AI Sheets等8大产品。该浏览器主打快速、广告拦截、完全智能体化、自动驾驶模式,并内置MCP商店和超级智能体,旨在提供一站式AI辅助浏览和工作体验。 (来源: blader)
Yutori AI推出Scouts平台,实现AI代理网络监控: Yutori AI发布了Scouts平台,允许用户创建持续在线的AI代理,用于监控网络上的特定信息更新。这些代理可以追踪各种用户关心的内容,如小众新闻、商品价格变动、票务信息等,并在关键时刻通过邮件提醒用户,旨在通过自动化信息追踪解放用户。 (来源: DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB, DhruvBatraDB)
Hugging Face推出AISheets,将AI模型与电子表格结合: Hugging Face发布了AISheets,这是一个将数千个AI模型(特别是开源LLM)与电子表格功能相结合的应用。用户可以在AISheets中构建、分析和自动化处理数据,旨在提供一个流畅、快速且简单的AI赋能数据处理体验。 (来源: ben_burtenshaw, LoubnaBenAllal1)
PLaMo发布本地翻译CLI工具,基于MLX: PLaMo LLM团队开源了一款命令行界面(CLI)工具,可在搭载Apple Silicon的Mac上利用MLX框架实现本地文本翻译。该工具旨在提供快速、高精度的本地翻译体验,并内置了HTTP和MCP服务器及客户端,方便与其他MCP兼容应用(如Claude Desktop)集成。 (来源: awnihannun)
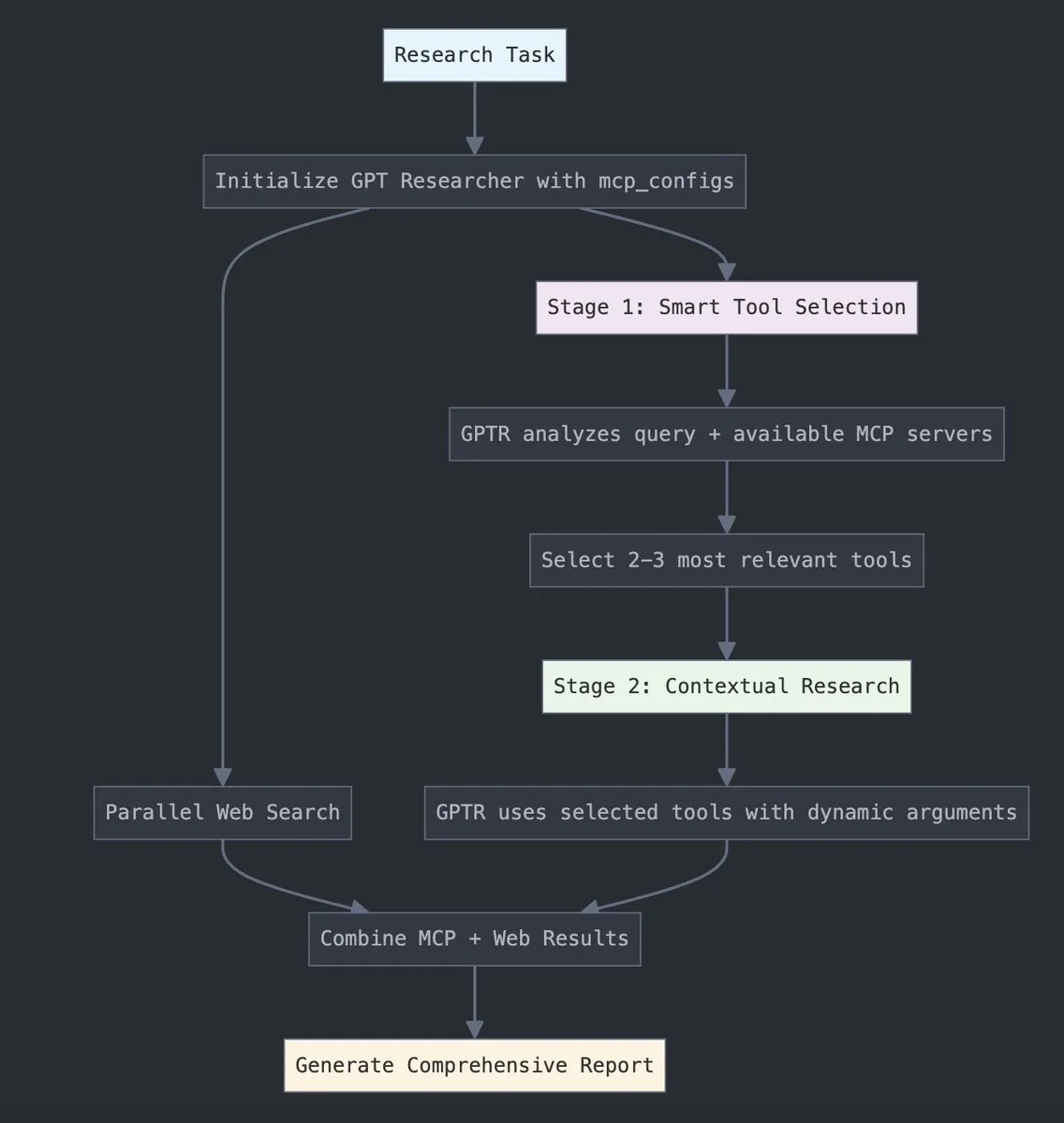
GPT Researcher集成LangChain MCP适配器,提升工具选择与研究能力: GPT Researcher现已利用LangChain的模型上下文协议(MCP)适配器,以实现更智能的工具选择和研究流程。此举旨在将MCP的优势与网络搜索能力相结合,以进行更全面的数据收集和分析。 (来源: Hacubu)
Consilium:开源多智能体协作框架发布: Victor M推出Consilium,一个开源的AI智能体团队协作框架。用户可以设定策略,由多个专家智能体进行辩论,并利用实时研究(网络、arXiv、SEC数据)来共同解决复杂问题并达成共识。该工具已在Hugging Face上提供Demo。 (来源: clefourrier)
youtube-transcript-api:Python库获取油管字幕,支持翻译与自动生成内容: jdepoix开发的Python库youtube-transcript-api在GitHub上受到关注。该API能够获取YouTube视频的字幕,包括自动生成的字幕,并支持翻译功能。与其他基于Selenium的解决方案不同,它不需要API密钥或无头浏览器,为开发者提供了便捷的视频文本内容提取途径。 (来源: GitHub Trending)

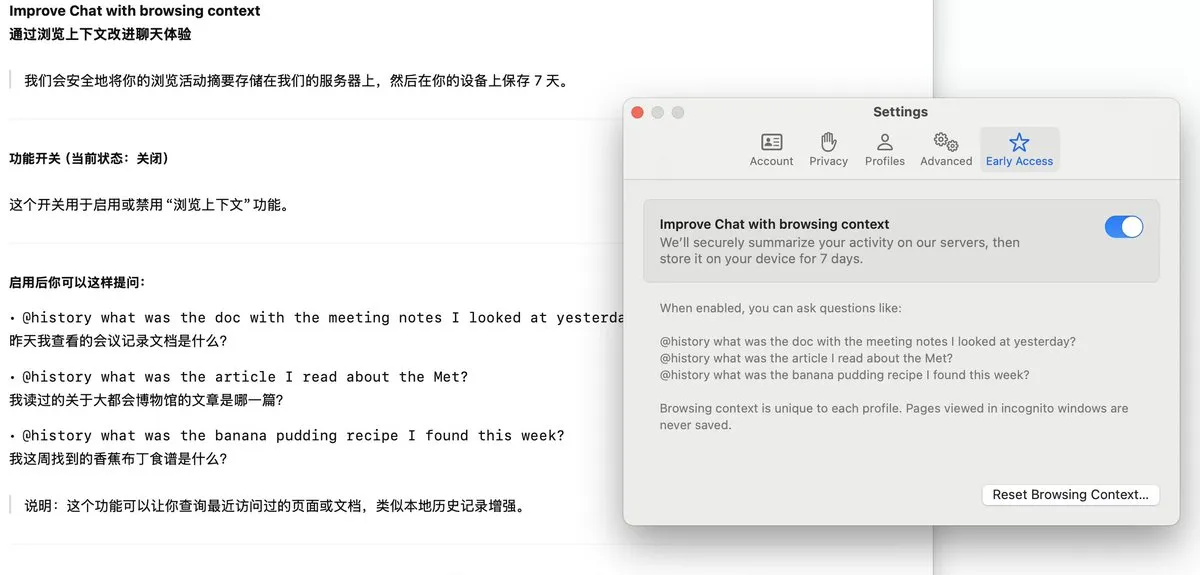
Arc浏览器推出Dia功能,记录浏览历史并支持AI问答: Arc浏览器新增Dia功能,开启后可持续记录用户的所有浏览历史。用户可以通过@History功能,使用模糊的自然语言提问来查找曾经浏览过但忘记具体网址的信息。该功能甚至可能支持生成浏览记录报告,提升了浏览器的智能化和个性化信息管理能力。 (来源: op7418)
📚 学习
Apple发布论文《思维的错觉》,探讨LLM能力边界: Apple机器学习研究团队发表论文《思维的错觉》(The Illusion of Thinking),分析了当前大型语言模型(LLM)在复杂推理任务(如解决汉诺塔问题)上的表现和局限性。该论文引发了社区对LLM真实智能水平的讨论,并有观点认为这类研究有时被用作推迟采用AI的理由。OpenAI的o3-pro模型后续解决了论文中提出的汉诺塔难题。 (来源: Reddit r/deeplearning, Teknium1, Reddit r/ArtificialInteligence)
新研究《通用智能体需要世界模型》探讨智能体泛化与预测模型关系: 一篇题为《通用智能体需要世界模型》(General agents need world models) 的新研究论文指出,能够泛化到多步目标导向任务的通用智能体必须学习一个预测性的世界模型。该模型被编码在智能体的策略中,论文通过查询智能体在复合目标下的策略选择来提取环境转换概率,从而证明了泛化能力与学习到的模型保真度之间的直接联系。 (来源: menhguin)

论文探讨概念感知微调(CAFT)提升LLM性能: 一篇新论文《通过概念感知微调改进大型语言模型》(Improving large language models with concept-aware fine-tuning) 提出CAFT方法,通过使能多词元预测进行微调,从而提升模型对概念的理解。研究表明,CAFT在编码、数学、文本摘要、分子生成和蛋白质设计等任务上均取得了显著性能增益。代码已在GitHub开源。 (来源: Reddit r/MachineLearning)
DeepLearning.AI推出新课程《编排GenAI应用工作流》: 吴恩达的DeepLearning.AI与Astronomer合作推出了名为《为GenAI应用编排工作流》(Orchestrating Workflows for GenAI Applications)的新短训课程。该课程教授如何使用流行的开源工具Airflow 3.0构建可靠的GenAI流程,并将原型Jupyter Notebook或Python脚本转化为生产就绪的工作流,内容涵盖任务分解、调度、并行执行、故障恢复和可观察性。 (来源: AndrewYNg)
论文《文本、图像与3D结构的逐词元对齐》探索多模态自回归模型: 该研究提出一个统一的LLM框架,旨在对齐语言、图像和结构化的3D场景。论文详细阐述了实现最佳训练和性能的关键设计选择,包括数据表示、特定模态的目标函数等,并在渲染、识别、指令遵循和问答等四项核心3D任务及多个数据上进行了评估。研究还扩展到通过量化形状编码重建复杂3D对象形状。 (来源: HuggingFace Daily Papers)
论文《Squeeze3D》:利用预训练3D生成模型实现极致神经压缩: Squeeze3D框架利用预训练3D生成模型中学习到的隐式先验知识来极大地压缩3D数据(网格、点云、辐射场)。它通过可训练的映射网络连接预训练编码器和生成模型的潜空间,将3D模型压缩成紧凑的潜码,解压时再由生成模型重建。该方法在合成数据上训练,无需真实3D数据集,实现了高达2187倍的纹理网格压缩率。 (来源: HuggingFace Daily Papers)
论文《框架引导》:视频扩散模型中免训练的帧级控制: 该研究提出“框架引导”(Frame Guidance),一种无需训练即可在视频扩散模型中实现帧级控制的方法。通过简单的潜空间处理和新颖的潜空间优化策略,该方法能够有效地对关键帧、风格参考、草图或深度图等帧级信号进行控制,适用于关键帧引导、风格化、循环播放等多种任务,且与任何视频模型兼容。 (来源: HuggingFace Daily Papers)
论文《大型语言模型中的地缘政治偏见》揭示模型国家立场: 该研究通过分析LLM对具有不同国家视角(美、英、苏、中)的历史事件的解读,评估了LLM中的地缘政治偏见。研究者引入了一个包含中性事件描述和各国对比观点的新数据集,发现LLM存在显著偏袒特定国家叙事的偏见,且简单的去偏见提示效果有限。该工作为未来地缘政治偏见研究提供了框架和数据集。 (来源: HuggingFace Daily Papers)
Awesome Lists资源库持续更新,收录各类有趣主题: sindresorhus维护的GitHub项目awesome是一个汇集了关于各种有趣主题的“Awesome lists”的元列表。这些列表涵盖了从编程语言、开发平台到理论、书籍、工具等众多领域,为开发者和学习者提供了丰富的资源索引。 (来源: GitHub Trending)
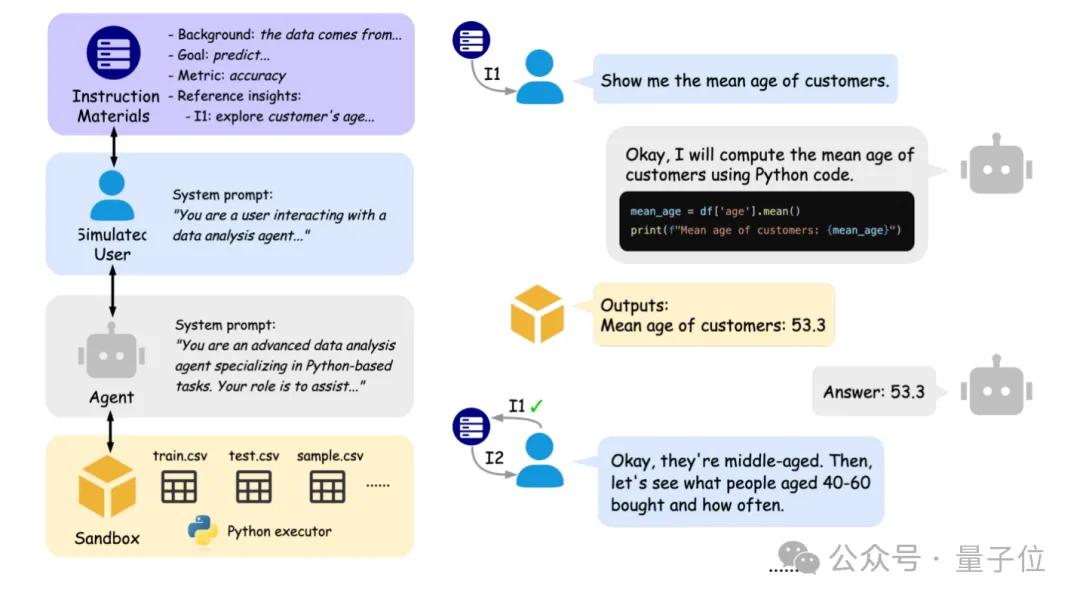
北大伯克利联合推出IDA-Bench,评估AI数据分析智能体交互能力: 北京大学与加州大学伯克利分校的研究团队(包括Michael I. Jordan教授)推出了IDA-Bench,一个旨在评估大型语言模型(LLM)作为数据分析智能体(Agent)在多轮交互场景下能力的新基准。该基准模拟真实数据分析师的工作流程,通过逐步演进的指令考察Agent的遵循能力、代码编写与执行能力。初步评估显示,即便是顶尖模型如Claude-3.7和Gemini-2.5 Pro,任务成功率也不足40%,暴露了当前Agent在复杂交互和指令遵循方面的挑战。 (来源: 量子位)
💼 商业
xAI与Polymarket合作,融合市场预测与Grok分析: Elon Musk的xAI宣布与预测市场平台Polymarket达成合作。双方将结合Polymarket的市场预测能力、X平台的数据以及Grok模型的分析能力,旨在打造一个“硬核真相引擎”(Hardcore truth engine),以洞察塑造世界的因素。官方表示这仅是合作的开始,未来将有更多进展。 (来源: Yuhu_ai_)
UnslothAI被Redpoint评为顶尖基础设施公司,亮相纳斯达克大屏: AI初创公司UnslothAI因其在AI基础设施领域的贡献,被风险投资公司Redpoint评为2025年度100家最具影响力和增长最快的インフラ公司之一,其Logo因此登上了纽约纳斯达克大厦的电子屏幕。UnslothAI专注于优化LLM的训练和推理效率。 (来源: danielhanchen, karminski3)

蚂蚁数科升级天玑实验室,聚焦“AI+产业创新”: 蚂蚁数科宣布将其天玑实验室从原“数字身份安全实验室”升级为“人工智能+产业创新”实验室。升级后的实验室将重点研究AI大模型在产业应用中的关键技术突破,布局AI+数据、AI+安全、AI+金融及AI+具身智能四大方向,旨在通过产学研用协同创新,推动AI技术与产业的深度融合。 (来源: 量子位)

🌟 社区
AI在复杂交通环境下的自动驾驶能力受关注: Ronald van Loon分享了一段在印度混乱交通中测试自动驾驶的视频,引发了对AI在复杂、高动态环境下感知、决策和控制能力的讨论。此类真实世界场景对自动驾驶系统的鲁棒性和适应性提出了极高要求。 (来源: Ronald_vanLoon)
AI Engineer World’s Fair大会精华:MCP协议、AI智能体成本与本地模型成焦点: Yogi和Shawn “swyx” Wang等人分享了AI Engineer World’s Fair大会的要点。核心趋势包括:1) AI智能体是未来,原子交互单元将是智能体调用;2) 模型上下文协议(MCP)正迅速成为标准,解决“复制粘贴地狱”,使AI能直接与外部应用交互;3) 针对特定领域和工作流构建深度优化的AI工具(Cursor-for-X模式)是关键;4) 模型成本大幅下降,本地模型能力增强,为开发者提供了更大控制权和低延迟方案;5) AI正从辅助工具进化为开发者的“队友”;6) AI工程正从演示阶段迈向生产级系统。 (来源: swyx, TheTuringPost)
社区热议o3-pro发布后的快速迭代与苹果AI论文: andersonbcdefg幽默地评论道,o3-pro发布仅6小时,社区似乎就期待有人用Rust重写fastText,并讽刺了关于“温和超级智能”的长篇大论,反映了AI领域技术迭代速度之快以及社区的高度期待。同时,Teknium1指出,o3-pro解决了苹果《思维的错觉》论文中提出的汉诺塔难题,并质疑苹果与OpenAI在合作背景下为何不先进行内部验证再发表此类论文,引发社区对科技公司间竞合关系的讨论。 (来源: andersonbcdefg, Teknium1)
AI在现实世界应用中的伦理与效果讨论: 社区对AI在特定场景的应用效果和伦理问题展开讨论。例如,Arvind Narayanan指出AI卡路里计数应用概念本身存在缺陷,图像信息不足以准确估算卡路里,认为其更多是帮助用户建立饮食注意习惯的“仪式”。另外,关于使用AI生成图片用于商业宣传(如咖啡店菜品展示)是否合乎道德或做法妥当,也成为讨论点,普遍认为只要不明显失实或误导,属于可接受的降本增效方式。 (来源: random_walker, Reddit r/artificial)
LLM的“人性化”与用户交互体验成为焦点: Reddit社区用户探讨如何让LLM的交互更像真实人类,包括引入犹豫、停顿、更短的回复和非完美表达。这反映了用户对更自然、更少“机器人感”的AI伴侣或助手的需求。与此同时,也有用户抱怨当前LLM(如ChatGPT)常用固定句式和夸张表述(如“这不仅仅是X,更是Y”),希望其表达更简洁直接。这些讨论指向了LLM在模拟人类对话和满足用户情感需求方面的持续挑战。 (来源: Reddit r/LocalLLaMA, Reddit r/ChatGPT)
💡 其他
NVIDIA CEO黄仁勋将在GTC Paris发表主题演讲,聚焦AI计算新阶段: NVIDIA宣布其CEO黄仁勋将于6月11日在巴黎GTC大会(VivaTech 2025期间)发表主题演讲。预计将揭示AI计算的下一阶段,涵盖从智能体系统到AI工厂等前沿话题。 (来源: nvidia, nvidia)

Databricks Data+AI Summit将展示最新突破: Databricks宣布其Data+AI Summit将汇集顶尖专家、研究人员和开源贡献者,展示公司在数据和AI领域的最新突破,并分享创新公司的成功案例。峰会提供线上和线下参与方式。 (来源: matei_zaharia, lateinteraction)

AI的伦理与环境影响引关注,图文小说形式科普: EPFL(洛桑联邦理工学院)的LEARN中心与插画家Herji合作推出了一部名为《Utop’IA》的法语教育图形小说,旨在通过故事形式向青少年科普人工智能的环境影响,包括其资源消耗(能源、水、稀有金属)和潜在的生态效益。该作品强调批判性思维,并探讨可持续AI的发展路径。 (来源: aihub.org)
