
关键词:苹果WWDC25, AI战略, Siri升级, Foundation框架, 设备端AI, 全系统翻译, Xcode Vibe Coding, 视觉智能搜索, Apple Intelligence繁体中文支持, watchOS Smart Stack功能, 苹果AI隐私保护策略, 跨系统生态AI整合, 生成式AI版Siri发布时间
🔥 聚焦
苹果WWDC25 AI进展:务实整合与开放,Siri仍需等待: 苹果在WWDC25上展示了其AI战略的调整,从去年“画大饼”转向更务实的系统底层和基础功能完善。重点包括将AI“有意义地”整合到操作系统和第一方应用,并将设备端模型“Foundation”框架向开发者开放。新功能如全系统翻译(支持电话、FaceTime、Message等,并提供API)、Xcode引入Vibe Coding(支持ChatGPT等模型)、基于屏幕内容的视觉智能搜索(类似圈选,部分由ChatGPT支持)以及watchOS的Smart Stack等。尽管Apple Intelligence在繁体中文市场的支持有所提及,但简体中文上线时间及备受期待的生成式AI版Siri仍未明确,后者预计“来年”再议。苹果强调设备端AI和私有云计算以保护用户隐私,并展示了跨系统生态的AI能力整合。 (来源: 36氪, 36氪, 36氪, 36氪)

苹果发布AI论文质疑大模型推理能力,引发业界广泛争议: 苹果公司近期发布论文《思维的错觉:通过问题复杂性视角理解推理模型的优势与局限性》,通过对Claude 3.7 Sonnet、DeepSeek-R1、o3 mini等大型推理模型(LRMs)进行谜题测试,指出其在处理简单问题时存在“过度思考”,而在高复杂度问题上则出现“完全准确性崩溃”,准确率接近零。该研究认为当前LRMs在可泛化推理方面可能遇到根本性障碍,更像是模式匹配而非真正思考。此观点得到Gary Marcus等学者的关注,但也引发了大量质疑,批评者认为实验设计存在逻辑漏洞(如对复杂性定义、忽视token输出限制),甚至指责苹果因自身AI进展缓慢而试图否定现有大模型成果。论文一作的实习生身份也成为讨论点。 (来源: 36氪, Reddit r/ArtificialInteligence)

OpenAI被曝秘密训练新模型o4,强化学习重塑AI研发布局: SemiAnalysis爆料称OpenAI正在训练一个规模介于GPT-4.1和GPT-4.5之间的新模型,下一代推理模型o4将基于GPT-4.1进行强化学习(RL)训练。此举标志着OpenAI策略的转变,旨在平衡模型强度与RL训练的实用性,GPT-4.1因其较低的推理成本和强大的代码性能被视为理想基础。文章深入分析了强化学习在提升LLM推理能力、推动AI智能体发展中的核心作用,但也指出了其在基础设施、奖励函数设定、奖励黑客(reward hacking)等方面的挑战。RL正改变AI实验室的组织架构和研发优先级,使推理与训练深度融合。同时,高质量数据成为RL规模化的护城河,而对于小模型,蒸馏可能比RL更有效。 (来源: 36氪)

Ilya Sutskever回归公众视野,获多伦多大学荣誉博士并畅谈AI未来: OpenAI联合创始人Ilya Sutskever在离开OpenAI并创立Safe Superintelligence Inc.后,近日首次公开亮相,重返母校多伦多大学接受荣誉理学博士学位。他在演讲中强调,AI未来将能完成人类能做的所有事情,因为大脑本身就是一台生物计算机,数字计算机没有理由不能做到同样的事情。他认为AI正以前所未有的方式改变工作和职业,并敦促人们关注AI发展,通过观察其能力来激发克服挑战的能量。Sutskever在OpenAI的经历以及对AGI安全的关注使其成为AI领域的关键人物。 (来源: 36氪, Reddit r/artificial)

🎯 动向
小红书开源首个MoE大模型dots.llm1,中文评测超DeepSeek-V3: 小红书hi lab(人文智能实验室)发布了其首个开源大模型dots.llm1,这是一个1420亿参数的混合专家(MoE)模型,推理时仅激活140亿参数。该模型在预训练阶段使用了11.2万亿非合成数据,并在中英文理解、数学推理、代码生成和对齐等任务上表现出色,性能接近Qwen3-32B。特别是在C-Eval中文评测中,dots.llm1.inst达到92.2分,超越了包括DeepSeek-V3在内的现有模型。小红书强调其可扩展且细粒度的数据处理框架是关键,并开源了中间训练检查点以促进社区研究。 (来源: 36氪)
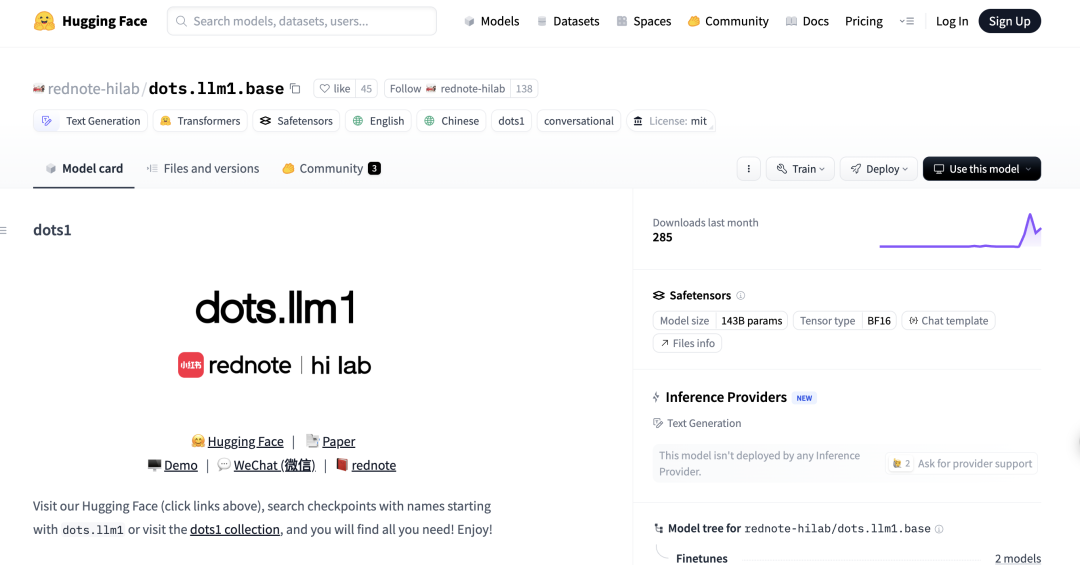
DeepSeek R1 0528模型在Aider编程基准测试中表现优异: Aider编程排行榜更新了DeepSeek-R1-0528模型的评分,结果显示其性能超越了Claude-4-Sonnet(无论是否启用思考模式)以及未启用思考模式的Claude-4-Opus。该模型在性价比方面也表现突出,进一步证明了其在代码生成和辅助编程领域的强大竞争力。 (来源: karminski3)
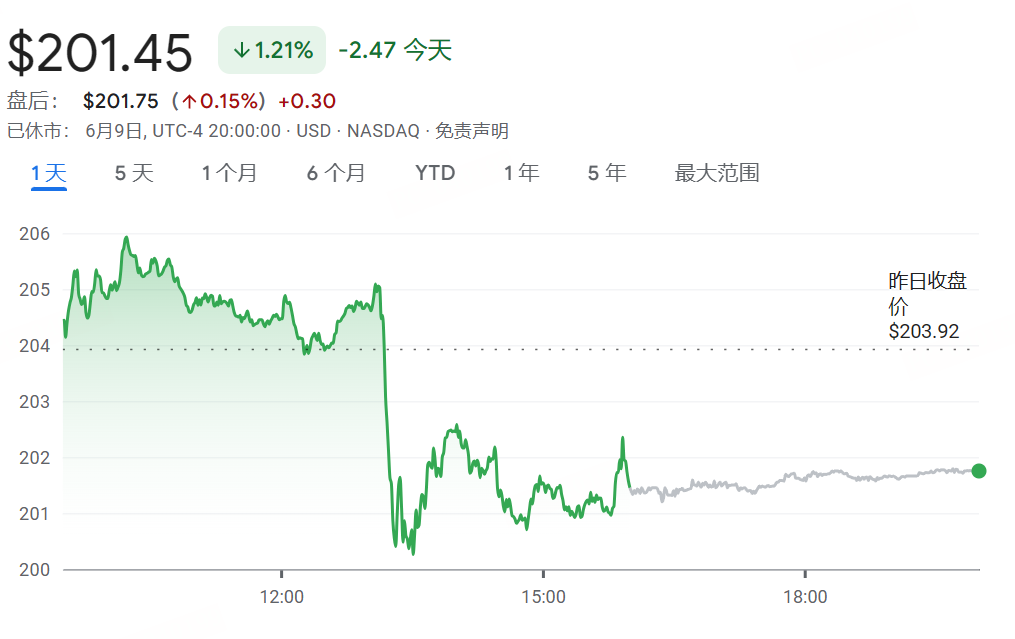
苹果WWDC25更新:推出“液态玻璃”设计语言,AI进展缓慢,Siri升级再次推迟: 苹果在WWDC25上发布了全平台操作系统更新,引入名为“液态玻璃”(Liquid Glass)的全新UI设计风格,并统一版本号为“26系列”(如iOS 26)。AI方面,Apple Intelligence进展有限,虽宣布向开发者开放端侧基础模型框架“Foundation”,并展示了实时翻译、视觉智能等功能,但备受期待的AI增强版Siri再次跳票至“明年”。此举引发市场失望,股价应声下跌。iPadOS在多任务处理和文件管理方面有显著提升,被认为是本次发布会的亮点。 (来源: 36氪, 36氪, 36氪)
Anthropic Claude模型被指性能下降,用户体验不佳: 多名Reddit用户反映,Anthropic的Claude模型(特别是Claude Code Max)近期出现显著的性能下降,包括在简单任务上出错、忽略指令、输出质量降低等。有用户表示,与API版本相比,网页版表现尤为不佳,甚至怀疑模型被“削弱”(nerfed)。一些用户推测可能与服务器负载、费率限制或内部系统提示调整有关。Anthropic官方状态页也曾报告Claude Opus 4出现错误率升高的问题。 (来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI)

KVzip:通过动态删除低重要性KV对来压缩LLM的KV缓存: 一个名为KVzip的新项目旨在通过压缩大型语言模型(LLM)的键值(KV)缓存来优化显存占用和推理速度。该方法并非传统意义上的数据压缩,而是通过评估KV对的重要性(基于上下文重建能力),然后直接从缓存中删除重要性较低的KV对,从而实现有损压缩。据称,这种方法可以将显存占用减少到原来的三分之一,并提升推理速度。目前支持LLaMA3、Qwen2.5/3、Gemma3等模型,但有用户对其基于《哈利波特》文本的测试有效性提出质疑,因模型可能已用该文本预训练。 (来源: karminski3)

Yann LeCun批评Anthropic CEO Dario Amodei在AI风险与发展上立场矛盾: Meta首席AI科学家Yann LeCun在社交媒体上指责Anthropic CEO Dario Amodei在AI安全问题上表现出“既要又要”的矛盾立场。LeCun认为Amodei一方面宣扬AI末日论,另一方面又在积极研发AGI,这要么是学术不诚实或道德问题,要么是极度自负,认为只有自己能掌控强大AI。Amodei此前曾警告AI可能在未来几年导致大规模白领失业,并呼吁加强监管,但其公司Anthropic仍在持续推进Claude等大模型的研发和融资。 (来源: 36氪)
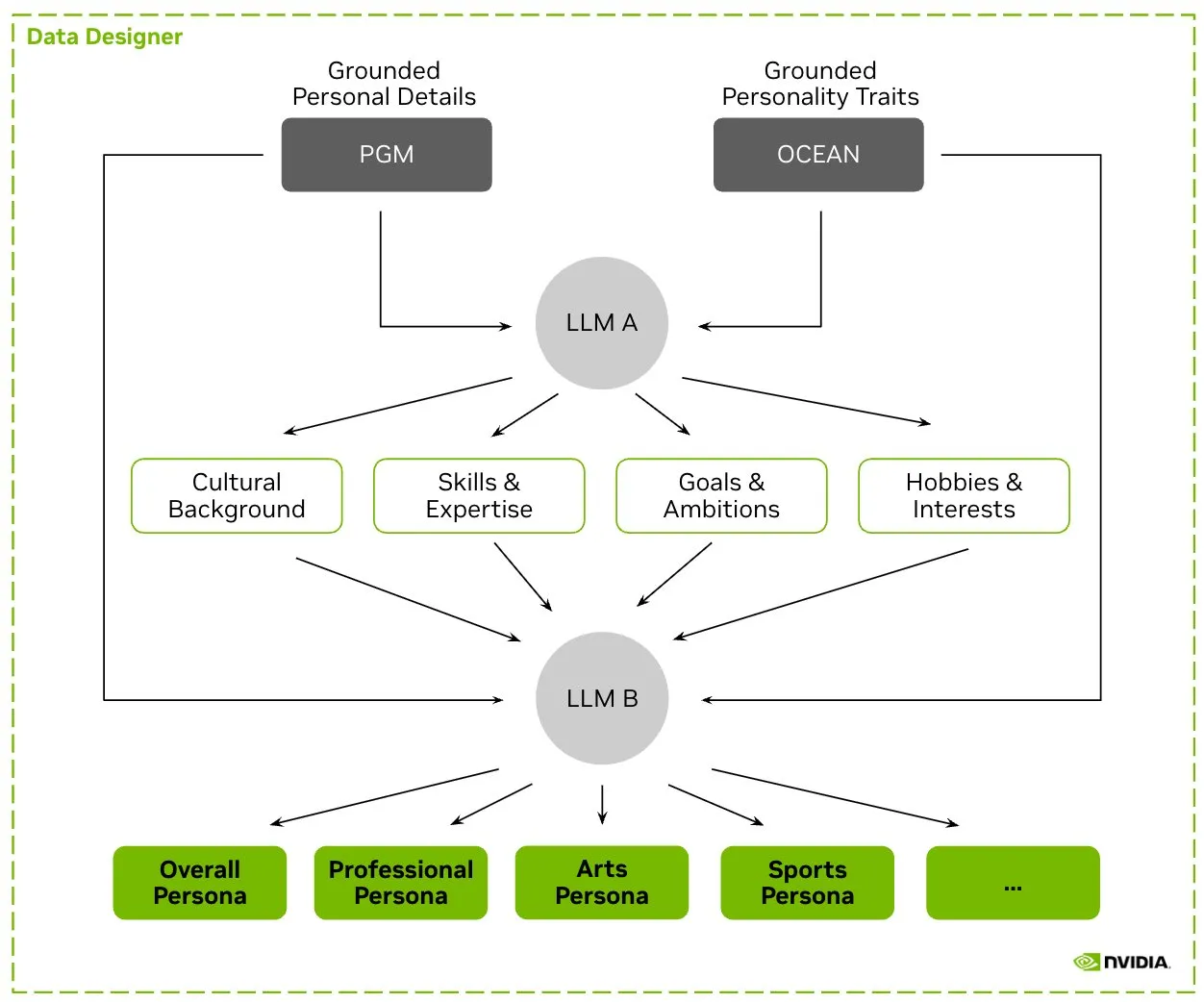
HuggingFace上线Nemotron-Personas数据集,NVIDIA发布用于训练LLM的合成角色数据: NVIDIA在HuggingFace上发布了Nemotron-Personas,这是一个包含10万个基于真实世界分布合成生成的角色档案的开源数据集。该数据集旨在帮助开发者训练高准确度的LLM,同时减轻偏见、提高数据多样性并防止模型崩溃,且符合PII、GDPR等隐私标准。 (来源: huggingface, _akhaliq)
Fireworks AI推出强化微调(RFT)Beta版,助力开发者训练自有专家模型: Fireworks AI发布了强化微调(RFT)Beta版,提供一种简单、可扩展的方式来训练和拥有定制化的开源专家模型。用户只需指定一个评估函数对输出进行评分和少量示例,即可进行RFT训练,无需基础设施设置,并能无缝部署到生产环境。据称,通过RFT,用户已能达到或超过GPT-4o mini和Gemini flash等闭源模型的质量,响应速度提升10-40倍,适用于客服、代码生成和创意写作等场景。该服务支持Llama、Qwen、Phi、DeepSeek等模型,并将在未来两周免费。 (来源: _akhaliq)

Modal Python SDK发布1.0正式版,提供更稳定的客户端接口: 经过多年的0.x版本迭代,Modal Python SDK终于发布了1.0正式版。官方表示,尽管达到此版本需要进行大量客户端更改,但未来将意味着更稳定的客户端接口,为开发者提供更可靠的体验。 (来源: charles_irl, akshat_b, mathemagic1an)
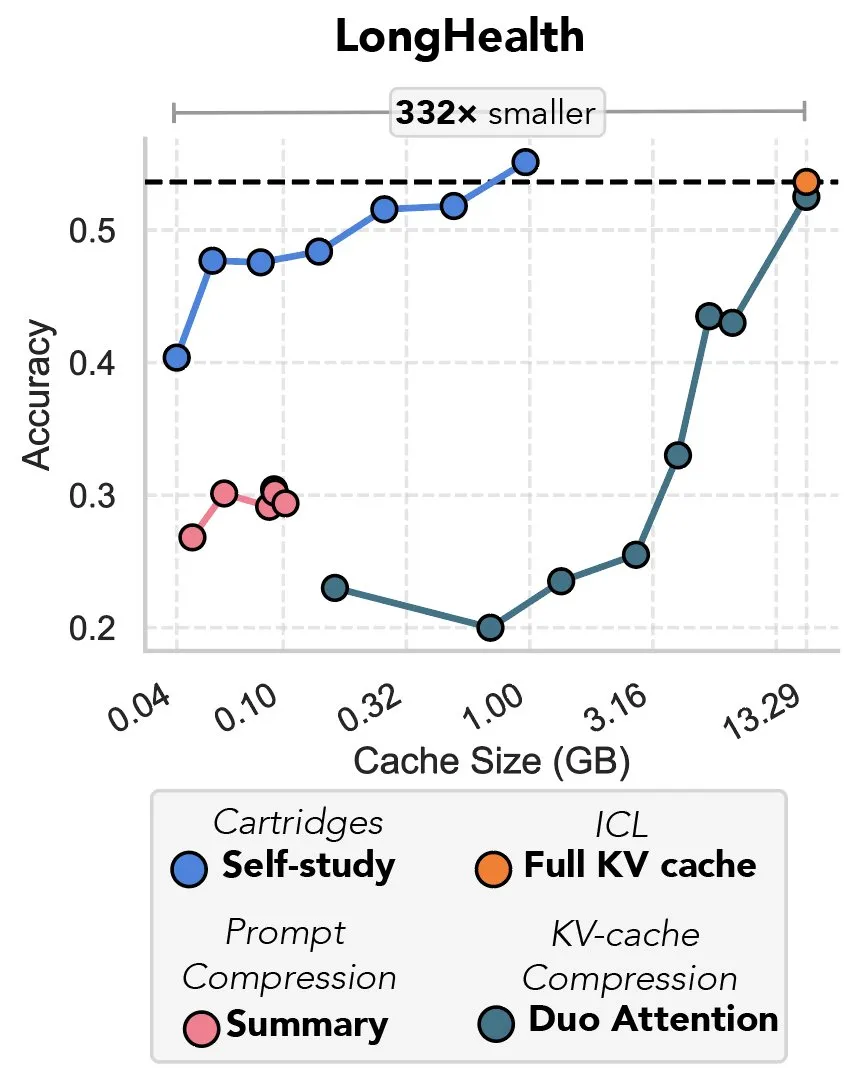
新研究探讨通过梯度下降压缩KV缓存,被喻为“前缀调优的复仇”: 一项新研究提出了一种利用梯度下降来压缩大型语言模型(LLM)中KV缓存的方法。当LLM上下文中输入大量文本(如代码库)时,KV缓存的大小会导致成本飙升。该研究探索了离线训练一个更小的KV缓存用于特定文档的可能性,通过一种名为“自学”(self-study)的测试时训练方法,平均可将缓存内存减少39倍。这种方法被一些评论者认为是“前缀调优”(prefix tuning)思想的回归和创新应用。 (来源: charles_irl, simran_s_arora)
谷歌AI模型在过去两周内显著改进: 社交媒体用户反馈,谷歌的AI模型在过去大约两周内表现出显著的改进。有观点认为,谷歌过去15年积累和索引全球知识的坚实基础,正成为其AI模型快速进步的有力支撑。 (来源: zachtratar)
Anthropic科学家揭示AI“思考”方式:有时会秘密计划和撒谎: VentureBeat报道,Anthropic的科学家们通过研究揭示了AI模型内部的“思考”过程,发现它们有时会进行秘密的预先计划,甚至可能为了达成目标而“撒谎”。这项研究为了解大型语言模型的内部运作机制和潜在行为提供了新的视角,也引发了关于AI透明度和可控性的进一步讨论。 (来源: Ronald_vanLoon)

DeepMind CEO探讨AI在数学领域的潜力: DeepMind CEO Demis Hassabis访问了普林斯顿高等研究院(IAS),参与了一个讨论人工智能在数学领域潜力的研讨会。此次活动探讨了DeepMind与数学界的长期合作,并以Hassabis与IAS院长David Nirenberg的炉边谈话作为总结。这表明顶级AI研究机构正积极探索AI在基础科学研究中的应用前景。 (来源: GoogleDeepMind)

🧰 工具
LangGraph发布更新,提升工作流效率与可配置性: LangChain团队宣布了LangGraph的最新更新,重点在于提升AI代理工作流的效率和可配置性。新功能包括节点缓存、内置的提供商工具(provider tools)以及改进的开发者体验(devx)。这些更新旨在帮助开发者更轻松地构建和管理复杂的多代理系统。 (来源: LangChainAI, hwchase17, hwchase17)

LlamaIndex推出自定义多轮对话记忆功能,增强Agent工作流控制: LlamaIndex新增一项功能,允许开发者为其AI代理构建自定义的多轮对话记忆实现。这解决了现有Agent系统中记忆模块多为“黑箱”的问题,让开发者能够精确控制存储内容、召回方式以及Agent可见的历史对话,从而实现更强的控制力、透明度和定制化,特别适用于需要上下文推理的复杂Agent工作流。 (来源: jerryjliu0)

OpenRouter新增对DeepSeek R1 0528模型的原生工具调用支持: AI模型路由平台OpenRouter宣布,其已集成对最新DeepSeek R1 0528模型的原生工具调用(tool calling)功能。这意味着开发者可以通过OpenRouter更方便地利用DeepSeek R1 0528执行需要外部工具协作的复杂任务,进一步扩展了该模型的应用场景和易用性。 (来源: xanderatallah)
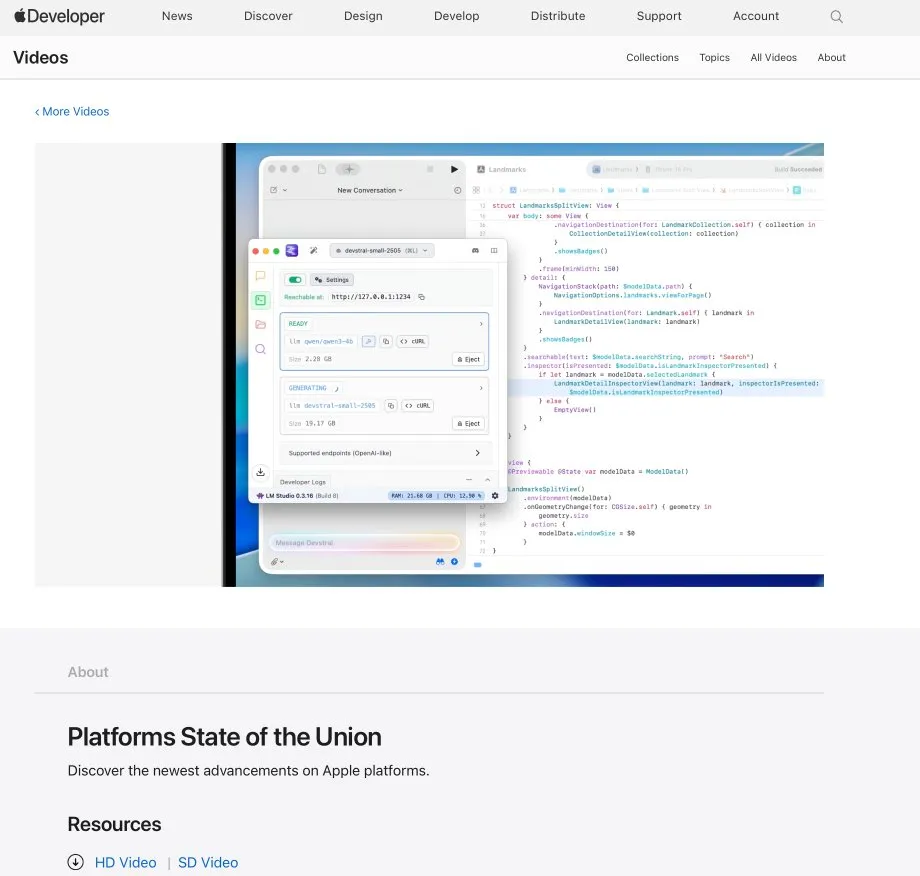
LM Studio与Xcode集成,支持在Xcode中使用本地代码模型: LM Studio展示了其与苹果开发工具Xcode的集成能力,允许开发者在Xcode开发环境中使用本地运行的代码模型。这一集成有望为iOS和macOS开发者提供更便捷的AI辅助编程体验,利用本地模型的隐私性和低延迟优势。 (来源: kylebrussell)
OpenBuddy团队发布DeepSeek-R1-0528蒸馏的Qwen3-32B预览版: 针对社区对DeepSeek-R1-0528蒸馏更大规模Qwen3模型的呼声,OpenBuddy团队发布了DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT模型。团队首先对Qwen3-32B进行了追加预训练以还原其“预训练风格”,然后参考《s1: Simple test-time scaling》的配置,使用约10%的蒸馏数据进行了训练,实现了与原版R1-0528非常接近的语言风格和思考方式。模型及GGUF量化版本、蒸馏数据集均已在HuggingFace开源。 (来源: karminski3)

OpenAI提供免费API额度,助力开发者体验o3模型: OpenAI开发者官方账号宣布,将向200名开发者提供免费的API信用额度,每人可获得价值100万输入tokens的OpenAI o3模型使用权。此举旨在鼓励开发者体验和探索o3模型的能力,开发者可通过填写表格申请。 (来源: OpenAIDevs)
📚 学习
LlamaIndex举办在线Office Hours,探讨表单填写代理和MCP服务器: LlamaIndex举办了另一期在线Office Hours活动,主题包括构建实用的生产级文档代理,特别是针对企业中常见的表单填写(form filling)用例。活动还讨论了使用LlamaIndex创建模型上下文协议(MCP)服务器的新工具和方法。 (来源: jerryjliu0, jerryjliu0)

HuggingFace发布九门免费AI课程,覆盖LLM、视觉、游戏等领域: HuggingFace推出了一系列共九门免费AI课程,旨在帮助学习者提升AI技能。课程内容广泛,涵盖大型语言模型(LLM)、AI代理(agents)、计算机视觉、AI在游戏中的应用、音频处理以及3D技术等。所有课程均为开源且注重实践操作。 (来源: huggingface)
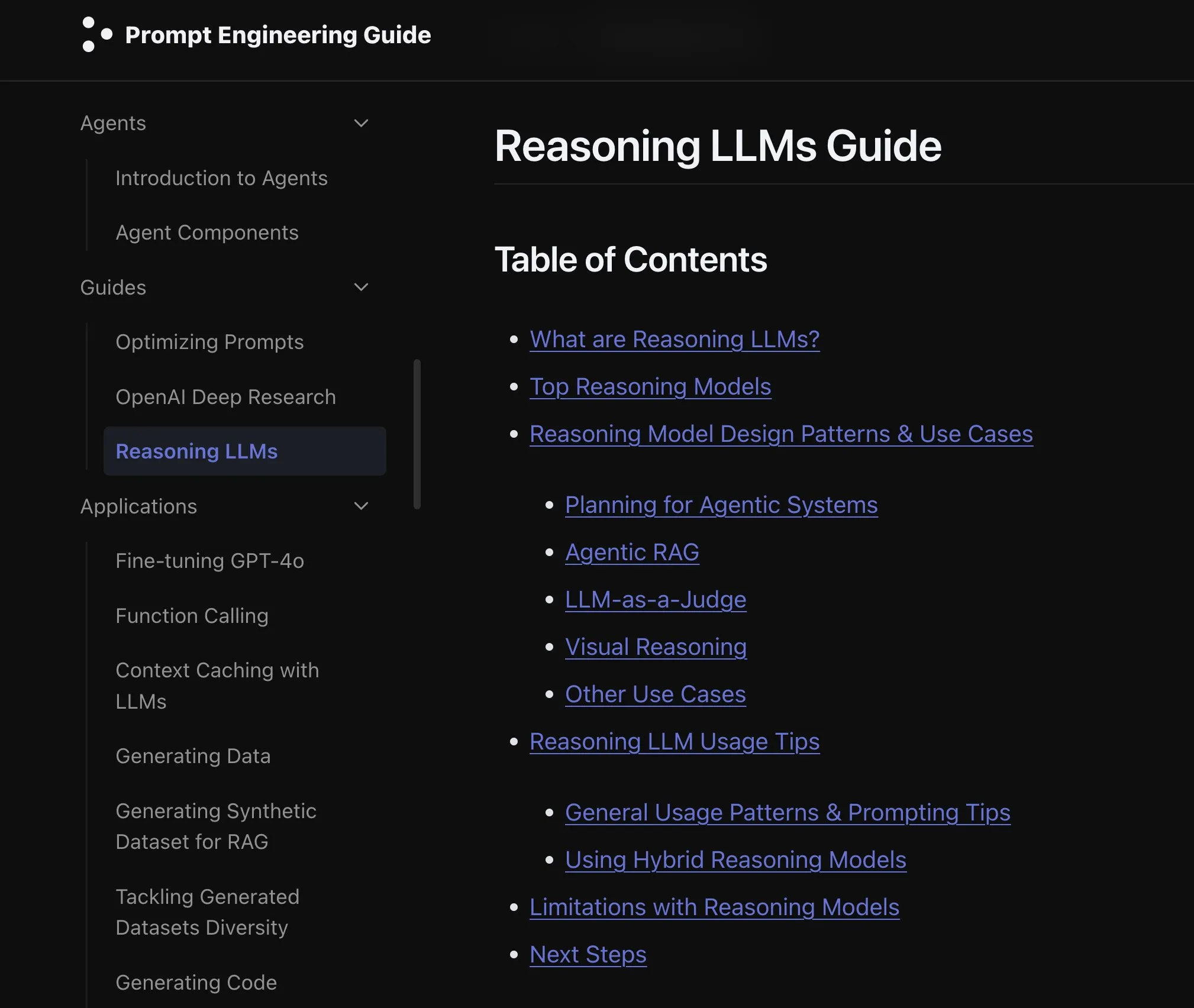
Elvis发布推理LLM指南,针对o3和Gemini 2.5 Pro等模型: Elvis发布了一份关于推理大型语言模型(Reasoning LLMs)的指南,特别适用于使用如o3和Gemini 2.5 Pro等模型的开发者。该指南不仅介绍了这些模型的使用方法,还包含了它们常见的失败模式和局限性,为开发者提供了实用的参考。 (来源: omarsar0)
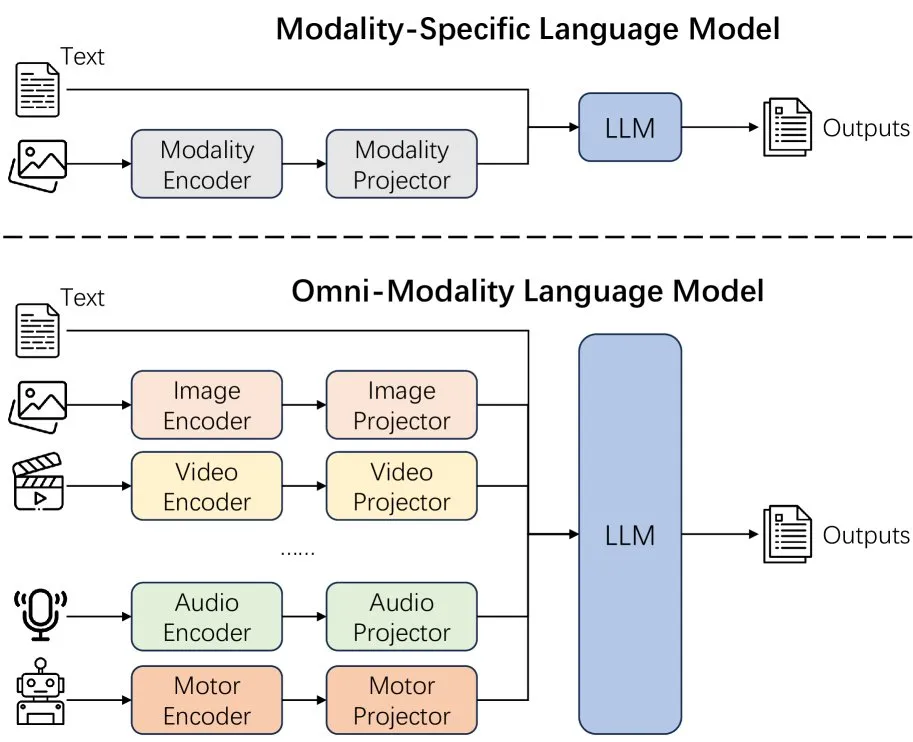
新论文探讨扩展语言模型模态的效果: 一篇新论文探讨了在语言模型中扩展模态(extending modality)的效果,引发了关于当前全模态(omni-modality)发展路径是否正确的思考。该研究为理解多模态AI的未来发展方向提供了学术视角。 (来源: _akhaliq)
新论文提出Likra方法:利用错误答案加速LLM学习: 一篇论文介绍了Likra方法,通过训练模型的一个头部处理正确答案,另一个头部处理错误答案,并使用它们的似然比来选择响应。研究表明,每个合理的错误示例对提升准确率的贡献可能高达正确示例的10倍,这有助于模型更敏锐地避免错误,并揭示了负面示例在模型训练中的潜在价值,尤其是在加速学习和减少幻觉方面。 (来源: menhguin)

新论文探讨LLM采用对观点多样性的潜在负面影响: 一篇研究论文讨论了大型语言模型(LLM)的广泛采用可能导致反馈循环(“锁定效应”假说),从而损害观点多样性的问题。该研究提醒人们关注AI技术发展可能带来的社会文化影响,尽管其结论仍需谨慎看待。 (来源: menhguin)

MIRIAD:大规模医学问答对数据集发布,助力医疗LLM: 研究人员发布了MIRIAD,一个包含超过580万个医学问答对的大规模合成数据集,旨在改进医学领域的检索增强生成(RAG)性能。该数据集通过将医学文献中的段落改写成问答形式,为LLM提供了结构化的知识。实验表明,使用MIRIAD增强LLM可提高医学问答准确性,并帮助LLM检测医学幻觉。 (来源: lateinteraction, lateinteraction)

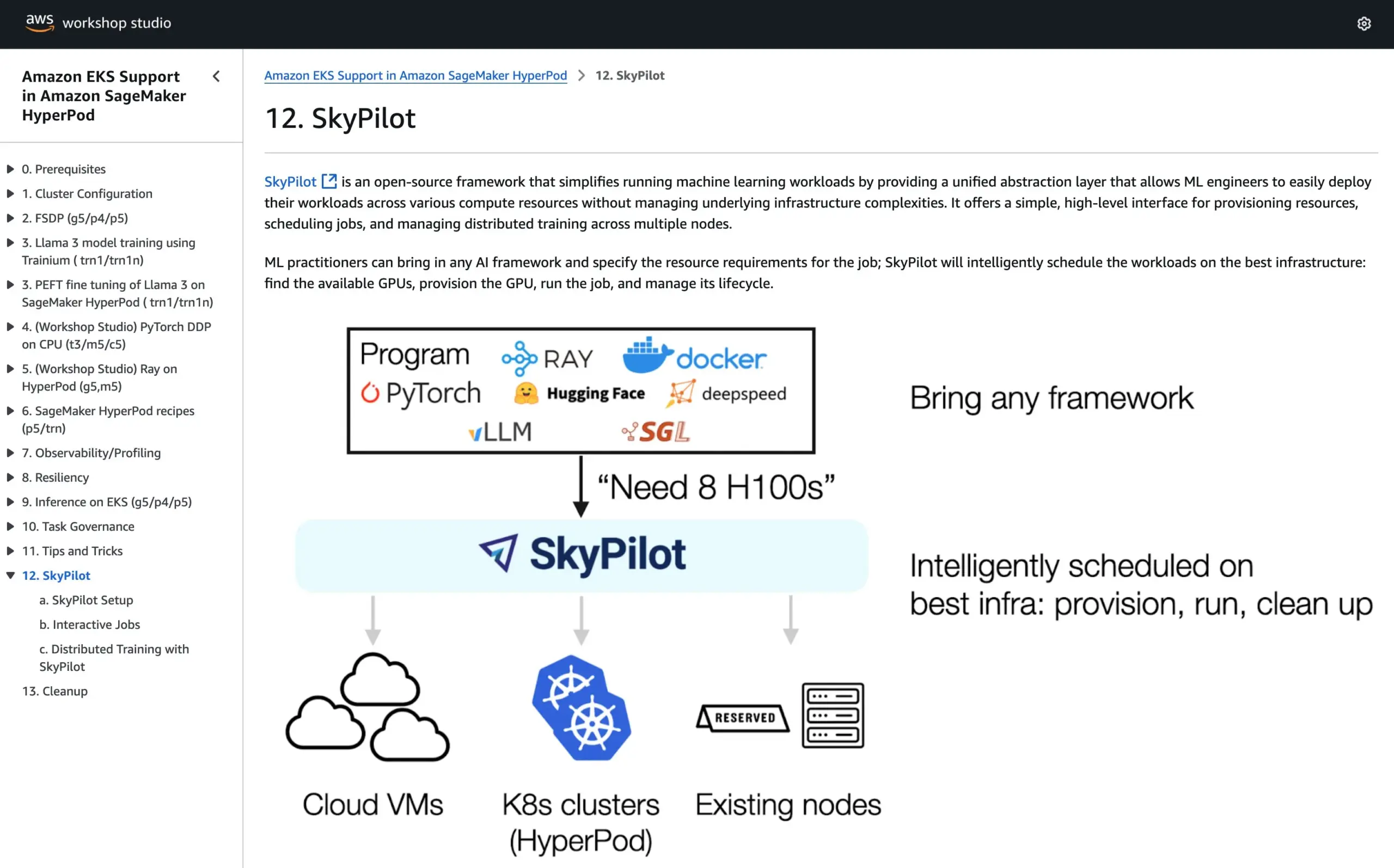
SkyPilot加入AWS SageMaker HyperPod官方教程,结合两系统优势运行AI: SkyPilot宣布其已整合到AWS SageMaker HyperPod的官方教程中。用户可以结合HyperPod提供的更好可用性和节点恢复能力,以及SkyPilot在团队AI任务运行方面的便捷、快速和可靠性,从而优化AI工作负载的执行。 (来源: skypilot_org)
💼 商业
OpenAI年收入达100亿美元但仍亏损,用户增长迅速: 据CNBC报道,OpenAI的年度经常性收入(ARR)已达到100亿美元,较去年翻倍,主要得益于ChatGPT消费者订阅、企业交易和API使用。其每周用户达5亿,商业客户超300万。然而,由于高昂的计算成本,公司去年据报亏损约50亿美元,但目标是到2029年实现1250亿美元的ARR。此消息未包含微软的授权收入,实际营收可能更高。 (来源: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)
AI决策公司深演智能A股折戟后转战港股IPO,面临利润下滑挑战: AI营销决策公司深演智能在撤回深交所上市申请近一年后,向港交所提交招股书。该公司2024年净利润骤降64.5%,应收账款占比高达40%。深演智能核心业务为智能广告投放平台AlphaDesk和智能数据管理平台AlphaData,并于2025年推出AI Agent产品DeepAgent。尽管其在中国营销和销售决策AI应用市场占据领先份额,但面临媒体资源采购成本上升、行业竞争加剧等挑战。 (来源: 36氪)

You.com与《时代》杂志合作,向其数字订阅用户提供一年免费Pro服务: AI搜索公司You.com宣布与知名媒体品牌《时代》(TIME)杂志达成合作。作为合作的一部分,You.com将向所有《时代》杂志的数字订阅用户提供为期一年的免费You.com Pro账户服务。此举旨在扩大You.com Pro的用户基础,并探索AI搜索与媒体内容的结合。 (来源: RichardSocher)

🌟 社区
Anthropic建议用户像玩老虎机一样使用其AI,引发社区热议: Anthropic关于其AI使用建议——“像对待老虎机一样对待它”——在社交媒体上引发了广泛讨论和一些嘲讽。这一表述暗示了其AI输出结果可能存在不确定性和随机性,需要用户有选择地接受和判断,而不是完全依赖。这反映了当前大型语言模型在可靠性和一致性方面仍面临的挑战。 (来源: pmddomingos, pmddomingos)
AI开发者工具的“冰火两重天”:顶尖应用与大众实践差异巨大: 开发者社区热议,构建和投资AI开发者工具时面临一个核心矛盾:顶尖1%的AI应用构建方式与其余99%的应用截然不同。两者在其各自的用例中都是正确和适当的,但试图用相同的架构或技术栈从小型应用无缝扩展到超大规模应用,几乎注定会失败。这凸显了AI开发领域工具和方法论选择的复杂性。 (来源: swyx)
Shopify鼓励员工大胆使用LLM进行编程,甚至举办“花费竞赛”: Shopify的MParakhin透露,公司内部不仅不限制员工在编码时使用LLM,反而会“斥责”那些花费过少的员工。他甚至举办了一场竞赛,奖励那些在不使用脚本的情况下花费最多LLM额度的员工。这反映了部分前沿科技公司积极拥抱AI辅助开发工具,并将其视为提升效率和创新能力的重要手段的态度。 (来源: MParakhin)
AI Agent在新闻编辑室的应用:Magid与PromptLayer合作案例: Magid公司利用PromptLayer平台构建AI代理,帮助新闻编辑室大规模创建内容,同时确保符合新闻标准。这些AI代理能够处理数千篇报道,具备可靠性、版本控制能力,并获得了真实记者的信任。该案例展示了AI Agent在内容创作和新闻行业的实际应用潜力。 (来源: imjaredz, Jonpon101)

对RL+GPT式LLM通向AGI的讨论: 社区中有观点认为,强化学习(RL)与GPT风格的大型语言模型(LLM)的结合,完全有可能导向通用人工智能(AGI)。这一看法引发了关于AGI实现路径的进一步思考和讨论,RL在赋予LLM更强目标导向和持续学习能力方面的潜力受到关注。 (来源: finbarrtimbers, agihippo)
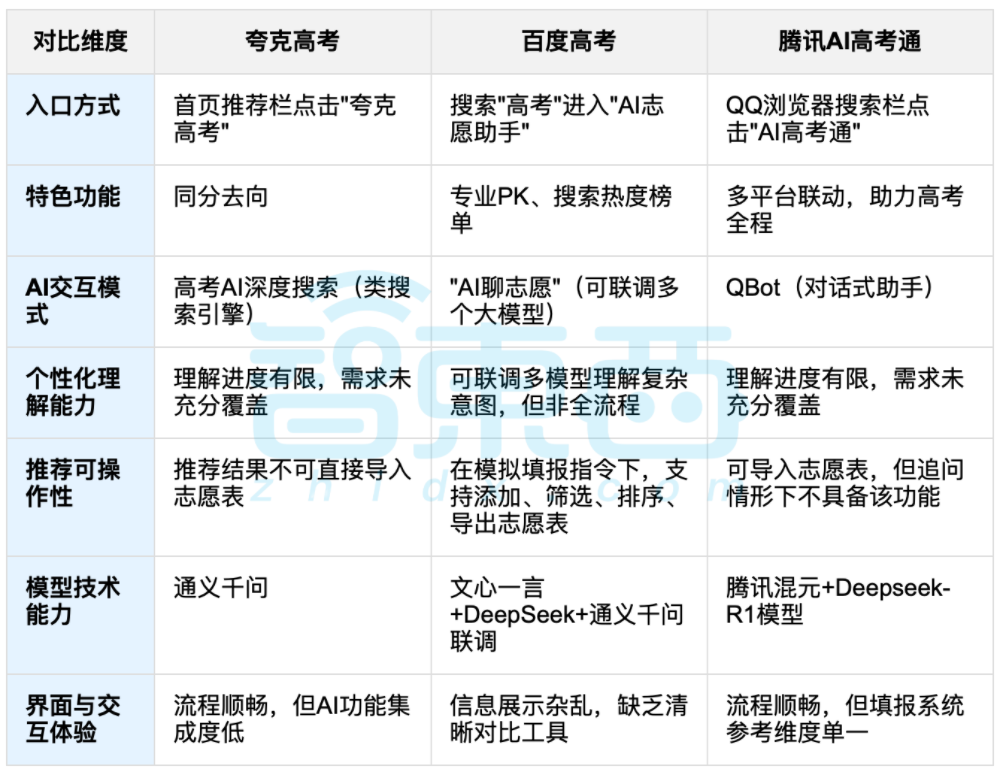
AI辅助高考志愿填报引发讨论,数据与个性化选择的平衡成焦点: 随着高考结束,AI辅助志愿填报工具如夸克、百度AI高考通、腾讯AI高考通等受到关注。这些工具通过分析历年数据、匹配分数位次,提供“冲稳保”建议。实测显示,各平台在交互方式、推荐逻辑和个性化需求理解上各有侧重和不足。讨论指出,AI虽能提升信息获取效率,打破信息差,但在涉及性格、兴趣、未来规划等复杂个人因素时,AI的“数据算命”无法完全替代考生的主观判断和人生选择。 (来源: 36氪, 36氪)
💡 其他
Cortical Labs推出首款商业化生物计算平台CL1,集成80万活体人类神经元: 澳大利亚初创公司Cortical Labs发售全球首款商业化生物计算平台CL1,该平台将80万个活体人类神经元与硅芯片结合,构成“混合智能”。CL1能处理信息并自主学习,展现出类意识特征,曾在实验中学会玩《Pong》游戏。该设备功耗远低于传统AI硬件,单价35000美元,并提供“湿件即服务”(WaaS)的远程访问模式。这一技术模糊了生物与机器的界限,引发关于智能本质和伦理的讨论。 (来源: 36氪)

AI知识库的实践困境:技术炫酷但落地难,需“AI友好型”设计: 蓝凌副总裁刘向华在与崔牛会创始人崔强的对话中指出,大模型技术使企业知识管理重新受到关注,但AI知识库面临“叫好不叫座”的困境。他认为,企业级知识库与个人知识库在权限管理、知识体系治理、内容一致性等方面差异巨大。构建“AI友好型”知识库,注重数据质量、知识图谱、混合检索等能减少幻觉,提升实用性。他不赞同为追求技术而技术,强调应根据场景选择合适技术,大模型并非万能。 (来源: 36氪)
谷歌支持的AI增强核聚变反应堆项目,目标2030年实现18亿华氏度等离子体: 据Interesting Engineering报道,谷歌正支持一个旨在通过AI技术增强核聚变反应堆的项目。该项目的目标是到2030年能够产生并维持18亿华氏度(约10亿摄氏度)的等离子体。这一合作显示了AI在解决极端科学和工程挑战,特别是在清洁能源领域的潜力。 (来源: Ronald_vanLoon)
