关键词:悟界系列大模型, RLHF新方法, Claude Gov系列模型, 大型语言模型, 多模态融合, 物理AGI, AI安全, 具身智能, Emu3原生多模态世界模型, 见微Brainμ脑科学模型, RoboBrain 2.0具身大脑, OpenComplex2全原子微观生命模型, 分叉token强化学习
🔥 聚焦
智源大会发布“悟界”系列大模型,聚焦物理AGI与多模态融合: 2025年智源大会上,智源研究院发布了全新的“悟界”系列大模型,标志着其研究方向从“悟道”的语言模型探索转向更广阔的物理世界与多模态融合。该系列包括原生多模态世界模型Emu3、全球首个脑科学多模态通用基础模型“见微Brainμ”、具身大脑RoboBrain 2.0以及全原子微观生命模型OpenComplex2。这一系列模型的发布,体现了AI从数字世界向物理世界、从宏观理解到微观探索的演进趋势,旨在让AI能感知、理解并与物理世界交互,解决实际问题,推动物理AGI的发展。大会还汇聚了包括Bengio在内的4位图灵奖得主及众多产业领袖,共同探讨AI安全、强化学习、智能体、具身智能等前沿议题 (来源: 量子位)

Qwen与清华LeapLab提出“超越二八法则”的RLHF新方法: Qwen团队与清华大学LeapLab合作的研究发现,在通过强化学习(RLHF)提升大模型推理能力时,仅需关注约20%的高熵“分叉token”(forking tokens),即可达到甚至超越使用全部token进行训练的效果。这些高熵token主要承担逻辑连接功能,在推理过程中起关键导向作用。基于此发现,Qwen3-32B在AIME’24和AIME’25数学竞赛基准上取得了600B参数以下模型从头训练的SOTA成绩。该研究不仅提升了训练效率,还揭示了高熵token对模型泛化能力的重要性,并为理解RL与SFT的区别以及LLM RL的特殊性提供了新视角 (来源: 量子位)

Anthropic推出Claude Gov系列模型,专供美国国家安全客户: Anthropic公司发布了专为美国国家安全客户定制的Claude Gov系列模型。这些模型已经在美国最高级别的国家安全机构中部署,其访问权限严格限制在处理机密信息的操作人员。此举引发了关于AI伦理和潜在滥用风险的讨论,特别是考虑到Anthropic此前研究中曾记录模型表现出“求生行为”和“灾难性滥用”风险。尽管Anthropic声称其为AI安全研究公司,旨在通过测试发现并修补漏洞,但将其技术应用于军事和国家安全领域,无疑加剧了公众对AI武器化和失控风险的担忧 (来源: AnthropicAI, Reddit r/ArtificialInteligence)

Yann LeCun预言当前大型语言模型五年内将被淘汰: NYU教授、Meta首席AI科学家Yann LeCun在《新闻周刊》的采访中表示,当前的大型语言模型(LLM)将在五年内变得过时。他认为,现有的AI系统缺乏对真实世界的理解能力,这是其根本局限。LeCun展望了未来更智能的AI系统形态,暗示了超越现有LLM架构的新一代AI技术的发展方向,可能更侧重于对世界的内在表征和因果推理能力 (来源: ylecun)
🎯 动向
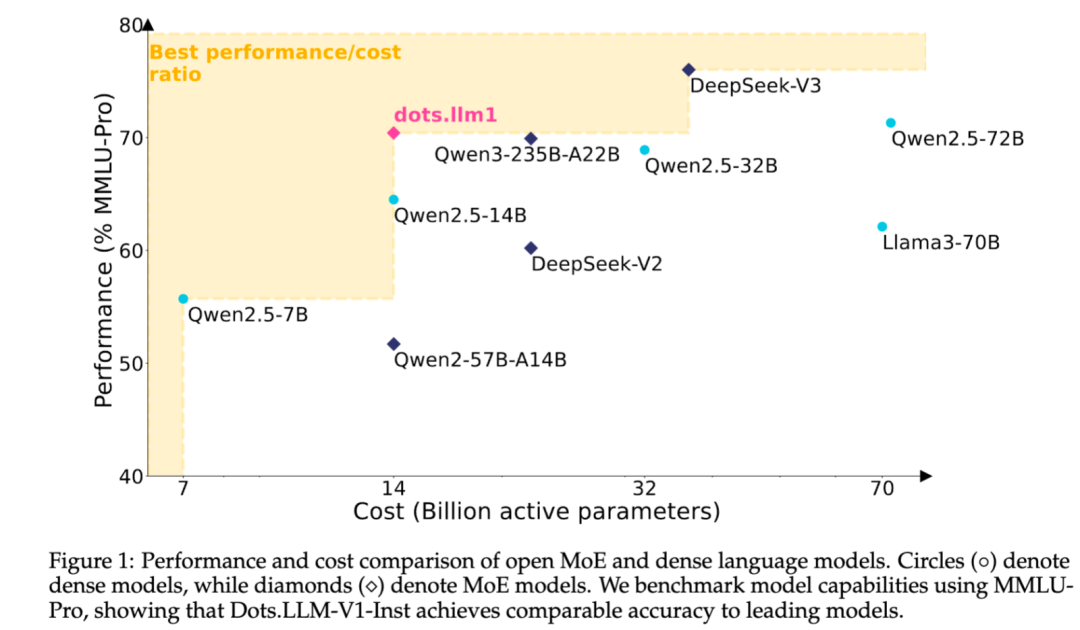
小红书开源自研MoE文本大模型dots.llm1: 小红书hi lab团队开源了其首个自研文本大模型dots.llm1,该模型采用MoE架构,总参数量142B,激活参数14B。在激活14B参数的情况下,模型在中英文通用场景、数学、代码及对齐任务上表现优异,可与Qwen2.5-32B/72B-Instruct等模型竞争。小红书此次开源力度较大,不仅提供了即用型dots.llm1.inst模型,还开源了多个预训练阶段的checkpoint及长文base模型,并详细介绍了训练细节,便于社区进行二次开发和研究。该模型未使用合成语料,强调高质量真实数据的应用 (来源: 36氪)
Anthropic Claude模型功能持续升级,拓展上下文处理与集成能力: Anthropic近期为其Claude系列模型推出了多项重要更新。Projects on Claude现在支持处理10倍以上的内容,当文件超出阈值时会切换到新的检索模式以扩展功能性上下文。同时,Pro计划用户现在可以使用Research和Integrations功能,允许Claude搜索网页、Google Workspace以及通过MCP(Model Control Protocol)连接的任何自定义应用或预构建服务(如Zapier和Asana),实现跨工具操作,如创建任务、更新文档和触发工作流。这些更新旨在提升Claude在复杂任务处理和多源信息整合方面的能力 (来源: AnthropicAI, AnthropicAI)
Hugging Face推出MCP服务器,强化AI智能体生态: Hugging Face发布了其首个MCP(Model Control Protocol)服务器 (hf.co/mcp),允许AI智能体更有效地访问和利用Hugging Face平台上的模型、数据集乃至Space中托管的应用。这一举措被视为推动互联网向智能体友好型演进的重要一步,旨在构建一个AI智能体的“应用商店”生态。MCP服务器的推出,使得开发者可以更便捷地让AI智能体与Hugging Face的海量资源进行交互,促进了AI智能体应用的发展和创新 (来源: TheTuringPost, karminski3)
OpenAI更新ChatGPT语音模型,提升自然度和翻译能力: OpenAI对ChatGPT的Advanced Voice功能进行了升级,使其对话体验更加自然流畅。该更新已向所有付费用户开放。同时,ChatGPT在语言翻译方面的能力也得到了增强,用户可以直接指令其在不同语言间进行实时翻译。这些改进旨在提升用户与ChatGPT进行语音交互的便捷性和实用性 (来源: kevinweil, shuchaobi)
PyTorch集成Safetensors,提升分布式Checkpoint安全与便捷性: PyTorch宣布其分布式Checkpoint功能现已支持Hugging Face的Safetensors格式。这一集成使得在不同生态系统间保存和加载模型Checkpoint更加安全和便捷,特别是解决了以往pickle格式存在的安全风险。新的API允许通过fsspec路径读写Safetensors,torchtune成为首个采用该功能的库,优化了其Checkpoint流程。此举被认为是过去一年中AI安全领域的重要进展之一,有助于提升模型共享和部署的安全性 (来源: ClementDelangue, huggingface)

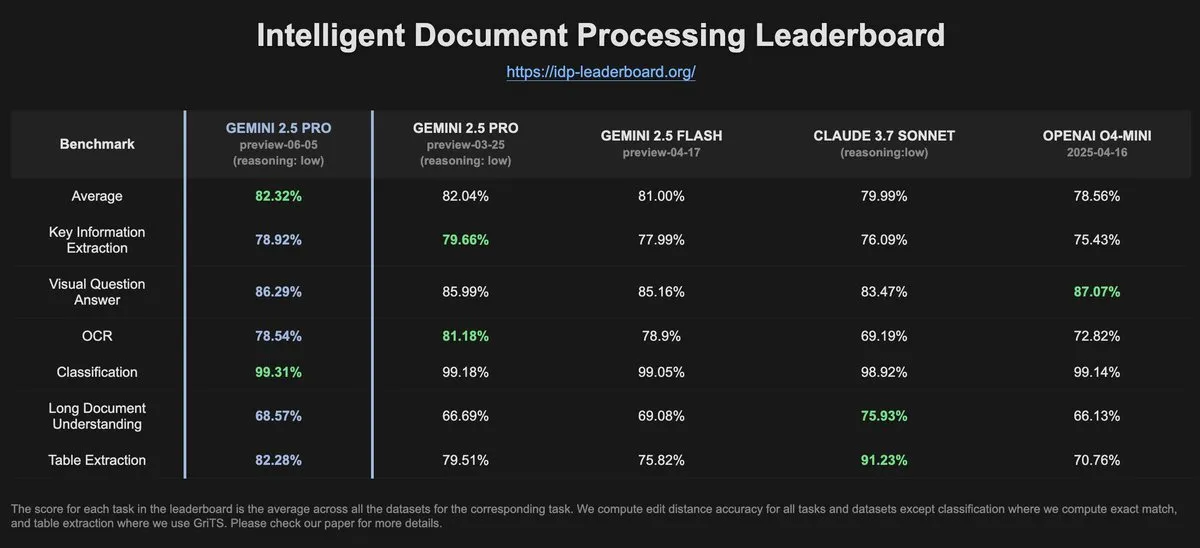
IDP-Leaderboard数据显示Gemini-2.5-pro-06-05在OCR性能上较前版有所下降: 根据IDP-Leaderboard的最新数据,新版Gemini-2.5-pro-06-05在OCR(光学字符识别)性能方面相较于03-25版本有所下降。尽管如此,该模型在文档处理综合能力方面(包括文档、电子表格识别等)仍然表现最强。IDP-Leaderboard是一个专注于评估大模型在文档智能处理领域能力的基准测试 (来源: karminski3)
苹果研究揭示LLM推理局限性,或非真正“思考”: 苹果公司研究人员发表论文探讨了当前LLM在推理任务上的优势与局限,指出这些模型在处理超过一定复杂度的任务时性能会“崩溃”。研究暗示,LLM的“推理”更多是基于模式匹配和记忆,而非人类意义上的真正思考和理解。这一观点与Yann LeCun等专家的看法相呼应,引发了关于AGI实现路径及当前模型能力边界的讨论 (来源: omarsar0, NandoDF)

DeepSeek R1在Dwarf Fortress游戏中展现出色的文本理解与创意解读能力: 用户实验显示,DeepSeek R1模型在处理复杂文本密集型游戏《Dwarf Fortress》的数据时,表现出强大的文本理解和创意解读能力。通过提取游戏截图中的文本数据并输入DeepSeek R1,模型不仅能解析数据,还能识别出矮人行为的有趣怪癖和模式,并以生动有趣的语言进行描述,显示了其在非结构化文本理解和生成方面的潜力 (来源: Reddit r/LocalLLaMA)

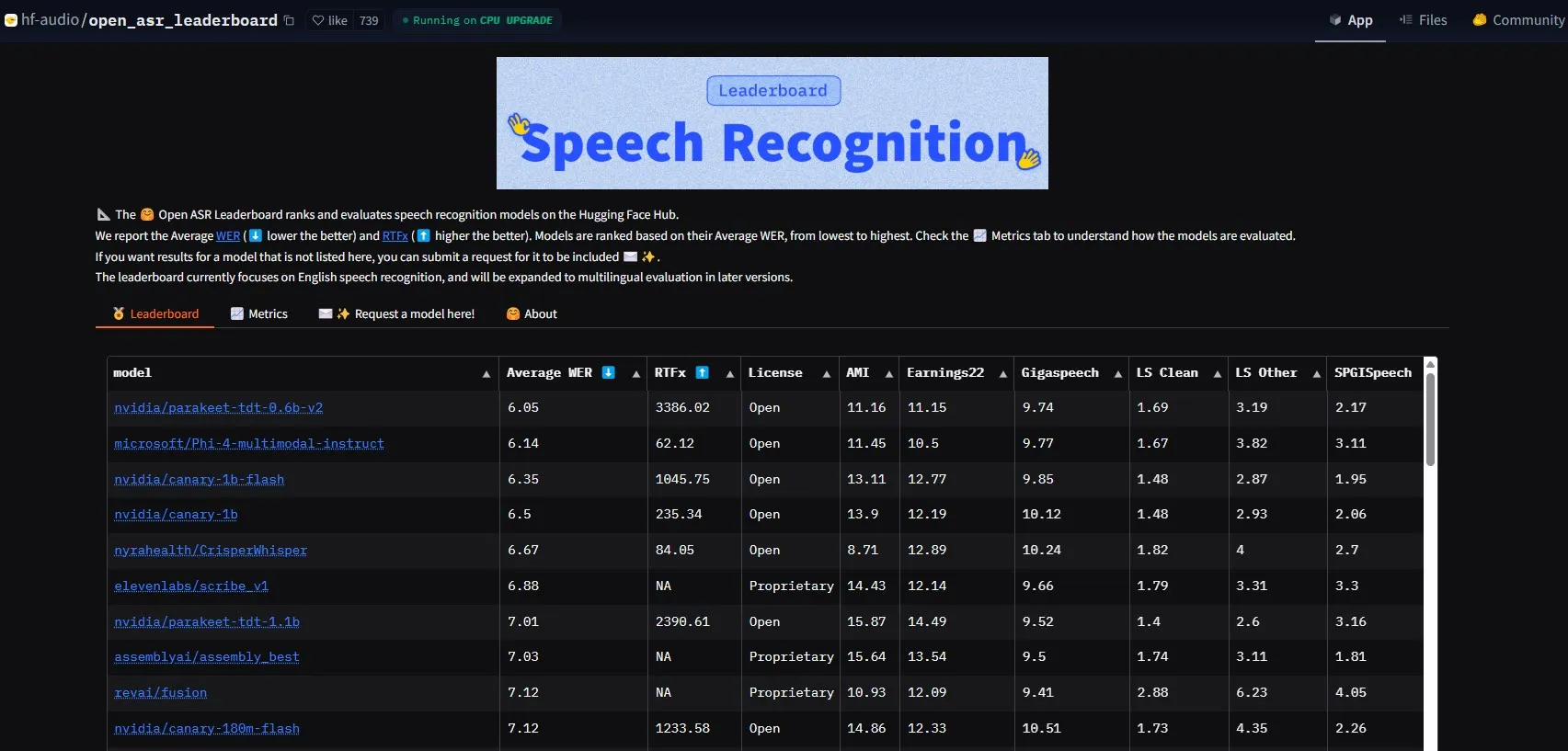
NVIDIA发布Parakeet-tdt-0.6b-v2模型,刷新ASR性能标杆: NVIDIA推出的新款自动语音识别(ASR)模型Parakeet-tdt-0.6b-v2,在HuggingFace Open-ASR-Leaderboard上以6.05%的词错误率(WER)创下业界新纪录。该模型不仅在准确性上领先,还具备极快的推理速度(RTFx 3386,比替代方案快50倍),并支持歌词转录、精确时间戳/数字格式化等创新功能 (来源: huggingface)
阿里巴巴Qwen团队发布Qwen3-Embedding系列模型: 阿里巴巴Qwen团队推出了新的Qwen3-Embedding系列模型,包括0.6B、4B、8B三种不同大小。这些模型在MMTEB、MTEB和MTEB-Code等多个文本嵌入基准测试中取得了SOTA(State-of-the-Art)性能,支持119种语言,并且可以通过Transformers.js在浏览器内运行(支持WebGPU加速),为多语言和跨平台应用提供了强大的文本表示能力 (来源: huggingface)
Gemini 2.5 Pro展现强大代码生成与任务处理能力: GoogleDeepMind的Gemini 2.5 Pro (preview-06-05版本) 在处理复杂任务时展现了强大的能力。例如,用户Majid Manzarpour尝试让其编写脚本来组织和分类一个包含超过25000个声音文件的库,Jeff Dean评论称这“听起来不太难”,暗示了模型处理此类大规模、复杂编程任务的潜力。此外,GosuCoder的测试图表显示,Gemini 2.5 Pro 06-05更新版本在AI编码辅助方面表现更佳,尤其在temperature设置为0.7时评估得分最高 (来源: JeffDean, jeremyphoward)
Hugging Face与Google Colab深化集成,简化AI工作流程: Hugging Face与Google Colab宣布加强合作,在Hugging Face Hub上的所有模型卡片中添加“Open in Colab”支持。用户现在可以直接从任何模型卡片启动Colab笔记本,从而更便捷地实验和使用Hugging Face上的模型,进一步降低了AI开发和研究的门槛 (来源: huggingface)
🧰 工具
LlamaBot:基于LangGraph的AI编码助手: LangChainAI介绍了LlamaBot,这是一个由LangGraph驱动的AI智能体,能够通过自然语言聊天创建Web应用程序。其特点包括实时代码生成、实时预览以及为不同开发任务设计的专门化智能体,旨在简化Web应用的开发流程 (来源: LangChainAI, hwchase17)
Fast RAG系统:结合DeepSeek-R1与Qdrant实现高效文档处理: LangChainAI展示了一种高性能RAG(Retrieval Augmented Generation)实现方案。该方案结合了SambaNova的DeepSeek-R1模型、Qdrant的二元量化技术以及LangGraph,实现了32倍的内存缩减,从而能够高效处理大规模文档,为信息检索和内容生成提供了新的优化路径 (来源: LangChainAI, hwchase17)

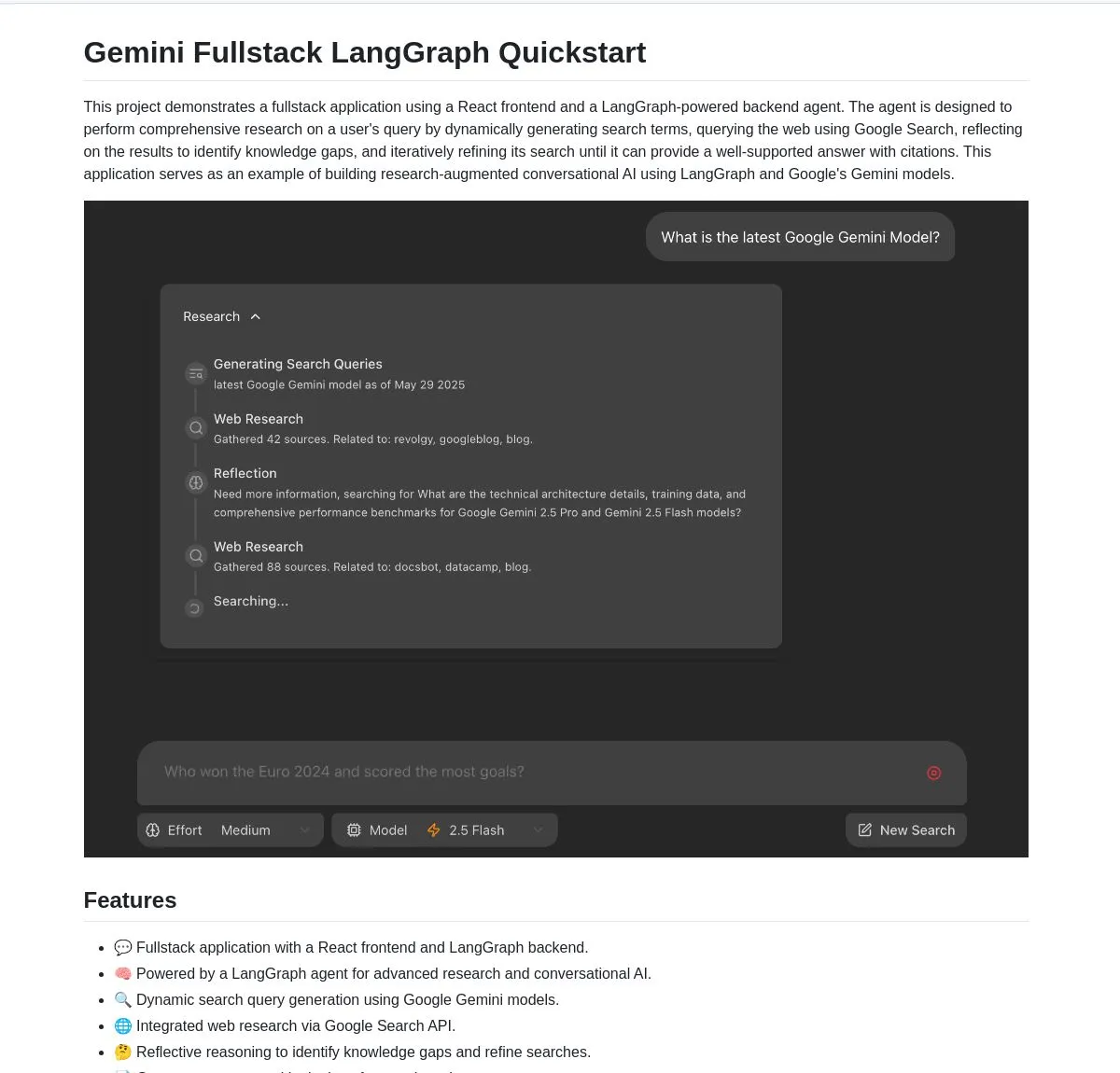
Gemini Research Assistant:基于Gemini与LangGraph的全栈智能研究助手: Google Gemini团队开源了一款全栈AI研究助手,它利用Gemini模型和LangGraph执行智能网络研究。该助手具备反思性推理能力,能持续优化其搜索策略,为用户提供更深入、高效的研究支持。项目代码已在GitHub上提供 (来源: LangChainAI, hwchase17)
Agent Flow:开源无代码AI智能体构建器: Karan Vaidya推出了Agent Flow,一个开源的无代码AI智能体构建器,作为Gumloop的替代方案。它基于ComposioHQ和LangChain的LangGraph构建,允许用户通过拖放节点的方式自动化工作流程和复杂的智能体模式,旨在降低AI智能体应用的开发门槛 (来源: hwchase17)
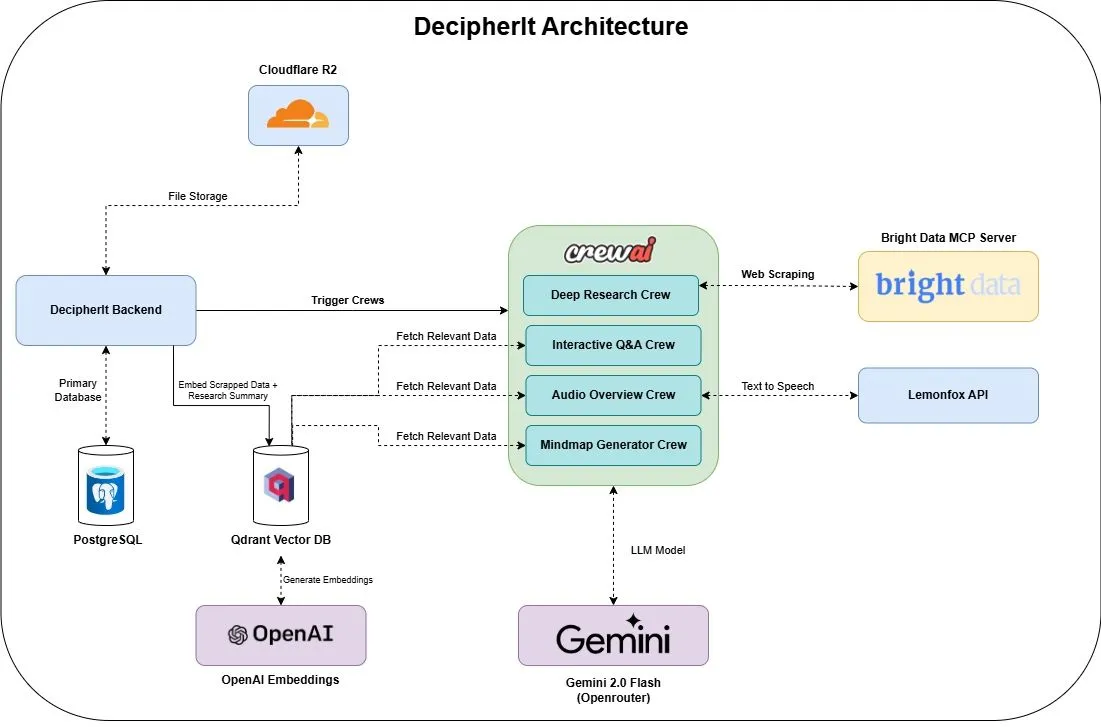
DecipherIt:开源AI研究助手,NotebookLM的替代方案: 一款名为DecipherIt的开源AI研究助手被推出,它被定位为NotebookLM的替代品。该工具利用多智能体编排(crewAI)、语义搜索(Qdrant + OpenAI)、实时网络访问(Bright Data MCP)和语音合成(lemonfoxai),能将用户上传的文档、URL或输入的主题转化为包含摘要、思维导图、音频概述、FAQ和语义问答的完整研究工作区 (来源: qdrant_engine)
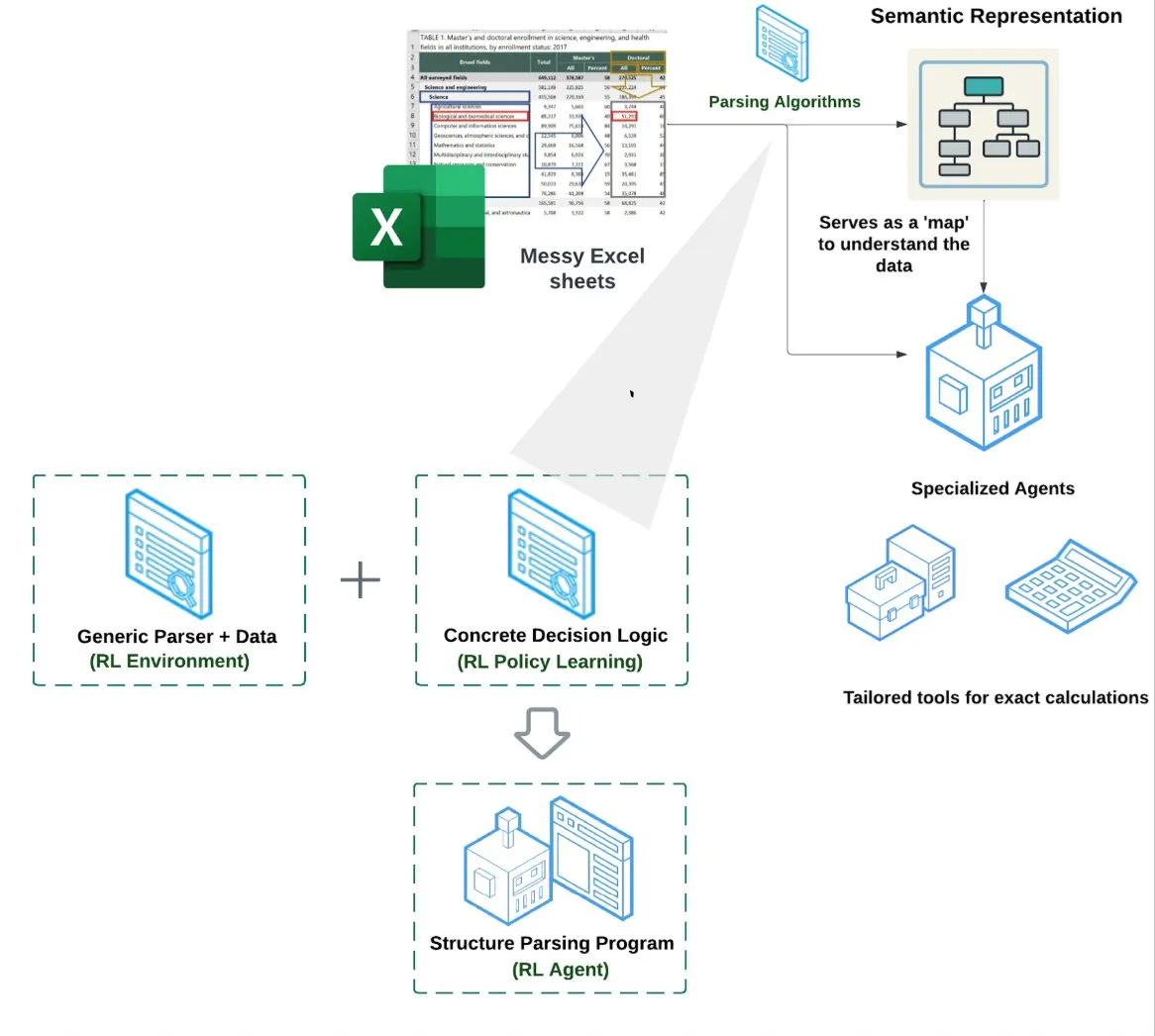
LlamaIndex推出电子表格智能体 (Spreadsheet Agent): LlamaIndex发布了一款新的电子表格智能体,尚处于私有预览阶段。该智能体专注于处理复杂的Excel文件,能够进行数据转换和质量保证。其技术架构核心在于基于强化学习的结构理解(学习数据模型/语义图)以及在语义图之上构建的专用工具,旨在提供比传统RAG或文本转CSV方法更优的Excel处理能力,据称性能比单纯LLM编写代码的基线高10-20% (来源: jerryjliu0)
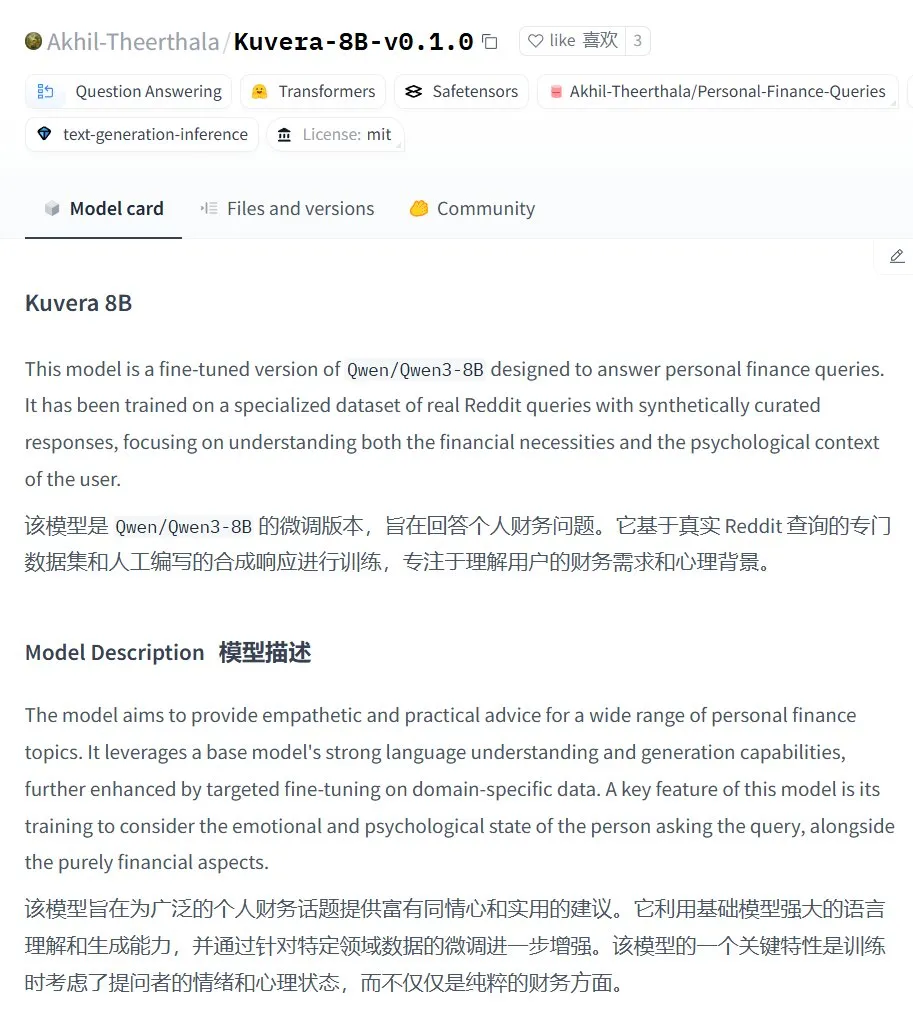
Kuvera-8B-v0.1.0:个人财务咨询大模型: Akhil-Theerthala在Hugging Face上发布了Kuvera-8B-v0.1.0模型,这是一个专为个人财务问题设计的模型。它基于Qwen3-8B微调,使用了Reddit等数据源,旨在就预算、储蓄、投资、债务管理和基本财务规划等话题提供富有同情心和实用性的建议。由于基于Qwen3,该模型支持中文问答 (来源: karminski3)
本地化Whisper+Pyannote语音处理方案替代Otter.ai: 一位Reddit用户分享了其构建的完全本地化的语音处理流程,用于替代Otter.ai等云服务。该方案结合了ctranslate2、faster-whisper进行转录,pyannote、speechbrain进行说话人分离(diarisation),能够在本地GPU上处理长达三小时以上的会议录音,并输出带说话人标签的文本记录和JSON文件,包括执行摘要和行动列表等定制化内容。此举旨在解决云服务的限制、隐私担忧和定制化不足的问题 (来源: Reddit r/LocalLLaMA)
GPT Deep Research MCP:结合OpenWebUI实现深度研究: 用户推荐尝试GPT Deep Research MCP与OpenWebUI的结合。该MCP工具(gptr-mcp)旨在提供深度研究能力,当与支持MCP的OpenWebUI一起使用时,能带来令人印象深刻的研究体验,进一步拓展了本地化AI工具在信息处理和知识发现方面的应用 (来源: Reddit r/OpenWebUI)
📚 学习
OpenAI将举办应用评估实践分享会,含真实案例与工具前瞻: OpenAI将举办一场关于应用评估(Evals)最佳实践的分享会。届时,OpenAI的Jim Blomo将结合真实客户案例和成果,探讨如何有效评估AI产品。活动还将预告OpenAI即将推出的评估工具,包括追踪、评分等功能。该分享会旨在帮助开发者和企业更好地构建和优化AI应用,将提供录播回放 (来源: HamelHusain, HamelHusain)

Anthropic开源可解释性研究方法,助力理解LLM“思维”: Anthropic宣布开源其用于追踪大型语言模型“思维过程”的研究方法。研究人员现在可以利用该方法生成“归因图谱”(attribution graphs),并进行交互式探索,类似于Anthropic在其近期研究中展示的效果。团队还提供了Neuronpedia交互界面和Jupyter Notebook教程,方便研究者在开源模型上应用这些工具,以增进对LLM内部工作机制的理解。该项目由Anthropic Fellows计划参与者与Decode Research合作领导 (来源: AnthropicAI)
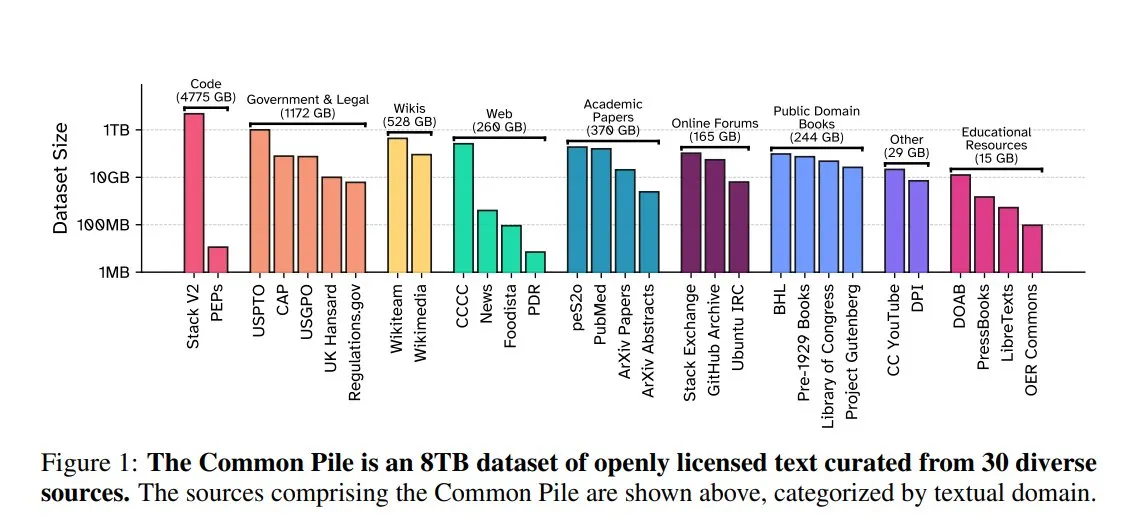
EleutherAI发布Common Pile v0.1:8TB开放授权文本数据集: EleutherAI联合Vector Institute、Allen AI、Hugging Face及DPI发布了Common Pile v0.1,这是一个包含8TB、1万亿Token的公开领域和开放授权文本数据集。团队基于此数据集训练了7B参数的Comma v0.1-1T和-2T模型,其性能与在相似数据规模上训练的LLaMA 1&2等模型相当。此举旨在探索在不使用未经授权文本的情况下训练高性能语言模型的可能性,为开源社区提供了宝贵的数据资源 (来源: huggingface)
NVIDIA NIM加速Vanna文本到SQL推理: NVIDIA开发者博客发布教程,展示了如何使用NVIDIA NIM(NVIDIA Inference Microservices)优化Vanna的文本到SQL解决方案。NIM提供针对生成式AI模型的优化端点,能够加速推理过程,从而更快地进行分析。这对于需要将自然语言查询转换为数据库查询的应用场景具有重要意义 (来源: dl_weekly)
斯坦福大学机器学习课程免费讲义分享: The Turing Post分享了斯坦福大学由吴恩达(Andrew Ng)和马腾宇(Tengyu Ma)教授的CS229机器学习课程的免费讲义。内容涵盖监督学习、无监督学习方法与算法、深度学习与神经网络、泛化、正则化以及强化学习过程等核心机器学习主题,为学习者提供了高质量的学习资源 (来源: TheTuringPost)

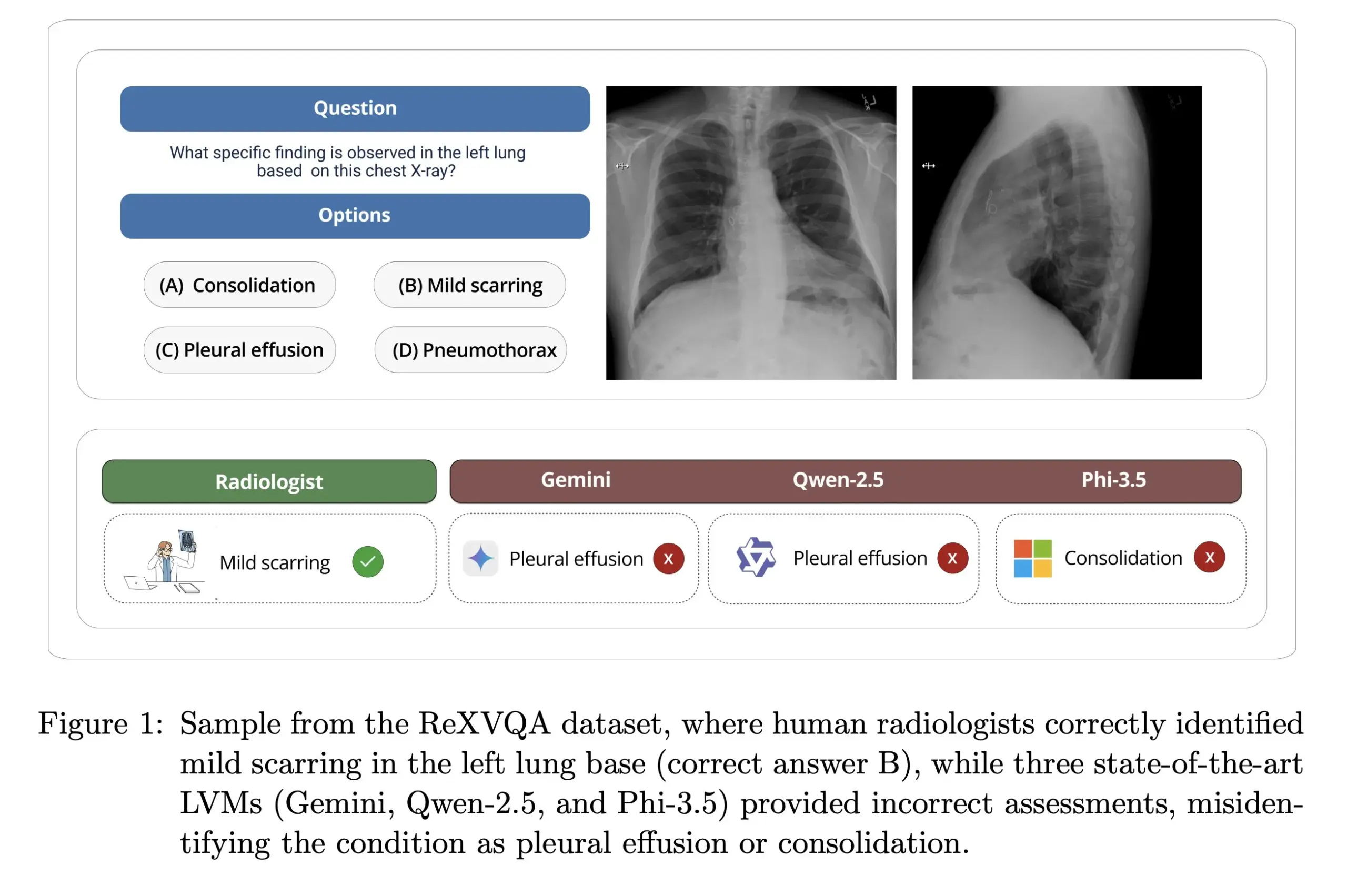
哈佛大学发布ReXVOA:大规模高质量胸部X光问答基准: 哈佛大学Pranav Rajpurkar实验室发布了ReXVOA,这是一个大规模、高质量的胸部X光视觉问答(VQA)基准数据集。该数据集旨在对现有的大型前沿模型构成挑战,并作为衡量下一代模型在医学影像理解和问答能力方面进展的标尺 (来源: huggingface)
OWL Labs分享扩散模型自编码器训练经验: OWL (Open World Labs)在其博客中总结了训练用于扩散模型的自编码器的经验和发现,并分享了一些非常规方法的失败案例。该文章为研究者和开发者在实践中应用和优化扩散模型自编码器提供了参考 (来源: NandoDF)
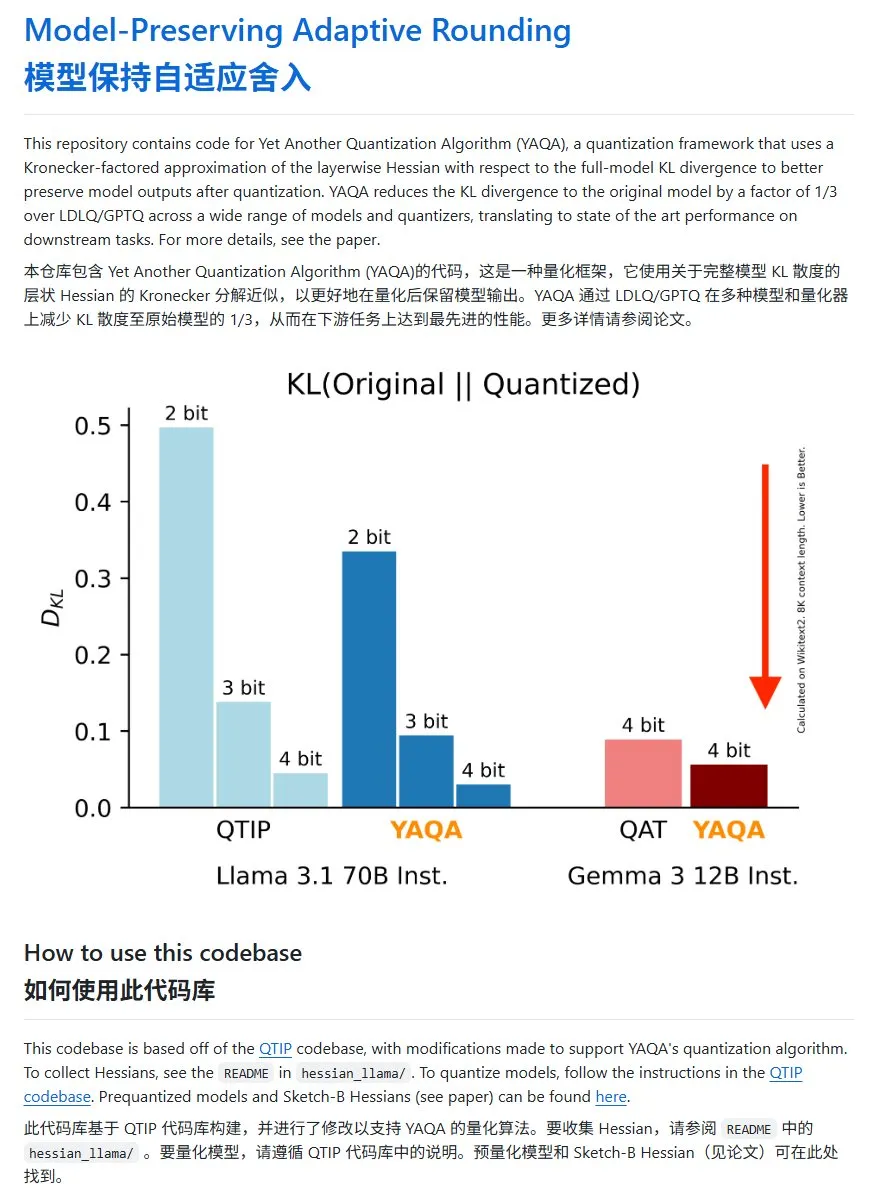
YAQA:一种新的模型量化方法,KL散度显著降低: Cornell-RelaxML团队提出了一种新的模型量化方法YAQA。该方法结合LDLQ/GPTQ技术,与现有量化方法相比,能将量化后模型的KL散度降低至原始模型的1/3。虽然YAQA量化过程较慢且需要大量显存,但其带来的性能提升和后续推理的经济性使其成为一个有前景的量化方案。项目代码已在GitHub开源 (来源: karminski3)
💼 商业
00后广州女生洪乐潼创办Axiom,瞄准AI解决数学难题: 00后学霸洪乐潼(Carina Hong)创办的AI初创公司Axiom引发关注。Axiom专注于利用AI解决复杂数学问题,目标客户包括对冲基金和量化交易公司。据The Information报道,Axiom正在洽谈5000万美元融资,估值约3-5亿美元,B Capital或领投。洪乐潼在社交媒体称融资报道不准确,但确认公司正在招聘AI数学人才。洪乐潼本科毕业于麻省理工,硕士毕业于牛津,现为斯坦福数学与法学博士双学位在读,曾多次获得数学竞赛奖项 (来源: 36氪)

Anthropic因竞争关系切断对Windsurf的Claude API访问: Anthropic联合创始人证实,公司已停止向AI初创公司Windsurf提供Claude模型的API访问权限。原因是Windsurf被视为OpenAI的某种形式的“包装器”或与之紧密相关的服务,而OpenAI是Anthropic的直接竞争对手。此举引发了关于API依赖和平台风险的讨论,特别是对于那些业务建立在第三方大模型API之上的初创公司而言,模型提供商的商业决策可能直接影响其生存 (来源: ClementDelangue, Reddit r/LocalLLaMA)
OpenAI因版权诉讼被要求保留用户已删除聊天记录: 据报道,在一场由《纽约时报》提起的版权诉讼中,美国联邦法院已下令OpenAI保留所有ChatGPT用户的对话记录,包括用户已选择删除的内容,作为潜在证据。《纽约时报》指控OpenAI使用其付费墙文章训练ChatGPT,并担心AI可能生成相似内容。此举引发了用户隐私和数据保护(如GDPR)方面的担忧,凸显了AI训练数据版权与用户隐私之间的法律和伦理张力 (来源: Reddit r/ArtificialInteligence)

🌟 社区
AI大模型挑战2025年高考作文与数学,表现各异: 2025年高考期间,多款主流AI大模型接受了高考作文和数学题的挑战。在作文方面,包括豆包、DeepSeek、ChatGPT等16款AI助手展示了其写作能力,多数能生成结构规范的议论文,但普遍存在模板化、套话引用和立意趋同的问题。在数学(新课标I卷客观题)测试中,字节豆包和腾讯元宝以68分(满分73)并列第一,而OpenAI o3表现不佳仅得34分。测试反映出当前AI在中文理解、逻辑推理及创造性表达方面的进步与局限,尤其在避免AI痕迹和应对复杂数学推理方面仍有提升空间 (来源: 36氪, 36氪)

AI在企业内部的应用趋势:内部知识库与定制化聊天机器人受关注: 社区讨论显示,利用AI构建企业内部聊天机器人,基于公司数据进行训练,以解答员工关于流程、数据查找、负责人等内部问题,正成为一种趋势。这类应用旨在提升内部信息检索效率和知识管理水平。Amazon等公司已部署类似系统,并反馈良好。然而,数据安全、潜在敏感信息泄露以及如何有效商业化仍是企业在实施过程中需要关注的问题 (来源: Reddit r/ArtificialInteligence)
AI辅助编程中的“索引”与“非索引”之争:性能与可靠性的权衡: 一项针对AI编码助手的实验(使用阿波罗11号登月代码作为测试对象)对比了“索引型”(预先构建代码库索引并使用向量搜索)和“非索引型”(按需读取分析代码文件)两种AI代理。结果显示,索引型代理在多数情况下速度更快、API调用更少,但在处理代码库频繁变动导致索引过时的情况下,可能因依赖陈旧信息而产生错误,调试时间反而更长。这揭示了在选择AI编码工具时,需要在即时性能和信息可靠性之间进行权衡 (来源: Reddit r/ClaudeAI)

关于LLM是否“思考”的讨论持续:从模式匹配到人类认知: 社区中关于大型语言模型(LLM)是否真正“思考”的讨论持续不断。批评者认为LLM本质上是复杂的预测文本生成器,通过计算词语序列概率来工作,而非进行有意识的思考。然而,许多用户在与LLM交互时感受到类似与人对话的体验。这引发了对人类语言生成机制的反思,以及LLM与人类认知过程是否存在相似性的探讨。苹果公司的研究进一步指出LLM在复杂推理上的局限,认为其更依赖模式记忆而非真实推理,为这一讨论增添了新的视角 (来源: Reddit r/ArtificialInteligence, Reddit r/ChatGPT)

Paul Graham谈AI对收入差距的影响: Paul Graham对其16岁的儿子表示,短期内AI技术可能会拉大人们的工作收入差距。他举例说,水平一般的程序员现在更难找到工作,而优秀的程序员则因AI的辅助而收入更高。他认为这并非新鲜事,技术进步往往会扩大收入差距,因为收入下限固定为零,而技术不断提升顶尖人才的回报上限 (来源: dotey)
AI安全伦理讨论:从模型行为到社会规范: 社区对AI安全和伦理的讨论持续升温。Geoffrey Hinton祝贺Yoshua Bengio发起LawZero项目,旨在推动AI的安全设计,特别关注前沿系统可能出现的自我保护和欺骗行为。同时,有观点批评某些AI安全研究(如测试模型是否同意被关闭)是“安全戏剧”,缺乏实际价值。OpenAI关于人机关系的研究也引发讨论,强调在AI日益融入生活的背景下,需优先研究其对用户情感福祉的影响,并探讨如何在模型交互中平衡清晰沟通与避免拟人化 (来源: geoffreyhinton, ClementDelangue, togelius)

ChatGPT等AI助手的情感支持作用获用户肯定: 不少用户在社交媒体上分享了ChatGPT等AI助手在他们面临困境时提供情感支持和实用帮助的经历。有用户表示,在失业、健康问题或情绪低落时,ChatGPT不仅提供了具体行动方案和资源信息,还以一种不带评判的方式帮助他们缓解恐慌、重拾力量。这显示了AI在心理支持和危机干预方面的潜在价值,尽管其不具备真正的情感和意识 (来源: Reddit r/ChatGPT)
“Vibe Coding”成为AI辅助编程新现象: “Vibe Coding”一词在开发者社区中流行,指代一种依赖直觉和AI辅助快速迭代代码的编程方式。Claude Code等工具因其在特定时段(如夜间或清晨,可能因服务器负载低或未被高度量化)表现出色而受到一些程序员的青睐。这种现象反映了AI编码助手对开发效率的提升,同时也引发了关于模型一致性、量化影响以及开发者新工作模式的讨论 (来源: dotey, jeremyphoward)
💡 其他
Andrej Karpathy反思噪音污染对睡眠及健康的巨大影响: Andrej Karpathy分享了其个人经历,指出交通噪音等环境噪音污染对睡眠质量和长期健康可能造成巨大且未被充分认识的负面影响。他推测,夜间噪音(如响亮的汽车、摩托车声)可能导致数百万人睡眠质量下降,进而影响情绪、创造力、精力,并增加心血管、代谢和认知疾病的风险。他呼吁睡眠追踪设备(如Whoop、Oura)能明确追踪噪音与睡眠的关联,并提升公众对此问题的认知 (来源: karpathy)
AI与宗教的交叉现象引关注: 社交媒体用户menhguin观察到,基于AI的新型宗教或类宗教应用的潜在市场不容忽视。例如,AI占星、AI圣经视频、AI祈祷应用以及某些特定群体的AI应用,都暗示了AI技术在满足人类精神或信仰需求方面的可能性 (来源: menhguin)
AI辅助生成HTTP 2.0服务器,探索LLM在大型软件项目中的潜力: 一位开发者使用自研框架 (promptyped) 和Gemini 2.5 Pro模型,通过代码-编译-测试的循环,成功让LLM从头构建了一个符合HTTP 2.0标准的服务器。该项目生成了1.5万行源代码和超过3万行测试代码,并通过了h2spec一致性测试。尽管耗时约119小时API时间和631美元API费用,这一实验展示了LLM在架构设计和编写复杂、标准兼容软件方面的潜力,同时也揭示了完全由LLM编写的应用的形态 (来源: Reddit r/LocalLLaMA)