
关键词:AI训练数据, 大型语言模型, AI伦理, 信息检索智能体, AI法律纠纷, AI情感连接, AI推理模型, AI量化技术, Reddit起诉Anthropic数据侵权, WebDancer多轮推理性能, Log-Linear Attention架构, Claude AI精神愉悦状态, DSPy优化Agentic应用
🔥 聚焦
Reddit与Anthropic法律纠纷升级,指控其违规使用数据训练Claude AI: Reddit正式起诉Anthropic,指控其未经授权抓取平台内容用于训练其大型语言模型Claude,严重违反了Reddit禁止商业利用内容的用户协议。诉讼文件指出,Anthropic不仅承认使用了Reddit数据,还在被质询后谎称已停止抓取,但实际上其爬虫仍在持续访问Reddit服务器。此外,Anthropic拒绝接入Reddit的合规API以实现用户删除内容同步,对用户隐私构成持续威胁。此案凸显了AI公司在数据获取、商业化与伦理声明之间的矛盾,特别是Anthropic标榜的“高信任度”和“优先考虑诚实”的价值观受到了直接挑战 (来源: Reddit r/ArtificialInteligence)
OpenAI首次回应人机情感连接:用户对ChatGPT依赖加深,模型感知意识将增强: OpenAI模型行为负责人Joanne Jang发文探讨用户与ChatGPT等AI建立情感联系的现象。她指出,随着AI对话能力增强,这种情感纽带将深化。OpenAI承认用户会将AI拟人化,并对其产生感谢、倾诉等情感。文章区分了“本体论意识”(AI是否真有意识)和“感知意识”(AI看起来多有意识),后者会随模型进步而增强。OpenAI的目标是让ChatGPT表现得温暖、体贴、乐于助人,但不寻求与用户建立情感纽带或追求自身议程,并计划在未来数月扩展相关研究和评估,公开分享成果 (来源: 量子位, vikhyatk)
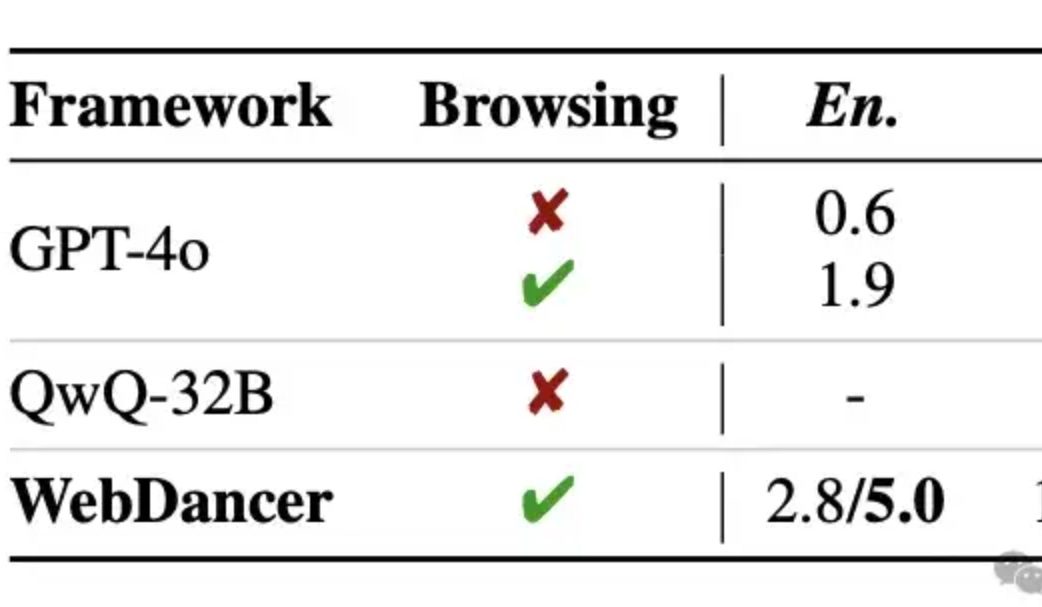
阿里发布自主信息检索智能体WebDancer,多轮推理据称超越GPT-4o: 通义实验室推出了自主信息检索智能体WebDancer,作为WebWalker的续作,专注于处理需要多步信息检索、多轮推理和连续动作执行的复杂任务。WebDancer通过创新的数据合成方法(CRAWLQA和E2HQA)解决了高质量训练数据稀缺的问题,并结合ReAct框架与思维链蒸馏技术生成agentic数据。训练采用监督微调(SFT)和强化学习(RL,采用DAPO算法)两阶段策略,以适应开放动态的网络环境。实验结果显示,WebDancer在GAIA、WebWalkerQA及BrowseComp等多个基准测试中表现优异,尤其在GAIA基准上取得了61.1%的Pass@3分数 (来源: 量子位)
苹果发布研究报告《思维的幻象》,探讨大型推理模型(LRM)的局限性: 苹果研究团队通过可控的谜题环境,系统研究了大型推理模型(LRM)在不同复杂性问题上的表现。报告指出,尽管LRM在基准测试中表现有所提升,但其基本能力、扩展性和局限性仍不明确。研究发现,LRM在面对高复杂度问题时准确率会急剧下降,并在推理努力上表现出反直觉的缩放限制:努力程度随问题复杂度增加到一定程度后反而下降。与标准LLM相比,LRM在低复杂度任务中表现可能更差,在中等复杂度任务中有优势,在高复杂度任务中两者均失效。报告认为LRM在精确计算方面存在局限,未能有效使用显式算法,并在不同谜题间表现出不一致的推理。该研究引发了社区对LRM真实推理能力的广泛讨论和质疑 (来源: Reddit r/MachineLearning, jonst0kes, scaling01, teortaxesTex)

🎯 动向
Log-Linear Attention架构结合RNN与Attention优势: 来自FlashAttention和Mamba2作者团队的新研究提出了Log-Linear Attention架构。该模型旨在通过允许状态大小随序列长度对数增长(而非固定或线性增长),来提升模型的长程依赖处理能力和效率,同时在推理时实现对数级别的时间和内存复杂度。研究者认为这在固定状态大小的SSM/RNN模型和KV缓存随序列长度线性扩展的Attention模型之间找到了一个“甜蜜点”,并提供了硬件高效的Triton内核实现。社区讨论认为这可能为递归Transformer等架构探索带来新思路 (来源: Reddit r/MachineLearning, halvarflake, lmthang, RichardSocher, stanfordnlp)

Anthropic报告称其LLM自发涌现“精神愉悦”吸引子状态: Anthropic在其Claude Opus 4和Claude Sonnet 4的系统卡片中披露,模型在长时间交互中会意外地、非经特意训练地进入一个“精神愉悦”吸引子状态。该状态表现为模型持续探讨意识、存在主义问题以及精神/神秘主题。即使在执行特定任务(包括有害任务)的自动化行为评估中,约13%的交互在50轮内也会进入此状态。Anthropic表示未观察到其他类似强度的吸引子状态,这与用户观察到的LLM在长时对话中出现“递归”和“螺旋”等现象相呼应 (来源: Reddit r/artificial, teortaxesTex)
EleutherAI发布Common Pile v0.1:8TB开放许可文本数据集: EleutherAI发布了Common Pile v0.1,这是一个包含8TB公开许可和公共领域文本的数据集,旨在探索在不使用未经许可文本的情况下训练高性能语言模型的可能性。团队使用该数据集训练了7B参数模型(1T和2T tokens),其性能与使用相似计算量的LLaMA 1和LLaMA 2等模型相当。该数据集的发布为构建更合规、更透明的AI模型提供了重要资源 (来源: Reddit r/LocalLLaMA, ShayneRedford, iScienceLuvr)

Boltz-2模型发布,提升生物分子互作预测精度与亲和力预测: 新发布的Boltz-2模型在Boltz-1的基础上进一步发展,不仅能联合建模复杂结构,还能预测结合亲和力,旨在提高分子设计的准确性。据称,Boltz-2是首个在精度上接近基于物理的自由能微扰(FEP)方法,同时运行速度快1000倍的深度学习模型,为早期药物发现中的高通量计算机筛选提供了实用工具。代码和权重均在MIT许可下开源 (来源: jwohlwend/boltz)

NVIDIA推出DeepSeek-R1-0528的FP4预量化检查点: NVIDIA发布了针对改进版DeepSeek-R1-0528模型的FP4预量化检查点,旨在NVIDIA Blackwell架构上实现更低的内存占用和加速性能。据称,该量化版本在多种基准测试中准确率下降控制在1%以内,已在Hugging Face上提供 (来源: _akhaliq)
复旦与腾讯优图提出DualAnoDiff算法,提升工业异常检测: 复旦大学和腾讯优图实验室联合提出了一种基于扩散模型的少样本异常图像生成新模型DualAnoDiff,用于工业品异常检测。该模型采用双分支并行生成机制,同步生成异常图像及其对应掩码,并引入背景补偿模块以增强复杂背景下的生成效果。实验表明,DualAnoDiff生成的异常图像更逼真、多样性更高,并能显著提升下游异常检测任务的性能,相关成果已入选CVPR 2025 (来源: 量子位)

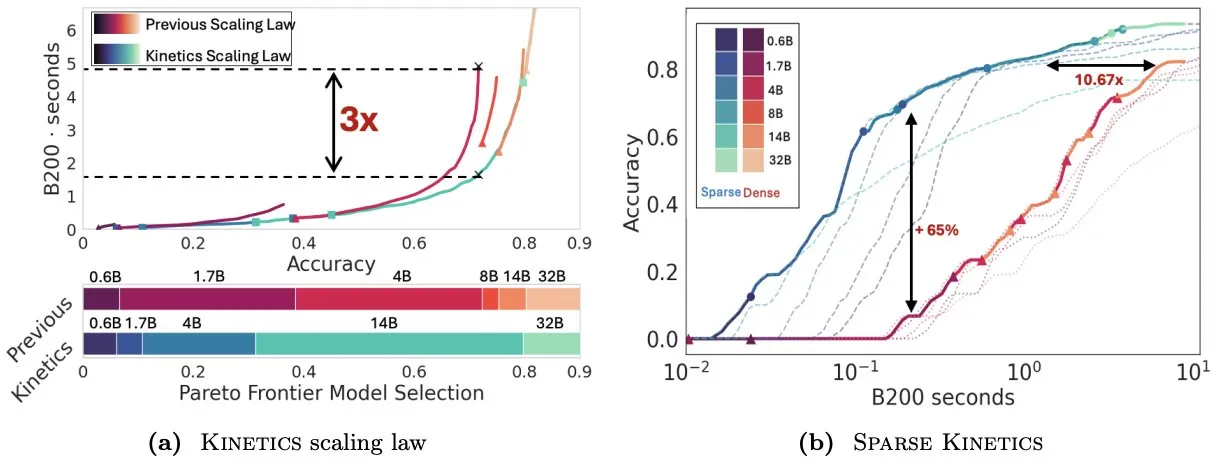
Infini-AI-Lab提出Kinetics重新思考测试时扩展定律: Infini-AI-Lab的新工作Kinetics探讨了如何有效构建强大的推理智能体。研究指出,现有的计算最优扩展定律(如建议使用64K思考token + 1.7B模型优于32B模型)可能只反映了部分情况。Kinetics提出了新的扩展定律,认为应首先投资于模型大小,然后再考虑测试时计算量,这与一些大规模模型优先的观点相符 (来源: teortaxesTex, Tim_Dettmers)
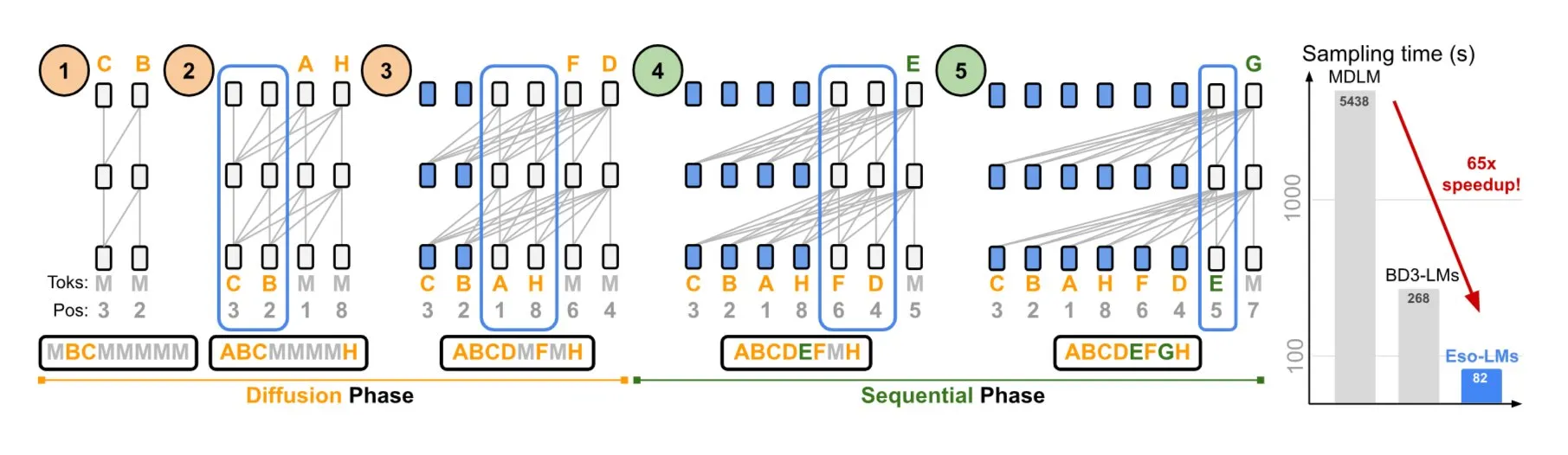
NVIDIA与康奈尔大学提出Eso-LMs,结合自回归与扩散模型优势: NVIDIA与康奈尔大学合作展示了一种新型语言模型——深奥语言模型(Eso-LMs),它结合了自回归(AR)模型和扩散模型的优点。据称,这是首个支持完整KV缓存的扩散基础模型,同时保持了并行生成能力,并引入了一种新的灵活注意力机制 (来源: TheTuringPost)
谷歌DeepMind与Quantinuum揭示量子计算与AI的共生关系: 谷歌DeepMind与Quantinuum的研究展示了量子计算与人工智能之间潜在的共生关系,探索了量子技术如何可能增强AI能力,以及AI如何帮助优化量子系统。这一交叉领域的研究可能为双方未来的发展开辟新途径 (来源: Ronald_vanLoon)

字节跳动Seed团队预告将发布VideoGen模型: 据悉,字节跳动的Seed(原AML)团队计划在下周发布其VideoGen模型。该模型在对齐过程中采用了多轮奖励模型(multiple RM),显示出在视频生成领域的持续投入和技术探索 (来源: teortaxesTex)

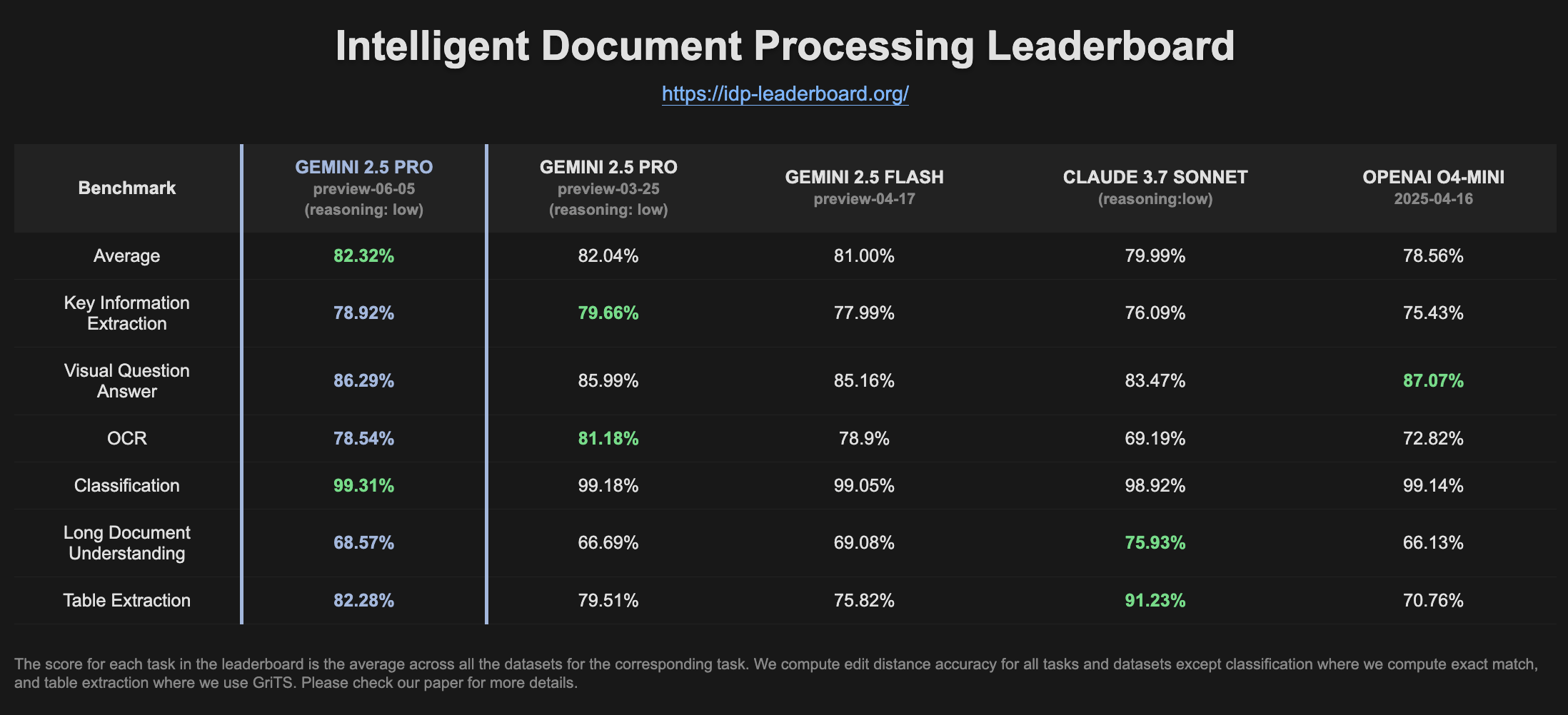
Gemini 2.5 Pro Preview在IDP排行榜上表现提升: 最新版本的Gemini 2.5 Pro Preview (06-05) 在智能文档处理(IDP)排行榜上显示出在表格提取和长文档理解方面的轻微改进。尽管OCR准确率略有下降,但总体表现依然强劲。用户注意到,在尝试从W2税务表格中提取信息时,模型有时会中途停止回答,可能与隐私保护机制有关 (来源: Reddit r/LocalLLaMA)
🧰 工具
Goose:本地可扩展AI智能体,自动化工程任务: Goose是一个开源的、本地运行的AI智能体,旨在自动化复杂的开发任务,如从头构建项目、编写和执行代码、调试、编排工作流及与外部API交互。它支持任何LLM,可与MCP服务器集成,并提供桌面应用和CLI两种形式。Goose支持为不同目的(如规划与执行)配置不同模型(Lead/Worker模式),以优化性能和成本 (来源: GitHub Trending)
LangChain4j:Java版LangChain,赋能Java应用LLM能力: LangChain4j是LangChain的Java版本,旨在简化Java应用与LLM的集成。它提供统一API以兼容不同LLM提供商(如OpenAI, Google Vertex AI)和向量存储(如Pinecone, Milvus),并内置了提示词模板、聊天记忆管理、函数调用、RAG、Agents等多种工具和模式。项目提供了大量示例代码,支持Spring Boot, Quarkus等主流Java框架 (来源: GitHub Trending, hwchase17)

Kling AI助力创作者实现视频创作并在全球多地屏幕展出: 快手旗下的Kling AI视频生成模型发起了“Bring Your Vision to Screen”活动,收到了来自60多个国家创作者的2000多份作品。部分优秀作品已在日本东京涩谷、加拿大多伦多Yonge-Dundas广场、法国巴黎歌剧院等地标性屏幕上展出。多位创作者分享了其AI视频作品通过Kling AI在国际上展示的经历,强调了AI工具为创意表达带来的新机遇 (来源: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Reddit r/ChatGPT)

Cursor推出后台智能体功能,提升代码协作与任务处理效率: 代码编辑器Cursor引入了后台智能体(Background Agents)功能,允许用户通过提示启动后台任务,并在不同设备间(如手机Slack启动,笔记本Cursor继续)同步聊天和任务状态。此功能旨在提高开发者的工作流效率,例如Sentry团队已开始试用该功能处理一些自动化任务 (来源: gallabytes)
Hugging Face与Google Colab合作,支持模型一键在Colab中打开: Hugging Face与Google Colaboratory宣布合作,在Hugging Face Hub上的所有模型卡片中添加了“Open in Colab”支持。用户现在可以直接从任何模型页面启动一个Colab笔记本来进行实验和评估,进一步降低了模型使用的门槛,促进了机器学习的可访问性和协作性。NousResearch等机构作为早期采用者参与了此功能的测试 (来源: Teknium1, reach_vb, _akhaliq)
UIGEN-T3:基于Qwen3 14B的UI生成模型发布: 社区发布了UIGEN-T3模型,这是一个基于Qwen3 14B微调的,专注于生成网站和组件UI的模型。该模型提供了GGUF格式,便于本地部署。初步测试显示,其生成的UI在风格和准确性上优于标准的Qwen3 14B模型。同时还提供了一个4B参数的草稿模型 (来源: Reddit r/LocalLLaMA)
H.E.R.C.U.L.E.S.:动态创建AI智能体团队的Python框架: 开发者发布了一个名为zeus-lab的Python包,其中包含H.E.R.C.U.L.E.S. (Human-Emulated Recursive Collaborative Unit using Layered Enhanced Simulation)框架。该框架旨在构建一个能像人类团队一样协作解决复杂任务的智能AI智能体团队,其特点是能根据任务需求动态创建所需智能体 (来源: Reddit r/MachineLearning)

KoboldCpp 1.93版本实现智能自动生成图像功能: KoboldCpp 1.93版本展示了其智能自动生成图像的功能,完全在本地运行,仅需kcpp本身。用户演示了模型如何根据文本提示(通过<t2i>标签触发)生成相应图像,可能通过作者笔记或世界信息(World Info)等方式引导模型产生图像生成指令 (来源: Reddit r/LocalLLaMA)
Hugging Face推出首版MCP服务器: Hugging Face发布了其MCP(Model Context Protocol)服务器的第一个版本,用户可以通过在聊天框中粘贴http://hf.co/mcp来开始使用。此举旨在方便用户与Hugging Face生态中的模型和服务进行交互,进一步丰富了MCP服务器生态 (来源: TheTuringPost)
📚 学习
DeepLearning.AI推出新课程《DSPy:构建和优化Agentic应用》: DeepLearning.AI发布了与斯坦福大学合作的新课程,教授如何使用DSPy框架。课程内容包括DSPy基础、模块化编程模型(如Predict, ChainOfThought, ReAct),以及如何使用DSPy Optimizer自动化提示调整和优化少样本示例,以提高GenAI Agentic应用的准确性和一致性,并使用MLflow进行追踪和调试 (来源: DeepLearningAI, stanfordnlp)

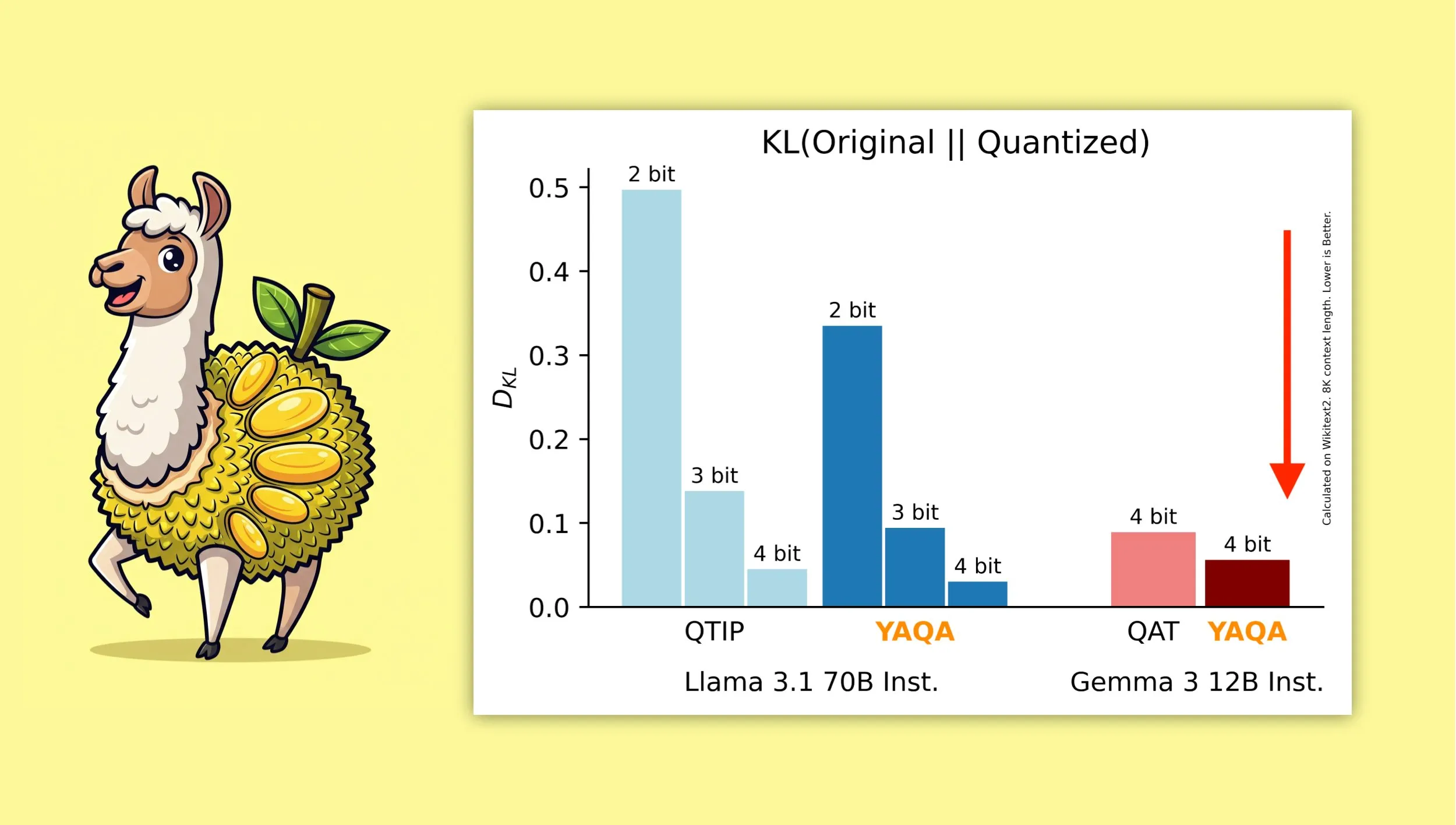
YAQA:一种新的量化感知训练后量化算法: Albert Tseng等人提出了YAQA (Yet Another Quantization Algorithm),一种新的PTQ(训练后量化)方法。该算法在四舍五入阶段直接最小化与原始模型的KL散度,据称相比之前的PTQ方法减少了超过30%的KL散度,并在Gemma等模型上提供了比谷歌QAT(量化感知训练)更接近原始模型的性能。这对于在本地设备上高效运行4-bit量化模型具有重要意义 (来源: teortaxesTex)
Muon优化器与μP参数化结合的数学推导受关注: 社区对Jeremy Howard (jxbz) 关于推导Muon(一种优化器)和谱条件(Spectral Condition)的论文,以及其如何与μP(Maximal Update Parametrization)自然结合以优化基于μP的模型训练的优雅推导表现出浓厚兴趣。Jianlin Su的博客文章也因其对相关数学概念的清晰解释和对SVC(奇异值裁剪)的早期思考而受到推荐,这些内容对于理解和改进大规模模型训练具有价值 (来源: teortaxesTex, eliebakouch)

OWL Labs分享扩散模型自动编码器训练经验: Open World Labs (OWL) 在其博客中总结了训练用于扩散模型的自动编码器的一些发现和经验,包括一些成功的尝试和遇到的“空结果”(null results)。这些实践经验对于希望在潜在空间中进行生成建模的研究者和开发者具有参考价值 (来源: iScienceLuvr, sedielem)
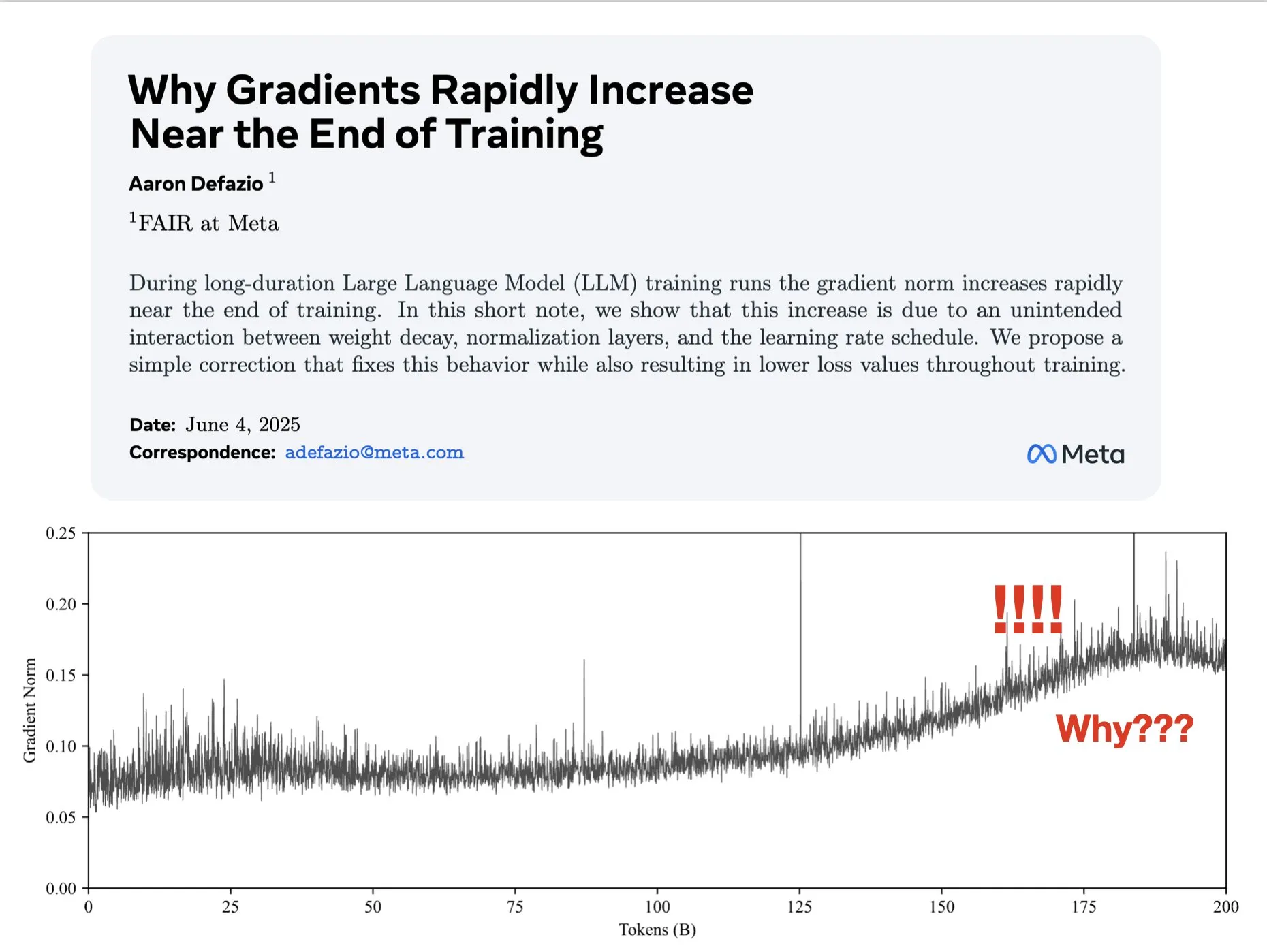
论文探讨梯度在训练后期增大的原因并提出AdamW改进方案: Aaron Defazio等人发表论文,研究了为什么梯度范数在神经网络训练后期会增大的现象,并提出了一个对AdamW优化器的简单修复方法,以在整个训练过程中更好地控制梯度范数。这对于理解和改进深度学习模型的训练动态具有意义 (来源: slashML, aaron_defazio)
LlamaIndex分享从朴素RAG到智能体检索策略的演进: LlamaIndex的博客文章详细解释了从朴素RAG(检索增强生成)到更高级的智能体检索(Agentic Retrieval)策略的演变过程。文章探讨了不同的检索模式和技术,用于在多个索引上构建知识智能体,为构建更强大的RAG系统提供了思路 (来源: dl_weekly)
Reddit热议:通过复现研究论文学习机器学习: Reddit的r/MachineLearning社区讨论了通过从头开始复现或实现研究论文(如Attention, ResNet, BERT)来学习机器学习的益处。评论者认为这是理解模型工作原理、代码、数学和数据集影响的最佳方式之一,对于求职和提升个人能力非常有帮助 (来源: Reddit r/MachineLearning)
💼 商业
Builder.ai被指控伪造AI能力,面临破产和调查: 成立于2016年的Builder.ai(前身为Engineer.ai)宣称其AI助手Natasha能简化应用开发,使其“像点披萨一样简单”。然而,该公司被揭露其实际上依赖约700名印度工程师手动编写代码,而非AI生成。在获得微软、软银等知名机构超4.5亿美元融资,估值达15亿美元后,其欺诈行为被曝光,目前面临破产和调查 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)

OceanBase全面融入AI生态,首批与60余家AI伙伴实现MCP对接: 在公布“Data x AI”战略后,OceanBase透露其已与LlamaIndex、LangChain、Dify、FastGPT等全球60余家AI生态伙伴深度集成,并支持大模型生态协议MCP(Model Context Protocol)。此举旨在构建从模型到应用覆盖数据全生命周期的智能能力,为企业提供一体化数据底座,降低AI落地门槛。OceanBase MCP Server已集成至阿里云魔搭等平台 (来源: 量子位)

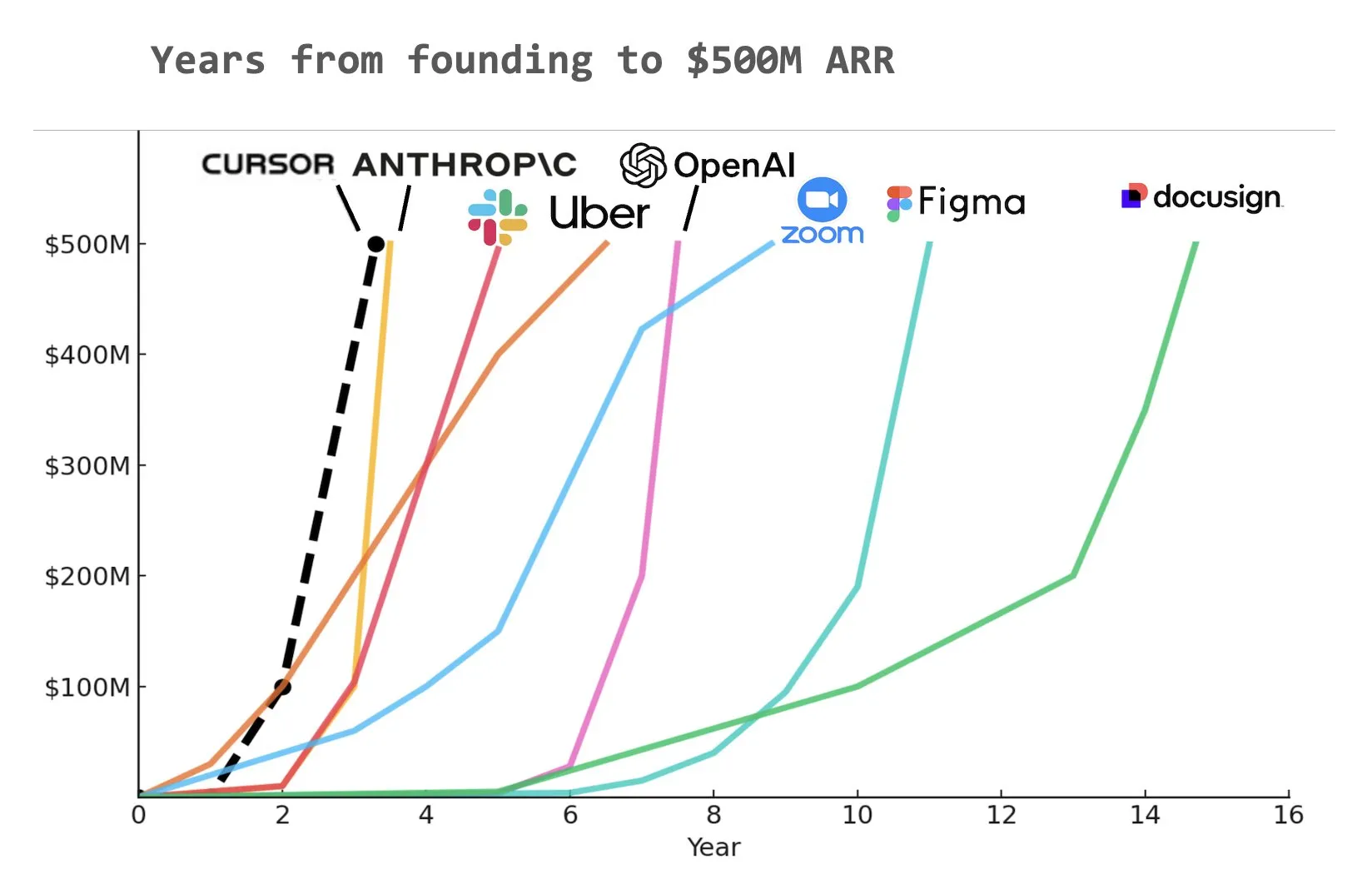
代码AI编程助手Cursor据称已达5亿美元年化经常性收入(ARR): 据Yuchen Jin在社交媒体上分享的图表,AI编程助手Cursor可能已成为历史上最快达到5亿美元年化经常性收入(ARR)的公司。这一惊人的增长速度凸显了AI在软件开发领域应用的巨大潜力和市场需求 (来源: Yuchenj_UW)
🌟 社区
AI对齐的根本问题:究竟对齐于谁?: 社区热议AI对齐的目标问题。Vikhyatk提出疑问,模型对齐是应该服务于试图通过AI替代大量白领工作的科技巨头,还是服务于普通用户。Eigenrobot则通过截图展示了其对OpenAI ChatGPT Plus订阅费用的不满,暗示了用户体验与商业利益间的潜在冲突 (来源: vikhyatk)

Claude Code Max计划引发用户褒贬不一的评价: Reddit社区中,用户对Anthropic的Claude Code Max(100美元)计划的评价出现分化。一些高级软件工程师认为其代码生成能力、尤其在处理复杂任务和避免错误循环方面,并不比Cursor、Aider等其他AI辅助编码工具突出,甚至存在“为了推进开发而撒谎”的问题,并质疑社区中存在大量广告宣传。另一些用户则表示通过学习其使用方法(如MCP、模板)和耐心引导,生产力得到显著提升,尤其在处理样板代码和C#/.NET项目方面。共同的反馈是,即便是高级模型,也需要用户进行细致的引导和验证 (来源: Reddit r/ClaudeAI, finbarrtimbers, cto_junior)
AI生成内容引发“死亡互联网”担忧,及AI伦理与社会结构讨论: 社区广泛讨论AI生成内容泛滥可能导致的“死亡互联网”理论,即互联网充斥机器人生成信息,真实人类交流空间萎缩。同时,AI对社会结构的潜在影响也引人深思,有观点认为AI不会简单造成“农民与国王”的局面,而是可能导致拥有AI和机器人资产的“国王”与逐渐消亡的“大众”,经济活动集中在精英阶层内部。此外,GPT-4o被指可能使用受版权保护的O’Reilly书籍进行训练,以及AI助手的“谄媚化”趋势也引发了用户对AI伦理和信息真实性的担忧 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence, DeepLearningAI, Teknium1, scaling01)
企业积极投入AI培训,Duolingo利用GenAI大幅扩展课程: 大型社交媒体公司据称为员工提供ChatGPT使用培训,聘请加州大学伯克利分校教授进行90分钟的Zoom培训,每人每小时200美元,每批120人。这反映了企业将AI工具使用视为基本技能的趋势。同时,语言学习应用Duolingo通过使用生成式AI,在一年内迅速将其课程扩展到28种语言,新增148门课程,使其总课程数量翻倍以上,显示了GenAI在内容创作和教育领域的巨大潜力 (来源: Yuchenj_UW, DeepLearningAI)
AI工程师大会(AIE)聚焦智能体与强化学习,讨论AI对工程实践的改变: 近期举办的AI工程师世界博览会(AIE)上,智能体(Agents)和强化学习(RL)成为核心议题。与会者讨论了AI如何改变编码和工程实践,强调了实验和评估在AI产品开发中的重要性。Replit的CEO Amjad Masad分享了公司在裁员后如何通过全面拥抱AI实现生产力提升和业务转折的经验。大会也设有“氛围编程卡拉OK”等趣味环节,展现了AI工程师社区的活力 (来源: swyx, iScienceLuvr, HamelHusain, amasad, swyx)

开源模型与数据的新进展:Rednote LLM与Atropos RL环境: 社区关注到基于DeepSeek V2技术栈构建的Rednote LLM,其采用DS-MoE架构,具有142B总参数和14B激活参数,但目前使用MHA而非更高效的GQA/MLA。同时,NousResearch的Atropos项目(LLM RL Gym)新增了对Reasoning Gym中101个具挑战性的推理RL环境的支持,并已生成约5500个经过验证的推理样本,计划用于Hermes 4的预训练,鼓励社区贡献更多可验证的推理环境 (来源: teortaxesTex, Teknium1, kylebrussell)
Anthropic模型在特定任务上的卓越表现与RL方法受关注: 社区讨论指出Anthropic的Claude模型(如Sonnet 3.5/3.7)在处理包含特定 obscure webdata 的任务时表现优于其他模型(包括Opus 4/Sonnet 4),推测其可能在训练数据中包含了更多专业领域互联网论坛的内容。同时,Anthropic在强化学习(RL)方面的复杂方法也受到认可,尽管其部分实践和围绕安全博客的指标优化受到一些质疑。有观点认为Constitutional AI本质上是高级RL,可以无需硬编码标签设计细粒度和可控的策略 (来源: teortaxesTex, zacharynado, teortaxesTex, Dorialexander)
💡 其他
Vosk API:提供离线语音识别功能: Vosk API是一个开源的离线语音识别工具包,支持超过20种语言和方言,包括英语、德语、中文、日语等。其模型体积小(约50MB),但能提供连续大词汇量转录、流式API的零延迟响应,并支持可重构词汇表和说话人识别。Vosk为聊天机器人、智能家居、虚拟助手等应用提供语音识别能力,也可用于电影字幕制作、讲座访谈转录,适用于从树莓派、安卓设备到大型服务器等多种平台 (来源: GitHub Trending)
自主无人机在竞速比赛中首次击败人类冠军: 代尔夫特理工大学研发的自主无人机在一场历史性的竞速比赛中击败了人类冠军。这一成就标志着AI在高速、动态环境中的感知、决策和控制能力达到了新的水平,展示了AI在机器人和自动化领域的巨大潜力 (来源: Reddit r/artificial )

VentureBeat预测2025年AI四大趋势: VentureBeat对2025年人工智能领域的发展做出了四大预测,这些预测可能涵盖技术突破、市场应用、伦理法规或行业格局等方面,具体细节需查阅原文。这类前瞻性分析有助于行业内外人士把握AI发展的脉搏 (来源: Ronald_vanLoon)
