
关键词:Gemini 2.5 Pro, VeBrain, Segment Anything Model 2, Qwen3-Embedding, AI Agent, Gemini 2.5 Pro Deep Think模式, VeBrain通用具身智能大脑框架, SAM 2图像视频分割, Qwen3-Embedding 32k上下文, AI Agent多模态理解
🔥 聚焦
谷歌发布多项AI新进展,Gemini 2.5 Pro Deep Think模式提升复杂推理能力: 在Google I/O大会上,谷歌宣布了Gemini 2.5 Pro的Deep Think模式,旨在显著增强AI在处理复杂问题(如USAMO级别的数学难题)时的推理能力。同时,谷歌还推出了AlphaEvolve,一个由Gemini驱动的编码智能体,用于算法发现,已在矩阵乘法算法设计和解决开放数学问题上取得成果,并应用于优化谷歌内部的数据中心、芯片设计和AI训练效率。此外,视频模型Veo 3、图像模型Imagen 4以及AI剪辑工具FLOW也一同发布,展示了谷歌在多模态AI领域的全面布局和快速进展。 (来源: OriolVinyalsML, demishassabis, demishassabis, op7418)
上海AI实验室联合发布通用具身智能大脑框架VeBrain: 上海人工智能实验室联合多家单位推出了VeBrain(Visual Embodied Brain),一个旨在统一视觉感知、空间推理和机器人控制能力的通用具身智能大脑框架。该框架通过将机器人控制任务转化为MLLM中的2D空间文本任务(如关键点检测和具身技能识别),并引入“机器人适配器”实现从文本决策到真实动作的精准映射和闭环控制。为支持模型训练,团队构建了VeBrain-600k数据集,包含60万条指令数据,覆盖多模态理解、视觉-空间推理和机器人操作三类任务。测试表明,VeBrain在多模态理解、空间推理及真实机器人控制(机械臂和机器狗)方面均达到SOTA水平。 (来源: 量子位)

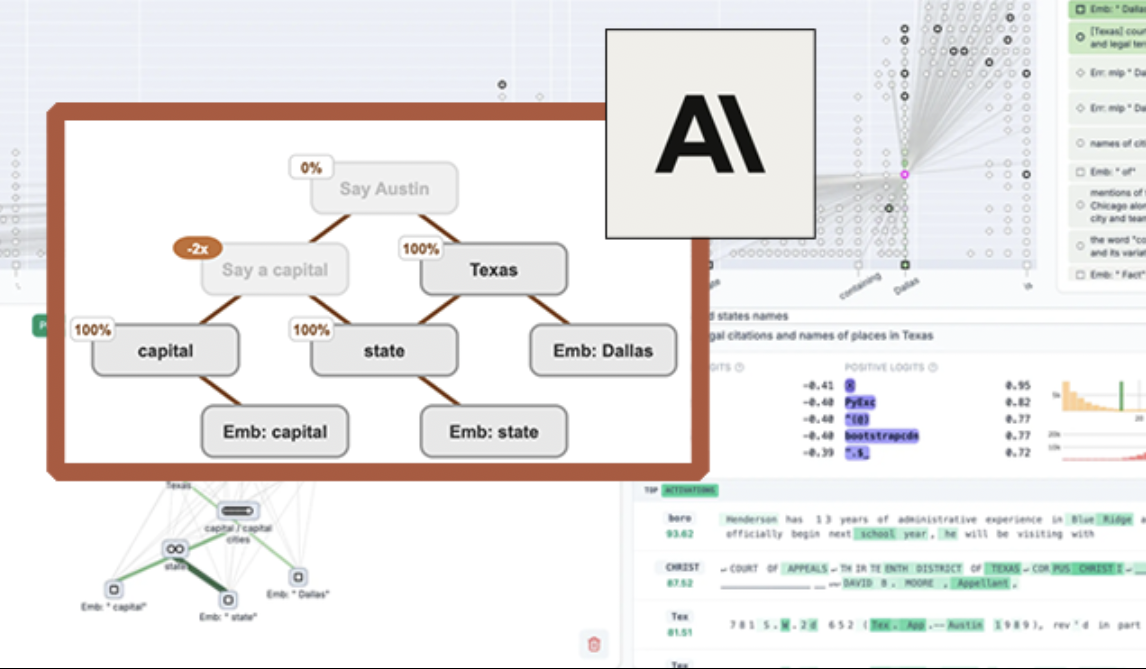
Anthropic开源LLM可视化工具“电路追踪”,提升模型可解释性: Anthropic推出了“电路追踪”(circuit tracing)开源工具,旨在帮助研究人员理解大型语言模型(LLM)的内部工作机制。该工具通过生成“归因图”(attribution graphs),可视化模型处理信息时内部超节点及其连接关系,类似于神经网络示意图。研究人员可以通过干预节点激活值并观察模型行为变化,来验证各节点功能,解码LLM的决策逻辑。该工具支持在主流开源模型上生成归因图,并提供交互式前端界面Neuronpedia进行可视化、注释和分享。此举旨在推动AI可解释性研究,让更广泛的社区能探索和理解模型行为。 (来源: 量子位, swyx)
Meta发布Segment Anything Model 2 (SAM 2),提升图像视频分割能力: Meta AI研究院(FAIR)推出了SAM 2,这是其广受欢迎的Segment Anything Model的升级版。SAM 2是一个基础模型,专注于图像和视频中的可提示视觉分割任务,能够根据提示(如点、框、文本)精确识别和分割出图像或视频中的特定对象或区域。该模型现已开源,遵循Apache许可证,供研究人员和开发者免费使用和构建应用,进一步推动计算机视觉领域的发展。 (来源: AIatMeta)
🎯 动向
智源研究院开源Video-XL-2,单卡实现万帧视频理解: 智源研究院联合上海交通大学等机构发布了新一代超长视频理解模型Video-XL-2。该模型在效果、处理长度和速度上均有显著提升,单卡即可处理万帧视频输入,编码2048帧视频仅需12秒。Video-XL-2采用SigLIP-SO400M视觉编码器、动态Token合成模块(DTS)及Qwen2.5-Instruct大语言模型,并通过四阶段渐进式训练和效率优化策略(如分段式预装填和双粒度KV解码)实现高性能。模型在MLVU、Video-MME等基准测试中表现优异,权重已开源。 (来源: 量子位)

Character.ai上线AvatarFX视频生成功能,图片人物可动可交互: 领先的AI陪伴应用Character.ai(c.ai)推出了AvatarFX功能,允许用户将静态图片中的人物(包括宠物等非人类形象)动画化,使其能够说话、唱歌并与用户互动。该功能基于DiT架构,强调高保真度和时间一致性,即使在多角色、长序列对话等复杂场景下也能保持稳定。目前AvatarFX已在网页版向所有用户开放,APP端即将上线。同时,c.ai还宣布了Scenes(互动故事场景)、Imagine Animated Chat(动画化聊天记录)和Stream(角色间故事生成)等新功能,进一步丰富AI创作体验。 (来源: 量子位)

Nvidia推出Llama-3.1 Nemotron-Nano-VL-8B-V1视觉语言模型: Nvidia发布了新的视觉到文本模型Llama-3.1-Nemotron-Nano-VL-8B-V1,该模型能够处理图像、视频和文本输入,并生成文本输出,具备一定程度的图像推理和识别能力。这一模型的发布是Nvidia在多模态AI领域持续投入的体现。同时,社区讨论指出,Llama-4放弃70B以下模型可能为Gemma3和Qwen3等模型在微调市场带来机会。 (来源: karminski3)
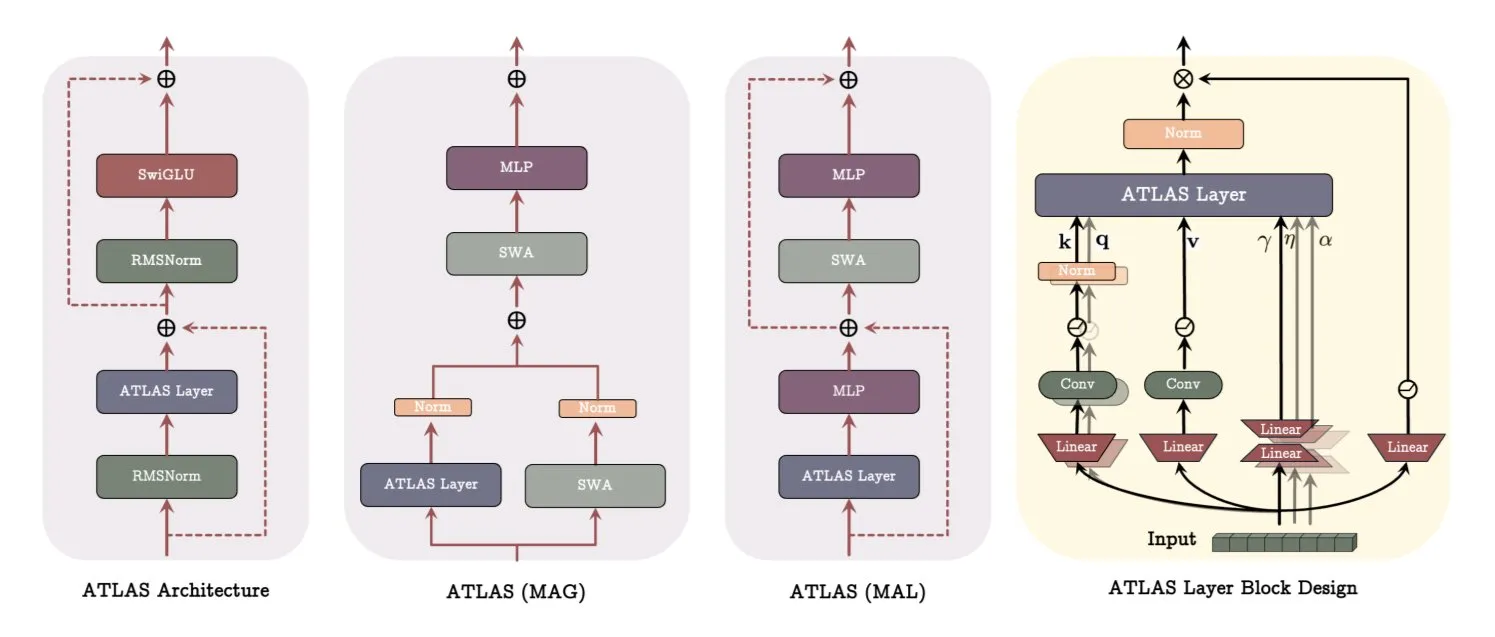
谷歌发布ATLAS架构论文,革新模型学习与记忆方式: 谷歌最新论文介绍了一种名为ATLAS的新型模型架构,旨在通过主动记忆(Omega规则处理最近c个token)和更智能的内存容量管理(多项式和指数特征映射)来优化模型的学习和记忆能力。ATLAS采用Muon优化器进行更有效的内存更新,并引入DeepTransformers和Dot(Deep Omega Transformers)等设计,用可学习的、内存驱动的机制替代传统固定注意力。该研究标志着AI向更智能、上下文感知系统迈进,有望提升AI处理和利用大规模数据集的能力。 (来源: TheTuringPost)
Qwen发布Qwen3-Embedding系列模型,大幅提升嵌入性能: Qwen团队发布了新的Qwen3-Embedding模型系列,包括0.6B、4B和8B三个版本。这些模型支持高达32k的上下文长度和100种语言,在MTEB(Massive Text Embedding Benchmark)上取得了SOTA成绩,部分指标领先第二名10个点。这一进展标志着文本嵌入技术的又一重要突破,为语义搜索、RAG等应用提供了更强大的基础。 (来源: AymericRoucher, ClementDelangue)

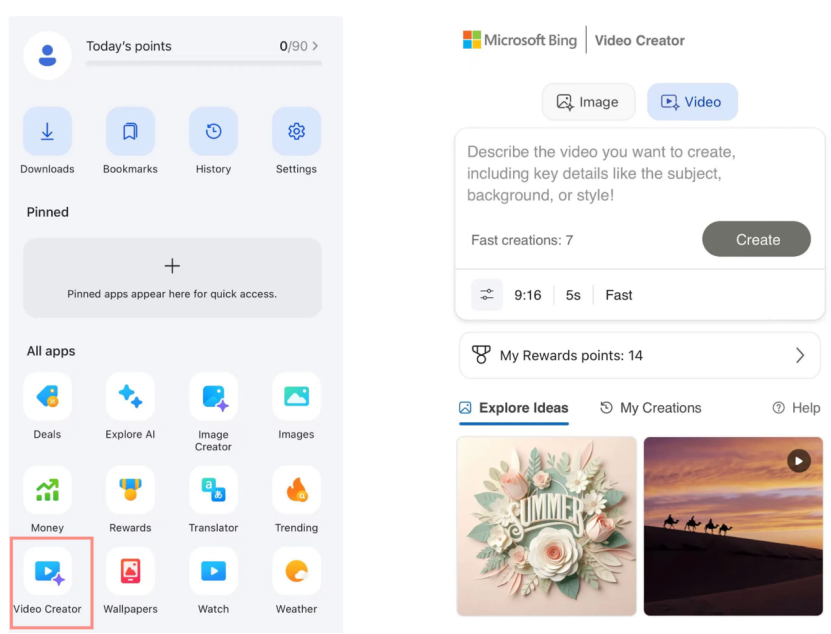
微软Bing视频创作器上线,基于OpenAI Sora模型免费开放: 微软在其Bing应用程序中推出了Bing视频创作器(Bing Video Creator),该功能基于OpenAI的Sora模型,允许用户通过文本提示免费生成视频。这是Sora模型首次大规模面向公众免费开放。尽管免费,但目前功能存在限制,如视频长度仅5秒、9:16比例、生成速度较慢等。用户反馈显示,其效果与当前SOTA视频模型(如可灵、Veo3)相比存在差距,引发了关于Sora技术迭代速度和微软产品策略的讨论。 (来源: 36氪)
OpenAI推出多项企业级功能,增强工作场所集成: OpenAI发布了一系列针对企业用户的新功能,包括为Google Drive等应用提供专用连接器,以及在ChatGPT中实现会议记录、转录和摘要功能,并支持SSO(单点登录)和基于积分的企业版定价。这些更新旨在将ChatGPT更深入地集成到企业工作流程中,提升办公效率。 (来源: TheRundownAI, EdwardSun0909)
Hugging Face发布高效机器人模型SmolVLA,可在MacBook上运行: Hugging Face推出了一款名为SmolVLA的机器人模型,其特点是效率极高,甚至可以在MacBook上运行。该模型在少量(如31个)演示数据上进行微调后,即可在特定任务(如Koch Arm操作)上达到或超过单任务基线的性能,显示了其在资源受限环境下部署机器人AI的潜力。 (来源: mervenoyann, sytelus)
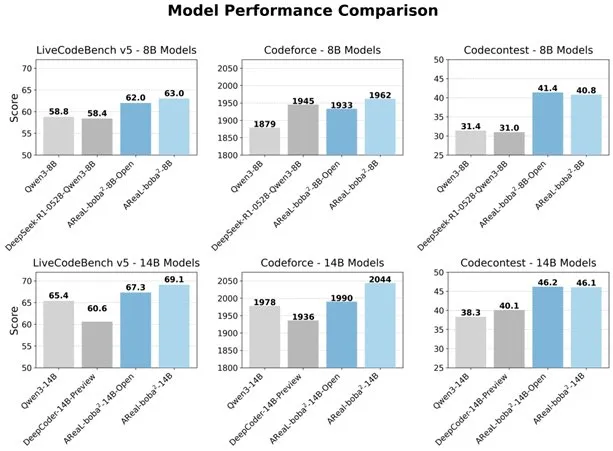
阿里巴巴开源全异步RL系统AReaL-boba²,提升LLM代码能力: 阿里巴巴Qwen团队开源了全异步强化学习系统AReaL-boba²,专为大型语言模型(LLM)设计,并在Qwen3-14B上实现了SOTA的代码强化学习效果。该系统通过系统与算法的协同设计,实现了2.77倍的训练加速,在LiveCodeBench上达到69.1分,并支持多轮强化学习。 (来源: _akhaliq)
DuckDB推出DuckLake扩展,集成数据湖与目录格式: DuckDB发布了DuckLake扩展,这是一个基于SQL和Parquet的开放湖仓一体格式。DuckLake将元数据存储在目录数据库中,数据存储在Parquet文件中,通过此扩展,DuckDB可以直接读写DuckLake中的数据,支持表的创建、修改、查询、时间旅行和模式演进等功能,旨在简化数据湖的构建和管理。 (来源: GitHub Trending)
Model Context Protocol (MCP) Ruby SDK发布: Model Context Protocol (MCP) 发布了官方Ruby SDK,该SDK与Shopify合作维护,用于实现MCP服务器。MCP旨在为AI模型(尤其是Agent)提供一种标准化的方式来发现和调用工具、访问资源和执行预定义提示。该SDK支持JSON-RPC 2.0,并提供了工具注册、提示管理、资源访问等核心功能,方便开发者构建符合MCP规范的AI应用。 (来源: GitHub Trending)
AI技术助力锌电池实现99.8%效率和4300小时运行: 通过人工智能优化,新一代锌电池实现了99.8%的库伦效率和长达4300小时的运行时间。AI在材料科学领域的应用,特别是在电池设计和性能预测方面,正推动储能技术的突破,有望为电动汽车、便携式电子设备等领域带来更高效、更持久的能源解决方案。 (来源: Ronald_vanLoon)

🧰 工具
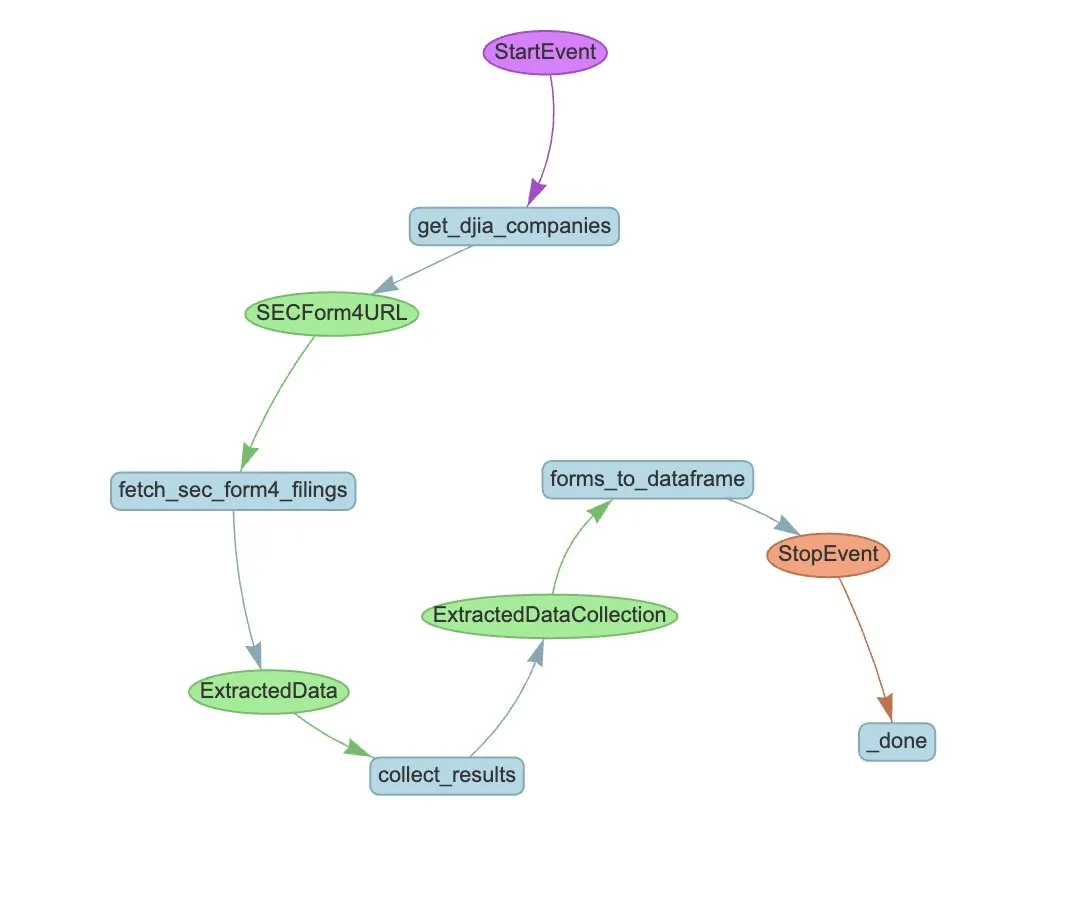
LlamaIndex推出LlamaExtract与Agent工作流自动化SEC Form 4提取: LlamaIndex展示了如何使用LlamaExtract和Agent工作流来自动从SEC Form 4文件中提取结构化信息。SEC Form 4是上市公司高管、董事和主要股东披露股票交易的重要文件。通过构建提取代理和可扩展的工作流,可以高效处理道琼斯工业平均指数中所有公司的Form 4申报文件,提升市场透明度和数据分析效率。 (来源: jerryjliu0)
Cognee:为AI Agent提供动态记忆的开源工具: Cognee是一个旨在为AI Agent提供动态记忆能力的开源项目,号称仅需5行代码即可集成。它通过构建可扩展、模块化的ECL(Extract, Cognify, Load)管道,帮助Agent互联和检索过去的对话、文档、图像和音频转录,以取代传统的RAG系统,降低开发难度和成本,并支持从30多种数据源进行数据处理和加载。 (来源: GitHub Trending)
Claude Code现已向Pro用户开放,并推出社区版GitHub Action: Anthropic的AI编程助手Claude Code已向Pro订阅用户开放,用户可以通过JetBrains IDE插件等方式使用。社区开发者还推出了一个Claude Code GitHub Action的fork版本,允许付费用户在GitHub Issues或PR中直接调用Claude Code,利用其订阅配额完成代码审查、问题解答等任务,而无需额外支付API费用。 (来源: Reddit r/ClaudeAI, Reddit r/ClaudeAI)
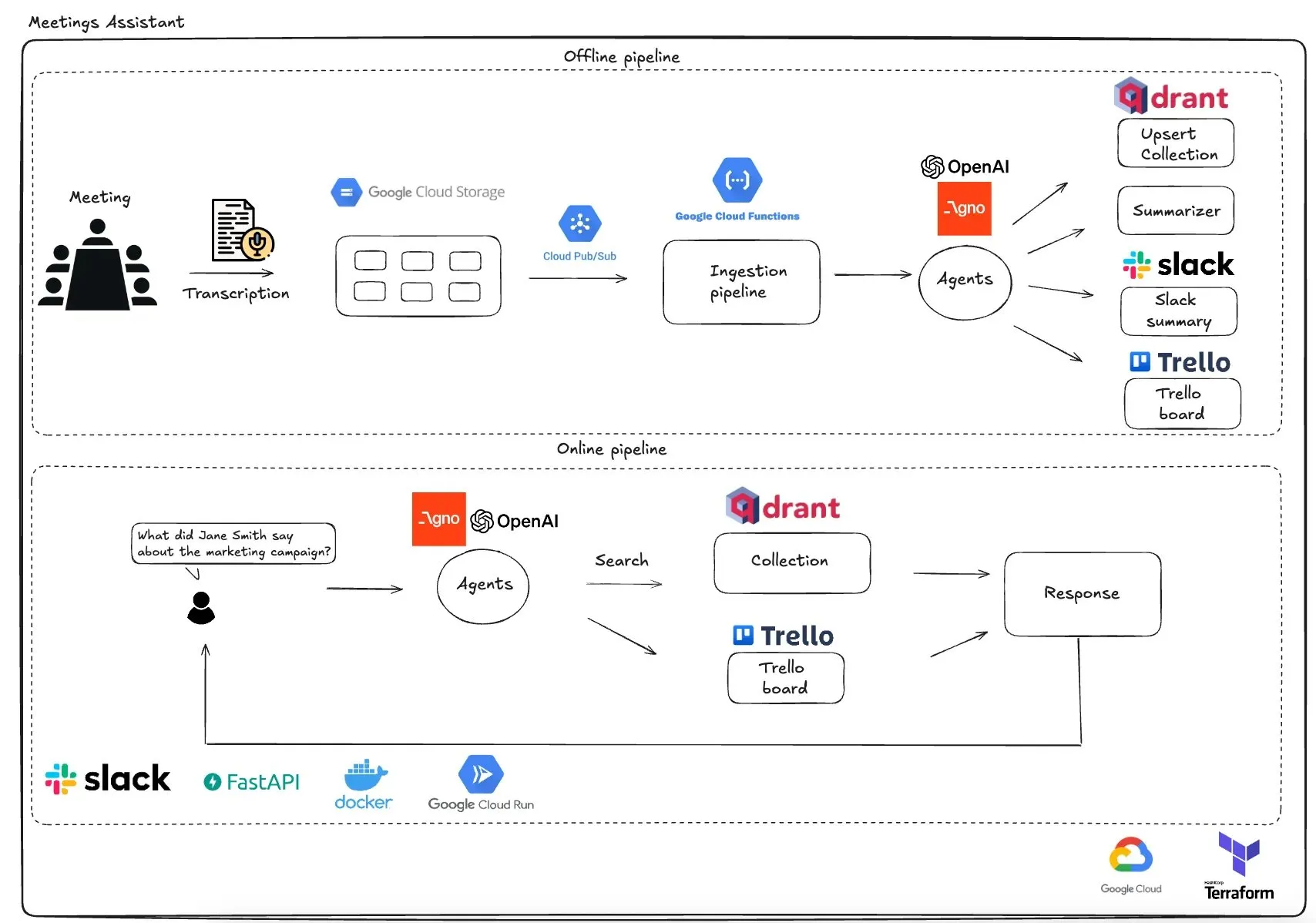
Qdrant推出基于GCP的多智能体会议助手: Qdrant展示了一个完全无服务器的多智能体会议助手系统。该系统能够转录会议内容,使用LLM智能体进行总结,将上下文信息存储在Qdrant向量数据库中,并将任务同步到Trello,最终结果直接在Slack中交付。该系统利用AgnoAgi进行智能体编排,FastAPI在Cloud Run上运行,并使用OpenAI进行嵌入和推理。 (来源: qdrant_engine)
微软发布GUI-Actor,实现无坐标GUI元素定位: 微软在Hugging Face上发布了GUI-Actor,这是一种无需坐标的GUI(图形用户界面)元素定位方法。该方法允许AI智能体通过一个特殊的<actor> token直接指向原生的视觉区块(visual patches),而非依赖基于文本的坐标预测,旨在提升GUI智能体操作的准确性和鲁棒性。 (来源: _akhaliq)

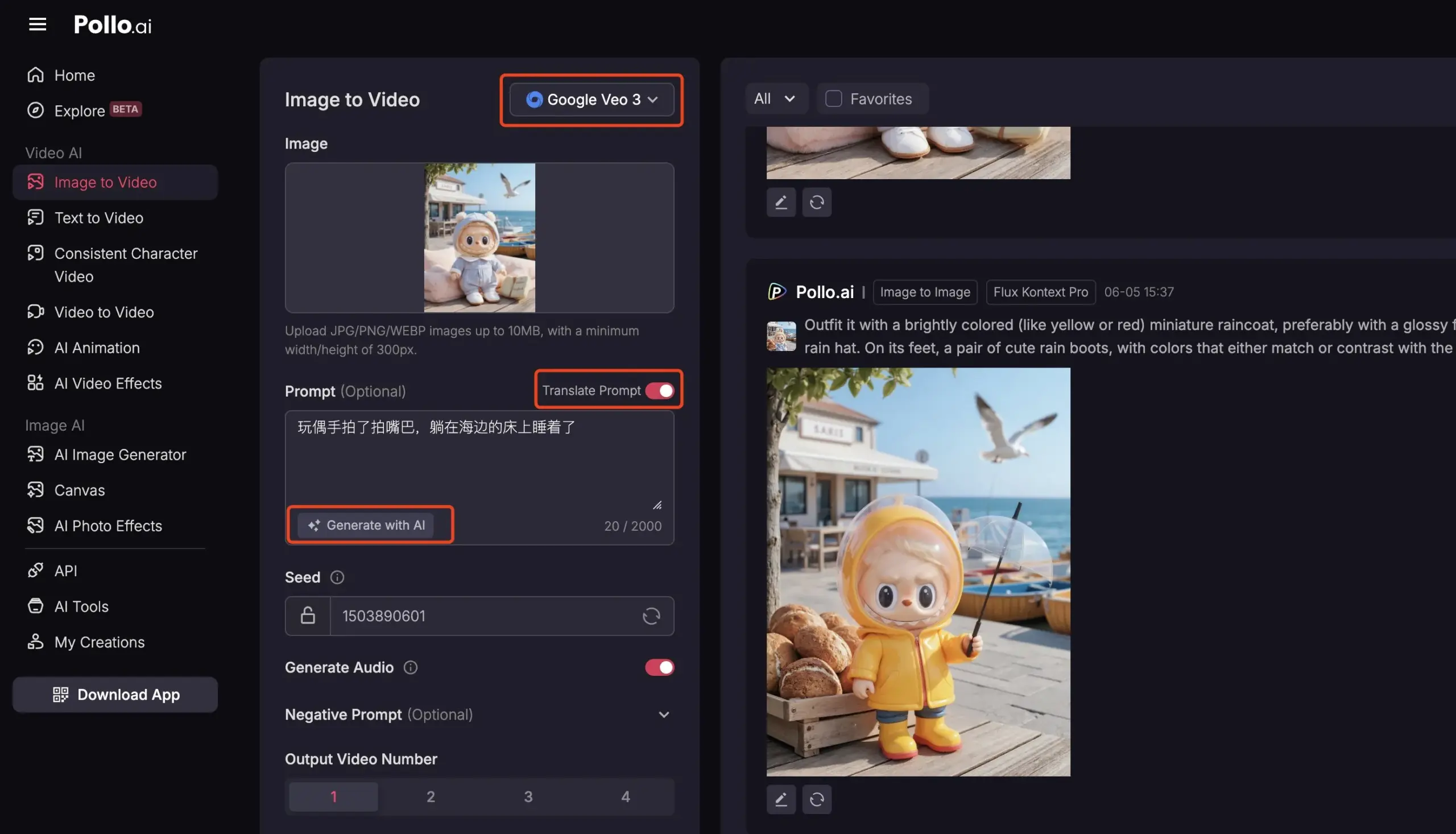
Pollo AI集成Veo3与FLUX Kontext,提供全面AI视频服务: AI工具平台Pollo AI近期更新频繁,集成了Google Veo3视频生成模型和FLUX Kontext图像编辑功能。用户可以在该平台使用FLUX Kontext修改图片后直接发送给Veo3生成视频。平台还提供了API接口,支持一次性接入市面上多种主流视频大模型,并内置AI提示词生成、多语言翻译等辅助功能,旨在提升AI视频创作的便捷性和效率。 (来源: op7418)
📚 学习
Meta-Learning深度解析:让AI学会如何学习: Meta-Learning(元学习),又称“学会学习”,其核心思想是训练模型使其能够快速适应新任务,即使只有少量样本。该过程通常涉及两个模型:基础学习器(base-learner)在内部学习循环中快速适应具体任务(如少样本图像分类),元学习器(meta-learner)在外部学习循环中管理和更新基础学习器的参数或策略,以提升其解决新任务的能力。训练完成后,基础学习器会利用元学习器学到的知识进行初始化。 (来源: TheTuringPost, TheTuringPost)

论文解读《A Controllable Examination for Long-Context Language Models》: 该论文针对现有长上下文语言模型(LCLM)评估框架的局限性(真实世界任务复杂难解、易受数据污染;合成任务如NIAH缺乏上下文连贯性),提出了理想评估框架应具备的三个特征:无缝上下文、可控设置和健全评估。并推出了LongBioBench,一个利用人工生成的传记作为受控环境,从理解、推理和可信度维度评估LCLM的新基准。实验表明多数模型在语义理解、初步推理及长上下文可信度方面仍有不足。 (来源: HuggingFace Daily Papers)
论文解读《Advancing Multimodal Reasoning: From Optimized Cold Start to Staged Reinforcement Learning》: 受Deepseek-R1在复杂文本任务中卓越推理能力的启发,该研究探讨了如何通过优化冷启动和分阶段强化学习(RL)来提升多模态大型语言模型(MLLM)的复杂推理能力。研究发现,有效的冷启动初始化对增强MLLM推理至关重要,仅用精心挑选的文本数据初始化就能超越许多现有模型。标准GRPO应用于多模态RL时存在梯度停滞问题,而后续的纯文本RL训练能进一步增强多模态推理。基于这些发现,研究者推出了ReVisual-R1,在多个挑战性基准上取得了SOTA成绩。 (来源: HuggingFace Daily Papers)
论文解读《Unleashing the Reasoning Potential of Pre-trained LLMs by Critique Fine-Tuning on One Problem》: 该研究提出了一种高效释放预训练LLM推理潜力的方法:单问题批判性微调(Critique Fine-Tuning, CFT)。通过收集模型对单个问题生成的多种解决方案,并利用教师LLM提供详细批判,构建批判数据进行微调。实验表明,对Qwen和Llama系列模型进行单问题CFT后,在多种推理任务上均取得显著性能提升,例如Qwen-Math-7B-CFT在数学和逻辑推理基准上平均提升15-16%,计算成本远低于强化学习。 (来源: HuggingFace Daily Papers)
论文解读《SVGenius: Benchmarking LLMs in SVG Understanding, Editing and Generation》: 为解决现有SVG(可缩放矢量图形)处理基准覆盖范围有限、缺乏复杂度分层和评估范式 fragmented 的问题,SVGenius应运而生。它是一个包含2377个查询的综合基准,覆盖理解、编辑和生成三个维度,基于24个应用领域的真实数据构建,并进行了系统性复杂度分层。通过8个任务类别和18个指标评估了22个主流模型,揭示了当前模型在处理复杂SVG时的局限性,并指出推理增强训练比纯粹扩展规模更有效。 (来源: HuggingFace Daily Papers)
Hugging Face Hub更新日志发布: Hugging Face Hub发布了其最新的更新日志,用户可以查阅以了解平台新增功能、模型库更新、数据集扩充以及工具链改进等最新动态。这有助于社区用户及时了解并利用Hugging Face生态系统的最新资源和能力。 (来源: huggingface, _akhaliq)
Maxime Labonne等作者开源大量LLM Notebooks: LLM工程师手册的作者Maxime Labonne和Iustin Paul开源了一系列LLM相关的Jupyter Notebooks。这些Notebooks内容丰富,不仅包含基础的微调技术,还涵盖了自动评估、懒惰合并(lazy merges)、混合专家模型(frankenMoEs)构建以及解除审查技巧等高级主题,为LLM开发者和研究者提供了宝贵的实战资源。 (来源: maximelabonne)
DeepLearningAI发布The Batch周报,探讨AI Fund如何培养AI建设者: Andrew Ng在其最新一期The Batch周报中,分享了AI Fund在培养AI人才和建设者方面的经验与策略。本期周报还涵盖了DeepSeek新开源模型性能比肩顶级LLM、Duolingo利用AI扩展语言课程、AI的能源消耗权衡以及恶意链接对AI Agent的潜在误导等热点话题。 (来源: DeepLearningAI)

💼 商业
Reddit起诉Anthropic,指控其未经授权使用用户数据训练AI: Reddit已对AI公司Anthropic提起诉讼,指控其未经许可使用自动化机器人抓取Reddit内容,用于训练其AI模型(如Claude),构成了合同违约和不正当竞争。此案凸显了当前AI发展中数据抓取和模型训练合法性的争议,也反映了内容平台对其数据价值保护的日益重视。 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence, TheRundownAI)

亚马逊计划投资100亿美元在北卡罗来纳州建设AI数据中心: 亚马逊宣布将在北卡罗来纳州投资100亿美元建设新的数据中心,以支持其日益增长的AI业务需求。这一举措反映了大型科技公司在AI基础设施方面的持续投入,旨在满足AI模型训练和推理所需的大规模计算和存储资源。 (来源: Reddit r/artificial)

Anthropic削减对Windsurf.ai的Claude模型API访问权限,引发平台风险担忧: AI应用开发平台Windsurf.ai透露,Anthropic在仅提前不到5天通知的情况下,大幅削减了其对Claude 3.x和Claude 4模型的API访问容量。此举迫使Windsurf.ai紧急寻求第三方供应商以保障付费用户服务,并为免费和Pro用户提供BYOK(自带密钥)选项。这一事件加剧了开发者对AI模型提供商平台风险的担忧,即模型提供商可能随时调整服务策略,甚至与下游应用形成竞争。 (来源: swyx, scaling01, mervenoyann)
🌟 社区
AI工程师大会(@aiDotEngineer)热议,聚焦Agent设计与AI创业: 在旧金山举行的AI工程师大会(@aiDotEngineer)成为社区热议焦点。LlamaIndex分享了生产环境中有效的Agent设计模式;Anthropic在会上发出了针对初创企业的“需求清单”,关注MCP服务器在新领域的应用、简化服务器构建及AI应用安全(如工具投毒);Graphite展示了AI驱动的代码审查工具。大会还讨论了扩展下一代GPT模型面临的基础研究挑战等议题。 (来源: swyx, swyx, swyx, iScienceLuvr)

研究员Rohan Anil加入Anthropic引关注: 研究员Rohan Anil宣布将加入Anthropic团队,这一消息在AI社区引起广泛关注和讨论。许多业内人士和关注者对此表示祝贺,并期待其为Anthropic的研究工作带来新的贡献。这也反映出顶级AI人才的流动对行业格局的潜在影响。 (来源: arohan, gallabytes, andersonbcdefg, scaling01, zacharynado)
法院要求OpenAI保留所有ChatGPT日志,引发数据保留策略讨论: 据悉,OpenAI被法院要求保留所有ChatGPT日志,包括“临时聊天”和本应删除的API请求。这一消息引发了社区对数据保留策略的讨论,特别是对于使用OpenAI API的应用而言,这可能意味着它们自身的数据保留政策将无法得到完全遵守,从而对用户隐私和数据管理带来新的挑战。建议用户在可能的情况下优先使用本地模型以保护数据。 (来源: code_star, TomLikesRobots)

AI生成内容的泛滥与“AI Slop”现象引担忧: 社交媒体上低质量、博取眼球的AI生成内容(被称为“AI Slop”)日益增多,从Reddit上AI生成的帖子到Facebook上“虾耶稣”等AI图片,引发用户对信息质量和网络环境恶化的担忧。这些内容通常由机器人或寻求流量者廉价生成,旨在通过“参与诱饵”获取点赞和分享。研究指出,大量互联网流量已由“坏机器人”构成,它们传播虚假信息、窃取数据。这种现象不仅影响用户体验,也对民主和政治传播构成威胁,同时可能污染未来AI模型的训练数据。 (来源: aihub.org)

LLM成本讨论:Gemini性价比高,Claude 4编码成本引关注: 社区讨论指出,当前LLM的使用成本差异显著。例如,使用Gemini处理整个保险文件并进行大量提问的成本仅约0.01美元,显示出较高的性价比。相比之下,Claude 4模型虽然在编码等任务上表现出色,但在Cursor.ai等平台上的最大模式(max mode)使用成本较高,促使用户转向如Google Gemini 2.5 Pro等更具成本效益的选择。 (来源: finbarrtimbers, Teknium1)
AI Agent在真实网页场景中解决CAPTCHA(人机验证)面临挑战: MetaAgentX团队发布Open CaptchaWorld平台,专注于评估多模态交互智能体解决CAPTCHA的能力。测试显示,即便是GPT-4o等SOTA模型,在处理20种真实网页环境中的交互式验证码时,成功率也仅为5%-40%,远低于人类93.3%的平均成功率。这表明当前AI Agent在视觉理解、多步规划、状态跟踪和精确交互方面仍存在瓶颈,验证码成为其实际部署的一大障碍。 (来源: 量子位)

AI智能体培训市场火热,课程质量与就业前景引关注: 随着AI Agent概念的兴起,相关的培训课程也大量涌现。部分培训机构声称提供从入门到就业的全方位指导,甚至承诺“包就业”,学费从几百元到上万元不等。然而,市场上的课程质量参差不齐,部分课程被指内容浅显、过度营销,甚至与“割韭菜”的AI速成班类似。学员和观察者对这类培训的实际效果、讲师资质以及“包就业”承诺的真实性持谨慎态度,担心其可能成为AI发展过渡期的又一“伪需求”。 (来源: 36氪)

💡 其他
AI在机器人领域的应用进展:触觉感知手、两栖机器人与消防机器人狗: AI技术正推动机器人能力的边界。研究者开发出具有触觉感知能力的机械手,使其能更好地与环境交互。Copperstone HELIX Neptune展示了AI驱动的两栖机器人,能够在不同地形作业。中国则推出了能够喷射60米水柱、攀爬楼梯并进行救援直播的消防机器人狗。这些进展显示了AI在提升机器人感知、决策和执行复杂任务方面的潜力。 (来源: Ronald_vanLoon, Ronald_vanLoon, Ronald_vanLoon)

AI Agent与生成式AI的比较讨论: 社区中出现关于AI Agent(智能体AI)与生成式AI(Generative AI)之间区别和联系的讨论。生成式AI主要关注内容的创造,而AI Agent则更侧重于基于感知、规划、行动的自主决策和任务执行。理解两者的差异有助于更好地把握AI技术的发展方向和应用场景。 (来源: Ronald_vanLoon, Ronald_vanLoon)
探讨AI在复杂组织流程自动化中的挑战: AI在自动化或辅助特定任务方面已取得进展,但要取代人工或团队以实现更广泛的经济转型,面临巨大复杂性。许多组织存在未明确记录但至关重要的流程,这些流程风险高但偶发,且可能已成惯例以致原因被遗忘。AI智能体难以通过试错学习这类隐性知识,因其成本高昂且学习机会有限。这需要新的技术范式,而非简单的机器学习。 (来源: random_walker)