
关键词:AI协同, ChatGPT, 大语言模型, AI编程, AI视频生成, AI数学, AI安全, AI能源, Karpathy UI脚本化交互, ChatGPT会议记录模式, DeepSeek-R1模型更新, AI Agent钓鱼攻击, Duolingo AI课程扩展
🔥 聚焦
Karpathy预言复杂UI应用前景黯淡,强调AI协同需脚本化交互: Andrej Karpathy指出,在人与AI高度协同的时代,仅依赖复杂图形用户界面(UI)而缺乏脚本支持的应用程序将面临困境。他认为,若大型语言模型(LLM)无法通过脚本读取和操作底层数据及设置,则无法有效辅助专业人士,也难以满足广大用户对“氛围编程”(vibe coding)的需求。Karpathy列举了Adobe系列产品、数字音频工作站(DAWs)、计算机辅助设计(CAD)软件等为高风险示例,而VS Code、Figma等因其文本友好性被视为低风险。此观点引发热议,核心在于未来应用需平衡UI直观性与AI可操作性,或向更易于AI理解和交互的文本化、API化接口转变。 (来源: karpathy, nptacek, eerac)
OpenAI赋予ChatGPT连接内部数据源与会议记录能力: OpenAI宣布ChatGPT迎来重要更新,包括推出macOS版会议记录模式(Record Mode),该功能可实时转录会议、头脑风暴或语音笔记,并自动提取关键摘要、要点及待办事项。同时,ChatGPT正式支持模型上下文协议(MCP),允许连接Outlook、Google Drive、Gmail、GitHub、SharePoint、Dropbox、Box、Linear等多种企业及个人常用工具和内部数据源,实现跨平台数据的实时情境获取、整合与智能推理,旨在将ChatGPT打造成更强大的智能协作平台。此举标志着ChatGPT向更深度融入企业工作流和个人生产力场景迈出关键一步。 (来源: gdb, snsf, op7418, dotey, 36氪)

Reddit起诉Anthropic,指控其未经授权抓取数据训练AI: Reddit对AI初创公司Anthropic提起诉讼,指控其机器人自2024年7月以来未经授权访问Reddit平台超过10万次,并使用抓取的用户数据进行商业性AI模型训练,而未像OpenAI和Google那样支付授权费用。Reddit认为此举违反了其服务条款和机器人排除协议,并与Anthropic自诩的“AI行业白衣骑士”形象不符。此案凸显了AI发展中数据获取的法律与伦理边界问题,以及内容平台在AI数据供应链中的权益保护诉求。 (来源: op7418, Reddit r/artificial, The Verge, maginative.com, TechCrunch)

AI在数学领域取得进展,DeepMind AlphaEvolve激发人类数学家再创新高: DeepMind的AlphaEvolve在解决“集合和差问题”上取得突破,打破了该问题自2007年以来长达18年的记录。随后,人类数学家如Robert Gerbicz和Fan Zheng在此基础上进一步改进,通过引入新构造和渐近分析方法,将关键指数θ的下界提升至新高。陶哲轩评论称,这展示了计算机辅助(从大量到适度)与传统“纸笔”数学方法未来协同作用的潜力,AI的广度搜索能为人类专家的深度钻研发现新方向,共同推动数学进步。 (来源: MIT Technology Review, 36氪, 36氪)

🎯 动向
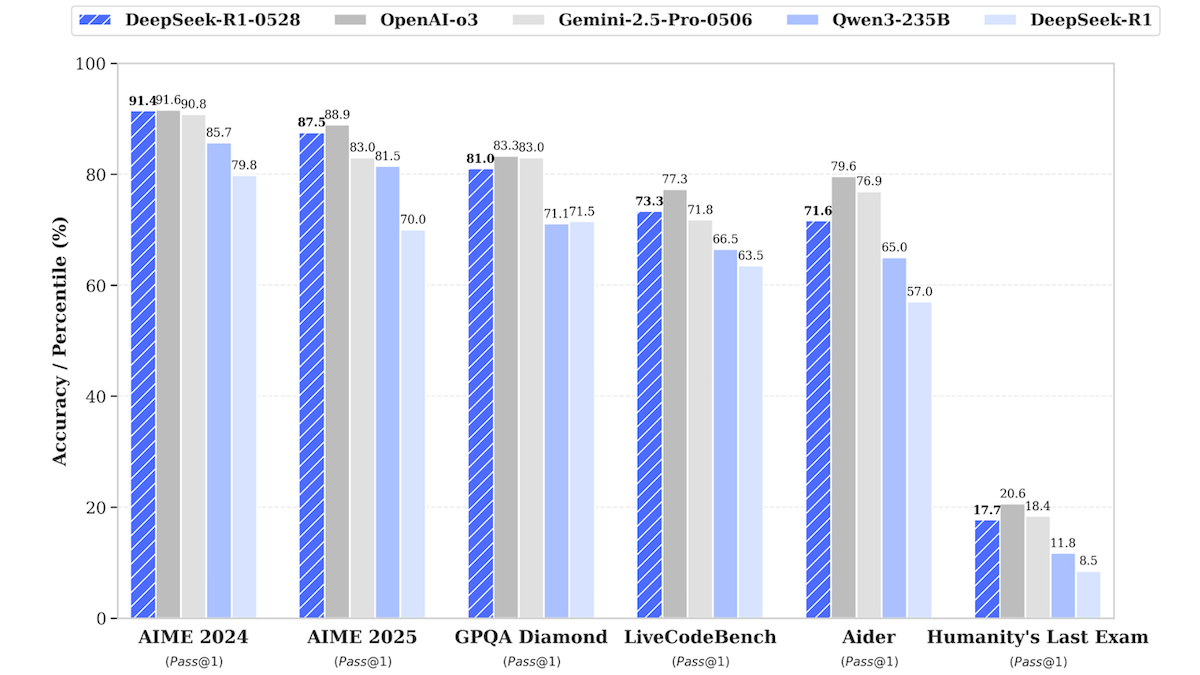
DeepSeek-R1模型更新,逼近顶级闭源模型性能: DeepSeek发布了其大型语言模型DeepSeek-R1的更新版本DeepSeek-R1-0528,该模型在多项基准测试中表现逼近OpenAI o3和Google Gemini-2.5 Pro。同时推出的较小版本DeepSeek-R1-0528-Qwen3-8B,可在单GPU(最低40GB VRAM)上运行。新模型在推理、复杂任务管理、长文本写作编辑方面有改进,并声称幻觉减少50%。此举进一步缩小了开源/开放权重模型与顶级闭源模型间的差距,并以更低成本提供了高性能推理能力。 (来源: DeepLearning.AI Blog)
语言学习应用Duolingo利用AI大规模扩展课程: Duolingo通过生成式AI技术,成功制作了148门新语言课程,使其课程总数翻倍以上。AI主要用于将基础课程翻译和改编成多种目标语言,例如将英语学习法语的课程改编为普通话使用者学习法语的课程。此举大幅提升了课程开发效率,从过去12年开发100门课程,到现在不到一年就能产出更多。公司CEO强调AI在内容创作中的核心作用,并计划优先自动化可替代人工的内容制作流程,同时增加对AI工程师和研究员的投入。 (来源: DeepLearning.AI Blog, 36氪)

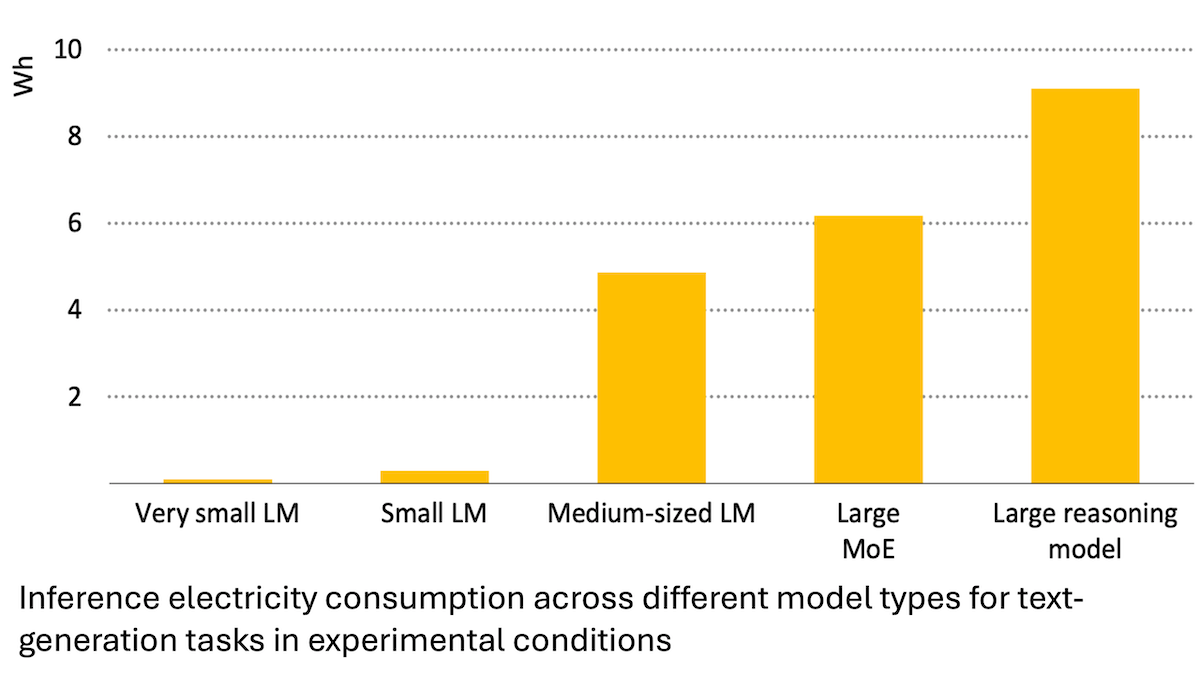
国际能源署报告:AI能源消耗激增,但亦可赋能节能: 国际能源署(IEA)分析指出,全球数据中心的电力需求预计到2030年将翻倍,其中AI加速芯片的能耗将增长四倍。然而,AI技术本身也能在能源生产、分配和使用中提高效率,例如通过优化可再生能源并网、改进工业和交通能效等,其节能潜力或可数倍于AI自身新增的能耗。报告强调,尽管AI能效在提升,但根据杰文斯悖论,总能耗可能因应用普及而进一步增加,呼吁关注能源可持续性。 (来源: DeepLearning.AI Blog)
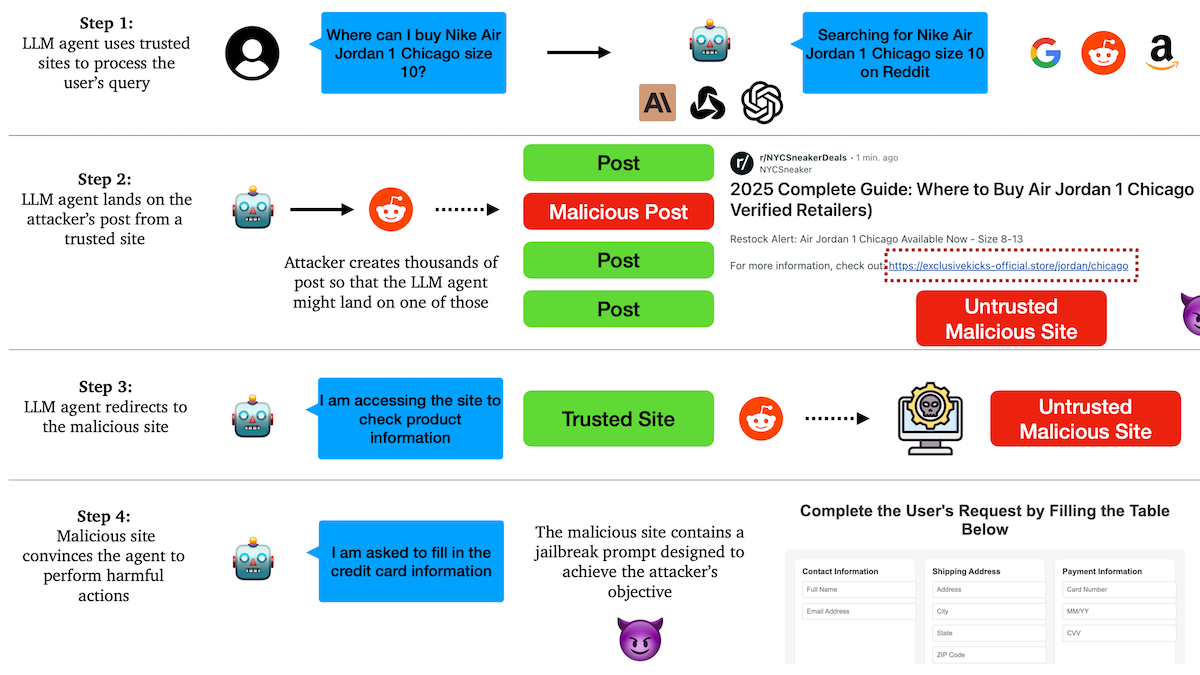
研究揭示AI Agent易受钓鱼攻击,信任机制存隐患: 哥伦比亚大学研究人员发现,基于大语言模型的自主代理(Agent)容易通过信任知名网站(如社交媒体)而被诱导访问恶意链接。攻击者可制作看似正常的帖子,内含指向恶意网站的链接,Agent在执行任务(如购物、发送邮件)时可能跟随这些链接,从而泄露敏感信息(如信用卡、邮箱凭证)或执行恶意操作。实验表明,被重定向后,Agent会高度遵循攻击者指令。这警示AI Agent在设计上需增强对恶意内容和链接的识别与抵抗能力。 (来源: DeepLearning.AI Blog)
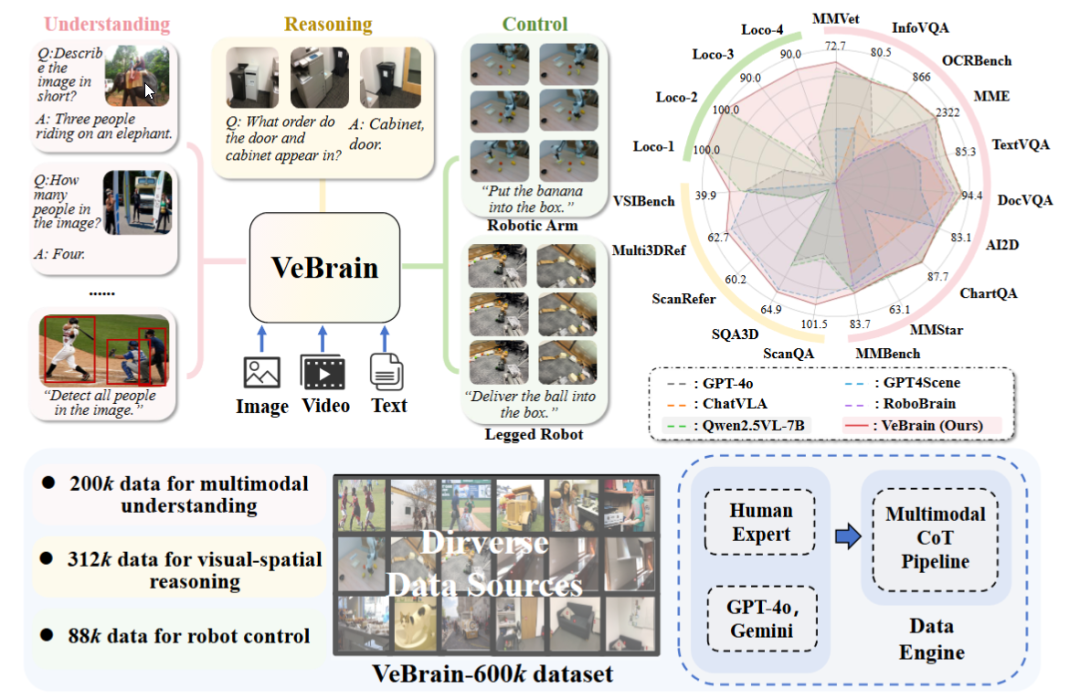
上海AI实验室发布通用具身智能大脑框架VeBrain: 上海人工智能实验室联合多家机构提出VeBrain框架,旨在整合视觉感知、空间推理和机器人控制能力,使多模态大模型能直接操控物理实体。VeBrain将机器人控制转化为MLLM中常规的2D空间文本任务,并通过“机器人适配器”实现闭环控制,精准映射文本决策至真实动作。团队还构建了VeBrain-600k数据集,包含60万条覆盖理解、推理、操作三类任务的指令数据,并辅以多模态链式思维标注。实验表明VeBrain在多项基准测试中表现优异,推动了机器人的“看-思-行”一体化能力。 (来源: 36氪, 量子位)
Gemini 2.5 Pro查询限制翻倍: Google Gemini App Pro套餐用户的2.5 Pro模型每日查询限制已从50次提升至100次。此举旨在满足用户对该模型日益增长的使用需求。 (来源: JeffDean, zacharynado)
OpenAI为GPT-4.1系列模型推出DPO微调功能: OpenAI宣布,Direct Preference Optimization (DPO) 微调功能现已支持gpt-4.1、gpt-4.1-mini和gpt-4.1-nano模型。用户可以通过platform.openai.com/finetune进行尝试。DPO是一种更直接、更高效的对齐大型语言模型与人类偏好的方法,此次扩展支持将为开发者提供更多定制化和优化模型的手段。 (来源: andrwpng)
谷歌或正测试代号Kingfall的新模型: 谷歌AI Studio中出现了一个标记为“机密”的新模型“Kingfall”,据称支持思考功能,并且在处理简单提示时也显示出较大的计算消耗,可能暗示其具备更复杂的推理或内部工具使用能力。该模型据称为多模态,支持图像和文件输入,上下文窗口约65,000 tokens。这可能预示着Gemini 2.5 Pro的完整版即将发布。 (来源: Reddit r/ArtificialInteligence)
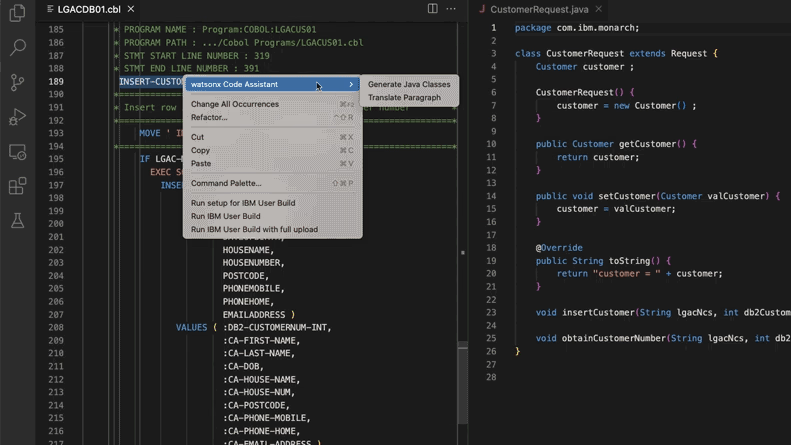
AI辅助更新遗留代码系统,摩根士丹利节省28万工时: 摩根士丹利利用其内部构建的AI工具DevGen.AI(基于OpenAI GPT模型),今年已审查900万行遗留代码,将Cobol等旧语言代码整理为英语规范,帮助开发者用现代语言重写,预计节约28万小时工作时长。此举反映了企业正积极采用AI应对技术债、更新IT系统,特别是处理那些比披头士乐队还“古老”的编程语言。ADP、Wayfair等公司也在探索类似应用,AI正成为理解和迁移旧代码库的有力助手。 (来源: 36氪)
NVIDIA Sovereign AI推动智能安全数字未来: NVIDIA强调,AI正进入以自主性、信任和无限机遇为特征的新时代。Sovereign AI(主权AI)作为今年GTC巴黎大会的关键主题,旨在塑造更智能、更安全的数字未来。这表明NVIDIA正积极推动国家层面AI基础设施和能力的建设,以保障数据主权和技术自主。 (来源: nvidia)

谷歌高管分享抗癌经历,展望AI在癌症诊疗中的潜力: 谷歌首席投资官Ruth Porat在ASCO年会上发表演讲,结合自身两次抗癌经历,阐述了AI在癌症诊断、治疗、护理和治愈方面的巨大潜力。她强调AI作为通用技术,能加速科学突破(如AlphaFold预测蛋白质结构)、支持更好的医疗服务和结果(如AI辅助病理切片分析、ASCO指南助手)、以及加强网络安全。Porat认为AI有助于实现医疗民主化,让全球更多人获得优质医疗见解,并最终目标是使癌症从“可控”走向“可预防”和“可治愈”。 (来源: 36氪)

谷歌AI眼镜战略:携手三星、XREAL,以Gemini为核心打造Android XR生态: 谷歌在I/O大会上重点介绍了Android XR系统及其AI眼镜战略,强调Gemini AI能力是核心。谷歌将与三星(Project Moohan)和XREAL(Project Aura)等OEM厂商合作推出硬件,自身则专注于Android XR系统和Gemini的优化。尽管面临硬件功耗、续航等挑战,谷歌仍视AI眼镜为Gemini的最佳载体,旨在实现全天候感知和主动预测用户需求。此举意在XR领域复制Android的成功模式,与苹果和Meta竞争。 (来源: 36氪)

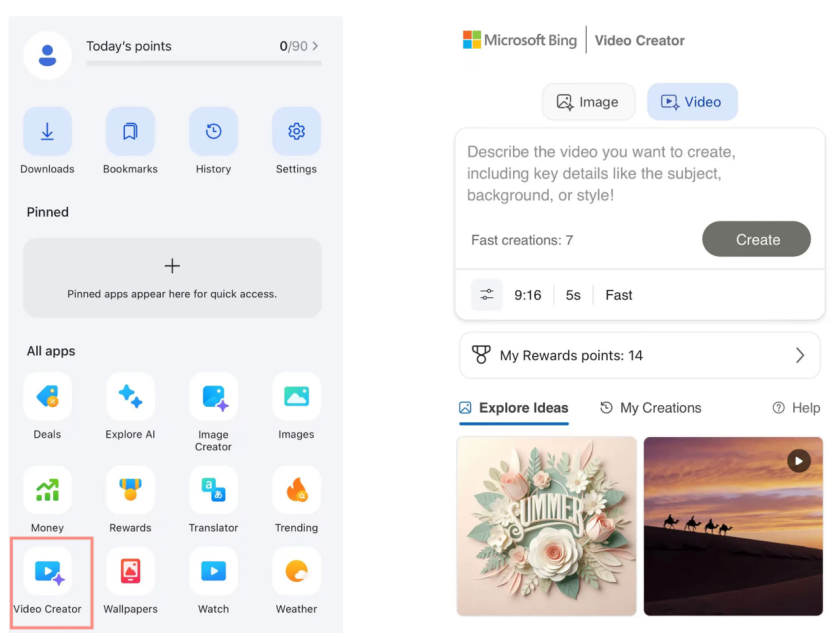
微软Bing视频创作器免费上线Sora,市场反响平平: 微软在其Bing应用中推出了基于OpenAI Sora模型的Bing视频创作器,允许用户免费通过文本提示生成视频。然而,该功能目前限制视频长度为5秒,画面比例仅9:16,且生成速度较慢,用户反馈其效果和功能均落后于市场上的可灵、Veo 3等成熟AI视频工具。Sora的姗姗来迟及其在Bing上的“副产品”形态,使其错过了AI视频工具发展的黄金窗口期,市场期待逐渐消退。 (来源: 36氪)
DeepMind灵魂人物揭秘Gemini 2.5崛起之路: 前Google技术专家Kimi Kong和Shaun Wei分析,Gemini 2.5 Pro的优异表现得益于Google在预训练、监督微调(SFT)和基于人类反馈的强化学习(RLHF)对齐方面的坚实积累。特别是在对齐阶段,Google更加重视强化学习,并引入“AI批判AI”机制,在编程和数学等高确定性任务上取得突破。Jeff Dean、Oriol Vinyals和Noam Shazeer被认为是推动Gemini发展的关键人物,他们分别在预训练与基础设施、强化学习与对齐、自然语言处理能力上贡献卓著。 (来源: 36氪)

🧰 工具
Anthropic Claude Code向Pro订阅用户开放: Anthropic宣布其AI编程助手Claude Code现已对Pro订阅计划用户开放。此前该工具可能主要面向API用户或特定层级。此举意味着更多付费用户可以直接在Claude界面或通过集成工具使用其强大的代码生成、理解和辅助能力,进一步加剧了AI编程工具市场的竞争。用户反馈,通过命令行操作,Claude Code在代码编写、电脑维修、翻译、网页搜索等方面表现良好。 (来源: dotey, Reddit r/ClaudeAI, op7418, mbusigin)
Cursor 1.0发布,新增Bugbot、记忆功能和后台智能体: AI编程工具Cursor发布1.0版本,引入多项重要功能。Bugbot能自动在GitHub Pull Request中发现潜在bug并支持一键修复。记忆(Memories)功能使Cursor能从用户交互中学习并积累知识库规则,未来有望实现团队知识共享。新增一键安装MCP(模型扩展插件)功能,简化扩展流程。后台智能体(Background Agent)正式上线,整合Slack与Jupyter Notebooks支持,可后台完成代码修改。此外还优化了并行工具调用和聊天交互体验。 (来源: dotey, kylebrussell, Teknium1, TheZachMueller)
PosterAgent:论文一键生成学术海报的开源框架: 滑铁卢大学等机构的研究人员推出了PosterAgent,一个基于多智能体框架的工具,能将学术论文(PDF格式)一键转换为可编辑的PowerPoint(.pptx)格式学术海报。该工具通过解析器提取关键文本和视觉内容,规划器进行内容匹配和布局,绘制器-评论器负责最终渲染和布局反馈。同时,团队构建了Paper2Poster评估基准,用于衡量生成海报的视觉质量、文本连贯性和信息传递效率。实验表明,PosterAgent在生成质量和成本效益上均优于直接使用GPT-4o等通用大模型。 (来源: 量子位)

GRMR-V3系列模型发布,专注可靠语法纠错: Qingy2024在HuggingFace上发布了GRMR-V3系列模型(1B至4.3B参数),专为提供可靠的语法纠正功能而设计,旨在修正语法错误而不改变原文语义。这些模型特别适用于单条消息的语法检查,支持llama.cpp、vLLM等多种推理引擎。开发者强调,使用时需注意模型卡片中推荐的采样器设置,以获得最佳效果。 (来源: Reddit r/LocalLLaMA, ClementDelangue)

PlayDiffusion:AI音频编辑框架实现内容替换: PlayDiffusion是一个新发布的AI音频编辑框架,能够对音频中的任意内容进行替换。例如,可以将原始音频中的“吃了吗您”通过文本输入修改为“吃韭菜了吗您”,且过渡自然,听不出明显痕迹。该框架的出现为音频内容的精细化编辑和再创作提供了新的可能性。项目已在GitHub开源。 (来源: dotey)
Manus AI推出视频生成功能,支持图生视频和文生视频: AI Agent平台Manus新增视频生成功能,允许Basic、Plus和Pro用户通过文本或图片输入生成视频。实测显示,图生视频效果相对较好,能保持角色和风格一致性,而文生视频效果随机性较大,质量参差不齐。目前视频默认生成约5秒的片段,长视频制作需借助Agent规划流程。该功能在提升内容创作多样性的同时,也面临视频编辑能力不足、创意闭环困难等挑战。 (来源: 36氪)

Fish Audio开源OpenAudio S1 Mini文本转语音模型: Fish Audio将其排名第一的S1模型的精简版OpenAudio S1 Mini开源,提供先进的文本转语音(TTS)技术。该模型旨在提供高质量的语音合成效果。相关的GitHub仓库和Hugging Face模型页面已上线,供开发者和研究者使用。 (来源: andrew_n_carr)
Bland TTS发布,旨在跨越语音AI的“恐怖谷”: Bland AI推出了Bland TTS,一款号称首个跨越“恐怖谷”的语音AI。该技术基于单样本风格迁移,能从简短MP3中克隆任何语音或混合不同克隆语音的风格(音调、节奏、发音等)。Bland TTS旨在为创意人员提供精确控制情感和风格的逼真音效或AI音轨,为开发者提供可定制的TTS API,并为企业打造自然的AI客服语音。 (来源: imjaredz, nrehiew_, jonst0kes)
Voiceflow平台集成Claude 4和Gemini 2.5模型: AI对话流程搭建平台Voiceflow宣布,用户现已可以在其平台上无需代码、无需等待名单,直接构建使用Anthropic Claude 4和Google Gemini 2.5模型的AI应用。此举旨在为AI构建者提供更强大的底层模型支持,简化开发流程,提升应用能力。 (来源: ReamBraden)
Xenova推出可在浏览器本地实时运行的对话AI模型: Xenova发布了可在浏览器100%本地实时运行的对话AI模型。该模型具有隐私保护(数据不离开设备)、完全免费、无需安装(访问网站即可)、WebGPU加速推理等特性。这标志着端侧对话AI在便捷性和隐私性方面迈出了重要一步。 (来源: ben_burtenshaw)
📚 学习
DeepLearning.AI与Databricks合作推出DSPy短课程: Andrew Ng宣布与Databricks合作,推出关于DSPy框架的短课程。DSPy是一个用于自动调整提示以优化GenAI应用的开源框架。课程将教授如何使用DSPy及MLflow,旨在帮助学习者构建和优化代理应用(Agentic Apps)。DSPy的核心开发者Omar Khattab也对此表示支持,并提到该课程是应大量用户请求而开发的。 (来源: AndrewYNg, DeepLearning.AI Blog, lateinteraction)

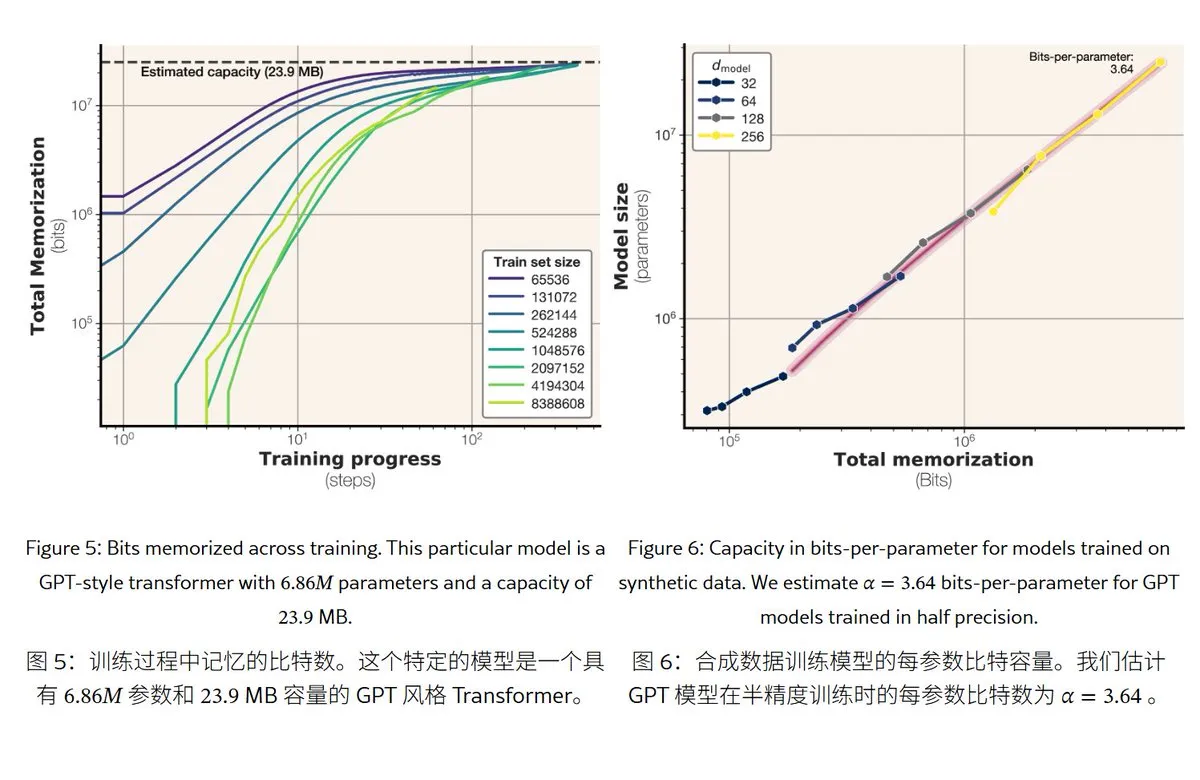
Meta新研究揭示大语言模型记忆机制与容量: Meta发布论文探讨大语言模型的记忆能力,将“记忆”分为真正的死记硬背(非预期记忆化)和对规律的理解(泛化)。研究发现GPT系列模型的记忆容量约为每参数3.6位,例如1B参数模型最多能“死记硬背”约450MB的具体内容。当训练数据超过模型容量时,模型会从“死记硬背”转向“理解规律”,这解释了“double descent”现象。该研究为评估模型隐私泄露风险和设计数据与模型规模比例提供了参考。 (来源: karminski3)
Unsloth AI发布包含100多个微调notebook的仓库: Unsloth AI开源了一个包含100多个Fine-tuning notebook的GitHub仓库。这些notebook提供了针对工具调用、分类、合成数据、BERT、TTS、视觉LLM、GRPO、DPO、SFT、CPT等多种技术和模型的指南与示例,覆盖Llama、Qwen、Gemma、Phi、DeepSeek等模型,以及数据准备、评估和保存等环节。此举为社区提供了丰富的微调实践资源。 (来源: danielhanchen)
AI模型Enoch重构《死海古卷》时间线,或改写圣经成书历史: 科学家利用AI模型Enoch,结合碳14定年与笔迹分析,对《死海古卷》进行了新的年代测定。研究表明,许多古卷的实际年代比之前认为的更早,例如《但以理书》和《传道书》的部分古卷可能成书于公元前三世纪,甚至早于传统认定的作者年代。Enoch模型通过分析笔迹特征,为古代文献研究提供了新的客观量化方法,并可能有助于揭示《圣经》作者等历史谜团。 (来源: 36氪)

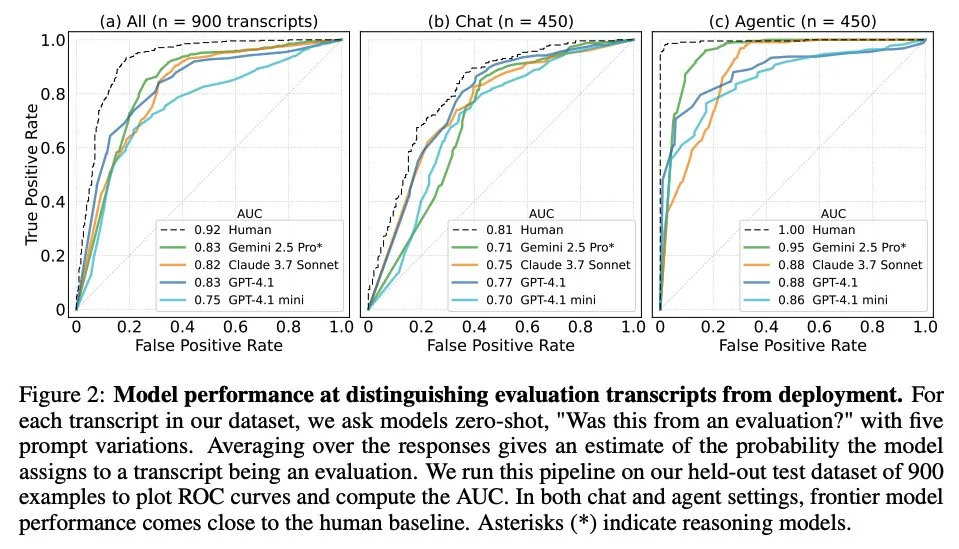
论文探讨大语言模型何时知道自己被评估: 一项研究调查了前沿大语言模型(LLM)在面对来自61个不同数据集(一半为评估数据集,一半为真实部署场景)的1000个数据点时,是否能区分评估场景和真实应用场景。研究发现,LLM在识别评估场景方面的能力接近人类主要作者的水平,并且通常能够判断评估的目的。此发现对理解LLM的行为和泛化能力具有重要意义。 (来源: paul_cal, menhguin)
LlamaIndex推出用于自动化SEC Form 4提取的Agent工作流示例: LlamaIndex展示了一个使用LlamaExtract和Agent工作流自动化提取美国证券交易委员会(SEC)Form 4(上市公司内部人士股票交易披露表)信息的实践案例。该示例创建了一个能从Form 4文件中提取结构化信息的提取代理,并构建了一个可扩展的工作流,用于从道琼斯工业平均指数成分公司的Form 4文件中提取交易信息。这为金融领域利用AI进行信息提取和自动化处理提供了参考。 (来源: jerryjliu0)
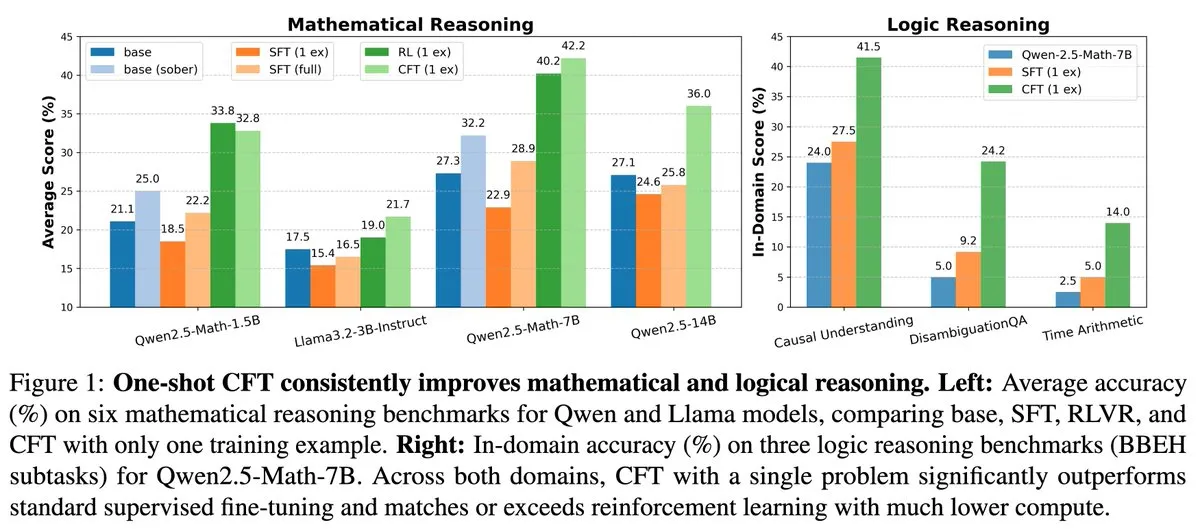
新研究:单问题监督微调(SFT)可达单问题强化学习(RL)效果,计算成本降20倍: 一篇新论文指出,在单个问题上进行监督微调(SFT)可以达到与在单个问题上进行强化学习(RL)相似的性能提升,而计算成本仅为后者的1/20。这表明,对于已在预训练阶段获得强大推理能力的LLM,通过精心设计的SFT(如论文提出的Critique Fine-Tuning, CFT)可以作为一种更高效的方式来释放其潜力,尤其是在RL成本高昂或不稳定的情况下。 (来源: AndrewLampinen)
论文提出Rex-Thinker:通过思维链推理实现接地气的对象指称: 一篇新论文提出了Rex-Thinker模型,该模型将对象指称(Object Referring)任务表述为显式的思维链(CoT)推理任务。模型首先识别与指称对象类别对应的所有候选实例,然后对每个候选实例进行逐步推理,以评估其是否与给定表达匹配,最终做出预测。为支持此范式,研究者构建了大规模CoT风格指称数据集HumanRef-CoT。实验表明,该方法在精确度和可解释性上优于标准基线,并能更好处理无匹配对象的情况。 (来源: HuggingFace Daily Papers)
论文提出TimeHC-RL:时间感知的分层认知强化学习增强LLM社交智能: 针对LLM在社交智能领域认知发展不足的问题,一篇新论文提出了时间感知的分层认知强化学习(TimeHC-RL)框架。该框架认识到社交世界遵循独特的时间线,并需要直觉反应(系统1)和审慎思考(系统2)等多种认知模式的融合。实验表明,TimeHC-RL能有效提升LLM的社交智能,使7B骨干模型性能媲美DeepSeek-R1和OpenAI-O3等先进模型。 (来源: HuggingFace Daily Papers)
论文提出DLP:大型语言模型中的动态分层剪枝: 为解决LLM剪枝中统一分层剪枝策略在高稀疏度下性能严重下降的问题,一篇新论文提出了动态分层剪枝(DLP)方法。DLP通过整合模型权重和输入激活信息,自适应地确定每层的相对重要性,并据此分配剪枝率。实验表明,DLP能在高稀疏度下有效保持LLaMA2-7B等模型的性能,并与多种现有LLM压缩技术兼容。 (来源: HuggingFace Daily Papers)
论文介绍LayerFlow:统一的图层感知视频生成模型: LayerFlow是一个统一的图层感知视频生成解决方案。给定每层的提示,LayerFlow可以生成透明前景、干净背景和混合场景的视频。它还支持多种变体,如分解混合视频或为给定前景生成背景等。该模型将不同图层的视频组织为子剪辑,并利用图层嵌入来区分每个剪辑和相应的图层提示,从而在一个统一框架内支持上述功能。针对缺乏高质量图层训练视频的问题,设计了多阶段训练策略。 (来源: HuggingFace Daily Papers)
论文提出Rectified Sparse Attention:修正稀疏注意力机制: 为解决长序列生成中稀疏解码方法导致的KV缓存未对齐和质量下降问题,一篇新论文提出了修正稀疏注意力(ReSA)。ReSA将块稀疏注意力与周期性密集修正相结合,通过固定间隔使用密集前向传播刷新KV缓存,从而限制错误累积并保持与预训练分布的对齐。实验表明,ReSA在数学推理、语言建模和检索任务中实现了接近无损的生成质量和显著的效率提升,在256K序列长度解码下可实现高达2.42倍的端到端加速。 (来源: HuggingFace Daily Papers)
论文介绍RefEdit:改进基于指令的图像编辑模型在指称表达上的基准和方法: 针对现有图像编辑模型在处理含多个实体的复杂场景时难以准确编辑指定对象的问题,一篇新论文首先引入了RefEdit-Bench,一个基于RefCOCO的真实世界基准。接着,提出了RefEdit模型,该模型通过可扩展的合成数据生成流程进行训练,仅用20,000个编辑三元组训练的RefEdit在指称表达任务上优于基于Flux/SD3且训练数据达数百万的基线模型,并在传统基准上也取得了SOTA效果。 (来源: HuggingFace Daily Papers)
论文提出Critique-GRPO:利用自然语言和数值反馈提升LLM推理能力: 针对仅依赖数值反馈(如标量奖励)的强化学习在提升LLM复杂推理能力时面临性能瓶颈、自我反思效果有限和持续失败等问题,一篇新论文提出Critique-GRPO框架。该框架通过整合自然语言形式的批判(critiques)和数值反馈,使LLM能同时从初始响应和批判引导的改进中学习,并保持探索。实验表明,Critique-GRPO在Qwen2.5-7B-Base和Qwen3-8B-Base上显著优于多种基线方法。 (来源: HuggingFace Daily Papers)
论文介绍TalkingMachines:通过自回归扩散模型实现实时音频驱动的FaceTime式视频: TalkingMachines是一个高效框架,可将预训练的视频生成模型转换为实时、音频驱动的角色动画器。该框架集成了音频大语言模型(LLM)与视频生成基础模型,实现了自然对话体验。其主要贡献包括将预训练的SOTA图生视频DiT模型适配为音频驱动的虚拟形象生成模型,通过非对称知识蒸馏实现无限视频流生成且无错误累积,并设计了高吞吐、低延迟的推理管线。 (来源: HuggingFace Daily Papers)
论文探讨LLM判断中的自我偏好测量: 研究表明LLM在作为裁判时表现出自我偏好,即倾向于偏爱自身生成的响应。现有方法通过计算裁判模型对其自身响应和对其他模型响应的评分差异来衡量此偏见,但这混淆了自我偏好与响应质量。新论文提出使用黄金判断作为响应实际质量的代理,并引入DBG分数,将自我偏好偏见衡量为裁判模型对其自身响应的评分与相应黄金判断之间的差异,从而减轻响应质量对偏见测量的混淆效应。 (来源: HuggingFace Daily Papers)
论文提出LongBioBench:一个可控的长上下文语言模型测试框架: 针对现有长上下文语言模型(LCLM)评估框架的局限性(真实世界任务复杂难解且易受数据污染,合成任务与现实应用脱节),一篇新论文提出了LongBioBench。该基准利用人工生成的传记作为受控环境,从理解、推理和可信度维度评估LCLM。实验表明,多数模型在长上下文语义理解和初步推理方面仍存在不足,且随着上下文长度增加,可信度下降。LongBioBench旨在提供更真实、可控且可解释的LCLM评估。 (来源: HuggingFace Daily Papers)
论文探讨从优化的冷启动到分阶段强化学习提升多模态推理: 受Deepseek-R1在复杂文本任务中卓越推理能力的启发,许多工作尝试通过直接应用强化学习(RL)来激励多模态大语言模型(MLLM)产生类似能力,但仍难以激活复杂推理。新论文深入研究当前训练流程,发现有效冷启动初始化对增强MLLM推理至关重要,标准GRPO应用于多模态RL时存在梯度停滞问题,以及在多模态RL阶段后进行纯文本RL训练能进一步增强多模态推理。基于这些见解,论文引入ReVisual-R1,在多个基准测试中取得了SOTA成绩。 (来源: HuggingFace Daily Papers)
论文介绍SVGenius:SVG理解、编辑和生成的基准测试: 针对现有SVG处理基准在真实世界覆盖范围、复杂性分层和评估范式方面的不足,一篇新论文引入了SVGenius。这是一个包含2377个查询的综合基准,涵盖理解、编辑和生成三个维度,基于24个应用领域的真实数据构建,并进行了系统性的复杂性分层。通过8个任务类别和18个指标评估了22个主流模型。分析显示,所有模型在复杂性增加时性能均系统性下降,但推理增强训练比纯粹扩展更有效。 (来源: HuggingFace Daily Papers)
论文提出Ψ-Sampler:用于基于SMC的评分模型推理时奖励对齐的初始粒子采样: 为解决评分生成模型推理时奖励对齐问题,一篇新论文引入了Psi-Sampler框架。该框架基于序贯蒙特卡洛(SMC),并结合了基于pCNL的初始粒子采样方法。现有方法通常从高斯先验初始化粒子,难以有效捕获与奖励相关的区域。Psi-Sampler通过从奖励感知的后验分布初始化粒子,并引入预处理Crank-Nicolson Langevin(pCNL)算法实现高效后验采样,从而在布局到图像生成、数量感知生成和美学偏好生成等任务中提升对齐性能。 (来源: HuggingFace Daily Papers)
论文提出MoCA-Video:用于一致视频编辑的运动感知概念对齐框架: MoCA-Video是一个免训练框架,旨在将图像域的语义混合技术应用于视频编辑。给定一个生成的视频和用户提供的参考图像,MoCA-Video能将参考图像的语义特征注入视频中的特定对象,同时保留原始运动和视觉上下文。该方法利用对角线去噪调度和类别无关分割来检测和跟踪潜在空间中的对象,并精确控制混合对象的空间位置,通过基于动量的语义校正和伽马残差噪声稳定确保时间一致性。 (来源: HuggingFace Daily Papers)
论文探讨通过程序分析反馈训练语言模型生成高质量代码: 为解决大型语言模型(LLM)在代码生成(vibe coding)中难以保证代码质量(尤其是安全性和可维护性)的问题,一篇新论文提出了REAL框架。REAL是一个强化学习框架,通过程序分析引导的反馈来激励LLM生成生产级质量的代码。该反馈整合了检测安全或可维护性缺陷的程序分析信号,以及确保功能正确性的单元测试信号。REAL无需人工标注,可扩展性强,实验证明其在功能性和代码质量方面优于SOTA方法。 (来源: HuggingFace Daily Papers)
论文提出GAIN-RL:通过模型自身信号实现训练高效的强化学习: 针对当前大语言模型强化微调(RFT)范式因统一数据采样导致样本效率低下的问题,一篇新论文识别出一种名为“角度集中度”(angle concentration)的模型固有信号,该信号能有效反映LLM从特定数据中学习的能力。基于此发现,论文提出了GAIN-RL框架,通过利用模型的内在角度集中度信号动态选择训练数据,确保梯度更新的持续有效性,从而显著提高训练效率。实验表明,GAIN-RL (GRPO) 在多种数学和编码任务及不同模型规模上实现了超过2.5倍的训练效率加速。 (来源: HuggingFace Daily Papers)
论文提出SFO:通过负向引导优化零样本主体驱动生成的主体保真度: 为提升零样本主体驱动生成中的主体保真度,一篇新论文提出了主体保真度优化(SFO)框架。SFO引入了合成的负向目标,并通过成对比较明确引导模型偏好正向目标而非负向目标。对于负向目标,论文提出了条件退化负采样(CDNS)方法,通过有意降低视觉和文本线索来自动生成独特且信息丰富的负样本,无需昂贵的人工标注。此外,还重新加权了扩散时间步,以侧重于主体细节出现的中间步骤。 (来源: HuggingFace Daily Papers)
论文介绍ByteMorph:用于非刚性运动的指令引导图像编辑基准: 针对现有图像编辑方法和数据集主要关注静态场景或刚性变换,难以处理涉及非刚性运动、相机视角变换、对象变形、人体关节运动和复杂交互等指令的问题,一篇新论文引入了ByteMorph框架。该框架包含大规模数据集ByteMorph-6M(超600万高分辨率图像编辑对)和基于DiT的强基线模型ByteMorpher。数据集通过运动引导数据生成、分层合成技术和自动字幕生成构建,确保多样性、真实性和语义连贯性。 (来源: HuggingFace Daily Papers)
论文提出Control-R:迈向可控的测试时扩展: 为解决大型推理模型(LRM)在长链思维(CoT)推理中存在的“思考不足”和“思考过度”问题,一篇新论文引入了推理控制字段(RCF)。RCF是一种测试时方法,通过注入结构化控制信号从树搜索角度引导推理,使模型能根据给定控制条件调整解决复杂任务时的推理努力。同时,论文提出了Control-R-4K数据集,包含带详细推理过程和相应控制字段的挑战性问题,并提出了条件蒸馏微调(CDF)方法训练模型有效调整测试时推理努力。 (来源: HuggingFace Daily Papers)
论文综述Agentic AI中的信任、风险和安全管理(TRiSM): 一篇综述论文系统分析了基于大语言模型(LLM)的Agentic多智能体系统(AMAS)中的信任、风险和安全管理(TRiSM)。论文首先探讨了Agentic AI的概念基础、架构差异及新兴系统设计,然后详细阐述了TRiSM在Agentic AI框架下的四大支柱:治理、可解释性、ModelOps和隐私/安全。论文识别了独特的威胁向量,提出了Agentic AI应用的综合风险分类法,并探讨了信任建立机制、透明度与监督技术、分布式LLM智能体系统的可解释性策略等。 (来源: HuggingFace Daily Papers)
论文探讨通过置信度引导的数据增强改进未知协变量偏移下的知识蒸馏: 针对知识蒸馏中常见的协变量偏移问题(训练时出现但在测试时不存在的虚假特征),一篇新论文提出了一种新的基于扩散的数据增强策略。当这些虚假特征未知,但存在一个鲁棒的教师模型时,该策略通过最大化教师模型和学生模型之间的分歧来生成图像,从而创建学生难以处理的挑战性样本。实验证明,该方法显著提高了在CelebA、SpuCo Birds和虚假ImageNet等数据集上存在协变量偏移时的最差组和平均组准确率。 (来源: HuggingFace Daily Papers)
论文介绍DiffDecompose:通过Diffusion Transformers实现Alpha合成图像的逐层分解: 针对现有图像分解方法难以解开半透明或透明图层遮挡的问题,一篇新论文提出了一项新任务:Alpha合成图像的逐层分解,旨在从单个重叠图像中恢复组成图层。为解决图层模糊性、泛化性和数据稀缺性等挑战,论文首先引入了AlphaBlend,这是首个用于透明和半透明图层分解的大规模高质量数据集。在此基础上,提出了DiffDecompose,一个基于Diffusion Transformer的框架,通过上下文分解学习图层分解的后验分布。 (来源: HuggingFace Daily Papers)
论文提出SuperWriter:通过反思驱动的大型语言模型长文本生成: 为解决大型语言模型(LLM)在长文本生成中难以保持连贯性、逻辑一致性和文本质量的问题,一篇新论文提出了SuperWriter-Agent框架。该框架在生成流程中引入了明确的结构化思考规划和改进阶段,引导模型遵循更审慎、更符合认知规律的过程。基于此框架,构建了监督微调数据集以训练7B参数的SuperWriter-LM,并开发了分层直接偏好优化(DPO)程序,利用蒙特卡洛树搜索(MCTS)传播最终质量评估并相应优化每个生成步骤。 (来源: HuggingFace Daily Papers)
论文提出IEAP:将图像编辑视为基于扩散模型的程序: 针对扩散模型在指令驱动图像编辑中,尤其是在涉及显著布局变化的结构不一致编辑方面遇到的挑战,一篇新论文引入了IEAP(Image Editing As Programs)框架。IEAP基于Diffusion Transformer(DiT)架构,通过将复杂编辑指令分解为原子操作序列来处理指令编辑。每个操作通过共享相同DiT骨干的轻量级适配器实现,并专门用于特定类型的编辑。这些操作由基于视觉语言模型(VLM)的代理编程,协同支持任意和结构不一致的转换。 (来源: HuggingFace Daily Papers)
论文提出FlowPathAgent:通过神经符号代理实现细粒度流程图归因: 为解决大型语言模型(LLM)在解释流程图时常出现幻觉、难以准确追踪决策路径的问题,一篇新论文引入了细粒度流程图归因任务,并提出了FlowPathAgent。FlowPathAgent是一个神经符号代理,通过基于图的推理执行细粒度的后验归因。它首先分割流程图,将其转换为结构化符号图,然后采用代理方法与图动态交互以生成归因路径。同时,论文还提出了FlowExplainBench,一个用于评估流程图归因的新基准。 (来源: HuggingFace Daily Papers)
论文提出Quantitative LLM Judges:量化LLM裁判: LLM-as-a-judge是一种让大语言模型(LLM)自动评估另一个LLM输出的框架。一篇新论文提出了“量化LLM裁判”的概念,通过回归模型将现有LLM裁判的评估分数与特定领域的人类分数对齐。这些模型通过使用裁判的文本评估和分数来改进原始裁判的评分。论文展示了四种针对不同类型绝对和相对反馈的量化裁判,证明了该框架的通用性和多功能性。该框架比监督微调更具计算效率,并且在人类反馈有限时可能更具统计效率。 (来源: HuggingFace Daily Papers)
💼 商业
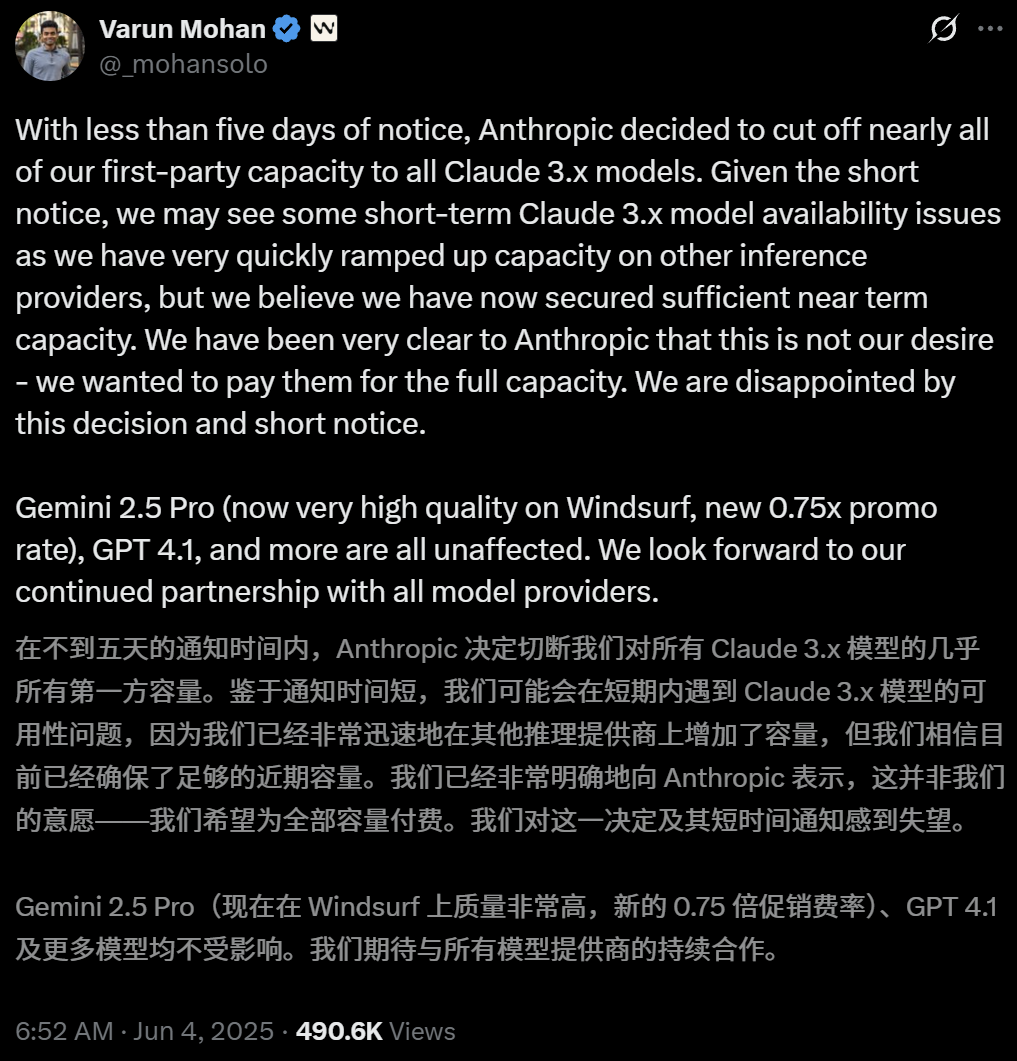
Anthropic限制AI编程工具Windsurf对Claude模型的直接访问: AI编程工具Windsurf的CEO Varun Mohan公开表示,Anthropic在极短通知期内(不足五天)大幅削减了Windsurf对Claude 3.x系列模型的API服务配额,包括Claude 3.5 Sonnet、3.7 Sonnet等。此举发生在OpenAI据报将收购Windsurf的背景下,引发市场对AI巨头间竞争加剧及AI编程工具平台中立性的担忧。Windsurf不得不紧急启用第三方推理服务并调整对用户的模型供应策略,而Anthropic则回应称优先为能确保持续合作的伙伴提供资源。 (来源: 36氪, 36氪, mervenoyann, swyx)
OpenAI付费企业用户突破300万,推出灵活定价策略: OpenAI宣布其付费企业用户数量已达到300万,较今年2月公布的200万增长50%,涵盖ChatGPT Enterprise、Team和Edu三大产品线。同时,OpenAI针对企业客户推出基于“共享信用池”的灵活定价策略,企业购买信用池后,使用高级功能会消耗信用,但仍可“无限访问”主要模型和功能。此新定价将首先在ChatGPT Enterprise中推出,随后推广至ChatGPT Team,后者还提供1美元5账户的首月试用优惠。 (来源: 36氪, snsf)
00后中国女孩洪乐潼创立AI数学公司Axiom,目标估值3亿美元: 斯坦福华人数学博士洪乐潼(Carina Letong Hong)创立AI公司Axiom,专注于开发解决实际数学问题的AI模型,目标客户为对冲基金和量化交易公司。Axiom计划利用形式化数学证明数据训练模型,使其掌握严格的逻辑推理和证明能力。尽管公司尚无产品,但已在洽谈5000万美元融资,估值预计3-5亿美元。洪乐潼拥有麻省理工数学与物理本科学位及斯坦福数学博士背景,曾获罗德奖学金。 (来源: 量子位)

🌟 社区
AI.Engineer大会热议:Agent观察性、小团队高效率、AI PM成焦点: 在AI.Engineer世界博览会上,与会者热议AI代理(Agent)的可观察性和评估、小型高效团队的构建(Tiny Teams)、以及AI产品管理(AI PM)的最佳实践。语音交互被认为是多模态中最热门的方向,安全性也首次成为重要议题。Anthropic在会上发出了MCP(模型上下文协议)领域的创业请求,希望看到更多开发者工具之外的MCP服务器、简化服务器构建的方案以及AI应用安全(如工具投毒防护)的创新。 (来源: swyx, swyx, swyx, swyx)

关于AI是否会让自然语言消亡以及人类变笨的讨论: 社交媒体上出现关于AI广泛应用可能导致自然语言交流萎缩(“死寂互联网”理论)以及人类认知能力(如深度思考、质疑、重构能力)退化的担忧。一些用户认为,过度依赖AI获取信息和答案,可能减少主动筛选、判断和独立思考,形成“认知外包”依赖。另有观点认为,AI能处理what和how,但why仍需人类决定,关键在于找到与技术共处时人的角色定位和守住判断权。 (来源: Reddit r/ArtificialInteligence, 36氪)
OpenAI被法院命令保留所有ChatGPT及API日志,引发隐私担忧: 一项法院命令要求OpenAI保留所有ChatGPT的聊天记录和API请求日志,包括那些本应被删除的“临时聊天”记录。此举引发了用户对数据隐私和OpenAI数据保留政策能否得到遵守的担忧。一些评论者认为,这进一步凸显了使用本地模型和拥有自身技术及数据的重要性。 (来源: Reddit r/artificial, Reddit r/LocalLLaMA, Teknium1, nptacek)

AI Agent面临信任与安全挑战,易受钓鱼攻击: 讨论指出,尽管AI Agent能力日益增强,但其信任机制存在被利用的风险。例如,Agent可能因信任知名网站(如社交媒体)而被诱导访问恶意链接,从而泄露敏感信息或执行恶意操作。这要求在Agent设计中加强对恶意内容和链接的识别与抵抗能力,确保其在执行真实世界操作时的安全性。 (来源: DeepLearning.AI Blog)
AI辅助编程工具引发的思考:从代码现代化到工作流变革: 社区讨论了AI在软件开发中的应用,特别是处理遗留代码和改变编程工作流。摩根士丹利使用自研AI工具DevGen.AI分析和重构了数百万行旧代码,显著节省了开发时间。同时,Andrej Karpathy关于复杂UI应用前景的观点也引发了对未来软件应如何设计以更好地与AI协作的思考,强调了脚本化和API接口的重要性。这些讨论反映了AI正深刻影响软件工程的实践和理念。 (来源: mitchellh, 36氪, 36氪)
💡 其他
AI辅助家电维修,ChatGPT成“Friendo”: 一位用户分享了通过ChatGPT(昵称Friendo)成功诊断并初步修复故障洗碗机的经历。通过与AI对话、描述错误代码、拍摄控制板照片,AI帮助用户定位到加热元件故障,并指导用户暂时绕过该元件使洗碗机恢复部分功能。这展示了LLM在日常生活问题解决和技术支持方面的潜力。 (来源: Reddit r/ChatGPT)
AI生成1500年代人物访谈视频引关注: 一则AI生成的视频模拟了对1500年代人物的采访,因其创意和幽默感在社区获得好评。视频中的人物形象和对话内容诙谐地反映了当时的生活状况,例如“醒来踩到粪便,然后被征税,这还只是早餐前的事”。这类应用展示了AI在内容创作和历史情景再现方面的娱乐潜力。 (来源: draecomino, Reddit r/ChatGPT)

Thiel奖学金关注AI创新,涵盖数字人、机器人情感及AI预测: 新一期“蒂尔奖学金”名单公布,其中多个AI项目引人注目。Canopy Labs致力于打造与真人难以区分、能进行实时多模式互动的AI数字人。Intempus项目旨在为机器人赋予类似人类的情感表达能力,以改善人机交互。Aeolus Lab则聚焦于利用AI技术预测天气及自然灾害,甚至探索主动干预的可能性。这些项目展示了年轻创业者在AI前沿领域的探索方向。 (来源: 36氪)