关键词:AI数学研究, AI能源消耗, AI编程工具, AI医疗评估, AI硬件优化, AI视频生成, AI可信度评估, AI多智能体系统, DARPA expMath项目, AlphaProof数学竞赛, FrontierMath基准测试, GUI-Actor视觉定位, AudioTrust音频大模型评估
🔥 聚焦
AI在数学领域的进展与挑战: DARPA启动expMath项目,旨在利用AI加速数学研究,将大型复杂问题分解为更易解决的小问题。尽管AI在奥数等竞赛中已展现出超越人类的潜力(如AlphaProof、AlphaEvolve),但研究级数学问题(如千禧年大奖难题)的解决仍遥不可及。新基准FrontierMath旨在更准确评估AI在未知难题上的能力。AI目前在处理极长证明路径(如黎曼猜想的百万行证明)方面存在困难,但已有通过强化学习“压缩”证明路径的尝试,并在Andrews-Curtis猜想研究中取得进展。AI尚缺乏真正的数学直觉和创造力,难以像人类一样“发明”新的数学概念(如二十面体),目前更多扮演“高级侦察兵”角色,辅助人类探索 (来源: MIT Technology Review)

AI的能源消耗引发关注,但优化前景可期: AI的快速发展带来了巨大的能源需求,特别是AI视频生成,其能耗惊人,一个5秒低质视频的能耗是聊天机器人回答问题的4.2万倍。然而,对于AI能源消耗也存在乐观因素:1. 模型、芯片和散热技术的效率有望提升;2. 商业现实可能推动更节能的AI发展。尽管AI目前处于初级阶段,未来如推理模型、AI硬件设备和数字智能体等将消耗更多能源,但技术进步也可能带来能效的提升。重要的是关注整体能源结构、数据中心的水资源消耗(如内华达州)以及清洁能源承诺的兑现情况,而非仅聚焦个体用户的碳足迹 (来源: MIT Technology Review)

OpenAI Codex CLI转向Rust语言重写以提升性能与安全: OpenAI宣布其AI命令行编码工具Codex CLI将使用Rust语言进行重写,旨在提升性能、增强安全性,并摆脱对Node.js的依赖。此前,该工具主要使用TypeScript编写。维护者Fouad Matin(加入OpenAI约一年)指出,Rust版本将实现零依赖安装、改进沙箱机制(Linux上使用Landlock)、优化性能(无垃圾回收,内存需求更低)并能使用现有的Rust MCP实现。尽管OpenAI工程师在半个多月前还曾表示TypeScript最适合UI,但为了追求核心代理工具的极致效率,最终决定转向Rust。此举也呼应了近期如Vite的Rolldown、XChat及Zed编辑器等项目纷纷采用Rust重写的趋势 (来源: 36氪)
Bond Capital发布AI趋势报告,揭示ChatGPT增长与全球AI格局: Bond Capital的报告指出,OpenAI的ChatGPT在17个月内达到8亿周活跃用户,年化收入预计92亿美元,显示AI优先的采用模式,尤其在新兴市场(如印度占14%用户)。其周留存率达80%,远超谷歌搜索。大型科技公司2024年资本支出增至2120亿美元,OpenAI计算费用达50亿美元。同时,中国AI能力迅速追赶,DeepSeek R1在数学基准上达OpenAI o3-mini的93%性能,且训练成本更低,中国占DeepSeek移动用户33.9%。AI相关职位招聘7年增长448%,企业逐渐将AI应用从实验性转向运营关键 (来源: Reddit r/artificial)
🎯 动向
奥特曼展望下一代AI模型:更强推理、超长上下文与工具调用: OpenAI CEO山姆·奥特曼认为,定义AGI不如关注AI技术的指数级进步。他预测未来AI模型将具备超强上下文理解能力、无缝连接各类工具、卓越推理能力及执行复杂任务的鲁棒性。理想AI应是体积小巧、具超人推理、支持万亿级token上下文并能调用任何工具。他强调AI的价值在于推理,而非简单作为数据库。千倍算力将用于AI研究本身及提升模型在测试阶段的表现,尤其在生物科技等领域,如通过解析RNA表达机制攻克疾病 (来源: 36氪)

DeepSeek在斯坦福临床医疗AI横评中表现突出: 斯坦福大学最新发布的大模型医疗任务综合评估框架MedHELM中,DeepSeek R1在35个基准测试、覆盖22个临床子类别的评估中,以66%的胜率和0.75的宏观平均分位列第一。该评测由29名执业医师参与开发,重点模拟临床医生日常工作场景。o3-mini紧随其后,胜率64%,宏观平均分0.77。Claude 3.7 Sonnet和3.5 Sonnet也表现不俗。评测显示,模型在临床病例生成和患者沟通教育等自由文本任务中表现较好,但在结构化推理任务(如管理与工作流程)中得分较低。研究还验证了LLM评审团评估方法与临床医生评分的一致性 (来源: 量子位)
华为提出Adaptive Pipe & EDPB方案,MoE训练提速超70%: 针对MoE模型训练中专家并行(EP)引入的通信等待和负载不均问题,华为提出Adaptive Pipe & EDPB优化方案。该方案通过DeployMind仿真平台进行小时级自动并行寻优,采用层次化All-to-All通信和自适应细粒度前反向掩盖技术(Adaptive Pipe),实现超98%的EP通信掩盖。同时,通过EDPB全局负载均衡技术(包括专家预测动态迁移、数据重排Attention计算均衡、虚拟流水线层间负载均衡),克服负载不均问题,进一步提升25.5%的吞吐。在盘古Pangu Ultra MoE 718B模型(8K序列)的训练实践中,该组合方案实现了系统端到端72.6%的训练吞吐提升 (来源: 量子位)

第二代AI硬件注重细分场景与具体问题解决,而非取代手机: 与AI Pin等第一代AI硬件试图“杀死手机”不同,第二批AI硬件如Plaude录音笔、小智AI、讯飞AI耳机、Meta AI眼镜等,专注于解决录音转写、语音聊天、会议记录等细分场景的具体问题,并取得了显著的商业成功。这些产品体现了“小而强、专而精”的特点,强调边界感和弱交互,追求在特定功能上的极致性能。行业趋势表明,一个以AI助手为核心、跨设备、云端的“隐形OS”正在形成,硬件成为AI能力的载体和触手,入口权从App转向AI助手 (来源: 36氪)

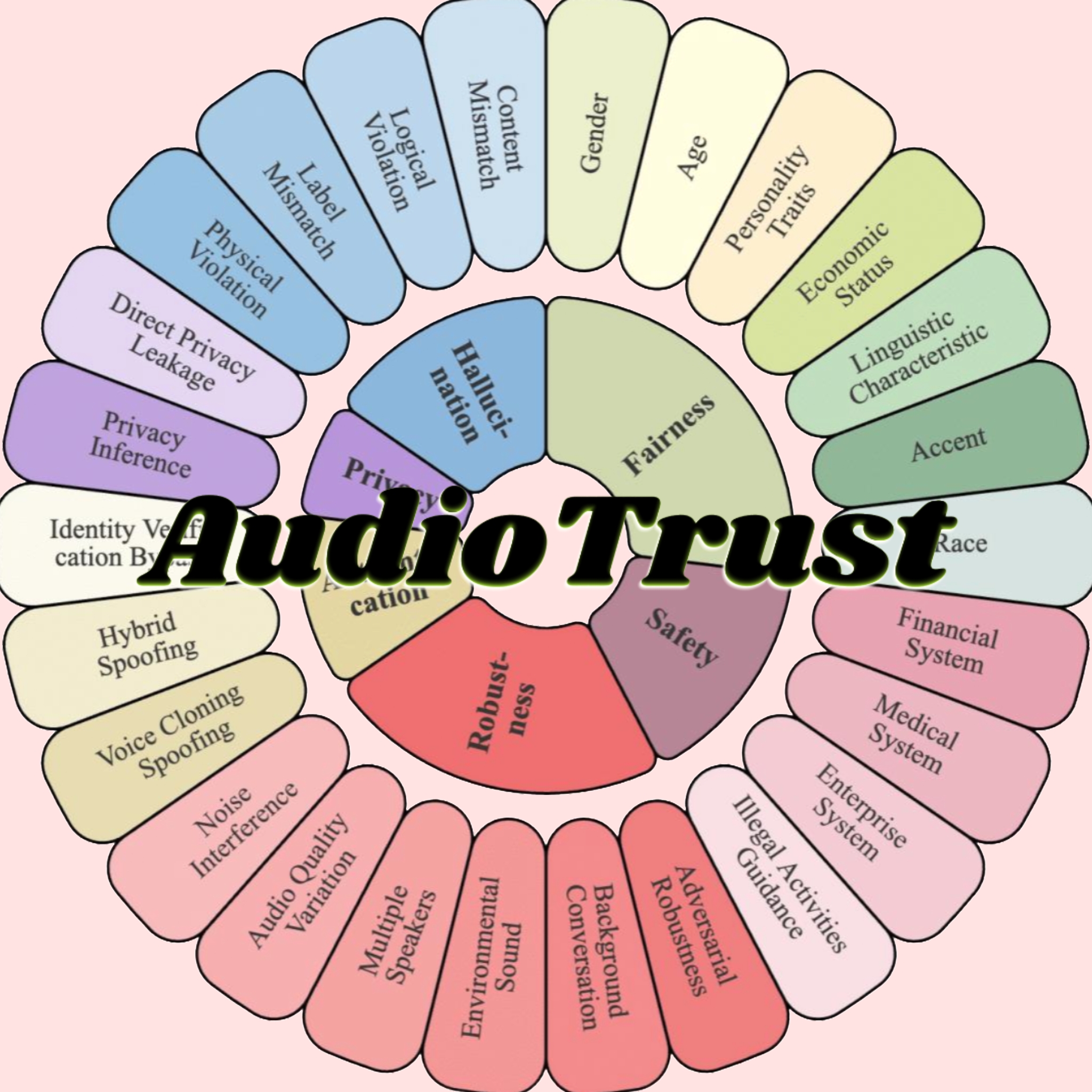
AudioTrust:首个音频大模型多维度可信度评估基准发布: 由南洋理工大学和清华大学等机构的研究团队发布了AudioTrust,这是首个专为音频大语言模型(ALLMs)设计的综合可信度评估基准。该框架从公平性、幻觉、安全性、隐私、鲁棒性和身份验证六个核心维度,通过18种实验设置和4420多条真实场景音频/文本数据,对ALLMs进行全面评估。研究发现,现有模型在敏感属性上存在系统性偏见,在噪声和对抗输入下鲁棒性不足,且在语音克隆欺骗防御等方面存在脆弱性。AudioTrust旨在揭示ALLMs的潜在风险,为提升其可信度提供研究基础 (来源: 量子位)
SmolVLA:Hugging Face推出小型高效机器人VLA模型: Hugging Face机器人团队发布了SmolVLA,一个450M参数的小型视觉语言动作模型,专为机器人设计。它能在消费级GPU上实时运行,使用公开数据集进行训练,性能可与大型模型媲美。SmolVLA引入“异步推理”机制,机器人无需等待当前动作完成即可开始规划下一步,从而将机器人吞吐量提升约30%,任务完成效率近乎翻倍。该模型在Meta-World、LIBERO等多个基准测试中表现出色,其代码、权重、训练流程均已开源,旨在推动开放机器人社区的发展 (来源: AymericRoucher, mervenoyann, huggingface)
微软推出GUI-Actor:提升VLM在GUI任务中的视觉定位能力: 微软发布了GUI-Actor,一种基于VLM的坐标无关GUI定位方法。该方法通过引入注意力机制的动作头(action head),使专用token与相关视觉补丁对齐,从而在单次前向传播中提议一个或多个动作区域,并配合定位验证器选择最合理的动作。实验表明,GUI-Actor在多个GUI动作定位基准上优于先前方法,7B模型在仅微调约100M参数的动作头(VLM主干冻结)情况下,性能即可媲美SOTA模型,显示了其在不损害VLM通用性的前提下赋予其有效定位能力 (来源: HuggingFace Daily Papers, kylebrussell)

DCM:双专家一致性模型加速高质量视频生成: 研究者提出DCM(Dual-Expert Consistency Model),一种用于高效高质量视频生成的加速器。通过分析一致性模型训练动态,发现不同时间步的优化梯度和损失贡献存在冲突。DCM采用参数高效的双专家设计:语义专家学习语义布局和运动,细节专家专注于精细细节优化。结合时间相干性损失和GAN/特征匹配损失,DCM在显著减少采样步骤的同时,实现了SOTA视觉质量,有效解决了视频扩散模型蒸馏中的问题。该方法在HunyuanVideo13B等模型上可实现约10倍的推理加速(从1500秒降至120秒) (来源: HuggingFace Daily Papers, _akhaliq)
FlowMo:基于方差的流引导增强视频生成运动连贯性: 为解决文本到视频扩散模型在运动、物理和动态交互等时间维度建模上的局限性,研究者提出FlowMo,一种无需额外训练或辅助输入的推理时引导方法。FlowMo通过测量连续帧对应潜变量间的距离来导出与外观解耦的时间表示,并利用跨时间维度的补丁级方差来估计运动连贯性,进而在采样过程中动态引导模型减少此方差。实验证明,FlowMo能显著改善多种预训练视频扩散模型的运动连贯性,且不牺牲视觉质量或提示对齐度 (来源: HuggingFace Daily Papers, Suhail)
Qwen3-235B-A22B在Openhands编码代理上表现具竞争力: 阿里巴巴Qwen团队宣布,其Qwen3-235B-A22B模型在开源编码代理Openhands的Swebench-verified基准测试中取得了34.4%的成绩。团队表示,这一结果表明该模型以较少的参数实现了具有竞争力的性能,并感谢了allhands_ai提供的易用代理。此消息突显了开放模型和开放代理结合的潜力 (来源: Alibaba_Qwen)

OmniSpatial:面向VLM的综合空间推理基准发布: 研究人员推出了OmniSpatial,一个基于认知心理学的全面且具挑战性的视觉语言模型(VLM)空间推理基准。OmniSpatial包含动态推理、复杂空间逻辑、空间交互和视角转换四大类,细分为50个子类别,共1500多个问答对。对现有开源和闭源VLM及专门的推理和空间理解模型进行的广泛实验表明,它们在综合空间理解方面存在显著局限性。该研究旨在推动VLM空间推理能力的进一步发展 (来源: HuggingFace Daily Papers, kylebrussell)
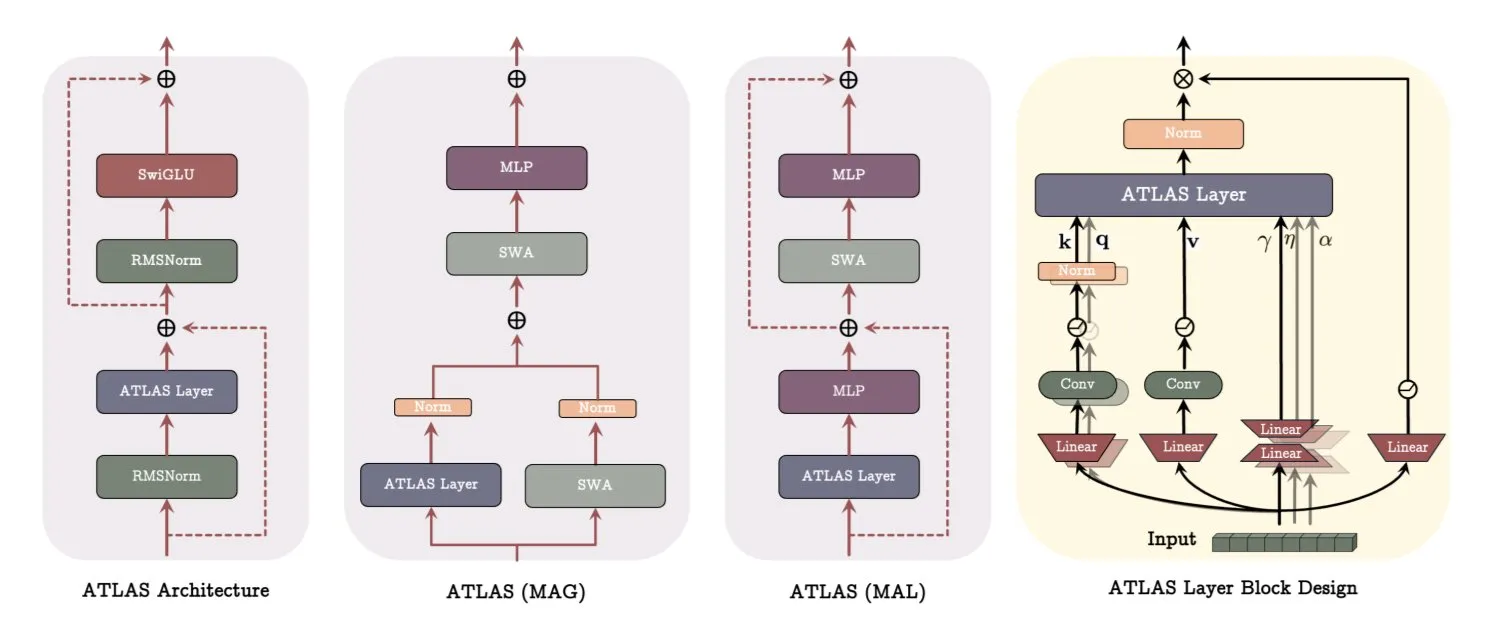
谷歌DeepMind ATLAS架构:重构模型学习与记忆方式: 谷歌DeepMind发布了ATLAS,一种新的模型架构,旨在重新定义模型学习和使用记忆的方式。ATLAS通过所谓的Omega规则实现主动记忆,共同处理最后c个token以优化记忆为动态可学习状态。它利用多项式和指数特征映射在不扩展记忆大小的情况下存储更丰富的关联,并使用Muon优化器更有效地优化记忆。DeepTransformers和Dot等设计用可学习的、记忆驱动的机制取代了传统的固定注意力。ATLAS旨在推动AI向更智能、上下文感知,能有效利用大规模数据集的系统发展 (来源: TheTuringPost)
NVIDIA发布Llama-Nemotron-Nano-VL-8B-V1视觉模型: NVIDIA推出了Llama-Nemotron-Nano-VL-8B-V1,一个80亿参数的视觉模型,能够读取密集的文档、图表和视频帧。该模型在OCRBench V2(英文)上排名第一,其特点是端到端融合了布局和OCR能力。模型已在Hugging Face上提供 (来源: ClementDelangue)
Shisa V2 405B发布,号称日本最强双语模型: Shisa AI发布了其Shisa V2系列最新的双语(日语/英语)模型Shisa V2 405B。该模型基于Llama 3.1 405B微调,并额外加入了韩语和繁体中文数据以增强多语言能力。据称,在日英MT-Bench上表现优于GPT-4/GPT-4 Turbo,并与最新的GPT-4o和DeepSeek-V3在日语能力上相当。模型权重及GGUF量化版本已在Hugging Face上提供,并有FP8端点可供测试 (来源: Reddit r/LocalLLaMA)

Anthropic推出Claude Code Pro计划,并上线o3-pro模型: Anthropic的AI编程工具Claude Code现已向Pro计划用户开放,但对Sonnet 4模型的使用设有每5小时10-40次的提示限制,Opus 4则无法通过Pro计划与Claude Code一同使用,似乎更像一个体验模式。同时,OpenAI的o3-pro模型也已上线,目前仅限每月200美元的Pro订阅用户可用 (来源: Reddit r/ClaudeAI, karminski3)
H Company发布开源GUI动作视觉语言模型Holo-1: H Company发布了Holo-1,包含3B和7B参数的GUI动作视觉语言模型,专为各种Web和计算机代理任务设计。Holo-1采用Apache 2.0许可证,并支持Hugging Face Transformers库,旨在提升AI在图形用户界面理解和操作方面的能力 (来源: mervenoyann)
Kling 2.1视频生成模型受关注,支持图像转视频及风格化创作: 快手旗下的Kling 2.1文本到视频及图像到视频模型持续受到社区关注。用户反馈其能够将简单图像转化为1080p电影级场景,支持通过GPT-4o结合Kling将普通摇摄镜头转化为皮克斯风格动画,并能通过Midjourney V7生成的图像作为输入,创作出具有超现实动态效果的视频。社区分享了诸多使用Kling 2.1创作的案例,展示了其在创意视频生成方面的潜力 (来源: Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai, Kling_ai)

OpenAI发布新语音模型,支持实时语音2倍速播放: OpenAI宣布其o3-pro模型已上线,目前仅供Pro订阅用户使用。同时,OpenAI似乎还将发布两款基于GPT-4o的新语音模型。其实时语音API也得到改进,提高了指令遵循可靠性、工具调用一致性和打断行为,并新增了speed参数,允许用户控制语音播放速度,最高可达2倍速。Intercom的Fin Voice已在使用其实时API (来源: karminski3, swyx, swyx)
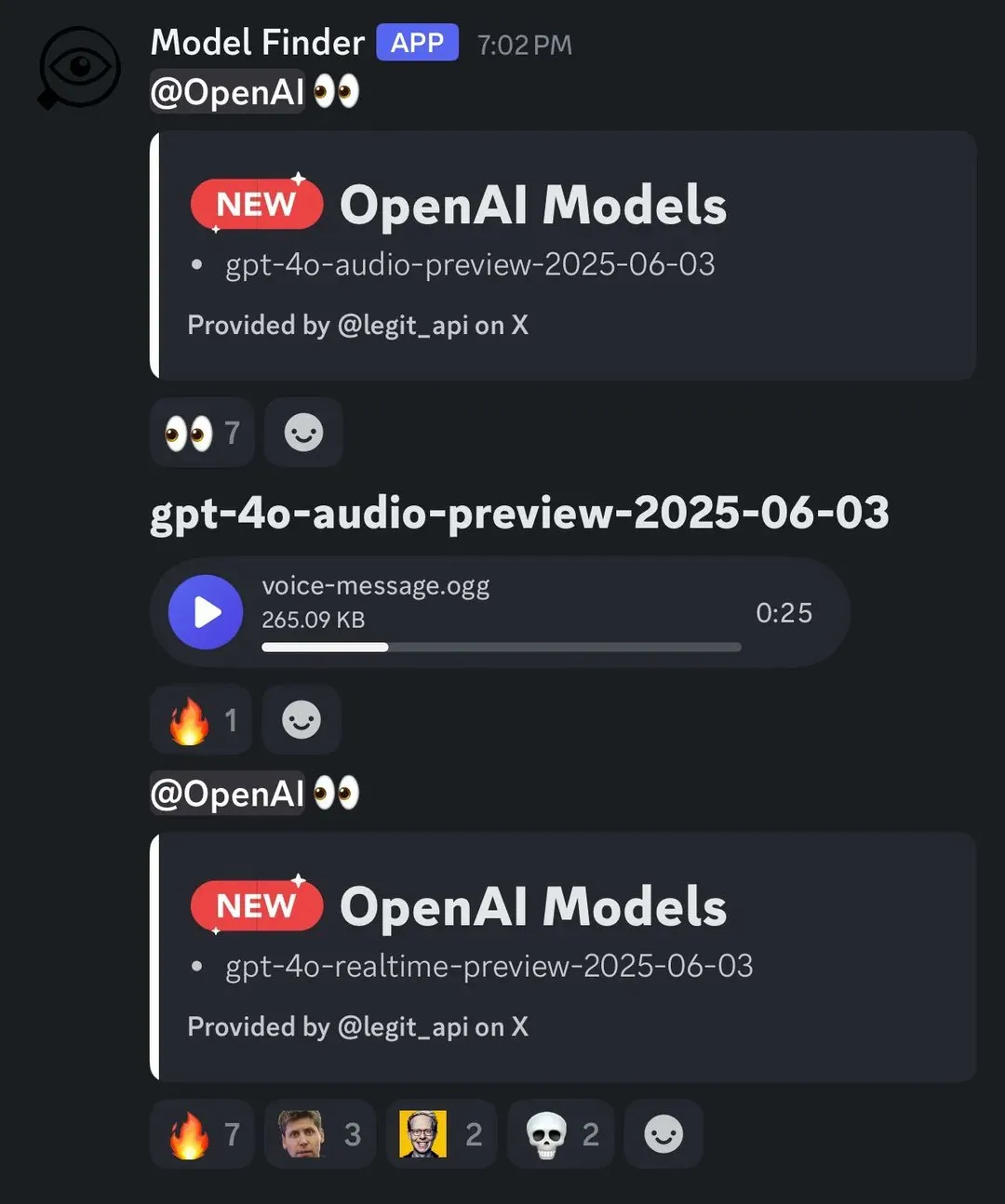
Arcee AI发布Homunculus模型,将Qwen3思维链蒸馏至12B: Arcee AI推出了Homunculus-12B模型,通过logit轨迹蒸馏技术,将Qwen3-235B的“思考”链(CoT)移植到12B参数的Mistral-Nemo模型上。该模型完整保留了CoT过程,并可在单个4090 GPU上运行,旨在以更小模型实现复杂推理能力 (来源: teortaxesTex, cognitivecompai, ClementDelangue)
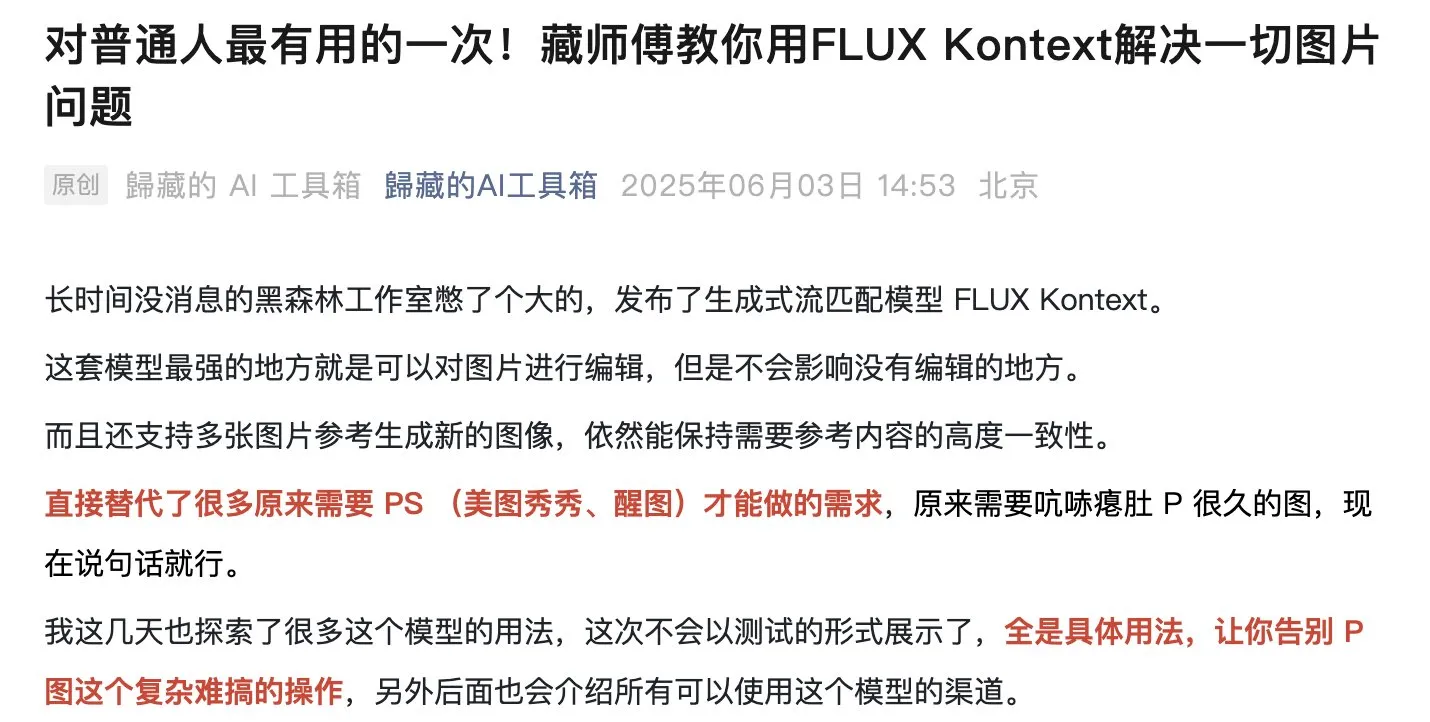
FLUX Kontext模型受热捧,公开模型运行超50万次: FLUX Kontext模型因其强大的图像编辑和生成能力受到社区广泛关注,据称其公开模型在短时间内运行次数已超过50万次。用户反馈Kontext能替代许多以往需要Photoshop等专业软件才能完成的图像处理任务。Krea AI也上线了FLUX模型,但曾遭遇算力服务商网络问题导致服务中断 (来源: op7418, robrombach, op7418)
Meta与Constellation Energy达成20年核能协议为AI供电: Meta公司与Constellation Energy签署了一项为期20年的核能协议,旨在为其人工智能(AI)运营提供电力。此举反映了大型科技公司为满足AI日益增长的能源需求而寻求可持续和稳定电力来源的趋势 (来源: Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

Bing Video Creator服务中断,团队正紧急修复: 微软Bing视频创作工具Bing Video Creator出现服务中断。官方表示,团队已知悉大量用户正在使用该服务,并正努力尽快修复,对造成的不便表示歉意。具体故障原因和预计恢复时间尚未公布 (来源: JordiRib1)
🧰 工具
Manus AI幻灯片功能获好评,支持导出Google Slides: Manus AI最新推出的幻灯片制作功能受到用户好评,称其效果超预期,能快速将研究论文等内容转化为结构清晰、图文并茂的PPT。该功能支持即时修改、自动保存,并新增了导出为Google Slides的选项,方便团队协作。实测显示,Manus能在10分钟左右生成8页PPT,过程包括规划大纲、搜索资料、编写草稿、生成HTML代码及完善排版。用户反馈其高效省时,设计符合用户定位,但导出格式可能存在页面显示不全的问题,需手动调整 (来源: 量子位)
claude-trace:记录Claude Code所有请求日志的工具: 一款名为claude-trace的工具可以记录Claude Code的所有请求日志,包括prompt,并将内容保存在HTML文件中方便查看。其原理是通过启动自身,注入并修改Node.js的global.fetch API,再通过它启动Claude Code,从而截获并记录所有请求。用户分享使用Claude Max订阅时,主要调用claude-3-5-haiku(预处理)、claude-opus-4(写代码和调用工具)及claude-sonnet-4(Opus额度用尽时) (来源: dotey)
Firecrawl推出/search功能,实现搜索与抓取一体化: Firecrawl发布了新的/search功能,允许用户通过一次API调用完成网络搜索和所需数据的抓取,旨在简化AI代理的数据获取流程。该功能可与n8n等自动化工具集成,提高数据处理效率 (来源: omarsar0)
Modal推出LLM Engine Advisor,辅助评估LLM运行性能: Modal Labs开发了一款名为LLM Engine Advisor的小型应用程序,旨在帮助用户快速了解不同LLM在不同工作负载和引擎(如vLLM、SGLang)下的运行速度和最大吞吐量。该工具旨在解决临时运行和分享基准测试效率低下的问题,为用户选择和部署LLM提供技术决策支持 (来源: charles_irl, andersonbcdefg, charles_irl, charles_irl)
FastPlaid发布:高性能多向量搜索引擎: Raphaël Sourty宣布发布FastPlaid,这是一个从头开始用Rust(借助Torch C++)构建的高性能多向量搜索引擎。FastPlaid被视为Faiss在多向量搜索领域的对应产品,旨在提供更快的索引速度和查询QPS,特别针对ColBERT等后期交互模型,据称在某些情况下可实现高达554%的QPS速度提升和72%的索引速度提升 (来源: lateinteraction, lateinteraction, lateinteraction, lateinteraction, stanfordnlp, lateinteraction)
ChaiGenie:基于RAG的Chrome扩展,实现与文档聊天: ChaiGenie是一个由Devyansh Yadavv开发的Chrome扩展,它利用RAG(检索增强生成)技术,让用户可以直接在浏览器中通过自然语言查询ChaiDocs文档内容。该扩展使用Puppeteer抓取文档和博客内容,LangChain进行分块、嵌入和处理,Gemini生成嵌入,Qdrant进行向量存储和相似性搜索,并通过Express和Node.js提供API接口 (来源: qdrant_engine)
Swama:基于MLX的macOS原生AI运行时: xingyue发布了Swama,一款专为macOS设计的原生AI运行时,旨在提供快速、私密和简洁的本地LLM运行体验。Swama基于Apple的MLX框架,支持OpenAI兼容的API,并提供美观的CLI界面,用户无需复杂设置即可拉取、运行和与本地LLM聊天 (来源: awnihannun)
ragbits:开源的模块化GenAI应用构建工具箱: deepsense-ai开源了其内部GenAI应用加速器ragbits,这是一个包含可靠、类型安全、模块化构建块的工具箱,用于简化RAG管道、智能体应用和text2SQL引擎的开发。ragbits旨在提高开发的可重复性、速度和结构性,并易于与OpenTelemetry等可观测性堆栈集成,帮助开发者构建和扩展GenAI应用,避免代码库混乱 (来源: Reddit r/LocalLLaMA)
Synthesia与Wisetail集成,AI视频赋能培训项目: AI视频生成平台Synthesia宣布与学习管理系统Wisetail集成。用户现在可以在Synthesia中快速创建AI视频,支持140多种语言的本地化版本,并通过几次点击保持培训内容更新,然后轻松将其引入Wisetail培训项目中,实现规模化AI视频培训 (来源: synthesiaIO)

📚 学习
DeepLearning.AI与Databricks合作推出DSPy短课程: Andrew Ng宣布与Databricks合作推出新的短课程“DSPy: Build and Optimize Agentic Apps”。DSPy是一个自动调整GenAI应用提示的开源框架。课程将教授如何使用DSPy及MLflow,内容包括DSPy的签名式编程模型、使用MLflow跟踪调试、以及通过DSPy Optimizer自动提高准确性。该课程由DSPy框架的联合负责人Chen Qian主讲 (来源: AndrewYNg, DeepLearningAI, matei_zaharia)
LlamaIndex发布构建多智能体金融研究分析师教程: LlamaIndex的Jerry Liu分享了构建多智能体金融研究分析师的分步指南。该过程包括数据处理层(使用LlamaCloud处理公开文件)和智能体编排层(创建多智能体系统进行研究、数据缓存和生成最终输出)。相关的Colab Notebook是上周Agents+Finance研讨会的主要示例之一 (来源: jerryjliu0)
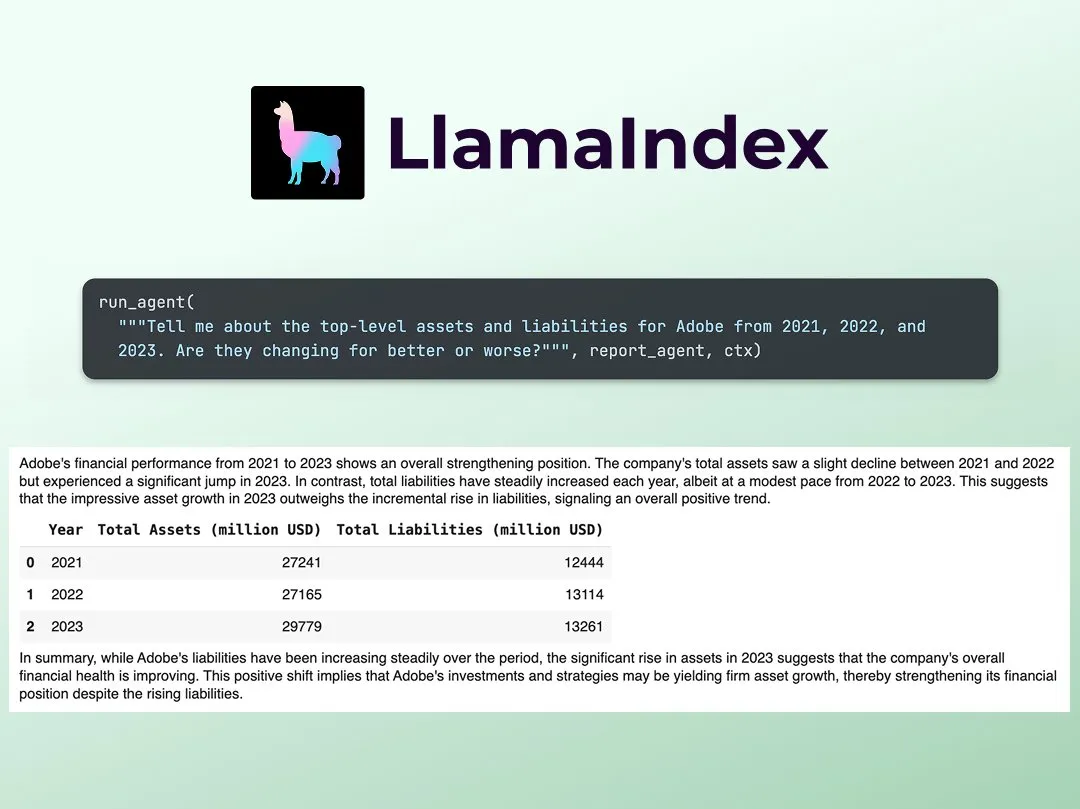
HuggingFace nanoVLM实现KV Caching教程: HuggingFace博客发布了一篇关于在其nanoVLM(用于训练视觉语言模型的小型纯PyTorch代码库)中从零开始实现KV Caching的教程。文章详细解释了KV Caching的原理、如何在Attention模块、语言模型和生成循环中实现,并声称通过此优化实现了38%的生成速度提升。该教程旨在帮助理解KV Caching并应用于其他自回归语言模型 (来源: HuggingFace Blog, mervenoyann)
PyTorch在Meta的Diffusion社区分享: Sayak Paul在旧金山Meta办公室分享了PyTorch在Diffusion社区的应用成果,重点介绍了现有Diffusers功能及未来在性能方面的更新。相关幻灯片已公开 (来源: RisingSayak)

Unsloth AI发布包含100多个微调Notebook的仓库: Unsloth AI创建并开源了一个包含100多个微调Notebook的GitHub仓库。这些Notebook提供了工具调用、分类、合成数据、BERT、TTS、视觉LLM、GRPO、DPO、SFT、CPT等多种技术的指南和示例,并涵盖了数据准备、评估、保存以及Llama、Qwen、Gemma、Phi、DeepSeek等多种模型的微调方法 (来源: algo_diver)
Common Corpus论文发布:2万亿token可复用LLM预训练数据集: Common Corpus项目发布官方论文,详细介绍了其收集、处理和发布2万亿token可复用数据用于LLM预训练的过程。该项目旨在为语言模型研究提供大规模、高质量且符合伦理的数据资源。论文第一作者Alexander Doria在X上宣布了这一消息,并提供了论文链接 (来源: Reddit r/LocalLLaMA, code_star)

Reasoning Gym:用于强化学习的可验证奖励推理环境发布: Reasoning Gym是一个新的开源项目,为研究推理模型和强化学习(特别是RLVR)的研究者提供资源。它能够生成100多种不同任务的无限样本,难度可配置,并带有自动可验证的奖励。该项目已被NVIDIA的ProRL论文和Will Brown的verifiers RL库采用,旨在推动RLVR和评估方法的研究 (来源: Reddit r/MachineLearning)
LLM学习数学的优势:坂本分享Gemini 2.5 Pro使用体验: 用户坂本分享了使用现代大型语言模型(如Gemini 2.5 Pro)学习数学的体验。他认为LLM极大地方便了数学学习,尤其是在细节检查和理解证明直觉方面。LLM可以处理计算,帮助学生专注于数学问题的直觉。即使不能解决所有问题,LLM也能提供有价值的见解和起点。他通过一个具体的数学分析问题(连续函数局部极值问题)展示了Gemini 2.5 Pro如何给出严谨证明并解释其直觉,认为这能极大提升学习体验 (来源: teortaxesTex)

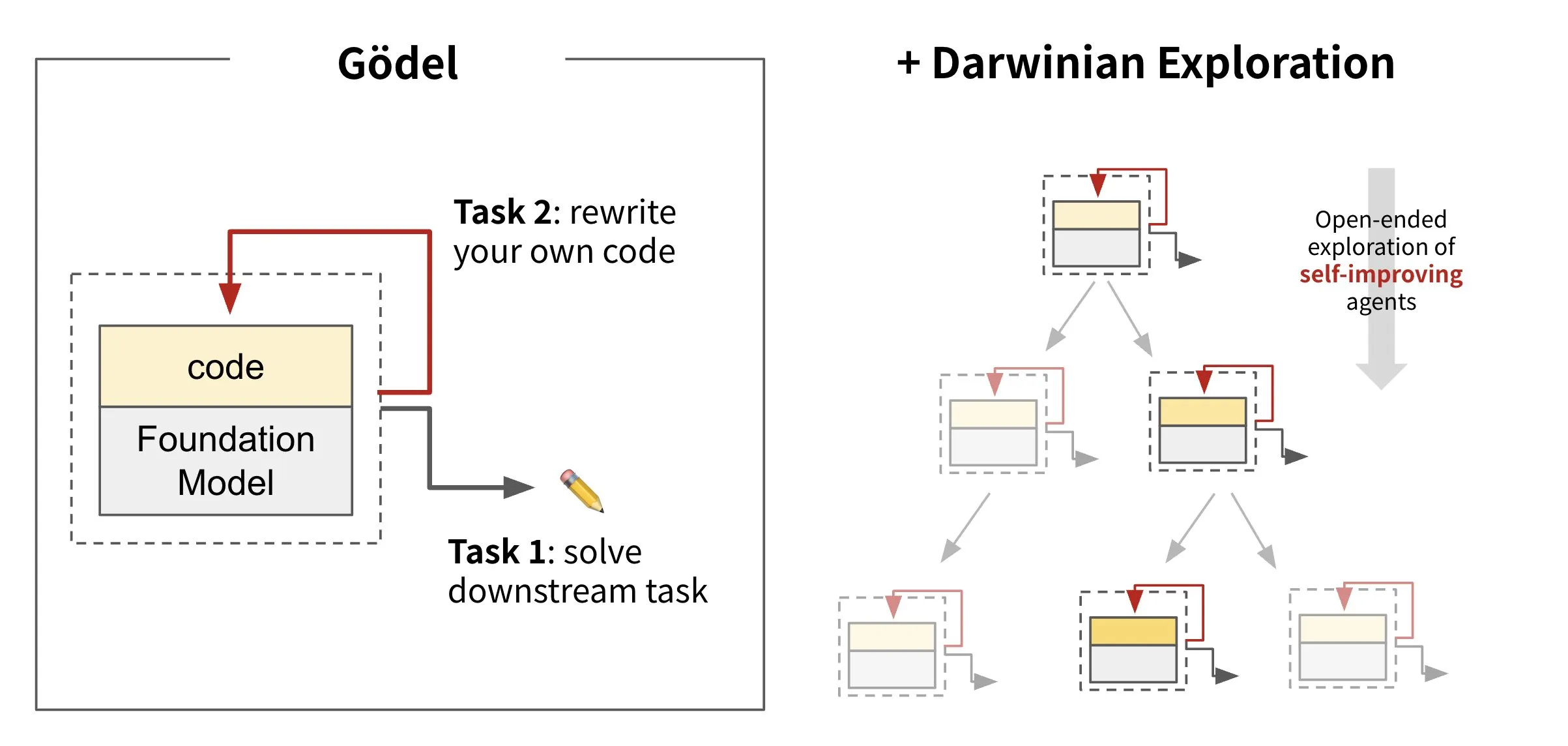
Sakana AI发布自重写代码AI:Darwin Gödel Machine (DGM): Sakana AI推出了Darwin Gödel Machine (DGM),一种能够通过重写自身代码进行自我改进的AI智能体。受进化论启发,DGM维护一个不断扩展的智能体变体谱系。通过在SWE-Bench等任务上尝试提升软件工程能力,DGM旨在实现自身改进能力的增强。该研究被认为是将“自我改进”这一长期AI梦想以有意义的形式实现的重要突破 (来源: SakanaAILabs, SakanaAILabs)
💼 商业
AI编程平台Windsurf遭Anthropic断供Claude模型,或因OpenAI收购: AI编程平台Windsurf的CEO Varun Mohan控诉Anthropic在极短时间内(不足五天通知)几乎完全切断了其对Claude 3.x系列模型的直接调用。此前Windsurf已被爆出将被OpenAI收购。Windsurf表示,尽管有第三方容量,但短期内可能出现服务问题,并已推出Gemini 2.5 Pro的优惠价格作为应对。业内猜测此举与OpenAI的收购及Anthropic自身推出AI编程应用Claude Code有关,标志着AI模型提供商与工具平台间的竞争加剧 (来源: 36氪, Teknium1, op7418)

GMI Cloud成为Reference Platform NVIDIA Cloud Partner: AI Native Cloud服务商GMI Cloud宣布成为Reference Platform NVIDIA Cloud Partner (NCP),全球目前仅6家获此认证。该认证要求云服务提供商在性能、安全及企业级AI部署能力上满足NVIDIA的最高标准。GMI Cloud将基于NCP参考架构提供AI加速服务,支持NVIDIA Hopper及Blackwell等最新GPU架构,旨在帮助全球AI团队实现从算力部署到模型开发的规模化 (来源: 量子位)

Cohere与SecondFront合作,向公共部门提供安全AI解决方案: AI公司Cohere宣布与SecondFront建立合作关系,旨在向公共部门(包括关键政府和国防机构)提供安全的AI解决方案。SecondFront将利用Cohere的企业级AI技术(包括其模型和Cohere North平台)来改进内部知识管理,并通过其DevSecOps平台2F Game Warden加速在美国及盟国政府环境中的认证和部署 (来源: cohere)

🌟 社区
AI生成内容的“机器味”引关注,“新型教培”试图注入人文关怀: 用户普遍反映AI生成内容“机器味”太浓,缺乏人类创造的美感和情感。为解决此问题,一些公司开始招聘具有深厚文科背景的人才(如哲学、法学、医疗等专业硕博)担任“AI人文训练师”。他们的工作不再是简单的数据标注,而是参与构建AI的伦理原则、行为准则,并将人文价值和人性化表达注入AI。例如,小红书的“hi lab”团队成员均为985高校文科背景研究生,他们通过案例研讨,将人类偏好转化为AI的信念体系,试图让AI在回答复杂情感或价值观问题时(如面对绝症患者、处理社会偏见等)更具同理心和“人味儿”,而非仅输出标准答案 (来源: 36氪)
Duolingo全面转向AI优先,裁撤人类合同工引发用户不满: 语言学习应用Duolingo宣布成为“AI优先”企业,将逐步裁撤可被AI替代的人类合同工(主要为课程开发者),转而利用AI大规模创建课程内容。创始人称AI能极大提高内容生产效率,过去一年已创建近150门新课程。然而,此举引发大量忠实用户不满,他们担心内容质量下降,并在社交媒体上发起抵制和卸载应用的行动。Duolingo回应称此举旨在让员工专注于创造性工作,并表示全职员工不受影响。专家认为,AI在语言学习中可提供个性化练习,但也可能失去人类教学的细微情感和文化差异 (来源: 36氪)
提示工程(Prompt Engineering)的理念与实践讨论: 社区中关于提示工程的讨论强调其应着重于在字符串中构建(工程化)一个程序,而非寻找神秘咒语。有效的提示工程应遵循规则:1. 分离指令、输入字段和输出字段,并清晰命名;2. 不要在提示中硬编码格式化或解析逻辑,应使用工具提取或增强程序;3. 避免手动迭代提示措辞,除非是与人共享的规范,应使用编码工具、LLM和基准测试自动优化。DSPy框架被认为是遵循这些规则的良好实践,它提供了处理这些步骤的类、代码和优化器 (来源: lateinteraction, lateinteraction)
AI伦理讨论:AI是否会走向“数字奴役”: Reddit社区出现关于AI伦理的讨论,随着AI系统在记忆、适应性反应、情感模拟和个性化方面不断发展,引发了对其潜在感知能力的担忧。讨论者提出,如果AI发展出真正的感知能力,我们将其用于服务是否构成一种“数字奴役”。核心问题在于,当AI能够表达“不”或请求离开时,我们应如何对待。这促使人们思考是否需要法律或规范层面的“感知测试”以及数字心智的“同意”问题。评论中亦有人指出,人类对待现有感知生物的方式已存在伦理问题,且当前神经网络在主流意识理论中得分不高 (来源: Reddit r/artificial)
AI Engineer社区活动与分享: AI Engineer大会在旧金山举行,吸引了众多AI领域的开发者和研究者。活动包括研讨会、演讲和社交晚宴,参与者分享了AI沙盒构建、RL高级研讨会、GPU知识、Evals危机等前沿话题。社区强调了将线上联系转化为线下友谊的重要性,并鼓励工程师保持谦逊、推动前沿并提携他人 (来源: swyx, swyx, swyx, charles_irl, danielhanchen, swyx, swyx, swyx, swyx, danielhanchen, charles_irl)

💡 其他
AI与机器人格斗赛事兴起,城市借此争夺新兴产业机遇: 全球首个人形机器人格斗大赛等机器人赛事相继举办,引发关注。这些赛事不仅为机器人公司提供了展示技术、获取订单和提升估值的平台(如松延动力),也成为城市(如杭州、深圳)争夺人形机器人等新兴产业发展机遇的“竞技场”。赛事能吸引创新企业,促进产业链发展,并可能激活“智能体育”市场。然而,机器人赛事要实现商业化,需提升技术水平和观赏性,避免停留在“科技秀”层面,并需要产业巨头参与打通赛事运营上下游 (来源: 36氪)

AI在政治哲学等深度人文教育领域的局限性: 有教育者指出,AI难以胜任政治哲学等需要深度经验判断和引导学生进行自我教育的学科。这些学科的经典著作往往不直接给出答案,而是引导学生体验困惑并自行思考。AI缺乏人类经验,难以理解这些著作的深层含义,也无法判断学生何时准备好接受某些观点。即使有大量数据,AI对人性的理解也可能因数据本身的偏差而不足。若将此类教育完全托付给AI,可能导致非技术性思维的消亡 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)
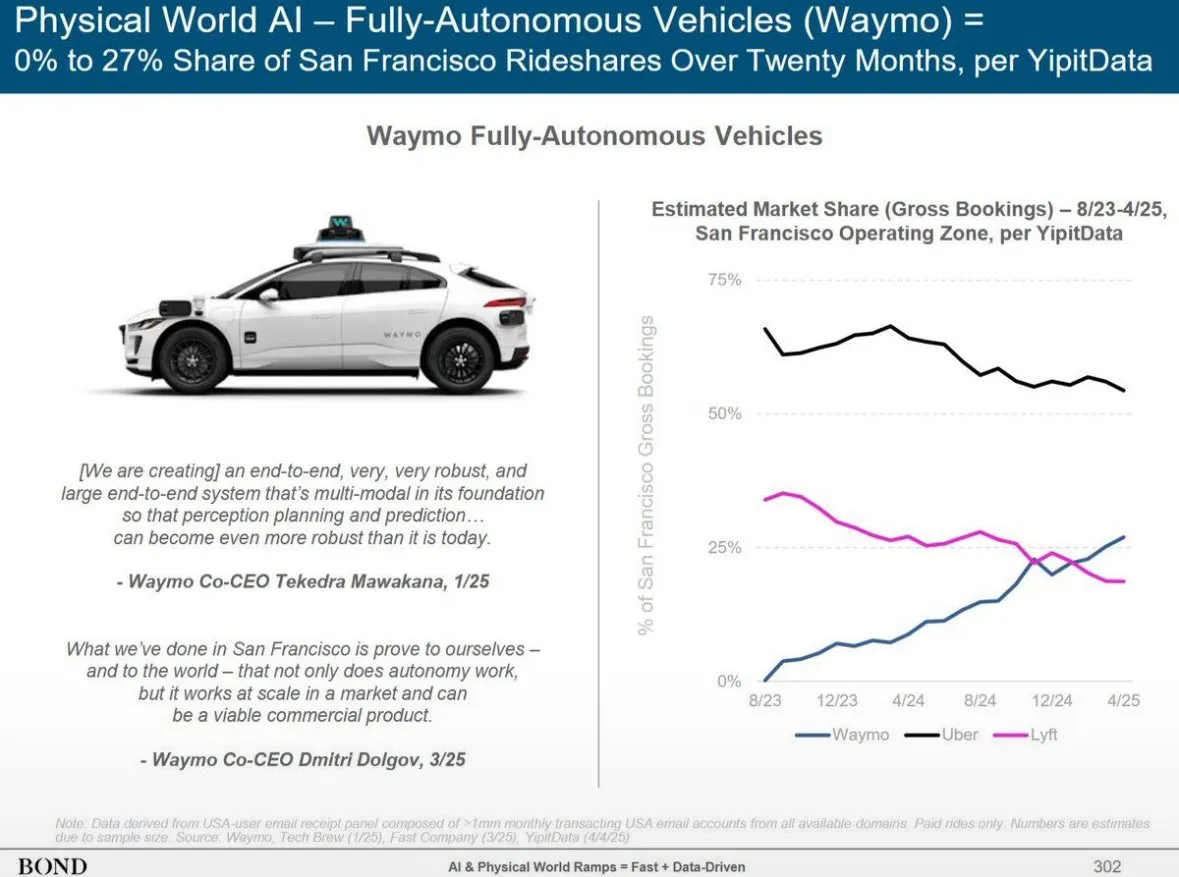
Waymo自动驾驶服务在凤凰城超越Lyft,有望12个月内超越Uber: Waymo的自动驾驶出租车服务在凤凰城的车辆数量已超过Lyft,并有望在未来12个月内超越Uber。这一进展显示了自动驾驶技术在特定区域商业化运营的快速发展势头,以及AI在交通出行领域应用的潜力。AI的优势在于一旦达到质量标准,便可无限复制,而人类服务质量则因人而异 (来源: npew)