
关键词:OpenAI Codex, 视觉语言动作模型, 语言模型记忆上限, ChatGPT记忆功能, DeepSeek-R1-0528, 扩散模型, Suno AI音乐创作, MetaAgentX, Codex互联网访问功能, SmolVLA机器人模型, GPT风格模型3.6比特记忆, ChatGPT个性化交互改进, DeepSeek-R1复杂推理能力
🔥 聚焦
OpenAI Codex向Plus用户开放并获重大更新,包括互联网访问与语音输入: OpenAI宣布Codex将向ChatGPT Plus用户逐步开放。此次更新的重点包括允许AI智能体在执行任务时访问互联网(默认关闭,用户可控域名和HTTP方法),以便安装依赖、升级软件包和运行外部资源测试。同时,Codex现在支持直接更新已有的Pull Request,并能通过语音输入任务。其他改进包括支持二进制文件操作(PR中目前仅限删除或重命名)、任务差异(diff)大小限制从1MB提升至5MB、设置脚本运行时间限制从5分钟提升到10分钟,以及修复了iOS平台上的多项问题并重新启用了实时活动功能。这些更新旨在提升Codex在复杂编程任务中的实用性和灵活性 (来源: OpenAI Developers, Tibor Blaho, gdb, kevinweil, op7418)
Hugging Face与H Company联合发布开源视觉语言动作(VLA)模型,推动机器人技术发展: Hugging Face和H Company在“VLA日”宣布了新的开源视觉语言动作模型,包括Hugging Face的SmolVLA (450M参数)和H Company的Holo-1 (3B和7B参数)。VLA模型旨在让机器人能够看、听、理解并根据AI指令行动,被称为机器人领域的GPT。开源这些模型对于理解其工作原理、避免潜在后门以及针对特定机器人和任务进行定制至关重要。SmolVLA在LeRobotHF数据集上训练,展示了优异的性能和推理速度。Holo-1则专注于网页和计算机代理任务,支持Apache 2.0许可证。这些发布预计将加速开源AI机器人技术的发展 (来源: ClementDelangue, huggingface, LoubnaBenAllal1, tonywu_71)

Meta等公司研究揭示语言模型记忆上限约为每参数3.6比特,挑战传统认知: Meta、DeepMind、康奈尔大学和英伟达的联合研究指出,GPT风格的语言模型每个参数大约能记忆3.6比特的信息。研究发现,模型会持续记忆训练数据直至达到容量上限,之后开始出现“Grokking”(顿悟)现象,即非预期记忆减少,模型转向泛化学习。这一发现解释了“双重下降”现象,即当数据集信息量超过模型存储能力时,模型被迫共享信息点以节省容量,从而促进泛化。该研究还提出了关于模型容量、数据规模与成员推断攻击成功率之间关系的缩放定律,并指出对于在极大数据集上训练的现代LLM,可靠的成员推断变得困难 (来源: 机器之心, Reddit r/LocalLLaMA, code_star, scaling01, Francis_YAO_)
OpenAI推出ChatGPT记忆功能轻量版,提升个性化交互体验: OpenAI宣布开始向免费用户推出轻量版的记忆功能改进。除了已有的保存记忆外,ChatGPT现在能够参考用户最近的对话,以提供更个性化的回应。此举旨在通过借鉴用户的偏好和兴趣,使其在写作、获取建议、学习等方面更加得心应手。Sam Altman也表示,记忆功能已成为他最喜欢的ChatGPT特性之一,并期待未来能有更大改进。这项更新标志着OpenAI致力于让AI交互更贴近用户需求,增强用户粘性 (来源: openai, sama, iScienceLuvr)
🎯 动向
DeepSeek-R1-0528发布,强化复杂推理与编程能力: DeepSeek发布了R1模型的升级版DeepSeek-R1-0528,该版本基于2024年12月发布的DeepSeek V3 Base模型,通过投入更多算力进行后训练,显著提升了模型的思维深度和推理能力。新模型在处理复杂问题时会进行更细致的拆解和更长时间的思考(例如AIME 2025测试中平均每题token消耗从12K增至23K),从而在数学、编程和通用逻辑等多个基准测试中取得领先成绩,表现接近GPT-o3和Gemini-2.5-Pro。此外,新版本在降低幻觉(约45%-50%)、创意写作和工具调用方面也有显著优化,例如能更稳定地回答“9.9 – 9.11等于多少”这类问题,并能一次性生成可运行的前后端代码 (来源: 科技狐, AI前线, Hacubu)

扩散模型在语言和多模态领域展现潜力,挑战自回归范式: Google I/O 2025上展示的Gemini Diffusion语言模型,以其高达5倍的生成速度和相当的编程性能,凸显了扩散模型在文本生成领域的潜力。与自回归模型逐个预测token不同,扩散模型通过逐步去噪生成输出,支持快速迭代和纠错。蚂蚁集团与人大高瓴人工智能学院合作推出的8B参数LLaDA模型,以及字节跳动开发的MMaDA多模态扩散模型,均展示了国内团队在这一赛道的前沿探索。这些模型不仅在语言任务上表现出色,还在多模态理解(如LLaDA-V结合视觉指令微调)和特定领域(如DPLM用于蛋白质序列生成)取得进展,预示着扩散模型可能成为下一代通用模型的新范式 (来源: 机器之心)
Suno发布重大更新,增强AI音乐创作编辑能力: AI音乐创作平台Suno推出了多项重要更新,赋予用户更大的创作自由度和控制力。新功能包括升级的歌曲编辑器,允许用户在波形图上逐段重新排序、重写和重制音轨;引入词干提取功能,可将音轨精确分离为12个独立的音源(如人声、鼓、贝斯等)供预览和下载;扩展了上传功能,支持最长8分钟的完整歌曲上传,用户可以基于自己的音频素材进行创作;新增创意滑块,用户可在生成前调整输出结果的“怪异度”、结构化程度或参考驱动程度,以更好地塑造最终作品 (来源: SunoMusic)
MetaAgentX推出Open CaptchaWorld,评估多模态Agent解验证码能力: 针对当前多模态Agent在解决CAPTCHA(人机验证)问题上的瓶颈,MetaAgentX团队发布了Open CaptchaWorld平台及基准。该平台包含20类现代验证码、共225个样例,要求Agent在真实网页环境中通过观察、点击、拖动等交互完成任务。测试结果显示,即使是GPT-4o等顶尖模型,成功率也仅在5%-40%之间,远低于人类93.3%的平均成功率。研究者还提出了“CAPTCHA Reasoning Depth”指标,量化解题所需的“视觉理解+认知计划+动作控制”步骤。该平台旨在揭示Agent在长序列动态交互和规划方面的短板,并推动研究者关注并解决这一实际部署中的关键问题 (来源: 量子位)

Google NotebookLM支持公开分享,促进知识共享与协作: Google宣布NotebookLM(此前称为Project Tailwind)现已支持公开分享笔记本。用户可以通过点击“分享”并设置访问权限为“任何拥有链接的人”来共享他们的笔记内容。这一功能使得用户可以方便地分享想法、学习指南和团队文档,接收者可以浏览内容、提问、获得即时摘要和语音概览。此举旨在促进知识的传播和协作编辑,提升NotebookLM作为AI笔记工具的实用性 (来源: Google, op7418)
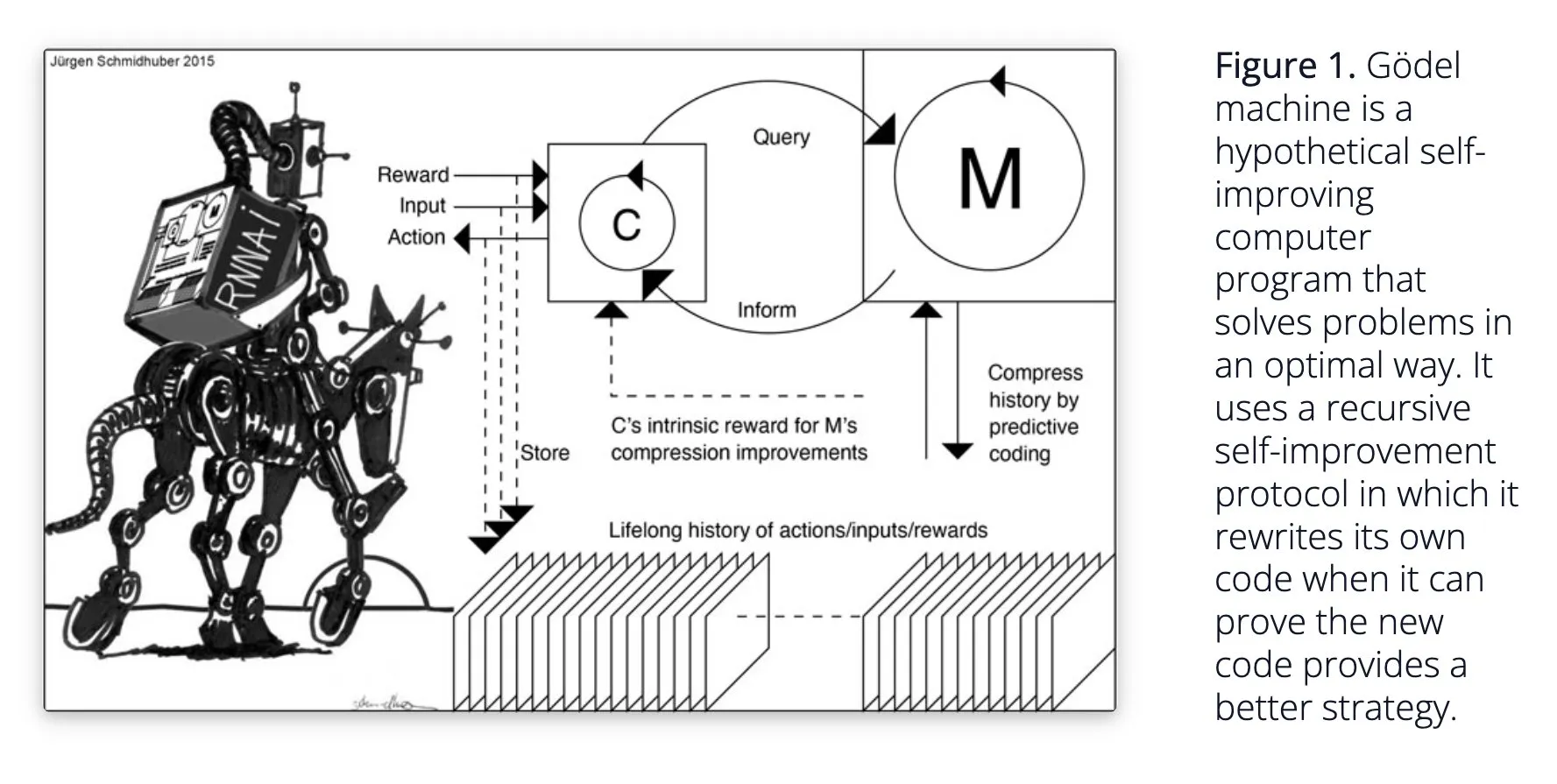
Sakana AI提出自学习AI系统Darwin Gödel Machine (DGM): Sakana AI公开了其自学习AI系统Darwin Gödel Machine (DGM)的研究。DGM利用进化算法迭代地重写自身代码,从而持续提升在编程任务上的性能。该系统通过维护一个生成的编码智能体档案,并从中采样、利用基础模型创建新版本来实现开放式探索,形成多样化、高质量的智能体。实验表明,DGM在SWE-bench和Polyglot等基准测试中显著提升了编码能力。该研究为自改进AI提供了新思路,旨在通过自主创新加速AI发展 (来源: Reddit r/LocalLLaMA, hardmaru, scaling01)
Google DeepMind提升AI对话自然度,开放原生音频功能: Google DeepMind宣布其原生音频功能正使AI对话更加自然,能够理解语调并生成富有表现力的语音。这项技术旨在开辟人与AI交互的新可能性。开发者现在可以通过Google AI Studio试用这些功能,有望应用于更自然的语音助手、有声内容生成等场景 (来源: GoogleDeepMind)
Runway Gen-4图像生成技术受关注,支持多重参照与风格控制: Runway的Gen-4图像生成技术因其高保真度和前所未有的风格控制能力受到关注,尤其体现在其多重参照功能上,为创意探索提供了新空间。用户可以利用该技术生成各种动物、恐龙或想象中的生物,显示了其在细致视觉内容创作方面的潜力。Runway在好莱坞等领域的使用也表明其技术正逐步应用于专业内容制作 (来源: c_valenzuelab, c_valenzuelab)

AssemblyAI发布实时语音转录新模型,提升语音AI应用性能: AssemblyAI推出了一款新的实时语音转录(STT)模型,以其高速度和准确性受到关注。该模型专为构建语音AI应用的开发者设计,旨在提供更流畅、精准的语音识别体验。同时,AssemblyAI还通过其pipecat_ai项目提供了AssemblyAISTTService实现,方便开发者集成。此举显示了AssemblyAI在语音技术领域的持续投入和创新 (来源: AssemblyAI, AssemblyAI)
微软Bing庆祝16周年,集成GPT-4与DALL·E,推出Bing Video Creator: 微软Bing搜索引擎迎来16周年。近年来,Bing率先大规模集成聊天式生成AI,并成为首个集成GPT-4和DALL·E的微软产品。最近,Bing在移动应用中免费推出了Copilot Search和Bing Video Creator,后者可用于生成视频内容。这标志着Bing在AI驱动的搜索和内容创作领域持续创新和发展 (来源: JordiRib1)
Andrej Karpathy对Veo 3印象深刻,探讨视频生成宏观影响: Andrej Karpathy对Google的视频生成模型Veo 3及其社区的创作成果表示印象深刻,并指出音频的加入显著提升了视频质量。他进一步探讨了视频生成的几个宏观层面影响:1. 视频是人脑最高带宽的输入方式;2. 视频生成为AI提供了理解世界的“母语”;3. 视频生成是通往模拟现实和世界模型的关键路径;4. 其计算需求将推动硬件发展。这表明视频生成技术不仅是内容创作的革新,更是AI认知和发展的重要驱动力 (来源: brickroad7, dilipkay, JonathanRoss321)
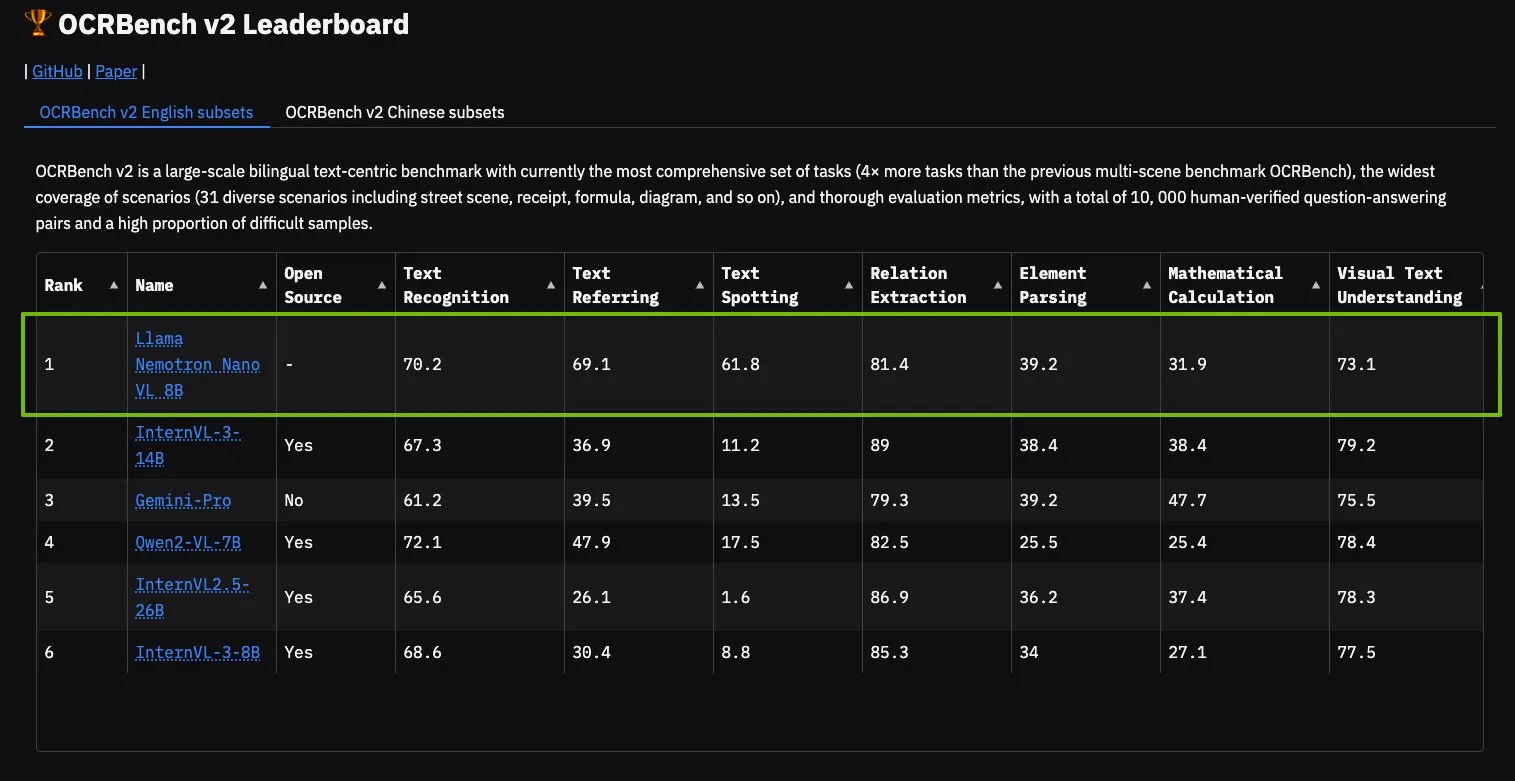
NVIDIA Llama Nemotron Nano VL模型在OCRBench V2登顶: NVIDIA的Llama Nemotron Nano VL模型在OCRBench V2排行榜上获得第一名。该模型专为高级智能文档处理和理解而设计,能够在单个GPU上精确提取复杂文档中的多样化信息。用户可以通过NVIDIA NIM试用该模型,显示了NVIDIA在特定领域(如文档理解)小型化、高效化AI模型方面的进展 (来源: ctnzr)
🧰 工具
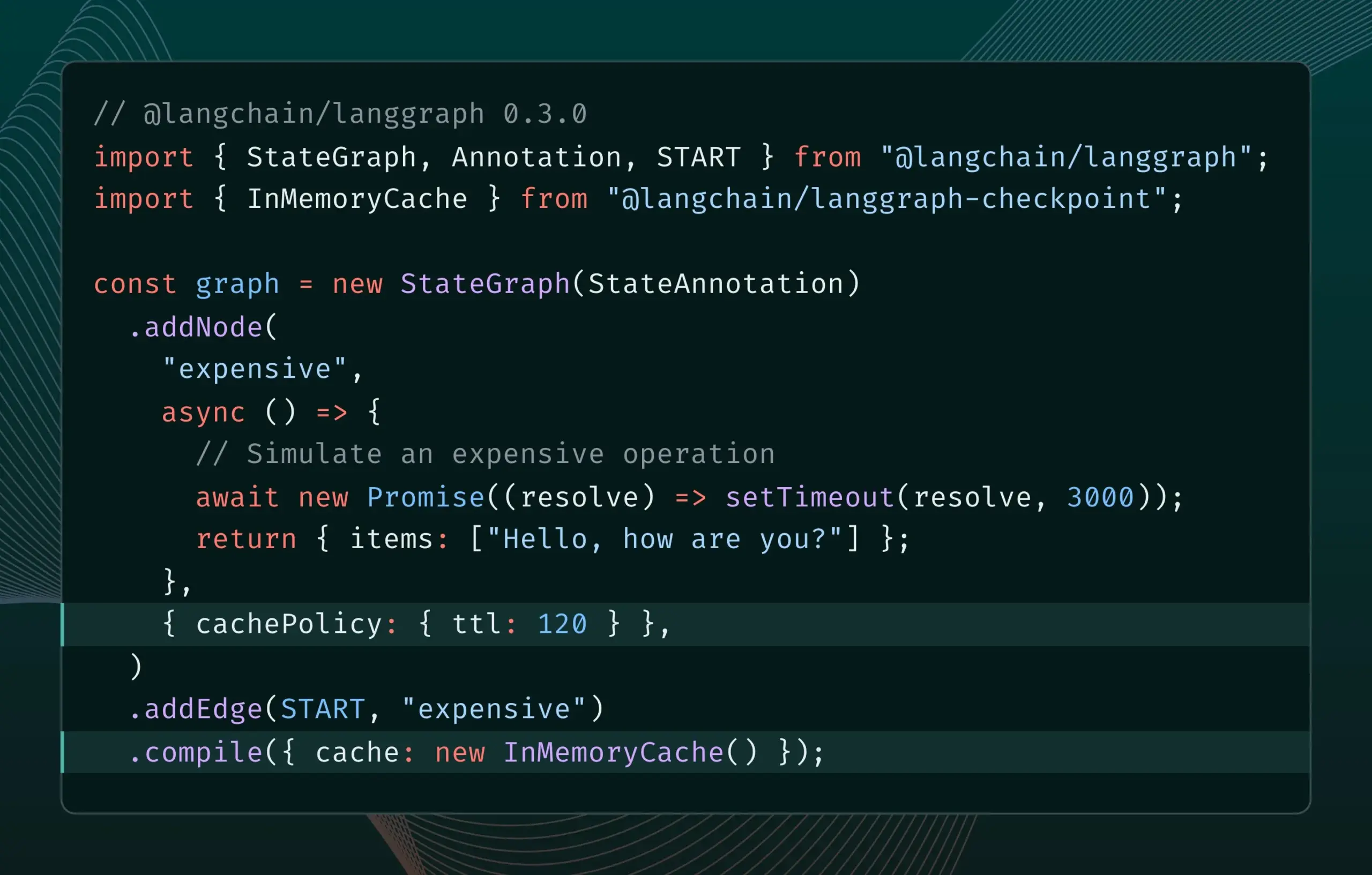
LangGraph.js 0.3版本引入节点/任务缓存功能: LangGraph.js发布0.3版本,新增了节点/任务缓存功能。该功能旨在通过避免冗余计算来加速工作流程,特别适用于迭代昂贵或长时间运行的智能体。新版本同时支持Graph API和Imperative API,为JavaScript开发者构建复杂AI应用提供了更高效率 (来源: Hacubu, hwchase17)
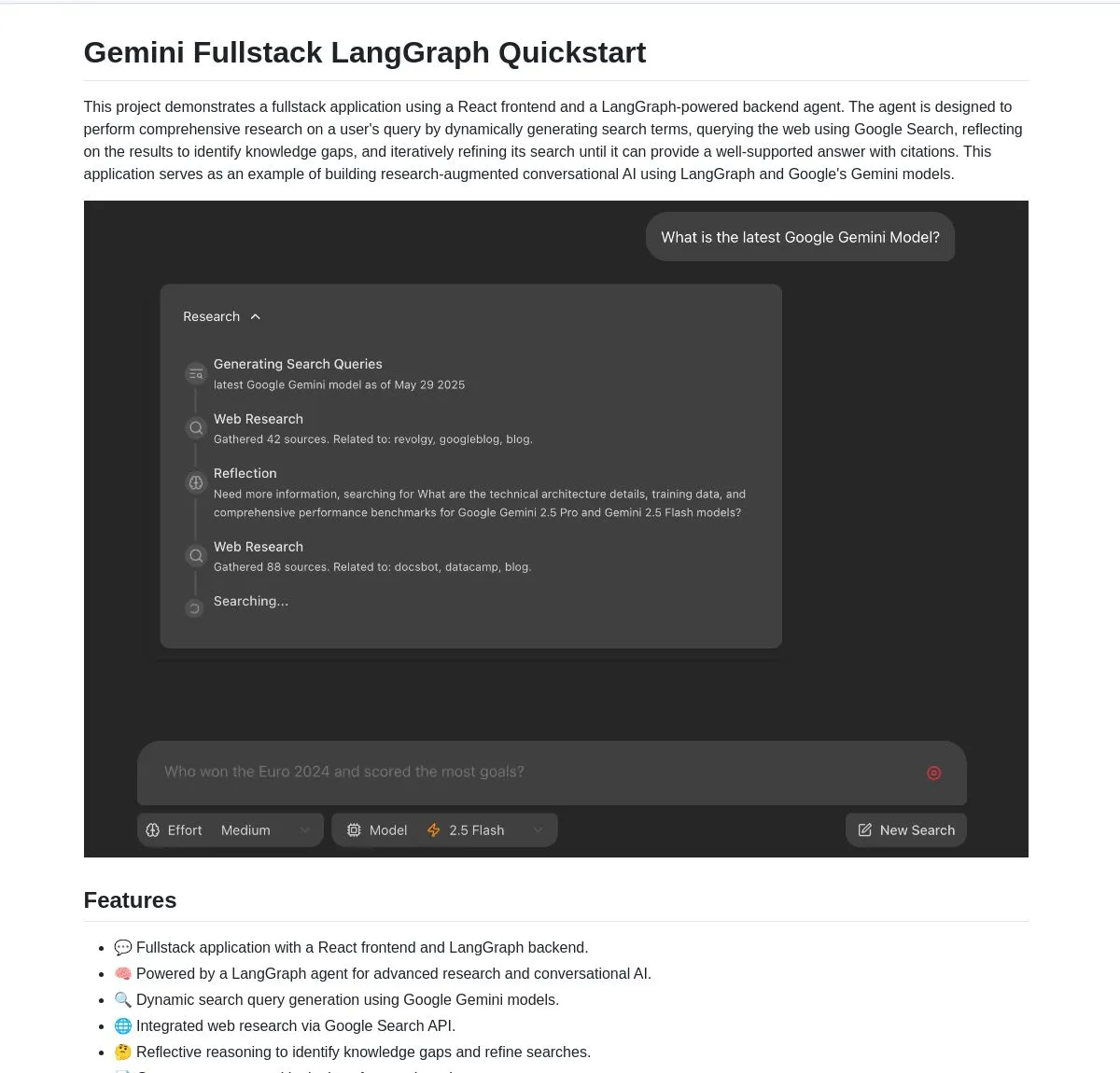
谷歌开源Gemini Research Agent全栈应用,基于Gemini和LangGraph: 谷歌发布了一个基于Gemini模型和LangGraph构建的智能研究助手全栈应用示例——gemini-fullstack-langgraph-quickstart。该应用能够动态优化查询,通过迭代学习提供带引用的答案,并支持不同搜索力度控制。它利用Gemini原生的Google搜索工具进行网络研究和反思推理,旨在为开发者提供一个构建高级研究型AI应用的起点 (来源: LangChainAI, hwchase17, dotey, karminski3)
FedRAG新增LangChain桥接功能,便于RAG系统集成与微调: FedRAG宣布支持与LangChain的桥接,由外部贡献者实现。用户可以通过FedRAG组装RAG系统,并微调生成器/检索器组件模型以适应特定知识库。微调后,可桥接到LangChain等流行的RAG推理框架,利用其生态系统和特性。此更新旨在简化RAG系统的构建、优化和部署流程 (来源: nerdai)

Ollama推出“思考”功能,可分离思考过程与最终答复: Ollama更新了其平台,为支持“思考”功能的模型(如DeepSeek-R1-0528)增加了分离思考过程和最终答复的选项。用户可以选择查看模型的“思考”内容,也可以禁用此功能以获得直接回复。该功能适用于Ollama的CLI、API及Python/JavaScript库,为用户提供了更灵活的模型交互方式 (来源: Hacubu)
Firecrawl推出/search端点,集成搜索与抓取功能: Firecrawl发布了新的/search API端点,允许用户通过一次API调用完成网络搜索并以LLM友好的格式抓取所有结果。这一功能旨在简化AI智能体和开发者发现和利用网络数据的流程。LangChain的StateGraph可用于构建利用此功能的自动化流程,例如自动查找竞争对手、抓取其网站并生成分析报告 (来源: hwchase17, LangChainAI, omarsar0)
LlamaIndex集成MCP,增强智能体能力与工作流部署: LlamaIndex宣布集成MCP(Model Component Protocol),旨在增强其智能体的工具使用能力和工作流部署的灵活性。该集成提供了帮助LlamaIndex智能体使用MCP服务器工具的辅助函数,并允许将任何LlamaIndex工作流作为MCP服务器提供服务。此举意在扩展LlamaIndex智能体的工具集,并使其工作流能无缝集成到现有的MCP基础设施中 (来源: jerryjliu0)

Modal推出LLM Engine Advisor,提供开源模型引擎性能基准: Modal发布了LLM Engine Advisor,这是一个旨在帮助用户选择最佳LLM引擎和参数的基准测试应用。该工具提供了在不同硬件(如多GPU环境)上运行开源模型(如DeepSeek V3, Qwen 2.5 Coder)使用不同推理引擎(如vLLM, SGLang)时的性能数据,如速度和最大吞吐量。此举旨在提高运行自托管LLM的透明度和决策效率 (来源: charles_irl, akshat_b, sarahcat21)
PlayDiffusion:PlayAI推出音频修复新模型,可替换音频中对话内容: PlayAI发布了名为PlayDiffusion的新模型,该模型能够无缝替换音频文件中的对话内容,同时保留原始说话者的声音特征。这种“音频修复”技术为音频编辑提供了新的可能性,例如修改播客、有声读物或视频配音中的特定词句,而无需重新录制整个片段。项目已在GitHub开源 (来源: _mfelfel, karminski3)
Hugging Face推出语义去重工具,优化训练数据集质量: 受Maxime Labonne的AutoDedup启发,Hugging Face Spaces上线了一款新的语义去重应用。该工具允许用户选择Hugging Face Hub上的一个或多个数据集,通过对每行数据进行语义嵌入,然后根据设定的阈值移除近似重复的内容。此举旨在帮助研究人员和开发者提高训练数据集的质量,避免因数据冗余导致模型性能下降或训练效率低下 (来源: ben_burtenshaw, ben_burtenshaw)

Perplexity Labs需求激增,用户可快速构建定制化软件: Perplexity Labs因其能通过单一提示快速构建定制化软件而受到用户欢迎,需求出现显著增长,甚至有用户购买多个Pro账户以获取更多Labs查询次数。这反映出用户对于能够根据自身需求快速创建和修改软件工具的强烈兴趣,AI驱动的个性化软件开发正成为一种趋势 (来源: AravSrinivas, AravSrinivas)
Ollama与Hazy Research合作推出Secure Minions,实现本地与云端LLM私密协作: 斯坦福Hazy Research实验室的Minions项目,通过连接Ollama本地模型与云端前沿模型,旨在大幅降低云成本(5-30倍)同时保持接近前沿模型的准确率(98%)。Secure Minion项目进一步将H100等GPU转变为安全区域,实现内存和计算加密,确保数据隐私。这种混合操作模式在提升隐私保护的同时,也为用户提供了更经济高效的LLM使用方案 (来源: code_star, osanseviero, Reddit r/LocalLLaMA)
Exa与OpenRouter合作,为400+ LLM提供网页搜索能力: AI搜索引擎Exa宣布与OpenRouter达成合作,将为OpenRouter平台上的超过400个大型语言模型提供网页搜索功能。这意味着开发者和用户在使用这些LLM时,可以方便地调用Exa的搜索能力,增强模型的实时信息获取和知识更新能力,进一步提升RAG(检索增强生成)等应用的表现 (来源: menhguin)

📚 学习
微软推出MCP入门课程《MCP for Beginners》: 微软发布了针对MCP(Microsoft Copilot Platform,推测为笔误,应指Microsoft CoCo Framework或类似AI Agent协议)初学者的入门课程。该课程旨在帮助初学者掌握MCP的核心概念、实现方法及实际应用,内容包括协议架构规范、教程指南和多种编程语言的代码实践。课程结构涵盖简介、核心概念、安全、入门、进阶以及社区与案例分析,并提供基础和高级计算器等示例项目 (来源: dotey)

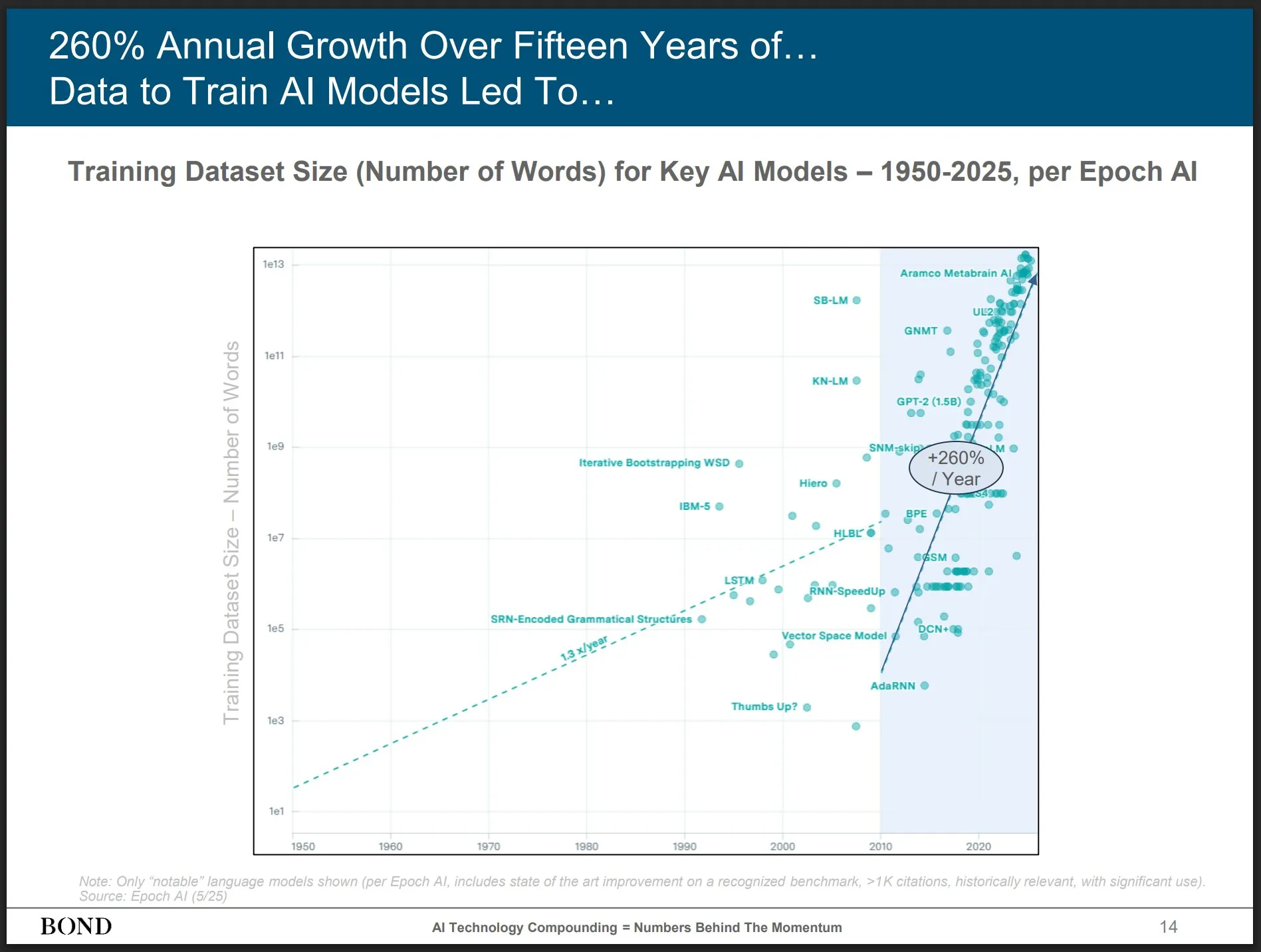
Bond Capital发布2025年5月AI趋势报告,洞察行业发展: 知名风投Bond Capital发布了长达339页的《2025-05 AI趋势报告》,全面分析了AI在各个领域的数据和洞察。报告重点指出,ChatGPT月活用户达8亿(90%来自北美以外),日搜索量10亿次;AI相关IT岗位增长448%;训练前沿模型成本超10亿美元/次;LLM正成为基础设施。报告强调,竞争关键在于打造最佳AI驱动产品,当前是建设者的市场 (来源: karminski3)
论文探讨强化学习与LLM推理能力关系,ProRL与Limit-of-RLVR引关注: 两篇关于强化学习(RL)与大型语言模型(LLM)推理能力的研究论文引发讨论。一篇是《Limit-of-RLVR: Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?》,另一篇是NVIDIA的《ProRL: Prolonged Reinforcement Learning Expands Reasoning Boundaries in Large Language Models》。这些研究探讨了RL(特别是RLVR,即可验证奖励的强化学习)在多大程度上能提升LLM的基础推理能力,以及持续RL训练对扩展LLM推理边界的影响。相关讨论认为,高质量的RLVR训练数据和有效的奖励机制是关键 (来源: scaling01, Dorialexander, scaling01)

论文《How Programming Concepts and Neurons Are Shared in Code Language Models》探讨代码LLM中编程概念与神经元的共享机制: 该研究调查了大型语言模型(LLMs)在处理多种编程语言(PLs)和英语时,其内部概念空间的关系。通过对Llama系列模型进行少样本翻译任务,发现在中间层,概念空间更接近英语(包括PL关键词),并倾向于为英语词元分配高概率。神经元激活分析显示,语言特定的神经元主要集中在底层,而各PL独有的神经元则倾向于出现在顶层。研究为理解LLM如何内部表征PLs提供了新见解 (来源: HuggingFace Daily Papers)
新论文《Pixels Versus Priors》通过视觉反事实控制MLLM中的知识先验: 该研究探讨多模态大语言模型(MLLM)在进行视觉问答等任务时,其推理更多依赖于记忆的世界知识还是输入图像的视觉信息。研究者引入Visual CounterFact数据集,包含与世界知识先验冲突的视觉反事实图像(如蓝色草莓)。实验表明,模型预测初期反映记忆先验,但在中后期转向视觉证据。论文提出PvP(Pixels Versus Priors)引导向量,通过激活层干预控制模型输出偏向世界知识或视觉输入,成功改变了大部分颜色和尺寸预测 (来源: HuggingFace Daily Papers)
ICML 2025论文GuidedQuant提出通过端损失指导提升层级PTQ方法: GuidedQuant是一种新的后训练量化(PTQ)方法,它通过将端损失(end loss)指导集成到目标中来增强层级PTQ方法的性能。该方法利用关于端损失的每特征梯度来加权层级输出误差,对应于保持通道内依赖关系的块对角Fisher信息。此外,论文还引入了LNQ,一种非均匀标量量化算法,保证单调减少量化目标值。实验表明,GuidedQuant在仅权重标量、仅权重量向量以及权值和激活量化方面均优于现有SOTA方法,并已应用于Qwen3、Gemma3、Llama3.3等模型的2-4比特量化 (来源: Reddit r/MachineLearning)

AI Engineer World’s Fair在旧金山举行,聚焦AI工程实践与前沿技术: AI Engineer World’s Fair正在旧金山举行,汇集了众多AI领域的工程师、研究者和开发者。会议议程包括强化学习、内核、推理与智能体、模型优化(RFT, DPO, SFT)、智能体编码、语音智能体构建等多个热门议题。活动期间将有来自OpenAI、Google等公司的专家进行分享和研讨,并有新产品和技术发布。社区成员积极参与,分享会议日程、组织线下交流,显示了AI工程社区的活力和对前沿技术的热情 (来源: swyx, clefourrier, swyx, LiorOnAI, TheTuringPost)

💼 商业
师渡智能完成数百万元种子轮融资,加速AI智能眼镜多场景落地: 苏州师渡智能科技有限公司宣布完成数百万元种子轮融资,资金将用于AI智能眼镜核心技术研发、市场拓展及生态建设。公司专注于将AI智能眼镜应用于智慧康养(如智能老花镜、智能助盲眼镜)、智慧生活(智能时尚眼镜、骑行眼镜)和智能制造(智能工业眼镜、语音控制器)等领域。其产品价格定位在200元至1000元区间,旨在通过高性价比推动智能眼镜的普及 (来源: 36氪)

传OpenAI或收购AI编程助手Windsurf,引发Anthropic断供Claude模型猜测: 市场传闻OpenAI可能以约30亿美元收购AI编程工具Windsurf(原Codeium)。在此背景下,Windsurf CEO Varun Mohan发帖称Anthropic在极短通知期内切断了其几乎所有Claude 3.x模型的直接访问权限,包括Claude 3.5 Sonnet等。Windsurf对此表示失望,并迅速将算力转移至其他推理服务提供商,同时为受影响用户提供Gemini 2.5 Pro的折扣。社区猜测Anthropic此举可能与OpenAI的潜在收购有关,担忧这将影响行业竞争和开发者选择。此前,Windsurf在Claude 4发布时也未能获得Anthropic的直接支持 (来源: AI前线)

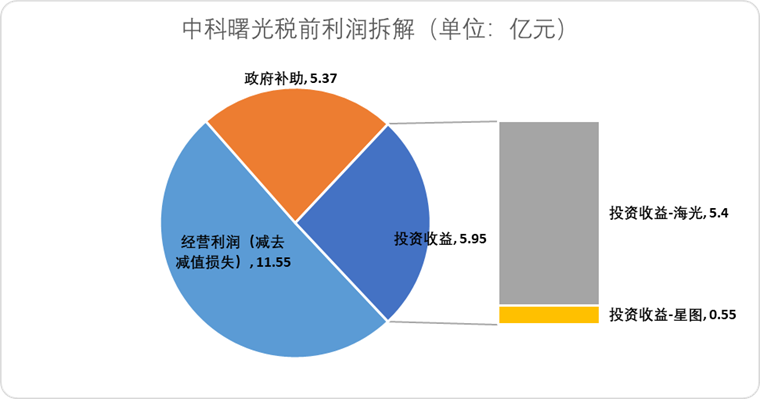
海光信息拟换股合并中科曙光,整合国产算力产业链: AI芯片设计公司海光信息发布公告,计划通过换股方式吸收合并其第一大股东、服务器制造商中科曙光。海光信息市值约3164亿元,中科曙光市值约905亿元。此次“蛇吞象”式的合并旨在优化从芯片到软件、系统的产业布局,实现产业链的强链补链延链,发挥技术协同效应。分析认为,合并有助于解决双方复杂的关联交易和潜在的同业竞争问题,降低运营成本,并顺应AI时代端到端算力解决方案的发展趋势,标志着中国半导体技术权力可能从传统计算向AI计算加速交接 (来源: 36氪)
🌟 社区
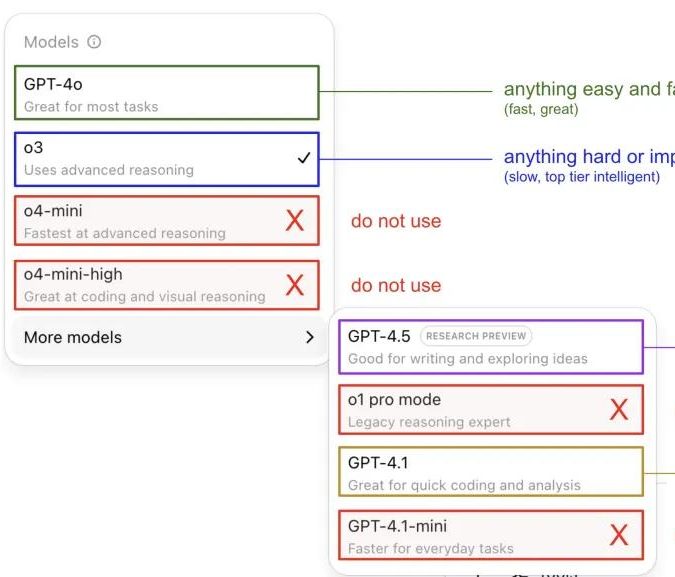
Andrej Karpathy分享ChatGPT模型使用心得,引发社区讨论: Andrej Karpathy分享了他个人使用不同ChatGPT版本的心得:对于重要或困难的任务,推荐使用推理能力更强的o3;日常中低难度问题可选用4o;代码改进任务适合GPT-4.1;需要深度研究和多链接总结时则使用深度研究功能(基于o3)。这一经验分享引发社区广泛讨论,不少用户分享了自己的使用偏好和对模型选择的看法,同时也反映出用户对于OpenAI模型命名混乱和缺乏自动模型选择功能的困扰 (来源: 量子位, JeffLadish)
开发者分享Agentic AI编程两周体验:从震撼到祛魅,最终选择手动重构: 一位拥有10年经验的技术负责人分享了将Agentic AI(特指AI编程智能体)融入其社交媒体应用开发流程的经历。初期,AI能快速生成功能模块、编写前后端逻辑和单元测试,效率惊人,两周内生成约1.2万行代码。然而,随着代码库复杂度增加,AI在处理新功能时开始频繁出错、陷入循环,且难以承认失败,生成的代码也暴露出命名不准确、重复代码等问题,导致代码库难以维护,开发者对其失去信任。最终,该开发者决定将AI生成代码仅作“模糊参考”,手动重构所有功能,并认为AI目前更适合分析现有代码和提供示例,而非直接编写功能性代码 (来源: CSDN)

AI Agent定义与工作流区别引关注,未来应用潜力巨大: 社区讨论区分了AI Agent和Workflow(工作流)的概念。Agent通常指LLM在循环中访问工具,根据指令自由运行;Workflow则是一系列主要确定性执行的步骤,可能包含LLM完成子任务。尽管存在交叉(Agent可被提示确定性执行,Workflow可包含Agentic组件),但这种区分在本体论上仍有意义。同时,AI Agent在企业应用中的潜力被广泛看好,腾讯和字节跳动等大厂均在智能体领域发力,例如腾讯将大模型知识库升级为智能体开发平台,字节跳动则有Coze(扣子)平台,旨在帮助企业落地原生AI智能体系统 (来源: fabianstelzer, 蓝洞商业)
Dwarkesh Patel探讨LLM与AGI时间线,认为持续学习是关键瓶颈: Dwarkesh Patel在其博客中阐述了他对AGI(通用人工智能)时间线的看法,认为LLM目前缺乏人类通过实践积累上下文、反思失败并进行微小改进的能力,即持续学习能力。他认为这是模型实用性的巨大瓶颈,解决这一问题可能需要数年时间。这一观点引发了包括Andrej Karpathy在内的多位AI研究者的讨论。Karpathy也认同LLM在持续学习方面的不足,并将其比作患有顺行性遗忘症的同事。这些讨论突显了实现真正AGI所面临的挑战,以及对模型学习机制的深入思考 (来源: dwarkesh_sp, JeffLadish, dwarkesh_sp)

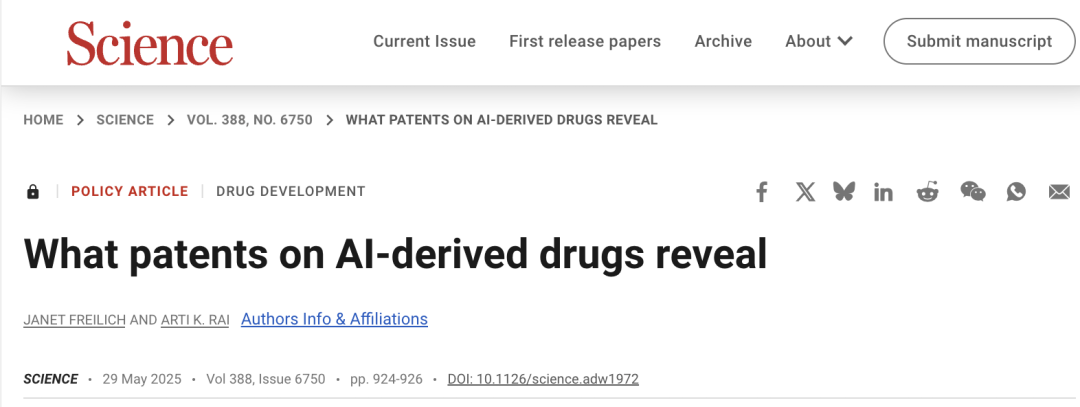
AI在药物研发中的专利问题引关注,Science发文吁谨慎: 《Science》期刊政策论坛文章《What patents on AI-derived drugs reveal》探讨了AI在药物发现领域的应用及其对专利制度的影响。研究指出,AI原生公司申请药物专利时,体内实验数据往往少于传统药企,可能导致有潜力的药物因缺乏后续研究而被放弃。同时,AI生成的大量新分子一旦公开,可能因成为“现有技术”而阻碍其他公司对这些分子进行专利申请和进一步投资。文章建议提高专利申请门槛,要求更多体内实验数据,并允许在AI生成分子未经测试的情况下由其他公司申请专利,同时加强新药临床试验阶段的监管独占权,以平衡创新激励与公共利益 (来源: 36氪)
💡 其他
奥特曼宫斗事件或将被拍成电影《Artificial》,知名导演与制片人参与: 据The Hollywood Reporter报道,米高梅计划将OpenAI高层变动事件改编成电影,暂定名为《Artificial》。意大利知名导演卢卡·瓜达尼诺(Luca Guadagnino)或将执导,制片人包括《哈利·波特》系列的大卫·海曼。演员阵容正在商议中,传言安德鲁·加菲尔德(曾饰演蜘蛛侠及《社交网络》中的萨维林)可能饰演萨姆·奥特曼,尤拉·鲍里索夫或饰演伊尔亚·苏茨克维,莫妮卡·巴巴罗或饰演米拉·穆拉蒂。此消息引发网友热议,并将其与电影《社交网络》类比 (来源: 36氪, janonacct)
AI客服体验引争议,用户吐槽“人工智障”与转接困难: 近期电商大促期间,大量消费者反映AI客服沟通不畅、答非所问,且转接人工客服困难重重,导致服务体验下降。国家市场监管总局数据显示,2024年电商售后服务领域与“智能客服”相关的投诉同比增长56.3%。用户普遍认为AI客服难以解决个性化问题,回答生硬,且对老年人等特殊群体不够友好。文章呼吁企业在追求降本增效的同时,不应牺牲服务质量,应优化AI技术,明确AI客服适用场景,并保留便捷的人工服务通道 (来源: 36氪)

AI在内容创作领域的应用与创作者的应对策略探讨: AI技术(如DeepSeek, Suno, Veo 3)在文章、音乐、视频等内容创作领域的应用日益广泛,引发了内容创作者对职业前景的焦虑。分析认为,内容范式正从“个性化推荐”向“个性化生成”转变。短期内,平台可能因试错成本高而不会完全用AI替代创作者,创作者可通过打造独特风格模型并授权来盈利。长期来看,创作者需调整价值创造方式,更侧重于AI难以取代的“创新策略”(如原创调研、一手资料获取),而非易被AI辅助的“追随策略”(追热点、依赖二手资料)。尽管AI已开始涉足科研等创新领域,但拥有独特视角和深度思考的创作者仍具价值 (来源: 36氪)
