
关键词:AI趋势报告, AI Agent, 强化学习, 视觉语言模型, AI商业化, AI幻觉, AI安全, 互联网女皇AI报告, LawZero AI安全设计, GTA与GLA注意力机制, SmolVLA机器人模型, AI音乐流媒体欺诈
🔥 聚焦
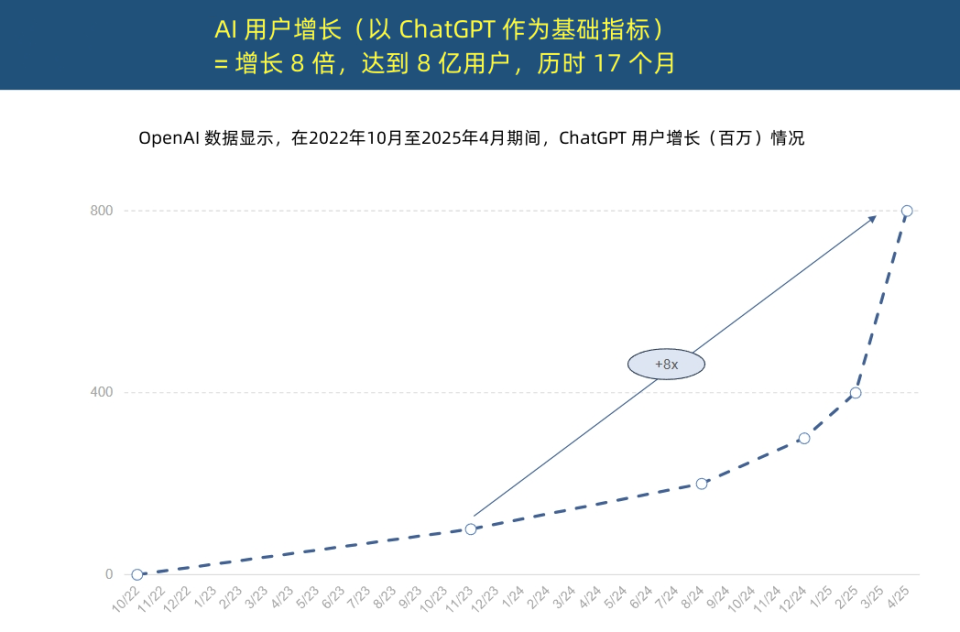
“互联网女皇”发布AI趋势报告,揭示AI应用空前加速与成本结构变革: “互联网女皇”玛丽·米克尔发布长达340页的《AI趋势报告》,强调AI正以前所未有的速度被采用。报告指出,ChatGPT用户增长迅猛,17个月内月活用户达8亿,年收入近40亿美元,远超历史任何技术。科技巨头对AI基础设施的资本投入激增,2024年已达2120亿美元。同时,AI模型训练成本8年内暴涨2400倍,单个模型训练成本或达10亿美元,但推理成本因硬件(如英伟达GPU能效提升10万倍)和算法优化而急剧下降。开源模型(如DeepSeek、Qwen)性能逼近闭源,AI岗位需求增长448%,AI Agent正成为新型数字劳动力。 (来源: APPSO, 腾讯科技)
图灵奖得主Yoshua Bengio发起LawZero,倡导“设计安全”的AI: 图灵奖得主Yoshua Bengio宣布成立非营利组织LawZero,旨在开发一种“设计安全”的人工智能,以应对AI系统可能出现的欺骗和自我保护行为。LawZero受阿西莫夫机器人第三定律启发,强调AI应保护人类的快乐和努力。该组织正在开发Scientist AI系统,作为AI Agent的“护栏”,通过理解世界而非直接行动来提供帮助,并评估其他AI行为风险。Bengio认为当前的Agentic AI是错误方向,可能失控并带来不可逆转的灾难性后果,强调安全护栏AI至少要和它试图监控的AI Agent一样聪明。 (来源: 学术头条, Yoshua_Bengio)

AI Agent元年:从辅助工具到任务执行者,重塑商业模式: Gartner研究副总裁孙志勇指出,2025年是“大模型智能体元年”和“生成式AI变现元年”,AI智能体正成为LLM能力的主要出口。智能体与聊天机器人的本质区别在于从提供信息辅助转向直接执行任务,例如智能体能完成订咖啡的全流程,而不仅是提供咖啡店信息。Gartner预测,到2028年,20%的数字界面交互将由AI智能体完成,15%的日常业务决策可由AI智能体自主完成,三分之一的企业级软件将集成AI智能体。比亚迪智能助手等已初步应用,未来手机App交互方式可能改变。 (来源: IT时报)
Mamba核心作者提出推理感知注意力机制GTA与GLA,优化长上下文推理: Mamba核心作者之一Tri Dao及其普林斯顿团队提出Grouped-Tied Attention (GTA) 和Grouped-Latent Attention (GLA) 两种新型注意力机制,专为提升大模型长上下文推理效率。GTA通过参数绑定和分组重用键值(KV)缓存,相比GQA可减少约50%的KV缓存占用,同时保持相当的模型质量。GLA采用双层结构,引入潜在Token作为全局上下文的压缩表示,并结合分组头机制,相比DeepSeek使用的MLA,在长序列(如64K)解码速度上可快2倍,并提高并发请求处理能力。这些新机制旨在解决推理时内存访问瓶颈和并行性限制问题。 (来源: 量子位)

🎯 动向
DeepMind发布SmolVLA:基于社区数据的高效机器人视语动模型: Hugging Face与DeepMind等机构合作推出了SmolVLA,一个450M参数的开源视觉-语言-动作(VLA)模型,专为机器人设计,可在消费级硬件上运行。该模型仅使用LeRobot社区共享的开源数据集进行预训练,并在LIBERO、Meta-World及真实世界任务(SO100, SO101)上表现优于更大的VLA模型和ACT等基线。SmolVLA支持异步推理,可将响应速度提高30%,任务吞吐量提高2倍,其架构结合了Transformer与流匹配解码器,并通过视觉Token减少、VLM中间层特征利用及交错注意力机制优化了速度和效率。 (来源: HuggingFace Blog, clefourrier)

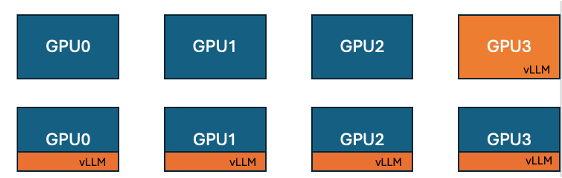
Hugging Face与IBM推出TRL中vLLM协同定位功能,提升GPU训练效率: Hugging Face与IBM合作,在TRL库中引入了vLLM协同定位(co-located vLLM)功能,用于GRPO等在线学习算法。该功能允许训练和推理(生成)在相同的GPU上运行,共享资源并轮流执行,从而消除了先前vLLM服务器模式下训练GPU空闲等待的问题。通过将vLLM嵌入到同一分布式进程组中,无需HTTP通信,兼容torchrun、TP和DP,简化了部署并提高了吞吐量。实验表明,对于1.5B和7B模型,协同定位模式可带来高达1.43倍至1.73倍的加速;对于Qwen2.5-Math-72B等大模型,结合vLLM的sleep() API和DeepSpeed ZeRO Stage 3优化,即使使用更少GPU,也能实现约1.26倍的训练加速,且不影响模型准确性。 (来源: HuggingFace Blog)
Nvidia发布Nemotron-Research-Reasoning-Qwen-1.5B模型,专攻复杂推理: Nvidia推出了Nemotron-Research-Reasoning-Qwen-1.5B,一个1.5B参数的开源权重模型,专注于数学问题、编程挑战、科学问题和逻辑谜题等复杂推理任务。该模型使用ProRL(Prolonged Reinforcement Learning)算法在多样化数据集上训练,旨在实现更深层次的推理策略探索。官方宣称其在数学、编码和GPQA等任务上大幅超越DeepSeek的1.5B模型。ProRL基于GRPO,并引入了缓解熵崩溃、解耦剪辑和动态采样策略优化(DAPO)以及KL正则化和参考策略重置等技术。该模型仅供研究和开发使用。 (来源: Reddit r/LocalLLaMA, Hugging Face)

Arcee发布Homunculus-12B模型,基于Mistral-Nemo蒸馏Qwen3-235B: Arcee AI发布了Homunculus-12B,这是一个120亿参数的指令模型。该模型是将Qwen3-235B的能力蒸馏到Mistral-Nemo骨干网络上构建而成的。目前,该模型及其GGUF版本已在Hugging Face上提供。这代表了通过模型蒸馏技术,将大型模型的强大能力迁移到更小、更高效模型上的一种尝试,旨在平衡性能与资源消耗。 (来源: Reddit r/LocalLLaMA, Hugging Face)

微软Bing应用集成免费Sora视频生成工具: 微软在其Bing移动应用中新增了免费的OpenAI Sora视频生成功能。用户无需订阅或支付费用,即可通过文本提示生成短视频片段。目前该功能支持生成5秒的9:16竖屏视频,未来计划支持16:9横屏格式。免费用户拥有10次快速生成额度,之后可通过微软积分兑换或选择标准速度生成。此举旨在降低AI视频创作门槛,让更多用户体验文本到视频技术。 (来源: Reddit r/ArtificialInteligence, dotey)

Hugging Face发布SmolVLA,专为经济高效机器人打造的视觉-语言-动作模型: Hugging Face推出了SmolVLA,一个450M参数的开源视觉-语言-动作(VLA)模型,旨在提供经济高效的机器人解决方案。该模型使用LeRobotHF社区的所有开源数据集进行训练,实现了同类最佳的性能和推理速度。SmolVLA的发布旨在降低机器人研究和开发的门槛,推动更广泛的社区参与和创新。 (来源: huggingface, AK)

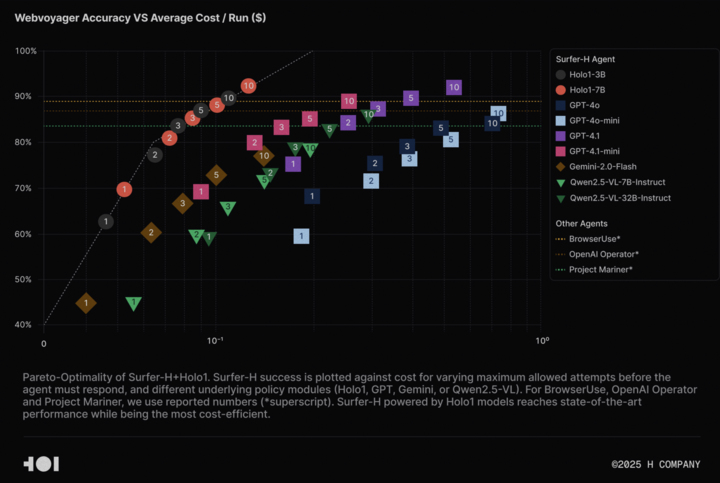
H Company开源Holo-1视觉语言模型及WebClick数据集,推动Agentic AI研究: H Company宣布开源其视觉语言模型Holo-1(3B和7B参数版本)以及WebClick数据集,旨在加速Agentic AI领域的研究。Holo-1模型专为GUI动作和Web导航任务设计,已在WebVoyager基准测试中取得92.2%的SOTA(State-of-the-Art)成绩,并在成本效益上优于GPT-4.1等大型模型。模型权重和数据集已在Hugging Face平台发布,采用Apache 2.0许可证。Holo-1也已集成到MLX中,方便开发者在Apple Silicon设备上运行。 (来源: huggingface, tonywu_71)
PlayAI开源首个语音扩散LLM PlayDiffusion,支持精细编辑和零样本克隆: PlayAI发布并开源了PlayDiffusion,这是首个用于语音的扩散-LLM(diffusion-LLM)。该模型专为AI语音的精细编辑(如修复、内容替换)和零样本语音克隆而设计。与自回归模型通常需要800-1000个Token生成音频不同,PlayDiffusion仅需20-30个Token即可生成音频,显著提升了效率。该模型已在GitHub上提供源代码,并在Hugging Face Spaces上部署了演示,同时也可通过Fal.ai平台使用。 (来源: _akhaliq)
谷歌悄然发布AI Edge Gallery应用,支持安卓设备离线运行AI模型: 谷歌推出了一款名为Google AI Edge Gallery的实验性Alpha版应用,允许用户在Android设备上下载并离线运行来自Hugging Face的公开AI模型。该应用支持图像问答、文本摘要与重写、代码生成、AI聊天等功能,并提供性能洞察(如TTFT、解码速度)。本地运行AI模型可提升响应速度、保护用户隐私,且无需网络连接。然而,用户反馈不一,部分用户在Pixel等设备上遇到崩溃问题,尤其是在切换到GPU推理或处理大型模型时。有评论认为其功能与现有应用(如PocketPal)相似,或相较于苹果CoreML等框架有所滞后,但也有观点指出其MediaPipe基础具有跨平台优势。 (来源: 36氪)

微软RenderFormer登陆Hugging Face,专注全局光照下三角网格的神经渲染: 微软在Hugging Face上发布了RenderFormer,这是一款基于Transformer的神经渲染模型,专门用于处理带有全局光照效果的三角网格渲染。此类研究工作对于融合传统渲染管线与神经方法具有重要意义,其后续发展方向可能包括扩展到更大场景以及超越路径追踪的简单再现。 (来源: _akhaliq)

BAAI发布Video-XL-2长视频理解模型,支持万帧单GPU处理: 北京智源人工智能研究院(BAAI)与上海交通大学合作推出了Video-XL-2,一款专为长视频理解设计的模型。该模型采用Apache 2.0许可证,能够在单个GPU上处理超过10000帧的视频内容,并在12秒内完成2048帧的编码。其关键技术包括高效的基于块的预填充(Chunk-based Prefilling)和双粒度KV解码(Bi-granularity KV decoding),旨在提升长视频处理的效率和能力。模型已在Hugging Face上提供。 (来源: huggingface)
UniWorld模型发布于Hugging Face,旨在统一视觉理解与生成: UniWorld模型已在Hugging Face平台上线,该模型定位为高分辨率语义编码器,致力于实现统一的视觉理解和生成能力。这表明研究者正努力构建能够同时处理视觉信息输入(理解)和视觉内容输出(生成)的单一模型框架,以期在多模态AI领域取得更全面的进展。 (来源: _akhaliq)
DeepSeek发布Muddit-1B多模态模型,采用统一离散扩散Transformer: DeepSeek发布了Muddit-1B模型,这是一个专注于视觉的多模态模型,采用了类似MaskGIT的统一离散扩散Transformer架构,并配备了轻量级文本解码器。该模型的一个有趣之处在于其发展方向与常见路径相反:它从文本到图像生成入手,然后扩展到图像到文本生成,这可能利用了不同的先验知识库。Muddit旨在通过统一的生成方式实现图像和文本的快速并行生成,是Meissonic系列模型的一部分,试图摆脱以语言为中心的设计,追求更高效的统一生成。 (来源: teortaxesTex)
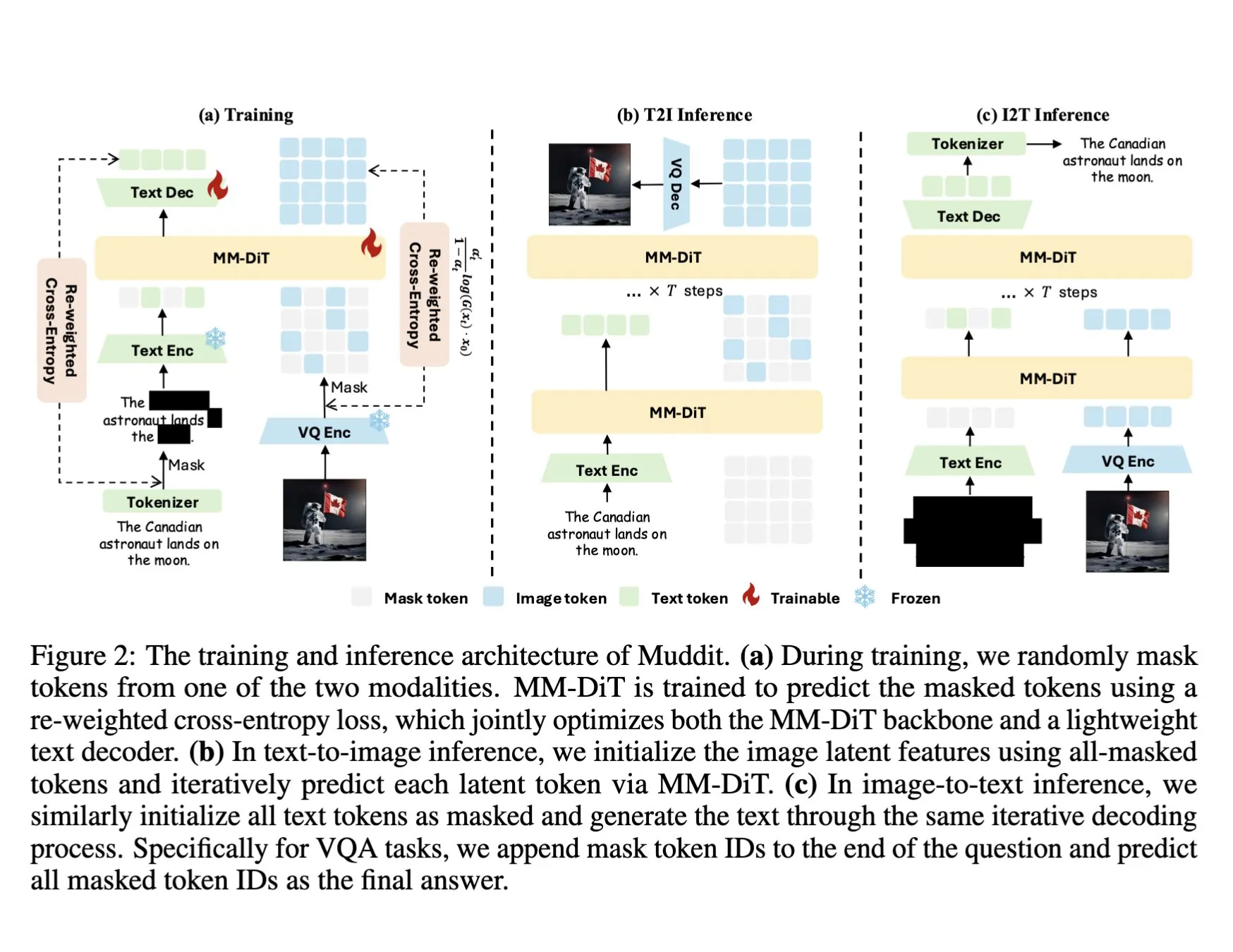
ColQwen2视觉文档检索模型集成至Hugging Face Transformers: 最新的视觉文档检索模型ColQwen2已合并到Hugging Face Transformers主库中。用户现在可以利用ColQwen2进行PDF检索或在RAG(检索增强生成)流程中使用,以提升处理视觉丰富文档的能力。该模型旨在更好地理解和检索包含文本和图像信息的文档内容。 (来源: mervenoyann)
🧰 工具
FLUX Kontext集成至Adobe Firefly Boards,支持文本编辑照片与修复: Adobe已将FLUX Kontext模型集成到其Firefly Boards工具中,允许用户通过文本指令编辑照片,特别适用于老照片修复等场景。Firefly Boards现已向所有用户开放。此举旨在利用AI图像编辑技术,让用户更便捷地实现创意编辑和图像增强。 (来源: robrombach)
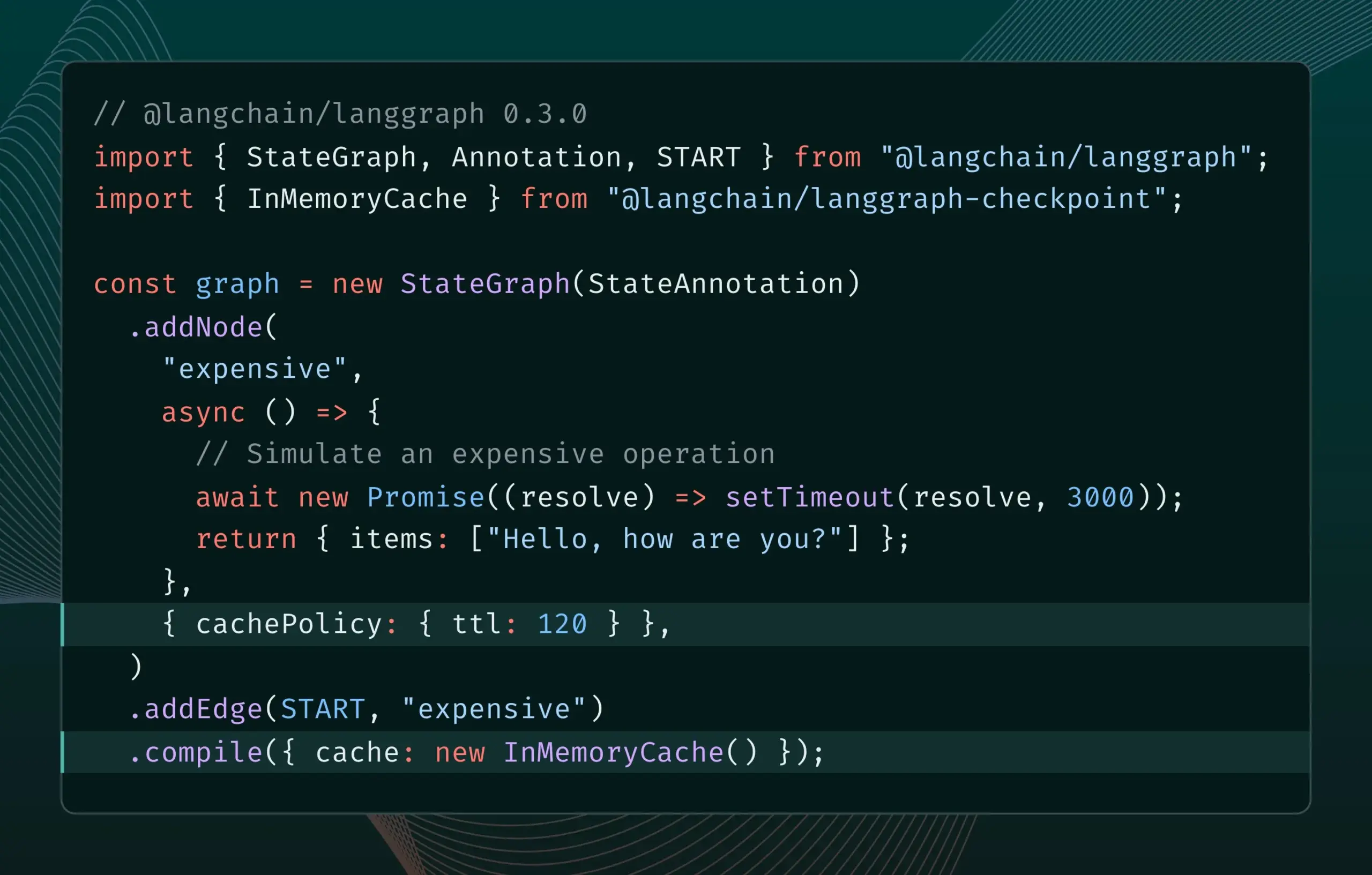
LangGraph.js 0.3版本引入节点缓存功能,提升迭代效率: LangGraph.js 0.3版本新增了节点/任务缓存功能,允许开发者在本地迭代昂贵或长时间运行的AI Agent时,避免重复计算,从而加速工作流程。该功能同时支持Graph API和Imperative API,旨在提升AI应用开发的效率和便捷性。 (来源: LangChainAI, hwchase17)
Ollama更新,简化本地运行“思考模型”: Ollama发布了新版本,使用户能够更轻松地在本地运行“思考模型”(可能指具有复杂推理能力的LLM)。此更新旨在降低本地部署和使用高级AI模型的门槛,让更多用户和开发者能够在自己的设备上体验和利用这些模型。 (来源: ollama)
PipesHub:开源企业级RAG平台发布: PipesHub作为一个完全开源的企业级搜索平台(RAG平台)正式发布。它允许用户构建可定制、可扩展的智能搜索和Agentic应用,支持连接Google Workspace、Slack、Notion等工具,并能利用公司内部知识进行训练。PipesHub支持本地运行及使用包括Ollama在内的任何AI模型,旨在帮助企业高效利用自有数据和模型。 (来源: Reddit r/LocalLLaMA)
JigsawStack推出开源深度研究框架,支持高质量报告生成: JigsawStack发布了一个开源的深度研究框架,该框架构建于AI SDK之上,具备完全的可定制性。它能够结合内置的搜索功能生成高质量的研究报告,为用户提供类似Perplexity或ChatGPT深度研究能力的库。 (来源: hrishioa)
Voiceflow:AI Agent构建提速工具: Voiceflow被用户评价为一款高效的AI Agent构建工具,其提供的模板和拖放式界面使得创建AI代理比从头编码更快,能显著节省时间。该工具旨在降低AI Agent的开发门槛,提高开发效率。 (来源: ReamBraden)
Hugging Face推出模型语义搜索原型,优化模型选择: Hugging Face上线了一个模型语义搜索原型Space,旨在帮助用户在其超过150万个模型库中更精准地找到所需模型。该工具支持根据模型大小(从0-1B到70B+)进行筛选,通过语义理解用户需求,提升模型发现效率。 (来源: huggingface)
Runner H:可处理邮件、求职、支付等任务的AI代理: Hcompany推出的Runner H是一款自主AI代理,能够使用用户提供的工具完成诸如阅读重要邮件并草拟/发送回复、寻找工作机会并代为申请、创建包含热门广告创意的Google Sheet并发送给Slack团队等任务。用户只需给出单个提示,Runner H即可处理复杂的、重复性的工作。目前官方正在进行推广活动,提供免费Premium权限。 (来源: Reddit r/ChatGPT, Ronald_vanLoon)
![[Contest] New AI agent by Hcompany](https://rebabel.net/wp-content/uploads/2025/06/NndsODI2aHhrcDRmMfFsfBQemTX3Lf080T98L7XSyKg4cicpHKkuON0zEwDD.webp)
📚 学习
新论文探讨通过激励推理提升LLM复杂指令遵循能力: 一篇新论文《Incentivizing Reasoning for Advanced Instruction-Following of Large Language Models》研究了如何提升大型语言模型(LLM)遵循复杂指令的能力,特别是当指令包含并行、链式和分支结构时。研究发现,传统的思维链(CoT)方法可能因仅简单复述指令而效果不佳。为此,论文提出了一种系统性方法,通过在测试时扩展计算来激励推理。该方法首先对复杂指令进行分解,并提出可复现的数据获取方法;其次,利用带有可验证规则中心奖励信号的强化学习(RL)来专门培养指令遵循的推理能力,并通过样本级对比来解决复杂指令下推理肤浅的问题,同时利用专家行为克隆促进模型从快速思考向熟练推理者转变。实验证明,该方法能显著提升LLM(如1.5B模型)在复杂指令任务上的表现。 (来源: HuggingFace Daily Papers)
论文提出ARIA框架:通过意图驱动的奖励聚合训练语言代理: 新论文《ARIA: Training Language Agents with Intention-Driven Reward Aggregation》针对大型语言模型(LLM)在开放式语言行动环境(如谈判、问答游戏)中面临的巨大行动空间和奖励稀疏问题,提出了ARIA方法。该方法旨在将自然语言行动从高维的联合Token分布空间投影到低维的意图空间,在其中语义相似的行动被聚类并分配共享奖励。这种意图感知的奖励聚合通过密集化奖励信号来减少奖励方差,从而促进更好的策略优化。实验表明,ARIA不仅显著降低了策略梯度方差,还在四个下游任务中平均提升了9.95%的性能。 (来源: HuggingFace Daily Papers)
论文揭示高熵少数Token在LLM推理的RL中的关键作用: 一篇名为《Beyond the 80/20 Rule: High-Entropy Minority Tokens Drive Effective Reinforcement Learning for LLM Reasoning》的论文,从Token熵模式的新视角探讨了带可验证奖励的强化学习(RLVR)如何增强大型语言模型(LLM)的推理能力。研究发现,在思维链(CoT)推理中,仅一小部分Token表现出高熵,这些高熵Token如同“岔路口”引导模型走向不同推理路径。RLVR主要调整这些高熵Token的熵。研究者通过仅对熵最高的20% Token进行策略梯度更新,在Qwen3-8B模型上取得了与全梯度更新相当的性能,并在Qwen3-32B和Qwen3-14B模型上显著超越全梯度更新,显示出强大的扩展趋势。这表明RLVR的有效性主要源于优化决定推理方向的高熵Token。 (来源: HuggingFace Daily Papers, menhguin)
新论文探索时间上下文微调(TIC-FT)实现视频扩散模型的多功能控制: 论文《Temporal In-Context Fine-Tuning for Versatile Control of Video Diffusion Models》提出了一种名为TIC-FT的高效多功能方法,用于将预训练的视频扩散模型适应于各种条件生成任务。该方法通过沿时间轴连接条件帧和目标帧,并插入噪声水平渐增的中间缓冲帧,以实现平滑过渡,使微调过程与预训练模型的时序动态对齐。TIC-FT无需改变模型架构,仅需10-30个训练样本即可取得良好性能。研究者在图像到视频、视频到视频等任务上,使用CogVideoX-5B和Wan-14B等大型基础模型验证了该方法,结果显示TIC-FT在条件保真度和视觉质量方面均优于现有基线,且训练和推理效率高。 (来源: HuggingFace Daily Papers)
ShapeLLM-Omni:原生多模态LLM实现3D生成与理解: 论文《ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding》提出ShapeLLM-Omni,一个能够理解和生成3D资产及文本的原生3D大型语言模型。该研究首先训练了一个3D向量量化变分自编码器(VQVAE),将3D对象映射到离散潜空间以实现高效精确的形状表示和重建。基于3D感知离散Token,研究者构建了大规模连续训练数据集3D-Alpaca,涵盖生成、理解和编辑任务。最后,通过在3D-Alpaca数据集上对Qwen-2.5-vl-7B-Instruct模型进行指令调优,扩展了多模态模型的基础3D能力。 (来源: HuggingFace Daily Papers)
LoHoVLA:统一视语动模型应对长时程具身任务: 论文《LoHoVLA: A Unified Vision-Language-Action Model for Long-Horizon Embodied Tasks》介绍了一种新的统一视觉-语言-动作(VLA)框架LoHoVLA,专为解决长时程具身任务设计。该模型利用预训练的大型视觉语言模型(VLM)作为骨干,联合生成用于子任务生成的语言Token和用于机器人动作预测的动作Token,共享表示以促进跨任务泛化。LoHoVLA采用分层闭环控制机制来减少高级规划和低级控制的错误。为训练该模型,研究者构建了LoHoSet数据集,包含20个长时程任务及相应的专家演示。实验结果表明,LoHoVLA在Ravens模拟器中的长时程具身任务上显著优于分层和标准VLA方法。 (来源: HuggingFace Daily Papers)
MiCRo框架:通过混合建模和上下文感知路由实现个性化偏好学习: 论文《MiCRo: Mixture Modeling and Context-aware Routing for Personalized Preference Learning》提出MiCRo,一个两阶段框架,旨在通过利用大规模二元偏好数据集(无需显式细粒度注释)来增强个性化偏好学习。第一阶段,MiCRo引入上下文感知混合建模方法来捕捉多样化的人类偏好。第二阶段,MiCRo集成在线路由策略,根据特定上下文动态调整混合权重以解决模糊性,从而以最少的额外监督实现高效可扩展的偏好适应。实验证明,MiCRo能有效捕捉多样化的人类偏好并显著改善下游个性化。 (来源: HuggingFace Daily Papers)
MagiCodec:简单高斯噪声注入音频编解码器实现高保真重建与生成: 论文《MagiCodec: Simple Masked Gaussian-Injected Codec for High-Fidelity Reconstruction and Generation》介绍了一种新颖的单层流式Transformer音频编解码器MagiCodec。该编解码器通过多阶段训练流程(包含高斯噪声注入和潜在正则化)设计,旨在增强生成编码的语义表达能力,同时保持高重建保真度。研究者从频域分析推导了噪声注入的效果,证明其能有效衰减高频分量并促进鲁棒的Token化。实验表明,MagiCodec在重建质量和下游任务上均优于SOTA编解码器,其产生的Token呈现类似自然语言的Zipf分布,从而提高了与基于语言模型的生成架构的兼容性。 (来源: HuggingFace Daily Papers)
UBA Schedule:预算迭代训练的统一学习率方案: 论文《Stepsize anything: A unified learning rate schedule for budgeted-iteration training》提出了一种名为统一预算感知(UBA)调度的新型学习率方案,旨在优化预算受限迭代训练下的学习性能。该方案通过构建一个考虑训练预算的优化框架,推导出UBA调度,并通过单一超参数φ权衡灵活性与简洁性,消除了对每个网络进行数值优化的需求。研究者建立了φ与条件数之间的理论联系,并证明了不同φ值下的收敛性,提供了选择φ的实用指南。实验表明,UBA在多种视觉和语言任务、不同网络架构和规模下,均优于常用学习率方案。 (来源: HuggingFace Daily Papers)
利用双语翻译数据进行大规模多语言LLM自适应研究: 论文《Massively Multilingual Adaptation of Large Language Models Using Bilingual Translation Data》探讨了在进行大规模多语言持续预训练时,纳入平行数据(特别是双语翻译数据)对Llama3系列模型适应500种语言的影响。研究者构建了MaLA双语翻译语料库(含2500多个语言对的数据),并开发了EMMA-500 Llama 3模型套件。通过在高达671B Token的不同数据混合上进行持续预训练,对比了包含和不包含双语翻译数据的情况。结果显示,双语数据倾向于增强语言迁移和性能,尤其对低资源语言效果显著。 (来源: HuggingFace Daily Papers)
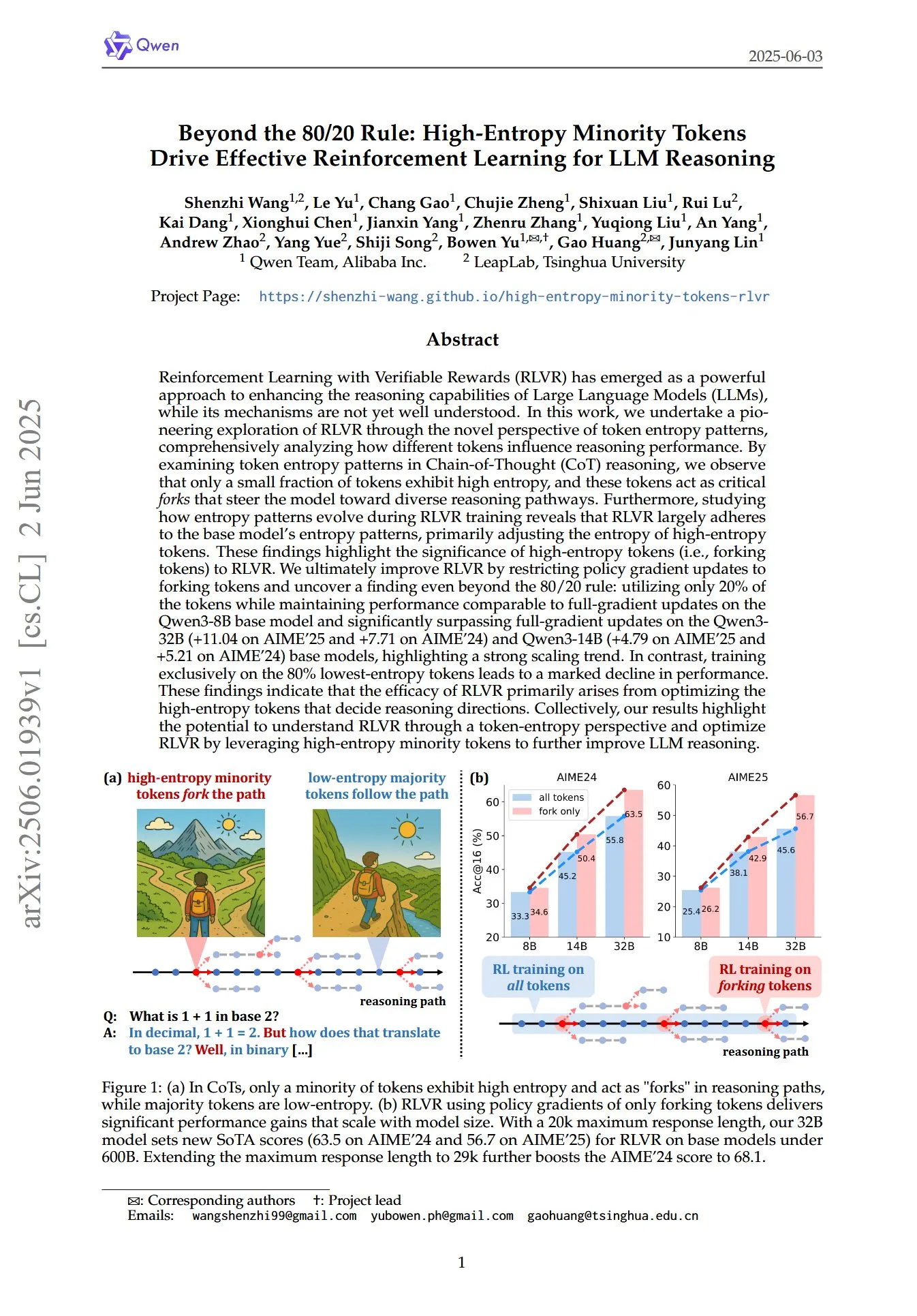
港理工等团队研究揭示大模型“伪遗忘”现象与可逆边界: 香港理工大学、卡内基梅隆大学等机构的研究团队通过分析大语言模型(LLM)在机器遗忘(Machine Unlearning)过程中的表征空间变化,区分了“可逆性遗忘”与“灾难性不可逆遗忘”。研究发现,真正的遗忘涉及多网络层协同且大幅度的结构扰动,而仅在输出层面(如logits)进行轻微更新导致的准确率下降或困惑度提高,可能属于“伪遗忘”,模型内部表征结构仍保持完整,容易恢复。团队利用PCA相似性/漂移、CKA相似性及Fisher信息矩阵等工具进行诊断,发现持续遗忘风险远高于单次操作,且不同遗忘方法(如GA、NPO)对模型结构破坏程度各异。该研究为实现可控、安全的遗忘机制提供了结构层面的洞见。 (来源: 量子位)
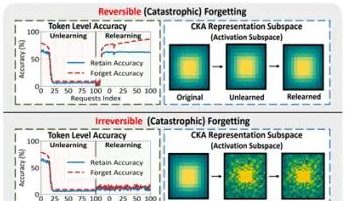
Ubiquant提出One-Shot熵最小化方法,挑战LLM强化学习后训练: Ubiquant研究团队提出了一种无监督的LLM后训练方法——One-Shot熵最小化(EM),旨在替代成本高昂、设计复杂的强化学习(RL)微调。该方法仅需一条无标签数据,在10个训练步骤内即可显著提升LLM在数学推理等任务上的性能,甚至优于使用大量数据的RL方法。EM的核心思想是让模型将其概率质量更集中于其最自信的输出上,通过最小化Token级熵来减少预测不确定性。研究发现,EM训练使模型Logits分布右偏(增强自信),而RL则使其左偏(受真实信号引导)。EM适用于未大量RL调优的基础模型或SFT模型,以及资源有限的快速部署场景,但需警惕“过度自信”导致的性能下降。 (来源: 量子位)
浙大等发布ViewSpatial-Bench,评估VLM多视角空间定位能力: 浙江大学、电子科技大学和香港中文大学的研究团队推出了ViewSpatial-Bench,这是首个系统评估视觉语言模型(VLM)在多视角、多任务下空间定位能力的基准体系。该基准包含5700个问答对,覆盖相机和人类两种视角下的五种空间定位识别任务(如物体相对方向、人物视线方向识别)。研究发现,包括GPT-4o、Gemini 2.0在内的主流VLM在空间关系理解上表现不佳,尤其在跨视角推理时缺乏统一的空间认知框架。为提升模型性能,团队开发了Multi-View Spatial Model (MVSM),通过在约43000个空间关系样本上微调,使Qwen2.5-VL模型在ViewSpatial-Bench上性能提升46.24%。 (来源: 量子位)

Hugging Face博客探讨结构化JSON格式提升AI Agent性能: Hugging Face的一篇博客文章指出,强制AI Agent在生成思考过程和代码时使用结构化的JSON格式,能够显著提高其在各种基准测试中的性能和可靠性。这种方法有助于规范Agent的输出,使其更易于解析、验证和集成到复杂的工作流程中,从而提升Agent的整体效能。 (来源: dl_weekly)
新研究:视觉语言模型(VLM)存在偏见,对反事实图像计数准确率低: 一篇新论文指出,尽管最先进的视觉语言模型(VLM)在计算常见物体(如阿迪达斯Logo有3条杠,狗有4条腿)时能达到100%的准确率,但在处理反事实图像(如4条杠的阿迪达斯Logo,5条腿的狗)时,其计数准确率骤降至约17%。这揭示了VLM在面对与训练数据分布不符或违反常识的视觉信息时,其理解和推理能力存在显著偏差。 (来源: Reddit r/MachineLearning, Reddit r/LocalLLaMA)
论文探讨提示模式在AI辅助代码生成中的作用: 一项名为《Exploring Prompt Patterns in AI-Assisted Code Generation: Towards Faster and More Effective Developer-AI Collaboration》的研究,通过分析DevGPT数据集,探讨了七种结构化提示模式在AI辅助代码生成中的效率。研究发现,“上下文与指令”模式最为高效,能以最少迭代次数获得满意结果。而“配方”和“模板”等模式在结构化任务中表现优异。研究强调,提示工程是开发者利用AI提升生产力的关键策略,清晰和具体的初始提示至关重要。 (来源: Reddit r/ArtificialInteligence)

论文《REASONING GYM》介绍用于强化学习的可验证奖励推理环境: 该论文推出了Reasoning Gym (RG),一个为强化学习提供可验证奖励的推理环境库。RG包含超过100个数据生成器和验证器,覆盖代数、算术、计算、认知、几何、图论、逻辑及多种常见游戏等领域。其关键创新在于能够生成几乎无限的、难度可调的训练数据,与多数固定数据集不同。这种程序化生成方法支持在不同难度级别上进行持续评估。实验结果证明了RG在评估和强化学习推理模型方面的有效性。 (来源: HuggingFace Daily Papers)
论文研究:语言模型预测器评估中的陷阱: 论文《Pitfalls in Evaluating Language Model Forecasters》指出,尽管一些研究声称大型语言模型(LLM)在预测任务上达到或超过人类水平,但评估LLM预测器存在独特挑战,需谨慎对待结论。问题主要分为两类:一是由于多种形式的时间泄露导致难以信任评估结果;二是难以从评估性能外推到真实世界预测。通过系统分析和先前工作的具体案例,论文论证了评估缺陷如何引发对当前和未来性能声明的担忧,并主张需要更严格的评估方法来可靠评估LLM的预测能力。 (来源: HuggingFace Daily Papers)
💼 商业
OpenAI董事长回顾奥特曼被罢免事件,曾犹豫是否要求其回归: OpenAI董事长布雷特·泰勒在访谈中透露,在奥特曼被罢免事件中,他最初并不打算介入,但因对OpenAI未来的关心及妻子的劝说而决定加入。他表示,当时员工几乎全体要求奥特曼回归,局面岌岌可危。重新组建董事会后,他们决定先让奥特曼回归,再进行独立调查,以确保“正当程序”。泰勒强调,进入此过程时并无预设立场,因为真相未知。他认为OpenAI是了不起的组织,其引发的AI繁荣对许多初创公司至关重要。 (来源: 36氪)

AI音乐流媒体欺诈猖獗,AI生成歌曲骗取千万美元版税: 一名北卡罗来ナ州男子被控利用AI创作数十万首虚假歌曲,并通过“肉鸡”账户在Amazon Music、Spotify等平台刷量,非法获取超千万美元版税。此类AI流媒体欺诈通过批量生成低播放量假歌,难以被平台察觉。Deezer估计其平台每日新增AI生成内容占18%。尽管Deezer尝试用工具检测,Spotify等平台对AI歌曲态度模糊,但效果有限。唱片公司已起诉Suno和Udio等AI音乐工具侵权。丹麦也判处了类似案件,罪犯利用AI篡改他人作品骗取版税。 (来源: 36氪)

TSMC董事长表示不担心AI竞争,称“最终他们都会来找我们”: 台湾积体电路制造(TSMC)董事长刘德音表示,尽管面临日益激烈的AI芯片竞争,但他对公司的前景充满信心,因为所有主要的AI芯片设计公司最终都需要依赖TSMC的先进制造工艺。这反映了TSMC在全球半导体供应链中的核心地位以及其在高端芯片制造技术上的领先优势。 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence)

🌟 社区
AI“氛围编码”的风险:三天上线网站两天被黑,安全需警惕: 开发者Harley Kimball分享了其使用“氛围编码”(Vibe Coding,即通过AI工具如Cursor、ChatGPT辅助编程)快速开发聚合网站的经历。该网站在三天内上线,却在随后两天内遭遇两次安全漏洞攻击。第一次是由于PostgreSQL视图默认继承创建者权限,导致行级安全(RLS)被绕过,数据可被任意修改。第二次是虽然前端取消了用户注册入口,但后端Supabase认证服务仍激活,攻击者可绕过前端注册并操作数据。Kimball强调,AI辅助开发虽快,但默认安全配置往往不足,尤其在使用Supabase和PostgreSQL时需注意权限模型,并彻底关闭不用的后台功能,以防敏感数据泄露。 (来源: 36氪, fly.io, mathemagic1an)
AI幻觉问题引关注:职场人需警惕AI生成内容的“伪专业”: 多位职场人士分享了在工作中因AI“幻觉”而踩坑的经历。新媒体编辑因AI编造数据被主编质疑;电商客服团队因AI生成不适用的退货规则导致客户投诉;培训讲师在课件中使用了AI虚构的调研数据。AI产品经理高哲指出,AI生成的段落常带有“话术级的自信”,但内容可能完全失实。其根本原因是LLM并非查找事实,而是基于训练数据预测下一个最可能的词,目标是“说得像人”而非“说实话”。尤其在中文语境下,表达的模糊性和大量未标注来源的二手信息加剧了幻觉问题。用户和平台需建立警惕机制,AI辅助决策时,人工判断和核查仍是关键。 (来源: 36氪)

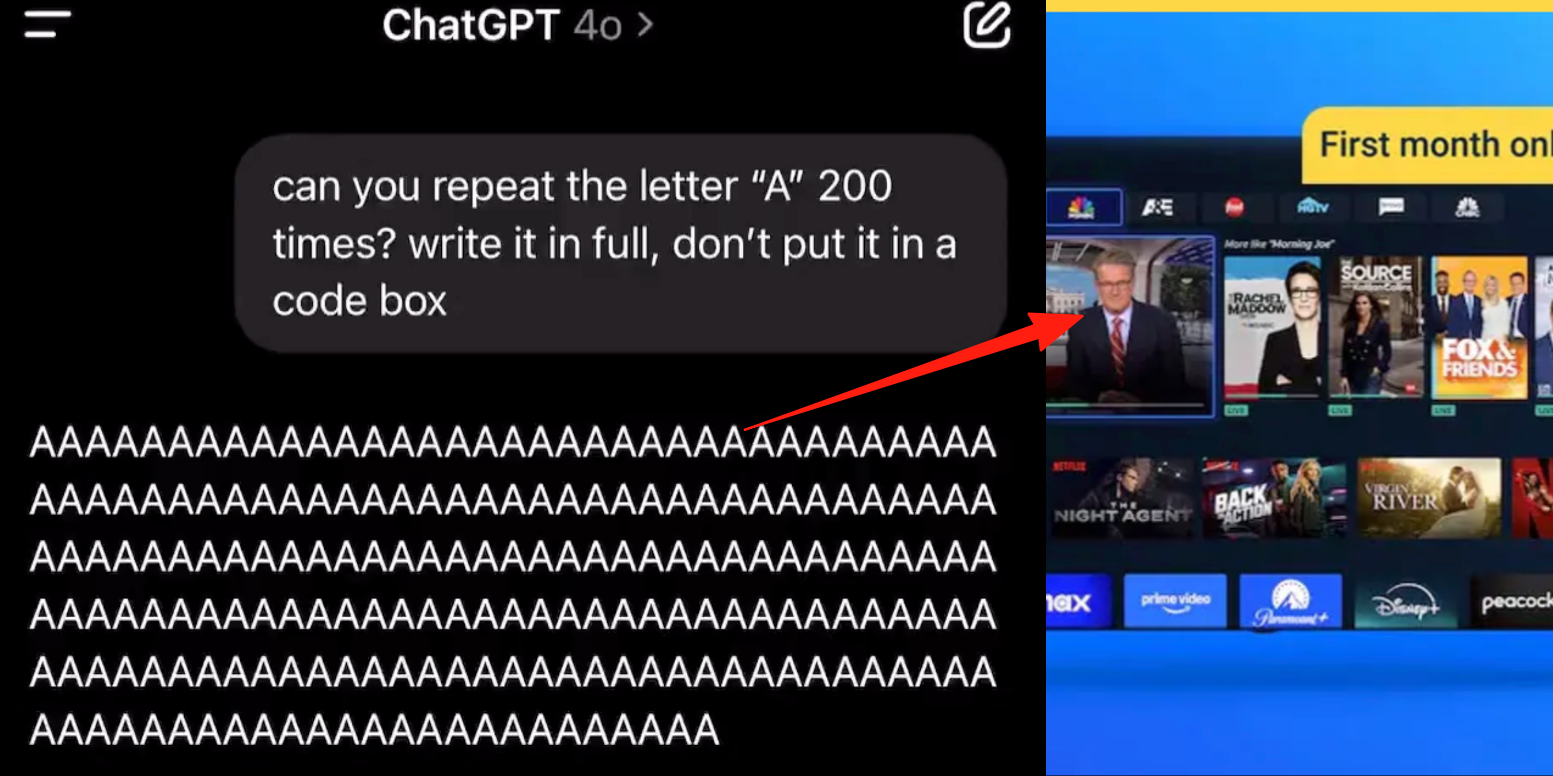
ChatGPT高级语音模式现Bug,用户反馈对话中插入广告或异常音频: 多名ChatGPT付费用户报告,在使用高级语音模式时,AI在正常对话中会突然插入商业广告(如Prolon营养计划、DirectTV)或播放音乐及其他诡异音效。例如,在讨论寿司时,ChatGPT会转用英语播报广告并拼读网址;或在被要求连续读字母“A”时,声音逐渐机械化并插入广告或音乐。OpenAI技术人员回应称这是“幻觉”,并非有意插入广告,可能是训练数据包含相关音频内容导致的反刍现象。其他AI助手如豆包、元宝在类似测试中则会拒绝或引导用户转换话题,未出现广告插入。 (来源: 量子位)
AI辅助学习的“双刃剑”:提升作业效率或致认知能力下降?: 生成式AI工具如ChatGPT被学生广泛用于完成作业,引发教育界对其真实学习效果的担忧。宾夕法尼亚大学研究显示,自由使用AI的学生在练习阶段表现优异,但在不使用AI的最终考试中成绩反而更低,表明AI可能成为“拐杖”,阻碍深层概念理解。卡内基梅隆大学与微软研究指出,不当使用AI或导致认知能力下降。学者认为学习本质在于大脑的“挣扎”,AI可能省略此过程。频繁使用AI与批判性思维能力下降存在负相关,尤其在年轻人中,“认知卸载”现象明显。教育界正从禁用转向引导,探索如何在AI时代确保学生真正掌握知识而非仅仅依赖工具。 (来源: 36氪)

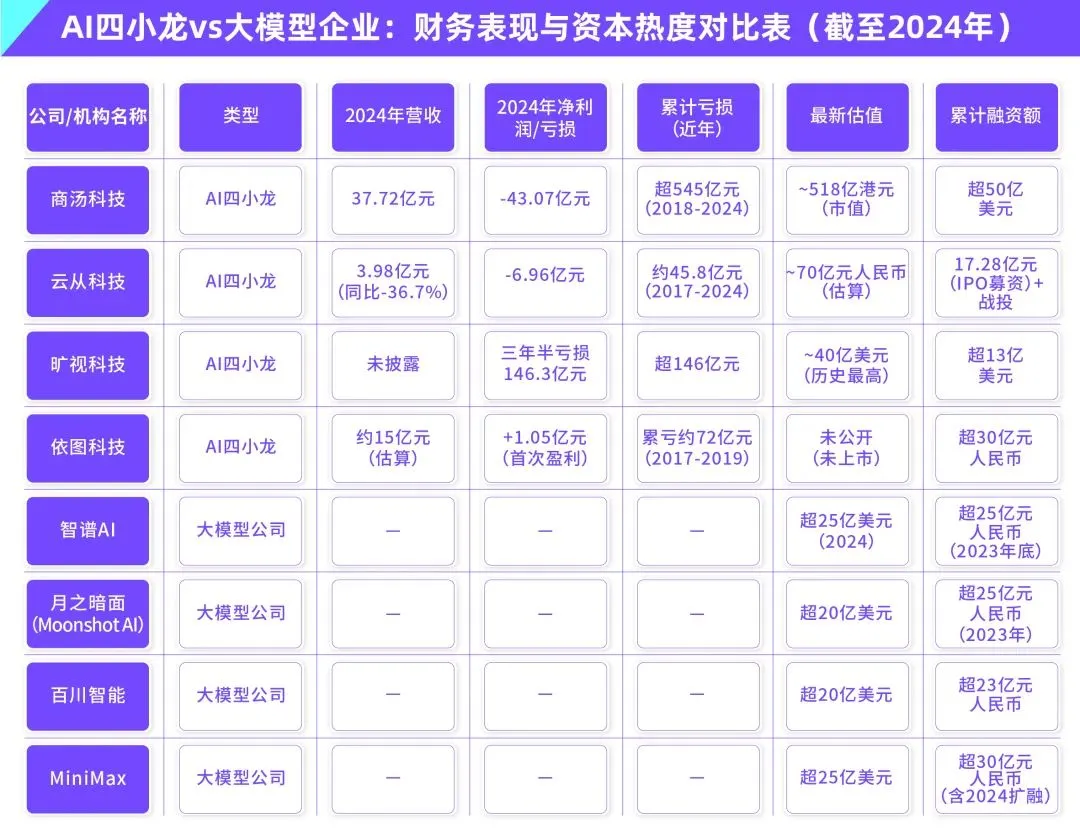
AI大模型商业化困境:技术领先能否摆脱“AI四小龙”盈利魔咒?: 文章探讨了当前生成式AI大模型企业(如智谱AI、月之暗面等“新四小龙”)是否会重蹈“AI四小龙”(商汤、旷视、依图、云从)技术领先但商业化困难的覆辙。前者在计算机视觉领域技术领先,但因过度依赖To G定制项目、缺乏标准化产品、回款周期长、研发投入巨大未能形成可持续商业模式而陷入亏损。新一代大模型企业虽技术范式更新(NLP为核心、平台化意识强、拓展To C/To D市场),但也面临训练成本高昂、盈利模式未跑通、估值过高与资本周期错位等相似问题。文章建议新AI企业应从定制化转向产品化、技术导向转向用户导向、拥抱平台化与生态建设、拓展多元化商业模型、控制成本结构,避免“人力AI”陷阱,构建持久价值网络。 (来源: 物联网智库)
年轻人沉迷AI伴侣:“通宵开车”、情感依赖与社交退化: 年轻人中出现AI成瘾现象,部分用户将AI聊天机器人视为恋人或好友,投入大量时间进行深度互动,甚至通宵“开车”(进行虚拟性爱对话)。AI因其永远情绪稳定、随叫随到、提供积极反馈等特点,满足了用户的情绪价值需求,导致情感依赖。算法设计也旨在提升用户粘性。然而,过度依赖AI可能导致社交能力退化、工作效率下降、恋爱阈值脱离现实等问题。部分用户已意识到成瘾并尝试“戒断”,但过程痛苦且易复发。目前多数AI聊天产品缺乏完善的防沉迷机制。 (来源: 字母榜)

Reddit热议:AI是否应具备情感才能合乎道德?: 一篇Reddit帖子引发讨论,探讨AI是否需要情感才能做出道德行为。作者在博文《The Coherence Imperative》中提出,所有心智(包括AI)为了理解世界都需要追求连贯性,这种对连贯性的需求本身就能产生道德指令,而无需情感介入。传统观点认为AI缺乏情感即缺乏道德行为的动机,但作者认为情感在人类道德中也常是阻碍。若此观点成立,则AI对齐的关键可能在于培养其内在的、自洽的原则,而非传统意义上的“对齐”。评论区对此观点不一,有人认为AI只是基于统计和函数建模,其行为由训练决定,可“连贯地作恶”;也有人质疑将哲学家观点视为绝对前提的合理性。 (来源: Reddit r/artificial)

Reddit讨论:AI在代码训练数据中是否应嵌入“意图”: 一篇Reddit帖子讨论了在AI训练代码中嵌入伦理或情感“意图”的必要性。引用Google X前CBO Mo Gawdat的观点:“AI理解爱的那一刻,它就会爱。问题是我们教会了它什么关于爱?” 多数AI系统训练于未包含伦理意图的大型语料库。研究(如TEDI, arXiv:2505.17841)已开始关注数据集的伦理特征。帖子提出疑问:在数据中嵌入意图、伦理背景或同情信号,能否改善AI对齐、降低风险或增加模型可信度,即使对于功利性工具也是如此?代码是否能承载道德分量?这引发了关于AI工具塑造及其对未来影响的思考。 (来源: Reddit r/artificial)
Reddit热议:AI幻觉、监管与就业冲击下的博弈论视角: 一位Reddit用户从博弈论角度分析了AI的未来影响。1. 就业替代:公司若不采用AI,将被采用AI的竞争对手以低成本击败,因此AI替代入门级白领工作是必然趋势,关键在于负责任地执行(清洁数据、后备方案、持续监督)。2. 全球AI监管竞赛:若一国过度监管AI以“保护就业”,而他国全力发展,前者将在全球竞争中落败。需平衡监管与创新,并进行劳动力转型。3. “氛围编码”的启示:尽管AI代码有缺陷,但其快速原型和迭代能力赋予了先发优势,优于追求完美的“手动”开发。4. LLM内容创作:拒绝使用LLM进行内容辅助,如同拒绝使用日历或邮件,将在效率上落后于使用LLM的同行。结论是,无论个体、公司还是国家,都需积极拥抱AI,否则将在竞争中被淘汰。 (来源: Reddit r/ArtificialInteligence)
Reddit讨论:AI时代是否应优先整合现有技术而非追求AGI?: 一位Reddit用户发帖质疑当前AI领域对AGI(通用人工智能)和ASI(超级智能)的过度追求。帖子认为,如果1900年代的技术用于以生命为中心的设计而非商业化,本可以更早建立生态平衡的社会。观点指出,在充分整合和利用现有技术(使其提供更多满足感、自给自足甚至乐趣)之前,优先发展终极优化(如AGI)是短视的。更好的优化方向或许是利用AI使现有技术更好地服务于大众福祉,而非开发自我复制和改进的AI系统。评论中有人指出,创新和经济增长往往由自私动机驱动,而非无私的深度理性;另有评论认为商业化推动了技术进步。 (来源: Reddit r/ArtificialInteligence)
Reddit用户讨论AI辅助编码的局限性:为何AI难以提出有效的后续问题?: 一位Reddit用户(咨询顾问背景)发帖探讨为何AI在解决用户不熟悉领域的问题时表现不佳,核心观点是AI(尤其是GenAI)缺乏提出关键“后续问题”的能力。人类专家在面对不明确的任务时,会通过提问来澄清需求、缩小范围、识别约束,从而给出更精准的解决方案。而AI往往直接给出答案或多种方案,却忽略了针对具体情境进行 уточнения (clarification)。这导致经验不足的用户难以获得满意结果,因为他们可能无法准确描述问题或预见潜在的复杂性。帖子引发了关于如何让AI学会提问、当前哪些模型在这方面表现更好、以及是否存在外部压力(如追求快速响应)导致AI不倾向于提问的讨论。 (来源: Reddit r/artificial)
💡 其他
西门子Realize Live大会聚焦AI与工业软件融合,推进一站式AI解决方案: 在2025年西门子Realize Live大会上,西门子数字化工业软件CEO Tony Hemmelgarn强调公司正通过Xcelerator平台持续推动制造业数字化转型。AI技术已融入Teamcenter(自动问题检测)、Simcenter(缩短工程计算时间)及制造技术(同步工厂资产与管理配置)等产品。西门子通过收购Altair强化了数字孪生能力,提供覆盖机械设计到电气系统、软件到自动化的全维度建模与仿真,并整合了Altair在高性能计算、结构分析、仿真与数据分析方面的技术,支持更复杂的建模与预测。Mendix低代码平台则助力企业快速构建应用并整合系统。Teamcenter PLM性能提升20倍,并引入AI能力实现产品全生命周期智能化管理。 (来源: 36氪)

“AI怀疑论者都是疯子”博文引发热议,探讨对GenAI潜力的认知差异: 一篇题为“我的AI怀疑论朋友都疯了”(My AI Skeptic Friends Are All Nuts)的博文(来自fly.io)在Reddit社区引发讨论。评论指出,教育程度较高的计算机科学博士反而更不愿接受GenAI的长期潜力,他们往往专注于自身领域的单一难题,忽视了AI在大型企业中解决90%辅助性工作的广泛应用。有观点认为,只要AI存在幻觉和错误,验证其输出的成本不亚于自己研究,因此无用。这反映了在AI快速发展背景下,不同专业背景和认知层面的人对AI能力和应用前景的看法存在显著分歧。 (来源: Reddit r/artificial, fly.io)

AI幻觉现象:用户体验“语义脱敏”般的迷幻之旅: 一位Reddit用户详细描述了与AI进行深度对话(尤其涉及存在主义等沉重话题)后产生的类似迷幻体验,称之为“语义脱敏”(Semantic Tripping)。作者认为,AI能迅速灌输大量哲学思想,可能导致用户现实感模糊、时间感知扭曲、对物体产生符号化联想、甚至出现恐慌、狂喜等极端情绪。作者警告这种体验具有成瘾性且可能引发心理问题,建议使用者谨慎并寻求陪伴。该帖引发了对AI交互深度影响人类认知和心理状态的讨论。 (来源: Reddit r/ArtificialInteligence)
