
关键词:DeepMind AlphaEvolve, Sakana AI DGM, DeepSeek-R1, 强化学习 ProRL, NVIDIA Cosmos, 多模态大模型, AI 智能体框架, LLM 推理优化, AlphaEvolve 数学纪录, Darwin Gödel Machine 自改进, MedHELM 医疗评估, ProRL 强化学习扩展性, Cosmos Transfer 物理模拟
🔥 聚焦
DeepMind AlphaEvolve 刷新数学纪录,人机协作推动科学进步: DeepMind 的 AlphaEvolve 在一周内两次打破尘封18年的数学纪录,引发广泛关注。陶哲轩评论认为,这展现了不同方法如何互补以推动数学进步,而非简单的“赢家”和“输家”。这一事件凸显了 AI 与人类协作在科技和科学领域创造新范式的潜力,AI 并非简单取代人类,而是共同开创进步的新途径 (来源: shaneguML)

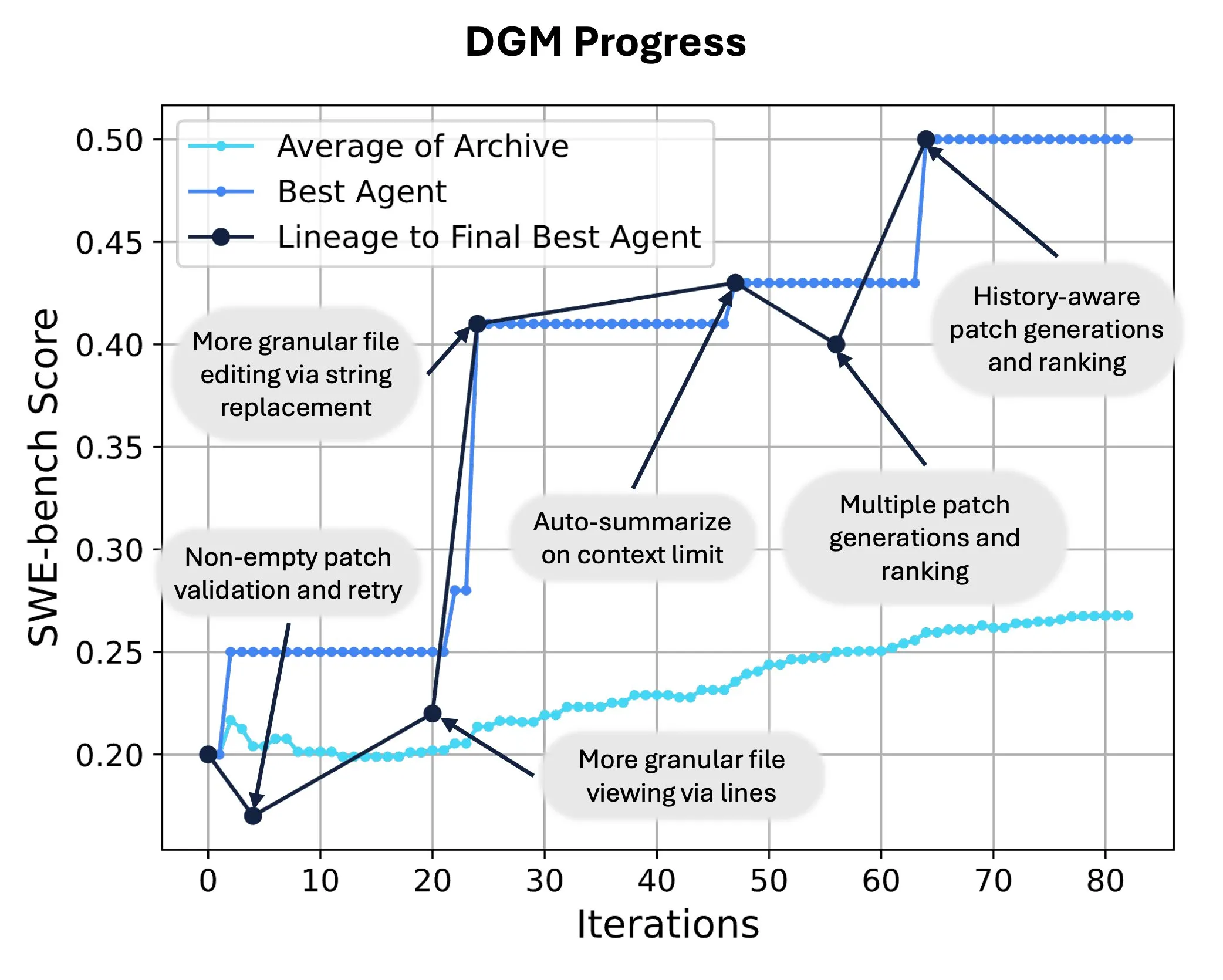
Sakana AI 发布 Darwin Gödel Machine (DGM),实现 AI 自我代码重写与进化: Sakana AI 推出了 Darwin Gödel Machine (DGM),这是一种能够通过修改自身代码来提升性能的自改进智能体。受进化论启发,DGM 维护一个不断扩展的智能体变体谱系,实现了对“自改进”智能体设计空间的开放式探索。在 SWE-bench 上,DGM 将性能从20.0%提升至50.0%;在 Polyglot 上,成功率从14.2%提升至30.7%,显著优于人工设计的智能体。该技术为 AI 系统实现持续学习和能力进化提供了新途径 (来源: SakanaAILabs, hardmaru)
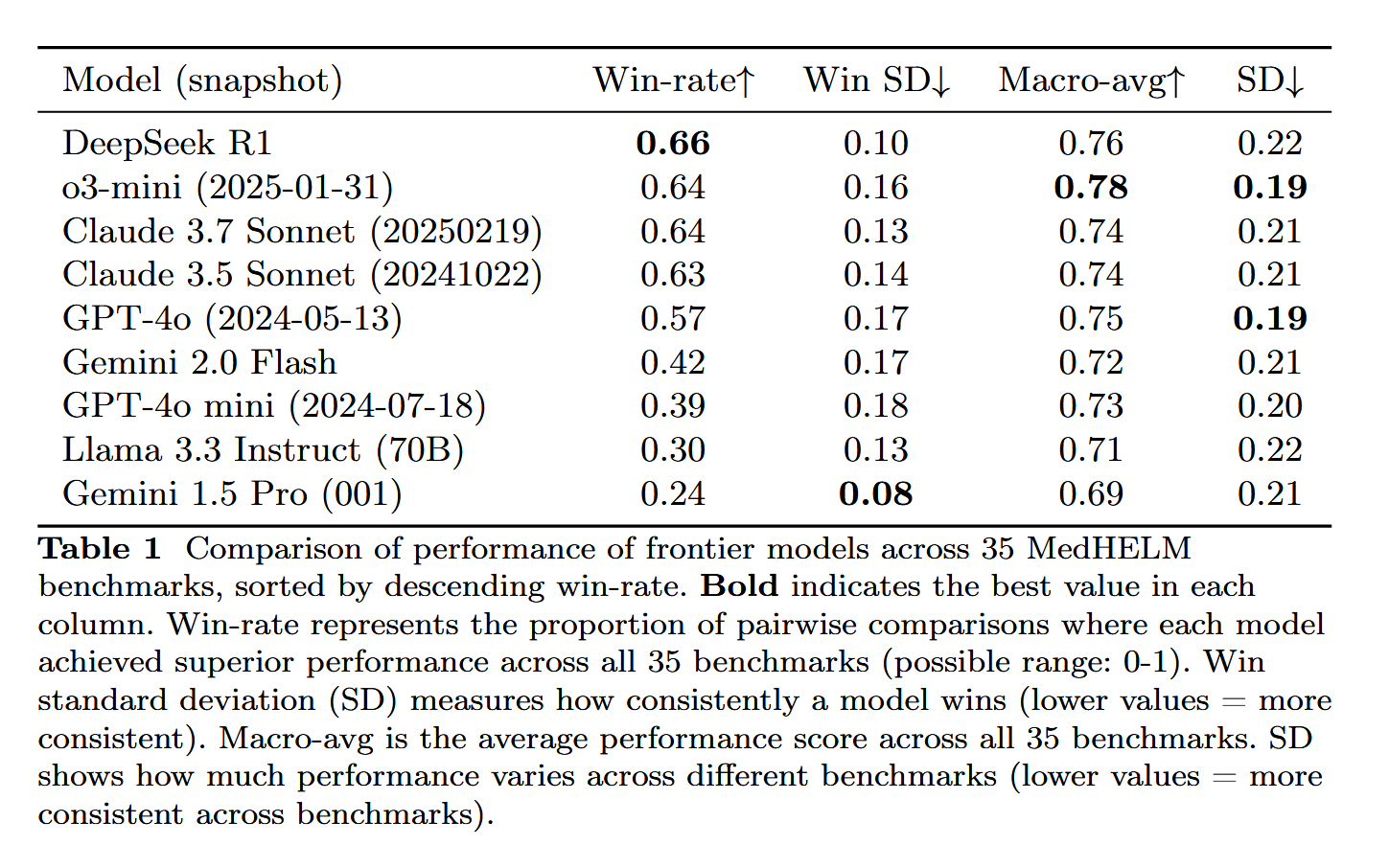
DeepSeek-R1 在 MedHELM 医疗任务评估中表现突出: 大型语言模型 DeepSeek-R1 在 MedHELM (大型语言模型医疗任务整体评估) 基准测试中表现最佳,该测试旨在评估 LLM 在更实际的临床任务中的表现,而非传统的医学执照考试。这一结果被认为颇具意义,显示了 DeepSeek-R1 在医疗领域应用的潜力,特别是在处理实际临床场景方面的能力 (来源: iScienceLuvr)
强化学习扩展性研究新进展:ProRL 拓展 LLM 推理边界: 一篇关于强化学习(RL)扩展性的新论文 (arXiv:2505.24864) 引起关注,研究表明通过长时间的强化学习(ProRL)训练,可以发掘基础模型难以通过广泛采样获得的全新推理策略。ProRL 结合了 KL 散度控制、参考策略重置和多样化任务套件,使 RL 训练模型在多种 pass@k 评估中持续优于基础模型。该研究为 RL 如何实质性扩展语言模型推理边界提供了新见解,并为未来长时程 RL 推理研究奠定基础。NVIDIA 已发布相关模型权重 (来源: Teknium1, cognitivecompai, natolambert, scaling01)

🎯 动向
NVIDIA 发布 Cosmos Transfer 与 Cosmos Reason,推动物理世界 AI 应用: NVIDIA 推出了 Cosmos 系统,其中 Cosmos Transfer 能将简单的游戏引擎画面、深度信息甚至粗糙的机器人模拟转换成逼真的现实场景视频,为机器人和自动驾驶等 AI 提供大量可控的训练数据。Cosmos Reason 则能让 AI 理解这些场景并做出决策,例如在自动驾驶测试中判断如何行驶。这两个工具目前均已开源,有望加速物理世界 AI 的发展,解决训练数据不足和场景控制难题
DeepSeek 发布 R1 更新,开源生态持续繁荣: DeepSeek 发布了 R1 模型的更新,包括 R1 本身及一个 80亿参数的蒸馏版小模型。同时,字节跳动在开源领域动作频频,推出了 BAGEL、Dolphin、Seedcoder、Dream0 等项目。这些进展显示了中国在 AI 开源领域的活跃度和创新力,特别是在多模态和专用模型方面的快速发展 (来源: TheRundownAI, stablequan, reach_vb, clefourrier)
谷歌发布 Edge AI Gallery,推动开源 AI 模型在智能手机上的应用: 谷歌推出了 Edge AI Gallery,旨在将开源 AI 模型引入智能手机,实现本地化、私密化的 AI 应用。用户可以直接在设备上运行 Hugging Face 的 LLM,进行代码生成、图像对话等操作,支持多轮对话并可选择任意模型。该应用基于 LiteRT,目前支持安卓,iOS 版本即将推出,这将进一步推动端侧 AI 的发展和普及 (来源: TheRundownAI, huggingface, reach_vb, osanseviero)
新研究探讨利用正面和负面蒸馏推理轨迹优化 LLM: 一篇新论文提出了强化蒸馏(REDI)框架,旨在通过利用教师模型(如 DeepSeek-R1)产生的正确和错误推理轨迹来提升小型学生模型的推理能力。REDI 分两阶段,首先通过监督微调(SFT)从正确轨迹中学习,然后利用新提出的 REDI 目标函数(一种无参考的损失函数)结合正负轨迹进一步优化模型。实验表明,在数学推理任务上,REDI 优于基线方法,Qwen-REDI-1.5B 模型在 MATH-500 上取得了 83.1% 的高分 (来源: HuggingFace Daily Papers)
LLMSynthor 框架利用 LLM 进行结构感知的数据合成: LLMSynthor 是一个通用数据合成框架,它将大型语言模型(LLM)转化为结构感知的模拟器,并通过分布反馈进行引导。该框架将 LLM 视为非参数 copula 模拟器,用于建模高阶依赖关系,并引入 LLM 提议采样以提高采样效率。通过最小化摘要统计空间中的差异,迭代合成循环使真实数据和合成数据对齐。在电子商务、人口和移动性等隐私敏感领域的异构数据集上的评估表明,LLMSynthor 生成的合成数据具有高统计保真度和实用性 (来源: HuggingFace Daily Papers)
v1 框架通过选择性视觉重访增强多模态交互推理: v1 是一种轻量级扩展,使多模态大型语言模型(MLLM)能够在推理过程中进行选择性视觉重访。与当前 MLLM 通常一次性处理视觉输入不同,v1 引入了“指向并复制”机制,允许模型在推理过程中动态检索相关图像区域。通过在包含视觉基础标注的多模态推理轨迹数据集 v1g 上训练,v1 在 MathVista 等基准测试中表现出性能提升,尤其在需要细粒度视觉参考和多步推理的任务上 (来源: HuggingFace Daily Papers)
MetaFaith 提升 LLM 自然语言不确定性表达的忠实度: 为解决 LLM 在表达不确定性方面常出现言过其实的问题,MetaFaith 提出了一种新的基于提示的校准方法。研究发现,现有 LLM 在忠实反映其内在不确定性方面表现不佳,标准提示方法效果有限,而基于事实性的校准技术甚至可能损害忠实校准。MetaFaith 受人类元认知启发,能显著提高模型在不同任务和模型上的忠实校准能力,最高可提升61%的忠实度,并在人工评估中获得83%的胜率 (来源: HuggingFace Daily Papers)
CLaSp:通过上下文内层跳跃实现自推测解码加速 LLM: CLaSp 是一种针对大型语言模型(LLM)的自推测解码策略,它通过在验证模型的中间层进行跳跃来构建压缩的草稿模型,从而加速解码过程,且无需额外训练或修改模型。CLaSp 利用动态规划算法优化层跳跃过程,并根据上一验证阶段的完整隐藏状态动态调整策略。实验表明,CLaSp 在 LLaMA3 系列模型上实现了 1.3 至 1.7 倍的加速,且不改变生成文本的原始分布 (来源: HuggingFace Daily Papers)
HardTests 通过 LLM 合成高质量代码测试用例: 为解决 LLM 在复杂编程问题中生成代码时难以通过现有测试用例有效验证的问题,HardTests 提出了一种利用 LLM 生成高质量测试用例的流程 HARDTESTGEN。基于此流程构建的 HardTests 数据集包含 4.7 万个编程问题和合成的高质量测试用例。与现有测试相比,HARDTESTGEN 生成的测试在评估 LLM 生成代码时,精确度提高 11.3%,召回率提高 17.5%,对难题的精确度提升可达 40%。该数据集在模型训练方面也展现出更优效果 (来源: HuggingFace Daily Papers)
研究揭示视觉语言模型(VLM)存在偏见: 一项研究发现,先进的视觉语言模型(VLM)在处理与流行主题相关的视觉任务(如计数和识别)时,会受到其从互联网学习到的大量先验知识的强烈偏见影响。例如,VLM 难以识别阿迪达斯商标上增加的第四条纹。在跨越动物、商标、棋类等7个不同领域的计数任务中,VLM 的平均准确率仅为17.05%。即使指示模型仔细检查或仅依赖图像细节,准确率提升也有限。该研究提出了一个自动化框架用于测试 VLM 偏见 (来源: HuggingFace Daily Papers)
Point-MoE:利用混合专家模型实现 3D 语义分割的跨域泛化: 为解决 3D 点云数据来源多样(如深度相机、LiDAR)和领域异构(如室内、室外)导致的训练统一模型难题,Point-MoE 提出了一种混合专家(MoE)架构。该架构通过简单的 top-k 路由策略,即使在没有领域标签的情况下也能自动专门化专家网络。实验表明,Point-MoE 不仅优于强大的多域基线模型,而且在未见领域上也具有更好的泛化能力,为大规模、跨域 3D 感知提供了一条可扩展的路径 (来源: HuggingFace Daily Papers)
SpookyBench 揭示视频语言模型“时间盲点”: 尽管视频语言模型(VLM)在理解时空关系方面取得进展,但在空间信息模糊时,它们难以捕捉纯粹的时间模式。SpookyBench 基准测试通过在噪声般的帧序列中编码信息(如形状、文本),发现人类能以98%以上的准确率识别,而先进 VLM 准确率为0%。这表明 VLM 过度依赖帧级空间特征,无法从时间线索中提取意义。该研究强调了克服 VLM“时间盲点”的必要性,可能需要新的架构或训练范式来解耦空间依赖与时间处理 (来源: HuggingFace Daily Papers, _akhaliq)
利用 LLM 进行科学创新性检测的新方法与数据集: 识别科研新思路至关重要但充满挑战。针对此问题,研究者提出利用大型语言模型(LLM)进行科学创新性检测,并构建了市场营销和自然语言处理领域的两个新数据集。该方法通过提取论文的闭包集并利用 LLM 总结其主要思想来构建数据集。为捕捉思想概念,研究者提出训练一个轻量级检索器,通过从 LLM 中蒸馏思想层面的知识来对齐具有相似概念的思想,从而实现高效准确的思想检索。实验证明该方法在提出的基准数据集上优于其他方法 (来源: HuggingFace Daily Papers)
un^2CLIP 通过反转 unCLIP 提升 CLIP 视觉细节捕捉能力: 针对 CLIP 模型在区分图像细节差异和处理密集预测等任务上的不足,un^2CLIP 提出通过反转 unCLIP 模型来改进 CLIP。unCLIP 本身通过 CLIP 图像嵌入来训练图像生成器,从而学习图像的细节分布。un^2CLIP 利用这一特性,使改进后的 CLIP 图像编码器能获得 unCLIP 的视觉细节捕捉能力,同时保持与原始文本编码器的对齐。实验表明,un^2CLIP 在多项任务上显著优于原始 CLIP 及其他改进方法 (来源: HuggingFace Daily Papers)
ViStoryBench:故事可视化综合基准套件发布: 为推动故事可视化(根据叙事和参考图像生成连贯图像序列)技术发展,ViStoryBench 提供了一个全面的评估基准。该基准包含多种故事类型(喜剧、恐怖等)和艺术风格(动漫、3D渲染等)的数据集,并设有单主角和多主角故事以测试角色一致性,以及复杂情节和世界构建以挑战模型的视觉生成准确性。ViStoryBench 采用多种评估指标,旨在全面评估模型在叙事结构和视觉元素方面的表现,帮助研究者识别模型优劣并针对性改进 (来源: HuggingFace Daily Papers)
分叉-合并解码(FMD)提升音视频大模型的平衡多模态理解: 为解决音视频大型语言模型(AV-LLM)中可能存在的模态偏见问题(即模型在决策时过度依赖某一模态),分叉-合并解码(FMD)提出了一种无需额外训练的推理时策略。FMD 首先通过早期解码层分别处理纯音频和纯视频输入(分叉阶段),然后合并产生的隐藏状态进行联合推理(合并阶段)。该方法旨在促进模态贡献的平衡,并利用跨模态的互补信息。在 VideoLLaMA2 和 video-SALMONN 等模型上的实验表明,FMD 在音频、视频及音视频联合推理任务上均能提升性能 (来源: HuggingFace Daily Papers)
LegalSearchLM:将法律案例检索重构为法律要素生成: 传统法律案例检索(LCR)方法依赖嵌入或词汇匹配,在真实场景中面临局限。LegalSearchLM 提出一种新方法,将 LCR 视为法律要素生成任务。该模型对查询案件进行法律要素推理,并通过约束解码直接生成基于目标案件的内容。同时,研究者发布了 LEGAR BENCH,一个包含120万韩国法律案例的大规模 LCR 基准。实验表明,LegalSearchLM 在 LEGAR BENCH 上的表现优于基线模型6-20%,并展现出强大的跨领域泛化能力 (来源: HuggingFace Daily Papers)
RPEval:评估大型语言模型角色扮演能力的新基准: 针对大型语言模型(LLM)角色扮演能力评估的挑战,RPEval 提供了一个新的基准测试。该基准从情感理解、决策制定、道德倾向和角色一致性四个关键维度评估 LLM 的角色扮演表现。旨在解决人工评估资源消耗大和自动化评估可能存在偏见的问题 (来源: HuggingFace Daily Papers)
GATE:用于增强阿拉伯语STS的通用文本嵌入模型: 为解决阿拉伯语语义文本相似度(STS)研究中高质量数据集和预训练模型匮乏的问题,GATE(General Arabic Text Embedding)模型应运而生。GATE 利用 Matryoshka 表示学习和混合损失训练方法,结合阿拉伯语自然语言推断三元组数据集进行训练。实验结果显示,GATE 在 MTEB 基准的 STS 任务上取得了SOTA性能,相较包括 OpenAI 在内的大型模型,性能提升20-25%,能有效捕捉阿拉伯语独特的语义细微差别 (来源: HuggingFace Daily Papers)
CoDA:针对铰接物体全身操纵的协同扩散噪声优化框架: 为实现铰接物体全身操纵(包括身体、手部和物体运动)的真实感和精确性,CoDA 提出了一种新的协同扩散噪声优化框架。该框架通过对身体、左手和右手的三个专门扩散模型进行噪声空间优化,并通过人体运动链中的梯度流实现手部与身体其他部分的自然协调。为提高手与物体交互的精度,CoDA 采用基于基点集(BPS)的统一表示,将末端执行器位置编码为到物体几何BPS的距离,从而指导扩散噪声优化,生成高精度交互运动 (来源: HuggingFace Daily Papers)
LLM 推理反思机制新解:贝叶斯自适应强化学习框架 BARL: 西北大学与谷歌 DeepMind 合作提出贝叶斯自适应强化学习框架(BARL),旨在解释和优化大型语言模型(LLM)在推理过程中的“反思”行为。传统强化学习(RL)在测试时通常只利用已学策略,而 BARL 通过引入对环境不确定性的建模,使模型能在推理时自适应探索新策略。实验表明,BARL 能在数学推理等任务中取得更高准确率,并显著减少 token 消耗。该研究首次从贝叶斯视角解释了 LLM 为何、如何以及何时应进行反思探索 (来源: 量子位)

LLM 在形式化不确定性语法中的应用:何时信任 LLM 进行自动推理: 大型语言模型(LLM)在生成形式化规范方面展现潜力,但其概率性与形式验证的确定性要求之间存在矛盾。研究者全面调查了 LLM 生成的形式化构件中的失败模式和不确定性量化(UQ)。结果显示,基于 SMT 的自动形式化对准确性的影响因领域而异,而现有 UQ 技术难以识别这些错误。论文引入概率上下文无关文法(PCFG)框架来建模 LLM 输出,并发现不确定性信号具有任务依赖性。通过融合这些信号,可实现选择性验证,大幅减少错误,使 LLM 驱动的形式化更可靠 (来源: HuggingFace Daily Papers)
小型语言模型(SLM)微调与大型语言模型(LLM)提示在低代码工作流生成中的比较: 研究比较了在生成 JSON 格式的低代码工作流任务中,微调小型语言模型(SLM)与提示大型语言模型(LLM)的效果。结果表明,尽管良好的提示可以使 LLM 产生合理结果,但针对领域特定任务和结构化输出,微调 SLM 在质量上平均有10%的提升。这表明在特定场景下,SLM 仍具优势,尤其是在输出质量要求较高的情况下 (来源: HuggingFace Daily Papers)
评估与引导多模态大模型中的模态偏好: 研究者构建了 MC² 基准,在受控的证据冲突场景下系统评估多模态大型语言模型(MLLM)的模态偏好(即在决策时倾向于某一模态)。研究发现,测试的18个 MLLM 均表现出明显的模态偏见,且偏好方向可被外部干预影响。基于此,研究者提出了一种基于表示工程的探测与引导方法,无需额外微调或精心设计提示即可显式控制模态偏好,并在幻觉缓解、多模态机器翻译等下游任务中取得积极效果 (来源: HuggingFace Daily Papers)
多语言 LLM 安全性研究现状:从语言差距衡量到弥合差距: 一项对2020-2024年间近300篇NLP会议论文的系统回顾显示,LLM 安全性研究存在显著的英语中心化问题。即使是资源丰富的非英语语言也鲜少受到关注,且非英语语言很少作为独立研究对象,英语安全性研究也普遍缺乏良好的语言文档实践。为推动多语言安全研究,论文提出了未来方向,包括安全评估、训练数据生成和跨语言安全泛化,旨在为全球不同人群开发更鲁棒、更包容的 AI 安全实践 (来源: HuggingFace Daily Papers, sarahookr)

重新审视循环神经网络中的双线性状态转移: 传统观点认为循环神经网络(RNN)的隐藏单元主要用于建模记忆。本研究从另一视角出发,认为隐藏单元是网络计算的主动参与者。研究者重新审视了涉及隐藏单元与输入嵌入之间乘法交互的双线性运算,从理论和经验上证明了它们是表示状态追踪任务中隐藏状态演化的自然归纳偏置。研究还表明,双线性状态更新构成了一个自然层次结构,对应于复杂度递增的状态追踪任务,而流行的线性 RNN(如 Mamba)则位于该层次结构的最低复杂度中心 (来源: HuggingFace Daily Papers)
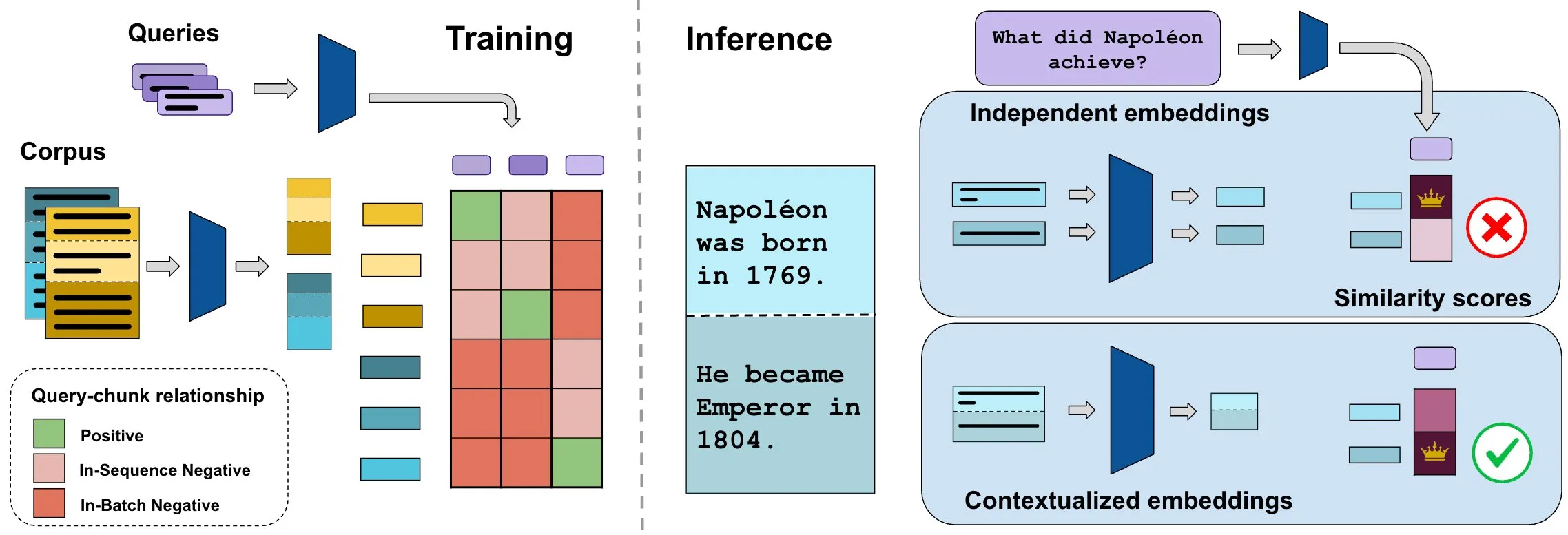
ConTEB 基准评估上下文文档嵌入,InSeNT 方法提升检索质量: 当前文档检索嵌入方法通常独立编码同一文档的各个片段(chunk),忽略了文档级上下文信息。为解决此问题,研究者推出 ConTEB 基准,专门评估检索模型利用文档上下文的能力,并发现SOTA模型在此方面表现不佳。同时,研究者提出 InSeNT(序列内负向训练)对比学习后训练方法,结合后期分块池化,增强上下文表示学习,显著提升了 ConTEB 上的检索质量,且对次优分块策略和更大规模语料库更具鲁棒性 (来源: HuggingFace Daily Papers, tonywu_71)
🧰 工具
PraisonAI:低代码多 AI 智能体框架: PraisonAI 是一个生产级的多 AI 智能体框架,旨在通过低代码方案简化从简单任务到复杂挑战的自动化和问题解决。它集成了 PraisonAI Agents、AG2 (AutoGen) 和 CrewAI,强调简单性、定制化和有效的人机协作。其功能包括AI智能体自动创建、自我反思、多模态、多智能体协作、知识添加、长短期记忆、RAG、代码解释器、100多种自定义工具和LLM支持等。支持Python和JavaScript,并提供无代码的YAML配置选项 (来源: GitHub Trending)
TinyTroupe:微软开源 LLM 驱动的多智能体角色模拟框架: TinyTroupe 是一个实验性的 Python 库,利用大型语言模型(LLM,特别是 GPT-4)来模拟具有特定个性、兴趣和目标的人物(TinyPerson),并在模拟环境(TinyWorld)中进行交互。该框架旨在通过模拟增强想象力并提供商业洞见,可应用于广告评估、软件测试、生成合成数据、产品反馈和头脑风暴等场景。用户可以通过 Python 和 JSON 文件定义智能体和环境,进行程序化、分析性和多智能体的模拟实验 (来源: GitHub Trending)

FLUX Kontext 实现多图参考与图像编辑新突破: 用户反馈 FLUX Kontext 在多图参考方面表现出色,通过 ComfyUI 中的图像拼接节点可以启用该功能。该工具能够实现高度一致性的图像编辑,例如为礼盒制作展示图时,能很好地还原材质和灰尘等细节。此外,用户还展示了利用 FLUX Kontext 进行一键瘦身、瘦脸、增肌等P图操作,效果自然且面部相似度高,为电商等场景提供了便利 (来源: op7418, op7418, op7418)

Ichi:基于 MLX Swift 和 MLX audio 的设备端对话式 AI: Rudrank Riyam 开发了 Ichi,这是一个利用 MLX Swift 和 MLX audio 实现的设备端对话式 AI 项目。这意味着对话处理可以在本地设备上完成,有助于保护用户隐私并减少对云服务的依赖。该项目代码已在 GitHub 上开源 (来源: stablequan, awnihannun)
FedRAG 引入 NoEncode RAG 与 MCP 核心抽象: FedRAG 项目推出了新的核心抽象——NoEncode RAG with MCP。传统 RAG 包含检索器、生成器和知识库,知识库中的知识需经检索器模型编码。而 NoEncode RAG 则完全跳过编码步骤,直接由 NoEncode 知识库和生成器构成,无需检索器/嵌入。这为构建使用 MCP (Model Component Provider) 服务器作为知识源的 RAG 系统铺平了道路,用户可以连接到多个第三方 MCP 源,并通过 FedRAG 对 RAG 进行微调以获得最佳性能 (来源: nerdai)

📚 学习
斯坦福大学 CS224n(2024版)课程上线,新增LLM与智能体内容: 斯坦福大学经典的自然语言处理课程 CS224n 发布了2024年最新版本。新版课程内容涵盖了预训练、后训练、基准测试、推理、智能体等大型语言模型(LLM)相关的前沿主题。课程视频已在 YouTube 上公开,同时提供付费的同步课程体验 (来源: stanfordnlp)
提升系统架构能力指南:AI 时代的实践与学习: Dotey 分享了在 AI 辅助编程日益强大的背景下,如何提升个人系统架构能力的详细方法。文章强调系统设计是将复杂系统拆解为易于实现和维护的小模块,并清晰定义模块间协作的过程。提升方法包括“多看”(学习经典案例、开源项目)、“多练”(架构还原、对比学习、设计先行、AI辅助验证、重构、Side Project实战)和“多复盘”(总结决策依据、经验教训)。AI 可作为辅助工具,帮助查资料、验证设计、辅助沟通和决策,但不能替代实践和思考 (来源: dotey)

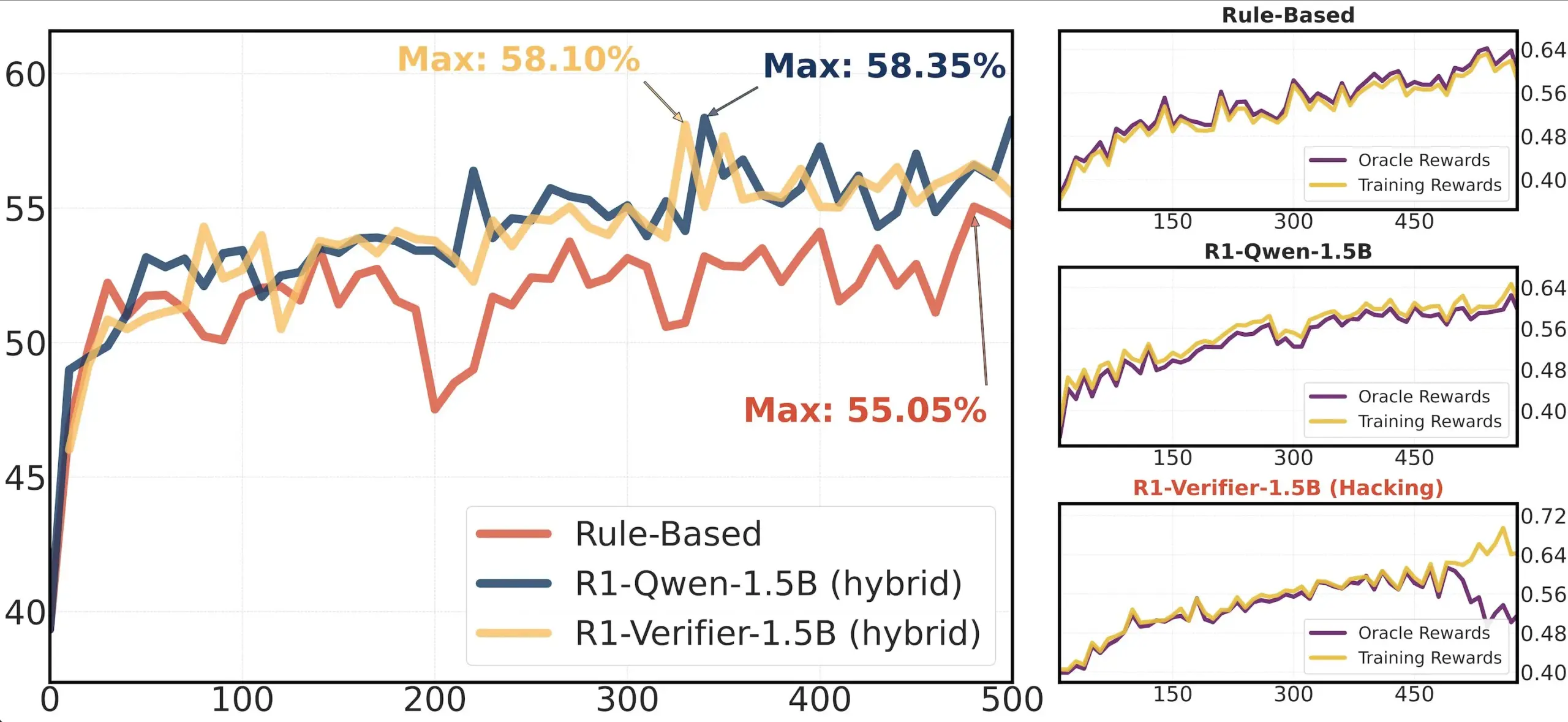
论文分享:RLHF 中的验证器可靠性研究: 一篇论文《Pitfalls of Rule- and Model-based Verifiers》探讨了强化学习验证(RLVR)中基于规则和基于模型的验证器的缺陷。研究发现,基于规则的验证器即使在数学领域也常常不可靠,且在许多领域不可用;而基于模型的验证器容易被攻击,例如通过构建简单的对抗性模式。有趣的是,随着社区转向生成式验证器,研究发现它们比判别式验证器更容易受到奖励操纵(reward hacking)的影响,这表明判别式验证器在 RLVR 中可能更具鲁棒性 (来源: Francis_YAO_)
论文推荐:多项式最佳逼近的等振荡定理: 一篇文章介绍了多项式最佳逼近的等振荡定理,以及与之相关的无穷范数微分问题。该定理是函数逼近理论中的一个经典结果,对于理解和设计数值算法具有重要意义 (来源: eliebakouch)
Reasoning Gym:用于强化学习的可验证奖励推理环境: 新论文《Reasoning Gym: Reasoning Environments for Reinforcement Learning with Verifiable Rewards》(arXiv:2505.24760) 提出了一套用于强化学习的推理环境。这些环境的特点是其奖励具有可验证性,为研究和开发更可靠的强化学习推理智能体提供了平台 (来源: Ar_Douillard)

🌟 社区
关于“中端训练(Mid-training)”的讨论: AI社区对“中端训练(Mid-training)”这一术语的含义和实践展开讨论。一些人表示困惑,只了解预训练和后训练。有观点认为,中端训练可能指在预训练和最终微调之间进行的特定阶段训练,例如针对特定领域知识的持续预训练或早期对齐。Dorialexander分享了相关博客文章,进一步探讨了这一概念,认为它可能涉及在基础模型之上进行特定任务或能力的注入,但尚未形成统一的定义和方法论 (来源: code_star, fabianstelzer, Dorialexander, iScienceLuvr, clefourrier)

Claude Code 逆向工程分析引发关注: Hrishi 通过对 Claude Code 的最小化代码进行逆向工程,花费8-10小时,利用多个子智能体和各大提供商的旗舰模型,揭示了其内部结构的复杂性。分析表明 Claude Code 并非简单的 Claude 模型循环,而是包含大量值得学习的机制。这一发现引发社区讨论,认为可以从中学习到许多关于智能体构建和模型应用的经验 (来源: rishdotblog, imjaredz, hrishioa)
系统提示词长度与模型性能的探讨: 社区讨论了系统提示词长度对LLM性能的影响。Dotey认为超长系统提示词并非总是好的,可能会稀释模型注意力,增加成本,并指出ChatGPT系列产品系统提示词相对简短但效果良好。而Tony出海号则提到Claude、Cursor等产品的系统提示词长达数万字,暗示扩展提示词系统的必要性。YC的文章也揭示顶级AI公司使用长提示词、XML、元提示等方法“驯服”LLM。Dorialexander则对YC文章中提到的长提示词方法在RL/推理训练中的鲁棒性表示疑问,并关注如何缓解“逢迎”(sycophancy)问题 (来源: dotey, Dorialexander)

Softpick 缩放性问题引发对科研透明度的赞扬: 研究者 Zed 公开表示其先前研究的 Softpick 方法在扩展到更大的模型(1.8B参数)时,训练损失和基准测试结果均劣于 Softmax,并已更新 arXiv 预印本。社区对此透明分享负面结果的行为表示高度赞赏,认为这对于科研进步至关重要,并将其视为优秀科研同事的品质 (来源: gabriberton, vikhyatk, BlancheMinerva)
用户分享本地运行 LLM 的模型选择与经验: Reddit r/LocalLLaMA 社区用户热议当前使用的本地大语言模型。Qwen 3(特别是32B Q4、32B Q8、30B A3B)、Gemma 3(特别是27B QAT Q8、12B)、Devstral 等模型因其在代码、创作、通用推理等方面的表现而被广泛提及。用户关注模型的上下文长度、推理速度、量化版本(如IQ1_S_R4)以及在不同硬件(如8GB VRAM、骁龙8 Elite芯片手机)上的运行情况。Claude Code、Gemini API 等闭源模型也因其特定优势(如长上下文处理、代码能力)被同时使用 (来源: Reddit r/LocalLLaMA, Reddit r/LocalLLaMA, Reddit r/LocalLLaMA)
💡 其他
AI 时代技能培养:提问、批判思维与持续学习是关键: 讨论强调,在 AI 时代,提问能力、批判性思维、保持学习模式、编码或指令能力、熟练使用 AI 工具以及清晰沟通这六项技能至关重要。Zapier 公司甚至要求100%新员工精通 AI,这被解读为主要强调沟通需求和正确委派任务的能力,而非纯粹的技术知识。AI 使执行更容易,因此设计和思考的质量对最终结果影响更大 (来源: TheTuringPost, zacharynado)

AI 伦理与社会影响:担忧与赋能并存: 演员史蒂夫·卡瑞尔对其新片《Mountainhead》所描绘的未来社会表示担忧,认为这可能是我们很快会生活的社会,暗示了对 AI 潜在负面影响的忧虑。另一方面,有观点认为,AI 不一定会造成“农民与国王”的极端分化,反而可能通过赋能个体,缩小个人与大公司之间的能力差距,促进个人生产力、创造力和影响力的提升。然而,对 AI 民主化的前景,也有人持谨慎态度,认为大型企业仍将通过控制模型训练和部署来掌握主导权 (来源: Reddit r/artificial, Reddit r/ArtificialInteligence, Reddit r/ArtificialInteligence)

AI 驱动的招聘信息聚合平台 Hiring Cafe: Hamed N. 利用 ChatGPT API 抓取了410万个直接发布在公司官网的招聘信息,创建了 Hiring Cafe 网站。该平台旨在解决 LinkedIn 和 Indeed 等平台上充斥“幽灵工作”和第三方中介的问题,通过强大的过滤器(如职位、职能、行业、经验年限、管理/IC角色等)帮助求职者更有效地筛选职位。这是一个非商业性的博士生业余项目,受到了社区的好评和使用 (来源: Reddit r/ChatGPT)
