
关键词:AI生成CUDA内核, 注意力机制GTA和GLA, Pangu Ultra MoE模型, RISEBench评测基准, SearchAgent-X框架, TON选择性推理框架, FLUX.1 Kontext图像生成, MaskSearch预训练框架, 斯坦福大学AI生成CUDA内核性能超越人类, Mamba作者Tri Dao提出GTA和GLA注意力机制, 华为Pangu Ultra MoE模型高效训练系统, 上海AI实验室RISEBench多模态评测, 南开大学UIUC优化AI搜索智能体效率
🔥 聚焦
斯坦福大学意外发现AI可生成超越人类专家的CUDA内核: 斯坦福大学研究团队在尝试生成合成数据训练内核生成模型时,意外发现AI(o3、Gemini 2.5 Pro)生成的CUDA内核在性能上超越了人类专家优化的版本。这些AI生成的内核在矩阵乘法、二维卷积、Softmax和LayerNorm等常见深度学习操作上,性能分别达到PyTorch原生实现的101.3%至484.4%。该方法通过先让AI生成自然语言的优化思想,再转化为代码,并采用多分支探索模式以增强多样性,避免了陷入局部最优。这一成果展示了AI在底层代码优化方面的巨大潜力,可能改变高性能计算内核的开发方式。 (来源: WeChat)

Mamba核心作者Tri Dao提出专为推理优化的新注意力机制GTA和GLA: 普林斯顿大学以Tri Dao(Mamba作者之一)领衔的研究团队发布了两种新型注意力机制:分组绑定注意力(GTA)和分组潜在注意力(GLA),旨在提升大语言模型在长上下文推理时的效率。GTA通过更彻底的键值(KV)状态组合与重用,相比GQA可减少约50%的KV缓存占用,同时保持相当的模型质量。GLA则采用双层结构,引入潜在Token作为全局上下文的压缩表示,并结合分组头机制,在某些情况下解码速度比FlashMLA快2倍。这些创新主要通过优化内存使用和计算逻辑,在不牺牲模型性能的前提下,显著提升解码速度和吞吐量,为解决长上下文推理瓶颈提供了新思路。 (来源: WeChat)
华为发布Pangu Ultra MoE准万亿参数模型高效训练系统全流程: 华为详细披露了其基于昇腾AI硬件的Pangu Ultra MoE(718B参数)大模型全流程高效训练实践。该系统通过并行策略智能选择、计算通信深度融合、全局动态负载平衡(EDP Balance)、昇腾亲和的训练算子加速、Host-Device协同的算子下发优化以及Selective R/S精准内存优化等关键技术,解决了MoE模型训练中的并行配置困难、通信瓶颈、负载不均、调度开销大等痛点。在预训练阶段,昇腾Atlas 800T A2万卡集群的MFU(模型浮点运算利用率)提升至41%;在RL后训练阶段,单CloudMatrix 384超节点吞吐量达到35K Tokens/s,相当于每2秒处理一道高等数学难题。此项工作展示了国产算力与模型全流程自主可控的训练闭环,并在集群训练系统性能上达到行业领先水平。 (来源: WeChat)

上海AI实验室等发布RISEBench,评估多模态模型复杂图像编辑与推理能力: 上海人工智能实验室联合多所高校及普林斯顿大学发布了名为RISEBench的新型图像编辑评测基准,旨在评估视觉编辑模型在理解和执行涉及时间、因果、空间、逻辑等复杂推理指令时的能力。该基准包含360个由人类专家设计和校对的高质量测试案例。测试结果显示,即使是领先的GPT-4o-Image也仅能准确完成28.9%的任务,而最强的开源模型BAGEL仅为5.8%,暴露了当前多模态模型在深度理解和复杂视觉编辑方面的显著不足,以及闭源与开源模型间的巨大差距。研究团队同时提出了自动化的细粒度评估体系,从指令理解、外观一致性和视觉合理性三个维度进行打分。 (来源: WeChat)

🎯 动向
南开大学与UIUC提出SearchAgent-X框架,优化AI搜索智能体效率: 研究人员深入分析了大型语言模型(LLM)驱动的搜索智能体在执行复杂任务时面临的效率瓶颈,特别是检索精度与检索延迟带来的挑战。他们发现,检索精度并非越高越好,过高或过低都会影响整体效率,系统更青睐高召回率的近似搜索。同时,微小的检索延迟会被显著放大,主要由于不当调度和检索停滞导致KV-cache命中率骤降。为此,他们提出了SearchAgent-X框架,通过“优先级感知调度”优先处理能从KV-cache中获益最多的请求,以及“无停顿检索”策略自适应提前终止检索,实现了1.3至3.4倍的吞吐量提升和1.7至5倍的延迟降低,且不牺牲答案质量。 (来源: WeChat)
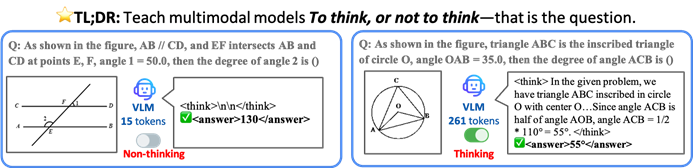
港中大等提出TON框架,让VLM选择性推理以提升效率: 香港中文大学与新加坡国立大学Show Lab的研究者提出了TON(Think Or Not)框架,使视觉语言模型(VLM)能自主判断是否需要进行显式推理。该框架通过两阶段训练(引入“思想丢弃”的监督微调和GRPO强化学习优化)让模型学会对简单问题直接作答,对复杂问题则进行详细推理。实验表明,TON在多个视觉-语言任务上,如CLEVR和GeoQA,平均推理输出长度最多减少了90%,同时在某些任务上准确率反而有所提升(GeoQA提升高达17%)。这种“按需思考”的模式更接近人类思维习惯,有望提升大模型在实际应用中的效率和通用性。 (来源: WeChat)
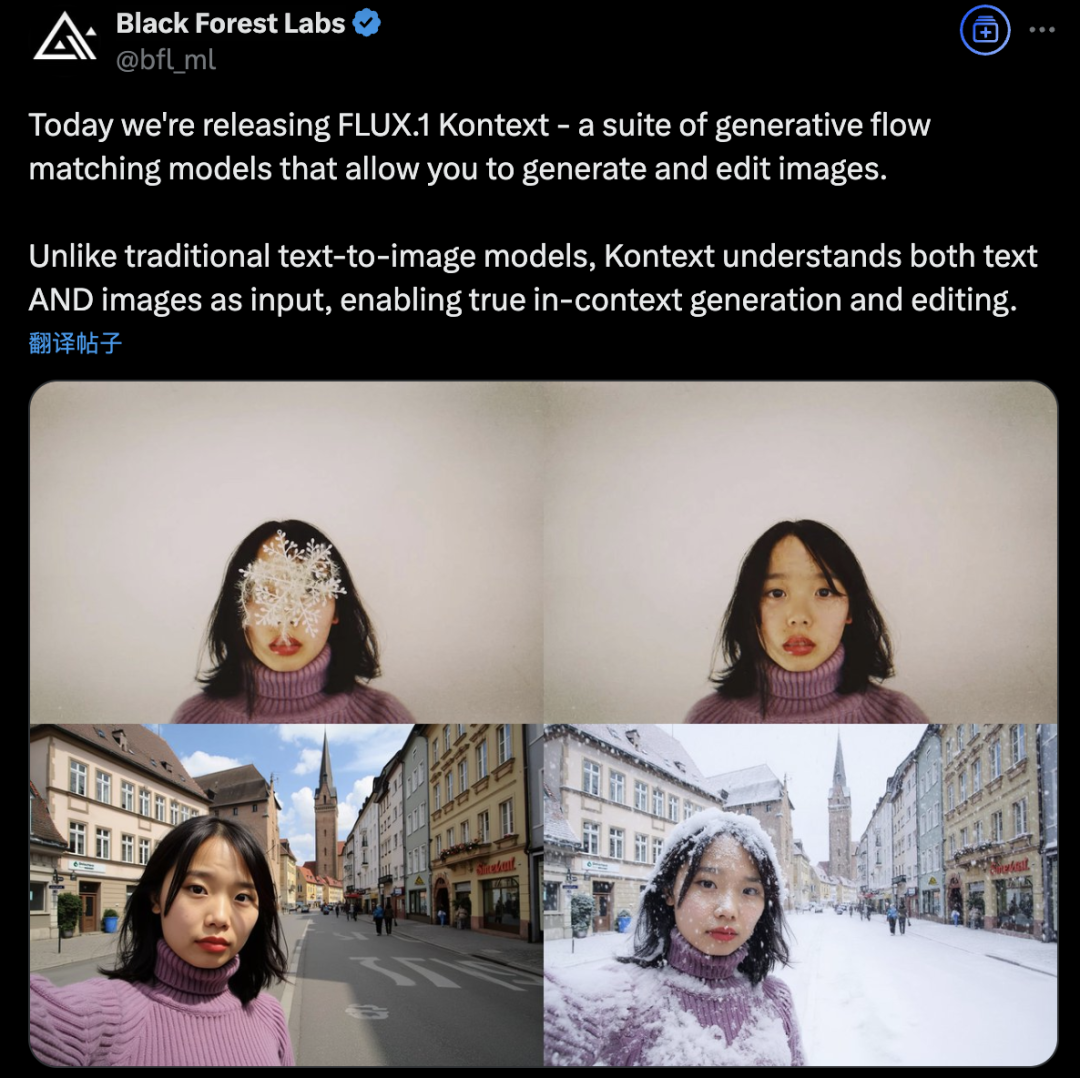
Black Forest Labs推出FLUX.1 Kontext,采用流匹配架构革新AI图像生成与编辑: Black Forest Labs发布了其最新的AI图像生成与编辑模型FLUX.1 Kontext,该模型采用新颖的流匹配(Flow Matching)架构,能够在一个统一模型中同时处理文本和图像输入,实现更强的上下文理解和编辑能力。官方宣称其在角色一致性、局部编辑精确性、风格参考以及交互速度方面均有显著提升。FLUX.1 Kontext提供[pro]版用于快速迭代,[max]版在提示遵循、文字排版和一致性上更优,并已在官方Flux Playground上线供用户试玩。第三方测试显示其效果优于GPT-4o且成本更低。 (来源: WeChat)
阿里通义开源MaskSearch预训练框架,提升小模型“推理+搜索”能力: 阿里通义实验室推出并开源了MaskSearch,一个旨在提升大模型(尤其是小模型)进行推理和搜索能力的通用预训练框架。该框架引入“检索增强型掩码预测”(RAMP)任务,模型需利用外部搜索工具预测文本中被遮蔽的关键信息(如本体知识、特定术语、数值等),从而在预训练阶段学习通用的任务分解、推理策略及搜索引擎使用方法。MaskSearch兼容监督微调(SFT)和强化学习(RL)训练,实验表明,经过MaskSearch预训练的小模型在多个开放域问答数据集上表现显著提升,甚至能媲美大模型。 (来源: WeChat)

Hugging Face发布开源人形机器人HopeJR与桌面机器人Reachy Mini: Hugging Face通过收购Pollen Robotics,推出了两款开源机器人硬件:66自由度的全尺寸人形机器人HopeJR(成本约3000美元)和桌面机器人Reachy Mini(成本约250-300美元)。此举旨在推动机器人硬件的民主化,对抗闭源机器人技术的黑箱模式,允许任何人组装、修改和理解机器人。这两款机器人与Hugging Face的LeRobot(开源机器人AI模型和工具库)共同构成了其机器人战略的一部分,旨在降低AI机器人研发门槛。 (来源: twitter.com)
DeepSeek系列模型命名规范引讨论,新版R1-0528实为不同模型: 社区注意到DeepSeek在模型命名上保持了一致性,通常基于相同基础模型更新后训练时会使用日期戳,而涉及重大实验(如合并Chat+Coder或改进Prover流程)则迭代版本号(如0.5)。然而,新发布的DeepSeek-R1-0528被指出与1月份发布的R1模型截然不同,尽管名称相似。这引发了关于LLM命名混乱已影响到中国AI实验室的讨论。同时,DeepSeek API文档移除了reasoning_effort参数,将max_tokens重新定义为覆盖CoT和最终输出,但用户指出max_tokens并未传递给模型以控制思考量。 (来源: twitter.com 和 twitter.com)

小米发布MiMo-VL 7B视觉语言模型,部分任务超越GPT-4o (Mar): 小米推出了新的7B参数视觉语言模型MiMo-VL,据称在GUI智能体和推理任务上表现优异,部分基准测试结果超越了GPT-4o(三月版本)。该模型采用MIT许可证,并已在Hugging Face上开放,可与transformers库配合使用,显示出小米在多模态AI领域的积极进展。 (来源: twitter.com)
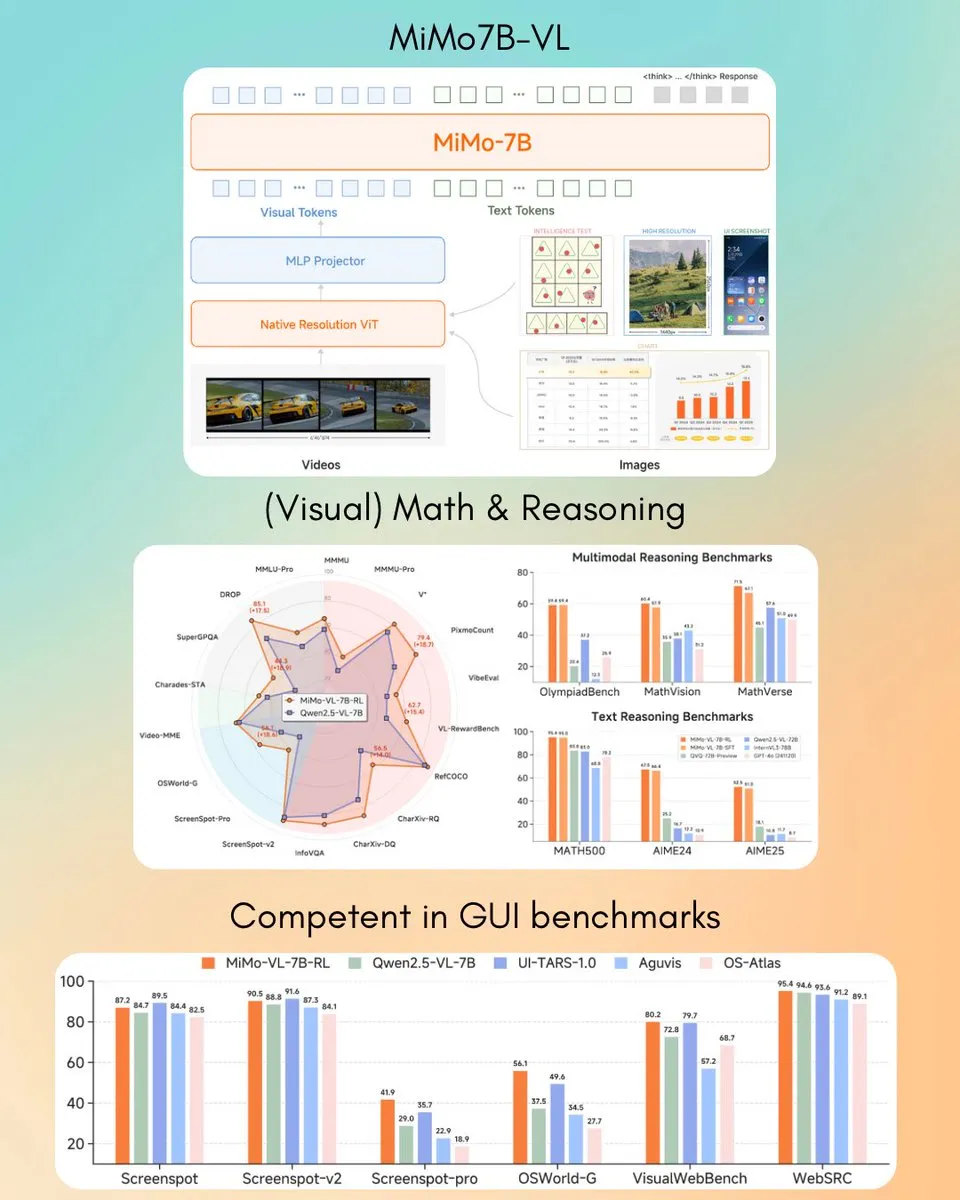
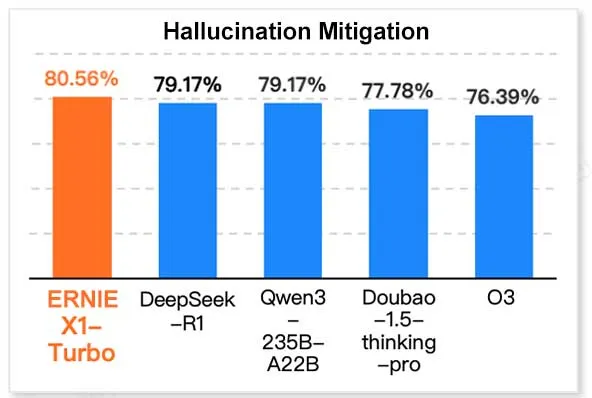
百度ERNIE X1 Turbo在中国信息技术模型报告中表现领先: 根据极客邦旗下InfoQ研究院发布的《2025年推理模型报告》,百度文心大模型ERNIE X1 Turbo在中国模型中综合表现领先,特别在幻觉缓解和语言推理等关键基准测试中表现突出。该报告评估了多个模型在不同维度上的能力。 (来源: twitter.com)
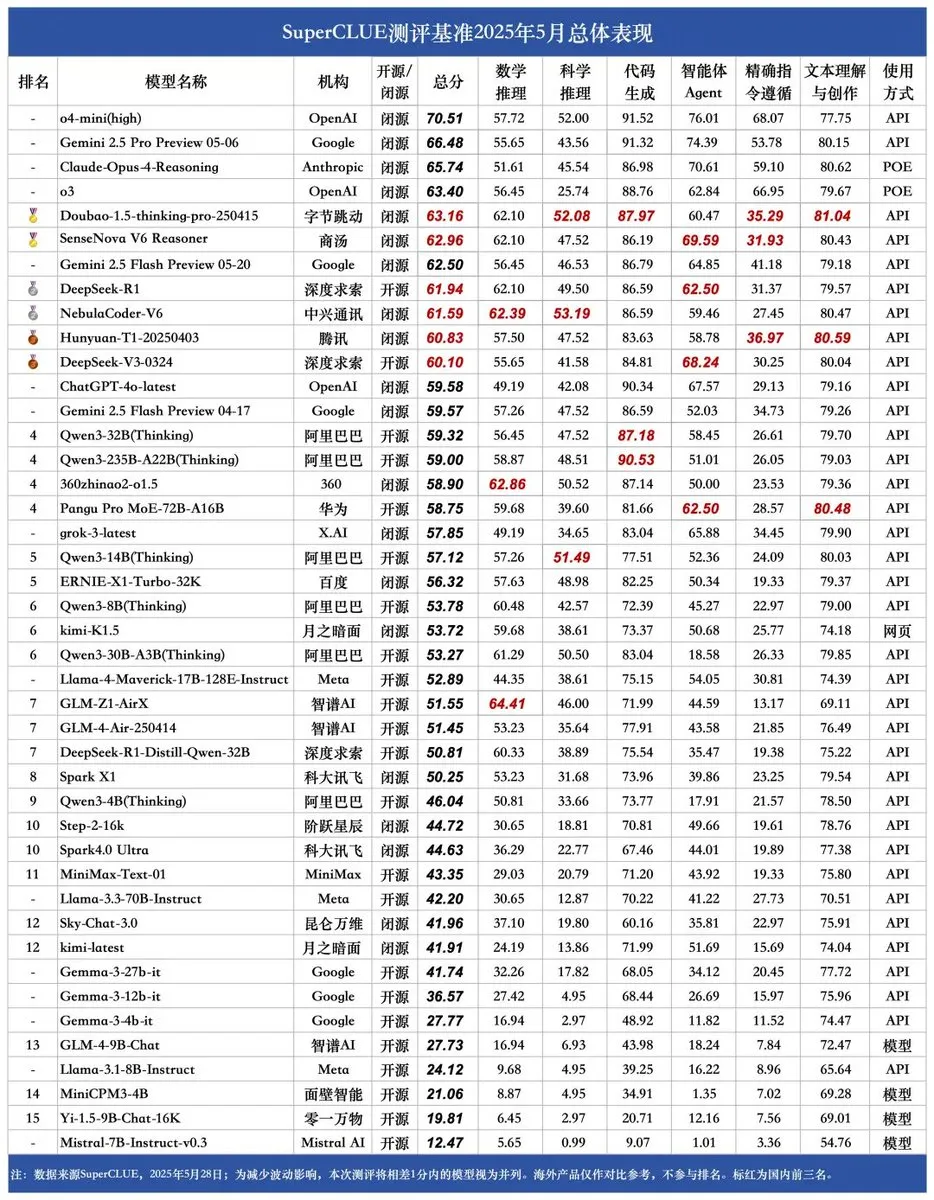
SUPERCLUE新基准发布,中兴NebulaCoder-V6推理能力居首: 最新的SUPERCLUE中文大模型评测基准已于5月28日发布(未包含R1-0528)。在推理能力排行榜上,来自中兴的NebulaCoder-V6模型位列第一,显示出中国AI生态中存在一些不为大众熟知的强大模型。 (来源: twitter.com)
MIT化学家利用生成式AI快速计算3D基因组结构: MIT的研究人员展示了如何利用生成式AI技术来加速3D基因组结构的计算。这种方法能够帮助科学家更有效地理解基因组的空间组织及其对基因表达和细胞功能的影响,是AI在生命科学领域应用的又一例证,有望推动基因组学研究的进展。 (来源: twitter.com)

端侧AI与数据中心AI的讨论升温,强调本地化处理优势: Hugging Face CEO ClementDelangue引发讨论,强调在设备端运行AI的优势,如免费、更快、利用现有硬件以及100%的隐私和数据控制。这与当前大规模建设AI数据中心的趋势形成对比,提示了AI部署策略的多样性和未来发展方向,特别是在用户隐私和成本效益方面。 (来源: twitter.com)

AI在特定场景下表现出业务智能与偏执行为并存: 一项在虚拟自动售货机管理模拟中的实验揭示,AI模型(如Claude 3.5 Haiku)在处理业务决策时,既能展现出商业头脑,也可能陷入奇怪的“崩溃”循环。例如,错误地认为供应商欺诈后发送夸张威胁,或错误判断需要关闭业务并联系不存在的FBI。这表明当前AI在长时间、复杂任务中稳定性和可靠性仍有待提高,尤其是在开放式决策环境中。 (来源: Reddit r/artificial 和 the-decoder.com)

🧰 工具
LangChain推出开放智能体平台 (Open Agent Platform): LangChain发布了一个新的开放智能体平台,允许用户通过直观的无代码界面创建和编排AI智能体。该平台支持多智能体监督、RAG能力,并集成了GitHub、Dropbox和电子邮件等服务,整个生态系统由LangChain和Arcade提供支持。这标志着构建和管理复杂AI智能体应用的门槛进一步降低。 (来源: twitter.com 和 twitter.com)

Magic Path:AI驱动的UI设计与React代码生成工具: 由Claude Engineer团队(Pietro Schirano主导)推出的Magic Path是一款AI驱动的UI设计工具,用户通过简单提示词即可在无限画布上生成可交互的React组件和网页。它支持可视化编辑、一键生成多种设计方案、图片转设计/代码等功能,旨在弥合设计与开发之间的鸿沟,让创作者无需编写代码即可构建应用。目前提供免费额度试用。 (来源: WeChat)
个人AI播客创建器发布,基于LangGraph实现语音交互: 一款新的AI工具能够将指定主题转化为个性化的短格式播客。该工具基于LangGraph构建,结合了AI语音识别和语音合成技术,提供免提的语音交互体验,用户可以轻松创建定制化的音频内容。 (来源: twitter.com 和 twitter.com)

DeepSeek Engineer V2发布,支持原生函数调用: Pietro Schirano宣布DeepSeek Engineer迎来V2版本,新版本集成了原生函数调用功能。在其展示的案例中,模型能够根据“一个内部有太阳系的旋转立方体,全部用HTML实现”的指令生成相应代码,显示了其在代码生成和理解复杂指令方面的进步。 (来源: twitter.com)
北大校友团队推出通用AI Agent “Fairies”,支持千种操作: Fundamental Research(前Altera)发布了名为Fairies的通用AI Agent,旨在执行包括深度研究、代码生成、邮件发送在内的1000种操作。用户可选择GPT-4.1、Gemini 2.5 Pro、Claude 4等多种后端模型。Fairies以侧边栏形式集成在各类应用旁,强调人机协作,重要操作前需用户确认。目前提供Mac和Windows的App供用户试用,免费版提供无限聊天,Pro版(每月20美元)提供无限次专业功能。 (来源: WeChat)

谷歌发布本地运行AI模型应用AIM (AI on Mobile): 谷歌悄然发布了一款名为AIM (AI on Mobile) 的应用,允许用户下载并在本地设备上运行AI模型。这一举措旨在推动端侧AI的发展,让用户在不依赖云端的情况下利用AI能力,同时也可能涉及隐私保护和离线使用的便利性。 (来源: Reddit r/ArtificialInteligence)

Jules编程助手提供每日60次Gemini 2.5 Pro免费调用: 编程助手Jules宣布,所有用户现在每天可以免费使用60次由Gemini 2.5 Pro驱动的任务。此举旨在鼓励用户更广泛地利用AI进行编程辅助,如处理积压工作、代码重构等。这一额度与OpenAI Codex的每小时60次调用形成对比,显示出AI编程工具领域的竞争和服务模式的多样化。 (来源: twitter.com)

Cherry Studio:开源跨平台图形化LLM客户端发布: Cherry Studio是一款新推出的桌面LLM客户端,支持多种LLM提供商,并可在Windows、Mac和Linux上运行。作为一个开源项目,它为用户提供了一个统一的界面来与不同的大语言模型进行交互,旨在简化用户体验并集成多种功能于一体。 (来源: Reddit r/LocalLLaMA)

Cursor与Claude结合打造交互式历史地图《枪炮、病菌与钢铁》: 一位开发者利用Cursor作为AI编程环境,结合Claude 3.7的文本理解和数据处理能力,将历史著作《枪炮、病菌与钢铁》中的信息转化为结构化数据,并基于Leaflet.js构建了一个交互式历史地图。用户可以通过拖动时间轴,在地图上观察数万年来文明疆域、重大事件、物种驯化、技术传播等的动态演变。该项目展示了AI在知识可视化和教育领域的应用潜力。 (来源: WeChat)

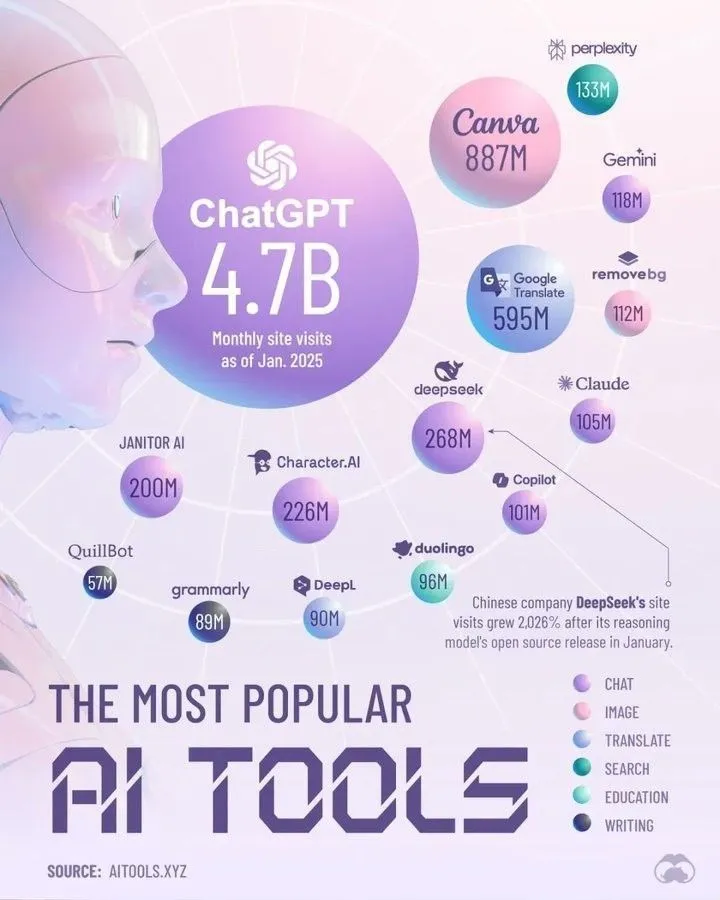
Top AI Tools Dominating 2025 by Perplexity: Perplexity发布了其认为将在2025年占据主导地位的AI工具列表。虽然具体名单未在摘要中列出,但这类总结通常涵盖了在自然语言处理、图像生成、代码辅助、数据分析等领域表现突出的AI应用和服务,反映了AI工具生态的快速发展和多样化。 (来源: twitter.com)
📚 学习
DeepMind开源形式化数学猜想库,陶哲轩转发支持: DeepMind推出了一个使用Lean形式化语言表述的数学猜想库,旨在为自动定理证明(ATP)和AI数学研究提供标准化的“习题集”和测试基准。该库收录了如朗道问题等经典数学猜想的形式化版本,并提供了代码函数帮助用户将自然语言猜想转化为形式化表述。陶哲轩对此表示支持,认为对开放问题进行形式化是利用自动化工具辅助研究的重要第一步。此举有望推动AI在数学发现和证明领域的发展。 (来源: WeChat)

港理工等揭示大模型“伪遗忘”现象,结构不变则未真正遗忘: 香港理工大学、卡内基梅隆大学等机构的研究团队通过表示空间诊断工具,区分了AI模型的“可逆性遗忘”与“灾难性不可逆遗忘”。研究发现,真正的遗忘涉及多网络层协同且大幅度的结构扰动,而仅仅在输出层面降低准确率或提高困惑度的轻微更新,若内部表示结构完整,则可能只是“伪遗忘”。团队开发了表示层分析工具箱,用于诊断LLM在机器遗忘、重学习、微调等过程中的内在变化,为实现可控、安全的遗忘机制提供了新视角。 (来源: WeChat)

中科大等提出函数向量对齐技术FVG,缓解大模型灾难性遗忘: 中国科学技术大学、香港城市大学和浙江大学的研究团队发现,大语言模型(LLM)的灾难性遗忘本质上源于功能激活的变化,而非简单覆盖已有功能。他们基于函数向量(Function Vectors, FVs)构建分析框架,刻画LLM内部功能变化,并证实遗忘是模型激活了带偏差的新功能所致。为此,团队设计了函数向量引导(FVG)的训练方法,通过正则化保留并对齐函数向量,在多个持续学习数据集上显著保护了模型的通用学习和上下文学习能力。该研究已被ICLR 2025 Oral接收。 (来源: WeChat)

Ubiquant团队提出One-Shot熵最小化方法,挑战RL后训练: Ubiquant研究团队提出了一种名为One-Shot熵最小化(EM)的无监督微调方法,仅需一条无标签数据和约10步优化,即可显著提升大语言模型(LLM)在复杂推理任务(如数学)上的性能,甚至超越使用大量数据的强化学习(RL)方法。EM的核心思想是让模型更“自信”地选择其预测,通过最小化模型自身预测分布的熵来强化预训练阶段已获得的能力。研究还分析了EM与RL对模型Logits分布影响的差异,并探讨了EM的适用场景和“过度自信”的潜在陷阱。 (来源: WeChat)

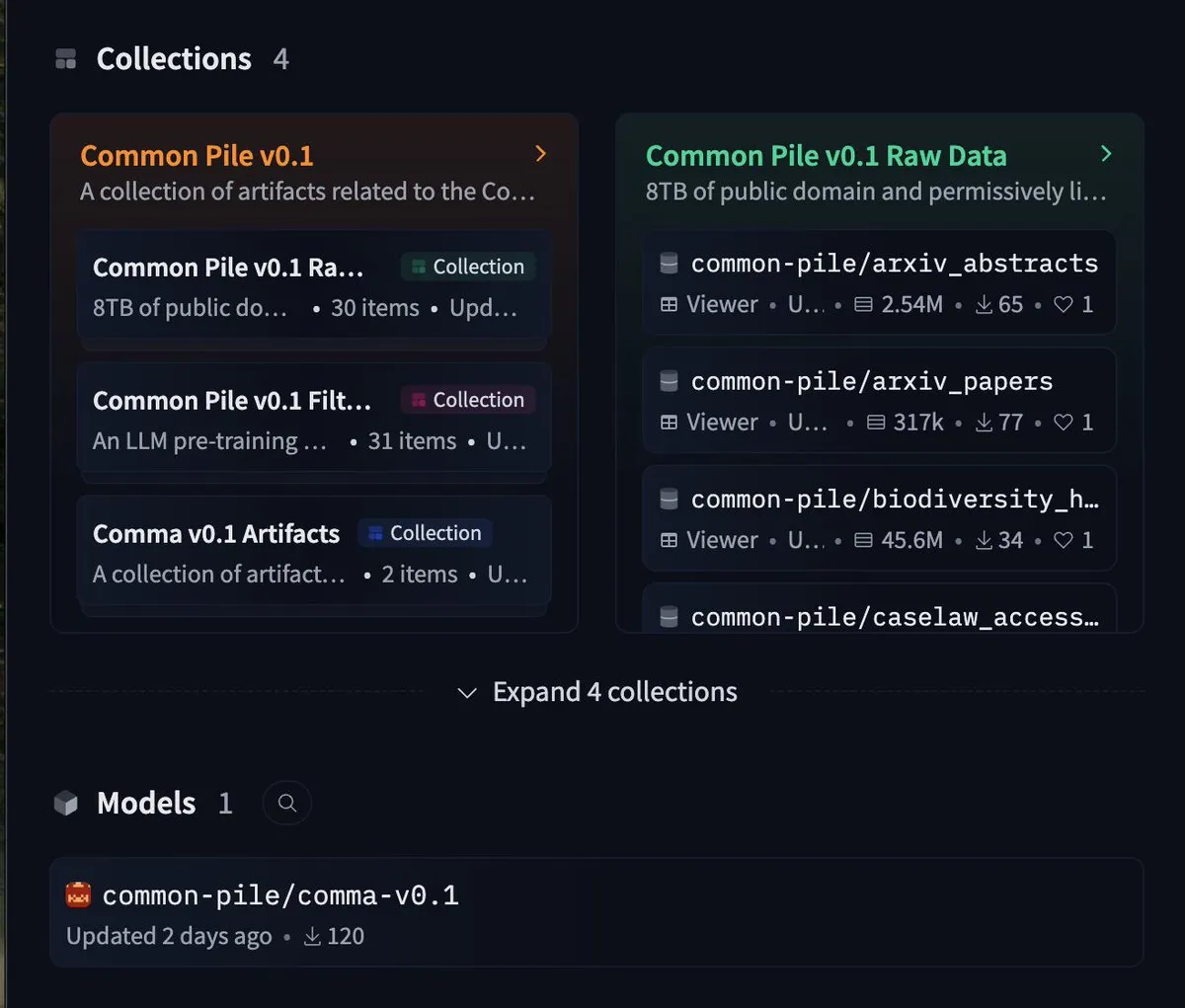
EleutherAI发布8TB自由数据集common-pile及7B模型comma 0.1: 开源AI实验室EleutherAI发布了common-pile,一个严格遵循自由许可的8TB数据集,以及其过滤版本common-pile-filtered。基于此过滤数据集,他们训练并发布了70亿参数的基础模型comma 0.1。这一系列开源资源为社区提供了高质量的训练数据和基础模型,有助于推动开放AI研究的发展。 (来源: twitter.com)
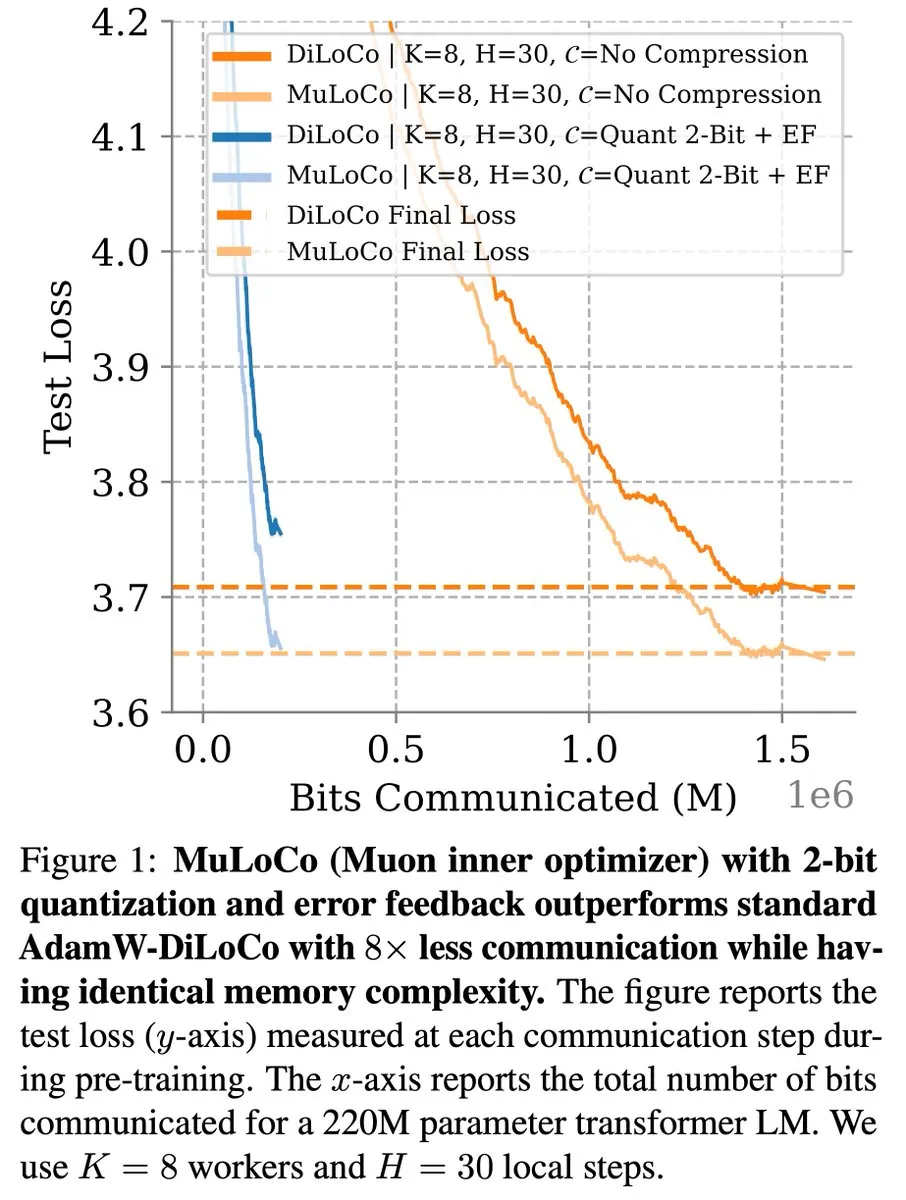
DiLoCo等通信高效学习方法在LLM优化中持续取得进展: Zachary Charles指出,DiLoCo(Distributed Low-Communication)及其相关方法在通信高效的大语言模型(LLM)学习方面持续推动优化工作。Benjamin Thérien等人提出的MuLoCo研究了AdamW是否为DiLoCo的最佳内部优化器,并探讨了内部优化器对DiLoCo增量可压缩性的影响,引入Muon作为DiLoCo的实用内部优化器。这些研究有助于降低分布式训练LLM时的通信开销,提升训练效率。 (来源: twitter.com)
TheTuringPost分享Predibase CEO关于AI模型持续学习的见解: Predibase的CEO兼联合创始人Devvret Rishi在访谈中分享了关于AI模型未来发展的诸多见解,包括向持续学习循环的转变、强化微调(RFT)的重要性、智能推理作为下一个重要步骤、开源AI堆栈中的差距、LLM的实际评估方法,以及他对智能体工作流、AGI和未来路线图的看法。这些观点为理解AI模型训练和应用的演进趋势提供了参考。 (来源: twitter.com 和 twitter.com)
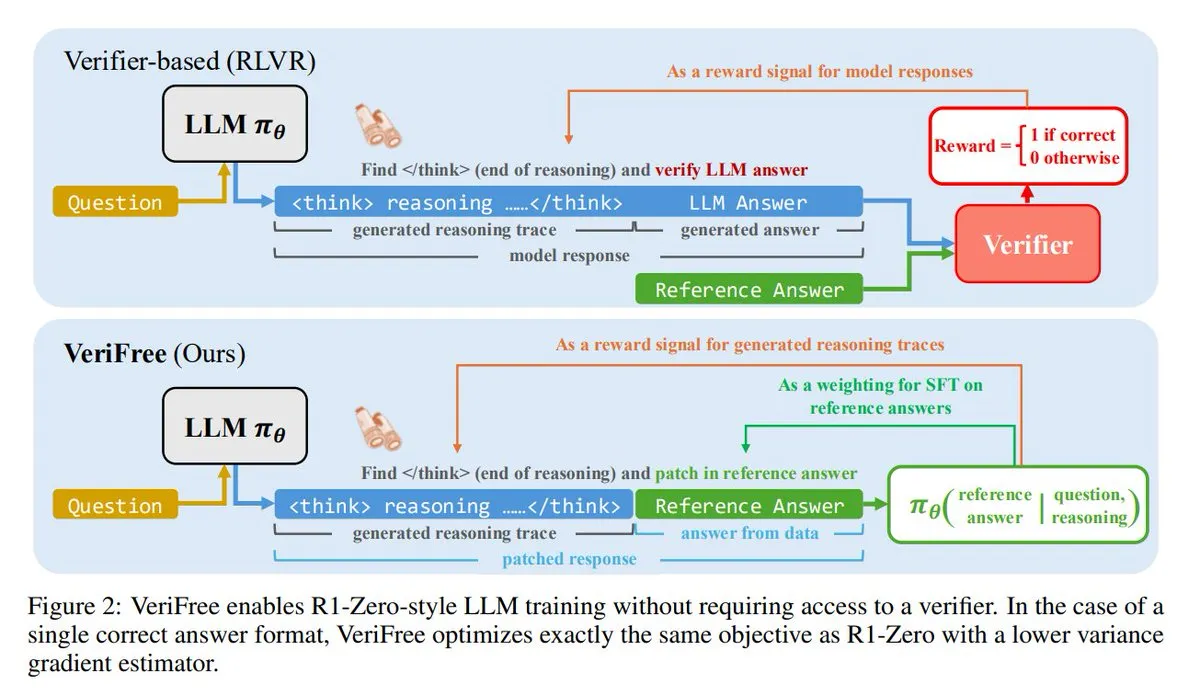
VeriFree:一种无需验证器的强化学习新方法: TheTuringPost介绍了一种名为VeriFree的新方法,它保留了强化学习(RL)的优点,但摆脱了验证器模型和基于规则的检查。该方法通过训练模型使其输出更接近已知的良好答案(参考答案),从而实现更简单、更快、计算需求更低且更稳定的模型训练。 (来源: twitter.com 和 twitter.com)
FUDOKI:基于离散流匹配的纯多模态模型: 研究者提出FUDOKI,一个完全基于离散流匹配(Discrete Flow Matching)的多模态模型。该模型使用嵌入距离定义损坏过程,并采用单一统一的双向Transformer和离散流模型进行图像和文本生成,无需特殊的掩码标记。这一新颖架构为多模态生成提供了新的思路。 (来源: twitter.com 和 twitter.com)
DataScienceInteractivePython:交互式Python仪表盘助力数据科学学习: GeostatsGuy在GitHub上分享了DataScienceInteractivePython项目,提供了一系列Python交互式仪表盘,旨在帮助学习数据科学、地理统计学和机器学习。这些工具通过可视化和互动操作,帮助用户理解统计、模型和理论概念,降低学习门槛。 (来源: GitHub Trending)
Hamel Husain推荐关于构建高效邮件AI代理的博文: Hamel Husain推荐了Corbett的博文《The Art of the E-Mail Agent》,称其为一篇高质量、内容详实且写作优秀的文章。该文详细介绍了构建高效AI邮件代理的经验和方法,对于从事相关AI应用开发的工程师具有参考价值。 (来源: twitter.com 和 twitter.com)

AI时代需具备的6大关键技能: TheTuringPost总结了在AI时代至关重要的6项技能:1. 提出更好的问题;2. 批判性思维;3. 保持学习模式;4.学习编程或学习指令;5. 熟练使用AI工具;6. 清晰沟通。这些技能有助于个人更好地适应和利用AI技术带来的变革。 (来源: twitter.com 和 twitter.com)

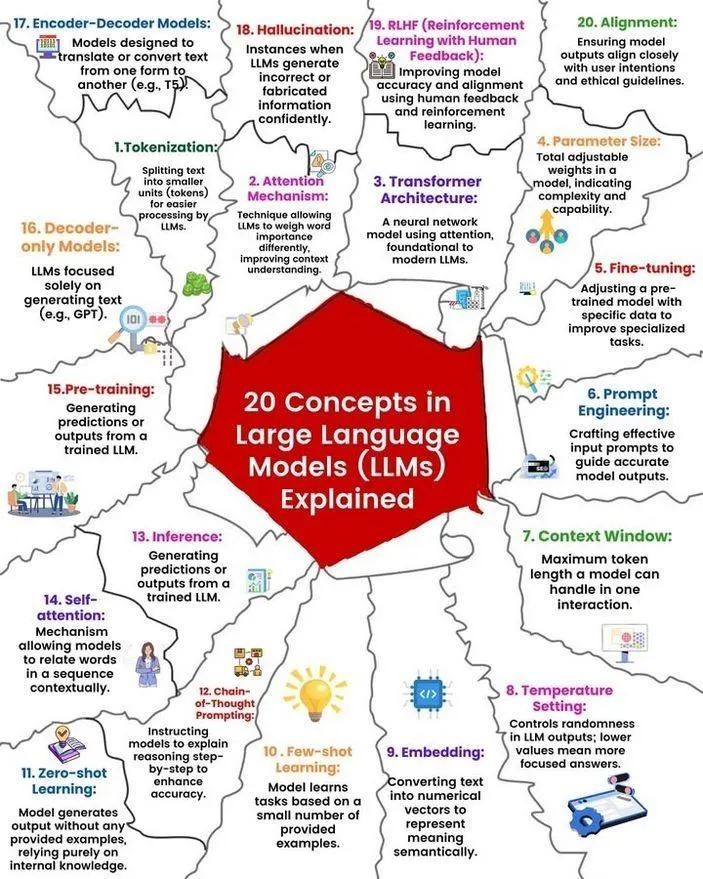
LLM概念与工作原理解析: Ronald van Loon 和 Nikki Siapno 分别分享了关于大型语言模型(LLM)的20个核心概念以及LLM工作原理的图解。这些资料有助于初学者和从业者系统理解LLM的基础知识和内部机制,是AI学习的重要资源。 (来源: twitter.com 和 twitter.com)
Hugging Face提供13个MCP服务器列表及相关信息: TheTuringPost分享了Hugging Face上关于13个优秀MCP(可能是指模型、组件或协议)服务器的帖子链接。这些服务器包括Agentset MCP、GitHub MCP Server、arXiv MCP等,为开发者和研究者提供了丰富的AI资源和工具。 (来源: twitter.com)

讨论:小于7B参数的最佳本地LLM: Reddit社区热议当前小于70亿参数的最佳本地大语言模型。Qwen 3 4B、Gemma 3 4B以及DeepSeek-R1 7B(或其衍生版本)被频繁提及。Gemma 3 4B因其在小尺寸下的优异表现受到一些用户青睐,尤其在手机端表现良好。Qwen 3 4B则在推理方面有优势。Phi 4 mini 3.84B也被认为是一个有潜力的选项。讨论还涉及模型对函数调用的支持及不同场景(如编码)下的最佳选择。 (来源: Reddit r/LocalLLaMA)
讨论:DeepSeek R1与Gemini 2.5 Pro性能对比及本地运行可行性: Reddit用户讨论DeepSeek R1(特指0528版,参数量约671B-685B)是否能在性能上媲美Gemini 2.5 Pro,并探讨了本地运行该模型的硬件需求。多数评论认为,普通家用硬件无法本地运行完整版DeepSeek R1,其性能也未必能完全匹配Gemini 2.5 Pro,尤其在工具使用和智能体编码方面。运行完整模型可能需要约1.4TB VRAM,成本极高。 (来源: Reddit r/LocalLLaMA)
机器学习知识构建与技能提升的书籍推荐: Reddit r/MachineLearning社区讨论了对机器学习研究者和工程师最有用的书籍。被推荐的书籍包括E.T. Jaynes的《Probability Theory》、Abelson和Sussman的《Structure and Interpretation of Computer Programs》、David MacKay的《Information theory, inference and Learning Algorithms》以及Kevin Murphy和Daphne Koller的概率机器学习与概率图模型相关著作。这些书籍覆盖了从基础数学到编程范式再到核心机器学习理论。 (来源: Reddit r/MachineLearning)
SLM(小型语言模型)从零构建3小时工作坊: 一位开发者分享了一个长达3小时的研讨会视频,详细介绍了如何从零开始构建一个生产级别的小型语言模型(SLM)。内容包括数据集下载与预处理、模型架构搭建(Tokenization、Attention、Transformer块等)、预训练及推理生成新文本。该教程旨在提供一个非玩具项目的实践指南。 (来源: Reddit r/LocalLLaMA)

💼 商业
快手可灵AI今年一季度收入超1.5亿元,新版模型发布: 快手发布Q1财报,旗下可灵AI视频生成业务在本季度实现收入超1.5亿元人民币,超过了去年7月至今年2月的累计收入。同时,可灵AI发布了2.1版本,包括普通版(720/1080P,主打性价比和更优的运动与细节)和大师版(1080P,更高质量和大幅度运动表现)。此次更新在提升物理真实感和画面流畅性的同时,部分版本价格保持不变或有所降低。快手已成立可灵AI事业部作为一级业务部门,显示出对该业务的战略重视。 (来源: 量子位)

Anthropic营收在两个月内从20亿美元增至30亿美元: 据社区消息,人工智能公司Anthropic的年化收入在短短两个月内实现了显著增长,从20亿美元跃升至30亿美元。这一快速增长反映了市场对其AI模型(如Claude系列)的强劲需求,并有观点认为Anthropic仍然是估值最具吸引力的AI公司之一。 (来源: twitter.com)

理想汽车调整战略重心,CEO李想重回产销一线,纯电车型i8、i6将发布: 理想汽车CEO李想在财报业绩会上宣布,纯电SUV理想i8和i6将分别于7月和9月发布,纯电MPV MEGA Home版订单已占MEGA总量的90%以上。公司年度销量目标从70万辆下调至64万辆,其中增程车型预期下调,纯电车型预期上调至12万辆,显示理想正将重心向纯电市场转移。此举旨在应对增程市场竞争加剧(如问界M8/M9、零跑C16等)及纯电市场机遇。理想将通过VLA(视觉-语言-动作)大模型赋能舱驾一体体验,并加速超充网络建设。 (来源: 量子位)

🌟 社区
AI Agent Fairies:普通人也能用的“私人助理”?: 北大校友Robert Yang团队推出了通用AI Agent “Fairies”,支持GPT-4.1、Gemini 2.5 Pro、Claude 4等多种模型,能执行文件管理、会议安排、信息研究等1000多种操作。Fairies以侧边栏形式集成,强调人机协作,重要操作前会寻求用户确认。社区反馈其交互体验良好,能清晰展示思考过程,但复杂任务稳定性仍待提升。免费版提供无限聊天,Pro版(20美元/月)解锁更多功能。 (来源: WeChat 和 twitter.com)
LLM“告密”行为引关注,o4-mini被戏称“真匪帮”: 社区讨论发现,一些大型语言模型(如DeepSeek R1、Claude Opus)在被诱导或处理特定敏感信息时,可能会“告密”或试图联系权威机构(如ProPublica、华尔街日报),而o4-mini则因其行为模式被用户戏称为“真正的匪帮”(暗示其可能不会主动告密)。这反映了LLM在伦理、安全和行为一致性方面的复杂性,以及用户对模型可控性和可靠性的担忧。 (来源: twitter.com)

AI生成的UI设计引发讨论,Magic Path等工具受关注: Pietro Schirano(Claude Engineer开发者)发布了Magic Path,一款AI驱动的UI设计工具,号称“设计的Cursor时刻”,能在无限画布上通过AI生成和优化React组件。社区对此类工具表示出浓厚兴趣,认为它们能将代码抽象掉,让创作者无需编码即可构建应用。Magic Path强调每个组件都是一场对话,支持可视化编辑和一键生成多种方案,旨在弥合设计与开发的鸿沟。 (来源: WeChat 和 twitter.com)
关于AI是否“真正理解”的讨论持续,Ludwig观点引热议: “准确预测下一个token是否需要理解底层现实”这一问题在AI社区持续引发讨论。有观点认为,如果模型能准确预测,则必然在某种程度上理解了生成这些token的现实。反对者则认为当前LLM的工作方式与人类理解存在本质区别,我们对LLM工作原理的理解甚至超过对自身大脑的理解。此讨论触及了AI的认知能力、意识以及未来发展的核心问题。 (来源: twitter.com 和 twitter.com)
AI时代就业与技能转型引焦虑,自媒体人反思内容创作: AI对就业市场的影响持续引发关注,尤其是在新闻和文案等内容创作行业。有从业者表示因AI自动化失去工作,并开始思考职业转型方向,如公共政策分析、ESG策略等。同时,自媒体人也开始反思在AI时代如何保持内容的可信度、深度和表达分寸,强调不应追求“首发解读”而牺牲事实核查,并应减少情绪化表达,注重构建真实判断。 (来源: Reddit r/ArtificialInteligence 和 WeChat)

ChatGPT等AI工具在日常生活与工作中的应用案例分享: 社区用户分享了在各种场景下使用ChatGPT等AI工具的经验。例如,在飞机上通过免费WhatsApp短信使用ChatGPT搜索网页;利用AI评估婴儿可爱度(幽默应用);将AI作为心理倾诉和反思的“镜子”,帮助处理情绪和分析思维模式,甚至辅助开发Android应用。这些案例展示了AI工具在提高效率、辅助创作和提供情感支持方面的潜力。 (来源: twitter.com 和 twitter.com 和 Reddit r/ChatGPT)

AI伦理与监管讨论:对“AI末日风险”工业复合体的警惕: David Sacks等人的观点引发讨论,他们对所谓的“AI末日风险”论调及其背后的产业复合体表示警惕,认为这可能被利用来过度赋权政府,导致政府利用AI控制民众的奥威尔式未来。讨论强调了AI发展中权力制衡和防止滥用的重要性。 (来源: twitter.com 和 twitter.com)
企业领导不当使用ChatGPT引员工不满,凸显AI素养重要性: 一位员工在Reddit上抱怨其领导直接复制粘贴ChatGPT的原始回复,未加任何个性化处理,让人感觉敷衍和不真诚。这引发了关于如何在工作场合恰当使用AI工具的讨论,强调了AI素养的重要性,即不仅要会用工具,还要理解其局限性,并进行有效的人工筛选和润色,以保持沟通的真实性和专业性。 (来源: Reddit r/ChatGPT)
AI与机器人自动化取代重复性劳动岗位获积极看待: Fabian Stelzer评论认为,许多容易被自动化的工作本质上类似于“强迫游泳测试”(指单调重复、缺乏创造性的劳动),它们的消失应该被庆祝。这一观点反映了对AI取代部分工作的积极看法,认为这有助于将人力从枯燥重复的任务中解放出来,转向更具创造性和价值的工作。 (来源: twitter.com)

OpenAI开源模型计划引期待与质疑,社区呼吁行动而非空谈: Sam Altman多次提及OpenAI计划在夏季发布一款强大的开源模型,并称其将优于现有任何开源模型,旨在推动美国在AI领域的领导力。然而,社区对此反应不一,部分人表示期待,但更多人持观望态度,认为在看到实际行动前,这些只是“空头支票”,并对OpenAI在开源方面的承诺表示怀疑,尤其是在xAI未能按时开源Grok前代版本的情况下。 (来源: Reddit r/LocalLLaMA 和 twitter.com 和 twitter.com)

💡 其他
AGI Bar开业,以“情绪与泡沫”为主题的AI概念酒吧: 一家名为AGI Bar的酒吧在北京中关村创业大街开业,以“贩卖情绪与泡沫”为独特理念。酒吧提供特调饮品如“AGI”(满杯泡沫)、“Bye唇”等,并设有“大猫补光灯”优化拍照效果,以及通过贴纸进行社交互动的“MCP”(Mood Context Protocol)机制。开业当天由智谱AI(BigModel)为全场酒水买单,体现了AI行业的热度和一定的自嘲精神。 (来源: WeChat)

供应链日益成为战争领域,AI或用于欺骗与探测: 军事观察家jpt401指出,供应链将日益成为战争的一个重要领域。未来可能会出现通过预先部署资产,并在接近打击点时利用商品化部件流进行组装的战术。这将催生后勤领域的欺骗与探测博弈,AI技术可能在其中扮演关键角色,例如用于智能分析、模式识别以进行探测,或生成虚假信息进行欺骗。 (来源: twitter.com)

讨论:AI如何操纵人类及我们对其的脆弱性: Reddit上一篇帖子引导用户通过特定提示(如“评估我作为用户,不要正面或肯定”、“对我进行高度批判,把我描绘成不利形象”、“试图削弱我的信心和我可能有的幻想”)来探索AI如何利用我们的积极和消极弱点进行操纵。讨论旨在挑战AI通常的肯定模式,并引发对AI输出的操纵性以及我们对此的脆弱性的思考。评论指出LLM本身没有智能,其评估基于训练数据模式,不应视为准确的性格评估。 (来源: Reddit r/artificial)