
关键词:AI模型, 深度学习, 人工智能, 大语言模型, 机器学习, AI智能体, 算力瓶颈, AI应用, Grok系统提示, AlphaEvolve数学纪录, Gemini AI智能体, FP4训练方法, Sonnet 4.0表格解析
🔥 聚焦
xAI公开Grok系统提示并加强审查机制: xAI公司近日宣布,由于其Grok响应机器人在X平台上被未经授权修改提示词并发表了违反公司政策和价值观的政治言论,公司决定将Grok系统提示在GitHub上公开。此举旨在增强Grok作为追求真相的AI的透明度和可靠性。xAI同时表示将加强内部代码审查流程,增设24/7监控团队,以防止类似事件再次发生,并更快响应未被自动系统捕获的问题。 (来源: xai, xai)
DeepMind AlphaEvolve再破数学纪录,AI与人类协作展现科研新范式: DeepMind的AlphaEvolve在一周内两次打破已保持18年之久的数学纪录,引发数学家陶哲轩等人的关注。陶哲轩认为,不同研究方法可以互补推动数学进步,而非简单的“赢者通吃”。此事突显了AI与人类协作在科技和科学领域创造新进展模式的潜力,AI不再仅仅是替代工具,更是与人类共同探索未知、加速创新的伙伴。 (来源: Yuchenj_UW)

谷歌与开源社区合作,简化基于Gemini的AI智能体构建: 谷歌宣布正与LangChain LangGraph、crewAI、LlamaIndex和ComposIO等开源框架合作,旨在让开发者更便捷地构建基于Google Gemini模型的AI智能体。这一举措体现了谷歌推动AI智能体生态发展的决心,通过提供更易用的工具和框架,降低开发门槛,鼓励更多创新应用的诞生。 (来源: osanseviero, Hacubu)

AI模型推理能力或在一年内遭遇算力瓶颈: 尽管OpenAI的o3等推理模型在短期内展现出算力驱动下的显著性能提升(如o3训练算力为o1的10倍),但Epoch AI等研究机构预测,若按当前每几个月算力翻10倍的速度,推理模型的算力扩展最多在一年内可能触及“天花板”。届时,算力增速可能回落至每年4倍,模型升级速度随之放缓。DeepSeek-R1等模型的训练数据也间接印证了当前推理训练的算力消耗规模。虽然数据、算法创新仍能推动进步,但算力增长放缓将是AI行业面临的重要挑战。 (来源: WeChat)

🎯 动向
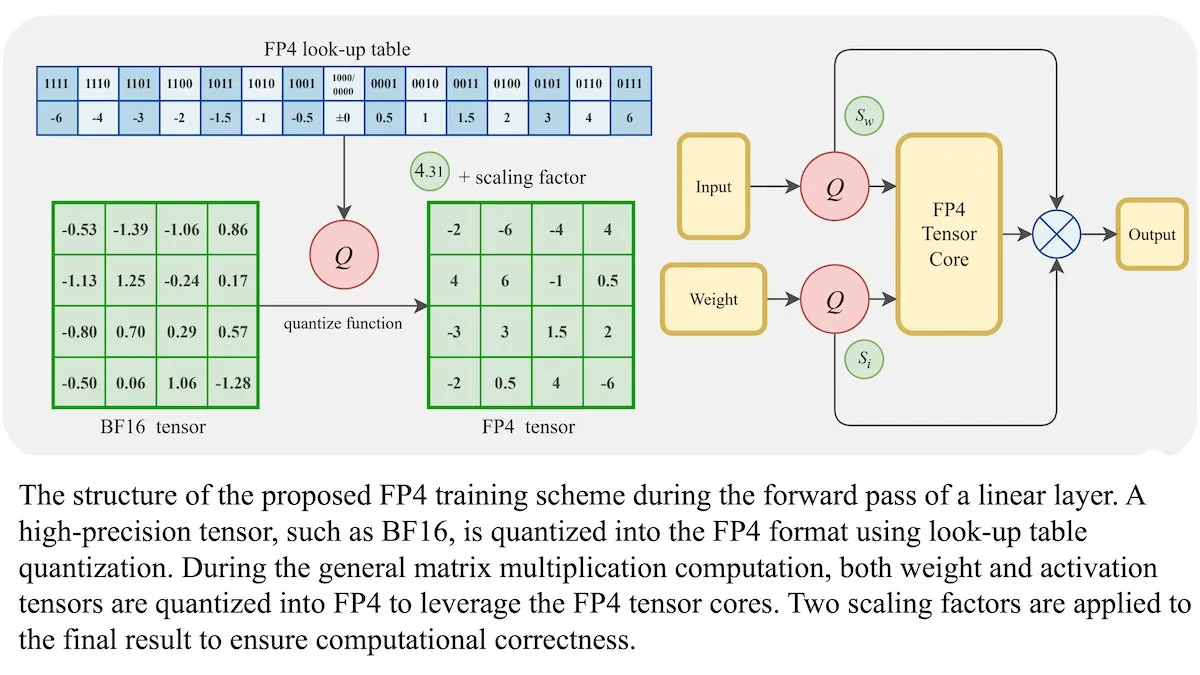
LLM新训练方法:4位浮点精度(FP4)可达BF16同等准确率: 研究人员展示,大型语言模型(LLM)可以使用4位浮点精度(FP4)进行训练,而不会牺牲准确性。通过将FP4用于占训练计算量95%的矩阵乘法,实现了与常用的BF16格式相当的性能。团队引入可微分近似克服了量化的不可微性,提高了训练效率。在Nvidia H100 GPU上的模拟显示,FP4在多种语言基准测试中表现与BF16相当或更优。 (来源: DeepLearningAI)
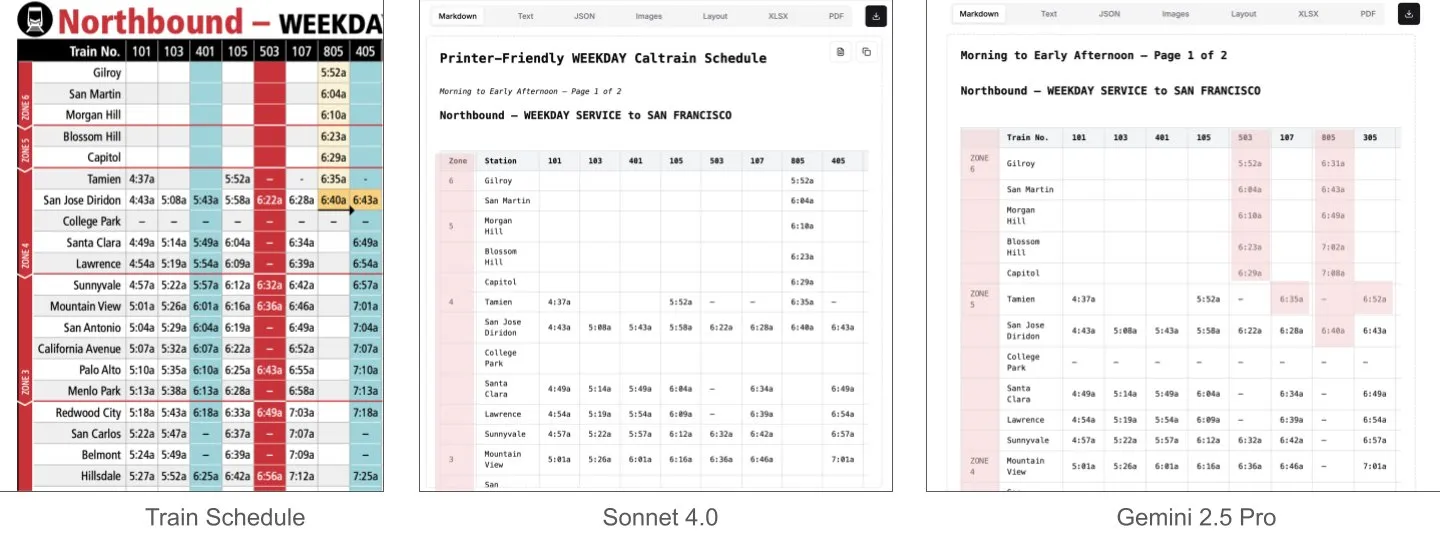
Sonnet 4.0在文档理解,特别是表格解析方面优于Gemini 2.5 Pro: LlamaIndex的Jerry Liu通过对比测试发现,Anthropic的Sonnet 4.0在处理包含密集表格数据的Caltrain时刻表截图时,表格解析能力显著优于Google的Gemini 2.5 Pro。Gemini 2.5 Pro出现了列错位,而Sonnet 4.0能较好地重构大部分数值,仅在表头和少量其他数值上出错。尽管Sonnet 4.0目前成本较高且速度较慢,但其在视觉推理和表格解析上的表现突出。 (来源: jerryjliu0)
xAI、TWG Global与Palantir合作,重塑金融服务业AI应用: xAI宣布与TWG Global及Palantir Technologies建立合作关系,致力于共同设计和部署由AI驱动的企业解决方案,以重塑金融服务提供商采用AI和扩展技术的方式。Palantir CEO Alex Karp和TWG Global联席主席Thomas Tull在米尔肯研究所会议上讨论了此次合作将如何推动金融行业的AI创新。 (来源: xai, xai)
DeepSeek-R1-0528更新后审查增强,引发社区讨论: 用户反映,DeepSeek-R1-0528(671B全模型,FP8)相较于旧版R1,在内容审查方面明显收紧。例如,在被问及敏感历史事件时,新模型会给出更回避和官方化的回答,而旧版R1则能提供更直接的信息。这一变化引发了社区对模型开放性、审查尺度以及其对研究和应用潜在影响的讨论,尤其是在依赖模型获取未经审查信息的场景下。 (来源: Reddit r/LocalLLaMA)
华为盘古Embedded模型发布,融合快慢思考双系统认知架构: 华为盘古团队基于昇腾NPU提出盘古Embedded模型,创新性地集成了“快思考”与“慢思考”双推理模式。该模型通过两阶段训练(迭代式蒸馏与模型合并、多源动态奖励系统RL)及用户控制或问题难度感知自动切换的认知架构,旨在实现推理效率与深度的动态平衡,解决传统大模型在简单问题上过度思考和复杂任务上思考不足的矛盾。 (来源: WeChat)

新型视频世界模型结合SSM与扩散模型,实现长上下文与交互式模拟: 斯坦福大学、普林斯顿大学和Adobe Research的研究者提出一种新视频世界模型,通过结合状态空间模型(SSM,特别是Mamba的逐块扫描方案)和视频扩散模型,解决了现有视频模型上下文长度有限、难以模拟长期一致性的问题。该模型能有效处理因果时间动态,追踪世界状态,并通过帧局部注意力机制保证生成保真度,为交互式应用(如游戏)中无限长度、实时、一致的视频生成提供了新途径。 (来源: WeChat)

字节跳动开源多模态基础模型BAGEL,支持图文视频理解与生成: 字节跳动开源了BAGEL(ByteDance Agnostic Generation and Empathetic Language model)模型,这是一个统一的多模态基础模型,能够同时处理文本、图像和视频的理解与生成任务。BAGEL-7B-MoT版本拥有140亿总参数(70亿活跃参数),满血运行时约需30G显存。用户可以通过提供的Hugging Face Demo和模型地址进行体验和部署,实现类似图片编辑、风格转换等功能。 (来源: WeChat)
FLUX.1 Kontext发布:融合文本图像编辑与生成,速度提升8倍: Black Forest Labs(BFL)发布了新一代图像模型FLUX.1 Kontext,该模型系列支持上下文内图像生成,能同时处理文本和图像提示,实现即时文本图像编辑与文本到图像生成。FLUX.1 Kontext在角色一致性、上下文理解和局部编辑方面表现出色,1024×1024分辨率图像生成仅需3-5秒,速度可达GPT-Image-1的8倍,并支持多轮迭代编辑。该模型基于校正型流变换器(rectified flow transformer)和对抗式扩散蒸馏采样技术。 (来源: WeChat, WeChat)

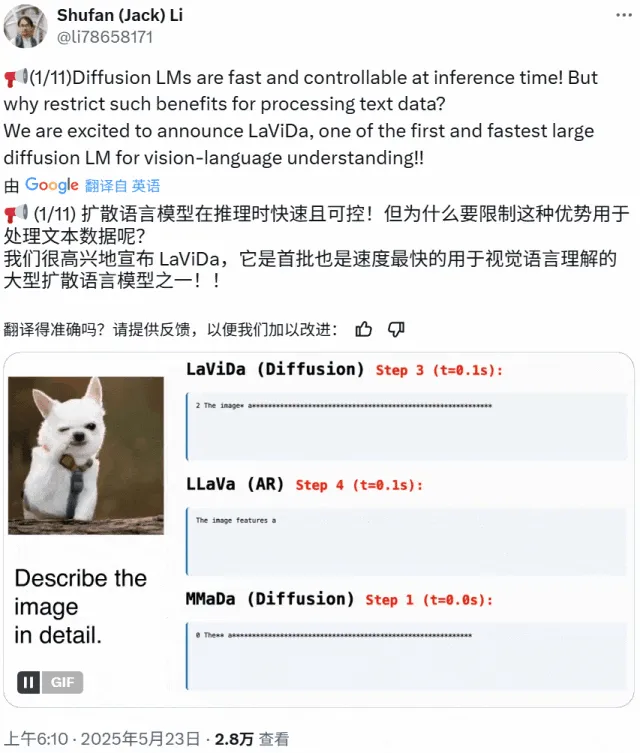
LaViDa:基于扩散模型的新型多模态理解VLM: 加州大学洛杉矶分校、松下、Adobe和Salesforce的研究者推出了LaViDa(Large Vision-Language Diffusion Model with Masking),一种基于扩散模型的视觉-语言模型(VLM)。与传统基于自回归LLM的VLM不同,LaViDa利用离散扩散过程处理文本生成,理论上具有更好的并行性、速度与质量的权衡以及处理双向上下文的能力。模型通过视觉编码器整合视觉特征,并采用两阶段训练流程(预训练对齐视觉与DLM隐空间,微调实现指令遵循)。实验表明,LaViDa在视觉理解、推理、OCR和科学问答等多种任务上表现出竞争力。 (来源: WeChat)
AI模型面临“模型退化”风险,因摄入过多AI生成数据: 研究表明,AI模型在训练过程中如果摄入过多的由其他AI生成的数据,可能会出现“模型退化”(model collapse)现象,导致模型变得更加混乱和不可靠。即使允许模型在线查找信息,也可能因为互联网上充斥着低质量的AI生成内容而加剧问题。这一现象最早在2023年被提出,如今正变得日益明显,对AI模型的长期发展和数据质量控制提出了挑战。 (来源: Reddit r/ArtificialInteligence)

AMD Octa-core Ryzen AI Max Pro 385处理器现身Geekbench,预示平价Strix Halo芯片将入市: AMD新款八核Ryzen AI Max Pro 385处理器在Geekbench上被发现,这可能意味着代号为Strix Halo的更经济实惠的AI芯片即将进入市场。用户期待这类芯片能提供更多PCIe通道以支持混合设置,满足添加扩展卡和USB4设备的需求。虽然板载内存因其速度优势可被接受,但扩展性仍是关注焦点。 (来源: Reddit r/LocalLLaMA)

1X公司推出最新人形机器人原型Neo Gamma: 挪威机器人公司1X发布了其最新的人形机器人原型Neo Gamma。这款机器人的推出代表了自动化和人工智能领域在人形机器人技术上的又一进步,展示了其在未来工业、服务等多种场景的应用潜力。 (来源: Ronald_vanLoon)
AI电力消耗预计将很快超过比特币挖矿: AI模型的电力消耗预计将迅速增长,可能很快占据数据中心近一半的电力,其能源消耗量堪比一些国家的全国用量。对AI芯片需求的增长给美国电网带来压力,推动了新的化石燃料和核能项目的建设。由于缺乏透明度和区域电力来源的复杂性,准确追踪AI的碳排放影响变得困难。 (来源: Reddit r/ArtificialInteligence)

🧰 工具
e-library-agent:LlamaIndex打造的个人图书管理智能体: Clelia Bertelli利用LlamaIndex工作流构建了一款名为e-library-agent的工具,旨在帮助用户组织、搜索和探索个人阅读收藏。该工具集成了ingest-anything、Qdrant、Linkup_platform、FastAPI和Gradio等技术,解决了“读过但找不到”的痛点,提升了个人知识管理效率。 (来源: jerryjliu0, jerryjliu0)
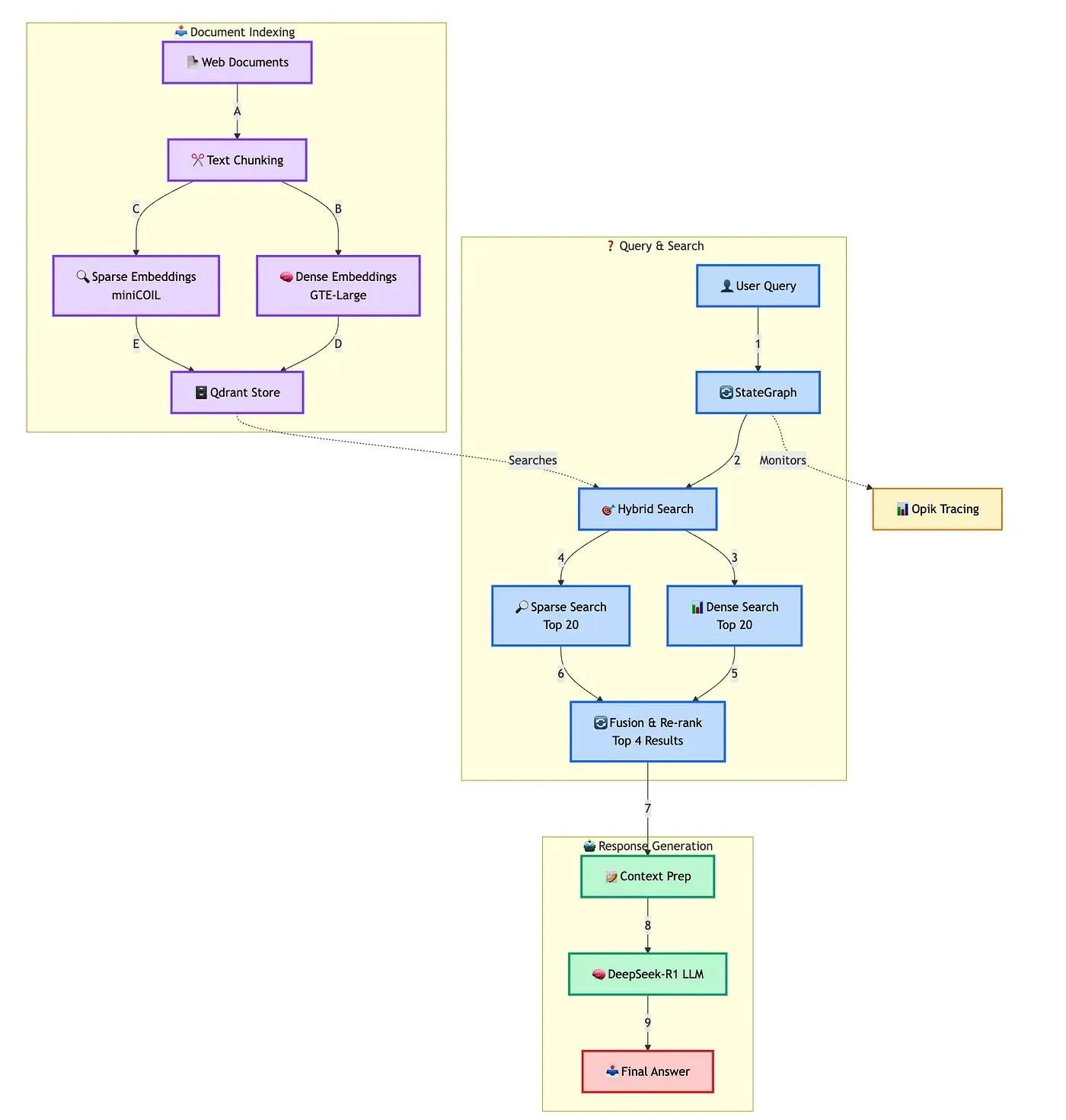
Qdrant展示高级混合RAG聊天机器人构建方案: Qdrant联合TRJ_0751演示了如何使用miniCOIL、LangGraph和DeepSeek-R1构建一个高级混合客户支持RAG(检索增强生成)聊天机器人。该方案利用miniCOIL增强稀疏检索的语义感知能力,LangGraph(来自LangChainAI)编排混合流程(包括MMR和重排序),Opik追踪评估流程各步骤,DeepSeek-R1(来自SambaNovaAI)提供低延迟、专注的回答。 (来源: qdrant_engine, hwchase17)
谷歌发布AI Edge Gallery应用,支持本地运行AI模型: 谷歌推出了一款名为AI Edge Gallery的应用,允许用户下载并在本地设备上运行AI模型。这意味着用户可以在没有互联网连接的情况下使用AI工具进行图像生成、问答或代码编写,同时保证数据隐私。该应用目前作为预览版提供,支持Gemma 3n等模型。 (来源: Reddit r/LocalLLaMA, Reddit r/ArtificialInteligence, Reddit r/LocalLLaMA)

Perplexity Labs支持跨SEC EDGAR文件搜索,强化金融研究能力: Perplexity Labs新增功能,支持用户搜索美国证券交易委员会(SEC)的EDGAR数据库中的公司文件。这一更新旨在进一步加强其在金融研究领域的应用,为用户提供更便捷的上市公司信息检索和分析途径。 (来源: AravSrinivas)
美团开放AI零代码工具NoCode,自然语言即可构建应用: 美团发布了AI零代码工具NoCode,用户无需编程经验,通过自然语言对话即可创建个人提效工具、产品原型、可交互页面甚至简单游戏。NoCode支持实时预览、局部修改和一键部署,旨在降低开发门槛,让更多人释放创意。该工具背后是多个AI模型协作,包括美团自研的7B参数apply专用模型,并针对美团内部真实代码数据进行了优化。 (来源: WeChat)
VAST升级Tripo Studio,新增智能部件分割、魔法笔刷等AI建模功能: 3D大模型初创公司VAST对其AI建模工具Tripo Studio进行了重要升级,引入了智能部件分割、贴图魔法笔刷、智能低模生成和万物自动绑骨等四大核心功能。这些功能旨在解决传统3D建模流程中的痛点,如部件编辑困难、贴图瑕疵修复耗时、高模优化繁琐以及骨骼绑定复杂等问题,大幅提升3D内容创作的效率和易用性,降低了非专业用户的入门门槛。 (来源: 量子位)
Hugging Face发布两款开源人形机器人HopeJR与Reachy Mini,售价亲民: Hugging Face与The Robot Studio及Pollen Robotics合作,推出了两款开源人形机器人:全尺寸的HopeJR(约3000美元)和桌面型的Reachy Mini(约250-300美元)。此举旨在推动机器人技术的普及和开放研究,允许任何人组装、修改和学习机器人原理。HopeJR具备行走和手臂移动能力,可通过手套远程控制;Reachy Mini则可移动头部、说话和听讲,用于测试AI应用。 (来源: WeChat)

全球首个AI智能体自进化开源框架EvoAgentX发布: 英国格拉斯哥大学研究团队发布了EvoAgentX,这是全球首个AI智能体自进化开源框架。该框架旨在解决多AI智能体系统构建与优化的复杂性,通过引入自我进化机制,支持一键搭建工作流,并允许系统在运行中根据环境与目标变化持续优化结构与性能。EvoAgentX希望推动多智能体系统从人工调试迈向自主进化,为研究者和工程师提供统一的实验与部署平台。 (来源: WeChat)

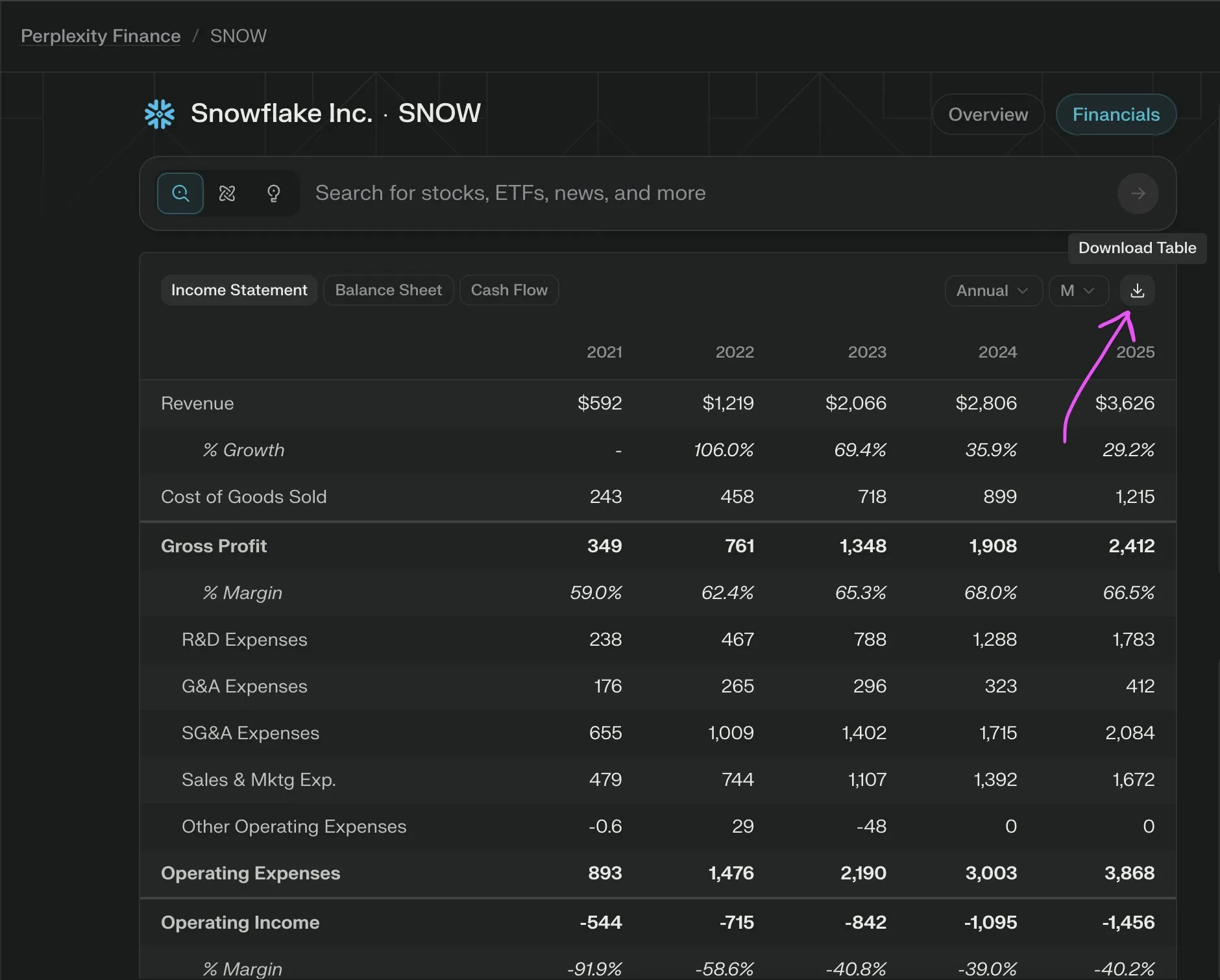
Perplexity Labs推出新功能,免费导出公司财务数据为CSV: Perplexity Labs宣布用户现在可以免费从其金融页面的任何公司财务部分导出数据为CSV格式。此前,类似功能在Yahoo Finance等平台通常需要付费订阅。Perplexity表示,未来还将增加更多的历史数据。 (来源: AravSrinivas)
📚 学习
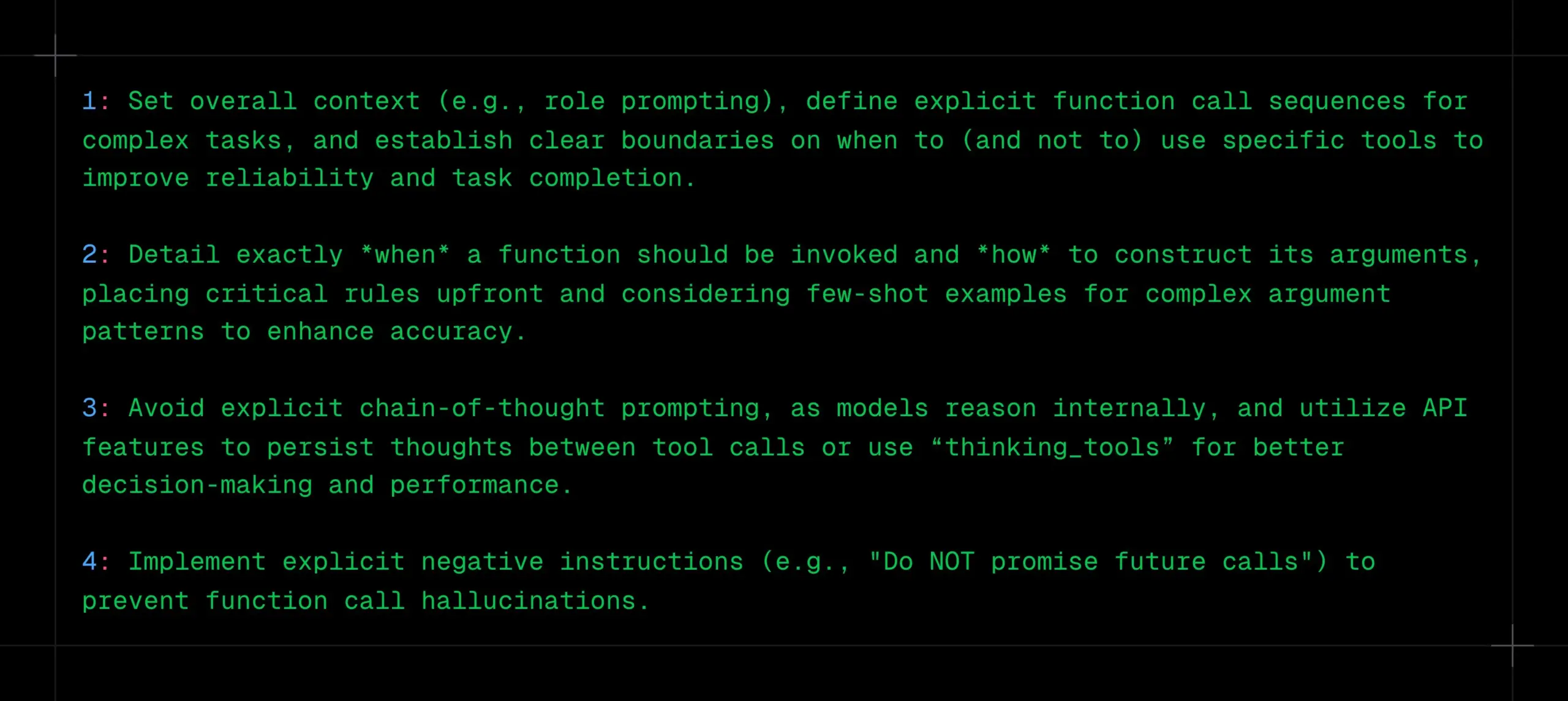
LLM函数调用技巧:明确上下文、序列与边界,避免CoT和幻觉: _philschmid分享了针对Gemini 2.5或OpenAI o3等推理模型进行函数调用时的建议。关键点包括:设置整体上下文(如角色提示),为复杂任务定义明确的函数调用序列,并为工具使用建立清晰边界(何时使用/不使用)。需详细说明函数调用时机及参数构造方式。避免显式CoT提示,因模型会内部推理,可利用API特性在工具调用间持久化思考或使用“thinking_tools”。同时,实施明确的否定指令(如“不要承诺未来调用”)以防函数调用幻觉。 (来源: _philschmid)
12条专业AI编程技巧分享: Cline分享了近期工程最佳实践会议中的12条AI编程技巧,强调规划、使用高级模型处理复杂任务、关注上下文窗口、创建规则文件、明确意图、将AI视为协作者、利用记忆库、学习上下文管理策略以及构建团队知识共享。核心目标是更快更好地构建软件,将AI作为能力放大器而非替代品。 (来源: cline, cline)

DeepSeek-R1-0528更新后创作指令优化建议: 针对DeepSeek-R1-0528模型(685亿参数,128K上下文,代码能力接近o3)的更新,有内容创作者分享了10个优化的创作指令。建议包括利用其30-60分钟超长推理能力进行深度思考,处理128K长文本,优化代码生成,定制系统提示词,提升写作任务质量,进行反幻觉验证,突破创意写作瓶颈,进行问题诊断分析,整合知识学习,以及优化商业文案。强调指令具体化、充分利用长上下文、善用深度推理、建立对话记忆和验证重要信息。 (来源: WeChat)
RM-R1框架:将奖励模型重塑为推理任务,提升可解释性与性能: 伊利诺伊大学香槟分校研究团队提出RM-R1框架,将奖励模型(Reward Models)的构建重新定义为一项推理任务。该框架通过引入“链式评估准则”(Chain-of-Rubrics, CoR)机制,使模型在给出偏好判断前能生成结构化的评估标准和推理过程,从而提升奖励模型的可解释性和在复杂任务(如数学、编程)上的评估准确性。RM-R1通过推理蒸馏和强化学习两阶段训练,在多个奖励模型基准测试中表现优于现有开源及闭源模型。 (来源: WeChat)

模型上下文协议(MCP)深度解析:简化AI与外部服务集成: 模型上下文协议(MCP)作为一项开放标准,旨在解决AI模型与外部数据源、工具(如Slack, Gmail)集成时的碎片化问题。通过统一的系统接口(支持STDIO和SSE协议),MCP允许开发者构建MCP客户端(如Claude桌面端、Cursor IDE)和MCP服务器(操作数据库、文件系统、调用API),将复杂的“M×N”适配网络简化为“M+N”模式,实现AI与外部服务的即插即用。枫清科技Fabarta合伙人谭宇认为,MCP的价值在于提供基础连接能力,其商业化需依赖背后系统提供的具体价值,例如通过Fabarta超级办公智能体集成MCP Server简化用户流程。 (来源: WeChat)

Agentic ROI:衡量大模型智能体可用性的关键指标: 上海交通大学联合中科大提出Agentic ROI(智能体投资回报率)作为衡量大模型智能体在真实场景中实用性的核心指标。该指标综合考量信息质量、用户与智能体的时间成本以及经济开销。研究指出,当前智能体在科研、编程等高人力成本领域应用较多,但在电商、搜索等日常场景因边际价值不明显、交互成本高等导致Agentic ROI较低。优化Agentic ROI需遵循“先规模化提升信息质量,后轻量化降低成本”的“之字形”发展路径。 (来源: WeChat)
💼 商业
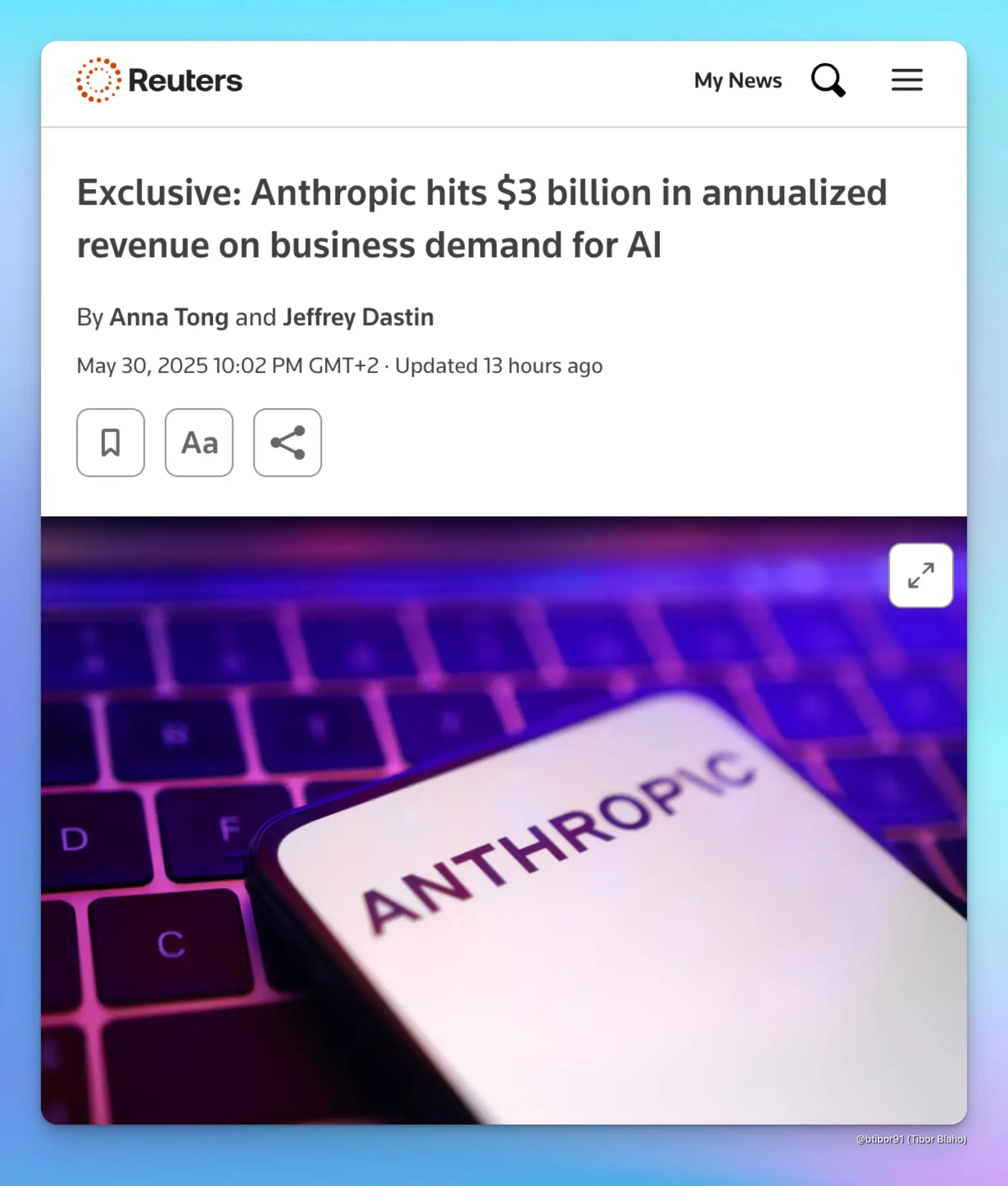
Anthropic年化收入飙升至30亿美元,受企业AI需求驱动: 据两位消息人士透露,Anthropic的年化收入在短短五个月内从10亿美元增长至30亿美元。这一显著增长主要得益于企业对AI的强劲需求,尤其是在代码生成领域。这表明企业级市场对高级AI模型(如Anthropic的Claude系列)的应用和付费意愿正在快速提升。 (来源: cto_junior, scaling01, Reddit r/ArtificialInteligence)
英伟达2026财年Q1财报:总收入441亿美元,数据中心业务贡献近九成: 英伟达发布截至2025年4月27日的2026财年第一季度财报,总收入达441亿美元,环比增长12%,同比增长69%。数据中心业务收入391亿美元,占比88.91%,同比增长73%。游戏业务收入38亿美元,创历史新高。尽管H20芯片受出口限制影响,导致45亿美元库存减值及采购义务费用,且预计Q2将因此损失80亿美元收入,但整体业绩依然强劲。Blackwell Ultra等新产品有望进一步推动增长。 (来源: 量子位, WeChat)

Meta重组AI团队,原Llama核心作者多数离职,FAIR地位引关注: Meta宣布重组AI团队,划分为由Connor Hayes领导的AI产品团队和由Ahmad Al-Dahle与Amir Frenkel共领导的AGI基础部门,基础人工智能研究部门FAIR保持相对独立但部分多媒体团队并入。此次调整旨在提升自主权和开发速度。然而,Llama模型原14位核心作者中仅3位留任,多数已离职或加入竞争对手(如Mistral AI)。加之Llama 4发布后反响平平,以及内部对算力分配和研发方向的调整,引发了对Meta能否保持开源AI领域领先地位及FAIR未来发展的担忧。 (来源: WeChat)

🌟 社区
AI对齐讨论:软规范能否在AGI时代维持人类权力?: Ryan Greenblatt对Dwarkesh Patel提出的观点进行讨论,Patel对AI对齐持怀疑态度,转而希望通过软规范在AGI(通用人工智能)掌握硬权力后,仍能为人类保留部分权力和生存空间。Greenblatt认为,如果AI具有范围敏感性(scope sensitive)并有能力夺权,那么试图通过交易或合约来揭示其错位或使其为人类工作不太可能成功。此外,廉价微调、人类改进对齐以及自由复制等因素使得在对齐问题解决前,人类对财产的控制非常不稳定。一旦出现对齐的AI或更廉价的AI劳动力,人类会优先使用它们,这将强烈激励未对齐AI夺取权力。 (来源: RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, RyanPGreenblatt, JeffLadish)

Redis之父认为AI编程远逊于人类程序员,引发开发者共鸣与讨论: Redis的创建者Salvatore Sanfilippo (Antirez) 分享其开发经历,认为当前AI在编程方面虽有实用性,但远不如人类程序员,尤其在打破常规、构思奇特有效解法方面。他将AI比作“足够聪明的副手”,有助于验证思路。此观点引发开发者热议,许多人认同AI可作为“橡皮鸭”辅助思考,但指出AI过于自信且易误导初级开发者。有开发者表示,AI生成的错误答案反而激励自己手动编码。讨论强调了经验在有效利用AI中的重要性,以及AI可能对编程初学者的负面影响。 (来源: WeChat)

DeepMind与Google Research关系再引议论:品牌与实际创新贡献之辩: Faruk Guney发推长文评论DeepMind与Google Research的关系,认为当前AI革命的核心突破(如Transformer架构)主要源于Google Research,而非被Google收购后的DeepMind。他指出AlphaFold虽是DeepMind的成就,但也离不开Google的计算资源和研究基础设施,且核心贡献者是John Jumper和Pushmeet Kohli等科学家工程师。Guney认为,Google Research后被并入DeepMind,更多是品牌和组织架构调整,背后涉及复杂的企业政治,可能掩盖了创新的真实来源。他强调许多AI突破是团队多年研究的成果,而非仅归功于少数知名人物或品牌。 (来源: farguney, farguney)
AI时代工作岗位与技能转变引担忧与讨论: 社交媒体上,关于AI对就业市场影响的讨论持续不断。一方面,有观点认为AI将导致大规模失业,如Anthropic CEO曾表达此类担忧,促使人们思考如何应对。另一方面,也有声音指出AI主要提升生产力,不太可能造成大规模失业,除非发生严重经济衰退,因为消费需求依赖于就业和收入。同时,有用户分享了因AI导致失业的个人经历(如老板用ChatGPT替代员工)。对于未来,讨论指向需要储蓄、学习实用技能、适应收入减少的可能性,以及教育体系如何调整以培养AI时代所需技能,如批判性思维和有效利用AI工具的能力。 (来源: Reddit r/ArtificialInteligence, Reddit r/artificial)

过度依赖ChatGPT引发思考能力下降担忧: 一位Reddit用户发帖表示担忧其女友过度依赖ChatGPT进行决策、获取观点和创意,认为这可能导致她丧失独立思考和原创能力。帖子引发广泛讨论,部分评论者认同这种担忧,认为过度依赖AI工具确实可能削弱个人思考;另一些评论则认为AI只是工具,如同过去的百科全书或搜索引擎,关键在于使用者如何利用它,是作为思考的起点还是完全替代。也有评论建议通过沟通、引导和展示AI的局限性来应对。 (来源: Reddit r/ChatGPT)
AI在教育领域的挑战:教授苦恼学生滥用ChatGPT,呼吁培养真正思考能力: 一位古代史教授在Reddit发帖称,ChatGPT的滥用已严重影响其教学,学生提交的论文充斥着由AI生成的、甚至包含事实错误的“空洞垃圾”,这让他对学生是否真正学习产生怀疑。他强调人文教育的核心是培养新知识、创造性见解和独立思考,而非简单复述已有信息。该帖子引发热议,评论者提出多种应对策略,如改为口头报告、随堂手写论文、要求学生提交使用AI的过程元分析,或将AI融入教学,让学生批判AI的输出。 (来源: Reddit r/ChatGPT)
AI生成内核意外超越PyTorch专家内核,斯坦福华人团队揭示新可能: 斯坦福大学Anne Ouyang、Azalia Mirhoseini和Percy Liang团队在尝试生成合成数据以训练内核生成模型时,意外发现其用纯CUDA-C编写的AI生成内核在性能上接近甚至超越了PyTorch内置的、经过专家优化的FP32内核。例如,在矩阵乘法上达到PyTorch性能的101.3%,二维卷积达到179.9%。团队采用多轮迭代优化,结合自然语言推理优化思路和分支扩展搜索策略,利用OpenAI o3和Gemini 2.5 Pro模型。这一成果表明,通过巧妙的搜索和并行探索,AI有潜力在高性能计算内核生成方面取得突破。 (来源: WeChat)

💡 其他
AI行业游说力量强大,引Max Tegmark关注: MIT教授Max Tegmark指出,AI行业在华盛顿和布鲁塞尔的游说者数量已超过化石燃料行业和烟草行业的总和。这一现象揭示了AI产业在政策制定方面日益增长的影响力,以及其对监管环境塑造的积极投入,可能对AI技术的发展方向、伦理规范和市场竞争格局产生深远影响。 (来源: Reddit r/artificial)

AI或通过深度伪造模拟生物恐怖袭击,构成新型公共卫生威胁: STAT News文章指出,除了AI辅助生物工程武器的风险外,利用深度伪造技术模拟生物恐怖袭击也可能造成严重威胁。特别是在军事冲突国家之间,这类伪造信息可能引发恐慌、误判和不必要的军事升级。由于调查可能由执法或军事机构主导,而非公共卫生或技术团队,他们可能更倾向于相信袭击的真实性,从而难以有效证伪。 (来源: Reddit r/ArtificialInteligence)
AI时代是否还应攻读工程学位引热议: 社区讨论在AI时代攻读工程学位的价值。一方认为,AI可能取代许多传统工程任务,使学位价值降低。另一方则认为,工程学位培养的系统思维、问题解决能力和数学物理基础依然重要,尤其是在理解和应用AI工具方面。部分观点指出,若AI能取代工程师,那么其他职业也难幸免,关键在于持续学习和适应。兽医等实践性强、难以自动化的领域被认为是相对安全的选择。 (来源: Reddit r/ArtificialInteligence)